A Deep Learning-Based Robust Change Detection Approach for Very High Resolution Remotely Sensed Images with Multiple Features

Abstract
:
1. Introduction
2. Methodology
2.1. Feature Space Construction
2.1.1. VGG Depth Feature
2.1.2. Object-Based Feature
2.1.3. Texture Feature
2.2. Constructing a Robust Difference Image
2.3. Change Detection Based on U-Net
3. Experiment
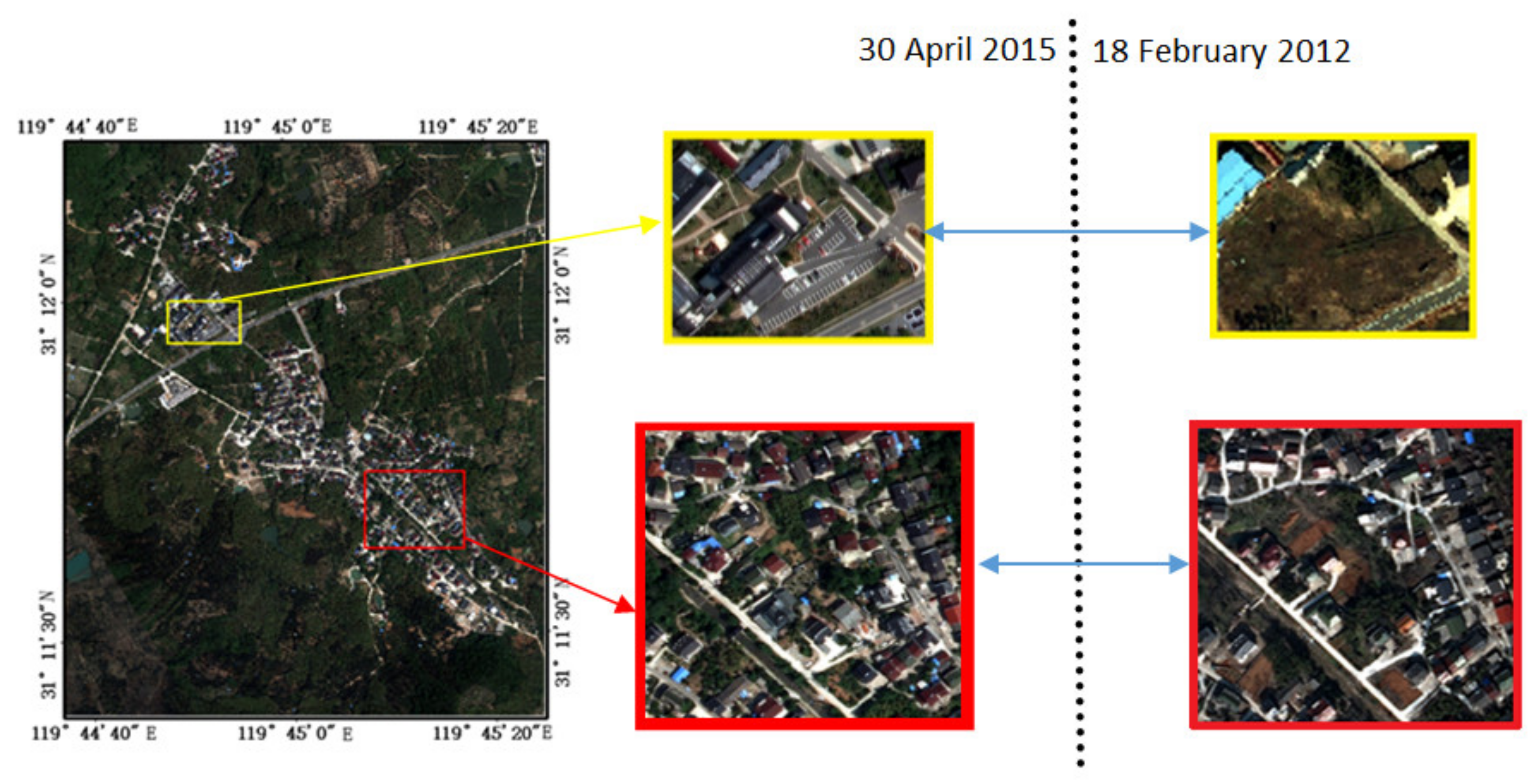
3.1. Data and Study Site
3.2. Feature Space Construction Experiment
3.3. Constructing the Difference Image
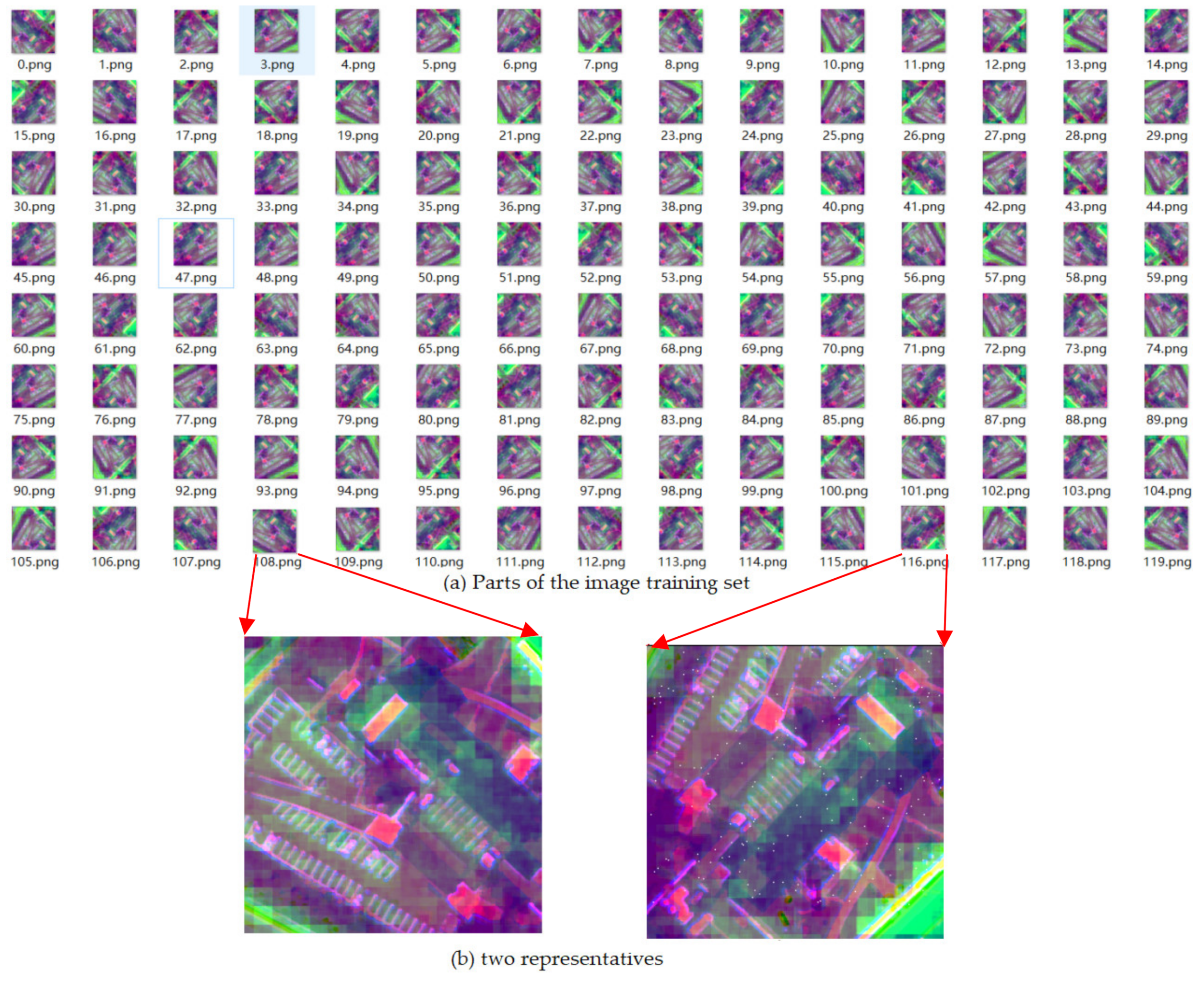
3.4. Constructing a Robust Training Set for U-Net
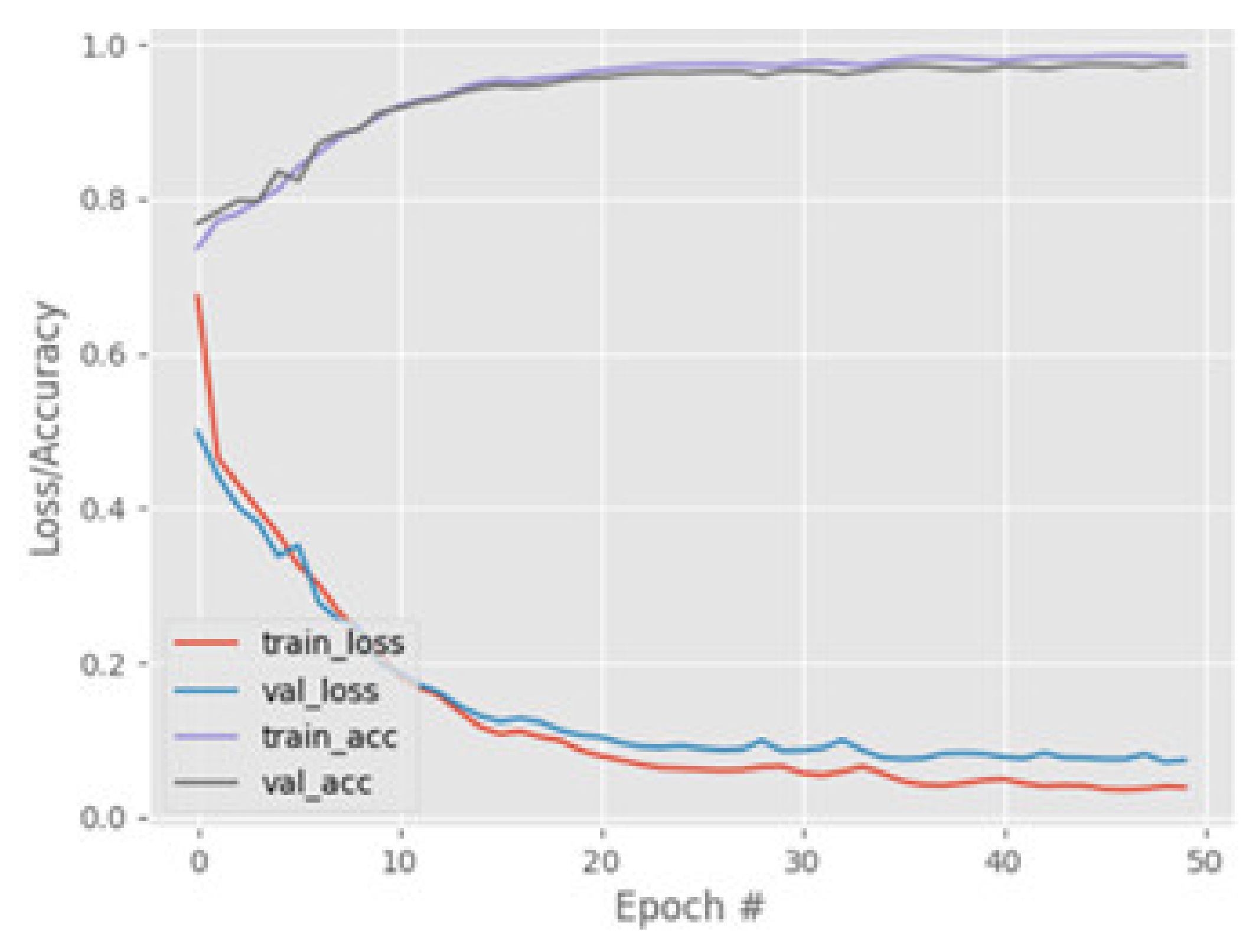
3.5. Model Training and Prediction Experiment
3.6. Model Working on the Expanded Experimental Area for Testing
3.7. Method Testing on Public Dataset Comparing with SVM and Siamese Network
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Du, P.J.; Liu, S.C. Change detection from multi-temporal remote sensing images by; integrating multiple features. J. Remote Sens. 2012, 16, 663–677. [Google Scholar]
- ZHANG, L.P.; WU, C. Advance and Future Development of Change Detection for multi-temporal Remote Sensing Imagery. Acta Geodaeticaet Cartographica Sinica 2017, 46, 1447–1459. [Google Scholar] [CrossRef]
- Xiao, P.; Zhang, X.; Wang, D.; Yuan, M.; Feng, X.; Kelly, M. Change detection of built-up land: A framework of combining pixel-based detection and object-based recognition. ISPRS J. Photogramm. 2016, 119, 402–414. [Google Scholar]
- Xiao, P.; Wang, X.; Feng, X.; Zhang, X.; Yang, Y. Detecting China’s Urban Expansion over the Past Three Decades Using Nighttime Light Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4095–4106. [Google Scholar] [CrossRef]
- Huang, J.; Liu, Y.; Wang, M.; Zheng, Y.; Wang, J.; Ming, D. Change Detection of High Spatial Resolution Images Based on Region-Line Primitive Association Analysis and Evidence Fusion. Remote Sens. 2019, 11, 2484. [Google Scholar] [CrossRef] [Green Version]
- Yan, J.; Wang, L.; Song, W.; Chen, Y.; Chen, X.; Deng, Z. A time-series classification approach based on change detection for rapid land cover mapping. ISPRS J. Photogramm. 2019, 158, 249–262. [Google Scholar] [CrossRef]
- Horch, A.; Djemal, K.; Gafour, A.; Taleb, N. Supervised fusion approach of local features extracted from SAR images for detecting deforestation changes. IET Image Process. 2019, 13, 2866–2876. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zheng, Z.; Liu, Y.; Zhao, J.; Ma, A.; Yang, J. Multi-Scale and Multi-Task Deep Learning Framework for Automatic Road Extraction. IEEE T. Geosci. Remote. 2019, 57, 9362–9377. [Google Scholar] [CrossRef]
- Thonfeld, F.; Feilhauer, H.; Braun, M.; Menz, G. Robust Change Vector Analysis (RCVA) for multi-sensor very high resolution optical satellite data. Int. J. Appl. Earth Obs. 2016, 50, 131–140. [Google Scholar] [CrossRef]
- Zhang, X.L.; Chen, X.W.; Li, F.; Yang, T. Change Detection Method for High Resolution Remote Sensing Images Using Deep Learning. Acta Geodaetica Cartographica Sinica 2017, 46, 999–1008. [Google Scholar]
- Li, K.; Shi, D.; Zhang, Y.; Li, R.; Qin, W.; Li, R. Feature Tracking Based on Line Segments With the Dynamic and Active-Pixel Vision Sensor (DAVIS). IEEE Access 2019, 7, 110874–110883. [Google Scholar] [CrossRef]
- Neagoe, V.; Ciotec, A.; Carata, S. A new multispectral pixel change detection approach using pulse-coupled neural networks for change vector analysis. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 3386–3389. [Google Scholar]
- Zhao, J. Research on change detection method in multi-temporal polarimetric SAR imagery. Acta Geodetica Cartographica Sinica 2019, 48, 536. [Google Scholar]
- AL-Alimi, D.; Shao, Y.; Feng, R.; Al-qaness, M.A.A.; Abd Elaziz, M.; Kim, S. Multi-Scale Geospatial Object Detection Based on Shallow-Deep Feature Extraction. Remote Sens. 2019, 11, 2525. [Google Scholar] [CrossRef] [Green Version]
- Mei, S.; Fan, C.; Liao, Y.; Li, Y.; Shi, Y.; Mai, C. Forestland change detection based on spectral and texture features. Bull. Surv. Mapp. 2019, 140–143. [Google Scholar] [CrossRef]
- Song, F.; Yang, Z.; Gao, X.; Dan, T.; Yang, Y.; Zhao, W.; Yu, R. Multi-Scale Feature Based Land Cover Change Detection in Mountainous Terrain Using Multi-Temporal and Multi-Sensor Remote Sensing Images. IEEE Access 2018, 6, 77494–77508. [Google Scholar] [CrossRef]
- Zhao, S.Y.; An, R.; Zhu, M.R. Urban change detection by aerial remotesensing using combining features of pixel-depth-object. Acta Geodaetica Cartographica Sinica 2019, 48, 1452–1463. [Google Scholar]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef]
- Long, F. Microscopy cell nuclei segmentation with enhanced U-Net. BMC Bioinf. 2020, 21, 8. [Google Scholar] [CrossRef]
- Li, L.; Wang, C.; Zhang, H.; Zhang, B.; Wu, F. Urban Building Change Detection in SAR Images Using Combined Differential Image and Residual U-Net Network. Remote Sens. 2019, 11, 1091. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Z.; Cao, J.; Lv, Z.; Benediktsson, J.A. Spatial-Spectral Feature Fusion Coupled with Multi-Scale Segmentation Voting Decision for Detecting Land Cover Change with VHR Remote Sensing Images. Remote Sens. 2019, 11, 190316. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Lecture Notes in Computer Science; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Yang, G.; Yu, S.; Dong, H.; Slabaugh, G.; Dragotti, P.L.; Ye, X.; Liu, F.; Arridge, S.; Keegan, J.; Guo, Y.; et al. DAGAN: Deep De-Aliasing Generative Adversarial Networks for Fast Compressed Sensing MRI Reconstruction. IEEE T. Med. Imaging 2018, 37, 1310–1321. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Falk, T.; Mai, D.; Bensch, R.; Cicek, O.; Abdulkadir, A.; Marrakchi, Y.; Boehm, A.; Deubner, J.; Jaeckel, Z.; Seiwald, K.; et al. U-Net: Deep learning for cell counting, detection, and morphometry. Nat. Methods 2019, 16, 67. [Google Scholar] [CrossRef] [PubMed]
- Cheng, B.; Liang, C.; Liu, X.; Liu, Y.; Ma, X.; Wang, G. Research on a novel extraction method using Deep Learning based on GF-2 images for aquaculture areas. Int. J. Remote Sens. 2020, 41, 3575–3591. [Google Scholar] [CrossRef]
- Wen, C.; Sun, X.; Li, J.; Wang, C.; Guo, Y.; Habib, A. A deep learning framework for road marking extraction, classification and completion from mobile laser scanning point clouds. ISPRS J. Photogramm. 2019, 147, 178–192. [Google Scholar] [CrossRef]
- Dalmis, M.U.; Litjens, G.; Holland, K.; Setio, A.; Mann, R.; Karssemeijer, N.; Gubern-Merida, A. Using deep learning to segment breast and fibroglandular tissue in MRI volumes. Med. Phys. 2017, 44, 533–546. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Automat. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Yao, W.; Zeng, Z.; Lian, C.; Tang, H. Pixel-wise regression using U-Net and its application on pansharpening. Neurocomputing 2018, 312, 364–371. [Google Scholar] [CrossRef]
- Yang, M.; Jiao, L.; Liu, F.; Hou, B.; Yang, S. Transferred Deep Learning-Based Change Detection in Remote Sensing Images. IEEE T. Geosci. Remote. 2019, 57, 6960–6973. [Google Scholar] [CrossRef]
- Rundo, L.; Han, C.; Nagano, Y.; Zhang, J.; Hataya, R.; Militello, C.; Tangherloni, A.; Nobile, M.S.; Ferretti, C.; Besozzi, D.; et al. USE-Net: Incorporating Squeeze-and-Excitation blocks into U-Net for prostate zonal segmentation of multi-institutional MRI datasets. Neurocomputing 2019, 365, 31–43. [Google Scholar] [CrossRef] [Green Version]
- Debayle, J.; Pinoli, J. General Adaptive Neighborhood Viscous Mathematical Morphology. In Lecture Notes in Computer Science; Soille, P., Pesaresi, M., Ouzounis, G.K., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6671, pp. 224–235. [Google Scholar]
- Pinoli, J.; Debayle, J. Adaptive generalized metrics, distance maps and nearest neighbor transforms on gray tone images. Pattern Recogn. 2012, 45, 2758–2768. [Google Scholar] [CrossRef]
- Pinoli, J.; Debayle, J. Spatially and Intensity Adaptive Morphology. IEEE J. Sel. Top. Signal Process. 2012, 6, 820–829. [Google Scholar] [CrossRef]
- Debayle, J.; Gavet, Y.; Pinoli, J. General adaptive neighborhood image restoration, enhancement and segmentation. In Lecture Notes in Computer Science; Campilho, A., Kamel, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4141, pp. 29–40. [Google Scholar]
- Debayle, J.; Pinoli, J. General Adaptive Neighborhood-Based Pretopological Image Filtering. J. Math. Imaging Vis. 2011, 41, 210–221. [Google Scholar] [CrossRef]
- Pinoli, J.; Debayle, J. General Adaptive Neighborhood Mathematical Morphology. In Proceedings of the 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 2249–2252. [Google Scholar]
- Gonzalez-Castro, V.; Debayle, J.; Pinoli, J. Color Adaptive Neighborhood Mathematical Morphology and its application to pixel-level classification. Pattern Recogn. Lett. 2014, 47, 50–62. [Google Scholar] [CrossRef] [Green Version]
- Fouladivanda, M.; Kazemi, K.; Helfroush, M.S. Adaptive Morphology Active Contour for Image Segmentation. In Proceedings of the 24th Iranian Conference on Electrical Engineering (ICEE), Shiraz, Iran, 10–12 May 2016; pp. 960–965. [Google Scholar]
- Das, A.; Rangayyan, R.M. Adaptive region-based filtering of multiplicative noise. In Nonlinear Image Processing VIII; Dougherty, E.R., Astola, J.T., Eds.; The Society of Photo-Optical Instrumentation Engineers (SPIE): Bellingham, WA, USA, 1997; Volume 3026, pp. 338–348. [Google Scholar]
- Debayle, J.; Pinoli, J. General adaptive neighborhood image processing: Part I: Introduction and theoretical aspects. J. Math. Imaging Vis. 2006, 25, 245–266. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Bruzzone, L.; Zhu, X.X. Learning Spectral-Spatial-Temporal Features via a Recurrent Convolutional Neural Network for Change Detection in Multispectral Imagery. IEEE T. Geosci. Remote 2019, 57, 924–935. [Google Scholar] [CrossRef] [Green Version]
- Dong, Y.; Wang, F. Change Detection of Remote Sensing Imagery Supported by KCCA and SVM Algorithms. Remote Sens. Inf. 2019, 34, 144–148. [Google Scholar]
- Dunnhofer, M.; Antico, M.; Sasazawa, F.; Takeda, Y.; Camps, S.; Martinel, N.; Micheloni, C.; Carneiro, G.; Fontanarosa, D. Siam-U-Net: Encoder-decoder siamese network for knee cartilage tracking in ultrasound images. Med. Image Anal. 2019, 60, 101631. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Commission (Percent) | Omission (Percent) | Commission (Pixels) | Omission (Pixels) | Overall Accuracy % | Kappa |
|---|---|---|---|---|---|---|
| No-change | 7.29 | 15.87 | 3437/47,172 | 8247/51,982 | 92.3205 | 0.8254 |
| Change | 7.86 | 3.43 | 8247/104,973 | 3437/100,163 |
| Predict\Ground Truth (Pixels) | Change (Pixels) | No-Change (Pixels) | The Total (Pixels) | Overall Accuracy (Percent) | Commission (Percent) | Omission (Percent) | Kappa |
|---|---|---|---|---|---|---|---|
| Change | 195159 | 61894 | 257053 | 83.36 | 24.08 | 7.17 | 0.67047 |
| No-change | 15066 | 190277 | 205343 | ||||
| Total | 210225 | 252171 | 462396 |
| Method | Overall Accuracy % | Omission % | Commission % | Kappa |
|---|---|---|---|---|
| SVM | 79.44 | 11.4 | 29 | 0.5703 |
| Siamese Network | 92.04 | 21.03 | 24.42 | 0.7429 |
| This paper’s method | 93.68 | 16 | 4.578 | 0.7634 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, L.; An, R.; Zhao, S.; Jiang, T.; Hu, H. A Deep Learning-Based Robust Change Detection Approach for Very High Resolution Remotely Sensed Images with Multiple Features. Remote Sens. 2020, 12, 1441. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12091441
Huang L, An R, Zhao S, Jiang T, Hu H. A Deep Learning-Based Robust Change Detection Approach for Very High Resolution Remotely Sensed Images with Multiple Features. Remote Sensing. 2020; 12(9):1441. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12091441
Chicago/Turabian StyleHuang, Lijun, Ru An, Shengyin Zhao, Tong Jiang, and Hao Hu. 2020. "A Deep Learning-Based Robust Change Detection Approach for Very High Resolution Remotely Sensed Images with Multiple Features" Remote Sensing 12, no. 9: 1441. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12091441