1. Introduction
Wheat is the most important food crop in the world, comprising 38.76% of the total area cultivated for food crops and 29.38% of total food crop production in 2016 [
1]. In China, these numbers are 21.38% and 21.00%, respectively [
2]. Accurate estimations of crop spatial distribution and total cultivated area are of great significance for agricultural disciplines such as yield estimation, food policy development, and planting management, which are of great importance for ensuring national food security [
3,
4].
Traditionally, obtaining crop area required large-scale field surveys. Although this approach produces high-accuracy results, it is time-consuming, labor-intensive, and often lacking in spatial information [
5]. The use of remotely sensed data is an effective alternative that has been widely used over the past few decades at regional or global scales [
6,
7,
8]. As extraction of crop spatial distribution mainly relies on pixel-based image classification, correctly determining pixel features for accurate classification is the basis for this approach [
9,
10,
11,
12].
The spectral characteristics of low- and middle-resolution remote sensing images are usually stable. Vegetation indexes are generally used as pixel features in studies using data from sources including the Moderate Resolution Imaging Spectroradiometer (MODIS) [
6,
13,
14,
15,
16], Enhanced Thematic Mapper/Thematic Mapper [
13,
17], and Systeme Probatoire d’ Observation de la Terre [
7,
10]. These indices include the normalized difference vegetation index (NDVI) [
5,
6,
13,
14,
15], relationship analysis of NDVI [
8], and enhanced vegetation index (EVI) [
3,
18], which are extracted from band values. Common classification methods include decision trees [
5,
11,
13], linear regression [
6], statistics [
7], filtration [
13], time-series analysis [
14,
15], the iterative self-organizing data analysis technique (ISODATA) [
16], and the Mahalanobis distance [
17]. Texture features can better describe the spatial structure of pixels, the Gray-Level Co-Occurrence Matrix is a commonly used texture feature [
19], and Gabor [
20] and wavelet transforms [
19,
21] are often used to extract texture features. Moreover, object-based image analysis technology is also widely used in pre-pixel classification [
22,
23]. Such methods can successfully extract the spatial distribution of winter wheat and other crops, but limitations in spatial resolution restrict the applicability of the results.
The spatial resolution and precision of crop extraction can be significantly improved by using high-resolution imagery [
8,
24,
25]. However, as the spectral characteristics of such imagery are not as stable as those of low- and middle-resolution imagery, traditional feature extraction methods struggle to extract effective pixel features [
26,
27]. Neural networks [
28,
29] and support vector machines [
30,
31] have been applied to this problem, but both are shallow-learning algorithms [
32] that have difficulty effectively expressing complex features, producing unsatisfactory results.
Convolutional neural networks (CNN) were developed from neural networks. The standard CNN follows an “image-label” approach, and its output is a probability distribution over different class. Typical examples include AlexNet [
33], GoogLeNet [
34], Visual Geometry Group Network (VGG) [
35], and Resnet [
36]. Due to their strong feature extraction ability, these networks have achieved remarkable results in camera image classification [
37,
38]. The fully convolutional network, a “per-pixel-label” model based on standard CNNs, was proposed in 2015 [
39]. This network uses a multi-layer convolutional structure to extract pixel features, applies appropriate deconvolutional layers to up-sample the feature map of the last convolution layer to restore it to the same size of the input image, and classified the up-sampled feature map pixel by pixel. Accordingly, a series of convolution-based per-pixel-label models have been developed including SegNet [
40], UNet [
41], DeepLab [
42], and ReSeg [
43]. Of these, SegNet and UNet have the clearest and easiest-to-understand convolution structures. DeepLab uses a method called “Atrous Convolution”, which has a strong advantage in processing detailed images. ReSeg exploits local generic features extracted by CNNs and the capacity of recurrent neural networks to retrieve distant dependencies. Each model has its own strengths and is adept at dealing with certain image types. As conditional random field (CRF) have the ability to learn the dependencies between categories of pixels, CRF can be used to further refine segmentation results [
44].
These convolution-based per-pixel-label models have been applied in remote sensing image segmentation with remarkable results. For example, researchers have used CNN to carry out remote sensing image segmentation and used conditional random fields to further refine the output class map [
45,
46,
47,
48]. To suit the characteristics of specific remote sensing imagery, other researchers have established new convolution-based per-pixel-label models, such as multi-scale fully convolutional networks [
49], patch-based CNNs [
50], and two-branch CNNs [
51]. Effective work has also been carried out in extracting information from remote sensing imagery using convolution-based per-pixel-label models, e.g., extracting crop information for rice [
52,
53], wheat [
54], leaf [
55], and rape [
56], as well as target detection for weeds [
57,
58,
59], diseases [
60,
61,
62], and extracting road information using improved FCN [
63]. Some new feature extraction techniques are being applied to crop information extraction, including 3D-CNN [
64], deep recurrent neural networks [
65], and CNN-LSTM [
66], and Recurrent Neural Networks (RNN) was also used to correct satellite image classification maps [
67]. Some new techniques are proposed to improve the segmentation accuracy, including structured autoencoders [
68] and locality adaptive discriminant analysis [
69]. Moreover, the research on how to automatically determine the feature dimension that could be adaptive to different data distributions will help to obtain a good performance in machine learning and computer vision [
70].
How to determine the optimal value of the parameters is an important problem in the use of convolutional neural networks. Stochastic gradient descent with momentum [
45] is a common and effective training method. Data augmentation technology [
33,
35,
41] and dropout technology [
33] used to prevent overfitting, so as to ensure that the model can obtain the optimal parameters. Practice has proved that reasonable use of a BN (Batch Normalization) layer is also helpful for model training to obtain the optimal parameters [
42,
43].
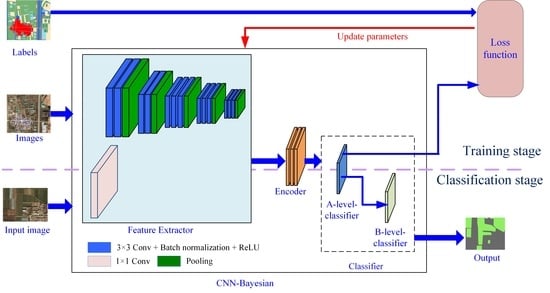
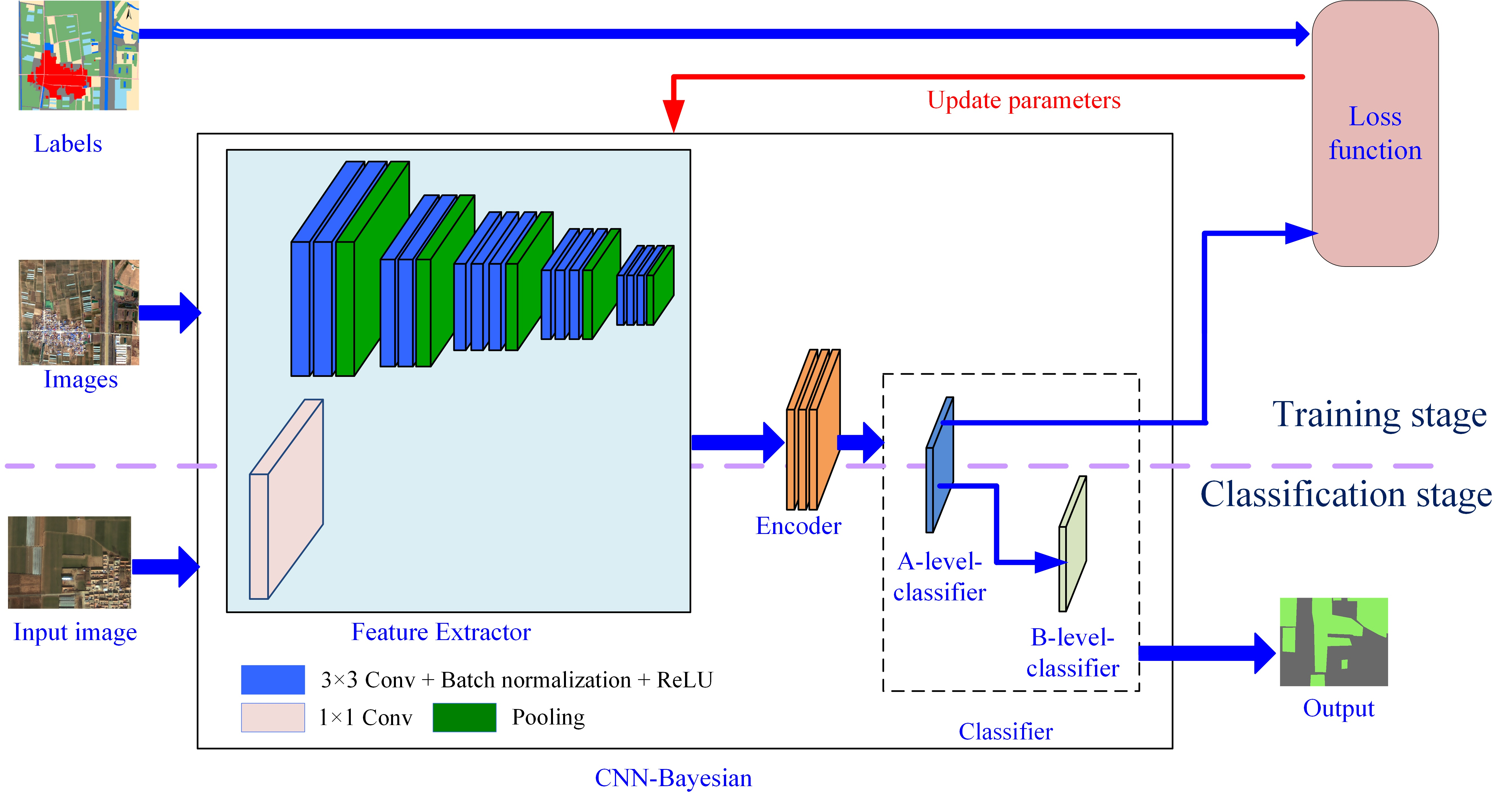
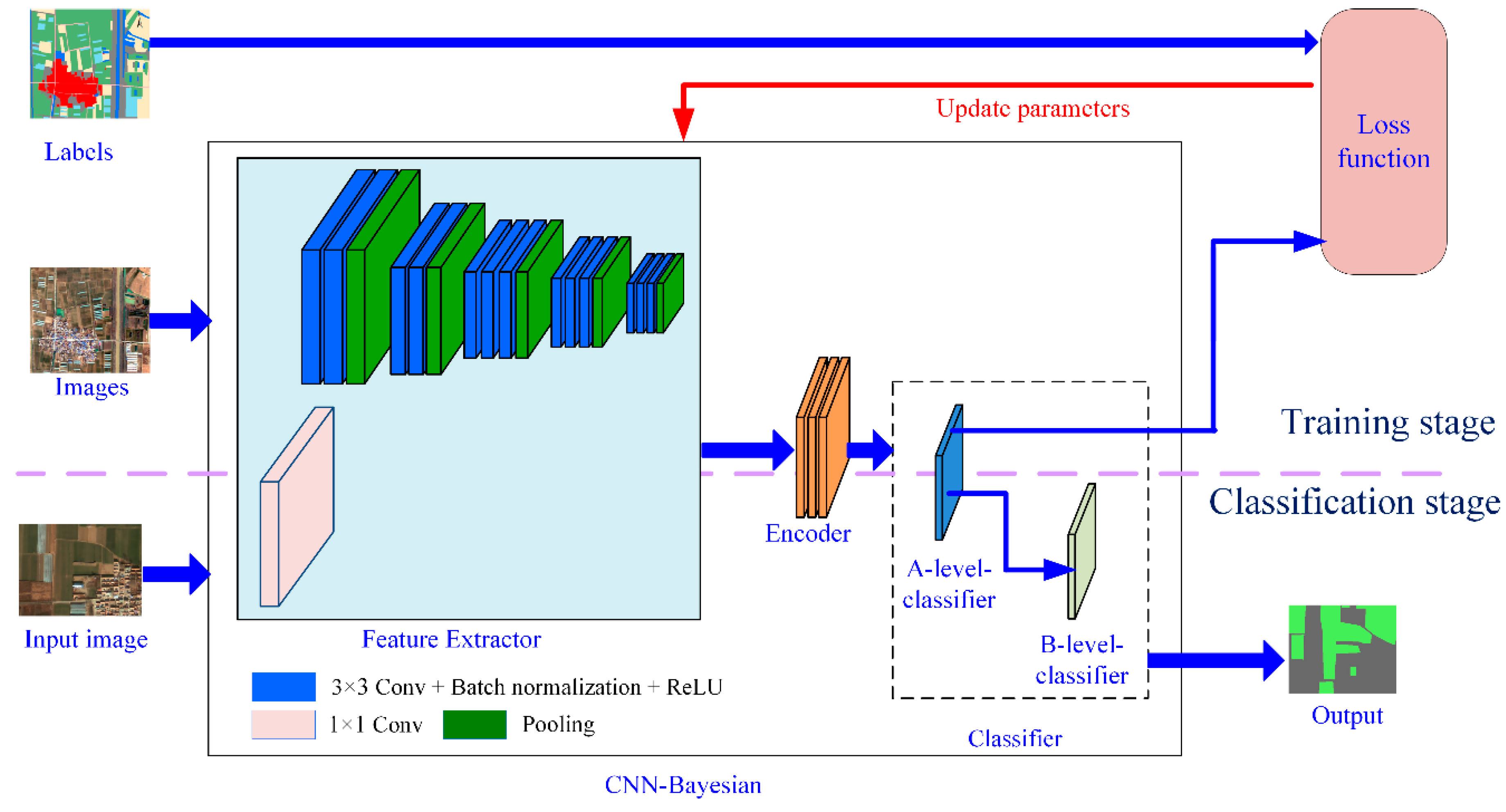
At present, the CNN structure used in the pre-pixel classification of remote sensing imagery generally includes two parts: feature extractor and classifier. The former has been the focus of many researchers with good results. The convolution value acquired by the convolution kernel and pixel block operations is regarded as a feature of central pixels in the pixel blocks and is the common technique for existing feature extractors. However, with regard to classifying pixels with acquired features, most studies have only used classifiers with relatively ordinary functions. These classifiers use a set of linear regression functions to encode the features of pixels and obtained category-code vectors. The SoftMax function is then used to convert the category-code vector into a category probability vector, and the category corresponding to the maximum probability value is taken as the pixel category.
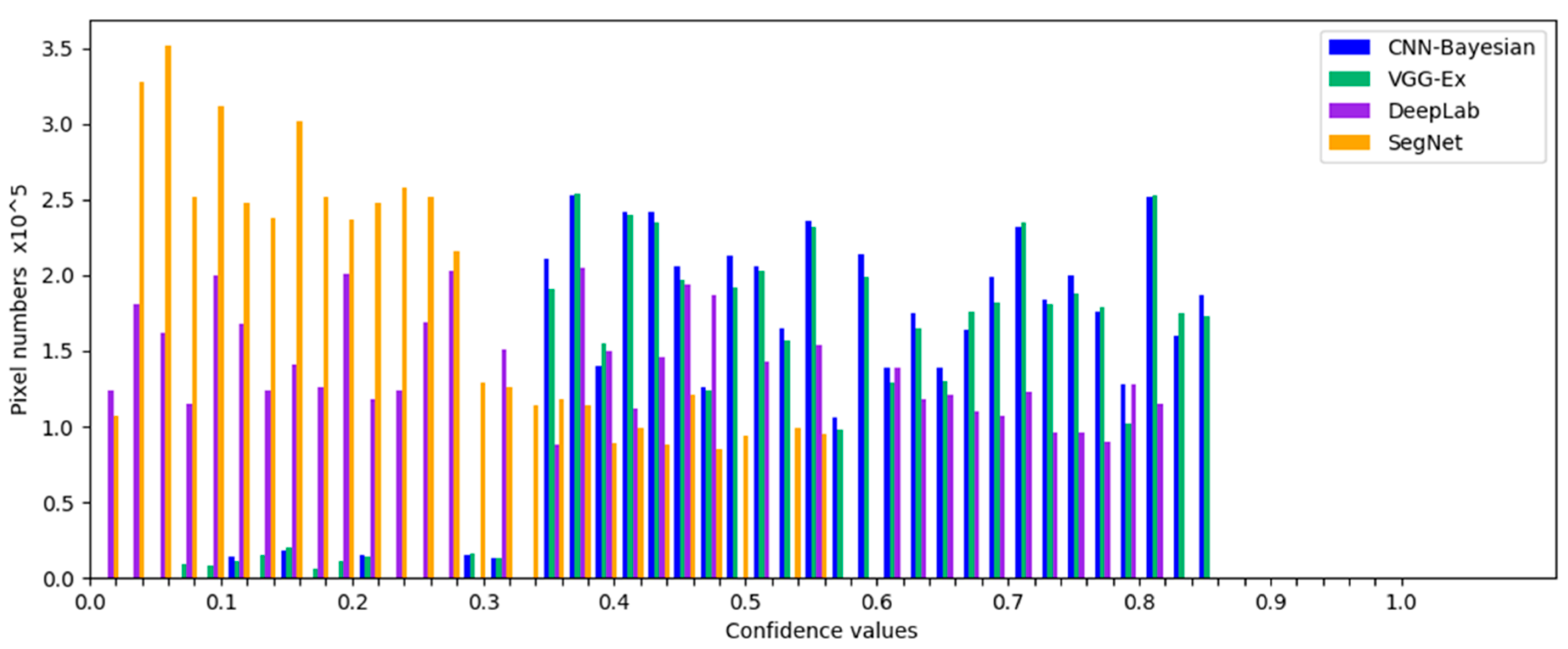
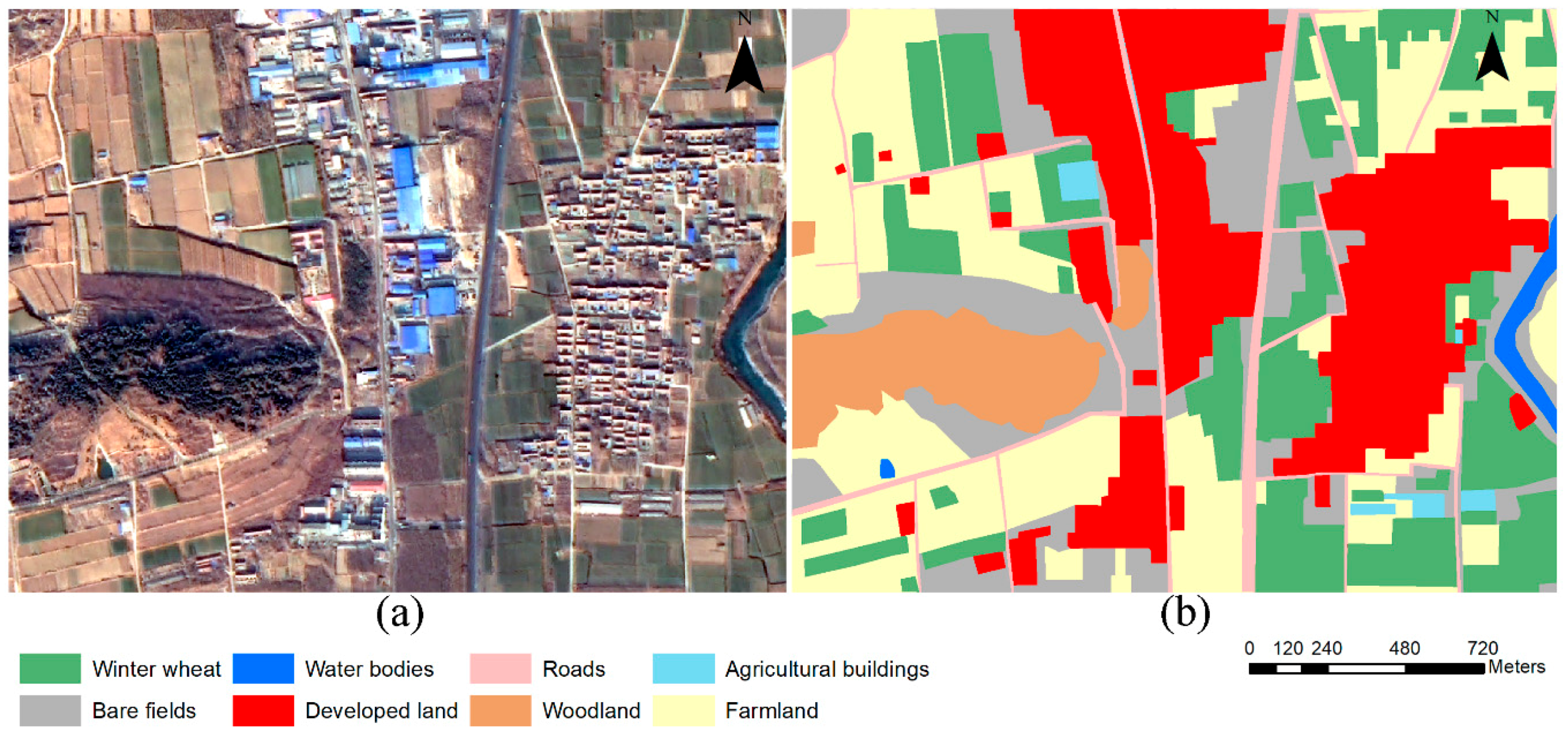
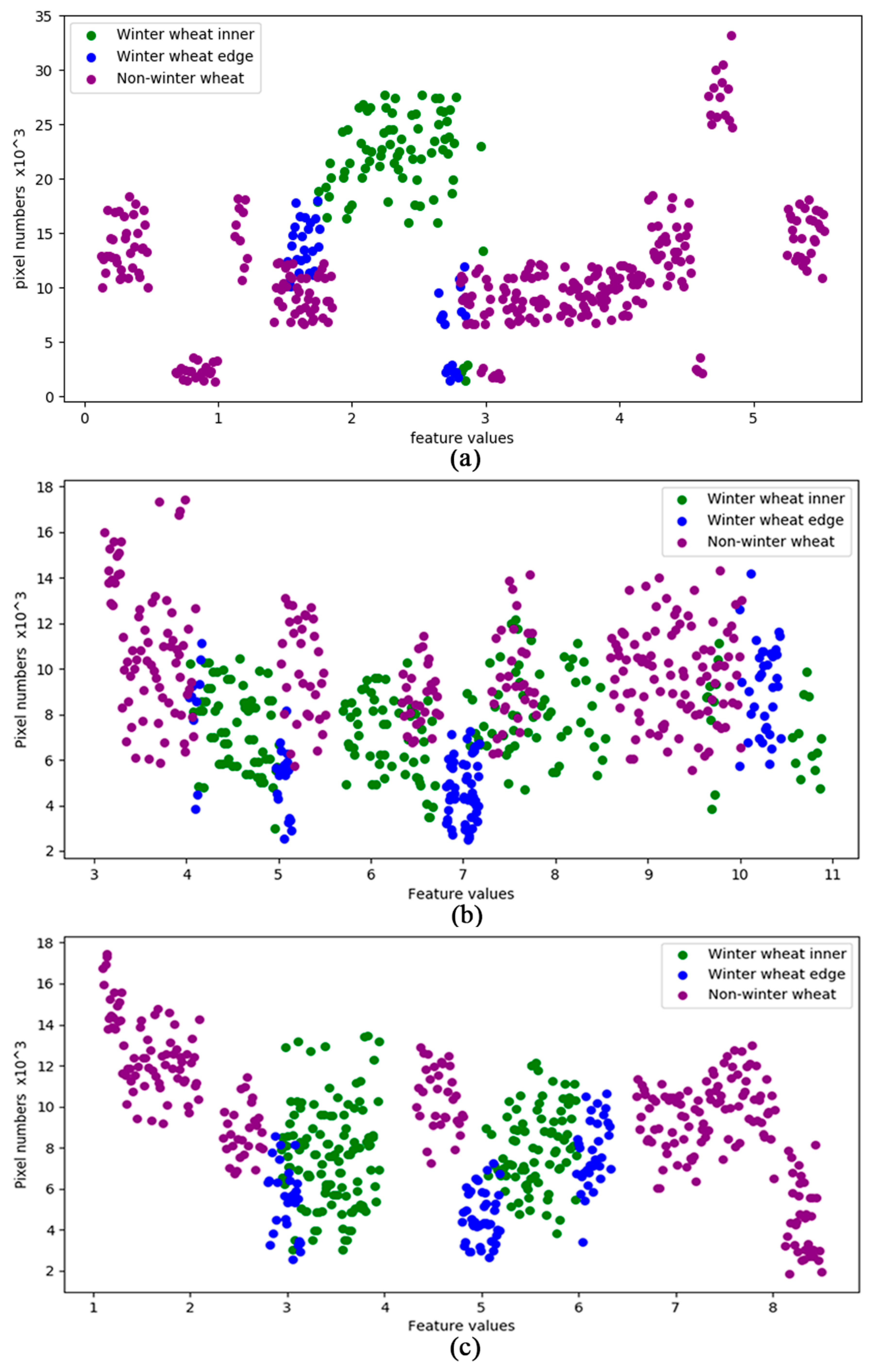
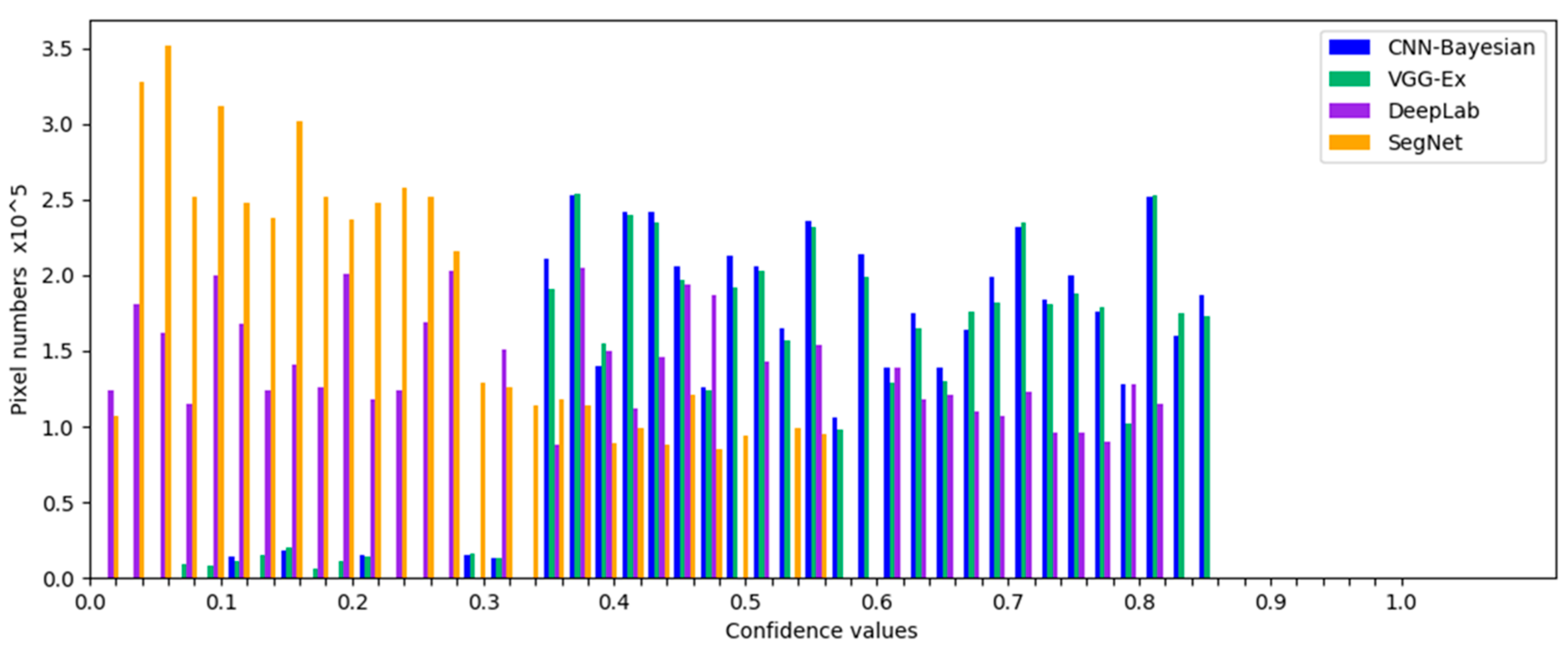
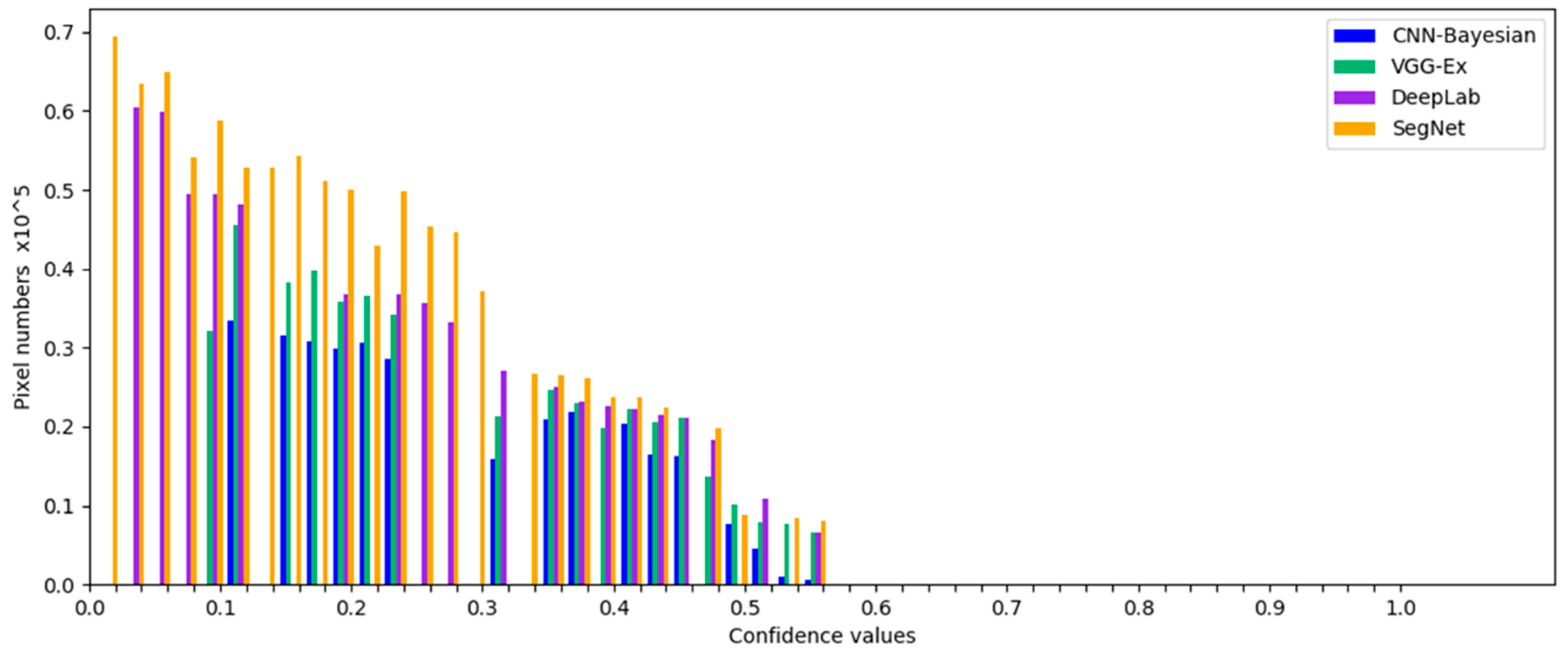
Previous experimental results [
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54,
55,
56] have shown that misclassified pixels are primarily located at the intersections of two land use types, such as field edges or corners. This is because when the features of pixels in these areas are acquired, the used pixel blocks usually contain more pixels of other categories, resulting in the features often being different from the feature of inner pixels of the planting area, which frequently cause classification errors. By analyzing the probability vector of these misclassified pixels, it can be found that the difference between the maximum probability value and the second-maximum probability value is generally small. These errors are due to the inherent structure of the convolutional layer, which needs to be combined with the classifier to be improved.
The Bayesian model can synthesize information from different sources and improve the reliability of inferred conclusions [
71,
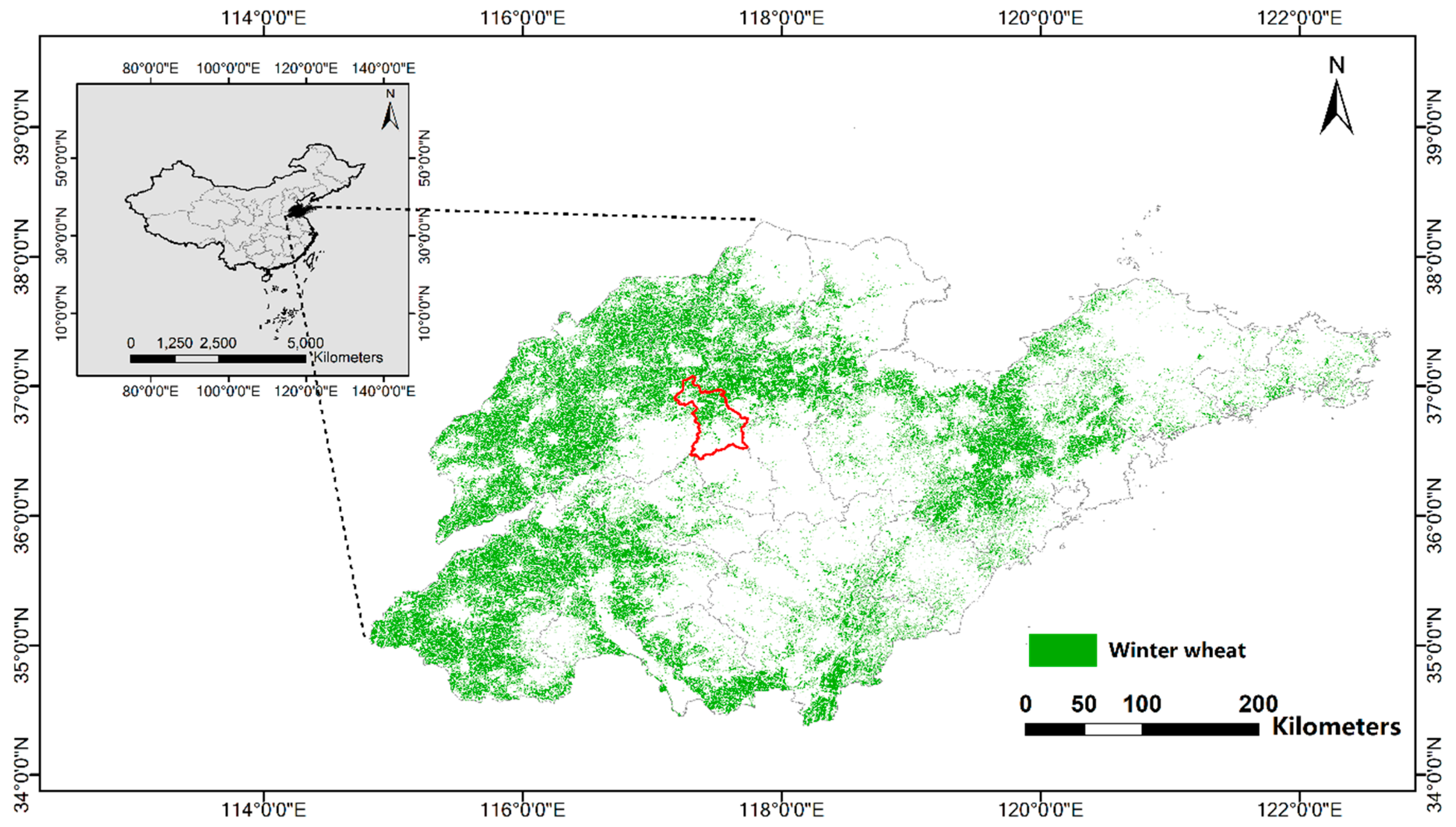
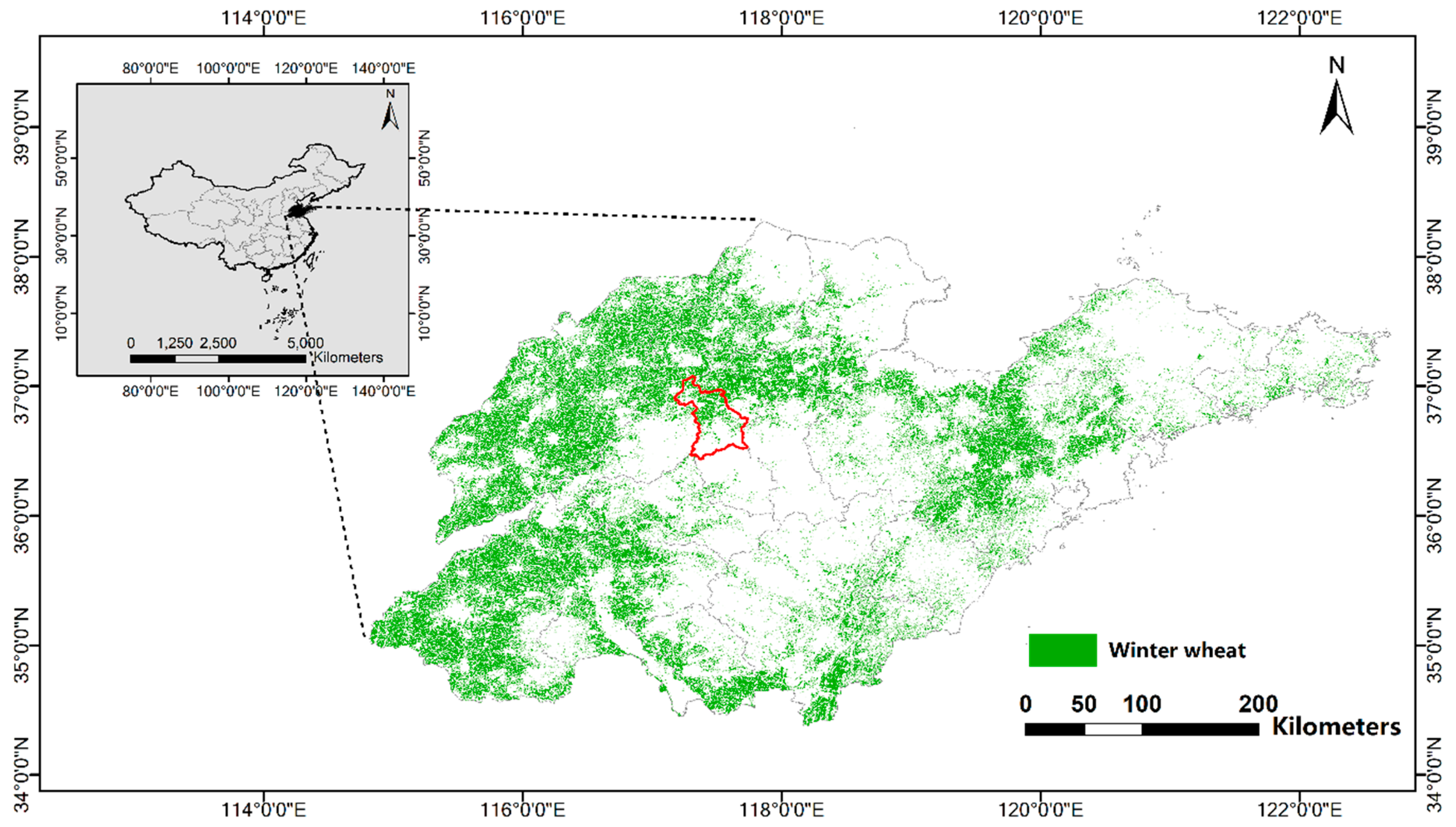
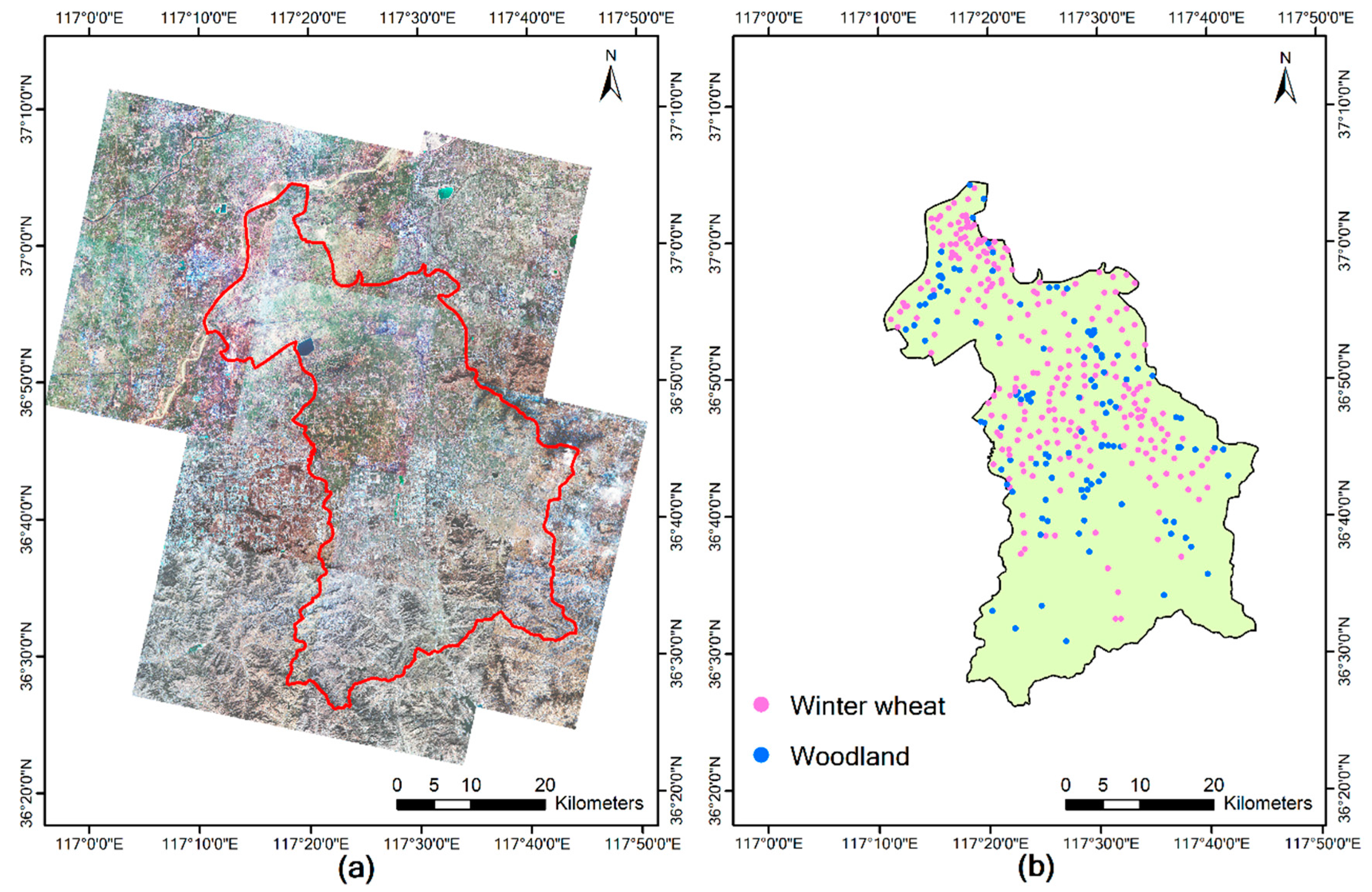
72]. Therefore, when judging the category of a pixel whose difference between the maximum probability value and the second-maximum probability value is small, the spatial structure information of the pixels can be further introduced to improve the reliability of the judgment by using the Bayesian model. In this study, we developed a new CNN consisting of a feature extractor, encoder, and a Bayesian classifier, which we refer to as a Bayesian Convolutional Neural Network (CNN-Bayesian model). We then used this model to extract winter wheat spatial distribution information from Gaofen 2 (GF-2) remote sensing imagery and compared the results with those achieved by other methods.
6. Conclusions
Using satellite remote sensing has become a mainstream approach for extracting winter wheat spatial distribution, but field edge results are usually rough, resulting in lowered overall accuracy. In this paper, we proposed a new approach for extracting spatial distribution information for winter wheat, which significantly improves the accuracy of edge extraction results. The main contributions of this paper are as follows: (1) Our feature extractor is designed to meet the characteristics of remote sensing image data, avoiding extra calculations and errors caused by using deconvolution in the feature extraction process. The feature extractor can fully explore the deep and spatial semantic features of the remote sensing image. (2) Our classifier effectively uses the confidence value of the category probability vector and combines the planting structure characteristics of winter wheat to reclassify pixels with a low confidence value, thus effectively reducing classification errors for edge pixels. As we optimized the method of extracting and using remote sensing image features and rationally used color, texture, semantic, and statistical features to obtain high-precision spatial distribution data of winter wheat. The spatial distribution data of winter wheat in Shandong Province in 2017 and 2018 obtained by the proposed approach has been used by the Meteorological Bureau of Shandong Province.
The number of categories that can be extracted by the proposed CNN-Bayesian model is determined by the number of categories of samples in the training dataset. When the model is used to extract other land use types or applied to another area, only a new training dataset is needed to retrain the model. The successfully trained model can then be used to extract high-precision spatial distribution data of land use from high-resolution remote sensing images.
The main disadvantage of our approach is that it requires more pre-pixel label files. Future research should test the use of semi-supervised classification to reduce the dependence on pre-pixel label files.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}