Content-Sensitive Multilevel Point Cluster Construction for ALS Point Cloud Classification

 , ,
, ,  , ,
, ,
Abstract
:
1. Introduction
2. Related Work
2.1. Construction of (Multilevel) Point Clusters
2.2. Hierarchical Classification Framework
3. Proposed Method
- A method of constructing content-sensitive hierarchical point clusters is proposed, which can sense the densities of the object distribution and hierarchies of spatial structure. The content-sensitive hierarchical point clusters can adapt the contents of the ground objects, meaning that a small point set appears in a content-dense area, and a large set is generated in a content-sparse area. Thus, the segmented hierarchical point clusters can achieve improved construction of a multilevel object.
- Based on the content-sensitive hierarchical point clusters, a hierarchical classification framework is designed, which can fully exploit the spatial multilevel structures to accurately label unknown point clusters.
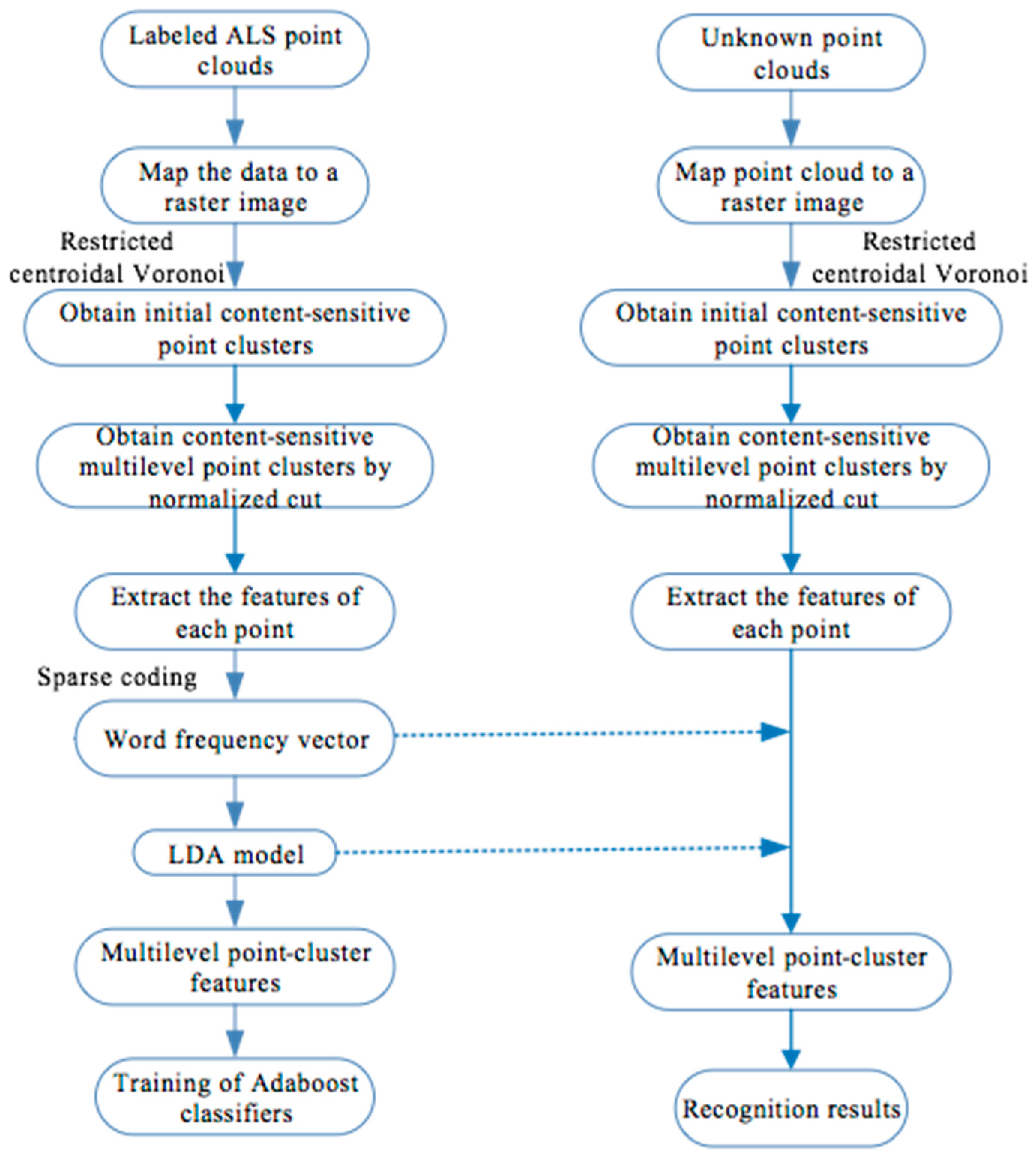
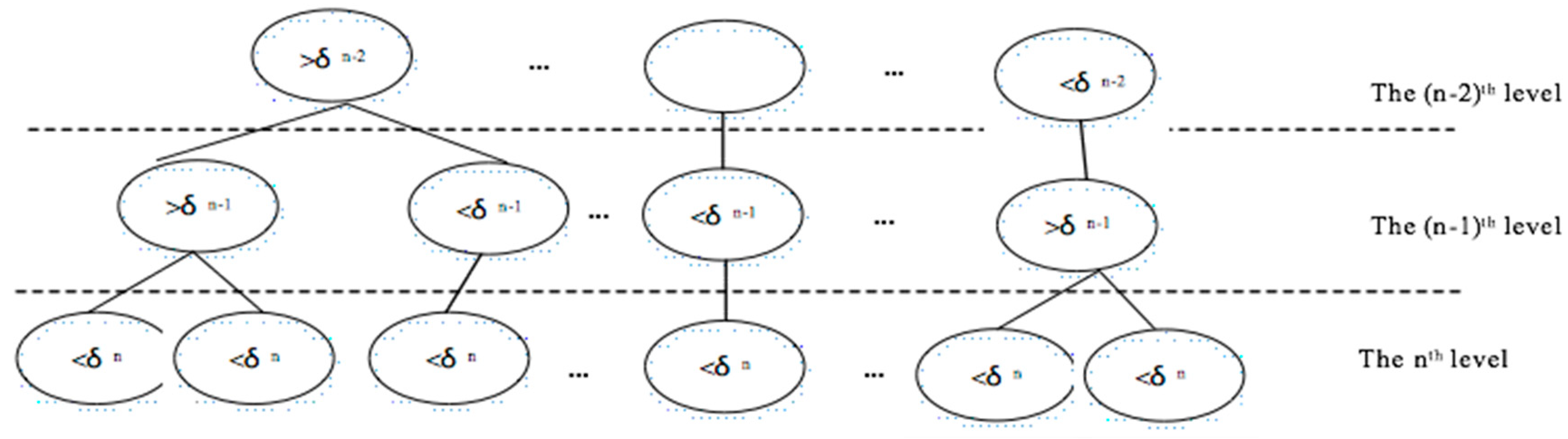
3.1. Construction of Content-Sensitive Multilevel Point Clusters
3.1.1. Construction of Initial Content-Sensitive Point Sets of Point Cloud
3.1.2. Construction of Multilevel Point Clusters
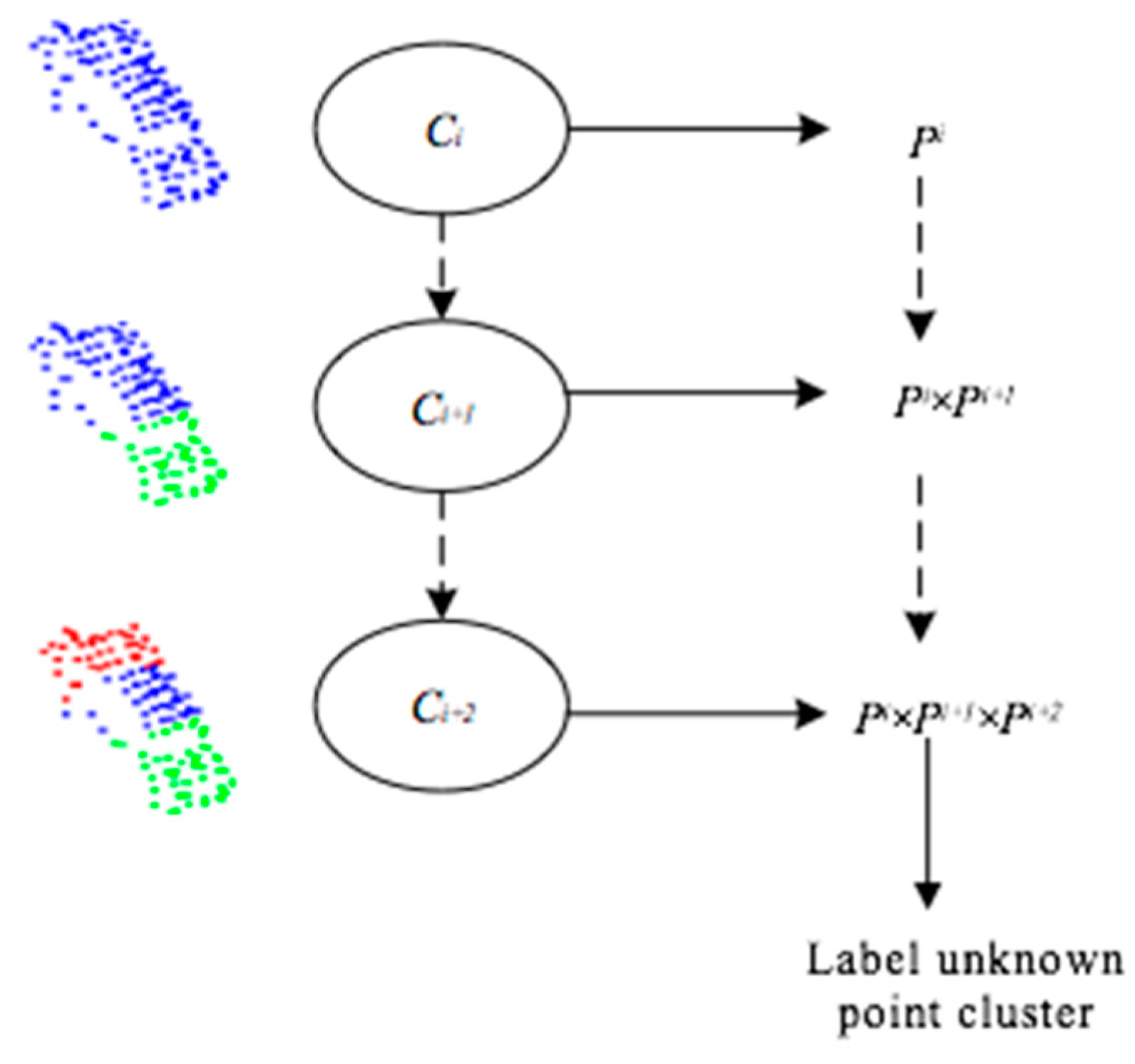
3.2. Feature Construction of Content-Sensitive Multilevel Point Clusters
3.2.1. Extraction of the Point-Based Features
3.2.2. Feature Construction of Multilevel Point Clusters by Sparse Coding and LDA
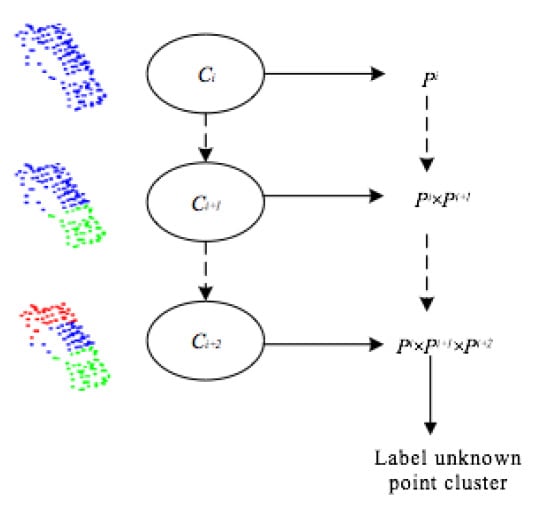
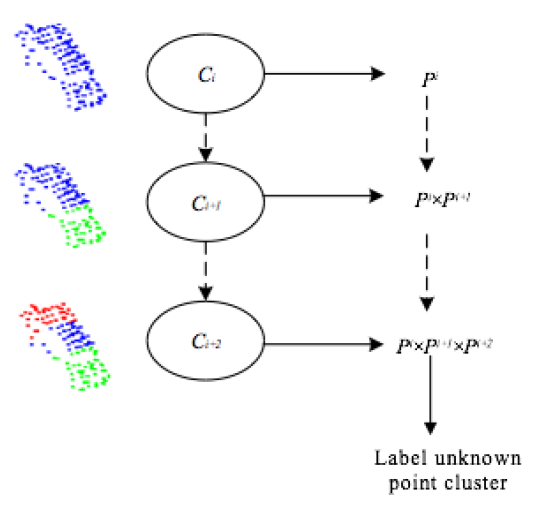
3.2.3. Hierarchical Framework of Point Cloud Classification
4. Results
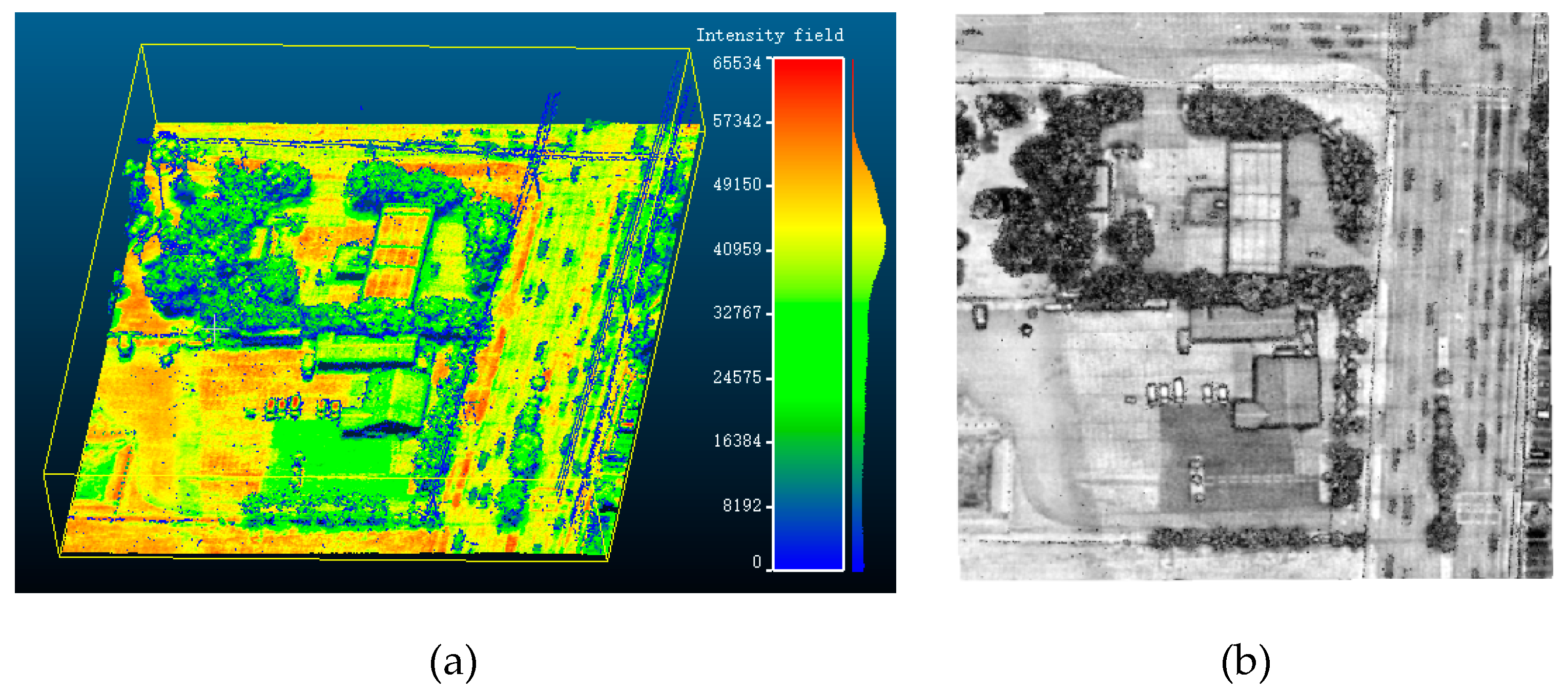
4.1. Experimental Datasets
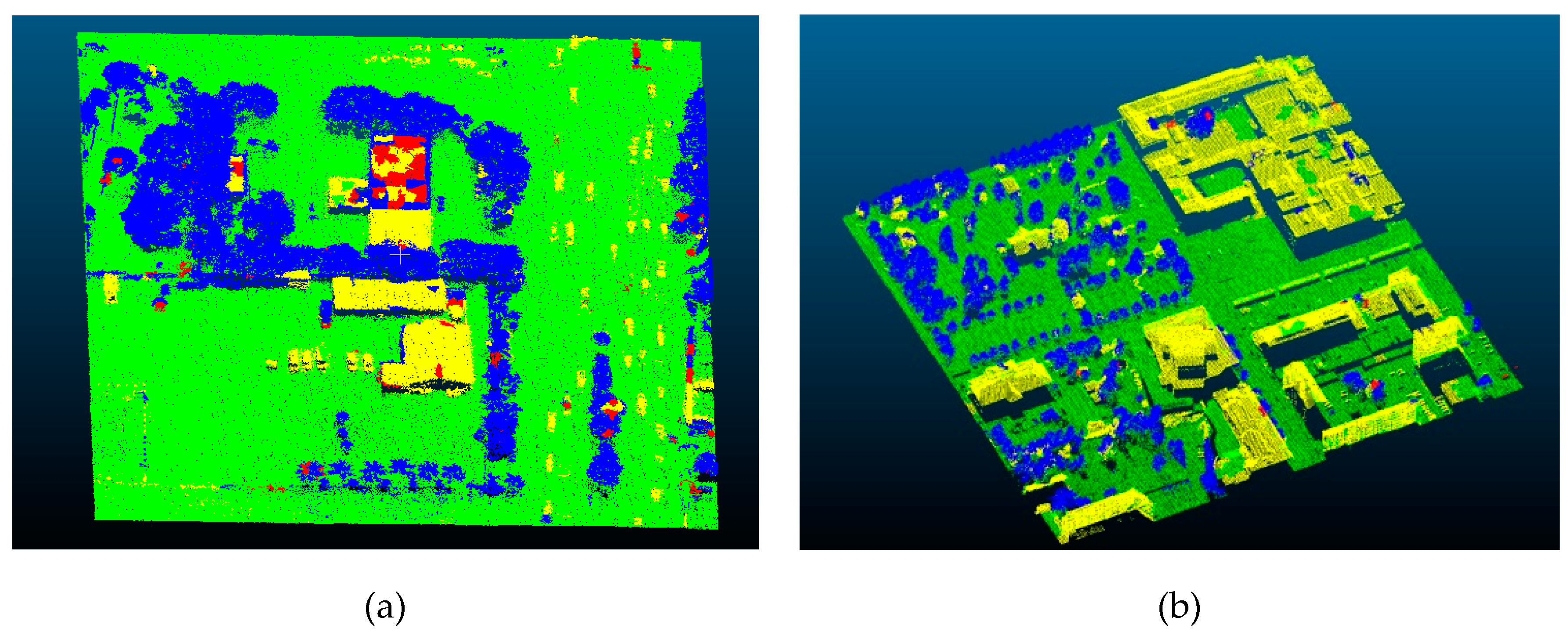
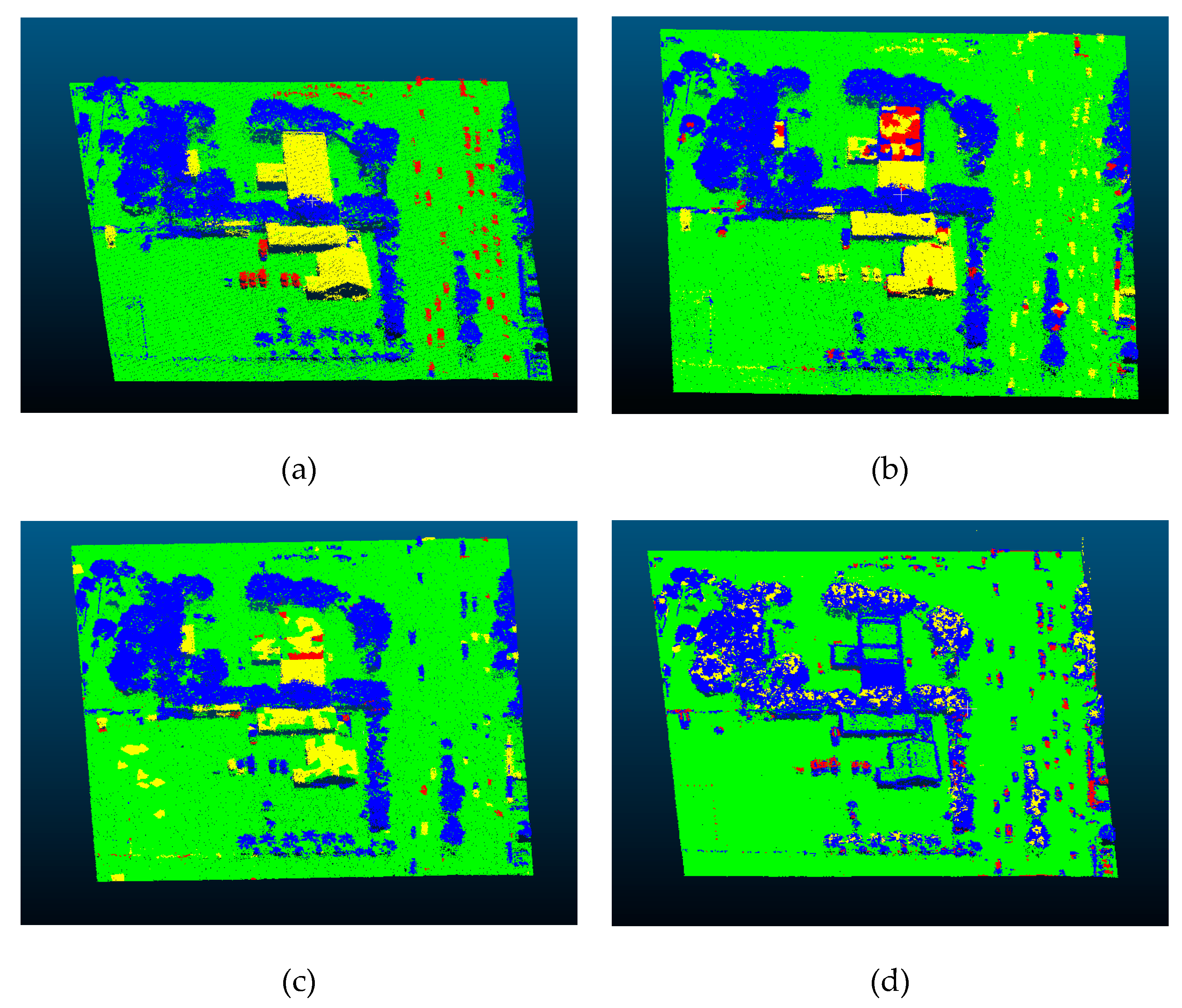
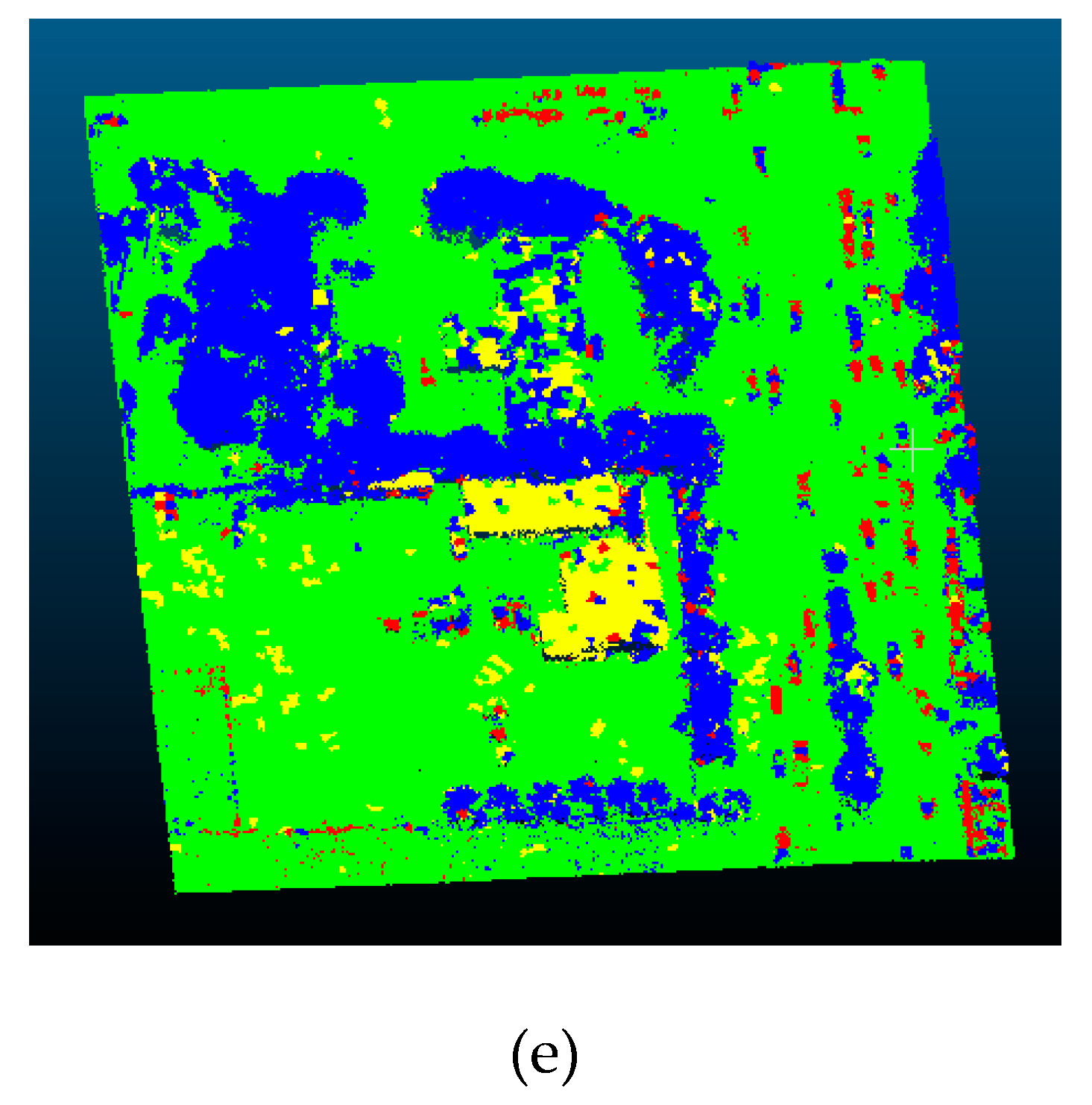
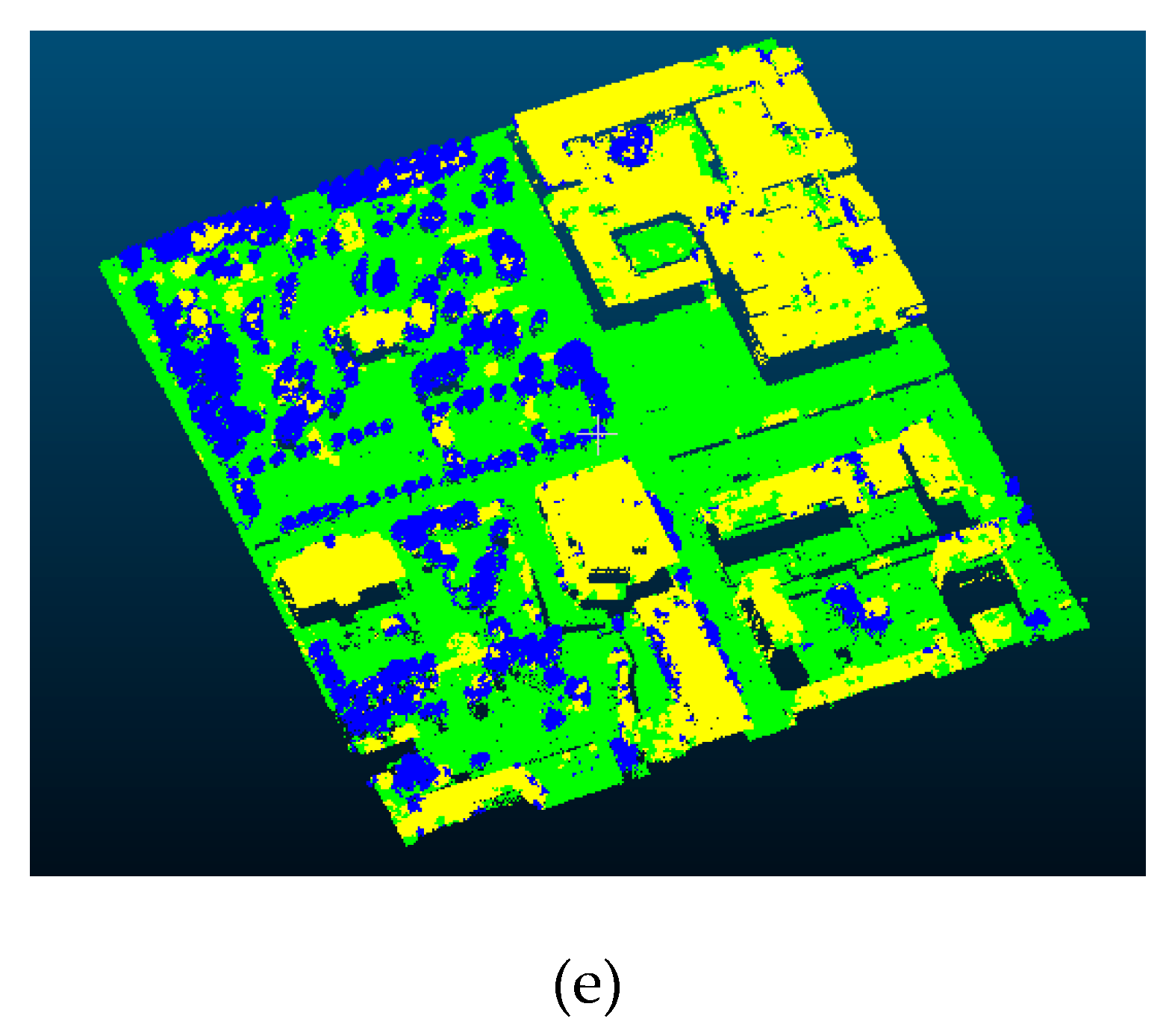
4.2. Experimental Results and Analysis
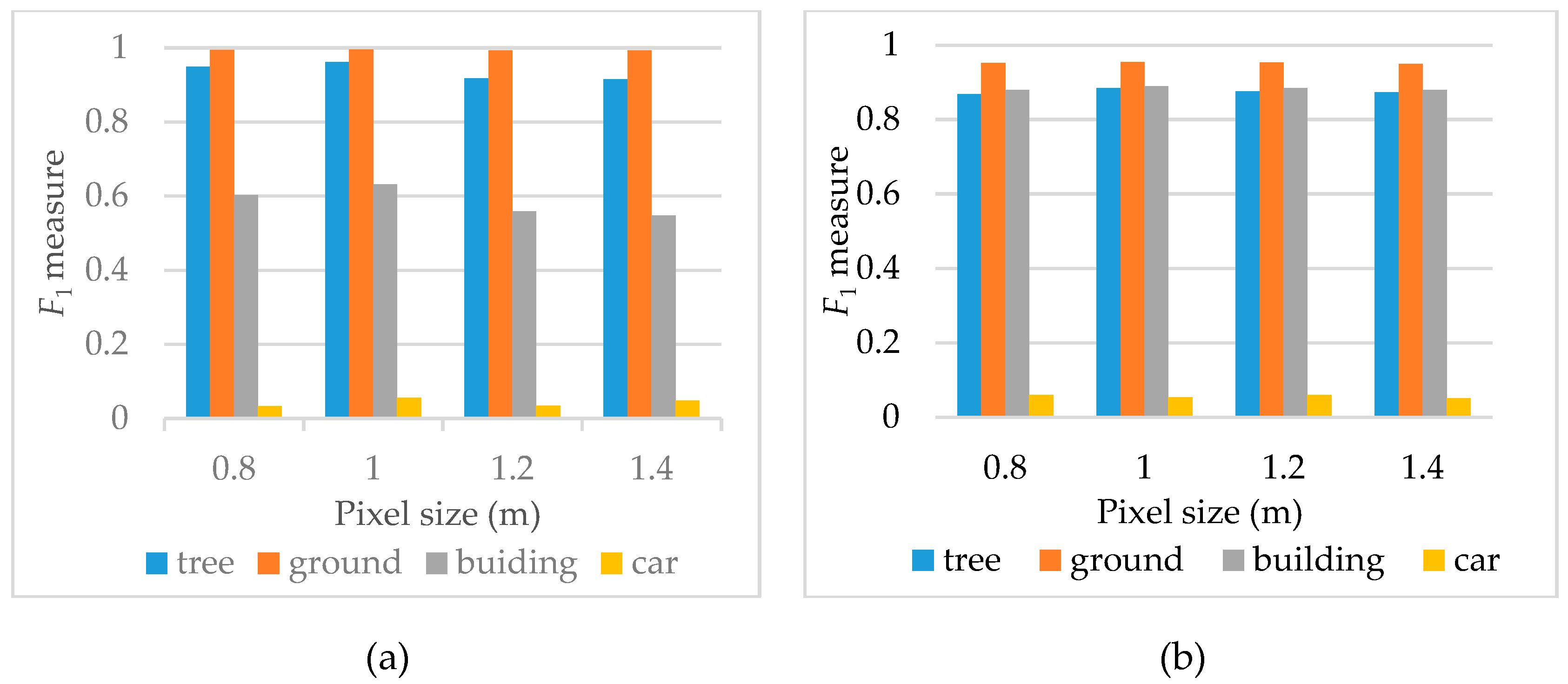
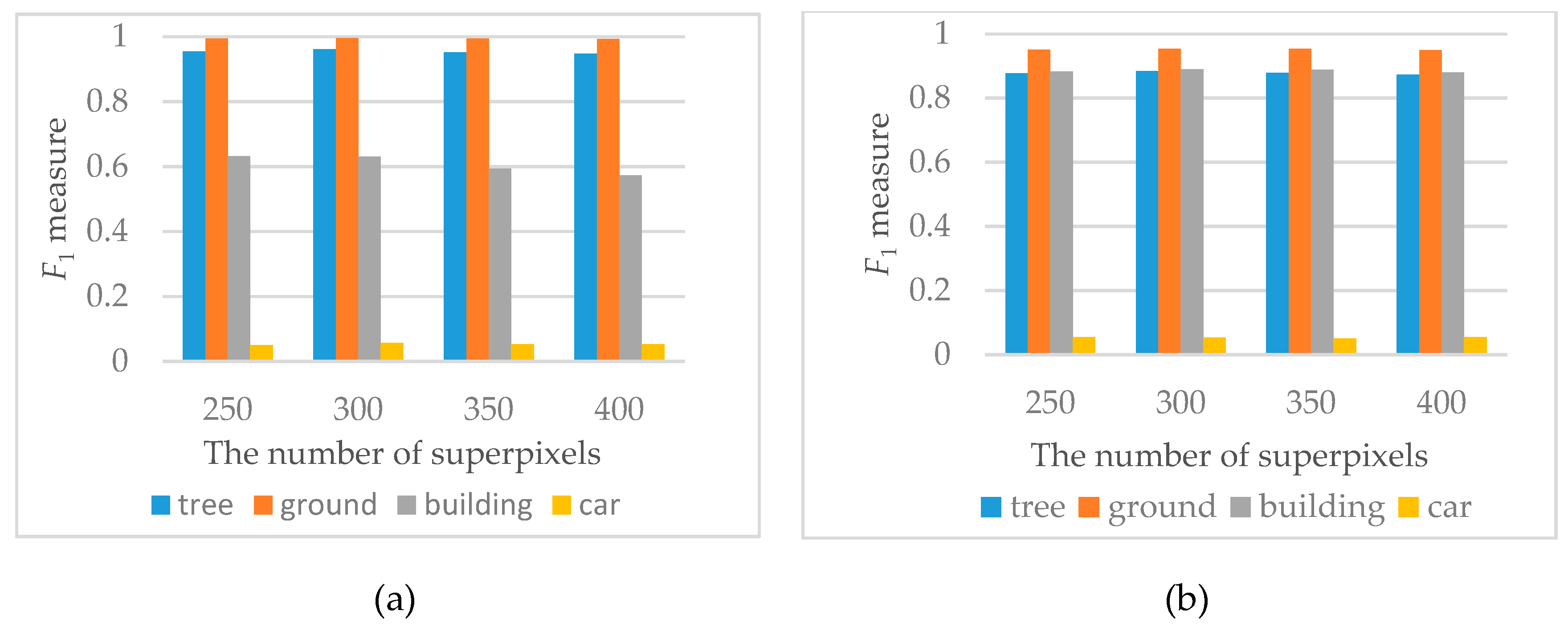
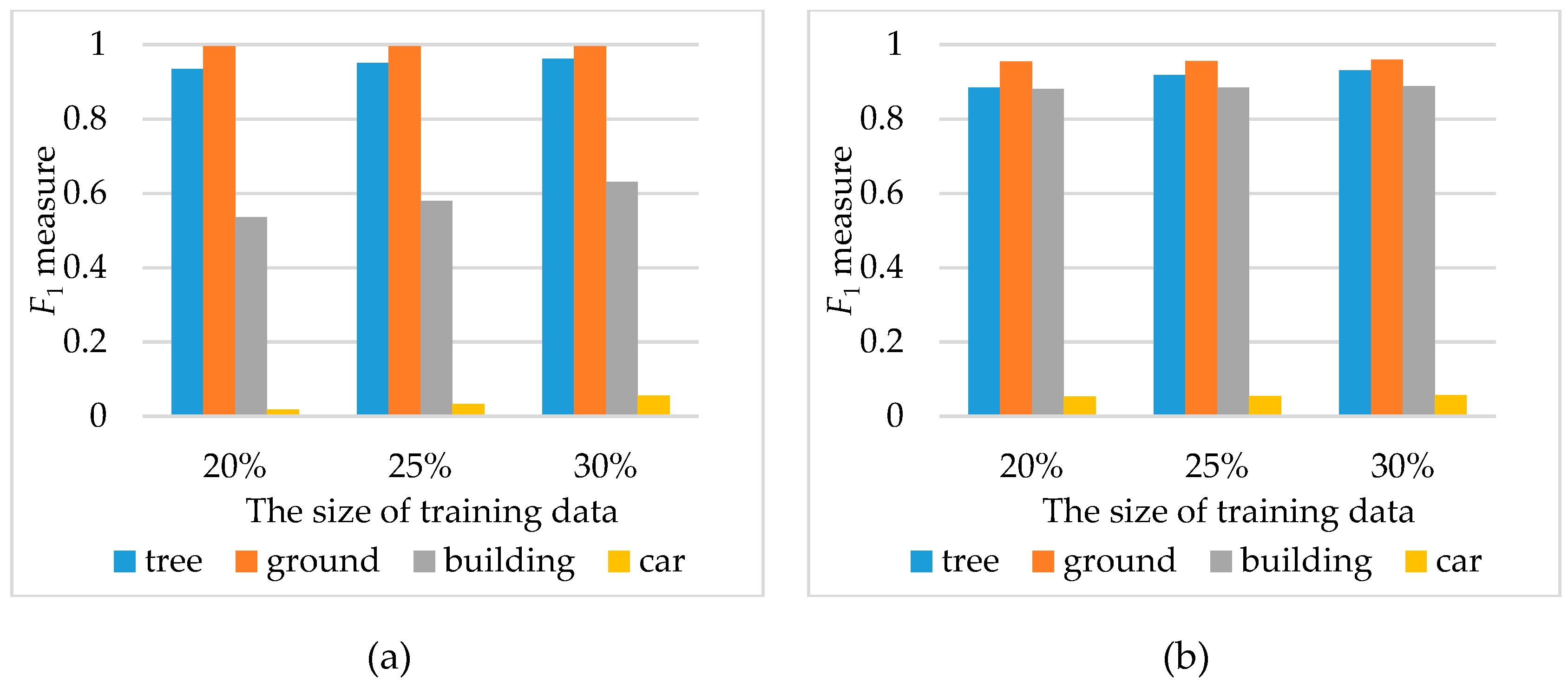
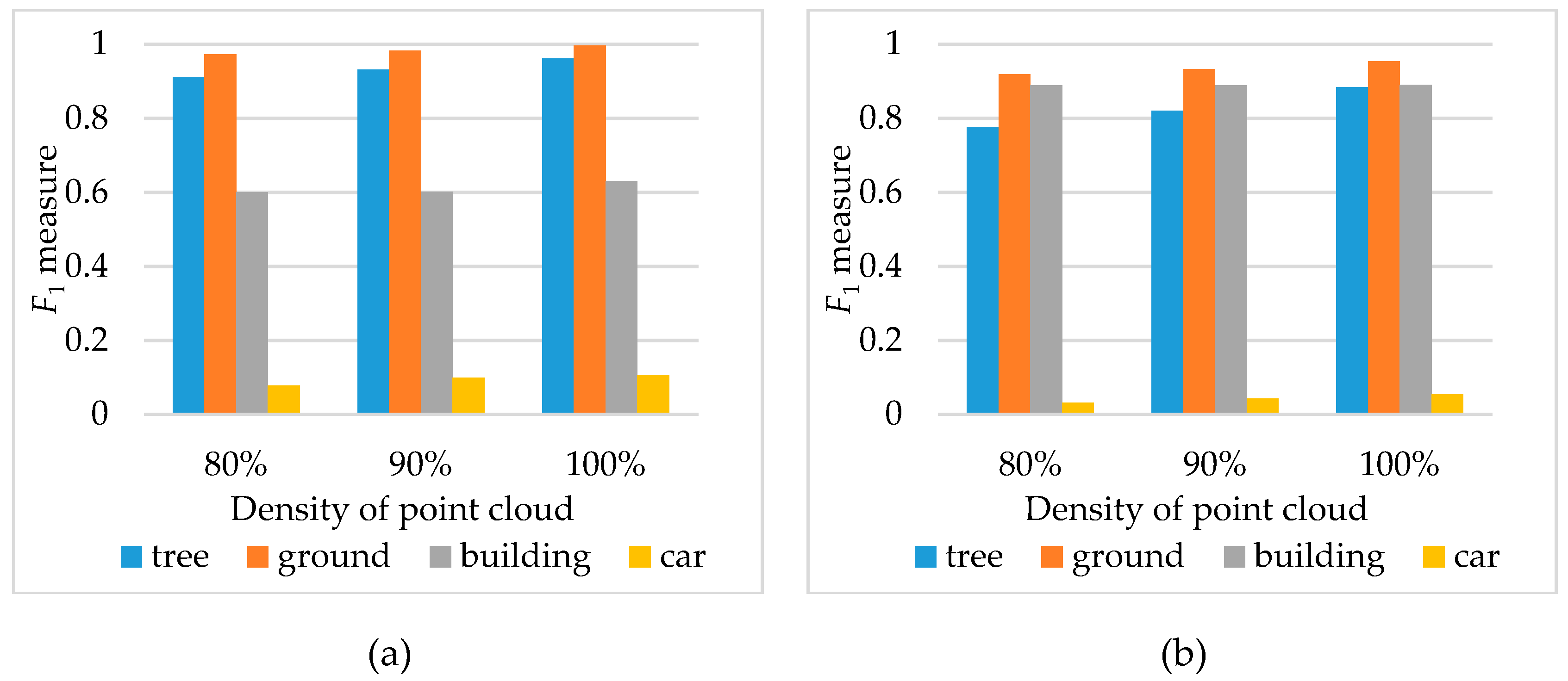
4.3. Sensitivities of Parameters
4.3.1. Pixel Size
4.3.2. Effects of Superpixel Number
4.3.3. Ratio of the Training Data to Total Data (s)
4.3.4. Density of the Point Cloud
4.4. Error Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Polewski, P.; Yao, W.; Heurich, M.; Krzystek, P.; Stilla, U. Detection of fallen trees in ALS point clouds using a normalized cut approach trained by simulation. ISPRS J. Photogramm. Remote Sens. 2015, 105, 252–271. [Google Scholar] [CrossRef]
- Rodriguez-Cuenca, B.; Garcia-Cortes, S.; Ordonez, C.; Alonso, M.C. Automatic detection and classification of pole-like objects in urban point cloud data using an anomaly detection algorithm. Remote Sens. 2015, 7, 12680–12703. [Google Scholar] [CrossRef]
- Wu, B.; Yu, B.; Wu, Q.; Huang, Y.; Chen, Z.; Wu, J. Individual tree crown delineation using localized contour tree method and airborne lidar data in coniferous forests. Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 82–94. [Google Scholar] [CrossRef]
- Garnett, R.; Adams, M.D. LiDAR—A Technology to Assist with Smart Cities and Climate Change Resilience: A Case Study in an Urban Metropolis. ISPRS Int. J. Geo-Inf. 2018, 7, 161. [Google Scholar] [CrossRef]
- Serna, A.; Marcotegui, B. Urban accessibility diagnosis from mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2013, 84, 23–32. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Dong, Z.; Liu, Y.; Liang, F.; Wang, Y. Computing multiple aggregation levels and contextual features for road facilities recognition using mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2017, 126, 180–194. [Google Scholar] [CrossRef]
- Golovinskiy, A.; Kim, V.G.; Funkhouser, T. Shape-based recognition of 3D point clouds in urban environments. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2154–2161. [Google Scholar]
- Guo, B.; Huang, X.; Zhang, F.; Sohn, G. Classification of airborne laser scanning data using JointBoost. ISPRS J. Photogramm. Remote Sens. 2015, 100, 71–83. [Google Scholar] [CrossRef]
- Lodha, S.K.; Fitzpatrick, D.M.; Helmbold, D.P. Aerial Lidar Data Classification using AdaBoost. In Proceedings of the International Conference on 3-D Digital Imaging and Modeling, Montreal, QC, Canada, 21–23 August 2007; pp. 435–442. [Google Scholar]
- Chehata, N.; Guo, L.; Mallet, C. Airborne Lidar Feature Selection for Urban Classification Using Random Forests. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.471.8566&rep=rep1&type=pdf (accessed on 31 January 2019).
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar]
- Tóvári, D. Segmentation Based Classification of Airborne Laser Scanner Data. Ph.D. Thesis, Universität Karlsruhe, Karlsruhe, Germany, 2006. [Google Scholar]
- Darmawati, A. Utilization of Multiple Echo Information for Classification of Airborne Laser Scanning Data. Master’s Thesis, ITC Enschede, Enschede, The Netherlands, 2008. [Google Scholar]
- Yao, W.; Hinz, S.; Stilla, U. Object extraction based on 3d-segmentation of lidar data by combining mean shift with normalized cuts: Two examples from urban areas. In Proceedings of the 2009 Joint Urban Remote Sensing Event, Shanghai, China, 20–22 May 2009; pp. 1–6. [Google Scholar]
- Yang, B.S.; Dong, Z.; Zhao, G.; Dai, W.X. Hierarchical extraction of urban objects from mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2015, 99, 45–57. [Google Scholar] [CrossRef]
- Zhang, J.X.; Lin, X.G.; Liang, X.H. Research progress and prospects of point cloud information extraction. Acta Geodaetica et Cartographica Sinica. 2017, 46, 1460–1469. [Google Scholar]
- Wang, Y.; Cheng, L.; Chen, Y.M.; Wu, Y.; Li, M.C. Building point detection from vehicle-borne LIDAR data based on voxel group and horizontal hollow analysis. Remote Sens. 2016, 8, 419. [Google Scholar] [CrossRef]
- Zhang, J.X.; Lin, X.G.; Ning, X.G. SVM-based classification of segmented airborne lidar point clouds in urban areas. Remote Sens. 2013, 5, 3749–3775. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, L.; Tan, Y.; Zhang, L.; Liu, F.; Zhong, R. Joint discriminative dictionary and classifier learning for ALS point cloud classification. IEEE Trans. Geosci. Remote Sens. 2017, 56, 524–538. [Google Scholar] [CrossRef]
- Liu, Y.J.; Yu, C.C.; Yu, M.J. Manifold SLIC: A Fast Method to Compute Content-Sensitive Superpixels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 651–659. [Google Scholar]
- Niemeyer, J.; Mallet, C.; Rottensteiner, F.; Sörgel, U. Conditional random fields for the classification of lidar point clouds. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2011, 38, 209–214. [Google Scholar] [CrossRef]
- Kim, H.B.; Sohn, G. Random forests based multiple classifier system for power-line scene classification. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Calgary, AB, Canada, 29–31 August 2011. [Google Scholar]
- Lin, X.G.; Zhang, J.X. Multiple-primitives-based hierarchical classification of airborne laser scanning data in urban areas. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 837–843. [Google Scholar]
- Zhang, Z.; Zhang, L.; Tong, X.; Wang, Z.; Guo, B.; Huang, X. A multilevel point-cluster-based discriminative feature for ALS point cloud classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3309–3321. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, L.; Tong, X.; Wang, Z.; Guo, B.; Zhang, L.; Xing, X. Discriminative-dictionary-learning-based multilevel point-cluster features for ALS point-cloud classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7309–7322. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, L.Q.; Tian, F.; Chen, D. A Multiscale and Hierarchical Feature Extraction Method for Terrestrial Laser Scanning Point Cloud Classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2409–2425. [Google Scholar] [CrossRef]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans Pattern Anal Mach Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef] [Green Version]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans Pattern Anal Mach Intell. 2000, 22, 888–905. [Google Scholar] [Green Version]
- Yokoyama, H.; Date, H.; Kanai, S.; Takeda, H. Detection and classification of pole-like objects from mobile laser scanning data of urban environments. Int. J. Cad/Cam. 2013, 13, 31–40. [Google Scholar]
- Barnea, S.; Filin, S. Segmentation of terrestrial laser scanning data by integrating range and image content. In Proceedings of the XXIth ISPRS Congress, Beijing, China, 3–11 July 2008. [Google Scholar]
- Comaniciu, D.; Meer, P. Mean Shift: A Robust Approach Toward Feature Space Analysis. IEEE Trans Pattern Anal Mach Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Barnea, S.; Filin, S. Segmentation of terrestrial laser scanning data using geometry and image information. ISPRS J. Photogramm. Remote Sens. 2013, 76, 33–48. [Google Scholar] [CrossRef]
- Farabet, C.; Couprie, C.; Najman, L.; Lecun, Y. Learning hierarchical features for scene labeling. IEEE Trans Pattern Anal Mach Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed]
- Brodu, N.; Lague, D. 3D terrestrial lidar data classification of complex natural scenes using a multi-scale dimensionality criterion: applications in geomorphology. ISPRS J. Photogramm. Remote Sens. 2012, 68, 121–134. [Google Scholar] [CrossRef]
- Pauly, M.; Keiser, R.; Gross, M. Multi-scale feature extraction on point-sampled surfaces. In Computer Graphics Forum; Blackwell Publishing, Inc.: Oxford, UK, 2003; pp. 281–289. [Google Scholar]
- Xiong, X.; Munoz, D.; Bagnell, J.A.; Hebert, M. 3-d scene analysis via sequenced predictions over points and regions. In Proceedings of the IEEE International Conference on the Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 2609–2616. [Google Scholar]
- Xu, S.; Oude, E.S.; Vosselman, G. Entities and features for classification of airborne laser scanning data in urban area. In Proceedings of the XXII ISPRS Congress, Melbourne, VIC, Australia, 25 August–1 September 2012; pp. 257–2662. [Google Scholar]
- Mallet, C. Analysis of Full-Waveform LIDAR Data for Urban Area Mapping. Ph.D. Thesis, Télécom ParisTech, Paris, France, 2010. [Google Scholar]
- Weinmann, M.; Urban, S.; Hinz, S.; Jutzi, B.; Mallet, C. Distinctive 2D and 3D features for automated large-scale scene analysis in urban areas. Comput. Graph. 2015, 49, 47–57. [Google Scholar] [CrossRef]
- Liu, Y.J.; Yu, M.; Li, B.J.; He, Y. Intrinsic manifold SLIC: A simple and efficient method for computing content-sensitive superpixels. IEEE Trans Pattern Anal Mach Intell. 2018, 40, 653–666. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Tang, Z.; Cui, Y.; Wu, G. Local competition-based superpixel segmentation algorithm in remote sensing. Sensors. 2017, 17, 1364. [Google Scholar] [CrossRef]
- Nadarajah, S. An approximate distribution for the normalized cut. J. Math Imaging. Vis. 2008, 32, 89–96. [Google Scholar] [CrossRef]
- Nowak, E.; Frédéric, J.; Triggs, B. Sampling strategies for bag-of-features image classification. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 490–503. [Google Scholar]
- Han, B.; He, B.; Sun, T.; Ma, M.; Shen, Y.; Lendasse, A. HSR: L1/2-regularized sparse representation for fast face recognition using hierarchical feature selection. Neural Comput Appl. 2016, 27, 305–320. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Point Number of the Training Data | Point Number of the Test Data | |||||||
|---|---|---|---|---|---|---|---|---|
| Trees | Ground | Buildings | Cars | Trees | Ground | Buildings | Cars | |
| Scene I | 33,882 | 143,907 | 15,587 | 5939 | 217,869 | 453,102 | 32,153 | 12,407 |
| Scene II | 22,836 | 76,816 | 70,808 | 882 | 171,657 | 337,478 | 305,625 | 5239 |
| Tree (%) | Ground (%) | Building (%) | Car (%) | Accuracy (%) | |
|---|---|---|---|---|---|
| Scene I | 96.92/95.35 | 99.23/99.93 | 61.24/65.04 | 6.04/5.23 | 95.29 |
| Scene II | 96.54/84.22 | 96.7/94.09 | 85.02/94.44 | 9.72/4.2 | 91.60 |
| Tree | Ground | Building | Car | Recall | |
|---|---|---|---|---|---|
| Overall Accuracy | 95.29% | ||||
| Tree | 207,013 | 1449 | 3592 | 5044 | 0.9535 |
| Ground | 0 | 446,350 | 216 | 80 | 0.9993 |
| Building | 5888 | 354 | 20,869 | 4973 | 0.6504 |
| Car | 695 | 1661 | 9402 | 649 | 0.0523 |
| Precision | 0.9692 | 0.9923 | 0.6124 | 0.0604 | |
| Tree | Ground | Building | Car | Recall | |
|---|---|---|---|---|---|
| Overall Accuracy: | 91.07% | ||||
| Tree | 138,335 | 0 | 29,606 | 1497 | 0.8164 |
| Ground | 0 | 316,857 | 19,888 | 0 | 0.9409 |
| Building | 5027 | 10,637 | 286,741 | 1230 | 0.9444 |
| Car | 93 | 188 | 4640 | 216 | 0.0420 |
| Precision | 0.9643 | 0.9670 | 0.8412 | 0.0734 | |
| Scene I | Tree(%) | Ground(%) | Building(%) | Car(%) | Accuracy(%) |
| Proposed method | 96.92/95.35 | 99.23/99.93 | 61.24/65.04 | 6.04/5.23 | 95.29 |
| Method I | 96.53/94.4 | 95.18/99.18 | 69.39/53.67 | 11.5/4.25 | 94.18 |
| Method II | 87.15/79.75 | 94.65/99.24 | 0.045/0.044 | 38.91/30.64 | 87.74 |
| Method III | 92.80/93.48 | 96.76/97.97 | 63.60/49.22 | 44.21/49.08 | 93.17 |
| Scene II | Tree(%) | Ground(%) | Building(%) | Car(%) | Accuracy(%) |
| Proposed method | 96.54/84.22 | 96.7/94.09 | 85.02/94.44 | 9.72/4.2 | 91.60 |
| Method I | 94.36/89.11 | 96.14/92.24 | 85.98/91.33 | 2.31/4.21 | 90.70 |
| Method II | 69.47/4.50 | 45.22/97.17 | 88.38/24.13 | 23.51/1.35 | 49.93 |
| Method III | 91.60/82.71 | 89.91/94.02 | 84.87/86.62 | 7.69/0.19 | 88.31 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Zhang, Z.; Zhong, R.; Chen, D.; Sun, T.; Deng, X.; Li, Z.; Qin, C.-Z. Content-Sensitive Multilevel Point Cluster Construction for ALS Point Cloud Classification. Remote Sens. 2019, 11, 342. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11030342
Xu Z, Zhang Z, Zhong R, Chen D, Sun T, Deng X, Li Z, Qin C-Z. Content-Sensitive Multilevel Point Cluster Construction for ALS Point Cloud Classification. Remote Sensing. 2019; 11(3):342. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11030342
Chicago/Turabian StyleXu, Zongxia, Zhenxin Zhang, Ruofei Zhong, Dong Chen, Taochun Sun, Xin Deng, Zhen Li, and Cheng-Zhi Qin. 2019. "Content-Sensitive Multilevel Point Cluster Construction for ALS Point Cloud Classification" Remote Sensing 11, no. 3: 342. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11030342