Tensor Discriminant Analysis via Compact Feature Representation for Hyperspectral Images Dimensionality Reduction


Abstract
:1. Introduction
2. Related Work
2.1. Linear Discriminant Analysis
2.2. Tensor Analysis
3. Tensor Discriminant Analysis via Compact Feature Representation
3.1. Tensor Discriminant Analysis
| Algorithm 1: Tensor discriminant analysis |
| INPUT: Original cube hyperspectral image and the corresponding labels, the dimensionality of projection space , spatial size of tensor training samples and , the training samples number of each class , parameter , maximum iteration number and iteration error tolerance . Construct tensor training samples for each class with spatial size Initialize . For For do compute by Equation (11). compute by Equation (12). compute factor matrix by Equation (16). end check end OUTPUT: The optimal factor matrices |
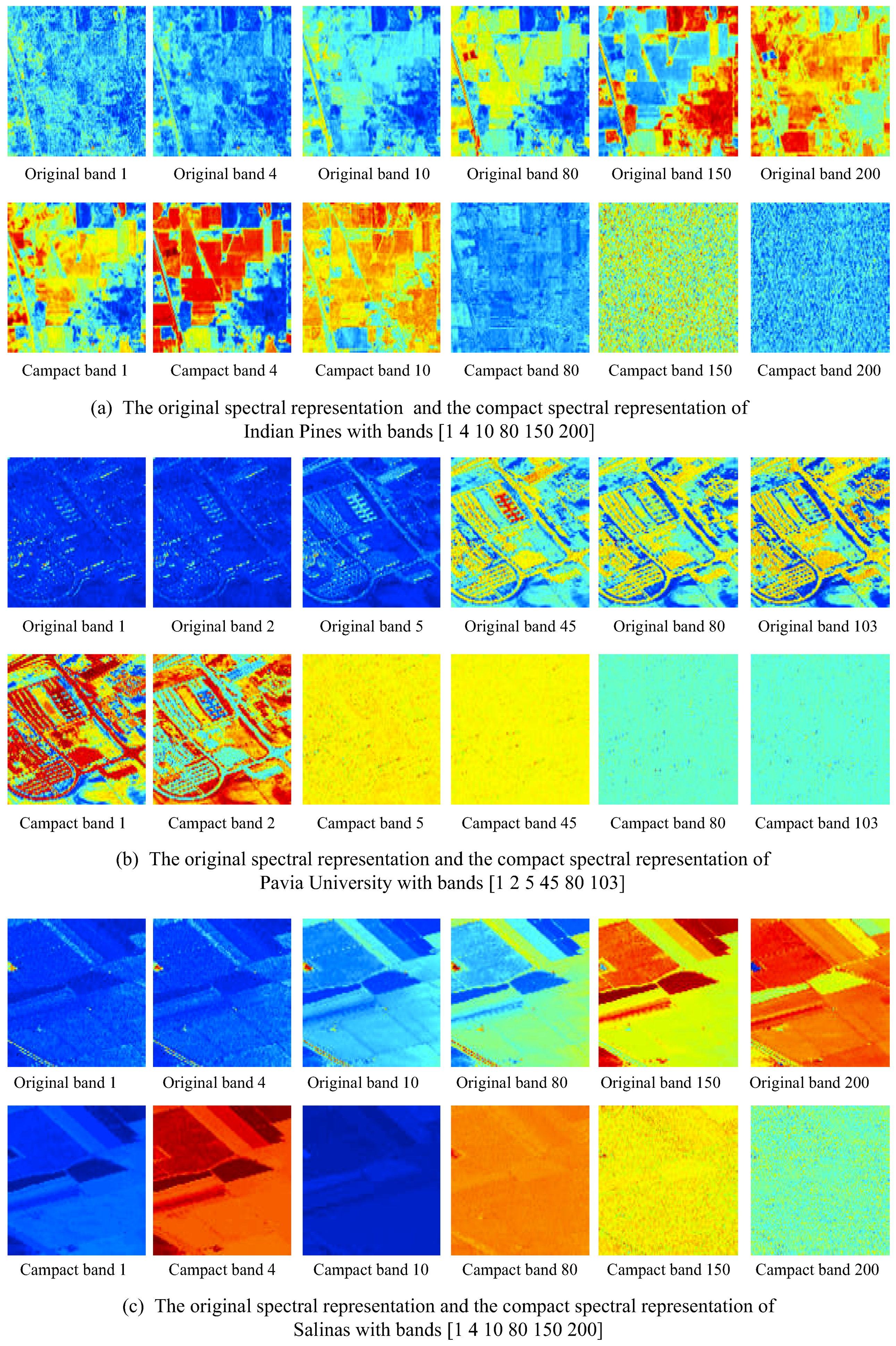
3.2. Compact Feature Representation of Hyperspectral Images
3.3. Dimensionality Reduction of Hyperspectral Images by TDA-CFR
| Algorithm 2: The Proposed TDA-CFR |
| INPUT: Original cube hyperspectral image , the spatial size of sub-tensor samples and , the training samples number of each class , parameter , maximum iteration number and iteration error tolerance . Calculate the compact representation of hyperspectral image by Equation (21). Construct tensor training samples for each class with spatial size Calculate the factor matrices by Algorithm 1. Calculate the low dimensionality projection of all tensor samples by Equation (22). Rearrange the projected dataset . OUTPUT: The dimensionality reduction dataset |
4. Experimental Results and Analysis
4.1. Experimental Setup
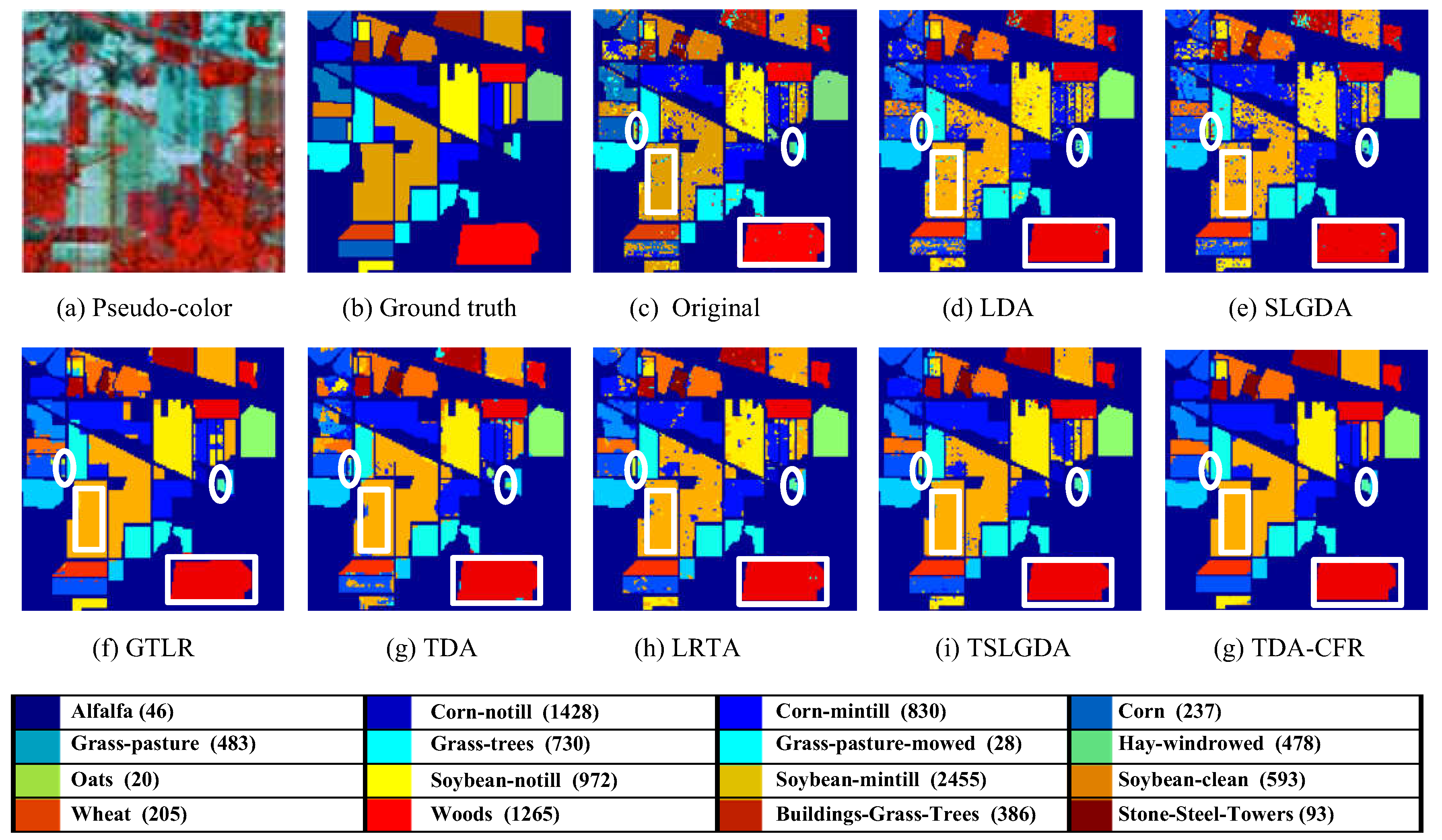
4.2. Classification Results
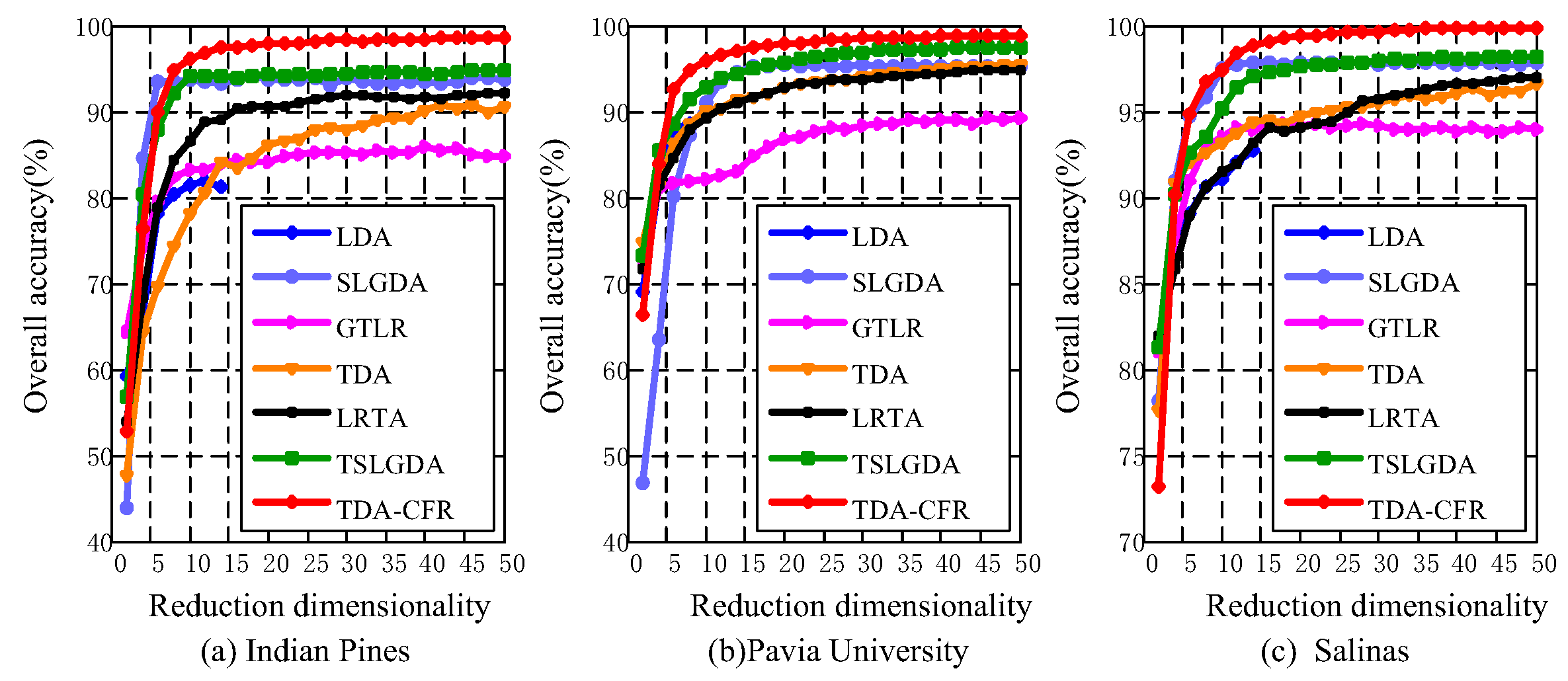
4.3. The Effect of Reduced Dimensionality
4.4. Analysis of Computation Efficiency
5. Discussion
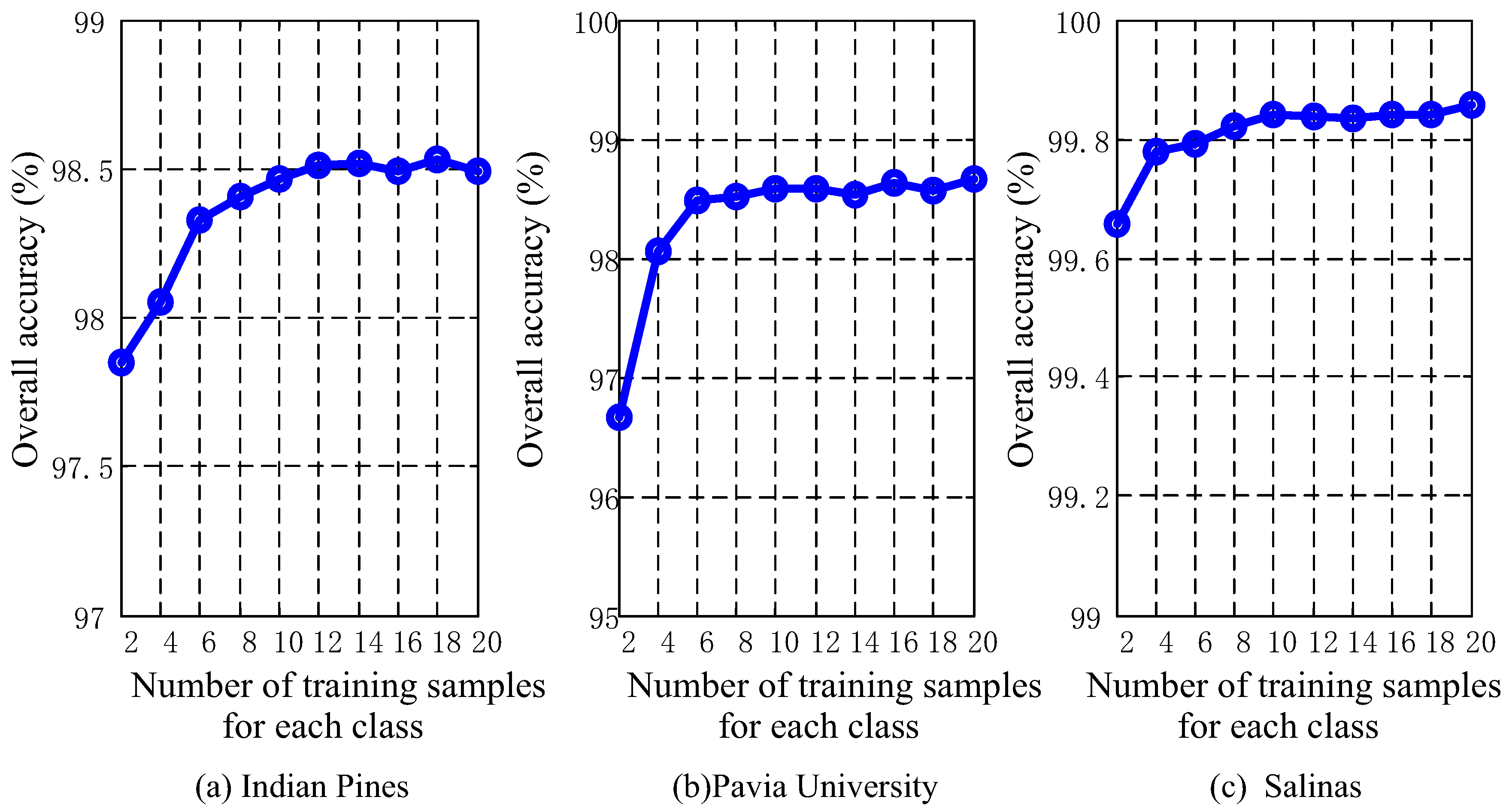
5.1. Discussion of the Number of Training Samples
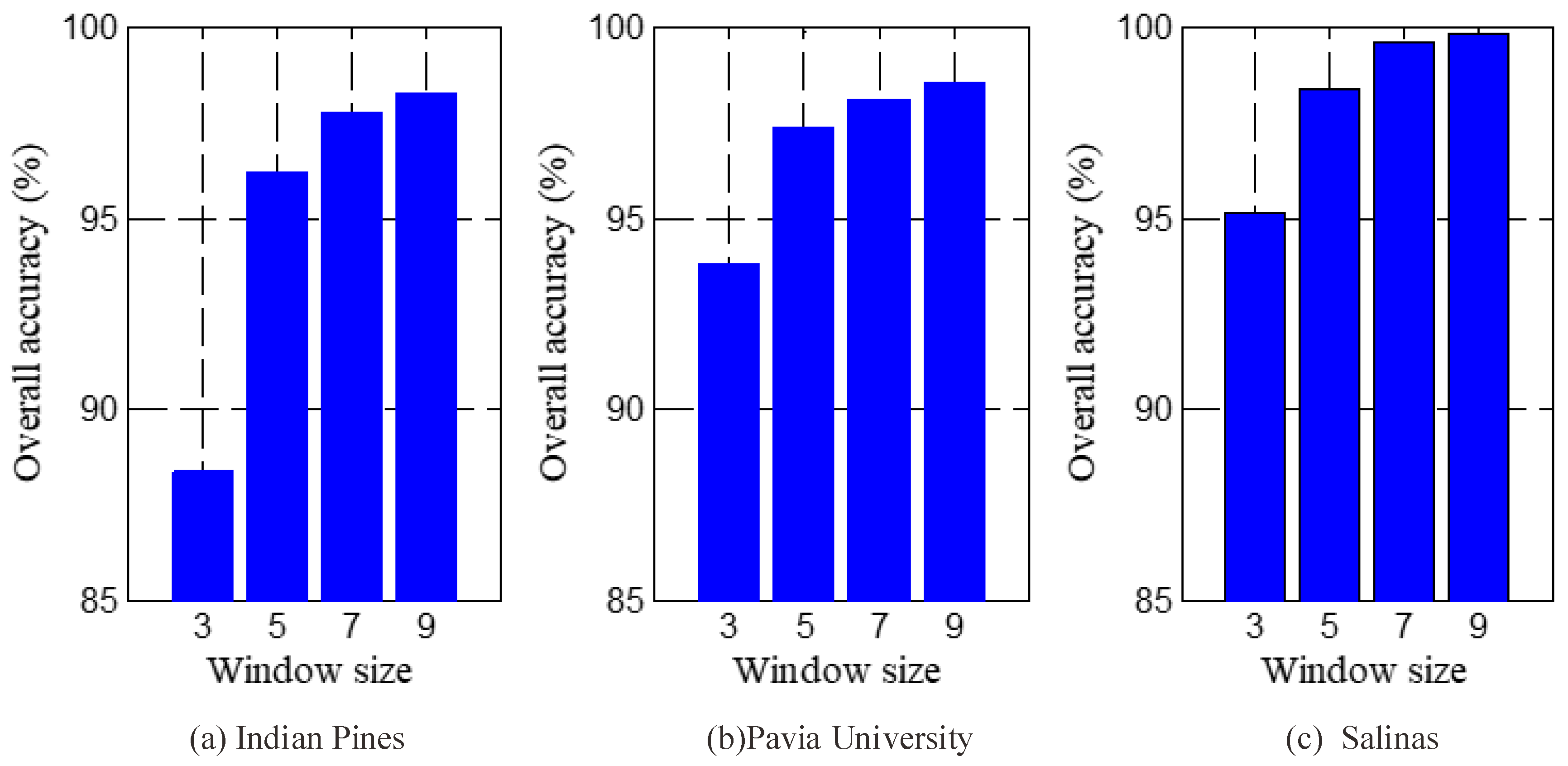
5.2. Discussion of the Spatial Size of Tensor Samples
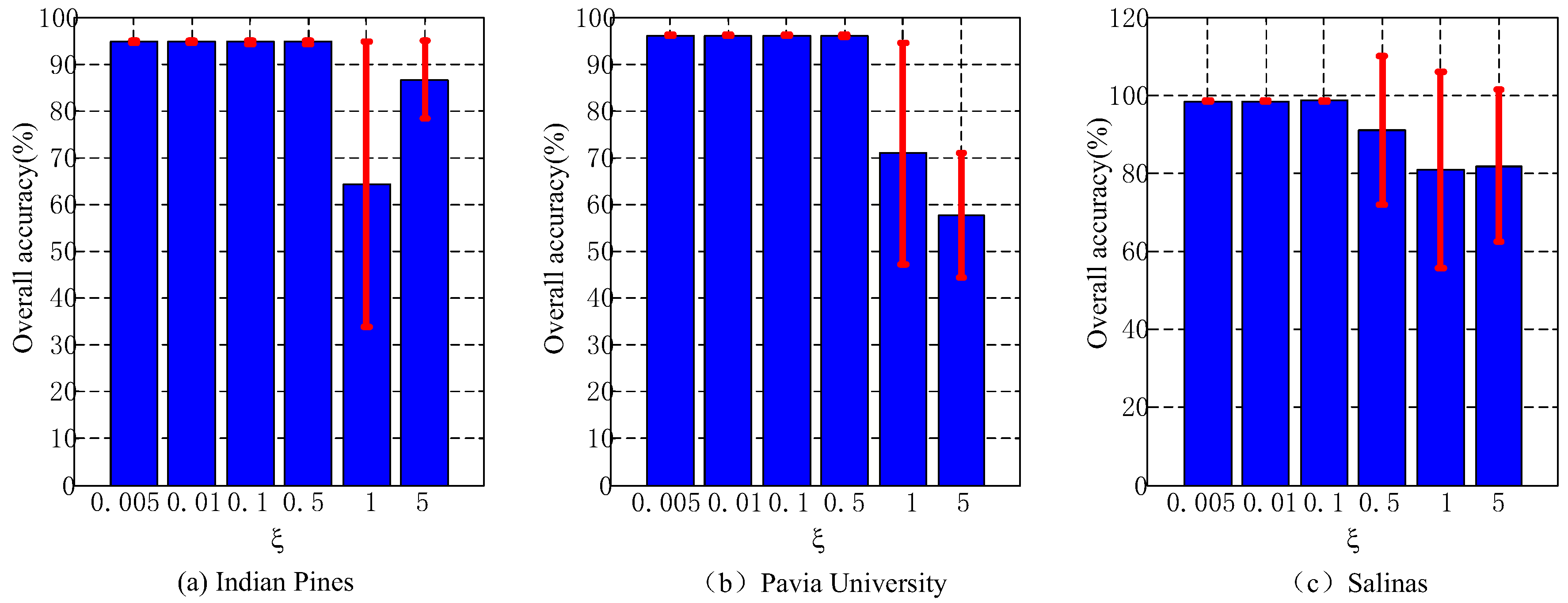
5.3. Discussion of the Parameter
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chang, C.I. A Review of Virtual Dimensionality for Hyperspectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2018, 11, 1285–1305. [Google Scholar] [CrossRef]
- Harsanyi, J.C.; Chang, C. Hyperspectral image classification and dimensionality reduction: An orthogonal subspace projection approach. IEEE Trans. Geosci. Remote Sens. 1994, 32, 779–785. [Google Scholar] [CrossRef]
- Mohanty, R.; Happy, S.L.; Routray, A. A Semisupervised Spatial Spectral Regularized Manifold Local Scaling Cut With HGF for Dimensionality Reduction of Hyperspectral Images. IEEE Trans. Geosci. Remote. Sens. 2018, 57, 3423–3435. [Google Scholar] [CrossRef]
- Du, W.; Qiang, W.; Meng, L.; Hou, Q.; Ling, Z.; Ling, J. Semi-supervised dimension reduction based on hypergraph embedding for hyperspectral images. Int. J. Remote Sens. 2018, 39, 1696–1712. [Google Scholar] [CrossRef]
- Li, J.; Huang, X.; Gamba, P.; Bioucas-Dias, J.M.; Zhang, L.; Benediktsson, J.A.; Plaza, A. Multiple Feature Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1592–1606. [Google Scholar] [CrossRef]
- Luo, F.; Bo, D.; Zhang, L.; Zhang, L.; Tao, D. Feature Learning Using Spatial-Spectral Hypergraph Discriminant Analysis for Hyperspectral Image. IEEE Trans. Cybern. 2019, 49, 2406–2419. [Google Scholar] [CrossRef] [PubMed]
- Cheng, G.; Zhenpeng, L.; Junwei, H.; Xiwen, Y.; Lei, G. Exploring Hierarchical Convolutional Features for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6712–6722. [Google Scholar] [CrossRef]
- Pal, M.; Foody, G.M. Feature Selection for Classification of Hyperspectral Data by SVM. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2297–2307. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Li, X.; Zhao, L. Band Priority Index: A Feature Selection Framework for Hyperspectral Imagery. Remote Sens. 2018, 10, 1095. [Google Scholar] [CrossRef]
- Gong, C.; Zhou, P.; Han, J. RIFD-CNN: Rotation-Invariant and Fisher Discriminative Convolutional Neural Networks for Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Fraley, C.; Raftery, A.E. Model-Based Clustering, Discriminant Analysis, and Density Estimation. Publ. Am. Stat. Assoc. 2002, 97, 611–631. [Google Scholar] [CrossRef]
- Liu, Q.; Lu, H.; Ma, S. Improving kernel Fisher discriminant analysis for face recognition. Circuits Syst. Video Technol. IEEE Trans. 2004, 14, 42–49. [Google Scholar] [CrossRef]
- Prntland, A. Viewbased and modular eigenspaces for face recognition. In Proceedings of the 1994 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 84–91. [Google Scholar]
- Kai, Z.; Min, W.; Yang, S.; Jiao, L. Spatial–Spectral-Graph-Regularized Low-Rank Tensor Decomposition for Multispectral and Hyperspectral Image Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2018, 11, 1030–1040. [Google Scholar]
- Qu, J.; Lei, J.; Li, Y.; Dong, W.; Zeng, Z.; Chen, D. Structure Tensor-Based Algorithm for Hyperspectral and Panchromatic Images Fusion. Remote Sens. 2018, 10, 373. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, Z.; Chanussot, J.; Wei, Z. Nonlocal Patch Tensor Sparse Representation for Hyperspectral Image Super-Resolution. IEEE Trans. Image Process. 2019, 28, 3034–3047. [Google Scholar] [CrossRef] [PubMed]
- Velascoforero, S.; Angulo, J. Classification of hyperspectral images by tensor modeling and additive morphological decomposition. Pattern Recognit. 2013, 46, 566–577. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Wang, B. Band-Wise Nonlinear Unmixing for Hyperspectral Imagery Using an Extended Multilinear Mixing Model. IEEE Trans. Geosci. Remote. Sens. 2018, 56, 6747–6762. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Tao, D.; Huang, X. Tensor Discriminative Locality Alignment for Hyperspectral Image Spectral-Spatial Feature Extraction. IEEE Trans. Geosci. Remote Sens. 2012, 51, 242–256. [Google Scholar] [CrossRef]
- Yan, S.; Xu, D.; Yang, Q.; Zhang, L.; Tang, X.; Zhang, H.J. Multilinear Discriminant Analysis for Face Recognition. IEEE Trans. Image Process. 2007, 16, 212–220. [Google Scholar] [CrossRef]
- Tao, D.; Li, X.; Wu, X.; Maybank, S.J. General tensor discriminant analysis and Gabor features for gait recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1700–1715. [Google Scholar] [CrossRef]
- Nie, F.; Xiang, S.; Song, Y.; Zhang, C. Extracting the optimal dimensionality for local tensor discriminant analysis. Pattern Recognit. 2009, 42, 105–114. [Google Scholar] [CrossRef]
- Zhong, Z.; Fan, B.; Duan, J.; Wang, L.; Ding, K.; Xiang, S.; Pan, C. Discriminant Tensor Spectral Spatial Feature Extraction for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2017, 12, 1028–1032. [Google Scholar] [CrossRef]
- Zhou, P.; Han, J.; Cheng, G.; Zhang, B. Learning Compact and Discriminative Stacked Autoencoder for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2019, 57, 4823–4833. [Google Scholar] [CrossRef]
- Bandos, T.V.; Bruzzone, L.; Camps-Valls, G. Classification of Hyperspectral Images with Regularized Linear Discriminant Analysis. IEEE Trans. Geosci. Remote Sens. 2009, 47, 862–873. [Google Scholar] [CrossRef]
- Wang, H.; Wu, Q.; Shi, L.; Yu, Y.; Ahuja, N. Out-of-core tensor approximation of multi-dimensional matrices of visual data. ACM Trans. Graph. 2005, 24, 527–535. [Google Scholar] [CrossRef]
- Li, Q.; Schonfeld, D. Multilinear Discriminant Analysis for Higher-Order Tensor Data Classification. Pattern Anal. Mach. Intell. IEEE Trans. 2014, 36, 2524–2537. [Google Scholar]
- Lathauwer, L.D.; Moor, B.D.; Vandewalle, J. On the best rank-1 and rank-(R1, R2,...,RN ) approximation of higher-order tensor. SIAM J. Matrix Anal. Appl. 2000, 21, 1324–1342. [Google Scholar] [CrossRef]
- Hyperspectral Remote Sensing Scenes. Available online: http://www.ehu.eus/ccwintco/index.php?title=Hyperspectral_Remote_Sensing_Scenes (accessed on 4 April 2018).
- Li, W.; Liu, J.; Du, Q. Sparse and Low-Rank Graph for Discriminant Analysis of Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4094–4105. [Google Scholar] [CrossRef]
- Renard, N.; Bourennane, S.; Blanc-Talon, J. Denoising and Dimensionality Reduction Using Multilinear Tools for Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2008, 5, 138–142. [Google Scholar] [CrossRef]
- An, J.; Zhang, X.; Jiao, L.C. Dimensionality Reduction Based on Group-Based Tensor Model for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1497–1501. [Google Scholar] [CrossRef]
- Pan, L.; Li, H.C.; Deng, Y.J.; Zhang, F.; Chen, X.D.; Du, Q. Hyperspectral Dimensionality Reduction by Tensor Sparse and Low-Rank Graph-Based Discriminant Analysis. Remote Sens. 2017, 9, 452. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Original | LDA | SLGDA | GTLR | TDA | LRTA | TSLGDA | TDA-CFR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | |
| 1 | 72.71 ±9.97 | 64.17 ±9.7 | 73.33 ±7.64 | 67.36 ±10.97 | 76.6 ±7.84 | 65.9 ±8.81 | 90.42 ±6.94 | 89.86 ±8.03 | 75.76 ±17.07 | 74.31 ±13.72 | 85.14 ±6.76 | 81.53 ±6.08 | 95.21 ±4.27 | 91.35 ±7.16 | 96.46 ±3.73 | 95.14 ±5.17 |
| 2 | 84.3 ±1.61 | 64.51 ±1.86 | 80.37 ±1.84 | 58.83 ±5.61 | 80.66 ±1.97 | 63.23 ±2.02 | 90.38 ±2.43 | 91.12 ±2.01 | 87.45 ±3.65 | 89.31 ±2.75 | 91.02 ±1.32 | 89.83 ±1.58 | 93.45 ±1.85 | 94.81 ±1.55 | 97.56 ±0.99 | 97.89 ±0.65 |
| 3 | 76.61 ±2.37 | 62.75 ±2.41 | 66.91 ±2.02 | 48.72 ±6.06 | 76.1 ±2.9 | 62.77 ±2.52 | 90.42 ±2.82 | 90.63 ±2.73 | 82.56 ±5.62 | 88.58 ±3.97 | 85.84 ±1.87 | 86.22 ±2.08 | 92.75 ±2.86 | 92.99 ±2.29 | 98.34 ±0.97 | 97.88 ±0.87 |
| 4 | 71.11 ±7 | 47.1 ±6.31 | 64.71 ±5.25 | 42.57 ±9.07 | 68.56 ±6.61 | 45.27 ±5.39 | 87.6 ±4.66 | 88.98 ±3.57 | 69.22 ±14.62 | 79.51 ±6.5 | 85.68 ±4.58 | 86.87 ±4.12 | 92.38 ±3.72 | 92.86 ±3.55 | 96.43 ±3.01 | 96.68 ±1.87 |
| 5 | 93.71 ±1.61 | 90.77 ±1.78 | 92.38 ±1.84 | 86.63 ±4.1 | 93.06 ±2.11 | 89.68 ±2.21 | 95.59 ±2.43 | 95.72 ±2.51 | 92.58 ±2.25 | 92.94 ±2.85 | 97.01 ±2.08 | 95.59 ±2.22 | 95.91 ±2.35 | 96.15 ±1.83 | 98.16 ±1.56 | 97.52 ±1.64 |
| 6 | 96.31 ±1.31 | 94.78 ±1.55 | 95.9 ±1.21 | 92.51 ±2.12 | 95.84 ±2.07 | 94.77 ±1.64 | 94.79 ±3.09 | 94.86 ±3.08 | 95.74 ±1.39 | 96.28 ±2.08 | 99.51 ±0.48 | 99.61 ±0.37 | 97.94 ±0.82 | 97.37 ±1.65 | 99 ±0.63 | 98.66 ±0.86 |
| 7 | 77.39 ±9.68 | 79.71 ±17 | 73.83 ±13.83 | 54.33 ±16.67 | 80.43 ±8.82 | 81.01 ±8.36 | 100 ±0 | 100 ±0 | 60.87 ±28 | 84.49 ±13 | 80.58 ±10 | 79.13 ±10 | 85.00 ±13.36 | 90.22 ±8.79 | 94.49 ±6.64 | 93.77 ±7.75 |
| 8 | 98.35 ±0.87 | 97.78 ±1.07 | 98.33 ±0.64 | 97.54 ±1.38 | 97.93 ±1.22 | 97.3 ±1.47 | 98.13 ±3.05 | 98.61 ±2.69 | 98.06 ±1.77 | 97.85 ±1.56 | 99.85 ±0.31 | 99.85 ±0.28 | 99.85 ±0.27 | 99.68 ±0.38 | 99.97 ±0.13 | 99.98 ±0.07 |
| 9 | 72.96 ±15.09 | 57.59 ±11.61 | 73.96 ±17.31 | 61.04 ±20.01 | 67.41 ±16.02 | 50.37 ±14.41 | 33.89 ±22.56 | 35.19 ±18.33 | 18.33 ±23.27 | 59.26 ±17.99 | 86.67 ±19.01 | 92.22 ±11.26 | 79.44 ±18.1 | 75.83 ±15.94 | 81.67 ±18.93 | 78.52 ±18.35 |
| 10 | 78.71 ±1.79 | 73.95 ±2.51 | 69.73 ±2.48 | 56.64 ±5.54 | 77.47 ±3.28 | 72.27 ±3.3 | 91.16 ±3.51 | 90.88 ±3.34 | 78.55 ±6.14 | 88.88 ±2.88 | 85.65 ±2.87 | 90.23 ±2.07 | 90.43 ±1.99 | 91.84 ±3.51 | 95.9 ±2.13 | 96.88 ±1.69 |
| 11 | 84.12 ±1.44 | 77.05 ±1.3 | 82.87 ±1.32 | 67.86 ±3.34 | 80.94 ±1.5 | 76.11 ±1.48 | 99.4 ±0.62 | 98.22 ±0.88 | 91.96 ±1.84 | 92.87 ±2.18 | 89.38 ±1.9 | 94.28 ±1.06 | 95.07 ±1.43 | 96.41 ±0.99 | 98.69 ±0.62 | 98.94 ±0.48 |
| 12 | 83.64 ±2.51 | 57.13 ±2.61 | 75.61 ±2.72 | 62.65 ±7.63 | 81.7 ±3.48 | 56.15 ±2.73 | 82.17 ±3.76 | 81.7 ±3.4 | 81.46 ±7.5 | 84.35 ±5.01 | 90.75 ±2.47 | 89.08 ±2.84 | 93.18 ±2.92 | 94.12 ±1.83 | 97.49 ±1.34 | 97.13 ±1.25 |
| 13 | 98.88 ±0.9 | 97.89 ±1.54 | 98.84 ±1.06 | 96.96 ±3.7 | 98.56 ±1.41 | 97.84 ±1.74 | 93.33 ±8.09 | 93.28 ±8.15 | 92.11 ±4.61 | 93.65 ±5.21 | 99.88 ±0.26 | 99.93 ±0.18 | 97.95 ±1.65 | 95.92 ±3.00 | 98.67 ±1.13 | 97.96 ±1.48 |
| 14 | 94.49 ±1.51 | 93.64 ±1.48 | 95.93 ±1.21 | 92.81 ±1.47 | 93.14 ±1.93 | 93.51 ±1.25 | 95.98 ±2.38 | 96.63 ±2.01 | 97.23 ±1.25 | 96.62 ±1.08 | 96.03 ±1.61 | 98.44 ±0.57 | 98.50 ±0.72 | 98.84 ±0.72 | 99.45 ±0.62 | 99.65 ±0.26 |
| 15 | 61.05 ±4.97 | 44.53 ±3.78 | 71.79 ±4.91 | 56.49 ±6.43 | 61.3 ±5.47 | 45.44 ±3.83 | 93.51 ±3.93 | 93.78 ±3.67 | 87.55 ±5.78 | 90.31 ±4.22 | 86.36 ±4.14 | 85.67 ±3.45 | 93.67 ±2.95 | 94.30 ±3.65 | 98.76 ±1.29 | 98.9 ±0.98 |
| 16 | 91.14 ±4.43 | 91.06 ±4.54 | 89.25 ±4.37 | 78.25 ±8.84 | 91.65 ±4.49 | 90.51 ±4.15 | 62 ±13.27 | 59.96 ±13.22 | 91.49 ±6.04 | 91.88 ±4.53 | 94.08 ±5.08 | 92.94 ±5.7 | 90.59 ±7.06 | 89.53 ±6.22 | 94.27 ±6.17 | 93.33 ±5.08 |
| OA | 85.44 ±0.41 | 76.27 ±0.6 | 82.81 ±0.51 | 70.56 ±3.37 | 83.62 ±0.62 | 75.55 ±0.58 | 93.52 ±0.66 | 93.44 ±0.7 | 88.98 ±2.07 | 91.54 ±2.1 | 91.49 ±0.7 | 93.07 ±0.56 | 94.86 ±1.02 | 95.55 ±1.13 | 98.18 ±0.3 | 98.26 ±0.22 |
| AA | 83.47 ±1.1 | 74.65 ±1.33 | 81.48 ±1.87 | 70.08 ±5.31 | 82.58 ±1.44 | 73.88 ±1.37 | 87.42 ±1.87 | 87.46 ±1.65 | 81.31 ±4.47 | 87.57 ±2.96 | 90.84 ±1.2 | 91.34 ±1.05 | 93.21 ±1.70 | 93.26 ±2.2 | 96.58 ±1.43 | 96.18 ±1.24 |
| Kappa | 0.85 ±0 | 0.76 ±0.01 | 0.84 ±0 | 0.73 ±0.03 | 0.83 ±0.01 | 0.75 ±0.01 | 0.93 ±0.01 | 0.93 ±0.01 | 0.89 ±0.02 | 0.91 ±0.02 | 0.91 ±0.01 | 0.93 ±0.01 | 0.95 ±0.01 | 0.95 ±0.01 | 0.98 ±0 | 0.98 ±0 |
| Class | Original | LDA | SLGDA | GTLR | TDA | LRTA | TSLGDA | TDA-CFR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | |
| 1 | 90.21 ±0.63 | 75.76 ±0.99 | 92.43 ±0.44 | 85.62 ±0.66 | 89.42 ±0.9 | 78.05 ±0.8 | 92.71 ±1.6 | 95.01 ±0.84 | 95.96 ±1.25 | 95.54 ±1.31 | 93.56 ±0.67 | 96.71 ±0.4 | 97.09 ±0.72 | 93.51 ±1.77 | 98.58 ±0.49 | 98.03 ±0.54 |
| 2 | 95.3 ±0.36 | 94.91 ±0.3 | 95.12 ±0.25 | 93.54 ±0.3 | 94.14 ±0.41 | 94.3 ±0.36 | 99.85 ±0.13 | 99.41 ±0.22 | 99.3 ±0.34 | 99.89 ±0.08 | 98.18 ±0.23 | 99.51 ±0.09 | 99.52 ±0.16 | 99.84 ±0.09 | 99.88 ±0.07 | 99.98 ±0.03 |
| 3 | 71.52 ±1.65 | 59.97 ±2.07 | 65.04 ±1.42 | 66.63 ±1.3 | 70.43 ±2.41 | 61.48 ±1.77 | 91.56 ±2.04 | 94.97 ±1.52 | 79.33 ±3.4 | 90.37 ±2.5 | 76.70 ±1.41 | 91.70 ±1.59 | 86.12 ±2.31 | 90.93 ±2.34 | 94.27 ±1.6 | 96.51 ±1.05 |
| 4 | 93.08 ±0.73 | 84.5 ±1.13 | 88.21 ±0.68 | 85.88 ±0.9 | 91.92 ±1.13 | 83.8 ±1.38 | 73.47 ±2.39 | 78.62 ±1.92 | 95.67 ±0.88 | 93.02 ±1.85 | 92.53 ±0.79 | 94.02 ±0.63 | 96.91 ±0.88 | 94.22 ±1.37 | 97.11 ±0.44 | 94.56 ±0.94 |
| 5 | 99.19 ±0.41 | 99.31 ±0.36 | 99.81 ±0.18 | 99.74 ±0.17 | 99.21 ±0.55 | 99.3 ±0.39 | 82.59 ±2.17 | 93.45 ±1.66 | 99.92 ±0.11 | 99.88 ±0.16 | 99.97 ±0.06 | 99.9 ±0.12 | 99.94 ±0.12 | 99.98 ±0.04 | 99.98 ±0.04 | 99.91 ±0.1 |
| 6 | 79.27 ±1.18 | 56.95 ±0.85 | 77.47 ±0.87 | 69.62 ±1.1 | 77.85 ±1.2 | 57.03 ±1.36 | 98.85 ±0.5 | 99.64 ±0.24 | 92.17 ±2.8 | 99.44 ±0.4 | 93.13 ±0.79 | 99.63 ±0.17 | 97.62 ±0.87 | 98.75 ±0.59 | 99.63 ±0.27 | 99.96 ±0.04 |
| 7 | 82.83 ±1.38 | 77.86 ±1.69 | 65.03 ±2.86 | 76.31 ±1.64 | 81.31 ±2.49 | 76.85 ±1.74 | 94.25 ±1.43 | 97.1 ±1.12 | 88.81 ±4.7 | 91.58 ±3 | 93.16 ±1.67 | 96.65 ±1.17 | 94.30 ±1.72 | 96.56 ±1.69 | 98.53 ±0.82 | 99.11 ±0.64 |
| 8 | 78.69 ±1.74 | 76.75 ±1.4 | 85.05 ±1.05 | 73.17 ±0.92 | 75.73 ±1.26 | 75.24 ±1.31 | 88.15 ±1.89 | 92.72 ±1.62 | 86.12 ±2.66 | 90.65 ±2.19 | 80.93 ±1.03 | 88.05 ±0.86 | 89.35 ±2.06 | 91.23 ±2.58 | 93.28 ±1.3 | 96.27 ±0.86 |
| 9 | 98.94 ±0.27 | 92.24 ±1.75 | 99.14 ±0.33 | 96.54 ±0.85 | 98.85 ±0.28 | 92.93 ±1.95 | 65.59 ±3.09 | 77.01 ±3.35 | 97.07 ±1.07 | 90.83 ±3.09 | 95.63 ±1.32 | 96.67 ±0.9 | 96.47 ±1.82 | 80.91 ±5.09 | 96.94 ±1.15 | 90.95 ±2.5 |
| OA | 89.63 ±0.21 | 82.89 ±0.26 | 89.02 ±0.14 | 85.51 ±0.22 | 88.39 ±0.25 | 82.87 ±0.21 | 93.59 ±0.41 | 95.53 ±0.23 | 95.14 ±0.59 | 96.86 ±0.73 | 93.67 ±0.14 | 97.11 ±0.16 | 96.93 ±0.41 | 96.54 ±0.82 | 98.46 ±0.16 | 98.51 ±0.11 |
| AA | 87.67 ±0.29 | 79.81 ±0.43 | 85.26 ±0.36 | 83.01 ±0.3 | 86.54 ±0.43 | 79.89 ±0.38 | 87.44 ±0.62 | 91.99 ±0.44 | 92.71 ±0.94 | 94.58 ±1.28 | 91.53 ±0.26 | 95.87 ±0.31 | 95.26 ±0.66 | 93.99 ±1.32 | 97.58 ±0.29 | 97.25 ±0.31 |
| Kappa | 0.88 ±0 | 0.8 ±0 | 0.88 ±0 | 0.85 ±0 | 0.86 ±0 | 0.8 ±0 | 0.92 ±0.01 | 0.95 ±0 | 0.94 ±0.01 | 0.96 ±0.01 | 0.93 ±0 | 0.97 ±0 | 0.96 ±0 | 0.96 ±0.01 | 0.98 ±0 | 0.98 ±0 |
| Class | Original | LDA | SLGDA | GTLR | TDA | LRTA | TSLGDA | TDA-CFR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | SVM | 1NN | |
| 1 | 99.61 ±0.3 | 99.3 ±0.24 | 99.93 ±0.07 | 99.87 ±0.15 | 99.47 ±0.49 | 99.31 ±0.31 | 98.3 ±0.86 | 99.08 ±0.64 | 99.4 ±0.62 | 99.79 ±0.22 | 99.91 ±0.15 | 99.85 ±0.16 | 99.97 ±0.05 | 99.86 ±0.07 | 99.98 ±0.05 | 99.97 ±0.05 |
| 2 | 99.76 ±0.18 | 99.32 ±0.24 | 99.96 ±0.03 | 99.95 ±0.03 | 99.69 ±0.26 | 99.27 ±0.26 | 98.75 ±0.76 | 99.31 ±0.57 | 99.77 ±0.24 | 99.95 ±0.09 | 100 ±0.01 | 100 ±0.01 | 100 ±0 | 100 ±0 | 100 ±0 | 100 ±0 |
| 3 | 99.73 ±0.14 | 97.96 ±0.64 | 99.78 ±0.11 | 99.72 ±0.11 | 99.57 ±0.21 | 97.8 ±0.7 | 98.43 ±1.1 | 99.15 ±0.7 | 99.92 ±0.11 | 99.9 ±0.16 | 99.94 ±0.12 | 99.93 ±0.09 | 99.90 ±0.19 | 99.9 ±0.12 | 100 ±0 | 100 ±0 |
| 4 | 99.25 ±0.42 | 99.33 ±0.33 | 99.26 ±0.27 | 99.08 ±0.39 | 99.31 ±0.46 | 99.46 ±0.22 | 92.01 ±3.09 | 93.68 ±2.41 | 98.52 ±0.5 | 98.46 ±0.72 | 97.49 ±0.91 | 98.35 ±0.69 | 96.68 ±1.77 | 97.46 ±1.43 | 98.84 ±0.76 | 99.36 ±0.39 |
| 5 | 99.19 ±0.26 | 96.93 ±0.64 | 99.1 ±0.17 | 98.95 ±0.23 | 98.75 ±0.49 | 96.88 ±0.56 | 95.56 ±1.44 | 96.53 ±1.09 | 99.43 ±0.37 | 99.67 ±0.29 | 98.3 ±0.44 | 99.14 ±0.31 | 98.48 ±0.48 | 98.9 ±0.79 | 99.19 ±0.51 | 99.6 ±0.18 |
| 6 | 99.83 ±0.11 | 99.77 ±0.12 | 99.95 ±0.03 | 99.94 ±0.03 | 99.76 ±0.18 | 99.7 ±0.17 | 96.9 ±0.88 | 96.95 ±0.91 | 99.99 ±0.01 | 99.99 ±0.01 | 99.97 ±0.03 | 99.95 ±0.03 | 99.99 ±0.01 | 100 ±0 | 100 ±0.01 | 100 ±0.01 |
| 7 | 99.57 ±0.18 | 99.44 ±0.17 | 99.94 ±0.04 | 99.91 ±0.06 | 99.65 ±0.15 | 99.5 ±0.15 | 97.5 ±1.04 | 97.41 ±0.9 | 99.75 ±0.27 | 99.82 ±0.17 | 99.99 ±0.01 | 99.99 ±0.03 | 99.99 ±0.01 | 99.98 ±0.02 | 100 ±0.01 | 99.99 ±0.03 |
| 8 | 83.54 ±0.88 | 77.74 ±0.84 | 89.06 ±0.56 | 79 ±0.73 | 87.88 ±0.66 | 77.36 ±0.67 | 99.54 ±0.18 | 99.32 ±0.27 | 92.51 ±1.06 | 99.16 ±0.4 | 93.03 ±0.72 | 94.26 ±0.32 | 95.76 ±1.08 | 95.75 ±2.45 | 99.68 ±0.15 | 99.86 ±0.08 |
| 9 | 99.83 ±0.14 | 99.11 ±0.31 | 99.91 ±0.08 | 99.76 ±0.13 | 99.45 ±0.34 | 99.04 ±0.35 | 99.15 ±0.58 | 99.55 ±0.36 | 99.99 ±0.03 | 99.99 ±0.03 | 99.84 ±0.13 | 99.92 ±0.05 | 99.98 ±0.01 | 99.99 ±0.02 | 100 ±0 | 100 ±0 |
| 10 | 97.31 ±0.56 | 94.74 ±0.65 | 98.09 ±0.32 | 97.84 ±0.35 | 96.87 ±0.58 | 94.51 ±0.73 | 97.47 ±0.9 | 97.66 ±0.74 | 99.49 ±0.31 | 99.69 ±0.26 | 99.22 ±0.28 | 99.01 ±0.24 | 99.50 ±0.64 | 99.45 ±0.38 | 99.96 ±0.12 | 99.92 ±0.24 |
| 11 | 99.16 ±0.54 | 98.84 ±0.73 | 99.14 ±0.4 | 98.26 ±0.52 | 98.92 ±0.82 | 98.59 ±0.83 | 95.27 ±2.34 | 95.16 ±2.29 | 99.86 ±0.28 | 99.81 ±0.35 | 99.59 ±0.32 | 99.03 ±0.47 | 99.93 ±0.09 | 99.93 ±0.12 | 99.99 ±0.04 | 100 ±0 |
| 12 | 99.9 ±0.12 | 99.81 ±0.12 | 99.76 ±0.16 | 99.65 ±0.21 | 99.87 ±0.16 | 99.8 ±0.21 | 95.77 ±1.67 | 95.66 ±1.68 | 99.91 ±0.2 | 99.97 ±0.13 | 99.87 ±0.14 | 99.6 ±0.2 | 99.96 ±0.06 | 99.93 ±0.12 | 100 ±0 | 100 ±0.01 |
| 13 | 99.17 ±0.66 | 97.79 ±0.61 | 99.05 ±0.41 | 98.95 ±0.28 | 99.22 ±0.66 | 97.85 ±0.58 | 89.39 ±3.47 | 89.13 ±3.85 | 99.7 ±0.39 | 99.94 ±0.16 | 99.41 ±0.34 | 98.95 ±0.52 | 99.76 ±0.29 | 99.48 ±0.62 | 99.88 ±0.18 | 99.96 ±0.1 |
| 14 | 97.75 ±0.95 | 95.04 ±1.41 | 97.71 ±0.56 | 97 ±0.9 | 98.09 ±0.68 | 95.5 ±0.87 | 88.72 ±3.66 | 87.6 ±3.69 | 99.28 ±0.74 | 99.71 ±0.49 | 99.04 ±0.48 | 98.54 ±0.69 | 99.51 ±0.31 | 99.57 ±0.33 | 99.88 ±0.19 | 99.85 ±0.22 |
| 15 | 75.63 ±0.9 | 67.6 ±1.08 | 66.09 ±0.84 | 70.3 ±1.26 | 78.65 ±0.78 | 67.57 ±1.12 | 99 ±0.4 | 98.95 ±0.34 | 83.4 ±2.86 | 99.23 ±0.53 | 80.47 ±1.13 | 91.94 ±0.58 | 93.34 ±2.01 | 93.64 ±3.78 | 99.32 ±0.28 | 99.85 ±0.09 |
| 16 | 98.72 ±0.46 | 98.15 ±0.69 | 99.43 ±0.31 | 99.44 ±0.29 | 98.71 ±0.46 | 98.3 ±0.44 | 98.07 ±0.76 | 98.86 ±0.74 | 99.94 ±0.16 | 99.92 ±0.11 | 99.35 ±0.41 | 99.26 ±0.47 | 99.92 ±0.13 | 99.83 ±0.28 | 99.92 ±0.19 | 99.9 ±0.19 |
| OA | 92.85 ±0.22 | 90 ±0.2 | 92.85 ±0.07 | 91.23 ±0.17 | 94.06 ±0.13 | 89.89 ±0.19 | 97.79 ±0.32 | 97.97 ±0.22 | 96.03 ±0.53 | 99.6 ±0.19 | 95.64 ±0.16 | 97.45 ±0.12 | 98.00 ±0.49 | 98.07 ±1.04 | 99.76 ±0.06 | 99.9 ±0.03 |
| AA | 96.75 ±0.14 | 95.06 ±0.14 | 96.63 ±0.06 | 96.1 ±0.09 | 97.12 ±0.1 | 95.03 ±0.14 | 96.24 ±0.57 | 96.5 ±0.47 | 98.18 ±0.25 | 99.69 ±0.14 | 97.84 ±0.11 | 98.61 ±0.09 | 98.92 ±0.24 | 98.98 ±0.49 | 99.79 ±0.06 | 99.89 ±0.05 |
| Kappa | 0.93 ±0 | 0.9 ±0 | 0.94 ±0 | 0.92 ±0 | 0.94 ±0 | 0.9 ±0 | 0.98 ±0 | 0.98 ±0 | 0.96 ±0.01 | 1 ±0 | 0.96 ±0 | 0.97 ±0 | 0.98 ±0 | 0.98 ±0.01 | 1 ±0 | 1 ±0 |
| Original | LDA | SLGDA | GTLR | TDA | LRTA | TSLGDA | TDA-CFR | |
|---|---|---|---|---|---|---|---|---|
| Indian Pines | 1.89 | 1.02 | 1.73 | 3.25 | 4.98 | 2.72 | 10.54 | 5.02 |
| Pavia University | 10.05 | 7.52 | 5.57 | 10.36 | 67.06 | 5.69 | 62.35 | 68.34 |
| Salinas | 18.02 | 13.46 | 7.82 | 13.71 | 75.62 | 9.14 | 156.25 | 78.02 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
An, J.; Song, Y.; Guo, Y.; Ma, X.; Zhang, X. Tensor Discriminant Analysis via Compact Feature Representation for Hyperspectral Images Dimensionality Reduction. Remote Sens. 2019, 11, 1822. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11151822
An J, Song Y, Guo Y, Ma X, Zhang X. Tensor Discriminant Analysis via Compact Feature Representation for Hyperspectral Images Dimensionality Reduction. Remote Sensing. 2019; 11(15):1822. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11151822
Chicago/Turabian StyleAn, Jinliang, Yuzhen Song, Yuwei Guo, Xiaoxiao Ma, and Xiangrong Zhang. 2019. "Tensor Discriminant Analysis via Compact Feature Representation for Hyperspectral Images Dimensionality Reduction" Remote Sensing 11, no. 15: 1822. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11151822