Spatial–Temporal Analysis of Land Cover Change at the Bento Rodrigues Dam Disaster Area Using Machine Learning Techniques



Abstract
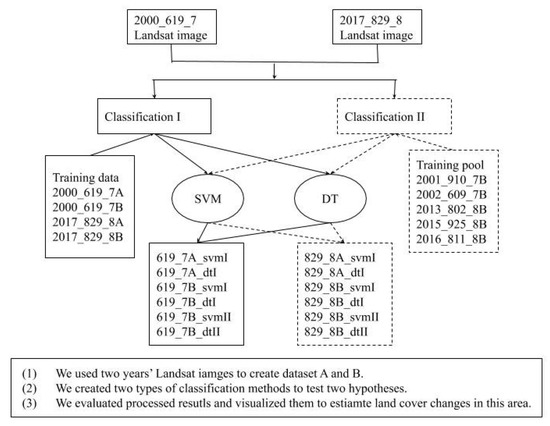
:
1. Introduction
2. Study Area
3. Materials and Methods
3.1. Data Collection and Pre-Processing
3.2. Training Data
3.3. Support Vector Machine and Decision Tree
3.4. Model Process and Validation
4. Results
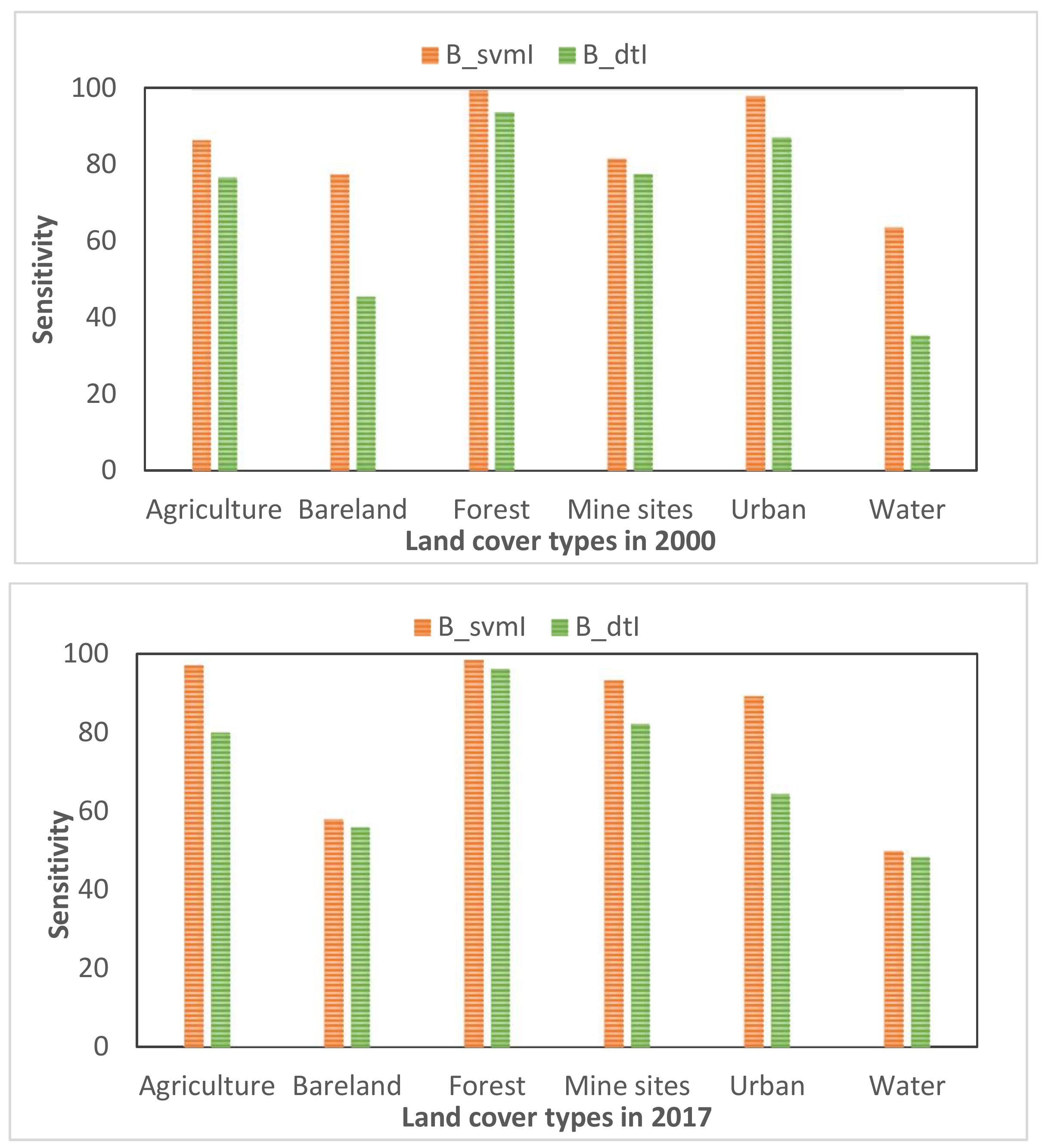
4.1. Performance of Processed Result with Adding NDVI as an Additional Feature
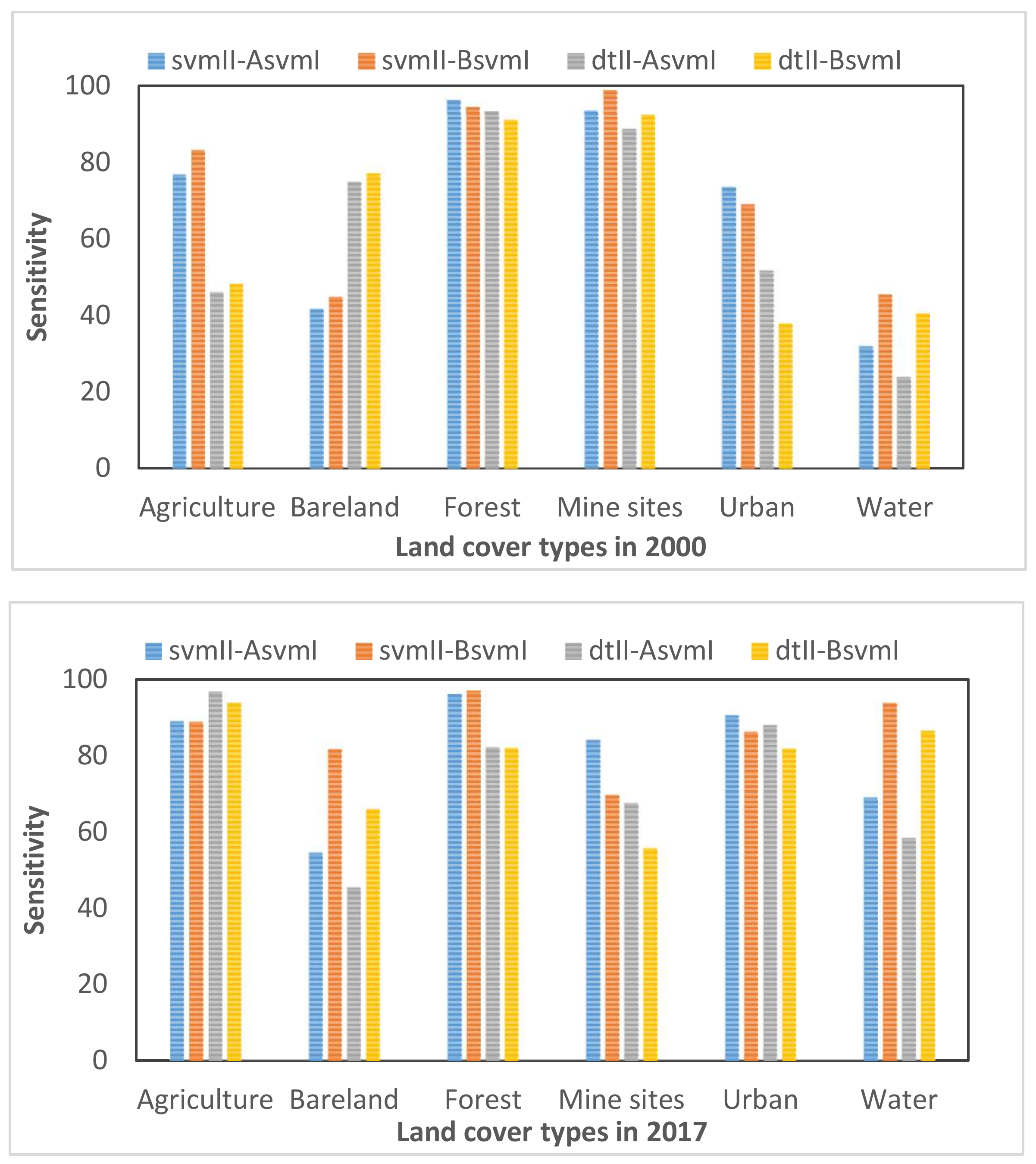
4.2. Performance Assessment of Classified Images using the Training Pool
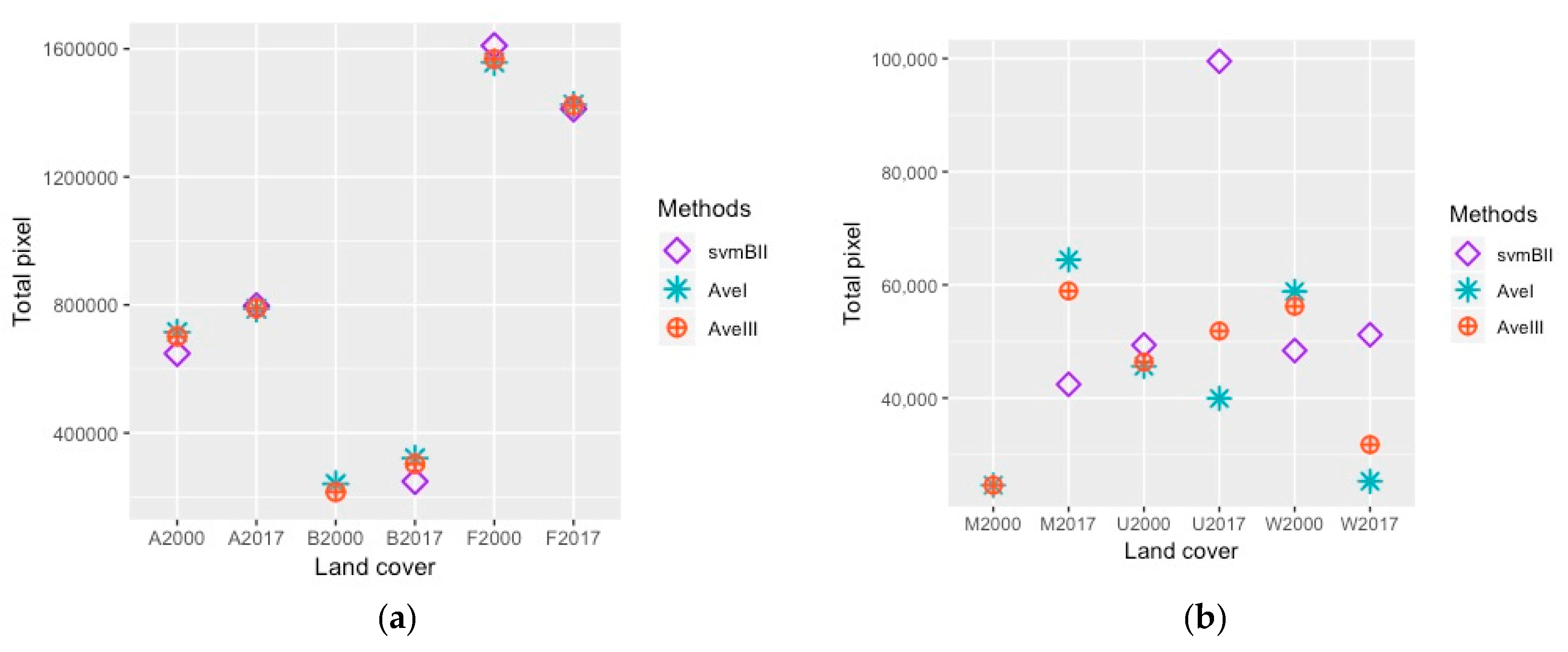
4.3. Land Cover Maps
4.4. Land Cover Change Estimation
5. Discussion
5.1. General Analysis of the Processed Methods
5.2. Limitations about Remote Sensing Images and Algorithms
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Aires, U.R.V.; Santos, B.S.M.; Coelho, C.D.; Da Silva, D.D.; Calijuri, M.L. Changes in land use and land cover as a result of the failure of a mining tailings dam in Mariana, MG, Brazil. Land Use Policy 2018, 70, 63–70. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Sahin, E.K.; Colkesen, I. Landslide susceptibility mapping using GIS-based multi-criteria decision analysis, support vector machines, and logistic regression. Landslides 2014, 11, 425–439. [Google Scholar] [CrossRef]
- Chen, W.; Chai, H.; Zhao, Z.; Wang, Q.; Hong, H. Landslide susceptibility mapping based on GIS and support vector machine models for the Qianyang County, China. Environ. Earth Sci. 2016, 75, 1–13. [Google Scholar] [CrossRef]
- IFRC. Leaving Millions Behind; IFRC: Geneva, Switzerland, 2018; ISBN 9782970128908. [Google Scholar]
- Habib, M.S.; Sarkar, B. An Integrated Location-Allocation Model for Temporary Disaster Debris Management under an Uncertain Environment. Sustainability 2017, 9, 716. [Google Scholar] [CrossRef]
- Rogan, J.; Chen, D. Remote sensing technology for mapping and monitoring land-cover and land-use change. Prog. Plan. 2004, 61, 301–325. [Google Scholar] [CrossRef]
- Otukei, J.; Blaschke, T. Land cover change assessment using decision trees, support vector machines and maximum likelihood classification algorithms. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, S27–S31. [Google Scholar] [CrossRef]
- Yuan, Z.; Khakzad, N.; Khan, F.; Amyotte, P. Risk analysis of dust explosion scenarios using bayesian networks. Risk Anal. 2015, 35, 278–291. [Google Scholar] [CrossRef] [PubMed]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote. Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Dewan, A.M.; Yamaguchi, Y. Land use and land cover change in Greater Dhaka, Bangladesh: Using remote sensing to promote sustainable urbanization. Appl. Geogr. 2009, 29, 390–401. [Google Scholar] [CrossRef]
- Khan, M.M.H.; Bryceson, I.; Kolivras, K.N.; Faruque, F.; Rahman, M.M.; Haque, U. Natural disasters and land-use/land-cover change in the southwest coastal areas of Bangladesh. Reg. Environ. Chang. 2014, 15, 241–250. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote. Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Olmo, M.C.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote. Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Maxwell, S.K.; Sylvester, K.M. Identification of “ever-cropped” land (1984–2010) using Landsat annual maximum NDVI image composites: Southwestern Kansas case study. Remote. Sens. Environ. 2012, 121, 186–195. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. ISPRS Journal of Photogrammetry and Remote Sensing A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Whiteside, T.G.; Boggs, G.S.; Maier, S.W. Comparing object-based and pixel-based classifications for mapping savannas. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 884–893. [Google Scholar] [CrossRef]
- Duro, D.C.; Franklin, S.E.; Dubé, M.G. A comparison of pixel-based and object-based image analysis with selected machine learning algorithms for the classification of agricultural landscapes using SPOT-5 HRG imagery. Remote. Sens. Environ. 2012, 118, 259–272. [Google Scholar] [CrossRef]
- Zheng, B.; Myint, S.W.; Thenkabail, P.S.; Aggarwal, R.M. A support vector machine to identify irrigated crop types using time-series Landsat NDVI data. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 103–112. [Google Scholar] [CrossRef]
- Blaschke, T. ISPRS Journal of Photogrammetry and Remote Sensing Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Goodin, D.G.; Anibas, K.L.; Bezymennyi, M. Mapping land cover and land use from object-based classification: An example from a complex agricultural landscape. Int. J. Remote. Sens. 2015, 36, 4702–4723. [Google Scholar] [CrossRef]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote. Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef] [Green Version]
- Guo, Q.; Kelly, M.; Graham, C.H.; Kelly, N.M. Support vector machines for predicting distribution of Sudden Oak Death in California. Ecol. Model. 2005, 182, 75–90. [Google Scholar] [CrossRef]
- Kotsiantis, S.B.; Zaharakis, I.D.; Pintelas, P.E.; Kotsiantis, S. Machine learning: A review of classification and combining techniques. Artif. Intell. Rev. 2006, 26, 159–190. [Google Scholar] [CrossRef]
- Shao, Y.; Lunetta, R.S. Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points. ISPRS J. Photogramm. Remote. Sens. 2012, 70, 78–87. [Google Scholar] [CrossRef]
- Huang, C.; Davis, L.S.; Townshend, J.R.G. An assessment of support vector machines for land cover classification. Int. J. Remote. Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Yao, X.; Tham, L.; Dai, F. Landslide susceptibility mapping based on Support Vector Machine: A case study on natural slopes of Hong Kong, China. Geomorphology 2008, 101, 572–582. [Google Scholar] [CrossRef]
- Ahmad, S.; Kalra, A.; Stephen, H. Estimating soil moisture using remote sensing data: A machine learning approach. Adv. Water Resour. 2010, 33, 69–80. [Google Scholar] [CrossRef]
- Ali, I.; Cawkwell, F.; Dwyer, E.; Green, S. Modeling Managed Grassland Biomass Estimation by Using Multitemporal Remote Sensing Data—A Machine Learning Approach. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 1–16. [Google Scholar] [CrossRef]
- Al-shalabi, M.; Billa, L.; Pradhan, B.; Mansor, S.; Al-Sharif, A.A.A. Modelling urban growth evolution and land-use changes using GIS based cellular automata and SLEUTH models: The case of Sana’a metropolitan city, Yemen. Environ. Earth Sci. 2013, 70, 425–437. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Colkesen, I. A kernel functions analysis for support vector machines for land cover classification. Int. J. Appl. Earth Obs. Geoinf. 2009, 11, 352–359. [Google Scholar] [CrossRef]
- DeFries, R. Multiple Criteria for Evaluating Machine Learning Algorithms for Land Cover Classification from Satellite Data. Remote. Sens. Environ. 2000, 74, 503–515. [Google Scholar] [CrossRef]
- Bhargava, N.; Sharma, G. Decision Tree Analysis on J48 Algorithm for Data Mining. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2013, 3, 1114–1119. [Google Scholar]
- Pal, M.; Mather, P.M. An assessment of the effectiveness of decision tree methods for land cover classification. Remote. Sens. Environ. 2003, 86, 554–565. [Google Scholar] [CrossRef]
- Fernandes, G.W.; Goulart, F.F.; Ranieri, B.D.; Coelho, M.S.; Dales, K.; Boesche, N.; Bustamante, M.; Carvalho, F.A.; Carvalho, D.C.; Dirzo, R.; et al. Deep into the mud: Ecological and socio-economic impacts of the dam breach in Mariana, Brazil. Nat. Conserv. 2016, 14, 35–45. [Google Scholar] [CrossRef]
- Neves, A.C.D.O.; Nunes, F.P.; De Carvalho, F.A.; Fernandes, G.W. Neglect of ecosystems services by mining, and the worst environmental disaster in Brazil. Nat. Conserv. 2016, 14, 24–27. [Google Scholar] [CrossRef] [Green Version]
- Carmo, F.F.D.; Kamino, L.H.Y.; Junior, R.T.; De Campos, I.C.; Carmo, F.F.D.; Silvino, G.; Castro, K.J.D.S.X.D.; Mauro, M.L.; Rodrigues, N.U.A.; Miranda, M.P.D.S.; et al. Fundão tailings dam failures: The environment tragedy of the largest technological disaster of Brazilian mining in global context. Perspect. Ecol. Conserv. 2017, 15, 145–151. [Google Scholar] [CrossRef]
- Lambin, E.F.; Geist, H.J.; Lepers, E.D. Ynamics of L and -U Se and L And -C over C Hange in T Ropical R Egions. Annu. Rev. Environ. Resour. 2003, 28, 205–241. [Google Scholar] [CrossRef]
- Teixeira, A.M.G.; Soares-Filho, B.S.; Freitas, S.R.; Metzger, J.P. Modeling landscape dynamics in an Atlantic Rainforest region: Implications for conservation. For. Ecol. Manag. 2009, 257, 1219–1230. [Google Scholar] [CrossRef]
- Mishra, N.; Helder, D.; Barsi, J.; Markham, B. Continuous calibration improvement in solar reflective bands: Landsat 5 through Landsat 8. Remote. Sens. Environ. 2016, 185, 7–15. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Wu, C.C.; Tsogt, K.; Ouyang, Y.C.; Chang, C.I. Effects of atmospheric correction and pansharpening on LULC classification accuracy using WorldView-2 imagery. Inf. Process. Agric. 2015, 2, 25–36. [Google Scholar] [CrossRef] [Green Version]
- Singh, S.K.; Srivastava, P.K.; Gupta, M.; Thakur, J.K.; Mukherjee, S. Appraisal of land use/land cover of mangrove forest ecosystem using support vector machine. Environ. Earth Sci. 2014, 71, 2245–2255. [Google Scholar] [CrossRef]
- Huang, C.; Yang, L.; Wylie, B.; Falls, S. Development of a circa 2000 landcover database for the United States. USGS 2000, 70, 13. [Google Scholar]
- Pal, M.; Mather, P.M. Support vector machines for classification in remote sensing. Int. J. Remote. Sens. 2005, 26, 1007–1011. [Google Scholar] [CrossRef]
- Zheng, D.; Rademacher, J.; Chen, J.; Crow, T.; Bresee, M.; Le Moine, J.; Ryu, S.R. Estimating aboveground biomass using Landsat 7 ETM+ data across a managed landscape in northern Wisconsin, USA. Remote Sens. Environ. 2004, 93, 402–411. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2012, 12, 2825–2830. [Google Scholar]
- Fushiki, T. Estimation of prediction error by using K-fold cross-validation. Stat. Comput. 2011, 21, 137–146. [Google Scholar] [CrossRef]
- Veropoulos, K.; Campbell, C.; Cristianini, N. Others Controlling the sensitivity of support vector machines. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 31 July–6 August 1999; pp. 55–60. [Google Scholar]
- Crosetto, M.; Tarantola, S.; Saltelli, A. Sensitivity and uncertainty analysis in spatial modelling based on GIS. Agric. Ecosyst. Environ. 2000, 81, 71–79. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Chica-Rivas, M. Evaluation of different machine learning methods for land cover mapping of a Mediterranean area using multi-seasonal Landsat images and Digital Terrain Models. Int. J. Digit. Earth 2014, 7, 492–509. [Google Scholar] [CrossRef]
- Edraki, M.; Baumgartl, T.; Manlapig, E.; Bradshaw, D.; Franks, D.M.; Moran, C.J. Designing mine tailings for better environmental, social and economic outcomes: A review of alternative approaches. J. Clean. Prod. 2014, 84, 411–420. [Google Scholar] [CrossRef]
- Sweet, S.K.; Asmus, A.; Rich, M.E.; Wingfield, J.; Gough, L.; Boelman, N.T. NDVI as a predictor of canopy arthropod biomass in the Alaskan arctic tundra. Ecol. Appl. 2015, 25, 779–790. [Google Scholar] [CrossRef]
- Ke, Y.; Im, J.; Lee, J.; Gong, H.; Ryu, Y. Characteristics of Landsat 8 OLI-derived NDVI by comparison with multiple satellite sensors and in-situ observations. Remote. Sens. Environ. 2015, 164, 298–313. [Google Scholar] [CrossRef]
- Brown, J.C.; Kastens, J.H.; Coutinho, A.C.; Victoria, D.D.C.; Bishop, C.R. Classifying multiyear agricultural land use data from Mato Grosso using time-series MODIS vegetation index data. Remote. Sens. Environ. 2013, 130, 39–50. [Google Scholar] [CrossRef] [Green Version]
- Lu, D.; Mausel, P.; Brondízio, E.; Moran, E. Change detection techniques. Int. J. Remote Sens. 2004, 25, 2365–2407. [Google Scholar] [CrossRef]
- Roy, D.; Kovalskyy, V.; Zhang, H.; Vermote, E.; Yan, L.; Kumar, S.S.; Egorov, A. Characterization of Landsat-7 to Landsat-8 reflective wavelength and normalized difference vegetation index continuity. Remote. Sens. Environ. 2016, 185, 57–70. [Google Scholar] [CrossRef] [Green Version]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote. Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint Deep Learning for land cover and land use classification. Remote. Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote. Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Yue, J.; Zhao, W.; Mao, S.; Liu, H. Spectral–spatial classification of hyperspectral images using deep convolutional neural networks. Remote. Sens. Lett. 2015, 6, 468–477. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, X.; Chen, G.; Dai, F.; Gong, Y.; Zhu, K. Change detection based on Faster R-CNN for high-resolution remote sensing images. Remote. Sens. Lett. 2018, 9, 923–932. [Google Scholar] [CrossRef]
- Lyu, H.; Lu, H.; Mou, L. Learning a Transferable Change Rule from a Recurrent Neural Network for Land Cover Change Detection. Remote. Sens. 2016, 8, 506. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Landsat sensor | Acquisition Date | Dataset (A) | Dataset (B) |
|---|---|---|---|---|
| 2000 | 7 ETM+ | 9 June | 1,2,3,4,5,7 | 1,2,3,4,5,7, NDVI |
| 2001 | 7 ETM+ | 10 September | 1,2,3,4,5,7 | 1,2,3,4,5,7, NDVI |
| 2002 | 7 ETM+ | 9 June | 1,2,3,4,5,7 | 1,2,3,4,5,7, NDVI |
| 2013 | 8 OLI | 2 August | 2,3,4,5,6,7 | 1,2,3,4,5,7, NDVI |
| 2015 | 8 OLI | 25 September | 2,3,4,5,6,7 | 1,2,3,4,5,7, NDVI |
| 2016 | 8 OLI | 11 August | 2,3,4,5,6,7 | 1,2,3,4,5,7, NDVI |
| 2017 | 8 OLI | 29 August | 2,3,4,5,6,7 | 1,2,3,4,5,7, NDVI |
| Class Number | Class Name | Description |
|---|---|---|
| 1 | Urban | Residential, commercial services, industrial, transportation, built-up land and other urban area |
| 2 | Agriculture | Cropland, some fallow land, pasture and other agricultural land |
| 3 | Mine sites | Strip mines, quarries and gravel pits, and mining factory |
| 4 | Forest | Deciduous, evergreen and mixed forest land |
| 5 | Bareland | Exposed soil, rocks and spare to no vegetation cover |
| 6 | Water | Lakes, reservoirs and stream or rivers |
| Full Name | Short Name | Classification I | Classification II |
|---|---|---|---|
| 2000_619_7_A_svm | 619_7A_svm | I | |
| 2000_619_7_A_dt | 619_7A_dt | I | |
| 2000_619_7_B_svm | 619_7B_svm | I | II |
| 2000_619_7_B_dt | 619_7B_dt | I | II |
| 2017_829_8_A_svm | 829_8A_svm | I | |
| 2017_829_8_A_dt | 829_8A_dt | I | |
| 2017_829_8_B_svm | 829_8B_svm | I | II |
| 2017_829_8_B_dt | 829_8B_dt | I | II |
| Models | Penalty | Kernel Width | Depth of Tree | 10 Fold Validation Average Accuracy | |
|---|---|---|---|---|---|
| classification I | 619_7A_svm | 10 | 0.5 | --- | 0.992 |
| 619_7B_svm | 100 | 0.2 | --- | 0.986 | |
| 829_8A_svm | 100 | 0.35 | --- | 0.990 | |
| 829_8B_svm | 100 | 0.35 | --- | 0.993 | |
| classifition II_svm | 100 | 0.2 | --- | 0.987 | |
| classification I | 619_7A_dt | --- | --- | 10 | 0.971 |
| 619_7B_dt | --- | --- | 10 | 0.970 | |
| 829_8A_dt | --- | --- | 10 | 0.973 | |
| 829_8B_dt | --- | --- | 10 | 0.985 | |
| classification II_dt | --- | --- | 10 | 0.972 | |
| 2000 | 619_7A_svmI | 619_7B_svmI | 619_7B_svmII | Evaluation | 829_8B_svmII | 829_8B_svmI | 829_8A_svmI | 2017 |
|---|---|---|---|---|---|---|---|---|
| 619_7B_svmI | 92.17 0.86 | 100 1 | Accuracy Kappa | 100 1 | 90.95 0.85 | 829_8B_svmI | ||
| 619_7B_svmII | 83.10 0.71 | 85.80 0.75 | 100 1 | Accuracy Kappa | 100 1 | 92.11 0.87 | 87.10 0.79 | 829_8B_svmII |
| 619_7A_dtI | 84.08 0.72 | 85.22 0.74 | 81.49 0.67 | Accuracy Kappa | 71.45 0.57 | 73.22 0.60 | 77.50 0.67 | 829_8A_dtI |
| 619_7B_dtI | 81.98 0.69 | 84.92 0.74 | 80.68 0.66 | Accuracy Kappa | 87.35 0.79 | 87.59 0.79 | 84.17 0.74 | 829_8B_dtI |
| 619_7B_dtII | 75.06 0.59 | 76.17 0.60 | 71.66 0.53 | Accuracy Kappa | 81.34 0.71 | 83.79 0.74 | 80.28 0.70 | 829_8B_dtII |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, D.; Goodin, D.G.; Caldas, M.M. Spatial–Temporal Analysis of Land Cover Change at the Bento Rodrigues Dam Disaster Area Using Machine Learning Techniques. Remote Sens. 2019, 11, 2548. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11212548
Luo D, Goodin DG, Caldas MM. Spatial–Temporal Analysis of Land Cover Change at the Bento Rodrigues Dam Disaster Area Using Machine Learning Techniques. Remote Sensing. 2019; 11(21):2548. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11212548
Chicago/Turabian StyleLuo, Dong, Douglas G. Goodin, and Marcellus M. Caldas. 2019. "Spatial–Temporal Analysis of Land Cover Change at the Bento Rodrigues Dam Disaster Area Using Machine Learning Techniques" Remote Sensing 11, no. 21: 2548. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11212548