Intensity Thresholding and Deep Learning Based Lane Marking Extraction and Lane Width Estimation from Mobile Light Detection and Ranging (LiDAR) Point Clouds


Abstract
:1. Introduction
- A lane marking extraction strategy is developed by thresholding normalized intensity values from multi-beam spinning LiDAR. The intensity normalization can be applied in any environment without the need for reference targets.
- For the deep learning strategy, an automated labeling procedure is developed, which can generate a large number of training samples in order to detect lane markings from LiDAR intensity images. In addition, a refinement strategy for the predictions has been developed to deliver corresponding LiDAR points for the extracted lane markings.
- It is hypothesized that the performance of the lane extraction procedure depends to a high degree on the pavement type. Therefore, a pavement surface-based evaluation of the lane marking extraction strategies in asphalt and concrete areas is conducted.
- Lane markings are extracted using the above four strategies from LiDAR-based MMS point clouds, collected on two-lane highways with a total length of 67 miles, which have different road geometry, such as turning lane, merging lane, and intersection areas. Additionally, this dataset can serve as a benchmark for performance evaluation of lane marking extraction algorithms.
- As a further evaluation of the performance of different lane marking extraction strategies, lane width estimates are derived for each strategy across the different datasets. These estimates have been compared to manually derived ones.
- Derived lane marking from the proposed strategies can be utilized to report lane marking gap regions. This reporting mechanism is quite valuable for departments of transportation (DOT) as it can be used to prioritize maintenance operations and gauge their infrastructure readiness for autonomous driving
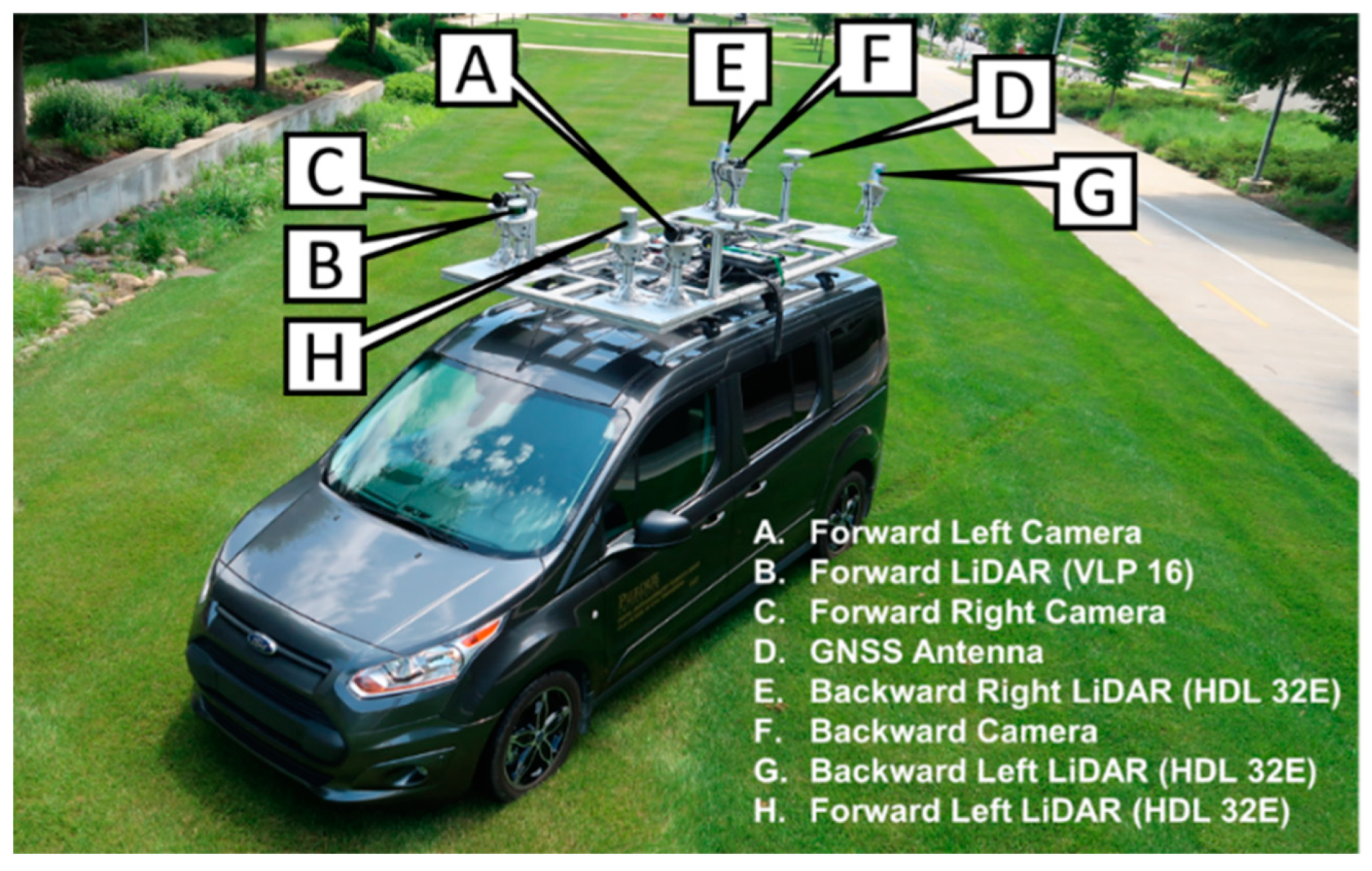
2. Mobile LiDAR System Used in This Research
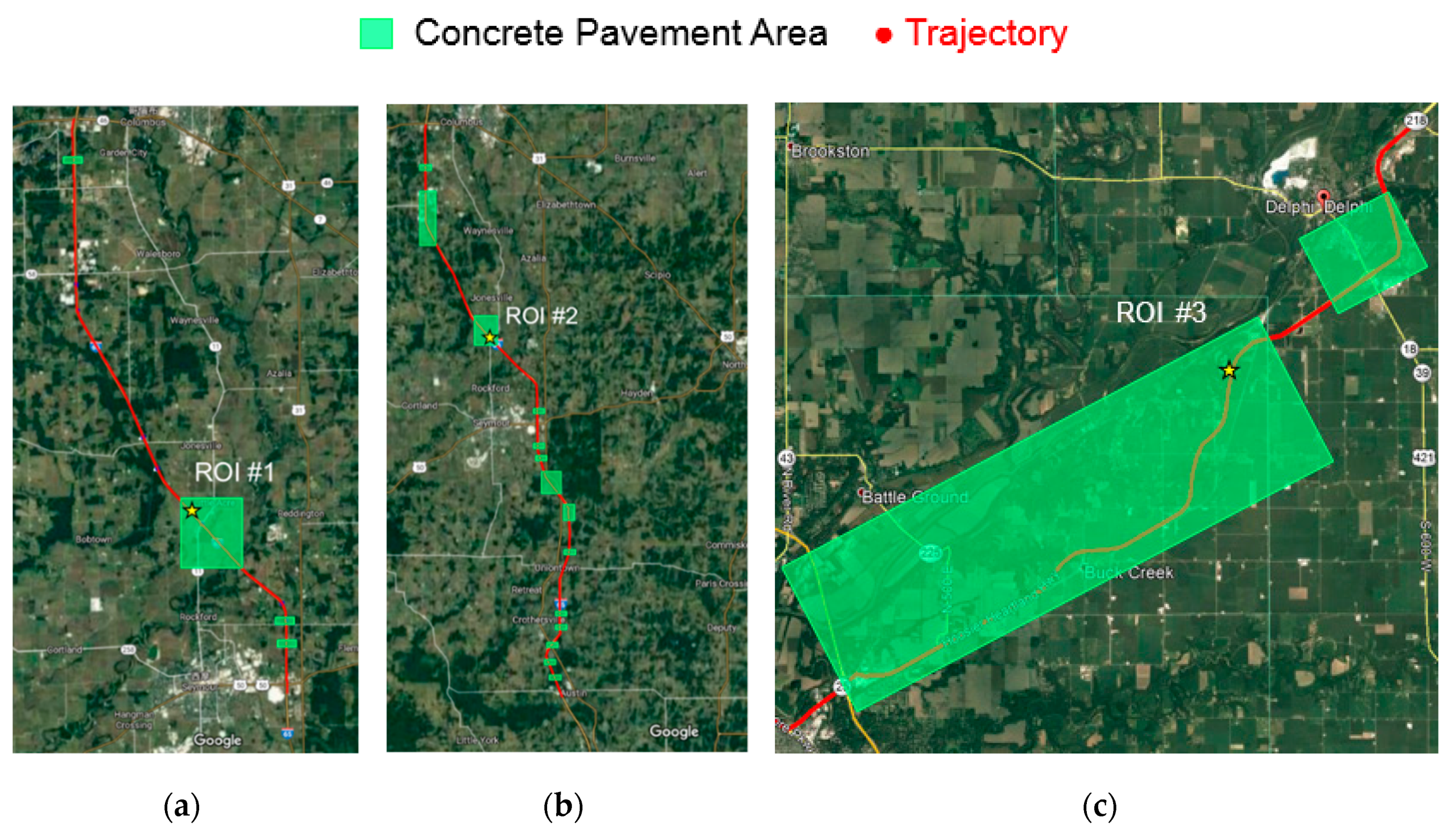
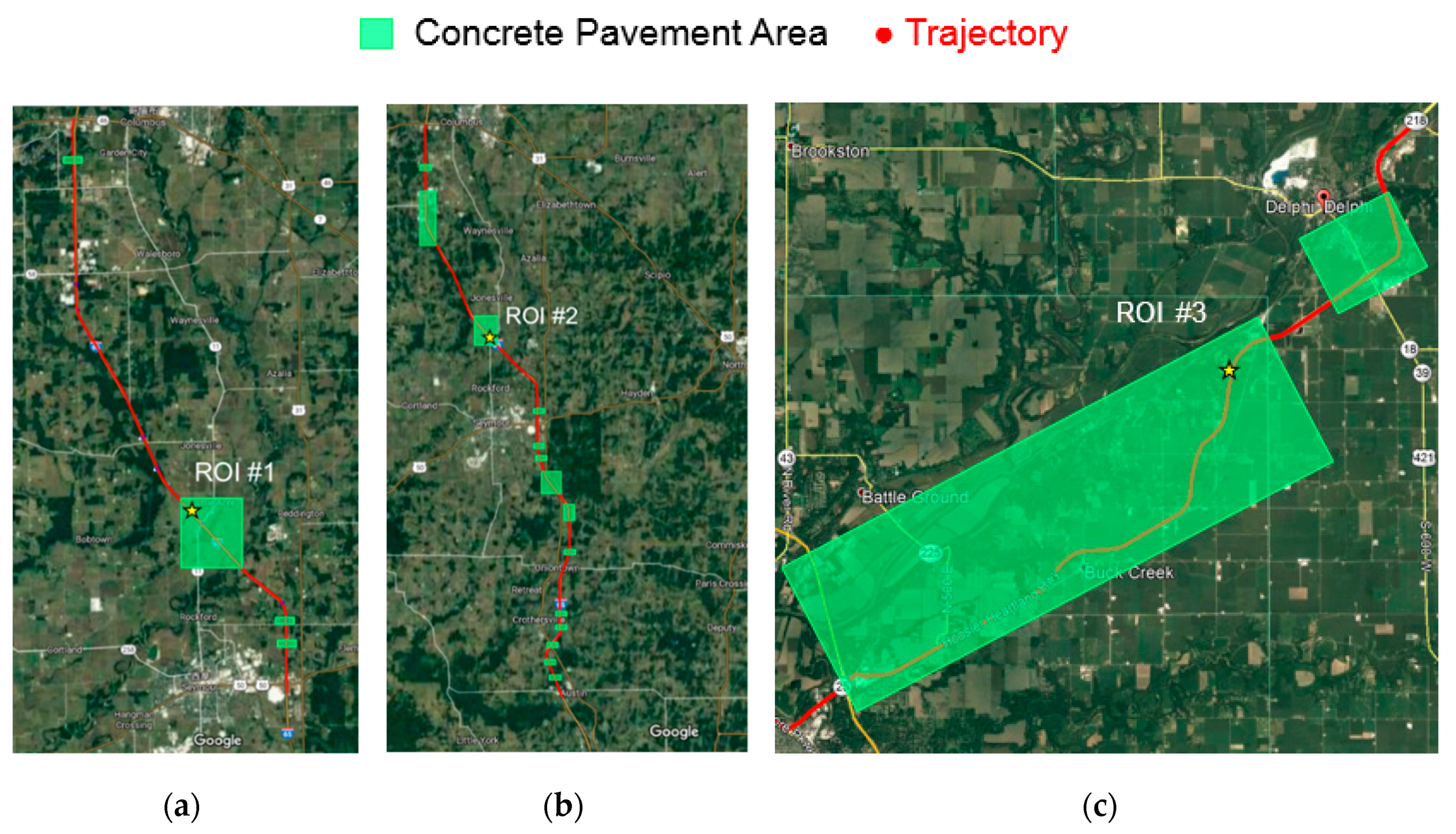
3. Datasets
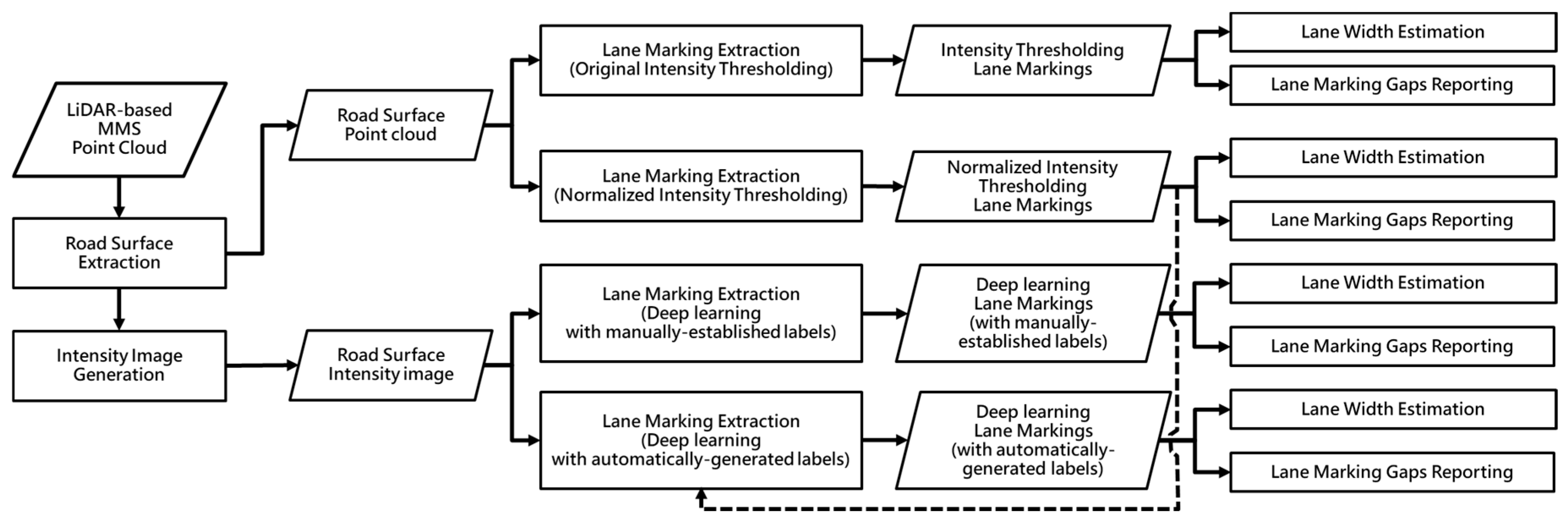
4. Methodology
4.1. Lane Marking Extraction Approaches
4.1.1. Intensity Thresholding Approaches
Original Intensity Thresholding Strategy
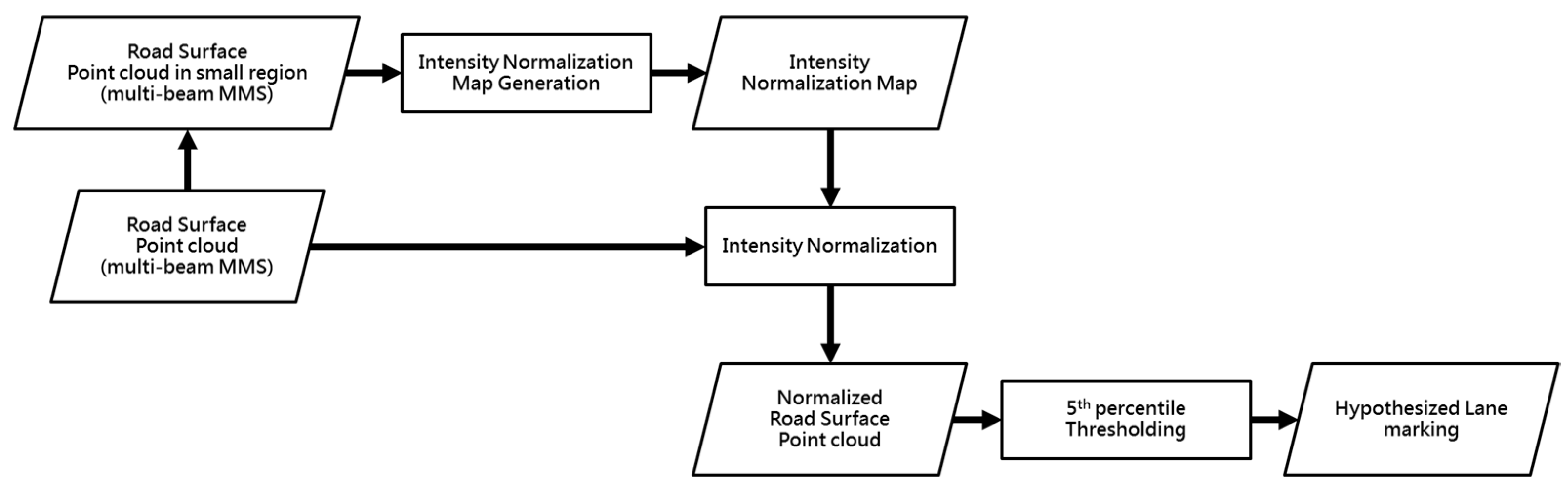
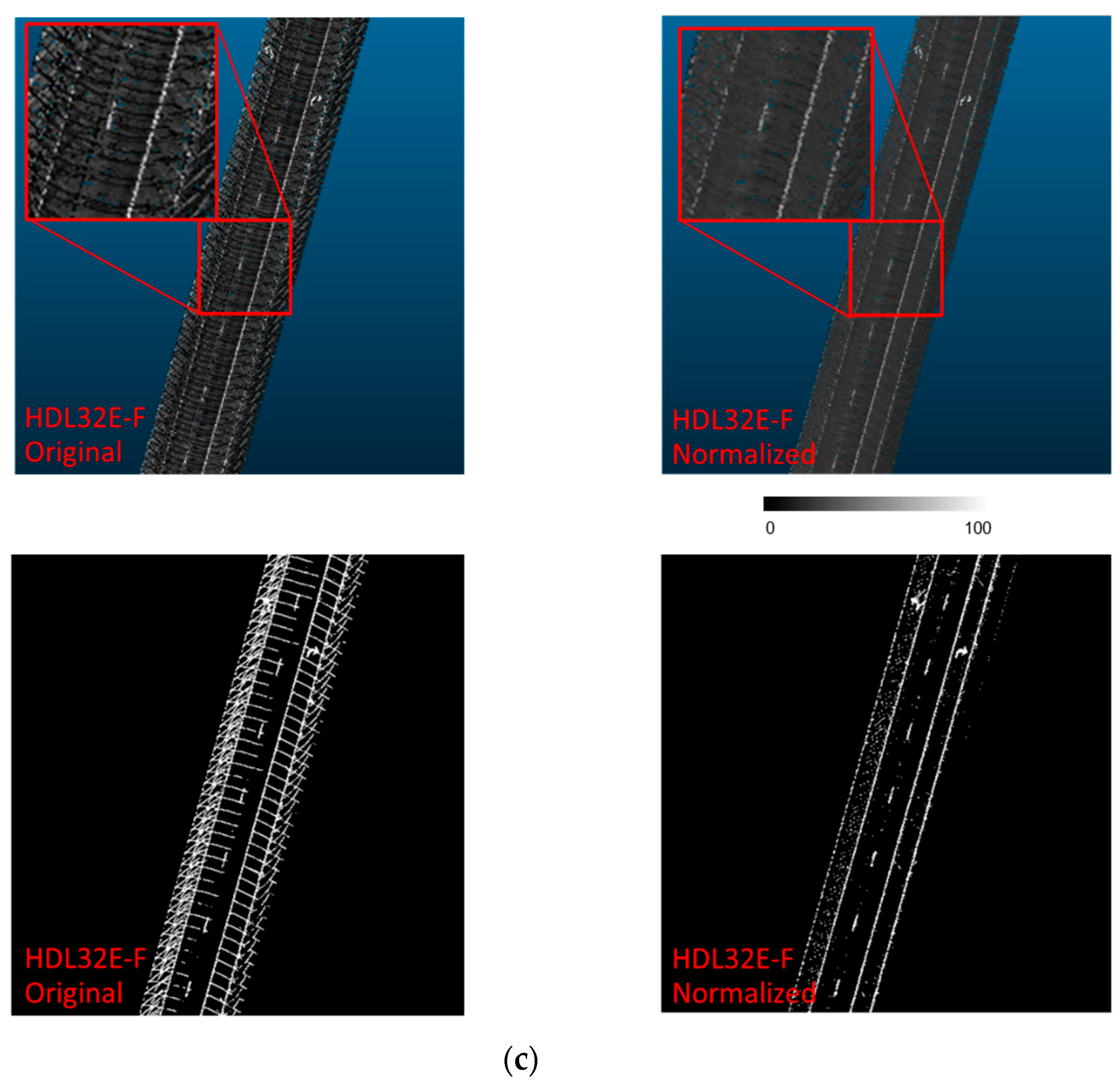
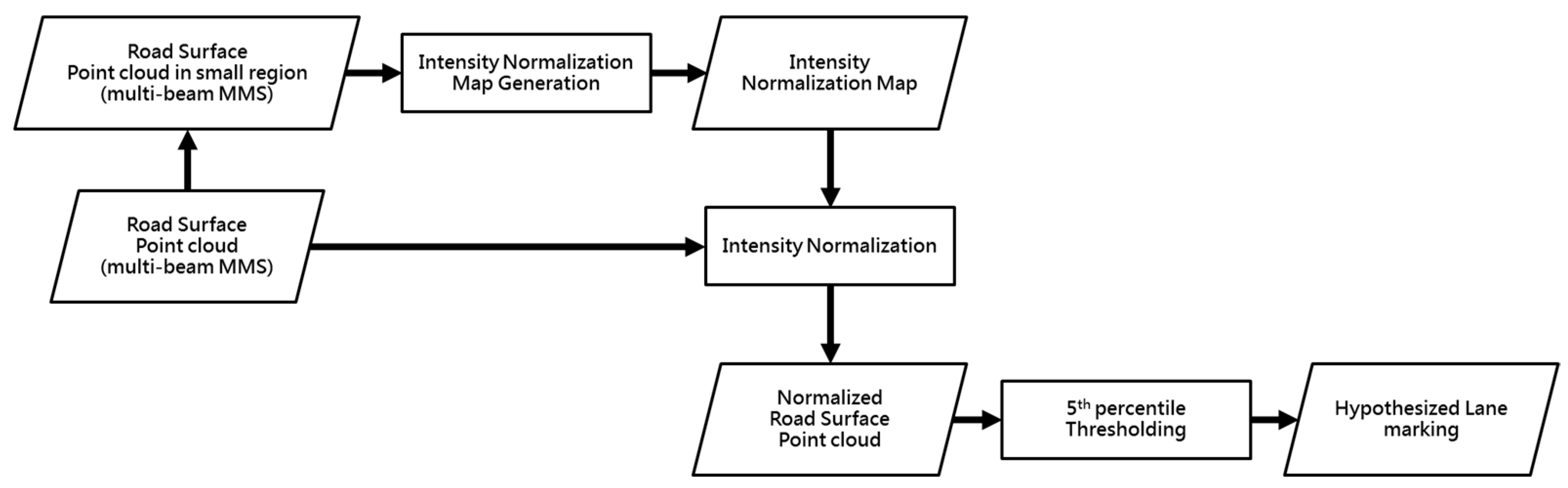
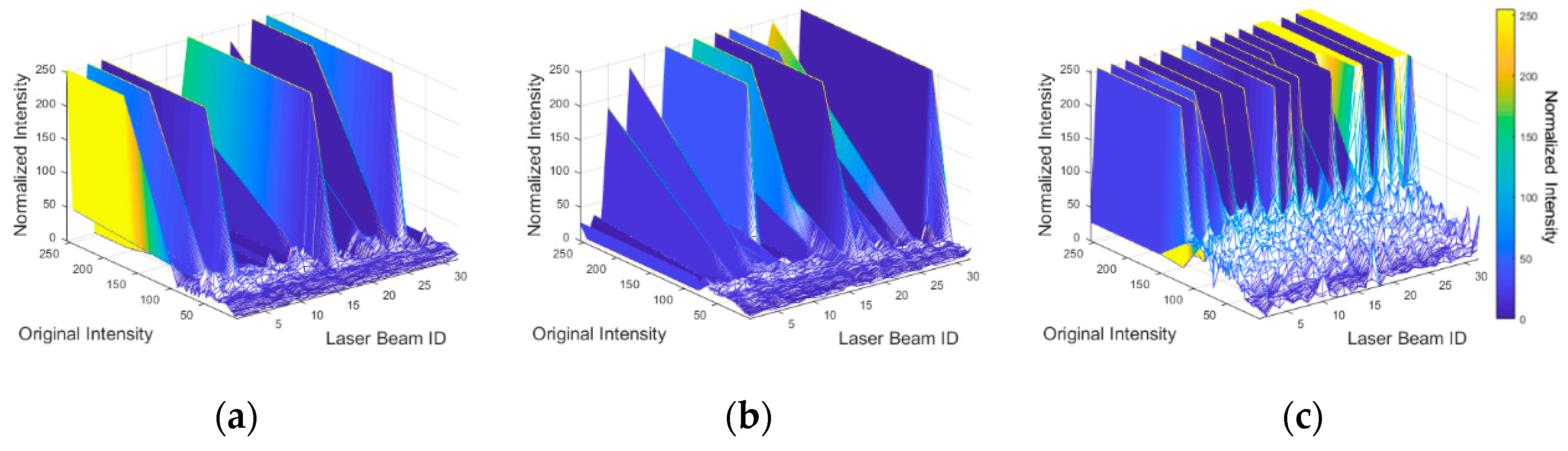
Normalized Intensity Thresholding Strategy
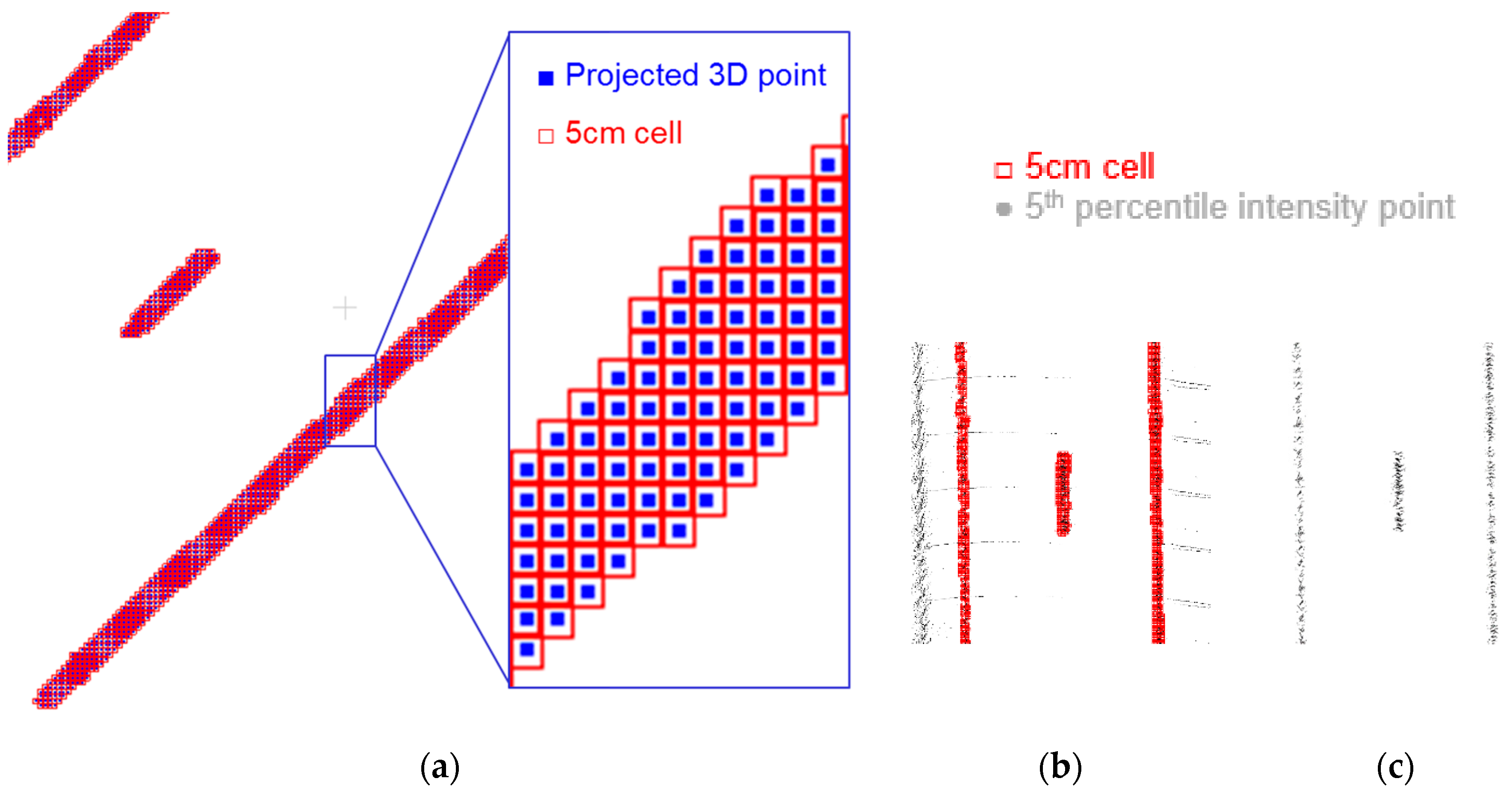
- The small road surface point cloud is gridded into cells. Each cell stores the list of points that lie within its bounding box. For each point, only the intensity value and laser beam ID are stored.
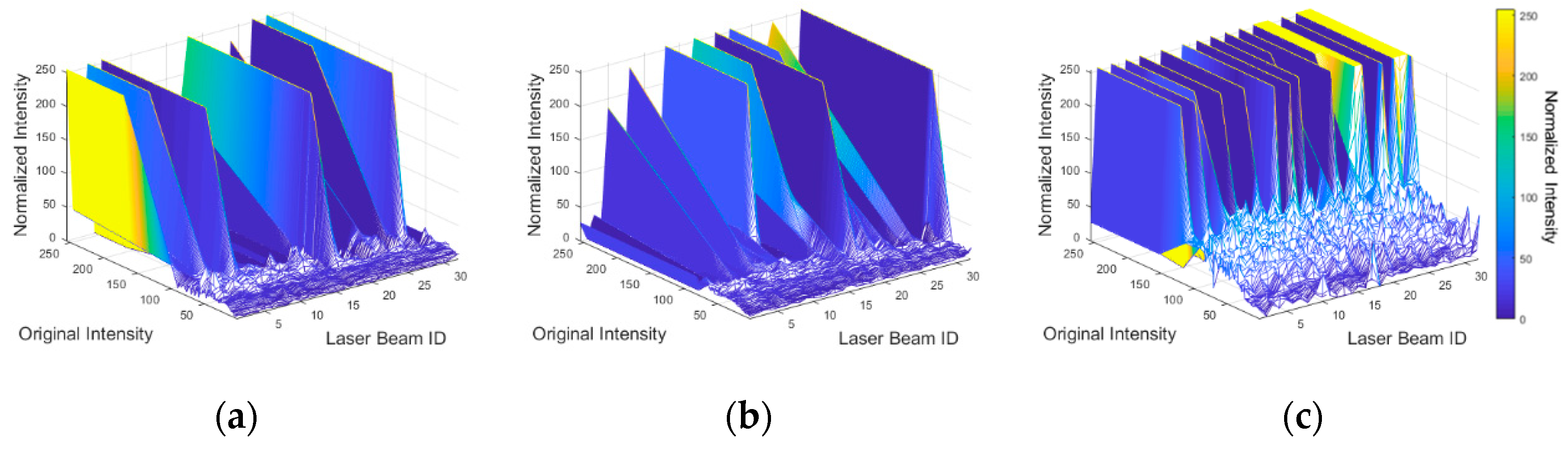
- In order to compute the normalized intensity value of a laser beam j that recorded an intensity value a, we seek all cells that contain the pair (j, a) in the raster grid. The average intensity is computed over these cells while excluding intensity values recorded by laser beam j. The normalized intensity of (j, a) is the resulting average. The original and normalized intensity values are stored in a lookup table (LUT) for the scanner/dataset in question.
- For the intensity values that are not observed in the small road surface point cloud, their normalized counterpart can be calculated by interpolation, using the normalized values associated with the observed intensities.
4.1.2. Deep Learning Approaches
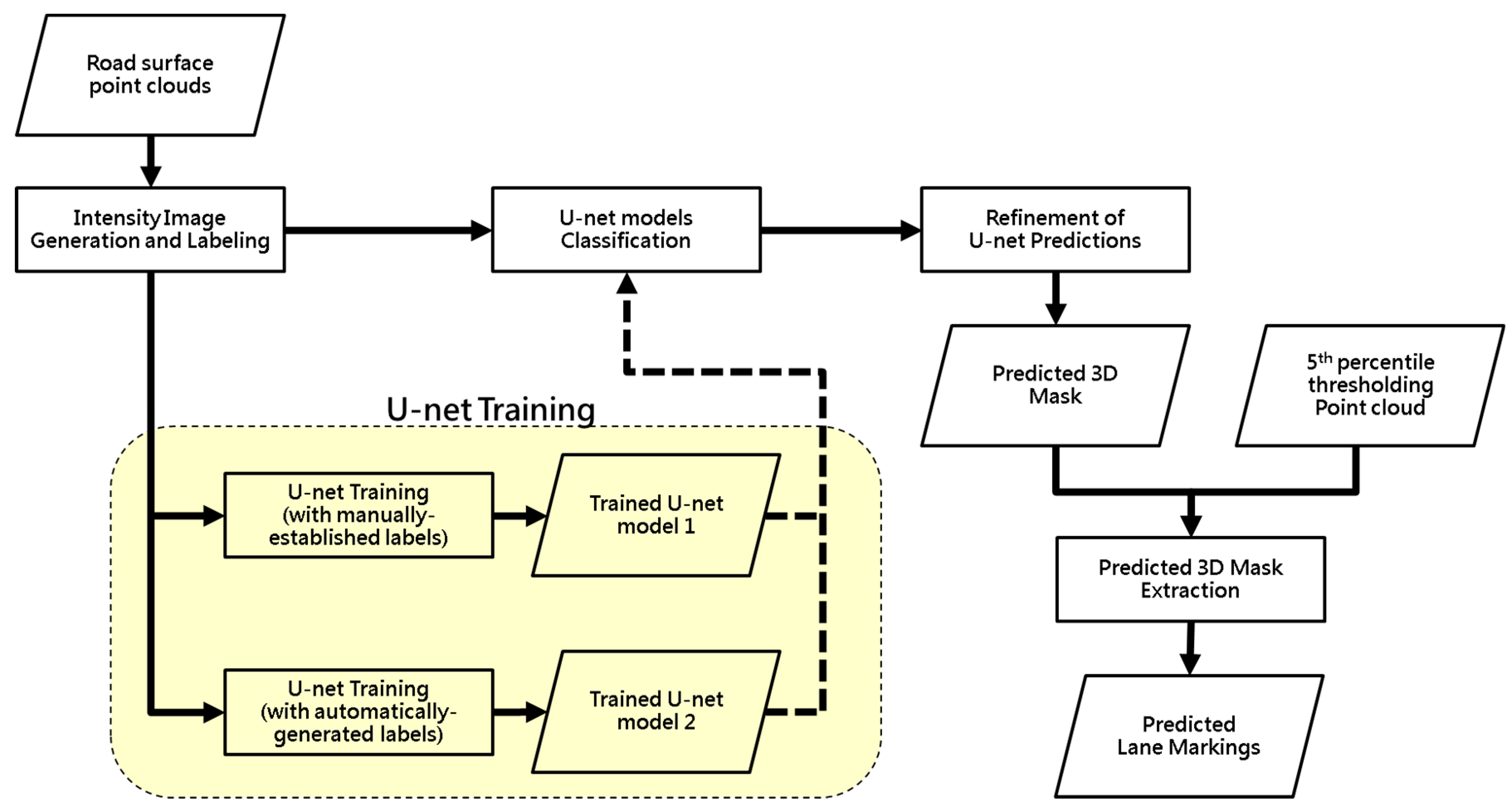
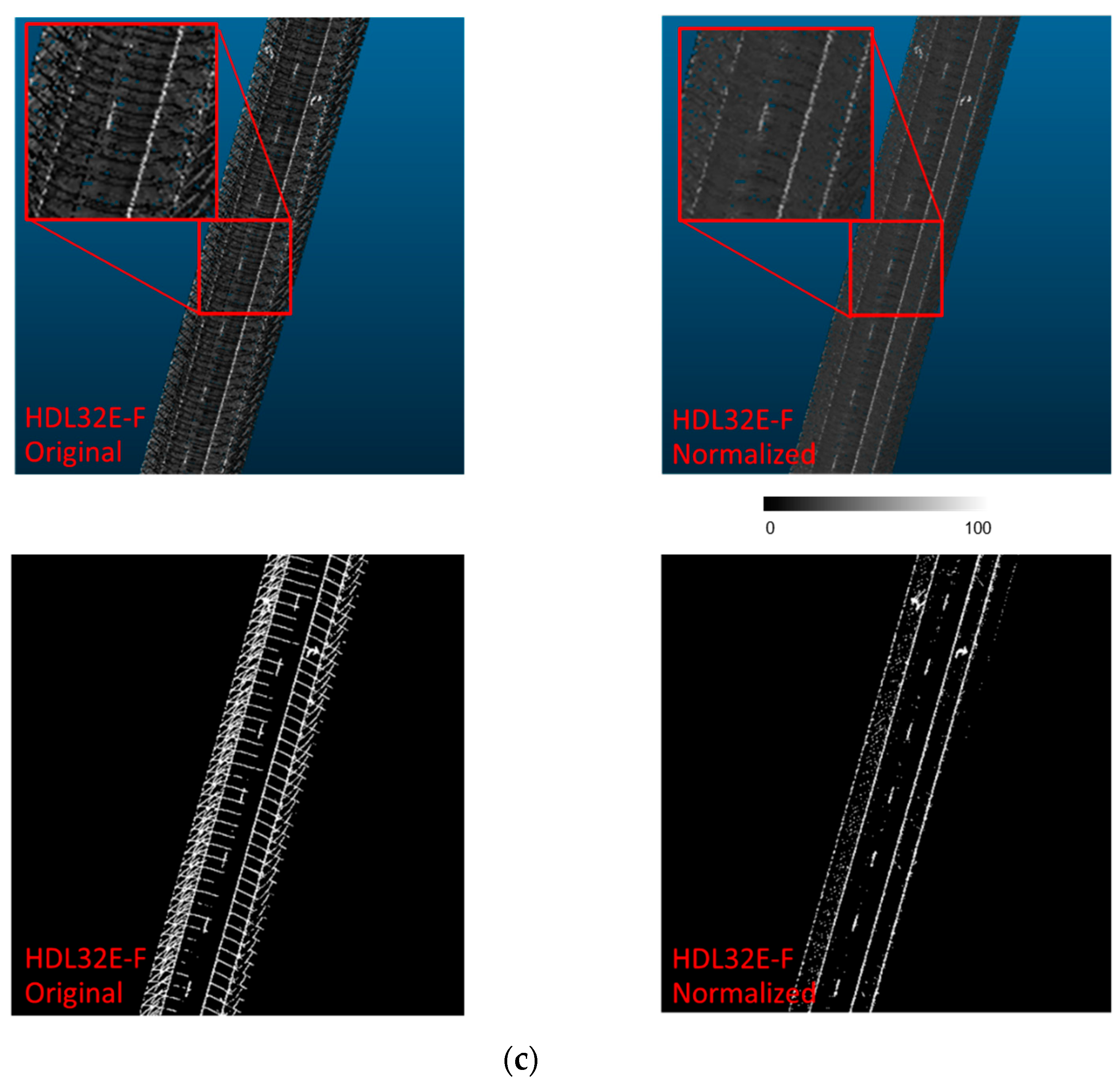
Intensity Image Generation and Labeling
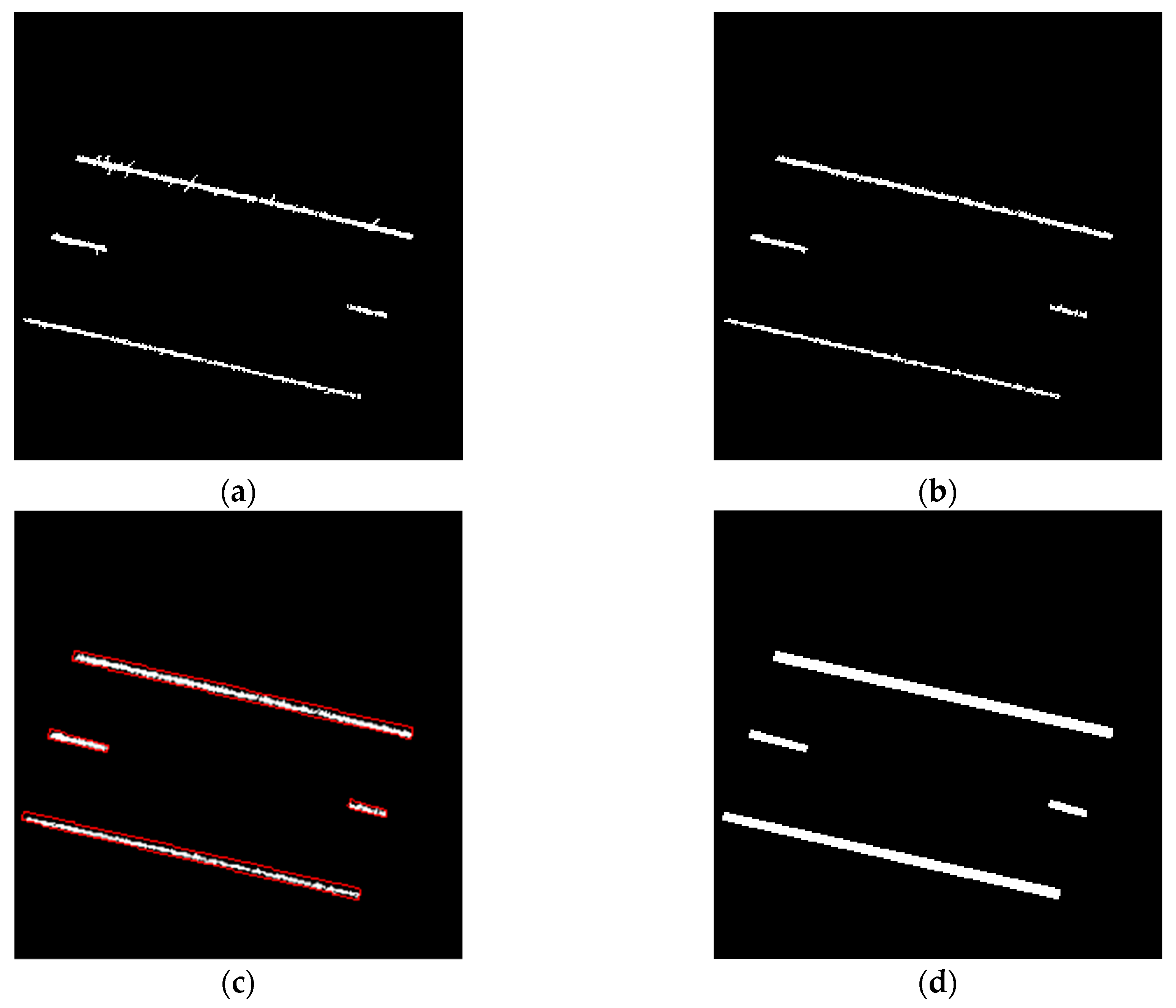
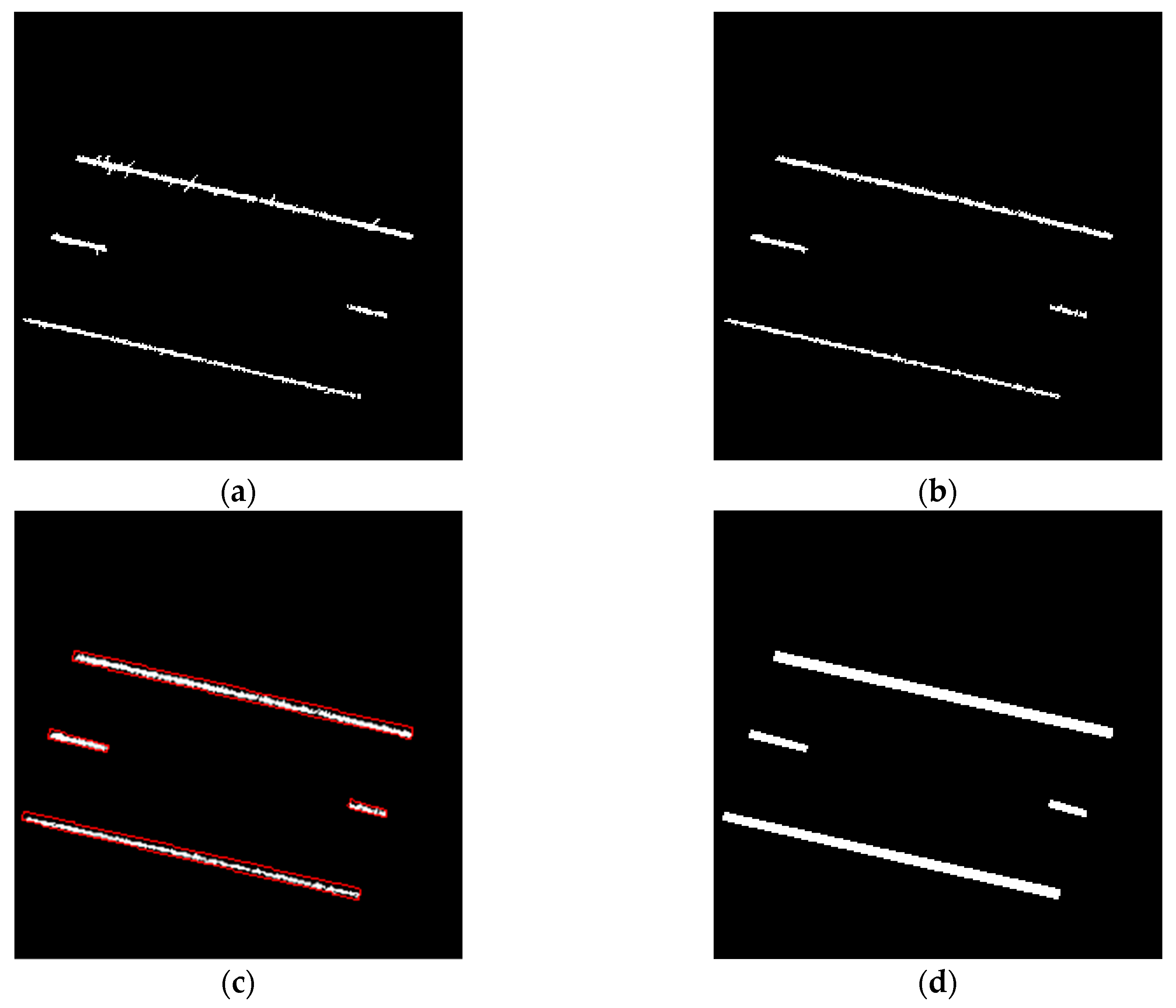
- The noise removal strategy proposed by Ravi et al. [18] (the details of which are described in Section 4.2) is applied to the hypothesized lane markings. Figure 11a,b illustrate the outcome from the normalized intensity thresholding strategy before and after noise removal.
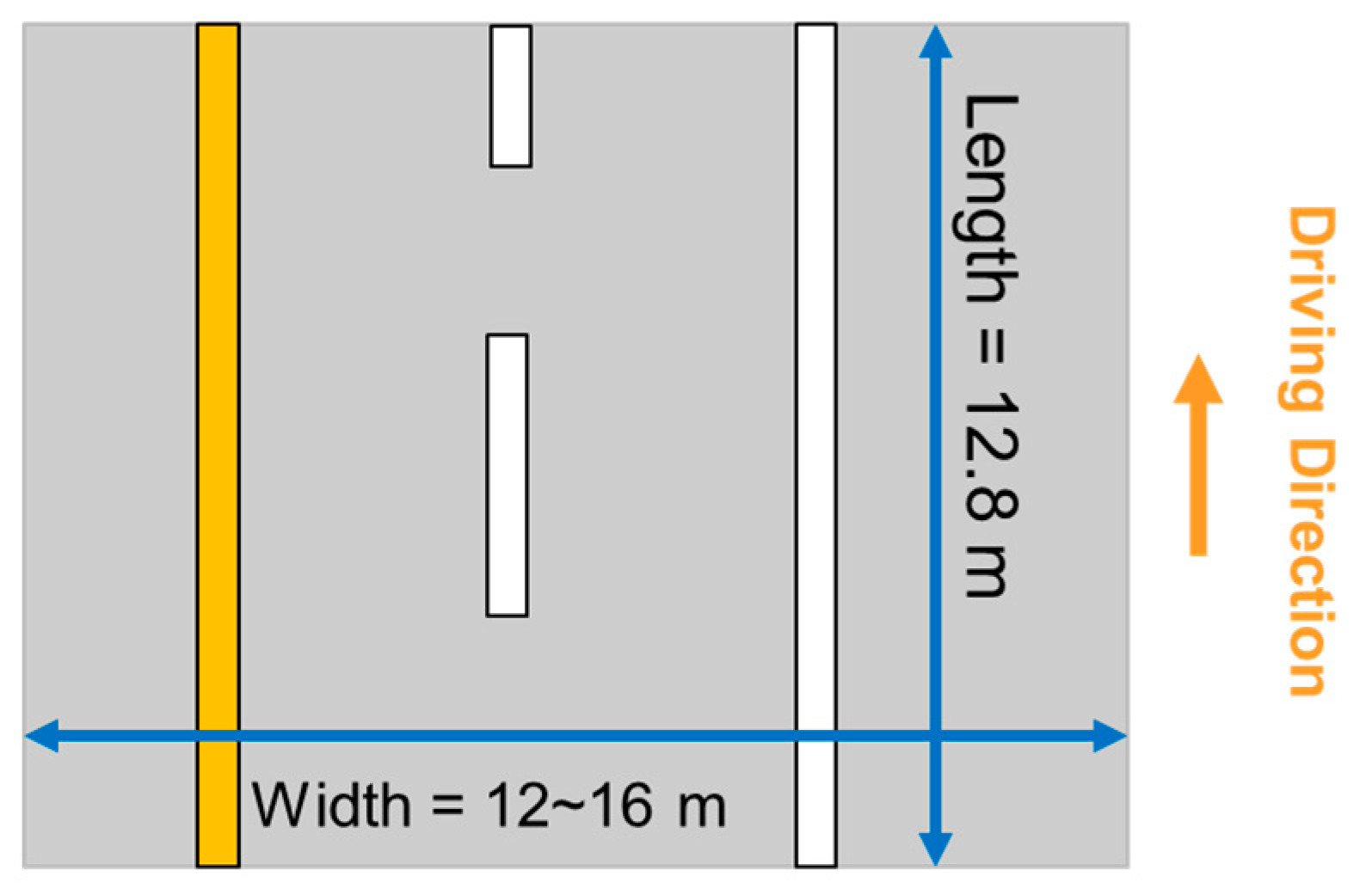
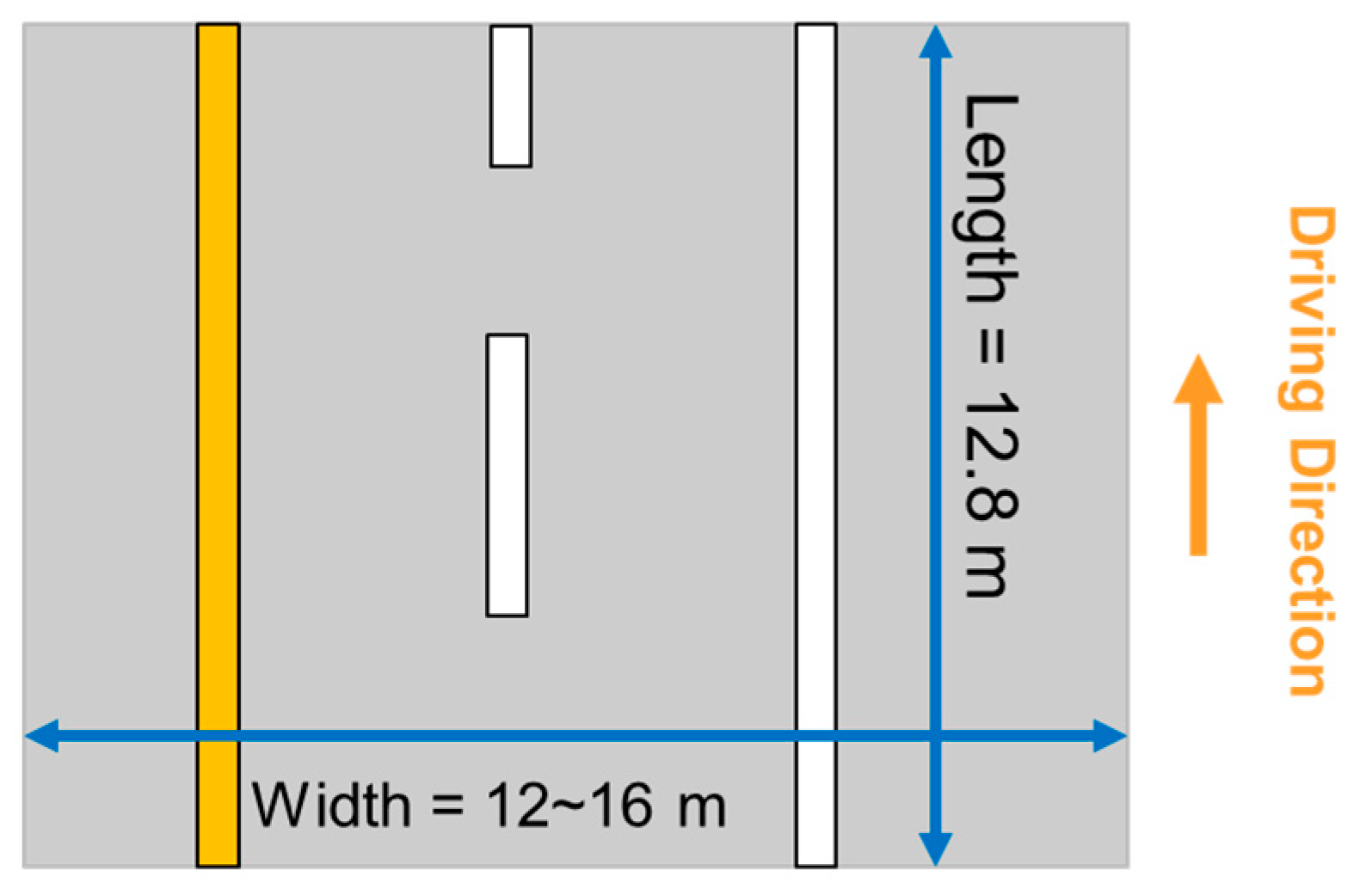
- The point cloud after noise removal, as shown in Figure 11b, is then divided into 12.8 m-long blocks for converting into images with a pixel size and image size of 5cm and 256 × 256, respectively.
- To ensure better spatial structure for the markings, a bounding box is created around each lane marking in the resulting intensity image, as shown in Figure 11c. Thereafter, all pixels falling within the bounding box are labeled as lane marking pixels. The resultant image, as shown in Figure 11d, serves as a labeled image for the training of U-net model 2.
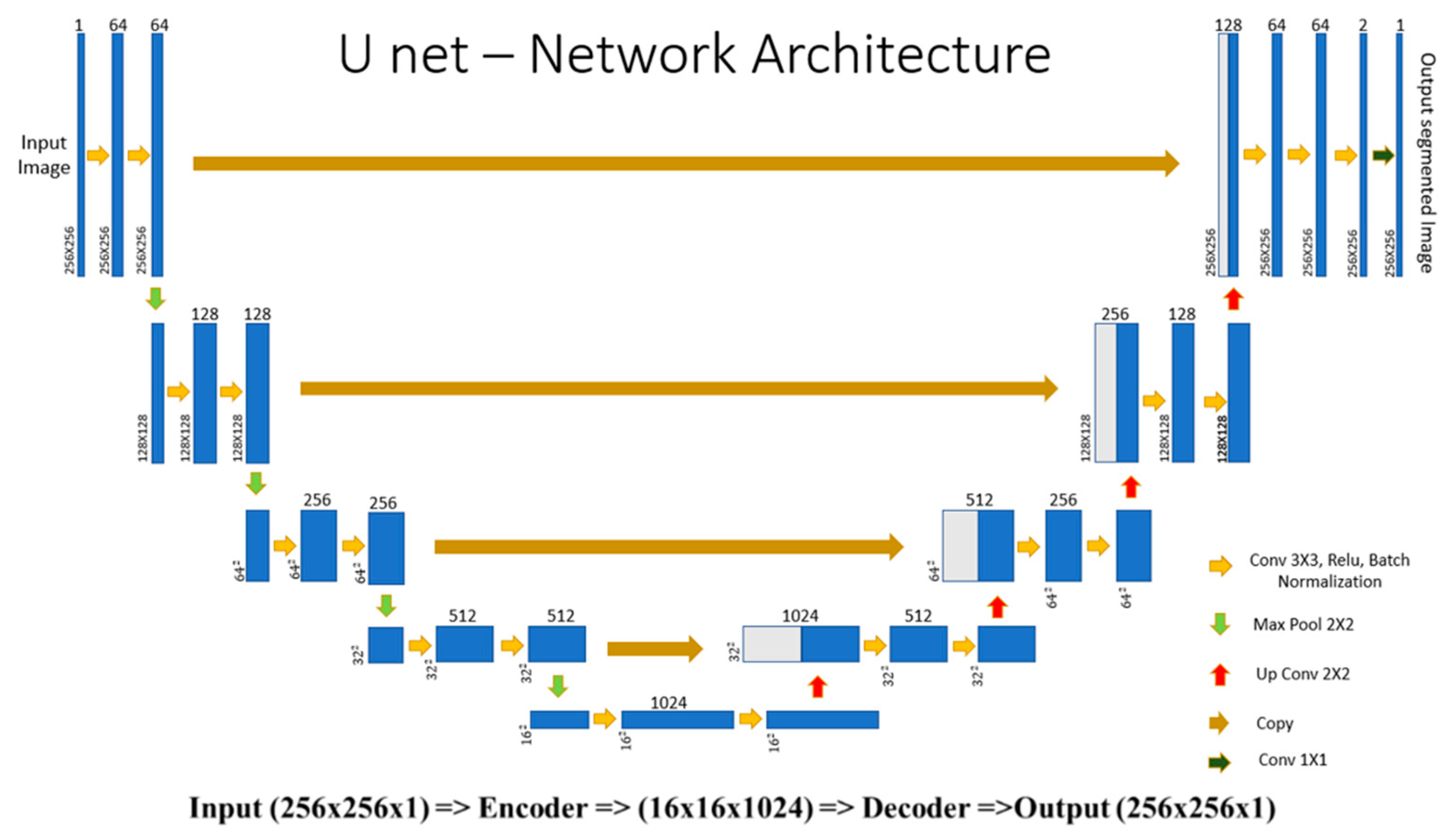
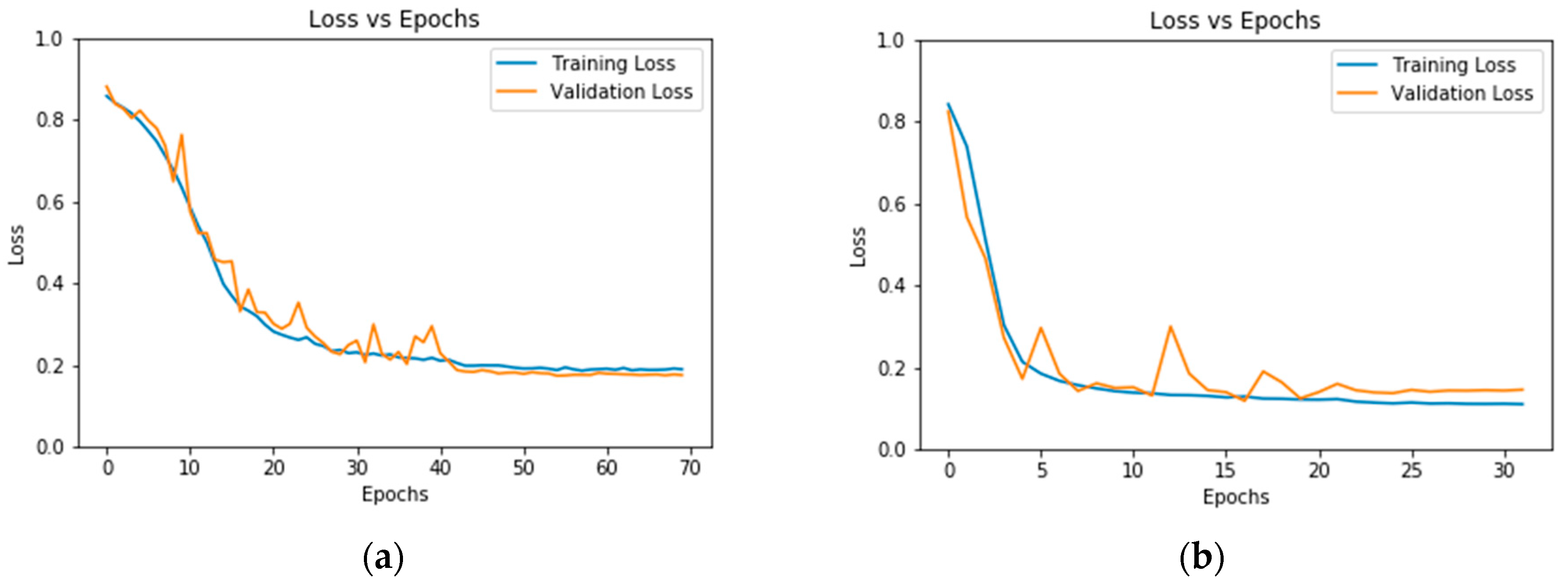
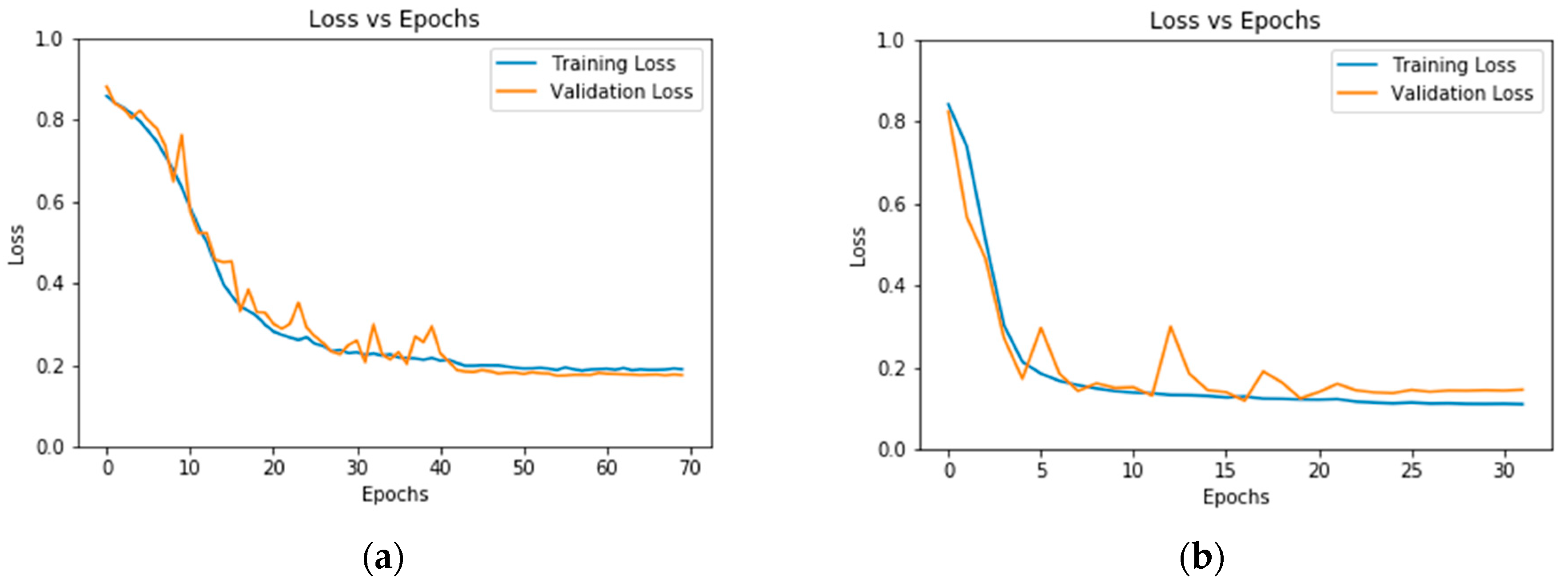
U-Net Model Training
Refinement of U-Net Predictions
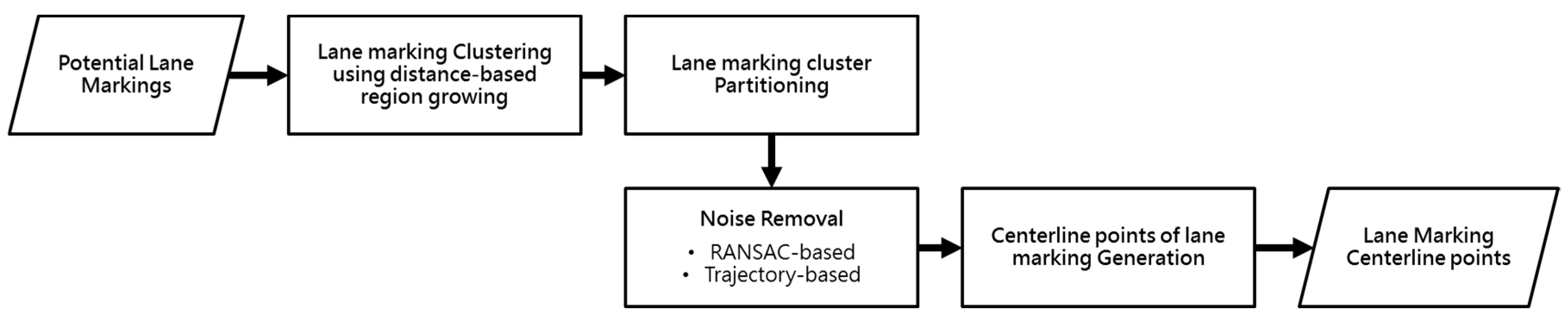
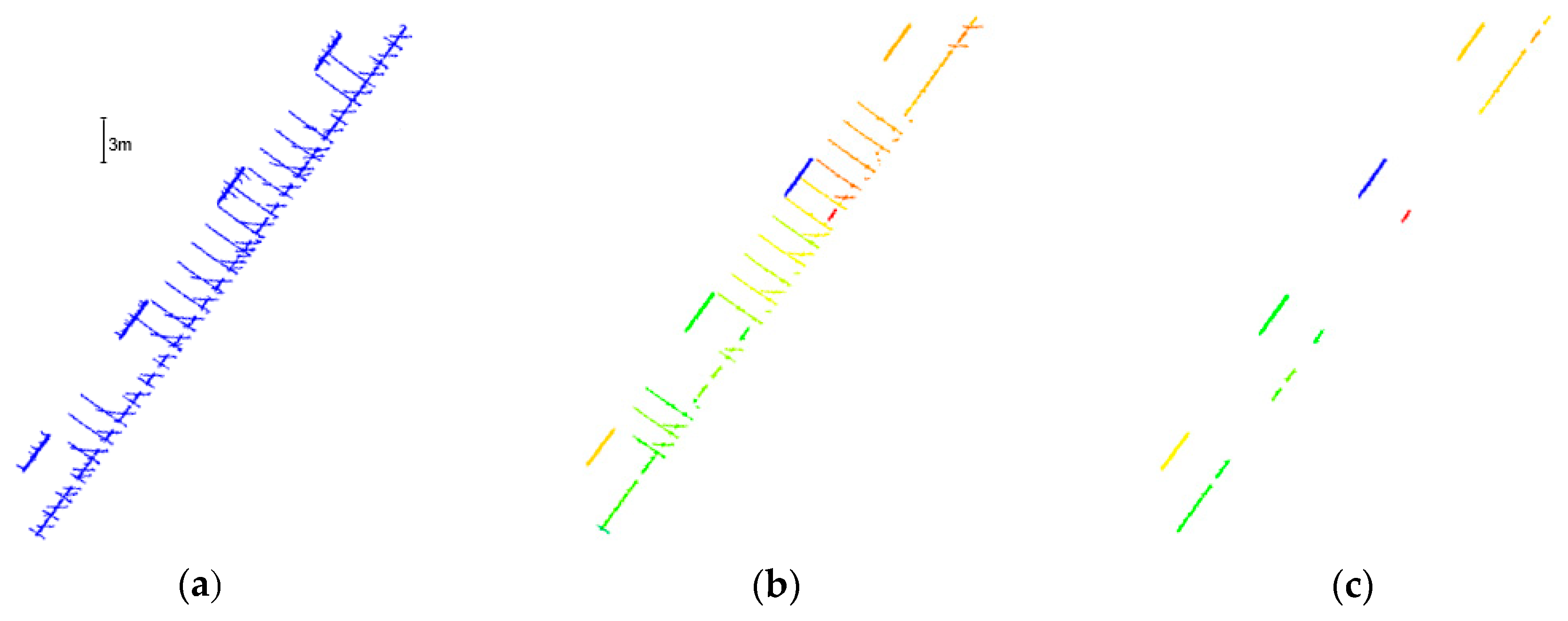
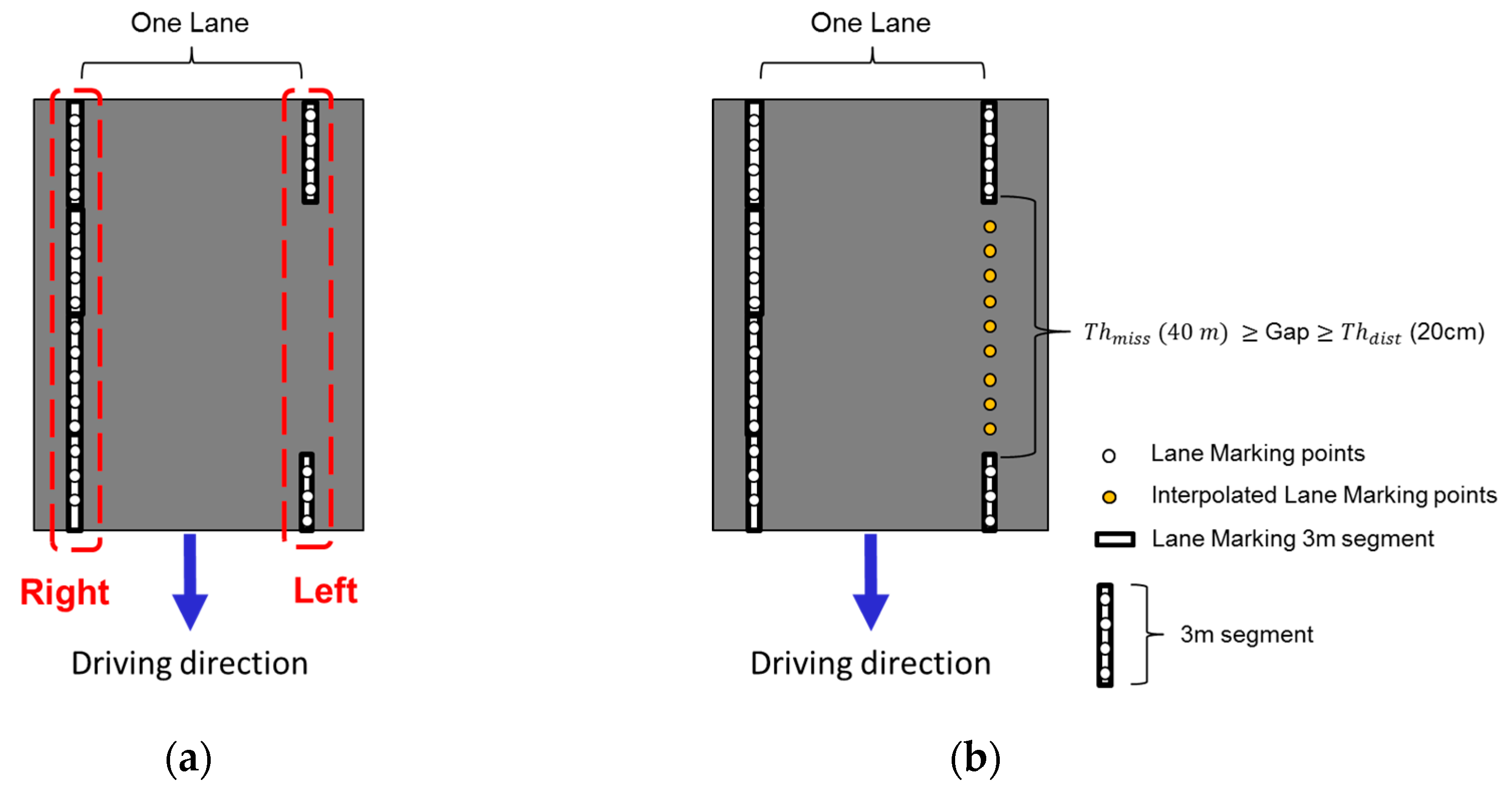
4.2. Lane Width Estimation Approach
4.3. Lane Marking Gap Reporting
5. Experimental Results and Discussion
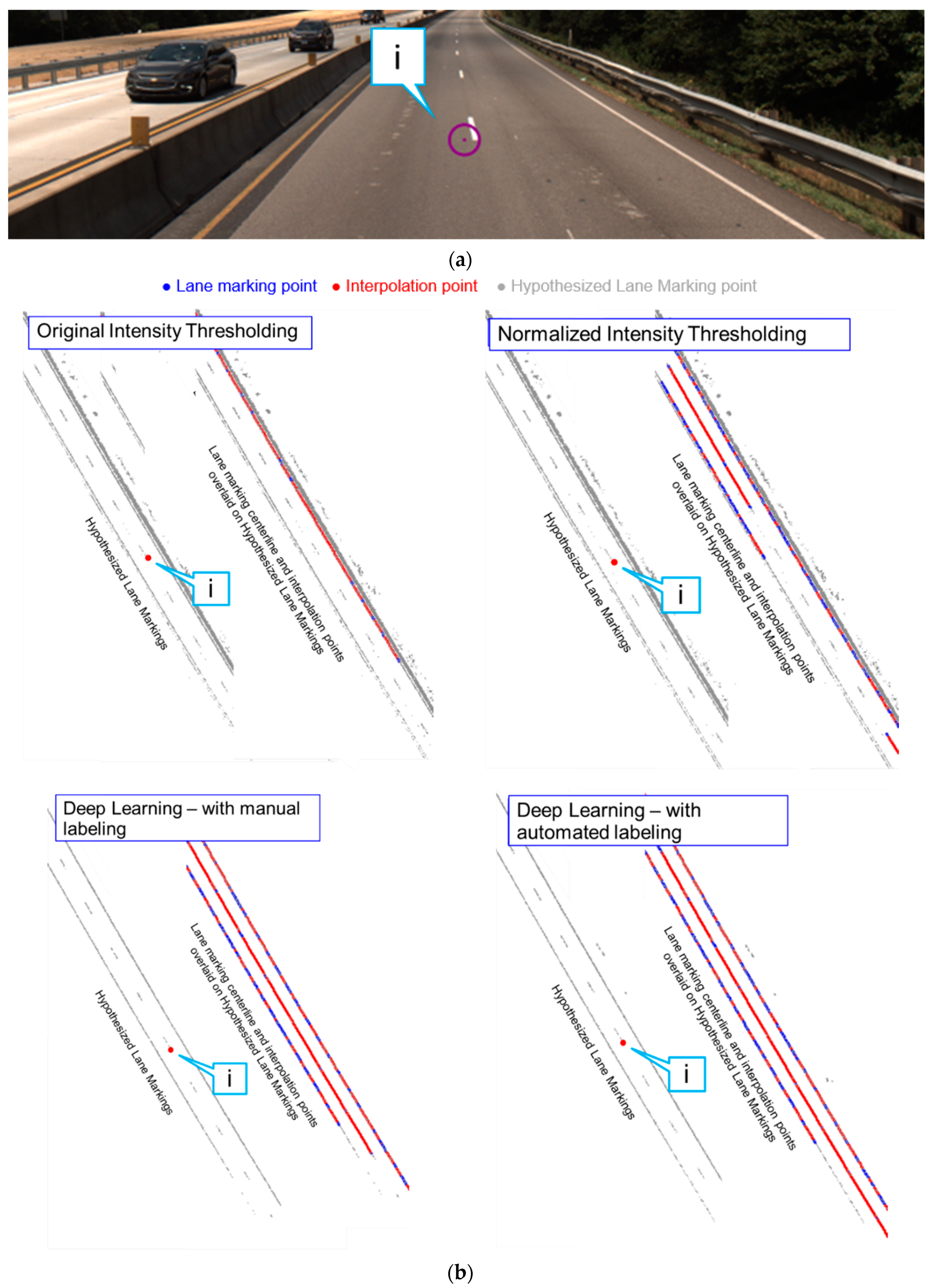
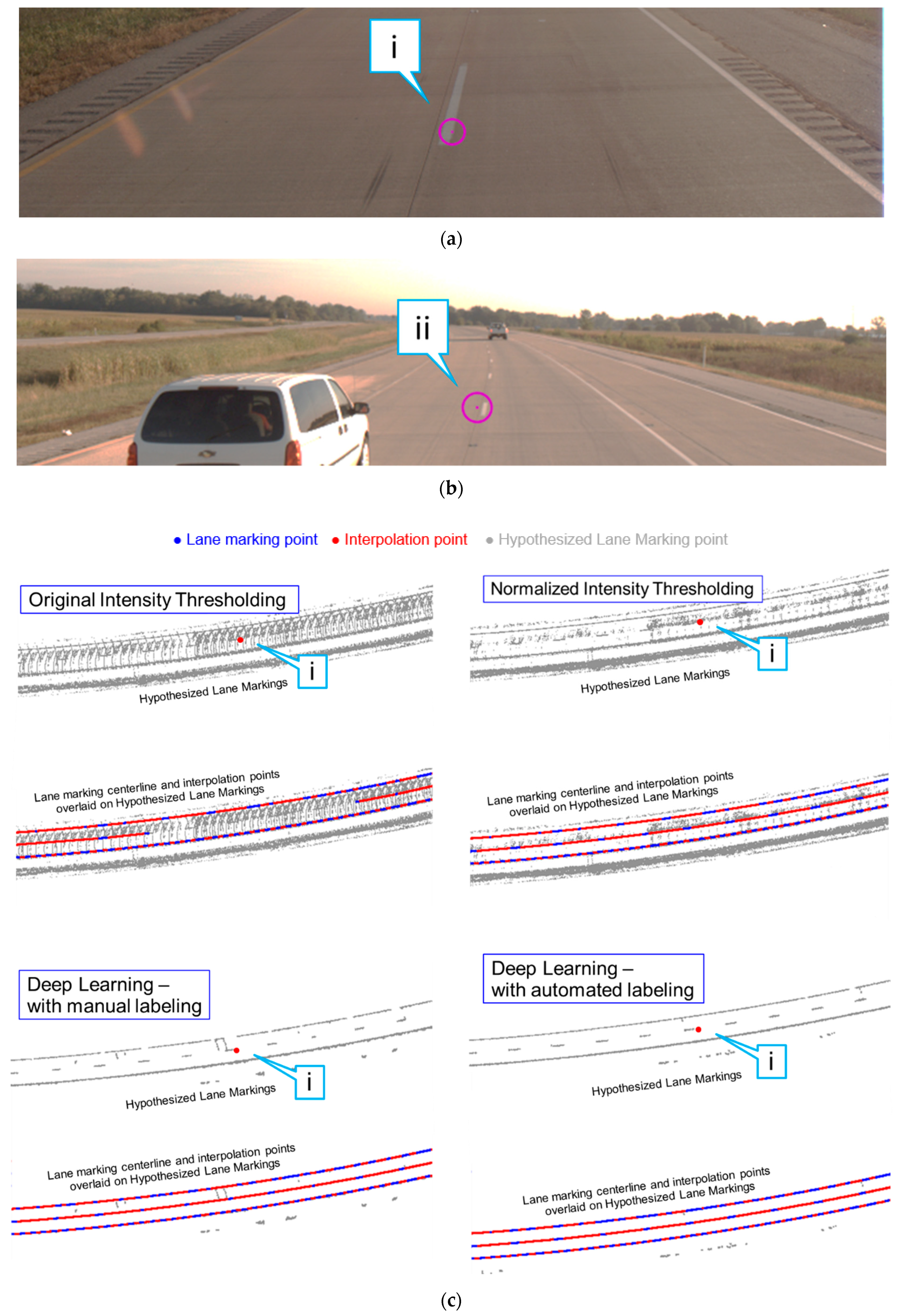
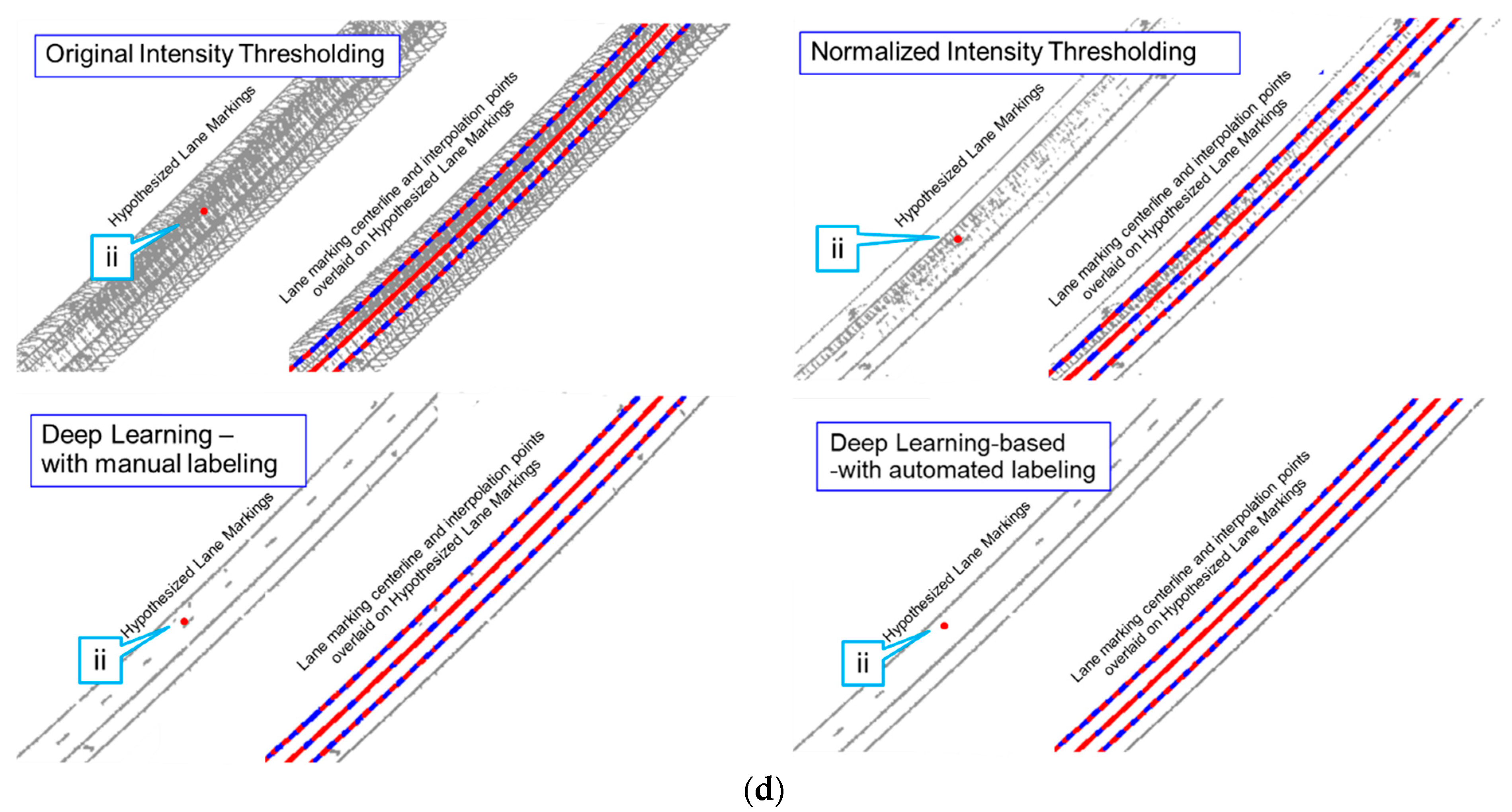
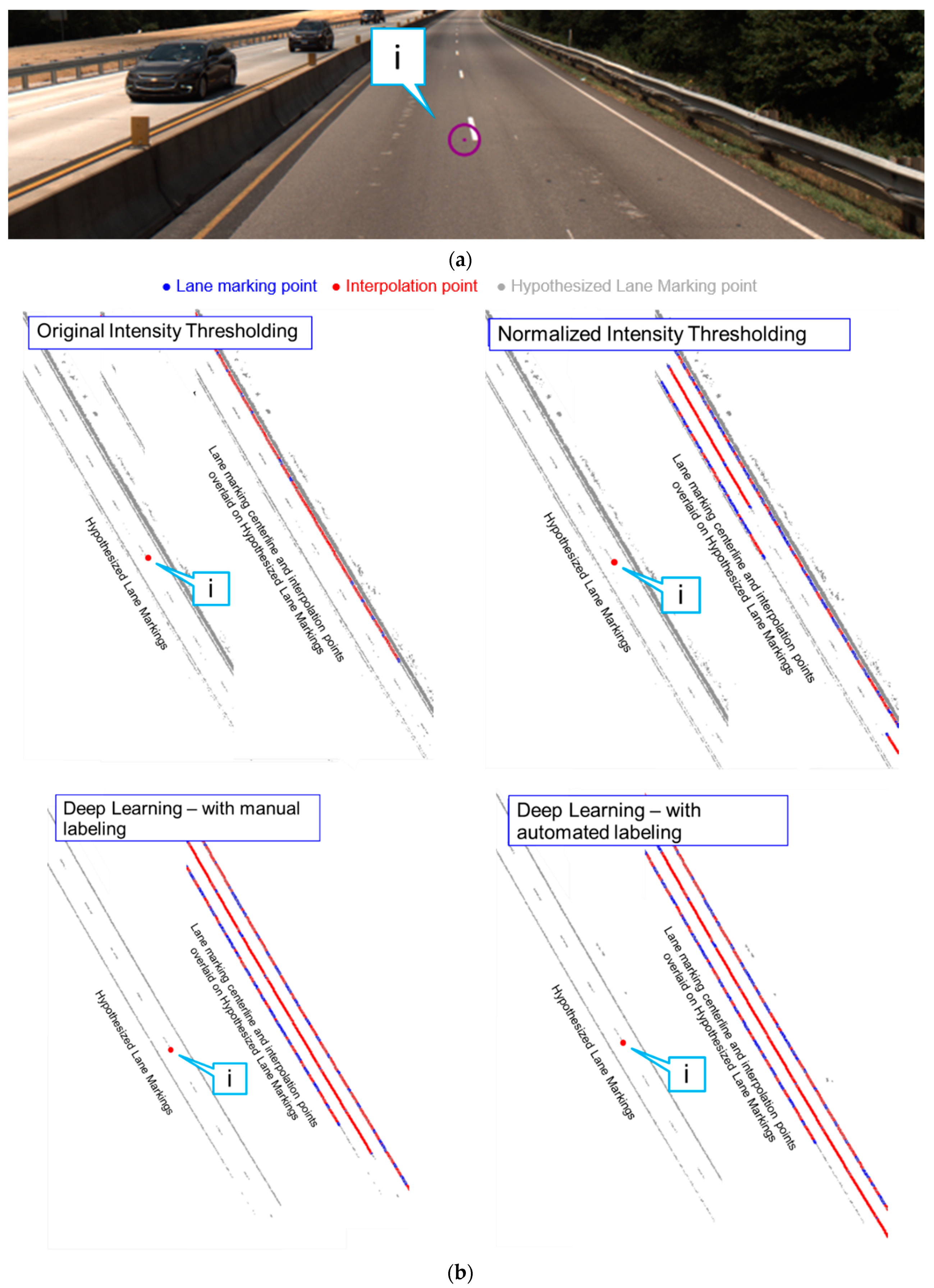
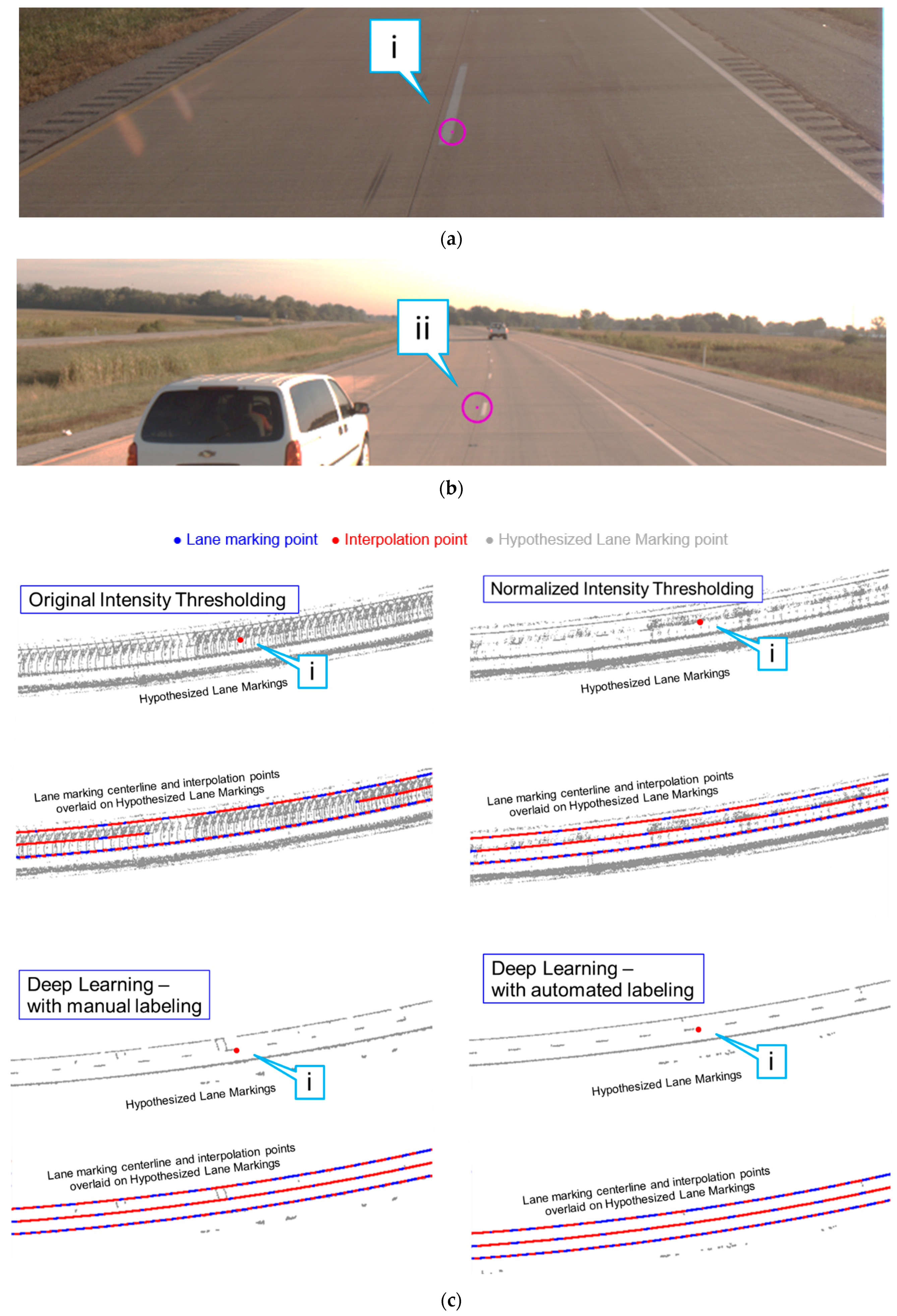
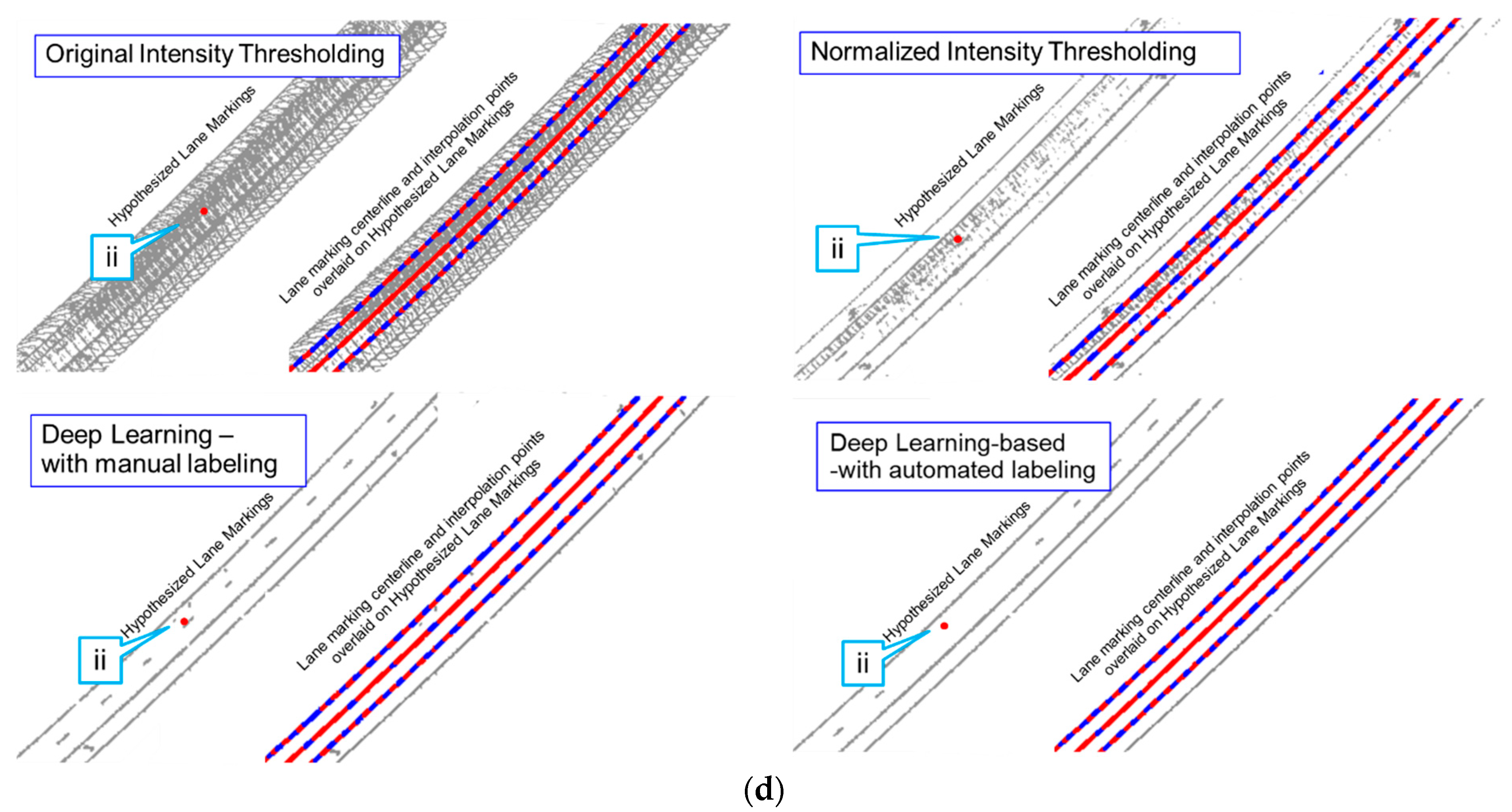
5.1. Lane Marking Extraction Results
5.1.1. Intensity Thresholding Approaches
5.1.2. Evaluation of Different Lane Marking Extraction Strategies
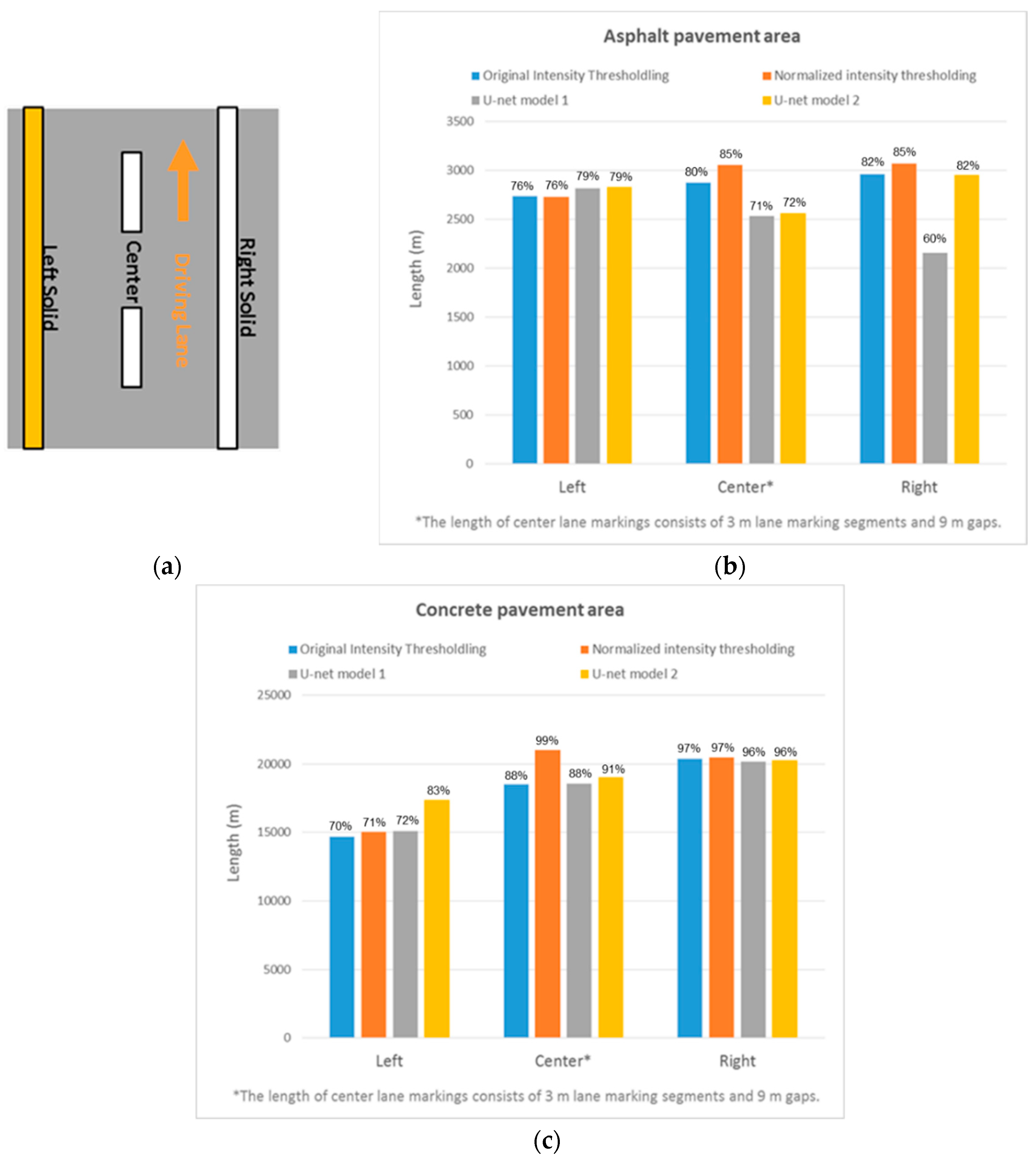
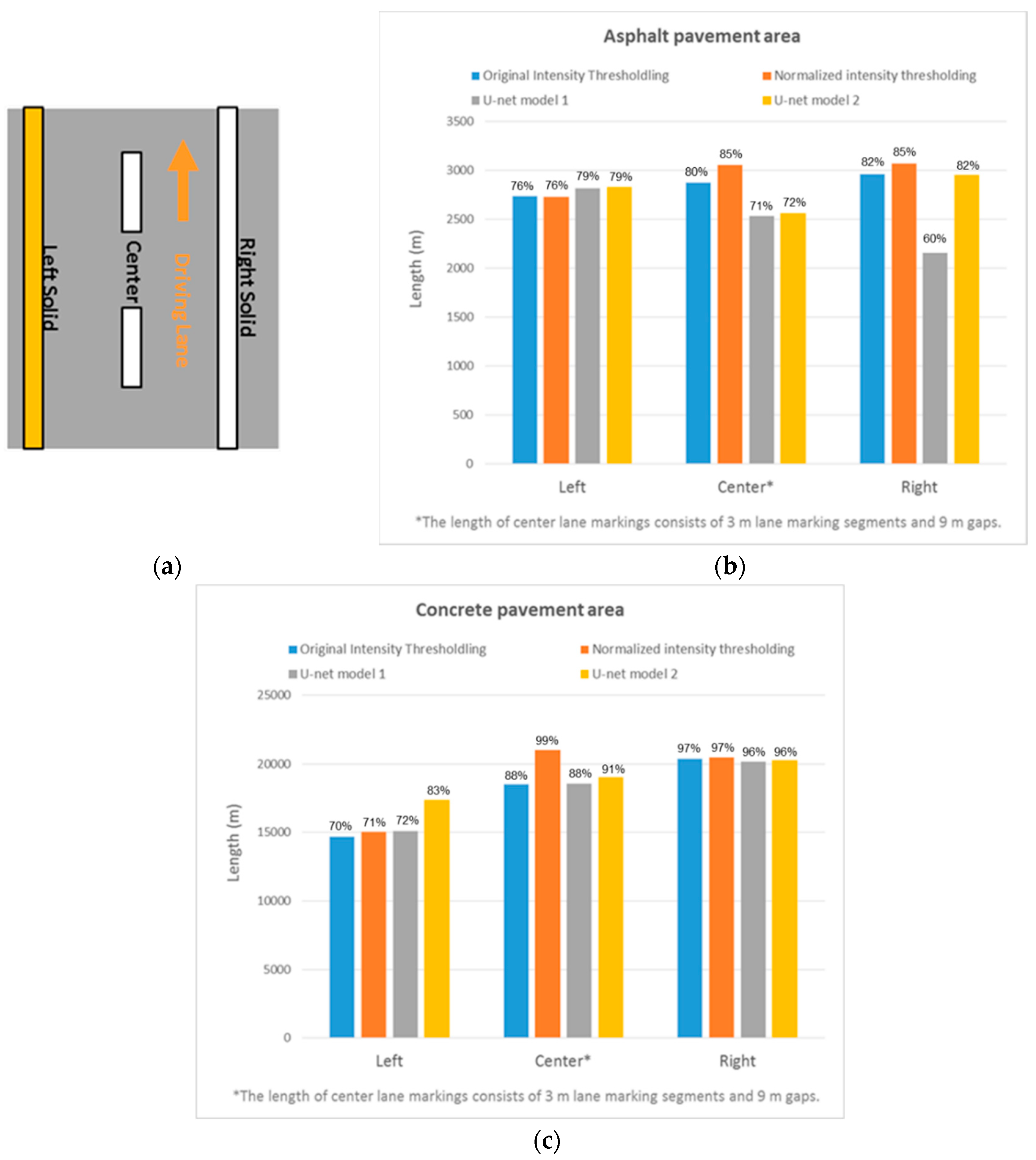
5.1.3. Comparison Between Asphalt and Concrete Pavement Areas
- In asphalt pavement area, the results from the different strategies are comparable except for the right lane markings where U-net model 1 has poor performance. The results of model 1 are unexpected, and it is hypothesized that this is a result of unintended adversarial noise [34] in intensity images generated for these areas.
- In concrete pavement area (however), U-net model 2 can extract much longer length of the left lane markings compared to other strategies. For the center lane markings, the normalized intensity thresholding strategy results in the largest lane marking extraction followed by the deep learning approaches. The right lane markings have consistent results under all strategies since it is near the driving lane where the lane markings have high point density. Overall, we conclude that the normalized intensity thresholding and deep learning approaches can extract lane marking much better than the original intensity thresholding strategy in concrete pavement area.
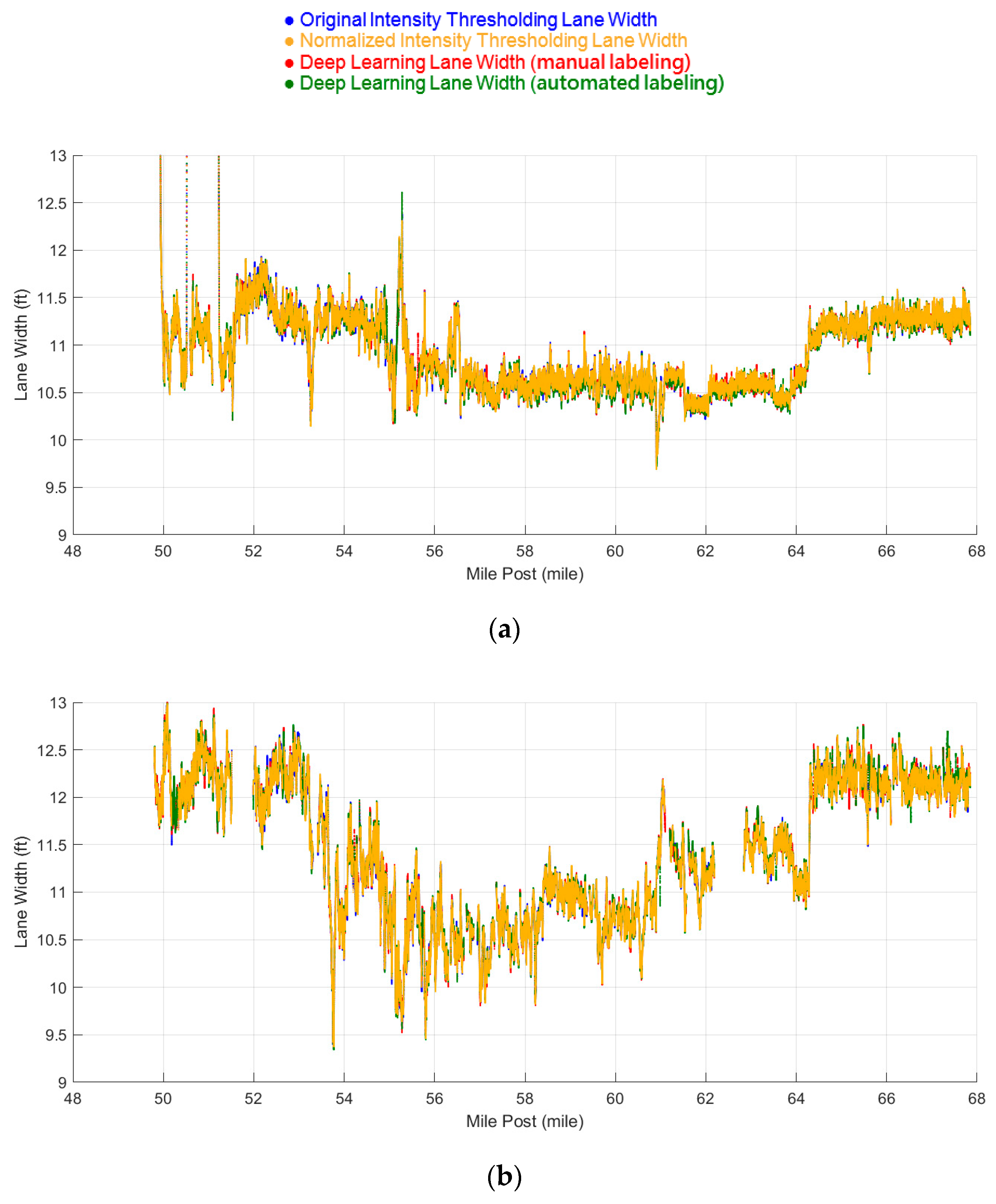
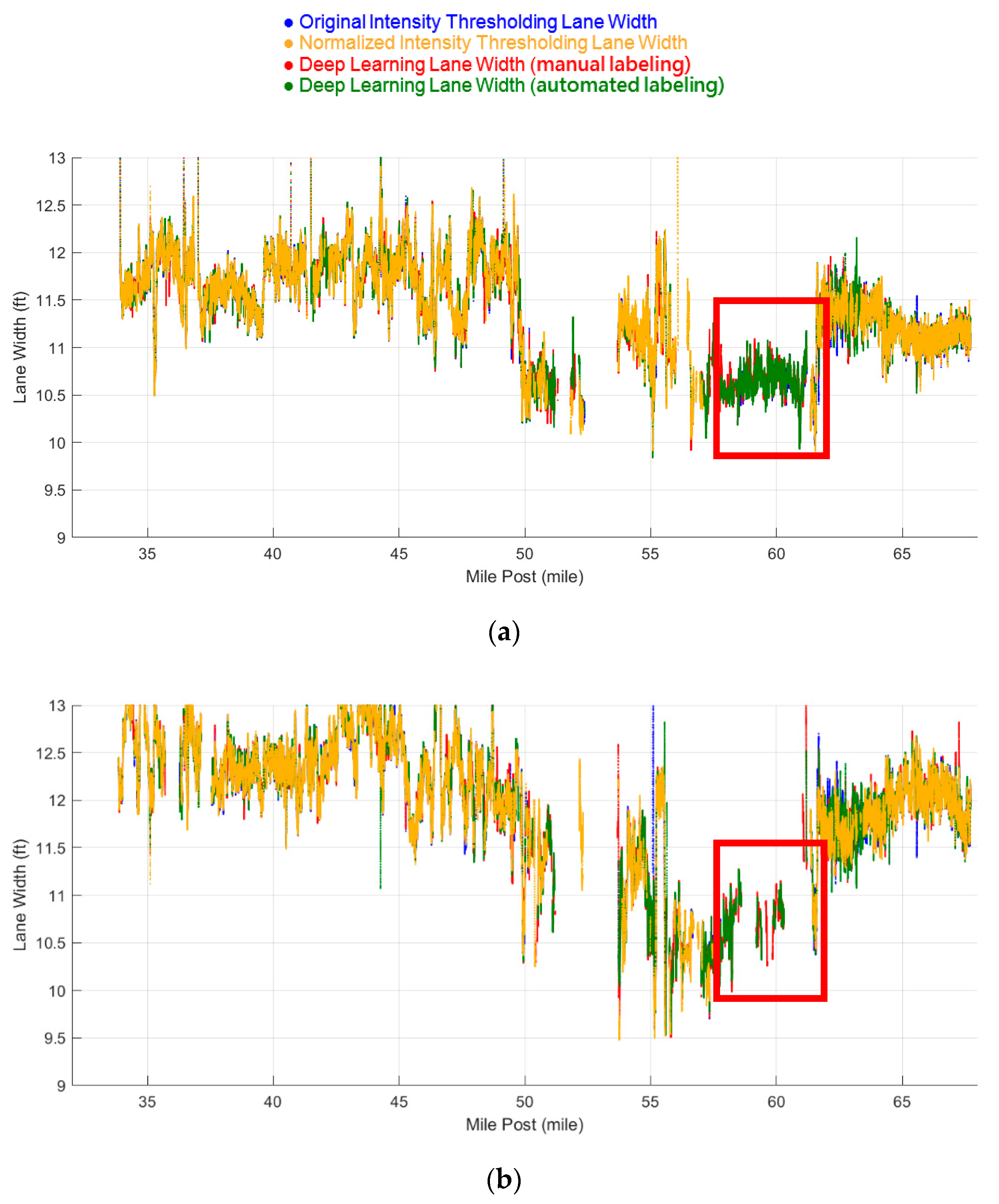
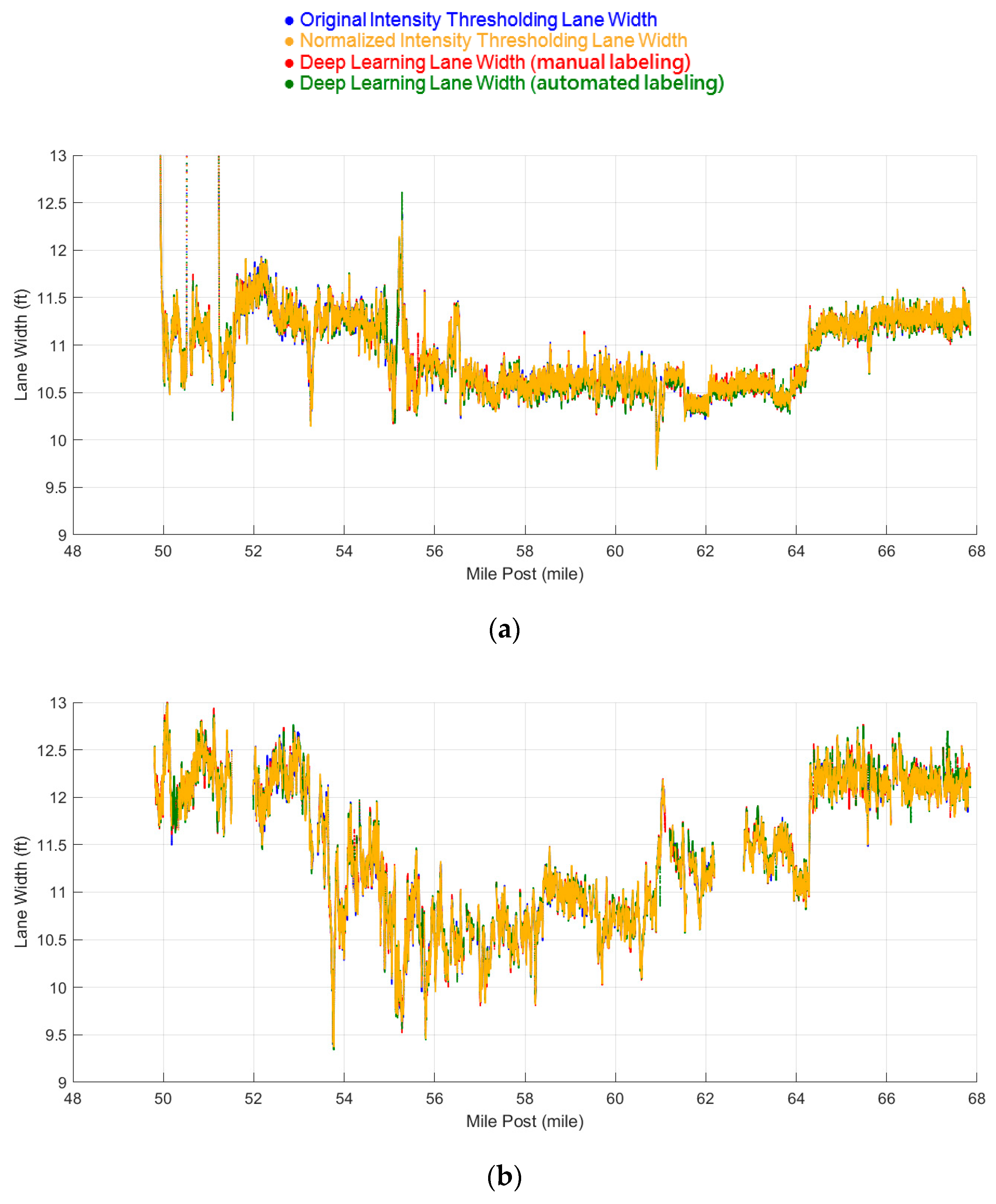
5.2. Lane Width Estimation Results
5.2.1. Datasets 1 and 2: Mainly Asphalt Pavement
5.2.2. Dataset 3: Mainly Concrete Pavement
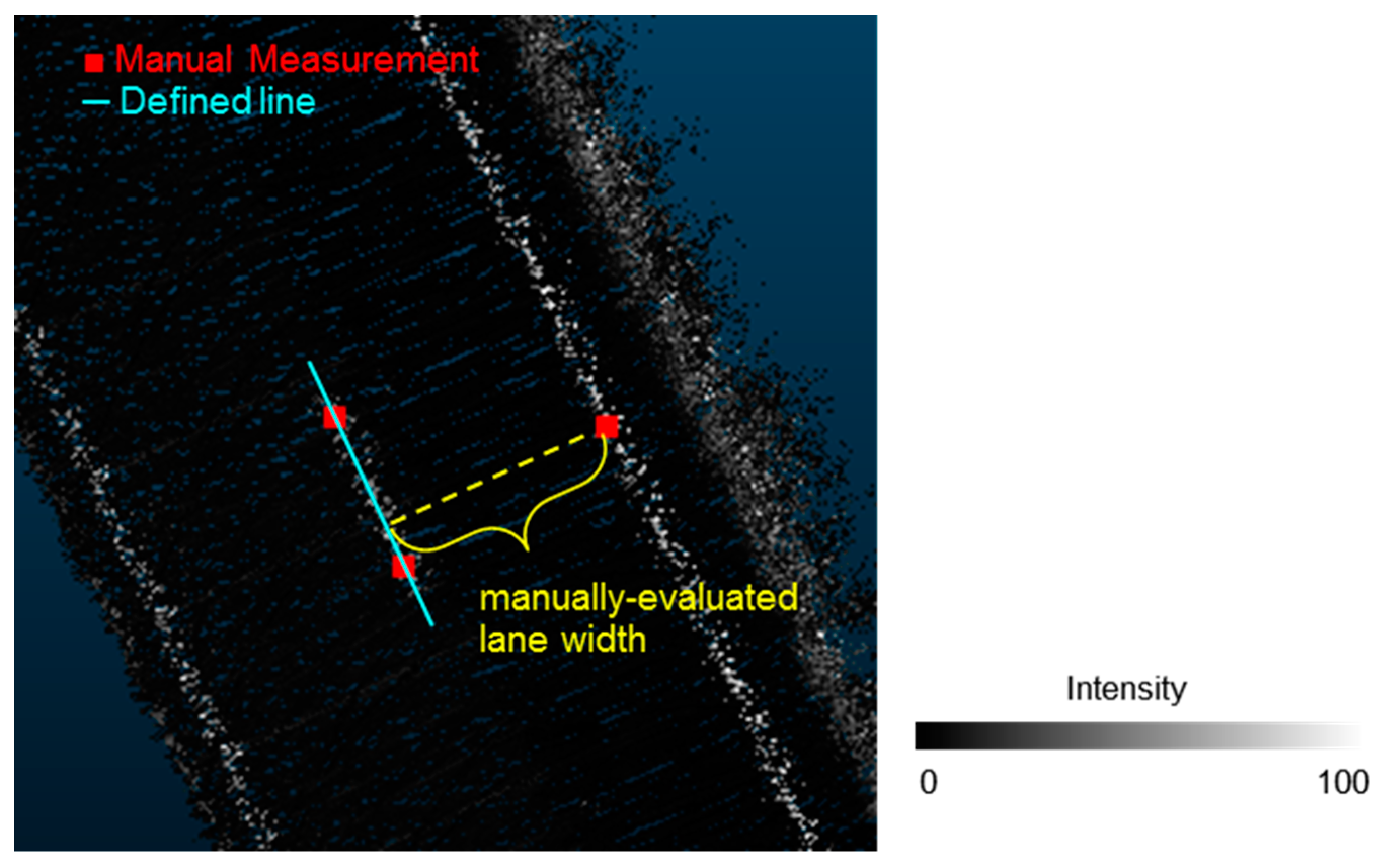
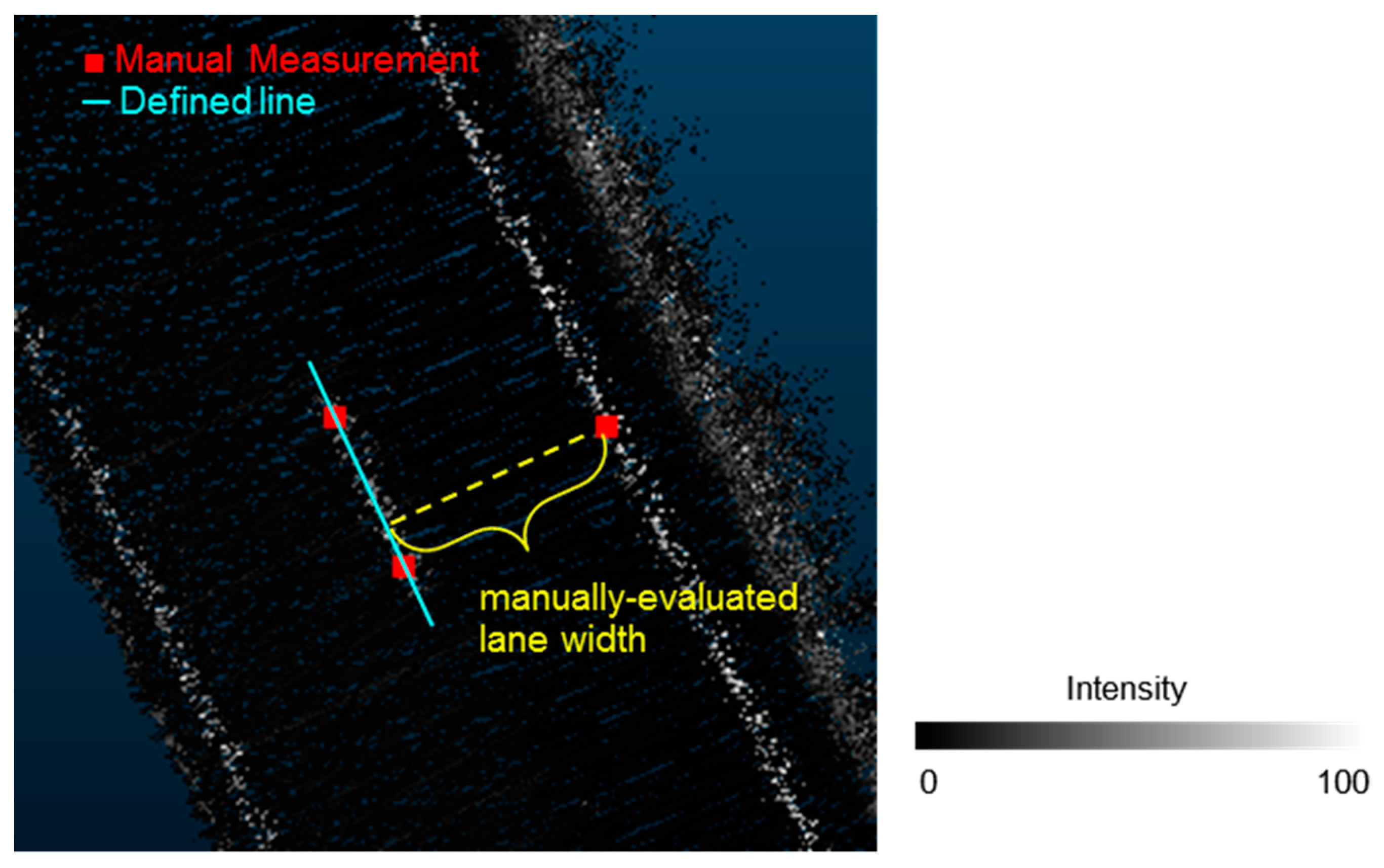
5.2.3. Comparison With Manual Lane Width Measurements
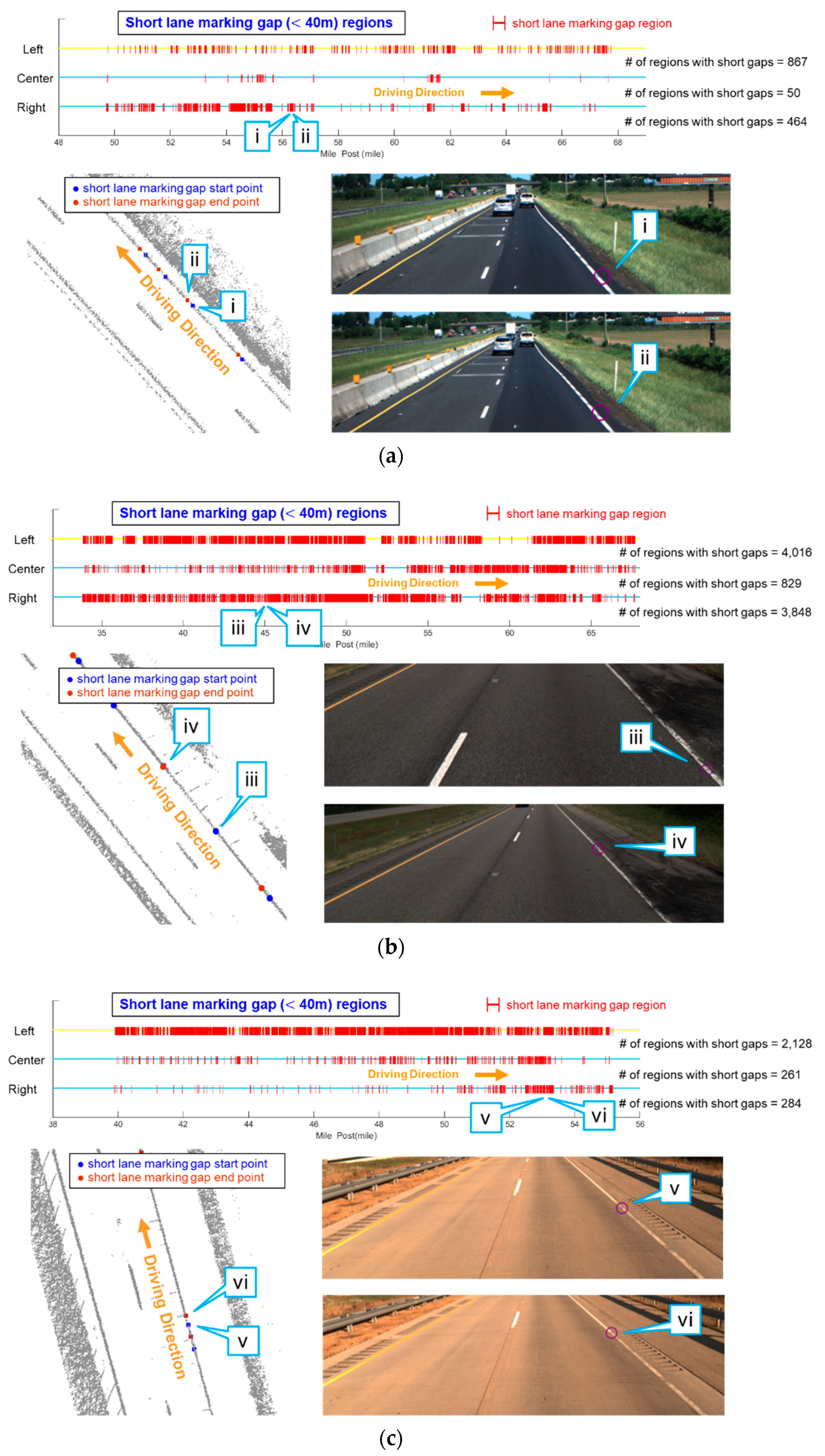
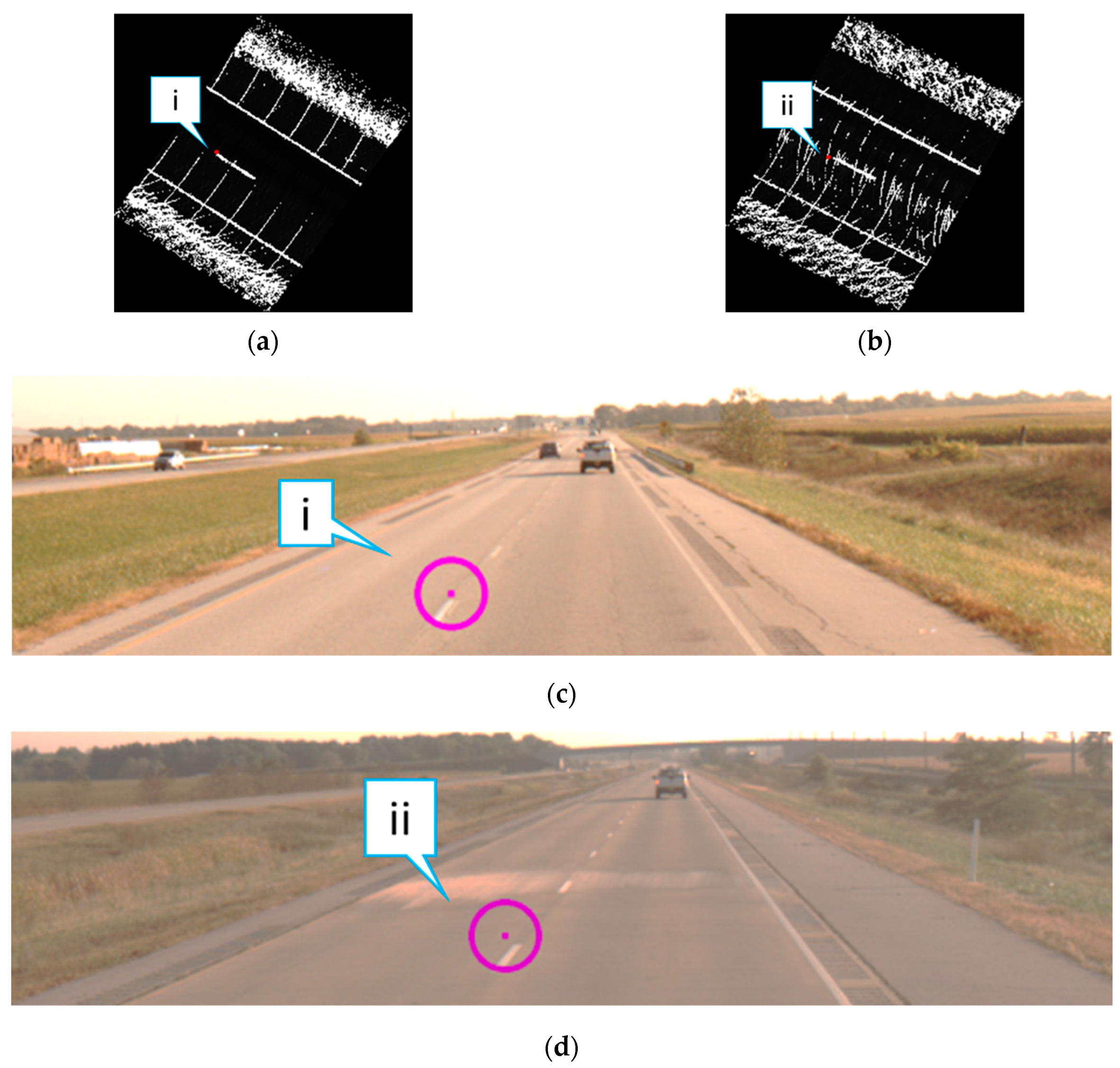
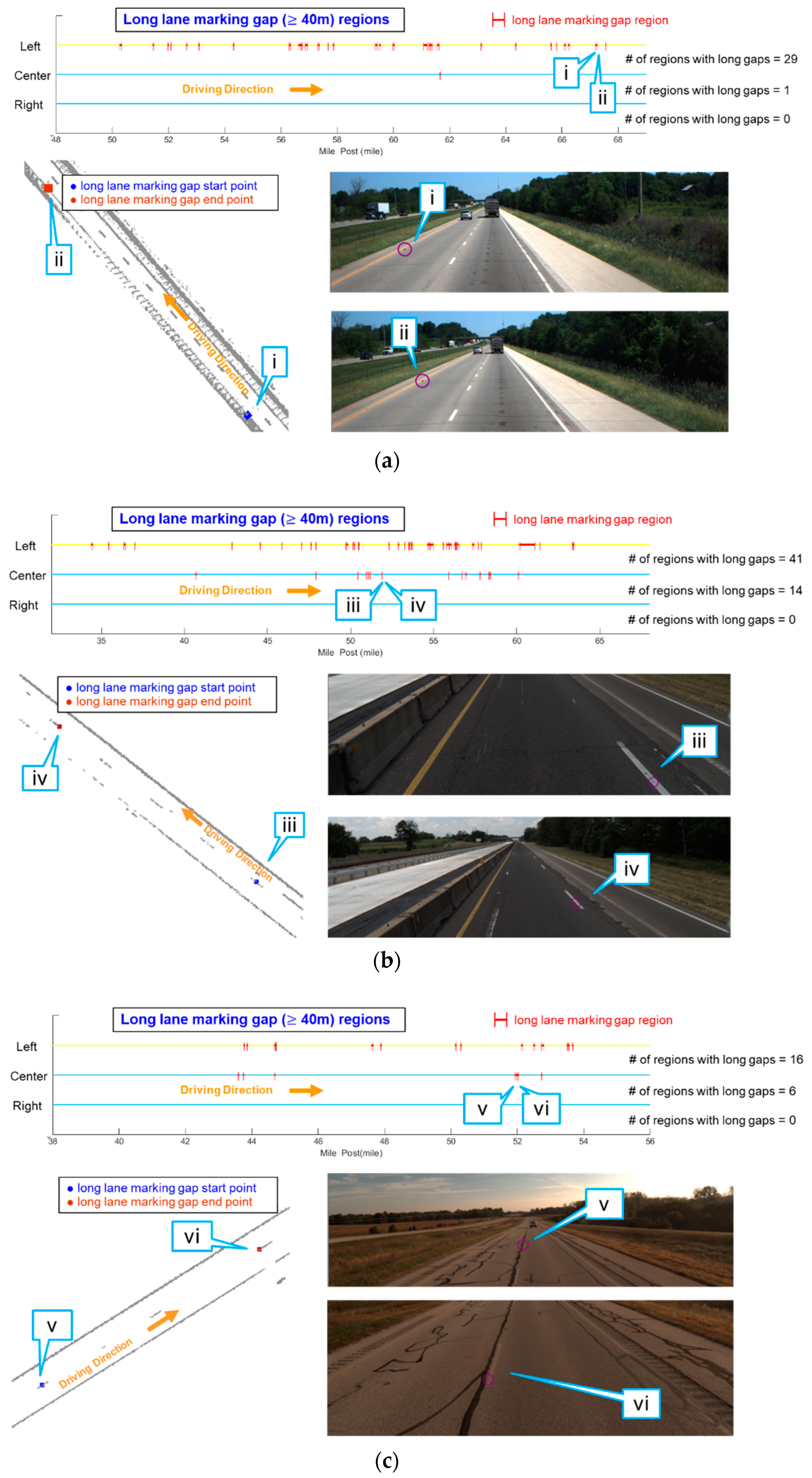
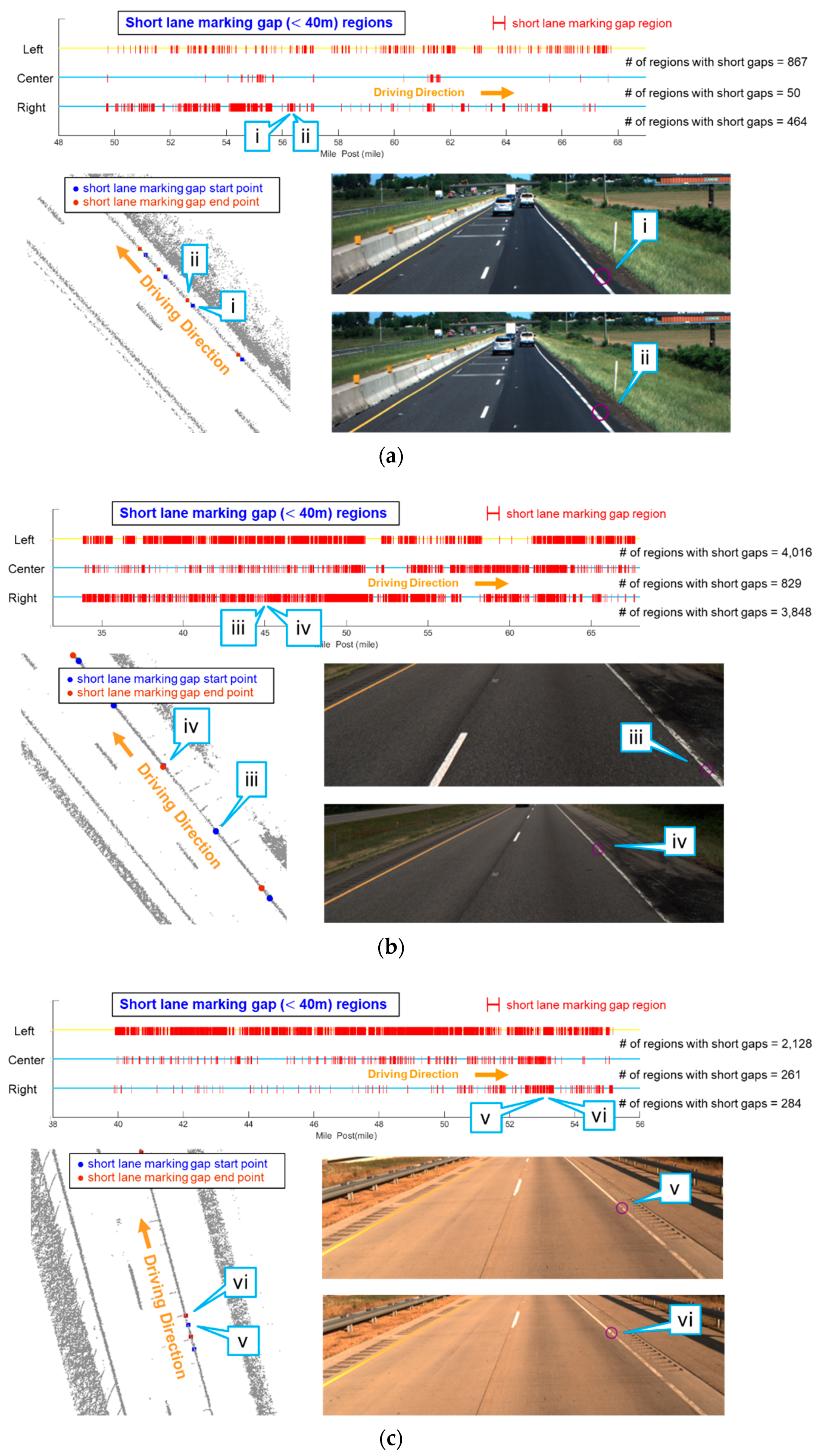
5.3. Lane Marking Gap Results
6. Conclusions and Recommendations for Future Research
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hernández, D.C.; Seo, D.; Jo, K.-H. Robust lane marking detection based on multi-feature fusion. In Proceedings of the 2016 9th International Conference on Human System Interactions (HSI), Portsmouth, UK, 6–8 July 2016; pp. 423–428. [Google Scholar]
- Jung, S.; Youn, J.; Sull, S. Efficient lane detection based on spatiotemporal images. IEEE Trans. Intell. Transp. Syst. 2015, 17, 289–295. [Google Scholar] [CrossRef]
- Azimi, S.M.; Fischer, P.; Körner, M.; Reinartz, P. Aerial LaneNet: Lane-marking semantic segmentation in aerial imagery using wavelet-enhanced cost-sensitive symmetric fully convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2920–2938. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Haffner, P.; Bottou, L.; Bengio, Y. Object recognition with gradient-based learning. In Shape, Contour and Grouping in Computer Vision; Springer: Berlin/Heidelberg, Germany, 1999; pp. 319–345. [Google Scholar]
- Guan, H.; Li, J.; Yu, Y.; Wang, C.; Chapman, M.; Yang, B. Using mobile laser scanning data for automated extraction of road markings. ISPRS J. Photogramm. Remote Sens. 2014, 87, 93–107. [Google Scholar] [CrossRef]
- Kumar, P.; McElhinney, C.P.; Lewis, P.; McCarthy, T. Automated road markings extraction from mobile laser scanning data. Int. J. Appl. Earth Obs. Geoinf. 2014, 32, 125–137. [Google Scholar] [CrossRef] [Green Version]
- Soilán, M.; Riveiro, B.; Martínez-Sánchez, J.; Arias, P. Segmentation and classification of road markings using MLS data. ISPRS J. Photogramm. Remote Sens. 2017, 123, 94–103. [Google Scholar] [CrossRef]
- Cheng, M.; Zhang, H.; Wang, C.; Li, J. Extraction and classification of road markings using mobile laser scanning point clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 1182–1196. [Google Scholar] [CrossRef]
- Ghallabi, F.; Nashashibi, F.; El-Haj-Shhade, G.; Mittet, M.-A. Lidar-based lane marking detection for vehicle positioning in an hd map. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2209–2214. [Google Scholar]
- Jung, J.; Che, E.; Olsen, M.J.; Parrish, C. Efficient and robust lane marking extraction from mobile lidar point clouds. ISPRS J. Photogramm. Remote Sens. 2019, 147, 1–18. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Guan, H.; Jia, F.; Wang, C. Learning hierarchical features for automated extraction of road markings from 3-D mobile LiDAR point clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 709–726. [Google Scholar] [CrossRef]
- Yan, L.; Liu, H.; Tan, J.; Li, Z.; Xie, H.; Chen, C. Scan line based road marking extraction from mobile LiDAR point clouds. Sensors 2016, 16, 903. [Google Scholar] [CrossRef] [PubMed]
- Jeong, J.; Kim, A. Lidar intensity calibration for road marking extraction. In Proceedings of the 2018 15th International Conference on Ubiquitous Robots (UR), Honolulu, HI, USA, 26–30 June 2018; pp. 455–460. [Google Scholar]
- He, B.; Ai, R.; Yan, Y.; Lang, X. Lane marking detection based on convolution neural network from point clouds. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 2475–2480. [Google Scholar]
- Wen, C.; Sun, X.; Li, J.; Wang, C.; Guo, Y.; Habib, A. A deep learning framework for road marking extraction, classification and completion from mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2019, 147, 178–192. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Hartigan, P.M. The dip test of unimodality. Ann. Stat. 1985, 13, 70–84. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Ravi, R.; Cheng, Y.-T.; Lin, Y.-C.; Lin, Y.-J.; Hasheminasab, S.M.; Zhou, T.; Flatt, J.E.; Habib, A. Lane Width Estimation in Work Zones Using LiDAR-Based Mobile Mapping Systems. IEEE Trans. Intell. Transp. Syst. 2019, 1–24. [Google Scholar] [CrossRef]
- Velodyne. HDL32E Data Sheet. Available online: https://velodynelidar.com/products/hdl-32e/ (accessed on 10 February 2020).
- Velodyne. Puck Hi-Res Data Sheet. Available online: https://velodynelidar.com/products/puck-hi-res/ (accessed on 10 February 2020).
- Applanix. POSLV Specifications. Available online: https://www.applanix.com/pdf/specs/POSLV_Specifications_dec_2015.pdf (accessed on 10 February 2020).
- Habib, A.; Lay, J.; Wong, C. Specifications for the quality assurance and quality control of lidar systems. In Proceedings of the Innovations in 3D Geo Information Systems; Springer: Berlin/Heidelberg, Germany, 2006; pp. 67–83. [Google Scholar]
- Ravi, R.; Lin, Y.-J.; Elbahnasawy, M.; Shamseldin, T.; Habib, A. Bias impact analysis and calibration of terrestrial mobile lidar system with several spinning multibeam laser scanners. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5261–5275. [Google Scholar] [CrossRef]
- Ravi, R.; Lin, Y.-J.; Elbahnasawy, M.; Shamseldin, T.; Habib, A. Simultaneous system calibration of a multi-lidar multicamera mobile mapping platform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1694–1714. [Google Scholar] [CrossRef]
- Lari, Z.; Habib, A. New approaches for estimating the local point density and its impact on LiDAR data segmentation. Photogramm. Eng. Remote Sens. 2013, 79, 195–207. [Google Scholar] [CrossRef]
- Levinson, J.; Thrun, S. Robust vehicle localization in urban environments using probabilistic maps. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 4372–4378. [Google Scholar]
- Levinson, J.; Thrun, S. Unsupervised calibration for multi-beam lasers. In Proceedings of the Experimental Robotics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 179–193. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint 2015, arXiv:1502.03167. [Google Scholar]
- Dice, L.R. Measures of the amount of ecologic association between species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- FHWA. Manual on Uniform Traffic Control Devices 2009; USD o. Transportation: Washington, DC, USA, 2009.
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- AASHTO. A Policy on Geometric Design of Highways and Streets, 7th ed.; American Association of State Highway and Transportation Officials: Washington, DC, USA, 2001. [Google Scholar]
- USGS. Materials in Use in U.S. Interstate Highway. Available online: https://pubs.usgs.gov/fs/2006/3127/2006-3127.pdf (accessed on 10 February 2020).
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv preprint 2014, arXiv:1412.6572. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strategy | Pros | Cons | Example References |
|---|---|---|---|
| Imagery-based |
|
| [1,2] |
| LiDAR (intensity image) |
|
| [5,6,7,8,9,10] |
| LiDAR (point cloud) |
|
| [11,12,13] |
| LiDAR (learning-based for intensity image) |
|
| [14,15] |
| Road Segment | Collection Date | Used Sensors | Length | Average LPS | Average Speed | Pavement |
|---|---|---|---|---|---|---|
| Dataset 1 | 2018/05/24 | HDL32E-F 1 HDL32E-L 1 HDL32E-R 1 | 18.04 mile | 3.11 cm | 45.62 mph | Asphalt mainly |
| Dataset 2 | 2019/07/19 | HDL32E-F 1 HDL32E-L 1 HDL32E-R 1 VLP16 | 33.87 mile | 3.19 cm | 47.42 mph | Asphalt mainly |
| Dataset 3 | 2019/10/05 | HDL32E-F 1 HDL32E-L 1 HDL32E-R 1 VLP16 | 15.29 mile | 3.16 cm | 47.70 mph | Concrete mainly |
| Design Speed | Minimum Radius of Curvature | Recommended Thmiss | Length of arc |
|---|---|---|---|
| 30 mph | 231 ft | 10 m | 10.01 m |
| 40 mph | 485 ft | 20 m | 20.02 m |
| 50 mph | 833 ft | 25 m | 25.01 m |
| 60 mph | 1330 ft | 35 m | 35.01 m |
| 70 mph | 2040 ft | 40 m | 40.01 m |
| Threshold | Description | Used for | Value |
|---|---|---|---|
| ThI | Percentile intensity threshold for lane marking extraction from point clouds | Intensity thresholding approaches | 5% |
| ThMF | LPS multiplication factor for cell size definition (generating intensity normalization maps) | Normalized intensity thresholding | 4 |
| ThEN | Percentile intensity threshold for intensity enhancement | Deep learning approaches | 5% |
| Thdist | Distance threshold for a distance-based region growing | Lane width estimation approach | 20 cm |
| Thpt | Minimum point threshold for cluster removal (intensity thresholding approaches) | Lane width estimation approach | 30 pts |
| Tharea | Minimum area threshold for 2D mask removal (deep learning approaches) | Lane width estimation approach | 50 cm2 |
| Thmiss | Missing lane marking threshold for reporting a missing lane marking region | Lane width estimation approach | 40 m |
| Thdash | Distance threshold for reporting short lane marking gaps of dash lines | Short lane marking gaps reporting | 10 m |
| ROI | 1 | 2 | 3 |
|---|---|---|---|
| Length of Dataset (m) | 29,032.57 (18.04 mile) | 54,508.48 (33.87 mile) | 24,606.87 (15.29 mile) |
| # of sensors | 3 | 4 | 4 |
| Mean. speed (mph) | 49.39 | 48.44 | 64.85 |
| Max. speed (mph) | 52.99 | 59.84 | 74.58 |
| Min. speed (mph) | 45.58 | 44.38 | 55.43 |
| Length of ROI (m) | 155 | 190 | 155 |
| Cell Size of HDL32E sensors (m) | 0.12 | 0.12 | 0.25 |
| Cell Size of VLP16 sensor (m) | 0.20 | 0.20 | 0.30 |
| Experimental Setting | Description | Associated Values |
|---|---|---|
| Learning rate | Step size by which gradient of the loss function is scaled to update the network weights | 8 × 10−4 |
| Batch size | Number of training examples fed to the network for a single update of the network weights | 8 |
| Epoch | One cycle (forward and backward pass) where the network has seen all training examples once constitutes an epoch. | 100 |
| Early stopping | The training is stopped when validation loss does not improve from the current lowest value for a certain number of consecutive epochs called patience. This helps in preventing overfitting to training data. | Patience: 15 |
| Decay of learning rate | The learning rate is also decayed by a factor of 10 when validation loss does not improve from the current lowest value for patience number of consecutive epochs. | Patience: 5 Decay factor: 10 |
| Lane Marking Extraction Strategies | Precision | Recall | F1-Score |
|---|---|---|---|
| Original intensity thresholding | 84.1% | 63.5% | 72.3% |
| Normalized intensity thresholding | 83.9% | 74.4% | 78.9% |
| Deep learning with manual labeling | 60.5% | 98.9% | 75.1% |
| Deep learning with automated labeling | 84.0% | 87.9% | 85.9% |
| Strategy | Original Intensity Thresholding | Normalized Intensity Thresholding | Deep Learning with Manual Labeling | Deep Learning with Automated Labeling | ||||
|---|---|---|---|---|---|---|---|---|
| Lane | 1 | 2 | 1 | 2 | 1 | 2 | 1 | 2 |
| Length of Dataset (mile) | 18.04 | |||||||
| Estimated Length (mile) | 17.74 | 15.22 | 17.81 | 15.11 | 17.79 | 15.90 | 17.68 | 15.70 |
| # of Comparisons | 142,689 | 121,115 | - | - | 142,312 | 121,615 | 141,424 | 121,256 |
| Mean (cm) | 0.2 | −0.3 | - | - | 0.2 | −0.4 | 0.3 | −0.5 |
| STD (cm) | 1.1 | 1.1 | - | - | 1.3 | 1.3 | 1.2 | 1.3 |
| RMSE (cm) | 1.1 | 1.1 | - | - | 1.3 | 1.3 | 1.3 | 1.4 |
| Max. (cm) | 7.0 | 13.3 | - | - | 18.5 | 13.2 | 16.8 | 15.6 |
| Min. (cm) | −7.0 | −7.2 | - | - | −19.8 | −10.9 | −11.7 | −16.1 |
| Strategy | Original Intensity Thresholding | Normalized Intensity Thresholding | Deep Learning with Manual Labeling | Deep Learning with Automated Labeling | ||||
|---|---|---|---|---|---|---|---|---|
| Lane | 1 | 2 | 1 | 2 | 1 | 2 | 1 | 2 |
| Length of Dataset (mile) | 33.87 | |||||||
| Estimated Length (mile) | 23.31 | 21.52 | 24.37 | 22.33 | 30.18 | 26.79 | 29.12 | 25.66 |
| # of Comparisons | 176,316 | 162,047 | - | - | 194,015 | 177,399 | 188,888 | 175,347 |
| Mean (cm) | 0.0 | 0.1 | - | - | −0.1 | 0.3 | 0.0 | 0.3 |
| STD (cm) | 1.8 | 2.1 | - | - | 2.2 | 2.4 | 2.3 | 3.0 |
| RMSE (cm) | 1.8 | 2.1 | - | - | 2.2 | 2.4 | 2.3 | 3.0 |
| Max. (cm) | 21.2 | 23.3 | - | - | 17.7 | 24.0 | 40.3 | 59.8 |
| Min. (cm) | −23.0 | −28.8 | - | - | −19.4 | −24.8 | −18.3 | −40.1 |
| Strategy | Original Intensity Thresholding | Normalized Intensity Thresholding | Deep Learning with Manual Labeling | Deep Learning with Automated Labeling | ||||
|---|---|---|---|---|---|---|---|---|
| Lane | 1 | 2 | 1 | 2 | 1 | 2 | 1 | 2 |
| Length of Dataset (mile) | 15.29 | |||||||
| Estimated Length (mile) | 14.50 | 13.88 | 14.98 | 14.28 | 14.53 | 14.37 | 14.66 | 14.39 |
| # of Comparisons | 116,432 | 111,426 | - | - | 116,851 | 112,660 | 117,905 | 112,955 |
| Mean (cm) | 0.1 | −0.1 | - | - | 0.1 | −0.2 | 0.0 | −0.1 |
| STD (cm) | 2.4 | 2.3 | - | - | 1.9 | 2.2 | 1.1 | 1.5 |
| RMSE (cm) | 2.4 | 2.3 | - | - | 1.9 | 2.2 | 1.1 | 1.5 |
| Max. (cm) | 53.7 | 25.4 | - | - | 40.4 | 15.8 | 58.9 | 14.2 |
| Min. (cm) | −24.7 | −32.4 | - | - | −13.2 | −34.3 | −19.4 | −32.9 |
| Dataset | Strategy | Original Intensity Thresholding | Normalized Intensity Thresholding | Deep Learning with Manual Labeling | Deep Learning with Automated Labeling | ||||
|---|---|---|---|---|---|---|---|---|---|
| Lane | 1 | 2 | 1 | 2 | 1 | 2 | 1 | 2 | |
| 1 | Length of Dataset (mile) | 18.04 | |||||||
| Estimated Length (mile) | 17.74 | 15.22 | 17.81 | 15.11 | 17.79 | 15.90 | 17.68 | 15.70 | |
| # of Comparisons | 150 | 148 | 149 | 146 | 147 | 153 | 149 | 152 | |
| Mean (cm) | 0.9 | 1.2 | 0.6 | 1.3 | 1.0 | 1.2 | 0.9 | 1.1 | |
| STD (cm) | 2.3 | 2.4 | 2.5 | 2.4 | 2.3 | 2.5 | 2.4 | 2.4 | |
| RMSE (cm) | 2.5 | 2.7 | 2.6 | 2.7 | 2.5 | 2.7 | 2.6 | 2.6 | |
| Max. (cm) | 6.9 | 6.2 | 6.6 | 6.9 | 6.6 | 6.6 | 6.9 | 7.0 | |
| Min. (cm) | −4.6 | −5.2 | −5.6 | −5.9 | −4.7 | −6.8 | −3.9 | −5.4 | |
| 2 | Length of Dataset (mile) | 33.87 | |||||||
| Estimated Length (mile) | 23.31 | 21.52 | 24.37 | 22.33 | 30.18 | 26.79 | 29.12 | 25.66 | |
| # of Comparisons | 176 | 204 | 190 | 204 | 218 | 222 | 215 | 219 | |
| Mean (cm) | −0.4 | −0.4 | −0.2 | −0.3 | −0.4 | −0.6 | −0.3 | −0.4 | |
| STD (cm) | 2.4 | 2.6 | 2.5 | 2.7 | 2.4 | 2.6 | 2.5 | 2.8 | |
| RMSE (cm) | 2.4 | 2.6 | 2.5 | 2.7 | 2.4 | 2.6 | 2.5 | 2.8 | |
| Max. (cm) | 6.7 | 6.5 | 6.5 | 6.5 | 4.9 | 6.8 | 6.9 | 6.9 | |
| Min. (cm) | −6.6 | −6.7 | −6.3 | −6.0 | −6.8 | −6.8 | −6.5 | −6.5 | |
| 3 | Length of Dataset (mile) | 15.29 | |||||||
| Estimated Length (mile) | 14.50 | 13.88 | 14.98 | 14.28 | 14.53 | 14.37 | 14.66 | 14.39 | |
| # of Comparisons | 196 | 181 | 204 | 192 | 200 | 192 | 203 | 193 | |
| Mean (cm) | 0.3 | 0.4 | 0.3 | 0.4 | 0.3 | 0.3 | 0.3 | 0.4 | |
| STD (cm) | 1.2 | 1.5 | 1.2 | 1.5 | 1.4 | 1.5 | 1.3 | 1.5 | |
| RMSE (cm) | 1.2 | 1.6 | 1.3 | 1.5 | 1.4 | 1.6 | 1.4 | 1.5 | |
| Max. (cm) | 3.5 | 5.0 | 3.7 | 4.8 | 3.9 | 6.6 | 6.5 | 4.8 | |
| Min. (cm) | −3.1 | −4.3 | −4.8 | −3.4 | −6.1 | −4.5 | −5.4 | −3.5 | |
| Dataset | Length of Dataset | Lane Marking | # of Long Gaps | Total Length of Long Gaps (ft) | Average Gap (ft/mile) |
|---|---|---|---|---|---|
| 1 | 18.04 mile | Left | 29 | 7431.8 (2265.2 m) | 412.0 |
| Center | 1 | 151.0 (46.0 m) | 8.4 | ||
| Right | 0 | 0.0 (0.0 m) | 0.0 | ||
| 2 | 33.87 mile | Left | 41 | 15,392.7 (4691.7 m) | 454.5 |
| Center | 14 | 3608.2 (1099.8 m) | 106.5 | ||
| Right | 0 | 0.0 (0.0 m) | 0.0 | ||
| 3 | 15.29 mile | Left | 16 | 3107.0 (947.0 m) | 203.2 |
| Center | 6 | 1136.7 (346.5 m) | 74.3 | ||
| Right | 0 | 0.0 (0.0 m) | 0.0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, Y.-T.; Patel, A.; Wen, C.; Bullock, D.; Habib, A. Intensity Thresholding and Deep Learning Based Lane Marking Extraction and Lane Width Estimation from Mobile Light Detection and Ranging (LiDAR) Point Clouds. Remote Sens. 2020, 12, 1379. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12091379
Cheng Y-T, Patel A, Wen C, Bullock D, Habib A. Intensity Thresholding and Deep Learning Based Lane Marking Extraction and Lane Width Estimation from Mobile Light Detection and Ranging (LiDAR) Point Clouds. Remote Sensing. 2020; 12(9):1379. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12091379
Chicago/Turabian StyleCheng, Yi-Ting, Ankit Patel, Chenglu Wen, Darcy Bullock, and Ayman Habib. 2020. "Intensity Thresholding and Deep Learning Based Lane Marking Extraction and Lane Width Estimation from Mobile Light Detection and Ranging (LiDAR) Point Clouds" Remote Sensing 12, no. 9: 1379. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12091379