Upscaling Household Survey Data Using Remote Sensing to Map Socioeconomic Groups in Kampala, Uganda

 ,
, 
 , , and
, , and 
Abstract
:
1. Introduction
- Which socioeconomic groups are present in the city?
- How can household surveys be upscaled using remote sensing to locate where socioeconomic groups are residing in the greater metropolitan area?
2. Materials and Methods
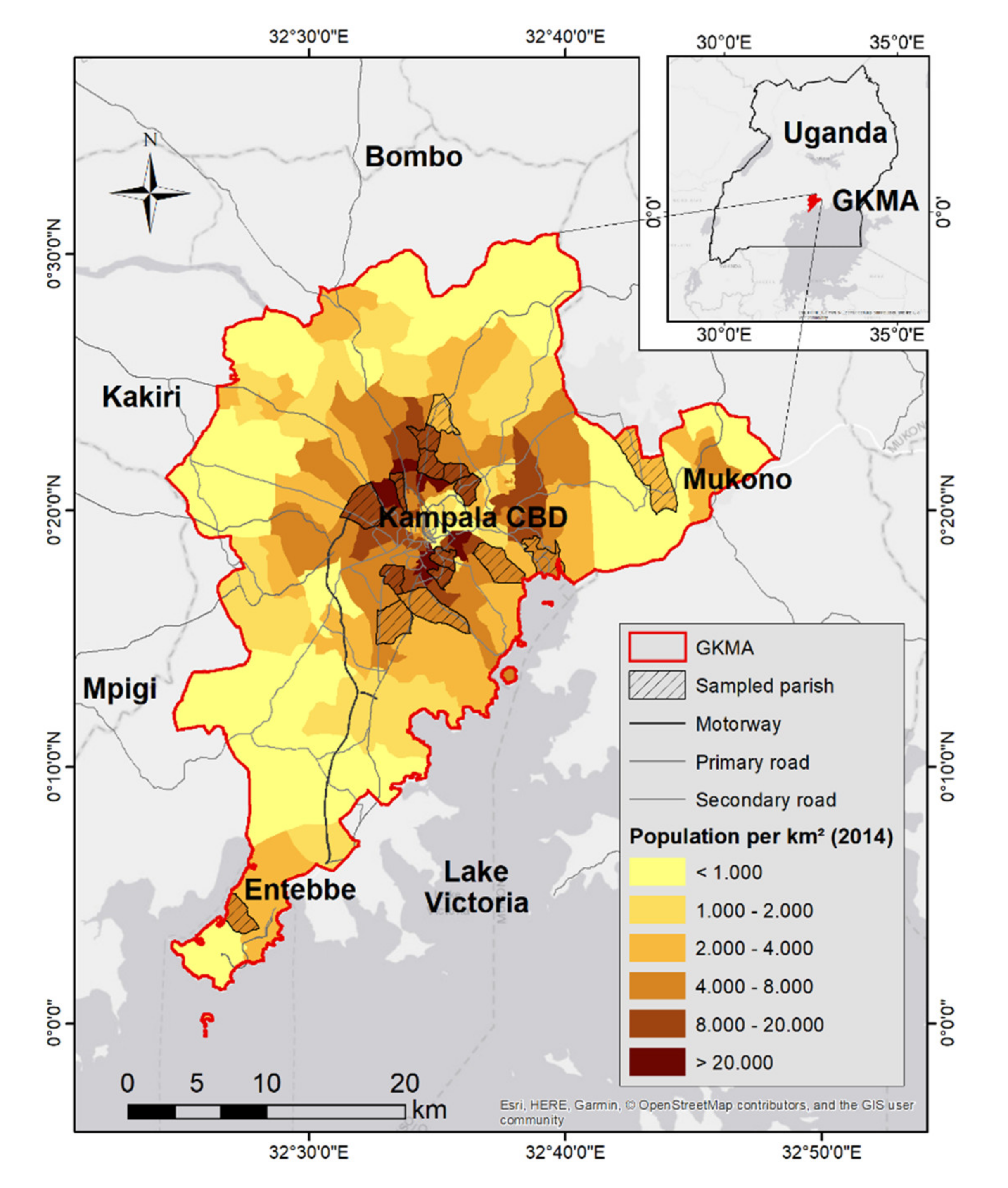
2.1. Study Area: The Greater Kampala Metropolitan Area
2.2. Household Surveys
2.3. Socioeconomic Survey Data Clustering
2.4. Remote Sensing Classification of Residential BUA
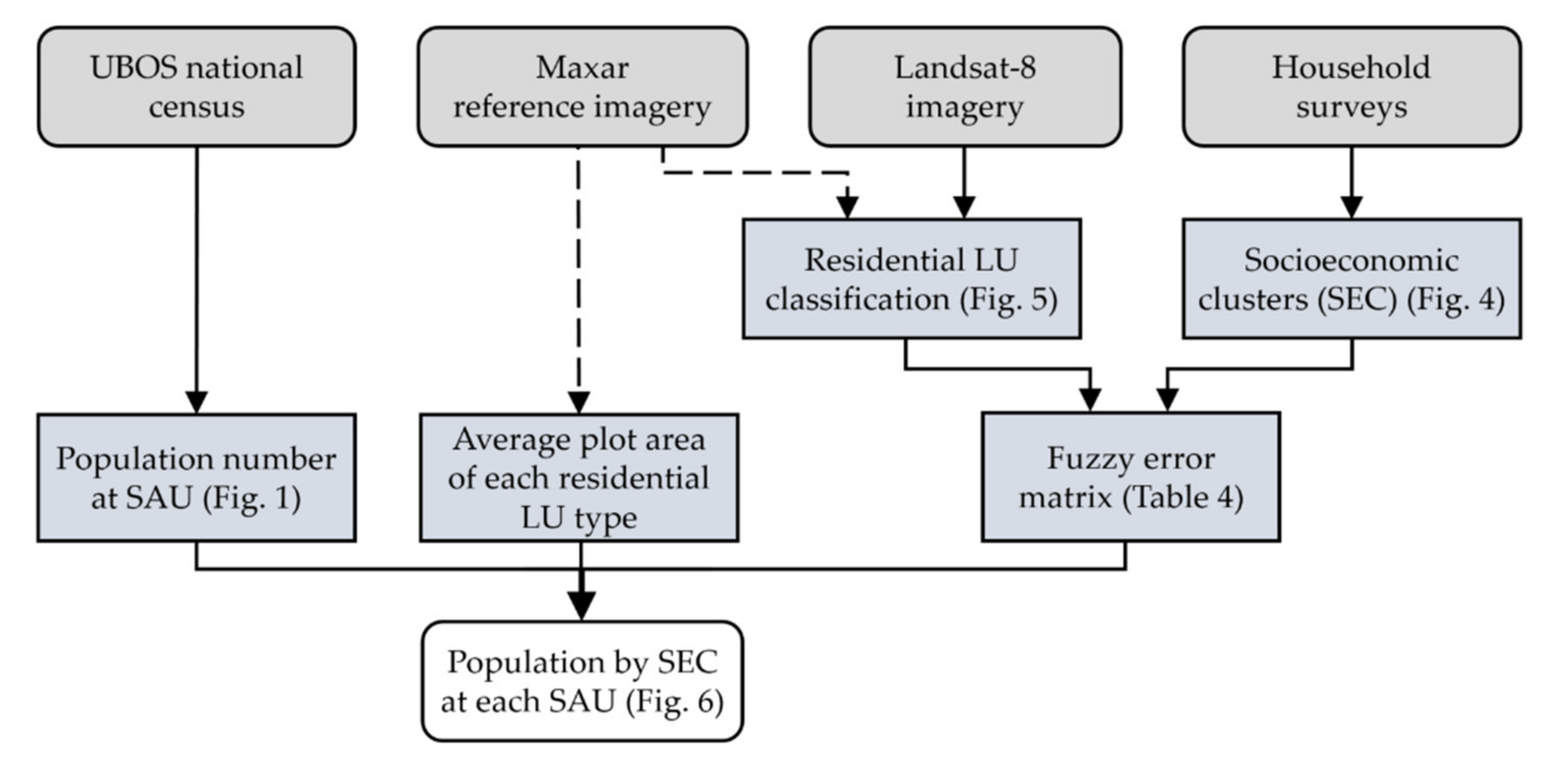
2.5. Upscaling Socioeconomic Clustered Data Using the Remote Sensing Classification
3. Results
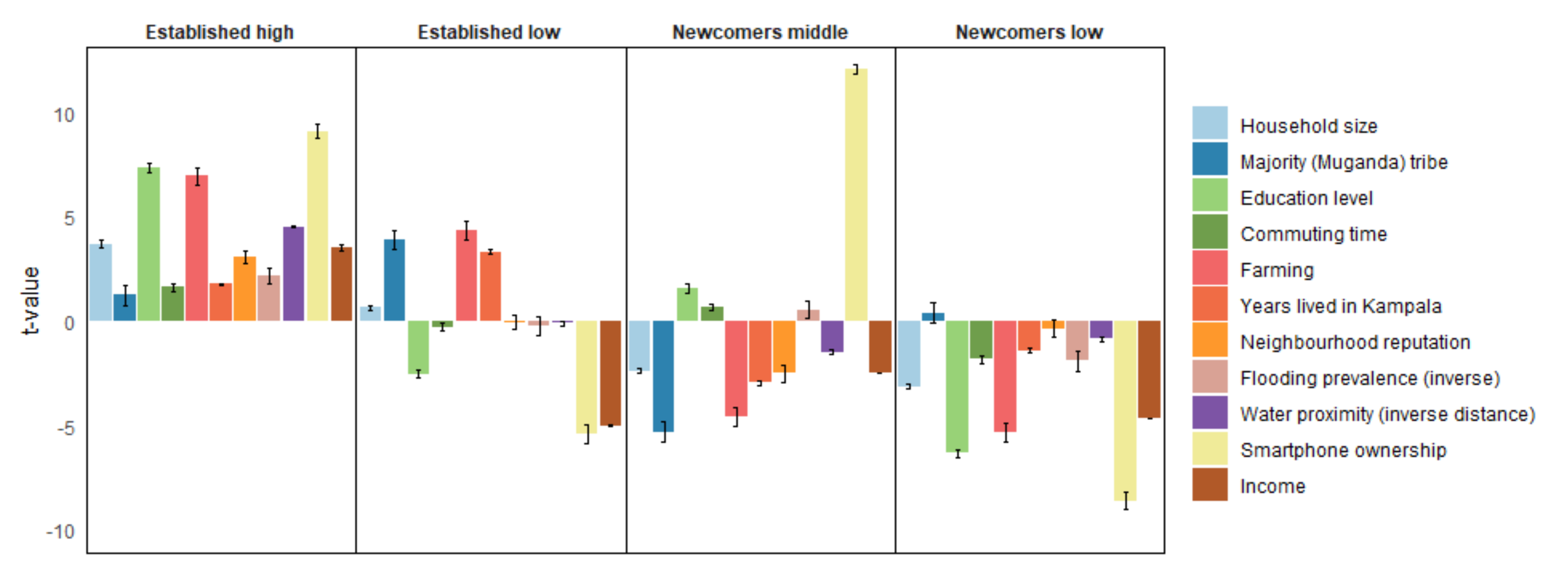
3.1. Socioeconomic Clustering
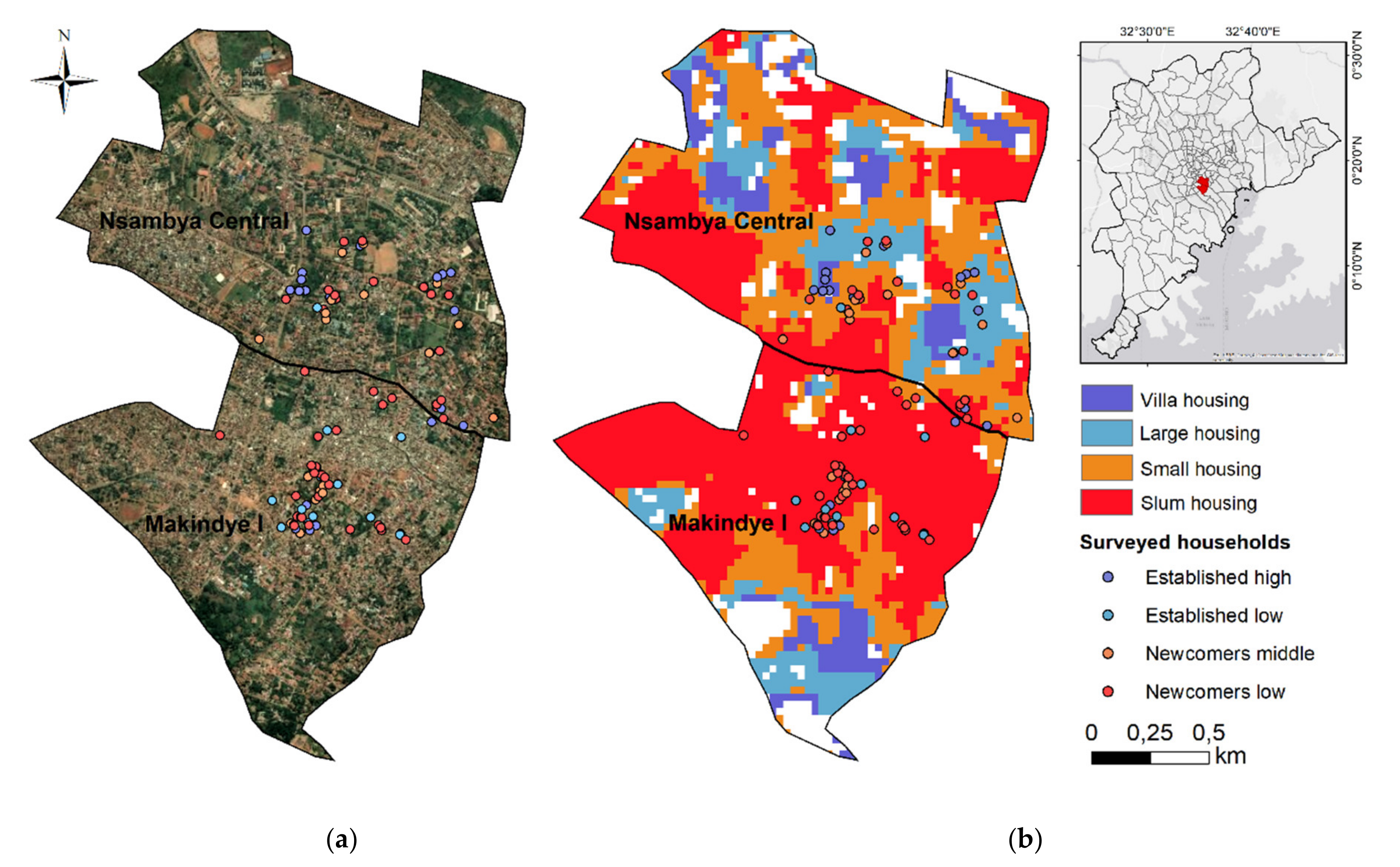
3.2. Residential Land Use Classification
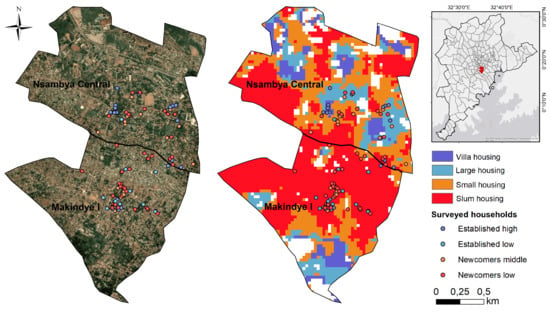
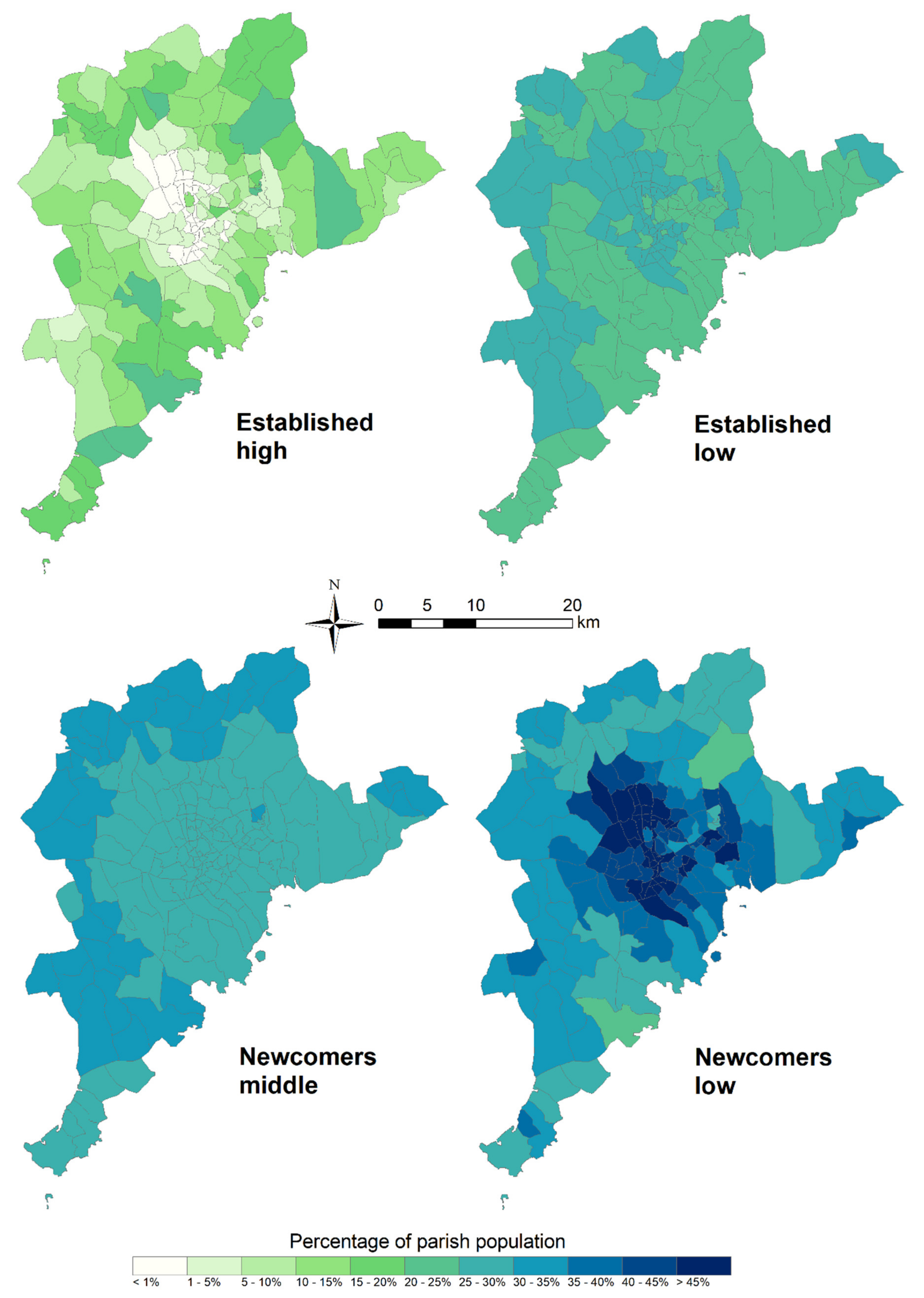
3.3. Socioeconomic Population Maps
4. Discussion
4.1. Which Socioeconomic Groups Are Present in the City?
4.2. How Can Household Surveys Be Upscaled Using Remote Sensing to Locate Where Socioeconomic Groups Are Residing in the Greater Metropolitan Area?
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Validation Points | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Pixel Value | Villa Housing | Large Housing | Small Housing | Slum Housing | Industry | Water | Other | Total (Pixels) | |
| ML classification | Villa housing | 49 * | 23 ** | 14 | 2 | 6 | 0 | 5 | 99 |
| Large housing | 22 ** | 48 * | 13 ** | 0 | 13 | 0 | 6 | 102 | |
| Small housing | 28 | 34 ** | 48 * | 3 ** | 14 | 0 | 9 | 136 | |
| Slum housing | 2 | 6 | 37 ** | 107 * | 14 | 0 | 1 | 167 | |
| Industry | 1 | 0 | 0 | 1 | 50 * | 0 | 2 | 54 | |
| Water | 0 | 0 | 0 | 0 | 0 | 118 * | 0 | 118 | |
| Other | 18 | 9 | 8 | 7 | 23 | 2 | 97 * | 164 | |
| Total (pixels) | 120 | 120 | 120 | 120 | 120 | 120 | 120 | 840 | |
Appendix B
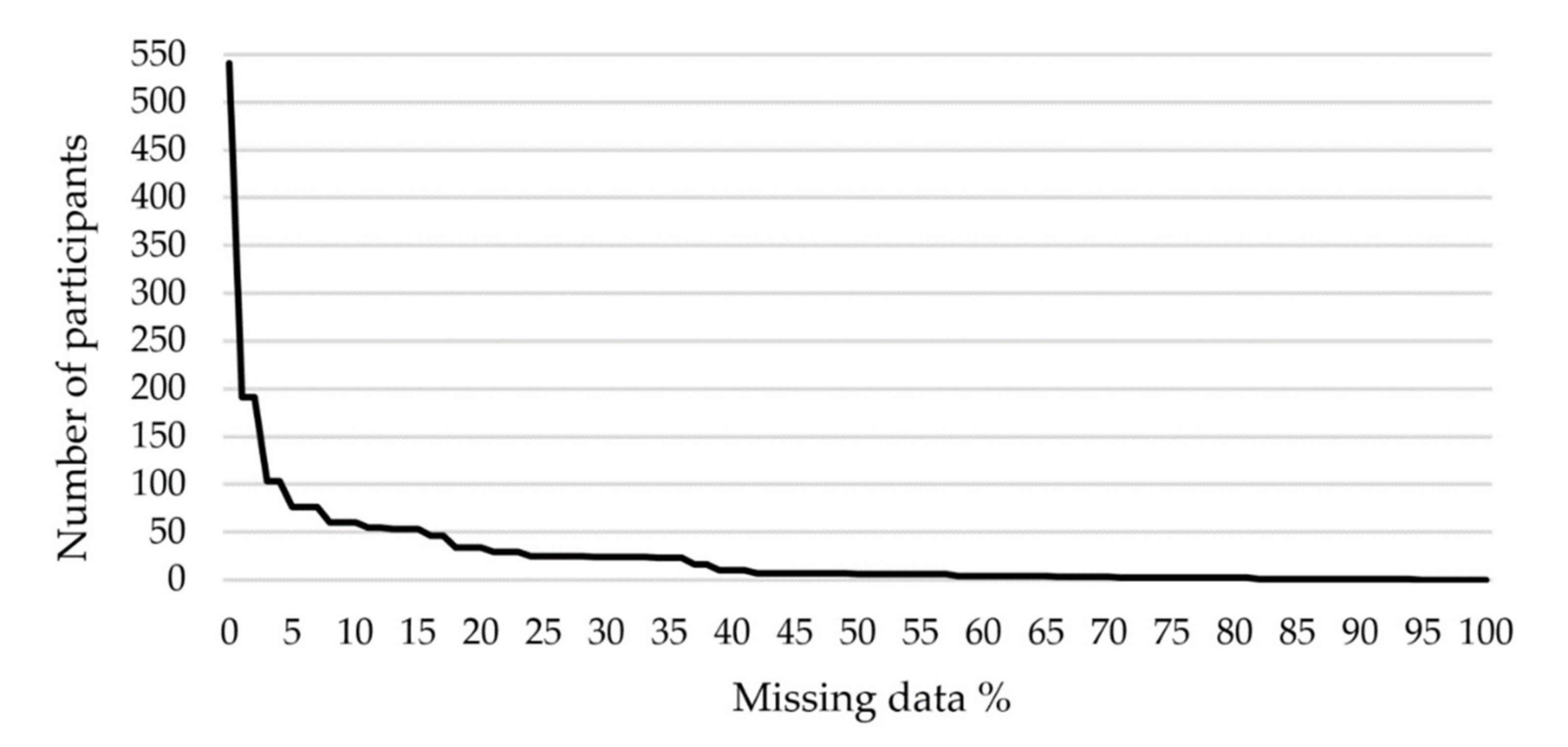
- n is the sample size (541 households, with 2487 individuals).
- p is the population proportion (assumed at 0.5 for complete uncertainty).
- Z the Z-score (1.96 for a confidence interval of 95%).
- e is the error margin (1.97%).
Appendix C

References
- UN-DESA. World Urbanization Prospects: The 2014 Revision; United Nations: New York, NY, USA, 2015. [Google Scholar]
- Vermeiren, K.; Vanmaercke, M.; Beckers, J.; Van Rompaey, A. ASSURE: A model for the simulation of urban expansion and intra-urban social segregation. Int. J. Geogr. Inf. Sci. 2016, 30, 2377–2400. [Google Scholar] [CrossRef]
- Dieleman, F.; Wegener, M. Compact City and Urban Sprawl. Built Environ. 2015, 30, 308–323. [Google Scholar] [CrossRef] [Green Version]
- Gaigné, C.; Riou, S.; Thisse, J.F. Are compact cities environmentally friendly? J. Urban Econ. 2012, 72, 123–136. [Google Scholar] [CrossRef]
- Smets, P.; Salman, T. Countering urban segregation: Theoretical and policy innovations from around the globe. Urban Stud. 2008, 45, 1307–1332. [Google Scholar] [CrossRef]
- Schirmer, P.M.; van Eggermond, M.A.B.; Axhausen, K.W. The role of location in residential location choice models: A review of literature. J. Transp. Land Use 2014, 7, 3–21. [Google Scholar] [CrossRef]
- Marx, C.; Johnson, C.; Lwasa, S. Multiple interests in urban land: Disaster-induced land resettlement politics in Kampala. Int. Plan. Stud. 2020, 25, 289–301. [Google Scholar] [CrossRef]
- Brousse, O.; Georganos, S.; Demuzere, M.; Vanhuysse, S.; Wouters, H.; Wolff, E.; Linard, C.; van Lipzig, N.P.M.; Dujardin, S. Using Local Climate Zones in Sub-Saharan Africa to tackle urban health issues. Urban Clim. 2019, 27, 227–242. [Google Scholar] [CrossRef] [Green Version]
- Kabumbuli, R.; Kiwazi, F.W. Participatory planning, management and alternative livelihoods for poor wetland-dependent communities in Kampala, Uganda. Afr. J. Ecol. 2009, 47, 154–160. [Google Scholar] [CrossRef]
- Cohen, B. Urbanization in developing countries: Current trends, future projections, and key challenges for sustainability. Technol. Soc. 2006, 28, 63–80. [Google Scholar] [CrossRef]
- Abdul-mumin, A.; Siwar, C. Emerging cities and sustainable global environmental management: Livelihood implications in the OIC countries. J. Geogr. Reg. Plan. 2009, 2, 111–120. [Google Scholar] [CrossRef]
- Fox, J.; Rindfuss, R.R.; Walsh, S.J.; Mishra, V. People and the Environment; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2003. [Google Scholar]
- Kim, H.; Woosnam, K.M.; Marcouiller, D.W.; Aleshinloye, K.D.; Choi, Y. Residential mobility, urban preference, and human settlement: A South Korean case study. Habitat Int. 2015, 49, 497–507. [Google Scholar] [CrossRef]
- Keunen, E. Finding a place to live in the city: Analyzing residential choice in Kampala. Hous. Soc. 2020. [Google Scholar] [CrossRef]
- Janusz, K.; Kesteloot, C.; Vermeiren, K.; Van Rompaey, A. Daily mobility, livelihoods and transport policies in Kampala, Uganda: A Hägerstrandian analysis. Tijdschr. Econ. Soc. Geogr. 2019, 110, 412–427. [Google Scholar] [CrossRef]
- Vermeiren, K.; Verachtert, E.; Kasaija, P.; Loopmans, M.; Poesen, J.; Van Rompaey, A. Who could benefit from a bus rapid transit system in cities from developing countries? A case study from Kampala, Uganda. J. Transp. Geogr. 2015, 47, 13–22. [Google Scholar] [CrossRef]
- Akampumuza, P.; Matsuda, H. Weather Shocks and Urban Livelihood Strategies: The Gender Dimension of Household Vulnerability in the Kumi District Of Uganda. J. Dev. Stud. 2017, 53, 953–970. [Google Scholar] [CrossRef]
- Kareem, B.; Lwasa, S. From dependency to Interdependencies: The emergence of a socially rooted but commercial waste sector in Kampala City, Uganda. African J. Environ. Sci. Technol. 2011, 5, 136–142. [Google Scholar] [CrossRef]
- Smit, W.; Lannoy, A.D.; Dover, R.V.H.; Lambert, E.V.; Levitt, N.; Watson, V. Making unhealthy places: The built environment and non-communicable diseases in Khayelitsha, Cape Town. Health Place 2016, 39, 196–203. [Google Scholar] [CrossRef] [Green Version]
- Linderhof, V.; Dijkxhoorn, Y.; Onyango, J.; Fongar, A.; Nalweyiso, M. Nouricity Progress Report: The Kanyanya Food Challenge—Food Systems Mapping; Wageningen University & Research: Wageningen, The Netherlands, 2019. [Google Scholar]
- Battersby, J.; Watson, V. Urban Food Systems Governance and Poverty in African Cities; Battersby, J., Watson, V., Eds.; Routledge: New York, NY, USA, 2019. [Google Scholar]
- Fung-Loy, K.; Van Rompaey, A.; Hemerijckx, L.-M. Detection and Simulation of Urban Expansion and Socioeconomic Segregation in the Greater Paramaribo Region, Suriname. Tijdschr. Voor Econ. Soc. Geogr. 2019, 110, 339–358. [Google Scholar] [CrossRef]
- Duque, J.C.; Patino, J.E.; Ruiz, L.A.; Pardo-Pascual, J.E. Measuring intra-urban poverty using land cover and texture metrics derived from remote sensing data. Landsc. Urban Plan. 2015, 135, 11–21. [Google Scholar] [CrossRef]
- Baud, I.; Kuffer, M.; Pfeffer, K.; Sliuzas, R.; Karuppannan, S. Understanding heterogeneity in metropolitan india: The added value of remote sensing data for analyzing sub-standard residential areas. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, 359–374. [Google Scholar] [CrossRef]
- Taubenbock, H.; Wurm, M.; Setiadi, N.; Gebert, N.; Roth, A.; Strunz, G.; Birkmann, J.; Dech, S. Integrating remote sensing and social science. In Proceedings of the 2009 Joint Urban Remote Sensing Event, Shanghai, China, 20–22 May 2009; pp. 1–7. [Google Scholar] [CrossRef]
- Sabiiti, E.N.; Katongole, C.B. Urban Agriculture: A Response to the Food Supply Crisis in Kampala City, Uganda. In The Security of Water, Food, Energy and Liveability of Cities; Maheshwari, B., Purohit, R., Malano, H., Singh, V.P., Amerasinghe, P., Eds.; Springer Science+Business Media: Dordrecht, The Netherlands, 2014; pp. 233–242. [Google Scholar]
- Hall, O. Remote sensing in social science research. Open Remote Sens. J. 2010, 3, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Wentzel, M.; Viljoen, J.; Kok, P. Contemporary South African migration patterns and intentions. In Migration and Development in Africa: An Overview; Kok, P., Gelderblom, D., Oucho, J., Eds.; HSRC Press: Cape Town, South Africa, 2006; pp. 171–204. [Google Scholar]
- De Soler, L.S.; Verburg, P.H. Combining remote sensing and household level data for regional scale analysis of land cover change in the Brazilian Amazon. Reg. Environ. Chang. 2010, 10, 371–386. [Google Scholar] [CrossRef] [Green Version]
- Vermeiren, K.; Van Rompaey, A.; Loopmans, M.; Serwajja, E.; Mukwaya, P. Urban growth of Kampala, Uganda: Pattern analysis and scenario development. Landsc. Urban Plan. 2012, 106, 199–206. [Google Scholar] [CrossRef]
- UBOS. Uganda National Population and Housing Census 2014 Main Report; UBOS: Kampala, Uganda, 2014. [Google Scholar]
- The World Bank. From Regulators to Enablers: The Role of City Governments in Economic Development of Greater Kampala; The World Bank Group: Washington, DC, USA, 2018. [Google Scholar]
- NEMA. Uganda: Atlas of Our Changing Environment; UNEP-GRID: Arendal, Norway, 2009. [Google Scholar]
- Herrin, W.E.; Knight, J.R.; Balihuta, A.M. Migration and wealth accumulation in Uganda. J. Real Estate Financ. Econ. 2009, 39, 165–179. [Google Scholar] [CrossRef]
- Mukwaya, P.; Bamutaze, Y.; Mugarura, S.; Benson, T. Rural—Urban Transformation in Uganda. In Proceedings of the Understanding Economic Transformation in Sub-Saharan Africa, Accra, Ghana, 10–11 May 2011. [Google Scholar]
- UN-DESA. World Population Prospects 2017—Volume II: Demographic Profiles; United Nations: New York, NY, USA, 2017. [Google Scholar]
- Atukunda, G.; Maxwell, D. Farming in the City of Kampala: Issues for Urban Management. Afr. Urban Q. 1996, 11, 264–276. [Google Scholar]
- Hennig, C.; Liao, T.F. How to find an appropriate clustering for mixed-type variables with application to socio-economic stratification. J. R. Stat. Soc. Ser. C Appl. Stat. 2013, 62, 309–369. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z. Extension to the k-means algorithm for clustering large data sets with categorical values. Data Min. Knowl. Discov. 1998, 304, 283–304. [Google Scholar] [CrossRef]
- Szepannek, G. ClustMixType: User-friendly clustering of mixed-type data in R. R. J. 2018, 10, 200–208. [Google Scholar] [CrossRef]
- Stekhoven, D.J.; Buehlmann, P. MissForest—Non-parametric missing value imputation for mixed-type data. Bioinformatics 2012, 28, 112–118. [Google Scholar] [CrossRef] [Green Version]
- Schowengerdt, R.A. Remote Sensing: Models and Methods for Image Processing, 3rd ed.; Elsevier Inc.: San Diego, CA, USA, 2007. [Google Scholar]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data, 3rd ed.; CRC Press; Taylor & Francis Group: Boca Raton, FL, USA, 2019. [Google Scholar]
- Zandbergen, P.A. Ensuring Confidentiality of Geocoded Health Data: Assessing Geographic Masking Strategies for Individual-Level Data. Adv. Med. 2014, 2014, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Van Vliet, J.; Birch-Thomsen, T.; Gallardo, M.; Hemerijckx, L.-M.; Hersperger, A.M.; Li, M.; Tumwesigye, S.; Twongyirwe, R.; Van Rompaey, A. Bridging the rural-urban dichotomy in land use science. J. Land Use Sci. 2020. [Google Scholar] [CrossRef]
- Taubenböck, H.; Kraff, N.J.; Wurm, M. The morphology of the Arrival City—A global categorization based on literature surveys and remotely sensed data. Appl. Geogr. 2018, 92, 150–167. [Google Scholar] [CrossRef]
- Xu, M.; Cao, C.; Jia, P. Mapping Fine-Scale Urban Spatial Population Distribution Based on High-Resolution Stereo Pair. Remote Sens. 2020, 12, 608. [Google Scholar] [CrossRef] [Green Version]
- Pan, W.K.Y.; Walsh, S.J.; Bilsborrow, R.E.; Frizzelle, B.G.; Erlien, C.M.; Baquero, F. Farm-level models of spatial patterns of land use and land cover dynamics in the Ecuadorian Amazon. Agric. Ecosyst. Environ. 2004, 101, 117–134. [Google Scholar] [CrossRef]
- Cochran, W.G. Sampling Techniques, 2nd ed.; John Wiley and Sons, Inc: New York, NY, USA, 1963. [Google Scholar]
- Farajollahi, A.; Asgari, H.R.; Ownagh, M.; Mahboubi, M.R.; Mahini, A.S. Socio-Economic Factors Influencing Land Use Changes in Maraveh Tappeh Region, Iran. Ecopersia 2017, 5, 1683–1697. [Google Scholar] [CrossRef]
- Khonje, A.A. A landscape design approach for urban household food security; Assessing people’s attitudes and opinions towards residential landscape design for food production—A case of Lilongwe City, Malawi. Acta Hortic. 2017, 1181, 49–54. [Google Scholar] [CrossRef]
- Gamer, M.; Lemon, J.; Fellows, I.; Singh, P. Package ‘irr’: Various Coefficients of Interrater Reliability and Agreement. Available online: http://cran.cc.uoc.gr/mirrors/CRAN/web/packages/irr/irr.pdf (accessed on 21 October 2020).







| Study | Region | Method | Criteria/Indicators | Residential Land Use Classes |
|---|---|---|---|---|
| Keunen (2020) [14] referring SITU-Transitions (2018) | Kampala, Uganda (cross section) | GIS mapping | Street layout, housing density, plot size, plot vegetation coverage, house size, roofing materials. | Type A Type B Type C Type D |
| Fung-Loy et al. (2019) [22] | Paramaribo, Suriname | Manual classification | Plot size, house size, street type, swimming pools, plot demarcation. | Rich Middle Middle to low Poor |
| Brousse et al. (2019) [8] | Kampala, Uganda | Local Climate Zones (LCZ) classification algorithm | Height and density of built-up fabric, vegetation coverage. | LCZ 8: Large low-rise LCZ 6: Open low-rise LCZ 2: Compact mid-rise LCZ 3: Compact low-rise LCZ 7: Lightweight low-rise |
| Vermeiren et al. (2016) [2] | Kampala, Uganda | Manual estimation | Plot size, housing quality, census data, field observations. | Rich Middle income Poor Extreme poor |
| Duque et al. (2015) [23] | Medellin, Colombia | Slum Index estimation model | Road entropy, vegetation coverage, profile convexity, road density, soil coverage, roofing materials. | Slum Index: Low-Low Slum Index: Low-High Slum Index: High-Low Slum Index: High-High |
| Baud et al. (2010) [24] | Delhi, India (12 wards) | Visual image interpretation | Street layout, green space, built-up density, building size. | Formal areas Basic built-up Informal built-up A Informal built-up B |
| Taubenböck et al. (2009) [25] | Padang, Indonesia | Object-oriented methodology and manual enhancement | Built-up density, average house size, average building height, location. | High class areas Middle class areas Low class areas Suburbs Slums |
| Variable Collection | Numeric Variables | Categorical Variables |
|---|---|---|
| Household characteristics (42 variables) | Total number of household members Number of children (< 18 y.o.) Number of adult women (≥ 18 y.o.) Average commuting time Average education level Number of years lived in Kampala | Household tribe (N) Most spoken language (N) Urban agricultural activity (B) Housing type (N) Roofing type (N) Toilet type (N) Road type in front of home (N) Water source (13 dummy var.) (B) Energy source (9 dummy var.) (B) Cooking energy source (7 dummy var.) (B) |
| Neighborhood characteristics (9 variables) | Distance to nearest water source | Parish name (N) Neighborhood reputation (O) Neighborhood cleanliness (O) Neighborhood safety (O) Gated home infrastructure (O) Tarmacked road infrastructure (O) Flooding prevalence (O) Overall happiness in neighborhood (O) |
| Income and ownership (20 variables) | Income (2 var.) Workers employed at household Food expenditure (2 var.) Vehicle ownership (5 var.) | Tenure status (N) Ownership of air-conditioning (B) Ownership of a radio (B) Ownership of a television (B) Online activity (3 var.: internet, e-mail, social media) (B) Ownership of a telephone (3 var.: basic mobile phone, home phone, smartphone) (B) |
| j = Columns (Clustered Survey) | Row Total | |||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | k | ni+ | ||
| i = Rows (Maximum likelihood classification) | 1 | n11 * | n12 | n13 | n1k | n1+ |
| 2 | n21 * | n22 * | n23 ** | n2k | n2+ | |
| 3 | n31 | n32 * | n33 * | n3k ** | n3+ | |
| k | nk1 | nk2 ** | nk3 * | nkk * | nk+ | |
| Column Total | n+j | n+1 | n+2 | n+3 | n+k | n |
| K-Prototypes Clustering SEC | ||||||
|---|---|---|---|---|---|---|
| Pixel Value | Established High | Established Low | Newcomers Middle | Newcomers Low | Total (%) | |
| ML classification | Villa housing | 2.8 * | 0.8 | 0.4 | 1.2 | 5.3 |
| Large housing | 2.8 * | 0.8 * | 1.4 ** | 2.2 | 7.3 | |
| Small housing | 9.9 | 5.3 * | 6.3 * | 7.1 ** | 28.6 | |
| Slum housing | 12.6 | 11.6 ** | 12.8 * | 21.9 * | 58.8 | |
| Total (%) | 28.2 | 18.5 | 20.9 | 32.5 | 100.0 | |
| K-Prototypes Clustering SEC | ||||||
|---|---|---|---|---|---|---|
| Pixel Value | Established High | Established Low | Newcomers Middle | Newcomers Low | Total (%) | |
| ML classification | Villa housing | 3.0 * | 0.0 | 0.0 | 0.0 | 3.0 |
| Large housing | 5.0 * | 0.0 * | 4.0 ** | 6.0 | 15.0 | |
| Small housing | 4.0 | 1.0 * | 6.0 * | 10.0 ** | 21.0 | |
| Slum housing | 8.0 | 11.0 ** | 14.0 * | 28.0 * | 61.0 | |
| Total (%) | 20.0 | 12.0 | 24.0 | 44.0 | 100.0 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hemerijckx, L.-M.; Van Emelen, S.; Rymenants, J.; Davis, J.; Verburg, P.H.; Lwasa, S.; Van Rompaey, A. Upscaling Household Survey Data Using Remote Sensing to Map Socioeconomic Groups in Kampala, Uganda. Remote Sens. 2020, 12, 3468. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12203468
Hemerijckx L-M, Van Emelen S, Rymenants J, Davis J, Verburg PH, Lwasa S, Van Rompaey A. Upscaling Household Survey Data Using Remote Sensing to Map Socioeconomic Groups in Kampala, Uganda. Remote Sensing. 2020; 12(20):3468. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12203468
Chicago/Turabian StyleHemerijckx, Lisa-Marie, Sam Van Emelen, Joachim Rymenants, Jac Davis, Peter H. Verburg, Shuaib Lwasa, and Anton Van Rompaey. 2020. "Upscaling Household Survey Data Using Remote Sensing to Map Socioeconomic Groups in Kampala, Uganda" Remote Sensing 12, no. 20: 3468. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12203468