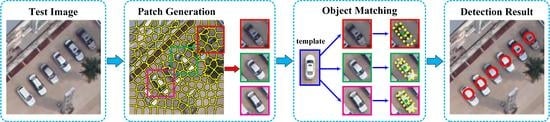
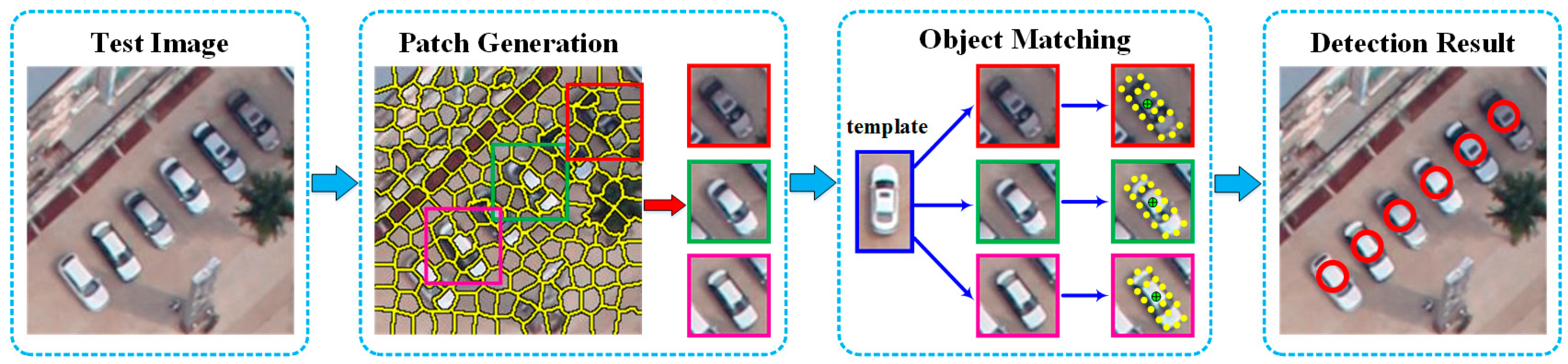
A detailed vehicle detection workflow is illustrated in
Figure 1. As shown in
Figure 1, for a test image, we first over-segment it into a group of superpixels using the simple linear iterative clustering (SLIC) superpixel segmentation method [
54]. Then, centered at each superpixel, a patch is generated with a size of
pixels. Then, to estimate the existence of vehicles from these patches, we proposed an affine-function transformation-based object matching method, in which both the template and each of the patches, a collection of scale-invariant feature transform (SIFT) feature points are generated and characterized with SIFT feature vectors, and then a vehicle template is selected for conducting matching between the template and each of the generated patches. Compared to traditional methods that usually adopt a sliding window strategy to generate a group of candidate regions for individual vehicle detection [
8], we, in this paper, the SLIC superpixel segmentation method to generate meaningful and non-redundant patches as operating units for individual vehicle detection. The SLIC superpixel segmentation method is detailed in the literature [
55]. In the following subsections, we focus on the description of the affine-function transformation-based object matching framework, followed by an optimal matching processing by using a successive convexification scheme in
Section 2.2.
2.1. Affine-Function Transformation Based Object Matching
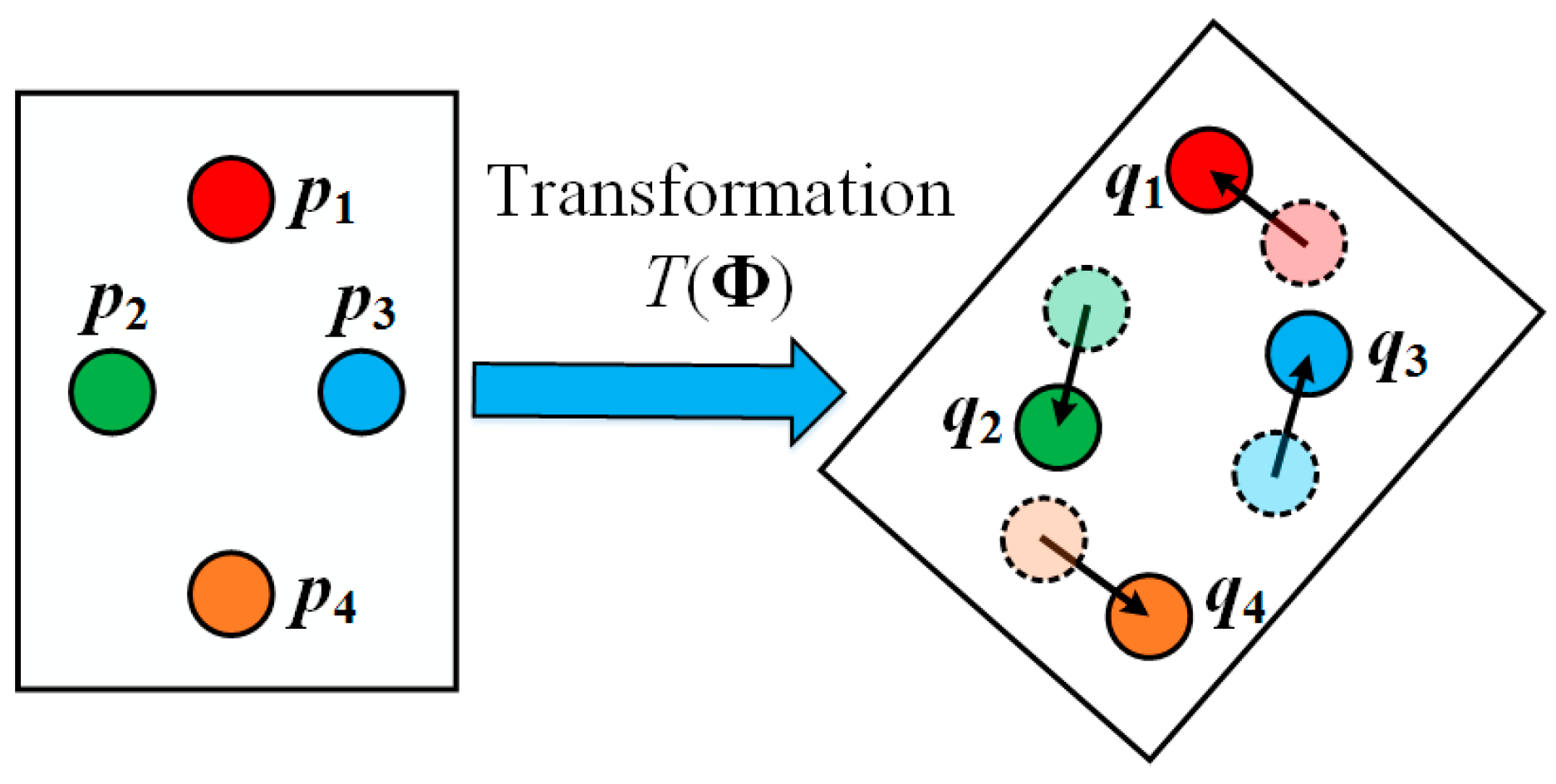
The problem of object matching can be defined as matching a group of template feature points, representing a specific object of interest, to another group of scene feature points, representing a scene containing an instance of the object of interest (See
Figure 2). Each feature point has a unique location and is depicted with a feature vector that characterizes the local appearance around that location. The matched scene feature points should preserve similar local features and relative spatial relationships of the template feature points. Most of existing object matching techniques dedicate to seek for point-to-point matching results, which might show low performance when dealing with occlusions. In contrast, we propose an affine-function transformation-based object matching framework, whose objective is to determine each template feature point’s optimal transformation parameters (not point-to-point matching) so that the matching location (which may not be a specific scene feature point) of each template feature point is close to a scene feature point with similar local appearance and geometric structure.
(1) Affine-function transformation
Denote
and
as the numbers of template feature points and scene feature points, respectively. Let
and
be the sets of template feature points and scene feature points, respectively. Then, our object matching objective is to optimize the transformation parameters of each template feature point in
P based on the scene feature points in
Q. Define
as an affine transformation function that transforms the
ith template feature point
into a location in the scene with transformation parameters
. The result of
is the corresponding matching location of template feature point
in the scene. In this paper, we define the affine transformation function as follows:
where
computes the matching location of template feature point
under an affine transformation with parameters
. We define a separate affine transformation function for each template feature point. The matching location of a template feature point
is computed by its corresponding function
. In Equation (1),
are the global affine transformation parameters that are shared by all template feature points, whereas
are the local translation parameters for only template feature point
. Therefore, different template feature points might have different versions of
. As illustrated in
Figure 3, the local translation parameters allow small local deformations between the template feature points and their matched locations.
(2) Dissimilarity measure
According to the object matching principles, one objective is to match each template feature point to the corresponding location in the scene with the constraint that the local appearances of and should be similar. Therefore, we define a dissimilarity measure function , respectively, for each template feature point to measure the local appearance dissimilarities between template feature point and its corresponding matched location q in the scene. Generally, two feature points having similar local appearances will result in a low dissimilarity measure value.
To solve the object matching problem, our overall objective is to determine the optimal transformation parameters
for template feature points
to minimize the following objective function:
where
computes the local appearance dissimilarity between template feature point
and its corresponding matching location
in the scene.
denotes a convex relaxation term regularizing the transformation parameters.
defines a series of convex constraints. Here,
is the number of convex constraints. By such a definition, the overall objective function in Equation (2) can be effectively solved through convex optimization techniques. Next, we focus on the design of the dissimilarity measure function.
Recall that each feature point is associated with a location, as well as a feature vector characterizing the local appearance around that location. In this paper, each feature point is described using a scale-invariant feature transform (SIFT) vector [
56]. Let
denote the feature dissimilarity between a template feature point
and a scene feature point
. Then, we define
as the square root of the
distance [
57] between the SIFT feature vectors of
and
as follows:
where
and
are the
kth channels of the SIFT feature vectors of feature points
and
, respectively. Then, for each template feature point
, we define a discrete version of the dissimilarity measure function
as follows:
The domain of this function indicates that a template feature point can be only matched to a certain scene feature point with the feature dissimilarity measure determined by function . Minimizing still results in a point-to-point matching pattern, which violates our objective to optimize the affine transformation parameters to compute the matching locations. Moreover, the discrete function is non-convex. Therefore, adopting as the dissimilarity measure in Equation (2) to minimize the overall objective function is difficult and cannot effectively obtain optimal solutions.
(3) Convex dissimilarity measure
To solve the aforementioned problem, we relax each discrete function
and construct a continuous and convex dissimilarity measure function
, which can be effectively optimized through convex optimization techniques. To this end, for each template feature point
, we organize all the scene feature points together with their feature dissimilarities
as a set of three-dimensional (3D) points
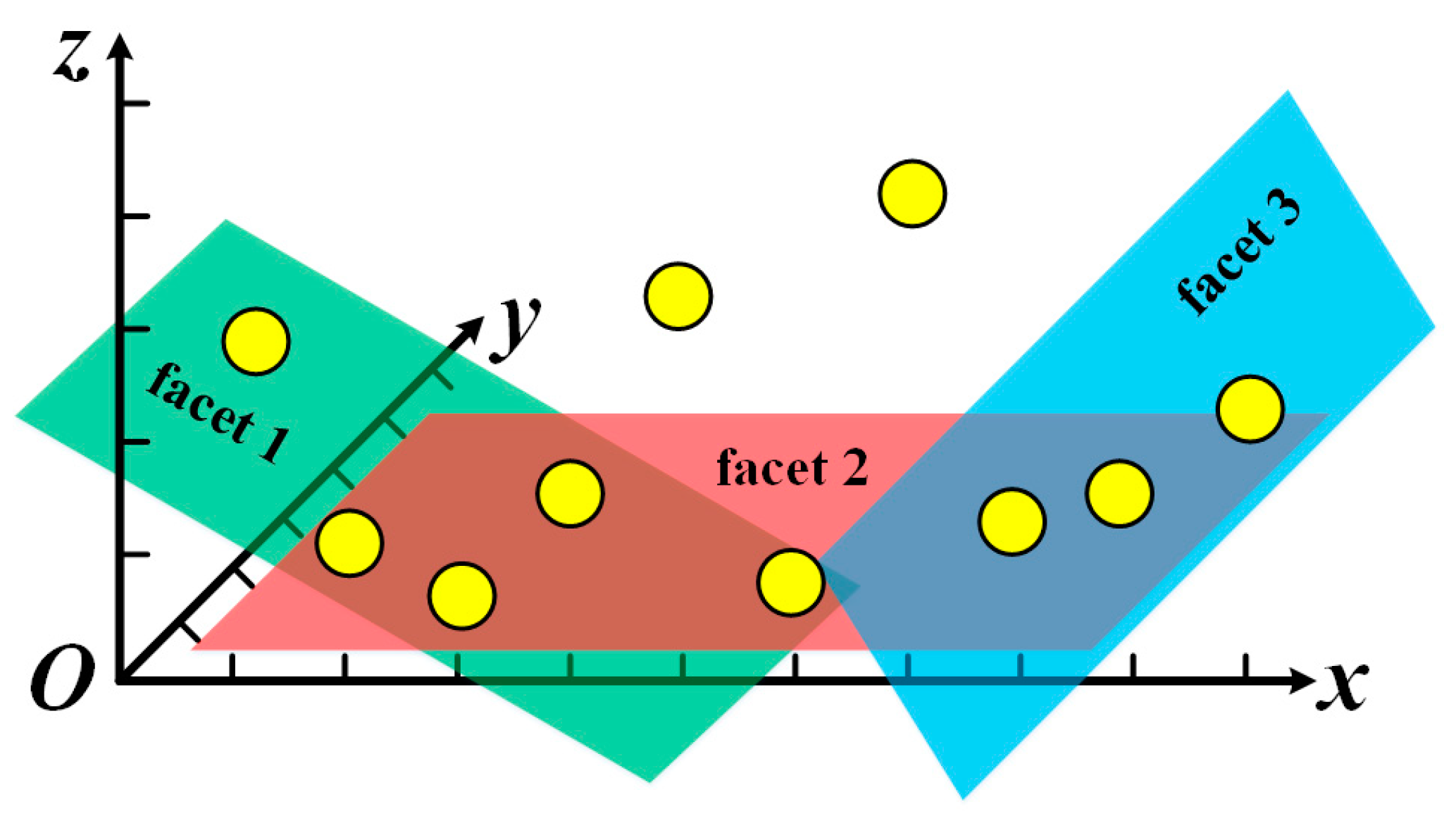
, whose first two dimensions are the location of a scene feature point and the third dimension is the corresponding feature dissimilarity. As illustrated in
Figure 4, we give an example of the feature dissimilarities, viewed as a 3D point set, of the scene feature points associated with a template feature point. Obviously, this is actually the discrete version of the dissimilarity measure function
.
We construct the convex dissimilarity measure function
based on the lower convex hull of the 3D point set associated with template feature point
with respect to the feature dissimilarity dimension. As shown in
Figure 3, the facets are the lower convex hull of the 3D point set. Denote
as the plane functions defining the
facets on the lower convex hull.
are the plane parameters of the
kth plane. Then, we define the continuous convex dissimilarity measure function as follows:
where
can be any location in the scene domain. In other words, by such a relaxation, template feature point
can be matched to any location
in the scene, not necessarily being a specific scene feature point. To effectively minimize Equation (5), we convert it into an equivalent linear programming problem:
where
is an auxiliary variable representing the upper bound of
. Equation (6) can be efficiently optimized using convex optimization techniques.
In order to use Equation (6) to minimize
in the overall objective function in Equation (2), we rewrite the affine transformation function
into
, where
and
are affine functions that computes the
x and
y components of the matching location of template feature point
. By substituting
x and
y in Equation (6) with
and
, we obtain the following convex optimization model which is equivalent to minimizing
with respect to transformation parameters
:
Then, summing up all the minimization terms
results in our overall objective function with respect to optimizing the affine transformation parameters
with convex constraints defined in Equation (7):
where the regularization term functions to penalize local deformations of the matching locations in the scene. It indicates that the local deformations of the matching locations should not be too large.
is a parameter that weights the dissimilarity measure term and the regularization term.
When partial occlusions of an object of interest exist in the scene, directly optimizing Equation (8) may degrade the performance of the proposed affine-function transformation-based object matching framework. To solve this problem, we assign a weight factor
for each template feature point
to describe its distinctiveness and contribution to the matching. Then, we obtain the final overall objective function with convex constraints defined in Equation (7) as follows:
2.2. Successive Convexification Scheme for Solving the Objective Function
Recall that the continuous convex dissimilarity measure function
is constructed by relaxing the discrete dissimilarity measure function
based on the lower convex hull. If the feature descriptions of feature points are distinctive, the dissimilarity measures, computed using
, between a template feature point and all the scene feature points differ significantly. Therefore, the lower convex hull relaxation provides a satisfactory lower bound to the discrete measure function
. However, when features are not distinctive, the lower convex hull might not generate a very tight lower bound to
. To solve this problem, we propose a successive convexification scheme, similar to that adopted by Jiang et al. [
58], to iteratively optimize the overall objective function to obtain a tighter solution.
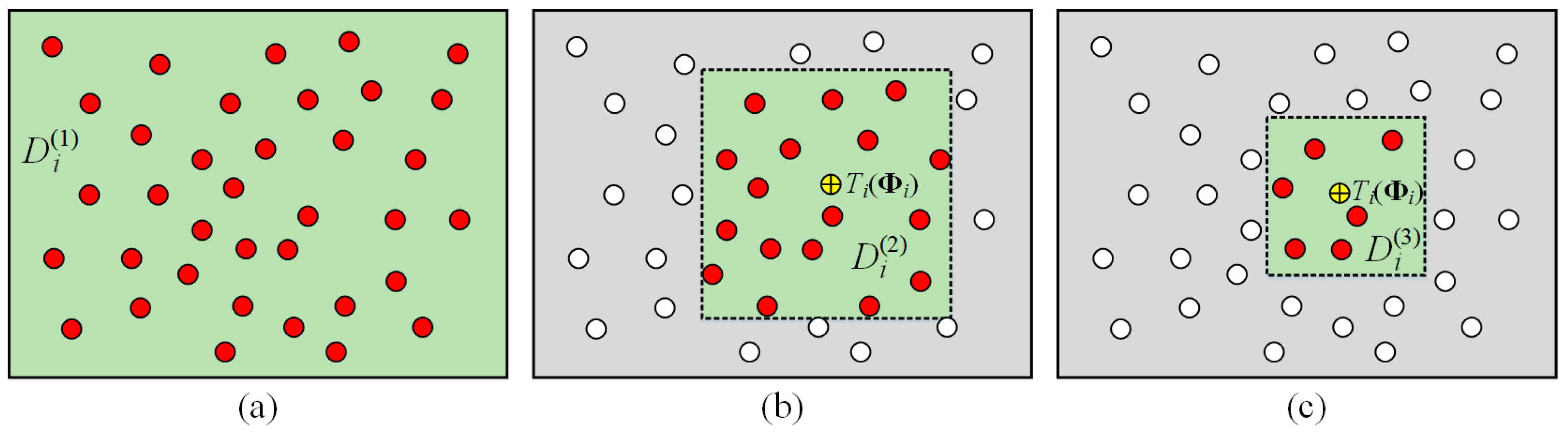
Initially, we assign an identical weight factor
to all template feature points. In each iteration of the convexification, a trust region is defined for each template feature point. Only the scene feature points within the trust region can be used to construct the convex dissimilarity measure functions. In the first iteration, we fix the weight factors
and define the entire scene as the trust region for each template feature point
, as illustrated by
in
Figure 5a. That is, initially, all scene feature points are used to construct the convex dissimilarity measure functions. Then, these convex dissimilarity measure functions are applied to the overall objective function in Equation (9) to optimize the affine transformation parameters
. The corresponding matching locations of template feature points are computed by
. Afterwards, we adjust the weight factors
to deal with partial occlusions. If the dissimilarity measure value
between template feature point
and its matching location
is high,
is decreased by
(i.e.,
) to degrade the contribution of
. Otherwise, if the dissimilarity measure value is low,
is increased by
(i.e.,
) to upgrade the contribution of
. In this way, the actual matching locations
occluded by other objects in the scene will be considered less to optimize the overall objective function.
In the second iteration, we fix the weight factors
and define a shrunken trust region centered at the matching location
for each template feature point
. Only the scene feature points located within the trust region are used to construct the convex dissimilarity measure functions (See
Figure 5b). Mathematically, the trust region of
in the second iteration is defined as follows:
where
is the side length of the trust region in the second iteration. Here,
and
are the height and width of the scene, respectively. Then, we apply the convex dissimilarity measure functions constructed using the scene feature points in trust regions
to optimize the overall objective function to obtain a set of tighter affine transformation parameters
. The tighter matching locations are represented by
. Afterwards, we adjust the weight factors
using the same principle as described in the first iteration.
The same optimization operations are performed in the subsequent iterations with smaller and smaller trust regions that consider fewer and fewer scene feature points (See
Figure 5c). Specifically, in the
kth iteration, the trust region is defined as follows:
where
is the side length of the trust region in the kth iteration. Generally, four iterations are enough. Through the proposed successive convexification scheme, we can obtain a tighter matching result with satisfactory consideration of handling partial occlusions.
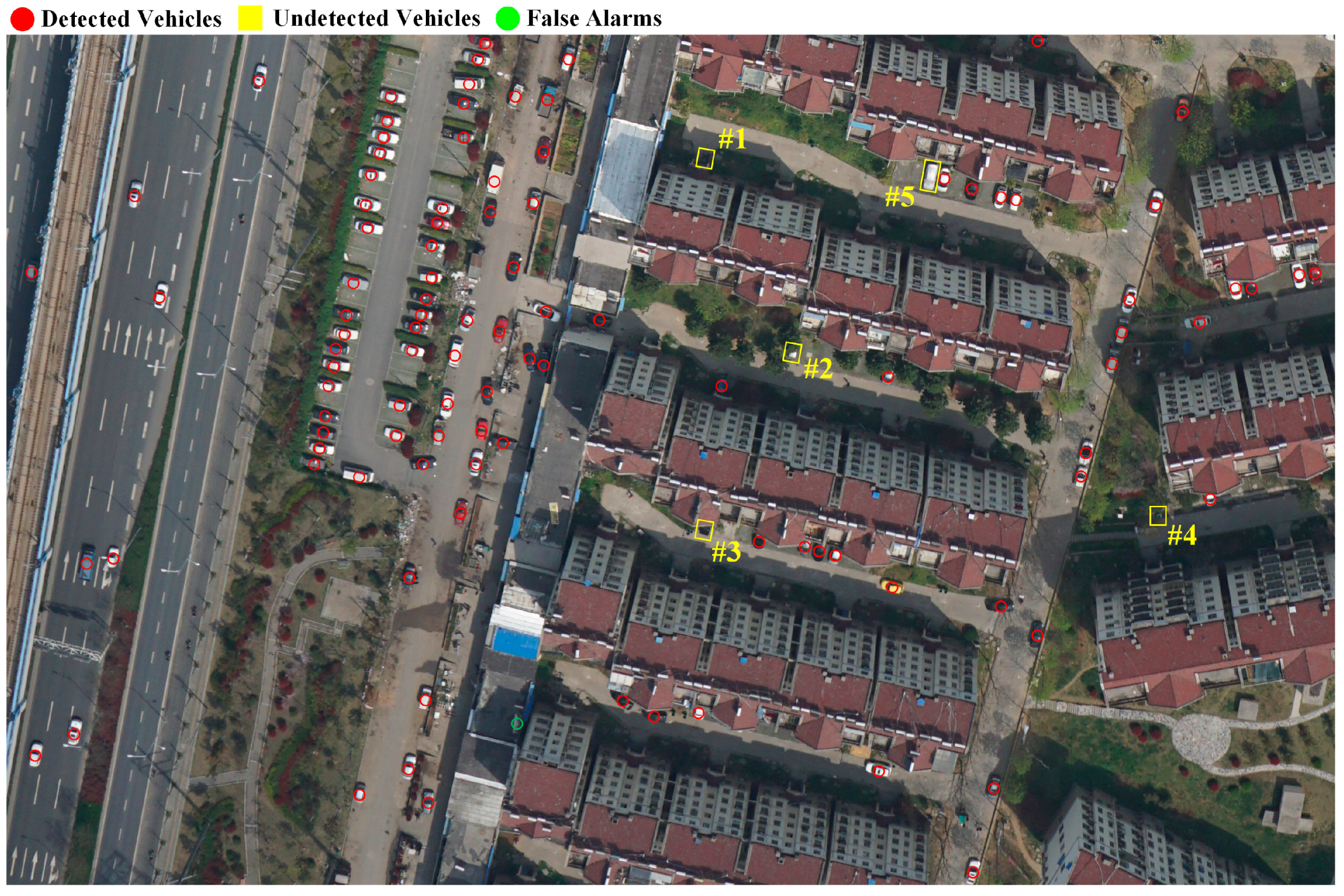
After optimizing the overall objective function in Equation (9) through the proposed successive convexification scheme, we obtain two results: a set of affine transformation parameters
and a matching cost (i.e., the value of the overall objective function). The corresponding matching locations in the patch can be computed by
, and the matching cost is used to estimate the existence of a vehicle in the patch. If the matching cost lies below a predefined threshold, we confirm that there is a vehicle instance in the patch. Then, as illustrated in
Figure 6a, the location of the vehicle is estimated as the geometric centroid of the matching locations
. However, as shown in
Figure 6b, a vehicle instance might exist in multiple patches by using the superpixel segmentation-based patch generation strategy. Consequently, multiple locations are estimated for a single vehicle instance. In fact, these locations associated with a vehicle instance exhibit a cluster form and are extremely close to each other. Thus, we further adopt a non-maximum suppression process [
55] to eliminate the repetitive detection results. The final vehicle detection result is illustrated in
Figure 5.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}