A Spatial-Channel Collaborative Attention Network for Enhancement of Multiresolution Classification

 and
and
Abstract
:1. Introduction
2. Related Work
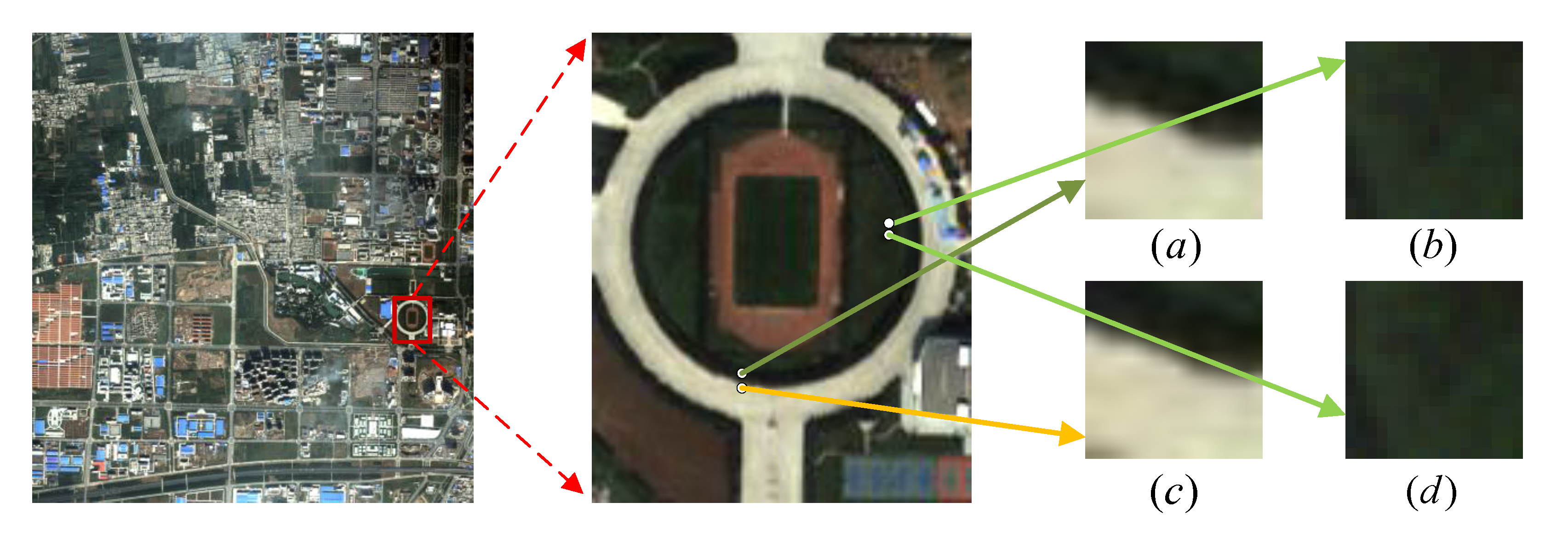
2.1. Sampling Strategy
2.2. Attention Module
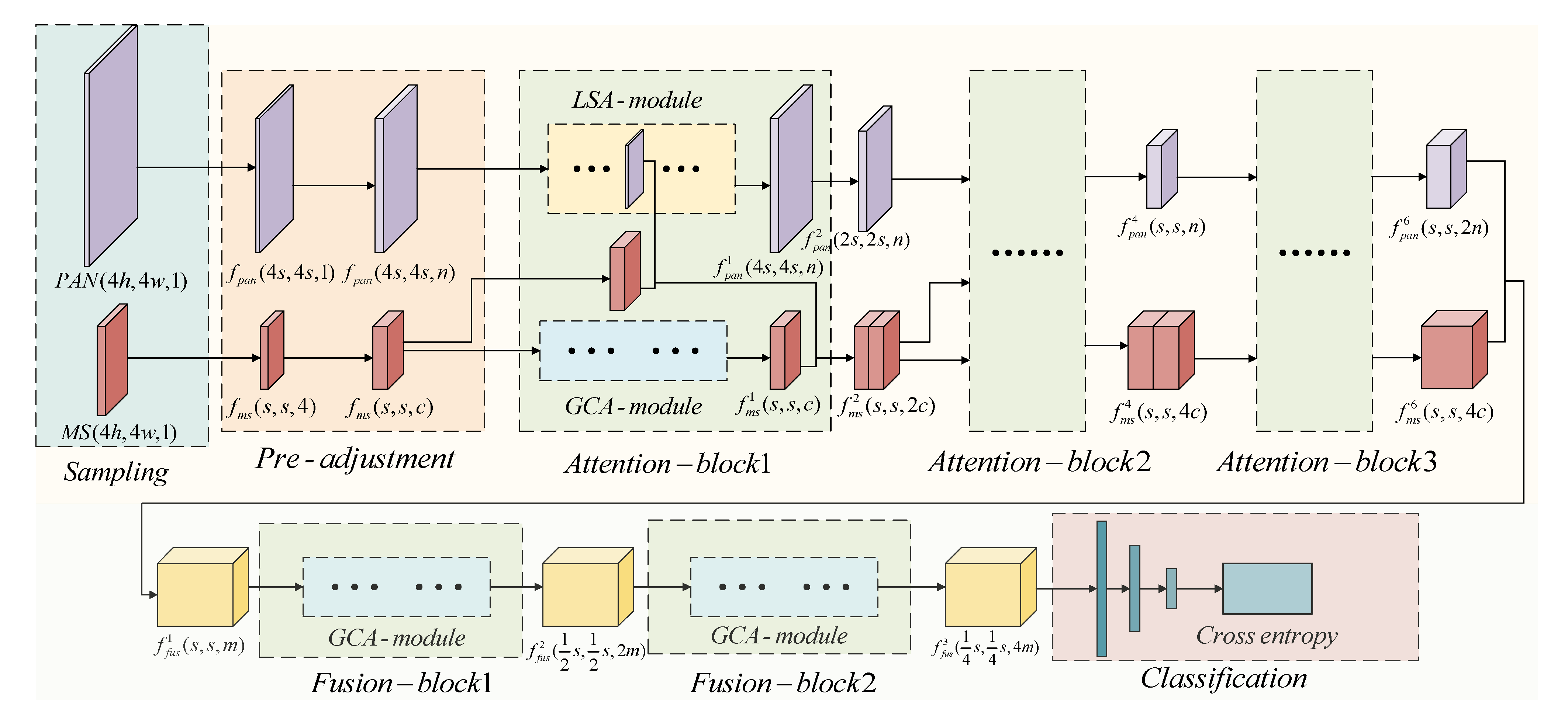
3. Methodology
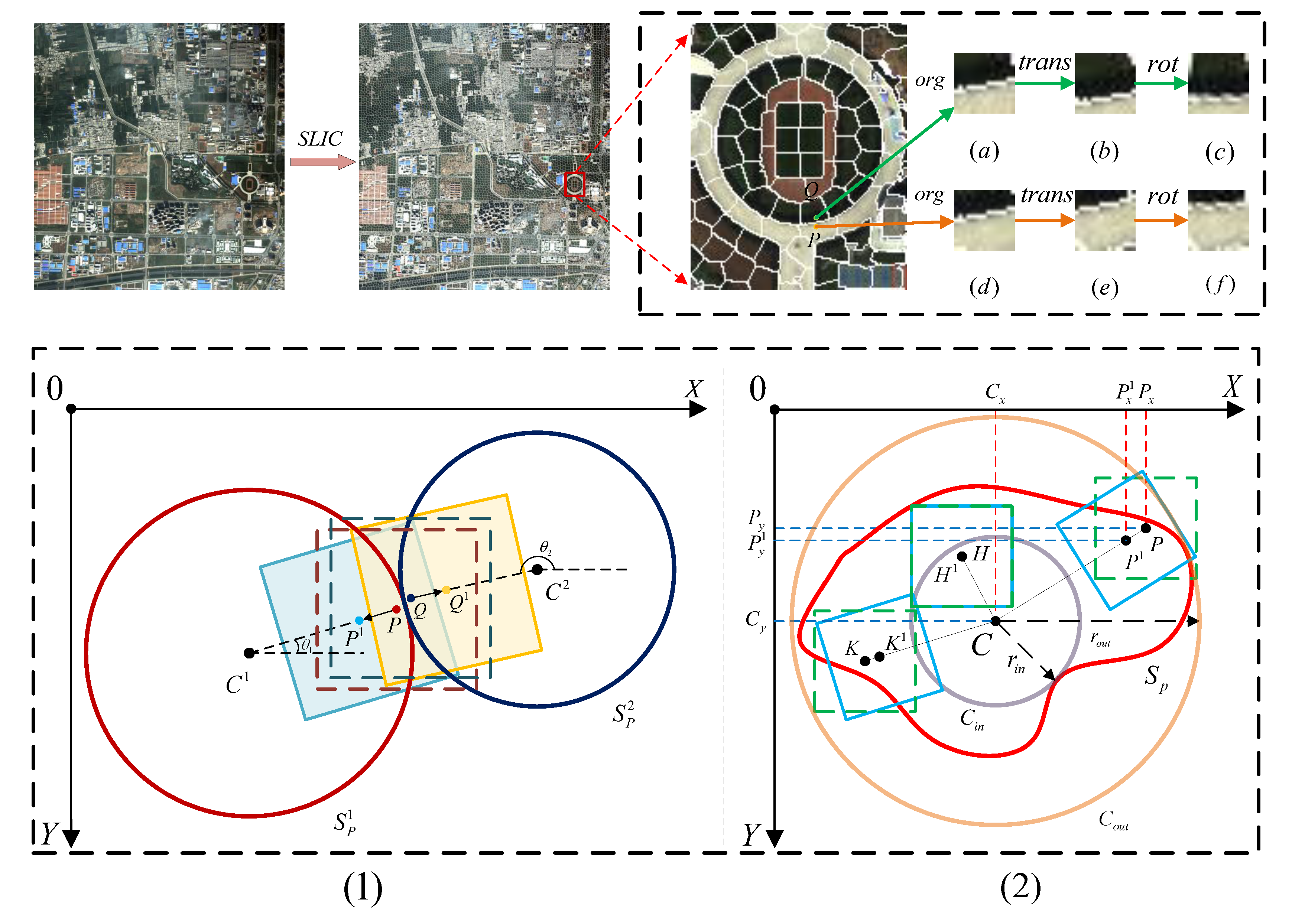
3.1. Adaptive Neighborhood Transfer Sampling Strategy
3.2. Spatial Attention Module and Channel Attention Module
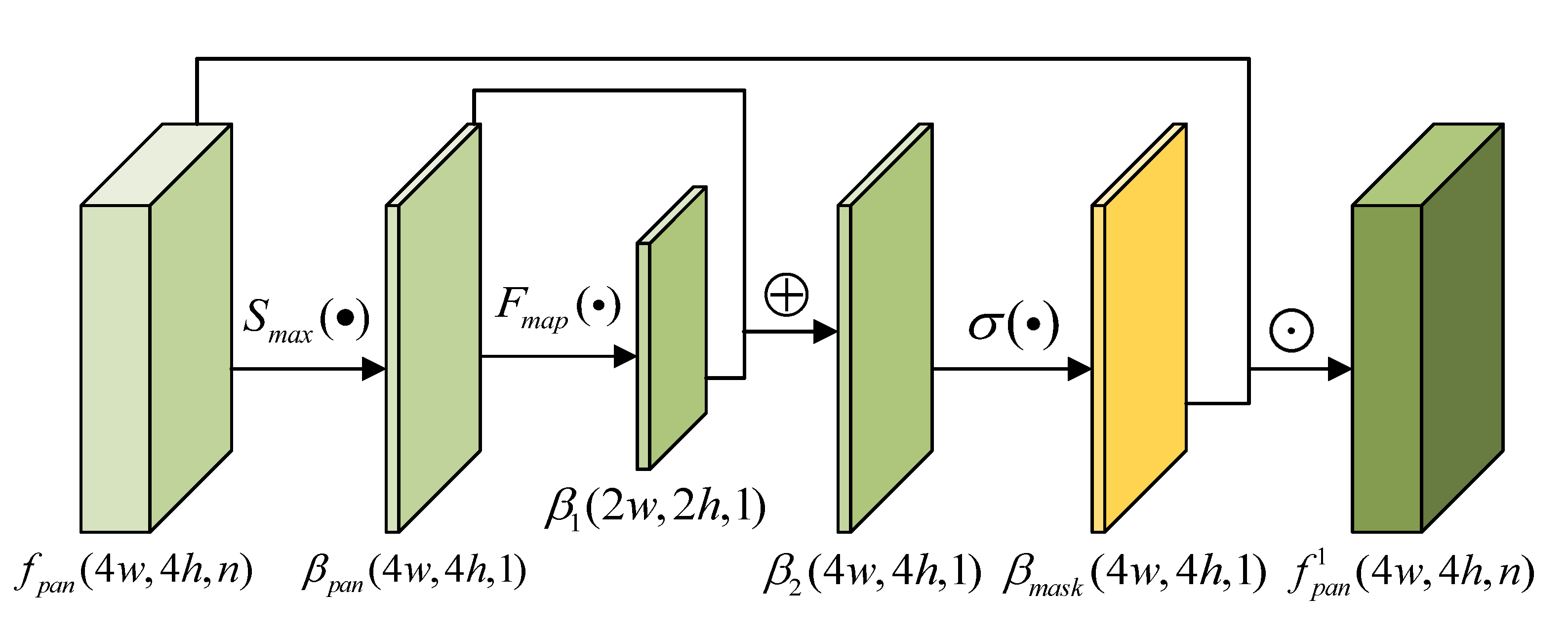
3.2.1. Spatial Attention Module
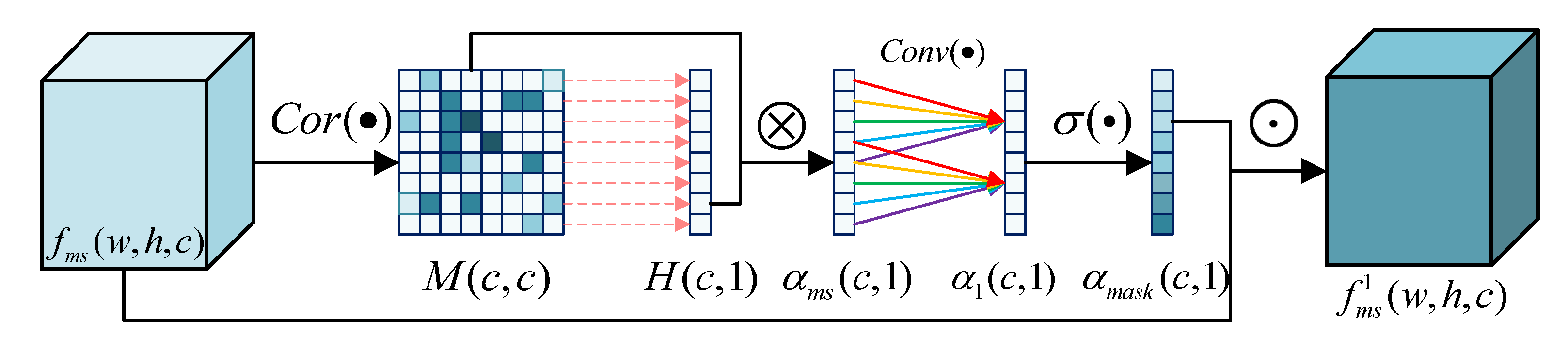
3.2.2. Channel Attention Module
3.3. A Spatial-Channel Collaborative Attention Network (SCCA-Net)
4. Experimental Study
4.1. Data Description
4.2. Experimental Setup
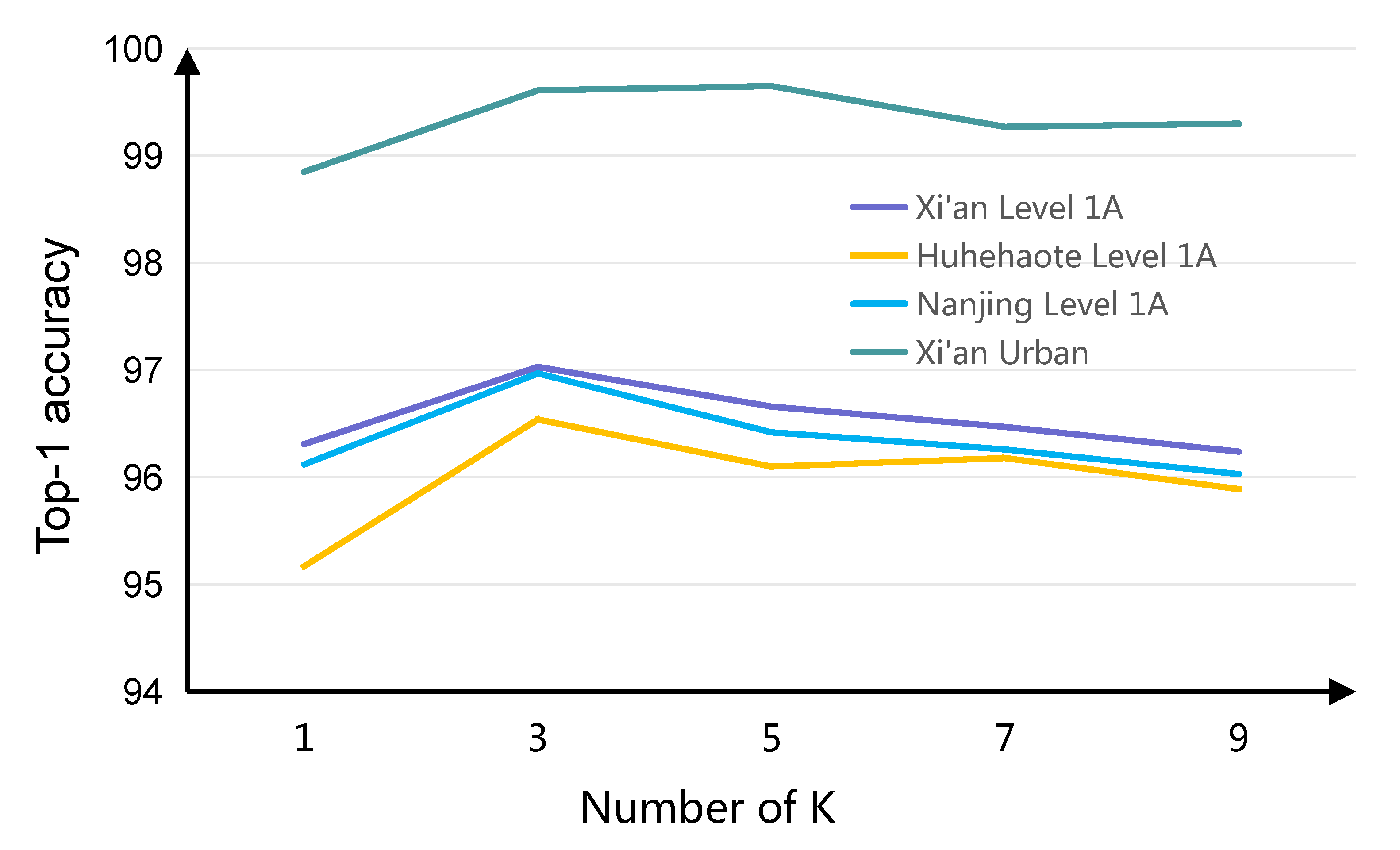
4.3. The Comparison and Analysis of Hyper-Parameters
Effect of Kernel Size Selection
4.4. Performance of The Proposed Sampling Strategy and Attention Module
4.4.1. Validation of the Proposed Adaptive Neighborhood Transfer Sampling Strategy (ANTSS) Performance
4.4.2. Validation of the Proposed Spatial-Channel Cooperative Attention Network (SCCA-Net) Performance
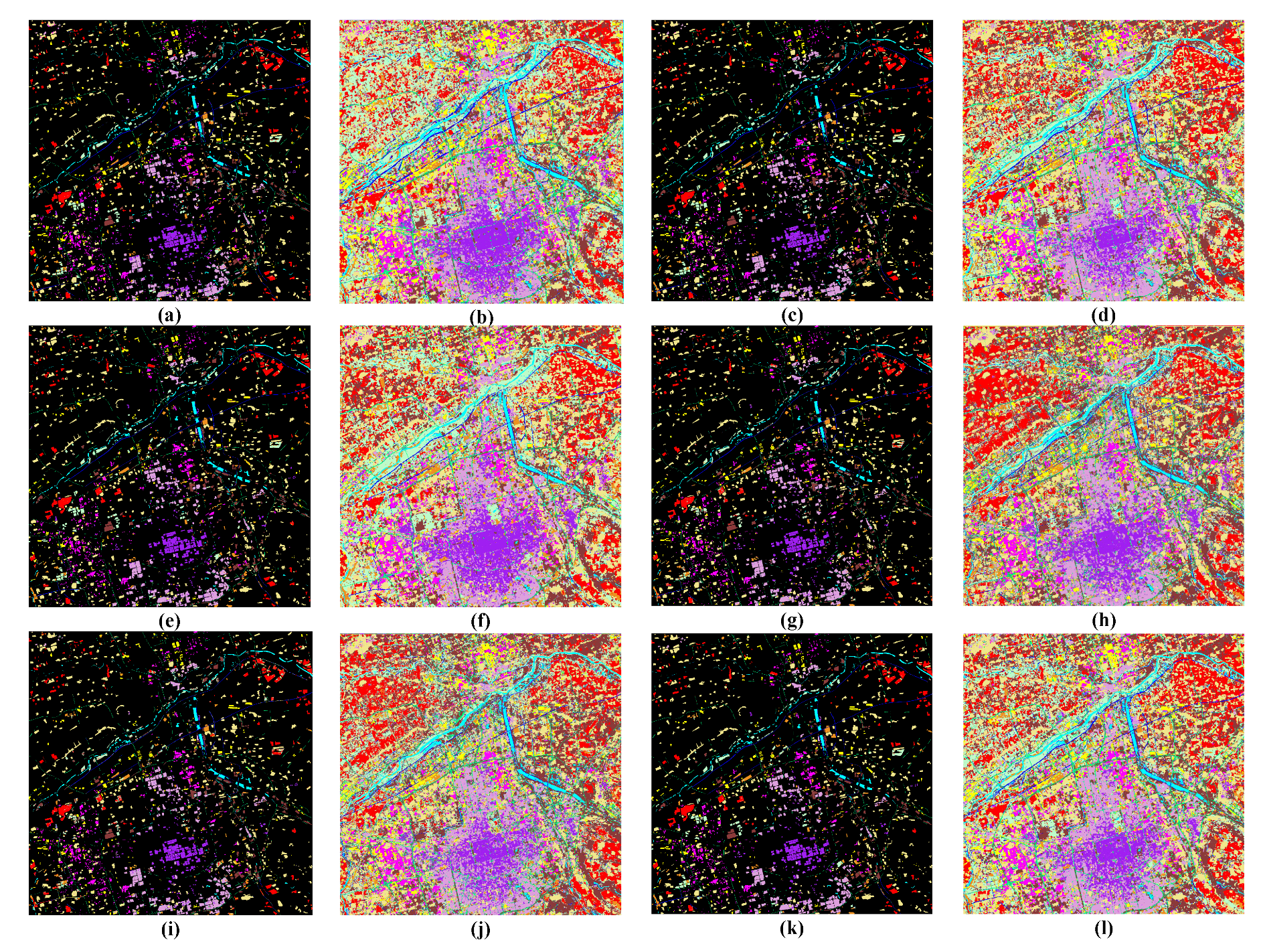
4.5. Performance of Experimental Results and Comparison Algorithm
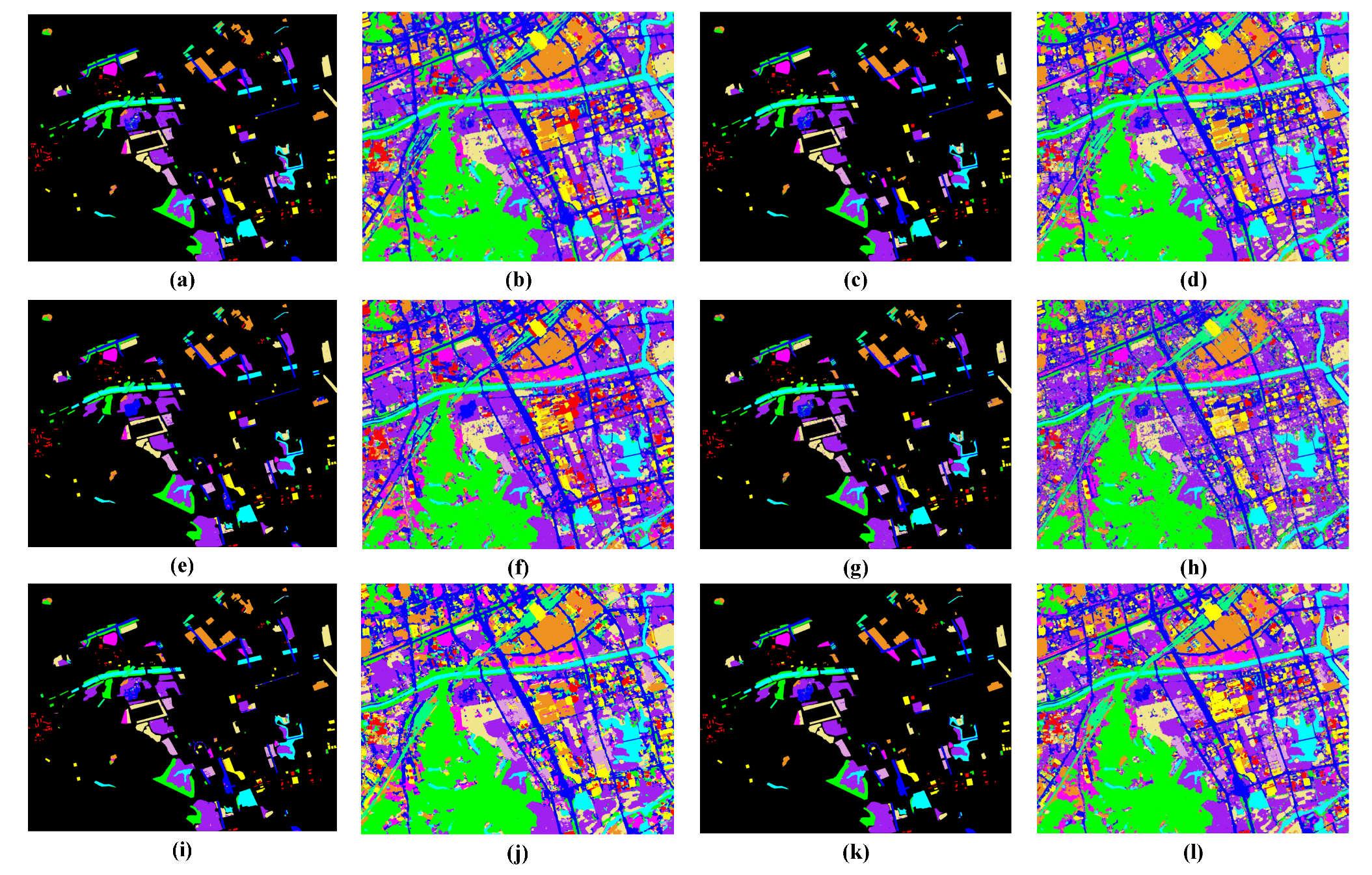
4.5.1. Experimental Results with Xi’an Level 1A Images
4.5.2. Experimental Results with Huhehaote Level 1A Images
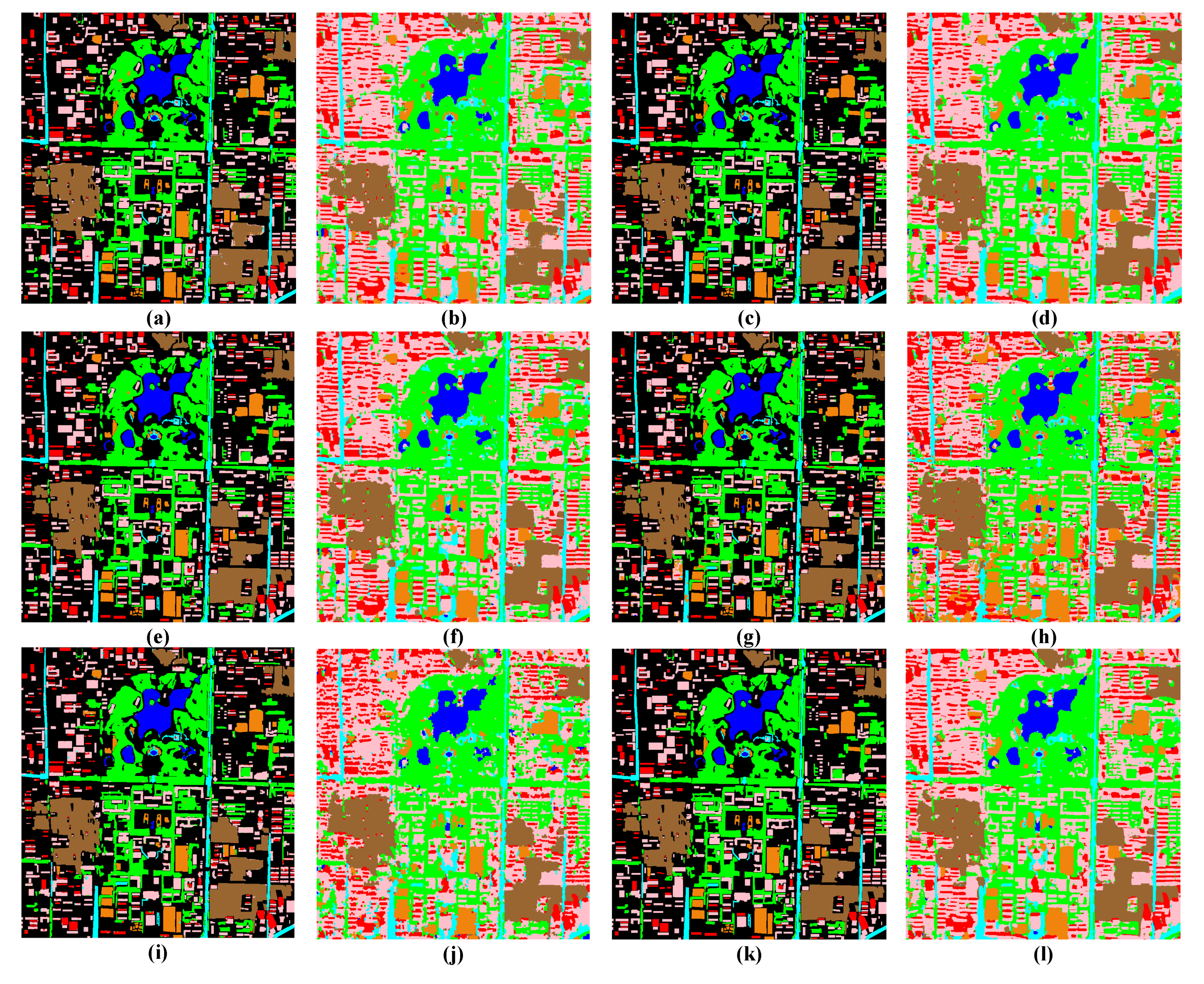
4.5.3. Experimental Results with Nanjing Level 1A Images
4.5.4. Experimental Results with Xi’an Urban Images
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nunez, J.; Otazu, X.; Fors, O.; Prades, A.; Pala, V.; Arbiol, R. Multiresolution-based image fusion with additive wavelet decomposition. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1204–1211. [Google Scholar] [CrossRef] [Green Version]
- Jia, X.; Richards, J.A. Cluster-space representation for hyperspectral data classification. IEEE Trans. Geosci. Remote Sens. 2002, 40, 593–598. [Google Scholar]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion:A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Israa, A.; Javier, M.; Miguel, V.; Rafael, M.; Katsaggelos, A. A survey of classical methods and new trends in pansharpening of multispectral images. EURASIP J. Adv. Signal Process. 2011, 1, 79. [Google Scholar]
- Giuseppe, M.; Davide, C.; Luisa, V.; Giuseppe, S. Pansharpening by Convolutional Neural Networks. Remote Sens. 2016, 8, 594. [Google Scholar]
- Zhong, J.; Yang, B.; Huang, G.; Zhong, F.; Chen, Z. Remote Sensing Image Fusion with Convolutional Neural Network. Sens. Imaging 2016, 17, 10. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.; Jane, K.W.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Shackelford, A.K.; Davis, C.H. A hierarchical fuzzy classification approach for high-resolution multispectral data over urban areas. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1920–1932. [Google Scholar] [CrossRef] [Green Version]
- Moser, G.; Serpico, S.B. Joint classification of panchromatic and multispectral images by multiresolution fusion through Markov random fields and graph cuts. In Proceedings of the 2011 17th International Conference on Digital Signal Processing (DSP), Corfu, Greece, 6–8 July 2011; pp. 1–8. [Google Scholar]
- Pham, M.; Mercier, G.; Michel, J. Pointwise Graph-Based Local Texture Characterization for Very High Resolution Multispectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1962–1973. [Google Scholar] [CrossRef]
- Moser, G.; De Giorgi, A.; Serpico, S.B. Multiresolution Supervised Classification of Panchromatic and Multispectral Images by Markov Random Fields and Graph Cuts. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5054–5070. [Google Scholar] [CrossRef]
- Zhang, J.; Li, T.; Lu, X.; Cheng, Z. Semantic Classification of High-Resolution Remote-Sensing Images Based on Mid-level Features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2343–2353. [Google Scholar] [CrossRef]
- Mao, T.; Tang, H.; Wu, J.; Jiang, W.; He, S.; Shu, Y. A Generalized Metaphor of Chinese Restaurant Franchise to Fusing Both Panchromatic and Multispectral Images for Unsupervised Classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4594–4604. [Google Scholar] [CrossRef]
- Thomas, C.; Ranchin, T.; Wald, L.; Chanussot, J. Synthesis of Multispectral Images to High Spatial Resolution: A Critical Review of Fusion Methods Based on Remote Sensing Physics. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1301–1312. [Google Scholar] [CrossRef] [Green Version]
- Tu, T.; Su, S.; Shyu, H.; Huang, P.S. A new look at IHS-like image fusion methods. Inf. Fusion 2001, 2, 177–186. [Google Scholar] [CrossRef]
- Tu, T.; Huang, P.S.; Hung, C.; Chang, C. A fast intensity-hue-saturation fusion technique with spectral adjustment for IKONOS imagery. IEEE Geosci. Remote Sens. Lett. 2004, 1, 309–312. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.H.; Geladi, P. Principal Component Analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Candes Emmanuel, J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis. J. ACM 2011, 58, 11. [Google Scholar]
- Huang, F.; Yan, L. Study on the Hyperspectral Image Fusion Based on the Gram Schmidt Improved Algorithm. Inf. Technol. J. 2013, 12, 6694–6701. [Google Scholar] [CrossRef]
- Pradhan, P.S.; King, R.L.; Younan, N.H.; Holcomb, D.W. Estimation of the Number of Decomposition Levels for a Wavelet-Based Multiresolution Multisensor Image Fusion. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3674–3686. [Google Scholar] [CrossRef]
- Zheng, S.; Shi, W.; Liu, J.; Tian, J. Remote Sensing Image Fusion Using Multiscale Mapped LS-SVM. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1313–1322. [Google Scholar] [CrossRef]
- Yang, S.; Wang, M.; Jiao, L. Fusion of multispectral and panchromatic images based on support value transform and adaptive principal component analysis. Inf. Fusion 2012, 13, 177–184. [Google Scholar] [CrossRef]
- Vivone, G.; Alparone, L.; Chanussot, J.; Dalla Mura, M.; Garzelli, A.; Licciardi, G.; Restaino, R.; Wald, L. A Critical Comparison Among Pansharpening Algorithms. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2565–2586. [Google Scholar] [CrossRef]
- Liu, X.; Jiao, L.; Zhao, J.; Zhao, J.; Zhang, D.; Liu, F.; Yang, S.; Tang, X. Deep Multiple Instance Learning-Based Spatial Spectral Classification for PAN and MS Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 461–473. [Google Scholar] [CrossRef]
- Zhao, W.; Jiao, L.; Ma, W.; Zhao, J.; Zhao, J.; Liu, H.; Cao, X.; Yang, S. Superpixel-Based Multiple Local CNN for Panchromatic and Multispectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4141–4156. [Google Scholar] [CrossRef]
- Ma, W.; Zhang, J.; Wu, Y.; Jiao, L.; Zhu, H.; Zhao, W. A Novel Two-Step Registration Method for Remote Sensing Images Based on Deep and Local Features. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4834–4843. [Google Scholar] [CrossRef]
- Zhu, H.; Ma, W.; Li, L.; Jiao, L.; Yang, S.; Hou, B. A Dual Branch Attention fusion deep network for multiresolution remote Sensing image classification. Inf. Fusion 2020, 58, 116–131. [Google Scholar] [CrossRef]
- Bergado, J.R.; Persello, C.; Stein, A. Recurrent Multiresolution Convolutional Networks for VHR Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6361–6374. [Google Scholar] [CrossRef] [Green Version]
- Zhu, H.; Jiao, L.; Ma, W.; Liu, F.; Zhao, W. A Novel Neural Network for Remote Sensing Image Matching. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2853–2865. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze and Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Carrasco, M. Visual attention: The past 25 years. Vis. Res. 2011, 51, 1484–1525. [Google Scholar] [CrossRef] [Green Version]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Beuth, F.; Hamker, F.H. A mechanistic cortical microcircuit of attention for amplification, normalization and suppression. Vis. Res. 2015, 116, 241–257. [Google Scholar] [CrossRef] [PubMed]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global Second Order Pooling Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Recalibrating Fully Convolutional Networks With Spatial and Channel `Squeeze and Excitation’ Blocks. IEEE Trans. Med. Imaging 2019, 38, 540–549. [Google Scholar] [CrossRef] [PubMed]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 3146–3154. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 603–612. [Google Scholar]
- Huang, G.; Liu, Z.; Der Maaten, L.V.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference On Computer Vision And Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Input | PAN | MS | Output |
|---|---|---|---|---|
() | () | |||
() | () | |||
() | () | |||
() | () | |||
| Sampling Strategies | Pixel-Centric | SML-SS | ACO-SS | ANTSS | |
|---|---|---|---|---|---|
| 97.73 | 95.76 | 98.11 | 99.36 | 99.45 | |
| 97.62 | 97.29 | 99.91 | 99.47 | 99.32 | |
| 96.74 | 94.25 | 99.90 | 99.14 | 98.74 | |
| 95.88 | 95.73 | 99.29 | 99.44 | 99.07 | |
| 97.98 | 98.42 | 99.81 | 99.83 | 99.65 | |
| 97.85 | 97.66 | 98.43 | 99.66 | 99.52 | |
| 98.54 | 96.35 | 99.61 | 99.64 | 99.46 | |
| OA(%) | 97.67 | 96.73 | 99.08 | 99.56 | 99.41 |
| AA(%) | 97.48 | 96.21 | 99.29 | 99.51 | 99.32 |
| Kappa(%) | 97.28 | 94.12 | 98.88 | 99.44 | 99.28 |
| Network Models | SE-Net | CBAM-Net | LSA-Net | GCA-Net | SCCA-Net |
|---|---|---|---|---|---|
| 96.83 | 99.16 | 99.50 | 99.55 | 99.50 | |
| 94.94 | 99.47 | 99.71 | 99.76 | 99.74 | |
| 97.94 | 98.90 | 98.65 | 98.67 | 99.13 | |
| 93.42 | 99.13 | 98.83 | 98.90 | 99.08 | |
| 99.90 | 99.63 | 99.79 | 99.72 | 99.89 | |
| 98.86 | 99.47 | 99.14 | 99.15 | 99.69 | |
| 98.01 | 98.40 | 99.77 | 99.55 | 99.64 | |
| OA(%) | 97.85 | 99.16 | 99.38 | 99.41 | 99.61 |
| AA(%) | 97.13 | 99.10 | 99.35 | 99.28 | 99.52 |
| Kappa(%) | 97.22 | 99.03 | 99.33 | 99.36 | 99.50 |
| Methods | Pixel-Centric (S = 32) +SE-Net | ANTSS (S = 32) +SE-Net | ANTSS (S = 32) +CBAM-Net | ACO-SS (S = 12, 16, 24) +DBFA-Net | DMIL (S = 16) | SML-CNN (S = 16) | ANTSS (S = 32) +SCCA-Net |
|---|---|---|---|---|---|---|---|
| 97.23 | 97.27 | 97.92 | 98.78 | 97.94 | 97.90 | 98.75 | |
| 88.41 | 90.76 | 94.88 | 98.41 | 83.86 | 81.5 | 97.01 | |
| 92.33 | 93.74 | 95.97 | 92.92 | 85.48 | 86.68 | 96.33 | |
| 86.70 | 89.33 | 93.31 | 92.04 | 76.93 | 87.89 | 97.78 | |
| 81.65 | 88.62 | 88.81 | 85.31 | 76.10 | 83.34 | 89.56 | |
| 91.38 | 93.78 | 95.89 | 99.08 | 90.49 | 93.66 | 99.28 | |
| 96.06 | 96.37 | 96.75 | 97.85 | 88.83 | 94.60 | 96.30 | |
| 85.47 | 88.66 | 91.24 | 94.52 | 91.00 | 90.42 | 99.79 | |
| 90.80 | 92.73 | 94.13 | 98.61 | 96.33 | 92.94 | 96.55 | |
| 97.66 | 97.23 | 97.90 | 95.76 | 97.83 | 95.96 | 99.53 | |
| 95.21 | 96.86 | 98.11 | 96.84 | 96.82 | 98.10 | 96.79 | |
| 89.04 | 92.71 | 93.49 | 98.12 | 92.35 | 92.95 | 96.74 | |
| OA(%) | 92.89 | 94.32 | 95.35 | 95.91 | 91.91 | 92.88 | 97.13 |
| AA(%) | 92.09 | 93.71 | 94.51 | 95.69 | 89.50 | 91.34 | 96.53 |
| Kappa(%) | 91.71 | 93.15 | 94.17 | 94.70 | 90.82 | 91.92 | 96.74 |
| Test Time(s) | 600.70 | 721.41 | 857.16 | 1125.78 | 900.56 | 702.96 | 2061.31 |
| Methods | Pixel-Centric+ (S = 32) +SE-Net | ANSS+ (S = 32) +SE-Net | ANTSS (S = 32) +CBAM-Net | ACO-SS+ (S = 12, 16, 24) +DBFA-Net | DMIL (S = 16) | SML-CNN (S = 16) | ANSS+ (S = 32) +SCCA-Net |
|---|---|---|---|---|---|---|---|
| 98.48 | 99.34 | 99.28 | 99.21 | 95.61 | 99.18 | 98.84 | |
| 88.11 | 90.36 | 94.02 | 92.24 | 91.25 | 91.04 | 94.72 | |
| 91.31 | 94.45 | 96.01 | 94.04 | 92.53 | 93.14 | 95.37 | |
| 92.12 | 95.13 | 95.43 | 97.60 | 92.35 | 91.59 | 96.24 | |
| 90.41 | 94.28 | 94.82 | 99.97 | 91.91 | 92.74 | 98.09 | |
| 94.69 | 95.98 | 95.64 | 91.14 | 92.40 | 94.72 | 96.12 | |
| 90.88 | 95.76 | 97.17 | 96.11 | 97.21 | 91.37 | 98.84 | |
| 89.61 | 89.42 | 96.97 | 96.42 | 98.30 | 95.48 | 96.57 | |
| 88.70 | 92.69 | 95.14 | 92.60 | 92.15 | 93.41 | 97.63 | |
| 94.49 | 93.81 | 95.47 | 92.27 | 84.09 | 92.99 | 96.93 | |
| 93.45 | 94.37 | 93.73 | 97.51 | 92.38 | 88.82 | 98.11 | |
| OA(%) | 92.20 | 94.78 | 95.62 | 94.80 | 92.60 | 93.20 | 96.80 |
| AA(%) | 91.89 | 94.32 | 95.79 | 95.38 | 92.74 | 93.13 | 96.95 |
| Kappa(%) | 90.63 | 93.87 | 95.09 | 94.18 | 91.72 | 92.39 | 96.42 |
| Test Time(s) | 198.76 | 226.04 | 362.02 | 454.21 | 322.94 | 346.86 | 386.28 |
| Methods | Pixel-Centric+ (S = 32) +SE-Net | ANSS+ (S = 32) +SE-Net | ANTSS (S = 32) +CBAM-Net | ACO-SS+ (S = 12, 16, 24) +DBFA-Net | DMIL (S = 16) | SML-CNN (S = 16) | ANSS+ (S = 32) +SCCA-Net |
|---|---|---|---|---|---|---|---|
| 95.95 | 96.80 | 96.85 | 96.97 | 96.10 | 95.87 | 96.01 | |
| 78.80 | 93.40 | 92.85 | 93.69 | 87.22 | 89.35 | 94.92 | |
| 87.25 | 96.85 | 97.89 | 98.36 | 94.16 | 95.97 | 96.53 | |
| 95.20 | 94.81 | 96.23 | 97.16 | 90.76 | 94.73 | 98.00 | |
| 89.34 | 97.36 | 97.07 | 96.28 | 94.80 | 95.96 | 96.82 | |
| 89.55 | 99.41 | 99.31 | 98.12 | 97.77 | 96.77 | 99.55 | |
| 94.42 | 94.89 | 94.17 | 97.59 | 90.65 | 93.60 | 98.58 | |
| 85.09 | 98.25 | 97.75 | 99.16 | 95.56 | 93.36 | 98.09 | |
| 95.19 | 96.61 | 96.94 | 95.36 | 92.78 | 91.65 | 98.30 | |
| 93.17 | 97.01 | 96.97 | 97.02 | 92.76 | 91.98 | 96.69 | |
| 87.48 | 90.72 | 92.77 | 75.23 | 77.87 | 86.36 | 93.54 | |
| OA(%) | 91.98 | 95.61 | 95.57 | 95.71 | 91.60 | 93.64 | 97.16 |
| AA(%) | 90.55 | 95.18 | 96.26 | 94.99 | 91.86 | 93.24 | 96.94 |
| Kappa(%) | 90.71 | 94.91 | 94.86 | 95.03 | 90.24 | 92.62 | 96.71 |
| Test Time(s) | 187.16 | 178.55 | 425.04 | 306.15 | 339.95 | 226.03 | 395.64 |
| Methods | Pixel-Centric+ (S = 32) +SE-Net | ANSS+ (S = 32) +SE-Net | ANTSS (S = 32) +CBAM-Net | ACO-SS+ (S = 12, 16, 24) +DBFA-Net | DMIL (S = 16) | SML-CNN (S = 16) | ANSS+ (S = 32) +SCCA-Net |
|---|---|---|---|---|---|---|---|
| 96.11 | 98.32 | 98.86 | 98.11 | 93.68 | 92.77 | 98.68 | |
| 92.20 | 96.12 | 99.36 | 99.91 | 95.15 | 95.29 | 99.97 | |
| 94.46 | 98.46 | 98.87 | 99.90 | 96.43 | 92.25 | 99.61 | |
| 91.13 | 96.81 | 97.88 | 99.29 | 93.47 | 92.27 | 99.38 | |
| 99.62 | 99.67 | 99.75 | 99.81 | 98.59 | 98.81 | 99.88 | |
| 98.80 | 99.07 | 99.01 | 98.43 | 96.65 | 97.66 | 99.70 | |
| 98.82 | 98.87 | 99.71 | 99.61 | 98.67 | 97.35 | 99.58 | |
| OA(%) | 96.25 | 98.62 | 99.08 | 99.08 | 96.09 | 95.20 | 99.65 |
| AA(%) | 95.88 | 98.19 | 99.06 | 99.29 | 94.89 | 95.58 | 99.51 |
| Kappa(%) | 96.11 | 98.23 | 98.81 | 98.88 | 93.21 | 94.69 | 99.58 |
| Test Time(s) | 113.80 | 77.54 | 94.26 | 364.79 | 263.19 | 165.57 | 324.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, W.; Zhao, J.; Zhu, H.; Shen, J.; Jiao, L.; Wu, Y.; Hou, B. A Spatial-Channel Collaborative Attention Network for Enhancement of Multiresolution Classification. Remote Sens. 2021, 13, 106. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13010106
Ma W, Zhao J, Zhu H, Shen J, Jiao L, Wu Y, Hou B. A Spatial-Channel Collaborative Attention Network for Enhancement of Multiresolution Classification. Remote Sensing. 2021; 13(1):106. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13010106
Chicago/Turabian StyleMa, Wenping, Jiliang Zhao, Hao Zhu, Jianchao Shen, Licheng Jiao, Yue Wu, and Biao Hou. 2021. "A Spatial-Channel Collaborative Attention Network for Enhancement of Multiresolution Classification" Remote Sensing 13, no. 1: 106. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13010106