A High-Performance Spectral-Spatial Residual Network for Hyperspectral Image Classification with Small Training Data

 , , ,
, , ,  and
and
Abstract
:
1. Introduction
- We propose TSRN, a Two-Stream Spectral-Spatial network with residual connections, to extract spectral and spatial features for HSI classification. The identity shortcut in the residual-unit is parameter-free, thus adding shortcut connections into a residual-unit does not increase the number of parameters. Furthermore, the use of 1D convolutional layers in the sRN and 2D convolutional layers in the saRN results in few trainable parameters. We can, therefore, construct a deeper and wider network with fewer parameters, making it particularly suitable for HSI classification when the amount of available labeled data is small.
- We achieve the state-of-the-art performance on HSI classification with various sizes of training samples (4%, 6%, 8%, 10%, and 30%). Moreover, compared to networks based on 3D convolutional layers, our proposed architecture is faster.
2. Technical Preliminaries
2.1. CNN
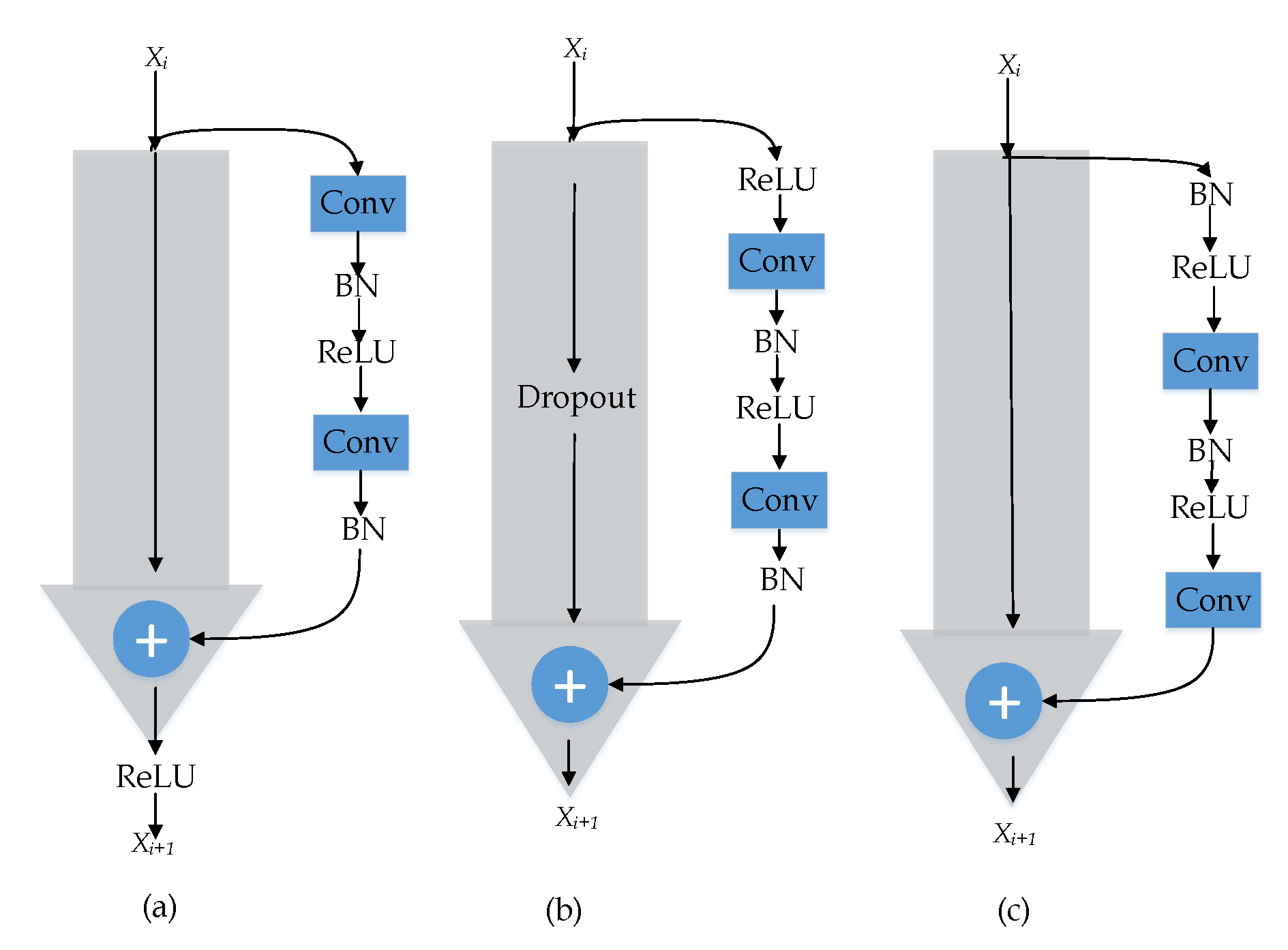
2.2. Residual Network
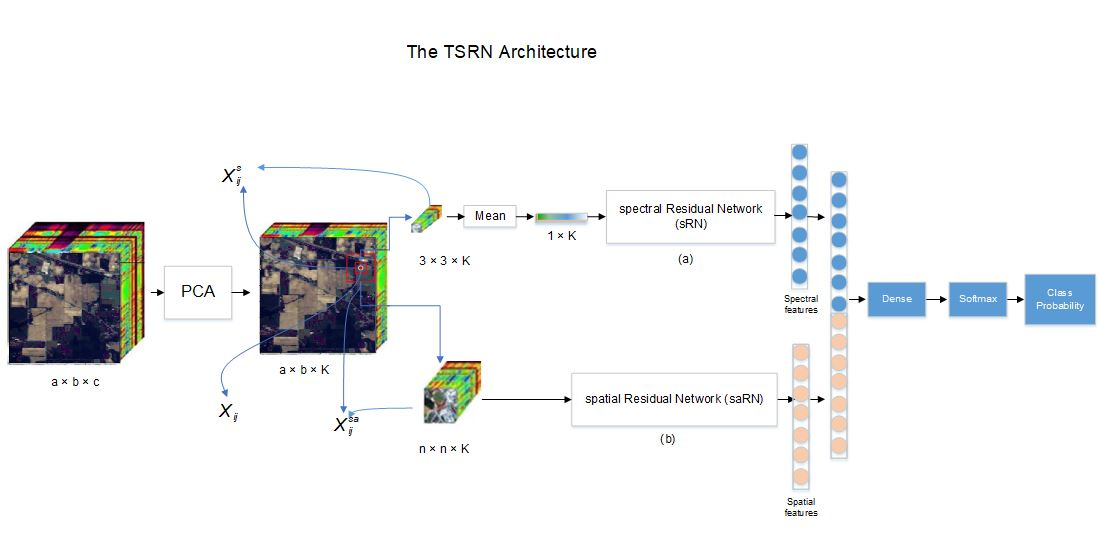
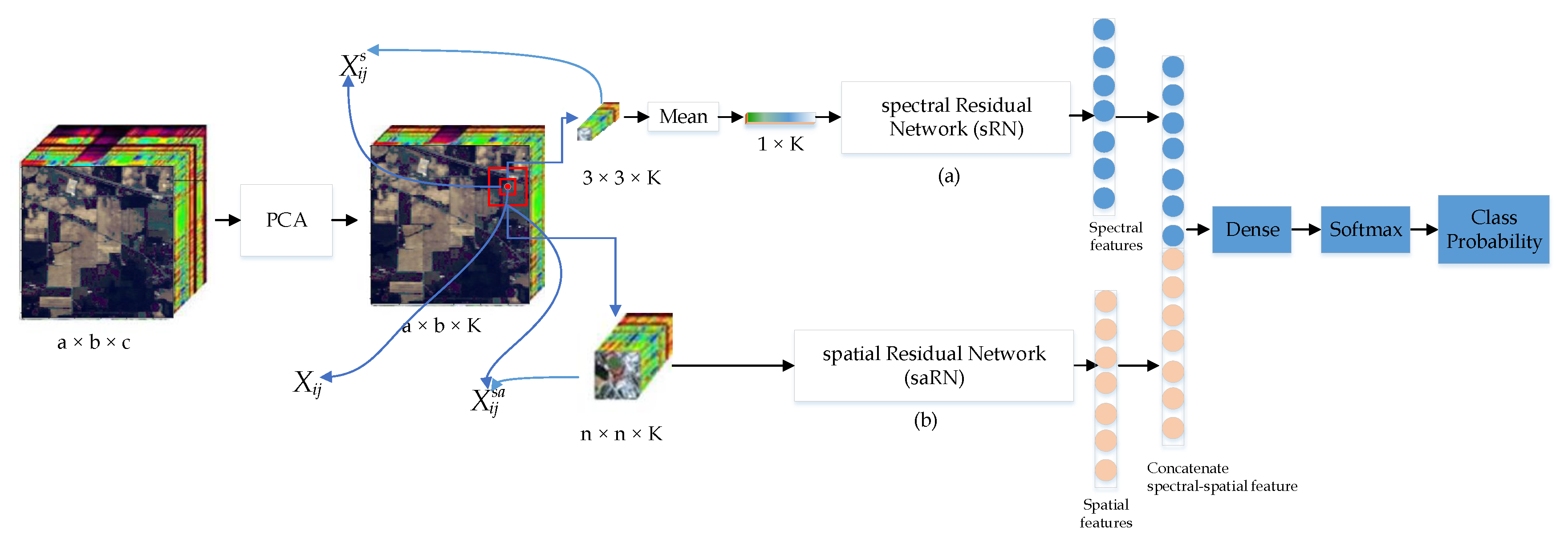
3. Proposed TSRN Network
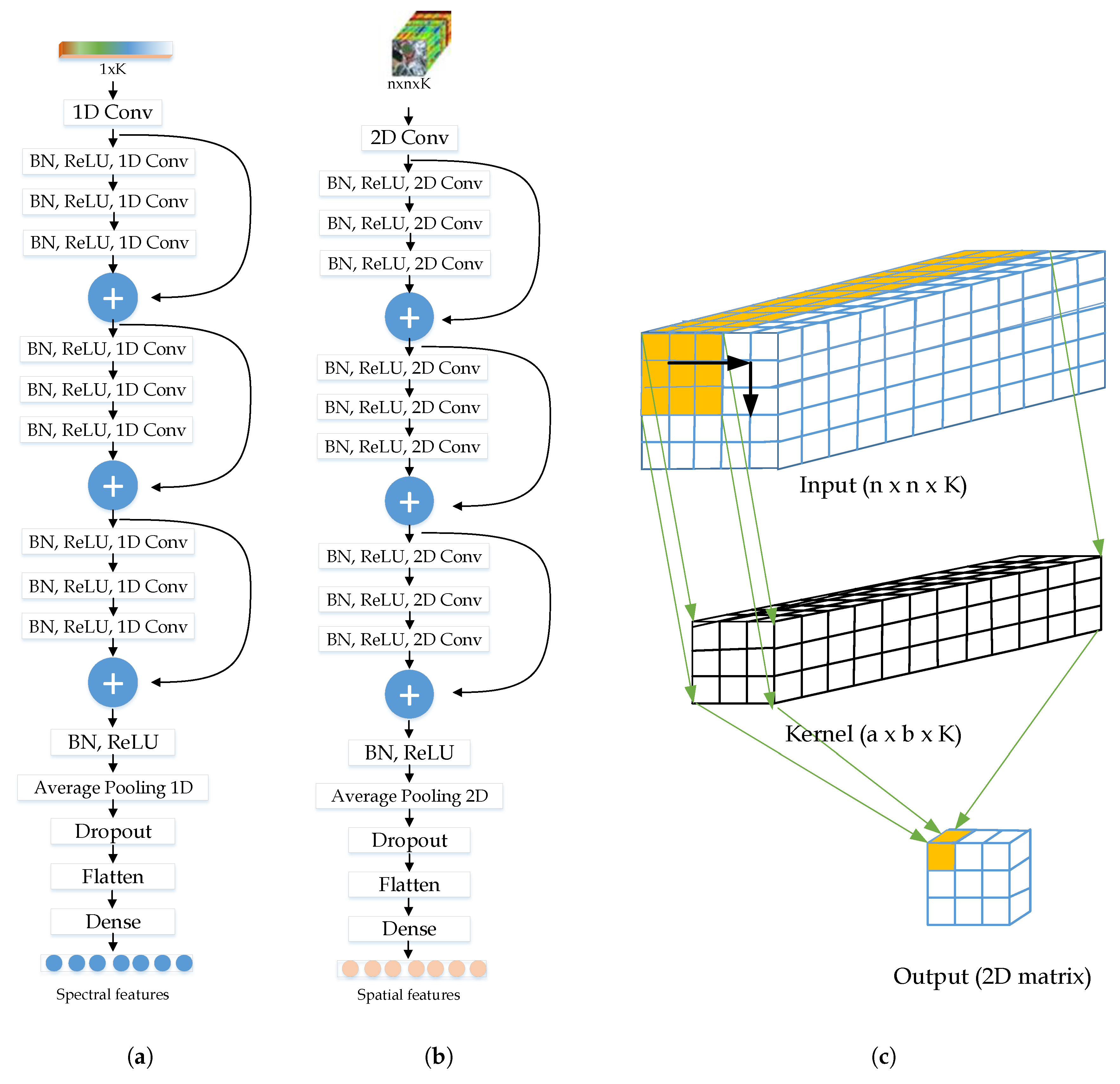
3.1. Spectral Residual Network
- One-dimensional convolutional layers, which perform a dot product between every small window of input data () and the kernel’s weights and biases (see Equation (1)).
- BN layer that normalizes the layer inputs of each training mini-batch to overcome the internal covariate shift problem [62]. The internal covariate shift problem is a condition which occurs when the distribution of each layer’s inputs in deep-network changes due to the change of the previous layer’s parameters. This situation slows down the training. Normalizing the layer’s inputs stabilizes its distribution and thus speeds up the training process.
- ReLU is an activation function, which learns the non-linear representations of each feature map’s components [63].
3.2. Spatial Residual Network
4. Experiments
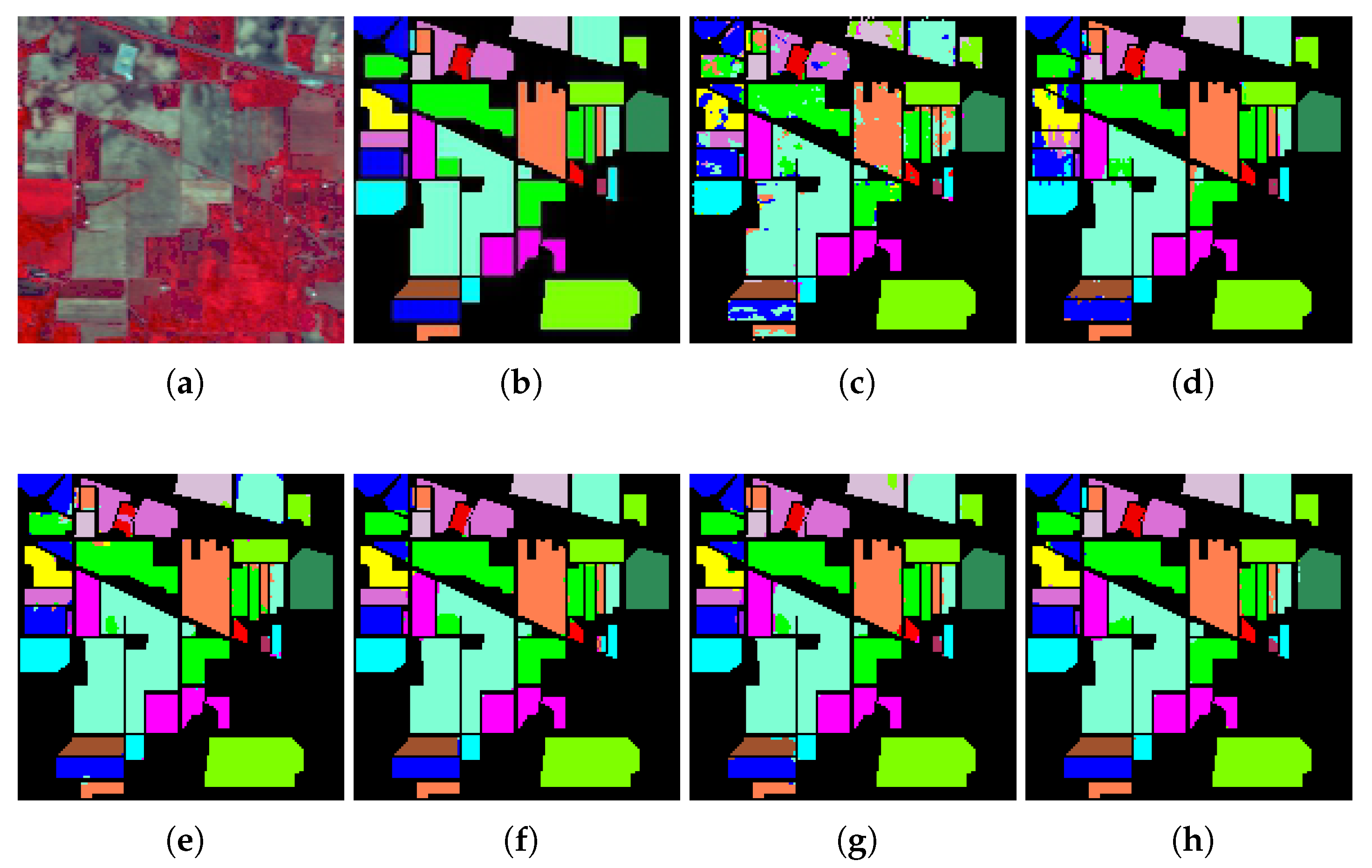
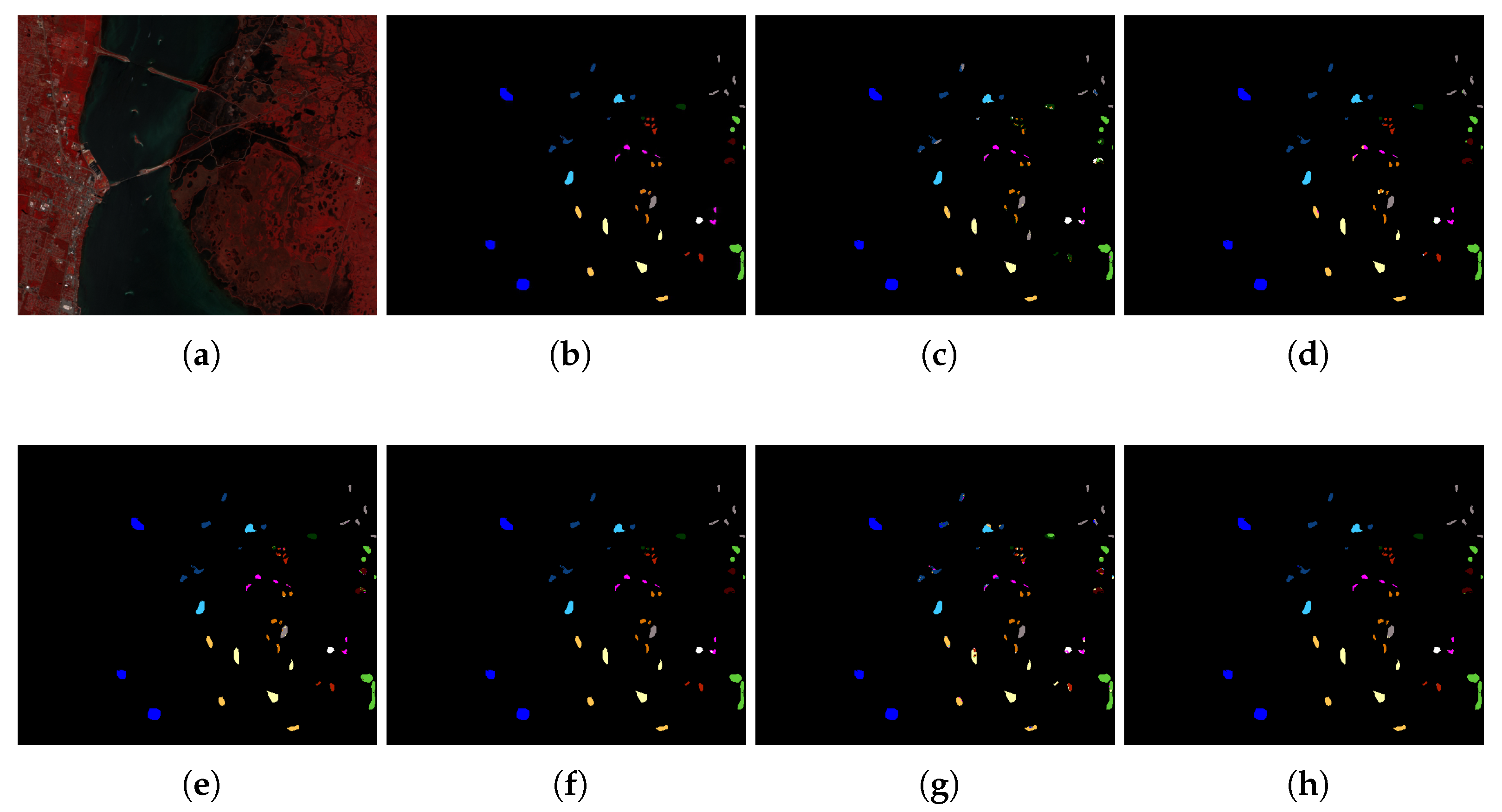
4.1. Experimental Datasets
- IP Dataset: IP dataset was acquired by Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) hyperspectral sensor data on 12 June 1992, over Purdue University Agronomy farm and nearby area, in Northwestern Indiana, USA. The major portions of the area are Indian Creek and Pine Creek watershed; thus, the dataset is known as the Indian Pine dataset. The captured scene contains pixels with a spatial resolution of 20 meters per pixel. In other words, the dataset has 21,025 pixels. However, not all of the pixels have ground-truth information. Only 10,249 pixels are categorized between 1 to 16 (as shown in Table 1a), and the remaining pixels remain unknown (labeled with zero in the ground truth). Regarding the spectral information, the entire spectral band of this dataset is 224, with wavelengths ranging from 400 to 2500 nm. Since some of the bands cover the region of water absorption, (104–108), (150–163), and 220, they are removed, so only 200 bands remain Reference [65].
- KSC Dataset: Same as the IP dataset, the KSC dataset was also collected by AVIRIS sensor in 1996 over the Kennedy Space Center, Florida, USA. Its size is ; thus, this dataset consists of 314,368 pixels, but only 5122 pixels have ground-truth information (as shown in Table 1b). The dataset’s spatial resolution is 18 meters per pixel, and its band number is 174.
- PU Dataset: The PU dataset was gathered during a flight campaign over the campus in Pavia, Northern Italy, using a Reflective Optics System Imaging Spectrometer (ROSIS) hyperspectral sensor. The dataset consists of pixels, with a spatial resolution 1.3 meters per pixel. Hence 207,400 pixels are available in this dataset. However, only 20% of these pixels have ground-truth information, which are labeled into nine different classes, as shown in Table 1c. The number of its spectral bands is 103, ranging from 430 to 860 nm.
4.2. Experimental Configuration
- To evaluate the effect of the mean operation in the sRN sub-network input, we performed experiments on our proposed architecture with two case scenarios. First, the sRN input is the mean of a spectral cube. Second, the sRN input is a spectral vector of a pixel without the mean operation. We performed experiments with 4%, 6%, 8%, 10%, and 30% training samples for IP dataset, PU dataset, and KSC dataset. We use the rest of the data that is not used in training for testing. In each run, we use the same data points for the training of both “with mean” and “without mean” setups.
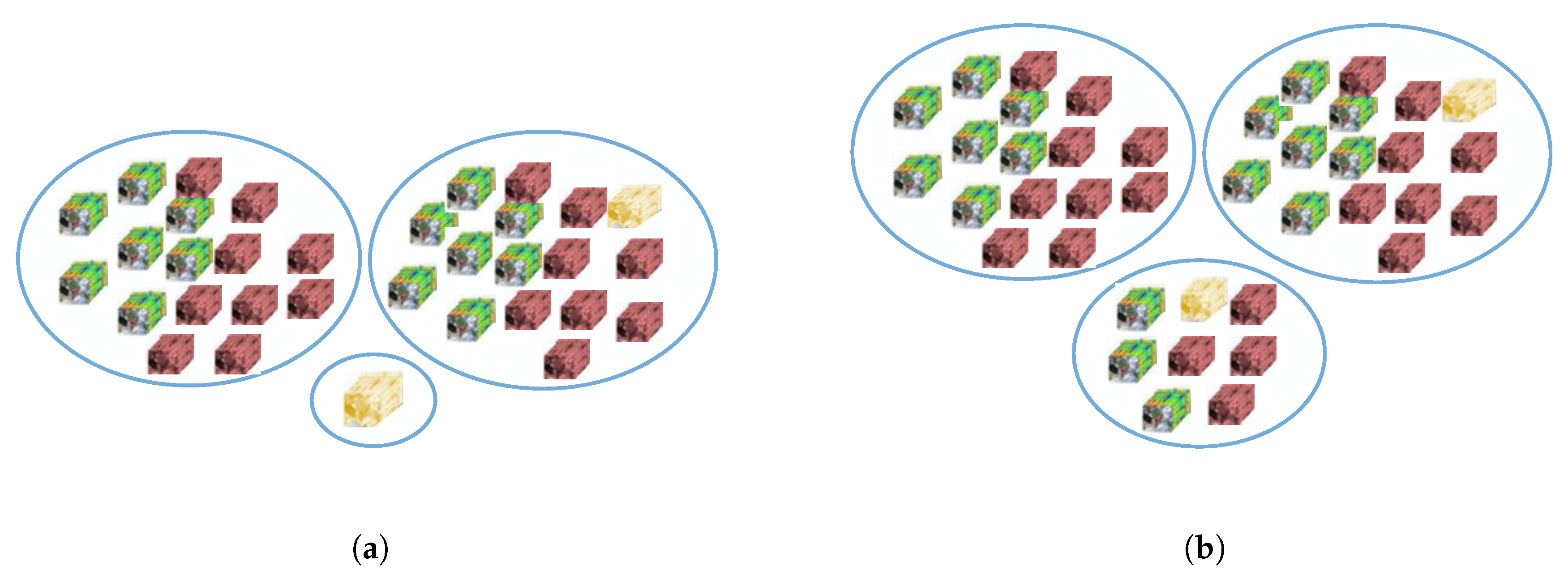
- To discover the concatenation effect of the sRN sub-network and the saRN sub-network on the performance accuracy, we performed experiments on three different architectures, the sRN network only, the saRN network only, and our proposed method with 30%, 10%, and 4% training samples. Here, we divided the data into a training set (30%) and a testing set (70%). Then, from the training set, we used all, one-third, and one-seventh point five for training. For testing, in all experiments in this part, we used all data in the testing set. The examples of train and test split on IP dataset with various percentage training samples are shown in Figure 5.
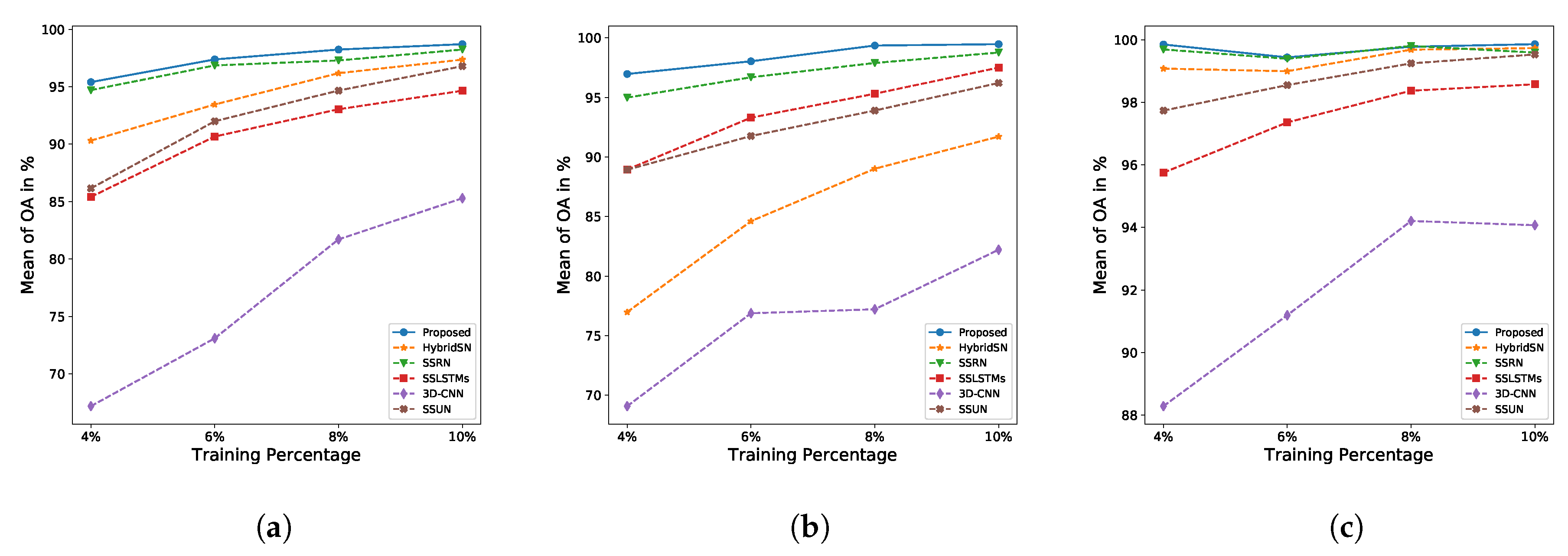
- In our third experiment, this proposed approach is compared to 3D-CNN, SSLSTMs, SSUN, SSRN, and HybridSN by using 10% training samples. We chose 10% training samples because the SSLSTMs and other experiments on SSUN, SSRN, and HybridSN have also been conducted using 10% training samples.
- In our fourth experiment, we compared all of those methods on the smaller training samples, 4%, 6%, and 8%. Besides, because 3D-CNN has been tested using 4% training samples, the use of small labeled samples during training can be used to investigate over-fitting issues.
- In the last experiment, we compared all of those methods on large training samples, 30%. Not only because HybridSN [61] had been tested on 30% training samples but also to investigate under-fitting issues with large training samples.
4.3. Experimental Results
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lu, G.; Fei, B. Medical hyperspectral imaging: A review. J. Biomed. Opt. 2014, 19, 010901. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Sun, C.; Fu, Y.; Kim, M.H.; Huang, H. Hyperspectral Image Reconstruction Using a Deep Spatial-Spectral Prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Shimoni, M.; Haelterman, R.; Perneel, C. Hypersectral Imaging for Military and Security Applications: Combining Myriad Processing and Sensing Techniques. IEEE Geosci. Remote Sens. Mag. 2019, 7, 101–117. [Google Scholar] [CrossRef]
- Stuart, M.B.; McGonigle, A.J.S.; Willmott, J.R. Hyperspectral Imaging in Environmental Monitoring: A Review of Recent Developments and Technological Advances in Compact Field Deployable Systems. Sensors 2019, 19, 3071. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, J.; Sun, D.W.; Pu, H.; Cheng, J.H.; Wei, Q. Advanced Techniques for Hyperspectral Imaging in the Food Industry: Principles and Recent Applications. Annu. Rev. Food Sci. Technol. 2019, 10, 197–220. [Google Scholar] [CrossRef] [PubMed]
- Mahlein, A.K.; Kuska, M.; Behmann, J.; Polder, G.; Walter, A. Hyperspectral Sensors and Imaging Technologies in Phytopathology: State of the Art. Annu. Rev. Phytopathol. 2018, 56, 535–558. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Wu, H.; Wan, D.; Zhu, J. An effective feature selection method for hyperspectral image classification based on genetic algorithm and support vector machine. Knowl. Based Syst. 2011, 24, 40–48. [Google Scholar] [CrossRef]
- Cao, F.; Yang, Z.; Ren, J.; Ling, W.K.; Zhao, H.; Sun, M.; Benediktsson, J.A. Sparse representation-based augmented multinomial logistic extreme learning machine with weighted composite features for spectral–spatial classification of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6263–6279. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Shah, S.A.A.; Bennamoun, M.; Boussaïd, F. Iterative deep learning for image set based face and object recognition. Neurocomputing 2016, 174, 866–874. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Haut, J.M.; Paoletti, M.E.; Plaza, J.; Li, J.; Plaza, A. Active learning with convolutional neural networks for hyperspectral image classification using a new bayesian approach. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6440–6461. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative Adversarial Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar] [CrossRef]
- Zhan, Y.; Hu, D.; Wang, Y.; Yu, X. Semisupervised Hyperspectral Image Classification Based on Generative Adversarial Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 212–216. [Google Scholar] [CrossRef]
- Angelopoulou, T.; Tziolas, N.; Balafoutis, A.; Zalidis, G.; Bochtis, D. Remote Sensing Techniques for Soil Organic Carbon Estimation: A Review. Remote Sens. 2019, 11, 676. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Ye, Y.; Li, X.; Lau, R.Y.; Zhang, X.; Huang, X. Hyperspectral image classification with deep learning models. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5408–5423. [Google Scholar] [CrossRef]
- Liu, B.; Gao, G.; Gu, Y. Unsupervised Multitemporal Domain Adaptation With Source Labels Learning. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1477–1481. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–Spatial Classification of Hyperspectral Imagery with 3D Convolutional Neural Network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Wang, W.; Dou, S.; Jiang, Z.; Sun, L. A Fast Dense Spectral–Spatial Convolution Network Framework for Hyperspectral Images Classification. Remote Sens. 2018, 10, 1068. [Google Scholar] [CrossRef] [Green Version]
- PV, A.; Buddhiraju, K.M.; Porwal, A. Capsulenet-Based Spatial–Spectral Classifier for Hyperspectral Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1849–1865. [Google Scholar] [CrossRef]
- Liu, Q.; Zhou, F.; Hang, R.; Yuan, X. Bidirectional-Convolutional LSTM Based Spectral-Spatial Feature Learning for Hyperspectral Image Classification. Remote Sens. 2017, 9, 1330. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Zhang, L.; Du, B.; Zhang, F. Spectral-Spatial Unified Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5893–5909. [Google Scholar] [CrossRef]
- Koda, S.; Melgani, F.; Nishii, R. Unsupervised Spectral-Spatial Feature Extraction With Generalized Autoencoder for Hyperspectral Imagery. IEEE Geosci. Remote Sens. Lett. 2019, 17, 469–473. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, Y.Q.; Chan, J.C.W. Learning and Transferring Deep Joint Spectral-Spatial Features for Hyperspectral Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4729–4742. [Google Scholar] [CrossRef]
- Hu, W.S.; Li, H.C.; Pan, L.; Li, W.; Tao, R.; Du, Q. Feature Extraction and Classification Based on Spatial-Spectral ConvLSTM Neural Network for Hyperspectral Images. arXiv 2019, arXiv:1905.03577. [Google Scholar]
- Zhou, F.; Hang, R.; Liu, Q.; Yuan, X. Hyperspectral image classification using spectral-spatial LSTMs. Neurocomputing 2019, 328, 39–47. [Google Scholar] [CrossRef]
- Liu, B.; Yu, X.; Zhang, P.; Tan, X.; Wang, R.; Zhi, L. Spectral–spatial classification of hyperspectral image using three-dimensional convolution network. J. Appl. Remote Sens. 2018, 12, 016005. [Google Scholar] [CrossRef]
- Pan, B.; Shi, Z.; Zhang, N.; Xie, S. Hyperspectral Image Classification Based on Nonlinear Spectral-Spatial Network. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1782–1786. [Google Scholar] [CrossRef]
- Hao, S.; Wang, W.; Ye, Y.; Nie, T.; Bruzzone, L. Two-stream deep architecture for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2349–2361. [Google Scholar] [CrossRef]
- Sun, G.; Zhang, X.; Jia, X.; Ren, J.; Zhang, A.; Yao, Y.; Zhao, H. Deep Fusion of Localized Spectral Features and Multi-scale Spatial Features for Effective Classification of Hyperspectral Images. Int. J. Appl. Earth Obs. Geoinf. 2020, 91, 102157. [Google Scholar] [CrossRef]
- Gao, L.; Gu, D.; Zhuang, L.; Ren, J.; Yang, D.; Zhang, B. Combining t-Distributed Stochastic Neighbor Embedding With Convolutional Neural Networks for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1368–1372. [Google Scholar] [CrossRef]
- He, M.; Li, B.; Chen, H. Multi-scale 3D deep convolutional neural network for hyperspectral image classification. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3904–3908. [Google Scholar] [CrossRef]
- Ben Hamida, A.; Benoit, A.; Lambert, P.; Ben Amar, C. 3-D deep learning approach for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef] [Green Version]
- Paoletti, M.E.; Haut, J.M.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.; Li, J.; Pla, F. Capsule Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2145–2160. [Google Scholar] [CrossRef]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 5533–5541. [Google Scholar]
- Lin, J.; Zhao, L.; Li, S.; Ward, R.; Wang, Z.J. Active-Learning-Incorporated Deep Transfer Learning for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4048–4062. [Google Scholar] [CrossRef]
- Alam, F.I.; Zhou, J.; Liew, A.W.C.; Jia, X.; Chanussot, J.; Gao, Y. Conditional Random Field and Deep Feature Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1612–1628. [Google Scholar] [CrossRef] [Green Version]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June 26–1 July 2016; pp. 770–778. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Hanif, M.S.; Bilal, M. Competitive residual neural network for image classification. ICT Express 2020, 6, 28–37. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Ma, L.; Jiang, H.; Zhao, H. Deep residual networks for hyperspectral image classification. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 1824–1827. [Google Scholar]
- Paoletti, M.E.; Haut, J.M.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.J.; Pla, F. Deep pyramidal residual networks for spectral–spatial hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 57, 740–754. [Google Scholar] [CrossRef]
- Kang, X.; Zhuo, B.; Duan, P. Dual-path network-based hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2018, 16, 447–451. [Google Scholar] [CrossRef]
- Aggarwal, H.K.; Majumdar, A. Hyperspectral Unmixing in the Presence of Mixed Noise Using Joint-Sparsity and Total Variation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4257–4266. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 630–645. [Google Scholar]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Khan, S.H.; Rahmani, H.; Shah, S.A.A.; Bennamoun, M. A Guide to Convolutional Neural Networks for Computer Vision; Morgan & Claypool: San Rafael, CA, USA, 2018. [Google Scholar]
- Kim, J.; Song, J.; Lee, J.K. Recognizing and Classifying Unknown Object in BIM Using 2D CNN. In Proceedings of the International Conference on Computer-Aided Architectural Design Futures, Daejeon, Korea, 26–28 June 2019; pp. 47–57. [Google Scholar]
- Parmar, P.; Morris, B. HalluciNet-ing Spatiotemporal Representations Using 2D-CNN. arXiv 2019, arXiv:1912.04430. [Google Scholar]
- Chen, Y.; Zhu, L.; Ghamisi, P.; Jia, X.; Li, G.; Tang, L. Hyperspectral Images Classification with Gabor Filtering and Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2355–2359. [Google Scholar] [CrossRef]
- He, N.; Paoletti, M.E.; Haut, J.M.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Feature extraction with multiscale covariance maps for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 755–769. [Google Scholar] [CrossRef]
- Fang, L.; Liu, G.; Li, S.; Ghamisi, P.; Benediktsson, J.A. Hyperspectral Image Classification With Squeeze Multibias Network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1291–1301. [Google Scholar] [CrossRef]
- Han, X.F.; Laga, H.; Bennamoun, M. Image-based 3D Object Reconstruction: State-of-the-Art and Trends in the Deep Learning Era. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [Green Version]
- Hara, K.; Kataoka, H.; Satoh, Y. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6546–6555. [Google Scholar]
- Gonda, F.; Wei, D.; Parag, T.; Pfister, H. Parallel separable 3D convolution for video and volumetric data understanding. arXiv 2018, arXiv:1809.04096. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6450–6459. [Google Scholar]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5353–5360. [Google Scholar]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. Hybridsn: Exploring 3-d-2-d cnn feature hierarchy for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 277–281. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th international conference on machine learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Baumgardner, M.F.; Biehl, L.L.; Landgrebe, D.A. 220 Band AVIRIS Hyperspectral Image Data Set: June 12, 1992 Indian Pine Test Site 3. 2015. Available online: https://0-doi-org.brum.beds.ac.uk/doi:10.4231/R7RX991C (accessed on 20 January 2020).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Singh, S.; Krishnan, S. Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Lian, X.; Liu, J. Revisit Batch Normalization: New Understanding and Refinement via Composition Optimization. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Okinawa, Japan, 16–18 April 2019. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Category Name | # Pixel |
|---|---|---|
| (a) Indian Pines Dataset | ||
| C1 | Alfafa | 46 |
| C2 | Corn-notil | 1428 |
| C3 | Corn-mintill | 830 |
| C4 | Corn | 237 |
| C5 | Grass-pasture | 483 |
| C6 | Grass-trees | 730 |
| C7 | Grass-pasture-mowed | 28 |
| C8 | Hay-windrowed | 478 |
| C9 | Oats | 20 |
| C10 | Soybean-notil | 972 |
| C11 | Soybean-mintill | 2455 |
| C12 | Soybean-clean | 593 |
| C13 | Wheat | 205 |
| C14 | Woods | 1265 |
| C15 | Building-Grass-Tress | 386 |
| C16 | Stone-Steel-Towers | 93 |
| (b) KSC Dataset | ||
| C1 | Scrub | 761 |
| C2 | Willow swamp | 253 |
| C3 | Cabbage palm hammock | 256 |
| C4 | Cabbage palm | 252 |
| C5 | Slash pine | 161 |
| C6 | Oak | 229 |
| C7 | Hardwood swamp | 105 |
| C8 | Graminoid marsh | 431 |
| C9 | Spartina marsh | 520 |
| C10 | Cattail marsh | 404 |
| C11 | Salt marsh | 419 |
| C12 | Mud flats | 503 |
| C13 | Water | 927 |
| (c) Pavia University Dataset | ||
| C1 | Asphalt | 6631 |
| C2 | Meadows | 18,649 |
| C3 | Gravel | 2099 |
| C4 | Trees | 3064 |
| C5 | Painted metal sheets | 1345 |
| C6 | Bare soil | 5029 |
| C7 | Bitumen | 1330 |
| C8 | Self-Blocking Bricks | 3682 |
| C9 | Shadows | 947 |
| SoP | 21 | 23 | 25 | 27 |
|---|---|---|---|---|
| IP | 98.73 ± 0.22 | 98.66 ± 0.29 | 98.77 ± 0.32 | 98.75 ± 0.16 |
| KSC | 97.73 ± 0.47 | 97.95 ± 1.12 | 96.74 ± 1.43 | 98.51 ± 0.31 |
| PU | 99.87 ± 0.06 | 99.46 ± 0.02 | 99.65 ± 1.28 | 99.82 ± 0.39 |
| nPCA | 25 | 30 | 35 | 40 |
|---|---|---|---|---|
| IP | 98.74 ± 0.24 | 98.77 ± 0.32 | 98.82 ± 0.38 | 98.80 ± 0.15 |
| KSC | 99.15 ± 0.18 | 98.51 ± 0.31 | 98.29 ± 0.82 | 98.10 ± 0.88 |
| PU | 99.72 ± 0.50 | 99.87 ± 0.06 | 99.91 ± 0.02 | 99.72 ± 0.47 |
| Training Percentage | Indian Pines | Pavia University | KSC | |||
|---|---|---|---|---|---|---|
| with Mean | w\o Mean | with Mean | w\o Mean | with Mean | w\o Mean | |
| 4% | 95.40 ± 0.79 | 95.07 ± 0.81 | 99.85 ± 0.06 | 99.62 ± 0.55 | 96.97 ± 0.86 | 95.32 ± 1.16 |
| 6% | 97.38 ± 0.58 | 97.37 ± 0.63 | 99.44 ± 1.54 | 99.93 ± 0.03 | 98.04 ± 0.65 | 96.62 ± 1.46 |
| 8% | 98.24 ± 0.50 | 98.14 ± 0.43 | 99.78 ± 0.55 | 99.94 ± 0.05 | 99.36 ± 0.31 | 99.02 ± 0.28 |
| 10% | 98.70 ± 0.26 | 98.81 ± 0.24 | 99.86 ± 0.27 | 99.67 ± 0.74 | 99.48 ± 0.34 | 99.20 ± 0.42 |
| 30% | 99.70 ± 0.10 | 99.75 ± 0.15 | 99.89 ± 0.20 | 99.03 ± 3.04 | 99.96 ± 0.02 | 99.93 ± 0.06 |
| Training | 30% | 10% | 4% | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Dataset | sRN | saRN | TSRN | sRN | saRN | TSRN | sRN | saRN | TSRN |
| IP | 92.16 ± 0.66 | 99.75 ± 0.18 | 99.69 ± 0.15 | 86.61 ± 0.86 | 98.44 ± 0.26 | 99.03 ± 0.24 | 79.94 ± 1.54 | 94.20 ± 0.43 | 95.50 ± 0.87 |
| PU | 98.96 ± 0.08 | 99.97 ± 0.02 | 99.95 ± 0.13 | 98.05 ± 0.19 | 99.84 ± 0.05 | 99.93 ± 0.10 | 96.68 ± 0.14 | 99.56 ± 0.11 | 99.82 ± 0.10 |
| KSC | 95.55 ± 0.77 | 100 ± 0.02 | 99.95 ± 0.05 | 92.52 ± 0.86 | 99.55 ± 0.2 | 99.52 ± 0.29 | 82.42 ± 3.48 | 94.60 ± 1.25 | 95.62 ± 1.27 |
| Label | 3D-CNN [34] | SSLSTMs [27] | SSUN [23] | SSRN [19] | HybridSN [61] | Proposed |
|---|---|---|---|---|---|---|
| OA | 85.29 ± 7.24 | 94.65 ± 0.72 | 96.79 ± 0.36 | 98.24 ± 0.29 | 97.36 ± 0.82 | 98.70 ± 0.25 |
| AA | 81.11 ± 0.12 | 94.47 ± 1.77 | 95.78 ± 2.97 | 91.69 ± 3.46 | 95.70 ± 1.08 | 98.71 ± 0.61 |
| K × 100% | 83.20 ± 0.08 | 93.89 ± 0.82 | 96.33 ± 0.41 | 97.99 ± 0.32 | 96.99 ± 0.93 | 98.52 ± 0.28 |
| C1 | 68.70 ± 0.28 | 99.32 ± 2.05 | 99.51 ± 0.98 | 100 ± 0 | 97.80 ± 3.53 | 98.72 ± 3.83 |
| C2 | 84.30 ± 0.17 | 93.09 ± 1.71 | 94.65 ± 1.33 | 98.63 ± 0.82 | 96.76 ± 1.44 | 98.02 ± 1.08 |
| C3 | 75.50 ± 0.11 | 86.37 ± 1.81 | 96.09 ± 1.87 | 96.82 ± 0.70 | 96.27 ± 2.58 | 97.08 ± 1.72 |
| C4 | 74.50 ± 0.09 | 89.35 ± 4.41 | 94.65 ± 4.90 | 99.20 ± 1.37 | 96.67 ± 2.44 | 99.16 ± 1.22 |
| C5 | 88.80 ± 0.07 | 93.69 ± 3.10 | 94.89 ± 2.09 | 96.95 ± 2.27 | 94.57 ± 3.93 | 99.41 ± 0.36 |
| C6 | 96.00 ± 0.02 | 95.46 ± 0.92 | 99.06 ± 0.78 | 98.19 ± 1.17 | 98.48 ± 0.70 | 99.76 ± 0.26 |
| C7 | 61.90 ± 0.27 | 99.22 ± 1.57 | 93.20 ± 4.75 | 70 ± 45.83 | 88.80 ± 13.24 | 99.15 ± 1.71 |
| C8 | 96.80 ± 0.02 | 98.16 ± 1.73 | 99.81 ± 0.49 | 99.15 ± 2.13 | 99.81 ± 0.39 | 99.98 ± 0.07 |
| C9 | 60.00 ± 0.24 | 90.70 ± 19.01 | 86.67 ± 13.19 | 20.00 ± 40.00 | 86.11 ± 14.33 | 98.50 ± 4.50 |
| C10 | 82.70 ± 0.08 | 96.50 ± 1.42 | 95.18 ± 1.92 | 97.35 ± 1.55 | 97.34 ± 1.29 | 98.19 ± 1.10 |
| C11 | 87.30 ± 0.07 | 96.73 ± 0.85 | 98.13 ± 0.38 | 98.65 ± 0.40 | 98.22 ± 0.89 | 99.32 ± 0.46 |
| C12 | 77.40 ± 0.11 | 88.92 ± 1.58 | 92.85 ± 4.39 | 95.51 ± 1.28 | 93.82 ± 2.73 | 97.87 ± 1.82 |
| C13 | 97.70 ± 0.02 | 93.83 ± 4.27 | 99.57 ± 0.22 | 98.21 ± 2.38 | 99.02 ± 0.94 | 98.76 ± 2.15 |
| C14 | 95.30 ± 0.03 | 98.07 ± 1.03 | 98.66 ± 0.54 | 99.57 ± 0.42 | 99.39 ± 0.40 | 98.98 ± 0.91 |
| C15 | 69.30 ± 0.05 | 96.63 ± 3.98 | 97.32 ± 2.91 | 99.34 ± 0.82 | 95.48 ± 2.81 | 98.44 ± 1.74 |
| C16 | 81.50 ± 0.28 | 95.48 ± 4.10 | 92.26 ± 6.74 | 99.48 ± 0.85 | 92.74 ± 4.95 | 98.11 ± 1.20 |
| Label | 3D-CNN [34] | SSLSTMs [27] | SSUN [23] | SSRN [19] | HybridSN [61] | Proposed |
|---|---|---|---|---|---|---|
| OA | 94.07 ± 0.86 | 98.58±0.23 | 99.53 ± 0.09 | 99.59 ± 0.72 | 99.73 ± 0.11 | 99.86 ± 0.26 |
| AA | 96.54 ± 0.01 | 98.65 ± 0.16 | 99.18 ± 29.9 | 99.31 ± 1.48 | 99.43 ± 0.23 | 99.77 ± 0.54 |
| K × 100% | 92.30 ± 0.01 | 98.11 ± 0.31 | 99.38 ± 0.12 | 99.46 ± 0.95 | 99.65 ± 0.15 | 99.82 ± 0.34 |
| C1 | 96.50 ± 0.01 | 97.47 ± 0.46 | 99.29 ± 0.22 | 99.85 ± 0.17 | 99.91 ± 0.18 | 99.94 ± 0.07 |
| C2 | 95.20 ± 0.01 | 98.95 ± 0.34 | 99.91 ± 0.04 | 99.93 ± 0.07 | 100 ± 0.01 | 99.94 ± 0.06 |
| C3 | 92.20 ± 0.03 | 98.80 ± 0.59 | 97.67 ± 0.74 | 99.56 ± 0.56 | 99.22 ± 0.81 | 98.56 ± 4.09 |
| C4 | 97.20 ± 0.01 | 98.43 ± 0.46 | 99.36 ± 0.29 | 99.66 ± 0.33 | 98.4 ± 0.96 | 99.99 ± 0.03 |
| C5 | 99.90 ± 0 | 99.87 ± 0.15 | 99.93 ± 0.07 | 99.91 ± 0.08 | 99.97±0.06 | 99.84 ± 0.10 |
| C6 | 97.60 ± 0.02 | 98.92 ± 0.51 | 99.89 ± 0.12 | 99.99 ± 0.05 | 99.99 ± 0.01 | 100 ± 0 |
| C7 | 95.50 ± 0.02 | 98.36 ± 1.03 | 97.87 ± 1.64 | 95.67 ± 12.94 | 100 ± 0 | 99.73 ± 0.75 |
| C8 | 95.40 ± 0.02 | 97.67 ± 0.60 | 99.19 ± 0.36 | 99.28 ± 1.11 | 99.41 ± 0.45 | 99.92 ± 0.08 |
| C9 | 99.40 ± 0.01 | 99.44 ± 0.50 | 99.54 ± 0.35 | 99.92 ± 0.12 | 97.98 ± 0.95 | 100 ± 0 |
| Label | 3D-CNN [34] | SSLSTMs [27] | SSUN [23] | SSRN [19] | HybridSN [61] | Proposed |
|---|---|---|---|---|---|---|
| OA | 82.21 ± 2.96 | 97.51 ± 0.63 | 96.22 ± 0.86 | 98.77 ± 0.75 | 91.72 ± 1.52 | 99.48 ± 0.32 |
| AA | 71.68 ± 0.12 | 97.36 ± 0.69 | 94.65 ± 2.87 | 98.10 ± 1.13 | 88.94 ± 1.53 | 99.04 ± 0.46 |
| K × 100% | 80.20 ± 0.03 | 97.22 ± 0.71 | 95.79 ± 0.96 | 98.63 ± 0.83 | 90.77 ± 1.69 | 99.42 ± 0.36 |
| C1 | 92.40 ± 0.03 | 96.65 ± 1.73 | 97.12 ± 0.98 | 100 ± 0 | 95.68 ± 4.17 | 100 ± 0 |
| C2 | 84.20 ± 0.08 | 97.57 ± 2.39 | 94.25 ± 4.04 | 96.90 ± 7.10 | 76.99 ± 5.48 | 99.77 ± 0.43 |
| C3 | 43.00 ± 0.27 | 96.75 ± 2.76 | 95.05 ± 3.41 | 100 ± 0 | 90.35 ± 3.60 | 97.17 ± 4.41 |
| C4 | 33.50 ± 0.16 | 98.41 ± 1.38 | 89.08 ± 5.15 | 88.86 ± 11.12 | 70.40 ± 5.30 | 98.39 ± 2.69 |
| C5 | 34.70 ± 0.19 | 97.55 ± 2.52 | 89.93 ± 8.78 | 96.66 ± 5.93 | 97.24 ± 3.26 | 97.91 ± 4.81 |
| C6 | 40.90 ± 0.22 | 97.82 ± 2.84 | 79.56 ± 3.851 | 99.90 ± 0.30 | 81.89 ± 6.60 | 99.19 ± 1.42 |
| C7 | 59.30 ± 0.31 | 96.34 ± 4.93 | 98.19 ± 1.43 | 93.56 ± 10.79 | 82.23 ± 6.73 | 96.02 ± 4.26 |
| C8 | 75.60 ± 0.08 | 95.27 ± 2.83 | 93.61 ± 2.73 | 99.54 ± 0.76 | 93.40 ± 3.81 | 99.62 ± 0.35 |
| C9 | 84.10 ± 0.09 | 96.93 ± 2.34 | 98.25 ± 2.60 | 100 ± 0 | 88.29 ± 4.40 | 99.62 ± 0.42 |
| C10 | 94.40 ± 0.04 | 97.28 ± 3.23 | 96.95 ± 2.45 | 100 ± 0 | 90.08 ± 4.19 | 99.89 ± 0.33 |
| C11 | 97.70 ± 0.02 | 98.21 ± 1.35 | 98.86 ± 1.11 | 99.92 ± 0.24 | 97.19 ± 2.55 | 99.90 ± 0.32 |
| C12 | 92.10 ± 0.02 | 97.06 ± 1.52 | 99.56 ± 0.83 | 99.93 ± 0.20 | 92.50 ± 3.78 | 100 ± 0 |
| C13 | 99.90 ± 0 | 99.88 ± 0.14 | 100 ± 0 | 100 ± 0 | 100 ± 0 | 100 ± 0 |
| Fold | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | OA-Mean and Std |
|---|---|---|---|---|---|---|---|---|---|---|---|
| OA | |||||||||||
| Proposed | 99.80 | 99.71 | 99.61 | 99.72 | 99.57 | 99.54 | 99.69 | 99.85 | 99.68 | 99.79 | 99.70 ± 0.10 |
| HybridSN | 99.53 | 99.71 | 99.57 | 99.61 | 99.68 | 99.75 | 99.83 | 99.53 | 99.67 | 99.64 | 99.65 ± 0.09 |
| SSRN | 98.89 | 99.79 | 99.53 | 99.26 | 99.50 | 99.68 | 99.04 | 99.33 | 99.46 | 99.48 | 99.40 ± 0.26 |
| SSUN | 99.60 | 99.48 | 99.57 | 99.46 | 99.57 | 99.46 | 99.67 | 99.61 | 99.74 | 99.55 | 99.57 ± 0.09 |
| SSLSTMs | 99.16 | 99.19 | 99.07 | 99.15 | 98.94 | 99.23 | 97.09 | 98.91 | 99.4 | 99.32 | 98.95 ± 0.64 |
| 3D-CNN | 95.15 | 95.89 | 92.42 | 95.47 | 94.51 | 95.55 | 95.86 | 95.26 | 95.41 | 95.33 | 95.09 ± 0.96 |
| AA | |||||||||||
| Proposed | 99.89 | 99.66 | 99.68 | 99.73 | 99.61 | 99.58 | 99.77 | 99.82 | 99.65 | 99.58 | 99.70 ± 0.10 |
| HybridSN | 99.04 | 99.50 | 98.82 | 99.44 | 99.62 | 99.69 | 99.71 | 99.03 | 99.61 | 99.07 | 99.35 ± 0.31 |
| SSRN | 80.29 | 99.64 | 92.98 | 91.55 | 93.18 | 93.20 | 86.22 | 91.96 | 92.79 | 97.99 | 91.98 ± 5.19 |
| SSUN | 99.60 | 99.14 | 99.47 | 99.26 | 99.34 | 99.50 | 99.24 | 99.61 | 99.50 | 99.53 | 99.42 ± 0.15 |
| SSLSTMs | 99.04 | 99.12 | 98.26 | 99.34 | 98.77 | 97.10 | 97.66 | 98.65 | 99.55 | 99.31 | 98.68 ± 0.75 |
| 3D-CNN | 96.57 | 97.33 | 94.04 | 95.42 | 95.20 | 96.75 | 97.02 | 96.81 | 96.57 | 96.01 | 96.17 ± 0.96 |
| K × 100% | |||||||||||
| Proposed | 99.78 | 99.67 | 99.56 | 99.68 | 99.51 | 99.48 | 99.65 | 99.83 | 99.63 | 99.76 | 99.66 ± 0.11 |
| HybridSN | 99.46 | 99.67 | 99.51 | 99.56 | 99.63 | 99.71 | 99.81 | 99.46 | 99.62 | 99.59 | 99.60 ± 0.11 |
| SSRN | 98.73 | 99.76 | 99.46 | 99.16 | 99.43 | 99.63 | 98.90 | 99.24 | 99.38 | 99.41 | 99.31 ± 0.30 |
| SSUN | 99.54 | 99.41 | 99.51 | 99.38 | 99.51 | 99.38 | 99.62 | 99.56 | 99.70 | 99.49 | 99.51 ± 0.10 |
| SSLSTMs | 99.05 | 99.08 | 98.94 | 99.03 | 98.79 | 99.13 | 96.68 | 98.76 | 99.32 | 99.22 | 98.80 ± 0.73 |
| 3D-CNN | 94.49 | 95.33 | 91.40 | 94.85 | 93.75 | 94.95 | 95.29 | 94.61 | 94.78 | 94.69 | 94.41 ± 1.09 |
| Fold | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | OA-Mean and Std |
|---|---|---|---|---|---|---|---|---|---|---|---|
| OA | |||||||||||
| Proposed | 99.96 | 99.96 | 99.98 | 99.98 | 99.99 | 99.84 | 99.34 | 99.99 | 99.92 | 99.95 | 99.89 ± 0.19 |
| HybridSN | 99.97 | 99.96 | 99.97 | 99.96 | 99.99 | 100 | 99.96 | 99.97 | 99.92 | 99.98 | 99.97 ± 0.02 |
| SSRN | 99.93 | 99.83 | 99.83 | 99.92 | 99.81 | 99.89 | 99.82 | 99.86 | 97.44 | 99.58 | 99.59 ± 0.72 |
| SSUN | 99.94 | 99.95 | 99.92 | 99.91 | 99.91 | 99.94 | 99.9 | 99.91 | 99.94 | 99.96 | 99.93 ± 0.02 |
| SSLSTMs | 99.85 | 99.80 | 99.83 | 99.76 | 99.72 | 99.79 | 99.68 | 99.86 | 99.70 | 99.82 | 99.78 ± 0.06 |
| 3D-CNN | 95.76 | 95.80 | 95.80 | 95.30 | 95.75 | 95.76 | 94.75 | 95.94 | 95.92 | 94.06 | 95.48 ± 0.58 |
| AA | |||||||||||
| Proposed | 99.96 | 99.94 | 99.94 | 99.97 | 100 | 99.77 | 98.70 | 99.99 | 99.95 | 99.97 | 99.82 ± 0.38 |
| HybridSN | 99.97 | 99.93 | 99.95 | 99.94 | 99.97 | 100 | 99.93 | 99.95 | 99.81 | 99.96 | 99.94 ± 0.05 |
| SSRN | 99.93 | 99.74 | 99.85 | 99.86 | 99.81 | 99.92 | 99.84 | 99.74 | 94.88 | 99.48 | 99.31 ± 1.48 |
| SSUN | 99.90 | 99.91 | 99.81 | 99.84 | 99.82 | 99.92 | 99.82 | 99.79 | 99.87 | 99.94 | 99.86 ± 0.05 |
| SSLSTMs | 99.88 | 99.74 | 99.81 | 99.79 | 99.68 | 99.73 | 99.66 | 99.86 | 99.67 | 99.85 | 99.77 ± 0.08 |
| 3D-CNN | 97.46 | 97.69 | 97.54 | 97.00 | 97.68 | 97.54 | 96.91 | 97.77 | 97.79 | 94.80 | 97.22 ± 0.86 |
| K × 100% | |||||||||||
| Proposed | 99.95 | 99.94 | 99.97 | 99.98 | 99.99 | 99.78 | 99.12 | 99.98 | 99.90 | 99.93 | 99.85 ± 0.25 |
| HybridSN | 99.96 | 99.94 | 99.96 | 99.95 | 99.98 | 100 | 99.94 | 99.96 | 99.90 | 99.97 | 99.96 ± 0.03 |
| SSRN | 99.91 | 99.78 | 99.77 | 99.90 | 99.75 | 99.85 | 99.77 | 99.81 | 96.62 | 99.45 | 99.46 ± 0.95 |
| SSUN | 99.92 | 99.93 | 99.89 | 99.88 | 99.88 | 99.92 | 99.87 | 99.88 | 99.92 | 99.95 | 99.90 ± 0.03 |
| SSLSTMs | 99.80 | 99.74 | 99.77 | 99.68 | 99.63 | 99.72 | 99.58 | 99.82 | 99.60 | 99.77 | 99.71 ± 0.08 |
| 3D-CNN | 94.46 | 94.50 | 94.51 | 93.87 | 94.45 | 94.47 | 93.19 | 94.69 | 94.66 | 92.25 | 94.11 ± 0.75 |
| Fold | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | OA-Mean and Std |
|---|---|---|---|---|---|---|---|---|---|---|---|
| OA | |||||||||||
| Proposed | 99.95 | 99.97 | 100 | 99.95 | 99.97 | 99.97 | 99.92 | 99.95 | 99.92 | 99.95 | 99.96 ± 0.02 |
| HybridSN | 99.01 | 99.37 | 99.23 | 99.48 | 98.96 | 98.93 | 98.85 | 98.96 | 99.59 | 99.26 | 99.16 ± 0.24 |
| SSRN | 99.67 | 100 | 100 | 100 | 99.84 | 99.37 | 98.27 | 100 | 99.97 | 99.64 | 99.68 ± 0.51 |
| SSUN | 99.10 | 99.31 | 99.67 | 98.68 | 99.56 | 99.31 | 99.29 | 99.29 | 99.01 | 99.40 | 99.26 ± 0.27 |
| SSLSTMs | 99.78 | 99.95 | 99.56 | 99.73 | 99.95 | 99.10 | 99.78 | 99.42 | 99.26 | 99.78 | 99.63 ± 0.27 |
| 3D-CNN | 94.60 | 95.39 | 94.76 | 95.34 | 91.89 | 94.24 | 94.57 | 95.45 | 94.46 | 93.15 | 94.39 ± 1.05 |
| AA | |||||||||||
| Proposed | 99.95 | 99.97 | 100 | 99.96 | 99.97 | 99.97 | 99.90 | 99.95 | 99.92 | 99.96 | 99.96 ± 0.03 |
| HybridSN | 98.36 | 99.18 | 98.63 | 99.17 | 98.33 | 98.31 | 98.38 | 98.42 | 99.35 | 98.92 | 98.71 ± 0.39 |
| SSRN | 99.51 | 100 | 100 | 100 | 99.75 | 99.09 | 97.97 | 100 | 99.96 | 99.44 | 99.57 ± 0.61 |
| SSUN | 98.25 | 98.73 | 99.27 | 97.59 | 99.28 | 98.61 | 98.43 | 98.98 | 98.26 | 99.03 | 98.64 ± 0.50 |
| SSLSTMs | 99.74 | 99.85 | 99.44 | 99.62 | 99.95 | 98.95 | 99.66 | 99.49 | 99.34 | 99.78 | 99.58 ± 0.28 |
| 3D-CNN | 92.57 | 93.37 | 92.01 | 92.70 | 87.23 | 91.71 | 91.82 | 93.09 | 91.58 | 89.46 | 91.55 ± 1.77 |
| K × 100% | |||||||||||
| Proposed | 99.94 | 99.97 | 100 | 99.94 | 99.97 | 99.97 | 99.91 | 99.94 | 99.91 | 99.94 | 99.95 ± 0.03 |
| HybridSN | 98.90 | 99.30 | 99.15 | 99.42 | 98.84 | 98.81 | 98.72 | 98.84 | 99.54 | 99.18 | 99.07 ± 0.27 |
| SSRN | 99.63 | 100 | 100 | 100 | 99.82 | 99.30 | 98.08 | 100 | 99.97 | 99.60 | 99.64 ± 0.57 |
| SSUN | 98.99 | 99.24 | 99.63 | 98.53 | 99.51 | 99.24 | 99.21 | 99.21 | 98.90 | 99.33 | 99.18 ± 0.30 |
| SSLSTMs | 99.76 | 99.94 | 99.51 | 99.69 | 99.94 | 98.99 | 99.76 | 99.36 | 99.18 | 99.76 | 99.59 ± 0.30 |
| 3D-CNN | 93.99 | 94.88 | 94.18 | 94.81 | 90.98 | 93.60 | 93.97 | 94.94 | 93.85 | 92.39 | 93.76 ± 1.17 |
| Method | SSLSTMs | SSUN | SSRN | HybridSN | Proposed |
|---|---|---|---|---|---|
| # parameters | 343,072 | 949,648 | 346,784 | 5,122,176 | 239,672 |
| Model Size | 6.7 MB | 9.6 MB | 2.9 MB | 61.5 MB | 3.3 MB |
| Depth | 4 | 10 | 9 | 7 | 24 |
| Training Time | 300 s | 66 s | 150 s | 120 s | 60 s |
| Testing Time | 5.3 s | 3.03 s | 4.1 s | 2.57 s | 3.1 s |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khotimah, W.N.; Bennamoun, M.; Boussaid, F.; Sohel, F.; Edwards, D. A High-Performance Spectral-Spatial Residual Network for Hyperspectral Image Classification with Small Training Data. Remote Sens. 2020, 12, 3137. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12193137
Khotimah WN, Bennamoun M, Boussaid F, Sohel F, Edwards D. A High-Performance Spectral-Spatial Residual Network for Hyperspectral Image Classification with Small Training Data. Remote Sensing. 2020; 12(19):3137. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12193137
Chicago/Turabian StyleKhotimah, Wijayanti Nurul, Mohammed Bennamoun, Farid Boussaid, Ferdous Sohel, and David Edwards. 2020. "A High-Performance Spectral-Spatial Residual Network for Hyperspectral Image Classification with Small Training Data" Remote Sensing 12, no. 19: 3137. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12193137