Remote Sensing-Guided Sampling Design with Both Good Spatial Coverage and Feature Space Coverage for Accurate Farm Field-Level Soil Mapping


Abstract
:1. Introduction
2. Material and Methods
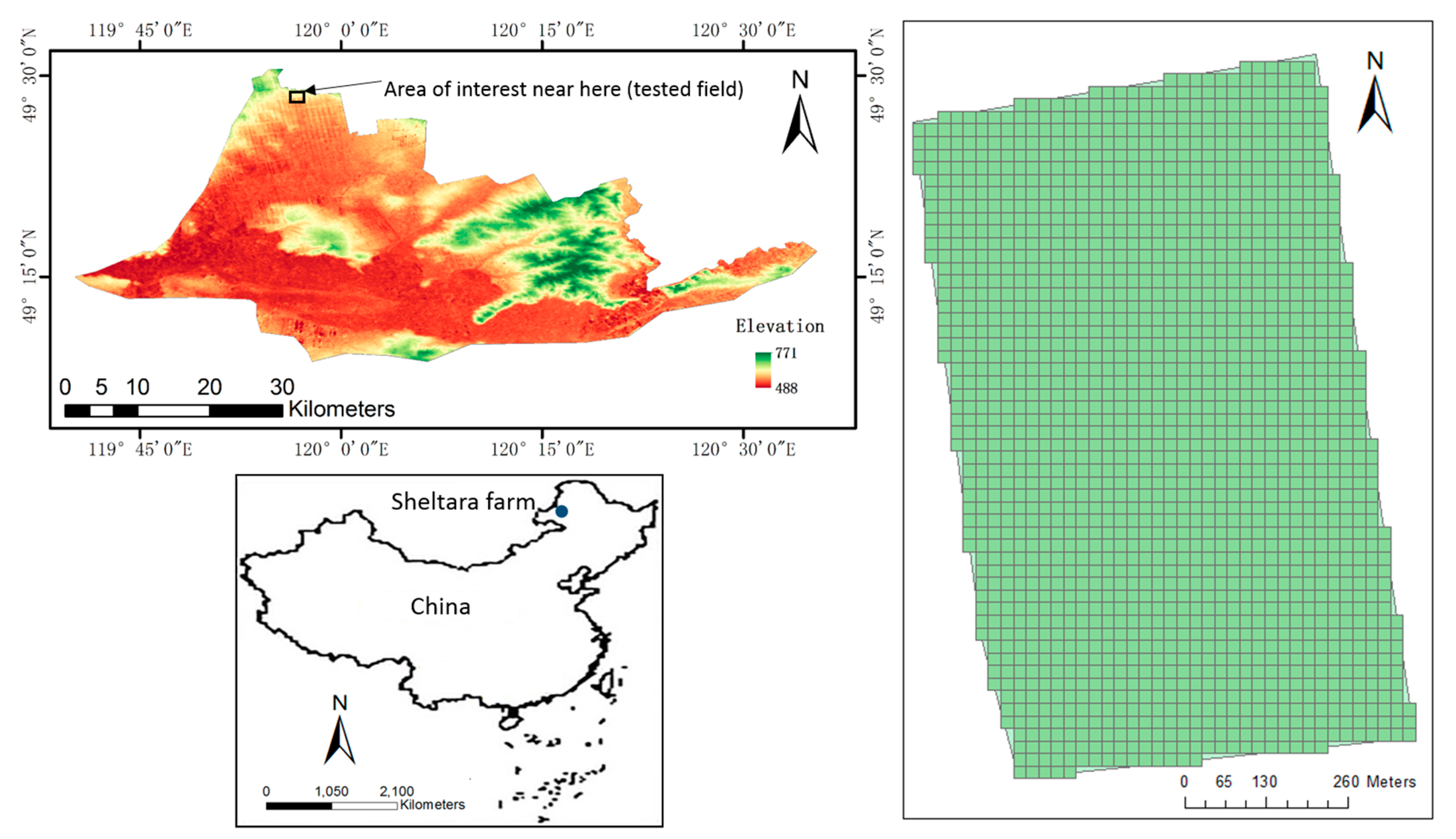
2.1. Study Area and Dataset
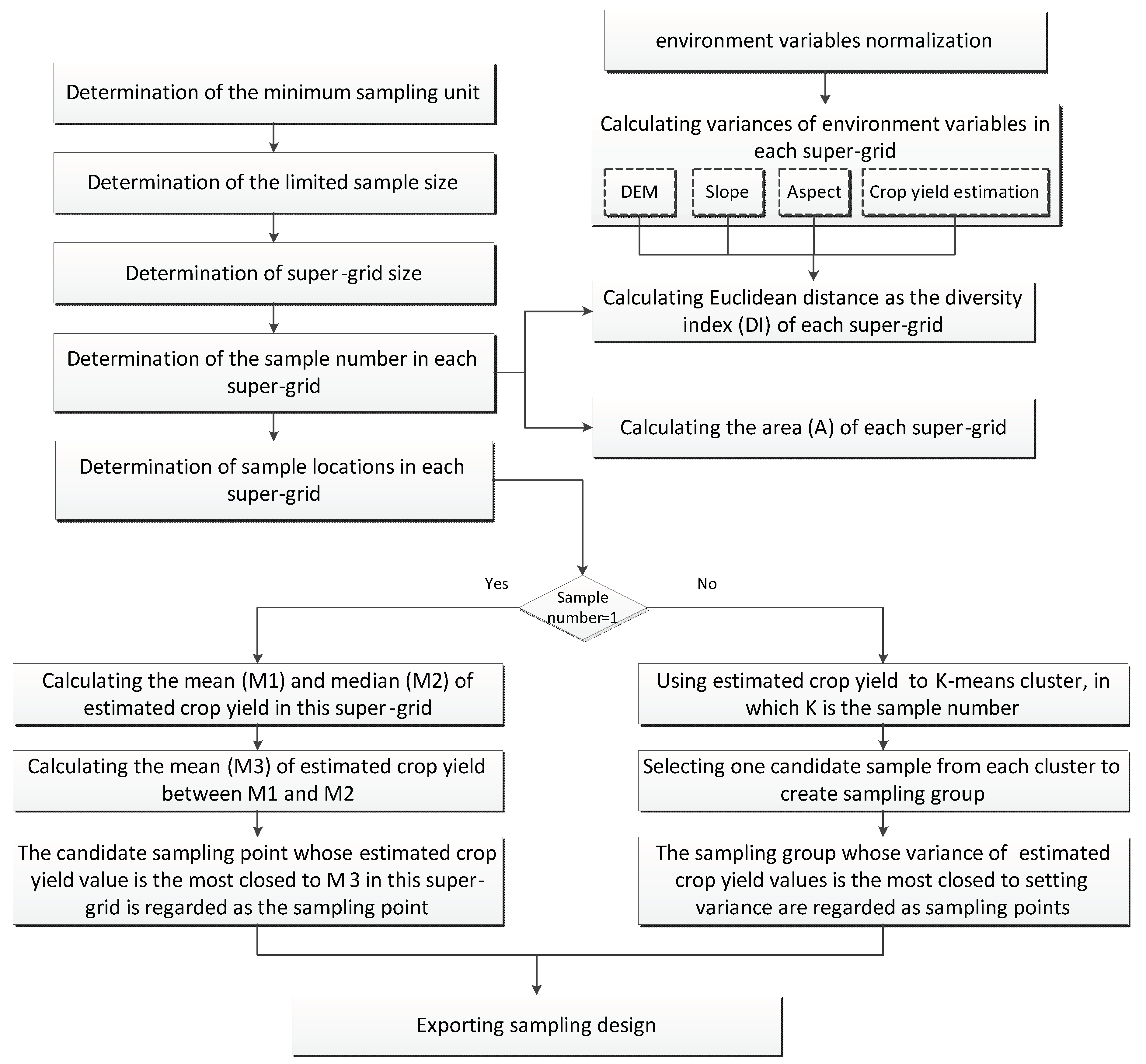
2.2. Sampling Design Method Considering Both Good Spatial Coverage and Feature Space Coverage
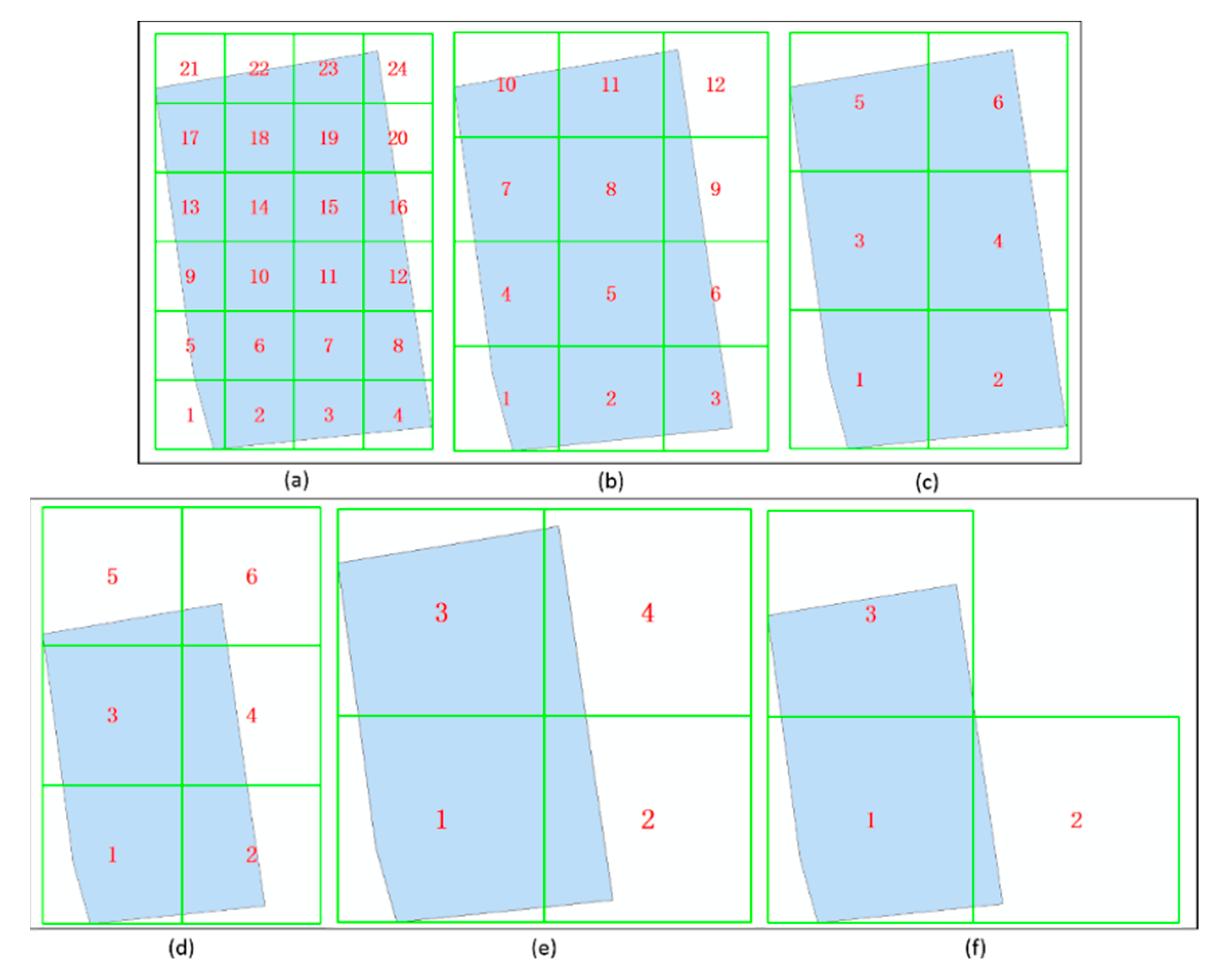
2.2.1. Determination of the Minimum Sampling Unit, Sample Size, and Super-Grid Size
2.2.2. Determination of the Number of Sampling Points in Each Super-Grid
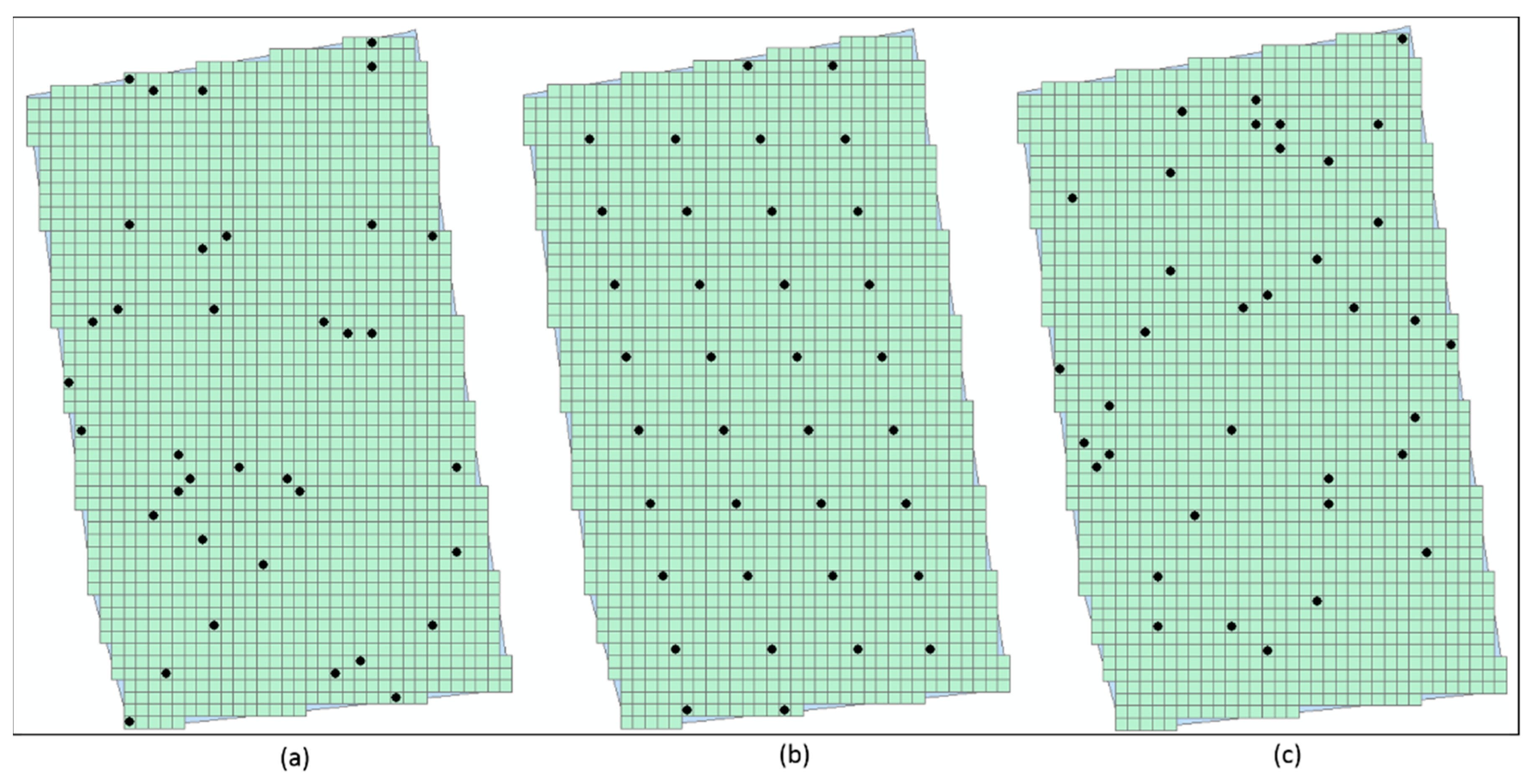
2.2.3. Determination of the Sampling Locations in Each Super-Grid
2.3. Farm Field Soil Mapping and Evaluation
3. Results
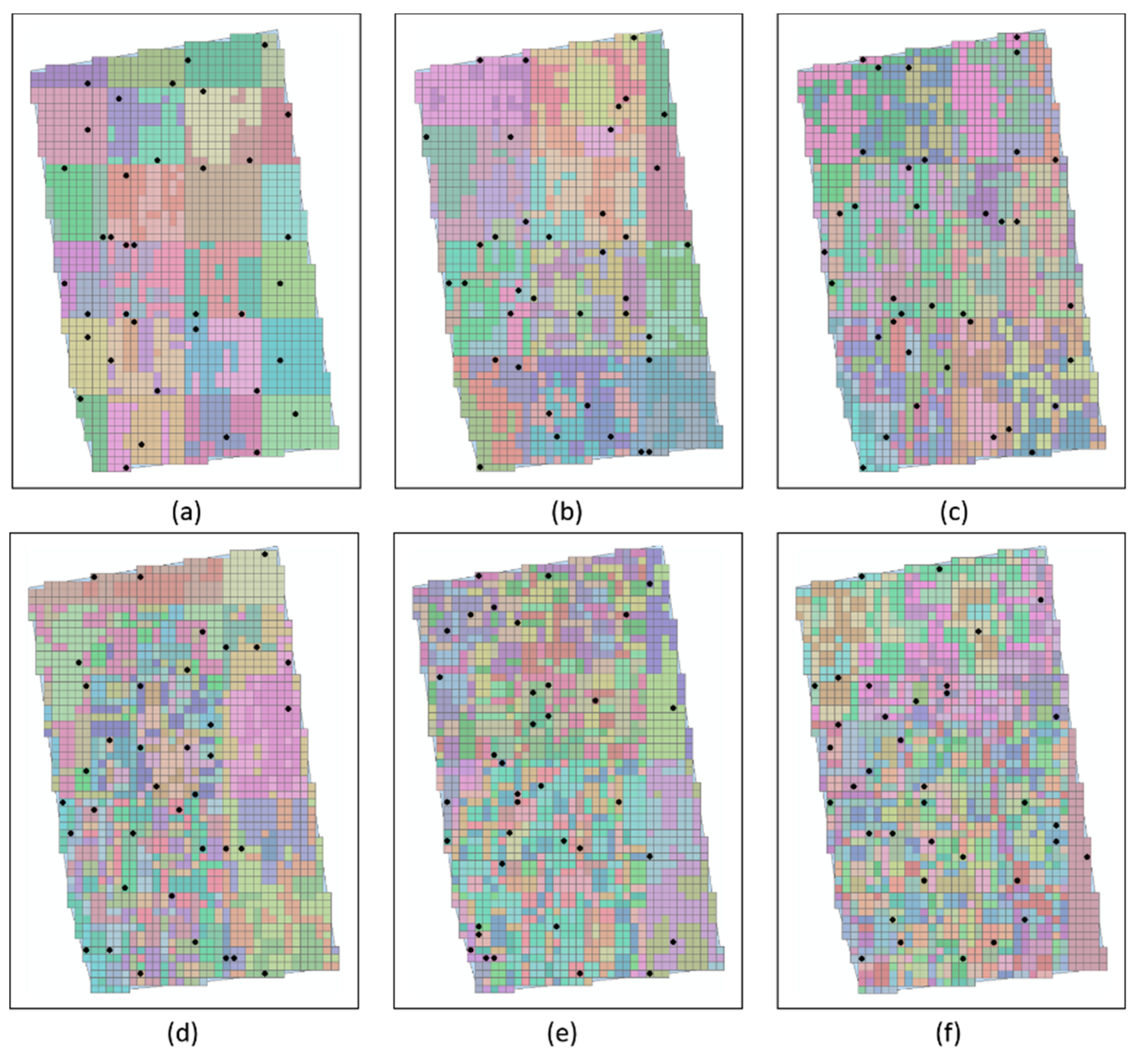
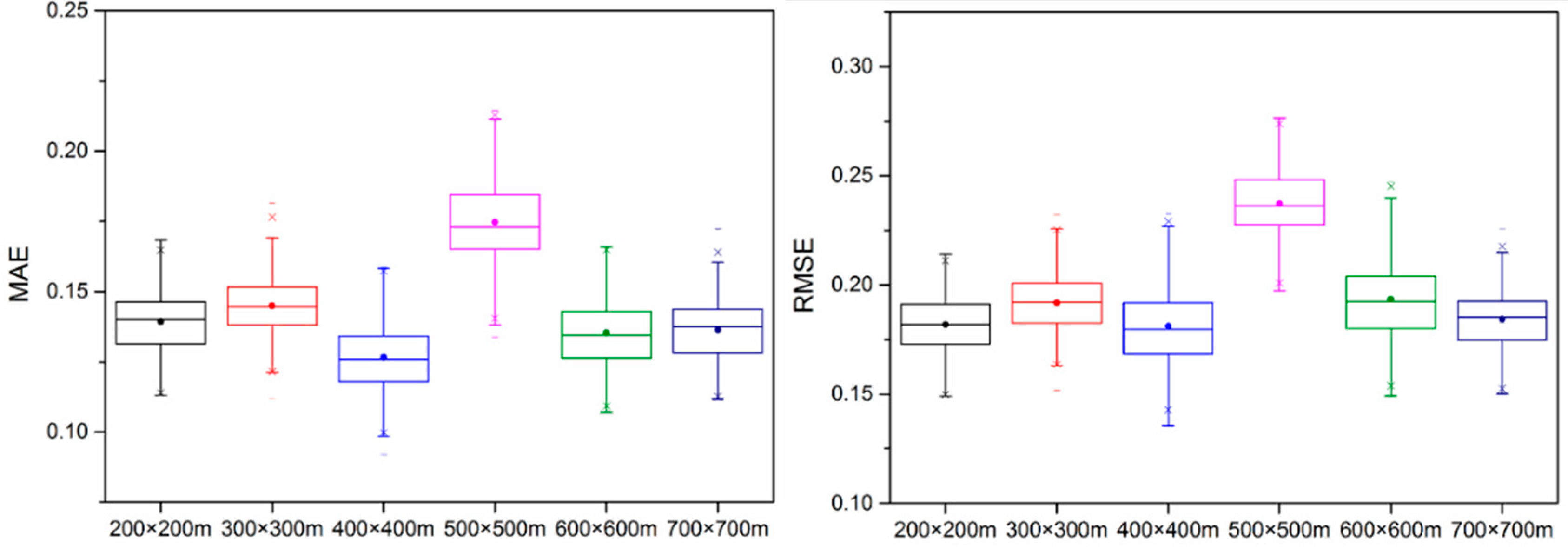
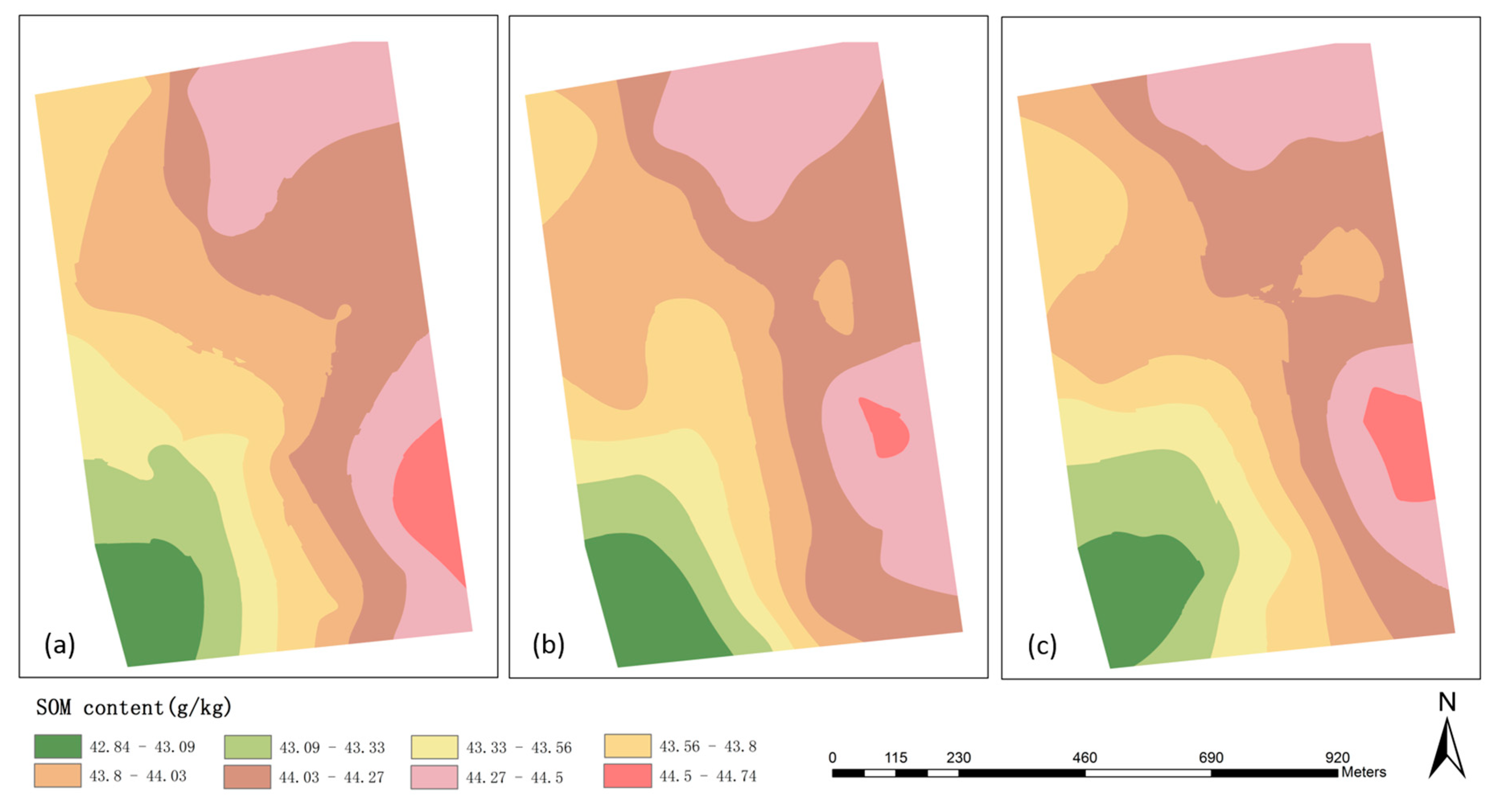
3.1. Analysis of the Influence of Super-Grid Size for the Proposed Sampling Design Method
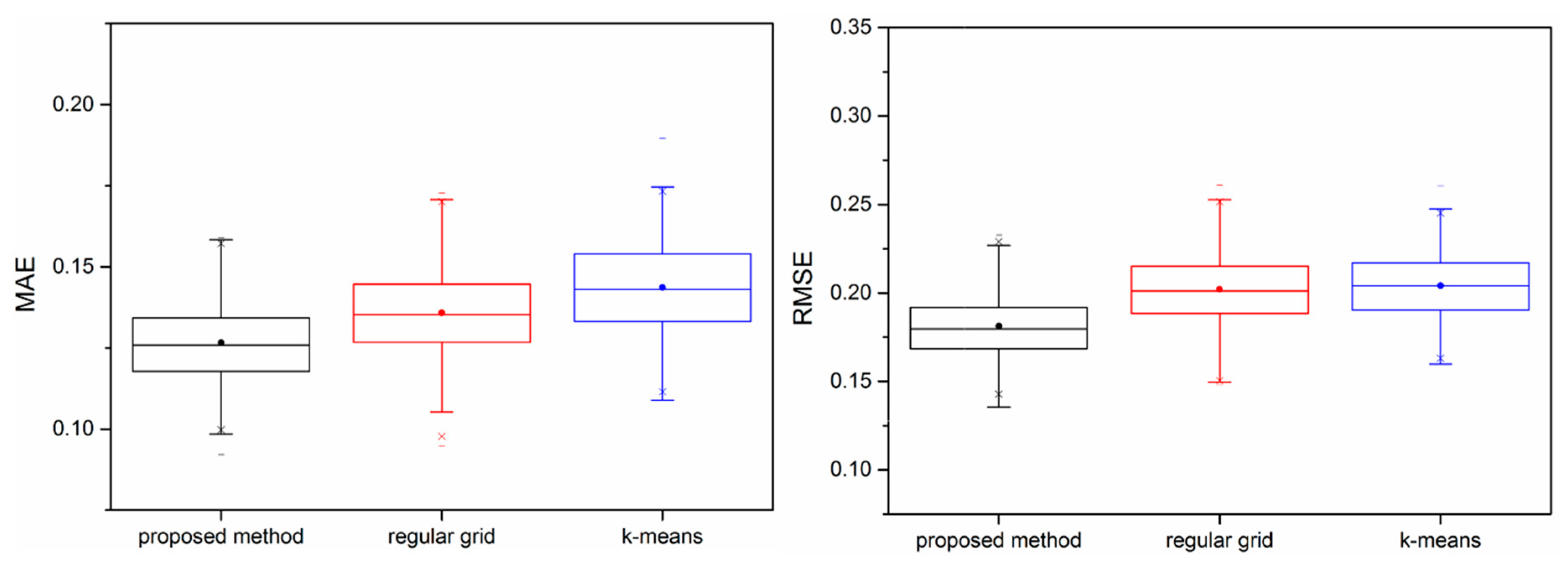
3.2. Comparison to Other Sampling Design Methods for Farm Field Soil Mapping
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Shi, Y.Y.; Hu, Z.C.; Wang, X.C.; Odhiambo, M.O.; Sun, G.X. Fertilization strategy and application model using a centrifugal variable-rate fertilizer spreader. Int. J. Agric. Biol. Eng. 2018, 11, 41–48. [Google Scholar] [CrossRef]
- Su, N.; Xu, T.S.; Song, L.T.; Wang, R.J.; Wei, Y.Y. Variable rate fertilization system with adjustable active feed-roll length. Int. J. Agric. Biol. Eng. 2015, 8, 19–26. [Google Scholar] [CrossRef]
- Cai, J.P.; Yao, Y.X. Application of Computer Technology in Maize Production Implementation Precision Agriculture. Adv. Mater. Res. 2014, 1049–1050, 1985–1988. [Google Scholar] [CrossRef]
- Ge, Y. Development of sensor systems for precision agriculture in cotton. Int. J. Agric. Biol. Eng. 2012, 5, 1–14. [Google Scholar]
- Du, R.C.; Gong, B.C.; Liu, N.N.; Wang, C.C.; Yang, Z.D.; Ma, M.J. A Design and experiment on intelligent fuzzy monitoring system for corn planters. Int. J. Agric. Biol. Eng. 2013, 6, 11–18. [Google Scholar] [CrossRef]
- Brus, D.J.; Noij, I.G.A.M. Designing sampling schemes for effect monitoring of nutrient leaching from agricultural soils. Eur. J. Soil Sci. 2008, 59, 292–303. [Google Scholar] [CrossRef]
- Corwin, D.L.; Lesch, S.M.; Segal, E.; Skaggs, T.H.; Bradford, S.A. Comparison of Sampling Strategies for Characterizing Spatial Variability with Apparent Soil Electrical Conductivity Directed Soil Sampling. J. Environ. Eng. Geophys. 2010, 15, 147–162. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Niu, R.Q.; Li, P.X.; Zhang, L.P.; Du, B. Regional soil erosion risk mapping using RUSLE, GIS, and remote sensing: A case study in Miyun Watershed, North China. Environ. Earth Sci. 2011, 63, 533–541. [Google Scholar] [CrossRef]
- Duffera, M.; White, J.G.; Weisz, R. Spatial variability of Southeastern US Coastal Plain soil physical properties: Implications for site-specific management. Geoderma 2007, 137, 327–339. [Google Scholar] [CrossRef]
- McBratney, A.B.; Odeh, I.O.A.; Bishop, T.F.A.; Dunbar, M.S.; Shatar, T.M. An overview of pedometric techniques for use in soil survey. Geoderma 2000, 97, 293–327. [Google Scholar] [CrossRef]
- Biswas, A.; Zhang, Y.K. Sampling Designs for Validating Digital Soil Maps: A Review. Pedosphere 2018, 28, 1–15. [Google Scholar] [CrossRef]
- Thompson, W.L.; Miller, A.E.; Mortenson, D.C.; Woodward, A. Developing effective sampling designs for monitoring natural resources in Alaskan national parks: An example using simulations and vegetation data. Biol. Conserv. 2011, 144, 1270–1277. [Google Scholar] [CrossRef]
- Domburg, P.; Degruijter, J.J.; Brus, D.J. A Structured Approach to Designing Soil Survey Schemes with Prediction of Sampling Error from Variograms. Geoderma 1994, 62, 151–164. [Google Scholar] [CrossRef]
- Wang, J.H.; Ge, Y.; Heuvelink, G.B.M.; Zhou, C.H. Spatial Sampling Design for Estimating Regional GPP With Spatial Heterogeneities. IEEE Geosci. Remote Sens. 2014, 11, 539–543. [Google Scholar] [CrossRef]
- Wang, J.F.; Stein, A.; Gao, B.B.; Ge, Y. A review of spatial sampling. Spat. Stat. 2012, 2, 1–14. [Google Scholar] [CrossRef]
- Brus, D.J. Sampling for digital soil mapping: A tutorial supported by R scripts. Geoderma 2019, 338, 464–480. [Google Scholar] [CrossRef]
- Wang, J.H.; Ge, Y.; Heuvelink, G.B.M.; Zhou, C.H.; Brus, D. Effect of the sampling design of ground control points on the geometric correction of remotely sensed imagery. Int. J. Appl. Earth Obs. 2012, 18, 91–100. [Google Scholar] [CrossRef]
- Wang, J.F.; Jiang, C.S.; Hu, M.G.; Cao, Z.D.; Guo, Y.S.; Li, L.F.; Liu, T.J.; Meng, B. Design-based spatial sampling: Theory and implementation. Environ. Model. Softw. 2013, 40, 280–288. [Google Scholar] [CrossRef]
- An, Y.M.; Yang, L.; Zhu, A.X.; Qin, C.Z.; Shi, J.J. Identification of representative samples from existing samples for digital soil mapping. Geoderma 2018, 311, 109–119. [Google Scholar] [CrossRef]
- Walvoort, D.J.J.; Brus, D.J.; de Gruijter, J.J. An R package for spatial coverage sampling and random sampling from compact geographical strata by k-means. Comput. Geosci. 2010, 36, 1261–1267. [Google Scholar] [CrossRef]
- Brus, D.J.; Saby, N.P.A. Approximating the variance of estimated means for systematic random sampling, illustrated with data of the French Soil Monitoring Network. Geoderma 2016, 279, 77–86. [Google Scholar] [CrossRef]
- Debaene, G.; Niedzwiecki, J.; Pecio, A.; Zurek, A. Effect of the number of calibration samples on the prediction of several soil properties at the farm-scale. Geoderma 2014, 214, 114–125. [Google Scholar] [CrossRef]
- Ramirez-Lopez, L.; Schmidt, K.; Behrens, T.; van Wesemael, B.; Dematte, J.A.M.; Scholten, T. Sampling optimal calibration sets in soil infrared spectroscopy. Geoderma 2014, 226, 140–150. [Google Scholar] [CrossRef]
- Kennard, R.W.; Stone, L.A. Computer Aided Design of Experiments. Technometrics 1969, 11, 137–148. [Google Scholar] [CrossRef]
- Totaro, S.; Coratza, P.; Durante, C.; Foca, G.; Vigni, M.L.; Marchetti, A.; Marchetti, M.; Cocchi, M. Soil sampling planning in traceability studies by means of Experimental Design approaches. Chemom. Intell. Lab. 2013, 124, 14–20. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B. A conditioned Latin hypercube method for sampling in the presence of ancillary information. Comput. Geosci. 2006, 32, 1378–1388. [Google Scholar] [CrossRef]
- Evans, D.M.; Hartemink, A.E. Digital soil mapping of a red clay subsoil covered by loess. Geoderma 2014, 230, 296–304. [Google Scholar] [CrossRef]
- Chaplot, V.; Lorentz, S.; Podwojewski, P.; Jewitt, G. Digital mapping of A-horizon thickness using the correlation between various soil properties and soil apparent electrical resistivity. Geoderma 2010, 157, 154–164. [Google Scholar] [CrossRef]
- Webster, R.; Welham, S.J.; Potts, J.M.; Oliver, M.A. Estimating the spatial scales of regionalized variables by nested sampling, hierarchical analysis of variance and residual maximum likelihood. Comput. Geosci. 2006, 32, 1320–1333. [Google Scholar] [CrossRef]
- Sun, X.L.; Wang, H.L.; Zhao, Y.G.; Zhang, C.S.; Zhang, G.L. Digital soil mapping based on wavelet decomposed components of environmental covariates. Geoderma 2017, 303, 118–132. [Google Scholar] [CrossRef]
- Walton, J.C.; Roberts, R.K.; Lambert, D.M.; Larson, J.A.; English, B.C.; Larkin, S.L.; Martin, S.W.; Marra, M.C.; Paxton, K.W.; Reeves, J.M. Grid soil sampling adoption and abandonment in cotton production. Precis. Agric. 2010, 11, 135–147. [Google Scholar] [CrossRef]
- Brus, D.J.; Kempen, B.; Heuvelink, G.B.M. Sampling for validation of digital soil maps. Eur. J. Soil Sci. 2011, 62, 394–407. [Google Scholar] [CrossRef]
- Jensen, W.A. Response Surface Methodology: Process and Product Optimization Using Designed Experiments 4th edition. J. Qual. Technol. 2017, 49, 186–187. [Google Scholar] [CrossRef]
- Arrouays, D.; Marchant, B.P.; Saby, N.P.A.; Meersmans, J.; Orton, T.G.; Martin, M.P.; Bellamy, P.H.; Lark, R.M.; Kibblewhite, M. Generic Issues on Broad-Scale Soil Monitoring Schemes: A Review. Pedosphere 2012, 22, 456–469. [Google Scholar] [CrossRef]
- Vasat, R.; Boruvka, L.; Jaksik, O. Number of sampling points influences the parameters of soil properties spatial distribution and kriged maps. In Digital Soil Assessments and Beyond; Minasny, B., Malone, B.P., McBratney, A.B., Eds.; CRC Press: Boca Raton, FL, USA, 2012; pp. 251–256. [Google Scholar]
- Morvan, X.; Saby, N.P.A.; Arrouays, D.; Le Bas, C.; Jones, R.J.A.; Verheijen, F.G.A.; Bellamy, P.H.; Stephens, M.; Kibblewhite, M.G. Soil monitoring in Europe: A review of existing systems and requirements for harmonisation. Sci. Total Environ. 2008, 391, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Kidd, D.; Malone, B.; Mcbratney, A.; Minasny, B.; Webb, M. Operational sampling challenges to digital soil mapping in Tasmania, Australia. Geoderma Reg. 2015, 4, 1–10. [Google Scholar] [CrossRef]
- Zhang, G.L.; Liu, F.; Song, X.D. Recent progress and future prospect of digital soil mapping: A review. J. Integr. Agric. 2017, 16, 2871–2885. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, A.X.; Shi, Z.; Liu, J.; Du, F. Supplemental sampling for digital soil mapping based on prediction uncertainty from both the feature domain and the spatial domain. Geoderma 2016, 284, 73–84. [Google Scholar] [CrossRef]
- Hu, M.G.; Wang, J.F. A spatial sampling optimization package using MSN theory. Environ. Model. Softw. 2011, 26, 546–548. [Google Scholar] [CrossRef]
- Lark, R.M. Multi-objective optimization of spatial sampling. Spat. Stat. 2016, 18, 412–430. [Google Scholar] [CrossRef]
- Nawar, S.; Mouazen, A.M. Optimal sample selection for measurement of soil organic carbon using online vis-NIR spectroscopy. Comput. Electron. Agric. 2018, 151, 469–477. [Google Scholar] [CrossRef]
- Brus, D.J.; Heuvelink, G.B.M. Optimization of sample patterns for universal kriging of environmental variables. Geoderma 2007, 138, 86–95. [Google Scholar] [CrossRef]
- Vasat, R.; Heuvelink, G.B.M.; Boruvka, L. Sampling design optimization for multivariate soil mapping. Geoderma 2010, 155, 147–153. [Google Scholar] [CrossRef]
- Heuvelink, G.B.M.; Brus, D.J.; Gruijter, J.J. Chapter 11 Optimization of Sample Configurations for Digital Mapping of Soil Properties with Universal Kriging. Dev. Soil Sci. 2006, 31, 137–151. [Google Scholar]
- Johnson, D.M. An assessment of pre- and within-season remotely sensed variables for forecasting corn and soybean yields in the United States. Remote Sens. Environ. 2014, 141, 116–128. [Google Scholar] [CrossRef]
- Prasad, A.K.; Chai, L.; Singh, R.P.; Kafatos, M. Crop yield estimation model for Iowa using remote sensing and surface parameters. Int. J. Appl. Earth Obs. 2006, 8, 26–33. [Google Scholar] [CrossRef]
- Lobell, D.B. The use of satellite data for crop yield gap analysis. Field Crop Res. 2013, 143, 56–64. [Google Scholar] [CrossRef] [Green Version]
- Bolton, D.K.; Friedl, M.A. Forecasting crop yield using remotely sensed vegetation indices and crop phenology metrics. Agric. For. Meteorol. 2013, 173, 74–84. [Google Scholar] [CrossRef]
- Johnson, M.D.; Hsieh, W.W.; Cannon, A.J.; Davidson, A.; Bedard, F. Crop yield forecasting on the Canadian Prairies by remotely sensed vegetation indices and machine learning methods. Agric. For. Meteorol. 2016, 218, 74–84. [Google Scholar] [CrossRef]
- Mkhabela, M.S.; Bullock, P.; Raj, S.; Wang, S.; Yang, Y. Crop yield forecasting on the Canadian Prairies using MODIS NDVI data. Agric. For. Meteorol. 2011, 151, 385–393. [Google Scholar] [CrossRef]
- Tennakoon, S.B.; Murty, V.V.N.; Eiumnoh, A. Estimation of Cropped Area and Grain-Yield of Rice Using Remote-Sensing Data. Int. J. Remote Sens. 1992, 13, 427–439. [Google Scholar] [CrossRef]
- Thenkabail, P.S.; Ward, A.D.; Lyon, J.G. Landsat-5 Thematic Mapper Models of Soybean and Corn Crop Characteristics. Int. J. Remote Sens. 1994, 15, 49–61. [Google Scholar] [CrossRef]
- Cheng, Z.Q.; Meng, J.H.; Wang, Y.M. Improving Spring Maize Yield Estimation at Field Scale by Assimilating Time-Series HJ-1 CCD Data into the WOFOST Model Using a New Method with Fast Algorithms. Remote Sens. 2016, 8, 303. [Google Scholar] [CrossRef]
- Huang, J.X.; Tian, L.Y.; Liang, S.L.; Ma, H.Y.; Becker-Reshef, I.; Huang, Y.B.; Su, W.; Zhang, X.D.; Zhu, D.H.; Wu, W.B. Improving winter wheat yield estimation by assimilation of the leaf area index from Landsat TM and MODIS data into the WOFOST model. Agric. For. Meteorol. 2015, 204, 106–121. [Google Scholar] [CrossRef] [Green Version]
- Li, R.; Li, C.J.; Dong, Y.Y.; Liu, F.; Wang, J.H.; Yang, X.D.; Pan, Y.C. Assimilation of Remote Sensing and Crop Model for LAI Estimation Based on Ensemble Kalman Filter. Agric. Sci. China 2011, 10, 1595–1602. [Google Scholar] [CrossRef]
- Ma, H.Y.; Huang, J.X.; Zhu, D.H.; Liu, J.M.; Su, W.; Zhang, C.; Fan, J.L. Estimating regional winter wheat yield by assimilation of time series of HJ-1 CCD NDVI into WOFOST-ACRM model with Ensemble Kalman Filter. Math. Comput. Model. 2013, 58, 753–764. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, Q.G.; Zhou, J.; Zhang, G.F.; Chen, C.; Wang, J. Assimilating remote sensing information into a coupled hydrology-crop growth model to estimate regional maize yield in arid regions. Ecol. Model. 2014, 291, 15–27. [Google Scholar] [CrossRef]
- Huang, J.X.; Ma, H.Y.; Su, W.; Zhang, X.D.; Huang, Y.B.; Fan, J.L.; Wu, W.B. Jointly Assimilating MODIS LAI and ET Products Into the SWAP Model for Winter Wheat Yield Estimation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4060–4071. [Google Scholar] [CrossRef]
- Soler, C.M.T.; Sentelhas, P.U.; Hoogenboom, G. Application of the CSM-CERES-maize model for planting date evaluation and yield forecasting for maize grown off-season in a subtropical environment. Eur. J. Agron. 2007, 27, 165–177. [Google Scholar] [CrossRef]
- de Wit, A.; Duveiller, G.; Defourny, P. Estimating regional winter wheat yield with WOFOST through the assimilation of green area index retrieved from MODIS observations. Agric. For. Meteorol. 2012, 164, 39–52. [Google Scholar] [CrossRef]
- Ma, G.N.; Huang, J.X.; Wu, W.B.; Fan, J.L.; Zou, J.Q.; Wu, S.J. Assimilation of MODIS-LAI into the WOFOST model for forecasting regional winter wheat yield. Math. Comput. Model. 2013, 58, 634–643. [Google Scholar] [CrossRef]
- Zhu, A.X.; Yang, L.; Li, B.L.; Qin, C.Z.; English, E.; Burt, J.E.; Zhou, C.H. Purposive Sampling for Digital Soil Mapping for Areas with Limited Data. Digital Soil Mapping with Limited Data; Springer: Dordrecht, The Netherlands; Berlin, Germany, 2008; pp. 233–245. [Google Scholar] [CrossRef]
- Yang, L.; Zhu, A.X.; Qi, F.; Qin, C.Z.; Li, B.L.; Pei, T. An integrative hierarchical stepwise sampling strategy for spatial sampling and its application in digital soil mapping. Int. J. Geogr. Inf. Sci. 2013, 27, 1–23. [Google Scholar] [CrossRef]
- Culman, W.S.; Snapp, S.S.; Green, M.J.; Gentry, E.L. Short- and Long-Term Labile Soil Carbon and Nitrogen Dynamics Reflect Management and Predict Corn Agronomic Performance. Agron. J. 2013, 105, 493–502. [Google Scholar] [CrossRef]
- de Moraes Sá, J.C.; Tivet, F.; Lal, R.; Briedis, C.; Hartman, D.C.; dos Santos, J.Z.; dos Santos, J.B. Long-term tillage systems impacts on soil C dynamics, soil resilience and agronomic productivity of a Brazilian Oxisol. J. Soil Tillage Res. 2014, 136, 38–50. [Google Scholar] [CrossRef]
- Lucas, T.S.; Weil, R.R. Can a Labile Carbon Test be Used to Predict Crop Responses to Improve Soil Organic Matter Management? Agron. J. 2012, 104, 1160–1170. [Google Scholar] [CrossRef] [Green Version]
- Brus, D.J.; Spatjens, L.E.E.M.; de Gruijter, J.J. A sampling scheme for estimating the mean extractable phosphorus concentration of fields for environmental regulation. Geoderma 1999, 89, 129–148. [Google Scholar] [CrossRef]
- Ding, C.; He, X.F. Cluster structure of K-means clustering via principal component analysis. Lect. Notes Artif. Intell. 2004, 3056, 414–418. [Google Scholar]
- Lloyd, S.P. Least-Squares Quantization in Pcm. IEEE Trans Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Lark, R.M.; Webster, R. Analysis and elucidation of soil variation using wavelets. Eur. J. Soil Sci. 1999, 50, 185–206. [Google Scholar] [CrossRef]
- Samuel-Rosa, A.; Heuvelink, G.B.M.; Vasques, G.M.; Anjos, L.H.C. Do more detailed environmental covariates deliver more accurate soil maps? Geoderma 2015, 243, 214–227. [Google Scholar] [CrossRef]
- Ma, Q.Y.; Chen, Q.; Shang, Q.S.; Zhang, C. The Data Acquisition for Precision Agriculture Based on Remote Sensing. In Proceedings of the 2006 IEEE International Symposium on Geoscience and Remote Sensing, Denver, CO, USA, 31 July–4 August 2006; p. 888. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Prediction Errors of the SOM Mapping of the Whole Farm | |||||
| Mean (g/kg) | Root-Mean-Square (g/kg) | Mean Standardized (g/kg) | Root-Mean-Square Standardized (g/kg) | Average Standard Error (g/kg) | |
| 0.08 | 5.42 | 0.02 | 0.79 | 6.79 | |
| The Descriptive Statistics of the Tested Farm Field SOM Map | |||||
| SOM Content | Min (g/kg) | Max (g/kg) | Median (g/kg) | Mean (g/kg) | Standard Deviation (g/kg) |
| Tested field | 42.86 | 44.75 | 43.94 | 43.89 | 0.45 |
| Dataset | Spatial Resolution | Time |
|---|---|---|
| Soil organic matter (SOM) map | Raster, 16 m | 2018 |
| Digital elevation model (DEM) | Raster, 16 m | 2009 |
| Slope | Raster, 16 m | 2009 |
| Aspect | Raster, 16 m | 2009 |
| Remote sensing crop yield data | Raster, 16 m | 2018 |
| Super-Grid ID | 200 × 200 m2 | 300 × 300 m2 | 400 × 400 m2 | 500 × 500 m2 | 600 × 600 m2 | 700 × 700 m2 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DI | DI | DI | DI | DI | DI | |||||||||||||
| 1 | 29 | 0.04 | 1 | 126 | 0.08 | 3 | 273 | 0.1 | 6 + 1 | 471 | 0.12 | 12 | 720 | 0.11 | 18 | 1020 | 0.1 | 23 |
| 2 | 93 | 0.09 | 2 | 203 | 0.1 | 5 | 335 | 0.07 | 6 | 302 | 0.07 | 5 | 219 | 0.06 | 3 | 85 | 0.07 | 1 |
| 3 | 83 | 0.09 | 2 | 112 | 0.06 | 2 | 341 | 0.11 | 9 | 577 | 0.1 | 13 | 708 | 0.09 | 14 | 654 | 0.08 | 12 |
| 4 | 69 | 0.07 | 1 | 166 | 0.12 | 5 | 321 | 0.06 | 5 | 250 | 0.07 | 4 | 112 | 0.07 | 2 | - | - | - |
| 5 | 51 | 0.07 | 1 | 225 | 0.1 | 5 | 267 | 0.08 | 5 | 106 | 0.08 | 2 | - | - | - | - | - | - |
| 6 | 100 | 0.12 | 3 | 107 | 0.06 | 2 | 222 | 0.07 | 4 | 53 | 0.05 | 1 | - | - | - | - | - | - |
| 7 | 100 | 0.06 | 2 | 196 | 0.08 | 4 | - | - | - | - | - | - | - | - | - | - | - | - |
| 8 | 83 | 0.05 | 1 | 225 | 0.08 | 4 | - | - | - | - | - | - | - | - | - | - | - | - |
| 9 | 64 | 0.13 | 2 | 75 | 0.07 | 1 | - | - | - | - | - | - | - | - | - | - | - | - |
| 10 | 100 | 0.12 | 3 | 123 | 0.07 | 2 | - | - | - | - | - | - | - | - | - | - | - | - |
| 11 | 100 | 0.07 | 2 | 164 | 0.06 | 3 | - | - | - | - | - | - | - | - | - | - | - | - |
| 12 | 67 | 0.07 | 1 | 37 | 0.05 | 1 | - | - | - | - | - | - | - | - | - | - | - | - |
| 13 | 77 | 0.08 | 2 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 14 | 100 | 0.09 | 2 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 15 | 100 | 0.05 | 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 16 | 54 | 0.07 | 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 17 | 91 | 0.06 | 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 18 | 100 | 0.09 | 2 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 19 | 100 | 0.07 | 2 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 20 | 39 | 0.06 | 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 21 | 30 | 0.08 | 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 22 | 46 | 0.09 | 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 23 | 64 | 0.06 | 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 24 | 19 | 0.05 | 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| Sampling Method | Min (g/kg) | Max (g/kg) | Median (g/kg) | Mean (g/kg) | Standard Deviation (g/kg) |
|---|---|---|---|---|---|
| Proposed method | 42.86 | 44.74 | 43.86 | 43.81 | 0.45 |
| Regular grid | 42.87 | 44.51 | 43.99 | 43.9 | 0.44 |
| k-means | 42.89 | 44.51 | 44.02 | 43.92 | 0.44 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Jiang, L.; Qi, Q.; Liu, Y.; Wang, J. Remote Sensing-Guided Sampling Design with Both Good Spatial Coverage and Feature Space Coverage for Accurate Farm Field-Level Soil Mapping. Remote Sens. 2019, 11, 1946. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11161946
Wang Y, Jiang L, Qi Q, Liu Y, Wang J. Remote Sensing-Guided Sampling Design with Both Good Spatial Coverage and Feature Space Coverage for Accurate Farm Field-Level Soil Mapping. Remote Sensing. 2019; 11(16):1946. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11161946
Chicago/Turabian StyleWang, Yongji, Lili Jiang, Qingwen Qi, Ying Liu, and Jun Wang. 2019. "Remote Sensing-Guided Sampling Design with Both Good Spatial Coverage and Feature Space Coverage for Accurate Farm Field-Level Soil Mapping" Remote Sensing 11, no. 16: 1946. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11161946