Addressing Challenges for Mapping Irrigated Fields in Subhumid Temperate Regions by Integrating Remote Sensing and Hydroclimatic Data

 , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
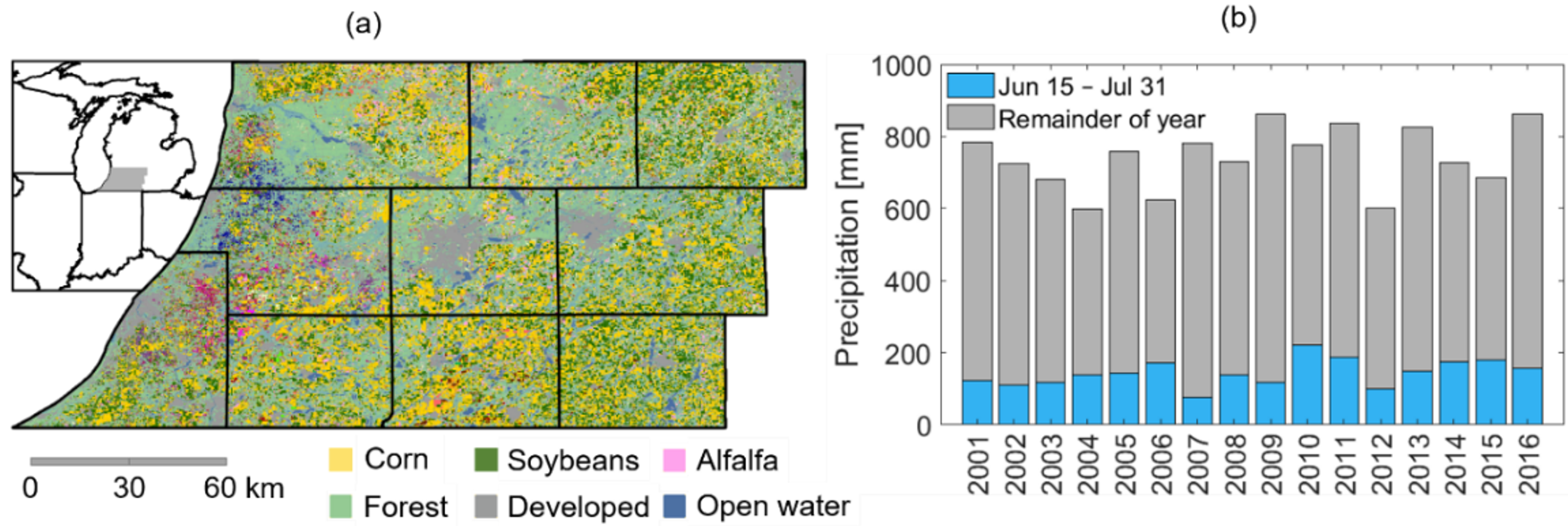
2.1. Study Area
2.2. Basic Remotely Sensed, Land Surface Model, and Climate Input Data
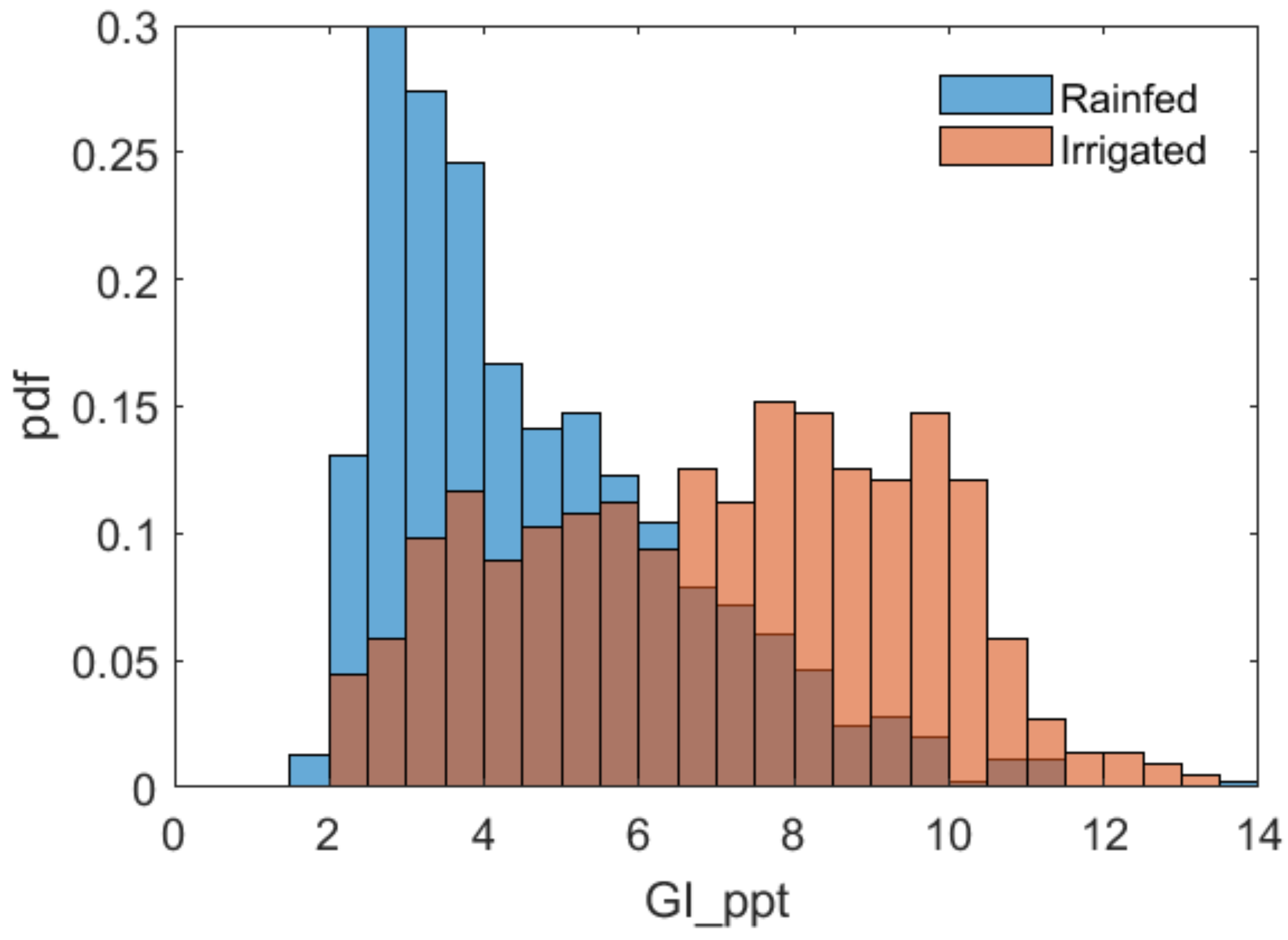
2.3. Weather-Sensitive Scene Selection, Spatial Anomaly Calculation, and Novel Composite Indices
2.4. Random Forest Classifier
2.5. Manually Labeled Dataset
2.6. Classification Accuracy Assessment
3. Results and Discussions
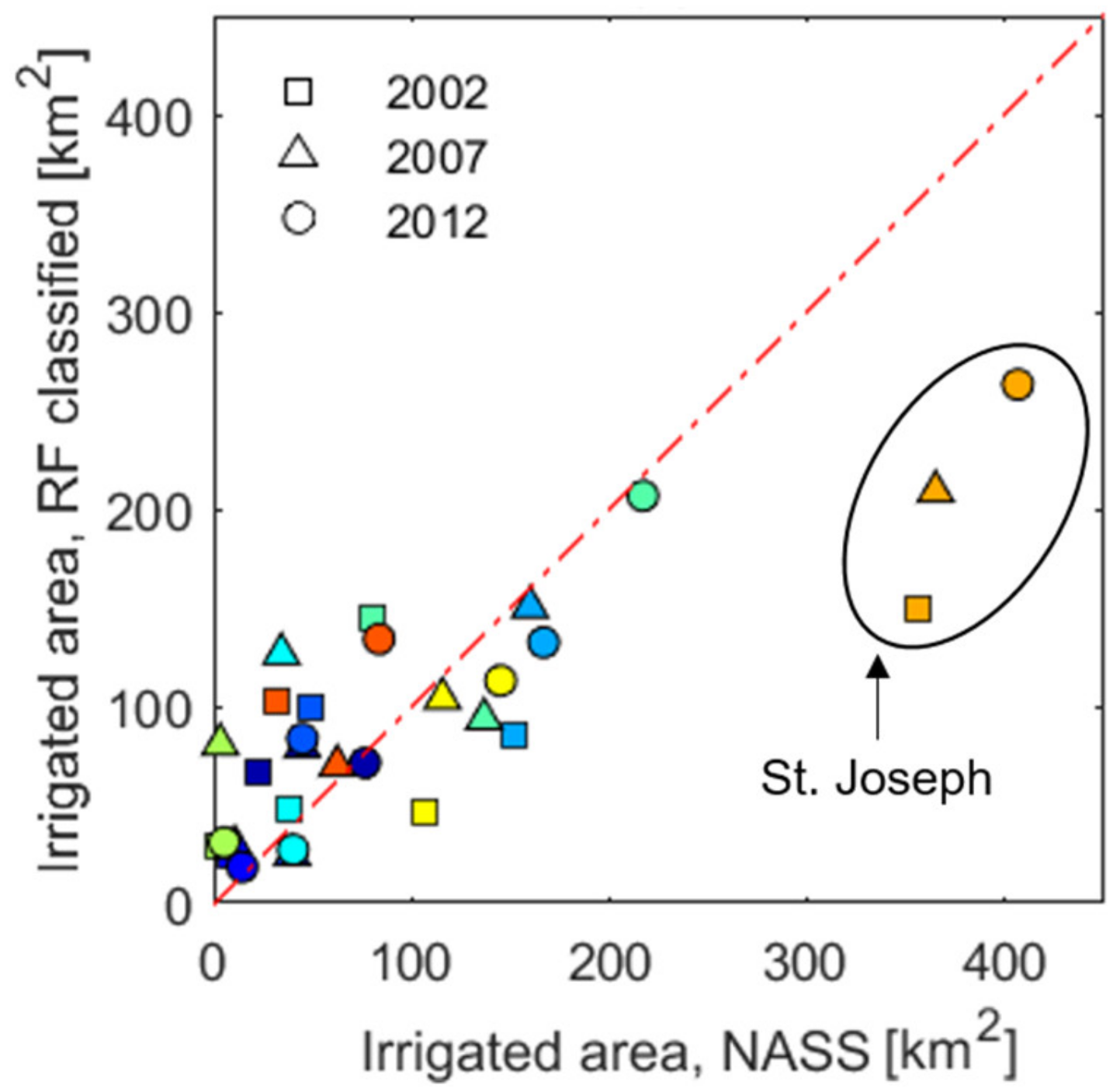
3.1. Classification Accuracy
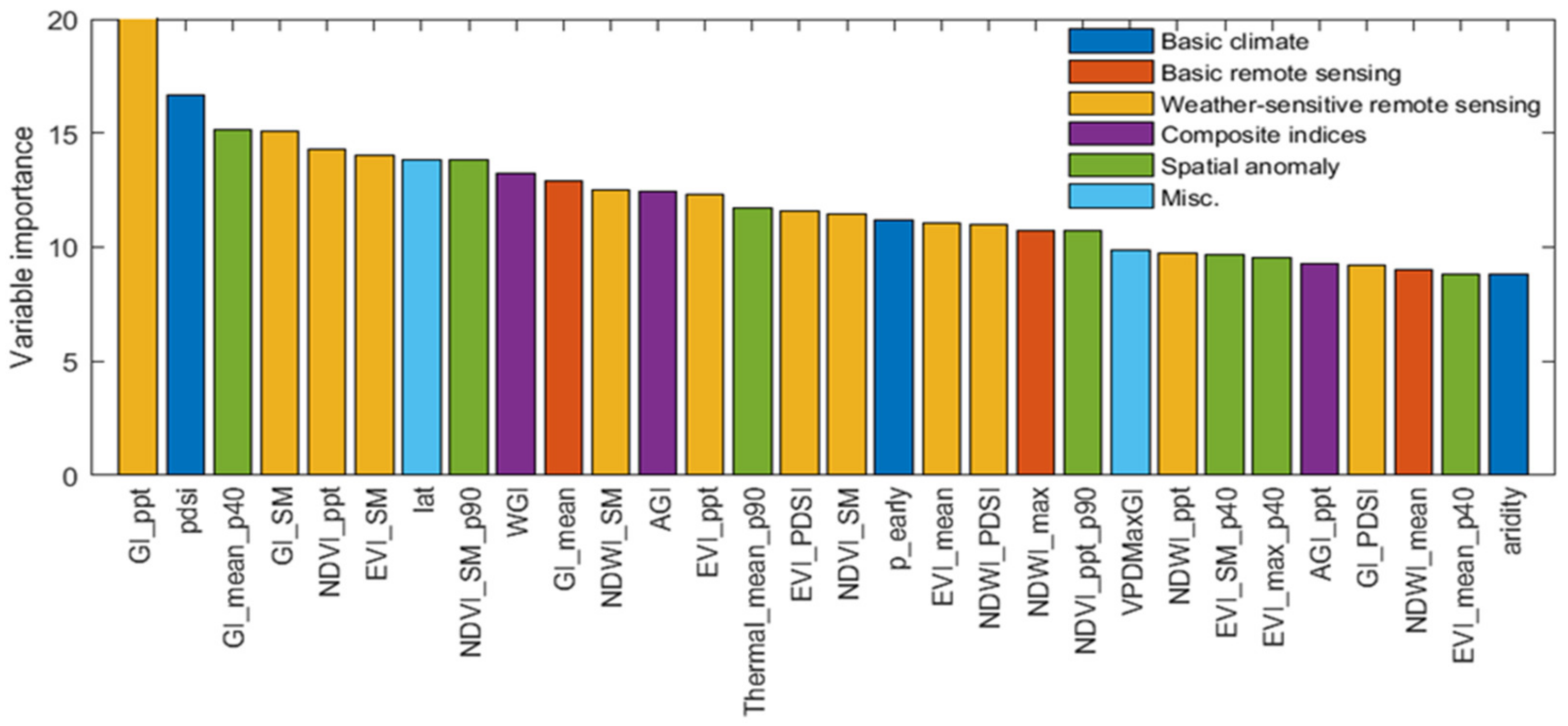
3.2. Important Input Variables
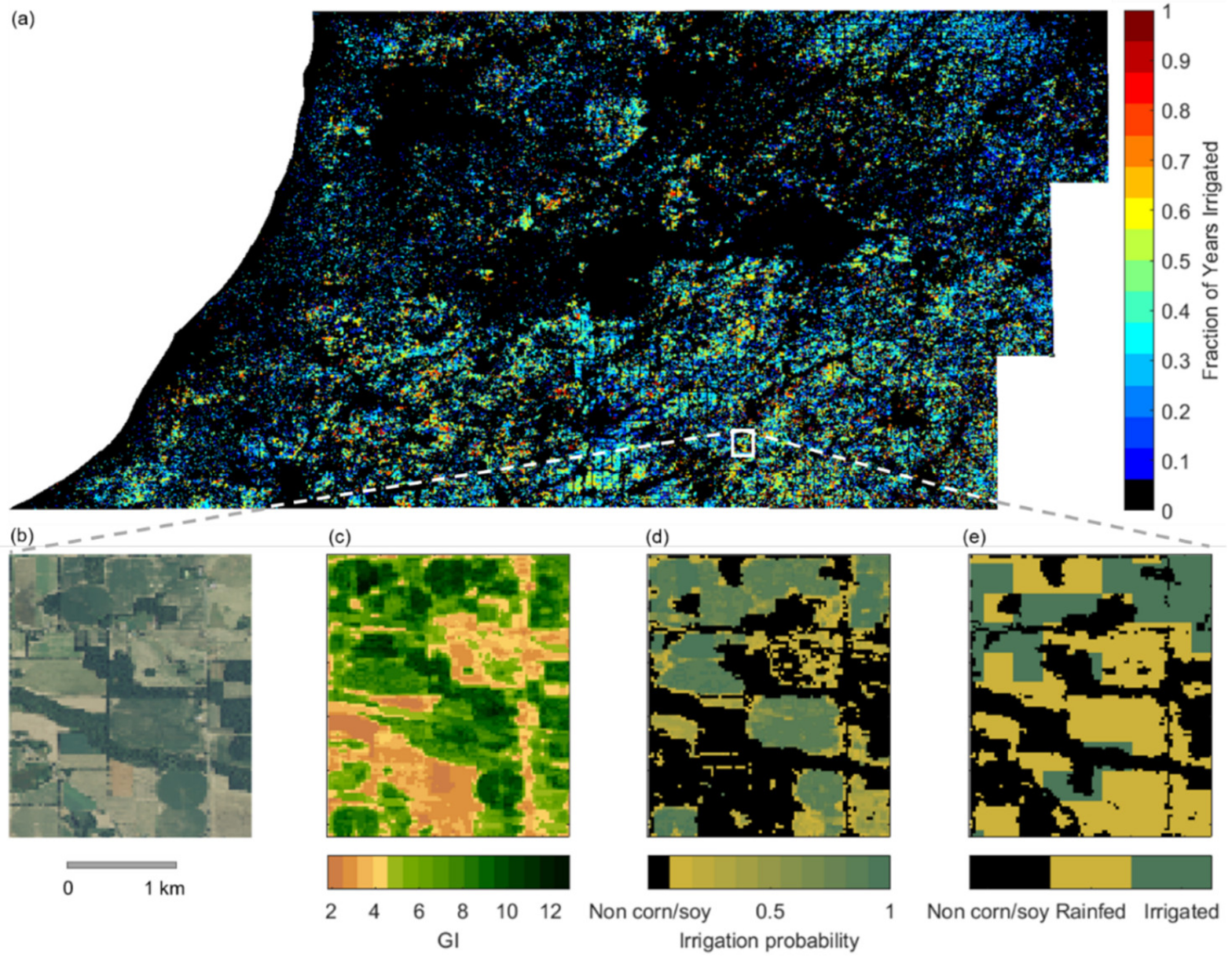
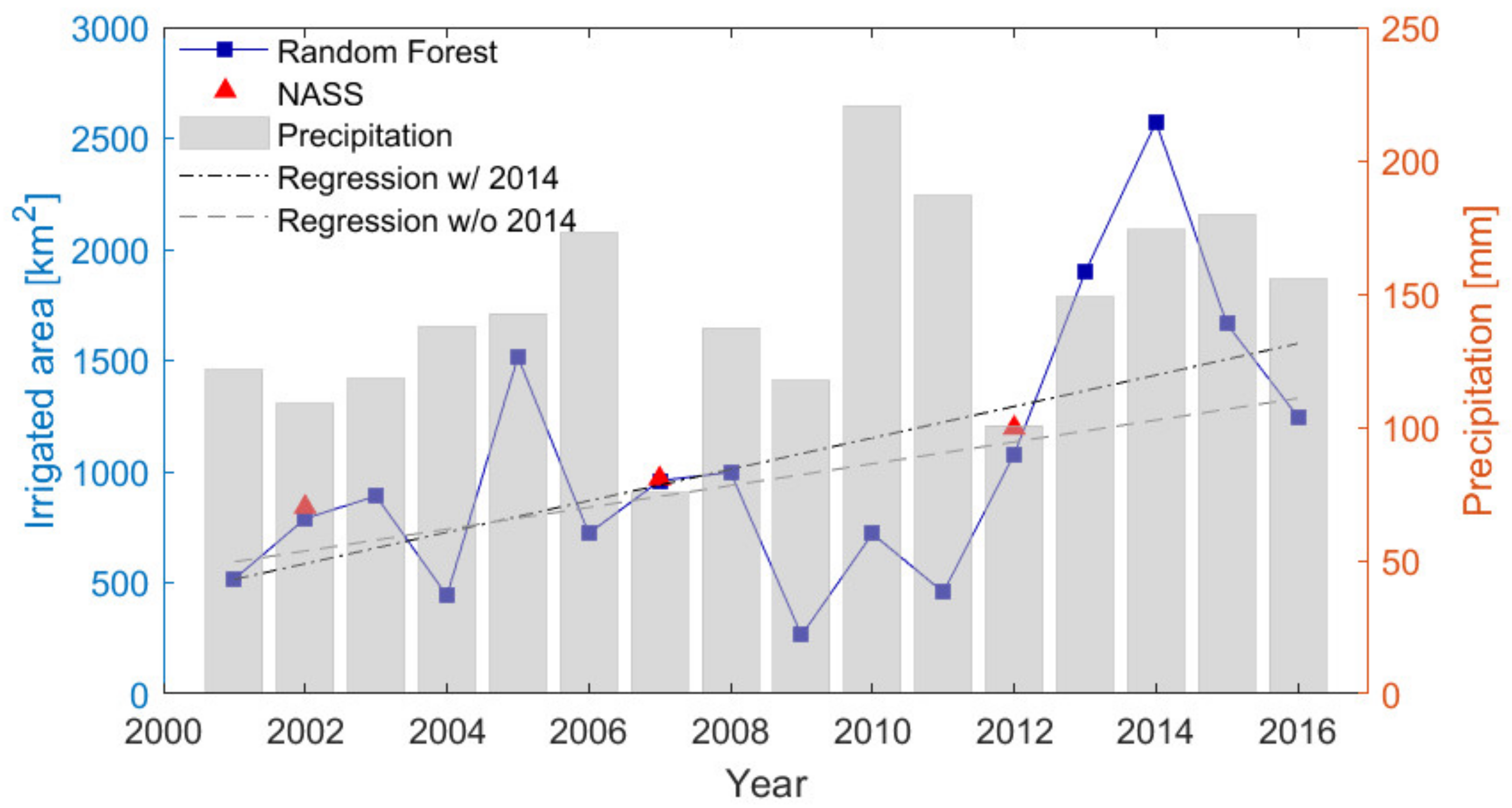
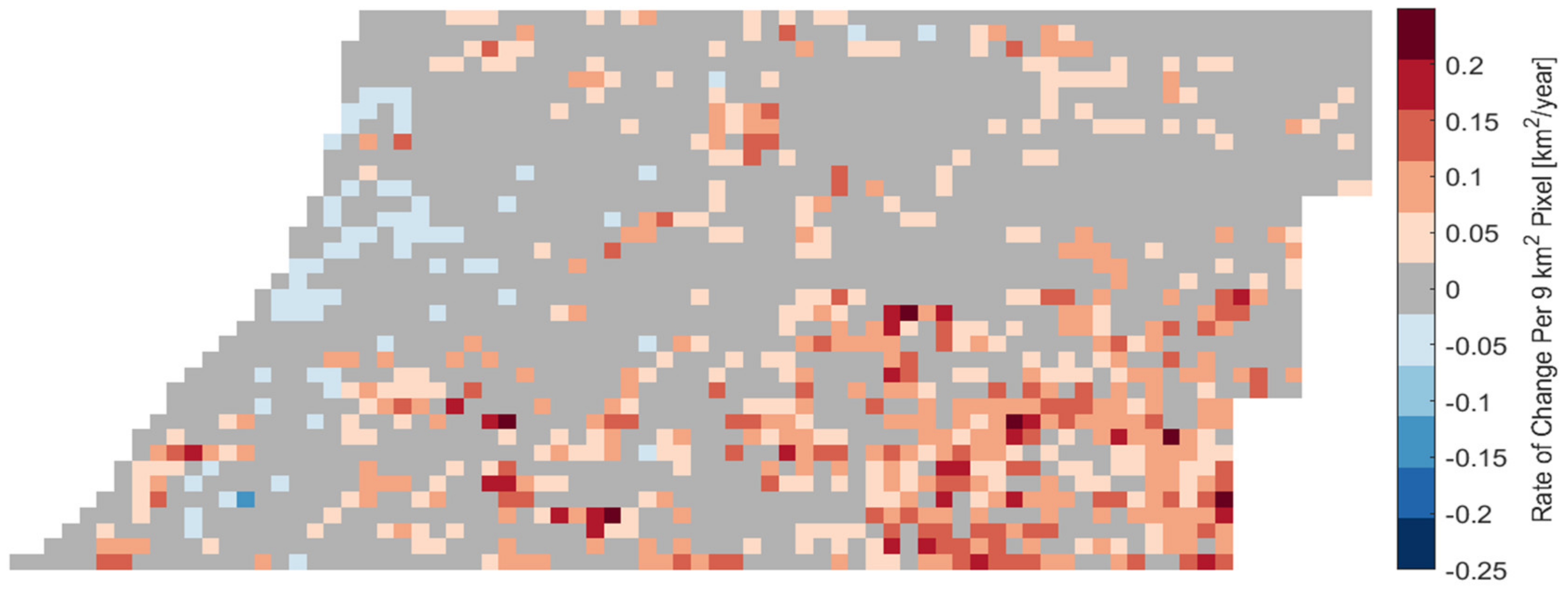
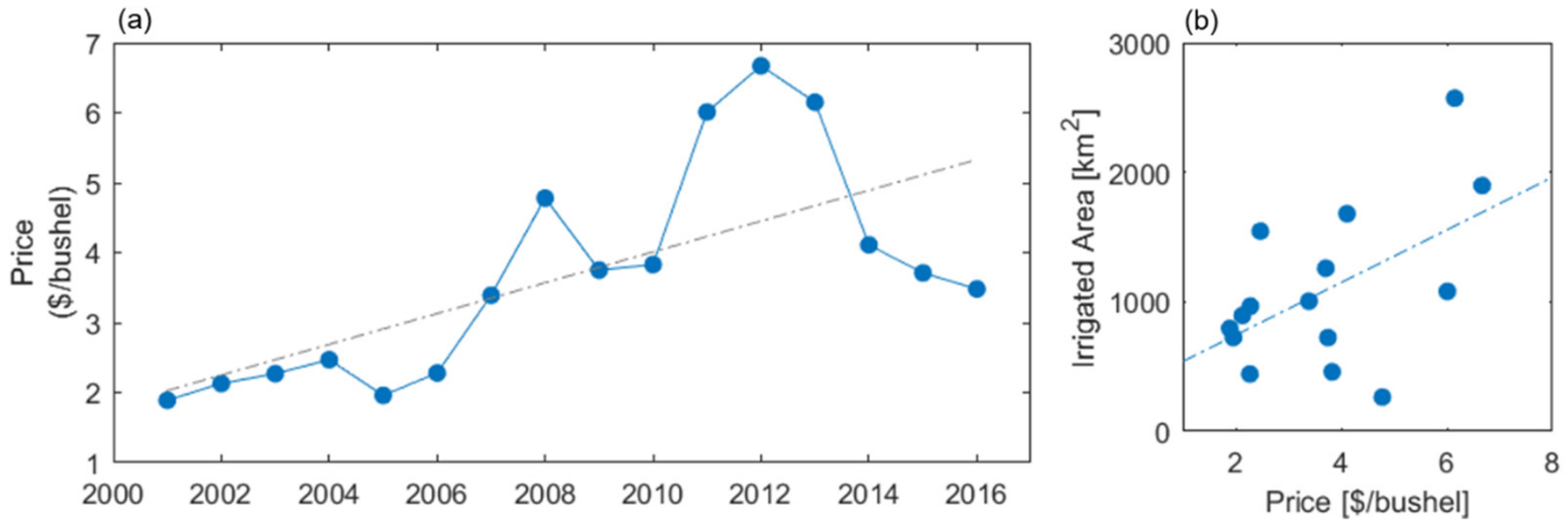
3.3. Expansion of Irrigation
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Food and Agriculture Organization of the United Nations (FAO) AQUASTAT Main Database. Available online: http://www.fao.org/nr/aquastat (accessed on 1 January 2016).
- U.S Department of Agriculture. National Agricultural Statistics Service (USDA NASS) QuickStats Ad-hoc Query Tool. Available online: https://quickstats.nass.usda.gov/ (accessed on 1 November 2017).
- Cotterman, K.A.; Kendall, A.D.; Basso, B.; Hyndman, D.W. Groundwater depletion and climate change: Future prospects of crop production in the Central High Plains Aquifer. Clim. Change 2018, 146, 187–200. [Google Scholar] [CrossRef]
- Pei, L.; Moore, N.; Zhong, S.; Luo, L.; Hyndman, D.W.; Heilman, W.E.; Gao, Z. WRF Model Sensitivity to Land Surface Model and Cumulus Parameterization under Short-Term Climate Extremes over the Southern Great Plains of the United States. J. Clim. 2014, 27, 7703–7724. [Google Scholar] [CrossRef]
- Pei, L.; Moore, N.; Zhong, S.; Kendall, A.D.; Gao, Z.; Hyndman, D.W. Effects of Irrigation on Summer Precipitation over the United States. J. Clim. 2016, 29, 3541–3558. [Google Scholar] [CrossRef]
- Smidt, S.J.; Haacker, E.M.K.; Kendall, A.D.; Deines, J.M.; Pei, L.; Cotterman, K.A.; Li, H.; Liu, X.; Basso, B.; Hyndman, D.W. Complex water management in modern agriculture: Trends in the water-energy-food nexus over the High Plains Aquifer. Sci. Total Environ. 2016, 566–567, 988–1001. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.V.; Peters-Lidard, C.D.; Santanello, J.A.; Reichle, R.H.; Draper, C.S.; Koster, R.D.; Nearing, G.; Jasinski, M.F. Evaluating the utility of satellite soil moisture retrievals over irrigated areas and the ability of land data assimilation methods to correct for unmodeled processes. Hydrol. Earth Syst. Sci. 2015, 12, 5967–6009. [Google Scholar] [CrossRef]
- Lawston, P.M.; Santanello, J.A.; Franz, T.E.; Rodell, M. Assessment of irrigation physics in a land surface modeling framework using non-traditional and human-practice datasets. Hydrol. Earth Syst. Sci. 2017, 21, 2953–2966. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McInerney, D.; Thyer, M.; Kavetski, D.; Githui, F.; Thayalakumaran, T.; Liu, M.; Kuczera, G. The Importance of Spatiotemporal Variability in Irrigation Inputs for Hydrological Modeling of Irrigated Catchments. Water Resour. Res. 2018, 54, 6792–6821. [Google Scholar] [CrossRef]
- Levin, S.B.; Zarriello, P.J. USGS Scientific Investigations Report 2013–5066: Estimating Irrigation Water Use in the Humid Eastern United States; USGS: Reston, VA, USA, 2013. [Google Scholar]
- Pervez, M.S.; Brown, J.F. Mapping irrigated lands at 250-m scale by merging MODIS data and National Agricultural Statistics. Remote Sens. 2010, 2, 2388–2412. [Google Scholar] [CrossRef]
- Brown, J.F.; Pervez, M.S. Variability and trends in irrigated and non-irrigated croplands in the central U.S. In Proceedings of the 2013 Second International Conference on Agro-Geoinformatics (Agro-Geoinformatics); IEEE, Fairfax, VA, USA, 12–16 August 2013; pp. 102–105. [Google Scholar]
- Deines, J.M.; Kendall, A.D.; Hyndman, D.W. Annual Irrigation Dynamics in the U.S. Northern High Plains Derived from Landsat Satellite Data. Geophys. Res. Lett. 2017, 44, 9350–9360. [Google Scholar] [CrossRef]
- Deines, J.M.; Kendall, A.D.; Butler, J.J.; Hyndman, D.W. Quantifying water use and farmer adaptation strategies in response to novel stakeholder-driven groundwater management in teh US High Plains Aquifer. Environ. Res. Lett. 2019. [CrossRef]
- Gao, Q.; Zribi, M.; Escorihuela, M.; Baghdadi, N.; Segui, P.; Gao, Q.; Zribi, M.; Escorihuela, M.J.; Baghdadi, N.; Segui, P.Q. Irrigation Mapping Using Sentinel-1 Time Series at Field Scale. Remote Sens. 2018, 10, 1495. [Google Scholar] [CrossRef]
- Michigan State University (MSU) Extension. Value of Irrigation to the Southwest Michigan Economy; MSU: Lansing, MI, USA, 2014. [Google Scholar]
- USDA Natural Resources Conservation Service (NRCS) Web Soil Survey. Available online: https://websoilsurvey.nrcs.usda.gov/ (accessed on 1 November 2017).
- Kaercher, M.; Neumann, B. St. Joseph County Agriculture: Past, Present and Future; MSU: Centreville, MI, USA, 2006. [Google Scholar]
- Kraft, G.J.; Clancy, K.; Mechenich, D.J.; Haucke, J. Irrigation Effects in the Northern Lake States: Wisconsin Central Sands Revisited. Ground Water 2012, 50, 308–318. [Google Scholar] [CrossRef] [PubMed]
- Wolock, D.M.; Winter, T.C.; McMahon, G. Delineation and Evaluation of Hydrologic-Landscape Regions in the United States Using Geographic Information System Tools and Multivariate Statistical Analyses. Environ. Manag. 2004, 34, S71–S88. [Google Scholar] [CrossRef] [PubMed]
- Daly, C.; Halbleib, M.; Smith, J.I.; Gibson, W.P.; Doggett, M.K.; Taylor, G.H.; Curtis, J.; Pasteris, P.P. Physiographically sensitive mapping of climatological temperature and precipitation across the conterminous United States. Int. J. Climatol. 2008, 28, 2031–2064. [Google Scholar] [CrossRef] [Green Version]
- U.S. Department of Agriculture. National Agricultural Statistics Service (USDA NASS) Cropland Data Layer. Available online: https://www.nass.usda.gov/Research_and_Science/Cropland/Release/index.php (accessed on 1 April 2018).
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- USGS 1 Arc-second Digital Elevation Models (DEMs)—USGS National Map 3DEP Downloadable Data Collection. Available online: https://www.sciencebase.gov/catalog/item/4f70aa71e4b058caae3f8de1 (accessed on 1 November 2017).
- Schaap, M.G.; Leij, F.J.; van Genuchten, M.T. ROSETTA: A computer program for estimating soil hydraulic parameters with hierarchical pedotransfer functions. J. Hydrol. 2001, 251, 163–176. [Google Scholar] [CrossRef]
- Abatzoglou, J.T. Development of gridded surface meteorological data for ecological applications and modelling. Int. J. Climatol. 2013, 33, 121–131. [Google Scholar] [CrossRef]
- Xia, Y.; Mitchell, K.; Ek, M.; Sheffield, J.; Cosgrove, B.; Wood, E.; Luo, L.; Alonge, C.; Wei, H.; Meng, J.; et al. Continental-scale water and energy flux analysis and validation for the North American Land Data Assimilation System project phase 2 (NLDAS-2): 1. Intercomparison and application of model products. J. Geophys. Res. Atmos. 2012, 117. [Google Scholar] [CrossRef] [Green Version]
- White, J.C.; Wulder, M.A.; Hobart, G.W.; Luther, J.E.; Hermosilla, T.; Griffiths, P.; Coops, N.C.; Hall, R.J.; Hostert, P.; Dyk, A.; et al. Pixel-Based Image Compositing for Large-Area Dense Time Series Applications and Science. Can. J. Remote Sens. 2014, 40, 192–212. [Google Scholar] [CrossRef] [Green Version]
- Gao, B. NDWI—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Ozdogan, M.; Gutman, G. A new methodology to map irrigated areas using multi-temporal MODIS and ancillary data: An application example in the continental US. Remote Sens. Environ. 2008, 112, 3520–3537. [Google Scholar] [CrossRef] [Green Version]
- Running, S.; Mu, Q.; Zhao, M.; Moreno, A. MODIS Global Terrestrial Evapotranspiration (ET) Product (NASA MOD16A2/A3) Collection 5; NASA Headquarters: Washington, DC, USA, 2013. [Google Scholar]
- McAllister, A.; Whitfield, D.; Abuzar, M. Mapping Irrigated Farmlands Using Vegetation and Thermal Thresholds Derived from Landsat and ASTER Data in an Irrigation District of Australia. Photogramm. Eng. Remote Sens. 2015, 81, 229–238. [Google Scholar] [CrossRef]
- Naghibi, S.A.; Pourghasemi, H.R.; Dixon, B. GIS-based groundwater potential mapping using boosted regression tree, classification and regression tree, and random forest machine learning models in Iran. Environ. Monit. Assess. 2016, 188, 44. [Google Scholar] [CrossRef] [PubMed]
- Xu, T.; Valocchi, A.J. Data-driven methods to improve baseflow prediction of a regional groundwater model. Comput. Geosci. 2015, 85, 124–136. [Google Scholar] [CrossRef]
- Xu, T.; Valocchi, A.J.; Ye, M.; Liang, F.; Lin, Y.F. Bayesian calibration of groundwater models with input data uncertainty. Water Resour. Res. 2017, 53, 3224–3245. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Fry, J.; Xian, G.Z.; Jin, S.; Dewitz, J.; Homer, C.G.; Yang, L.; Barnes, C.A.; Herold, N.D.; Wickham, J.D. Completion of the 2006 national land cover database for the conterminous united states. Photogramm. Eng. Remote Sens. 2011, 77, 858–864. [Google Scholar]
- Hastie, T.; Friedman, J.; Tibshirani, R. The Elements of Statistical Learning; Springer: New York, NY, USA, 2001. [Google Scholar]
- Abe, S. Feature Selection and Extraction; Springer: London, UK, 2010; pp. 331–341. [Google Scholar]
- National Agriculture Imagery Program (NAIP) USDA Farm Service Agency National Agriculture Imagery Program. Available online: https://www.fsa.usda.gov/programs-and-services/aerial-photography/imagery-programs/naip-imagery/ (accessed on 1 November 2017).
- Boschetti, L.; Roy, D.P.; Justice, C.O.; Humber, M.L. MODIS–Landsat fusion for large area 30 m burned area mapping. Remote Sens. Environ. 2015, 161, 27–42. [Google Scholar] [CrossRef]
- Wang, Q.; Blackburn, G.A.; Onojeghuo, A.O.; Dash, J.; Zhou, L.; Zhang, Y.; Atkinson, P.M. Fusion of Landsat 8 OLI and Sentinel-2 MSI Data. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3885–3899. [Google Scholar] [CrossRef]
- Boyer, J.S.; Byrne, P.; Cassman, K.G.; Cooper, M.; Delmer, D.; Greene, T.; Gruis, F.; Habben, J.; Hausmann, N.; Kenny, N.; et al. The U.S. drought of 2012 in perspective: A call to action. Glob. Food Sec. 2013, 2, 139–143. [Google Scholar] [CrossRef]
- Zhang, T.; Lin, X.; Sassenrath, G.F. Current irrigation practices in the central United States reduce drought and extreme heat impacts for maize and soybean, but not for wheat. Sci. Total Environ. 2015, 508, 331–342. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Source |
|---|---|---|
| EVI | Enhanced Vegetation Index | Landsat |
| GI | Green Index | Landsat |
| NDWI | Normalized Difference Water Index | Landsat |
| NDVI | Normalized Difference Vegetation Index | Landsat |
| Thermal | Landsat 5 & 7: 10.40–12.50 µm band Landsat 8: 11.50–12.51 µm band | Landsat |
| Dryspell | See text | Derived: PRISM |
| P | Precipitation | PRISM |
| VPD | Mean daily max. vapor pressure deficit | PRISM |
| GDD | Growing degree-day | PRISM |
| Aridity | Total precipitation/PET, May–Aug | Derived: GRIDMET |
| PDSI | Palmer Drought Severity Index | GRIDMET |
| Soil moisture | Root zone soil moisture | NLDAS-2 Noah |
| AWC | Available water capacity | SSURGO |
| Ksat | Vertical saturated hydraulic conductivity | SSURGO |
| Group | Variable Code or Suffix | Description |
|---|---|---|
| Weather-sensitive remote sensing indices | VDPMaxGI | 3-day average VPD before maximum Landsat GI day |
| dryspellMaxGI | Number of consecutive days with rainfall ≤ 5 mm before maximum GI day | |
| NDVI, EVI, GI and NDWI calculated using the Landsat scene after a dry period identified using three criteria | ||
| _SM | Descending soil moisture | |
| _pdsi | Lowest PDSI | |
| _ppt | Longest dryspell | |
| Spatial anomaly indices | NDVI, EVI, GI and NDWI statistics subtracted by neighborhood % | |
| _p40 | 40% | |
| _p90 | 90% | |
| Composite indices | WGI | Maximum GI mean NDWI (water-adjusted GI, [13] |
| AGI | Maximum GI/aridity (aridity normalized GI, [13] | |
| WGI_ppt, AGI_ppt | WGI and AGI calculated using GI from scenes that immediately follows a dry period |
| Year | Omission Error | Commission Error | Overall Accuracy |
|---|---|---|---|
| Dry (2009, 2012) | 40% | 9% | 85% |
| Wet (2005, 2006, 2010, 2014) | 38% | 14% | 78% |
| All years | 39% | 13% | 82% |
| 2012 RF (This study) | 39% | 6% | 84% |
| 2012 MIrAD-US [12] | 49% | 16% | 74% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, T.; Deines, J.M.; Kendall, A.D.; Basso, B.; Hyndman, D.W. Addressing Challenges for Mapping Irrigated Fields in Subhumid Temperate Regions by Integrating Remote Sensing and Hydroclimatic Data. Remote Sens. 2019, 11, 370. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11030370
Xu T, Deines JM, Kendall AD, Basso B, Hyndman DW. Addressing Challenges for Mapping Irrigated Fields in Subhumid Temperate Regions by Integrating Remote Sensing and Hydroclimatic Data. Remote Sensing. 2019; 11(3):370. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11030370
Chicago/Turabian StyleXu, Tianfang, Jillian M. Deines, Anthony D. Kendall, Bruno Basso, and David W. Hyndman. 2019. "Addressing Challenges for Mapping Irrigated Fields in Subhumid Temperate Regions by Integrating Remote Sensing and Hydroclimatic Data" Remote Sensing 11, no. 3: 370. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11030370