A Robust Rule-Based Ensemble Framework Using Mean-Shift Segmentation for Hyperspectral Image Classification



Abstract
:
1. Introduction
2. Methods and Datasets
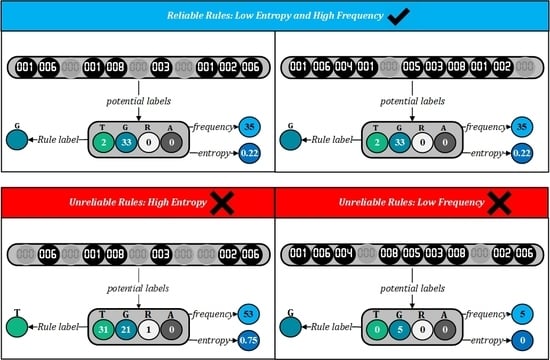
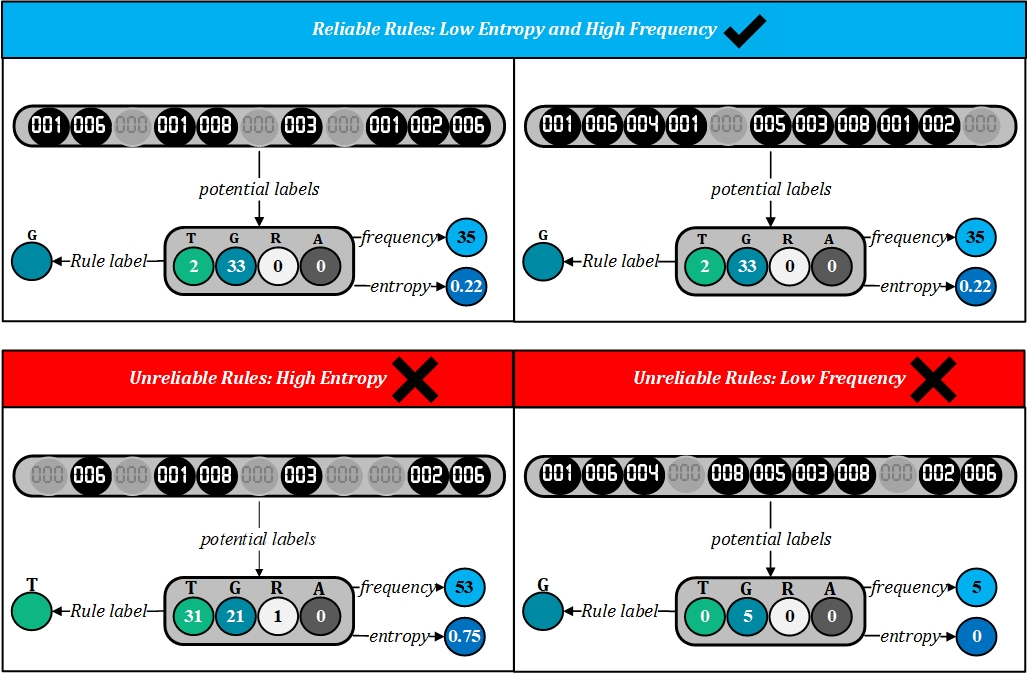
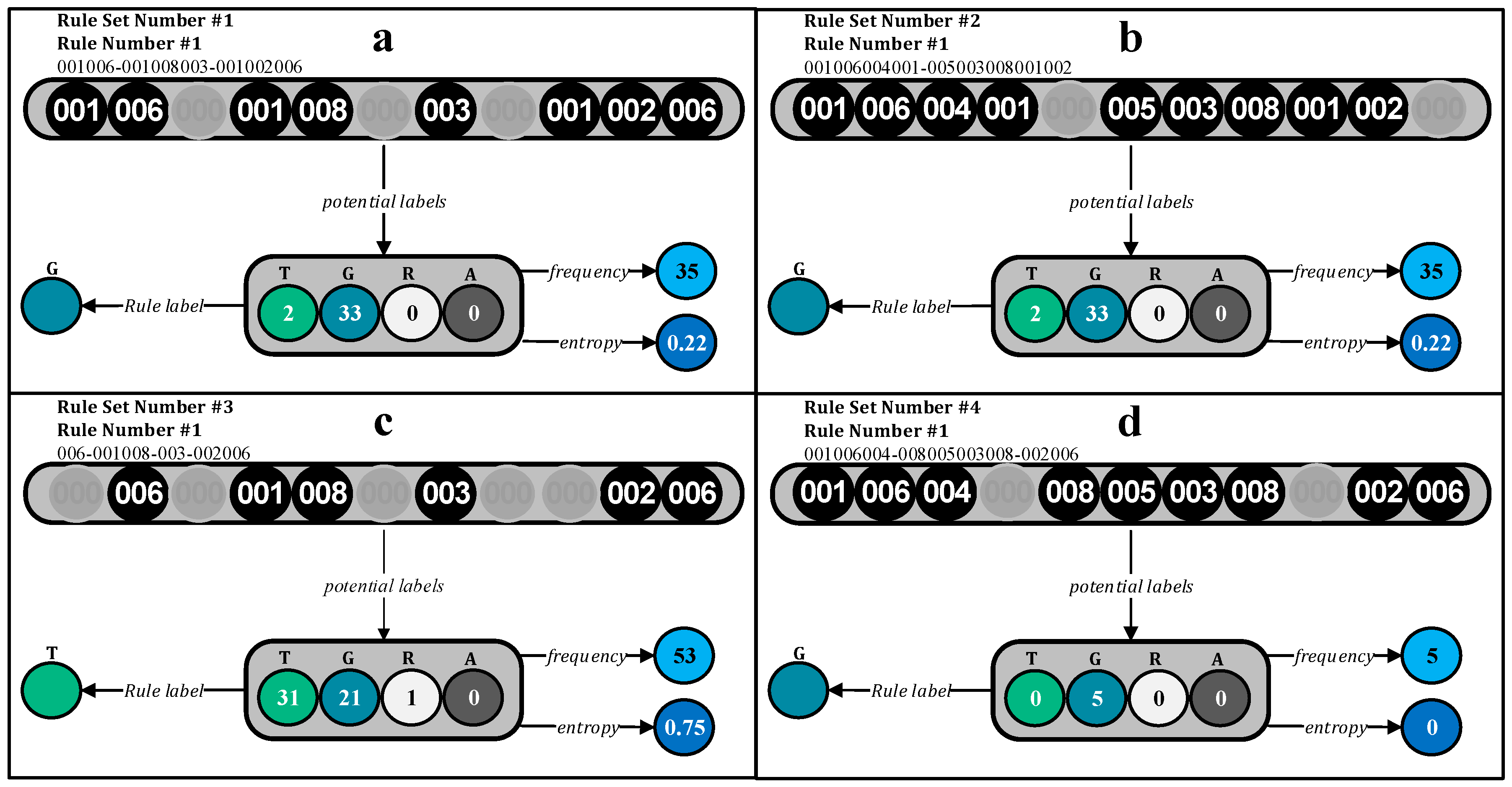
2.1. DoTRules
2.2. Rule Uncertainty Threshold
2.3. Comparing DoTRules with Other Methods
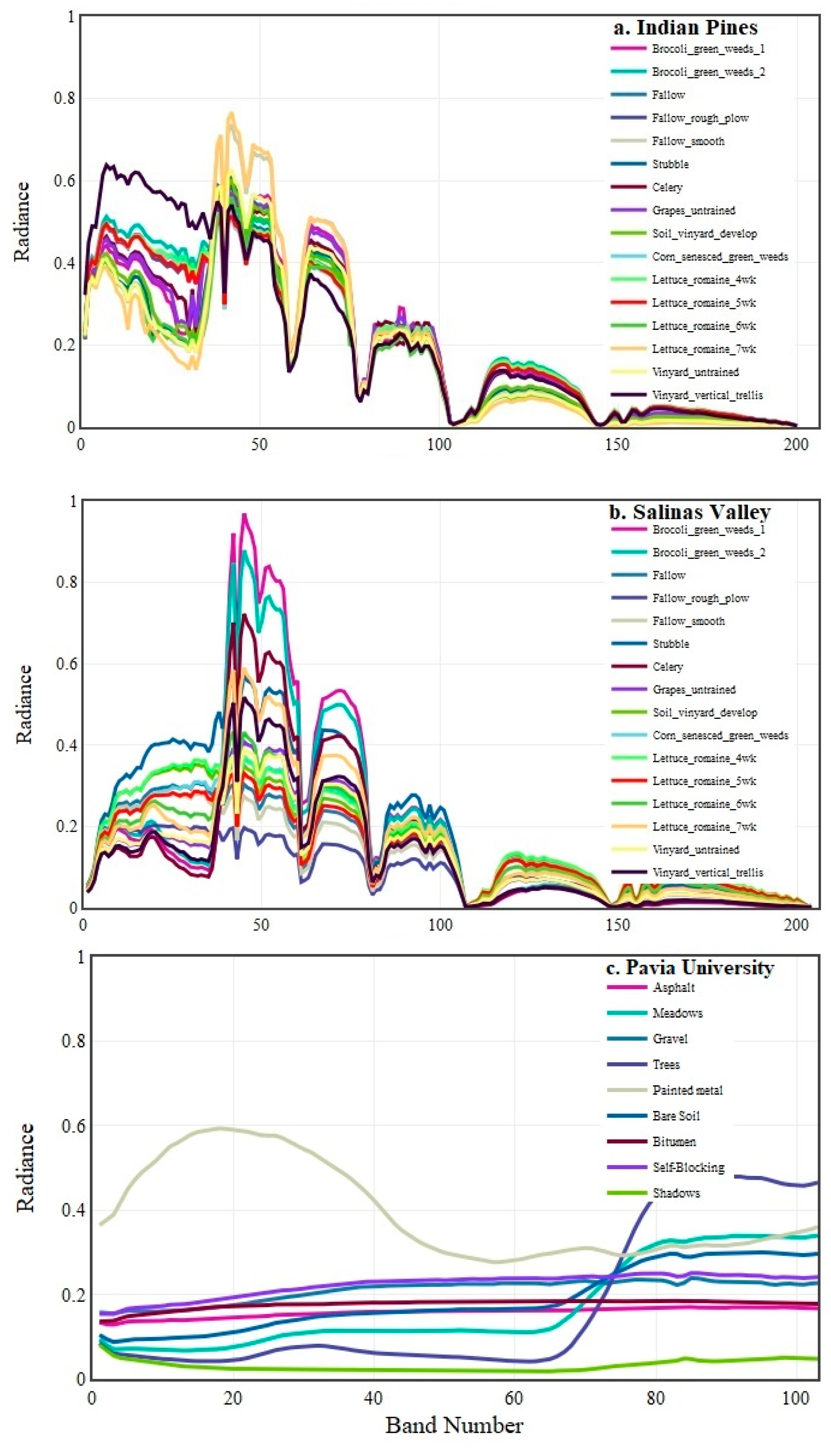
2.4. Datasets
3. Results
3.1. Simulation Experiments
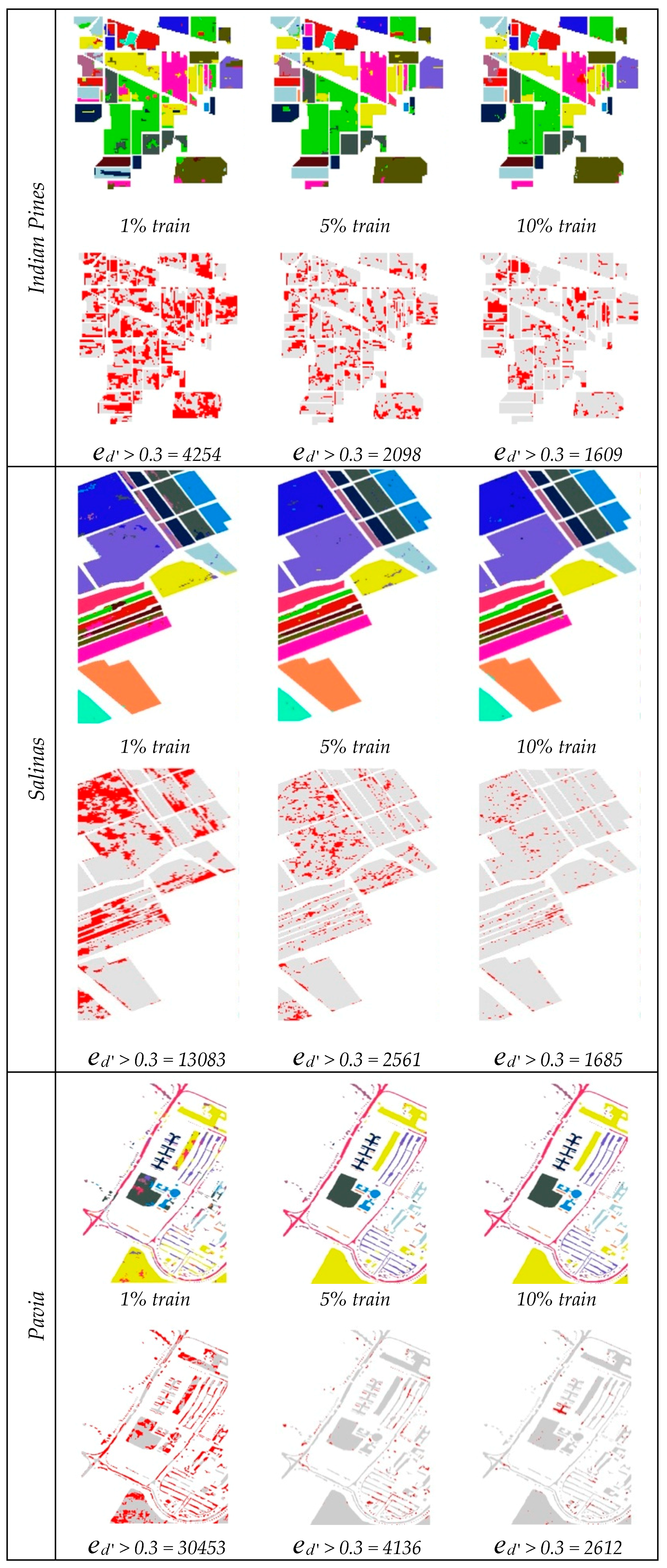
3.2. Uncertainty Mapping
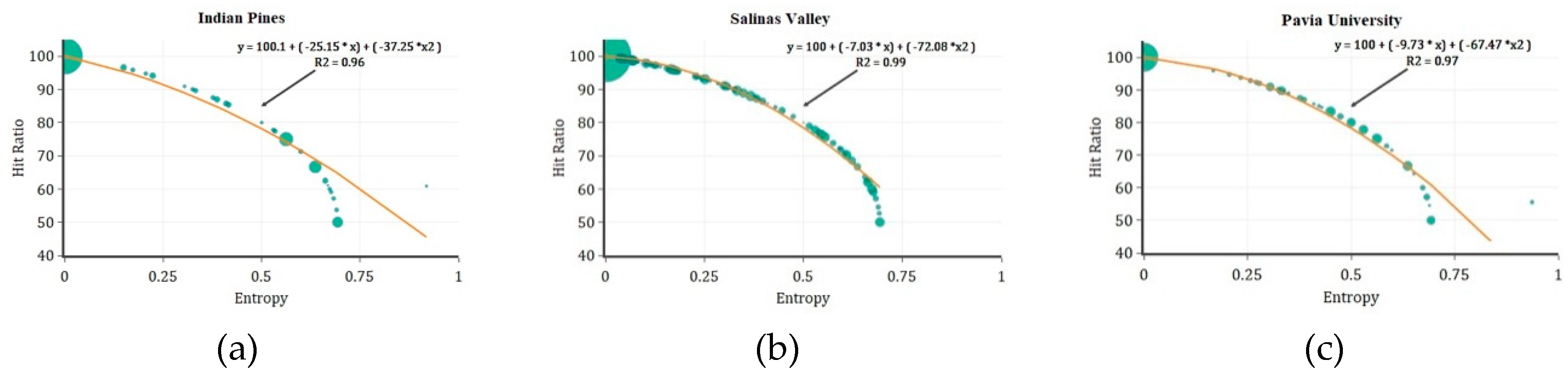
3.3. Correspondence Between Uncertainty and Hit Ratio of Rules
4. Discussion
4.1. The Overall Accuracy of Classification
4.2. Quantifying and Mapping the Uncertainty of Rules
4.3. Quantifying Hit Ratio of Rules
4.4. Limitations of DoTRules and Future Work
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chan, J.C.-W.; Paelinckx, D. Evaluation of random forest and adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Adep, R.N.; Vijayan, A.P.; Shetty, A.; Ramesh, H. Performance evaluation of hyperspectral classification algorithms on aviris mineral data. Perspect. Sci. 2016, 8, 722–726. [Google Scholar] [CrossRef]
- Van der Meer, F.D.; van der Werff, H.M.A.; van Ruitenbeek, F.J.A.; Hecker, C.A.; Bakker, W.H.; Noomen, M.F.; van der Meijde, M.; Carranza, E.J.M.; Smeth, J.B.D.; Woldai, T. Multi- and hyperspectral geologic remote sensing: A review. Int. J. Appl. Earth Obs. Geoinform. 2012, 14, 112–128. [Google Scholar] [CrossRef]
- Zarco-Tejada, P.J.; González-Dugo, M.V.; Fereres, E. Seasonal stability of chlorophyll fluorescence quantified from airborne hyperspectral imagery as an indicator of net photosynthesis in the context of precision agriculture. Remote Sens. Environ. 2016, 179, 89–103. [Google Scholar] [CrossRef]
- Wakholi, C.; Kandpal, L.M.; Lee, H.; Bae, H.; Park, E.; Kim, M.S.; Mo, C.; Lee, W.-H.; Cho, B.-K. Rapid assessment of corn seed viability using short wave infrared line-scan hyperspectral imaging and chemometrics. Sens. Actuators B Chem. 2018, 255, 498–507. [Google Scholar] [CrossRef]
- Rodger, A.; Laukamp, C.; Haest, M.; Cudahy, T. A simple quadratic method of absorption feature wavelength estimation in continuum removed spectra. Remote Sens. Environ. 2012, 118, 273–283. [Google Scholar] [CrossRef]
- Chen, F.; Wang, K.; Van de Voorde, T.; Tang, T.F. Mapping urban land cover from high spatial resolution hyperspectral data: An approach based on simultaneously unmixing similar pixels with jointly sparse spectral mixture analysis. Remote Sens. Environ. 2017, 196, 324–342. [Google Scholar] [CrossRef]
- Ma, X.; Wang, H.; Wang, J. Semisupervised classification for hyperspectral image based on multi-decision labeling and deep feature learning. ISPRS J. Photogramm. Remote Sens. 2016, 120, 99–107. [Google Scholar] [CrossRef]
- Huang, K.; Li, S.; Kang, X.; Fang, L. Spectral–spatial hyperspectral image classification based on knn. Sens. Imaging 2015, 17, 1. [Google Scholar] [CrossRef]
- Khodadadzadeh, M.; Li, J.; Plaza, A.; Bioucas-Dias, J.M. A subspace-based multinomial logistic regression for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2105–2109. [Google Scholar] [CrossRef]
- Peng, J.; Zhang, L.; Li, L. Regularized set-to-set distance metric learning for hyperspectral image classification. Pattern Recognit. Lett. 2016, 83, 143–151. [Google Scholar] [CrossRef]
- Goel, P.K.; Prasher, S.O.; Patel, R.M.; Landry, J.A.; Bonnell, R.B.; Viau, A.A. Classification of hyperspectral data by decision trees and artificial neural networks to identify weed stress and nitrogen status of corn. Comput. Electron. Agric. 2003, 39, 67–93. [Google Scholar] [CrossRef]
- Shao, Y.; Sang, N.; Gao, C.; Ma, L. Probabilistic class structure regularized sparse representation graph for semi-supervised hyperspectral image classification. Pattern Recognit. 2017, 63, 102–114. [Google Scholar] [CrossRef]
- Zhong, Y.; Zhang, L. An adaptive artificial immune network for supervised classification of multi-/hyperspectral remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2012, 50, 894–909. [Google Scholar] [CrossRef]
- Reshma, R.; Sowmya, V.; Soman, K.P. Dimensionality reduction using band selection technique for kernel based hyperspectral image classification. Procedia Comput. Sci. 2016, 93, 396–402. [Google Scholar] [CrossRef]
- Naidoo, L.; Cho, M.A.; Mathieu, R.; Asner, G. Classification of savanna tree species, in the greater kruger national park region, by integrating hyperspectral and lidar data in a random forest data mining environment. ISPRS J. Photogramm. Remote Sens. 2012, 69, 167–179. [Google Scholar] [CrossRef]
- Kayabol, K.; Kutluk, S. Bayesian classification of hyperspectral images using spatially-varying gaussian mixture model. Digit. Signal Process. 2016, 59, 106–114. [Google Scholar] [CrossRef]
- Gao, L.; Li, J.; Khodadadzadeh, M.; Plaza, A.; Zhang, B.; He, Z.; Yan, H. Subspace-based support vector machines for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 349–353. [Google Scholar]
- Feng, J.; Jiao, L.; Liu, F.; Sun, T.; Zhang, X. Unsupervised feature selection based on maximum information and minimum redundancy for hyperspectral images. Pattern Recognit. 2016, 51, 295–309. [Google Scholar] [CrossRef]
- Guo, B.; Gunn, S.R.; Damper, R.I.; Nelson, J.D. Band selection for hyperspectral image classification using mutual information. IEEE Geosci. Remote Sens. Lett. 2006, 3, 522–526. [Google Scholar] [CrossRef]
- Awad, M. Sea water chlorophyll-a estimation using hyperspectral images and supervised artificial neural network. Ecol. Inform. 2014, 24, 60–68. [Google Scholar] [CrossRef]
- Yu, S.; Jia, S.; Xu, C. Convolutional neural networks for hyperspectral image classification. Neurocomputing 2017, 219, 88–98. [Google Scholar] [CrossRef]
- Li, Y.; Xie, W.; Li, H. Hyperspectral image reconstruction by deep convolutional neural network for classification. Pattern Recognit. 2017, 63, 371–383. [Google Scholar] [CrossRef]
- Castelvecchi, D. Can we open the black box of ai? Nat. News 2016, 538, 20. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.-H.; et al. Challenges in representation learning: A report on three machine learning contests. Neural Netw. 2015, 64, 59–63. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ayerdi, B.; Marqués, I.; Graña, M. Spatially regularized semisupervised ensembles of extreme learning machines for hyperspectral image segmentation. Neurocomputing 2015, 149, 373–386. [Google Scholar] [CrossRef]
- Uslu, F.S.; Binol, H.; Ilarslan, M.; Bal, A. Improving svdd classification performance on hyperspectral images via correlation based ensemble technique. Opt. Lasers Eng. 2017, 89, 169–177. [Google Scholar] [CrossRef]
- Ayerdi, B.; Graña, M. Hyperspectral image nonlinear unmixing and reconstruction by elm regression ensemble. Neurocomputing 2016, 174, 299–309. [Google Scholar] [CrossRef]
- Tseng, M.-H.; Chen, S.-J.; Hwang, G.-H.; Shen, M.-Y. A genetic algorithm rule-based approach for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2008, 63, 202–212. [Google Scholar] [CrossRef]
- Russell, S.J.; Norvig, P.; Canny, J.F.; Malik, J.M.; Edwards, D.D. Artificial Intelligence: A Modern Approach; Prentice Hall: Upper Saddle River, NJ, USA, 2003; Volume 2. [Google Scholar]
- Bauer, T.; Steinnocher, K. Per-parcel land use classification in urban areas applying a rule-based technique. GeoBIT/GIS 2001, 6, 24–27. [Google Scholar]
- Benediktsson, J.A.; Garcia, X.C.; Waske, B.; Chanussot, J.; Sveinsson, J.R.; Fauvel, M. Ensemble methods for classification of hyperspectral data. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2008), Boston, MA, USA, 6–11 July 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 62–65. [Google Scholar]
- Ceamanos, X.; Waske, B.; Benediktsson, J.A.; Chanussot, J.; Fauvel, M.; Sveinsson, J.R. A classifier ensemble based on fusion of support vector machines for classifying hyperspectral data. Int. J. Image Data Fusion 2010, 1, 293–307. [Google Scholar] [CrossRef] [Green Version]
- Xia, J.; Ghamisi, P.; Yokoya, N.; Iwasaki, A. Random forest ensembles and extended multiextinction profiles for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 202–216. [Google Scholar] [CrossRef]
- Rokach, L. Ensemble-based classifiers. Artif. Intell. Rev. 2010, 33, 1–39. [Google Scholar] [CrossRef]
- Shadman, M.; Aryal, J.; Bryan, B. Dotrules: A novel method for calibrating land-use/cover change models using a dictionary of trusted rules. In Proceedings of the MODSIM2017, 22nd International Congress on Modelling and Simulation, Hobart, Australia, 3–8 December 2017; Syme, G., Hatton MacDonald, D., Fulton, B., Piantadosi, J., Eds.; Hobart, TAS, Australia, 2017; p. 508. [Google Scholar]
- Roodposhti, M.S.; Aryal, J.; Bryan, B.A. A novel algorithm for calculating transition potential in cellular automata models of land-use/cover change. Environ. Model. Softw. 2019, 112, 70–81. [Google Scholar] [CrossRef]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. Mapping per-pixel predicted accuracy of classified remote sensing images. Remote Sens. Environ. 2017, 191, 156–167. [Google Scholar] [CrossRef] [Green Version]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Wolff, E. Very high resolution object-based land use-land cover urban classification using extreme gradient boosting. IEEE Geosci. Remote Sens. Lett. 2018, 15, 607–611. [Google Scholar] [CrossRef]
- Loggenberg, K.; Strever, A.; Greyling, B.; Poona, N. Modelling water stress in a shiraz vineyard using hyperspectral imaging and machine learning. Remote Sens. 2018, 10, 202. [Google Scholar] [CrossRef]
- Crawford, M.M.; Ham, J.; Chen, Y.; Ghosh, J. Random forests of binary hierarchical classifiers for analysis of hyperspectral data. In Proceedings of the 2003 IEEE Workshop on Advances in Techniques for Analysis of Remotely Sensed Data, Greenbelt, MD, USA, 27–28 October 2003; IEEE: Piscataway, NJ, USA, 2003; pp. 337–345. [Google Scholar]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Ham, J.; Chen, Y.; Crawford, M.M.; Ghosh, J. Investigation of the random forest framework for classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 492–501. [Google Scholar] [CrossRef] [Green Version]
- Lawrence, R.L.; Wood, S.D.; Sheley, R.L. Mapping invasive plants using hyperspectral imagery and breiman cutler classifications (randomforest). Remote Sens. Environ. 2006, 100, 356–362. [Google Scholar] [CrossRef]
- Xia, J.; Du, P.; He, X.; Chanussot, J. Hyperspectral remote sensing image classification based on rotation forest. IEEE Geosci. Remote Sens. Lett. 2014, 11, 239–243. [Google Scholar] [CrossRef]
- Xia, J.; Chanussot, J.; Du, P.; He, X. Spectral—Spatial classification for hyperspectral data using rotation forests with local feature extraction and markov random fields. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2532–2546. [Google Scholar] [CrossRef]
- Xia, J.; Falco, N.; Benediktsson, J.A.; Chanussot, J.; Du, P. Class-separation-based rotation forest for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 584–588. [Google Scholar] [CrossRef]
- Feng, W.; Bao, W. Weight-based rotation forest for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2167–2171. [Google Scholar] [CrossRef]
- Izquierdo-Verdiguier, E.; Zurita-Milla, R.; Rolf, A. On the use of guided regularized random forests to identify crops in smallholder farm fields. In Proceedings of the 2017 9th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Brugge, Belgium, 27–29 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–3. [Google Scholar]
- Mureriwa, N.; Adam, E.; Sahu, A.; Tesfamichael, S. Examining the spectral separability of prosopis glandulosa from co-existent species using field spectral measurement and guided regularized random forest. Remote Sens. 2016, 8, 144. [Google Scholar] [CrossRef]
- Fauvel, M.; Benediktsson, J.A.; Chanussot, J.; Sveinsson, J.R. Spectral and spatial classification of hyperspectral data using svms and morphological profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3804–3814. [Google Scholar] [CrossRef]
- Tarabalka, Y.; Fauvel, M.; Chanussot, J.; Benediktsson, J.A. Svm-and mrf-based method for accurate classification of hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2010, 7, 736–740. [Google Scholar] [CrossRef]
- Bazi, Y.; Melgani, F. Toward an optimal svm classification system for hyperspectral remote sensing images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3374–3385. [Google Scholar] [CrossRef]
- Cui, M.; Prasad, S. Class-dependent sparse representation classifier for robust hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2683–2695. [Google Scholar] [CrossRef]
- Lv, Q.; Niu, X.; Dou, Y.; Wang, Y.; Xu, J.; Zhou, J. Hyperspectral image classification via kernel extreme learning machine using local receptive fields. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 256–260. [Google Scholar]
- Li, J.; Xi, B.; Li, Y.; Du, Q.; Wang, K. Hyperspectral classification based on texture feature enhancement and deep belief networks. Remote Sens. 2018, 10, 396. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–spatial classification of hyperspectral data based on deep belief network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Roodposhti, M.S.; Aryal, J.; Pradhan, B. A novel rule-based approach in mapping landslide susceptibility. Sensors 2019, 19, 2274. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Cheng, Y. Mean shift, mode seeking, and clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 790–799. [Google Scholar] [CrossRef]
- Fukunaga, K.; Hostetler, L. The estimation of the gradient of a density function, with applications in pattern recognition. IEEE Trans. Inf. Theory 1975, 21, 32–40. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Routledge: Abingdon, UK, 2018. [Google Scholar]
- Carreira-Perpinán, M.A. A review of mean-shift algorithms for clustering. arXiv 2015, arXiv:1503.00687. [Google Scholar]
- Huband, J.M.; Bezdek, J.C.; Hathaway, R.J. Bigvat: Visual assessment of cluster tendency for large data sets. Pattern Recognit. 2005, 38, 1875–1886. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Mahapatra, D. Analyzing training information from random forests for improved image segmentation. IEEE Trans. Image Process. 2014, 23, 1504–1512. [Google Scholar] [CrossRef] [PubMed]
- Golipour, M.; Ghassemian, H.; Mirzapour, F. Integrating hierarchical segmentation maps with mrf prior for classification of hyperspectral images in a bayesian framework. IEEE Trans. Geosci. Remote Sens. 2016, 54, 805–816. [Google Scholar] [CrossRef]
- Kuhn, M. Caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar]
- Yang, C.; Tan, Y.; Bruzzone, L.; Lu, L.; Guan, R. Discriminative feature metric learning in the affinity propagation model for band selection in hyperspectral images. Remote Sens. 2017, 9, 782. [Google Scholar] [CrossRef]
- Kianisarkaleh, A.; Ghassemian, H. Nonparametric feature extraction for classification of hyperspectral images with limited training samples. ISPRS J. Photogramm. Remote Sens. 2016, 119, 64–78. [Google Scholar] [CrossRef]
- Luo, F.; Huang, H.; Duan, Y.; Liu, J.; Liao, Y. Local geometric structure feature for dimensionality reduction of hyperspectral imagery. Remote Sens. 2017, 9, 790. [Google Scholar] [CrossRef]
- Palczewska, A.; Palczewski, J.; Robinson, R.M.; Neagu, D. Interpreting random forest models using a feature contribution method. In Proceedings of the 2013 IEEE 14th International Conference on Information Reuse and Integration (IRI), San Francisco, CA, USA, 14–16 August 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 112–119. [Google Scholar] [Green Version]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forest classification of multisource remote sensing and geographic data. In Proceedings of the 2004 IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004; IEEE: Piscataway, NJ, USA, 2004; pp. 1049–1052. [Google Scholar]
- Yang, X.; Chen, L.; Li, Y.; Xi, W.; Chen, L. Rule-based land use/land cover classification in coastal areas using seasonal remote sensing imagery: A case study from Lianyungang city, China. Environ. Monit. Assess. 2015, 187, 449. [Google Scholar] [CrossRef] [PubMed]
- Lucas, R.; Rowlands, A.; Brown, A.; Keyworth, S.; Bunting, P. Rule-based classification of multi-temporal satellite imagery for habitat and agricultural land cover mapping. ISPRS J. Photogramm. Remote Sens. 2007, 62, 165–185. [Google Scholar] [CrossRef]
- Bryan, B.A.; Barry, S.; Marvanek, S. Agricultural commodity mapping for land use change assessment and environmental management: An application in the Murray–darling basin, Australia. J. Land Use Sci. 2009, 4, 131–155. [Google Scholar] [CrossRef]
- Bruzzone, L.; Prieto, D.F. Unsupervised retraining of a maximum likelihood classifier for the analysis of multitemporal remote sensing images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 456–460. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train | Test | SVM | DBN | XGboost | RF | RoF | RRF | DoTRules | |
|---|---|---|---|---|---|---|---|---|---|
| Indian Pines | 1% | 50% | 62.2 | 56.0 | 52.9 | 64.8 | 70.5 | 58.8 | 68.6 |
| 0.558 | 0.486 | 0.453 | 0.593 | 0.650 | 0.521 | 0.640 | |||
| 5% | 50% | 75.0 | 73.0 | 69.8 | 69.3 | 77.9 | 64.6 | 87.3 | |
| 0.708 | 0.689 | 0.656 | 0.644 | 0.725 | 0.588 | 0.855 | |||
| 10% | 50% | 81.0 | 78.6 | 75.0 | 73.4 | 84.9 | 72.3 | 93.2 | |
| 0.781 | 0.755 | 0.710 | 0.693 | 0.788 | 0.675 | 0.928 | |||
| Salinas | 1% | 50% | 90.6 | 87.7 | 89.0 | 86.6 | 89.9 | 88.1 | 91.5 |
| 0.895 | 0.862 | 0.877 | 0.850 | 0.881 | 0.867 | 0.906 | |||
| 5% | 50% | 92.3 | 92.2 | 90.8 | 90.3 | 91.9 | 90.1 | 97.2 | |
| 0.914 | 0.913 | 0.898 | 0.892 | 0.908 | 0.888 | 0.969 | |||
| 10% | 50% | 93.3 | 92.3 | 92.1 | 91.5 | 92.9 | 90.6 | 98.7 | |
| 0.925 | 0.914 | 0.912 | 0.905 | 0.918 | 0.895 | 0.986 | |||
| Pavia | 1% | 50% | 92.0 | 86.7 | 81.6 | 81.8 | 84.9 | 81.6 | 79.1 |
| 0.893 | 0.820 | 0.748 | 0.749 | 0.790 | 0.732 | 0.720 | |||
| 5% | 50% | 93.0 | 93.0 | 88.7 | 87.6 | 88.2 | 87.3 | 93.1 | |
| 0.907 | 0.906 | 0.849 | 0.833 | 0.871 | 0.817 | 0.909 | |||
| 10% | 50% | 94.4 | 94.2 | 91.2 | 89.4 | 91.4 | 88.9 | 96.2 | |
| 0.925 | 0.920 | 0.882 | 0.857 | 0.895 | 0.850 | 0.951 |
| Dataset | R | R-Squared | p-Value | Train RMSE | Test RMSE |
|---|---|---|---|---|---|
| Indian Pines | 0.978 | 0.958 | 2.20 × 10−16 | 0.3261 | 0.0972 |
| Salinas Valley | 0.996 | 0.993 | 2.20 × 10−16 | 0.0195 | 0.1087 |
| Pavia University | 0.985 | 0.971 | 2.20 × 10−16 | 0.0142 | 0.0628 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shadman Roodposhti, M.; Lucieer, A.; Anees, A.; Bryan, B.A. A Robust Rule-Based Ensemble Framework Using Mean-Shift Segmentation for Hyperspectral Image Classification. Remote Sens. 2019, 11, 2057. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11172057
Shadman Roodposhti M, Lucieer A, Anees A, Bryan BA. A Robust Rule-Based Ensemble Framework Using Mean-Shift Segmentation for Hyperspectral Image Classification. Remote Sensing. 2019; 11(17):2057. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11172057
Chicago/Turabian StyleShadman Roodposhti, Majid, Arko Lucieer, Asim Anees, and Brett A. Bryan. 2019. "A Robust Rule-Based Ensemble Framework Using Mean-Shift Segmentation for Hyperspectral Image Classification" Remote Sensing 11, no. 17: 2057. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11172057