Two-Phase Object-Based Deep Learning for Multi-Temporal SAR Image Change Detection

 ,
,  , ,
, ,
Abstract
:
1. Introduction
- (1)
- Change detection through an object-based rather than pixel-wise approach. Superpixel generation is applied to SAR images to obtain objects via SLIC, such that the local spatial context is captured.
- (2)
- A two-phase approach is designed for multi-temporal SAR image change detection. Deep learning methods are developed to identify objects of FCC and RCC by combining low rank and sparse decomposition (LRSD) with reduced false alarms.
2. Methodology
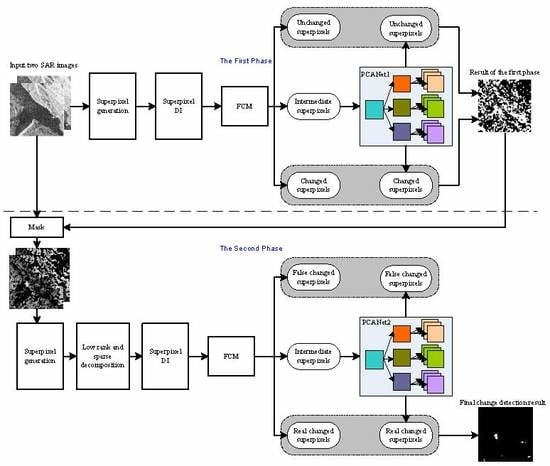
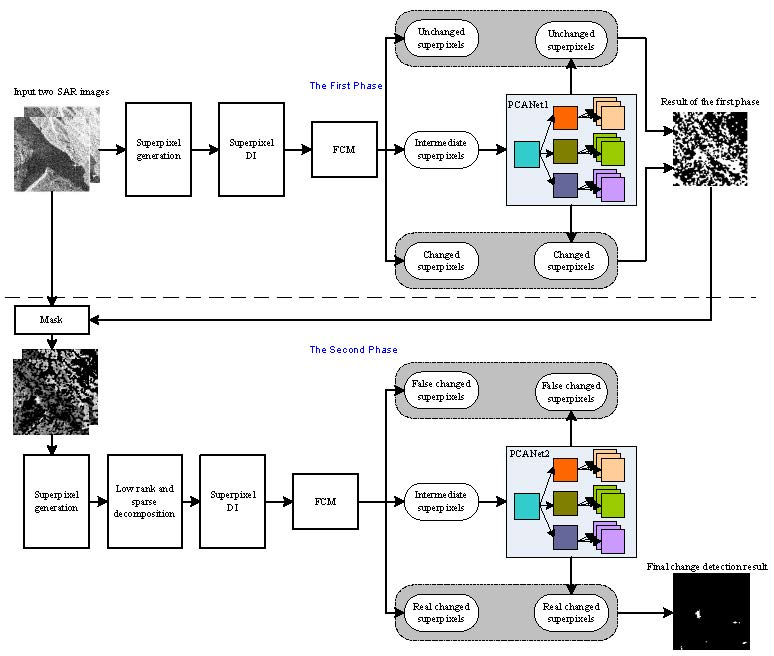
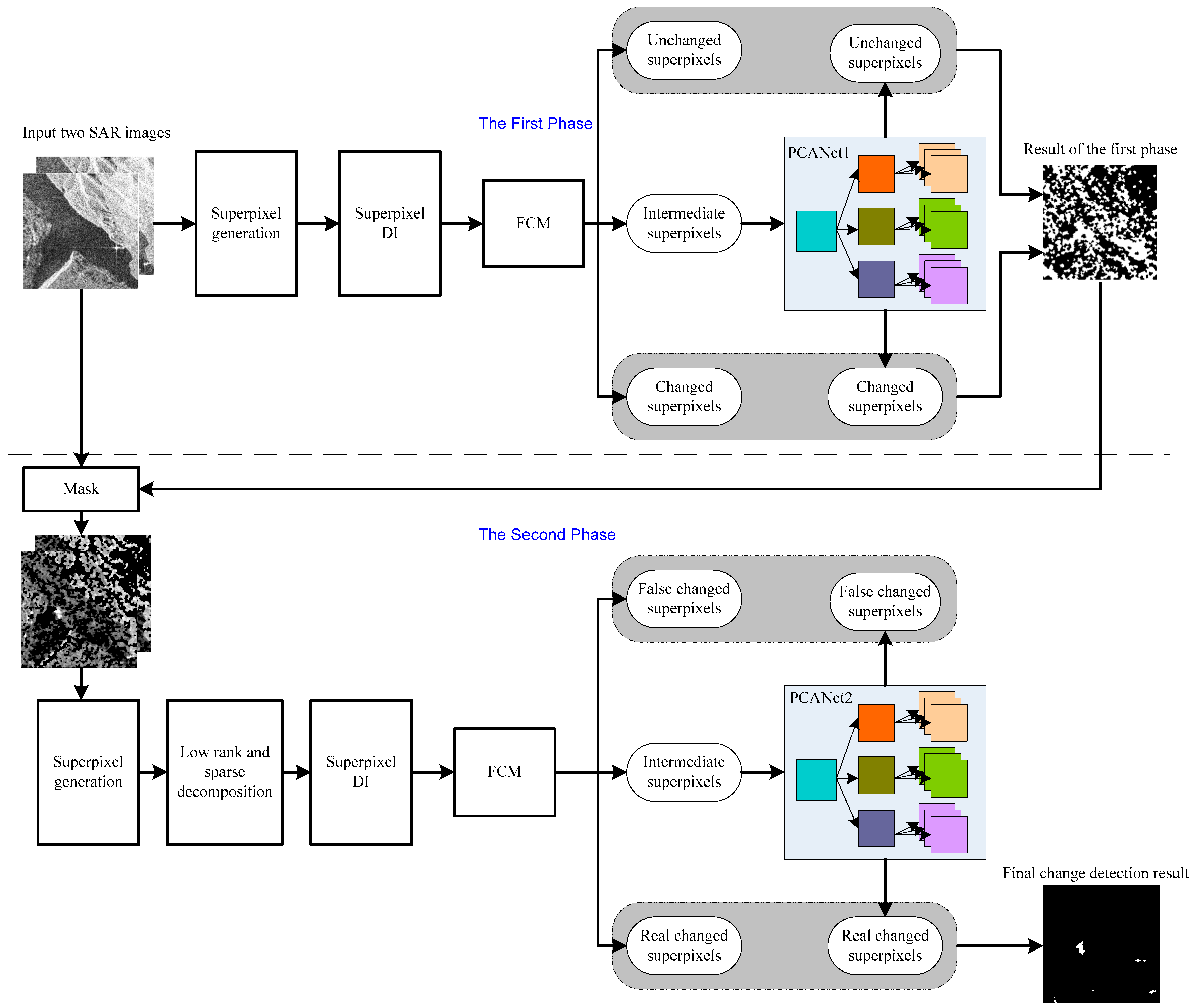
2.1. Problem Statement and Overview of the Proposed Method
2.2. First Phase Deep Learning
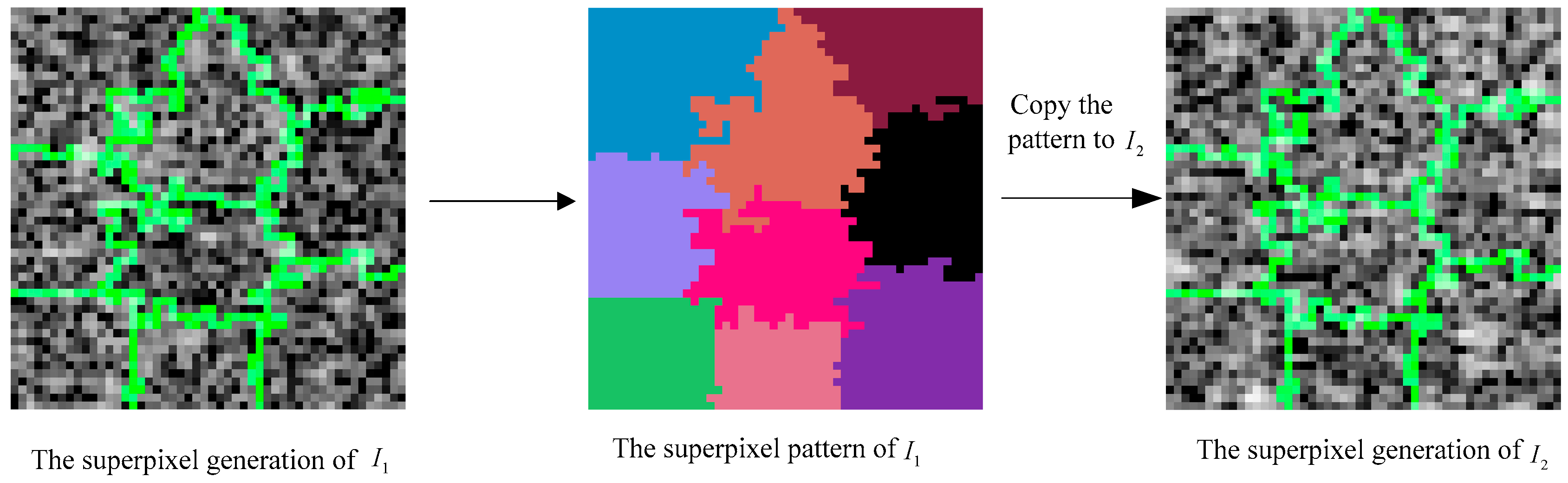
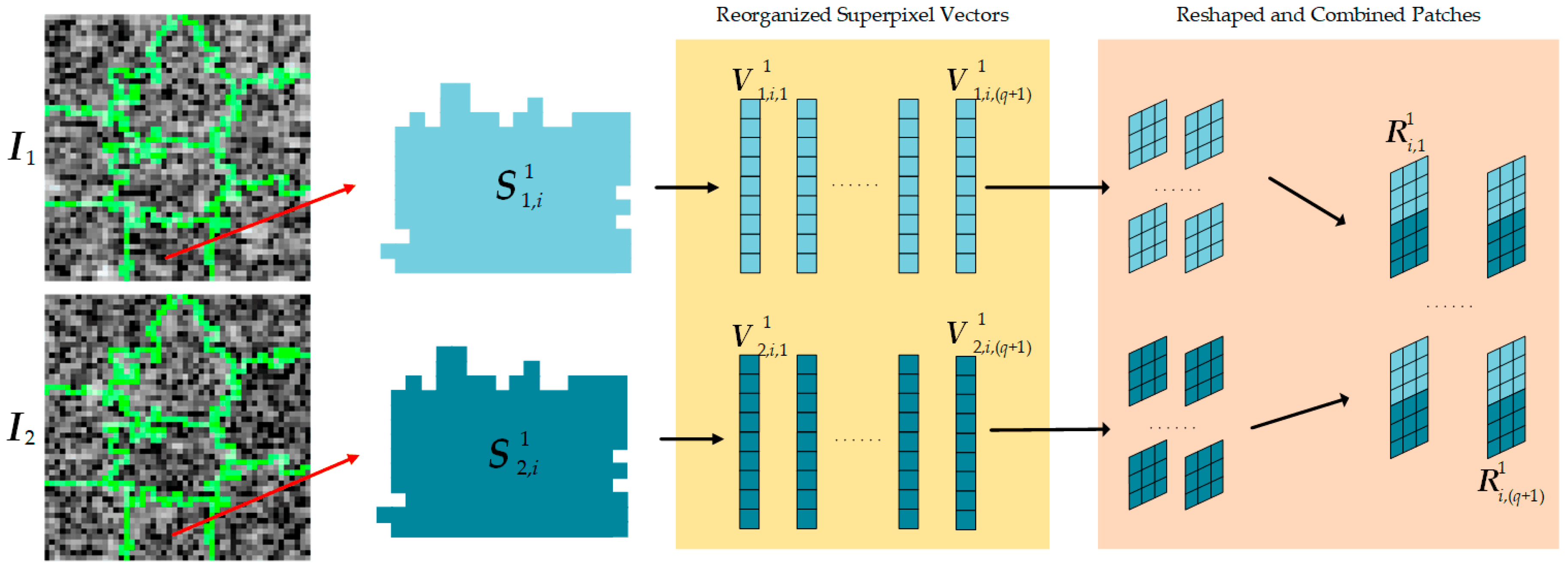
2.2.1. Superpixel Generation of Multi-Temporal SAR Images
2.2.2. Superpixel DI Generation and FCM
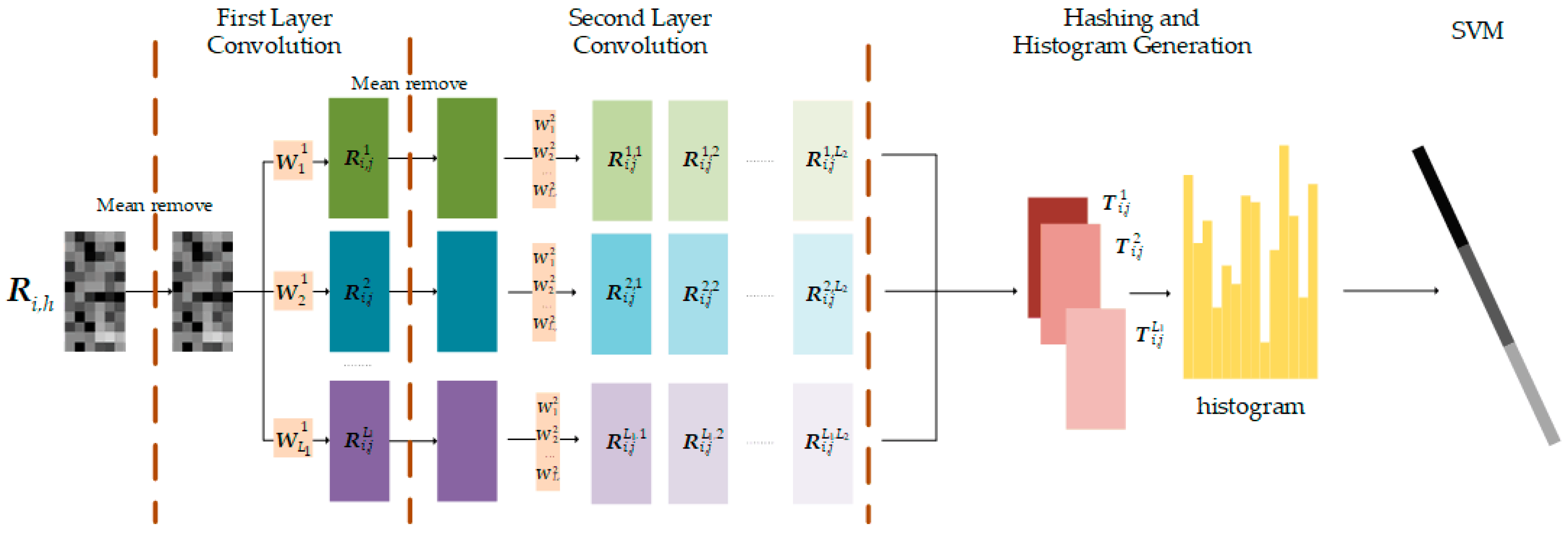
2.2.3. Training PCANet1
2.3. Second Phase Deep Learning
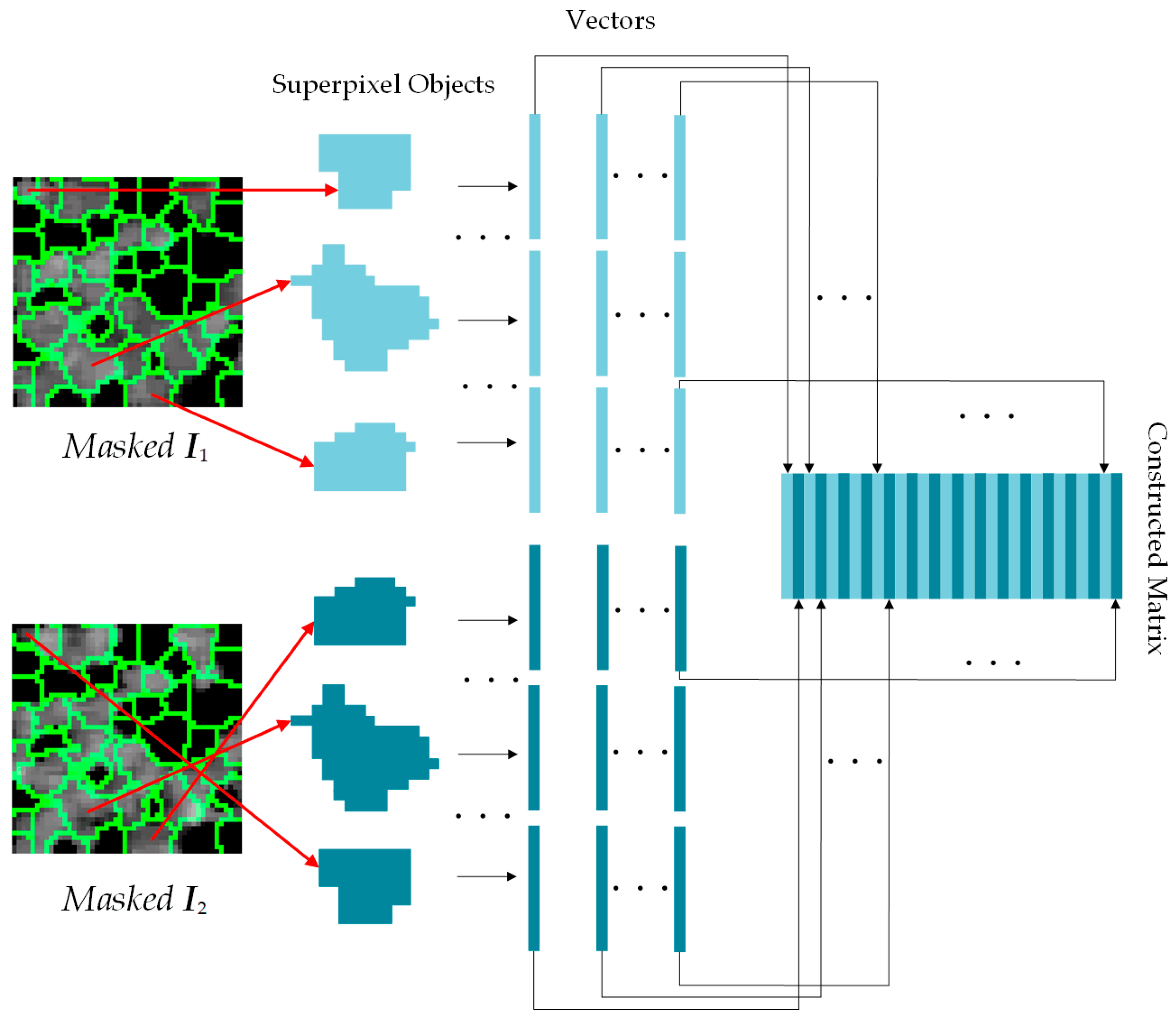
2.3.1. Superpixel Generation on the Updated SAR Images
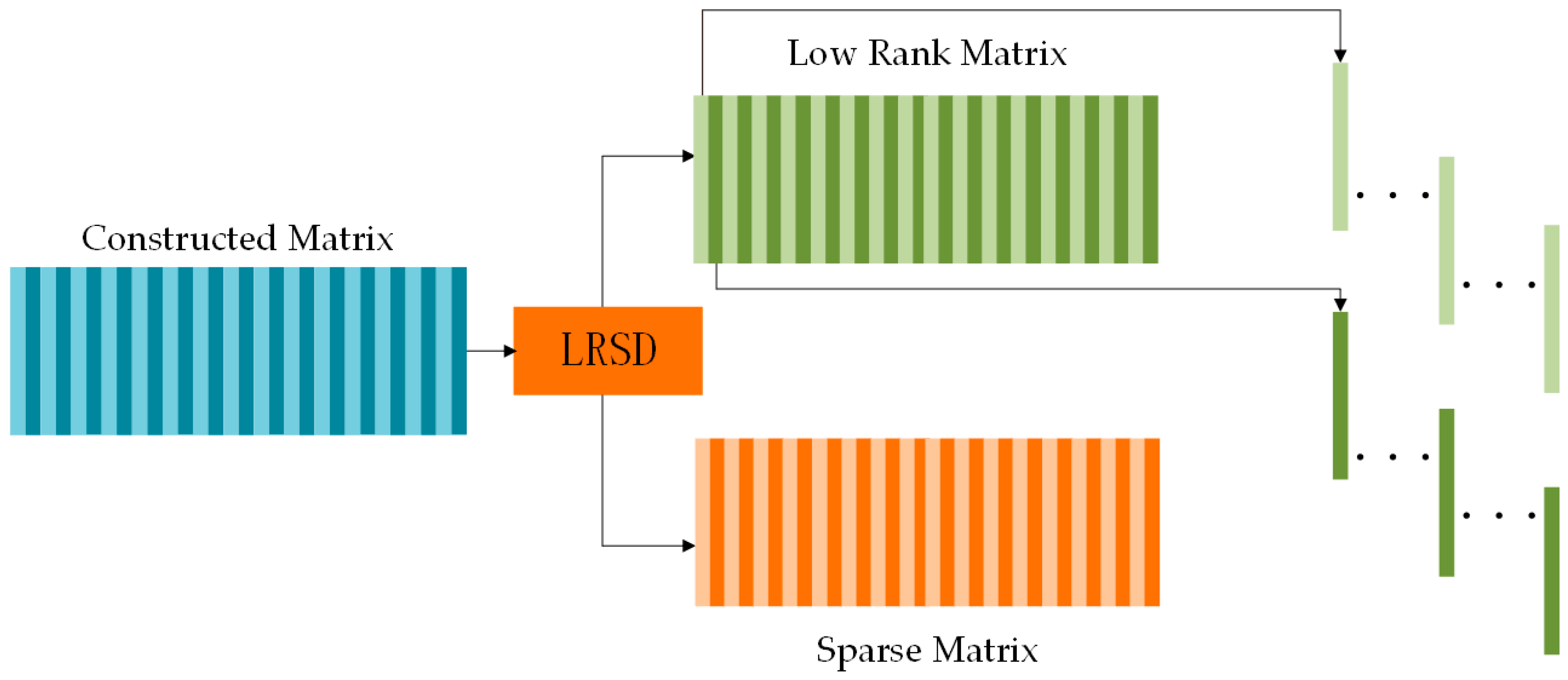
2.3.2. Low Rank and Sparse Decomposition
2.3.3. SPDI Generation and FCM
2.3.4. Training PCANet2 and Obtaining the Final Change Map
2.4. Computational Complexity
3. Experiments and Results
3.1. Datasets and Experimental Setup
3.2. Experiments
4. Discussion
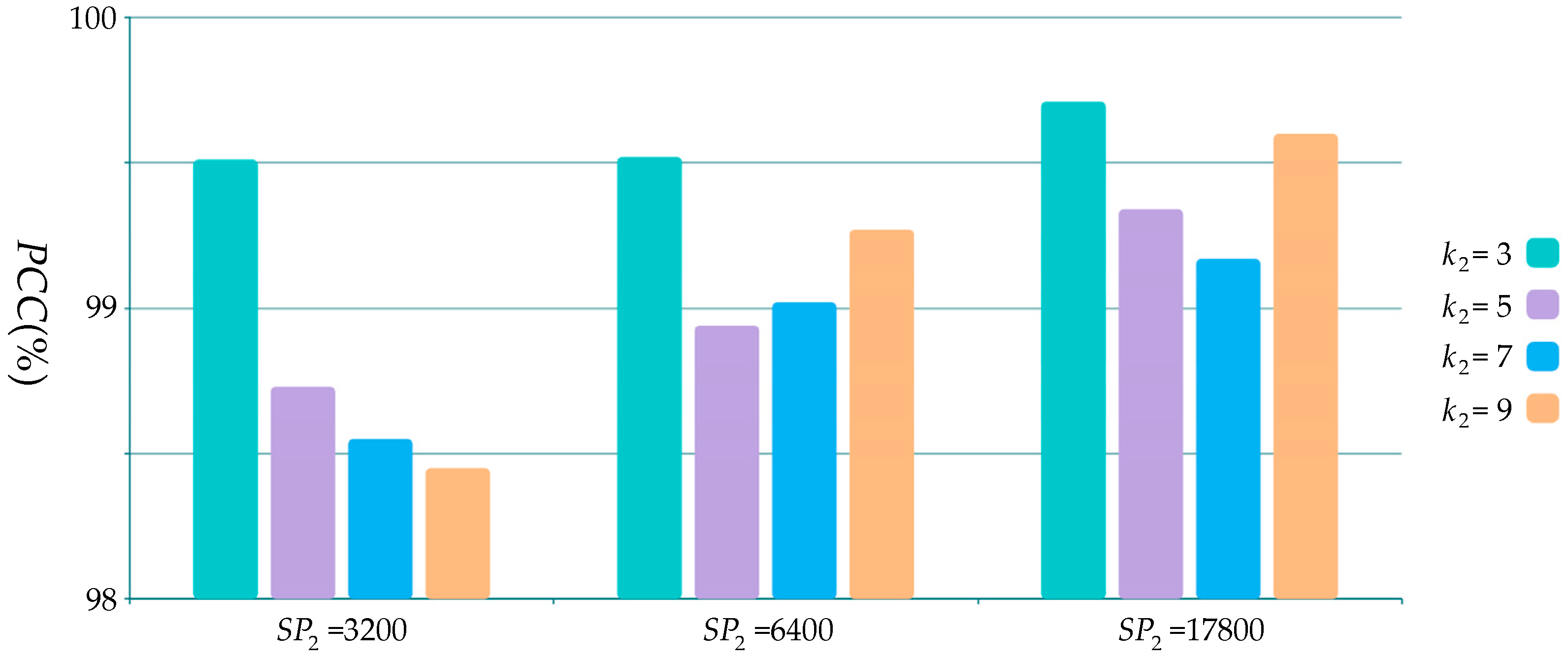
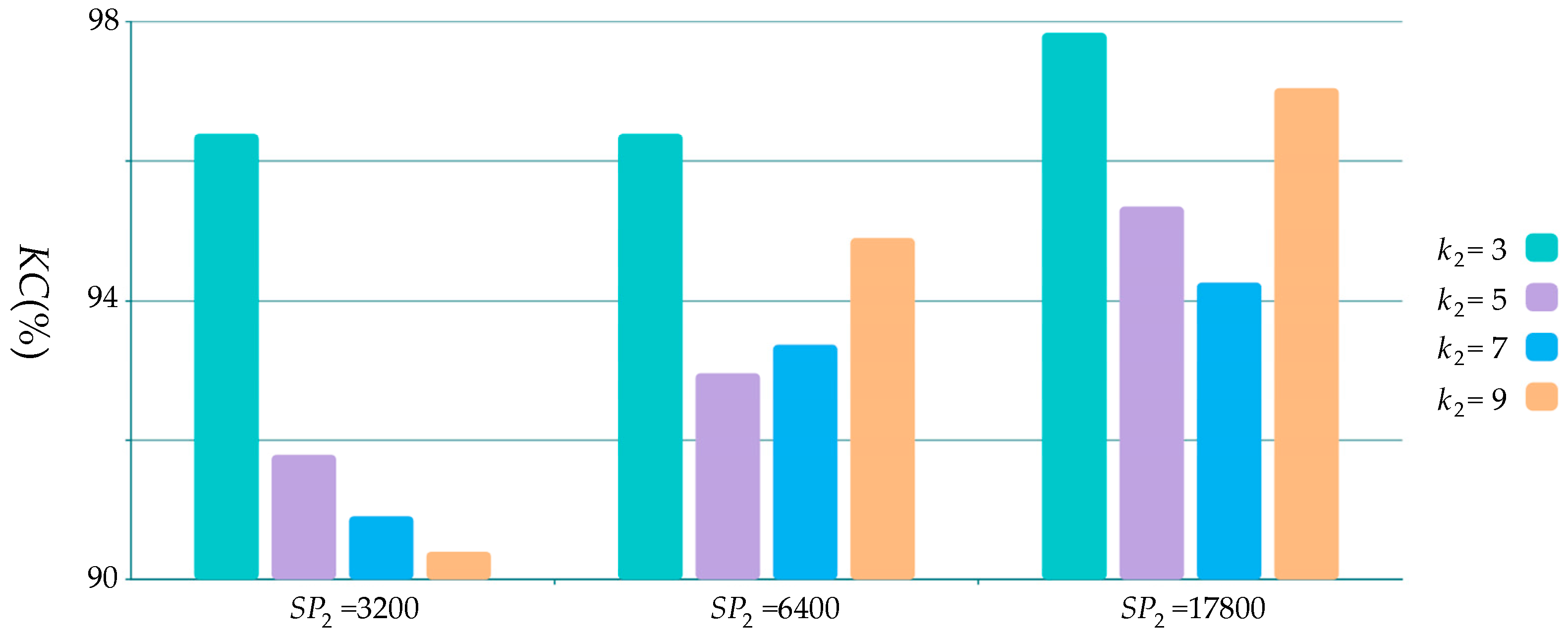
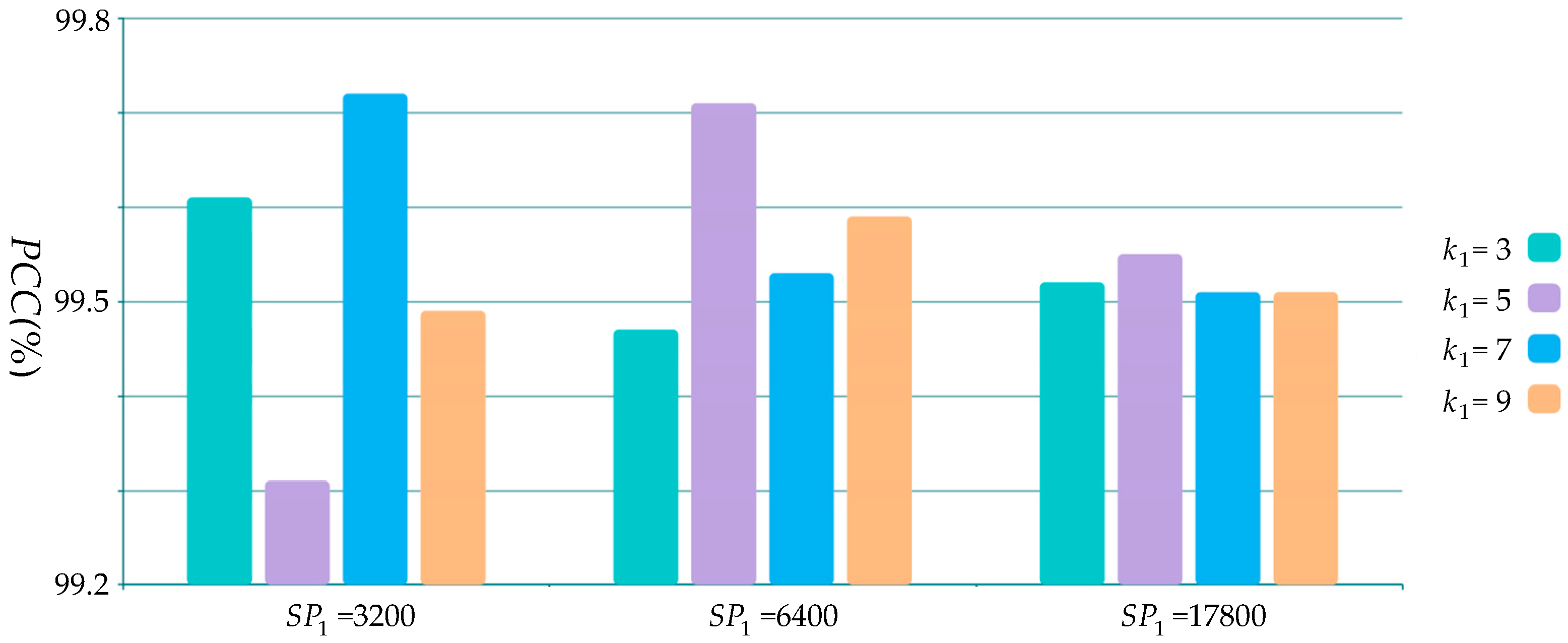
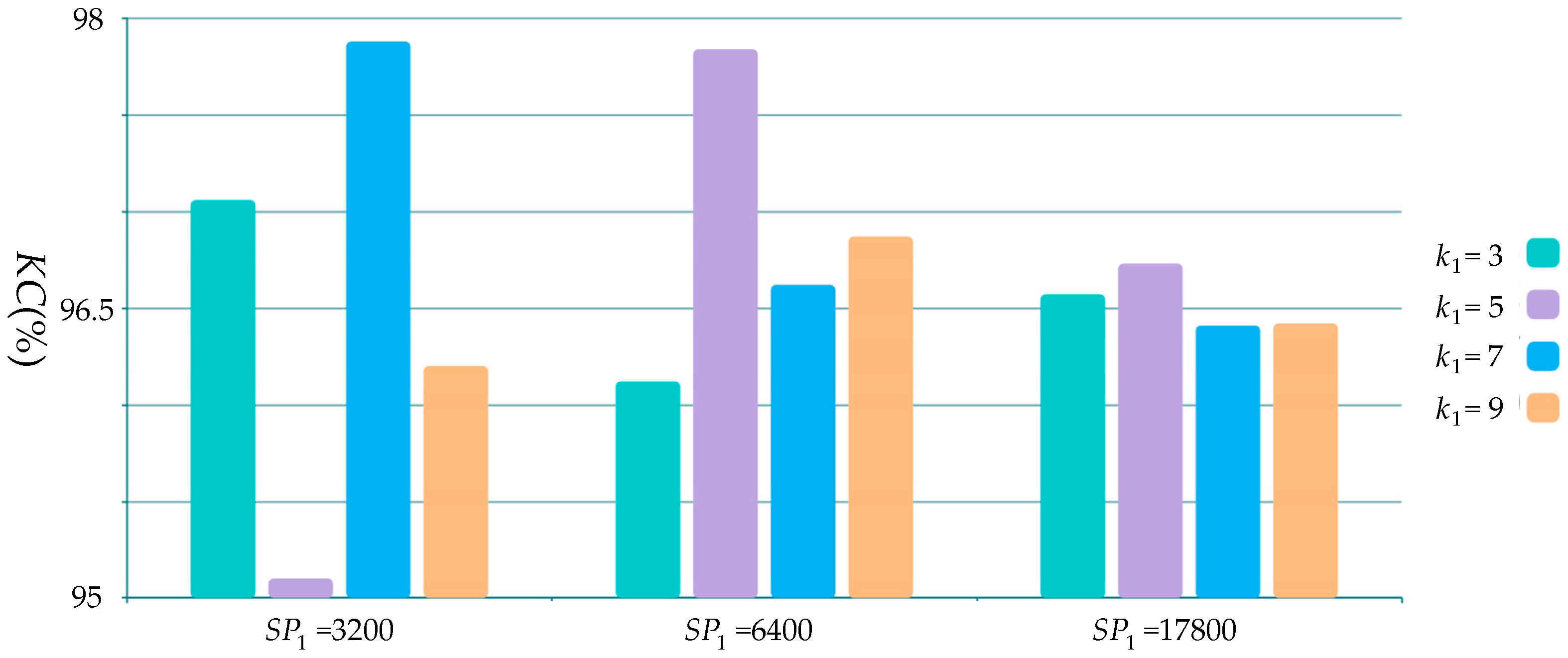
4.1. Parameters Selection
4.2. Comparison with Other Methods
4.3. Modular Deep Learning Framework for Change Detection
4.4. Time-Series SAR Images to Suppress Speckle Noise
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gong, M.; Zhao, J.; Liu, J.; Miao, Q.; Jiao, L. Change Detection in Synthetic Aperture Radar Images Based on Deep Neural Networks. IEEE Trans. Neural Netw. 2016, 27, 125–138. [Google Scholar] [CrossRef]
- Chavez, P.S.J.; MacKinnon, D.J. Automatic detection of vegetation changes in the southwestern United States using remotely sensed images. Photogram. Eng. Remote Sens. 1994, 60, 1285–1294. [Google Scholar]
- Bruzzone, L.; Prieto, D.F. Automatic analysis of the difference image for unsupervised change detection. IEEE Trans. Geosci. Remote Sens. 2000, 38, 1171–1182. [Google Scholar] [CrossRef] [Green Version]
- Neagoe, V.E.; Stoica, R.M.; Ciurea, A.I.; Bruzzone, L.; Bovolo, F. Concurrent Self-Organizing Maps for Supervised/Unsupervised Change Detection in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. 2017, 7, 3525–3533. [Google Scholar] [CrossRef]
- Li, C.; Gao, L. Context-Sensitive Similarity Based Supervised Image Change Detection. In Proceedings of the Int. Joint Conference on Neural Networks, Changsha, China, 13–15 August 2016. [Google Scholar]
- Bujor, F.; Trouvé, E.; Valet, L.; Nicolas, J.-M.; Rudant, J.-P. Application of log-cumulants to the detection of spatiotemporal discontinuities in multitemporal SAR images. IEEE Trans. Geosci. Remote Sens 2004, 42, 2073–2084. [Google Scholar] [CrossRef]
- Gong, M.; Zhou, Z.; Ma, J. Change detection in synthetic aperture radar images based on image fusion and fuzzy clustering. IEEE Trans. Image Process 2012, 21, 2141–2151. [Google Scholar] [CrossRef]
- Celik, T. Unsupervised Change Detection in Satellite Images Using Principal Component Analysis and k -Means Clustering. IEEE Trans. Geosci. Remote Sens. 2009, 6, 772–776. [Google Scholar] [CrossRef]
- Gong, M.; Su, L.; Jia, M.; Chen, W. Fuzzy Clustering With a Modified MRF Energy Function for Change Detection in Synthetic Aperture Radar Images. IEEE Trans. Fuzzy Syst. 2013, 2, 98–109. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, L.; Peng, C.; Jiao, L. Spatial Fuzzy Clustering and Deep Auto-encoder for Unsupervised Change Detection in Synthetic Aperture Radar Images. In Proceedings of the Geoscience and Remote Sensing (IGARSS) IEEE International Symposium, Valencia, Spain, 22–27 July 2018. [Google Scholar]
- Bengio, Y. Deep Learning of Representations for Unsupervised and Transfer Learning. Available online: http://www.iro.umontreal.ca/~lisa/pointeurs/DL_tutorial.pdf (accessed on 4 February 2020).
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, CA, USA, 3–8 December 2012. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the IEEE International Conference on Learning Representation (ICLR), Vancouver, BC, Canada, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, T.; Li, Y.; Xu, L. Dual-Channel Convolutional Neural Network for Change Detection of Multitemporal SAR Images. Available online: https://0-ieeexplore-ieee-org.brum.beds.ac.uk/document/8278979 (accessed on 4 February 2020).
- Liu, F.; Jiao, L.; Tang, X.; Yang, S.; Ma, W.; Hou, B. Local Restricted Convolutional Neural Network for Change Detection in Polarimetric SAR Images. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 818–833. [Google Scholar] [CrossRef]
- Lv, N.; Chen, C.; Qiu, T.; Sangaiah, A.K. Deep Learning and Superpixel Feature Extraction Based on Contractive Autoencoder for Change Detection in SAR Images. IEEE Trans. Ind. Inf. 2018, 14, 5530–5538. [Google Scholar] [CrossRef]
- De, S.; Pirrone, D.; Bovolo, F.; Bruzzone, L. A Novel Change Detection Framework Based on Deep Learning for The Analysis of Multi-Temporal Polarimetric SAR Images. In Proceedings of the Geoscience and Remote Sensing (IGARSS), IEEE International Symposium, Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Gao, Y.; Gao, F.; Dong, J.; Wang, S. Transferred Deep Learning for Sea Ice Change Detection From Synthetic-Aperture Radar Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1–5. [Google Scholar] [CrossRef]
- Chan, T.H.; Gao, J.K.; Lu, S.; Zeng, J.; Ma, Z.Y. PCANet: A Simple Deep Learning Baseline for Image Classification? IEEE Trans. Image Process 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, F.; Dong, J.; Li, B.; Xu, Q. Automatic Change Detection in Synthetic Aperture Radar Images Based on PCANet. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1792–1796. [Google Scholar] [CrossRef]
- Li, M.; Li, M.; Zhang, P.; Wu, Y.; Song, W.; An, L. SAR Image Change Detection Using PCANet Guided by Saliency Detection. IEEE Geosci. Remote Sens. Lett. 2018, 16, 402–406. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, J.; Chen, J.; Jiao, L.; Wang, M. Imbalanced Learning-Based Automatic SAR image change Detection by Morphologically Supervised PCA-Net. IEEE Geosci. Remote Sens. Lett. 2018, 16, 554–558. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. An object-based convolutional neural network (OCNN) for urban land use classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef] [Green Version]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrun, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Luo, F.L.; Huang, H.; Duan, Y.L.; Liu, J.M.; Liao, Y.H. Local Geometric Structure Feature for Dimensionality Reduction of Hyperspectral Imagery. Remote Sens. 2017, 9, 790. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Xia, J.; Tan, X.; Zhou, X.; Wang, T. PolSAR Image Classification via Learned Superpixels and QCNN Integrating Color Features. Remote Sens. 2019, 11, 1831. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint Deep Learning for land cover and land use classification. Remote Sens. Env. 2019, 221, 173–187. [Google Scholar] [CrossRef] [Green Version]
- Zou, H.; Qin, X.; Zhou, S.; Ji, K. A Likelihood-Based SLIC Superpixel Algorithm for SAR Images Using Generalized Gamma Distribution. Sensors 2016, 16, 1107. [Google Scholar] [CrossRef] [PubMed]
- Hou, B.; Kou, H.; Jiao, L. Classification of polarimetric SAR images using multilayer autoencoders and superpixels. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3072–3081. [Google Scholar] [CrossRef]
- Cannon, R.L.; Dave, J.V.; Bezdek, J.C. Efficient Implementation of the Fuzzy c-Means Clustering Algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 248–255. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust Recovery of Subspace Structures by Low-Rank Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 171–184. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Yang, J. Hyperspectral image denoising via sparse representation and low-rank constraint. IEEE Trans. Geosci. Remote Sens. 2014, 53, 296–308. [Google Scholar] [CrossRef]
- Gao, F.; Dong, J.; Li, B.; Xu, Q.; Xie, C. Change detection from synthetic aperture radar images based on neighborhood-based ratio and extreme learning machine. J. Appl. Remote Sens. 2016, 10, 046019. [Google Scholar] [CrossRef]
- Gao, F.; Wang, X.; Gao, Y.; Dong, J.; Wang, S. Sea Ice Change Detection in SAR Images Based on Convolutional-Wavelet Neural Networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1230–1244. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Results on C1(%) | ||||
|---|---|---|---|---|---|
| PCAKM [9] | 60.99 | 39.24 | 1.78 | 0.07 | 58.87 |
| GaborPCANet [23] | 64.67 | 35.46 | 4.88 | 0.08 | 59.36 |
| NR_ELM [33] | 73.85 | 26.26 | 9.86 | 0.11 | 61.39 |
| CWNN [34] | 85.22 | 14.69 | 29.18 | 0.19 | 65.67 |
| TPOBDL | 99.71 | 0.18 | 15.10 | 9.97 | 97.84 |
| Methods | Results on C2(%) | ||||
|---|---|---|---|---|---|
| PCAKM [9] | 55.65 | 45.24 | 1.81 | 0.07 | 58.13 |
| GaborPCANet [23] | 79.64 | 20.66 | 6.19 | 0.14 | 63.22 |
| NR_ELM [33] | 86.99 | 13.14 | 7.11 | 0.21 | 67.37 |
| CWNN [34] | 95.24 | 4.59 | 12.41 | 0.56 | 78.49 |
| TPOBDL | 99.43 | 0.26 | 15.02 | 4.70 | 95.67 |
| Methods | Results on C3(%) | ||||
|---|---|---|---|---|---|
| PCAKM [9] | 62.23 | 38.29 | 14.39 | 0.07 | 58.50 |
| GaborPCANet [23] | 84.61 | 15.32 | 18.92 | 0.16 | 64.84 |
| NR_ELM [33] | 89.54 | 9.98 | 31.90 | 0.21 | 67.56 |
| CWNN [34] | 94.53 | 5.02 | 25.90 | 0.43 | 75.55 |
| TPOBDL | 98.42 | 1.18 | 19.64 | 1.59 | 89.32 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Liu, G.; Zhang, C.; Atkinson, P.M.; Tan, X.; Jian, X.; Zhou, X.; Li, Y. Two-Phase Object-Based Deep Learning for Multi-Temporal SAR Image Change Detection. Remote Sens. 2020, 12, 548. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12030548
Zhang X, Liu G, Zhang C, Atkinson PM, Tan X, Jian X, Zhou X, Li Y. Two-Phase Object-Based Deep Learning for Multi-Temporal SAR Image Change Detection. Remote Sensing. 2020; 12(3):548. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12030548
Chicago/Turabian StyleZhang, Xinzheng, Guo Liu, Ce Zhang, Peter M. Atkinson, Xiaoheng Tan, Xin Jian, Xichuan Zhou, and Yongming Li. 2020. "Two-Phase Object-Based Deep Learning for Multi-Temporal SAR Image Change Detection" Remote Sensing 12, no. 3: 548. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12030548