Efficient Discrimination and Localization of Multimodal Remote Sensing Images Using CNN-Based Prediction of Localization Uncertainty


Abstract
:
1. Introduction
2. Related Work
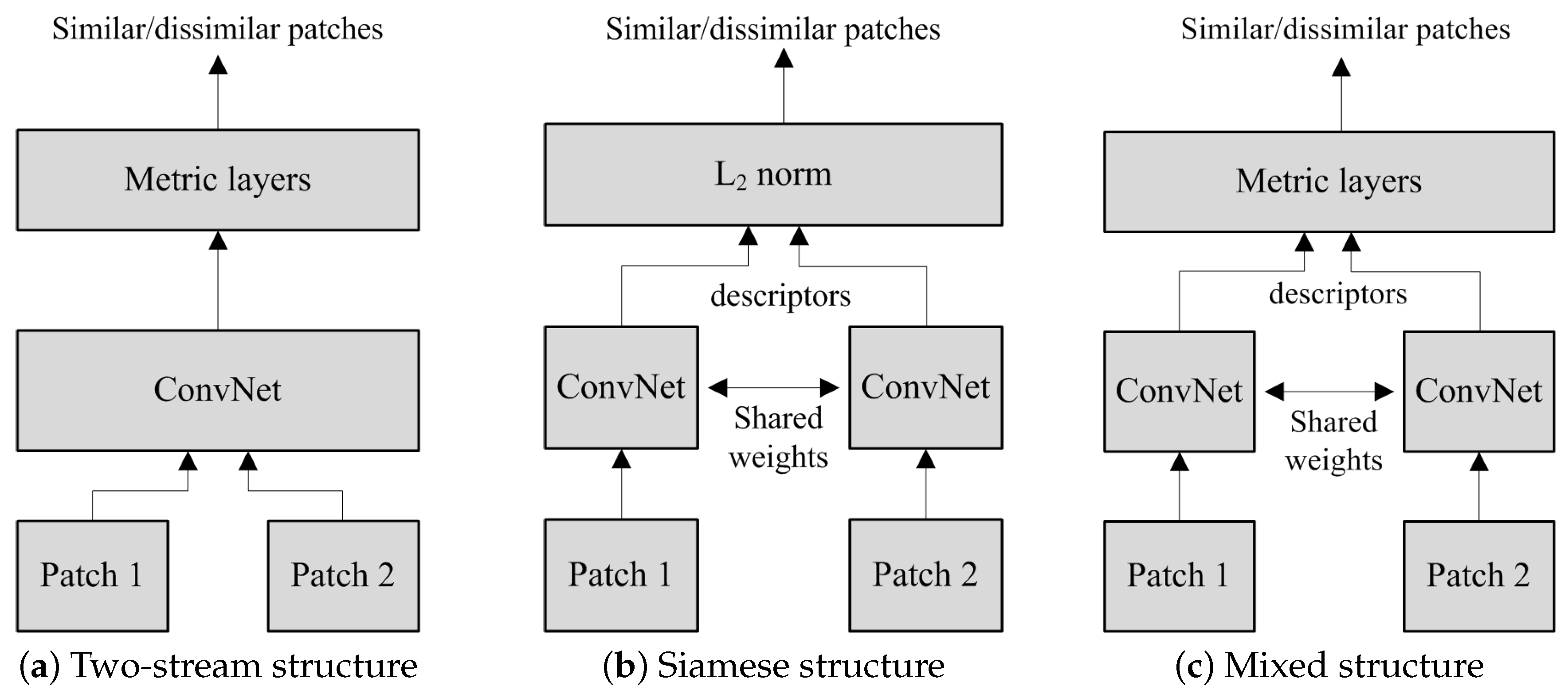
2.1. Overview of Existing Patch Matching CNN Structure and Loss Functions
2.2. Discrimination and Localization Ability of Existing Patch Matching CNNs
3. Training Convolutional Neural Network for Measuring Similarity between Multimodal Images with Enhanced Localization Accuracy
3.1. Requirements to Complexity of Geometrical Transform Between Patches in RS
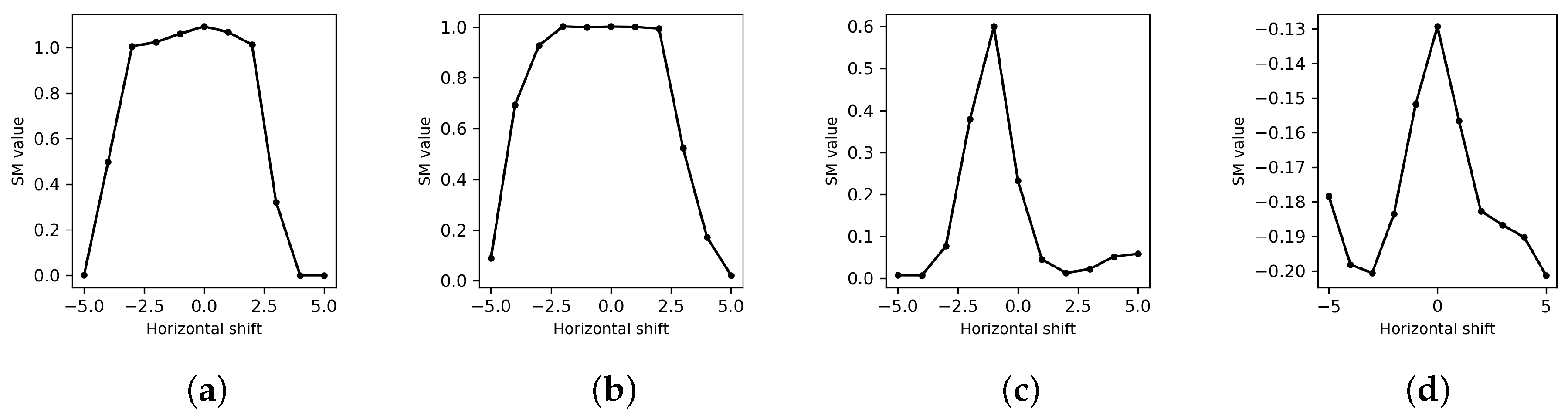
3.2. SM Performance Criteria
3.3. Patch Matching as Deep Regression with Uncertainty
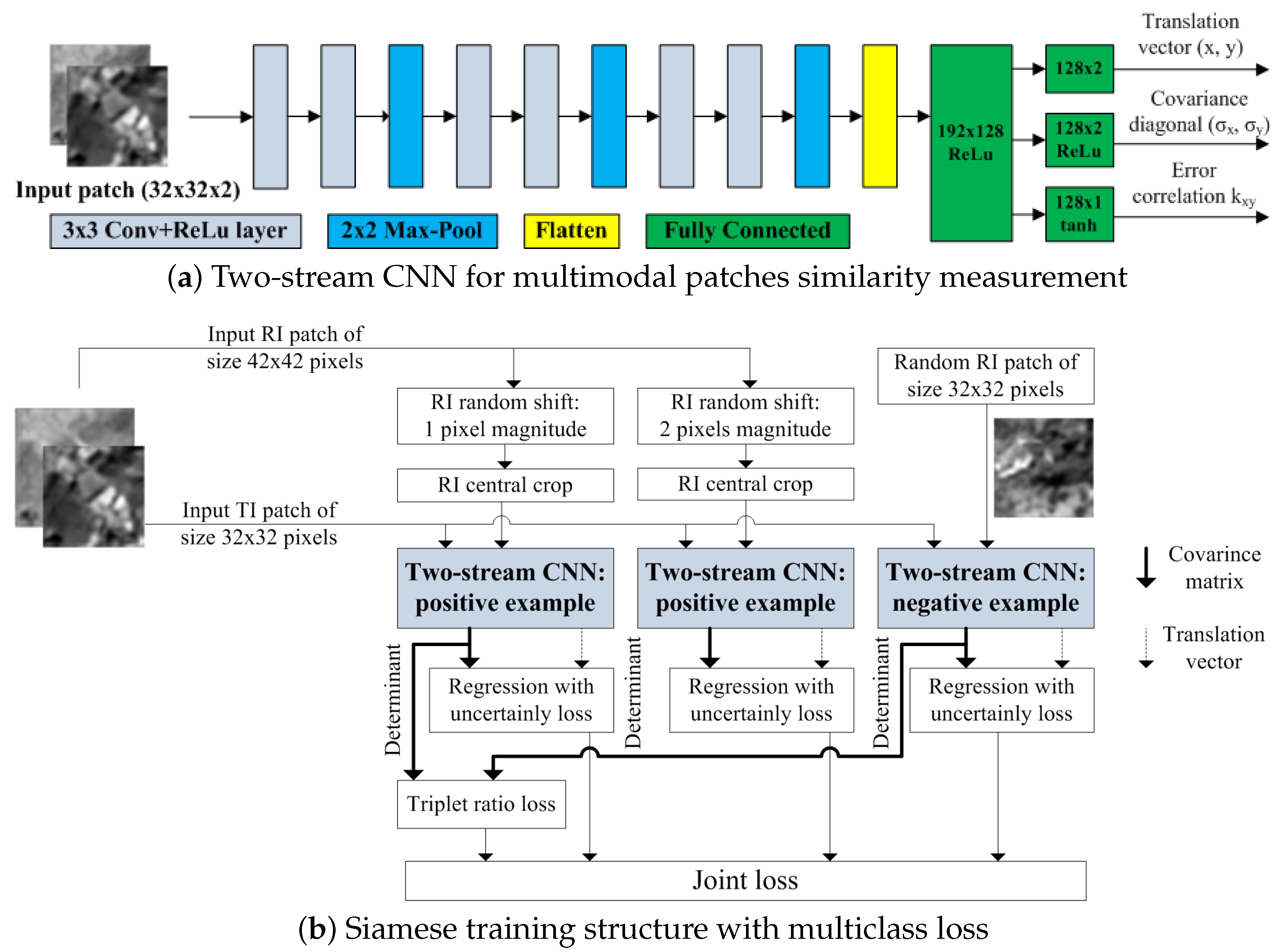
3.4. Siamese ConvNet Structure and Training Process Settings
3.5. Patch Pair Alignment with Subpixel Accuracy
4. Experimental Part
4.1. Multimodal Image Dataset
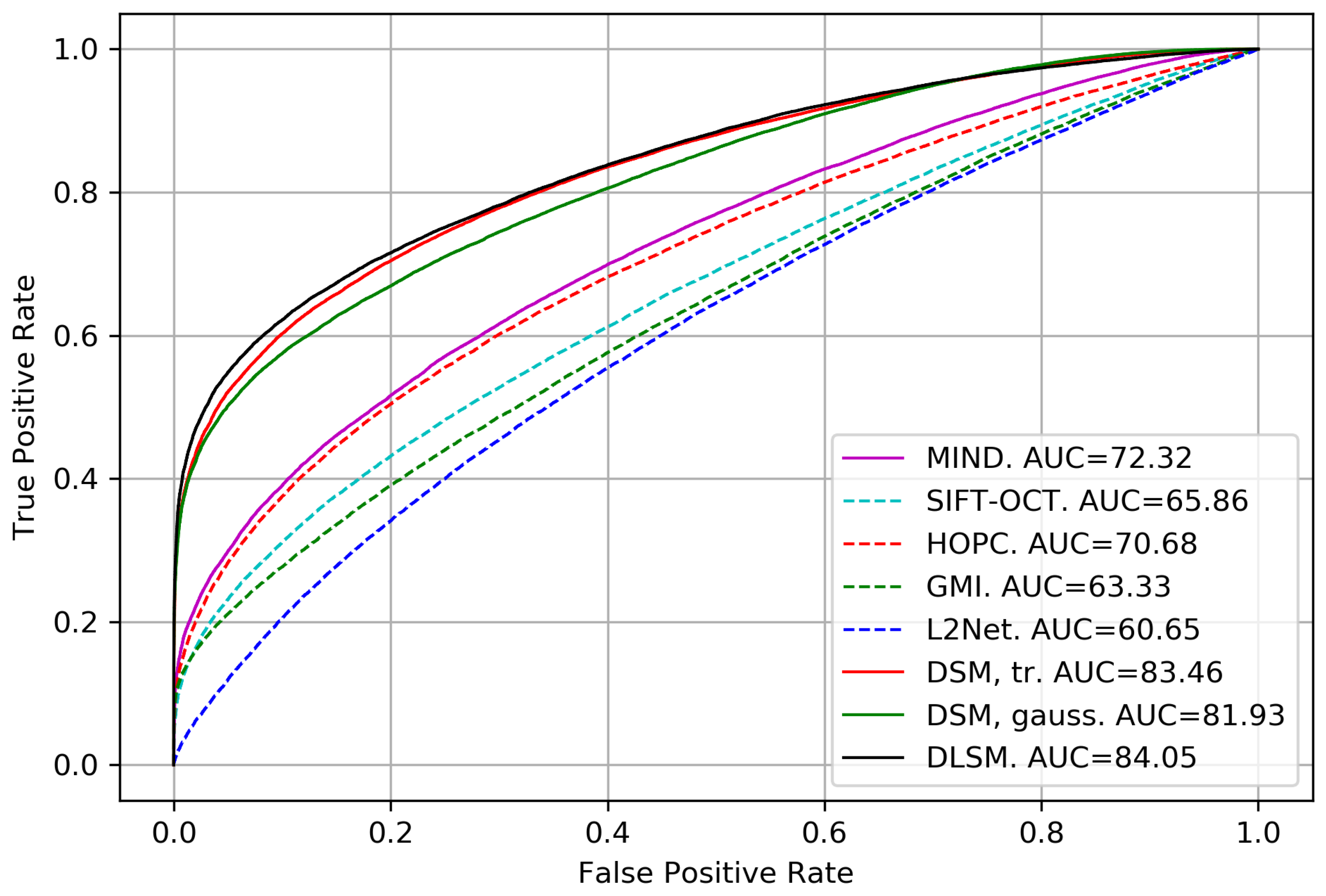
4.2. Discriminative Power Analysis
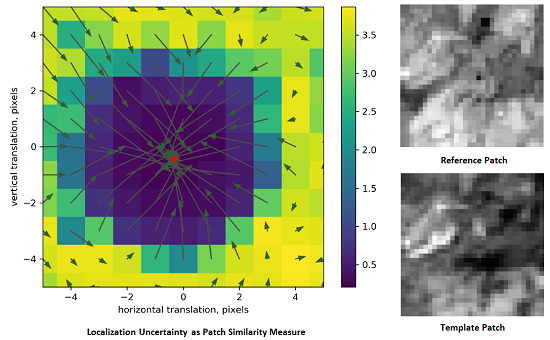
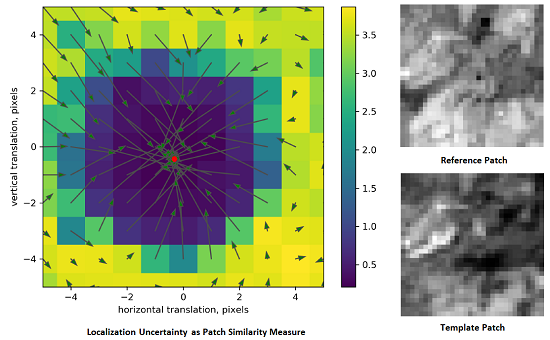
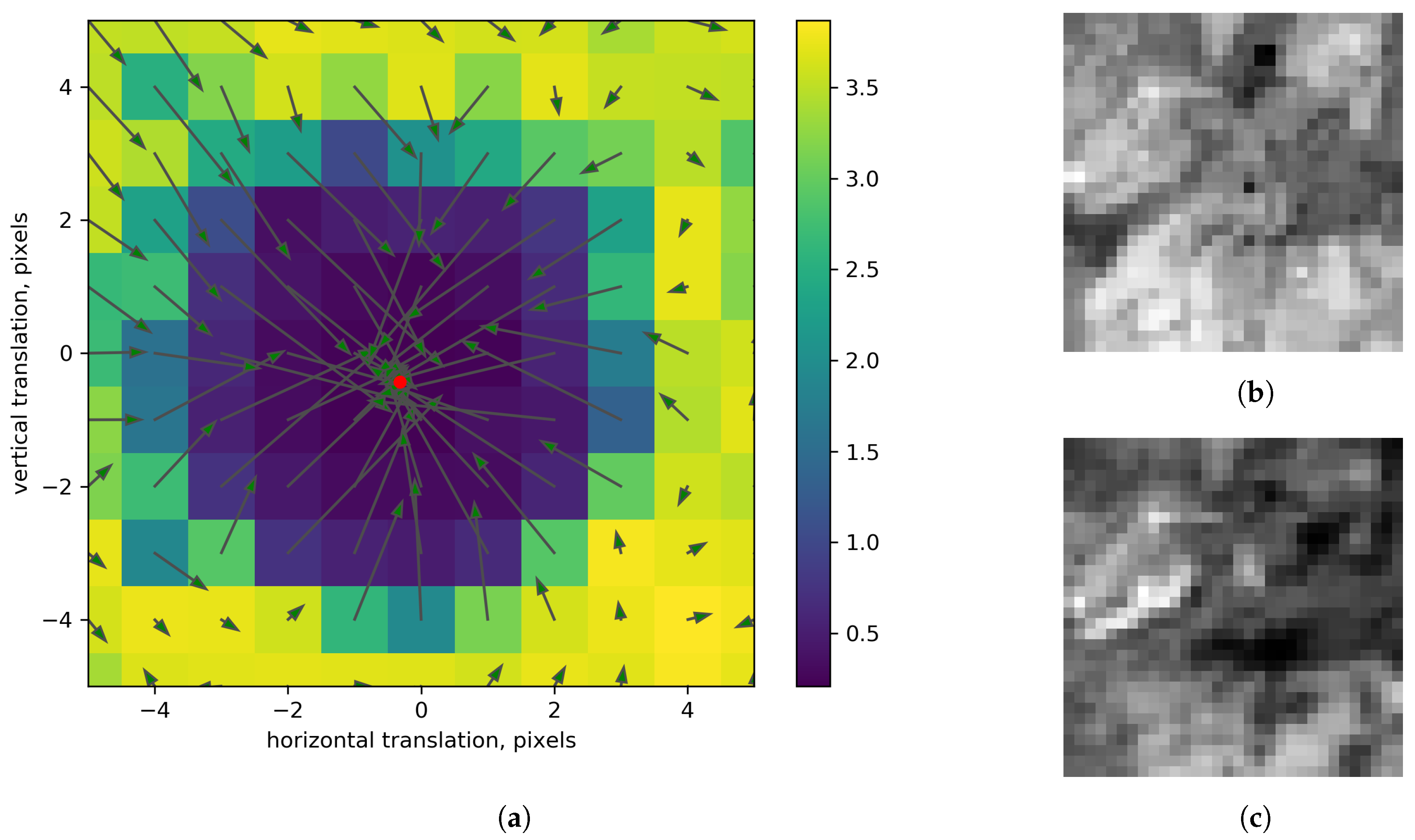
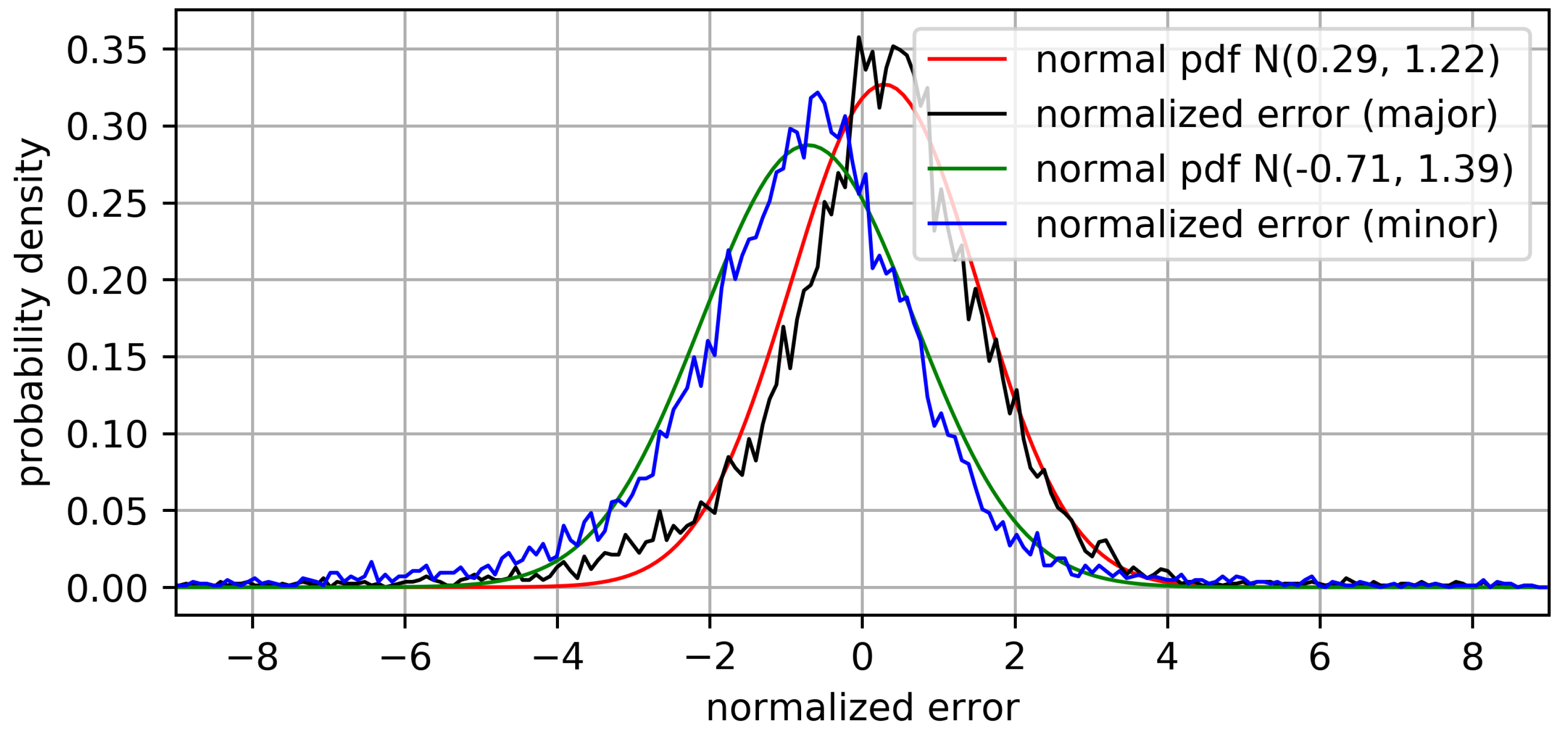
4.3. Patch Matching Uncertainty Analysis
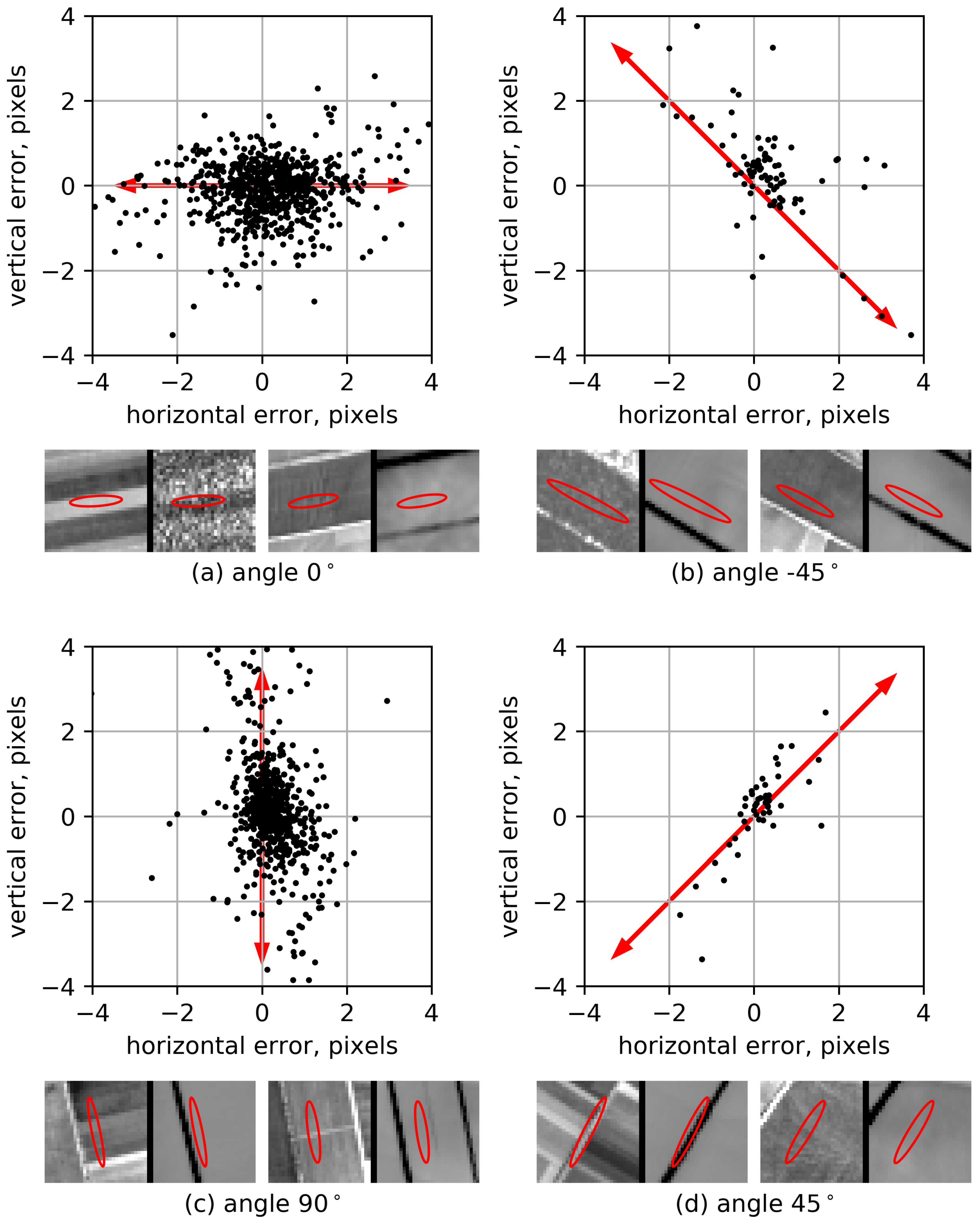
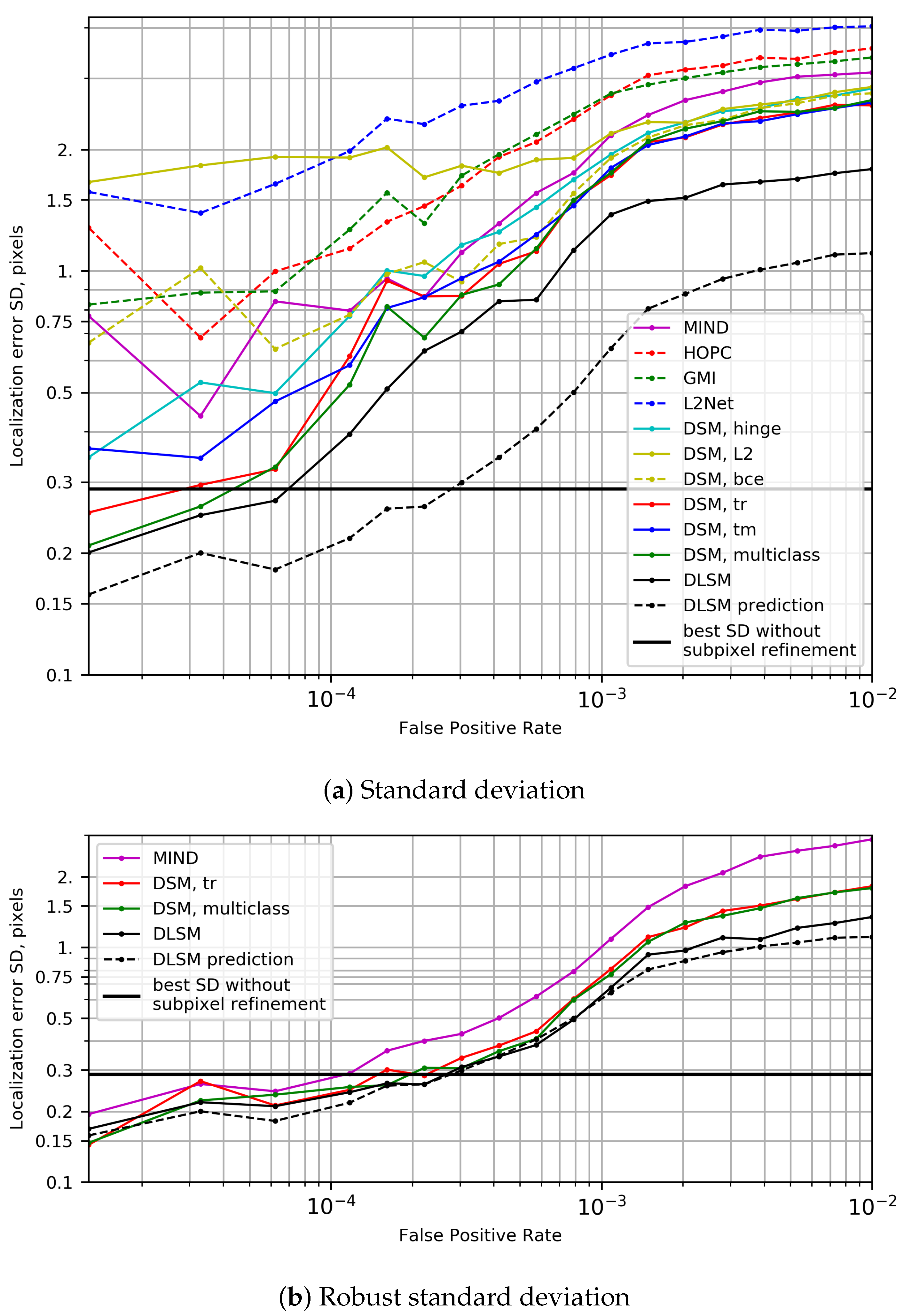
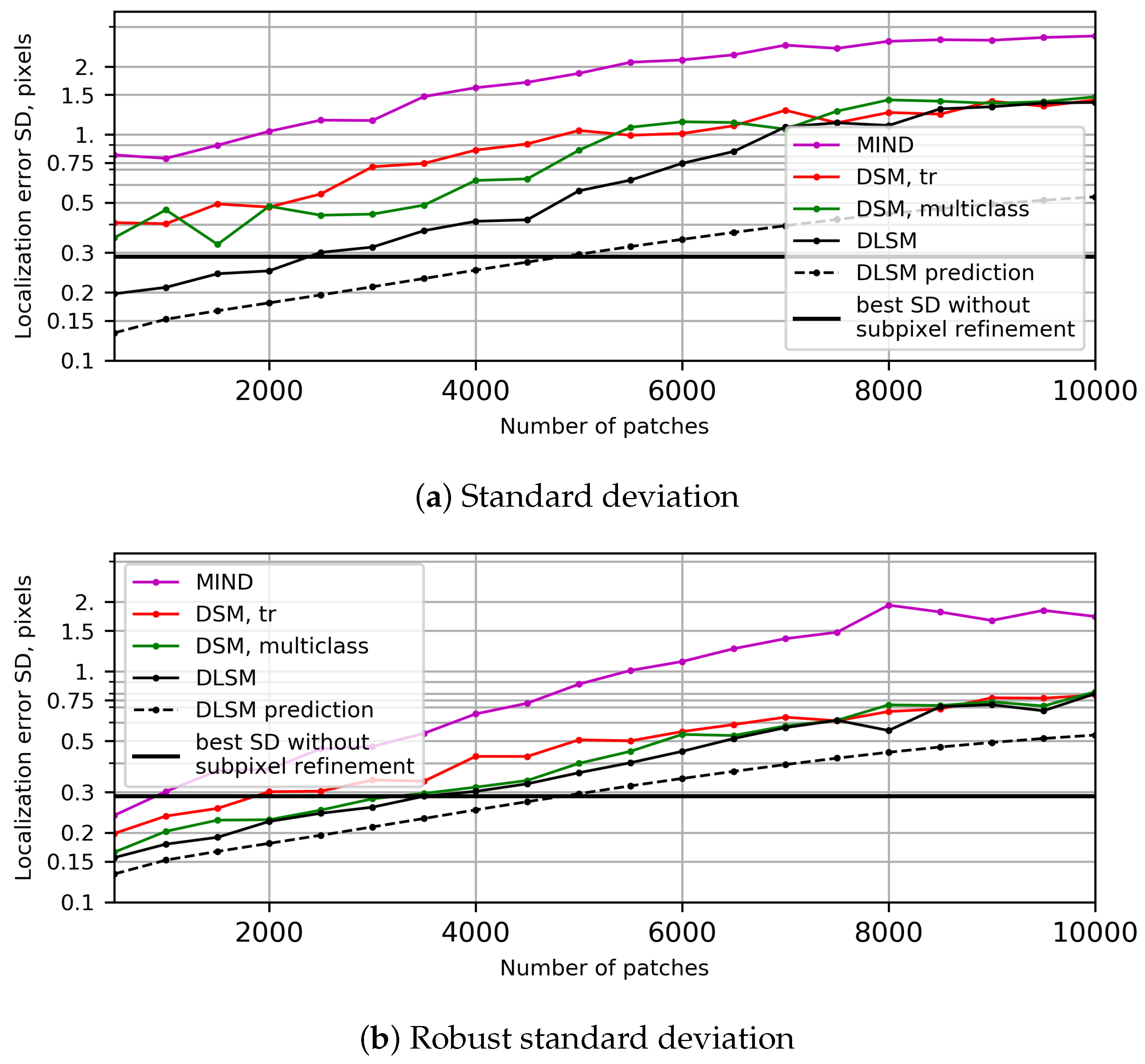
4.4. Localization Accuracy Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| RS | Remote Sensing |
| SM | Similarity Measure |
| CNN | Convolutional Neural Network |
| DLSM | Deep Localization Similarity Measure |
| PC | Putative Correspondence |
| DEM | Digital Elevation Model |
| SSD | Sum of Squared Differences |
| NCC | Normalized Correlation Coefficient |
| SIFT | Scale-Invariant Feature Transform |
| MI | Mutual Information |
| HOPC | Histogram of Orientated Phase Congruency |
| MIND | Modality Independent Neighborhood Descriptor |
| SNR | Signal-to-Noise Ratio |
| FC | Fully Connected (layer) |
| SAR | Synthetic Aperture Radar |
| RP | Reference Patch |
| TP | Template Patch |
| ROC | Receiver Operating Characteristic |
| AUC | Area Under the Curve |
| FPR | False Positive Rate |
| SD | Standard Deviation |
| MAD | Median Absolute Deviation |
| DSM | Deep Similarity Measure |
| probability density function |
References
- Uss, M.; Vozel, B.; Lukin, V.; Chehdi, K. Multimodal remote sensing images registration with accuracy estimation at local and global scales. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6587–6605. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Zhao, J.; Tian, J.; Yuille, A.L.; Tu, Z. Robust Point Matching via Vector Field Consensus. IEEE Trans. Image Process. 2014, 23, 1706–1721. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Le Moigne, J.; Netanyahu, N.S.; Eastman, R.D. Image Registration for Remote Sensing; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- En, S.; Lechervy, A.; Jurie, F. TS-NET: Combining Modality Specific and Common Features for Multimodal Patch Matching. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3024–3028. [Google Scholar] [CrossRef] [Green Version]
- Aguilera, C.A.; Aguilera, F.J.; Sappa, A.D.; Aguilera, C.; Toledo, R. Learning cross-spectral similarity measures with deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Aguilera, C.A.; Sappa, A.D.; Aguilera, C.; Toledo, R. Cross-Spectral Local Descriptors via Quadruplet Network. Sensors 2017, 17, 873. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goshtasby, A.; Le Moign, J. Image Registration: Principles, Tools and Methods; Springer: London, UK, 2012. [Google Scholar]
- Zitová, B.; Flusser, J. Image registration methods: A survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef] [Green Version]
- Roche, A.; Malandain, G.; Pennec, X.; Ayache, N. The correlation ratio as a new similarity measure for multimodal image registration. In Medical Image Computing and Computer-Assisted Interventation—MICCAI’98; Springer: Heidelberg, Germany, 1998; pp. 1115–1124. [Google Scholar]
- Foroosh, H.; Zerubia, J.B.; Berthod, M. Extension of phase correlation to subpixel registration. IEEE Trans. Image Process. 2002, 11, 188–200. [Google Scholar] [CrossRef] [Green Version]
- Suri, S.; Reinartz, P. Mutual-Information-Based Registration of TerraSAR-X and Ikonos Imagery in Urban Areas. IEEE Trans. Geosci. Remote Sens. 2010, 48, 939–949. [Google Scholar] [CrossRef]
- Uss, M.; Vozel, B.; Lukin, V.; Chehdi, K. Statistical power of intensity- and feature-based similarity measures for registration of multimodal remote sensing images. Proc. SPIE 2016, 10004. [Google Scholar] [CrossRef]
- Ye, Y.; Shan, J.; Bruzzone, L.; Shen, L. Robust Registration of Multimodal Remote Sensing Images Based on Structural Similarity. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2941–2958. [Google Scholar] [CrossRef]
- Lowe, D. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Suri, S.; Schwind, P.; Uhl, J.; Reinartz, P. Modifications in the SIFT operator for effective SAR image matching. Int. J. Image Data Fusion 2010, 1, 243–256. [Google Scholar] [CrossRef] [Green Version]
- Heinrich, M.P.; Jenkinson, M.; Bhushan, M.; Matin, T.; Gleeson, F.V.; Brady, S.M.; Schnabel, J.A. MIND: Modality independent neighbourhood descriptor for multi-modal deformable registration. Med. Image Anal. 2012, 16, 1423–1435. [Google Scholar] [CrossRef] [PubMed]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. Lift: Learned invariant feature transform. In European Conference on Computer Vision; Springer: Heidelberg, Germany, 2016; pp. 467–483. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Zeng, A.; Song, S.; Nießner, M.; Fisher, M.; Xiao, J.; Funkhouser, T. 3dmatch: Learning local geometric descriptors from rgb-d reconstructions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1802–1811. [Google Scholar]
- Schonberger, J.L.; Hardmeier, H.; Sattler, T.; Pollefeys, M. Comparative evaluation of hand-crafted and learned local features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1482–1491. [Google Scholar]
- Yang, X.; Kwitt, R.; Styner, M.; Niethammer, M. Quicksilver: Fast predictive image registration—A deep learning approach. NeuroImage 2017, 158, 378–396. [Google Scholar] [CrossRef] [PubMed]
- Balakrishnan, G.; Zhao, A.; Sabuncu, M.R.; Guttag, J.; Dalca, A.V. An unsupervised learning model for deformable medical image registration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9252–9260. [Google Scholar]
- Altwaijry, H.; Trulls, E.; Hays, J.; Fua, P.; Belongie, S. Learning to Match Aerial Images with Deep Attentive Architectures. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3539–3547. [Google Scholar] [CrossRef]
- Merkle, N.; Luo, W.; Auer, S.; Müller, R.; Urtasun, R. Exploiting Deep Matching and SAR Data for the Geo-Localization Accuracy Improvement of Optical Satellite Images. Remote Sens. 2017, 9, 586. [Google Scholar] [CrossRef] [Green Version]
- Uss, M.L.; Vozel, B.; Dushepa, V.A.; Komjak, V.A.; Chehdi, K. A precise lower bound on image subpixel registration accuracy. IEEE Trans. Geosci. Remote Sens. 2013, 52, 3333–3345. [Google Scholar] [CrossRef]
- Torr, P.H.S.; Zisserman, A. MLESAC: A New Robust Estimator with Application to Estimating Image Geometry. Comput. Vis. Image Underst. 2000, 78, 138–156. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Fan, B.; Wu, F. L2-net: Deep learning of discriminative patch descriptor in euclidean space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 661–669. [Google Scholar]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. Matchnet: Unifying feature and metric learning for patch-based matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3279–3286. [Google Scholar]
- Žbontar, J.; LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 2287–2318. [Google Scholar]
- Simo-Serra, E.; Trulls, E.; Ferraz, L.; Kokkinos, I.; Fua, P.; Moreno-Noguer, F. Discriminative learning of deep convolutional feature point descriptors. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 118–126. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Georgakis, G.; Karanam, S.; Wu, Z.; Ernst, J.; Košecká, J. End-to-end learning of keypoint detector and descriptor for pose invariant 3D matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1965–1973. [Google Scholar]
- Mobahi, H.; Collobert, R.; Weston, J. Deep learning from temporal coherence in video. In Proceedings of the 26th Annual International Conference on Machine Learning; ACM: New York, NY, USA, 2009; pp. 737–744. [Google Scholar]
- Balntas, V.; Johns, E.; Tang, L.; Mikolajczyk, K. PN-Net: Conjoined triple deep network for learning local image descriptors. arXiv 2016, arXiv:1601.05030. [Google Scholar]
- Choy, C.B.; Gwak, J.; Savarese, S.; Chandraker, M. Universal correspondence network. In Proceedings of the Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2414–2422. [Google Scholar]
- Deng, H.; Birdal, T.; Ilic, S. Ppfnet: Global context aware local features for robust 3d point matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 195–205. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep Metric Learning Using Triplet Network. International Workshop on Similarity-Based Pattern Recognition; Springer International Publishing: Cham, Switzerland, 2015; pp. 84–92. [Google Scholar]
- Khoury, M.; Zhou, Q.Y.; Koltun, V. Learning compact geometric features. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 153–161. [Google Scholar]
- Masci, J.; Migliore, D.; Bronstein, M.M.; Schmidhuber, J. Descriptor learning for omnidirectional image matching. In Registration and Recognition in Images and Videos; Springer: Heidelberg, Germany, 2014; pp. 49–62. [Google Scholar]
- Wang, J.; Song, Y.; Leung, T.; Rosenberg, C.; Wang, J.; Philbin, J.; Chen, B.; Wu, Y. Learning fine-grained image similarity with deep ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1386–1393. [Google Scholar]
- Suárez, P.L.; Sappa, A.D.; Vintimilla, B.X. Cross-spectral image patch similarity using convolutional neural network. In Proceedings of the 2017 IEEE International Workshop of Electronics, Control, Measurement, Signals and their Application to Mechatronics (ECMSM), Donostia-San Sebastian, Spain, 24–26 May 2017; pp. 1–5. [Google Scholar] [CrossRef]
- He, H.; Chen, M.; Chen, T.; Li, D. Matching of Remote Sensing Images with Complex Background Variations via Siamese Convolutional Neural Network. Remote Sens. 2018, 10, 355. [Google Scholar] [CrossRef] [Green Version]
- Kumar, B.; Carneiro, G.; Reid, I. Learning local image descriptors with deep siamese and triplet convolutional networks by minimising global loss functions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5385–5394. [Google Scholar]
- Yang, Z.; Dan, T.; Yang, Y. Multi-Temporal Remote Sensing Image Registration Using Deep Convolutional Features. IEEE Access 2018, 6, 38544–38555. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Kai, L.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Luo, W.; Schwing, A.G.; Urtasun, R. Efficient deep learning for stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June– 1 July 2016; pp. 5695–5703. [Google Scholar]
- Dosovitskiy, A.; Springenberg, J.T.; Riedmiller, M.; Brox, T. Discriminative unsupervised feature learning with convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 766–774. [Google Scholar]
- Ye, Y.; Bruzzone, L.; Shan, J.; Bovolo, F.; Zhu, Q. Fast and Robust Matching for Multimodal Remote Sensing Image Registration. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9059–9070. [Google Scholar] [CrossRef] [Green Version]
- Goncalves, H.; Corte-Real, L.; Goncalves, J.A. Automatic Image Registration Through Image Segmentation and SIFT. IEEE Trans. Geosci. Remote Sens. 2011, 49, 2589–2600. [Google Scholar] [CrossRef] [Green Version]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Huber, P.J. Robust Statistics; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Gurevich, P.; Stuke, H. Learning uncertainty in regression tasks by deep neural networks. arXiv 2017, arXiv:1707.07287. [Google Scholar]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5574–5584. [Google Scholar]
- Pluim, J.P.W.; Maintz, J.B.A.; Viergever, M.A. Image registration by maximization of combined mutual information and gradient information. IEEE Trans. Med. Imag. 2000, 19, 809–814. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | General | Optical-DEM | Optical-Optical | Optical-Radar | Radar-DEM |
|---|---|---|---|---|---|
| GMI | 63.33 | 60.83 | 72.16 | 64.39 | 60.19 |
| SIFT-OCT | 65.86 | 58.97 | 65.78 | 73.51 | 68.21 |
| HOPC | 70.67 | 67.43 | 78.41 | 70.16 | 67.26 |
| MIND | 72.32 | 68.61 | 85.15 | 70.31 | 64.51 |
| L2-Net | 60.65 | 61.85 | 71.21 | 55.50 | 55.41 |
| DSM, hinge | 80.66 | 76.74 | 87.77 | 79.32 | 76.20 |
| DSM, | 80.25 | 76.30 | 88.99 | 77.29 | 75.98 |
| DSM, binary cross-entropy | 81.14 | 76.36 | 89.88 | 78.60 | 76.68 |
| DSM, triplet ratio loss | 83.46 | 81.19 | 90.18 | 80.44 | 81.14 |
| DSM, triplet margin loss | 82.88 | 79.06 | 90.57 | 80.17 | 80.28 |
| DSM, multiclass loss | 81.93 | 75.03 | 92.49 | 79.44 | 78.32 |
| DLSM | 84.07 | 79.96 | 90.21 | 83.16 | 81.73 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uss, M.; Vozel, B.; Lukin, V.; Chehdi, K. Efficient Discrimination and Localization of Multimodal Remote Sensing Images Using CNN-Based Prediction of Localization Uncertainty. Remote Sens. 2020, 12, 703. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12040703
Uss M, Vozel B, Lukin V, Chehdi K. Efficient Discrimination and Localization of Multimodal Remote Sensing Images Using CNN-Based Prediction of Localization Uncertainty. Remote Sensing. 2020; 12(4):703. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12040703
Chicago/Turabian StyleUss, Mykhail, Benoit Vozel, Vladimir Lukin, and Kacem Chehdi. 2020. "Efficient Discrimination and Localization of Multimodal Remote Sensing Images Using CNN-Based Prediction of Localization Uncertainty" Remote Sensing 12, no. 4: 703. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12040703