A Method for Vehicle Detection in High-Resolution Satellite Images that Uses a Region-Based Object Detector and Unsupervised Domain Adaptation



Abstract
:
1. Introduction
2. Related Work
2.1. Object Detection by Deep Learning
2.2. Vehicle Detection by Deep Learning
2.3. Domain Adaptation
3. Methodology
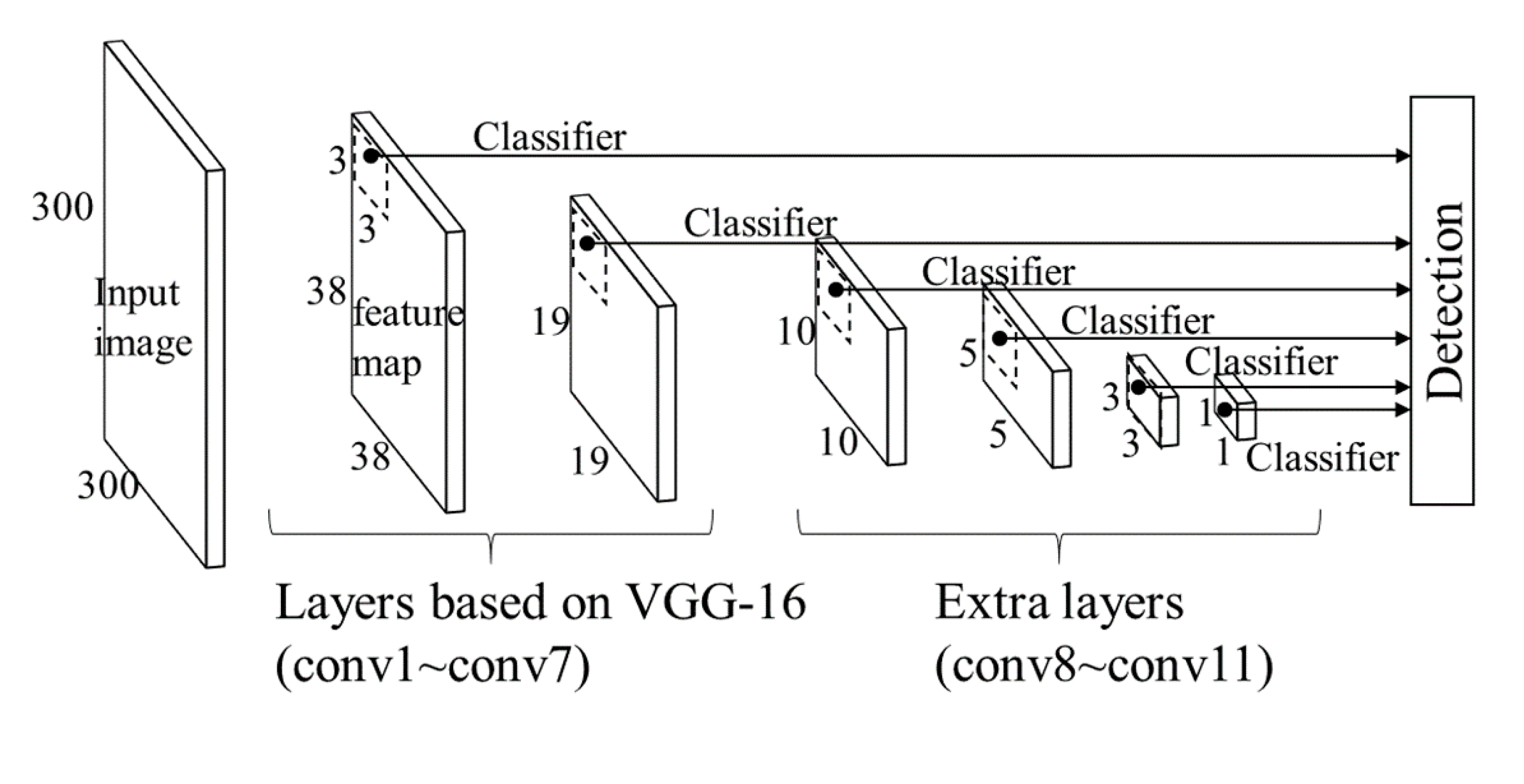
3.1. Vehicle Detection Method
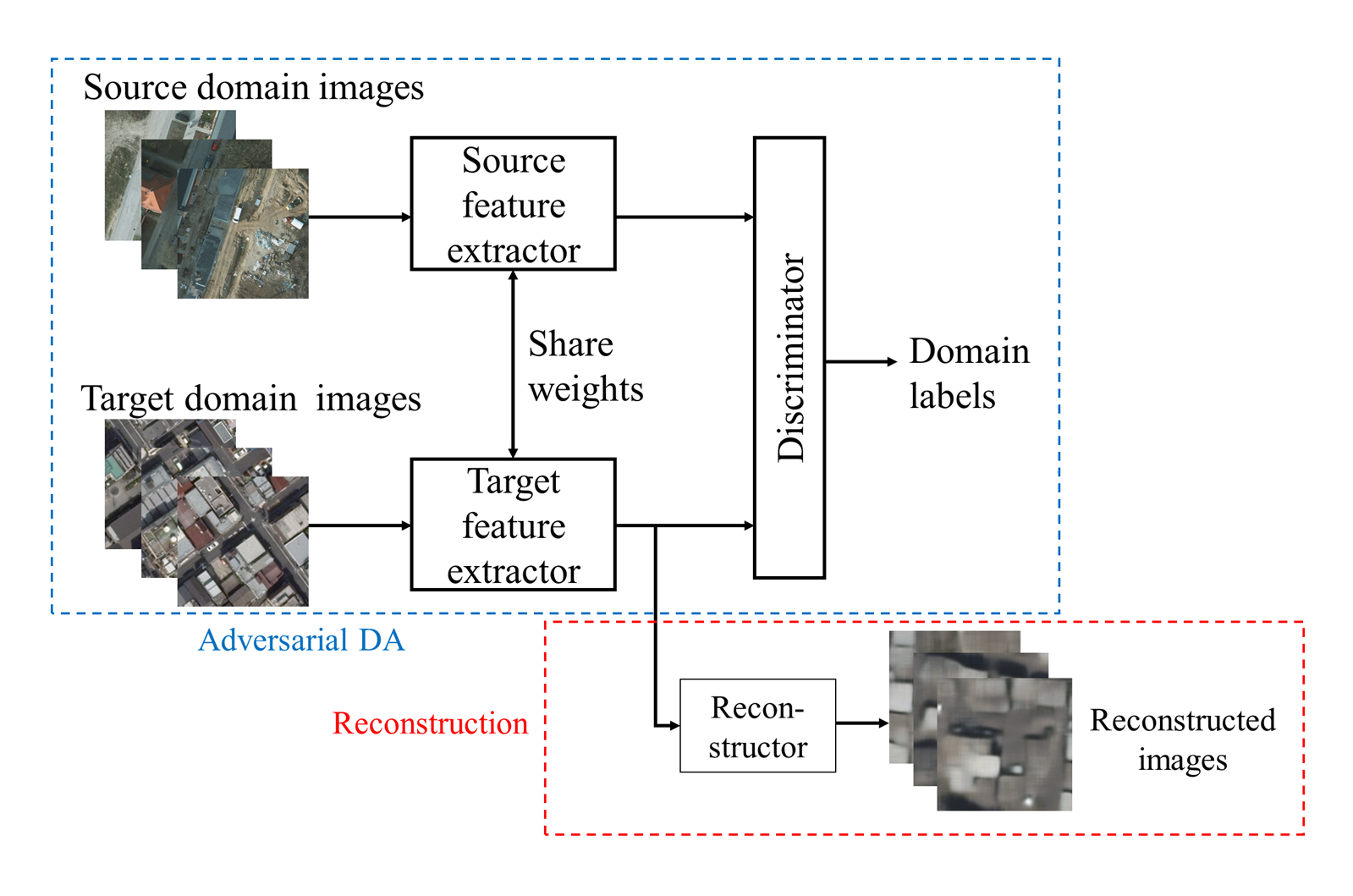
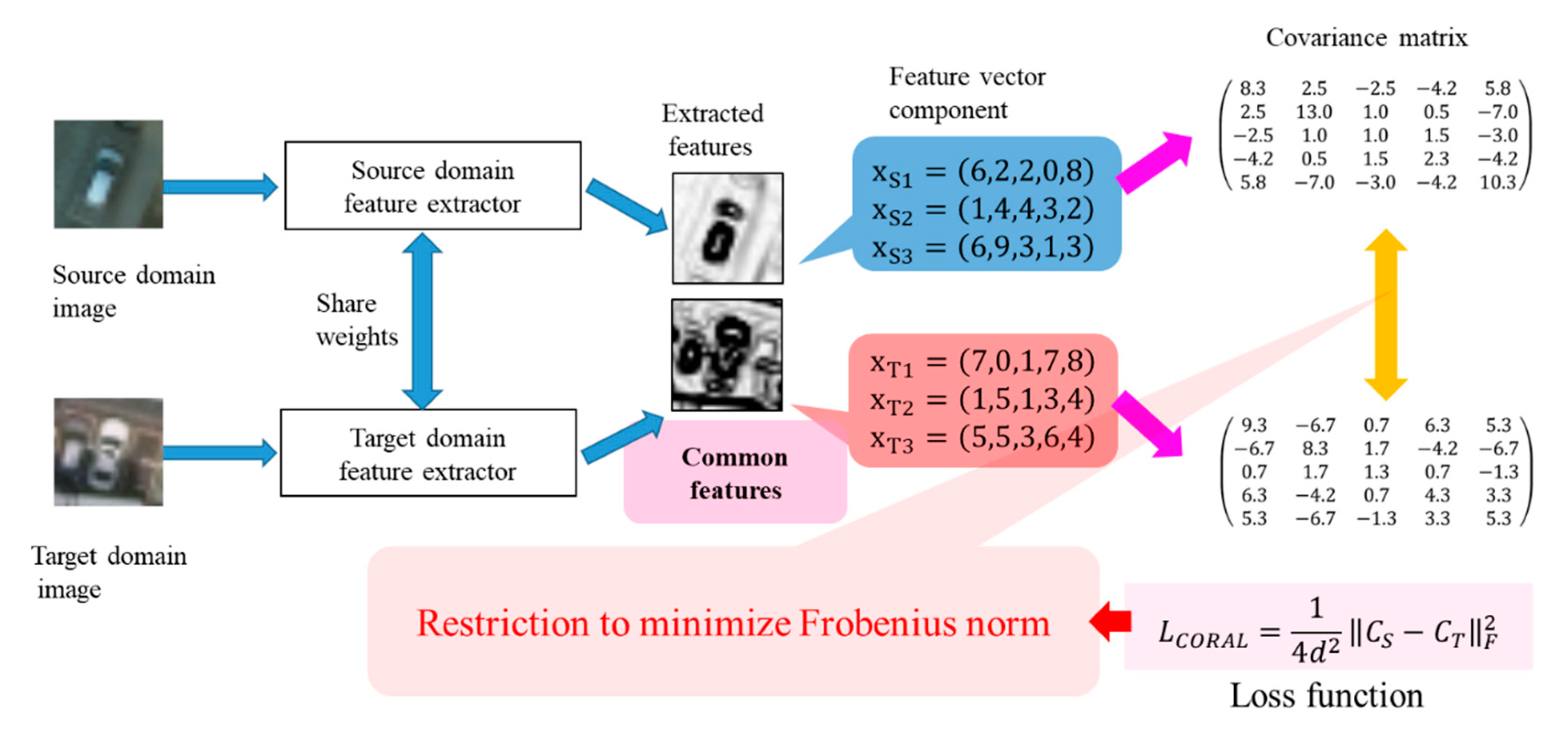
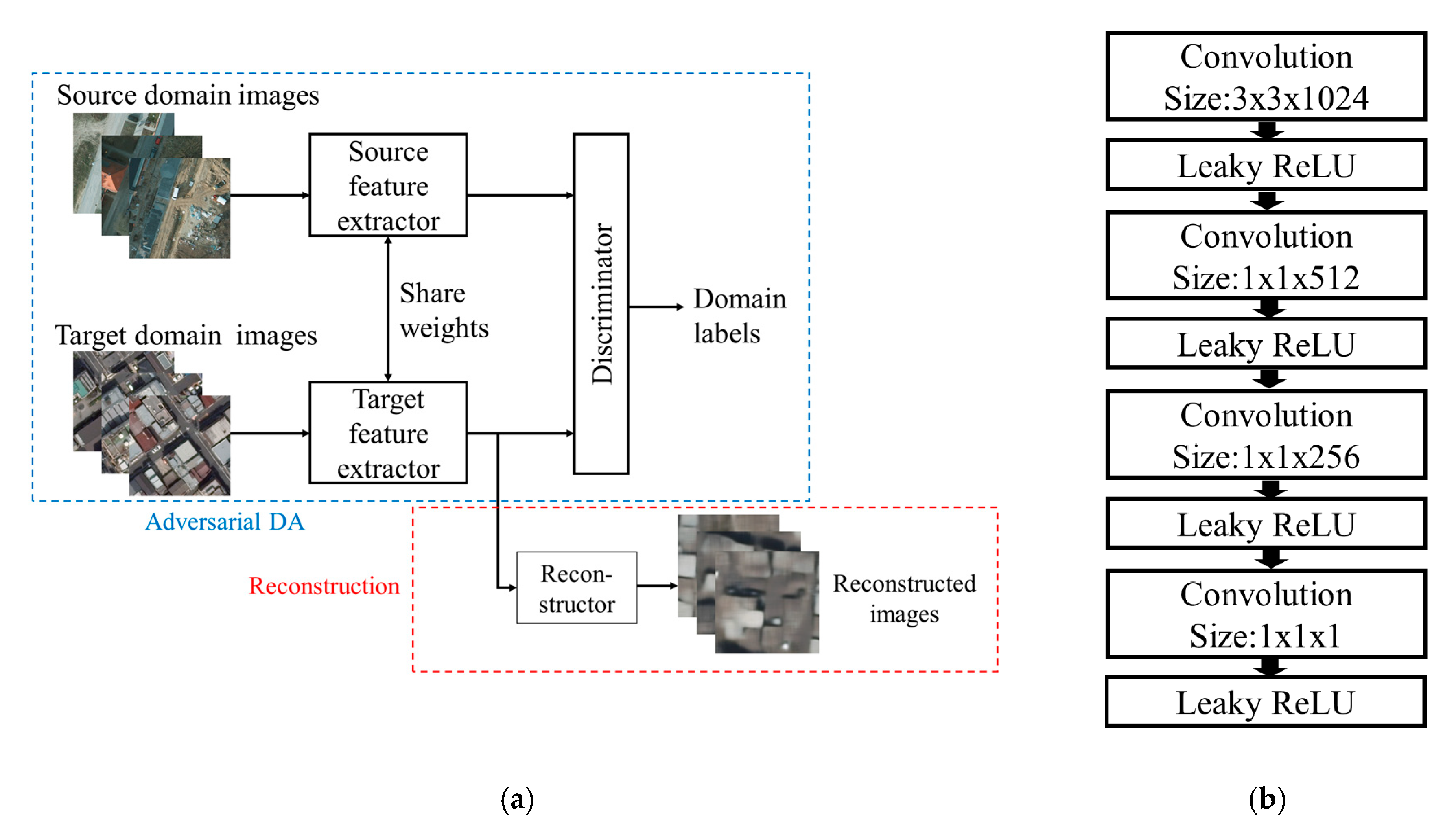
3.2. Domain Adaptation Method
3.3. Reconstruction Loss
4. Experiments and Results
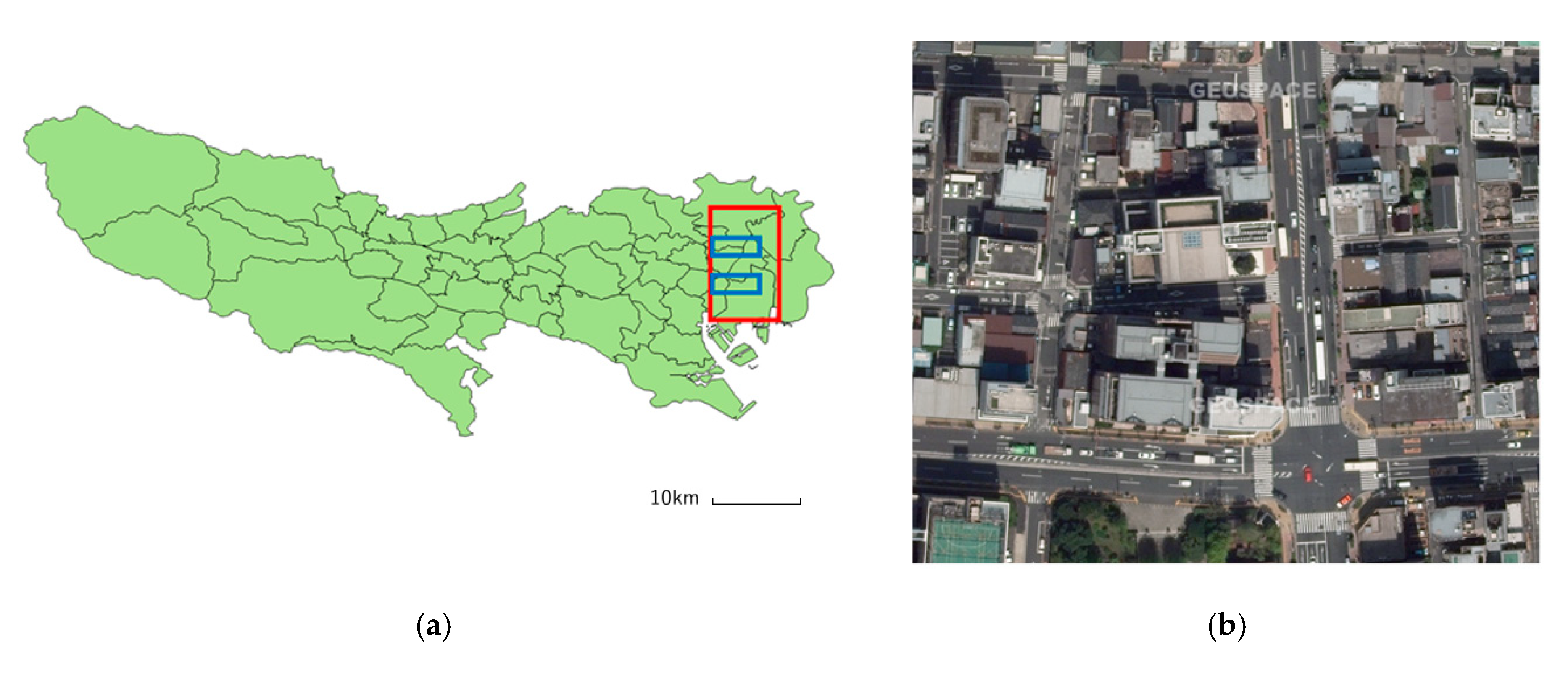
4.1. Dataset
- 1.
- Dataset S_train (Source domain training dataset with annotations)6264 images of 300 × 300 pixels
- 2.
- Dataset S_test (Source domain test dataset with annotations)2088 images of 300 × 300 pixels
- 3.
- Dataset T_train (Target domain training dataset without annotation)1408 images of 300 × 300 pixels
- 4.
- Dataset T_val (Target domain validation dataset with annotations)4 images of 1000 × 1000 pixels
- 5.
- Dataset T_test (Target domain test dataset with annotations)20 images of 1000 × 1000 pixels
- 6.
- Dataset T_labels (Target domain training dataset with annotations)52 images of 1000 × 1000 pixels
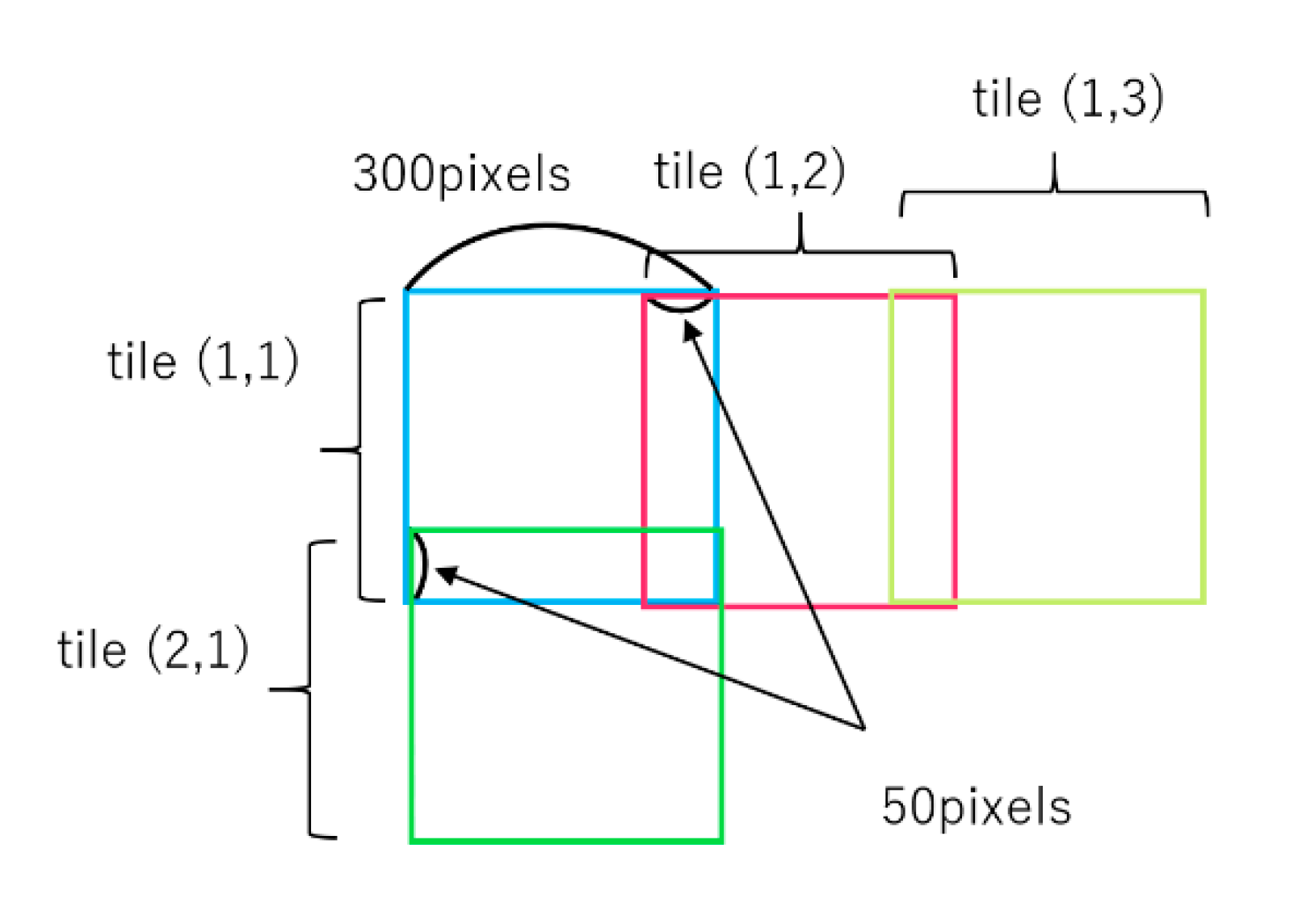
4.2. Detection Criteria and Accuracy Assessment
4.3. Reference Accuracy on the Target Domain
4.4. Detection Performance without DA
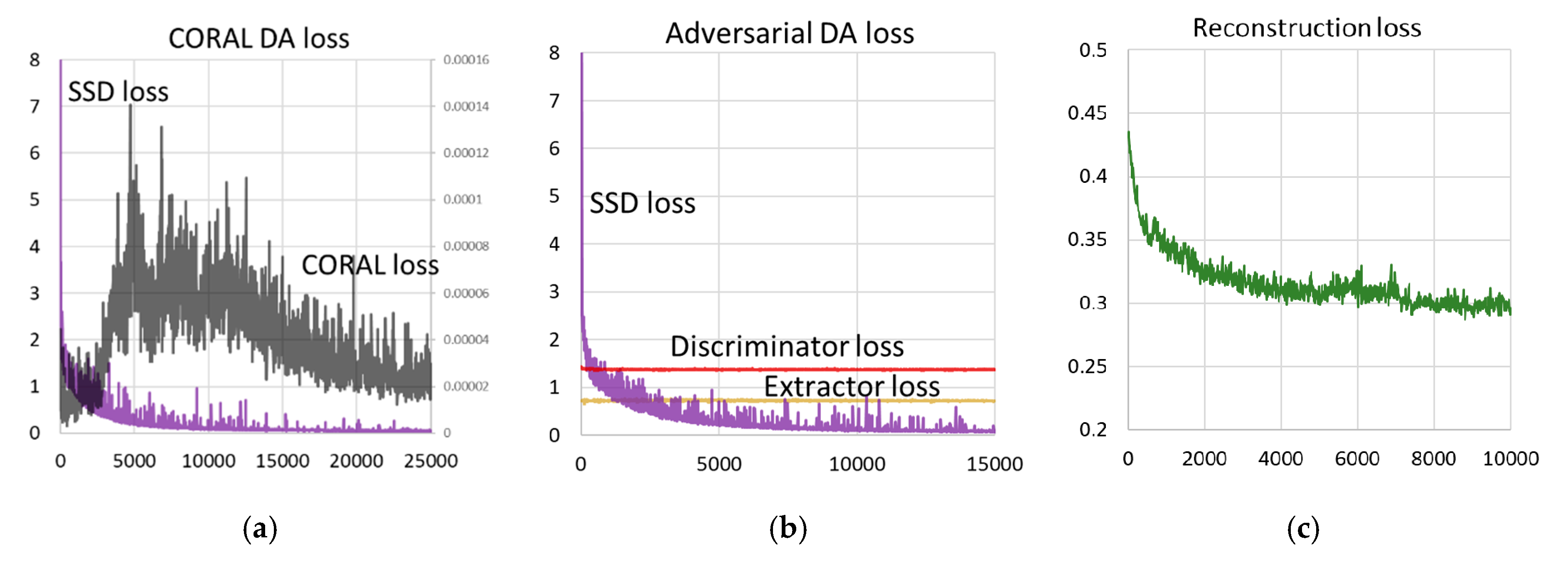
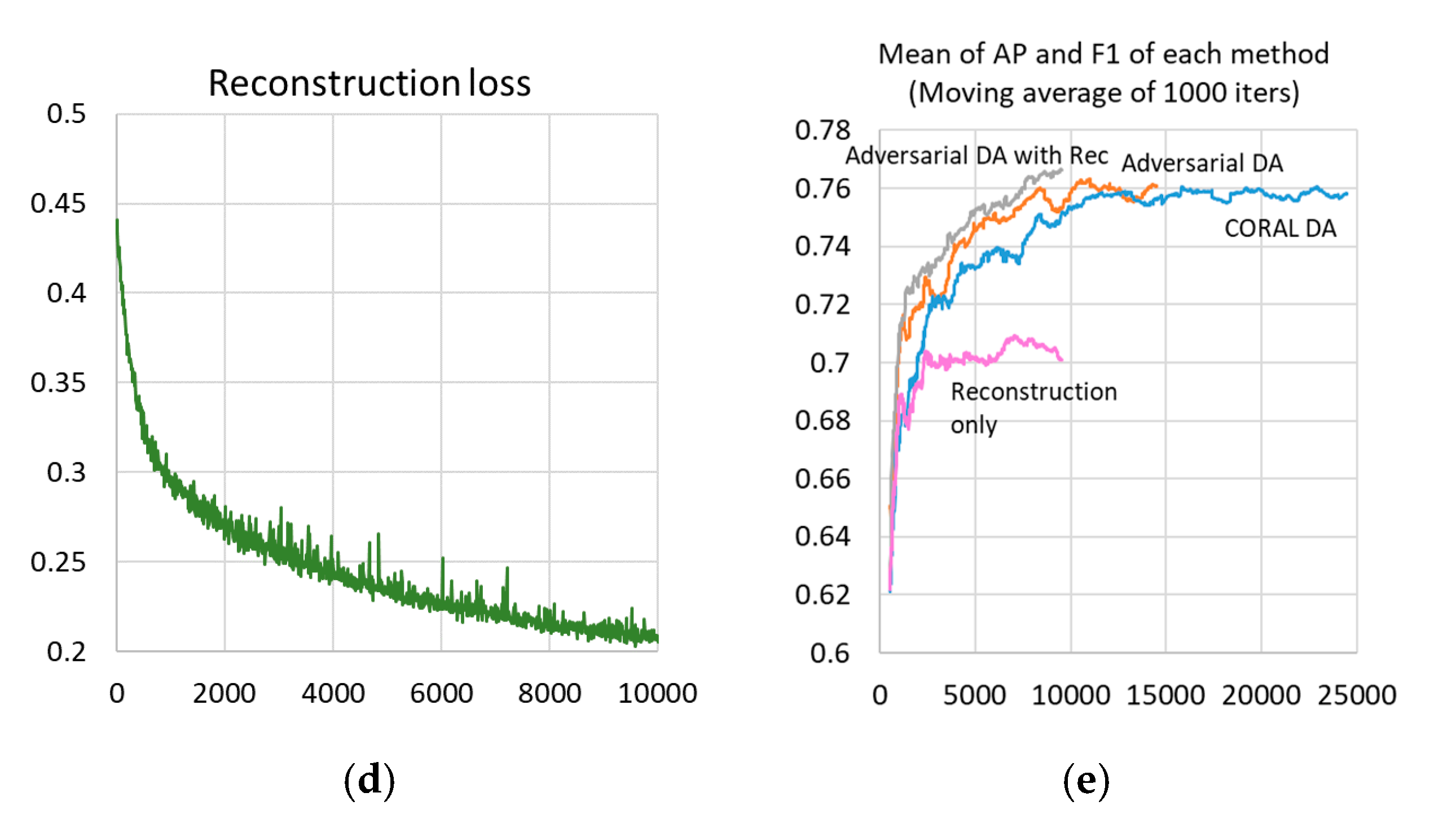
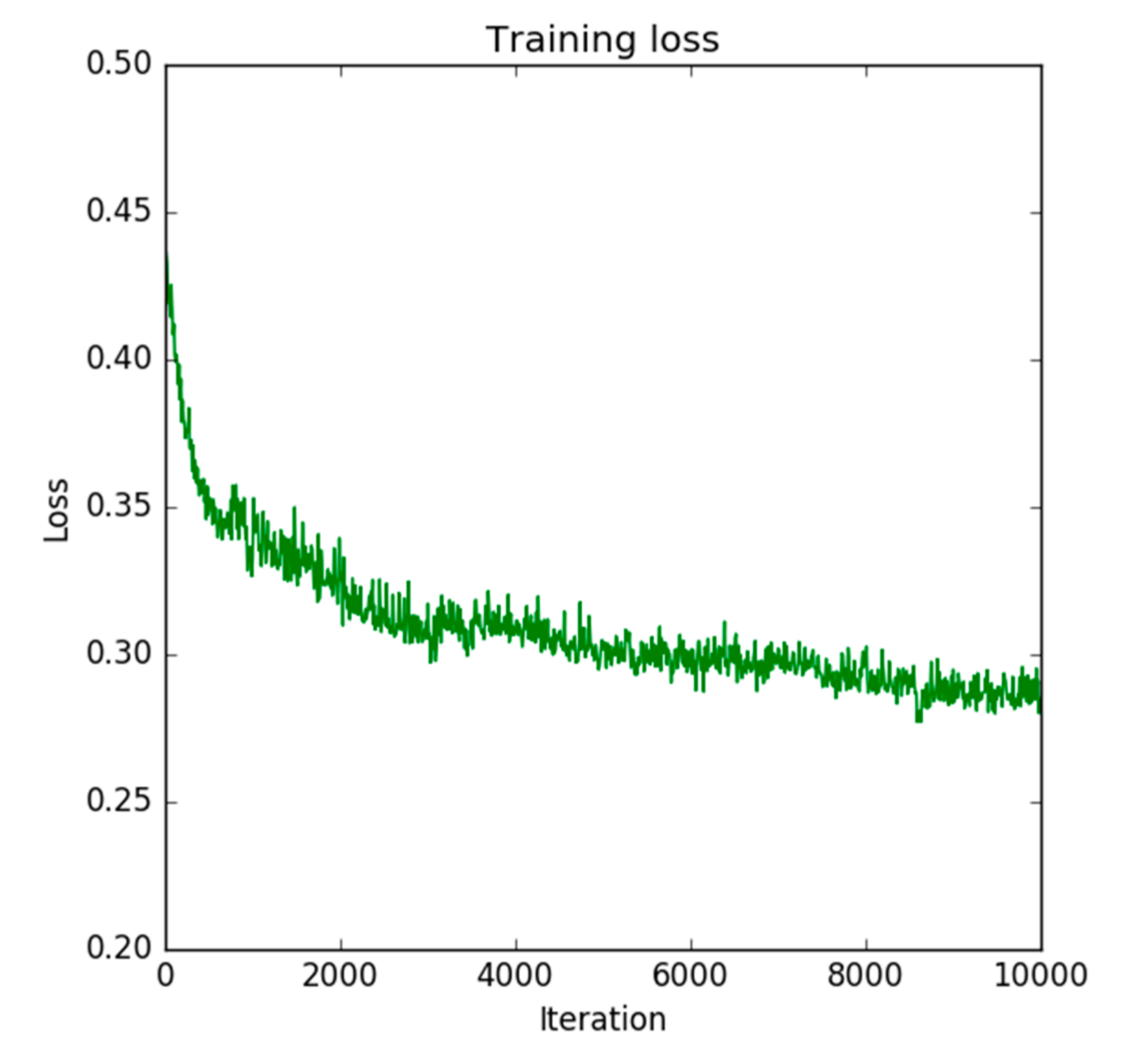
4.5. DA Training
4.6. Detection Performance with DA
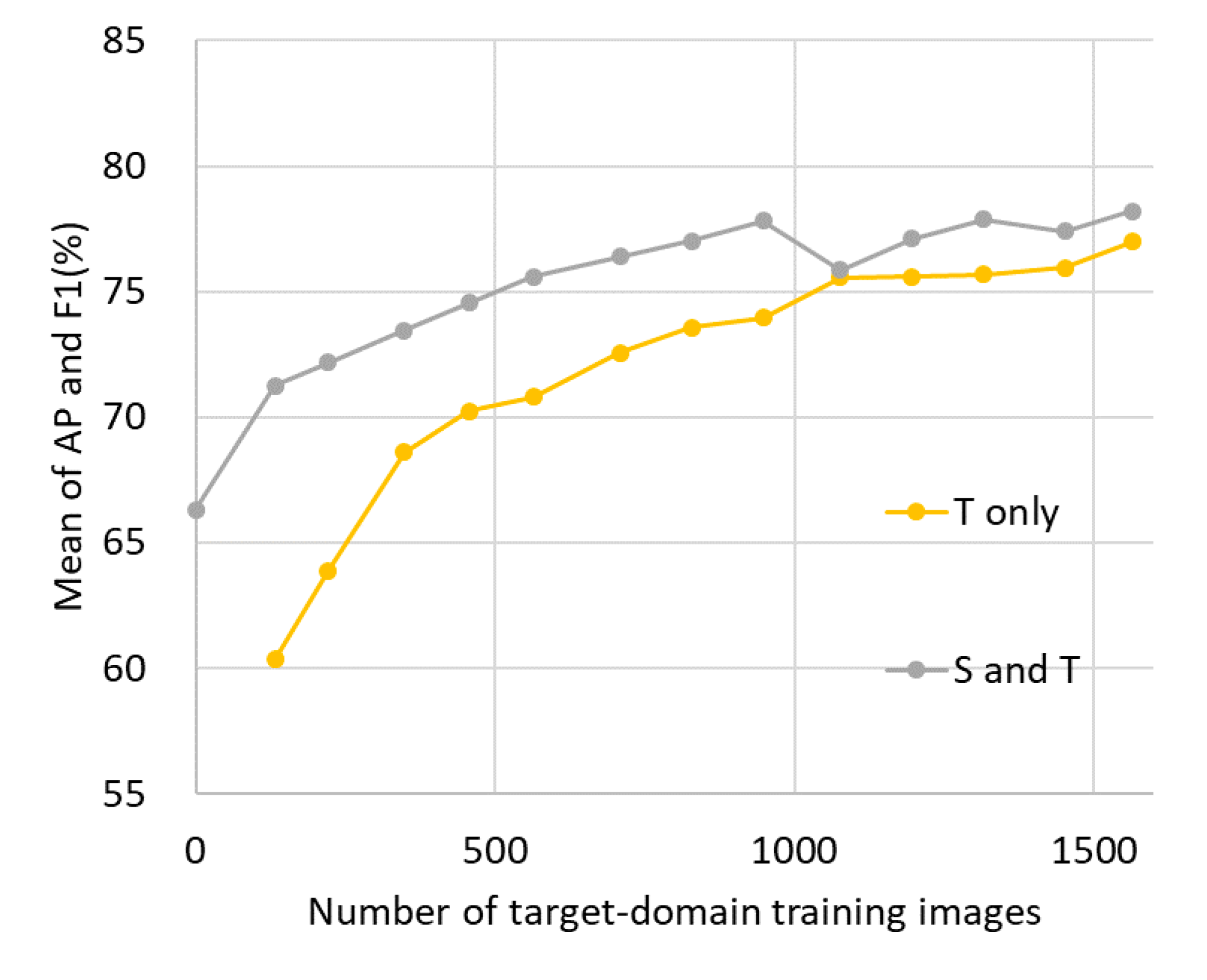
4.7. Utilizing Labeled Dataset with DA Method
5. Discussion
5.1. Performance Improvement by DA
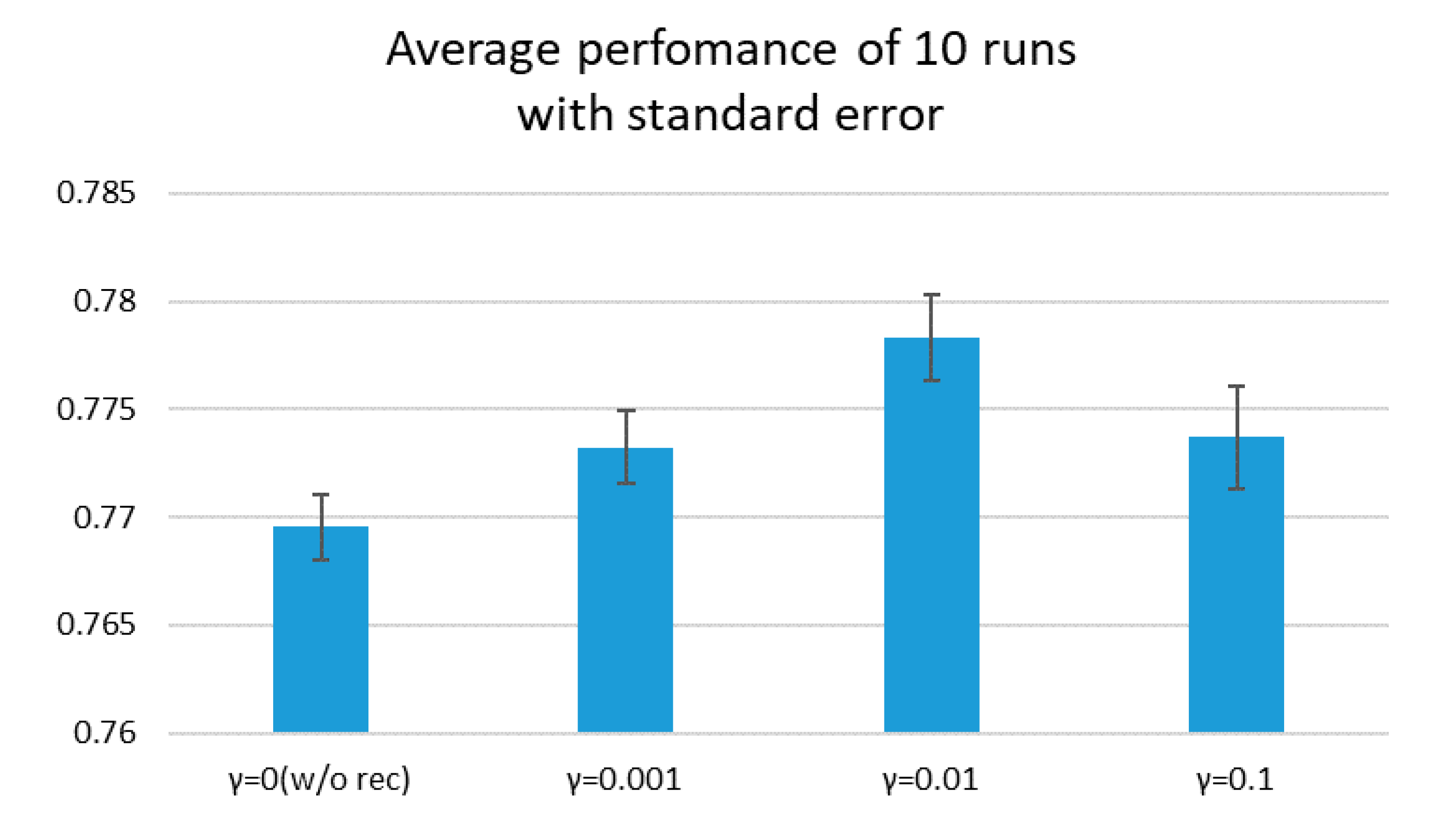
5.2. Learning Semantic Features by Reconstruction
5.3. Reconstruction Objective as Stabilizer
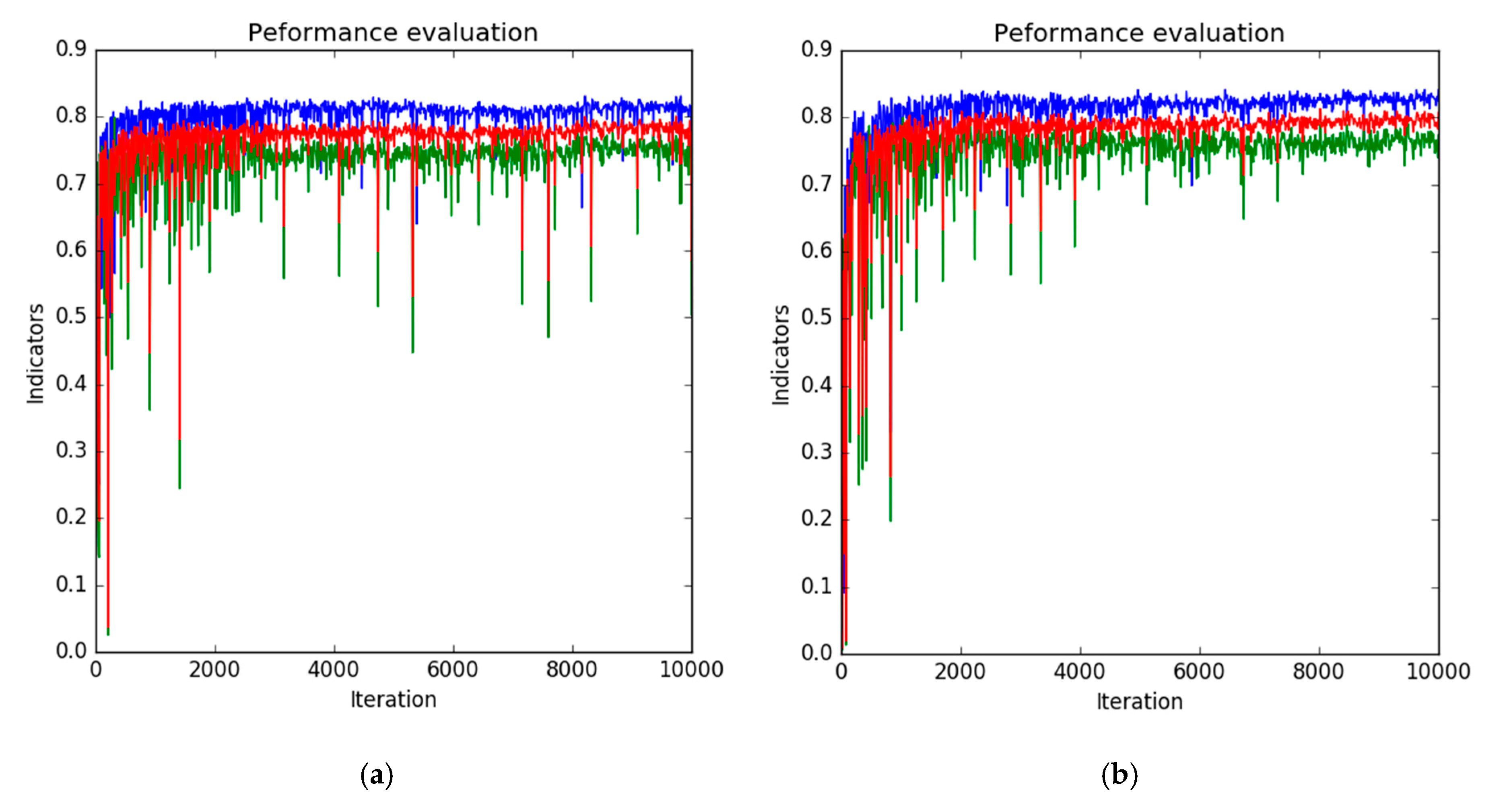
5.4. Effectiveness of Combining Labled Training Data with DA Method
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle Detection in Aerial Images Based on Region Convolutional Neural Networks and Hard Negative Example Mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gabriela, C. Domain Adaptation for Visual Applications: A Comprehensive Survey. In Domain Adaptation for Visual Applications; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef]
- Matasci, G.; Volpi, M.; Kanevski, M.; Bruzzone, L.; Tuia, D. Semisupervised Transfer Component Analysis for Domain Adaptation in Remote Sensing Image Classification. IEEE Trans. Geosci. Remote. Sens. 2015, 53, 3550–3564. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Uijlings, J.R.R.; Van De Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV2016), Amsterdam, The Netherlands, 8–16 October 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR2017), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2Det: A Single-Shot Object Detector Based on Multi-Level Feature Pyramid Network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, Hi, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar] [CrossRef]
- Chen, X.; Xiang, S.; Liu, C.-L.; Pan, C.-H. Vehicle Detection in Satellite Images by Hybrid Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1797–1801. [Google Scholar] [CrossRef]
- Qu, S.; Wang, Y.; Meng, G.; Pan, C. Vehicle Detection in Satellite Images by Incorporating Objectness and Convolutional Neural Network. J. Ind. Intell. Inf. 2016, 4, 158–162. [Google Scholar] [CrossRef]
- Cheng, M.-M.; Zhang, Z.; Lin, W.-Y.; Torr, P. BING: Binarized Normed Gradients for Objectness Estimation at 300fps. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 3286–3293. [Google Scholar] [CrossRef] [Green Version]
- Schapire, R.E.; Singer, Y. Improved Boosting Algorithms Using Confidence-rated Predictions. Mach. Learn. 1999, 37, 297–336. [Google Scholar] [CrossRef] [Green Version]
- Car Localization and Counting with Overhead Imagery, an Interactive Exploration. Available online: https://medium.com/the-downlinq/car-localization-and-counting-with-overhead-imagery-an-interactive-exploration-9d5a029a596b (accessed on 29 December 2019).
- Mundhenk, T.N.; Konjevod, G.; Sakla, W.A.; Boakye, K. A Large Contextual Dataset for Classification, Detection and Counting of Cars with Deep Learning. In Proceedings of the 14th European Conference on Computer Vision (ECCV2016), Amsterdam, The Netherlands, 8–16 October 2016; Volume 9907, pp. 785–800. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Cars Overhead With Context. Available online: https://gdo152.llnl.gov/cowc/ (accessed on 29 December 2019).
- Zheng, K.; Wei, M.; Sun, G.; Anas, B.; Li, Y. Using Vehicle Synthesis Generative Adversarial Networks to Improve Vehicle Detection in Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2019, 8, 390. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zhu, X. An Efficient and Scene-Adaptive Algorithm for Vehicle Detection in Aerial Images Using an Improved YOLOv3 Framework. ISPRS Int. J. Geo-Inf. 2019, 8, 483. [Google Scholar] [CrossRef] [Green Version]
- Bovik, A. Handbook of Image and Video Processing, 2nd ed.; A volume in Communications, Networking and Multimedia; Academic Press: Orlando, FL, USA, 2005. [Google Scholar]
- Kwan, C.; Hagen, L.; Chou, B.; Perez, D.; Li, J.; Shen, Y.; Koperski, K. Simple and effective cloud- and shadow-detection algorithms for Landsat and Worldview images. Signal Image Video Process. 2019, 14, 125–133. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.-P.; Schölkopf, B.; Smola, A.J. Integrating structured biological data by Kernel Maximum Mean Discrepancy. Bioinformatics 2006, 22, 49–57. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, B.; Feng, J.; Saenko, K. Return of frustratingly easy domain adaptation. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16), Phoenix, AZ, USA, 12–17 February 2016; pp. 2058–2065. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep domain confusion: Maximizing for domain invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning transferable features with deep adaptation networks. In Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; Volume 37, pp. 97–105. [Google Scholar]
- Sun, B.; Saenko, K. Deep CORAL: Correlation Alignment for Deep Domain Adaptation. In Proceedings of the 14th European Conference on Computer Vision (ECCV2016), Amsterdam, The Netherlands, 8–16 October 2016; pp. 443–450. [Google Scholar] [CrossRef] [Green Version]
- Tzeng, E.; Hoffman, J.; Darrell, T.; Saenko, K. Simultaneous Deep Transfer across Domains and Tasks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV2015), Santiago, Chile, 11–18 December 2015; pp. 4068–4076. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial Discriminative Domain Adaptation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR2017), Honolulu, HI, USA, 21–26 July 2017; pp. 2962–2971. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS2014), Montréal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Pan, S.J.; Tsang, I.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. Feb. 2011, 22, 199–210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garea, A.S.S.; Heras, D.B.; Argüello, F. TCANet for Domain Adaptation of Hyperspectral Images. Remote Sens. 2019, 11, 2289. [Google Scholar] [CrossRef] [Green Version]
- Bejiga, M.B.; Melgani, F.; Beraldini, P. Domain Adversarial Neural Networks for Large-Scale Land Cover Classification. Remote Sens. 2019, 11, 1153. [Google Scholar] [CrossRef] [Green Version]
- Rostami, M.; Kolouri, S.; Eaton, E.; Kim, K. Deep Transfer Learning for Few-Shot SAR Image Classification. Remote Sens. 2019, 11, 1374. [Google Scholar] [CrossRef] [Green Version]
- Rabin, J.; Peyré, G.; Delon, J.; Bernot, M. Wasserstein barycenter and its application to texture mixing. In International Conference on Scale Space and Variational Methods in Computer Vision; Springer: Berlin/Heidelberg, Germany, 2011; pp. 435–446. [Google Scholar]
- Benjdira, B.; Bazi, Y.; Koubaa, A.; Ouni, K. Unsupervised Domain Adaptation Using Generative Adversarial Networks for Semantic Segmentation of Aerial Images. Remote Sens. 2019, 11, 1369. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.; Isola, P.; Saenko, K.; Efros, A.; Darrell, T. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 1989–1998. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ghifary, M.; Kleijn, W.B.; Zhang, M.; Balduzzi, D.; Li, W. Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation. In Proceedings of the 14th European Conference on Computer Vision (ECCV2016), Amsterdam, The Netherlands, 8–16 October 2016; Volume 9908, pp. 597–613. [Google Scholar] [CrossRef] [Green Version]
- Niitani, Y.; Ogawa, T.; Saito, S.; Saito, M. ChainerCV: A Library for Deep Learning in Computer Vision. In Proceedings of the ACM Multimedia Conference, Mountain View, CA, USA, 23–27 October 2017; pp. 1217–1220. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar] [CrossRef] [Green Version]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning from Simulated and Unsupervised Images through Adversarial Training. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR2017), Honolulu, HI, USA, 21–26 July 2017; pp. 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2536–2544. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised Representation Learning by Predicting Image Rotations. In Proceedings of the 6th International Conference on Learning Representations (ICLR2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Singh, S.; Batra, A.; Pang, G.; Torresani, L.; Basu, S.; Paluri, M.; Jawahar, C.V. Self-Supervised Feature Learning for Semantic Segmentation of Overhead Imagery. In Proceedings of the 29th British Machine Vision Conference (BMVC2018), Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Chen, T.; Zhai, X.; Ritter, M.; Lucic, M.; Houlsby, N. Self-Supervised GANs via Auxiliary Rotation Loss. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12146–12155. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Description | Image Size | Num. of Images | Num. of Vehicles | Purpose | Can Be Seen in: |
|---|---|---|---|---|---|---|
| Dataset S_train | Source domain training dataset with annotations | 300 × 300 pixels | 6264 | 93,344 | Train all models without TONLY models | Section 4.3, Section 4.4, Section 4.5 and Section 4.7 |
| Dataset S_test | Source domain test dataset with annotations | 300 × 300 pixels | 2088 | 31,936 | Evaluate performance on source domain | Section 4.4 |
| Dataset T_train | Target domain training dataset without annotation | 300 × 300 pixels | 1408 | - | Train DA models | Section 4.5 |
| Dataset T_val | Target domain validation dataset with annotations | 1000 × 1000 pixels | 4 | 834 | Check validation accuracy during training to save best snapshot | Section 4.5 and Section 5.3 |
| Dataset T_test | Target domain test dataset with annotations | 1000 × 1000 pixels | 20 | 2722 | Evaluate performance on target domain | Section 4.3, Section 4.4, Section 4.6 and Section 4.7 |
| Dataset T_labels | Target domain training dataset with annotations | 1000 × 1000 pixels | 52 | 5756 | Train DA models with labeled dataset | Section 4.3, Section 4.7 and Section 5.4 |
| Method | PR | RR | FAR | AP | F1 | Mean of AP and F1 |
|---|---|---|---|---|---|---|
| Reference | 83.9% | 78.5% | 15.1% | 75.3% | 81.1% | 78.2% |
| Without DA | 82.6% | 65.1% | 13.7% | 61.7% | 72.8% | 67.2% |
| M2Det w/o DA | 82.4% | 73.7% | 15.7% | 69.7% | 77.8% | 73.7% |
| Reconstruction | 81.8% | 75.5% | 16.8% | 72.7% | 78.5% | 75.6% |
| CORAL | 86.3% | 77.1% | 12.2% | 73.3% | 81.5% | 77.4% |
| Adversarial | 85.4% | 76.5% | 13.0% | 74.0% | 80.7% | 77.4% |
| Adv + Rec | 88.0% | 77.9% | 10.7% | 75.2% | 82.6% | 78.9% |
| Method | Statistic | PR | RR | FAR | AP | F1 | Mean of AP and F1 |
|---|---|---|---|---|---|---|---|
| γ = 0 (w/o rec) | AVR | 85.09% | 76.52% | 13.50% | 73.36% | 80.55% | 76.96% |
| STDDEV | 2.09% | 1.18% | 2.42% | 0.84% | 0.51% | 0.45% | |
| STDERR | 0.70% | 0.39% | 0.81% | 0.28% | 0.17% | 0.15% | |
| γ = 0.001 | AVR | 85.27% | 76.87% | 13.34% | 73.82% | 80.83% | 77.32% |
| STDDEV | 1.79% | 1.08% | 2.04% | 0.91% | 0.49% | 0.51% | |
| STDERR | 0.60% | 0.36% | 0.68% | 0.30% | 0.16% | 0.17% | |
| γ = 0.01 | AVR | 84.37% | 77.75% | 14.52% | 74.78% | 80.89% | 77.83% |
| STDDEV | 2.64% | 0.93% | 3.01% | 0.68% | 0.98% | 0.60% | |
| STDERR | 0.88% | 0.31% | 1.00% | 0.23% | 0.33% | 0.20% | |
| γ = 0.1 | AVR | 84.57% | 77.26% | 14.17% | 74.02% | 80.72% | 77.37% |
| STDDEV | 2.10% | 1.17% | 2.42% | 0.97% | 0.78% | 0.72% | |
| STDERR | 0.70% | 0.39% | 0.81% | 0.32% | 0.26% | 0.24% |
| Method | PR | RR | FAR | AP | F1 | Mean of AP and F1 |
|---|---|---|---|---|---|---|
| Adv + target label | 87.3% | 79.8% | 13.0% | 77.4% | 83.4% | 80.4% |
| Adv + Rec + target label | 86.7% | 80.4% | 12.3% | 78.1% | 83.4% | 80.7% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koga, Y.; Miyazaki, H.; Shibasaki, R. A Method for Vehicle Detection in High-Resolution Satellite Images that Uses a Region-Based Object Detector and Unsupervised Domain Adaptation. Remote Sens. 2020, 12, 575. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12030575
Koga Y, Miyazaki H, Shibasaki R. A Method for Vehicle Detection in High-Resolution Satellite Images that Uses a Region-Based Object Detector and Unsupervised Domain Adaptation. Remote Sensing. 2020; 12(3):575. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12030575
Chicago/Turabian StyleKoga, Yohei, Hiroyuki Miyazaki, and Ryosuke Shibasaki. 2020. "A Method for Vehicle Detection in High-Resolution Satellite Images that Uses a Region-Based Object Detector and Unsupervised Domain Adaptation" Remote Sensing 12, no. 3: 575. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12030575