1. Introduction
Ship detection in remote sensing imagery has attracted the attention of many researchers due to its wide applications such as maritime surveillance, vessel traffic services, and naval warfare. Although many methods have shown promising results [
1,
2,
3], ship detection in optical remote sensing images with complex backgrounds is still challenging.
The optical remote sensing images are often contaminated by mists, clouds, and ocean waves, resulting in the low contrast and blurring of the ship targets. In complex scene, the background on the land would have similar textures and colors with the inshore ships. Moreover, unlike many objects in natural images, the ships in remote sensing images are relatively small and less clear. They are in narrow-rectangle shapes, with the orientation of arbitrary angles in the image, and usually docked very closely, making it difficult to detect each single ship separately.
Recently, convolutional neural networks (CNN)-based object detection methods for natural images have achieved great improvement in terms of detection accuracy and running efficiency [
4,
5,
6,
7]. These methods typically predict horizontal bounding boxes from horizontal region proposals (or anchors) to locate objects, since the objects in natural images are usually placed in horizontal or near-horizontal. Generally, the horizontal box and region proposal are described as a rectangle with 4 tuples
, in which
denotes the center location of the rectangle, and
h,
w are height and width, respectively. However, using the horizontal box is very difficult to accurately locate arbitrary-oriented ships in the remote sensing images [
8,
9,
10,
11]. Consequently, many CNN-based ship-detection methods are proposed to predict rotated bounding boxes from rotated region proposals [
8,
9,
10]. The rotated box and region proposal are usually described as a rotated rectangle with 5 tuples
, in which the additional variable
denotes the orientation (or angle) of the rotated box.
Many object detection methods for natural images [
5,
6] and ship-detection methods [
8,
10] usually use each pixel in the feature map as the center location
to generate region proposals. However, objects in remote sensing images usually only occupy a small portion of the images. This results in many useless region proposals at the locations without the objects. In addition, the feature map is usually generated with substantial downsampling, e.g., 1/16 in [
5] as compared to original image. Although all pixels of the feature map are used to generate region proposals, they are still sparse compared to the resolution of original image. This is unfavorable for detection of small objects, because there might be no pixel or only a few pixels on the feature map right locating on the objects.
On each center location
, the rotated region proposals are usually generated by predefining some fixed angles of orientation (
), scales (
), and aspect ratios (
) [
8,
10]. Predefining some fixed values of scales and aspect ratios can be fine for horizontal region proposal generation, which has been proved in many object detection methods (e.g., Faster R-CNN [
5], SSD [
6], YOLOv3 [
12]). However, predefining some fixed values for the angles may not be a good choice. Since ships are usually in narrow-rectangle shapes, the Intersection-over-Union (IoU) overlap between the region proposal and the ground-truth box is very sensitive to the angle variation of the region proposal. As shown in
Figure 1, in (a), when the angle difference between the region proposal (red box) and the ground-truth box (yellow box) is for example
, the IoU overlap is 0.61. However, in (c), when the angle difference increases to
, the IoU overlap drops to 0.15. Under such small IoU, it is very difficult for CNN to accurately predict the ground-truth box from the region proposal. Furthermore, the angle of the rotated region proposal can span a large range (i.e.,
). Hence, a relatively large number of fixed values need to be preset for the angle (for example, 6 values are set for the angle in ship-detection methods [
8,
10]), so as to reduce the angle difference, making the prediction from the region proposal to the ground-truth box easier. However, this would generate massive region proposals, leading to the increase of computational cost. In this case, we usually need to sample a relatively smaller number of region proposals from them for the following detection. This process, however, would unavoidably discard some relatively accurate region proposals, leading to the decrease of detection accuracy.
In this paper, we design center region prediction network to solve the problem caused by using each pixel in the feature map as the center location, and ship orientation classification network to avoid the problem caused by setting many coarse fixed values for the angle of orientation. Center region prediction network predicts whether each pixel in the image is in center region of the ship, and then the pixels in the center region are sampled to determine the center locations of region proposals. In this way, the number of generated region proposals can be greatly reduced and most of them are ensured to be located on the ship. To this end, we introduce per-pixel semantic segmentation into center region prediction network. Ship orientation classification network first predicts a rough angle range of orientation for each ship, and then several angles with higher accuracy can be defined among this range. This only needs a small number of predefined angles. The angle difference between the region proposal and the ground-truth box can also be limited to a smaller value, making the prediction from the region proposal to the ground-truth box easier.
To make the whole detection network simpler and more efficient, ship orientation classification network also performs semantic segmentation via sharing the convolutional features with center region prediction network. In this way, the ship orientation classification network yields nearly free computational cost, yet significantly increases detection accuracy. Moreover, since we do not need to predict very accuracy segmentation results for the center region and the angle range, it is unnecessary to construct very complex semantic segmentation network architecture. We only simply add several deconvolutional layers on the base convolutional layers to perform semantic segmentation for the two networks. By taking advantage of these two networks, a smaller number of rotated region proposals with higher accuracy can be generated. Then, each rotated region proposal is simultaneously classified and regressed to locate the ships in optical remote sensing images.
The rest of this paper is organized as follows. In
Section 2, we introduce the related work.
Section 3 describes the details of our accurate ship-detection method. In
Section 4, experimental results and comparisons are given to verify the superiority of our ship-detection method.
Section 5 analyzes the ship-detection network in detail. We conclude this paper in
Section 6.
2. Related Work
Ship detection in optical remote sensing images with complex backgrounds has become a popular topic of research. In the past few years, many researchers use hand-designed features to perform ship detection. Lin et al. [
13] use line segment feature to detect the shape of the ship. The ship contour feature is extracted in [
14,
15,
16] to perform contour matching. Yang et al. [
17] first extract candidate regions using a saliency segmentation framework, and then a structure-LBP (local binary pattern) feature that characterizes the inherent topology structure of the ship is applied to discriminate true ship targets. In addition, the ship head feature served as an important feature for ship detection is also usually used [
18,
19,
20,
21]. It is worth noting that it is very hard to design effective features to address various complex backgrounds in optical remote sensing images.
In recent years, CNN-based object detection methods for natural images have achieved great improvement since R-CNN [
22] is proposed. These methods can be typically classified into two categories: two-stage detection methods and one-stage detection methods. The two-stage detection methods (R-CNN [
22], Fast R-CNN [
4], Faster R-CNN [
5]) first generate some horizontal region proposals using selective search [
23], region proposal network [
5] or other sophisticated region proposal generation methods [
24,
25,
26,
27]. Then, the generated region proposals are classified as one of the foreground classes or the background, and regressed to accurately locate the object in the second stage. The two-stage methods are able to robustly and accurately locate objects in images and the current state-of-the-art detection performance is usually achieved by this kind of approach [
28]. In contrast, one-stage detection methods directly produce some default horizontal region proposals or locate the location of the object, which no longer needs the above region proposal methods. For example, SSD (single shot multibox detector) [
6] directly sets many default region proposals from multi-scale convolution feature maps. YOLOv3 (you only look once) [
12] divides a single image into multiple grids, and sets five default region proposals for each grid, and then directly classifies and refines these default region proposals. Compared with two-stage detection methods, one-stage methods are simpler and faster, but the detection accuracy is usually inferior to that of two-stage methods [
6].
Inspired by CNN-based object detection methods for natural images, many CNN-based ship-detection methods are proposed to perform accurate ship detection in remote sensing images. Unlike the general object detection methods for natural images, the ship detection needs to predict the rotated bounding box to accurately locate ships and avoid missing out the ships docked very closely. Since two-stage detection methods usually produce more accurate object detection results, the researchers pay more attention to this kind of methods. For instance, inspired by R-CNN [
22], S-CNN [
29] first generates rotated region proposals with line segment and salient map, and then CNN is used to classify these region proposals as ships or backgrounds. Liu et al. [
9] detect ships by adopting the framework of two-stage Fast R-CNN [
4], in which SRBBS [
30] replaces selective search [
23] so as to produce rotated region proposals. The above two ship-detection methods achieve better detection performance than the previous methods based on hand-designed features, but they cannot be trained and tested end-to-end, which results in long training and inference time.
Based on Faster R-CNN [
5], Yang et al. [
10] propose an end-to-end ship-detection network, which effectively uses multi-scale convolutional features and RoI align to more accurately and faster locate ships in remote sensing images. Furthermore, some one-stage ship-detection methods are also proposed. Liu et al. [
8] predefine some rotated boxes on the feature map, and then two convolutional layers are added to perform classification and rotated bounding box regression for each predefined box. When the size of the input image is relatively large, this method adopts slide-window strategy to detect multiple small-size images for the detection of the whole image, which greatly increases the detection time. In [
11], the coordinates of the rotated bounding boxes are directly predicted based on the detection framework of one-stage YOLO [
31]; however, this is quite difficult for CNN to produce accurate prediction results [
7].
3. The Proposed Ship-Detection Method
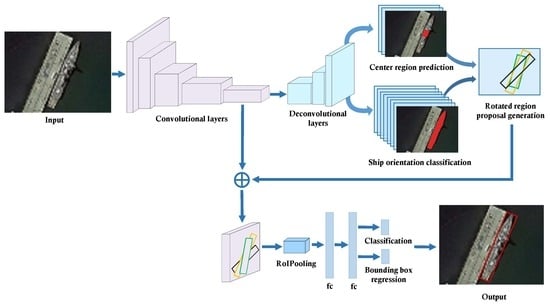
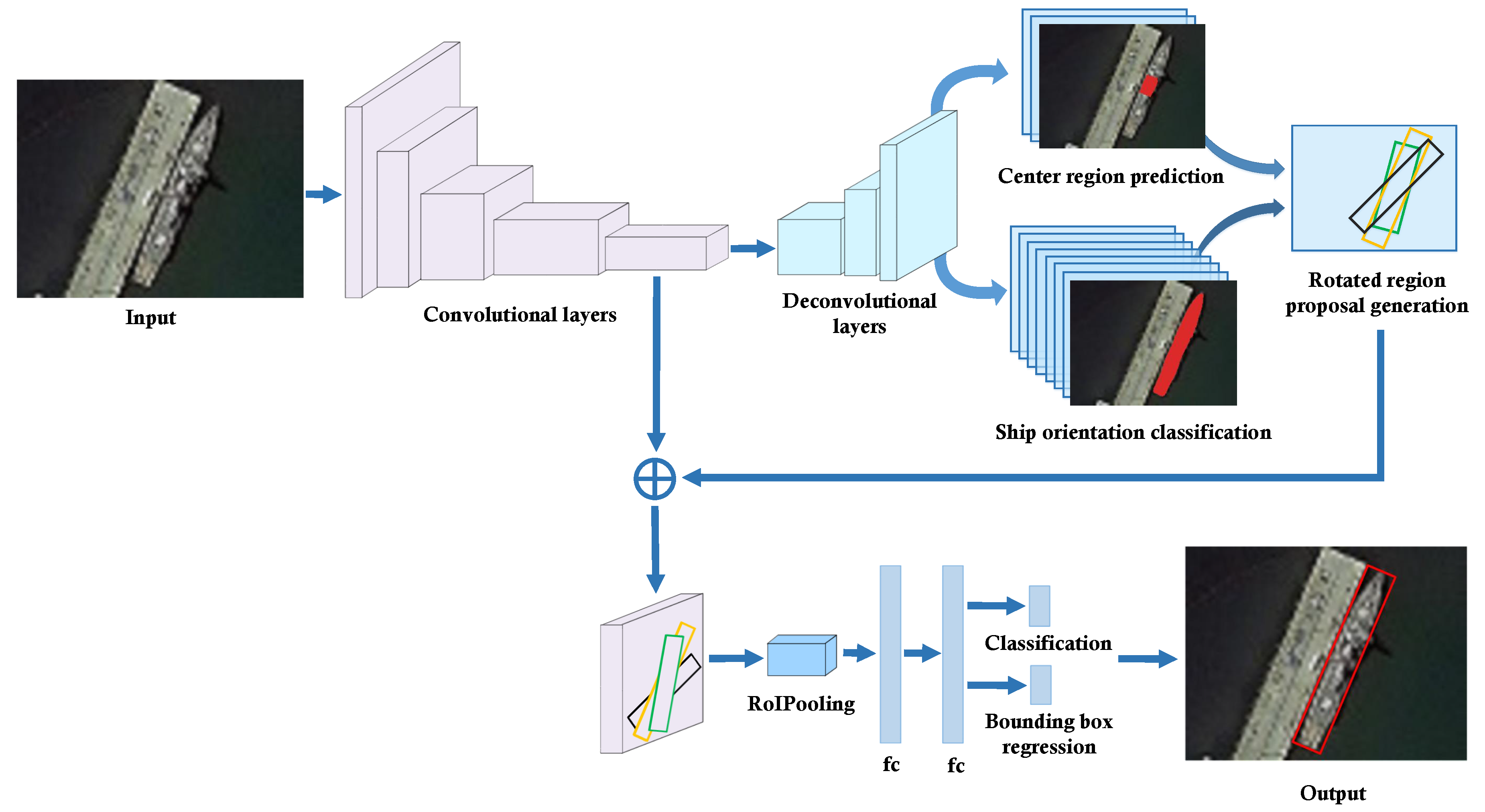
Figure 2 shows the pipeline of the proposed ship-detection method. First, the base convolutional layers are used to extract convolutional features from the input image. Then, unlike the general two-stage object detection methods, we upsample the convolutional features with several deconvolutional layers to perform per-pixel semantic segmentation. This aims to get relatively more accurate center location and orientation of the ship. With such information, more reliable and fewer number of rotated region proposals can be generated, helping to achieve more accurate detection of the ships. As shown in
Figure 2, by introducing several deconvolutional layers, center region prediction network and ship orientation classification network are constructed. They share the deconvolutional features with each other, predicting the center region and orientation of the ship, respectively. Based on those two networks, the rotated region proposals with different angles, aspect ratios, and scales are generated. Then, RoI pooling is performed to extract a fixed-size feature representation from the convolutional features of each region proposal. Finally, two fully connected layers (fc) are used to simultaneously perform classification and regression for each region proposal and ultimately generate the refined ship-detection results with rotated bounding boxes.
3.1. Center Region Prediction Network
Faster R-CNN [
5] first used each pixel in the feature map to generate region proposals, which effectively combines region proposal generation and bounding box regression into an end-to-end network, producing state-of-the-art detection performance. Since then, many object detection methods [
6,
32] and ship-detection methods [
8,
10] adopt this kind of strategy to produce region proposals. However, it might result in two problems in remote sensing images. (1) The sizes of objects in remote sensing images are usually small, only occupying a small portion of the images. In this case, the areas without objects may produce many useless region proposals, which increases the computational load and the risk of false detection in the subsequent stage. (2) The resolutions of the feature maps used to generate region proposals are usually much smaller than those of the input images. For example, in object detection methods [
5,
33], the resolutions of the feature maps are reduced to 1/16 of those of the input images. There would be no reliable pixel on the feature map to indicate the small objects. This would inevitably degrade the detection performance for small objects. To solve the above problems, the idea of semantic segmentation is incorporated in the detection framework to predict the center region for each object. We can then generate region proposals based on a group of pixels only picked from the center region. In this way, it can avoid blindly generating massive useless region proposals in the region without objects, and let the centers of region proposals could concentrate on the objects regardless of their sizes in the image.
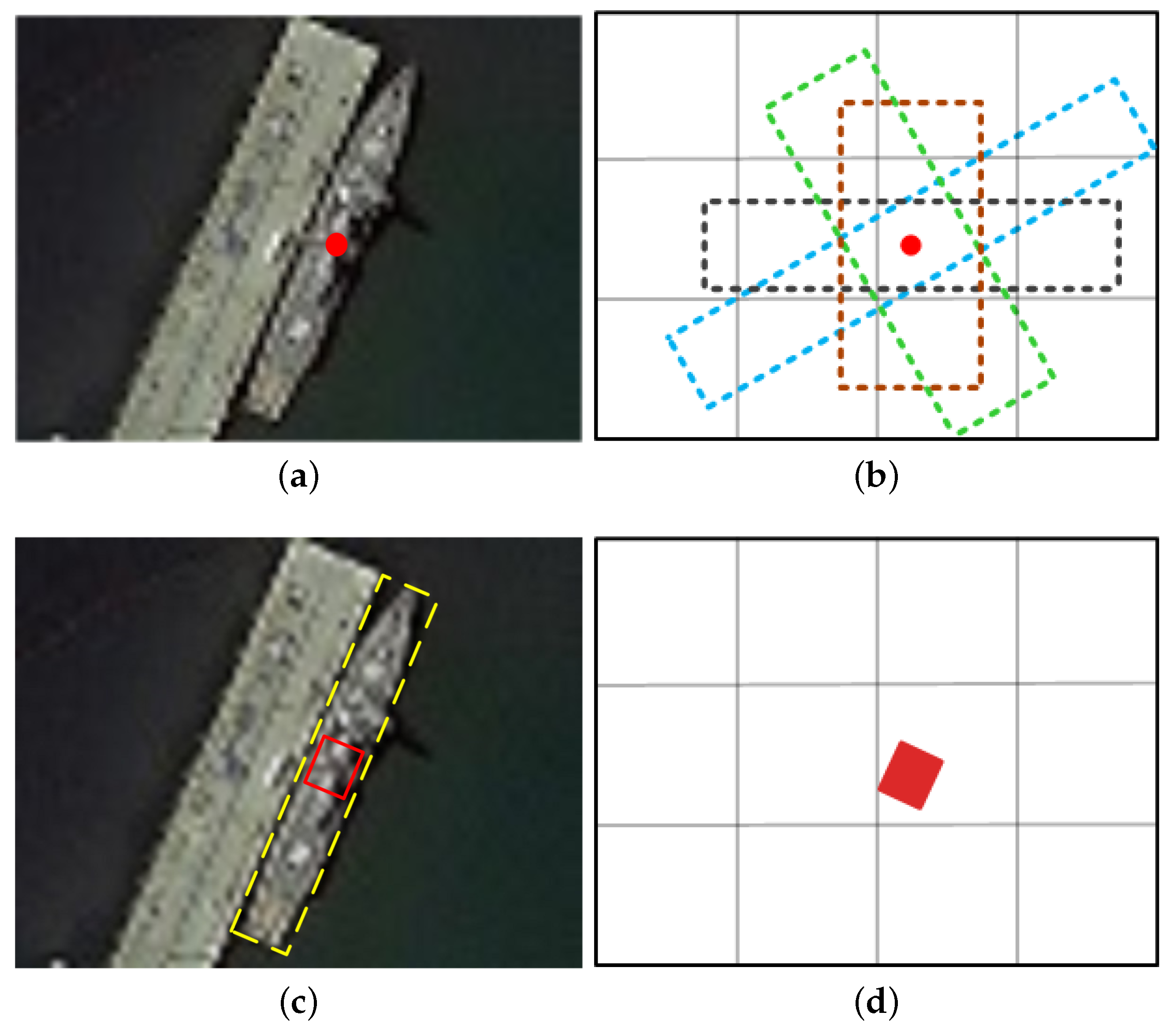
As shown in
Figure 3a, for a ship in optical remote sensing image, we first need to predict the center of ship. With the center point
, we can then define a set of rotated region proposals centered at
with differing angles, aspect ratios, and scales. As shown in
Figure 3b, different region proposals share the same center point, which is located on the ship center needing to be predicted. The purpose of defining multiple region proposals on one predicted center point is to get better adaptation for ships with various sizes and shapes.
It is not easy to directly predict the single center point of a ship in the image. As shown in
Figure 3c, instead of predicting the exact point of ship center, we change it to predict the center region of ship, i.e., a set of points located at the center of ship (see
Figure 3d). Then, a group of pixels sampled from the center region are used to generate region proposals, to increase the probability for accurate ship detection. Another important consideration for predicting the center region rather than the center point is that if only the center point is to be predicted, in the training stage of semantic segmentation, a center pixel for each ship is labeled as positive sample (i.e., 1) in optical remote sensing images, while most of other pixels would be labeled as negative samples (i.e., 0). This would result in a serious class-imbalanced problem. To alleviate this problem, we expand the single point of center to a center region which contains a much larger number of points.
As shown in
Figure 3c, the center region is defined as the area labeled by the red box, whose long side is 0.125 of the long side of the ground-truth box (the yellow box in
Figure 4c), and short side is 0.75 of the short side of the ground-truth box. We take the pixels in center region as the positive samples (see the red region in
Figure 3d), and the pixels in other regions as the negative samples (see the white region in
Figure 3d). However, in this way, the number of the positive sample is still small compared with that of the negative sample.
To further compensate for the shortage of the positive sample, we introduce a class-balanced weight to increase the loss of positive samples. This can make the losses of positive samples and negative samples comparable, even if the number of positive samples is smaller than that of negative samples, to avoid class-imbalanced problem. The class-balanced weight
is introduced into the following cross-entropy loss function:
where
and
denote the positive sample set and the negative sample set, respectively.
denotes the probability that the pixel
u is classified as the positive sample.
denotes the probability that the pixel
v is classified as the negative sample.
and
are computed with the SoftMax function.
, where
and
are the numbers of the positive samples and the negative samples, respectively.
Figure 4 shows some prediction results from center region prediction network. The prediction results are overlaid on input images for better display. The first row shows input images, and the second row shows the prediction results. We can see that the center regions of ships can be properly predicted as expected.
3.2. Ship Orientation Classification Network
The object detection methods for natural images usually generate horizontal region proposals by predefining several fixed scales and aspect ratios in each pixel of the feature map. Inspired by this way, many ship-detection methods [
8,
10] preset some fixed angles, scales, and aspect ratios to generate rotated region proposals. However, ships in optical remote sensing images are usually in narrow-rectangle shapes, and thus the accuracy of the rotated region proposal is greatly influenced by its orientation angle deviation. A small angle change can drastically reduce the accuracy of rotated region proposal. Thus, it is necessary to predefine more possible angles to improve the accuracy of rotated region proposals. However, the angle of the rotated region proposal spans a very large angle range (i.e.,
), and a large number of angles need to be predefined. This can reduce the interval between two adjacent angles and therefore improve the accuracy of some region proposal, but much more region proposals would be produced, resulting in significant increase of computational cost. In this situation, a smaller number of region proposals usually need to be sampled to increase detection efficiency. However, the sampling operation would inevitably discard some relatively accurate region proposals, causing the decrease of detection accuracy.
To solve this problem, we first predict a rough angle range orientation for each ship in the images. Several possible angles with higher confidence can then be defined among this range. This can limit the angle difference between region proposals and ground-truth boxes to a small value, and only need a limited number of predefined angles. To this end, we construct ship orientation classification network to predict the angle range of the ship. The ship orientation classification network also performs semantic segmentation, which enables it to share the convolutional features with the center region prediction network. In this way, ship orientation classification network yields nearly free computational cost, yet significantly increase detection accuracy.
We fix the whole angle range of orientation to
in this paper. To predict the angle range for each ship in the optical remote sensing images, the whole angle range
is divided into 6 bins (more analysis can be seen in
Section 5-B), and each bin is indexed by
. As shown in
Table 1, the first column lists index
i, and the second column lists the angle range of each bin
i. Ship orientation classification network performs semantic segmentation and outputs dense per-pixel classification. According to the orientation angle of each ship, the pixels in the ship region are all labeled by a corresponding index
i, while the pixels in other locations are labeled as 0. For example, for the remote sensing image shown in
Figure 5a,
Figure 5b illustrates the ground-truth segmentation label of ship orientation classification network. The orientation angle of the ship is
, and thus the pixels in the ship region are classified as index 4 (denoted with red color), and the pixels in other locations are classified as 0 (denoted with white color). Then, we can define multiple more confident angles for region proposals within the predicted angle range. As a result, the generated region proposals would have smaller number of the angle and higher accuracy.
Similar to center region prediction network, in order to solve the class-imbalanced problem, we define the following class-balanced cross-entropy loss function as
where
denotes the pixel set in ship region indexed by
i, and
is the pixel set in non-ship region.
denotes the probability that the pixel
u is classified as the angle index
i.
denotes the probability that the pixel
v is classified as 0.
and
are computed with the SoftMax function.
denotes the class-balanced weight of each angle index, and we set
, where
and
are numbers of
and
, respectively.
The segmentation results of ship orientation classification network are shown in the third row of
Figure 4, in which the ships in different angle ranges are denoted with different colors. We can see that the network can properly predict the angle range of each ship.
3.3. Rotated Region Proposal Generation
In this paper, the region proposal is described as a rotated rectangle with 5 tuples
. The coordinate
denotes the center location of the rectangle. The height
h and the width
w are the short side and the long side of the rectangle, respectively.
is the rotated angle of the long side. As mentioned in
Section 3.2,
.
Unlike the objects in natural images, for the ships in remote sensing images, the ratio of width to height can be very large. Thus, we set aspect ratios
:
of region proposals as 1:4 and 1:8. The scales
of region proposals are set as 32, 64, 128, 256. The angles of region proposals are listed in the third column of
Table 1. For example, when the orientation angle range of a ship is in
, the angles of region proposals are set as
. In this case, the angle difference between the region proposal and its ground-truth box will be no more than
. How to set scales, aspect ratios, and angles of region proposals is detailed in
Section 5-D.
For a pixel
A in the predicted center region of a ship, we can find the pixel
B at the same position from the output of ship orientation classification network. Taking the pixel
A as the center point of region proposals and the value (the index
i) of pixel
B to determine the angle range of region proposals, we can generate 3-angle, 2-aspect ratio, and 4-scale region proposals. In an image, the number of pixels in center regions can be very large. Taking all these pixels as the center points of region proposals will generate too many region proposals, which is time-consuming for subsequent operations. To reduce the number of region proposals, for each image, we randomly sample
N pixels from center regions to generate region proposals (see the more analysis in
Section 5-C).
There are a total of 2400 region proposals (100 sampling pixels × 3 angles × 2 aspect ratios × 4 scales) in an image. Some region proposals highly overlap with each other. To reduce redundancy, we adopt non-maximum suppression (NMS) [
34]. For NMS, we fix the IoU [
11] threshold at 0.7, and the score of each region proposal is set as the probability that the center point of the region proposal is classified as belonging to the center region of a ship. After NMS, per image remains about 400 region proposals.
With center region prediction network and ship orientation classification network, our method only generates 2400 region proposals in an image, which are much fewer than those generated with two-stage representative Faster R-CNN [
5]. For an image with size
, Faster R-CNN generates 6912 region proposals with 3 scales and 3 aspect ratios, which are about three times more than those generated with our method. Moreover, experimental results demonstrate that the detection accuracy can be satisfactory with much fewer region proposals.
3.4. Multi-Task Loss for Classification and Bounding Box Regression of Region Proposals
We first assign each region proposal as the positive sample (ship) or the negative sample (background). A region proposal is assigned as the positive sample if its IoU overlap with the ground-truth box is higher than 0.45, and the negative sample if its IoU overlap is lower than 0.45.
The detection network preforms classification and bounding box regression for each region proposal. For classification, the network outputs a discrete probability distribution, , over two categories (i.e., ship and background). p is computed with a SoftMax function. For bounding box regression, the network outputs bounding box regression offset, .
We use a multi-task loss to jointly train classification and bounding box regression:
where
u indicates the class label (
for ship and
for background), and
denotes the ground-truth bounding box regression offset. The classification loss
is defined as:
For the bounding box regression loss
, the term
denotes that the regression loss is activated only for the positive sample
and would be disabled for the negative sample
. We adopt smooth-
loss [
5] for
:
in which
The bounding box regression offsets
t and
are defined as follows:
where
x,
and
are for the predicted box, region proposal and ground-truth box (likewise for
), and
to ensure
.
3.5. End-to-End Training
We define the loss function of the whole detection network as
where
are balancing parameters. In the training process,
is about 2:1:1, and thus we set
as (0.5, 1, 1). Our detection network is trained end-to-end using stochastic gradient descent (SGD) optimizer [
35]. We use the VGG16 model pre-trained for ImageNet classification [
36] to initialize the network while all new layers (not in VGG16) is initialized with Xavier [
37]. The weights of the network are updated by using a learning rate of
for the first 80k iterations, and
for next 80k iterations. The momentum, the weight decay, and the batch size is set as 0.9, 0.0005 and 2, respectively. Moreover, online hard example mining (OHEM) [
38] is adopted to better distinguish ships from complex backgrounds. OHEM can automatically select hard examples to train object detectors, thus leading to better training convergence and higher detection accuracy.
3.6. Network Architecture
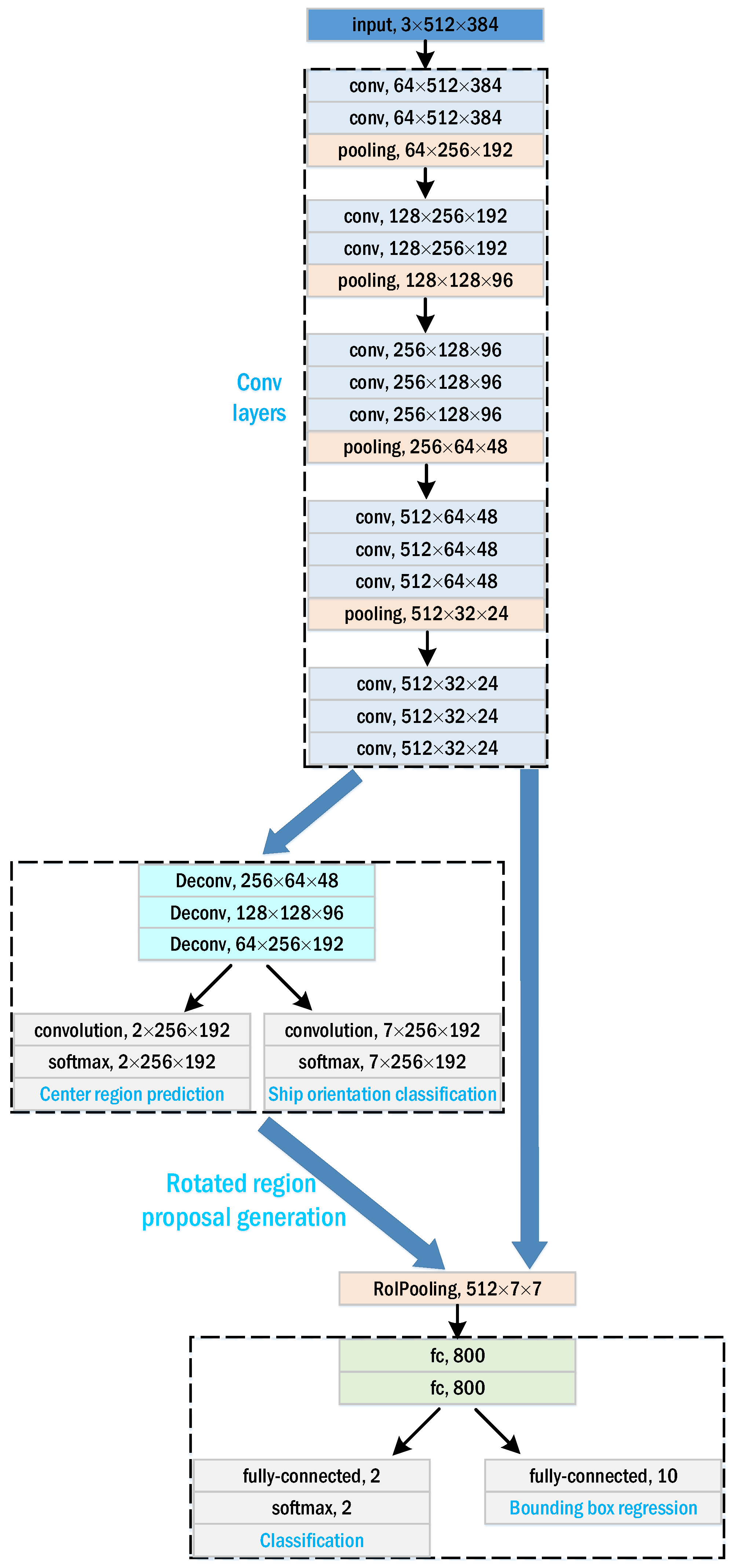
Figure 6 shows the network architecture of our detection network. Details of each part is described as follows:
Input image: the input image is a three-channel optical remote sensing image. The network can be applied on any-size images, but for simplicity, all input images are resized into (channel × width × height).
Conv layers: the 13 convolutional layers in VGG16 model [
36] served as the base convolutional layers have been widely used in many applications [
5,
39,
40], and we adopt these 13 convolutional layers to extract image features. As shown in
Figure 6, “conv” denotes a convolutional layer followed by a ReLU activation function [
41]. The output size of each layer is denoted as channel × width × height (for example,
). The pooling layer is inserted among the convolutional layers to implement downsampling.
Center region prediction network and ship orientation classification network: the deconvolutional layer is used to upsample feature maps to construct center region prediction network and ship orientation classification network. “Deconv” denotes a deconvolutional layer followed by a ReLU activation function. For speed/accuracy trade-off, the output size for the two networks is set as
(see the more analysis in
Section 5-A).
RoI Pooling: RoI pooling [
9,
42,
43,
44] is performed to extract a fixed-size feature representation (
) from convolutional features for each region proposal, so as to interface with the following fully connected network.
Classification and bounding box regression: Two fully connected layers are used to perform classification and bounding box regression for each region proposal. “fc” in
Figure 6 denotes the fully connected layer followed by a ReLU activation function and a dropout layer [
45]. “fully connected” denotes the fully connected layer. There are 2 outputs (the probabilities belonging to ship and background) for classification, and 10 outputs (5 offsets for the positive sample and 5 offsets for the negative sample) for bounding box regression.
5. Network Analysis
A. The output sizes of center region prediction network and ship orientation classification network. The output sizes of the two networks can influence the detection accuracy and the running efficiency. Some small ships just take up a small part of the input images. When the output sizes are much smaller than the input sizes, these small ships in outputs would only cover very small regions. In this situation, the two segmentation networks are easy to miss out these small ships. As listed in
Table 3, when the output size of networks is 128 × 96, the detection accuracy drops to 80.4%. In addition, compared with predicting small outputs, predicting large outputs is more difficult for the two networks. When the output sizes are very large, the detection accuracy will no longer increase; however, the computational time would become longer (see the last row in
Table 3). For speed/accuracy trade-off, we set the output size of the two networks as 256 × 192.
B.qfor ship orientation classification network. For ship orientation classification network, the whole angle range
is divided into
q bins. Please note that an appropriate
q is important for producing accurate detection results. When
q is small, each bin contains a large angle range. In this situation, the angle difference between the region proposal and the ground-truth box would be large, which is hard for the detection network to produce accurate detection results. For example, in the second column of
Table 4, when
, mAP falls to
. On the other hand, when
q is large, the angle range in each bin and the angle difference would become small, which is good for classification and bounding box regression of region proposals. However, in this case, ship orientation classification network must struggle to recognize more classes, and this may not be a good choice (see the fourth column in
Table 4).
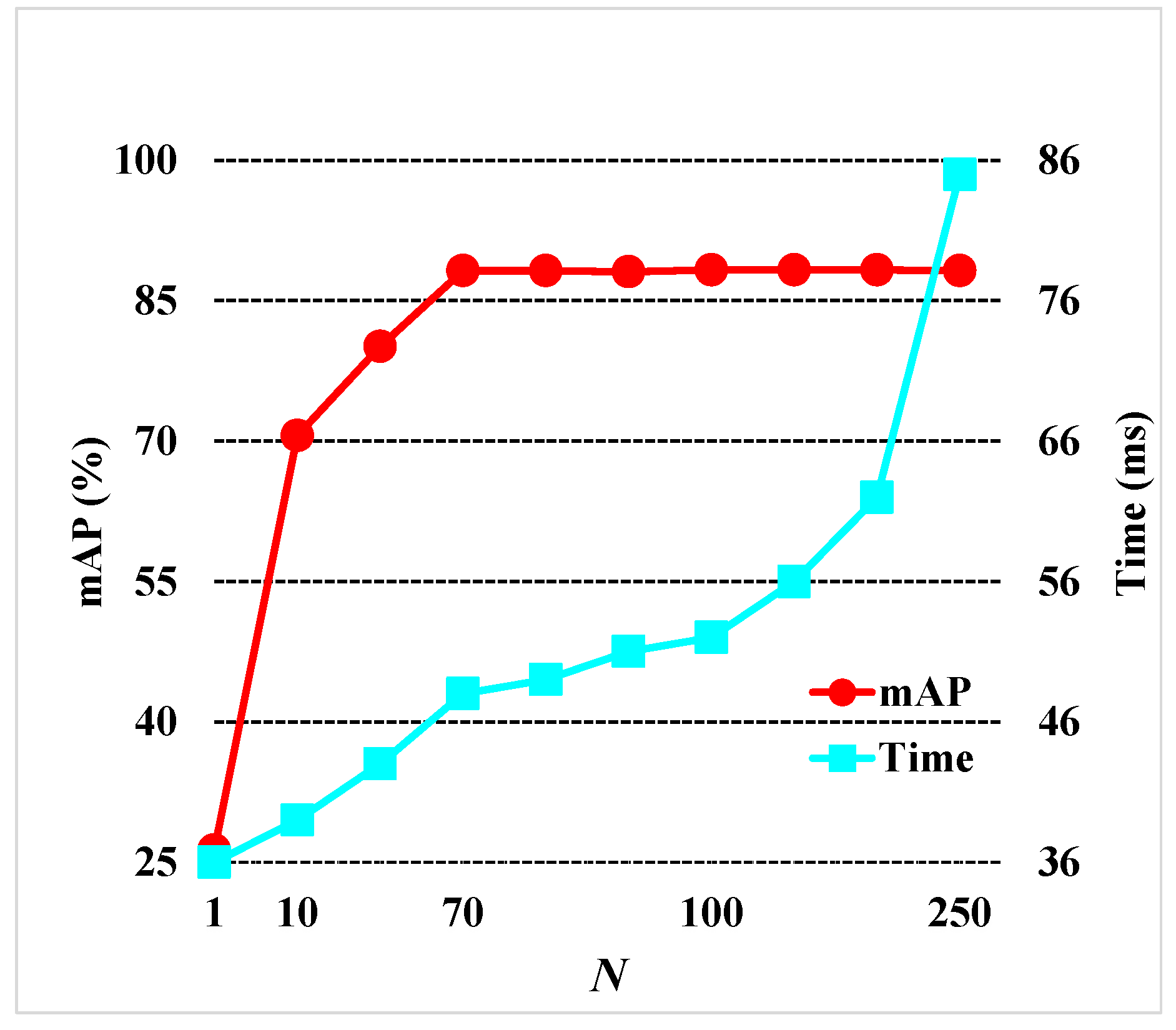
C. Number of sampling pixels for center region prediction network. To reduce the running time, for each image, we randomly sample
N (
) pixels from center regions to generate region proposals. On the one hand, when
N is relatively small, the number of generated region proposals is small. Although the running time is short, this is hard for the detection network to produce good detection results. For example, in
Figure 11, when
, the running time is short, but the accuracy is not satisfactory. On the other hand, since the sampled pixels are all from center regions, when
N becomes very large, these pixels can be very close to each other. In this situation, the overlaps of generated region proposals can be very high, and most of these region proposals will be eliminated via NMS. As a result, along with the increase of
N, the accuracy will no longer increase; however, the running time will become longer. In
Figure 11, we can see that when
, mAP will roughly remain at
, while the running time becomes much longer. For balancing speed and accuracy, we set
in the detection network.
D. Scales, aspect ratios, and angles of region proposals.Table 5 lists the detection accuracy and the running time using region proposals with different scales. We can see that for speed/accuracy trade-off, 4-scale region proposals are suitable for the detection network.
Unlike the objects in natural images, for the ships in optical remote sensing images, the ratio of width to height can be very large. To find appropriate aspect ratios of region proposals, we count aspect ratios of rotated boxes in training set (see
Figure 12). According to the statistical results, we test different aspect ratios in
Table 6. For balancing accuracy and speed, we set aspect ratios of region proposals as 1:4, 1:8.
3-angle region proposals are used in the detection network. With more angles, the angle difference between the region proposal and the ground-truth box can be small. This is beneficial for producing good detection results, but the running time would become longer (see the fifth column in
Table 7). On the contrary, when the number of angles is small, the angle difference will be large. Although the running time can be shortened, the detection accuracy would drop (see the second column in
Table 7). For speed/accuracy trade-off, 3-angle region proposals are employed in our detection network.
E. Context information of the ship. Context information of ships includes sea, shore, ship, dock, and so on. With the context information, CNN can grasp more useful information. This is beneficial for classification and bounding box regression of the region proposal, producing more accurate detection results. We enlarge the width and the height of the ground-truth box with a factor
to use the context information.
Table 8 gives mAP using different enlargement factors. We can see that without context information
, the accuracy is 87.1%, while with context information
, the accuracy can rise to 88.3%. We set
in this paper.
Finally, we evaluate the detection performance of the proposed method under different ship sizes. We divide the ship objects in remote sensing images into three groups, including small ships (
), medium ships (
) and relatively large ships (
). In our dataset, small ships (S), medium ships (M), and relatively large ships (L) account for 36%, 53%, 11%, respectively.
Table 9 lists the detection accuracy under different ship sizes. We can see that as the ship size becomes small, the detection accuracy gradually reduces. The reason is that small ship objects contain less feature information, and are more difficult to be detected. As shown in
Table 9, the detection accuracy of the proposed method for small ships can be satisfactory with mAP of about 81%.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}