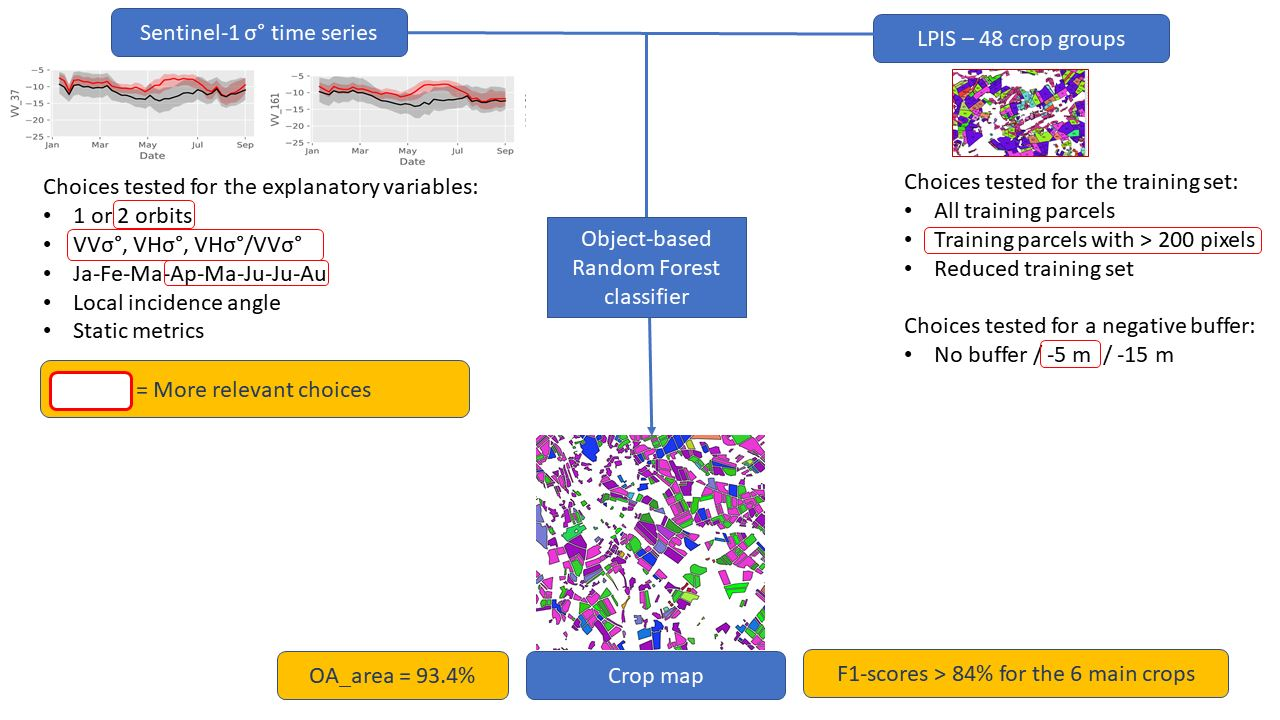
2.3.2. Parameters and Scenarios
Here follow the possible choices made for the 5 parameters, which define the different scenarios.
Parameter 1: the SAR input dataset
The explanatory variables used to build the classification model are computed from data coming either from the orbit 37 only, or from the orbit 161 only, or from both orbits 37 and 161. This impacts the number of images used during a considered period and the acquisition time of the images.
Comparing the results obtained from both orbits and from a single one allows to know if a higher temporal resolution (by doubling the number of acquisitions for a considered period) improves the quality of the crop type identification.
Images are acquired at different times depending on the orbit: early in the morning or late in the afternoon. The interest of testing each orbit separately is also to assess whether the acquisition time is important. For instance, images acquired early in the morning could be affected by dew.
Parameter 2: the explanatory variables
The starting idea is that the different crop types can be distinguished using temporal profiles of spectral features extracted from the SAR signal, these features are the explanatory variables of the model to be calibrated. Object-based features are preferred over pixel-based features because of the speckle effect, which needs to be filtered out or averaged out by working at object level. In the context of this study, this is possible since the parcel boundaries are known, and this is also true in each member states in the context of the CAP.
In this study, we have used the per-field mean backscattering coefficient (σ0), which is extracted for each parcel and each available date. The mean is computed as the average over the pixels whose center falls inside the parcel polygons after internal buffer application. Notice that all computations are done in linear units. This is done for both VV and VH polarizations. For each parcel, this gives two time series per orbit, which are used in all scenarios.
In addition to VV and VH, the effect of adding a third time series per orbit, called VRAT, is considered. It is defined as the ratio VH/VV. Indeed, in [
40], the authors recommend using VH/VV to separate maize, soybean, and sunflower, which could be applied to other crop types. This quantity is also considered as a variable sensitive to crop growth in several other studies [
41,
42,
43] and thus seems to be possibly a variable of interest for our purpose of crops classification.
Finally, the effect of adding some static variables is studied. For each orbit, the per-field mean of the local incidence angle is computed, together with its standard deviation. This is motivated by the fact that all types of cultural practices—that differ depending on the crop type—cannot be carried on in steep parcels and inhomogeneous reliefs. Hence, the local incidence angle and its intra-field variation could be correlated to the crop type cultivated in a parcel. Since the incidence angle is an almost constant value in time, we take it at a unique date only, which is on 3 May 2020 for orbit 37 and on 29 April 2020 for orbit 161. Some temporal statistics are also added: the mean, the minimum, the maximum, the range, the standard deviation, and the variance are computed for each of the VV, VH, and VRAT time series. For each orbit, there are thus 6 static variables for each time series and 2 for the local incidence angle.
The results obtained with and without these additional variables are compared in order to assess whether they are worth the additional model complexity and data preparation.
Parameter 3: the buffer size
The noise in the time series caused by heterogeneous pixels on the borders of parcels might be reduced by introducing an internal buffer before computing the per-field mean of the backscattering coefficient, thus keeping only clean pixels to represent the parcel. In some cases, it might also mitigate the negative effect of the imperfect geometric accuracy of the image. As was suggested in [
44] in the context of a Sentinel-2 analysis, a buffer size of −5 m is chosen in the present study. Another possible source of noise is the fact that the edges of the fields are sometimes managed differently from the central part of the fields (different machines passage orientation or inputs interdiction for example), which causes heterogeneity in the parcel signal. From that point of view, a bigger buffer size of −15 m might ensure a higher probability of having homogeneous pixels for a given parcel. However, a bigger buffer size implies that less pixels are used to average the parcel signal, which is less efficient to filter out the speckle. Therefore, the three following buffer sizes are tested in this study: 0 m (no buffer), −5 m and −15 m. In the −5 m scenario, no buffer is used on the parcels whose polygon after the buffer application is either empty or too thin to contain any pixel (1% of the parcels). In the −15 m scenario, for the parcels whose polygon after the −15 m buffer application is either empty or too thin to contain any pixel, the polygon from the −5 m buffer scenario is used (−5 m buffer for 7% of the parcels and no buffer for 1%). Notice that even when no buffer is applied, some parcels are too thin to contain the center of a SAR pixel, which implies that no signal can be extracted (0.007% of the parcels). Moreover, notice that, because of the “cascading” buffer application, the use of a buffer is more computationally demanding. Indeed, the extractions must be done for the buffer for all the parcels, then the extractions must be done for all smaller buffers for subsets of the parcels, since the number of pixels contained in a parcel is only known after the extraction. The percentage of parcels corresponding to each buffer is summarized in
Table 2.
Parameter 4: training set
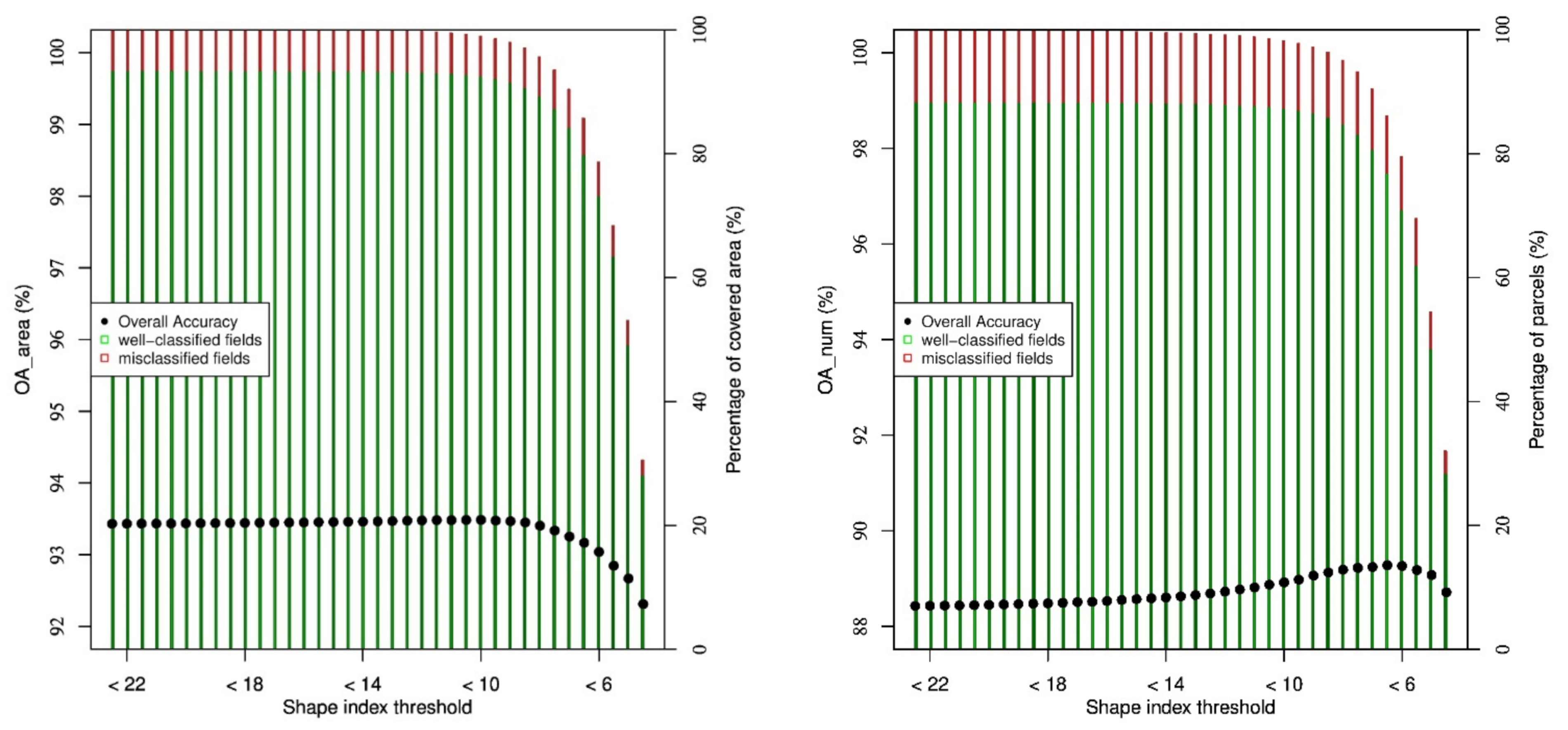
The set of all parcels is split in two disjoint halves, one being used to train the model and the other to score it. In order to improve the model quality, it is trained only on a subset of the training parcels, considered as having a good signal quality. For instance, small parcels are discarded since, because of the statistical uncertainties encountered in the SAR signal due to speckle, [
45] recommends averaging the signal over a certain number of pixels. Therefore, a ‘clean’ training dataset is built by selecting only the training parcels which contain at least 200 pixels for all dates after applying the buffer. Notice that in preliminary exploratory studies, some other criteria were considered. For instance, oddly shaped parcels were discarded based on the value of the ratio perimeter over square root of the area. Moreover, the parcel homogeneity was quantified in terms of the per-field standard deviation of the SAR sigma nought. However, these criteria were not retained since they did not seem to lead to significant improvements. The clean dataset contains 64.5% of the parcels in the full training set, and it is used in all the scenarios, unless otherwise specified. To assess the effect of using such a strict screening, a specific scenario is considered that uses the full training dataset to check if the score is then indeed lower.
On another vein, in some situations, only a very small training dataset might be available. In order to investigate the impact on the classification accuracy of a drastically limited training dataset, another scenario is considered where the model is trained using only 10% of the clean dataset. This leads to 3.2% of the full dataset and corresponds to about 6850 parcels. Such a calibration dataset is of the order of magnitude of a large field campaign feasible on the ground.
Parameter 5: the period of SAR acquisitions
This study compares different periods of the year for the time series used by the classification model. First, four periods are defined as starting in January and having different lengths: until May (5 months), June (6 months), July (7 months), or August (8 months). In this case, a shorter period would have the operational advantage of providing classification results earlier in the year, before the harvest time. In addition, 7 periods are defined as ending in August and beginning on different months: from February (7 months) to August (1 month). In this case, the operational advantage of a shorter period would be to deal with a smaller amount of data, which eases the procedure.
Scenarios
Table 3 gives a summary of all the scenarios that are considered, listing the corresponding choices made for each parameter.
In the training set column, “full” means that the full calibration set is used, without any quality filtering, and “10% clean” means that only 10% of the clean parcels are used. The number of acquisition dates for each orbit is also given. Nfeatures is the resulting number of features (i.e., explanatory variables) attached to each parcel that will feed the classification model. For instance, in the reference scenario, for each orbit (37 and 161), there are 2 features for the local incidence angle, plus, for each time series (VV, VH, and VRAT), 40 SAR images and 6 temporal statistics (mean, min, max, std, var, and range). This gives a total of 2*(2 + 3*(40 + 6)) = 280 features. The last two columns give the relative size of the calibration and validation sets compared to the total number (211,875) of considered parcels in the study area.
2.3.3. Classification Model
For our purpose, supervised machine learning is a natural choice since a lot of reference data are available from the farmers’ declaration. Dealing with a large input dataset and a big number of features (but not big enough to require neural networks), a random forest (RF) classifier is chosen as the classification model. Moreover, previous experience carried out in the benchmarking of Support Vector Machine (SVM), decision trees, gradient boosted trees, and RF models in the context of crop classification [
20] showed that RF performs generally better, even if SVM is expected to provide better classification results in the specific case of classes with few calibration samples.
The RF is implemented and trained using the python scikit-learn package. Because the goal of this study is not to optimize the machine learning model itself, the default hyper-parameters are kept. Exception is made on the number of trees, which is fixed to 250 in order to reduce the training time without significant performance drop.
Cross-validation is used to assess the model’s performance (full details are given in
Section 2.3.4). As previously mentioned, the set of considered parcels consists in those agricultural fields of the LPIS that are located under both orbits 37 and 161. When training a RF model, this set is randomly split in two disjoint equally sized subsets, a validation dataset and a training dataset. The splitting is stratified, that is, each crop group is equally represented in both datasets.
The training dataset is used to calibrate the RF model and is totally independent of the validation dataset.
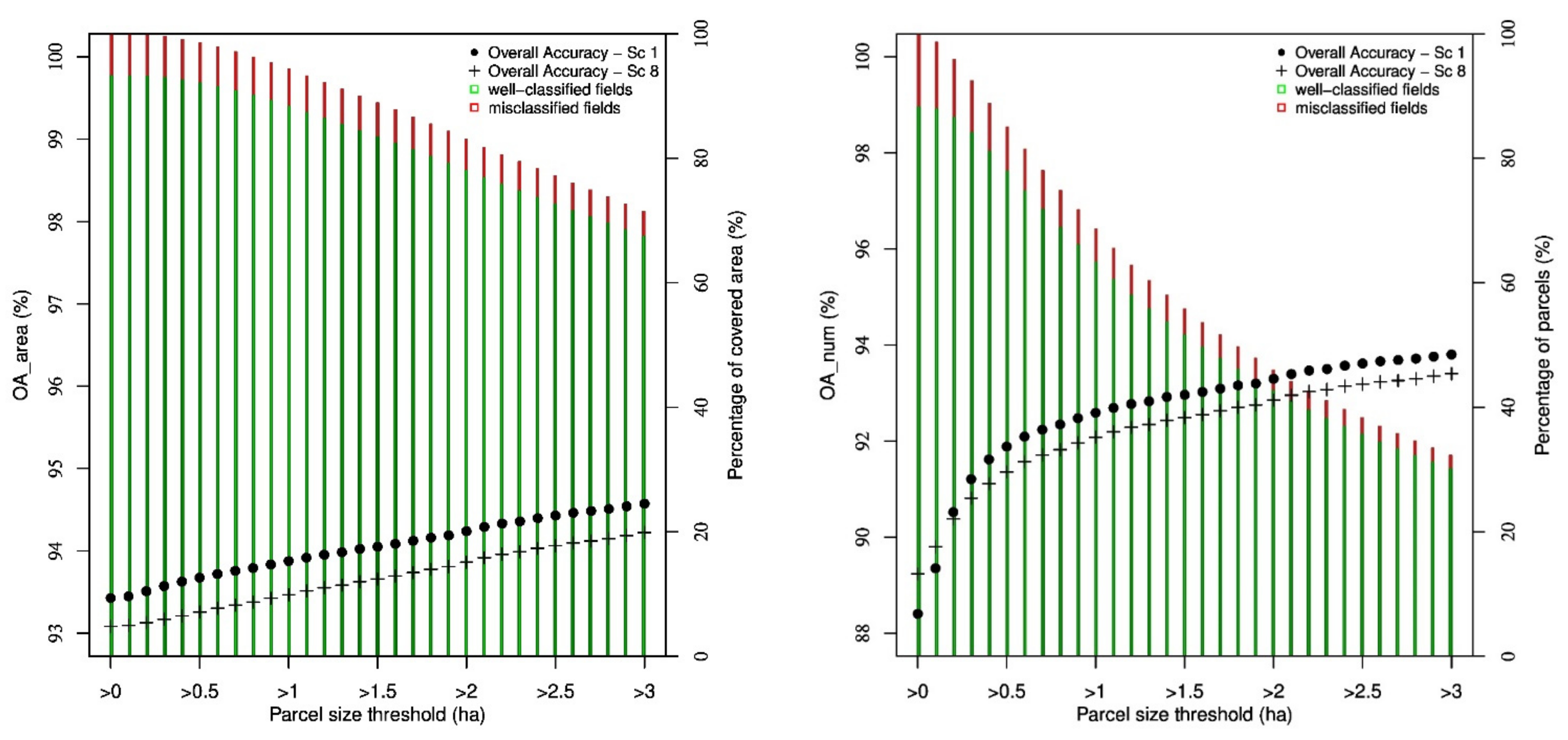
The validation dataset is used to compute two overall performance scores for the RF: OAnum, the overall accuracy based on the number of parcels (percentage of well-classified parcels compared to the total number of parcels), and OAarea, the overall accuracy based on the area (percentage of well-classified hectares).
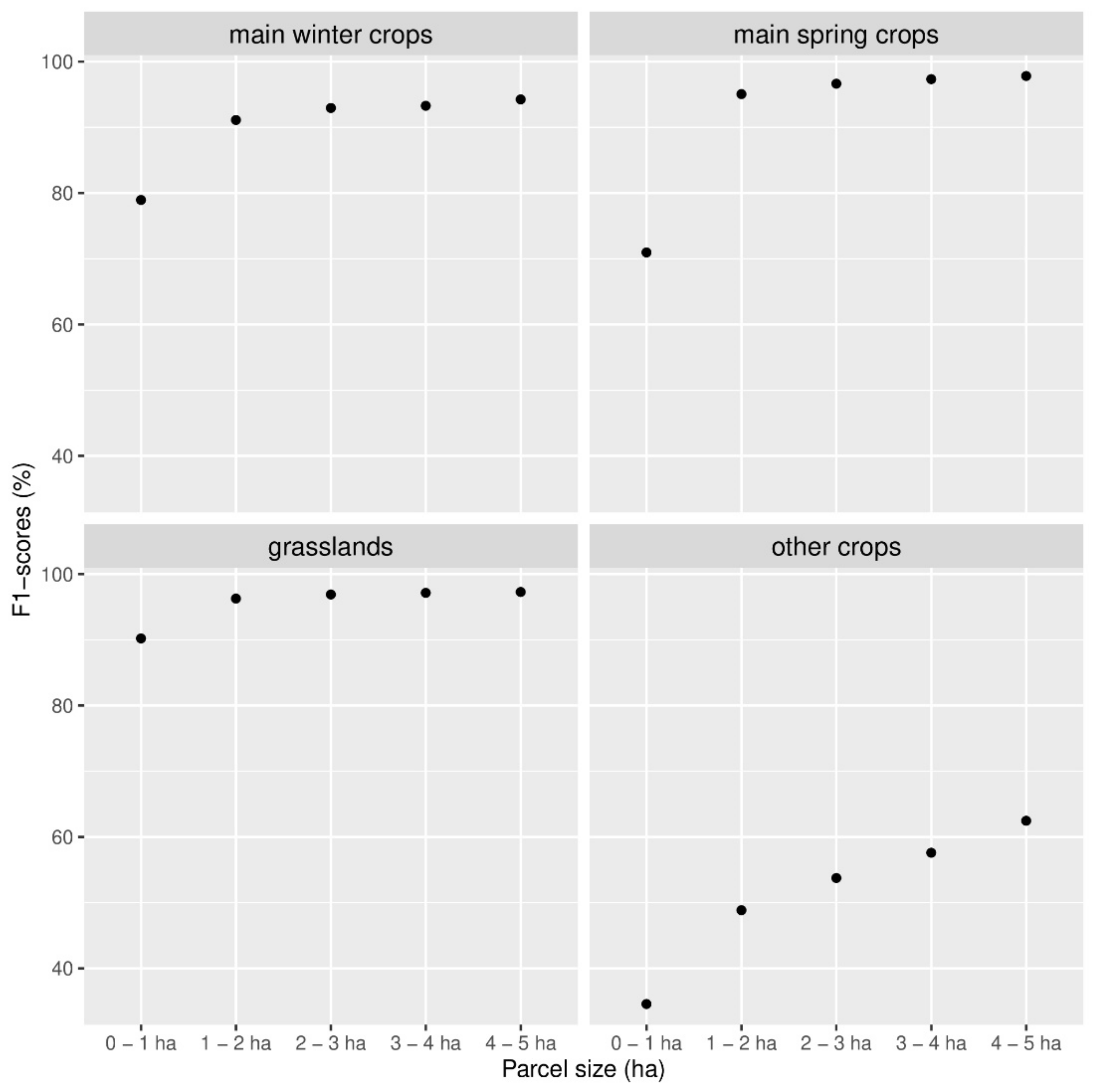
In addition, the F1-score of each crop group is used. In this multi-class classification context, it is defined as the harmonic mean of the group precision and recall (whose definitions are standard):
For each classified parcel, a confidence level is also assigned to the predicted class. It corresponds to the percentage of trees in the RF that predict the given class.
Notice that the few parcels for which no signal can be extracted because they are too small (see
Table 2) are considered as misclassified in the validation set. However, this has a negligeable effect on the scores since they represent 0.007% of the parcels (0.0001% in terms of area).
2.3.4. Test of Statistical Significance
There are several sources of randomness in the building of the RF classification model corresponding to each scenario: the training/validation split and several random choices in the RF initialization and training. This leads to some randomness in their performance scores, and therefore, the best scenario for a given training/validation split might not be the same for another split. This is especially true given that, as will be seen in the next section, the scores are sometimes very close. A test of statistical significance is therefore conducted in order to assess whether the difference in score for two scenarios is significant or if it might just be due to a random fluctuation.
The idea is to define several pairs of training/validation datasets and, for each scenario, to build several RFs, one for each pair. This gives an insight on how strongly the score of each scenario fluctuates. However, naively estimating the variance by computing the standard deviation of the scores is not recommended because the latter are strongly correlated (typically, the training datasets of each pair overlap and are thus not independent (same for the validation datasets)). Using a very high number of pairs would lead to an underestimated variance. This is therefore a complex question, to which many answers are proposed in the literature, some of them being summarized and compared in [
46]. Given the situation encountered in this paper, the 5 × 2 cross-validation F-test introduced in [
47] is chosen—which is a slight modification of the popular 5 × 2 cross-validation
t-test originally defined in [
48]. Here is a quick overview of the procedure. As previously mentioned, the goal is to repeat the training/validation several times for each scenario to estimate the score fluctuations, while finding a right balance between having a high number of repetitions, lowering the overlapping between all the training datasets (same for the validation datasets), and keeping enough data in each set. First, the full dataset is randomly split in two equally sized stratified parts, and this is independently repeated 5 times. This leads to 5 pairs of 50–50% disjoint subsets of the full dataset. Then, for each scenario and each pair, two classification models are built: the first one using one part as the training set and the other part as the validation set, and the second one by switching the role of each subset. For each scenario, this gives thus 10 performance scores. When comparing two scenarios, a standard hypothesis test is conducted, taking as null hypothesis that they both lead to the same score. From the 20 scores, a number t is computed—its exact definition can be found in [
47]—and the author argues that its statistic approximately follows a F-distribution, allowing to compute the corresponding
p-value. If this
p-value is higher than a chosen threshold α, the null hypothesis that the scenario scores are equal can be rejected at the corresponding confidence level. Now, the fact that several scenarios are compared has to be taken into account in order to get the expected
p-value for the multiple comparisons altogether. The Bonferroni correction is chosen, which suggests using α divided by the total number of comparisons as the
p-value threshold of each individual comparison. In this study, α is fixed to 0.05.
Since the goal of this study is to evaluate the effect on the classification performance of each parameter separately, there is no need to compare all the scenarios together. Instead, in order to reduce the number of comparisons, a reference scenario is chosen, against which all the other ones are compared. It corresponds to the scenario with both orbits 37 and 161 considered, all the explanatory variables (VV, VH, and VRAT time series + static variables), the 8 months period, a −5 m buffer, and the clean training set.
As a final note, it should be reminded that all these statistical tests are based on approximate hypotheses and that the numbers should therefore not be blindly taken as an absolute truth.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}