1. Introduction
A well-developed and accessible infrastructure is a prerequisite for a functioning economy. The essential infrastructure includes basic supplies, transport routes, and nodes but also elements necessary for the digital interconnection of society, such as broadband access. In most countries in the European Union, the basic supply and transport infrastructure network expands nationwide–preservation and maintenance are therefore the most important tasks for the future. The situation with regard to digital supply is significantly worse. The broadband network in particular still has many gaps and requires a high degree of densification, especially in rural areas.
A basic challenge for the construction and expansion of infrastructure—regardless of type—is the lack of documentation for existing natural (e.g., landscape and vegetation) and artificial objects (e.g., buildings) on sites. Often, accurate plans do not exist or are outdated [
1]. For small-scale construction sites, such as single-family houses, documentation can be produced with suitable, mostly terrestrial measuring methods [
2] to allow reliable planning. In the case of large structures—especially long-term infrastructure projects—full-coverage documentation is considerably more complex. Currently, documentation is either carried out (a) with little effort, resulting in a poor spatial resolution of the data (e.g., simple photo documentation of the conditions), or (b) with mobile measuring systems that generate dense spatial information, but produce a large amount of data (in the range of several GB per km) in very short time [
3,
4]. The process of transferring the recorded measurement data into digital models usable for infrastructure planning requires experience and time [
5]. Usage of digital models has the potential to reduce planning time compared to conventional manual planning. To fully or semi-automate the task of processing mobile mapping data and thus accelerate the modeling is, therefore, a much-researched topic; extensive reviews of the different techniques have, e.g., been published by Reference [
6,
7].
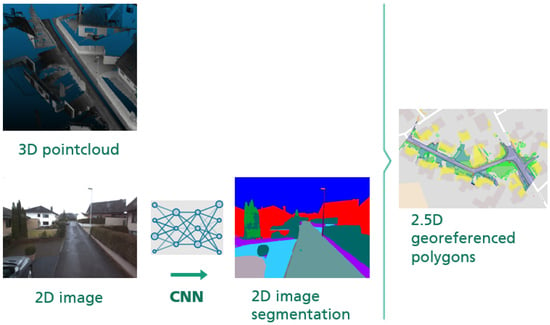
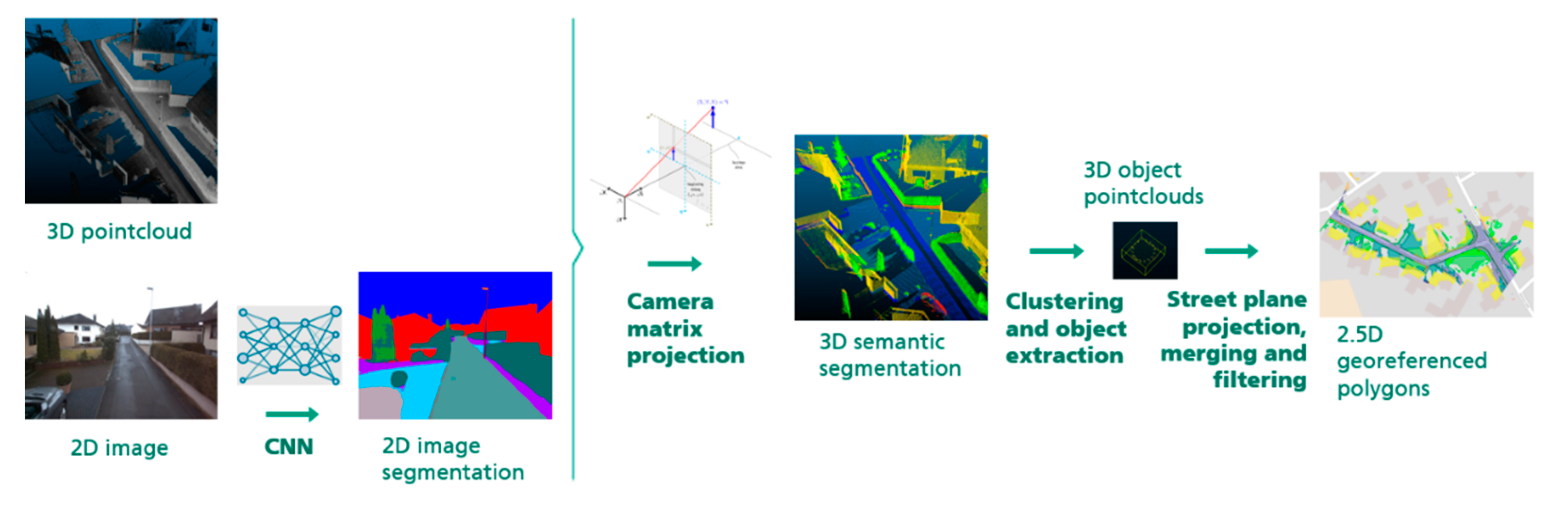
We present an approach specifically tailored to the application of digital planning for expanding a broadband network, utilizing mobile mapping data from both LiDAR (Light Detection and Ranging) and camera sensors. A key element of our approach is the use of supervised learning to train a convolutional neural network (CNN) that is able to distinguish surfaces and objects relevant to civil engineering (e.g., different types of pavement) in images captured by a mobile mapping system. We use this information to segment a dense point cloud, from which we extract localized objects and represent them as pairs of shape and height, yielding a 2.5D map of the recorded area with detailed surface texture information. The purpose of the resulting data stream is to inform a routing algorithm tasked with finding a reliable (i.e., not disrupted by objects hindering construction, such as rails) and cost-efficient (i.e., through surfaces that can be easily restored) route for construction work.
Deep learning techniques based on CNNs are the current state-of-the-art in computer vision, [
8,
9,
10]. For object detection, classification, or segmentation in 3D data, only recently approaches based on deep learning have gained traction due the lower resolution compared to images and sparseness of the point cloud. Approaches can be categorized into volumetric (e.g., VoxNet [
11], which transform the input point cloud into structured voxel data), point-wise (e.g., PointNet [
12], which use points as input without a previous transformation), and multi-view-based (e.g., VoteNet. [
13], where 3D point clouds are transferred into 2D images for classification or segmentation). Most recently, integrations of point-wise and volumetric methods have shown promise [
14]. A comprehensive survey of methods for 3D classification can be found for example in the work of Reference [
15].
Our approach can be placed within multi-view-based research, where most recently advanced ways of combining RGB and depth views of the point cloud have emerged, for example, with ImVoteNet [
16]. However, our goal differs from most applications in the field, which work on classification of indoors scenes or autonomous driving applications; we focus on distinguishing urban surface textures, such as concrete, asphalt, pavement, or gravel, for which color information is an essential feature, while depth is negligible. Instead of working with depth or intensity 2D maps, we extract object information from RGB images only, which have been recorded synchronously with the point cloud and offer multiple perspectives of the objects and surfaces visible in the 3D data. A similar approach is described by Reference [
17], who classified images with a CNN trained on the CityScapes dataset [
18], mapped segmentation results to 3D points using camera parameters, and refined the result with features extracted from the point clouds. However, their pipeline stops at the classified point cloud, while our procedure also includes the extraction of object instances and their shapes for the creation of a digital map. Since—to our knowledge—there is no dataset publicly available at the current time that provides annotations of fine-grained classes of urban surface textures, a custom dataset of 90,000 segmented RGB images was created in the process of building our system, as well as an extensive reference map in two different locations in Germany.
In general, the focus of our paper is not on novel methods for individual steps of the pipeline (e.g., image or point cloud segmentation) but on the practical application of scene classification and reaching high accuracy and robustness in feasible processing time in practice; so far, little research has been conducted in this direction [
19].
3. Results
In the route planning process based on the stream of data output by our system, detected objects serve different information needs. Broadly, two types of objects are of interest for this application: surface textures and objects disrupting a continuous surface.
- (a)
Surfaces, i.e., areas of ground covered with a specific material (e.g., asphalt or grass; see above). Knowing the exact extent of a surface is important in order to be able to calculate the cost of implementing a planned route though several areas and minimize this cost during the routing process (building through grass is cheaper than opening up pavement). We want to reflect this in our evaluation strategy and compute measures based on area overlap.
- (b)
Disrupting objects, i.e., objects placed on or inside a surface, which may disrupt a potential broadband route, such as curbstones or rail tracks. The exact area size of these objects is less relevant for the application, since the route planning establishes buffer zones around disrupting objects; however, since undetected “holes” in continuous objects can significantly alter planned routes, high recall is important in the detection of these objects.
3.1. Reference Data Set
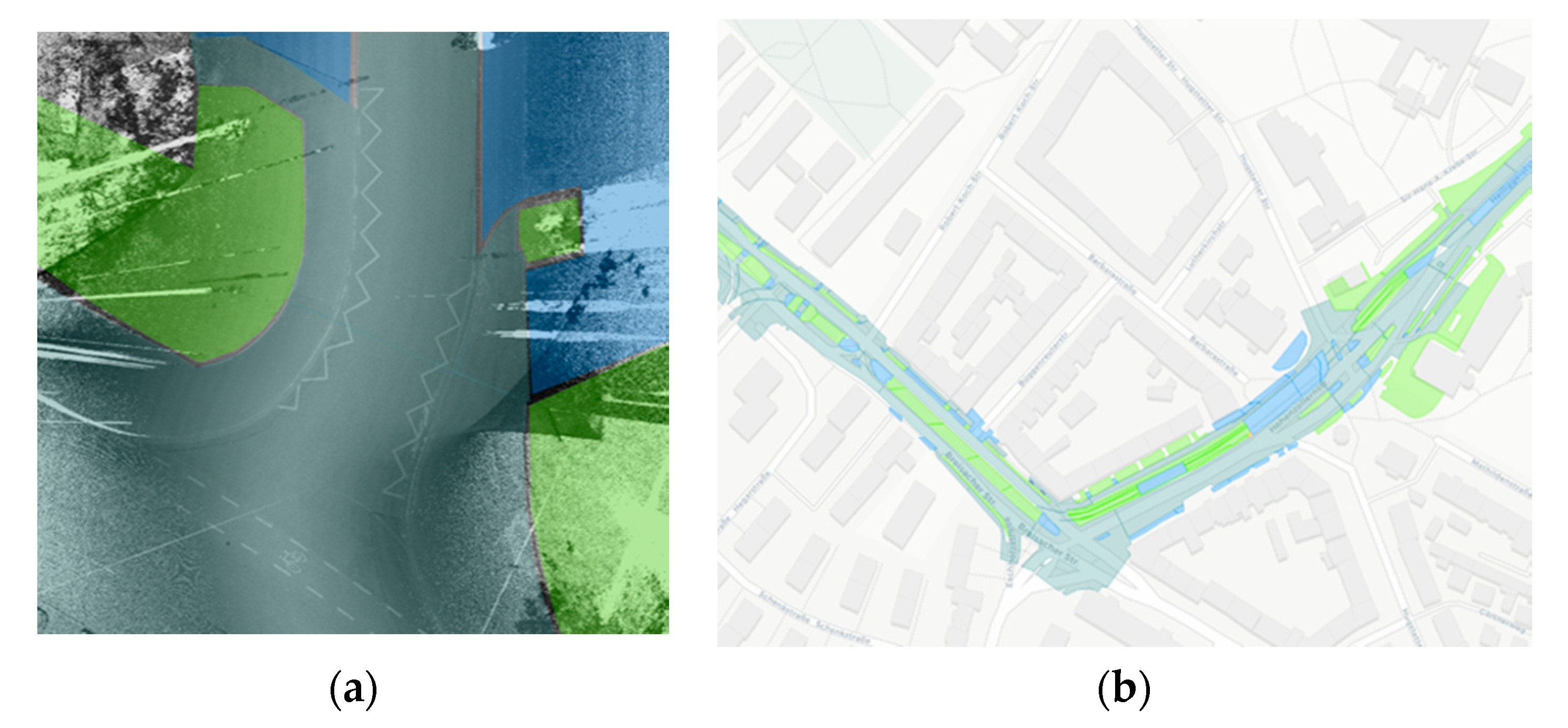
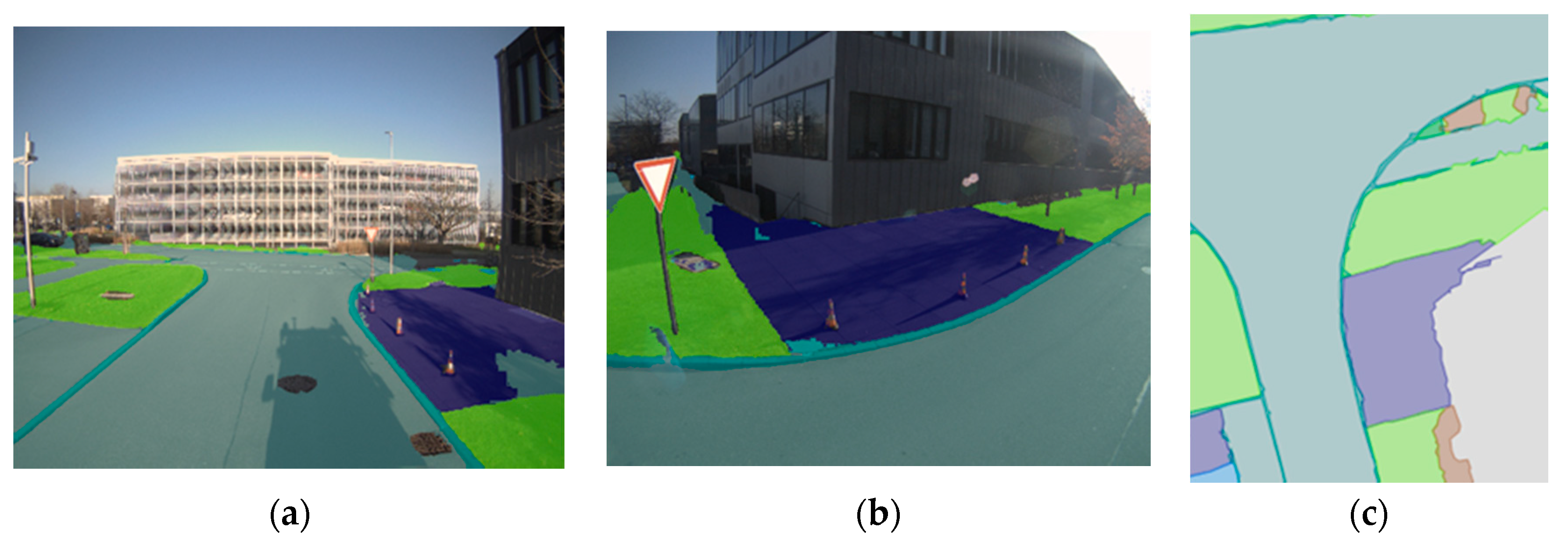
To guarantee that our system performs reliably in a real-world application with a broad range of different scenes, weather, and lighting settings all over Germany, we manually created an extensive reference map, covering all target objects and using diverse input data from various seasons and locations. We selected two areas for evaluation, for which data was recorded exclusively for evaluation and chronologically and geographically completely separate from the recording of the CNN training data, namely an inner-city area from Freiburg, Baden-Württemberg (Germany), and a mix of suburban and rural area from Bornheim, Nordrhein-Westfalen (Germany). Data from Bornheim was recorded in July 2018. For the Freiburg area, two recordings were available, from March 2018 and July 2018. We asked annotators to draw reference polygons of the shapes of surfaces and objects with the help of aerial images. Especially for narrow objects, such as curbstones and rail tracks, aerial images turned out to be far too low in resolution, as well as inaccurate in the exact localization of the objects. To solve this problem, we used birds-eye views of the point cloud, visualizing intensity values at different resolutions to help annotators identify reference shapes correctly, in combination with corresponding terrestrial images from the mobile mapping cameras, for identifying the surface texture correctly (see
Figure 8). In total, five annotators worked on the ground truth, polygons for all objects were double-checked, and more than 150,000 square meters of highly detailed ground truth created, corresponding to a route of 8 kilometers driven by the mobile mapping vehicle. The data set covers the six surface texture classes (concrete, asphalt, large paving, small paving, grass, and gravel) and two disrupting object classes (rail tracks and curbstone).
3.2. Evaluation
As we work towards a real-world application, we focus on a detailed inspection of the final pipeline output, i.e. the quality and accuracy of 2D polygons, instead of intermediary results, such as the segmentation of images and point clouds. Still, we use notions about the output quality similar to measuring the performance of classifiers: we count True and False Positives, as well as False Negatives, and compute evaluation measures based on these numbers.
Table 2 shows the definition of these terms in the context of our task,
Figure 9 a visualization. Based on these counts, we compute Precision, Recall, and F1-score.
Table 3 shows the evaluation results for the six individual surface classes on all data sets separately and averaged. Results show that the system can distinguish even similar looking surfaces, such as concrete and asphalt, with high reliability (between 75% and 95%) when averaged over location and season. Note that we did not filter the evaluation data with regard to image quality, so the set contains images both with over- and underexposed regions. Especially, the data recorded in summer contains a significant number of images, in which critical parts are over- and underexposed.
We chose to keep this data in the evaluation set regardless, to gain a realistic impression of the capabilities of a system faced with incomplete and impaired data.
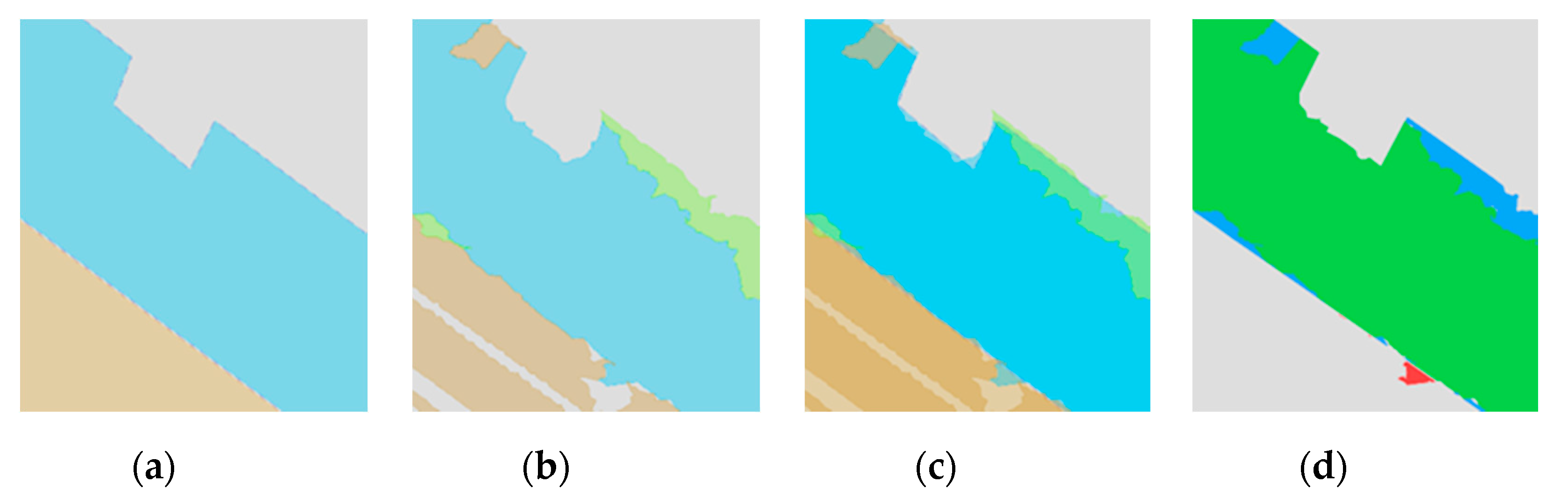
Figure 10 shows examples. Overall, results are lower for classes for which less data is available in the reference set (such as large paving), corresponding to lower frequency in the training set.
The main challenge for our system is to distinguish reliably surface textures that look similar; overexposed asphalt may closely resemble concrete and images of concrete, where no boundaries are visible, and can be easily mistaken for asphalt, even by the human eye. Strongly distressed asphalt often resembles gravel, and the difference between dirt and gravel is fluid. The same holds true for the division into small and large paving. Even though the CNN handles scaling quite well due to the fixed perspectives, there are paving patterns consisting of both large and small stones, leading to ambiguous cases. We therefore performed a paired evaluation of related surfaces (see
Table 4). Precision and Recall for all combinations were up to 90% and higher, supporting the hypothesis that the system mostly confuses visually similar textures. The paired evaluation of the surface classes makes sense in the context of the application, as well. The difference in cost between construction works through the respective surfaces is much smaller within those pairs than between pairs, meaning the error in cost calculation is smaller, when there is a confusion between members of a pair.
One aspect that makes the system robust in application is the availability of images taken from multiple perspectives. Surfaces that are further away or partially hidden may appear again in an image taken by a different camera. We experimented with two different settings for determining the label of a point based on information from different images: majority label (voting) and nearest label (nearest being the one received by the image taken from the camera position closest to the point in question).
Table 5 contains the results. Especially for object classes that appear less frequently, such as paving and gravel, taking labeling information from the nearest camera improves final classification accuracy.
Figure 11 shows the surface segmentation for two images taken of the same surfaces but from different angles. Final output is a correct polygon for the whole area due to the higher weight given to labeling information received from images taken closer to the point in question. On the other hand, gaps in continuous objects are a regular occurrence caused by incomplete recordings of objects in 3D (
Figure 12); this problem can be only fixed by changing the mode of data collection, e.g., by driving roads in both directions and adding additional LiDAR sensors at different angles.
Table 6 contains evaluation results for disrupting continuous objects, rail tracks, and curbstones. The results are conclusive; the percentage of False Positives is extremely low.
Note, that the ground truth annotation included parts of the objects that were obscured in 3D from the view point of the vehicle as discussed above, e.g., by parking or overtaking vehicles (again, we assume it is relevant to the application to assume input data may be incomplete regularly). Large continuous sections, where the object was obscured, e.g., at tram stations, which feature a high sidewalk on both sides of the track separating the rail tracks in the middle of the street from the driving lanes, were excluded from the annotation, though. The results should therefore closely reflect the performance of the system in application and the missing data accounts for the lower Recall compared to the high Precision. The larger presence of ambiguous objects can explain the lower precision for curbstones: in some cases, sidewalks feature intersecting stones, e.g., a paved line separating bike and pedestrian lane, which are visually indistinguishable from a low curbstone.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








