2.2. Existing Spectral Datasets
In satellite imaging, the Normalized Difference Vegetation Index (NDVI), as given by Equation (
1), is often used to estimate the vegetation density on the earth’s surface. The exact values for cutoff wavelengths of the near-infrared (NIR) and visible red (RED) bands in the spectrum depend on the use case and the sensor type. For example, Bradley et al. [
10] chose to sum the reflectance from 600 to 670 nm for RED and 900 to 1000 nm for NIR. They used the NDVI, among other vegetation indices, to classify between vegetation and non-vegetation areas.
Winkens et al. [
14] published an annotated dataset collected with both XIMEA VIS (430 to 630 nm) and NIR (600 to 975 nm) snapshot cameras. The dataset does not contain a large number of samples and some material types have only been collected from a single object. Their NIR camera was equipped with a long-pass filter and operated in the range from 675 to 975 nm. Using their NIR dataset, we plot the NDVI features of selected samples in
Figure 1. In our NDVI plot, we defined features RED and NIR as the sum of reflectance from the wavelengths 673 to 728 nm and from 884 to 944 nm, respectively.
Using the spectral reflectance database published by NASA [
17,
18], we can observe the reflectance of vegetation/soil vs. several man-made objects, e.g., asphalt, brick and metal. We have selected a few samples from the database and visualize them in
Figure 2. Vegetation shows a higher reflectance at around 540 nm compared to the ranges from 400 to 500 nm and from 640 to 660 nm, where absorption by the chlorophyll takes place. It also shows a pronounced increase of reflectance around 700 nm. Grönwall et al. [
11] performed a comprehensive comparison between active and passive sensors at different wavelengths. They also measured the spectral reflectance of several types of clothes. Their analysis shows that clothes exhibit a similar increase in reflectance around 700 nm.
2.3. Compact Passive Hyperspectral Cameras
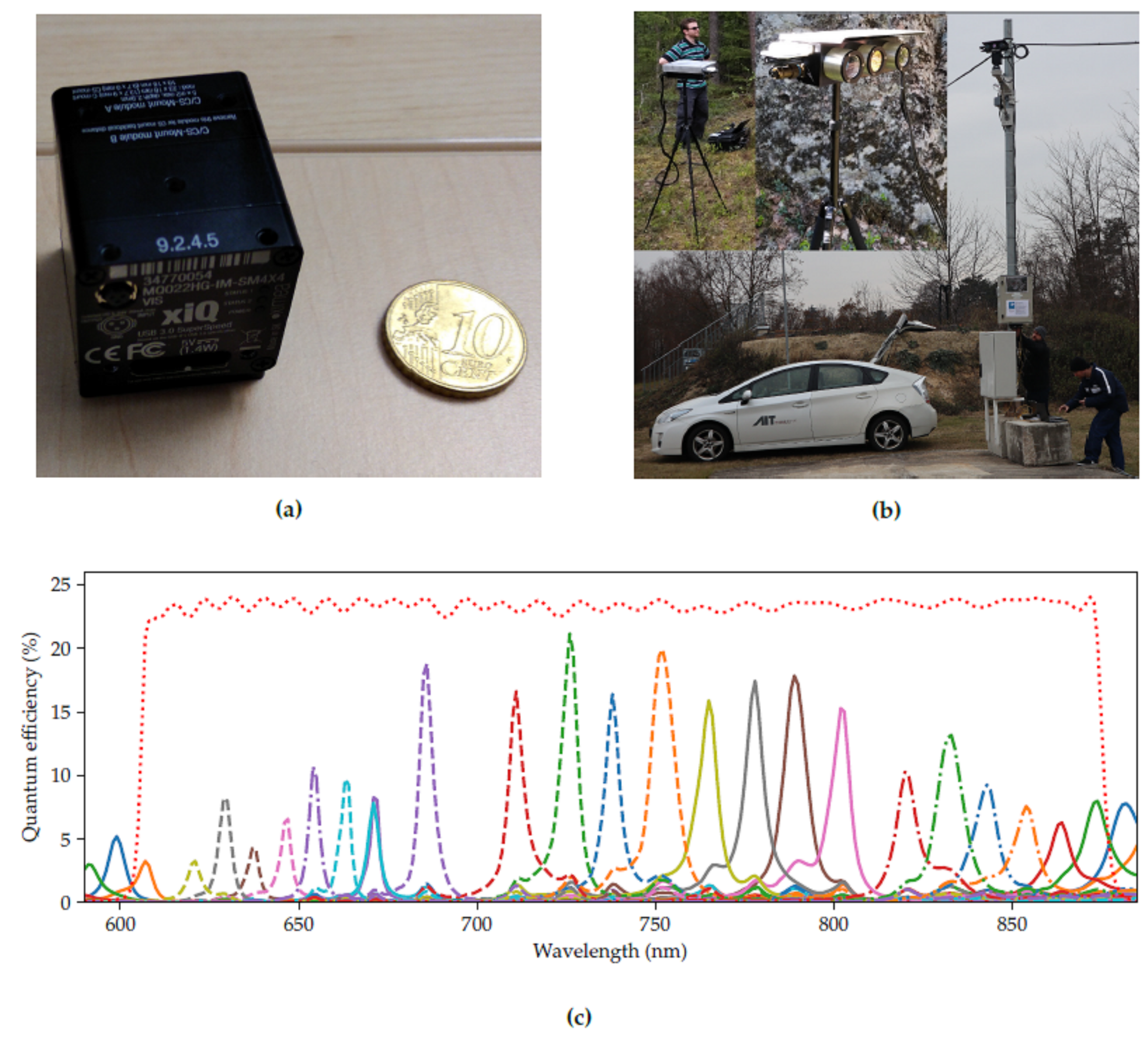
The current state-of-the-art solution for compact hyperspectral imaging has been developed by IMEC [
19]. One of the companies that produce off-the-shelf cameras with this technology is XIMEA. The XIMEA MQ022HG-IM cameras weigh around 32 g and consume 1.6 W of energy. At the time we started developing our system, XIMEA provided a range of models as detailed in
Table 1. For the MQ022HG-IM-SM5X5-NIR camera, an additional external optical filter was necessary to avoid double peaks, i.e., cross-talk between wavelength bands. From mid 2019—after we purchased our equipment—XIMEA started to introduce second-generation snapshot camera models and now offers solutions that do not require such an (external) filter. Additionally, XIMEA introduced a new model to specifically capture red and NIR portions of the spectrum from 600 to 860 nm, the MQ022HG-IM-SM4X4-REDNIR. In contrast to the other NIR hyperspectral cameras, it operates at a lower spectral (16 bands), but at a higher spatial (512 × 272 pixels/band) resolution.
The concept of the IMEC technology is that on top of a CMOS image sensor, filters are deposited and patterned directly. Depending on the spectral bands, they are organized in
or
arrays in a mosaic pattern. Each array captures the spectral information of the incident light. After a raw frame has been captured, see
Figure 3a, it needs to be demosaiced to receive a hyperspectral cube, see
Figure 3b. Depending on the use case, the bands can be stored interleaved
or planar
, where
H and
is the hyperspectral cube.
2.3.1. Hyperspectral Frame to Hyperspectral Cube Conversion
The first step in data processing is to convert the raw hyperspectral frame (
Figure 3a) to a hyperspectral cube (
Figure 3b). Let us denote the raw hyperspectral input frame as a tensor
with the indices
. Furthermore, let us denote the hyperspectral cube as a tensor
H with the indices
, where
x is the horizontal spatial coordinate,
y is the vertical spatial coordinate,
is the horizontal raw spectral coordinate in one mosaic pattern array,
is the vertical raw spectral coordinate in one mosaic pattern array,
is the corrected spectral coordinate.
Let be the camera parameter correction tensor with the indices , which is obtained during the camera factory calibration. Performing a tensor contraction operation, we can define the equation , which computes the corrected spectral values and also reorganizes the values to a hyperspectral cube. In case we require a planar representation of the hyperspectral cube, we can define with the indices and perform the tensor contraction as .
2.3.2. Overlapping Spectral Radiances
The filters on the CMOS sensor are organized in a or pattern, which captures the spectral information of the incident light. If more than one material contributes to the light received at a pattern, the spectral information represents, of course, a combination of those materials. Such inconsistency can appear when a mosaic pattern captures the border of two materials. This can lead to false classification due to the unreliable information.
To overcome this issue, we developed a filter method. It is based on the assumption that one material should exhibit a locally uniform spectral radiance, i.e., adjacent mosaic patterns covering the same material should deliver similar radiance values over all spectral bands. The core of this method resembles a standard edge detection, and positions, where a high difference value is detected, should not be considered in the classification process. We define this difference value
at a position
with respect to its neighborhood
V in Equation (
2). Finally, we empirically select a threshold for the computed difference value. The size and shape of the neighborhood set
V, and the threshold depends on the user’s choice of filter strength.
2.3.3. Radiance to Reflectance Transformation
Spectral analysis is based on the reflectance of the material. Unfortunately, data acquisition with a passive hyperspectral camera is affected by several factors, see
Table 2. The raw data from the camera are pixel intensities, which are affected by the camera characteristics. These parameters can be acquired in a laboratory after production for each camera, therefore eliminating this factor is straightforward. After the conversion from raw pixel intensities, the result will be radiance values.
Radiance is mainly determined by a combination of material properties and the light source. The difficulty of eliminating the light source and obtaining reflectance depends on the set-up of the measurement. In a controlled environment (e.g., a conveyor belt in an industrial building), this can be done by measuring the minimum radiance (no light source) and the maximum radiance (light source with a calibration board) [
9]. Calibration boards have a well-known reflectance in the spectral range in which the measurements will be executed. Once minimum and maximum measurable radiance are known, it is possible to calculate the reflectance of a material.
In aerial scenarios, the viewpoint limits the complexity of the scenario. This is because when looking towards the ground, illumination is generally evenly distributed and no direct sunlight will reach the sensor array. Two cases can be considered: Areas with direct sunlight and shadow. The calibration can be done in a similar fashion as in a controlled environment. Prior to the flight, a calibration board is measured in direct sunlight [
1]. Therefore, during the flight, the reflectance of objects in direct sunlight (e.g., tree canopy, soil) can be measured.
Terrestrial scenarios are more complicated, due to varying angles of incidence of the sunlight and generally more complex superposition of shadows. This makes it challenging to reliably convert radiance to reflectance in such scenarios. Winkens et al. [
14] proposed to apply normalization on the radiance values and to detect shadows with thresholds. Alternatively, a normalization technique like max-RGB could help to obtain approximated reflectance values in some cases, e.g., when parts of the camera’s field of view cover a highly reflective wall.
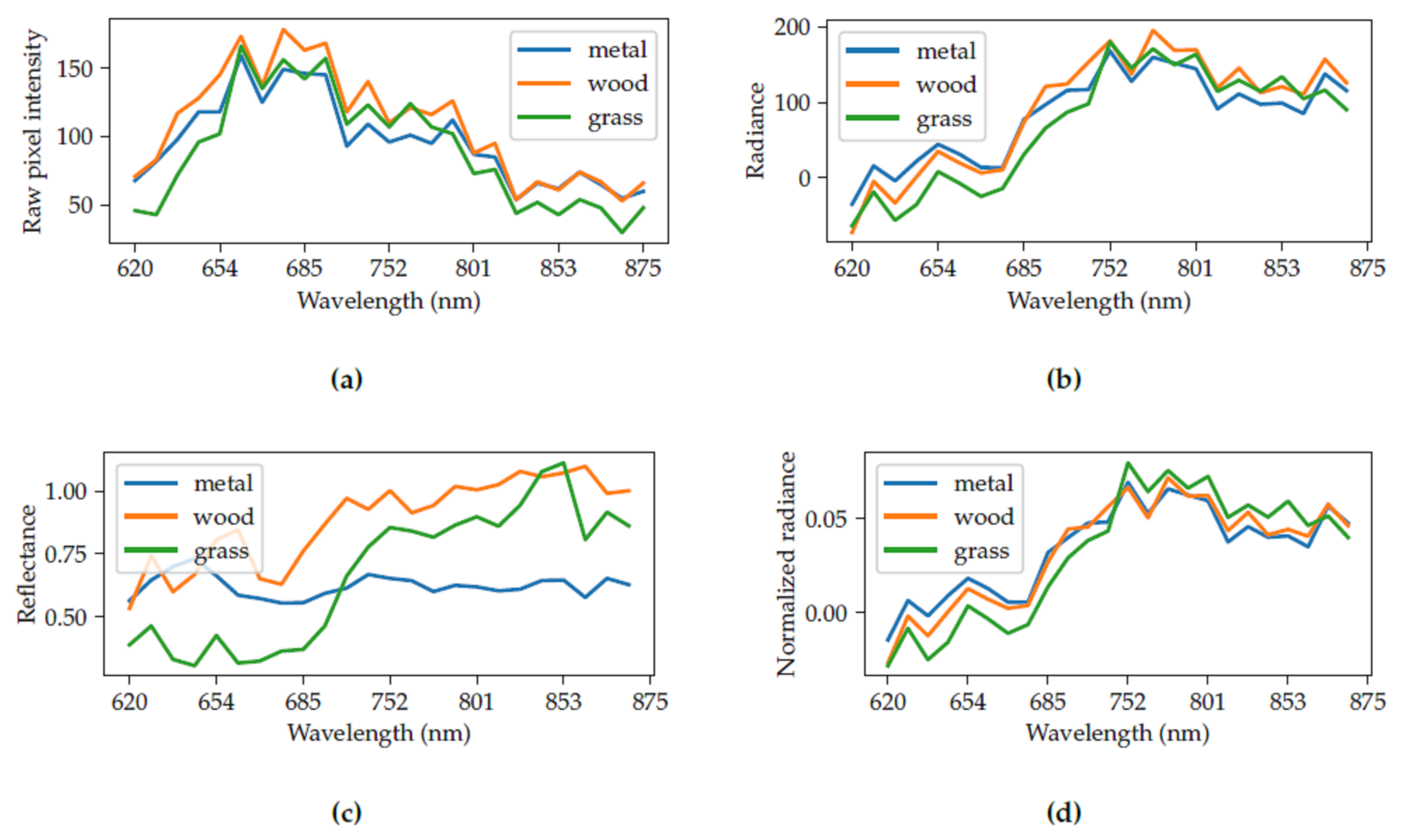
For demonstration, we have selected three materials from the scene in
Figure 3. The materials are the wooden bench, grass and the metal waste bin. We performed a maximum radiance calibration with a calibration board (not seen in the image).
Figure 4a shows the raw pixel intensities, which are received directly from the camera. After the elimination of the camera characteristics from the raw pixel intensities, we receive radiance in
Figure 4b. Knowing the maximum radiance, we can approximate the reflectance of the objects in
Figure 4c. It can be seen that the calibration was not perfect, as we get values higher than 1.0 for reflectance. Alternatively, we can calculate the normalized radiance in
Figure 4d as proposed by Winkens et al. [
14].
We conclude that, for a highly accurate classification, reflectance is an essential parameter. It solely depends on the material itself, not on ambient conditions. However, it is not always possible to estimate the reflectance of objects from hyperspectral images in uncontrolled environments.
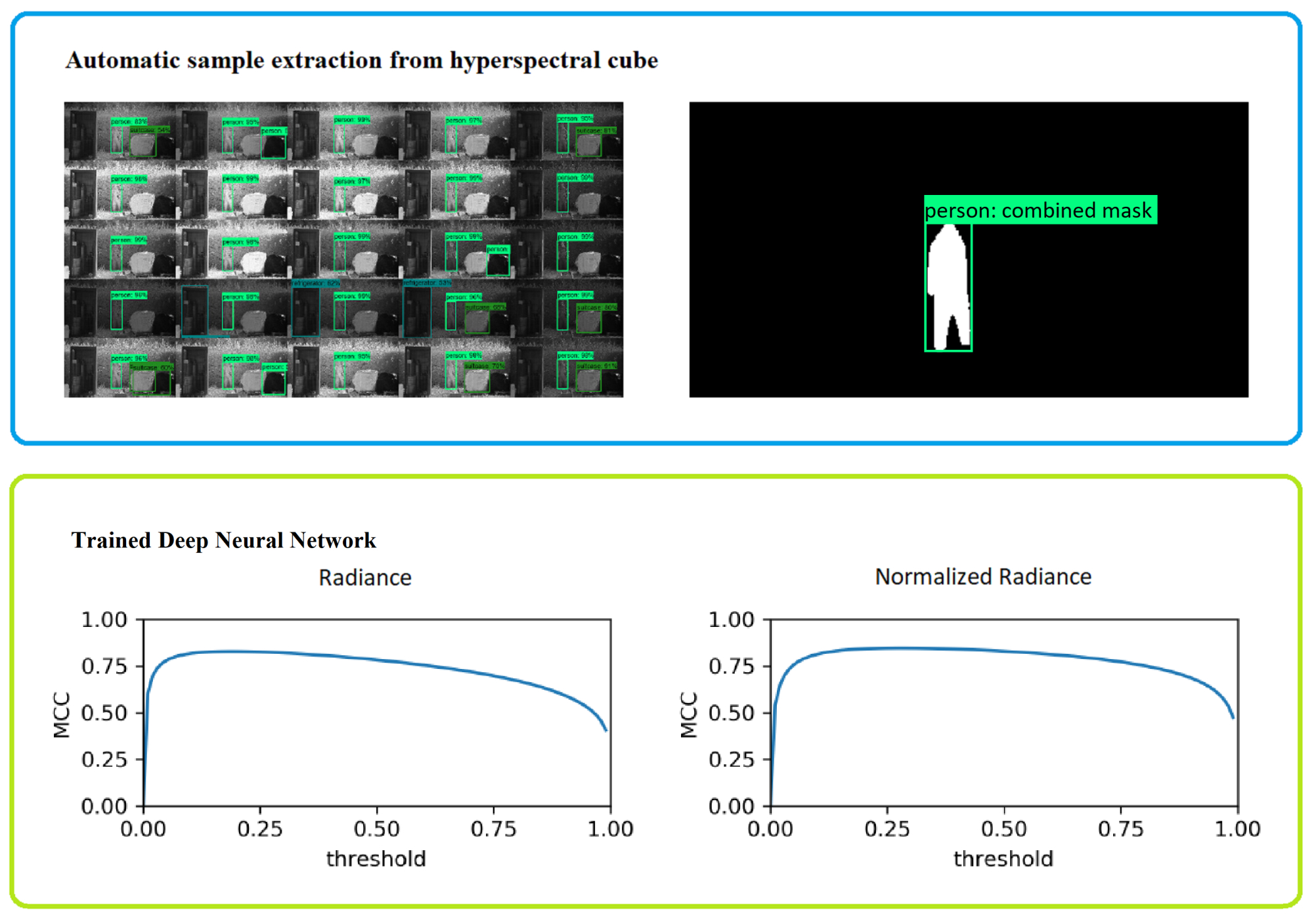
2.6. Spectral Signal Classification
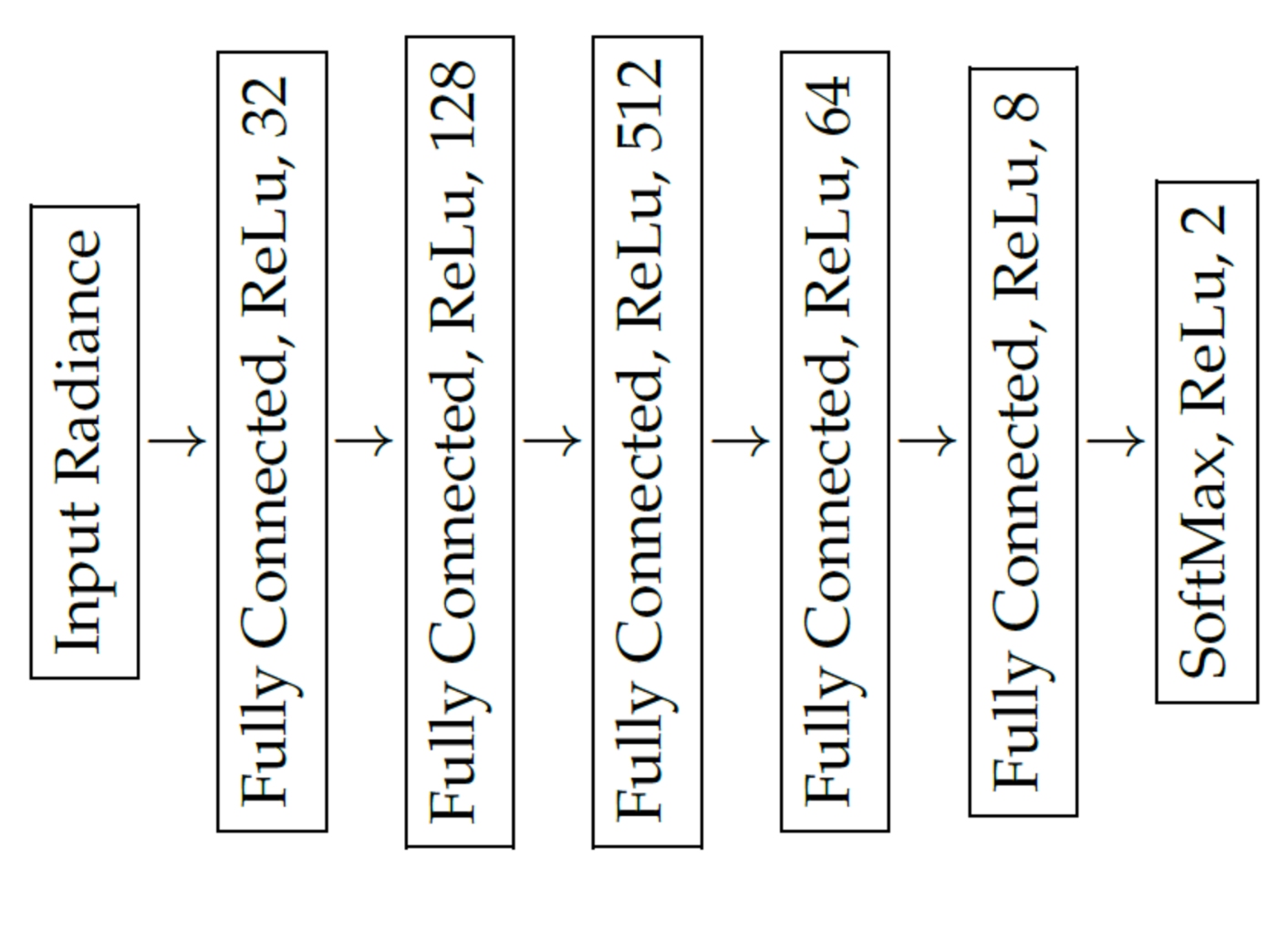
We trained a deep neural network as a binary classifier to decide whether a spectral radiance sample represents background (e.g., vegetation or tarmac) or a foreground object (e.g., textile, plastic or metal). As proposed by Cavigelli et al. [
15], the deep neural network has six fully connected layers with five consecutive ReLu activation functions and one SoftMax activation for the last layer, see
Figure 8. Each sample was presented to the network in vector form. In contrast to Cavigelli et al., we could not rely on structural information, because the objects can be partly occluded by vegetation. Therefore, we trained the classifier on spectral radiance measurements only. The feature values were the corrected radiance values, as described in
Section 2.3.3. Additionally, we repeated the analysis with the normalized radiance and added the normalization factor to the feature vector. The normalization was performed as proposed by Winkens et al. [
14].
| Algorithm 1: Automatic annotation of hyperspectral frames. |
![Remotesensing 12 02111 i001]() |
We defined a sample as the spectral radiance at one
-position in a hyperspectral cube
H, as defined in
Section 2.3.1. We called samples pertaining to person/car/truck/clothes objects positive and tarmac/tree/vegetation objects negative samples.
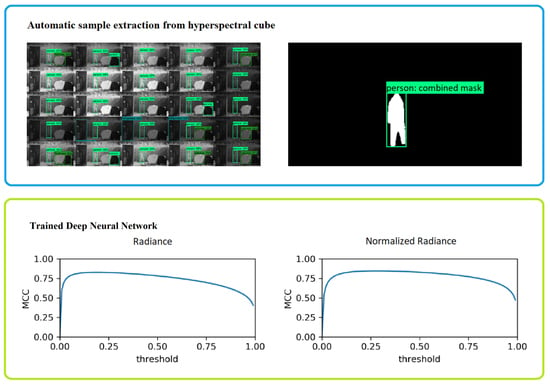
We used our automatic annotation method to collect positive samples (person, car, truck) in the Mast October/November datasets. The automatic annotation was able to collect samples only where no occlusion was present. This enabled us to train and test a classifier, and later perform visual evaluation where occlusion appeared.
In the Ground dataset, we manually annotated clothes as positive samples. To track individual pieces of clothes, we added a consecutive number to the respective labels, e.g., clothes-clothesid-01. The number was assigned in the order in which the clothes appeared in the video and does not indicate any specific characteristics of the fabric.
During the first manual annotations, we quickly noticed that occluded samples were nearly impossible to annotate manually. Therefore, manual annotation was only applied to non-occluded positive samples.
Negative samples (e.g., vegetation) were annotated manually in all datasets, except in the Mast November dataset. The Mast October and Mast November datasets both show the same location over an extended period of time with varying illumination and weather conditions. We concluded, that Mast November does not introduce much additional variation and would not change the statistics significantly. Hence we did not collect negative samples from it. There was only one tree in the field of view of the Mast October dataset, which is the reason for the low number of tree samples.
In the Ground and Quarry datasets, we introduced a simple taxonomy to study the performance of our classifier on different types of vegetation. First, we discriminated between forest (mix of standing trees, large bushes) and ground (generally low vegetation and little shadow, e.g., in clearances or open fields). We then evaluated the leaf density of forest areas ranging from low (very sparse leaves) to high (very dense leaves, not present in the data). In case of ground areas, we defined patches with a vegetation height up to 10 cm as low, and up to 30 cm as medium.
Training was performed on the Mast October dataset, where we obtained 6,198,185 positive and 2,475,260 negative samples. To maintain a balanced dataset we randomly selected 2,475,260 samples from the positive set. Finally, the data was split into 3,960,416 (80%) training samples and 990,104 (20%) validation samples. The test dataset was Mast Novemeber, which contains 11,439,949 positive samples. We did not explicitly train on clothes samples or persons seen in the Quarry or Ground datasets. In these instances, we accepted a positive classification, i.e., not vegetation/ground, regardless of the specific class of each sample.
To classify unseen data, each radiance sample was evaluated by the neural network. We thus obtained a confidence value (from 0 to 100%) indicating whether the evaluated sample belongs to a person/vehicle. The classification result with the higher confidence value was accepted.


 . The project AREAS is funded by the Austrian security research programme KIRAS of the Federal Ministry of Agriculture, Regions and Tourism.
. The project AREAS is funded by the Austrian security research programme KIRAS of the Federal Ministry of Agriculture, Regions and Tourism.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}