Fuzzy Superpixels Based Semi-Supervised Similarity-Constrained CNN for PolSAR Image Classification


Abstract
:1. Introduction
- In FS-SCNN, the fuzzy superpixels method is used to suppress the generation of mixed superpixels, considering that mixed superpixels can cause misclassification.
- Superpixels considers the spatial information of images, which reduces the impact of speckle noises on algorithm performance. Undetermined pixels helps to keep the tiny detail represented by pixels.
- The SCNN model uses a loss function with a similarity-constrained term to strengthen that the distance of the features of data in the same class are closer, and those in different classes are far from each other. The SCNN model thus provides a more accurate label propagation.
2. The FS-SCNN Method
2.1. Superpixels Segmentation
2.2. Fuzzy Superpixels-Based Samples Selection
2.3. Similarity-Constrained Convolutional Neural Network
2.3.1. Feature Representation of PolSAR images
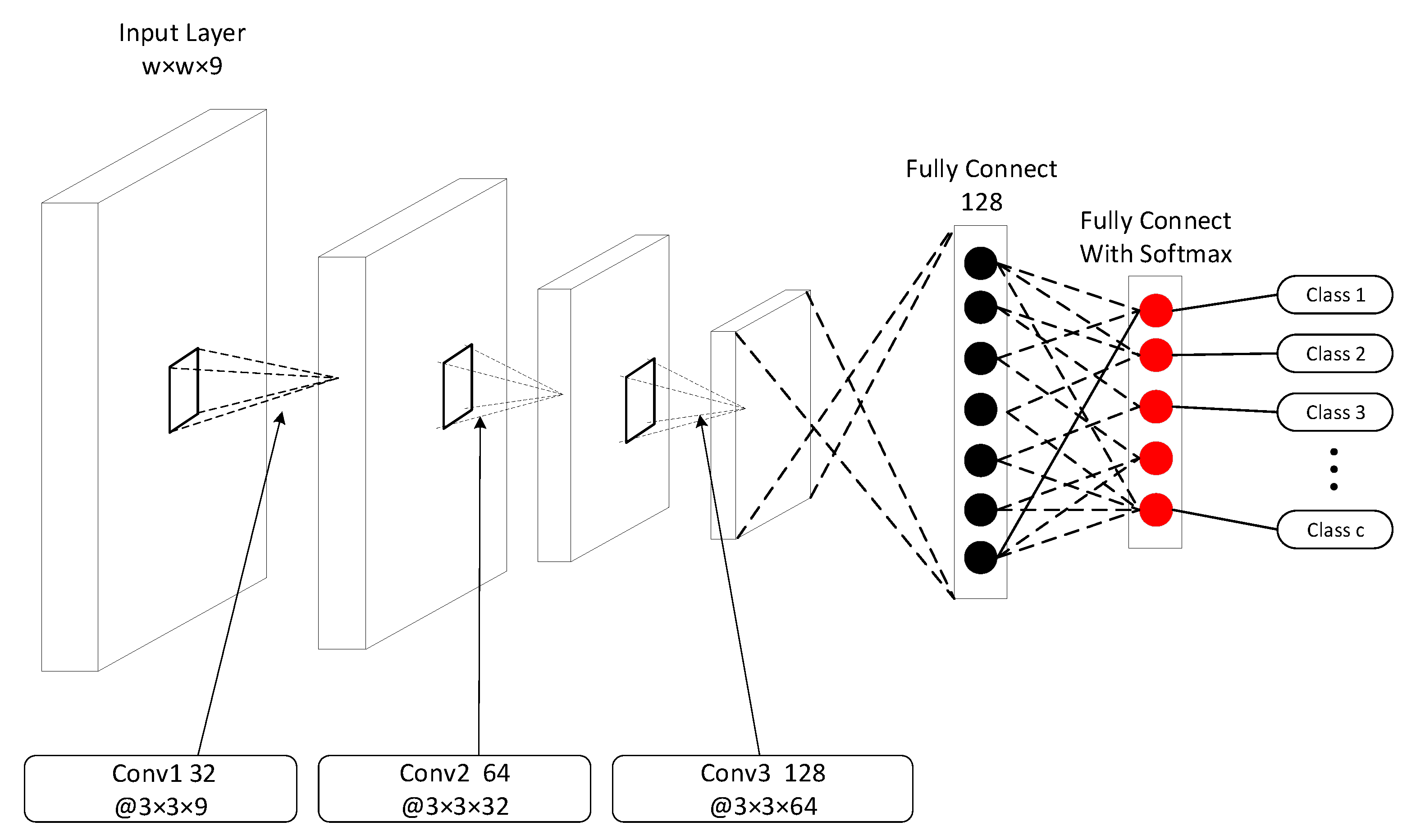
2.3.2. Network Architecture
2.4. Label Propagation
2.5. Procedure of the FS-SCNN Algorithm
| Algorithm 1 FS-SCNN |
Input: PolSAR image, the initialization iteration , the number of iterations Output: Trained classification model
|
3. Experiments
3.1. Data Sets and Experiments Setting
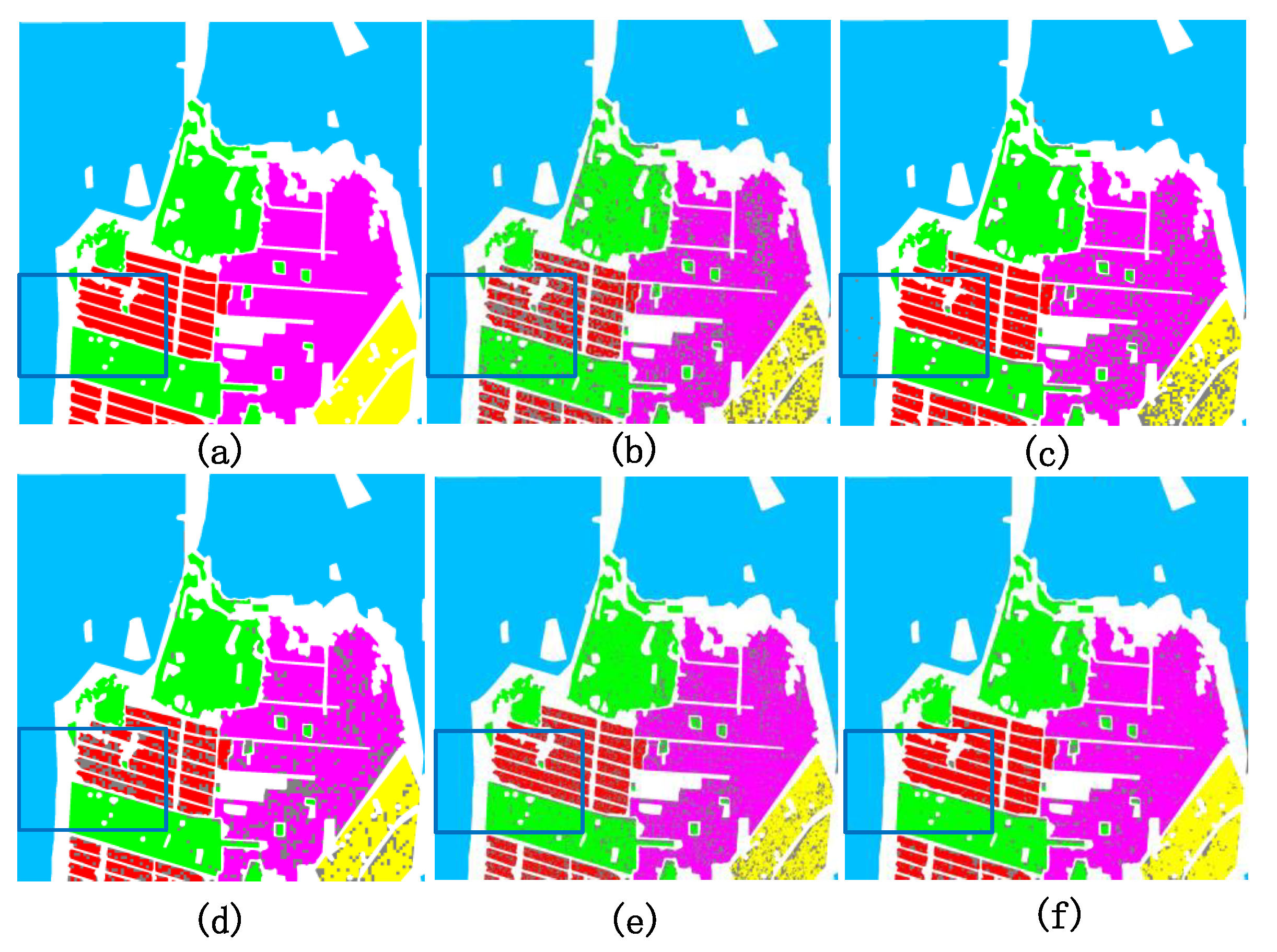
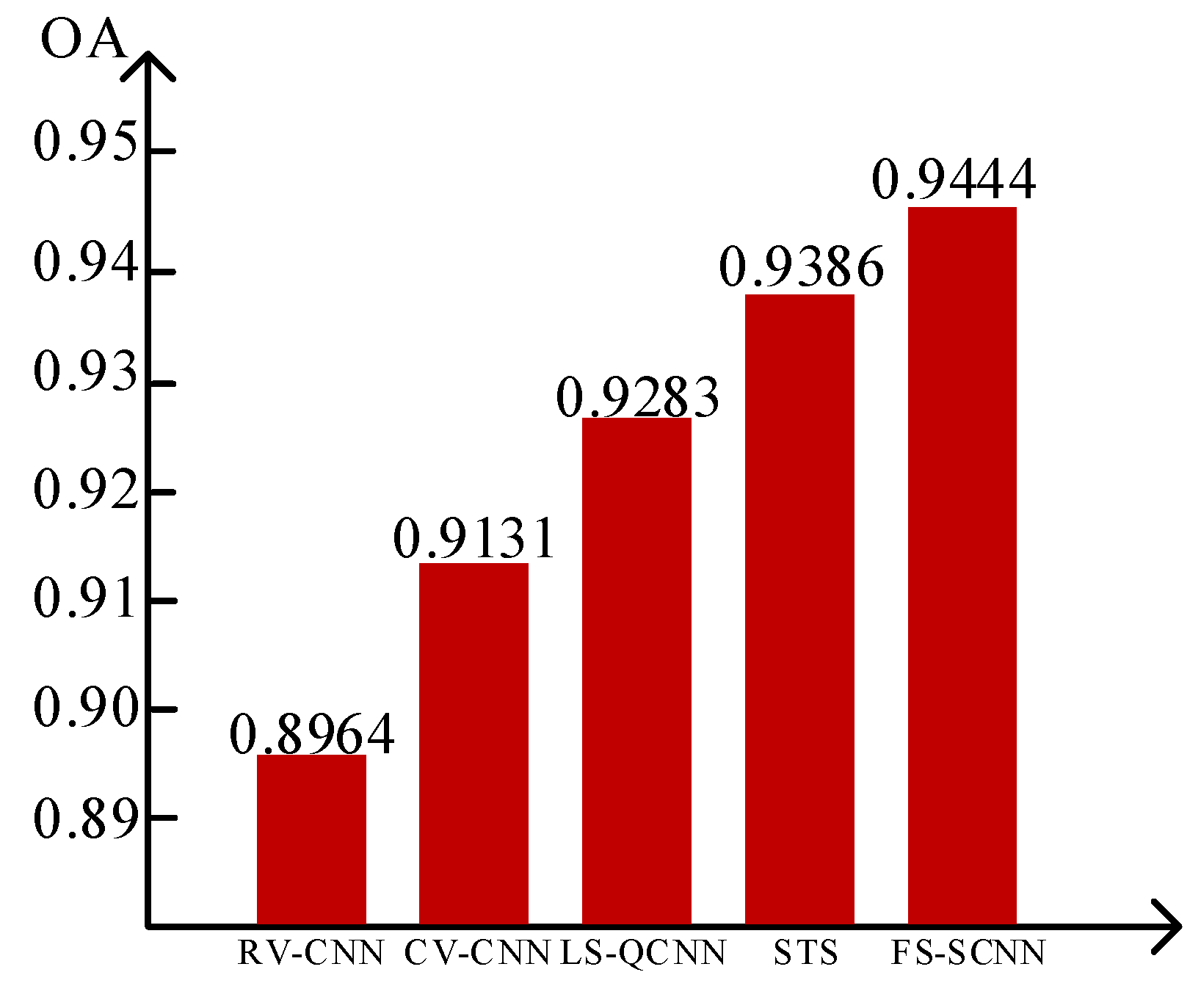
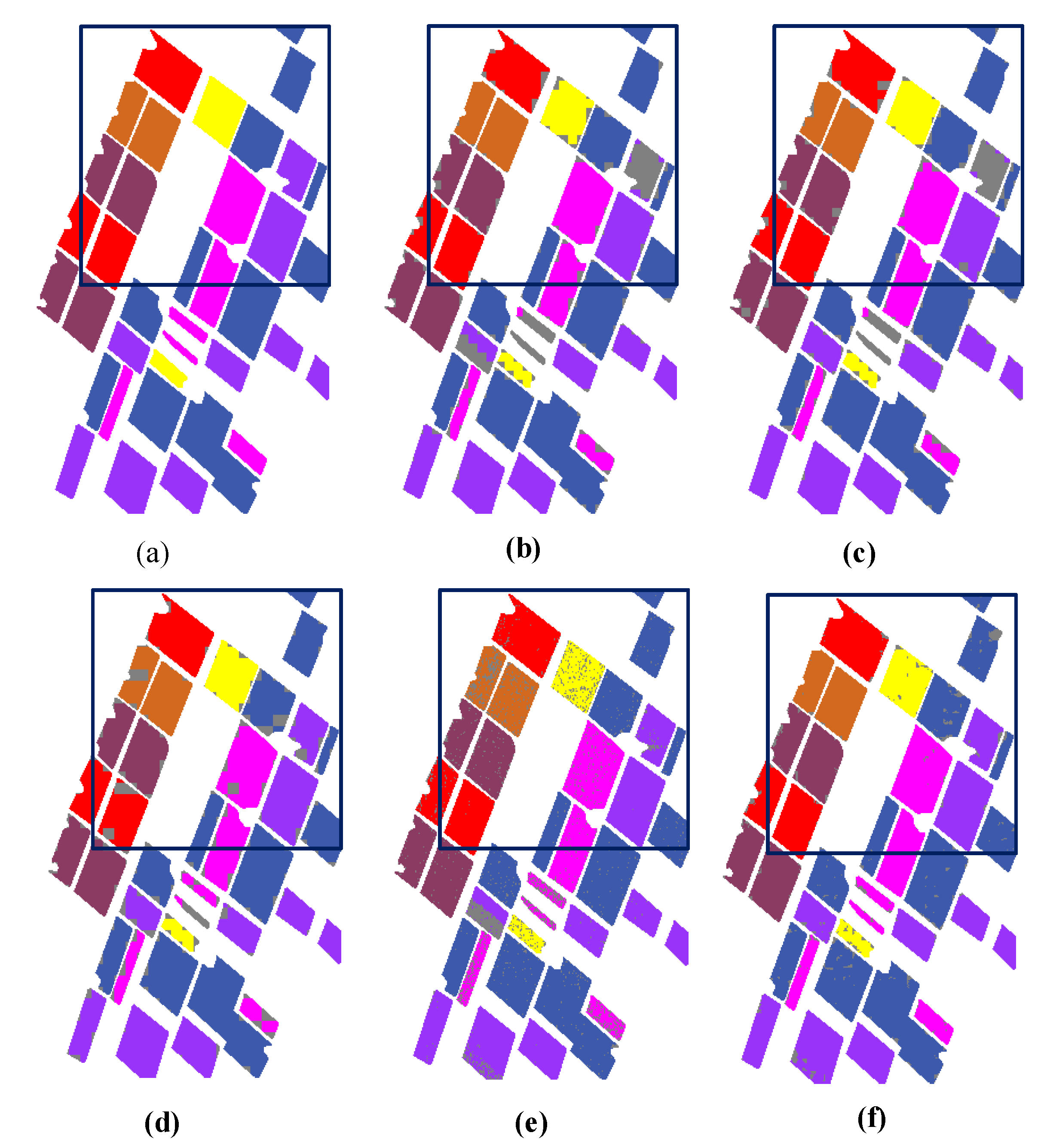
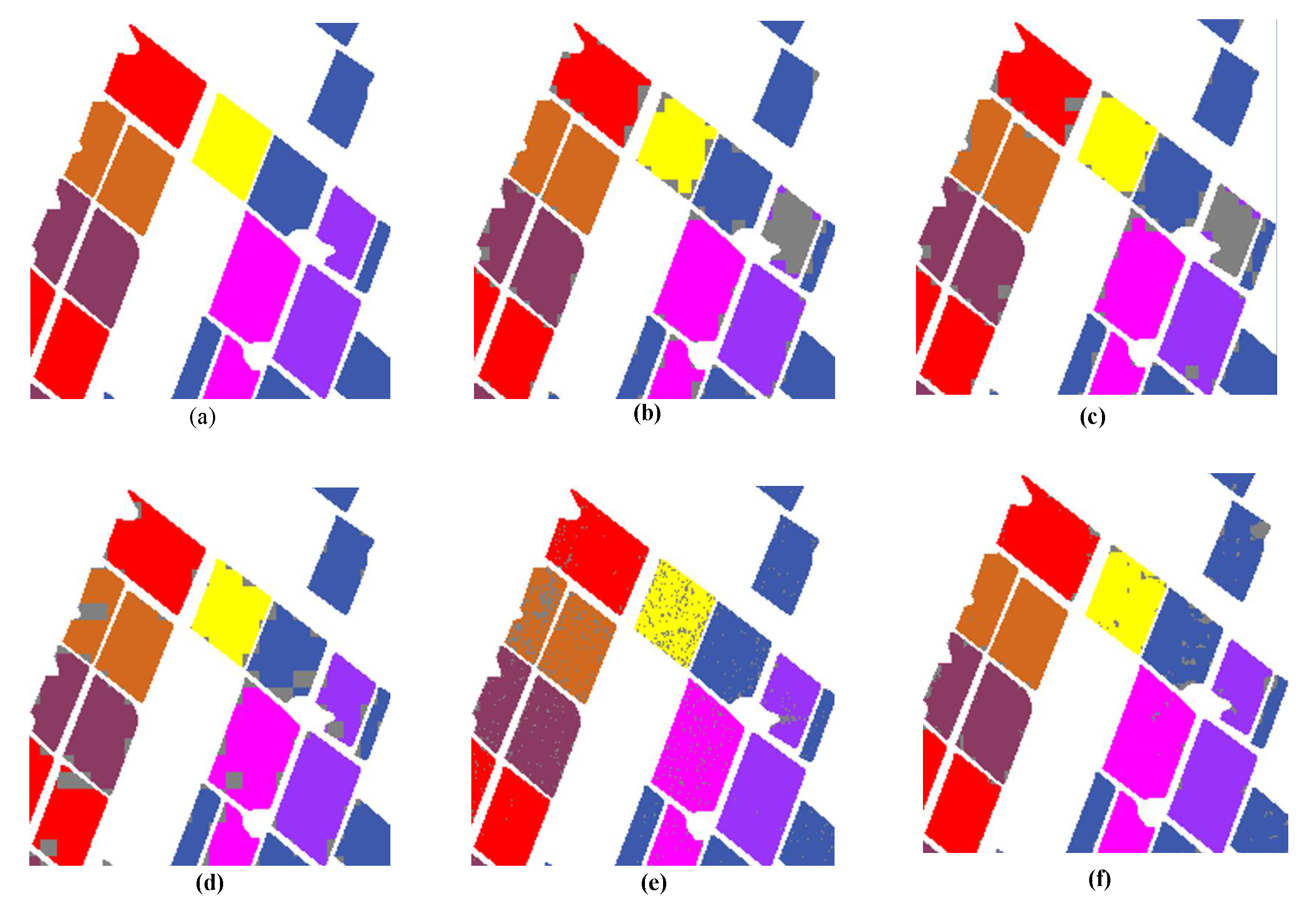
3.2. Experiments on San Francisco Data
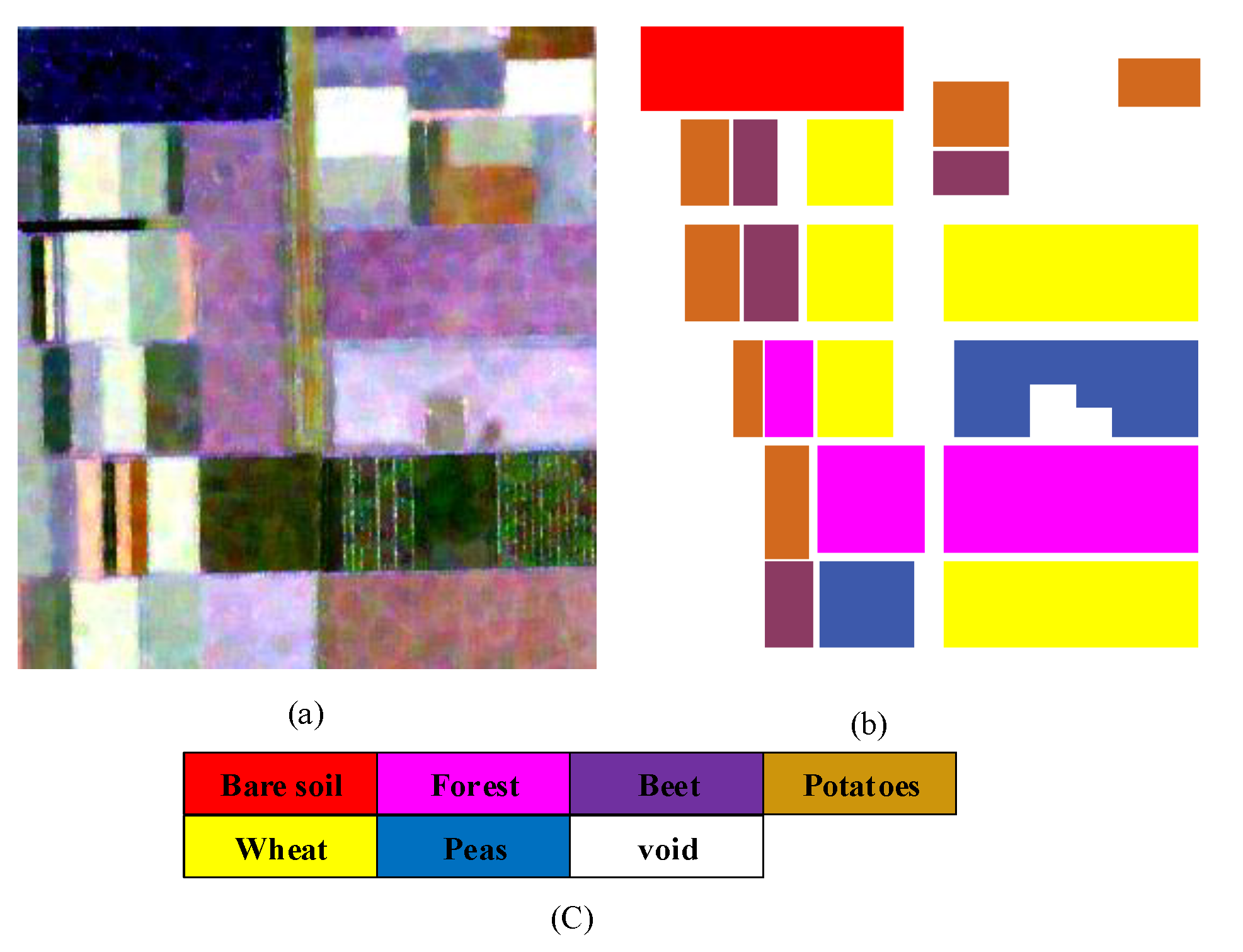
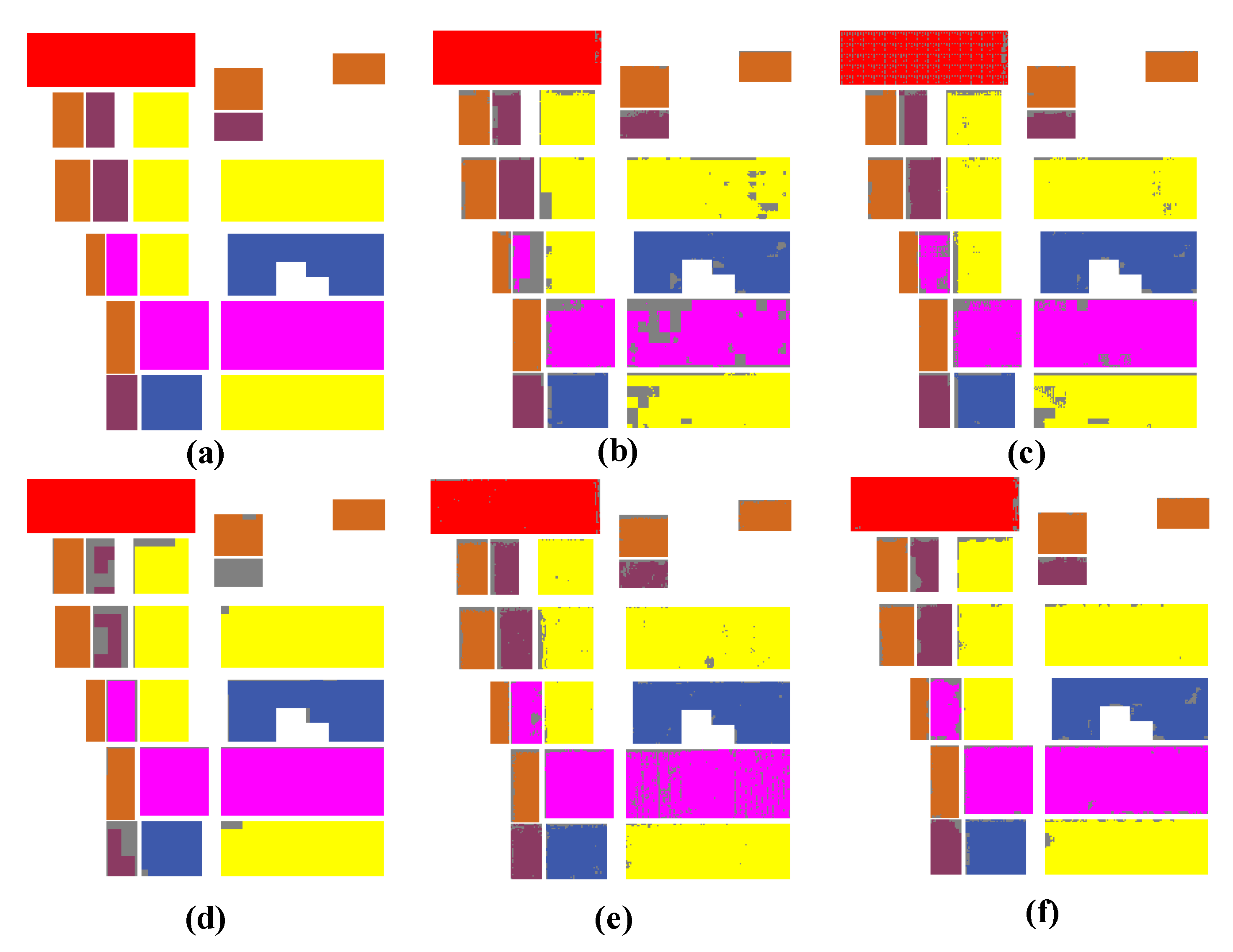
3.3. Experiments on Flevoland Data
3.4. Experiments on Flevoland1991 Data
4. Discussion
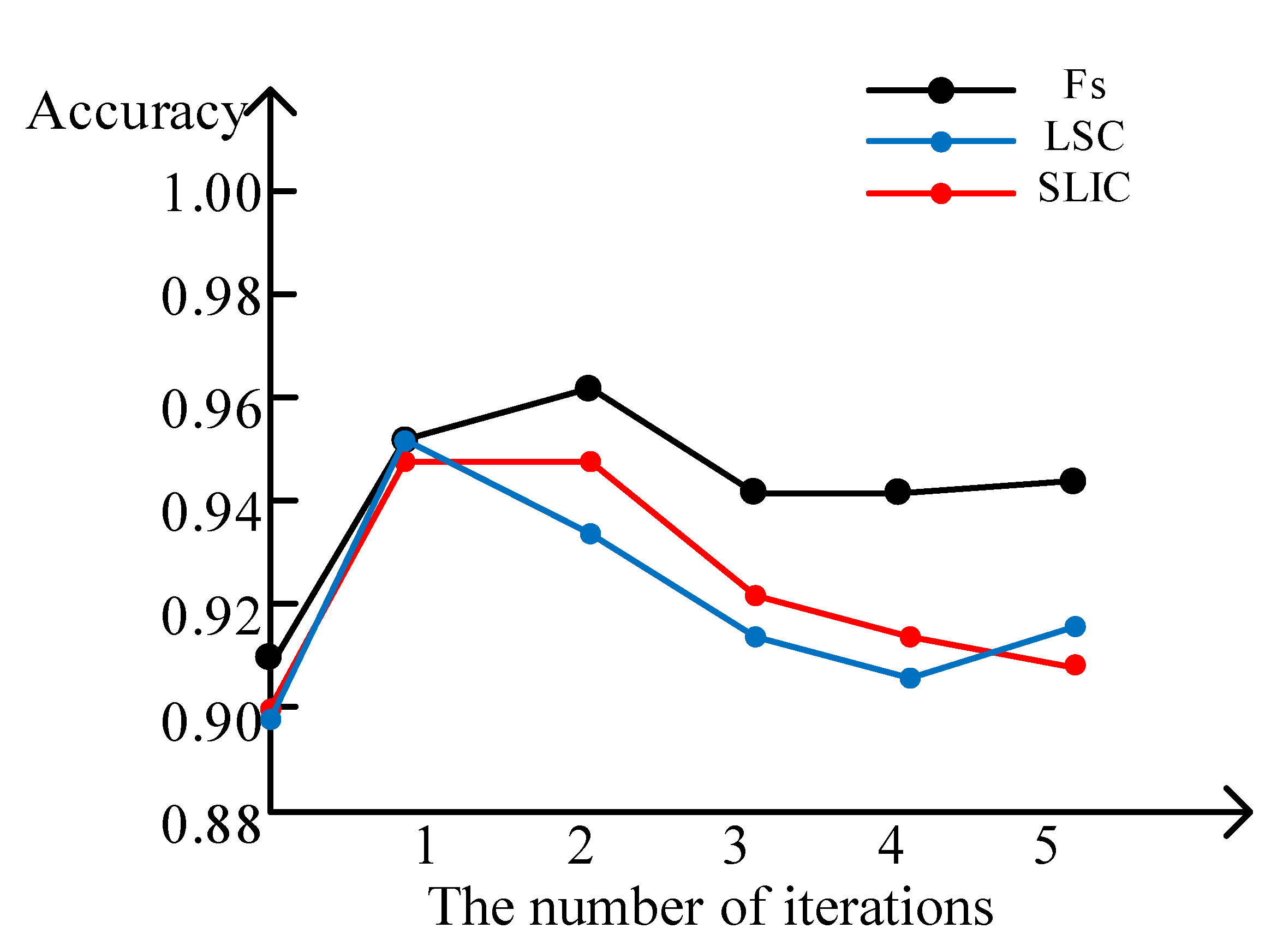
- The superiority of fuzzy superpixels. Superpixels generation techniques can be used to extend the labeled sample. That is, given the label of any pixel in a superpixel, all pixels in the superpixel will be labeled. However, there are mixed superpixels in practical applications. Figure 14 indicates that Fs is better than other superpixels algorithms. In the preprocessing step, the extended labeled samples by superpixels should be as accurate as possible. Fs divides an image into superpixels and undetermined pixels, which strengthens the correctness of the extended labeled samples.
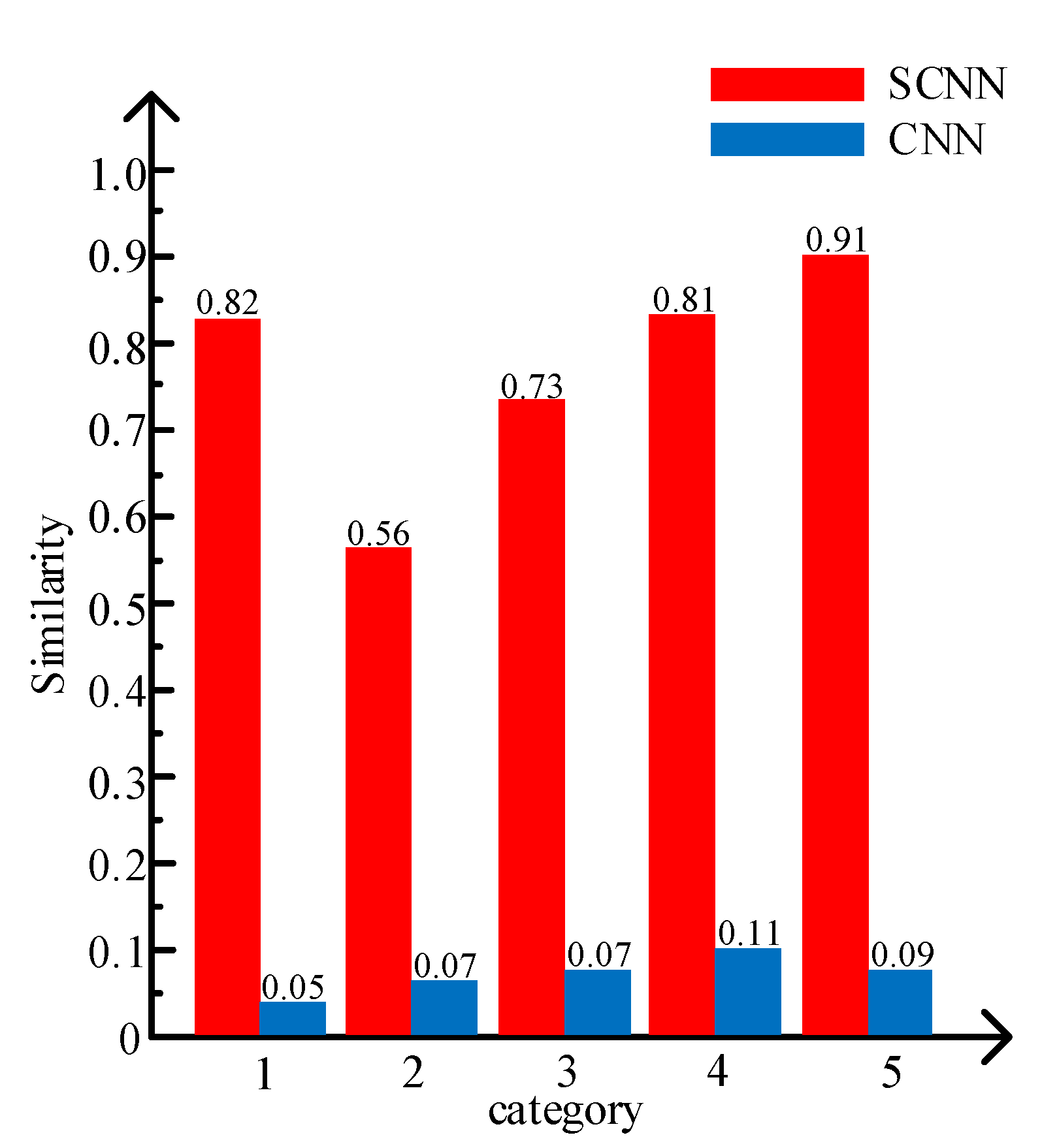
- The validity of the similarity-constrained term. Figure 7 shows that the features extracted from samples with the same category by SCNN are more similar than those extracted by CNN due to the similarity-constrained term, which strengthens the similarity between features of the same category.
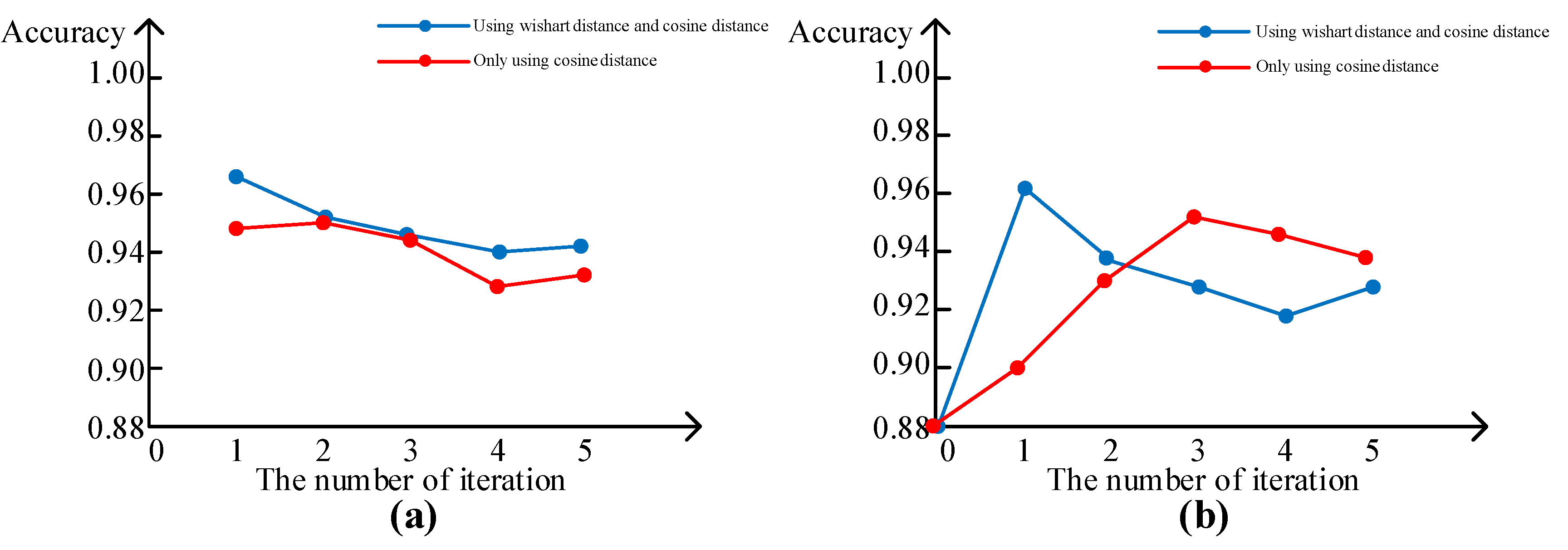
- The different distance measurement criteria. There are two steps in the label propagation. Step 1, cosine distance is used to assign pseudo labels to unlabeled samples. Step 2, Wishart distance is adopted to confirm the pseudo labels obtained in Step 1. Figure 6 shows that using both cosine distance and Wishart distance contributes to better PolSAR image classification.
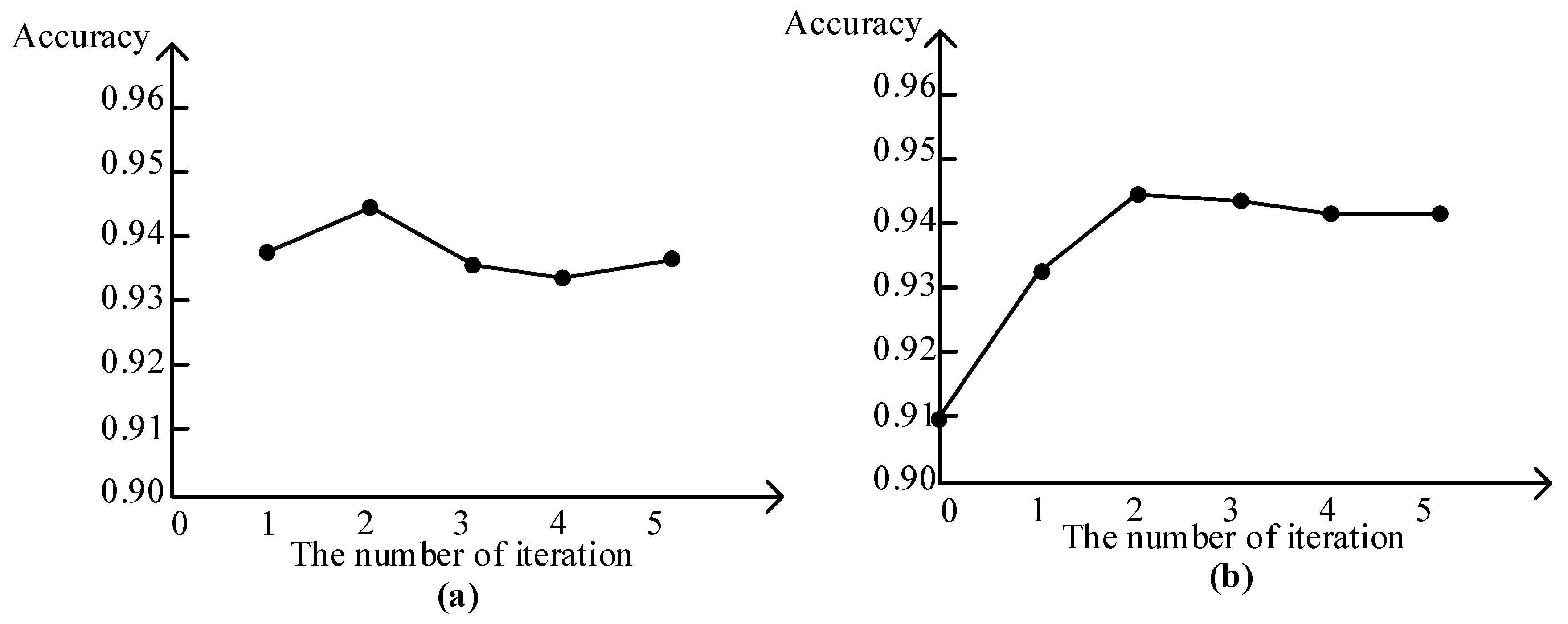
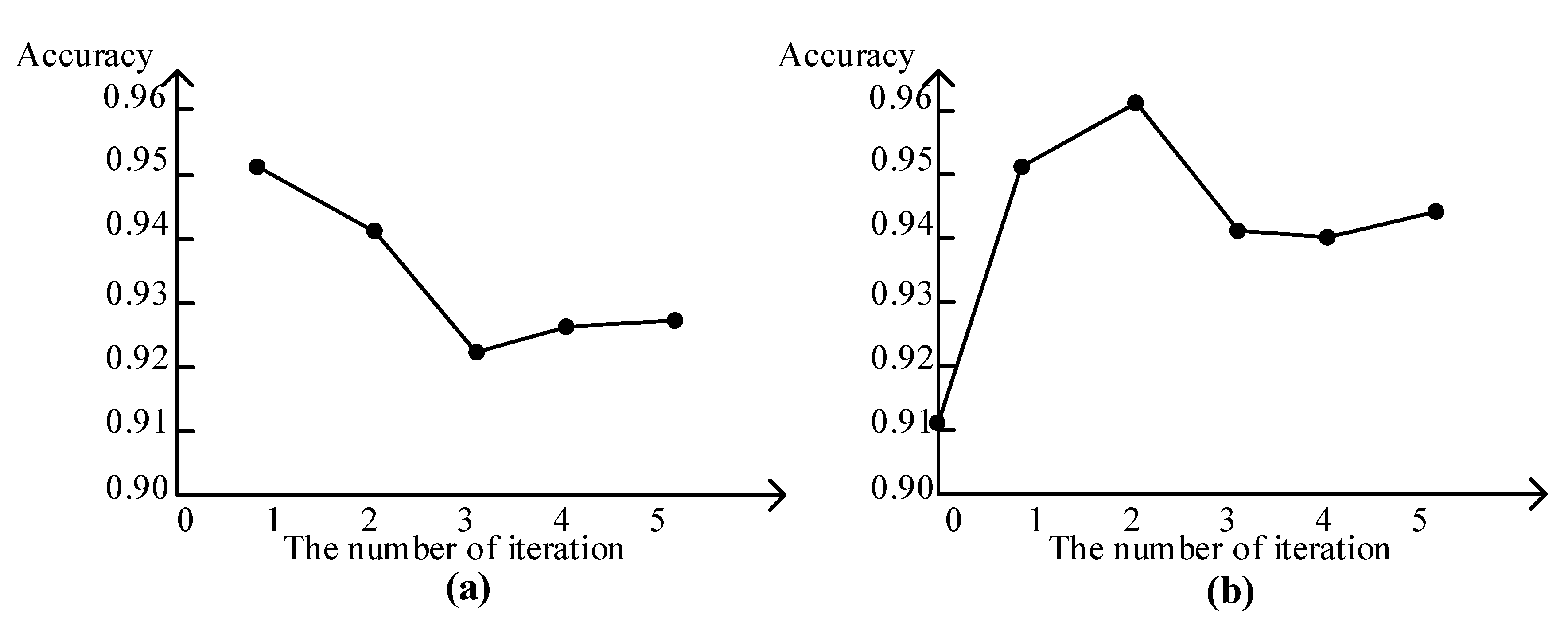
- The role of label propagation. As the iterations increases of Algorithm 1, the accuracy of the pseudo labels slowly decreases and then stabilizes. With an increased number of pseudo labels, the classification accuracy increases first, then decreases slowly after reaching the highest value, and finally stabilizes near a certain value. It demonstrates that the added of pseudo labels can improve the classification accuracy of the network model.
- The parameter S. Table 4 shows that the accuracy changes with parameter S, from which we can see that the value of S corresponding to the highest accuracy is different for different data. The best result for each dataset is in bold. In our experiments, to achieve better classification performance, we set S to 0.1, 0.5 and 0.3 for San Francisco, Flevoland and Flevoland1991 data, respectively.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Deng, L.; Yan, Y.; Sun, C. Use of sub-aperture decomposition for supervised PolSAR classification in urban area. Remote Sens. 2015, 7, 1380–1396. [Google Scholar] [CrossRef] [Green Version]
- Ji, Y.; Sumantyo, S.; Tetuko, J.; Chua, M.Y.; Waqar, M.M. Earthquake/tsunami damage assessment for urban areas using post-event PolSAR data. Remote Sens. 2018, 10, 1088. [Google Scholar] [CrossRef] [Green Version]
- Mascolo, L.; Lopez-Sanchez, J.M.; Vicente-Guijalba, F.; Nunziata, F.; Migliaccio, M.; Mazzarella, G. A complete procedure for crop phenology estimation with PolSAR data based on the complex Wishart classifier. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6505–6515. [Google Scholar] [CrossRef] [Green Version]
- Hajnsek, I.; Jagdhuber, T.; Schon, H.; Papathanassiou, K.P. Potential of estimating soil moisture under vegetation cover by means of PolSAR. IEEE Trans. Geosci. Remote Sens. 2009, 47, 442–454. [Google Scholar] [CrossRef] [Green Version]
- Safari, K.; Prasad, S.; Labate, D. A Multiscale Deep Learning Approach for High-Resolution Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Wu, X.; Sahoo, D.; Hoi, S.C. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.; Wang, Y. Classification of PolSAR Image Using Neural Nonlocal Stacked Sparse Autoencoders with Virtual Adversarial Regularization. Remote Sens. 2019, 11, 1038. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Gou, S.; Wang, X.; Li, X.; Jiao, L. Classification of PolSAR images using multilayer autoencoders and a self-paced learning approach. Remote Sens. 2018, 10, 110. [Google Scholar] [CrossRef] [Green Version]
- Bi, H.; Sun, J.; Xu, Z. A graph-based semisupervised deep learning model for PolSAR image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2116–2132. [Google Scholar] [CrossRef]
- Li, Y.; Xing, R.; Jiao, L.; Chen, Y.; Chai, Y.; Marturi, N.; Shang, R. Semi-Supervised PolSAR Image Classification Based on Self-Training and Superpixels. Remote Sens. 2019, 11, 1933. [Google Scholar] [CrossRef] [Green Version]
- Xie, W.; Ma, G.; Zhao, F.; Liu, H.; Zhang, L. PolSAR image classification via a novel semi-supervised recurrent complex-valued convolution neural network. Neurocomputing 2020, 388, 255–268. [Google Scholar] [CrossRef]
- Sun, Q.; Li, X.; Li, L.; Liu, X.; Liu, F.; Jiao, L. Semi-Supervised Complex-Valued GAN for Polarimetric SAR Image Classification. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3245–3248. [Google Scholar]
- Hou, B.; Guan, J.; Wu, Q.; Jiao, L. Semisupervised Classification of PolSAR Image Incorporating Labels’ Semantic Priors. IEEE Geosci. Remote Sens. Lett. 2019, 1–5. [Google Scholar] [CrossRef]
- Geng, J.; Ma, X.; Fan, J.; Wang, H. Semisupervised classification of polarimetric SAR image via superpixel restrained deep neural network. IEEE Geosci. Remote Sens. Lett. 2017, 15, 122–126. [Google Scholar] [CrossRef]
- Guo, Y.; Jiao, L.; Wang, S.; Wang, S.; Liu, F.; Hua, W. Fuzzy superpixels for polarimetric SAR images classification. IEEE Trans. Fuzzy Syst. 2018, 26, 2846–2860. [Google Scholar] [CrossRef]
- Oliver, A.; Odena, A.; Raffel, C.A.; Cubuk, E.D.; Goodfellow, I. Realistic evaluation of deep semi-supervised learning algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–8 December 2018; pp. 3235–3246. [Google Scholar]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Haeusser, P.; Mordvintsev, A.; Cremers, D. Learning by Association–A Versatile Semi-Supervised Training Method for Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 89–98. [Google Scholar]
- Ren, X.; Malik, J. Learning a classification model for segmentation. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; p. 10. [Google Scholar]
- Wang, W.; Xiang, D.; Ban, Y.; Zhang, J.; Wan, J. Superpixel-based segmentation of polarimetric SAR images through two-stage merging. Remote Sens. 2019, 11, 402. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Wang, H.; Xu, F.; Jin, Y.Q. Complex-valued convolutional neural network and its application in polarimetric SAR image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7177–7188. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhou, Y.; Wang, H.; Xu, F.; Jin, Y.Q. Polarimetric SAR image classification using deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1935–1939. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pintelas, E.; Pintelas, P. A CNN-LSTM model for gold price time-series forecasting. Neural Comput. Appl. 2020, 1–10. Available online: https://0-link-springer-com.brum.beds.ac.uk/article/10.1007%2Fs00521-020-04867-x (accessed on 26 April 2020).
- Luo, P.; Ren, J.; Peng, Z.; Zhang, R.; Li, J. Differentiable learning-to-normalize via switchable normalization. arXiv 2018, arXiv:1806.10779. [Google Scholar]
- Zhang, Y.; Zou, H.; Luo, T.; Qin, X.; Zhou, S.; Ji, K. A fast superpixel segmentation algorithm for PolSAR images based on edge refinement and revised Wishart distance. Sensors 2016, 16, 1687. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, X.; Xia, J.; Tan, X.; Zhou, X.; Wang, T. PolSAR Image Classification via Learned Superpixels and QCNN Integrating Color Features. Remote Sens. 2019, 11, 1831. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, J.; Li, Z.; Huang, B. Linear spectral clustering superpixel. IEEE Trans. Image Process. 2017, 26, 3317–3330. [Google Scholar] [CrossRef]
- Yu, G.; Zhang, G.; Yu, Z.; Domeniconi, C.; You, J.; Han, G. Semi-supervised ensemble classification in subspaces. Appl. Soft. Comput. 2012, 12, 1511–1522. [Google Scholar] [CrossRef]
- Wang, S.; Yin, Y.; Cao, G.; Wei, B.; Zheng, Y.; Yang, G. Hierarchical retinal blood vessel segmentation based on feature and ensemble learning. Neurocomputing 2015, 149, 708–717. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Num. of the Initially Labeled Pixels Pixels | Num. of the Extended Labeled Pixels | Num. of Labeled Pixels by Label Propagation (Iteration 1) | Num. of Labeled Pixels by Label Propagation (Iteration 2) | Num. of Labeled Pixels by Label Propagation (Iteration 3) | |
|---|---|---|---|---|---|
| Water | 50 | 6414 | 12,079 | 648 | 1375 |
| Veg | 50 | 6909 | 14,348 | 12,157 | 1175 |
| LD Urban | 50 | 4294 | 15,223 | 5857 | 5220 |
| HD Urban | 50 | 4970 | 14,557 | 20,047 | 12,232 |
| Developed | 50 | 4294 | 12,786 | 5007 | 2430 |
| All | 250 | 26,881 | 68,993 | 43,716 | 22,432 |
| OA | 0.8483 | 0.8813 | 0.9607 | 0.9382 | 0.9267 |
| RV-CNN | CV-CNN | LS-QCNN | STS | FS-SCNN | |
|---|---|---|---|---|---|
| Water | 0.9791 | 0.9978 | 0.9994 | 0.9984 | 0.9962 |
| Veg | 0.8830 | 0.9304 | 0.9647 | 0.8955 | 0.9287 |
| LD Urban | 0.6447 | 0.9042 | 0.7261 | 0.6300 | 0.9074 |
| HD Urban | 0.8624 | 0.8507 | 0.8395 | 0.8803 | 0.9275 |
| Developed | 0.8835 | 0.6946 | 0.8540 | 0.7745 | 0.9377 |
| OA | 0.9084 | 0.9350 | 0.9398 | 0.9140 | 0.9607 |
| RV-CNN | CV-CNN | LS-QCNN | STS | FS-SCNN | |
|---|---|---|---|---|---|
| Flax | 0.9460 | 0.9479 | 0.9268 | 0.9665 | 0.9740 |
| Rape Seed | 0.9886 | 0.9466 | 0.9167 | 0.8157 | 0.9893 |
| Barely | 0.9545 | 0.9424 | 0.9489 | 0.9633 | 0.9691 |
| Grass | 0.8702 | 0.9376 | 0.9276 | 0.8385 | 0.9398 |
| Wheat | 0.8361 | 0.8429 | 0.8450 | 0.8702 | 0.9737 |
| Potatoes | 0.9668 | 0.9542 | 0.9473 | 0.9753 | 0.9563 |
| Beet | 0.8474 | 0.8745 | 0.9447 | 0.9283 | 0.9758 |
| OA | 0.9177 | 0.9207 | 0.9296 | 0.9346 | 0.9672 |
| S | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | |
|---|---|---|---|---|---|---|
| Data | ||||||
| San Francisco | 0.9607 | 0.9397 | 0.9304 | 0.9275 | 0.9312 | |
| Flevoland | 0.9032 | 0.9133 | 0.9390 | 0.9385 | 0.9444 | |
| Flevoland1991 | 0.6929 | 0.7352 | 0.9672 | 0.9473 | 0.9239 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Y.; Sun, Z.; Qu, R.; Jiao, L.; Liu, F.; Zhang, X. Fuzzy Superpixels Based Semi-Supervised Similarity-Constrained CNN for PolSAR Image Classification. Remote Sens. 2020, 12, 1694. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12101694
Guo Y, Sun Z, Qu R, Jiao L, Liu F, Zhang X. Fuzzy Superpixels Based Semi-Supervised Similarity-Constrained CNN for PolSAR Image Classification. Remote Sensing. 2020; 12(10):1694. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12101694
Chicago/Turabian StyleGuo, Yuwei, Zhuangzhuang Sun, Rong Qu, Licheng Jiao, Fang Liu, and Xiangrong Zhang. 2020. "Fuzzy Superpixels Based Semi-Supervised Similarity-Constrained CNN for PolSAR Image Classification" Remote Sensing 12, no. 10: 1694. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12101694