1. Introduction
Synthetic aperture radar (SAR) is an important microwave remote sensing system in the domains of military and civilian applications. With the high-resolution coherent imaging capability of all weather and all day penetration, it can obtain more distinct information than optical sensors, infrared sensors, etc. [
1,
2]. Moreover, it is able to acquire abundant backscattering characteristics of the targets. These backscattering characteristics contain unique identifying information of target attributes, which is often difficult to accurately interpret from the perspective of human vision. Besides, it is usually a hard task to accomplish real-time processing when the size and number of SAR images are increasing. Therefore, SAR automatic target recognition (ATR) has become one of the most crucial and challenging issues in SAR application.
Basically, the fundamental problem of SAR ATR is to locate and recognize the objects of interest in an environment with clutters in SAR images [
3]. The standard architecture of the SAR ATR system proposed by MIT Lincoln Laboratory has three main stages: detection, discrimination and classification [
4]. In the detection stage, a constant false alarm rate (CFAR) detector is employed to localize where a potential target is likely to exist in the SAR image. Then, in the discrimination stage, some specific discriminating criteria are adopted to reject cultural and natural clutter false alarms. In the classification stage, an elaborate and efficient classifier provides additional false alarm rejection and categorizes the remaining detections as specific target types.
Many novel classification algorithms and systems have been proposed in recent years and performed well in applications [
5,
6,
7]. These various methods for the classification stage in general can be taxonomized into two mainstream paradigms: template-based and model-based. The template-based taxon is a pattern recognition approach solely relying on templates to represent the targets [
8]. These templates could be two-dimensional target templates or extracted feature vectors. The process of the template-based taxon involves two distinctive stages: offline classifier training and online classification. Despite templated-based taxon’s simplicity and popularity [
9], it may be unable to cope with extended operating conditions (EOCs). Unlike the template-based taxon, the model-based taxon mainly focuses on representing the characterization of the physical structure of the target [
10]. Typically, a model-based taxon consists of two main stages: holistic physical model construction for the target and the online classification prediction that yields close resemblance to the input SAR chips. Despite model-based taxon can circumvent the EOCs to some extent, it also faces the problem of the additional complexity in the SAR ATR system.
In recent decades, deep learning has been applied in signal and image processing fields and demonstrated its superior performance. As for the SAR ATR application, many excellent studies have proposed many deep learning methods with outstanding results [
11,
12,
13,
14,
15]. Chen et al. [
16] proposed an all-convolutional network replacing all the dense layers with the convolutional layers, which leads to outstanding recognition performance. Wagner et al. [
17] proposed a combination of a convolutional neural network and support vector machines to incorporate prior knowledge and enhance its robustness against imaging errors. Jiao et al. [
18] proposed a multi-scale and multi-scene ship detection approach for SAR images, which could detect small scale ships and avoid the interference of inshore complex background. Li et al. [
19] proposed block sparse Bayesian learning (BSBL) to synthetic aperture radar (SAR) target recognition, which considers the azimuthal sensitivity of SAR images and the sparse coefficients on the local dictionary.
However, most of the existing SAR ATR methods only focus on improving the detection or recognition performance and still need various separate subsystems for different functions. In practice, the whole system of SAR ATR has great demand in acquiring multifarious information of the given target, such as location, category, shape, morphological contour, ambient relationships, etc. Furthermore, when multiple subsystems are employed to achieve the goals of detection, recognition, etc., the complexity of the whole SAR ATR system will be too high to meet the practical demand.
In practice, for analyzing the purpose of the detected targets, it is necessary to get enough target attributes which are composed of multi-dimensional information. For example, it is critical to gain the categories and the tracks of detected ships simultaneously to judge if they are going to transport or attack. The category and geometric structure of the target contain substantial information among the multifarious target attributes [
20]. Therefore, it is necessary and valuable to extract the category and geometric structure of the given target with one system, namely one SAR ATR system deals with multiple tasks simultaneously.
Fortunately, multi-task learning (MTL) can handle different related tasks simultaneously, which can refer to the joint learning of multiple problems, enforce a common intermediate parameterization and replace multiple subsystems with one system. With the relevance of the different tasks, it could improve the generalization performance of the system, which is caused by leveraging the domain-specific information contained in the training dataset of related tasks [
21,
22,
23]. Besides, these related tasks are learned simultaneously by extracting and utilizing appropriate shared information across tasks. From a machine learning point of view, MTL could be regarded as a form of inductive transfer, which could improve a model by introducing an inductive bias provided by the related tasks [
24,
25].
Considering that the superior performance of deep learning, by introducing the deep learning theory into the framework of MTL, MTL will acquire the capability of adaptive feature learning and powerful feature representation to promote its performance [
26], which would be a perfect encounter in SAR ATR. Furthermore, it is possible that a neural network MTL module can increase the performance of the whole SAR ATR system using the relevance between tasks.
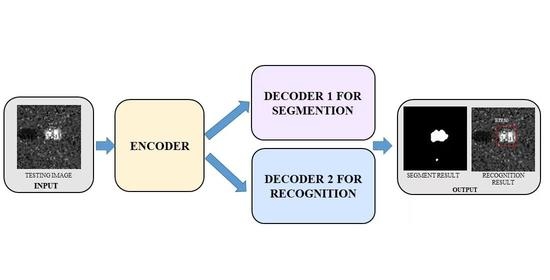
Therefore, in this paper, we propose a novel multi-task deep learning framework for recognition and segmentation of the SAR target to obtain both its category and shape information. First, we construct a multi-task deep learning framework to complete target recognition and segmentation in SAR images, which consists of two parts: encoder and decoder. Second, a shared encoder is designed to extract effective features in different scales for morphological segmentation and recognition. Then, through constructing two different sub-network structures, the two decoders have the capability of employing these extracted features adaptively and optimally to meet the different feature demands of the recognition and segmentation. Therefore, the proposed multi-task framework has the capability of extracting sufficient category and shape information of the SAR target.
The remainder of this paper is organized as follows. An overview of the multi-task deep learning framework is presented in
Section 2. The specific design and instantiation of the proposed framework are given in
Section 3.
Section 4 evaluates the performance of our proposed framework with experiments.
Section 5 gives the conclusions.
3. Network Architecture of MTL Deep Learning Framework
In this section, a specific implementation of the proposed MTL deep learning framework and the details of its configuration are presented. First, we elucidate the structure of the specific implementation. Then, the configurations of each layer are presented. Finally, the joint loss of the proposed network and the training implementation are given.
3.1. Specific Implementation
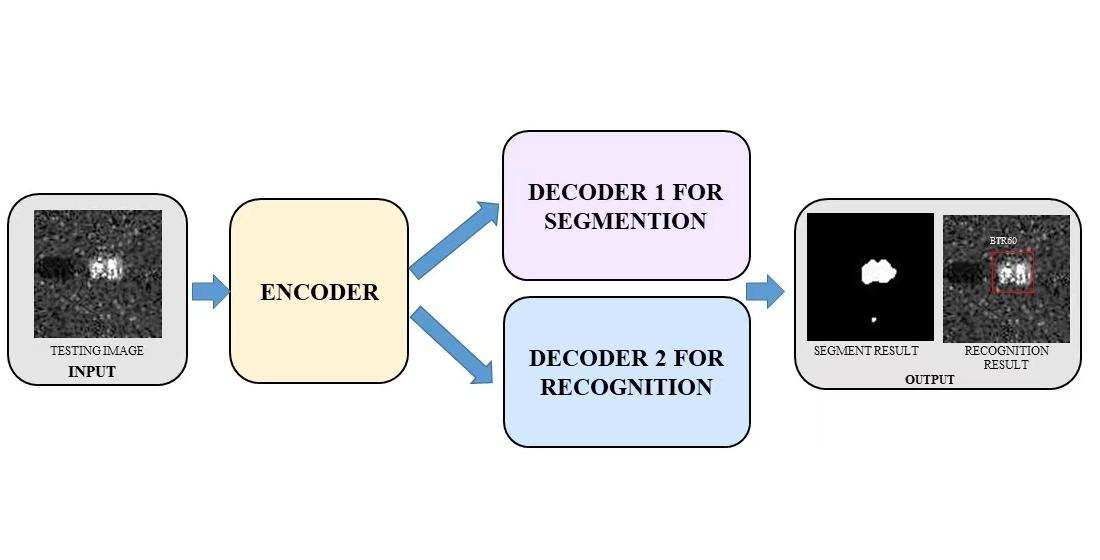
The specific implementation of the proposed MTL deep learning framework is presented in
Figure 2.
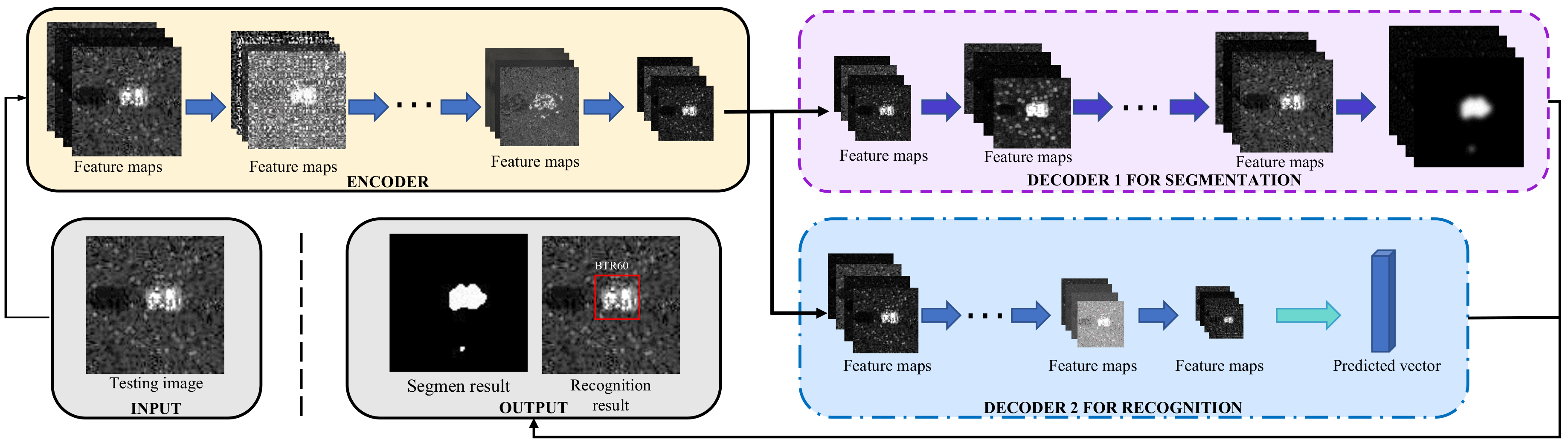
To gain sufficient image information to achieve the recognition and segmentation of the targets, the encoder is designed to consist of three convolutional layers and three max pooling layers to extract different forms of image features in different scales. A rectified linear unit (ReLU) [
27] is adopted as an activation function after each convolutional layer, which could increase nonlinear capability. A batch normalization [
28] is adopted before each convolutional layer, which could make the middle data distribution more consistent with the distribution of the input data and ensure the nonlinear expression ability of the whole architecture. Therefore, the encoder gets the capability of fitting nonlinear data distribution and acquiring a different form of optimal image features.
Then, owing to the different demands of structure and image feature for the recognition and segmentation, the decoder is designed, respectively, for the two tasks, whose specific forms are two different sub-decoders with two different feature utilizations. The sub-decoder for the recognition consists of two convolutional layers and one max pooling layer. At the last convolutional layer, SoftMax is adopted as a classifier to get the normalized probability distribution of the recognition results. As for the segmentation, the sub-decoder is designed as the structure consist of three transposed convolutional layers [
29] and three convolutional layers. After each convolutional layer, there is one skip connection [
30] for being combined with the image features extracted by the encoder. There are no activation functions after each convolutional layer. Through the two specific structures of decoder for the recognition and segmentation of the targets, the decoder gets the capability of gaining accurate recognition and precise segmentation.
The details of those layers, activation functions, etc. are described in the following.
3.2. Convolutional Layer and Transposed Convolutional Layer
The convolutional layer is the main component of the whole architecture to percept the local image information and extracts the image feature. Sparse connectivity and weight sharing are two advantages in the convolutional layer to reduce the number of parameters. Sparse connectivity means that the size of connection fields between the feature maps of the
layers and the
convolutional layer is the same as the size of convolutional kernels. Weight sharing means that each convolutional kernel is employed to be calculated with all the spatial area in the convolutional layer. Given the
feature map in the
layers as
,
as one convolutional kernel and
as the bias in the
convolutional layer. The operation of the
convolutional layer can be presented as
where ∗ denotes the convolution.
At the same time, the operation of the convolutional layers can be presented as
where
denotes the
dimension output vector which is reshaped into the matrix,
denotes the
dimension input vector which is reshaped from the matrix and
denoted the reshaped convolutional kernel whose size is
.
The transposed convolutional layer is an up-sampling method, which could seek for the optimal parameter to up-sample the images. The transposed convolutional layer is actually the reverse operation of the convolutional layer, which means that the forward and backward of the transposed convolutional layer are reverse to the convolutional layers. The operation of the transposed convolutional layer can be described as follows. First, the input image is padded with zero to expand the size. Then, the padded input images are convolved with the transposed convolutional kernels [
29]. After each operation of convolution, the position of the next convolution is shifted by the set stride.
The transposed convolutional layer is a main component of the decoder for the segmentation, which is adopted to up-sample and integrates the extracted feature maps adaptively layer by layer. The output size of the
transposed convolutional layer with the factor
is equal to the convolutional layer with a fractional stride
. Given the
feature map in the
layers as
, the operation of the transposed convolutional layer can be presented as
where
denotes the reshaped convolutional kernel, whose size is
.
3.3. Batch Normalization and Rectified Linear Unit
Batch normalization is a trick to train a deep learning network. It not only can accelerate the convergence speed of the network, but also solve the problem called gradient dispersion to a certain extent, which makes it easier and more stable to train a deep learning network [
31]. The processing of batch normalization could be divided into three steps as following. First, given a batch of the input images as
, the average value and the variance of each training data batch are calculated by
where
is the average value of this batch
B and
is the variance. Then, the batch
is normalized by
and
to get the 0–1 distribution:
where
is a small positive number to avoid the divisor as zero. Finally, the normalized batch
B is subjected to scale transformation and translation by
where
is the scale factor and
is the translation factor.
is denoted as the operation of the batch normalization. The two learnable parameters,
and
, are introduced to solve the problem that the expression ability of the network is decreased, which is caused by the normalized batch being basically limited to the normal distribution [
32].
The Rectified linear unit (ReLU) is an activation function which has less computational complexity than other activation functions [
33], such as sigmoid, and solves the problem called vanishing gradient to a certain extent. The formula of the ReLU can be presented as
The ReLU will make the output of some feature maps zero, which leads to the sparsity of the network and alleviates the occurrence of the overfitting problem.
3.4. Max Pooling and SoftMax
The max pooling layer is utilized to integrate the information of the feature maps with reducing the number of parameters and the computational complexity of the whole network. The operation of the max pooling layer is to get the maximum value in the window of the feature maps as
where
is the coordinate of the pixels in the pooling window,
is the output of the max pooling layer and
P is the pooling window. Although the max pooling layer has many advantages, it could also pool some crucial information for the segmentation or other tasks.
SoftMax is adopted as a classifier that could normalize the output of the network to be understood as posterior probability with the original intention to make the effect of the feature on probability multiplicative. Given the output vector of the network before SoftMax as
, the formula of SoftMax can be presented as
where
C is the number for the target types,
is the one-hot vector of the target type and
is the power of
e. Through the operation of SoftMax, the probability of each type of target is acquired corresponding to each element in the output vector of SoftMax.
3.5. Joint Loss and Backpropagation
The Joint loss is the combination of each task’s loss, which could highly influence the performance of the whole framework. Through choosing the appropriate weights between each task’s loss, the joint loss not only consider the difference between tasks, but also take the advantage of the relevance between tasks, which could lead to a better performance of the whole framework [
34]. As for the target recognition and segmentation, the target recognition needs to utilize the features of the scattering distribution and target morphology, which is the same as the target segmentation [
35]. Therefore, there is a strong coherence and relevance between the recognition and segmentation of target in the SAR image.
In the proposed multi-task deep learning framework, the joint loss is set as the weighted sum of the recognition loss and the segmentation loss. The recognition loss is set as the cross-entropy cost function, which is presented as
In nature, the target segmentation is a kind of classification in pixel level. To achieve accurate segmentation, the distance between the segmentation result and the ground truth should be calculated. Therefore, the segmentation loss is set as the cross-entropy cost function of all the pixels in a SAR chip. The segmentation loss is averaged to the same unified scale as the recognition loss, which leads to better and more robust performance [
36]. The function of the segmentation loss is defined as
where
is the probability vector f segmentation result of all pixel on the
ith SAR chip,
n is the number of pixels in a SAR chip,
is the segmentation labels in the form of one hot and
V is the number of the segmentation types. Therefore, the joint loss can be presented as
After the joint loss is obtained, the optimal performance of the whole architecture could be obtained through minimizing the joint loss using backpropagation [
37].
First, the total error is computed by comparing the output of the architecture with the ground truth.
Then, the error is spread from the high layer to the low layer in the architecture by computing the intermediate error of each layer. When the
layer is one convolutional layer, the intermediate error can be calculated by
where
denote the 1st derivative of the ReLU,
denotes the intermediate error of the
convolutional layer and ⊙ denotes Hadamard multiplication. As for the transposed convolutional layers, the formula is
The derivatives for updating
and
of the
layer can be presented as
This step is the same for the convolutional and transposed convolutional layers. When the backpropagation comes across the max pooling layers, only the unit with the max value in every pooling field receives the error term and the intermediate error on other units is set as zero.
Finally, Backpropagation updates the trainable parameters of the architecture by
where
denotes the convolutional kernels of the
layer,
denotes the bias of the
layer and
denotes the learning rate.
Through the process of the backpropagation, the network gradually achieves the optimal performance, which could achieve accuracy and effective target recognition and segmentation simultaneously. Its performance is presented and compared in the next section.
4. Experiments and Results
In this section, the performance of the multi-task deep learning framework is evaluated. First, the information of the used dataset is introduced in detail. Then, the steps of the data preprocessing are described and the hyperparameter and set-up of the specific implementation of the multi-task deep learning framework are described. Finally, the results and comparisons of the target recognition and segmentation are presented.
4.1. Dataset
The experiment dataset used to evaluate our proposed multi-task deep learning framework is collected from the Moving and Stationary Target Acquisition and Recognition (MSTAR) program. This dataset is released by the Defense Advanced Research Projects Agency and the Air Force Research Laboratory. The dataset is as part of the MSTAR program and collected using the Sandia National Laboratory STARLOS sensor platform [
38]. As a benchmark dataset for SAR ATR performance assessment, this dataset has a significant quantity of SAR images containing different types of military vehicles and clutter images. Ten different classes of ground targets (tank, T62 and T72; rocket launcher, 2S1; truck, ZIL131; armored personnel carrier, BTR70, BTR60, BRDM2 and BMP2; air defense unit, ZSU23/4; and bulldozer, D7) were captured as 1-ft resolution X-band SAR images with full aspect coverage (in the range of 0°–360°). They were collected under varying operating conditions, such as different aspect angles, depression angles and serial numbers. As for the segmentation labels, the segmented binary labels are a precise manual marking by the tool called OpenLabeling. The SAR images and corresponding optical images of the target at similar aspect angles are depicted in
Figure 3.
To comprehensively assess the performance of recognition, the proposed multi-task deep learning framework was evaluated under the standard operating condition (SOC) and extended operating condition (EOC) [
38]. SOC refers to that the serial numbers and target configurations of the train and test set are the same, but with different aspects and depression angles. EOC includes three extended operating conditions: depression variant, configuration variant and version variant. As for the performance of segmentation, the proposed multi-task deep learning framework was assessed with the merit of the visual and objective aspect at the same time as the assessment of the recognition performance.
4.2. Data Preprocessing
Before assessing the performance of the proposed multi-task deep learning framework, data preprocessing was employed to augment the training images and manually annotate the segmentation of the training and testing images. The specific processes are described as follows. At first, we employed data augmentation to generate more training images [
39]. The numbers of the training and testing images before the data augmentation are listed in
Table 1. The training images were augmented 10 times by randomly sampling ten
SAR image chips from one original
SAR image, which ensures the central target was complete [
16]. Then, the training and testing datasets of the segmentation were acquired by manual annotation using the tool named OpenLabeling. The manual annotation was based on the intensity and the contour of the target and shadow. The number of the segmentation labels was the same as the one of the original images, and, when the original images encountered the data augmentation, the segmentation labels also went through the data augmentation in the same way. Therefore, the segmentationwas synchronous with the recognition above when the proposed network architecture was being trained or tested. After the data preprocessing, the proposed multi-task deep learning framework could be regarded as a whole network to be trained and evaluated.
4.3. Network Setup
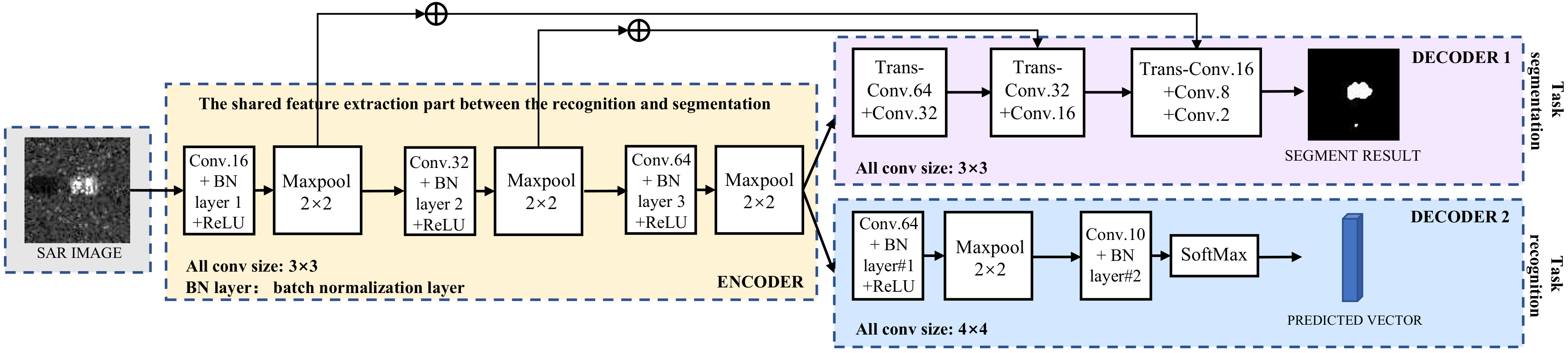
On the basis of the proposed multi-task deep learning framework, a specific implementation was employed to evaluate the proposed framework for SAR ATR. The specific implement is presented in
Figure 2. There are three convolutional and three max pooling layers forming the feature extractor. Two convolutional layers, one max pooling layers and one SoftMax layer are composed to accomplish the recognition task. Meanwhile, three de-convolutional layers and three convolutional layers are organized to segment the SAR images. The size of the input SAR images is
, the stride size of every convolutional layer is
and the stride size for each max pooling layer is
. Other hyper parameters in our network instances are shown in
Figure 2. The weights of convolutional layers are initialized from Gaussian distributions with zero mean and a standard deviation of 0.01, and biases are initialized with a small constant value of 0.1. The initial learning rate is set as 0.001 and is reduced by a factor of 0.1 after 5 epochs.
4.4. Recognition Results under SOC
In this SOC experimental setup, the performance of the proposed architecture was assessed on the classification of ten targets in the MSTAR dataset. The training and testing images have the same serial number, but are different in the depression angle. As listed in
Table 1, the training images were captured at 17° depression angle, while the testing images were captured at 15° depression angle. A summary of this experimental setup for training and testing datasets is listed in
Table 1. In
Table 1, the number of each target serial is the number of the original SAR images in MSTAR dataset before the data augmentation. The number of each class of the target after the data augmentation is 2700.
The recognition result of the proposed multi-task deep learning is presented in
Table 2.
Table 2 is a confusion matrix of ten targets, which is widely used to present the classification performance in SAR ATR [
40]. The numbers at the diagonal of the confusion matrix are the numbers of correct recognitions for each target.
In
Table 2, the recognition ratios of BTR60, I2S1 and D7 are above 96.5%, the recognition ratios of BRDM_2 and T62 are above 99.5%, and the others have achieved 100% recognition ratio. The overall recognition ratio is 99.13%, which is obviously satisfactory. From the recognition result, it is clear that, through the deep convolutional structure, there are some stable features extracted for the recognition of the ten targets among the different targets. Therefore, the proposed network architecture can achieve a satisfactory performance for the ten-target recognition, and these results can also verify the superiority of the proposed architecture in the SOC experiment.
4.5. Recognition Results under EOC
In realistic battlefield situations, there is more complex target recognition in varied operation conditions, such as the variances of the depression angle and target type. Therefore, it is necessary to assess the performance of the SAR ATR algorithm in the EOC. In this section, the stability and effectiveness of the proposed network architecture are evaluated in the variances of the depression angle, target configuration and version, which are denoted as EOC-D, EOC-C and EOC-V, respectively.
The SAR images are extremely sensitive to the variance of the depression angle, so it is important to evaluate the performance of the proposed network architecture at the variance of depression angle, EOC-D. However, the limitation that the MSTAR dataset only contains four targets (2S1, BRDM_2, T-72 and ZSU-234) which have a larger enough variance of depression angle to evaluate EOC-D. The SAR images at 17° depression angle are set as the training dataset and the corresponding SAR images at 30° depression angle are set as the testing dataset. The training dataset is generated by the same data augmentation as the SOC experiment. A summary of the training and testing dataset is listed in
Table 3. The number of each class of the training dataset was augmented to 2700, while the number of the training dataset was 10,800.
The recognition performance of the proposed network architecture in the variance of depression angle is presented in
Table 4. It can be seen that the recognition performance of the proposed multi-tasks is superior. The total recognition ratio is above 94.00% and the recognition ratios of 2S1, BRDM-2 and ZSU-234 at 30° depression angle are higher than 93.00%. The relatively low recognition ratio for T-72 is caused by the difference between the training and testing dataset at the depression angle and the serial number. From the recognition performance in
Table 4, the proposed network architecture is still stable and effective when the depression angle varies greatly.
The performance of the proposed network architecture with the variance of target configuration and version (EOC-C and EOC-V) was also evaluated. Limited by the difficulty of acquiring the SAR images of different configurations and versions of targets, the training datasets for EOC-C and EOC-V could only be set as four targets (BMP-2, BRDM_2, BTR-70 and T-72) at 17° depression angle and the testing datasets are set as the corresponding SAR images of the targets with different configurations and versions. The numbers of the training data of the four targets before the data augmentation are listed in
Table 5, and the testing datasets are listed in
Table 6 and
Table 7. The number of each class of the four targets in the training dataset was augmented to 2700. In
Table 5 and
Table 6, there are two different configurations of BMP2 and five different configurations of T72 captured at 17° and 15° depression angles to evaluate the recognition performance under the EOC of the target configuration varieties. In
Table 5 and
Table 7, it can be seen that the testing dataset for EOC-V has four different serial types of T72 from the training dataset, which are captured at 17° and 15° depression angles and utilized to evaluate the recognition performance of the proposed multi-task deep learning framework under the EOC of the target version varieties.
The recognition performance of the proposed network architecture in EOC-C is presented in
Table 8. The recognition performance of the proposed network architecture is 98.36% for the variance of target configuration. It can be proved that the proposed network architecture has the ability to recognize the targets with different configurations. As for the recognition performance in EOC-V, which is presented in
Table 9, the recognition ratio has reached 99.21% for the five versions of T72. The proposed network architecture is resilient to the variance of the target version.
From the four experiment results of SOC, EOC-D, EOC-C and EOC-V, the proposed network architecture has obtained superior recognition performance. It demonstrates that the proposed multi-task deep learning framework has the ability to extract optimal and effective target features from SAR images, which are also resilient to the variances of the depression angle, target configuration and version.
4.6. Results of SAR Target Segmentation
As mentioned above, the segmentation of the targets in SAR images not only is able to obtain more refined structural features in morphology, but also could obtain the semantic information in the pixel level. Some examples of the segmentation labels for targets are presented in
Figure 4. In
Figure 4, the left image is the original image in the MSTAR dataset and the middle one is the segmentation ground truth. The right image is the original image masked by the ground truth, which is denoted as the masked original image.
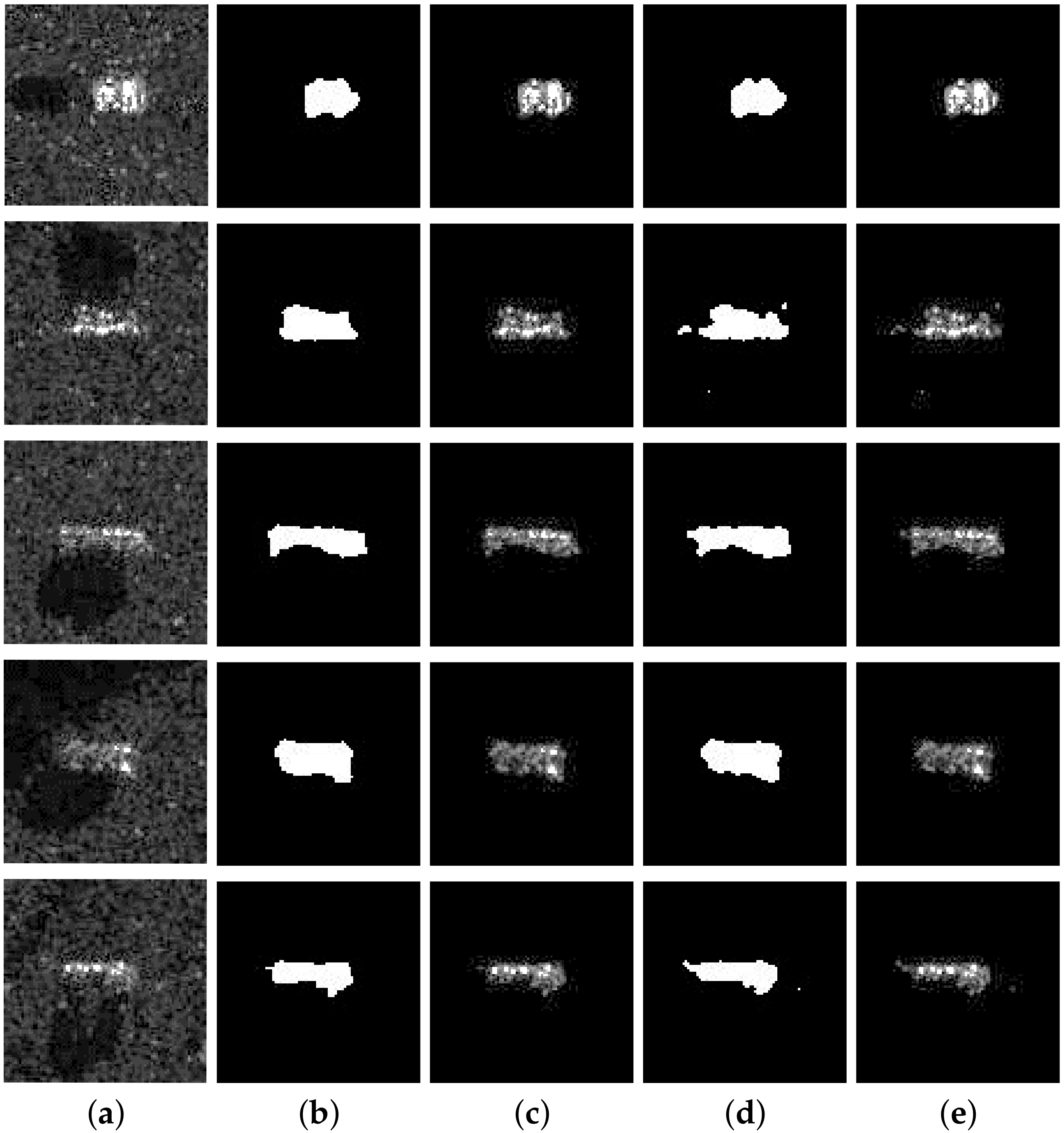
To present the segmentation results visually, some segmentation results of the proposed network architecture for different targets are shown in
Figure 5. The first three columns are the original SAR images from the MSTAR dataset, the segmentation ground truth and their corresponding masked original SAR images, respectively. The fourth column is the segmentation results of the proposed multi-task deep learning framework. The last column is the original SAR images masked by the segmentation results. It can be seen that the segmentation results of the proposed multi-task deep learning framework are quite close to the segmentation ground truth in the morphological contour. It can be concluded that the proposed network architecture can segment precisely when the contour and intensity of the targets are varying.
To evaluate the segmentation results more objectively, the pixel accuracy of the segmentation results is employed, which evaluates the accuracy of segmenting the targets from the background. The pixel accuracy is calculated as follows.
where
is the pixel accuracy,
is the correct predicted pixel and
is the total pixels in one SAR image. It means that the higher the pixel accuracy is, the better the performance is.
The pixel accuracy of the proposed multi-task deep learning framework is presented in the form of a confusion matrix in
Table 10. In
Table 10, the accuracy for the target or background is above 98.00% and the overall accuracy of the segmentation is higher than 99.00%. From the quantitative analyses, it is quite clear that the proposed network architecture has the ability to segment the targets from the backgrounds precisely and effectively.
From the evaluations of the performance of the target recognition and segmentation, it can be proved that, through the deep learning structure of multiple convolutional layers and the multi-task framework design of the encoder and two sub-decoders, the proposed multi-task deep learning framework can achieve the target recognition and segmentation accurately and effectively and finish those two tasks simultaneously with only one system.
4.7. Comparison of Performance of Segmentation and Recognition
In this section, we compare our proposed algorithm with other algorithms in recognition and segmentation. For recognition, seven SAR ATR algorithms are considered: support vector machine (SVM) [
41], adaptive boosting (AdaBoost) [
41] IGT [
41], CGM [
42], two DCNNs and gcForest [
43]. SVM and AdaBoost, both traditional algorithms, IGT, based on the probabilistic graphical model, and the two DCNNs [
44,
45] are state of the art in SAR ATR, while gcForest is recently published. For segmentation, two other algorithms are considered, namely Maximum Between-Class Variance (Otsu Method) [
46] and Canny edge detector (Canny) [
47], which are traditional algorithms for segmentation in SAR images.
For recognition performance comparison, we compare those algorithms with our proposed algorithm in terms of the recognition performance. The recognition performances are listed in
Table 11 under SOC and EOC. In
Table 11, the performance of our proposed algorithm is better than other algorithms under SOC and has significant improvement under EOC. Therefore, can be concluded that our proposed algorithm is superior to other algorithms in recognition performance.
For segmentation performance comparison, some segment images of different SAR images using Otsu, Canny and our proposed algorithm are shown in
Figure 6. In
Figure 6, it is obvious that our proposed algorithm has better performance than other algorithms when the image intensity varies and the contour of images is complicated. At the same time, the pixel accuracies of Otsu, Canny and our proposed algorithm are listed in
Table 12. In
Table 12, it is clear that the proposed multi-task deep learning framework has higher pixel accuracy than the other algorithms. From the comparisons of the segmentation above, it can be concluded that the proposed multi-task deep learning framework could obtain more accurate segmentation at both the overall contour and local details of the targets.
From the above all the contrast experiments, it is clear that, through the deep learning structure and the multi-task capability, the proposed multi-task deep learning framework not only could extract the optimal effective target feature to achieve the accurate robust recognition, but also could obtain the overall contour and local details of the targets to achieve elaborate segmentation at the same time as the recognition. All the evaluations and the contrast experiments verify that our proposed algorithm has the superiority in both recognition and segmentation with the capability of simultaneous target recognition and segmentation.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}