Increasing Precision for French Forest Inventory Estimates using the k-NN Technique with Optical and Photogrammetric Data and Model-Assisted Estimators

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Site
2.2. National Forest Inventory Data
2.3. Auxiliary Data
2.4. Optimization of the k-NN Model
2.5. Statistical Inference
2.6. External Validation
3. Results
3.1. k-NN Optimization
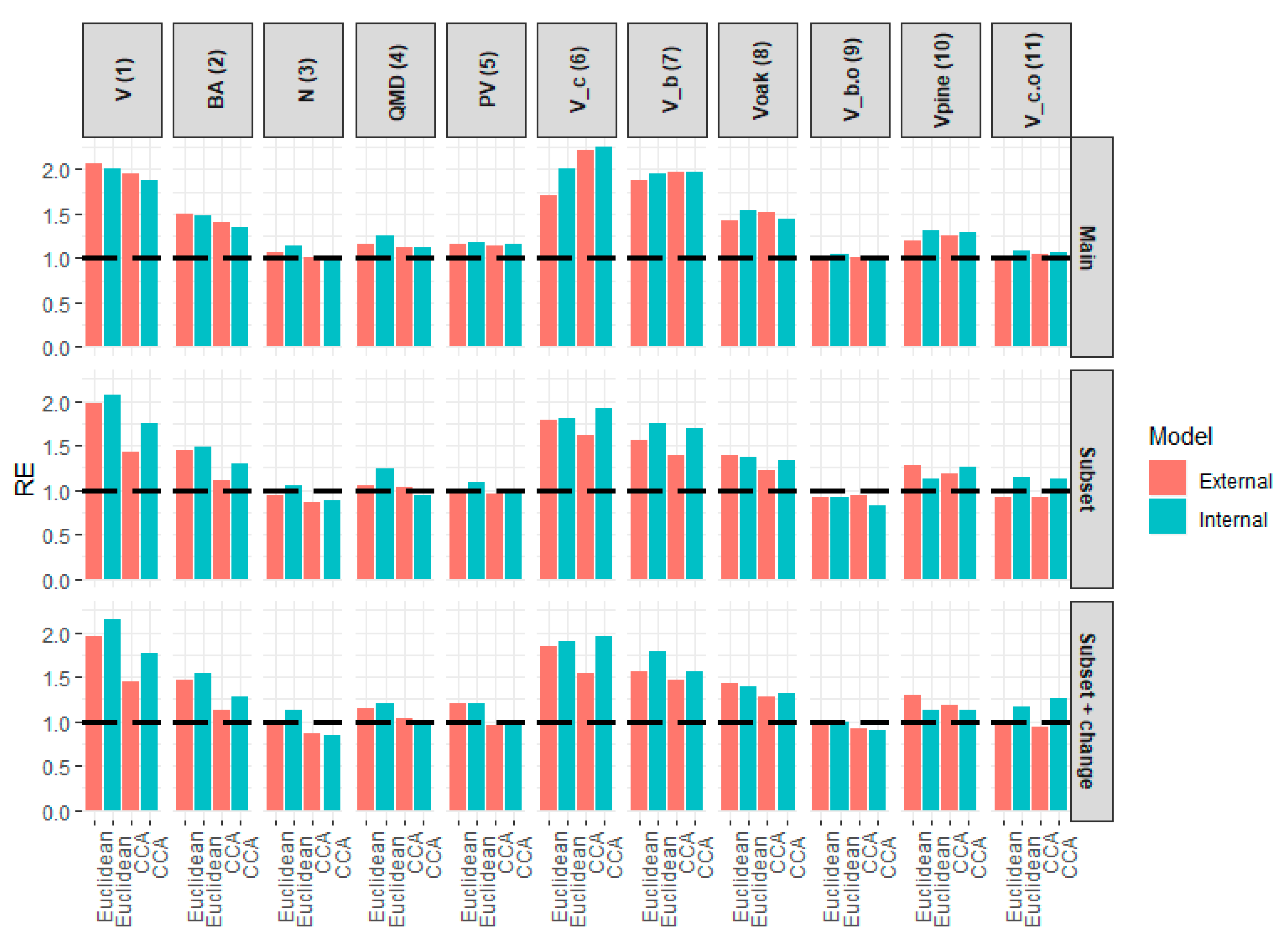
3.2. Statistical Inference
3.3. External Validation
4. Discussion
4.1. k-NN Optimization
4.2. Statistical Inference
4.3. External Validation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| Metric Name | Acronym | Equation |
|---|---|---|
| Gap area | Ga | |
| Mean inner canopy volume | Vi | |
| Mean outer canopy volume | Vo | |
| Mean inner gap canopy volume | Vgi | |
| Mean outer gap canopy volume | Vgo | |
| Rumple area | Ra | |
| No data | NA |
| Indice Name | Acronym | Equation |
|---|---|---|
| Simple Ratio | SR | NIR/R |
| Normalized Difference vegetation index | NDVI | (NIR − R)/(NIR + R) |
| Specific Leaf Area Vegetation Index | SLAVI | NIR/(R + SWIR1) |
| Soil Adjusted Vegetation Index | SAVI | ((NIR − R)/(NIR + R+Ls)) * (1+Ls) |
| Modified Soil Adjusted Vegetation Index | MSAVI | (2 * NIR + 1 − /2 |
| Enhance Vegetation Index | EVI | 2.5 * ((NIR − R)/(NIR + 6 * R − 7.5 * B + Lc)) |
| Normalized Difference Moisture Index | NDMI | (R − NIR)/(R + NIR) |
| Normalized Difference Water Index | NDWI | (NIR − SWIR1)/(NIR + SWIR1) |
| Green NDVI | GNDVI | (NIR − G)/(NIR + G) |
| Brightness | Br | 0.3029 B + 0.2786 G + 0.4733 R + 0.5599 NIR + 0.508 SWIR1 + 0.1872 SWIR2 |
| Greenness | Gr | −0.2941 B − 0.243 G − 0.5424 R + 0.7276 NIR − 0.0713 SWIR1 − 0.1608 SWIR2 |
| Wetness | We | 0.1511 B + 0.1973 G + 0.3283 R + 0.3707 NIR − 0.7117 SWIR1 − 0.4559 SWIR2 |
References
- Hervé, J.-C.; Wurpillot, S.; Vidal, C.; Roman-Amat, B. L’inventaire des ressources forestières en France: Un nouveau regard sur de nouvelles forêts. RFF 2014, 3, 247–260. [Google Scholar] [CrossRef]
- Tomppo, E.; Gschwantner, T.; Lawrence, M.; McRoberts, R.E. National Forest Inventories: Pathways for Common Reporting; Springer: Berlin, Germany, 2010; 612p. [Google Scholar]
- Denardou, A.; Hervé, J.-C.; Dupouey, J.-L.; Bir, J.; Audinot, T.; Bontemps, J.-D. L’expansion séculaire des forêts françaises est dominée par l’accroissement du stock sur pied et ne sature pas dans le temps. RFF 2017, 4–5, 319–339. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Tomppo, E.O.; Czaplewski, R.L. Sampling designs for national forest assessments. In Knowledge Reference for National Forest Assessments; FAO: Rome, Italy, 2015; pp. 23–40. [Google Scholar]
- Magnussen, S.; Nord-Larsen, T.; Riis-Nielsen, T. Lidar supported estimators of wood volume and aboveground biomass from the Danish national forest inventory (2012–2016). Remote Sens. Environ. 2018, 211, 146–153. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Chen, Q.; Gormanson, D.D.; Walters, B.F. The shelf-life of airborne laser scanning data for enhancing forest inventory inferences. Remote Sens. Environ. 2018, 206, 254–259. [Google Scholar] [CrossRef]
- Nilsson, M.; Nordkvist, K.; Jonzén, J.; Lindgren, N.; Axensten, P.; Wallerman, J.; Egberth, M.; Nilsson, L.; Eriksson, J.; Olsson, H. A nationwide forest attribute map of Sweden predicted using airborne laser scanning data and field data from the National Forest Inventory. Remote Sens. Environ. 2017, 194, 447–454. [Google Scholar] [CrossRef]
- Tomppo, E.; Olsson, H.; Ståhl, G.; Nilsson, M.; Hagner, O.; Katila, M. Combining national forest inventory field plots and remote sensing data for forest databases. Remote Sens. Environ. 2008, 112, 1982–1999. [Google Scholar] [CrossRef]
- Ene, L.T.; Næsset, E.; Gobakken, T.; Bollandsås, O.M.; Mauya, E.W.; Zahabu, E. Large-scale estimation of change in aboveground biomass in miombo woodlands using airborne laser scanning and national forest inventory data. Remote Sens. Environ. 2017, 188, 188. [Google Scholar] [CrossRef]
- Särndal, C.-E.; Thomsen, I.; Hoem, J.M.; Barndorff-Nielsen, O.; Dalenius, T. Design-Based and Model-Based Inference in Survey Sampling. Scand. J. Stat. 1978, 5, 27–52. [Google Scholar] [CrossRef]
- Gregoire, T.G.; Næsset, E.; McRoberts, R.E.; Ståhl, G.; Andersen, H.-E.; Gobakken, T.; Ene, L.; Nelson, R. Statistical rigor in LiDAR-assisted estimation of aboveground forest biomass. Remote Sens. Environ. 2016, 173, 98–108. [Google Scholar] [CrossRef]
- Kangas, A.; Myllymäki, M.; Gobakken, T.; Næsset, E. Model-assisted forest inventory with parametric, semiparametric, and nonparametric models. Can. J. For. Res. 2016, 46, 855–868. [Google Scholar] [CrossRef] [Green Version]
- Massey, A.; Mandallaz, D.; Lanz, A. Integrating remote sensing and past inventory data under the new annual design of the Swiss National Forest Inventory using three-phase design-based regression estimation. Can. J. For. Res. 2014, 44, 1177–1186. [Google Scholar] [CrossRef]
- Magnussen, S.; Tomppo, E. Model-calibrated k-nearest neighbor estimators. Scand. J. For. Res. 2016, 183–193. [Google Scholar] [CrossRef]
- Magnussen, S.; Mandallaz, D.; Breidenbach, J.; Lanz, A.; Ginzler, C. National forest inventories in the service of small area estimation of stem volume. Can. J. For. Res. 2014, 44, 1079–1090. [Google Scholar] [CrossRef]
- Longford, N.T. Editorial: Model selection and efficiency—is ‘Which model …?’ the right question? J. R. Stat. Soc. Series A 2005, 168, 469–472. [Google Scholar] [CrossRef]
- Rao, J.N.K.; Molina, I. Small Area Estimation, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2015; ISBN 9780471722182. [Google Scholar]
- Baffetta, F.; Fattorini, L.; Franceschi, S.; Corona, P. Design-based approach to k-nearest neighbours technique for coupling field and remotely sensed data in forest surveys. Remote Sens. Environ. 2009, 113, 463–475. [Google Scholar] [CrossRef] [Green Version]
- McRoberts, R.E.; Naesset, E.; Gobakken, T. Accuracy and Precision for Remote Sensing Applications of Nonlinear Model-Based Inference. IEEE J.-STARS 2013, 6, 27–34. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Næsset, E.; Gobakken, T. Optimizing the k-Nearest Neighbors technique for estimating forest aboveground biomass using airborne laser scanning data. Remote Sens. Environ. 2015, 163, 13–22. [Google Scholar] [CrossRef]
- Gagliasso, D.; Hummel, S.; Temesgen, H. A Comparison of Selected Parametric and Non-Parametric Imputation Methods for Estimating Forest Biomass and Basal Area. Open J. For. 2014, 4, 42. [Google Scholar] [CrossRef]
- Gregoire, T.G.; Ståhl, G.; Næsset, E.; Gobakken, T.; Nelson, R.; Holm, S. Model assisted estimation of biomass in a LiDAR sample survey in Hedmark County, Norway. Can. J. For. Res. 2011, 41, 83–95. [Google Scholar] [CrossRef]
- Opsomer, J.D.; Breidt, F.J.; Moisen, G.G.; Kauermann, G. Model-Assisted Estimation of Forest Resources With Generalized Additive Models. J. Am. Stat. Assoc. 2007, 102, 400–409. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.-J.; Tomppo, E. Model-based prediction error uncertainty estimation for k-nn method. Remote Sens. Environ. 2006, 104, 257–263. [Google Scholar] [CrossRef]
- Wallerman, J.; Joyce, S.; Vencatasawmy, C.P.; Olsson, H. Prediction of forest stem volume using kriging adapted to detected edges. Can. J. For. Res. 2002, 32, 509–518. [Google Scholar] [CrossRef]
- Hoef, J.M.V.; Temesgen, H. A Comparison of the Spatial Linear Model to Nearest Neighbor (k-NN) Methods for Forestry Applications. PLoS ONE 2013, 8, e59129. [Google Scholar] [CrossRef]
- Nieschulze, J.; Sabrowski, J. Regionalisation of Point Information: A Comparison of Parameter Estimation Techniques for Universal Kriging. Proceedings of IUFRO 4.11 Conference; Rennolls, K., Ed.; University of Greenwich: London, UK, 2003. [Google Scholar]
- Salvati, N.; Tzavidis, N.; Pratesi, M.; Chambers, R. Small area estimation via M-quantile geographically weighted regression. TEST 2012, 21, 1–28. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Chen, Q.; Walters, B.F. Multivariate inference for forest inventories using auxiliary airborne laser scanning data. For. Ecol. Manag. 2017, 401, 295–303. [Google Scholar] [CrossRef]
- Beaudoin, A.; Bernier, P.Y.; Guindon, L.; Villemaire, P.; Guo, X.J.; Stinson, G.; Bergeron, T.; Magnussen, S.; Hall, R.J. Mapping attributes of Canada’s forests at moderate resolution through kNN and MODIS imagery. Can. J. For. Res. 2014, 44, 521–532. [Google Scholar] [CrossRef]
- McRoberts, R.E. Estimating forest attribute parameters for small areas using nearest neighbors techniques. For. Ecol. Manag. 2012, 272, 3–12. [Google Scholar] [CrossRef]
- Muinonen, E.; Maltamo, M.; Hyppänen, H.; Vainikainen, V. Forest stand characteristics estimation using a most similar neighbor approach and image spatial structure information. Remote Sens. Environ. 2001, 78, 223–228. [Google Scholar] [CrossRef]
- Franco-Lopez, H.; Ek, A.R.; Bauer, M.E. Estimation and mapping of forest stand density, volume, and cover type using the k-nearest neighbors method. Remote Sens. Environ. 2001, 77, 251–274. [Google Scholar] [CrossRef] [Green Version]
- LeMay, V.; Temesgen, H. Comparison of Nearest Neighbor Methods for Estimating Basal Area and Stems per Hectare Using Aerial Auxiliary Variables. For. Sci. 2005, 51, 109–119. [Google Scholar] [CrossRef]
- Ohmann, J.L.; Gregory, M.J.; Roberts, H.M. Scale considerations for integrating forest inventory plot data and satellite image data for regional forest mapping. Remote Sens. Environ. 2014, 151, 3–15. [Google Scholar] [CrossRef]
- Eskelson, B.; Barrett, T.; Temesgen, H. Imputing mean annual change to estimate current forest attributes. Silva Fenn. 2009, 43, 185. [Google Scholar] [CrossRef]
- Muinonen, E.; Parikka, H.; Pokharel, Y.P.; Shrestha, S.M.; Eerikäinen, K. (2012) Utilizing a Multi-Source Forest Inventory Technique, MODIS Data and Landsat TM Images in the Production of Forest Cover and Volume Maps for the Terai Physiographic Zone in Nepal. Remote Sens. 2012, 4, 3920–3947. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Tomppo, E.O. Remote sensing support for national forest inventories. Remote Sens. Environ. 2007, 110, 412–419. [Google Scholar] [CrossRef]
- Vastaranta, M.; Niemi, M.; Karjalainen, M.; Peuhkurinen, J.; Kankare, V.; Hyyppä, J.; Holopainen, M. Prediction of Forest Stand Attributes Using TerraSAR-X Stereo Imagery. Remote Sens. 2014, 6, 3227–3246. [Google Scholar] [CrossRef] [Green Version]
- Haapanen, R.; Tuominen, S. Data Combination and Feature Selection for Multisource Forest Inventory. Photogramm. Eng. Remote Sens. 2008, 74, 869–880. [Google Scholar] [CrossRef]
- Breidenbach, J.; Astrup, R. Small area estimation of forest attributes in the Norwegian National Forest Inventory. Eur. J. For. Res. 2012, 131, 1255–1267. [Google Scholar] [CrossRef]
- Kangas, A.; Astrup, R.; Breidenbach, J.; Fridman, J.; Gobakken, T.; Korhonen, K.T.; Maltamo, M.; Nilsson, M.; Nord-Larsen, T.; Næsset, E.; Olsson, H. Remote sensing and forest inventories in Nordic countries – roadmap for the future. Scand. J. For. Res. 2018, 33, 397–412. [Google Scholar] [CrossRef] [Green Version]
- Goerndt, M.E.; Monleon, V.J.; Temesgen, H. Small-Area Estimation of County-Level Forest Attributes Using Ground Data and Remote Sensed Auxiliary Information. For. Sci. 2013, 59, 536–548. [Google Scholar] [CrossRef]
- Hudak, A.T.; Crookston, N.L.; Evans, J.S.; Hall, D.E.; Falkowski, M.J. Nearest neighbor imputation of species-level, plot-scale forest structure attributes from LiDAR data. Remote Sens. Environ. 2008, 112, 2232–2245. [Google Scholar] [CrossRef]
- Bohlin, J.; Wallerman, J.; Fransson, J.E.S. Forest variable estimation using photogrammetric matching of digital aerial images in combination with a high-resolution DEM. Scand. J. For. Res. 2012, 27, 692–699. [Google Scholar] [CrossRef]
- Waser, L.T.; Baltsavias, E.; Ecker, K.; Eisenbeiss, H.; Feldmeyer-Christe, E.; Ginzler, C.; Küchler, M.; Zhang, L. Assessing changes of forest area and shrub encroachment in a mire ecosystem using digital surface models and CIR aerial images. Remote Sens. Environ. 2008, 112, 1956–1968. [Google Scholar] [CrossRef]
- Askne, J.; Santoto, M.; Smith, G.; Fransson, E.S. Multitemporal repeat-pass SAR interferometry of boreal forests. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1540–1550. [Google Scholar] [CrossRef]
- St-Onge, B.; Véga, C.; Fournier, R.; Hu, Y. Mapping canopy height using a combination of digital photogrammetry and lidar. Int. J. Remote Sens. 2008, 29, 3343–3364. [Google Scholar] [CrossRef]
- Rahlf, J.; Breidenbach, J.; Solberg, S.; Næsset, E.; Astrup, R. Digital aerial photogrammetry can efficiently support large-area forest inventories in Norway. Forestry (Lond) 2017, 90, 710–718. [Google Scholar] [CrossRef]
- Véga, C.; St-Onge, B. Height Growth Reconstruction of a Boreal Forest Canopy Over a Period of 58 Years Using a Combination of Photogrammetric and Lidar Models. Remote Sens. Environ. 2008, 112, 1784–1794. [Google Scholar] [CrossRef]
- Granholm, A.-H.; Olsson, H.; Nilsson, M.; Allard, A.; Holgren, J. The potential of digital surface models based on aerial images for automated vegetation mapping. Int. J. Remote Sens. 2015, 36, 1855–1870. [Google Scholar] [CrossRef]
- Falkowski, M.J.; Hudak, A.T.; Crookston, N.L.; Gessler, P.E.; Uebler, E.H.; Smith, A.M.S. Landscape-scale parameterization of a tree-level forest growth model: A k-nearest neighbor imputation approach incorporating LiDAR data. Can. J. For. Res. 2010, 40, 184–199. [Google Scholar] [CrossRef]
- Véga, C.; Renaud, J.-P.; Durrieu, S.; Bouvier, M. On the interest of penetration depth, canopy area and volume metrics to improve Lidar-based models of forest parameters. Remote Sens. Environ. 2016, 175, 32–42. [Google Scholar] [CrossRef]
- Bouvier, M.; Durrieu, S.; Fournier, R.A.; Renaud, J.-P. Generalizing predictive models of forest inventory attributes using an area-based approach with airborne LiDAR data. Remote Sens. Environ. 2015, 156, 322–334. [Google Scholar] [CrossRef]
- Kane, V.R.; McGaughey, R.J.; Bakker, J.D.; Gersonde, R.F.; Lutz, J.A.; Franklin, J.F. Comparisons between field- and LiDAR-based measures of stand structural complexity. Can. J. For. Res. 2010, 40, 761–773. [Google Scholar] [CrossRef] [Green Version]
- Pestov, V. Is the k-NN classifier in high dimensions affected by the curse of dimensionality? Comput. Math. Appl. 2013, 65, 1427–1437. [Google Scholar] [CrossRef]
- Chirici, G.; Mura, M.; McInerney, D.; Py, N.; Tomppo, E.O.; Waser, L.T.; Travaglini, D.; McRoberts, R.E. A meta-analysis and review of the literature on the k-Nearest Neighbors technique for forestry applications that use remotely sensed data. Remote Sens. Environ. 2016, 176, 282–294. [Google Scholar] [CrossRef]
- Moser, P.; Vibrans, A.C.; McRoberts, R.E.; Næsset, E.; Gobakken, T.; Chirici, G.; Mura, M.; Marchetti, M. Methods for variable selection in LiDAR-assisted forest inventories. Forestry (Lond) 2017, 90, 112–124. [Google Scholar] [CrossRef]
- Saarela, S.; Andersen, H.-E.; Grafström, A.; Schnell, S.; Gobakken, T.; Næsset, E.; Nelson, R.F.; McRoberts, R.E.; Gregoire, T.G.; Ståhl, G. A new prediction-based variance estimator for two-stage model-assisted surveys of forest resources. Remote Sens. Environ. 2017, 192, 1–11. [Google Scholar] [CrossRef]
- Jarret, P. Guide des sylvicultures: Chênaie atlantique; Office National des Forêts: Paris, France, 2004. [Google Scholar]
- Vidal, C.; Bélouard, T.; Hervé, J.-C.; Robert, N.; Wolsack, J. A New Flexible Forest Inventory in France. In Proceedings of the seventh annual forest inventory and analysis symposium, Portland, OR, USA, 3–6 October 2005. [Google Scholar]
- Rupnik, E.; Daakir, M.; Pierrot Deseilligny, M. MicMac—A free, open-source solution for photogrammetry. Open Geospat. Data Softw. Stand. 2017, 2, 14. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Hagolle, O.; Huc, M.; Villa Pascual, D.; Dedieu, G. A Multi-Temporal and Multi-Spectral Method to Estimate Aerosol Optical Thickness over Land, for the Atmospheric Correction of FormoSat-2, LandSat, VENμS and Sentinel-2 Images. Remote Sens. 2015, 2668–2691. [Google Scholar] [CrossRef]
- Barati, S.; Rayegani, B.; Saati, M.; Sharifi, A.; Nasri, M. Comparison the accuracies of different spectral indices for estimation of vegetation cover fraction in sparse vegetated areas. Egypt. J. Remote Sens. Space Sci. 2011, 14, 49–56. [Google Scholar] [CrossRef] [Green Version]
- USGS Land Surface Reflectance-Derived Spectral Indices. Product Guide, Version 3.6. Available online: https://landsat.usgs.gov/documents/si_product_guide.pdf (accessed on 22 April 2019).
- Baig MHA, Zhang L, Shuai T, Tong Q (2014) Derivation of a tasselled cap transformation based on Landsat 8 at-satellite reflectance. Remote Sens. Lett. 2014, 5, 423–431. [CrossRef]
- Packalén, P.; Temesgen, H.; Maltamo, M. Variable selection strategies for nearest neighbor imputation methods used in remote sensing based forest inventory. Can. J. Remote. Sens. 2012, 38, 557–569. [Google Scholar] [CrossRef]
- Moeur, M.; Stage, A.R. Most Similar Neighbor: An Improved Sampling Inference Procedure for Natural Resource Planning. For. Sci. 1995, 41, 337–359. [Google Scholar] [CrossRef]
- Stage, A.R.; Crookston, N.L. Partitioning Error Components for Accuracy-Assessment of Near-Neighbor Methods of Imputation. For. Sci. 2007, 53, 62–72. [Google Scholar] [CrossRef]
- Crookston, N.L.; Finley, A.O. yaImpute: An R package for k-NN imputation. J. Stat. Softw. 2008, 23, 16. [Google Scholar] [CrossRef]
- Särndal, C.-E.; Swensson, B.; Wretman, J.H. Model Assisted Survey Sampling; Springer Series in Statistics; Springer: New York, NY, USA, 1992; 695p, ISBN 978-0-387-40620-6. [Google Scholar]
- Breidt, F.J.; Opsomer, J.D. Model-Assisted Survey Estimation with Modern Prediction Techniques. Stat. Sci. 2017, 32, 190–205. [Google Scholar] [CrossRef]
- Lehtonen, R.; Särndal, C.-E.; Veijanen, A. Does the model matter? Comparing model-assisted and model-dependent estimators of class frequencies for domains. Stat. Transit. 2005, 7, 649–673. [Google Scholar]
- Särndal, C.-E. Combined inference in survey sampling. Pak. J. Stat. 2011, 27, 359–370. [Google Scholar]
- Tuominen, S.; Pitkänen, T.; Balázs, A.; Kangas, A. Improving Finnish Multi-Source National Forest Inventory by 3D aerial imaging. Silva Fenn. 2017, 51, 7743. [Google Scholar] [CrossRef]
- Lu, D. Aboveground biomass estimation using Landsat TM data in the Brazilian Amazon. Int. J. Remote Sens. 2005, 26, 2509–2525. [Google Scholar] [CrossRef]
- Matasci, G.; Hermosilla, T.; Wulder, M.A.; White, J.C.; Coops, N.C.; Hobart, G.W.; Bolton, D.K.; Tompalski, P.; Bater, C.W. Three decades of forest structural dynamics over Canada’s forested ecosystems using Landsat time-series and lidar plots. Remote Sens. Environ. 2018, 216, 697–714. [Google Scholar] [CrossRef]
- Katila, M.; Tomppo, E. Stratification by ancillary data in multisource forest inventories employing k-nearest-neighbour estimation. Can. J. For. Res. 2002, 32, 1548–1561. [Google Scholar] [CrossRef]
- Wilson, B.T.; Knight, J.F.; McRoberts, R.E. Harmonic regression of Landsat time series for modeling attributes from national forest inventory data. ISPRS J. Photogramm. Remote Sens. 2018, 137, 29–46. [Google Scholar] [CrossRef]
- Tuominen, S.; Balazs, A.; Honkavaara, E.; Pölönen, I.; Saari, H.; Hakala, T.; Viljanen, N. Hyperspectral UAV-imagery and photogrammetric canopy height model in estimating forest stand variables. Silva Fenn. 2017, 51, 7721. [Google Scholar] [CrossRef]
- Véga, C.; Vepakomma, U.; Morel, J.; Bader, J.-L.; Rajashekar, G.; Jha, C.S.; Ferêt, J.; Proisy, C.; Pélissier, R.; Dadhwal,, V.K. Aboveground-Biomass Estimation of a Complex Tropical Forest in India Using Lidar. Remote Sens. 2015, 7, 10607–10625. [Google Scholar] [CrossRef] [Green Version]
- Kangas, A. Sampling rare populations. In Forest Inventory—Methodology and Applications; Kangas, A., Maltamo, M., Eds.; Springer: Berlin, Germany, 2006; pp. 119–139. ISBN 978-1-4020-4381-9. [Google Scholar]
- Hudak, A.T.; Crookston, N.L.; Evans, J.S.; Falkovski, M.J.; Smith, A.M.S.; Gessler, P.E.; Morgan, P. Regression modeling and mapping of coniferous forest basal area and tree density from discrete-return lidar and multispectral satellite data. Can. J. Remote Sens. 2006, 32, 126–138. [Google Scholar] [CrossRef]
- Dash, J.P.; Marshall, H.M.; Rawley, B. Methods for estimating multivariate stand yields and errors using k-NN and aerial laser scanning. Forestry (Lond) 2015, 88, 237–247. [Google Scholar] [CrossRef] [Green Version]
- Strunk, J.; Gould, P.; Packalen, P.; Poudel, K.; Andersen, H.-E.; Temesgen, H. An Examination of Diameter Density Prediction with k-NN and Airborne Lidar. Forests 2017, 8, 444. [Google Scholar] [CrossRef]
- Hou, Z.; Xu, Q.; McRoberts, R.E.; Greenberg, J.A.; Liu, J.; Heiskanen, J.; Pitkänen, S.; Packalen, P. Effects of temporally external auxiliary data on model-based inference. Remote Sens. Environ. 2017, 198, 150–159. [Google Scholar] [CrossRef]
- Gittins, R. Canonical Analysis: A Review with Applications in Ecology; Springer: Berlin/Heidelberg, Germany, 1985; 352p, ISBN 978-3-642-69878-1. [Google Scholar]


| Response Variable | Main Area (N = 775) | Subset Area (N = 346) | ||
|---|---|---|---|---|
| Mean | Variance | Mean | Variance | |
| 1: Total volume (m3/ha) | 152.14 | 13.03 | 143.64 | 28.27 |
| 2: Stand basal area (m2/ha) | 20.14 | 0.15 | 19.49 | 0.34 |
| 3: Stand density (n/ha) | 686.19 | 402.37 | 687.23 | 952.03 |
| 4: Quadratic mean diameter (cm) | 23.50 | 0.18 | 22.82 | 0.35 |
| 5: Production volume (m3/ha/yr) | 5.45 | 0.016 | 5.41 | 0.04 |
| 6: Conifers volume (m3/ha) | 46.06 | 10.13 | 50.22 | 28.40 |
| 7: Broadleaved volume (m3/ha) | 106.08 | 11.09 | 93.41 | 18.88 |
| 8: Oak volume (m3/ha) | 72.15 | 8.81 | 61.69 | 14.79 |
| 9: Other broadleaved volume (m3/ha) | 33.93 | 4.07 | 31.72 | 7.48 |
| 10: Scots pine volume (m3/ha) | 22.22 | 5.91 | 23.61 | 15.81 |
| 11: Other conifers volume (m3/ha) | 23.85 | 5.58 | 26.62 | 16.24 |
| Euclidean | CCA | |||||
|---|---|---|---|---|---|---|
| Auxiliary Variable Combination | Domain | No. of Variables | k | RMSD | k | RMSD |
| Landsat | Main | 15 | 6 | 1.00 (0.84;1.08) | 6 | 0.99 (0.83;1.07) |
| Landsat & Forest types | Main | 16 | 6 | 0.98 (0.73;1.09) | 6 | 0.97 (0.71;1.07) |
| 3D metrics | Main | 24 | 6 | 0.91 (0.72;1.04) | 6 | 0.91 (0.71;1.03) |
| 3D metrics and Forest types | Main | 25 | 5 | 0.85 (0.69;0.98) | 5 | 0.84 (0.67,1.00) |
| 3D metrics and Landsat | Main | 39 | 8 | 0.86 (0.68;1.00) | 5 | 0.86 (0.71;0.99) |
| All | Main | 40 | 5 | 0.84 (0.67;1.00) | 5 | 0.84 (0.64;0.97) |
| All | Subset | 41 | 4 | 0.87 (0.66;1.02) | 5 | 0.86 (0.66;1.01) |
| All and change | Subset | 45 | 5 | 0.85 (0.65;1.00) | 6 | 0.85 (0.64;1.01) |
| Landsat | Landsat and Forest Types | 3D Metrics | |||||||
| Forest Attributes 1 | Mean | SE | RE | Mean | SE | RE | Mean | SE | RE |
| 1 | 155.02 | 3.63 | 0.99 | 154.82 | 3.59 | 1.01 | 153.83 | 2.62 | 1.90 |
| 2 | 20.47 | 0.13 | 0.98 | 20.42 | 0.39 | 1.00 | 20.10 | 0.33 | 1.39 |
| 3 | 692.67 | 21.27 | 0.89 | 690.32 | 21.48 | 0.87 | 686.65 | 18.27 | 1.21 |
| 4 | 23.55 | 0.46 | 0.85 | 23.55 | 0.46 | 0.84 | 23.59 | 0.38 | 1.23 |
| 5 | 5.57 | 0.13 | 0.96 | 5.57 | 0.13 | 0.98 | 5.45 | 0.12 | 1.09 |
| 6 | 48.92 | 2.68 | 1.41 | 49.61 | 2.35 | 1.83 | 45.74 | 3.13 | 1.04 |
| 7 | 106.09 | 3.15 | 1.12 | 105.22 | 3.07 | 1.18 | 108.09 | 2.70 | 1.52 |
| 8 | 72.04 | 2.84 | 1.09 | 71.07 | 2.83 | 1.10 | 72.65 | 2.55 | 1.35 |
| 9 | 34.06 | 2.14 | 0.89 | 34.15 | 2.13 | 0.90 | 35.43 | 2.04 | 0.97 |
| 10 | 23.52 | 2.39 | 1.04 | 25.08 | 2.27 | 1.14 | 21.84 | 2.49 | 0.95 |
| 11 | 25.40 | 2.38 | 0.98 | 24.52 | 2.33 | 1.03 | 24.21 | 2.46 | 0.93 |
| 3D Metrics and Forest Types | Landsat and 3D Metrics | All | |||||||
| Forest Attributes 1 | Mean | SE | RE | Mean | SE | RE | Mean | SE | RE |
| 1 | 155.28 | 2.55 | 2.00 | 153.60 | 2.48 | 2.12 | 153.24 | 2.44 | 2.18 |
| 2 | 20.33 | 0.32 | 1.43 | 20.00 | 0.31 | 1.54 | 19.98 | 0.31 | 1.56 |
| 3 | 691.73 | 18.37 | 1.19 | 673.84 | 19.07 | 1.11 | 678.00 | 19.17 | 1.10 |
| 4 | 23.54 | 0.39 | 1.20 | 23.64 | 0.38 | 1.22 | 23.48 | 0.38 | 1.23 |
| 5 | 5.49 | 0.12 | 1.16 | 5.45 | 0.12 | 1.18 | 5.47 | 0.12 | 1.19 |
| 6 | 47.66 | 2.19 | 2.10 | 48.69 | 2.44 | 1.70 | 47.91 | 2.18 | 2.13 |
| 7 | 107.62 | 2.31 | 2.07 | 104.91 | 2.39 | 1.93 | 105.33 | 2.29 | 2.11 |
| 8 | 72.12 | 2.41 | 1.52 | 72.20 | 2.33 | 1.63 | 72.29 | 2.28 | 1.69 |
| 9 | 35.50 | 1.99 | 1.03 | 32.71 | 2.02 | 0.99 | 33.05 | 2.02 | 1.00 |
| 10 | 22.72 | 2.15 | 1.28 | 24.40 | 2.27 | 1.14 | 23.68 | 2.15 | 1.28 |
| 11 | 24.94 | 2.32 | 1.04 | 24.28 | 2.36 | 1.01 | 24.23 | 2.27 | 1.08 |
| Landsat | Landsat and Forest types | 3D metrics | |||||||
| Forest attributes 1 | Mean | SE | RE | Mean | SE | RE | Mean | SE | RE |
| 1 | 152.67 | 3.65 | 0.97 | 153.85 | 3.56 | 1.02 | 154.83 | 2.58 | 1.96 |
| 2 | 20.23 | 0.39 | 0.97 | 20.32 | 0.39 | 1.00 | 20.23 | 0.33 | 1.38 |
| 3 | 701.32 | 21.31 | 0.88 | 697.03 | 21.65 | 0.86 | 683.02 | 18.77 | 1.14 |
| 4 | 23.19 | 0.45 | 0.87 | 23.49 | 0.45 | 0.88 | 23.73 | 0.38 | 1.21 |
| 5 | 5.53 | 0.13 | 1.00 | 5.55 | 0.13 | 1.01 | 5.44 | 0.13 | 1.05 |
| 6 | 47.27 | 2.67 | 1.42 | 48.73 | 2.26 | 1.97 | 49.10 | 3.08 | 1.06 |
| 7 | 105.40 | 3.22 | 1.07 | 105.11 | 3.07 | 1.17 | 105.73 | 2.68 | 1.54 |
| 8 | 72.04 | 2.84 | 1.08 | 72.04 | 2.82 | 1.11 | 72.02 | 2.48 | 1.42 |
| 9 | 33.35 | 2.15 | 0.88 | 33.07 | 2.13 | 0.90 | 34.70 | 2.03 | 0.99 |
| 10 | 22.23 | 2.31 | 1.11 | 23.18 | 2.24 | 1.18 | 24.11 | 2.51 | 0.94 |
| 11 | 25.04 | 2.38 | 0.99 | 25.55 | 2.22 | 1.13 | 24.98 | 2.38 | 0.98 |
| 3D metrics and Forest types | Landsat and 3D metrics | All | |||||||
| Forest attributes 1 | Mean | SE | RE | Mean | SE | RE | Mean | SE | RE |
| 1 | 154.79 | 2.53 | 2.04 | 153.43 | 2.56 | 1.98 | 154.95 | 2.53 | 2.03 |
| 2 | 20.21 | 0.32 | 1.44 | 20.03 | 0.33 | 1.41 | 20.24 | 0.32 | 1.43 |
| 3 | 679.82 | 18.91 | 1.12 | 676.87 | 19.50 | 1.05 | 685.17 | 19.43 | 1.07 |
| 4 | 23.74 | 0.40 | 1.15 | 23.76 | 0.38 | 1.21 | 23.77 | 0.38 | 1.21 |
| 5 | 5.44 | 0.12 | 1.12 | 5.43 | 0.12 | 1.16 | 5.44 | 0.11 | 1.21 |
| 6 | 48.95 | 2.14 | 2.21 | 50.34 | 2.38 | 1.78 | 50.04 | 2.07 | 2.37 |
| 7 | 105.84 | 2.27 | 2.15 | 103.10 | 2.50 | 1.78 | 104.90 | 3.39 | 1.95 |
| 8 | 71.25 | 2.31 | 1.65 | 68.77 | 2.41 | 1.52 | 70.61 | 2.38 | 1.56 |
| 9 | 35.59 | 2.01 | 1.00 | 34.33 | 1.99 | 1.01 | 34.30 | 1.95 | 1.06 |
| 10 | 23.78 | 2.13 | 1.31 | 25.43 | 2.15 | 1.27 | 24.92 | 2.10 | 1.34 |
| 11 | 25.17 | 2.19 | 1.16 | 24.90 | 2.21 | 1.14 | 25.13 | 2.19 | 1.16 |
| Euclidean | CCA | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| All | All and Change | All | All and Change | |||||||||
| Forest Attributes 1 | Mean | SE | RE | Mean | SE | RE | Mean | SE | RE | Mean | SE | RE |
| 1 | 142.60 | 3.62 | 2.15 | 144.0 | 3.57 | 2.21 | 146.15 | 3.78 | 1.97 | 146.27 | 3.79 | 1.97 |
| 2 | 19.23 | 0.48 | 1.50 | 19.36 | 0.47 | 1.57 | 19.63 | 0.49 | 1.41 | 19.59 | 0.50 | 1.39 |
| 3 | 682.13 | 30.63 | 1.01 | 680.01 | 29.47 | 1.10 | 693.18 | 31.19 | 0.98 | 683.96 | 31.22 | 0.98 |
| 4 | 22.80 | 0.56 | 1.11 | 22.88 | 0.55 | 1.16 | 22.89 | 0.56 | 1.12 | 22.74 | 0.54 | 1.21 |
| 5 | 5.33 | 0.20 | 1.07 | 5.43 | 0.18 | 1.24 | 5.52 | 0.19 | 1.09 | 5.52 | 0.18 | 1.24 |
| 6 | 51.52 | 3.55 | 2.25 | 54.27 | 3.49 | 2.33 | 54.37 | 3.57 | 2.23 | 54.81 | 3.44 | 2.40 |
| 7 | 91.07 | 3.27 | 1.77 | 89.72 | 3.24 | 1.80 | 91.78 | 3.12 | 1.94 | 91.46 | 3.14 | 1.91 |
| 8 | 59.65 | 3.18 | 1.46 | 60.18 | 3.10 | 1.54 | 60.89 | 3.12 | 1.52 | 60.87 | 3.05 | 1.59 |
| 9 | 31.42 | 2.80 | 0.95 | 29.54 | 2.76 | 0.98 | 30.90 | 2.72 | 1.01 | 30.59 | 268 | 1.04 |
| 10 | 26.18 | 3.74 | 1.13 | 28.20 | 3.73 | 1.13 | 26.53 | 3.74 | 1.13 | 25.52 | 3.69 | 1.16 |
| 11 | 25.34 | 3.82 | 1.11 | 26.08 | 3.92 | 1.05 | 27.84 | 3.39 | 1.42 | 29.29 | 3.45 | 1.36 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Irulappa-Pillai-Vijayakumar, D.B.; Renaud, J.-P.; Morneau, F.; McRoberts, R.E.; Vega, C. Increasing Precision for French Forest Inventory Estimates using the k-NN Technique with Optical and Photogrammetric Data and Model-Assisted Estimators. Remote Sens. 2019, 11, 991. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11080991
Irulappa-Pillai-Vijayakumar DB, Renaud J-P, Morneau F, McRoberts RE, Vega C. Increasing Precision for French Forest Inventory Estimates using the k-NN Technique with Optical and Photogrammetric Data and Model-Assisted Estimators. Remote Sensing. 2019; 11(8):991. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11080991
Chicago/Turabian StyleIrulappa-Pillai-Vijayakumar, Dinesh Babu, Jean-Pierre Renaud, François Morneau, Ronald E. McRoberts, and Cédric Vega. 2019. "Increasing Precision for French Forest Inventory Estimates using the k-NN Technique with Optical and Photogrammetric Data and Model-Assisted Estimators" Remote Sensing 11, no. 8: 991. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11080991