1. Introduction
With the advancement of global observation technology and the development of increasingly higher-resolution sensors, it is now possible to acquire very high-resolution remote sensing images. Such images can capture detailed ground information, and facilitate the accurate analysis of scenes, and also objects within scenes. With the availability of high-resolution remote sensing images, the demand for extracting detailed information of interest regions in the images has increased. In recent years, a variety of methods focusing on semantic segmentation, i.e., pixel-level image segmentation with category labeling, have been proposed [
1]. Semantic segmentation has many practical applications such as plant disease detection [
2], vegetation extraction [
3], urban planning [
4,
5], building extraction [
6,
7], road extraction [
8,
9], etc. In this context, the main focus of this paper is on the task of semantic segmentation of high-resolution remote sensing images obtained by airborne sensors, proposing a novel deep-learning framework for addressing the multi-scale challenges.
Semantic segmentation refers to the process of partitioning an image into several regions, where all pixels in a scene are assigned a semantically meaningful category. Image segmentation is combined with category recognition by employing an appropriate classification technique [
10]. Recent years have seen rapid progress in this area within the computer vision community using conventional RGB and RGB-D cameras, e.g., 3D reconstruction of a scene with pixel-wise materials [
11] or object category [
12]. However, the application of such methods to remote sensing images still remains elusive.
Semantic segmentation of remote sensing (e.g., satellite) images is challenging for three key reasons [
13]. Firstly, the objects in remote sensing images often have different sizes. For example, the roof of a building may occupy a large area of pixels, while a car and a tree occupy a much smaller area, which results in an uneven distribution of categories. Secondly, remote sensing images are usually acquired by airborne or space-based sensors. They only provide a top-down view which does not contain many important characteristics of objects which would normally be visible in a ground-based or panoramic view of an object. This makes it difficult to understand objects with respect to contexts and scenes objects [
13]. For example, the images of a building’s roof and the road are very similar, while the car may be partially covered under a tree. Thirdly, many targets in the remote sensing image may belong to the same category, while having greatly different appearance and size, e.g., different sizes and styles of buildings. This leads to intra-class differences further affecting the segmentation [
13]. All these three factors make the task of semantic segmentation of remote sensing images highly challenging. In recent years, an increasing amount of research has been carried out in this field, and some notable achievements have been made.
Conventional remote sensing image segmentation methods usually rely on handcrafted features to extract spatial and texture information of the image and employ a classifier to classify each pixel in the image. Well-known feature extraction methods include histogram of oriented gradient (HOG) [
14], scale-invariant feature transform (SIFT) [
15], spatial orientation feature matching (SOFM) [
16], etc. In addition, some methods relied on corner point features [
17]. They mostly use contour-based detectors combined with a corner classifier based on the mean projection transform (MPT) [
18]. Some of the most commonly used classifiers for semantic segmentation are support vector machines [
19], logistic regression [
20], and random forest [
21]. Despite having faster segmentation rates, the pixel classification accuracy associated with these methods is not satisfactory. This is mainly due to their usage of handcrafted features.
In recent years, convolutional neural networks (CNNs) have achieved great success in computer vision [
22]. In general, a CNN contains two different parts: one for feature extraction and the other for classification. It extracts various features from the images by means of convolution, pooling, and activation functions and performs classification using fully connected layers. The network parameters are learned and updated via backpropagation and has a very strong nonlinear fitting ability. Its performance significantly exceeds the traditional machine learning methods. There are a variety of backbone networks, such as VGG [
23], deep residual networks, such as ResNet [
24] and ResNetXt [
25], and dense convolutional networks, such as DenseNet [
26]. ResNet [
24] uses skip connections to fuse input and output features to avoid the problem of vanishing gradient up to certain extent. DenseNet uses a dense connection method to fuse all current and previous features. The “Squeeze and Excitation” (SE) module [
27] represents the importance of each channel by learning the weight of each channel. All these above methods have been widely used for image classification tasks. In 2015, Long et al. [
28] proposed fully convolutional networks (FCN) by converting the convolutional layers of traditional CNNs into fully connected layers. The FCN uses upsampling to restore the resolution of feature maps. With this method, an end-to-end training has been used for the first time to accomplish image pixel classification. Despite demonstrating promising performance, the FCN still has some limitations. Firstly, since the backbone network continuously down-samples to extract image features, the size of the feature map is 1/32 of the original input size. While reducing the size of the feature map will reduce the amount of calculation, the spatial resolution of the feature map will also decrease simultaneously. This results in losing useful information, which makes it difficult for the feature map to recover fine details. Secondly, some categories in the remote sensing image have different sizes and it is difficult to extract suitable features through the backbone network.
Multi-scale context information is essential for targets with different scales. Context information of different scales can be concatenated to gain multi-scale information, thereby improving the performance of segmentation. Huang et al. [
29] proposed U-net, a segmentation model based on encoding and decoding, which fuses the semantic information in different layers to the corresponding decoding part. It makes full use of different levels of semantic information and solves the problem of loss of useful shallow feature information effectively. However, the fusion of U-net is performed simply by concatenating each channel’s features. PSPNet [
30] uses the pyramid pooling module to aggregate context information in different regions, thereby improving the ability to achieve global information. However, it is computationally inefficient. DeepLabv3+ [
31] uses a backbone network to down sample the image. Then, multi-scale information is obtained using atrous convolution with a different dilatation rate. Finally, the up-sampled features and low-level feature maps are added to make predictions. APPD [
32] combines the advantages of DeepLabv3+ and U-net and employs post-processing based on super pixels to further improve the segmentation performance. It is known that both the high-level and the low-level semantic information achieved by the backbone network has a great effect on the segmentation results. Currently available high-level and low-level feature fusion methods are divided into channel-dimensional concatenation and channel-dimensional addition. If the fusion of high-level and low-level features is performed by simple addition or concatenation, the effectiveness of the fusion will be reduced. Nevertheless, efficient and reasonable fusion of high-level and low-level semantic information can refine the image segmentation result. In addition, the context information of different scales can alleviate the degradation of segmentation performance caused by the difference in target size.
In this paper, we propose an end-to-end multi-scale adaptive feature fusion network (MANet) for semantic segmentation in remote sensing images. It is a coding and decoding structure that includes a multi-scale context extraction module and an adaptive fusion module. Specifically, we have used ResNet101 as the backbone network to extract various features of the images. Multi-scale context extraction module uses two layers of atrous convolution with different dilatation rate and global average pooling to extract different scales of context information in parallel. The feature map extracted from the backbone network is fed into a multi-scale context extraction module to generate the contextual information of different scales, which is then concatenated. We introduce the channel attention mechanism to fuse semantic features. The low-level and high-level semantic information are concatenated to generate global features via global average pooling. The global features are used as channel weights, and these weights are adaptively learned by the fully connected layer. Finally, the fused features are adjusted by multiplying with these weights. Experiments performed using the publicly available Potsdam and Vaihingen datasets show that the proposed MANet significantly outperforms the other existing networks, with overall accuracy reaching 89.4% and 88.2% respectively. The main contributions of this paper are summarized as follows:
We propose a multi-scale context extraction module. It consists of a two-layer atrous convolution with different dilatation rate, global information, and information of its own. The multi-scale context extraction module extracts the features of different scales of the image. These features are concatenated to form new features, which are used to tackle the problem of different target sizes in the images.
We designed a high-level and low-level feature adaptive fusion module. It combines both high- and low-level features to form new features and applies channel attention to these new features to obtain weights. These weights are multiplied with fused features to emphasize useful features and to suppress useless features. This alleviates the problem of misidentification of similar targets in remote sensing images.
Based on the above model, we construct an end-to-end network called MANet for semantic segmentation in remote sensing images. The performance of our proposed MANet on Potsdam and Vaihingen datasets is compared to other state-of-the-art methods.
The remainder of this paper is organized as follows.
Section 2 introduces our proposed method in detail.
Section 3 details the experiments along with in-depth analysis and discussion of results.
Section 4 discusses the performance of our proposed method.
Section 5 provides the conclusions and our future perspectives.
2. Multi-Scale Adaptive Feature Fusion Algorithm
As mentioned earlier, the large variations in the target sizes in the remote sensing images makes it difficult for the model to extract corresponding useful features of the target. This in turn has a significant effect on the overall segmentation performance. Moreover, the shooting angles of the remote sensing images are all from the top, which may lead to the same visual representation of different categories, e.g., low vegetation areas and the areas with trees, resulting in the wrong pixel segmentation. These problems can be handled effectively by our proposed MANet, which is consisted of a multi-scale extraction module and an adaptive feature fusion module. In this section, we present the details of these two modules.
2.1. Multi-Scale Context Extraction Module
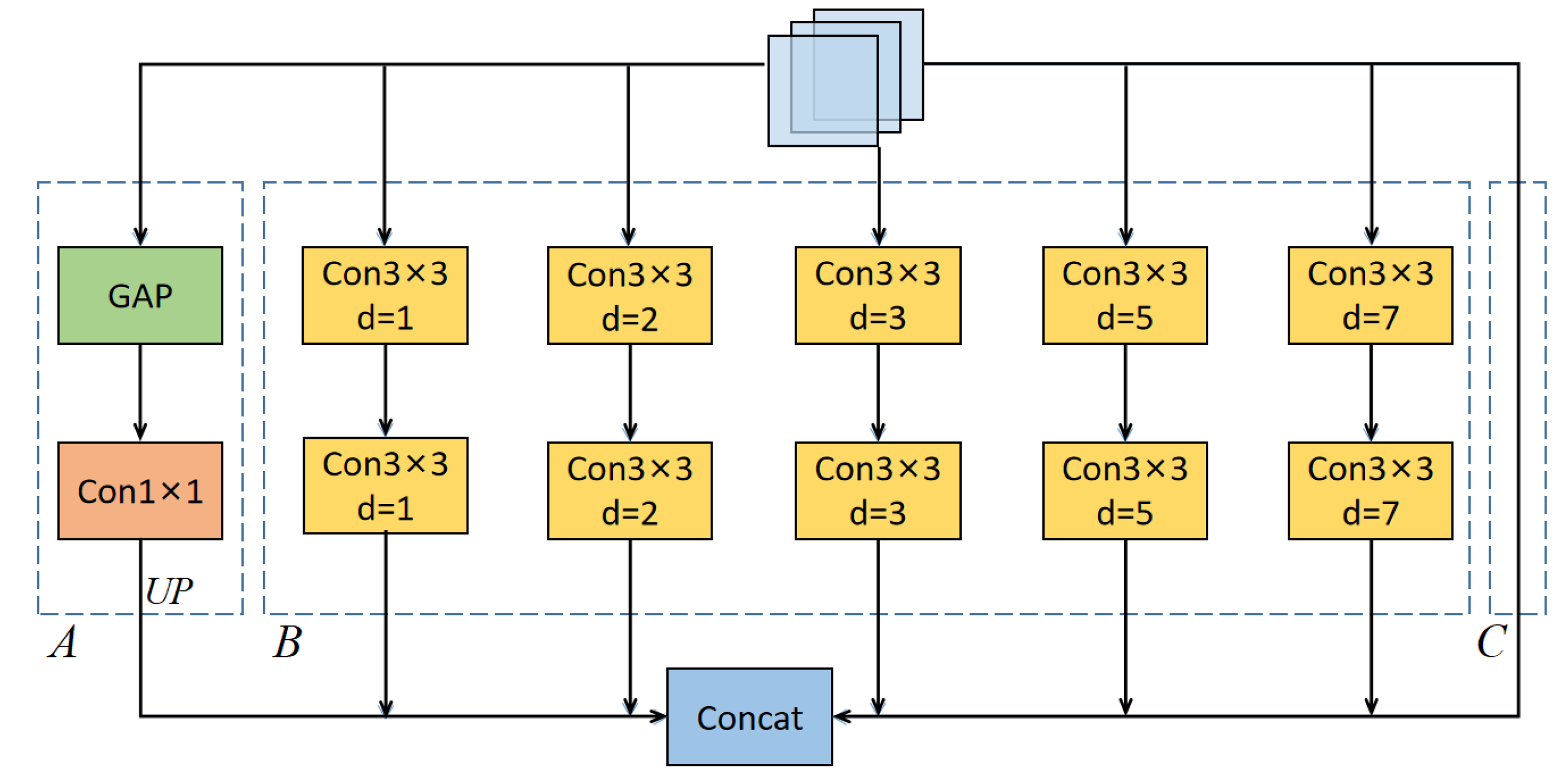
In remote sensing images, the scene is complex, and the size of the target is not same. In such cases, it is extremely difficult to extract target features only by a single scale. Therefore, multi-scale context information is indispensable to perform semantic segmentation. The difference in the size of the target and the complexity of the scene affect the feature extraction of the backbone network. In order to solve this problem, we propose a multi-scale context extraction module. It contains three main parts. The first part is responsible for extracting the global information; the second part uses atrous convolution to obtain information at several different scales; the third part is the feature map itself. The outputs of these three parts are concatenated at the end to form a multi-scale feature map. The structure of our multi-scale context extraction module is shown in
Figure 1.
In the figure, yellow boxes represent atrous convolutions with dilatation rate . The stride of an atrous convolution is 1. GAP stands for global average pooling. Con1 × 1 represents a 1 × 1 convolution layer. UP denotes upsample operation. Concat means that features are concatenated according to the channel. The output results of the three parts are concatenated together to achieve a multi-scale context information extraction. Atrous convolutions with different dilatation rates can improve the receptive field and can extract features at different scales without introducing too many calculations.
2.1.1. Global Information Extraction
In image processing, convolution is the process of convolving an image with a kernel of specified size. This is usually performed to extract local features of the image. Although the receptive field of each convolution kernel will increase with the increase in the network depth, it is still not possible to obtain the global information. The extraction of global information is referred to generalization and integration of the features of the whole feature map, which can obtain global context information. In this part, i.e., part A in
Figure 1, the features extracted from the last layer of the backbone network are subjected to global average pooling. The features obtained from each channel are averaged, and the number of channels is adjusted by a 1 × 1 convolution. Then, the global feature map is up-sampled. This part can be mathematically expressed as follows:
where,
X represents the feature map extracted by the backbone network and
represents a convolution layer.
2.1.2. Parallel Atrous Convolution Multi-Scale Context Extraction
Two layers of convolution operations at different scales can change the receptive field of the convolution kernel and can obtain context information at different scales. However, using multiple convolution kernels of different scales to extract multi-scale context information in the last feature map will increase the number of parameters as well as the computation steps. Inspired by the network structure of the DeepLab [
33,
34,
35], a
atrous convolution with different dilatation rate is used to substitute the conventional convolution. The main advantage is that it will obtain multi-scale context information without introducing too many parameters and computations. The dilatation rates of the atrous convolutions are 1, 2, 3, 5, and 7, respectively. This is equivalent to using the conventional convolution kernels of sizes 3, 5, 7, 11, and 15, respectively. The size of the training image is
and the size of the feature map after feature extraction is
. In order to extract context information as much as possible, the maximum value of the dilatation rate is selected to be 7. When the dilatation rate of the atrous convolution is 5, it is equivalent to inserting four kernel elements between each element in a
convolution kernel. The
convolution is transformed into a
convolution so as to enlarge the receptive field of each kernel element. Here, the strides of all
atrous convolutions are 1. It is worth noting that although the
convolution is transformed into an
one, only the original
kernel elements are used for calculations, that is to say that the total number of computations is not increased. Apart from that, the dilation rate
can be flexibly adjusted according to the image size. The maximum value of
is determined based on the size of the feature map extracted by the backbone network.
Assuming the feature map size is
, the minimum and maximum values of
are 1 and
, respectively. For our experiments, the size of the feature map extracted by the backbone network is
, so the maximum d is 7. When the d is 1, 2, and 3, the neighboring pixels are considered in the feature extraction. When d is 5 and 7, the receptive field becomes larger so that more context information is considered in the feature extraction. In order to further increase nonlinearity of the model, we used batch normalization and a ReLU activation function after each convolution layer. Finally, all the outputs of this part are concatenated together. This second part of our multi-scale context extraction module, i.e., part B in
Figure 1, can be expressed as follows:
where,
represents feature concatenation, i.e., each feature is concatenated according to the channel and
stands for a
atrous convolution with a dilatation rate of
.
In order to retain the original feature map, the input features extracted by the backbone network are directly combined with global context information and parallel multi-scale context information. In this way, we are able to extract the multi-scale context. The overall module is expressed as in Equation (
3).
where,
stands for a 3 × 3 atrous convolution with a dilation rate of
and
is a 1 × 1 convolution layer.
2.2. Adaptive Fusion Module
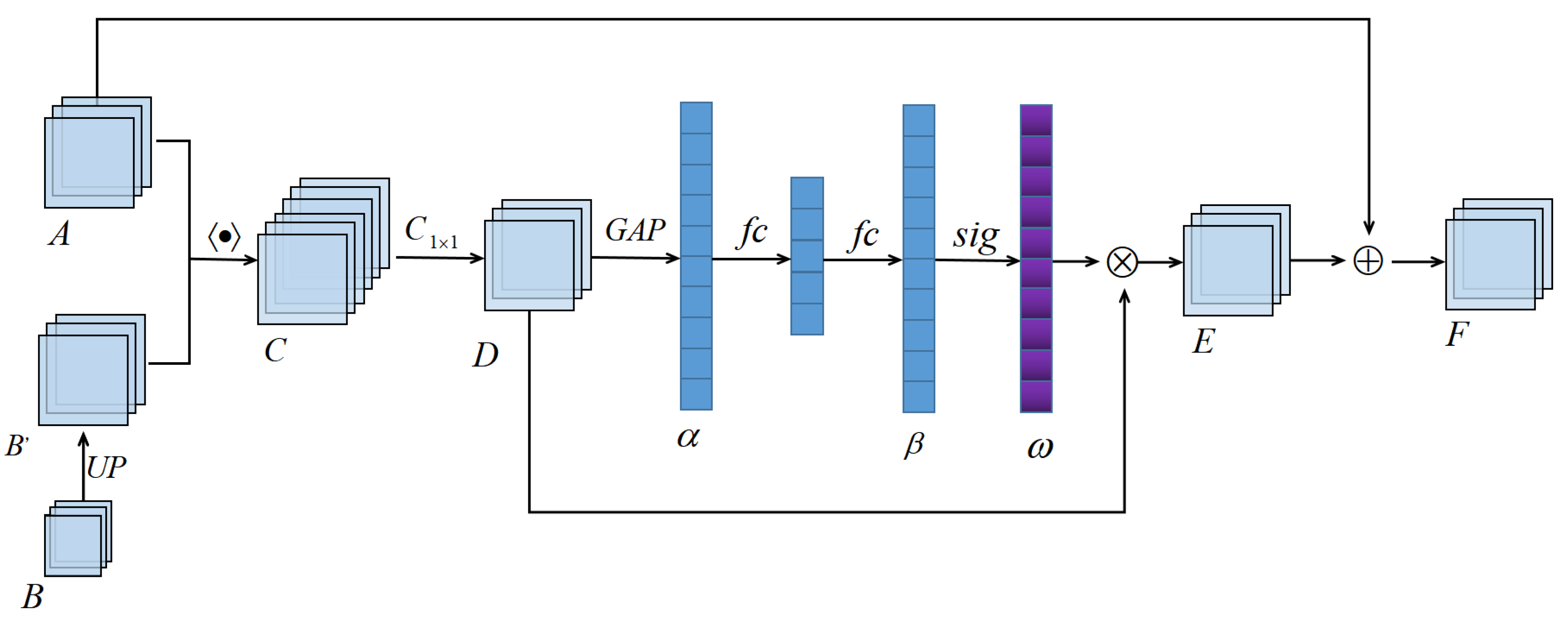
As mentioned before, the scene in remote sensing images is complicated and the visual effects are similar for different categories due to the shooting angle. To alleviate this problem, the fusion of high- and low-level features to generate key features is essential. In semantic segmentation, the features extracted by the backbone network are usually distributed into different levels. The low-level features contain a lot of contour information whereas the high-level features contain rich semantic information [
36]. In recent years, many methods were presented in the literature specifying the ways to fuse these high- and low-level features. FCN uses a skip-connection operation where the high-level abstract semantic information and the low-level fine semantic information are directly added according to corresponding channels to form new features. U-net [
29] combines the semantic features of each layer extracted from the backbone network and the corresponding size features according to the channel to restore the resolution layer by layer. Most of these fusion methods use pixel-by-pixel addition or channel-by-channel concatenation. Despite of fusing high-level and low-level semantic information, these methods do not determine the channels with useful features and the channels with useless features. Inspired by SENet [
27], in this work we introduce a channel attention mechanism to high- and low-level semantic information fusion module and propose an adaptive fusion module to fuse the high- and low-level semantic features. Its structure is shown in
Figure 2.
The upsampling of feature map
B is accomplished via bilinear interpolation through which we can obtain a new feature map
that is twice the size of
B. The low-level semantic features
A extracted from the backbone network and the features
are concatenated to form a new feature
C. The number of channels of
C is the sum of the channels in
and
A. Next, the feature map
D is generated from
C through a
convolution layer.
D has half as many channels as
C. The weight information
can be obtained using global average pooling for each channel of
D. The weights
can be generated from
via two full connected layers. The normalized weights
are acquired from
using a sigmoid function. Then, the weights
are multiplied with
D to get a new feature map
E. Feature map
E is readjusted using
D on the channel according to its importance.
E highlights features of useful channels and suppresses features of unwanted channels. Finally, the low-level feature map
A is directly added to the feature map
E to obtain the feature
F which is the final fusion feature. This part can be expressed as:
where,
is the sigmoid activation function and
is the fully connected layer. UP denotes the upsample.
represents each feature is concatenated according to the channel.
represents the high-level semantic features and
represents the low-level semantic features.
represents a 1 × 1 convolution layer.
2.3. Multi-Scale Adaptive Feature Fusion Network (MANet)
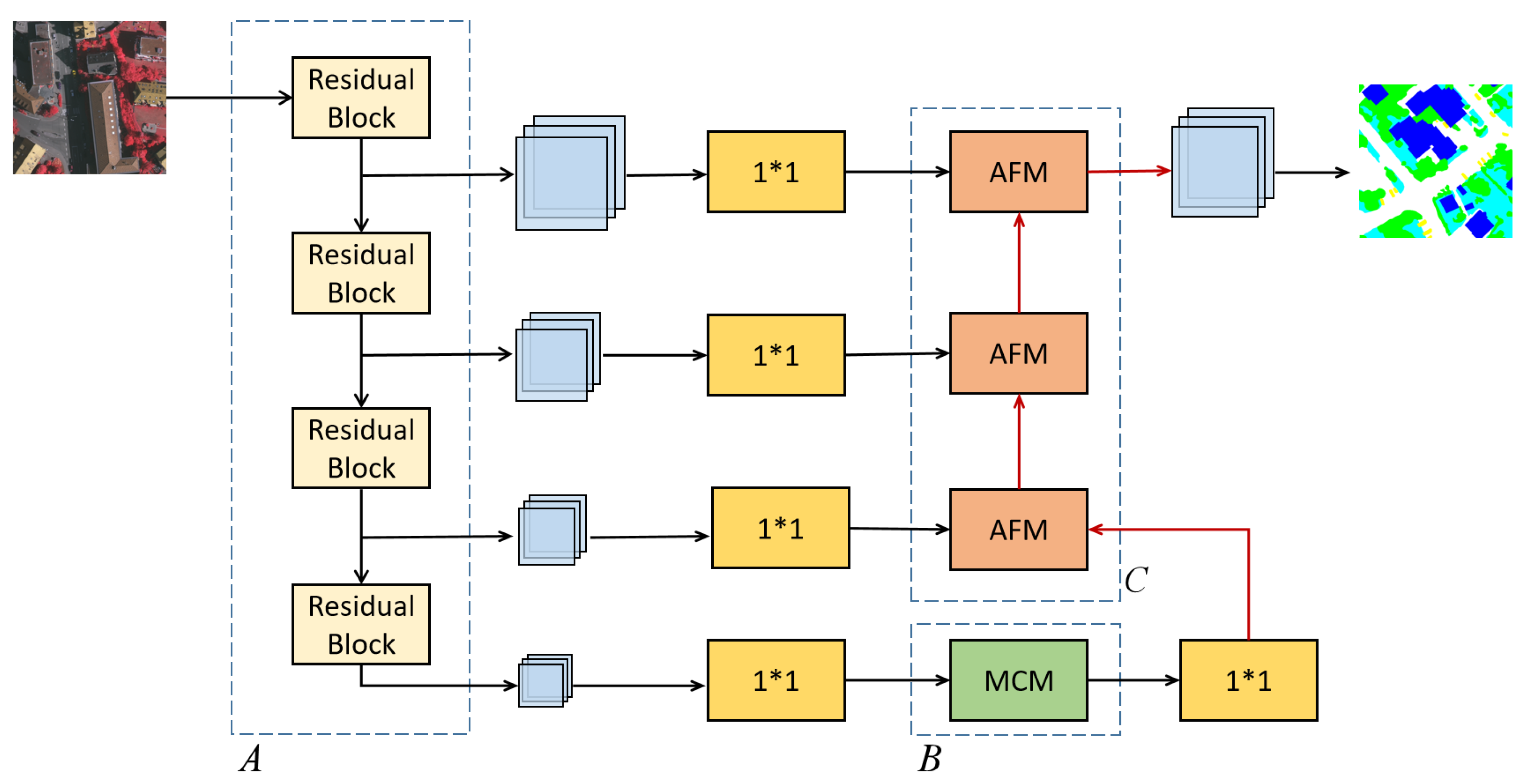
Based on the two modules above, we propose an end-to-end multi-scale adaptive feature fusion network. Its overall structure is shown in
Figure 3.
The parts A, B, and C of our proposed MANet algorithm can be seen in
Figure 3. As a reminder, part A is the backbone network, part B is a multi-scale context extraction module, and part C is a high- and low-level feature adaptive fusion module. The red arrow in the figure represents upsampling. The signifier ’1 * 1’ represents a
convolution layer to change the number of channels. The multi-scale context extraction module (MCM) is the context extraction module that extracts the multi-scale context information to solve the problem associated with difference target sizes. The adaptive fusion module introduces channel attention to the fusion process of high-level and low-level layers. The efficient fusion of features can alleviate the problem of incorrect segmentation caused by similar features of similar categories.
In this work we have used ResNet101 as our backbone network to extract image features. Given an input image feed to the backbone network, it passes through four stages of the network, where each stage generates features with different sizes and channels. As the number of channels at each stage is different, a convolution is adopted to reduce the channels so as to have the same number of channels maintained at each stage’s output. The final stage features are fed to the context extraction module where the multi-scale context information is extracted and concatenated. This solves the problem of excessive target size differences in remote sensing images. The channels of the concatenated features are reduced by 1*1 to generate new features, which are up-sampled and fed to the adaptive fusion module. The adaptive fusion module fuses high-level and low-level semantic information efficiently and emphasize the useful features by learned weights. Later, the features extracted at each stage of the network are fused with the integrated features in a bottom-up manner by the adaptive fusion module. Through this we can get a feature map with 1/4th the size of the input image. Then, we adopt bilinear interpolation to restore the feature map to the same size as the input image. Finally, the output is sent to the classifier to receive the segmentation results.
In order or classify the output, We have used a softmax classifier [
37] with our network. Softmax is a multi-class classifier that can calculate the probability of each category and the sum of the probabilities of all categories is 1. The classification of a pixel can be expressed as:
where
n is the total number of categories.
represents the probability of a pixel
l belongs to category
i. Cross entropy loss function [
38] has been adopted to represent the difference between the prediction and the label. Suppose that there is a training sample set
with
m pixels, the cross-entropy loss function is:
where
is an indicator function. The result is 1 when the prediction is equal to the label, and the result is 0 otherwise. The network can get a loss via forward propagation, and the back propagation algorithm can be adopted to transfer the loss from the back to the front to update network parameters [
39]. In this paper, the stochastic gradient descent method is used to update the network parameters.
5. Conclusions
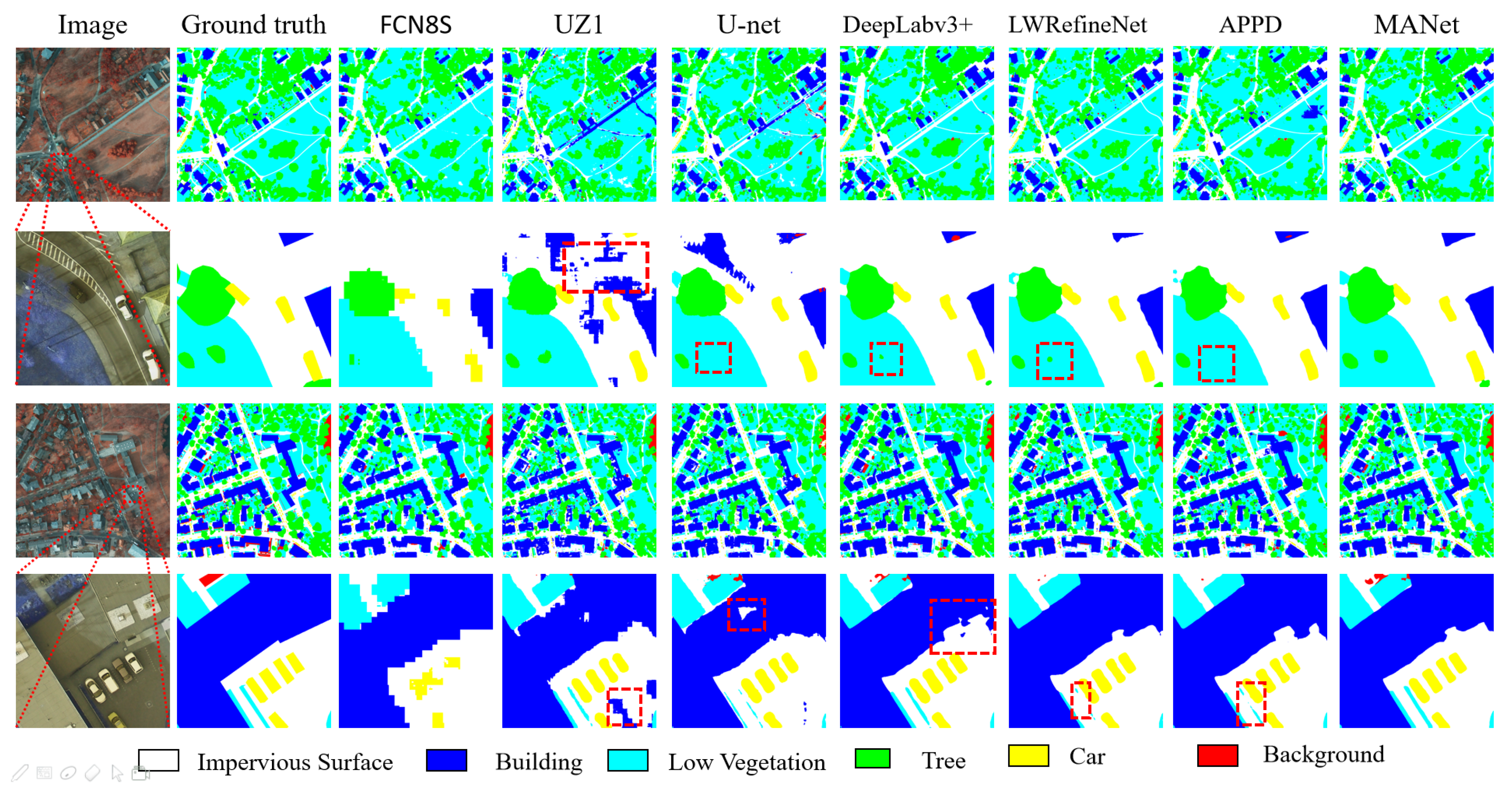
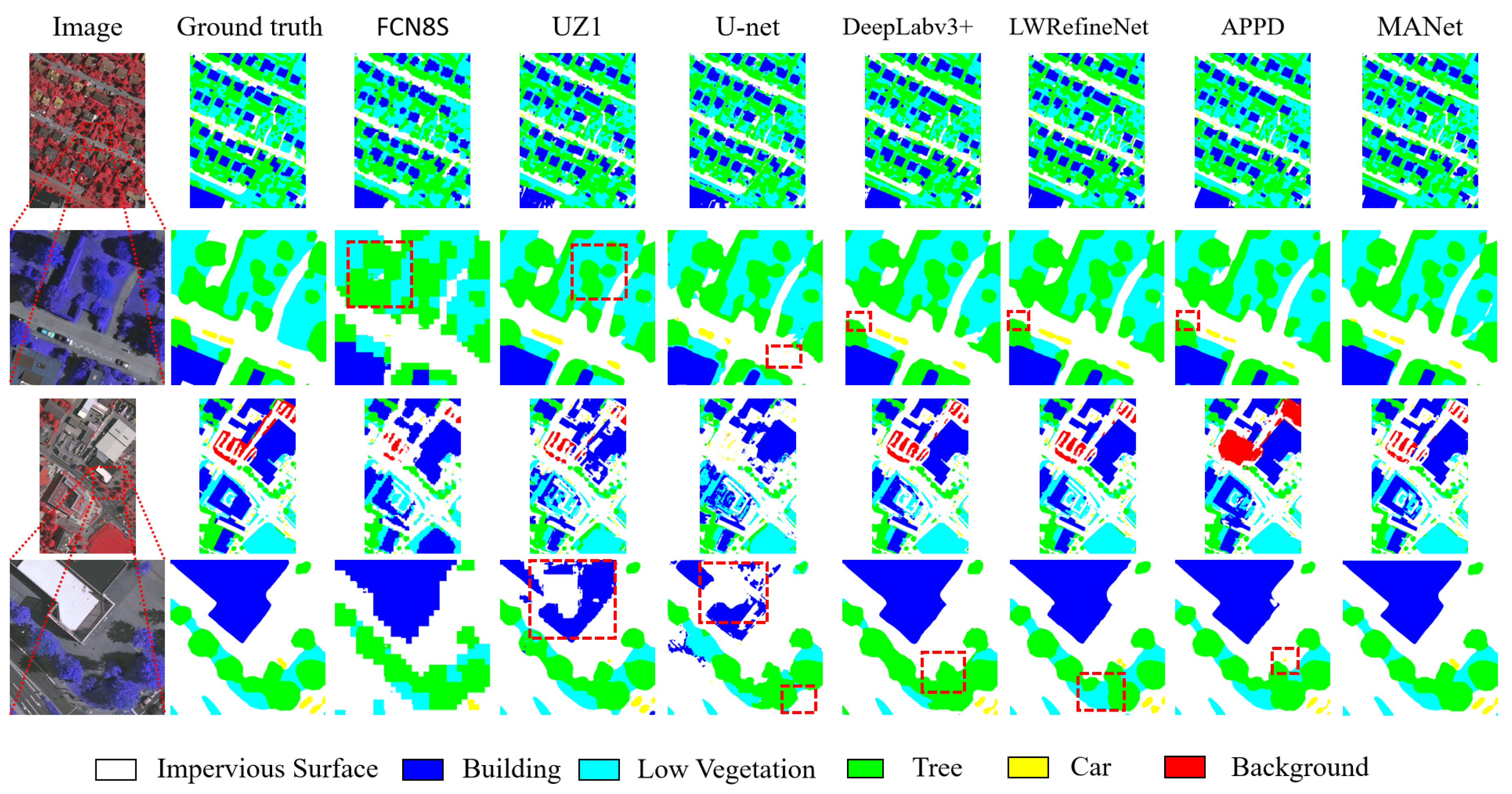
In this paper, we propose a multi-scale adaptive feature fusion network for semantic segmentation in remote sensing images, namely MANet. The MANet uses encoding–decoding architecture with multi-scale context extraction and adaptive fusion modules. It uses ResNet101 as the backbone network for encoding and multi-scale context extraction and adaptive fusion modules for decoding. The multi-scale context extraction module is composed of two parallel layers of atrous convolutions with different dilatation rates, global information, and its own features. It extracts multi-scale context information to solve the problem of high differences in target sizes in remote sensing images. The adaptive fusion module introduces the channel attention mechanism into high-level and low-level semantic features in the fusion process, which adjust the fused features by the learned weights. By integrating these two modules together, the overall segmentation performance is significantly boosted up.
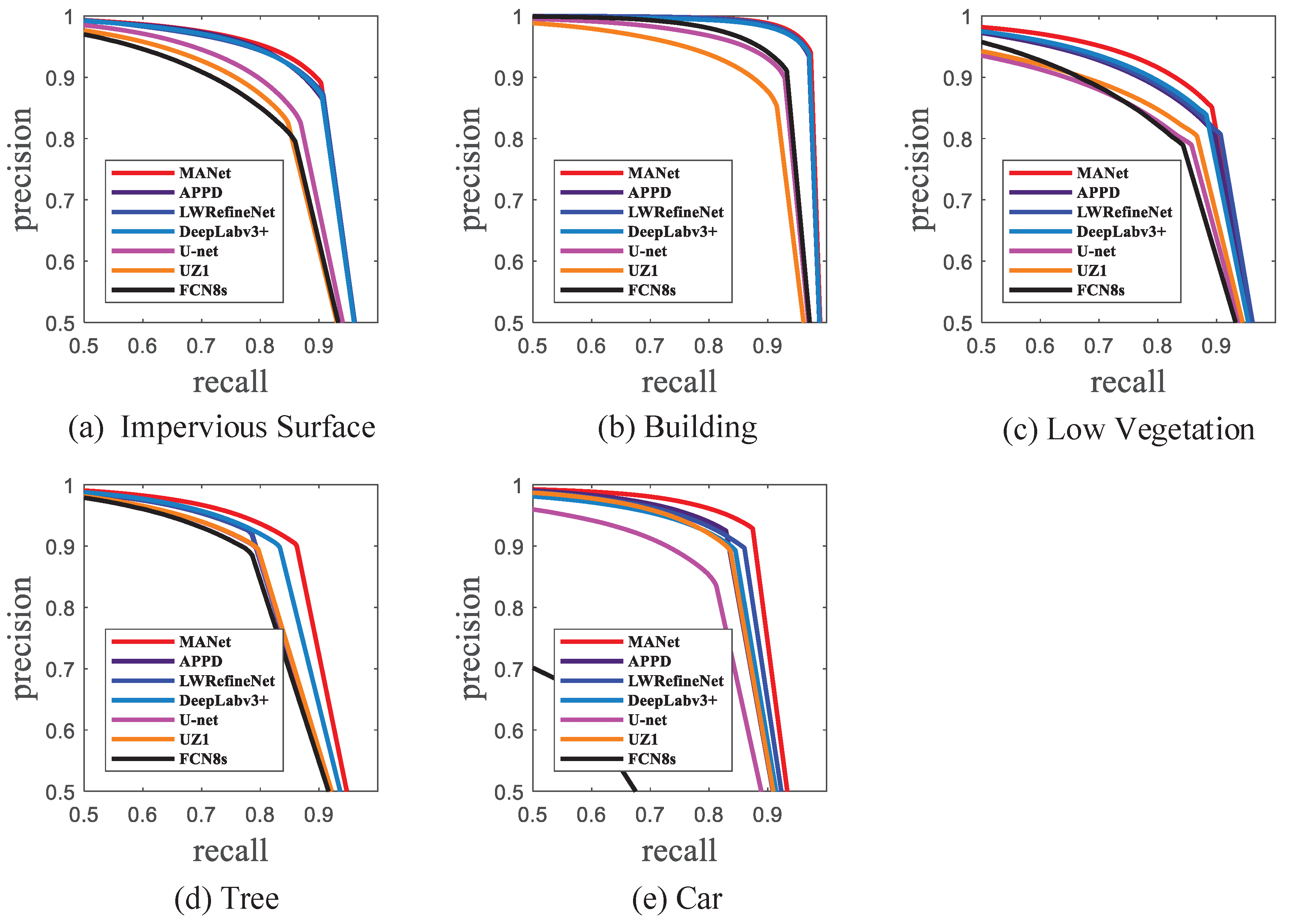
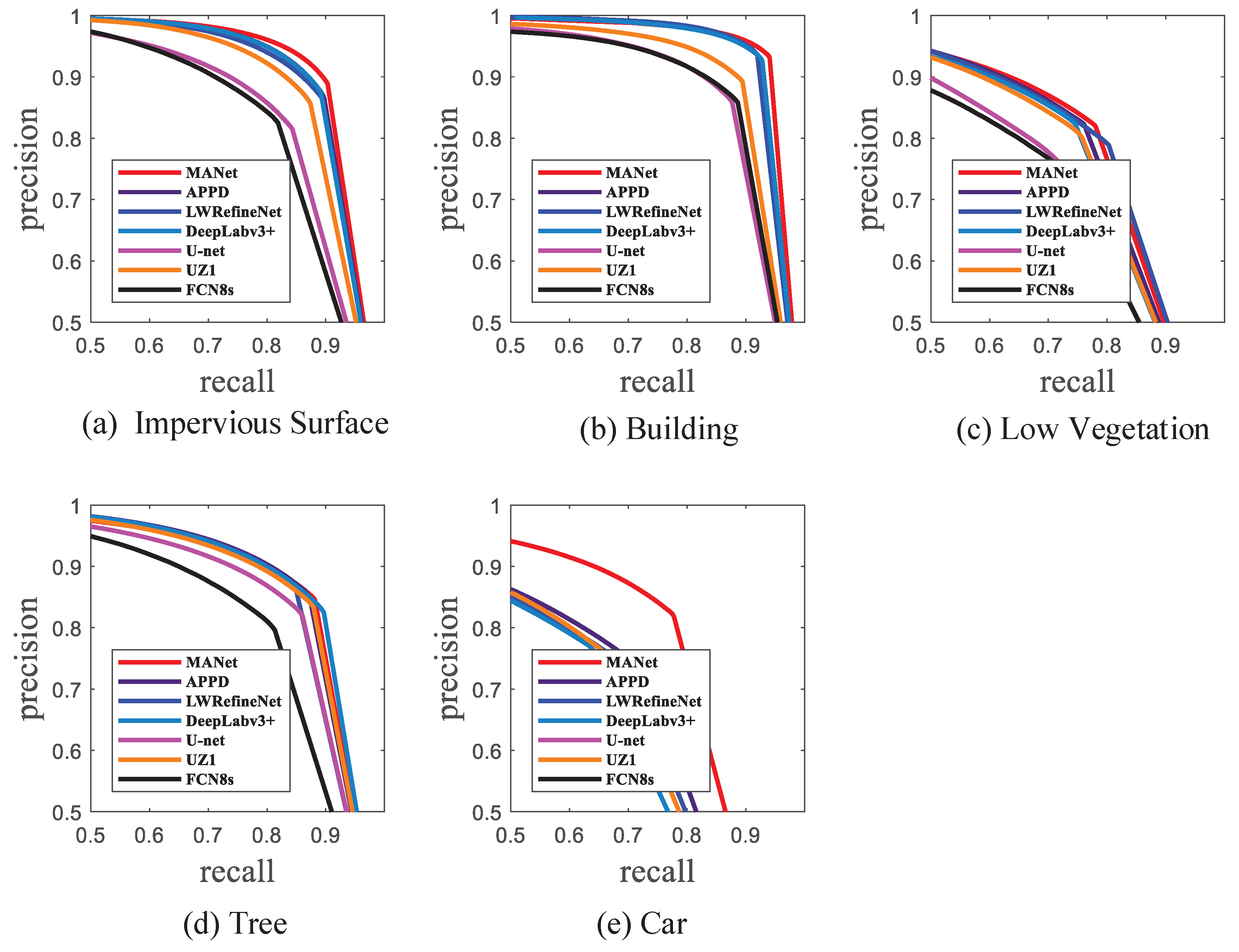
We have evaluated the proposed MANet on two publicly available benchmark datasets, Potsdam and Vaihingen datasets. With the Potsdam dataset, MANet achieved a result of 89.4% in overall accuracy and 90.4% in the average of F1 which brings 1% and 1.1% improvement in OA and the average of F1 compared with APPD, respectively. On the Vaihingen dataset, the OA of MANet is 88.2% and the average of F1 is 86.7%. Experimental results show that our proposed MANet outperforms other state-of-the-art models on both datasets, in terms of overall accuracy and F1. In ablation experiments, the performance of the “Res101+AMM+CFM” is increased over “Res101” by 4.4% in OA and 5.9% in mean F1. The ablation experiments further verify the effectiveness of the proposed module in semantic segmentation of remote sensing images. It is worth noting that the available information of the corresponding DSM and NDSM data in the Potsdam dataset is not used to assist in segmentation. Nevertheless, the parameter size of our proposed method is large. In the future, we aim to reduce this count. Moreover, semantic segmentation of remote sensing images belongs to supervised learning. The data labeling workload of semantic segmentation is huge, especially for remote sensing images. Semantic segmentation based on semi-supervised and unsupervised learning is therefore an important future research direction.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}