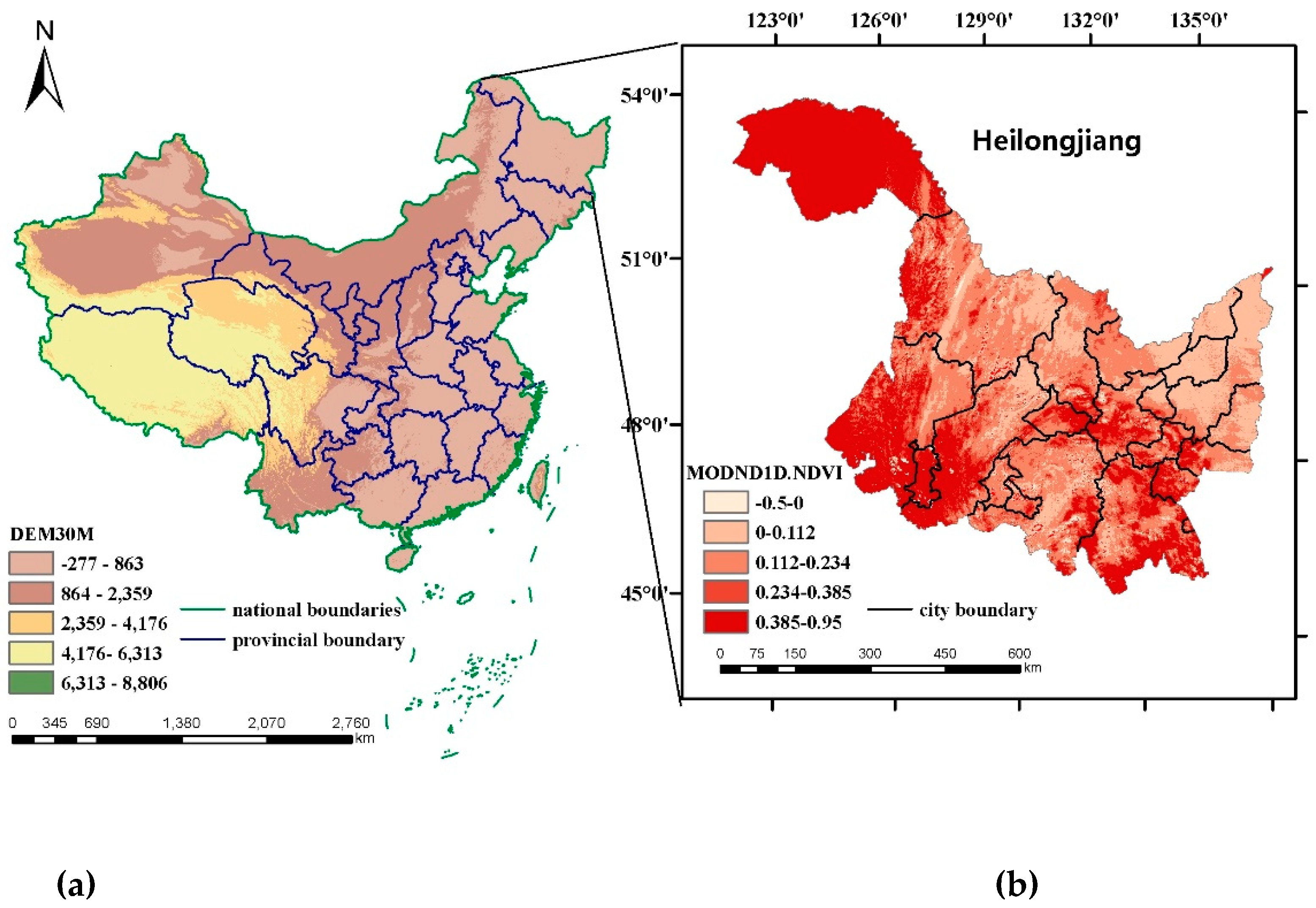
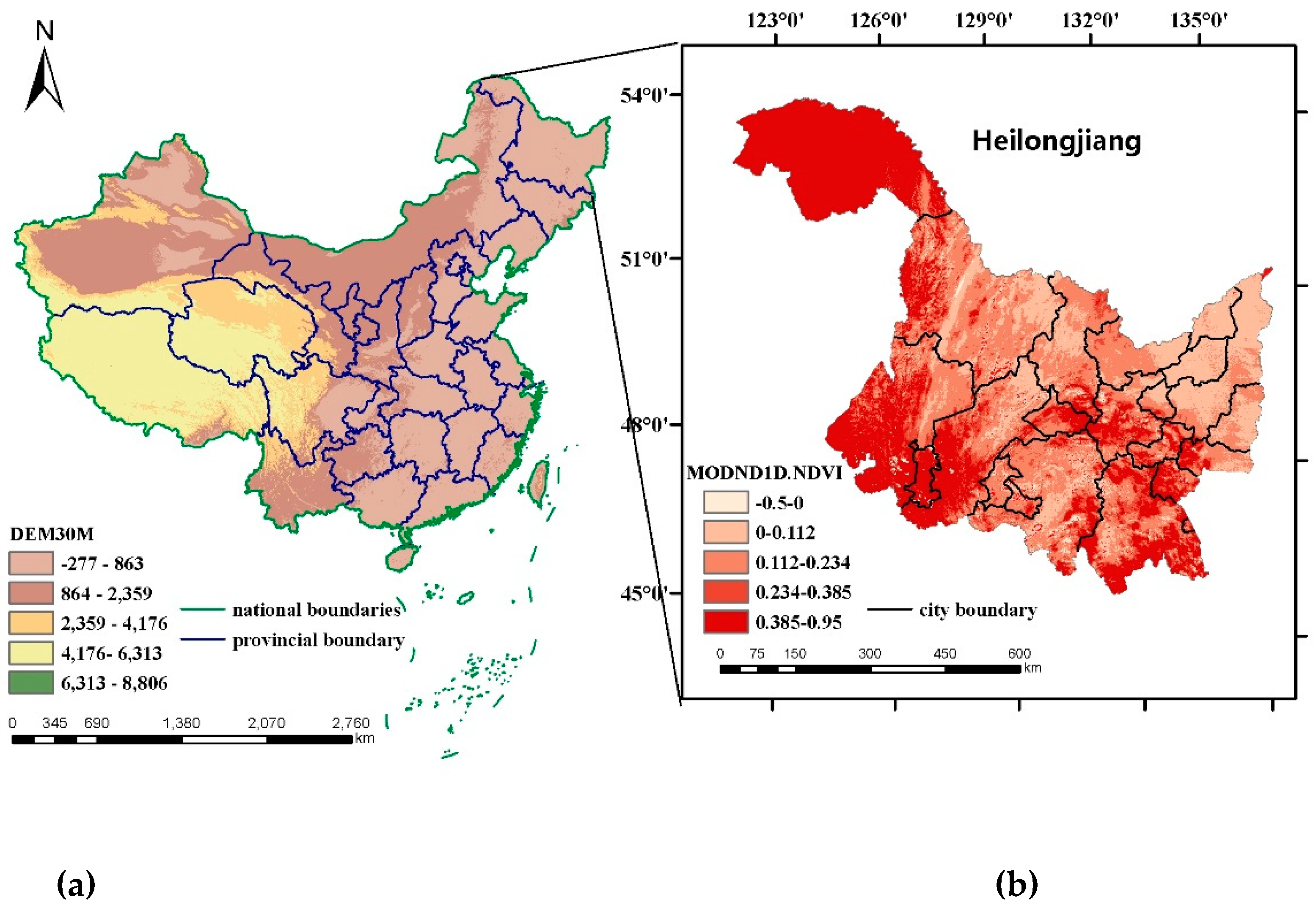
Figure 1.
Study area. (a) China. The Chinese map overlays the digital elevation model (DEM) 30 M base map. (b) Shape, latitude, and longitude of Heilongjiang. Heilongjiang Province overlays the moderate resolution imaging spectroradiometer (MODIS) China 500 M normalized difference vegetation index (NDVI) for dairy products.
Figure 1.
Study area. (a) China. The Chinese map overlays the digital elevation model (DEM) 30 M base map. (b) Shape, latitude, and longitude of Heilongjiang. Heilongjiang Province overlays the moderate resolution imaging spectroradiometer (MODIS) China 500 M normalized difference vegetation index (NDVI) for dairy products.
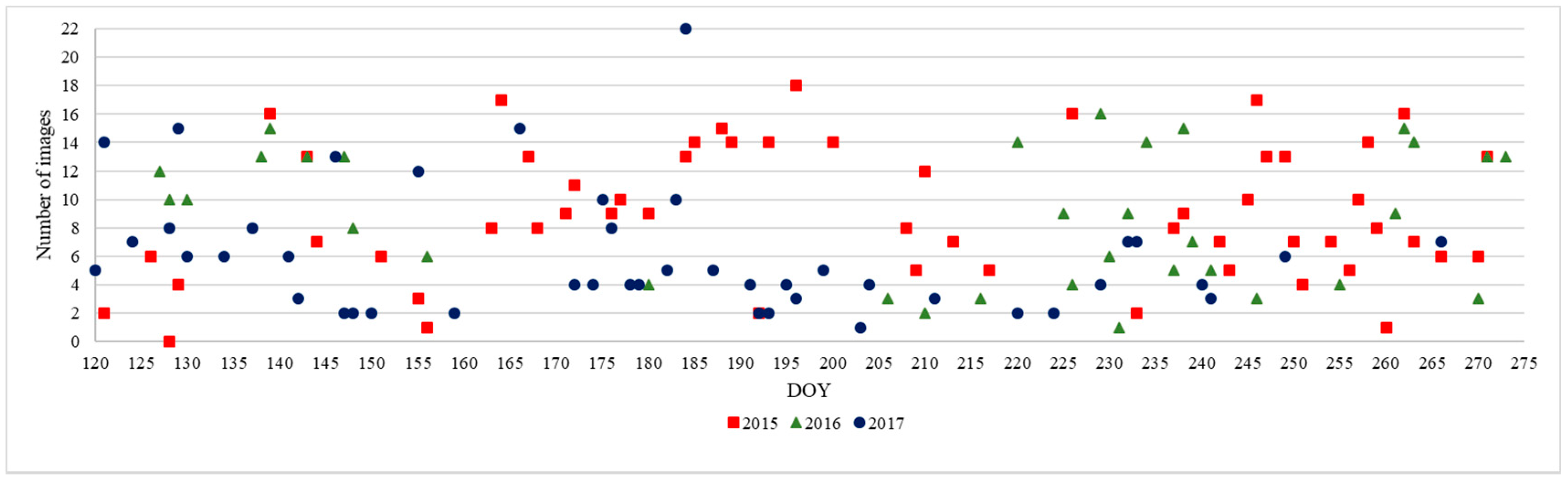
Figure 2.
Heilongjiang Province 2015–2017, three-year time series distribution map, including the number of scene images available for each day of the year (DOY).
Figure 2.
Heilongjiang Province 2015–2017, three-year time series distribution map, including the number of scene images available for each day of the year (DOY).
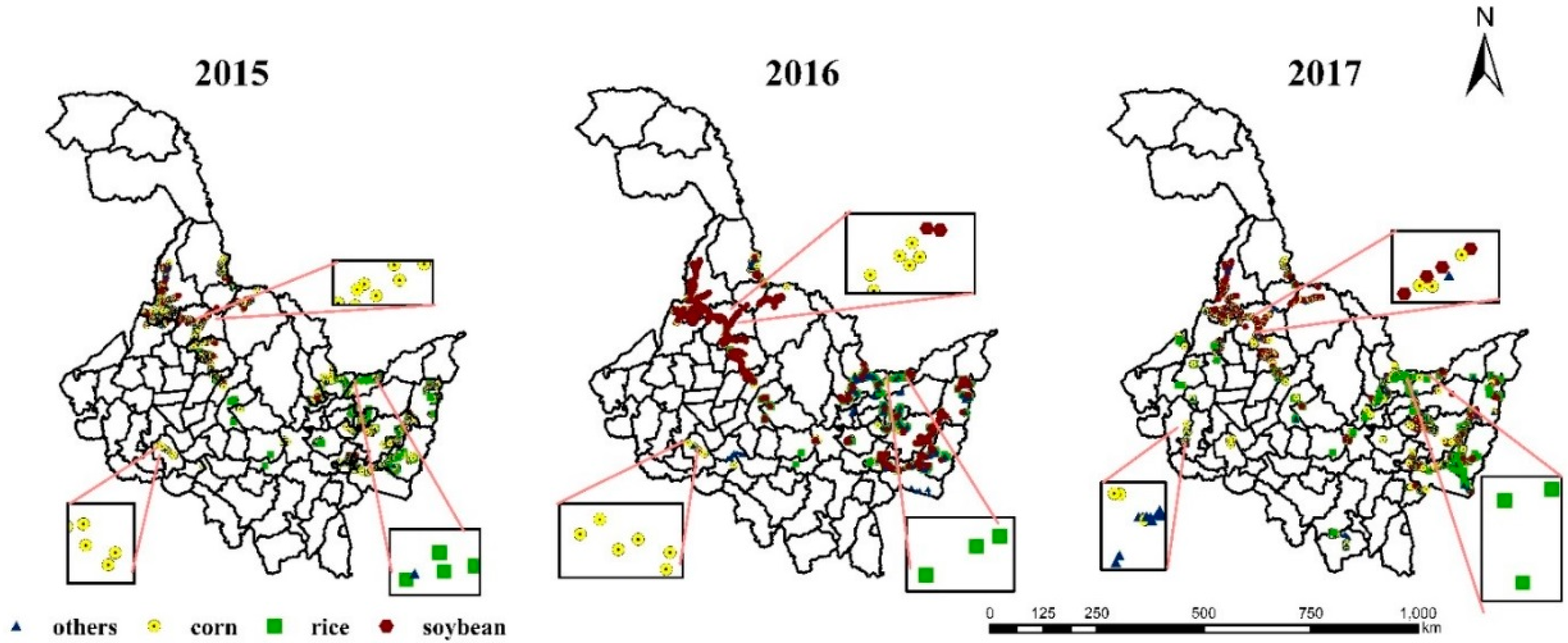
Figure 3.
Heilongjiang three-year crop distribution map: yellow for corn, green for rice and red for soybean.
Figure 3.
Heilongjiang three-year crop distribution map: yellow for corn, green for rice and red for soybean.
Figure 4.
Raster dataset clean and reconstitution multigrid (RDCRMG) coding rules and storage methods.
Figure 4.
Raster dataset clean and reconstitution multigrid (RDCRMG) coding rules and storage methods.
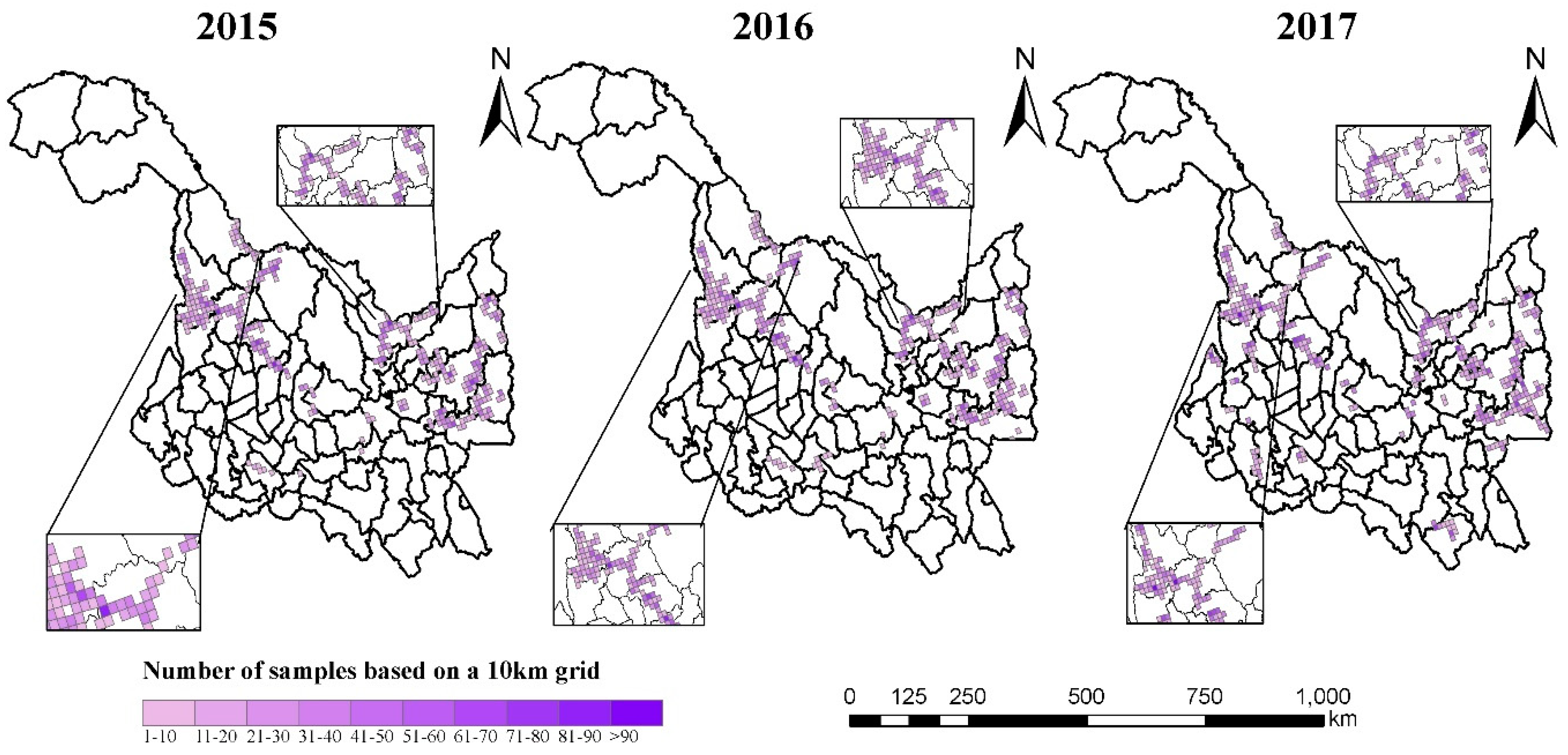
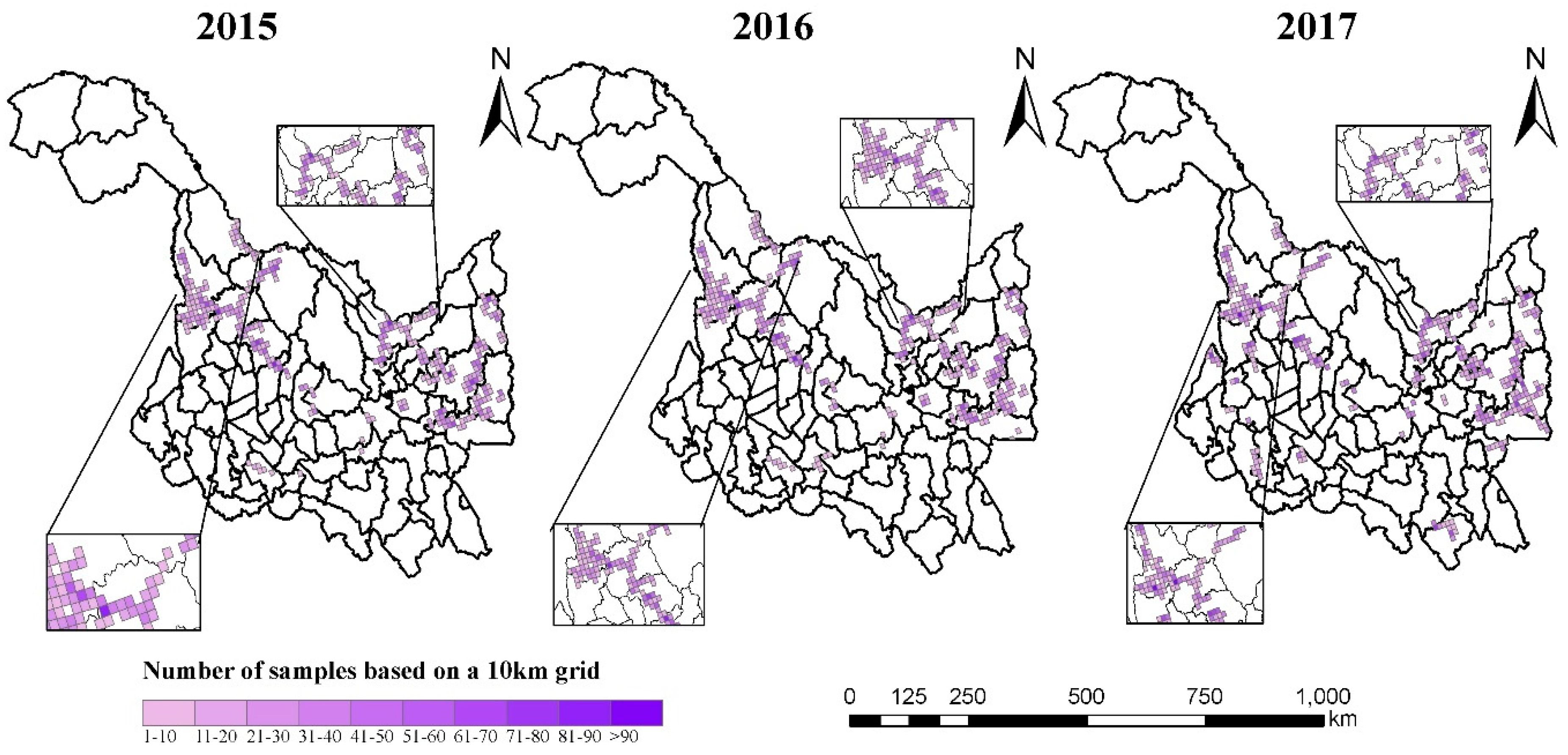
Figure 5.
Heilongjiang Province 2015–2017, three-year time series distribution map, including the number of scene images for each 10 km grid.
Figure 5.
Heilongjiang Province 2015–2017, three-year time series distribution map, including the number of scene images for each 10 km grid.
Figure 6.
Graph showing how many samples per grid in each year after the three-year sample of Heilongjiang Province was entered into the RDCRMG. Grids from the blank areas do not contain samples. The color depth indicates the number of samples, and each grid has a maximum of 91 samples.
Figure 6.
Graph showing how many samples per grid in each year after the three-year sample of Heilongjiang Province was entered into the RDCRMG. Grids from the blank areas do not contain samples. The color depth indicates the number of samples, and each grid has a maximum of 91 samples.
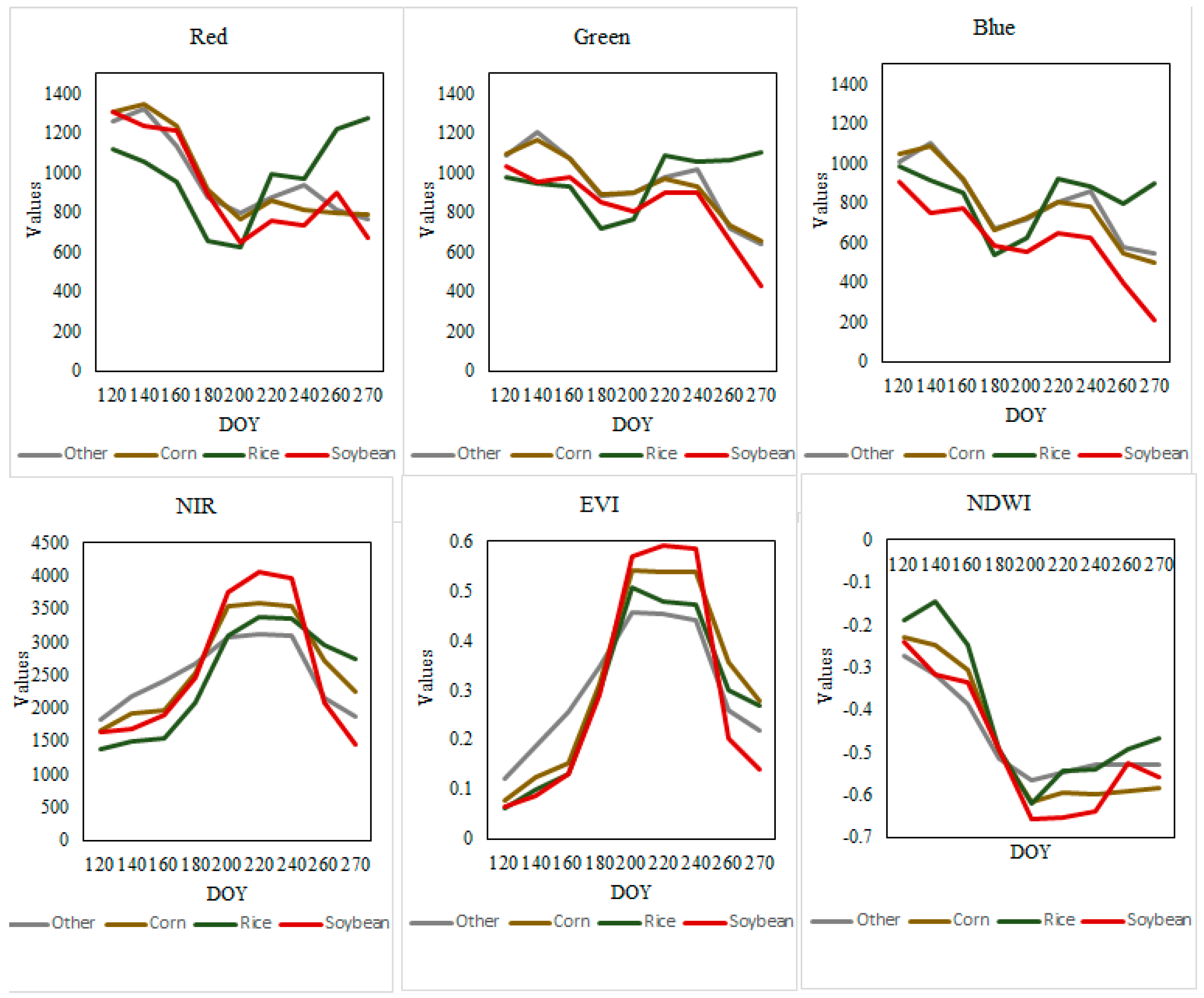
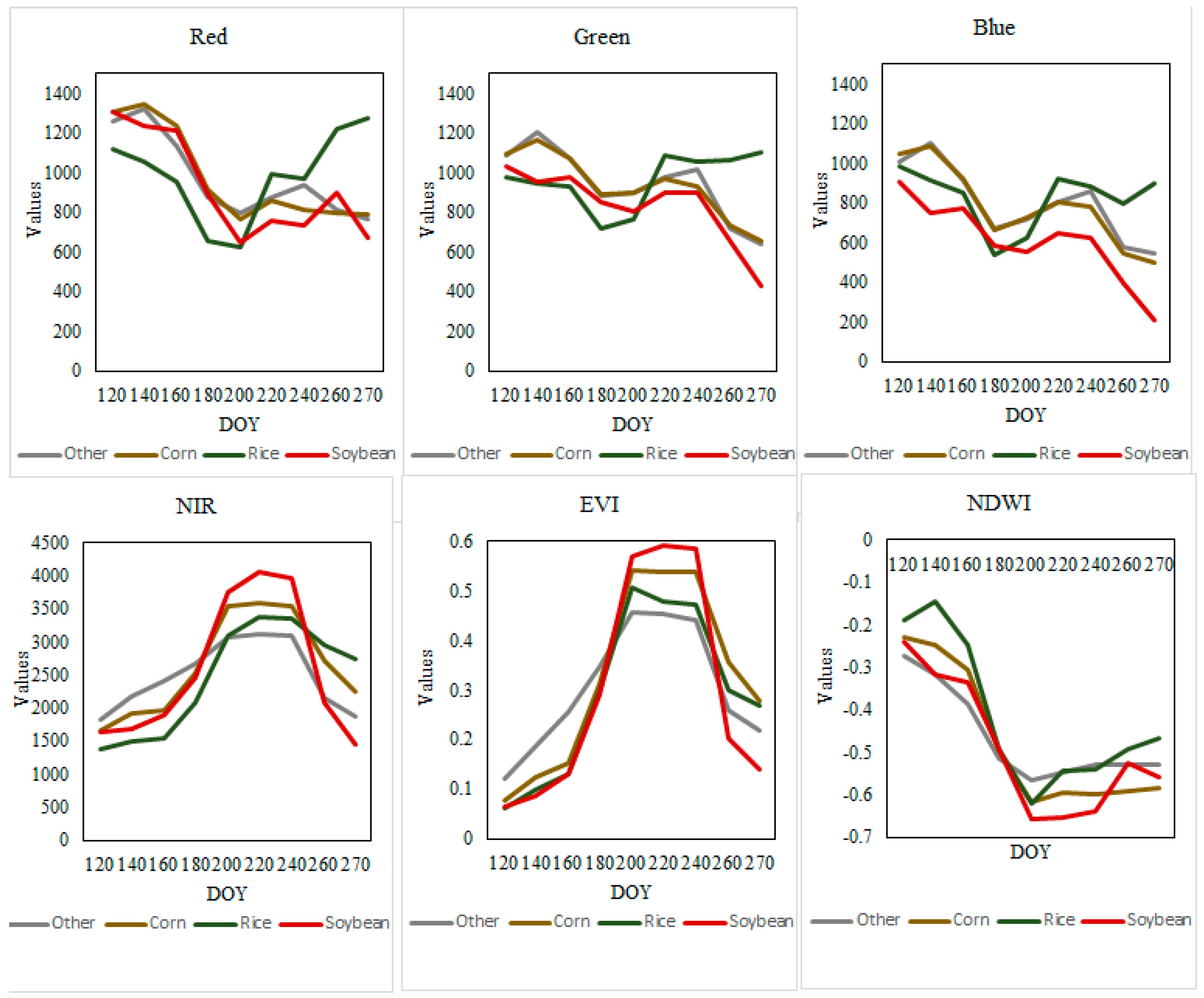
Figure 7.
Temporal profile based on the blue, green, red and NIR bands as well as the EVI and NDWI and the timing curves of the corn, rice, and soybean growth periods.
Figure 7.
Temporal profile based on the blue, green, red and NIR bands as well as the EVI and NDWI and the timing curves of the corn, rice, and soybean growth periods.
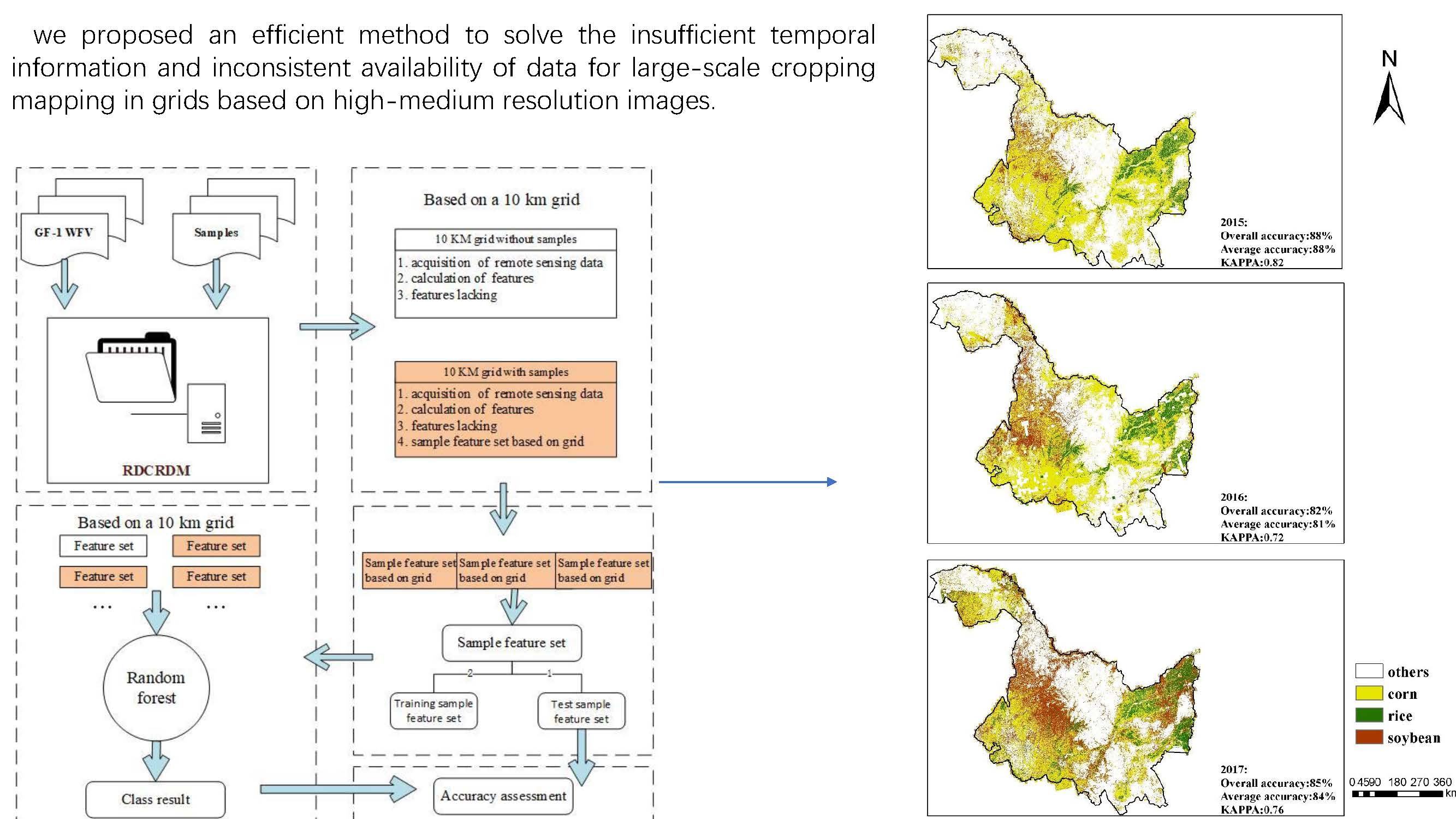
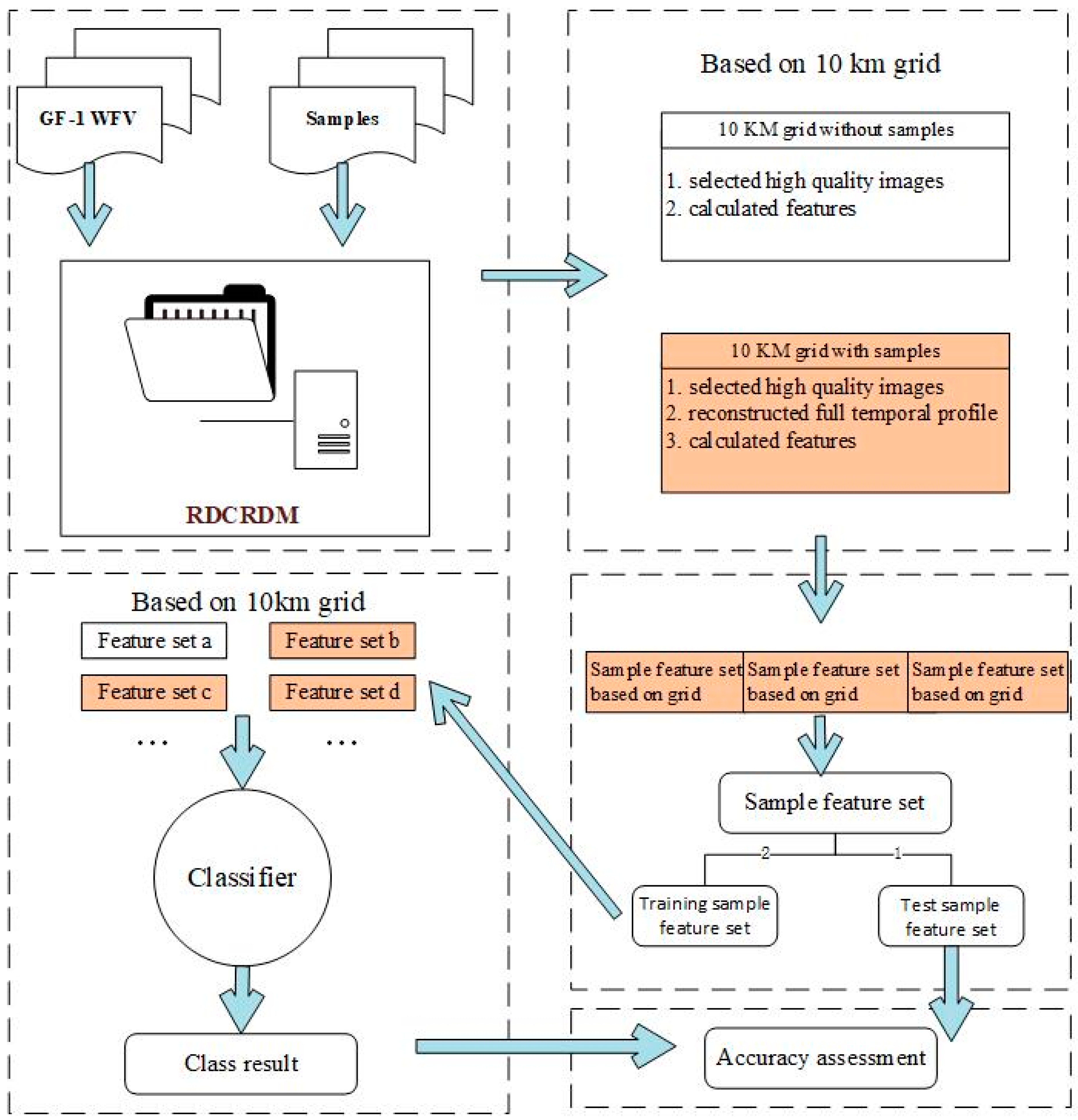
Figure 8.
Workflow of our study, including five important steps: (1) data fed into the grid; (2) calculation of multitemporal features; (3) generation of training and test data; (4) classification. Steps 2 and 4 were based on a 10 km grid.
Figure 8.
Workflow of our study, including five important steps: (1) data fed into the grid; (2) calculation of multitemporal features; (3) generation of training and test data; (4) classification. Steps 2 and 4 were based on a 10 km grid.
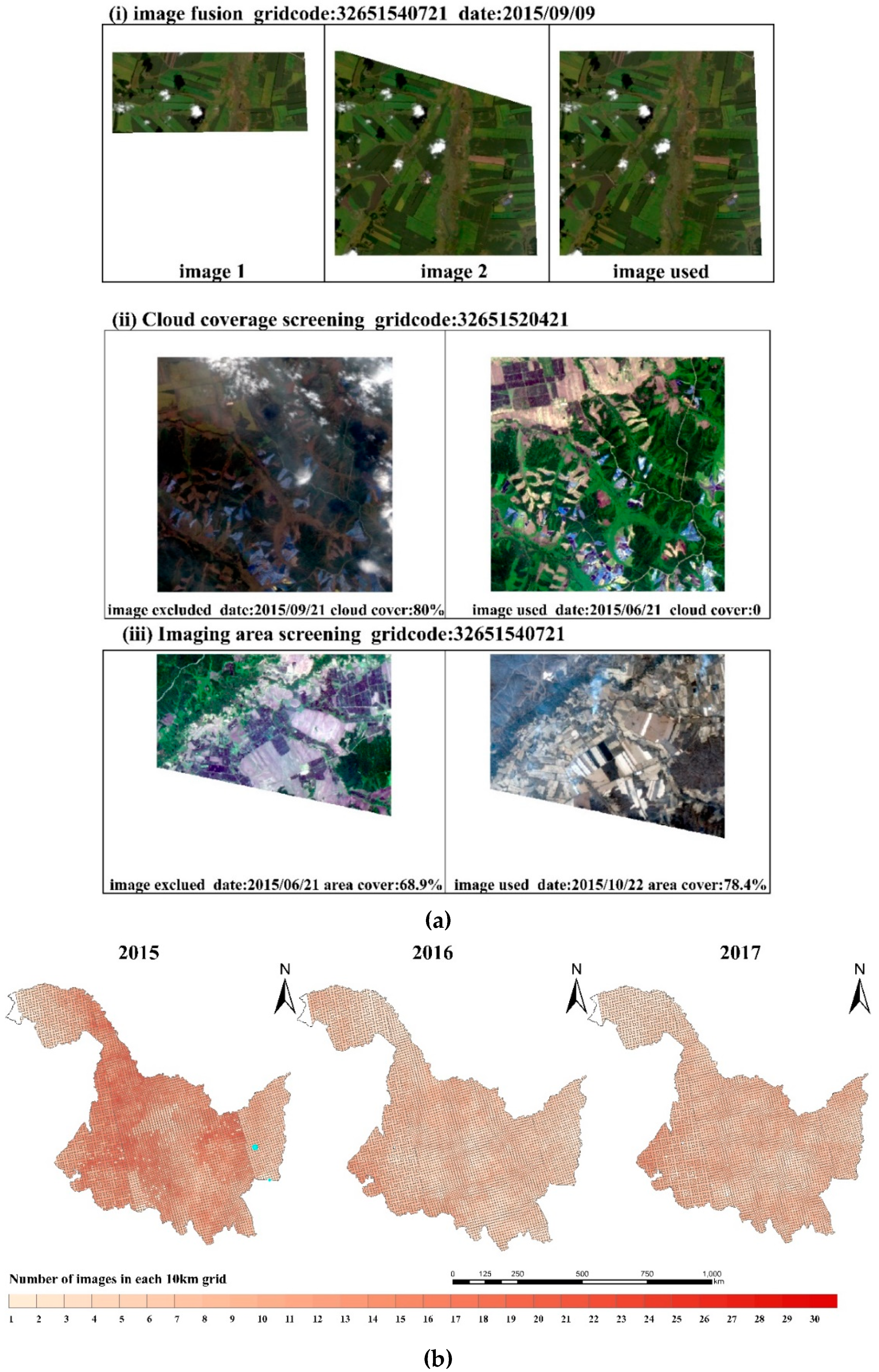
Figure 9.
(a) Data selection for three data quality problems. (b) Available dates count statistics of Heilongjiang Province in 2015, 2016 and 2017.
Figure 9.
(a) Data selection for three data quality problems. (b) Available dates count statistics of Heilongjiang Province in 2015, 2016 and 2017.
Figure 10.
(a) Calculation the union of all observation time points of GF-1 satellite. (b) Full temporal profile reconstruction. (c) Training and classification.
Figure 10.
(a) Calculation the union of all observation time points of GF-1 satellite. (b) Full temporal profile reconstruction. (c) Training and classification.
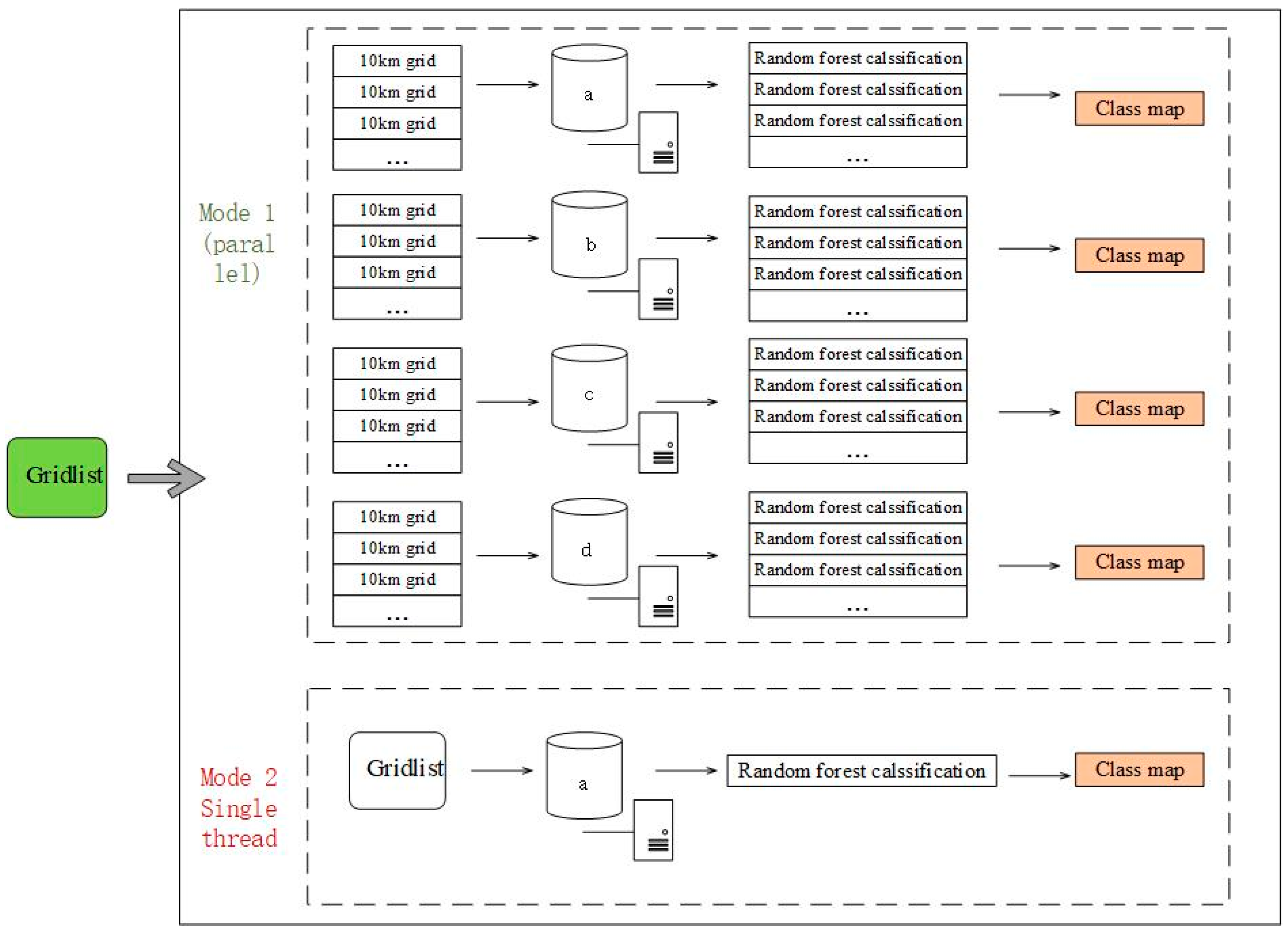
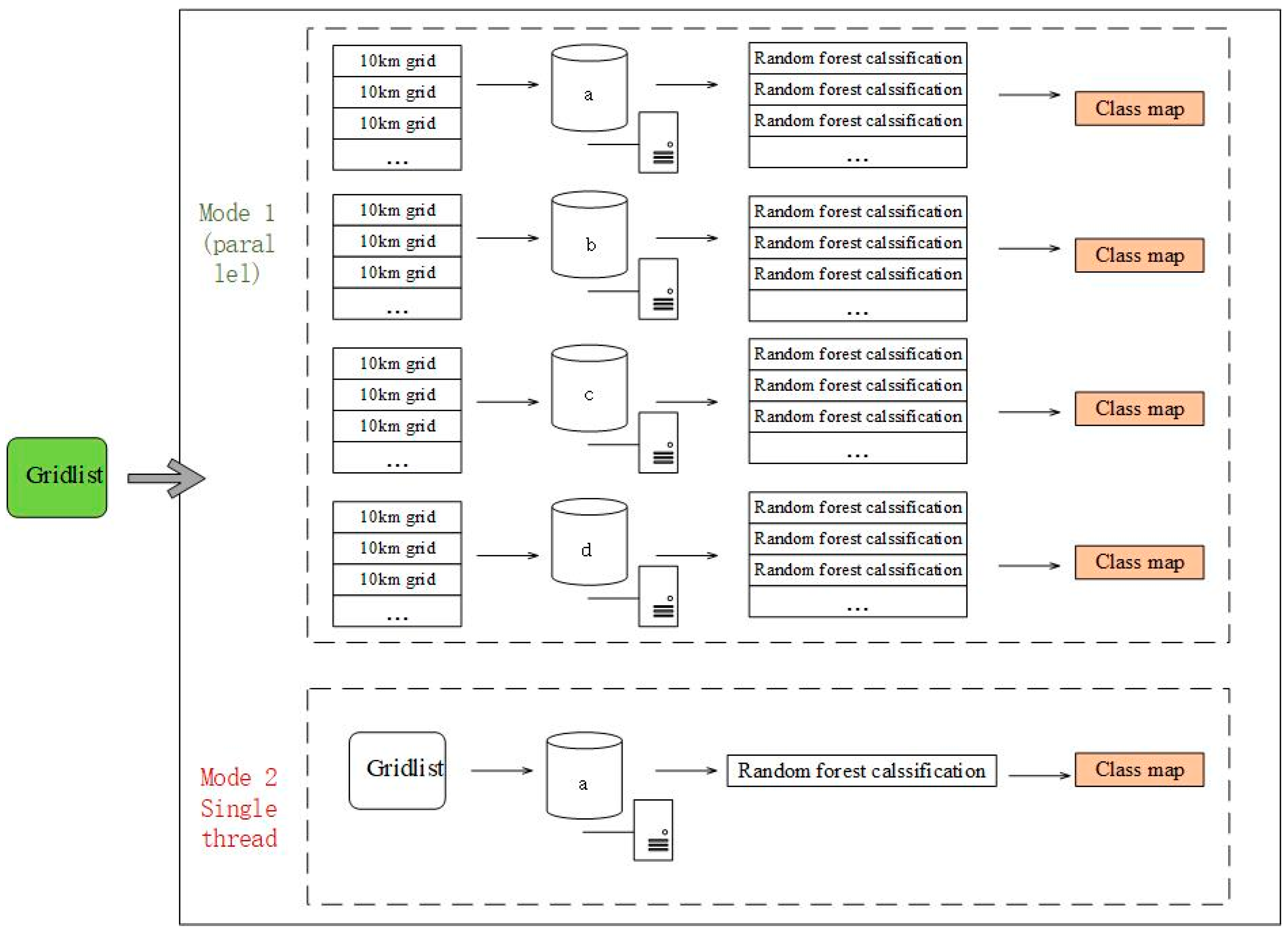
Figure 11.
A set of controlled experiments was designed to verify the computational performance improvement of parallel classification with a group of multithread parallel classifications based on computational clusters and a set of single-thread classifications based on one server.
Figure 11.
A set of controlled experiments was designed to verify the computational performance improvement of parallel classification with a group of multithread parallel classifications based on computational clusters and a set of single-thread classifications based on one server.
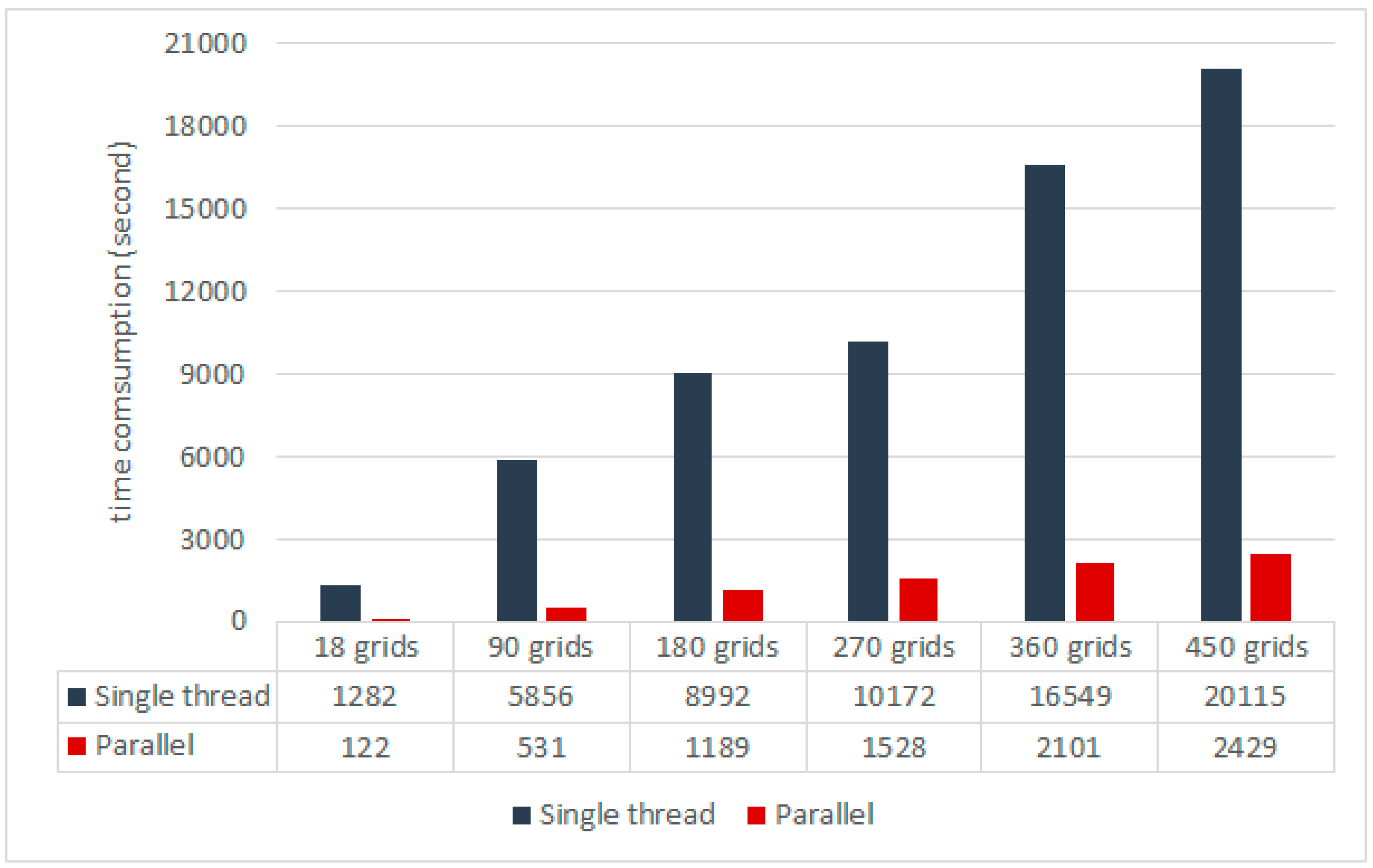
Figure 12.
Classification of the time consumption of modes 1 and 2 with different sizes of grids.
Figure 12.
Classification of the time consumption of modes 1 and 2 with different sizes of grids.
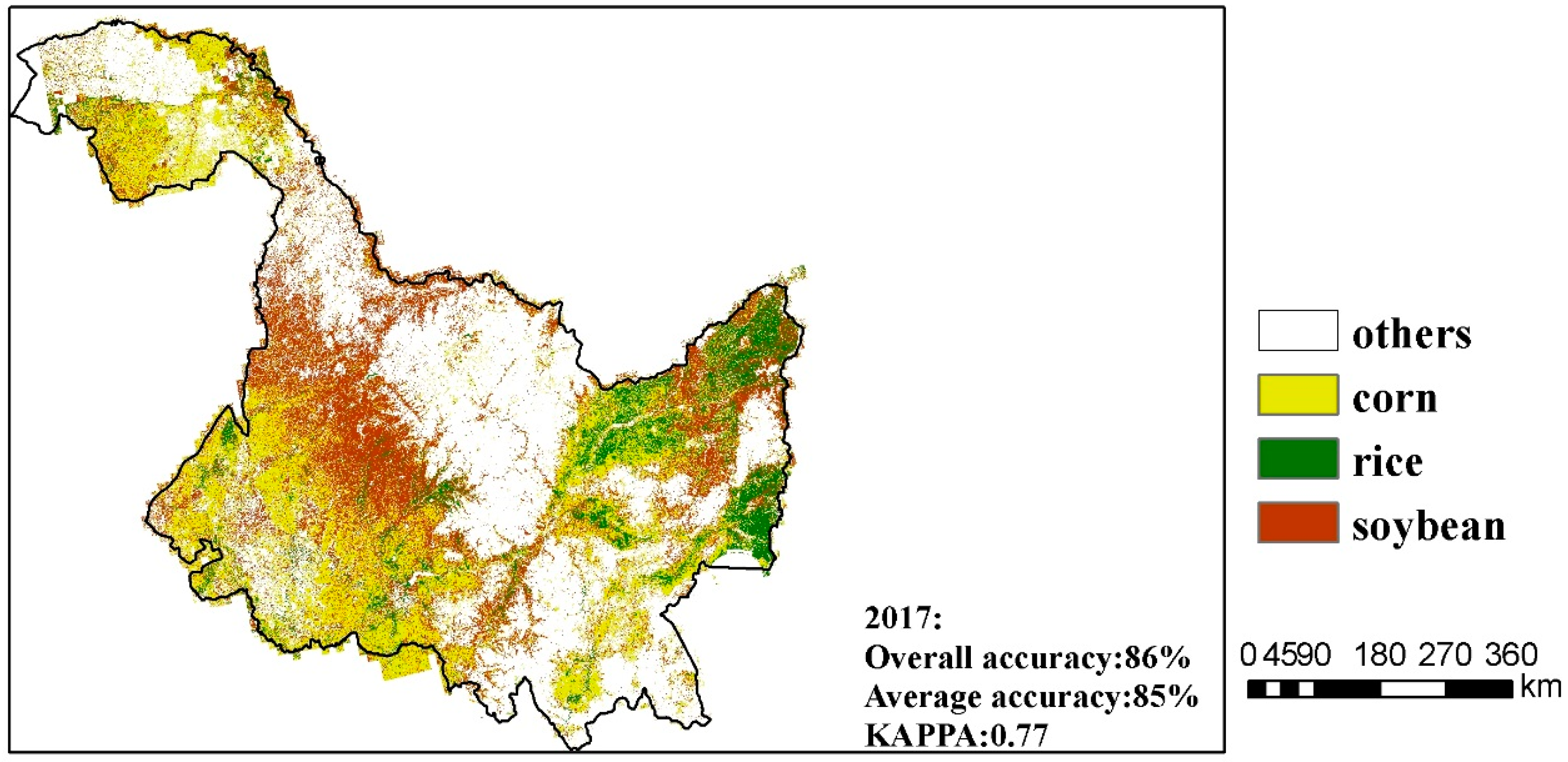
Figure 13.
The crop distribution map of Heilongjiang with the overall classification accuracy, average classification accuracy, and Kappa coefficient for year 2015, 2016 and 2017.
Figure 13.
The crop distribution map of Heilongjiang with the overall classification accuracy, average classification accuracy, and Kappa coefficient for year 2015, 2016 and 2017.
Figure 14.
The classification result details of Heilongjiang with four 10 km grids for year 2015, 2016 and 2017.
Figure 14.
The classification result details of Heilongjiang with four 10 km grids for year 2015, 2016 and 2017.
Figure 15.
Classification results with trees, rivers, buildings, corn, rice and soybeans.
Figure 15.
Classification results with trees, rivers, buildings, corn, rice and soybeans.
Table 1.
The basic specifications of the computing clusters in terms of the processor and RAM.
Table 1.
The basic specifications of the computing clusters in terms of the processor and RAM.
| Server ID | Processor | RAM |
|---|
| Server A | Intel E5-2680 × 2 | 32 G |
| Server B | Intel E5-2620 × 2 | 16 G |
| Server C | Intel E5-2620 × 2 | 16 G |
| Server D | Intel E5-2407 × 2 | 8 G |
Table 2.
Parameter group setting details in parameter tuning.
Table 2.
Parameter group setting details in parameter tuning.
| Random Forest Algorithm | Support Vector Machine |
|---|
| n_estimators | 50, 100, 150, 200, 250, 300, 350, 400, 450, 500 | Kernel Function: linear, C: [1,10,100,100,1000] |
| max_features | ‘auto’, ‘sqrt’, ‘log2’ | Kernel Function: poly, C: [1], degree: [2,3] |
| | | Kernel Function: rbf, C: [1,10,100,100,1000], gamma: [1,0.1,0.01,0.001] |
Table 3.
Comparison of the accuracy of the classifiers.
Table 3.
Comparison of the accuracy of the classifiers.
| Classifier | Random Forest Algorithm | Support Vector Machine |
|---|
| Overall accuracy (%) | 86 | 84 |
| Average accuracy (%) | 85 | 83 |
| kappa | 0.76 | 0.74 |
Table 4.
Accuracy comparison of the GF- WFV and Sentinel-2 images.
Table 4.
Accuracy comparison of the GF- WFV and Sentinel-2 images.
| Classifier | GF-1 WFV | Sentinel-2 |
|---|
| Overall accuracy (%) | 83 | 77 |
| Average accuracy (%) | 82 | 83 |
| Kappa | 0.68 | 0.70 |
| Number of images | 10 | 7 |
Table 5.
Comparison of the accuracy among the widely used nonparallel classification methods. A refers to the method we propose, and B refers to the widely used classification methods.
Table 5.
Comparison of the accuracy among the widely used nonparallel classification methods. A refers to the method we propose, and B refers to the widely used classification methods.
| | Experiment-I | Experiment-II | Sample Count |
|---|
| | UA (%) | PA (%) | UA (%) | PA (%) |
|---|
| Corn | 85 | 95 | 85 | 96 | 159 |
| Rice | 91 | 88 | 76 | 92 | 24 |
| Soybean | 97 | 68 | 97 | 71 | 41 |
| Other | 82 | 69 | 84 | 54 | 39 |
| | AA:87 | OA:86 | AA:86 | OA:86 | |
Table 6.
Confusion matrix of the three-year classification results, the user accuracy and producer accuracy of various crops, the overall classification accuracy, and the average classification accuracy.
Table 6.
Confusion matrix of the three-year classification results, the user accuracy and producer accuracy of various crops, the overall classification accuracy, and the average classification accuracy.
| Reference Class |
|---|
| | Predicted Class | Corn | Rice | Soybean | Other | Total | UA (%) |
|---|
| 2015 | Corn | 699 | 9 | 16 | 25 | 745 | 93 |
| Rice | 24 | 184 | 2 | 2 | 213 | 87 |
| Soybean | 51 | 1 | 364 | 17 | 436 | 84 |
| Other | 46 | 6 | 7 | 196 | 255 | 77 |
| Total | 820 | 200 | 389 | 240 | 1649 | 88 |
| PA (%) | 85 | 92 | 94 | 82 | 88 | |
| 2016 | Corn | 651 | 8 | 59 | 27 | 745 | 87 |
| Rice | 15 | 189 | 4 | 5 | 213 | 89 |
| Soybean | 91 | 0 | 336 | 9 | 436 | 77 |
| Other | 67 | 2 | 27 | 159 | 255 | 62 |
| Total | 824 | 199 | 426 | 200 | 1649 | 81 |
| PA (%) | 79 | 95 | 79 | 80 | 81 | |
| 2017 | Corn | 697 | 5 | 31 | 12 | 745 | 94 |
| Rice | 36 | 176 | 0 | 1 | 213 | 93 |
| Soybean | 64 | 0 | 370 | 2 | 436 | 85 |
| Other | 85 | 5 | 12 | 153 | 255 | 60 |
| Total | 872 | 185 | 409 | 173 | 1649 | 85 |
| PA (%) | 79 | 95 | 90 | 91 | 86 | |
Table 7.
Leave one year out method accuracy assessment result.
Table 7.
Leave one year out method accuracy assessment result.
| Year of Classification Result | Overall Accuracy (%) | Average Accuracy (%) |
|---|
| 2015 | 70 | 73 |
| 2016 | 64 | 67 |
| 2017 | 71 | 65 |

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}