Spatial-Spectral Multiple Manifold Discriminant Analysis for Dimensionality Reduction of Hyperspectral Imagery


Abstract
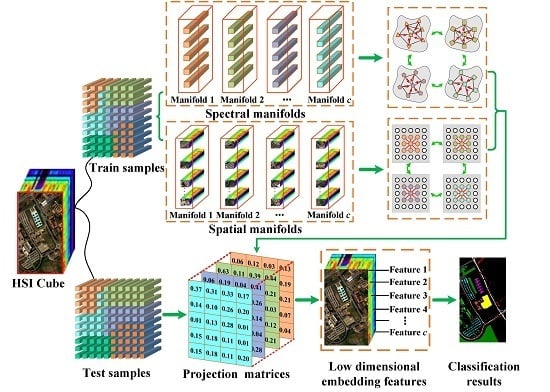
:
1. Introduction
2. Related Works
2.1. Graph Embedding
2.2. Local Scaling Cut
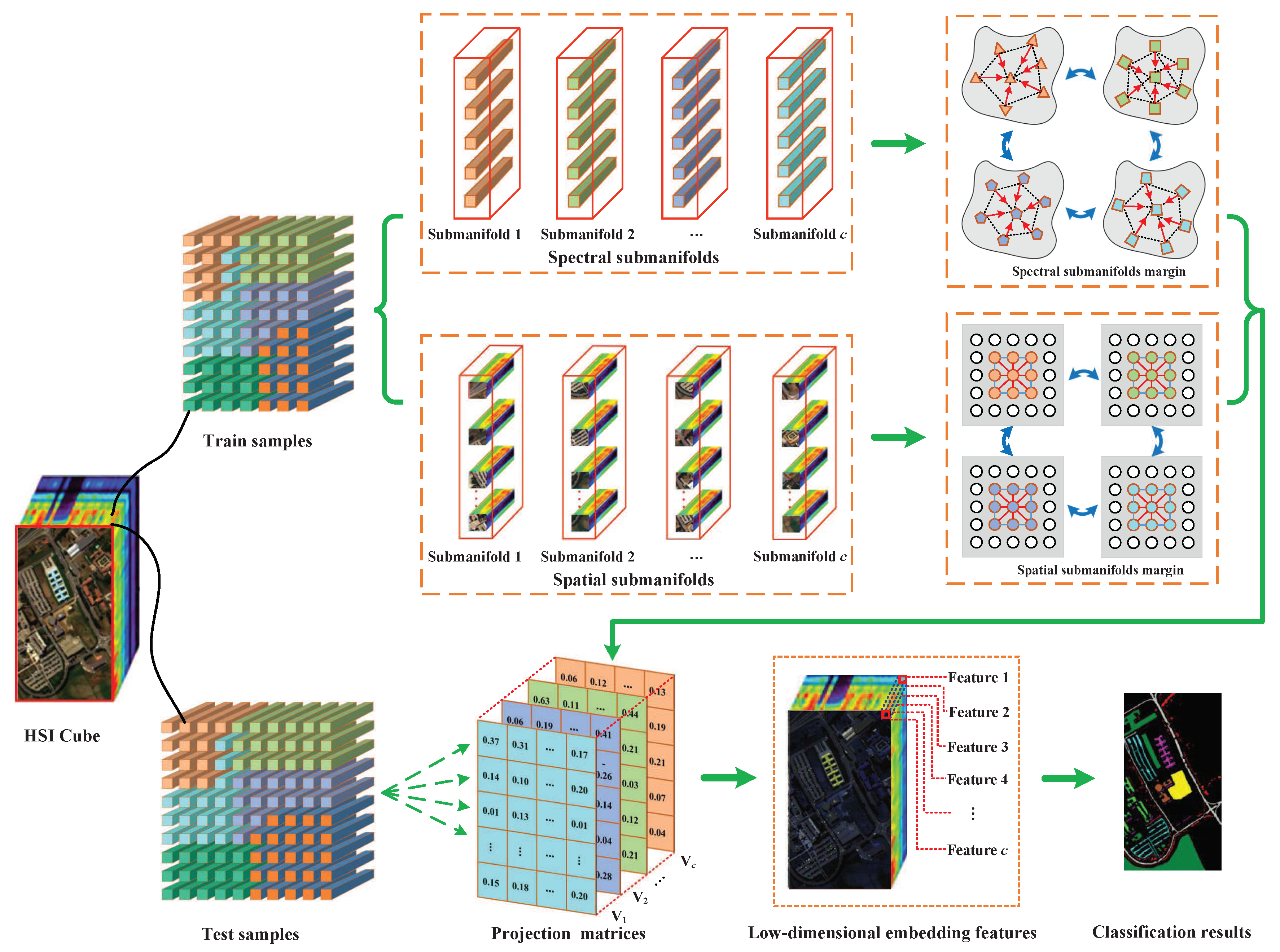
3. Spatial-Spectral Multi-Manifold Discriminant Analysis
3.1. Spectral-Domain Multi-Manifold Analysis Model
3.2. Spatial-Domain Multi-Manifold Analysis Model
3.3. Spatial-Spectral Multi-Manifold Analysis Model
| Algorithm 1 SSMMDA |
|
4. Experimental Results
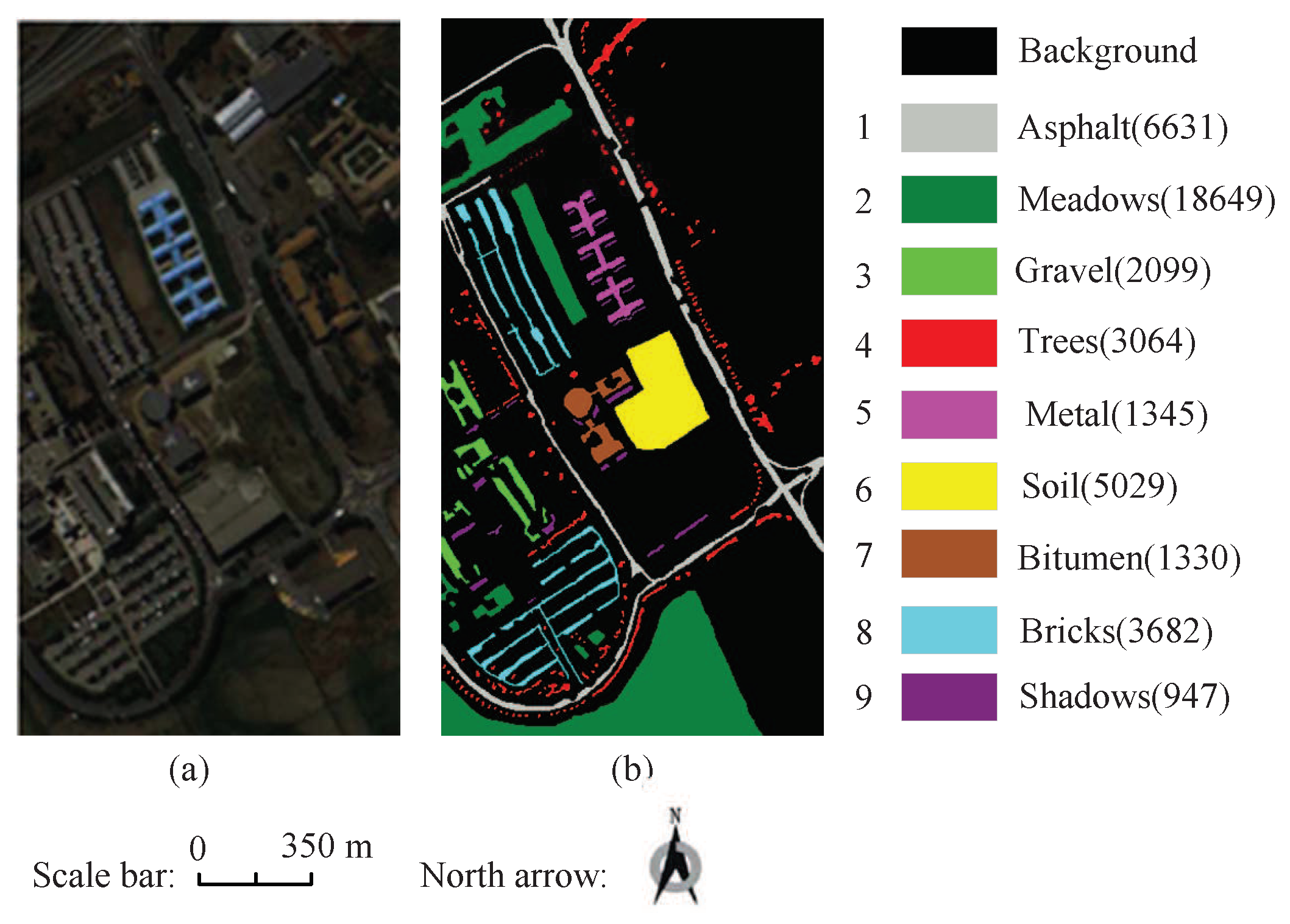
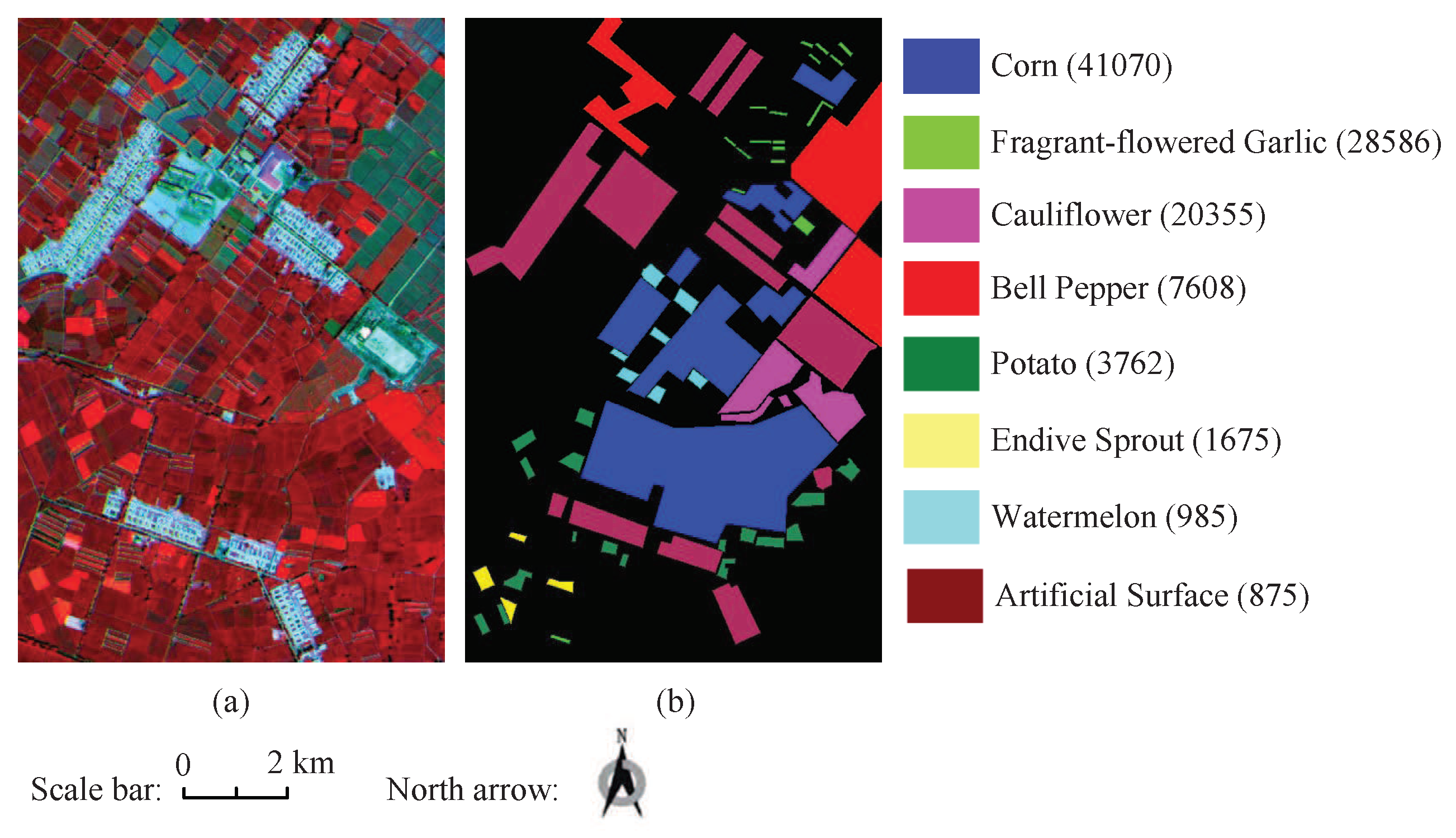
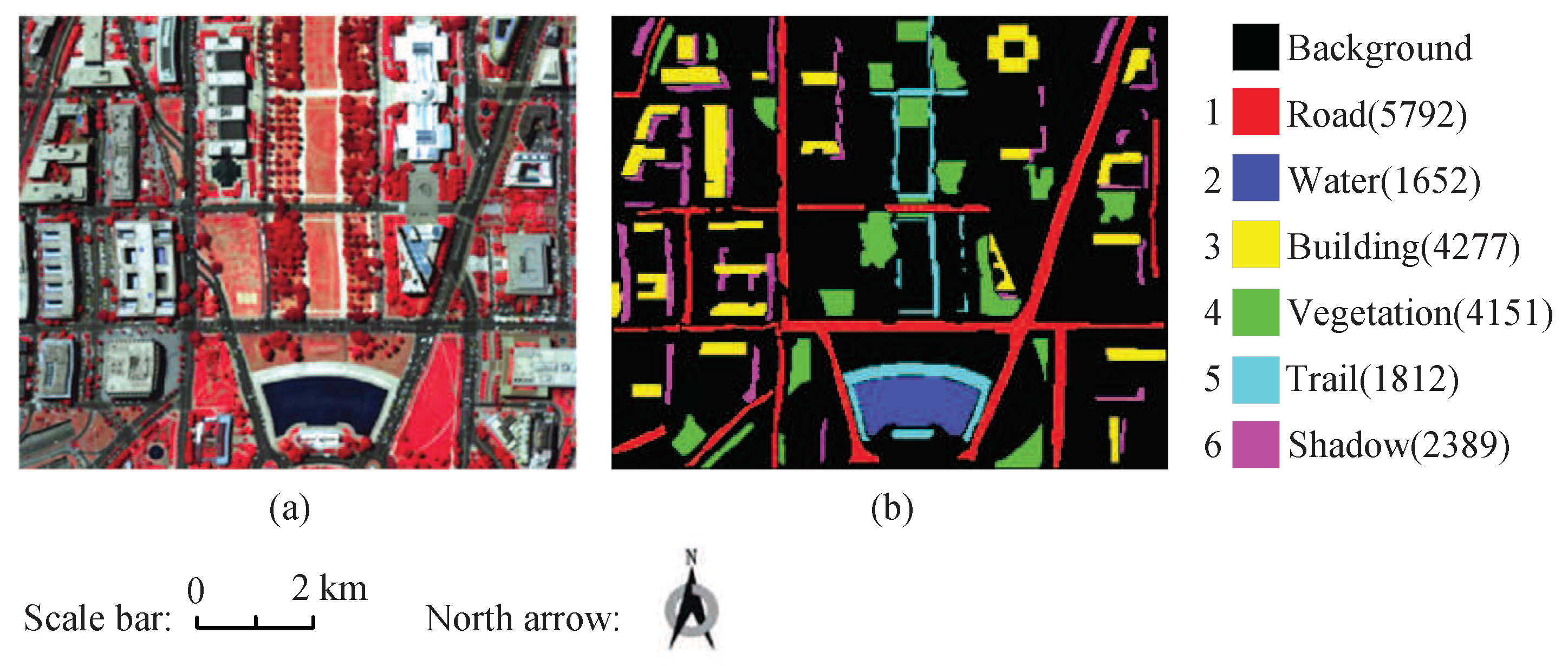
4.1. Experiment Data Set
4.2. Experimental Setup
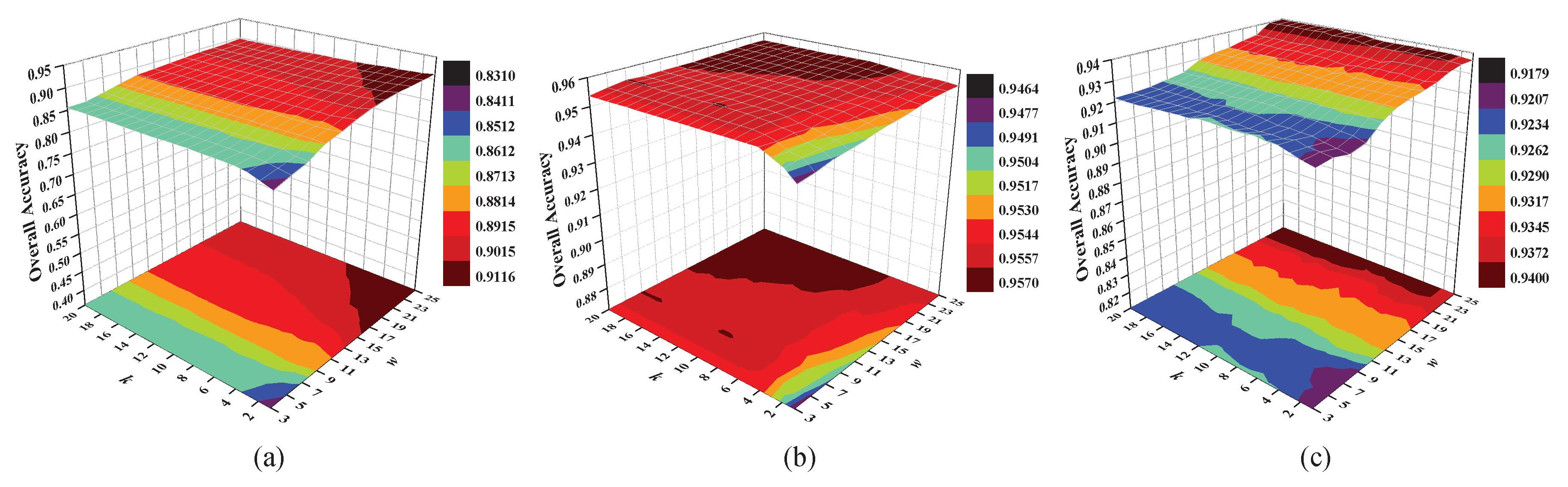
4.3. Analysis of Window Size w and Neighbor Number k
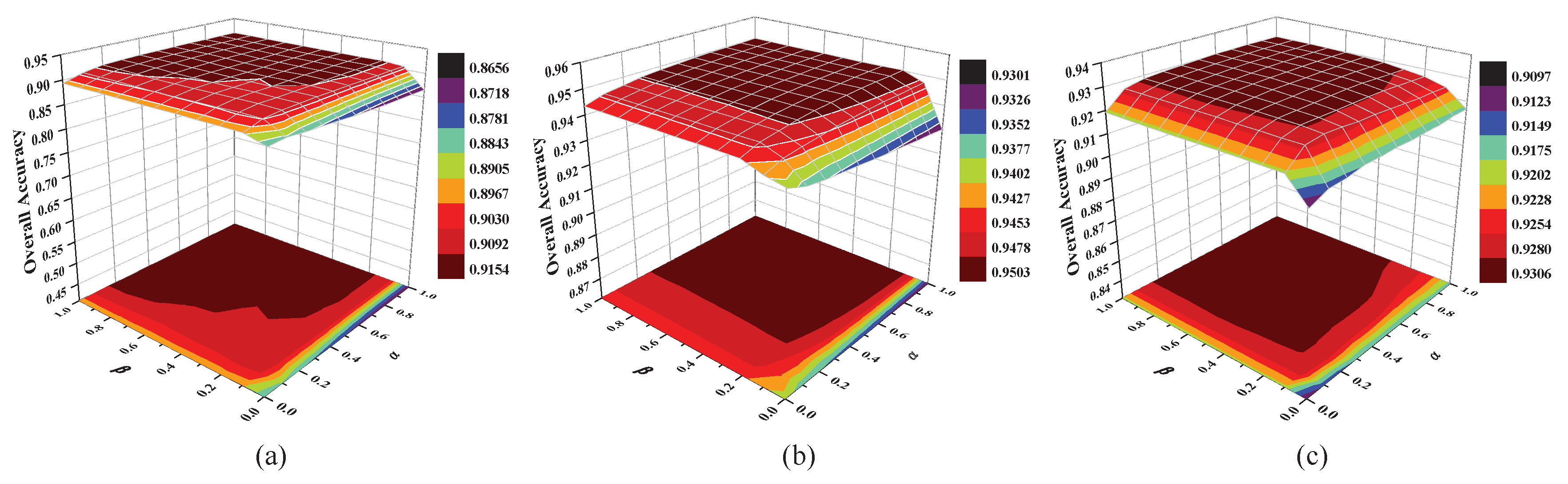
4.4. Analysis of Tradeoff Parameters and
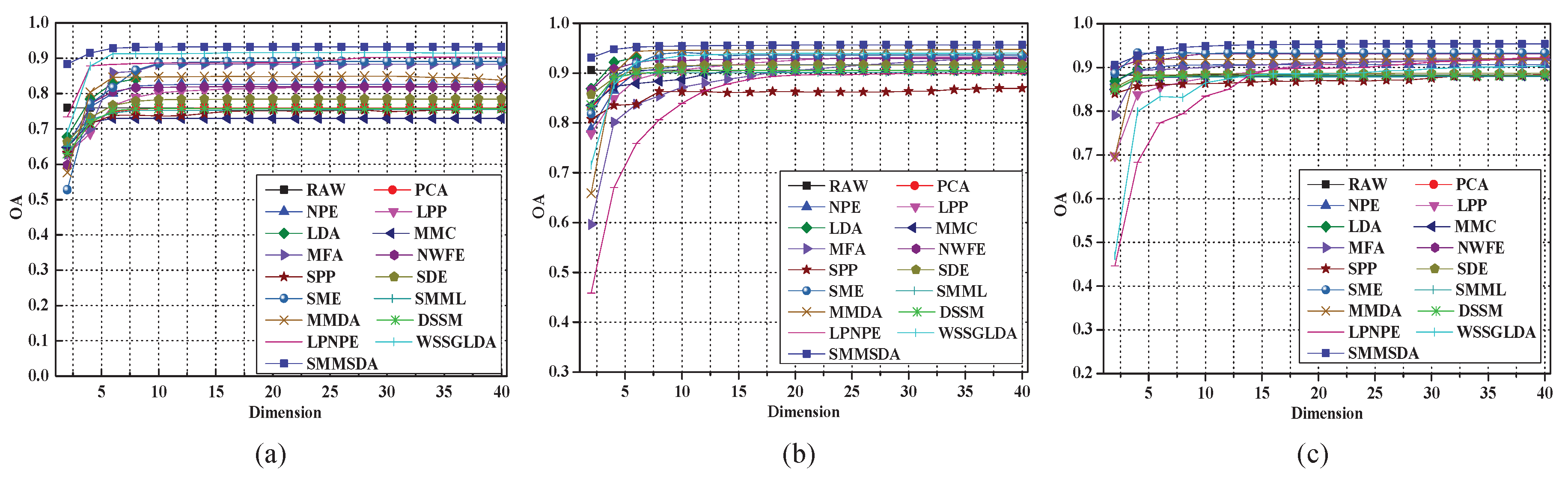
4.5. Investigation of Embedding Dimension d
5. Analysis and Discussion
5.1. Analysis of Training Sample Size
5.2. Analysis of Classification Results
5.3. Analysis of Computational Efficiency
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, S.T.; Hao, Q.B.; Kang, X.; Benediktsson, J.A. Gaussian Pyramid Based Multiscale Feature Fusion for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3312–3324. [Google Scholar] [CrossRef]
- Zhai, H.; Zhang, H.Y.; Zhang, L.P.; Li, P.X. Laplacian-Regularized Low-Rank Subspace Clustering for Hyperspectral Image Band Selection. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1723–1740. [Google Scholar] [CrossRef]
- Luo, F.L.; Zhang, L.P.; Zhou, X.C.; Guo, T.; Cheng, Y.X.; Yin, T.L. Sparse-Adaptive Hypergraph Discriminant Analysis for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2019, 99, 1–5. [Google Scholar] [CrossRef]
- Peng, J.T.; Du, Q. Robust joint sparse representation based on maximum correntropy criterion for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7152–7164. [Google Scholar] [CrossRef]
- Li, W.; Wu, G.D.; Du, Q. Transferred Deep Learning for Anomaly Detection in Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2017, 14, 597–601. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Wang, Z.F.; Huang, X.; Zhang, L.P.; Sun, H. Unsupervised feature learning via spectral clustering of patches for remotely sensed scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2015–2030. [Google Scholar] [CrossRef]
- Song, W.W.; Li, S.T.; Fang, L.Y.; Lu, T. Hyperspectral Image Classification with Deep Feature Fusion Network. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4544–4554. [Google Scholar] [CrossRef]
- Zhai, H.; Zhang, H.Y.; Zhang, L.P.; Li, P.X. Total Variation Regularized Collaborative Representation Clustering with a Locally Adaptive Dictionary for Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 57, 166–180. [Google Scholar] [CrossRef]
- Yuan, Y.; Zheng, X.T.; Lu, X.Q. Discovering diverse subset for unsupervised hyperspectral band selection. IEEE Trans. Image Process. 2017, 26, 51–64. [Google Scholar] [CrossRef]
- Jia, S.; Tang, G.H.; Zhu, J.S.; Li, Q.Q. A Novel Ranking-Based Clustering Approach for Hyperspectral Band Selection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 88–102. [Google Scholar] [CrossRef]
- Dong, Y.N.; Du, B.; Zhang, L.P.; Zhang, L.F. Dimensionality reduction and classification of hyperspectral images using ensemble discriminative local metric learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2509–2524. [Google Scholar] [CrossRef]
- Luo, Y.; Wen, Y.G.; Tao, D.C.; Gui, J.; Xu, C. Large Margin Multi-Modal Multi-Task Feature Extraction for Image Classification. IEEE Trans. Image Process. 2016, 25, 414–427. [Google Scholar] [CrossRef]
- Hang, R.L.; Liu, Q.S.; Sun, Y.B.; Yuan, X.T.; Pei, H.C.; Plaza, J.; Plaza, A. Robust matrix discriminative analysis for feature extraction from hyperspectral images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2002–2011. [Google Scholar] [CrossRef]
- Li, Q.; Ji, H.B. Multimodality image registration using local linear embedding and hybrid entropy. Neurocomputing 2013, 111, 34–42. [Google Scholar] [CrossRef]
- Tu, S.T.; Chen, J.Y.; Yang, W.; Sun, H. Laplacian Eigenmaps-Based Polarimetric Dimensionality Reduction for SAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 170–179. [Google Scholar] [CrossRef]
- Li, W.; Zhang, L.P.; Zhang, L.F.; Du, B. GPU Parallel Implementation of Isometric Mapping for Hyperspectral Classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1532–1536. [Google Scholar] [CrossRef]
- Chen, J.; Liu, Y. Locally linear embedding: A survey. Artif. Intell. Rev. 2011, 36, 29–48. [Google Scholar] [CrossRef]
- Belkin, M.; Niyogi, P. Laplacian Eigenmaps for Dimensionality Reduction and Data Representation. Neural Comput. 2003, 15, 1373–1396. [Google Scholar] [CrossRef] [Green Version]
- Feilhauer, H.; Faude, U.; Schmidtlein, S. Combining Isomap ordination and imaging spectroscopy to map continuous floristic gradients in a heterogeneous landscape. Remote Sens. Environ. 2011, 115, 2513–2524. [Google Scholar] [CrossRef]
- Sun, W.W.; Yang, G.; Du, B.; Zhang, L.F.; Zhang, L.P. A sparse and low-rank near-isometric linear embedding method for feature extraction in hyperspectral imagery classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4032–4046. [Google Scholar] [CrossRef]
- Huang, H.; Li, Z.Y.; Pan, Y.S. Multi-Feature Manifold Discriminant Analysis for Hyperspectral Image Classification. Remote Sens. 2019, 11, 651. [Google Scholar] [CrossRef]
- Fang, L.Y.; Wang, C.; Li, S.T.; Beneditsson, J.A. Hyperspectral image classification via multiple-feature- based adaptive sparse representation. IEEE Trans. Instrum. Meas. 2017, 7, 1646–1657. [Google Scholar] [CrossRef]
- Wang, Q.; Wan, J.; Yuan, Y. Locality Constraint Distance Metric Learning for Traffic Congestion Detection. Pattern Recognit. 2018, 9, 272–281. [Google Scholar] [CrossRef]
- Feng, F.B.; Li, W.; Du, Q.; Zhang, B. Dimensionality reduction of hyperspectral image with graph-based discriminant analysis considering spectral similarity. Remote Sens. 2017, 9, 323. [Google Scholar] [CrossRef]
- Gui, J.; Sun, Z.N.; Jia, W.; Hu, R.X.; Lei, Y.K.; Ji, S.W. Discriminant sparse neighborhood preserving embedding for face recognition. Pattern Recognit. 2012, 45, 2884–2893. [Google Scholar] [CrossRef]
- Wong, W.K.; Zhao, H.T. Supervised optimal locality preserving projection. Pattern Recognit. 2012, 45, 186–197. [Google Scholar] [CrossRef]
- Zhang, X.R.; He, Y.D.; Zhou, N.; Zheng, Y.G. Semisupervised Dimensionality Reduction of Hyperspectral Images via Local Scaling Cut Criterion. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1547–1551. [Google Scholar] [CrossRef]
- Lu, G.F.; Jin, Z.; Zou, J. Face recognition using discriminant sparsity neighborhood preserving embedding. Knowl.-Based Syst. 2012, 31, 119–127. [Google Scholar] [CrossRef]
- Qiao, L.S.; Chen, S.C.; Tan, X.Y. Sparsity preserving projections with applications to face recognition. Pattern Recognit. 2010, 43, 331–341. [Google Scholar] [CrossRef] [Green Version]
- Mohanty, R.; Happy, S.L.; Routray, A. A Semisupervised Spatial Spectral Regularized Manifold Local Scaling Cut With HGF for Dimensionality Reduction of Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3423–3435. [Google Scholar] [CrossRef] [Green Version]
- Pang, Y.W.; Ji, Z.; Jing, P.G.; Li, X.L. Ranking Graph Embedding for Learning to Rerank. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1292–1303. [Google Scholar] [CrossRef] [PubMed]
- Luo, F.L.; Huang, H.; Duan, Y.L.; Liu, J.M.; Liao, Y.H. Local Geometric Structure Feature for Dimensionality Reduction of Hyperspectral Imagery. Remote Sens. 2017, 9, 790. [Google Scholar] [CrossRef]
- Yang, W.K.; Sun, C.Y.; Zhang, L. A multi-manifold discriminant analysis method for image feature extraction. Pattern Recognit. 2011, 44, 1649–1657. [Google Scholar] [CrossRef] [Green Version]
- Hettiarachchi, R.; Peters, J.F. Multi-manifold LLE learning in pattern recognition. Pattern Recognit. 2015, 48, 2947–2960. [Google Scholar] [CrossRef]
- Jiang, J.J.; Hu, R.M.; Wang, Z.Y.; Cai, Z.H. CDMMA: Coupled discriminant multi-manifold analysis for matching low-resolution face images. Signal Process. 2016, 124, 162–172. [Google Scholar] [CrossRef]
- Chu, Y.J.; Zhao, L.D.; Ahmad, T. Multiple feature subspaces analysis for single sample per person face recognition. Vis. Comput. 2019, 35, 239–256. [Google Scholar] [CrossRef]
- Shi, L.K.; Hao, J.S.; Zhang, X. Image recognition method based on supervised multi-manifold learning. J. Intell. Fuzzy Syst. 2017, 32, 2221–2232. [Google Scholar] [CrossRef]
- Jiang, J.J.; Ma, J.Y.; Chen, C.; Wang, Z.Y.; Cai, Z.H.; Wang, L.Z. SuperPCA: A Superpixelwise PCA Approach for Unsupervised Feature Extraction of Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4581–4593. [Google Scholar] [CrossRef] [Green Version]
- Tu, B.; Zhang, X.F.; Kang, X.D.; Wang, J.P.; Benediktsson, J.A. Spatial Density Peak Clustering for Hyperspectral Image Classification with Noisy Labels. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5085–5097. [Google Scholar] [CrossRef]
- Fang, L.Y.; Zhuo, H.J.; Li, S.T. Super-resolution of hyperspectral image via superpixel-based sparse representation. Neurocomputing 2018, 273, 171–177. [Google Scholar] [CrossRef]
- Zhao, W.Z.; Du, S.H. Spectral-Spatial Feature Extraction for Hyperspectral Image Classification: A Dimension Reduction and Deep Learning Approach. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4544–4554. [Google Scholar] [CrossRef]
- He, L.; Li, J.; Liu, C.Y.; Li, S.T. Recent advances on spectral-spatial hyperspectral image classification: An overview and new guidelines. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1579–1597. [Google Scholar] [CrossRef]
- Zhang, L.F.; Zhang, Q.; Du, B.; Huang, X.; Tang, Y.Y.; Tao, D.C. Simultaneous Spectral-Spatial Feature Selection and Extraction for Hyperspectral Images. IEEE Trans. Cybern. 2018, 48, 16–28. [Google Scholar] [CrossRef] [PubMed]
- Liao, W.Z.; Mura, M.D.; Chanussot, J.; Pizurica, A. Fusion of spectral and spatial information for classification of hyperspectral remote sensed imagery by local graph. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 9, 583–594. [Google Scholar] [CrossRef]
- Kang, X.D.; Li, S.T.; Benediktsson, J.A. Feature extraction of hyperspectral images with image fusion and recursive filtering. IEEE Geosci. Remote Sens. Lett. 2014, 52, 3742–3752. [Google Scholar] [CrossRef]
- Huang, H.; Shi, G.Y.; He, H.B.; Duan, Y.L.; Luo, F.L. Dimensionality Reduction of Hyperspectral Imagery Based on Spatial-spectral Manifold Learning. IEEE Trans. Cybern. 2019, 1–14. [Google Scholar] [CrossRef]
- Luo, F.L.; Du, B.; Zhang, L.P.; Zhang, L.F.; Tao, D.C. Feature Learning Using Spatial-Spectral Hypergraph Discriminant Analysis for Hyperspectral Image. IEEE Trans. Cybern. 2019, 49, 2406–2419. [Google Scholar] [CrossRef]
- Zhou, Y.C.; Peng, J.T.; Chen, C.L.P. Dimension reduction using spatial and spectral regularized local discriminant embedding for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1082–1095. [Google Scholar] [CrossRef]
- Feng, Z.X.; Yang, S.Y.; Wang, S.G.; Jiao, L.C. Discriminative Spectral-Spatial Margin-Based Semisupervised Dimensionality Reduction of Hyperspectral Data. IEEE Geosci. Remote Sens. Lett. 2015, 12, 224–228. [Google Scholar] [CrossRef]
- Mohanty, R.; Happy, S.L.; Routray, A. Spatial-Spectral Regularized Local Scaling Cut for Dimensionality Reduction in Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 932–936. [Google Scholar] [CrossRef]
- Sellami, A.; Farah, I.R. High-level hyperspectral image classification based on spectro-spatial dimensionality reduction. Spat. Stat. 2016, 16, 103–117. [Google Scholar] [CrossRef]
- Huang, H.; Chen, M.L.; Duan, Y.L. Dimensionality Reduction of Hyperspectral Image Using Spatial-Spectral Regularized Sparse Hypergraph Embedding. Remote Sens. 2019, 11, 1039. [Google Scholar] [CrossRef]
- Xiao, Q.; Wen, J.G. HiWATER: Thermal-Infrared Hyperspectral Radiometer (4th, July, 2012). Heihe Plan Sci. Data Center 2013. [Google Scholar] [CrossRef]
- Xue, Z.H.; Su, H.J.; Du, P.J. Sparse graph regularization for robust crop mapping using hyperspectral remotely sensed imagery: A case study in Heihe Zhangye oasis. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 779–782. [Google Scholar] [CrossRef]
- Li, W.; Du, Q.; Zhang, F.; Hu, W. Collaborative-representation-based nearest neighbor classifier for hyperspectral imagery. IEEE Geosci. Remote Sens. Lett. 2015, 12, 389–393. [Google Scholar] [CrossRef]
- Datta, A.; Ghosh, S.; Ghosh, A. Unsupervised band extraction for hyperspectral images using clustering and kernel principal component analysis. Int. J. Remote Sens. 2017, 38, 850–873. [Google Scholar] [CrossRef]
- Liao, W.Z.; Pizurica, A.; Scheunders, P.; Philips, W.; Pi, Y.G. Semisupervised Local Discriminant Analysis for Feature Extraction in Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2013, 51, 184–198. [Google Scholar] [CrossRef]
- Li, H.F.; Jiang, T.; Zhang, K.S. Efficient and robust feature extraction by maximum margin criterion. IEEE Trans. Neural Netw. 2006, 17, 157–165. [Google Scholar] [CrossRef]
- Kuo, B.C.; Landgrebe, D.A. Nonparametric weighted feature extraction for classification. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1096–1105. [Google Scholar] [CrossRef]
- Huang, H. Classification of hyperspectral remote-sensing images based on sparse manifold learning. J. Appl. Remote Sens. 2013, 7, 073464. [Google Scholar] [CrossRef]
- Huang, H.; Luo, F.L.; Liu, J.M.; Yang, Y.Q. Dimensionality reduction of hyperspectral images based on sparse discriminant manifold embedding. ISPRS-J. Photogramm. Remote Sens. 2015, 106, 42–54. [Google Scholar] [CrossRef]
- Zeng, S.; Wang, Z.Y.; Gao, C.J.; Kang, Z.; Feng, D.G. Hyperspectral Image Classification With Global-Local Discriminant Analysis and Spatial-Spectral Context. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 5005–5018. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | 10 | 20 | 30 | 40 | 50 | 60 |
|---|---|---|---|---|---|---|
| RAW | 67.71 + 3.44 (0.601) | 73.53 + 2.51 (0.669) | 76.49 + 1.62 (0.703) | 78.41 + 1.42 (0.726) | 79.72 ± 1.56 (0.742) | 82.25 ± 1.26 (0.772) |
| PCA [56] | 67.71 ± 3.44 (0.601) | 73.53 ± 2.51 (0.669) | 76.49 ± 1.61 (0.703) | 78.40 ± 1.42 (0.726) | 79.71 ± 1.57 (0.742) | 82.24 ± 1.26 (0.772) |
| NPE [28] | 73.62 ± 3.84 (0.670) | 80.15 ± 2.73 (0.748) | 84.30 ± 1.75 (0.798) | 86.34 ± 2.13 (0.824) | 88.37 ± 2.05 (0.850) | 90.36 ± 1.82 (0.874) |
| LPP [29] | 75.88 ± 2.25 (0.698) | 82.96 ± 1.43 (0.782) | 85.27 ± 0.67 (0.810) | 86.47 ± 1.66 (0.826) | 87.37 ± 1.56 (0.837) | 89.32 ± 1.83 (0.861) |
| LDA [57] | 75.59 ± 3.51 (0.696) | 80.60 ± 1.66 (0.754) | 86.66 ± 1.75 (0.827) | 88.32 ± 1.57 (0.848) | 90.43 ± 1.69 (0.875) | 91.68 ± 1.25 (0.891) |
| MMC [58] | 67.03 ± 3.18 (0.593) | 70.94 ± 2.79 (0.638) | 73.10 ± 1.73 (0.662) | 74.95 ± 1.34 (0.684) | 75.94 ± 1.66 (0.697) | 78.14 ± 1.50 (0.722) |
| MFA [31] | 79.67 ± 3.54 (0.742) | 86.40 ± 1.95 (0.824) | 88.63 ± 1.68 (0.852) | 89.31 ± 1.52 (0.861) | 90.53 ± 2.11 (0.876) | 92.46 ± 1.44 (0.901) |
| NWFE [59] | 73.07 ± 3.79 (0.664) | 78.89 ± 1.92 (0.733) | 82.89 ± 1.85 (0.78) | 83.15 ± 1.78 (0.784) | 84.61 ± 1.87 (0.802) | 85.35 ± 1.45 (0.811) |
| SPP [29] | 60.83 ± 3.74 (0.519) | 66.62 ± 1.91 (0.586) | 74.66 ± 1.84 (0.679) | 76.87 ± 2.54 (0.707) | 78.29 ± 1.90 (0.725) | 78.68 ± 1.60 (0.730) |
| SDE [60] | 67.42 ± 3.29 (0.597) | 73.73 ± 1.55 (0.671) | 78.85 ± 1.50 (0.730) | 79.94 ± 2.37 (0.744) | 81.00 ± 1.74 (0.758) | 83.54 ± 1.35 (0.789) |
| SME [61] | 77.43 ± 5.10 (0.717) | 84.31 ± 2.65 (0.799) | 89.05 ± 1.69 (0.857) | 90.14 ± 1.04 (0.872) | 90.26 ± 1.50 (0.873) | 91.87 ± 0.89 (0.894) |
| SMML [37] | 67.43 ± 3.34 (0.598) | 73.09 ± 2.39 (0.663) | 75.90 ± 1.55 (0.696) | 77.78 ± 1.34 (0.718) | 79.02 ± 1.43 (0.734) | 81.34 ± 1.19 (0.761) |
| MMDA [33] | 73.00 ± 3.94 (0.659) | 81.00 ± 2.89 (0.758) | 85.83 ± 1.82 (0.818) | 88.04 ± 1.56 (0.845) | 88.28 ± 1.42 (0.849) | 90.76 ± 1.20 (0.879) |
| DSSM [49] | 67.60 ± 3.44 (0.600) | 73.19 ± 3.10 (0.665) | 76.39 ± 1.61 (0.702) | 78.34 ± 1.42 (0.725) | 79.47 ± 1.52 (0.739) | 82.16 ± 1.28 (0.771) |
| LPNPE [48] | 82.17 ± 4.12 (0.773) | 86.79 ± 2.59 (0.830) | 90.17 ± 1.83 (0.873) | 92.41 ± 0.89 (0.901) | 92.48 ± 1.07 (0.902) | 93.71 ± 1.04 (0.917) |
| WSSGLDA [62] | 82.12 ± 2.75 (0.772) | 88.30 ± 2.53 (0.849) | 91.40 ± 1.77 (0.888) | 92.79 ± 1.15 (0.906) | 93.19 ± 1.06 (0.911) | 94.48 ± 1.05 (0.927) |
| SSMMFL | 85.86 ± 4.34 (0.820) | 91.00 ± 2.35 (0.884) | 93.27 ± 1.74 (0.912) | 94.06 ± 0.80 (0.922) | 94.39 ± 0.95 (0.927) | 95.76 ± 1.06 (0.944) |
| Algorithm | 10 | 20 | 30 | 40 | 50 | 60 |
|---|---|---|---|---|---|---|
| RAW | 87.60 + 1.15 (0.833) | 89.72 + 1.60 (0.862) | 91.02 + 0.70 (0.879) | 91.49 + 1.00 (0.885) | 91.86 ± 0.69 (0.890) | 92.08 ± 1.35 (0.893) |
| PCA [56] | 87.60 ± 1.15 (0.833) | 89.71 ± 1.60 (0.862) | 91.02 ± 0.70 (0.879) | 91.48 ± 1.00 (0.885) | 91.86 ± 0.69 (0.890) | 92.07 ± 1.35 (0.893) |
| NPE [28] | 87.36 ± 2.37 (0.831) | 90.41 ± 1.44 (0.871) | 91.39 ± 1.26 (0.884) | 92.06 ± 1.08 (0.893) | 92.78 ± 0.96 (0.903) | 93.31 ± 1.09 (0.910) |
| LPP [29] | 90.30 ± 1.95 (0.869) | 93.42 ± 1.14 (0.911) | 93.90 ± 1.01 (0.917) | 94.22 ± 0.97 (0.922) | 94.68 ± 0.95 (0.928) | 94.91 ± 0.84 (0.931) |
| LDA [57] | 89.37 ± 1.18 (0.857) | 92.44 ± 1.76 (0.898) | 93.65 ± 0.63 (0.914) | 93.74 ± 0.90 (0.915) | 94.49 ± 0.30 (0.925) | 94.50 ± 1.03 (0.925) |
| MMC [58] | 86.56 ± 1.13 (0.820) | 89.27 ± 1.83 (0.856) | 90.66 ± 0.75 (0.874) | 91.10 ± 1.09 (0.880) | 91.48 ± 0.84 (0.885) | 91.73 ± 1.44 (0.889) |
| MFA [31] | 88.99 ± 3.04 (0.854) | 90.65 ± 4.56 (0.876) | 92.35 ± 1.01 (0.897) | 92.86 ± 1.48 (0.904) | 93.50 ± 1.85 (0.912) | 93.71 ± 1.68 (0.915) |
| NWFE [59] | 90.33 ± 2.29 (0.871) | 92.75 ± 2.49 (0.903) | 93.42 ± 1.55 (0.911) | 94.08 ± 1.01 (0.920) | 94.13 ± 0.53 (0.921) | 94.74 ± 0.20 (0.929) |
| SPP [29] | 64.53 ± 5.61 (0.555) | 80.89 ± 2.35 (0.749) | 85.00 ± 2.47 (0.802) | 86.54 ± 1.24 (0.821) | 87.72 ± 3.28 (0.837) | 90.40 ± 0.95 (0.871) |
| SDE [60] | 85.84 ± 2.59 (0.812) | 88.96 ± 1.59 (0.852) | 91.15 ± 1.44 (0.881) | 91.77 ± 0.71 (0.889) | 91.93 ± 1.22 (0.891) | 92.48 ± 0.11 (0.898) |
| SME [61] | 89.32 ± 3.24 (0.858) | 92.52 ± 2.05 (0.899) | 94.12 ± 1.01 (0.921) | 94.85 ± 0.82 (0.930) | 94.92 ± 0.82 (0.931) | 95.56 ± 0.42 (0.940) |
| SMML [37] | 87.46 ± 1.13 (0.832) | 89.29 ± 1.93 (0.856) | 90.70 ± 0.65 (0.875) | 91.17 ± 1.15 (0.881) | 91.56 ± 0.85 (0.886) | 91.72 ± 1.49 (0.888) |
| MMDA [33] | 90.63 ± 1.64 (0.875) | 93.72 ± 1.23 (0.915) | 94.10 ± 0.44 (0.923) | 94.55 ± 1.12 (0.930) | 95.57 ± 0.25 (0.941) | 96.47 ± 0.92 (0.952) |
| DSSM [49] | 87.64 ± 1.15 (0.834) | 89.70 ± 1.63 (0.862) | 91.02 ± 0.70 (0.879) | 91.49 ± 1.00 (0.885) | 91.87 ± 0.69 (0.890) | 92.08 ± 1.35 (0.893) |
| LPNPE [48] | 86.04 ± 2.41 (0.817) | 92.23 ± 2.10 (0.896) | 93.07 ± 1.30 (0.907) | 93.51 ± 0.91 (0.913) | 95.14 ± 0.85 (0.934) | 95.34 ± 0.52 (0.937) |
| WSSGLDA [62] | 87.33 ± 2.93 (0.834) | 93.24 ± 1.37 (0.907) | 94.09 ± 1.38 (0.921) | 94.54 ± 1.26 (0.926) | 95.45 ± 1.30 (0.938) | 95.92 ± 0.60 (0.945) |
| SSMMFL | 92.79 ± 2.10 (0.903) | 94.95 ± 1.32 (0.932) | 95.47 ± 0.94 (0.939) | 95.71 ± 1.02 (0.942) | 96.60 ± 0.65 (0.954) | 97.30 ± 0.89 (0.959) |
| Algorithm | 10 | 20 | 30 | 40 | 50 | 60 |
|---|---|---|---|---|---|---|
| RAW | 84.70 ± 2.86 (0.810) | 87.28 ± 1.45 (0.842) | 88.05 ± 1.47 (0.851) | 89.39 ± 1.02 (0.868) | 90.40 ± 0.60 (0.880) | 90.57 ± 0.86 (0.882) |
| PCA [56] | 84.70 ± 2.86 (0.810) | 87.28 ± 1.44 (0.842) | 88.05 ± 1.46 (0.851) | 89.37 ± 1.03 (0.868) | 90.39 ± 0.59 (0.880) | 90.55 ± 0.87 (0.882) |
| NPE [28] | 86.84 ± 2.68 (0.836) | 89.49 ± 1.69 (0.869) | 90.57 ± 1.30 (0.883) | 91.07 ± 1.33 (0.889) | 91.81 ± 0.91 (0.898) | 92.28 ± 0.99 (0.903) |
| LPP [29] | 88.69 ± 2.46 (0.859) | 90.21 ± 1.79 (0.878) | 91.50 ± 1.19 (0.894) | 92.03 ± 0.96 (0.901) | 93.34 ± 0.91 (0.917) | 93.83 ± 0.62 (0.923) |
| LDA [57] | 85.67 ± 3.13 (0.822) | 89.44 ± 1.32 (0.868) | 89.44 ± 2.84 (0.868) | 90.64 ± 0.97 (0.883) | 91.63 ± 0.85 (0.896) | 92.06 ± 0.69 (0.901) |
| MMC [58] | 83.88 ± 3.50 (0.800) | 87.12 ± 1.40 (0.840) | 87.86 ± 1.43 (0.849) | 89.19 ± 1.02 (0.865) | 90.19 ± 0.61 (0.878) | 90.23 ± 0.93 (0.878) |
| MFA [31] | 88.18 ± 2.54 (0.853) | 90.48 ± 1.62 (0.881) | 90.54 ± 1.03 (0.882) | 91.40 ± 0.98 (0.893) | 92.58 ± 1.39 (0.907) | 92.95 ± 1.04 (0.912) |
| NWFE [59] | 87.98 ± 1.88 (0.850) | 91.22 ± 2.28 (0.891) | 91.48 ± 1.63 (0.894) | 92.38 ± 1.79 (0.905) | 92.68 ± 1.28 (0.908) | 92.99 ± 1.37 (0.912) |
| SPP [29] | 83.33 ± 2.67 (0.793) | 83.53 ± 1.94 (0.796) | 86.19 ± 2.06 (0.828) | 88.99 ± 1.27 (0.863) | 90.29 ± 1.12 (0.879) | 91.57 ± 0.58 (0.895) |
| SDE [60] | 85.17 ± 1.87 (0.815) | 87.21 ± 2.53 (0.841) | 88.10 ± 1.52 (0.852) | 89.81 ± 1.02 (0.873) | 90.06 ± 0.87 (0.876) | 91.56 ± 0.39 (0.894) |
| SME [61] | 86.84 ± 2.67 (0.836) | 91.29 ± 2.19 (0.891) | 92.18 ± 1.34 (0.902) | 93.76 ± 0.64 (0.922) | 94.29 ± 0.80 (0.929) | 94.47 ± 0.34 (0.931) |
| SMML [37] | 84.42 ± 3.09 (0.807) | 87.13 ± 1.32 (0.840) | 87.77 ± 1.39 (0.848) | 89.04 ± 1.07 (0.863) | 90.07 ± 0.56 (0.876) | 90.23 ± 0.93 (0.878) |
| MMDA [33] | 86.53 ± 3.91 (0.833) | 89.77 ± 2.07 (0.873) | 92.17 ± 0.97 (0.902) | 93.91 ± 1.01 (0.924) | 94.39 ± 0.75 (0.930) | 95.30 ± 0.53 (0.941) |
| DSSM [49] | 85.68 ± 3.32 (0.822) | 87.29 ± 1.43 (0.842) | 88.06 ± 1.45 (0.851) | 89.35 ± 1.06 (0.867) | 90.38 ± 0.59 (0.880) | 90.58 ± 0.86 (0.882) |
| LPNPE [48] | 86.99 ± 2.62 (0.838) | 89.39 ± 1.01 (0.868) | 90.17 ± 1.38 (0.878) | 91.42 ± 0.80 (0.893) | 92.09 ± 1.24 (0.901) | 93.61 ± 0.96 (0.921) |
| WSSGLDA [62] | 88.22 ± 1.96 (0.853) | 90.14 ± 1.08 (0.877) | 90.63 ± 1.99 (0.883) | 91.43 ± 1.17 (0.893) | 92.72 ± 1.30 (0.909) | 93.98 ± 0.89 (0.925) |
| SSMMFL | 90.93 ± 1.42 (0.887) | 93.44 ± 1.38 (0.918) | 94.66 ± 1.17 (0.933) | 95.72 ± 0.89 (0.947) | 96.33 ± 0.79 (0.954) | 96.79 ± 0.65 (0.960) |
| Class | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | AA | OA | KC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RAW | 89.21 | 94.05 | 41.31 | 70.42 | 99.48 | 55.76 | 79.09 | 74.26 | 99.79 | 78.15 | 82.64 | 0.765 |
| PCA [56] | 89.21 | 94.04 | 41.31 | 70.42 | 99.48 | 55.76 | 79.02 | 74.24 | 99.79 | 78.14 | 82.63 | 0.765 |
| NPE [28] | 90.09 | 97.35 | 65.53 | 83.11 | 99.63 | 70.38 | 91.52 | 92.96 | 99.79 | 87.84 | 90.04 | 0.866 |
| LPP [29] | 91.97 | 96.89 | 63.62 | 78.39 | 99.55 | 76.74 | 94.92 | 80.76 | 99.89 | 86.97 | 89.50 | 0.859 |
| LDA [57] | 89.54 | 93.05 | 67.88 | 81.99 | 99.03 | 81.35 | 70.15 | 78.03 | 97.44 | 84.27 | 87.38 | 0.833 |
| MMC [58] | 88.85 | 89.30 | 37.87 | 69.14 | 99.48 | 48.04 | 76.52 | 73.61 | 99.79 | 75.84 | 79.21 | 0.719 |
| MFA [31] | 93.24 | 98.51 | 74.25 | 83.83 | 98.28 | 83.91 | 94.85 | 87.23 | 99.89 | 90.44 | 92.67 | 0.902 |
| NWFE [59] | 93.94 | 95.38 | 62.09 | 75.14 | 99.63 | 65.11 | 84.47 | 88.18 | 99.89 | 84.88 | 87.79 | 0.835 |
| SPP [29] | 82.54 | 86.50 | 45.38 | 67.07 | 99.78 | 41.99 | 59.47 | 62.83 | 99.47 | 71.66 | 75.07 | 0.659 |
| SDE [60] | 90.71 | 96.50 | 51.27 | 74.06 | 99.55 | 59.43 | 85.91 | 77.48 | 99.79 | 81.63 | 85.62 | 0.805 |
| SME [61] | 91.63 | 98.38 | 72.47 | 83.14 | 99.33 | 83.31 | 94.85 | 86.30 | 99.47 | 89.87 | 92.10 | 0.894 |
| SMML [37] | 89.28 | 93.16 | 41.17 | 69.92 | 99.48 | 54.04 | 78.64 | 74.48 | 99.79 | 77.77 | 82.03 | 0.757 |
| MMDA [33] | 94.15 | 95.34 | 71.33 | 83.67 | 100.00 | 70.30 | 85.68 | 88.07 | 99.68 | 87.58 | 89.51 | 0.860 |
| DSSM [49] | 89.00 | 94.01 | 41.60 | 70.68 | 99.48 | 55.54 | 79.17 | 74.45 | 99.79 | 78.19 | 82.62 | 0.764 |
| LPNPE [48] | 92.51 | 99.59 | 60.89 | 78.42 | 97.68 | 98.24 | 80.30 | 81.74 | 99.89 | 87.70 | 92.73 | 0.903 |
| WSSGLDA [62] | 95.68 | 99.04 | 62.42 | 84.59 | 99.85 | 97.82 | 91.67 | 78.96 | 99.89 | 89.99 | 93.63 | 0.915 |
| SSMMDA | 97.83 | 99.43 | 63.52 | 85.18 | 99.93 | 94.32 | 97.80 | 93.53 | 99.89 | 92.38 | 95.26 | 0.937 |
| Class | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | AA | OA | KC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RAW | 94.85 | 88.73 | 88.51 | 73.99 | 74.15 | 89.43 | 80.31 | 90.29 | 85.03 | 89.44 | 0.857 |
| PCA [56] | 94.85 | 88.73 | 88.51 | 73.99 | 74.15 | 89.43 | 80.31 | 90.29 | 85.03 | 89.44 | 0.857 |
| NPE [28] | 94.86 | 90.92 | 88.39 | 82.78 | 74.31 | 86.55 | 75.18 | 91.21 | 85.53 | 90.57 | 0.872 |
| LPP [29] | 94.90 | 90.92 | 91.72 | 87.35 | 65.51 | 81.50 | 84.82 | 90.64 | 85.92 | 91.26 | 0.882 |
| LDA [57] | 93.88 | 89.39 | 87.62 | 54.41 | 70.42 | 78.20 | 67.59 | 87.28 | 78.60 | 87.19 | 0.827 |
| MMC [58] | 94.76 | 88.55 | 88.43 | 71.85 | 73.77 | 88.71 | 78.77 | 90.29 | 84.39 | 89.14 | 0.853 |
| MFA [31] | 94.46 | 92.95 | 91.78 | 82.17 | 93.10 | 89.97 | 89.44 | 91.10 | 90.62 | 92.44 | 0.897 |
| NWFE [59] | 94.76 | 95.26 | 90.75 | 84.60 | 96.19 | 91.41 | 81.95 | 93.76 | 91.20 | 93.52 | 0.912 |
| SPP [29] | 87.32 | 89.60 | 85.24 | 35.96 | 54.37 | 63.66 | 55.38 | 75.95 | 68.43 | 81.87 | 0.756 |
| SDE [60] | 95.06 | 91.10 | 87.92 | 75.01 | 71.83 | 89.73 | 78.15 | 89.48 | 84.78 | 90.02 | 0.864 |
| SME [61] | 94.97 | 90.94 | 89.72 | 85.29 | 90.30 | 93.99 | 84.72 | 93.41 | 90.41 | 91.86 | 0.889 |
| SMML [37] | 94.83 | 88.31 | 88.42 | 73.73 | 73.77 | 89.55 | 79.59 | 89.71 | 84.74 | 89.26 | 0.855 |
| MMDA [33] | 95.64 | 94.54 | 92.89 | 97.43 | 95.66 | 66.13 | 76.72 | 95.49 | 89.31 | 94.29 | 0.922 |
| DSSM [49] | 94.83 | 88.75 | 88.48 | 73.91 | 74.23 | 89.49 | 79.69 | 90.64 | 85.00 | 89.42 | 0.857 |
| LPNPE [48] | 94.45 | 90.66 | 97.98 | 96.09 | 70.10 | 76.82 | 89.85 | 97.80 | 89.22 | 93.05 | 0.905 |
| WSSGLDA [62] | 92.91 | 93.64 | 98.89 | 97.53 | 68.44 | 75.80 | 86.67 | 98.15 | 89.00 | 93.44 | 0.911 |
| SSMMDA | 97.38 | 95.39 | 94.30 | 95.72 | 72.89 | 75.38 | 91.18 | 96.65 | 91.76 | 94.83 | 0.929 |
| Class | 1 | 2 | 3 | 4 | 5 | 6 | AA | OA | KC |
|---|---|---|---|---|---|---|---|---|---|
| RAW | 92.85 | 96.09 | 87.01 | 97.13 | 79.15 | 78.01 | 88.37 | 89.75 | 0.872 |
| PCA [56] | 92.76 | 96.09 | 87.03 | 97.13 | 79.15 | 78.10 | 88.38 | 89.74 | 0.872 |
| NPE [28] | 92.03 | 96.27 | 87.53 | 96.81 | 79.26 | 83.55 | 89.24 | 90.25 | 0.878 |
| LPP [29] | 94.14 | 98.78 | 91.59 | 97.76 | 89.80 | 88.75 | 93.47 | 93.69 | 0.921 |
| LDA [57] | 73.98 | 95.29 | 59.12 | 84.94 | 55.57 | 66.26 | 72.53 | 72.25 | 0.656 |
| MMC [58] | 92.76 | 96.09 | 86.75 | 97.10 | 78.04 | 78.05 | 88.13 | 89.57 | 0.869 |
| MFA [31] | 93.55 | 96.76 | 89.68 | 95.21 | 85.79 | 79.83 | 90.13 | 91.00 | 0.887 |
| NWFE [59] | 93.91 | 96.88 | 93.81 | 97.13 | 89.69 | 84.99 | 92.73 | 93.36 | 0.916 |
| SPP [29] | 92.52 | 94.37 | 84.88 | 98.52 | 80.04 | 83.26 | 88.93 | 90.06 | 0.875 |
| SDE [60] | 92.40 | 95.72 | 87.41 | 97.25 | 77.20 | 81.31 | 88.54 | 89.92 | 0.873 |
| SME [61] | 93.74 | 98.10 | 91.00 | 97.44 | 91.58 | 87.99 | 93.31 | 93.40 | 0.917 |
| SMML [37] | 92.68 | 96.09 | 86.66 | 97.10 | 78.04 | 78.01 | 88.10 | 89.52 | 0.869 |
| MMDA [33] | 95.62 | 98.96 | 87.15 | 96.84 | 93.70 | 88.58 | 93.48 | 93.33 | 0.917 |
| DSSM [49] | 92.90 | 96.09 | 86.84 | 97.13 | 79.26 | 77.84 | 88.34 | 89.72 | 0.871 |
| LPNPE [48] | 95.48 | 98.53 | 88.80 | 95.89 | 94.59 | 79.11 | 92.07 | 92.37 | 0.905 |
| WSSGLDA [62] | 92.20 | 96.76 | 89.49 | 96.88 | 83.84 | 83.68 | 90.48 | 91.20 | 0.890 |
| SSMMDA | 96.13 | 99.27 | 96.98 | 96.88 | 92.36 | 89.98 | 95.27 | 95.65 | 0.946 |
| Data Set | RAW | PCA [56] | NPE [28] | LPP [29] | LDA [57] | MMC [58] | MFA [31] | NWFE [59] | SPP [29] |
|---|---|---|---|---|---|---|---|---|---|
| PaviaU | 0.697 | 0.641 | 0.665 | 0.654 | 0.619 | 0.702 | 0.659 | 0.709 | 0.962 |
| Heihe | 1.662 | 1.366 | 1.393 | 1.348 | 1.314 | 2.133 | 1.356 | 1.021 | 1.191 |
| Washington DC Mall | 0.241 | 0.198 | 0.237 | 0.215 | 0.227 | 0.676 | 0.202 | 0.400 | 0.560 |
| Data Set | SDE [60] | SME [61] | SMML [37] | MMDA [33] | DSSM [49] | LPNPE [48] | WSSGLDA [62] | SSMMDA | |
| PaviaU | 0.661 | 3.988 | 0.662 | 0.867 | 1.283 | 1.498 | 2.164 | 3.723 | |
| Heihe | 0.965 | 3.346 | 1.368 | 1.707 | 2.253 | 3.359 | 3.626 | 5.429 | |
| Washington DC Mall | 0.443 | 3.146 | 0.231 | 0.734 | 0.552 | 1.587 | 2.774 | 3.541 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, G.; Huang, H.; Liu, J.; Li, Z.; Wang, L. Spatial-Spectral Multiple Manifold Discriminant Analysis for Dimensionality Reduction of Hyperspectral Imagery. Remote Sens. 2019, 11, 2414. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11202414
Shi G, Huang H, Liu J, Li Z, Wang L. Spatial-Spectral Multiple Manifold Discriminant Analysis for Dimensionality Reduction of Hyperspectral Imagery. Remote Sensing. 2019; 11(20):2414. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11202414
Chicago/Turabian StyleShi, Guangyao, Hong Huang, Jiamin Liu, Zhengying Li, and Lihua Wang. 2019. "Spatial-Spectral Multiple Manifold Discriminant Analysis for Dimensionality Reduction of Hyperspectral Imagery" Remote Sensing 11, no. 20: 2414. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11202414