
Hybridizing Cross-Level Contextual and Attentive Representations for Remote Sensing Imagery Semantic Segmentation


Abstract
:
1. Introduction
2. Related Works
2.1. Semantic Segmentation of RSI
2.2. Attention Mechanism
3. The Proposed Method
3.1. Preliminaries
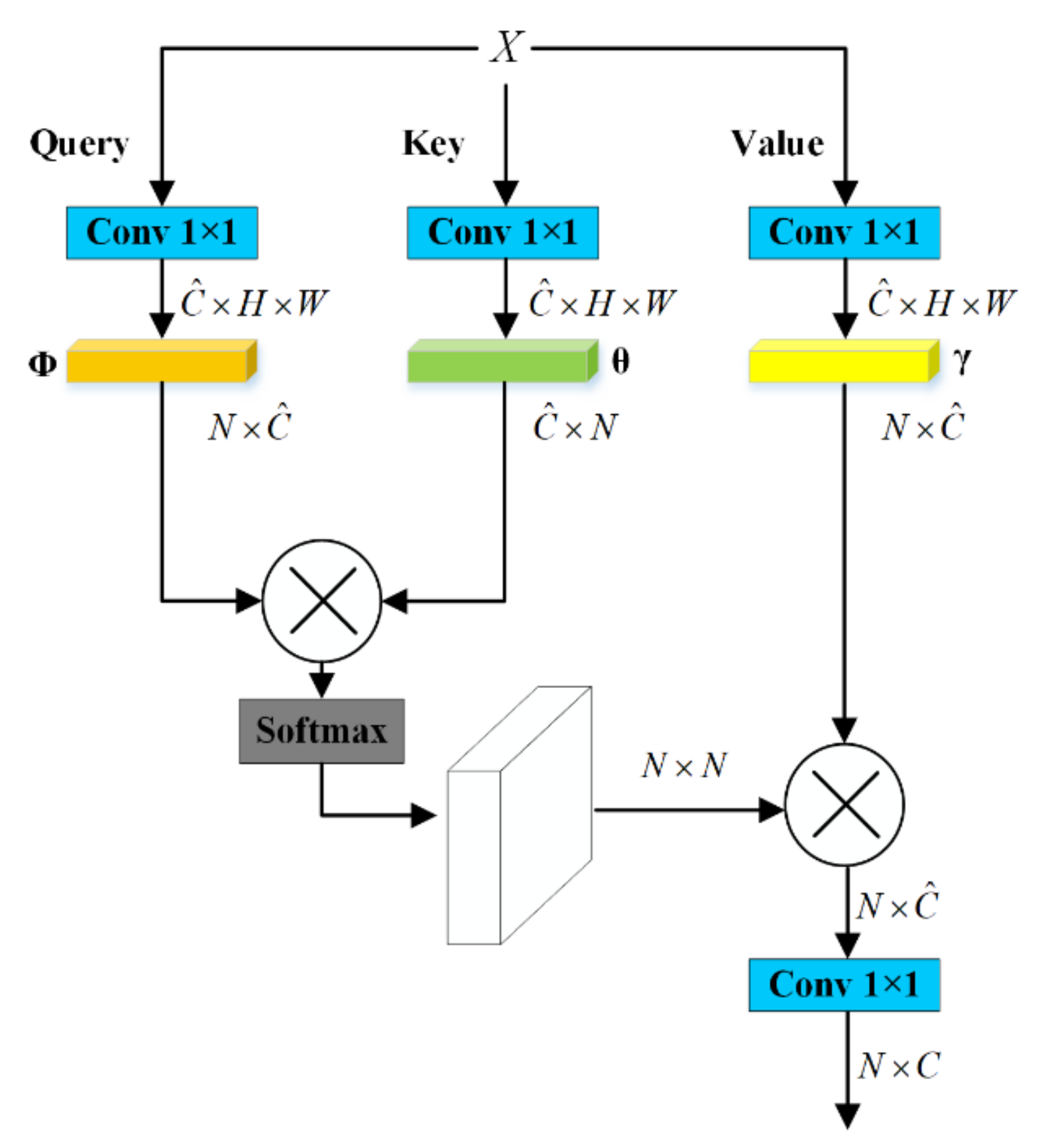
3.1.1. Non-Local Block
3.1.2. Superpixel Context
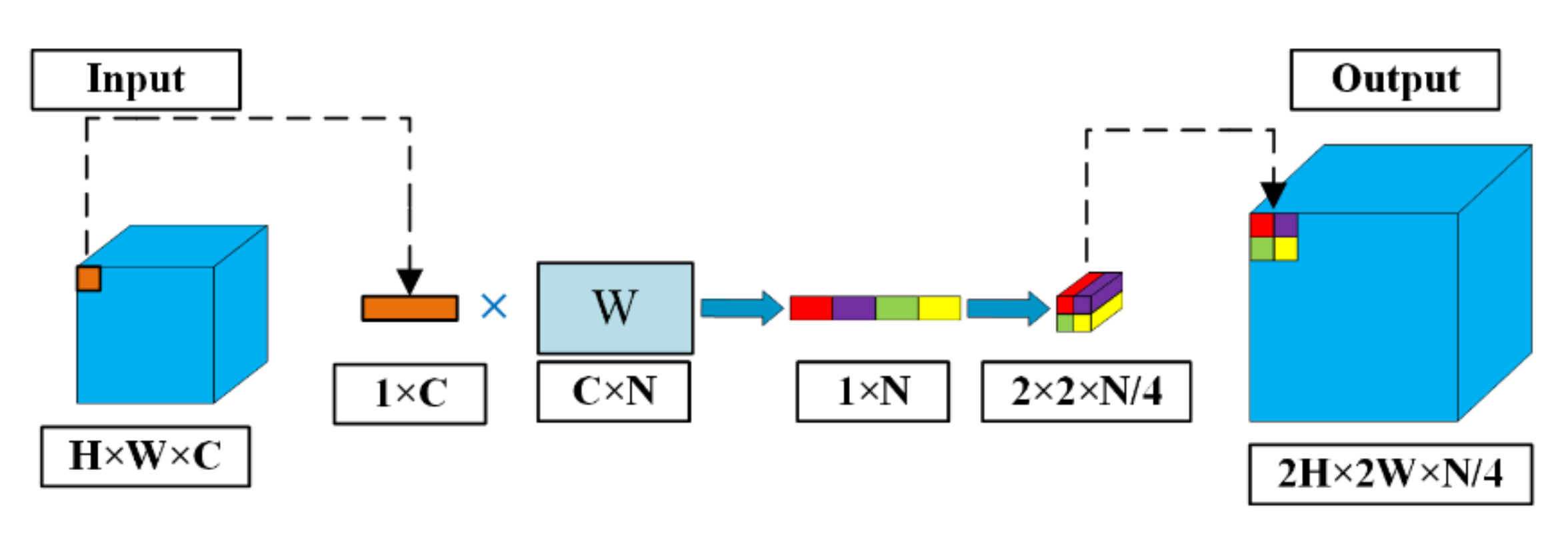
3.1.3. DUpsampling
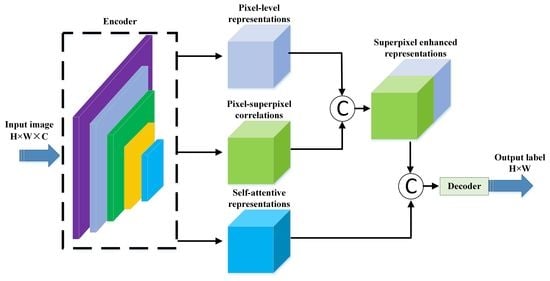
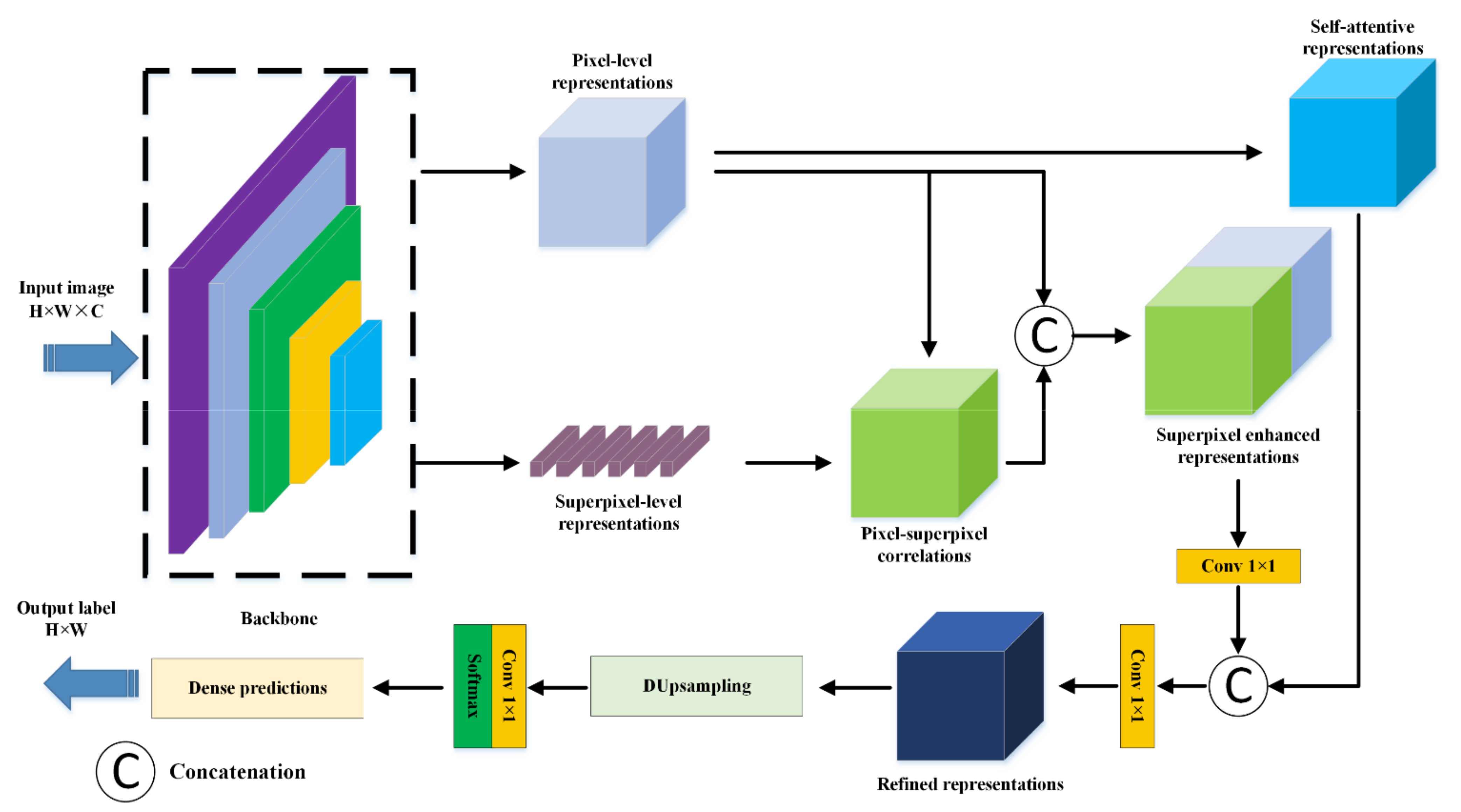
3.2. The Framework of HCANet
3.3. Cross-Level Contextual Representation Module
3.3.1. Superpixel Region Generation and Representation
3.3.2. Cross-Level Contextual Representation
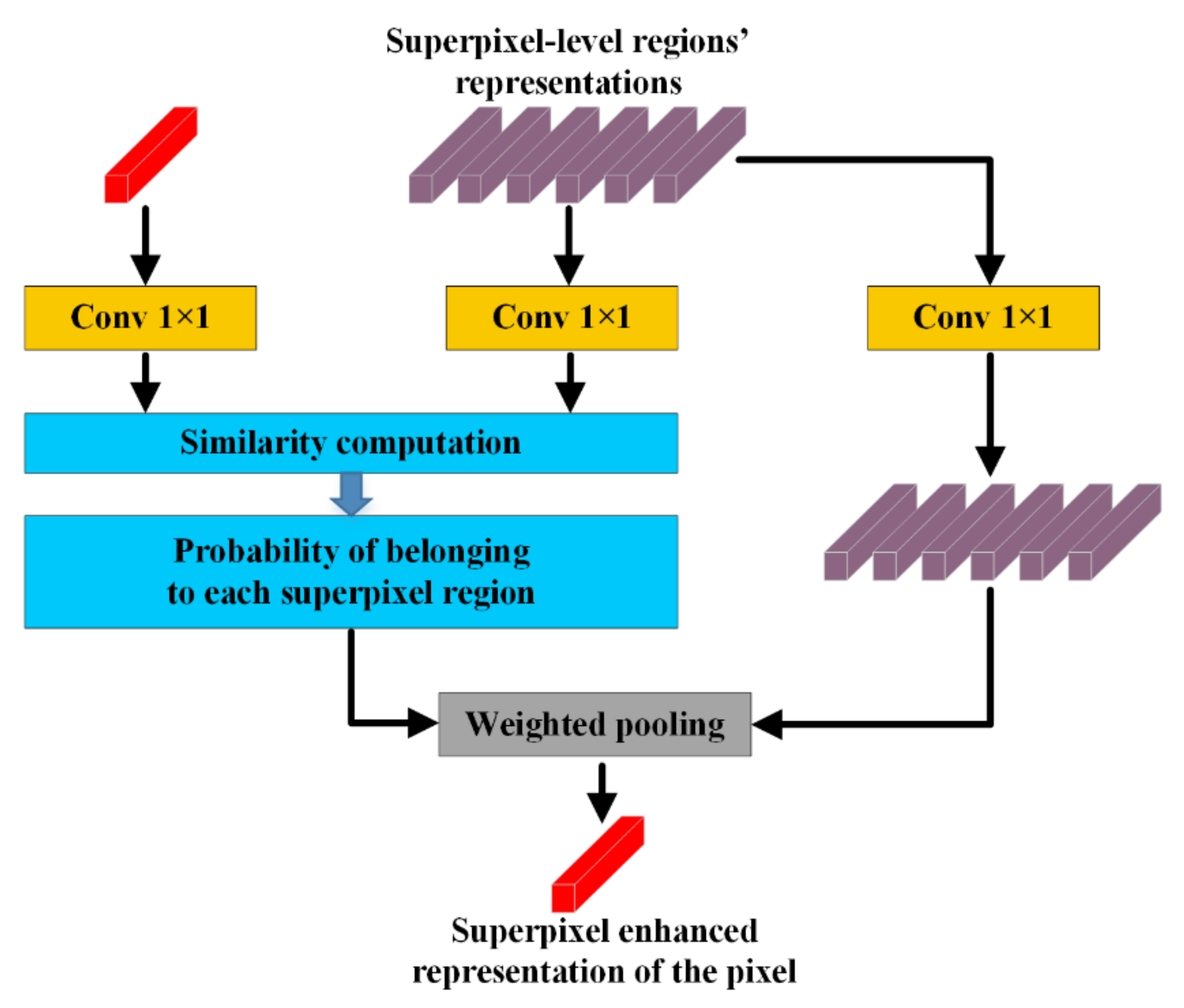
3.4. Hybrid Representation Enhancement Module
4. Experiments
4.1. Datasets
4.1.1. ISPRS Vaihingen Dataset
4.1.2. ISPRS Potsdam Dataset
4.2. Implement Details
4.3. Evaluation Metrics
4.4. Compare to State-of-the-Art Methods
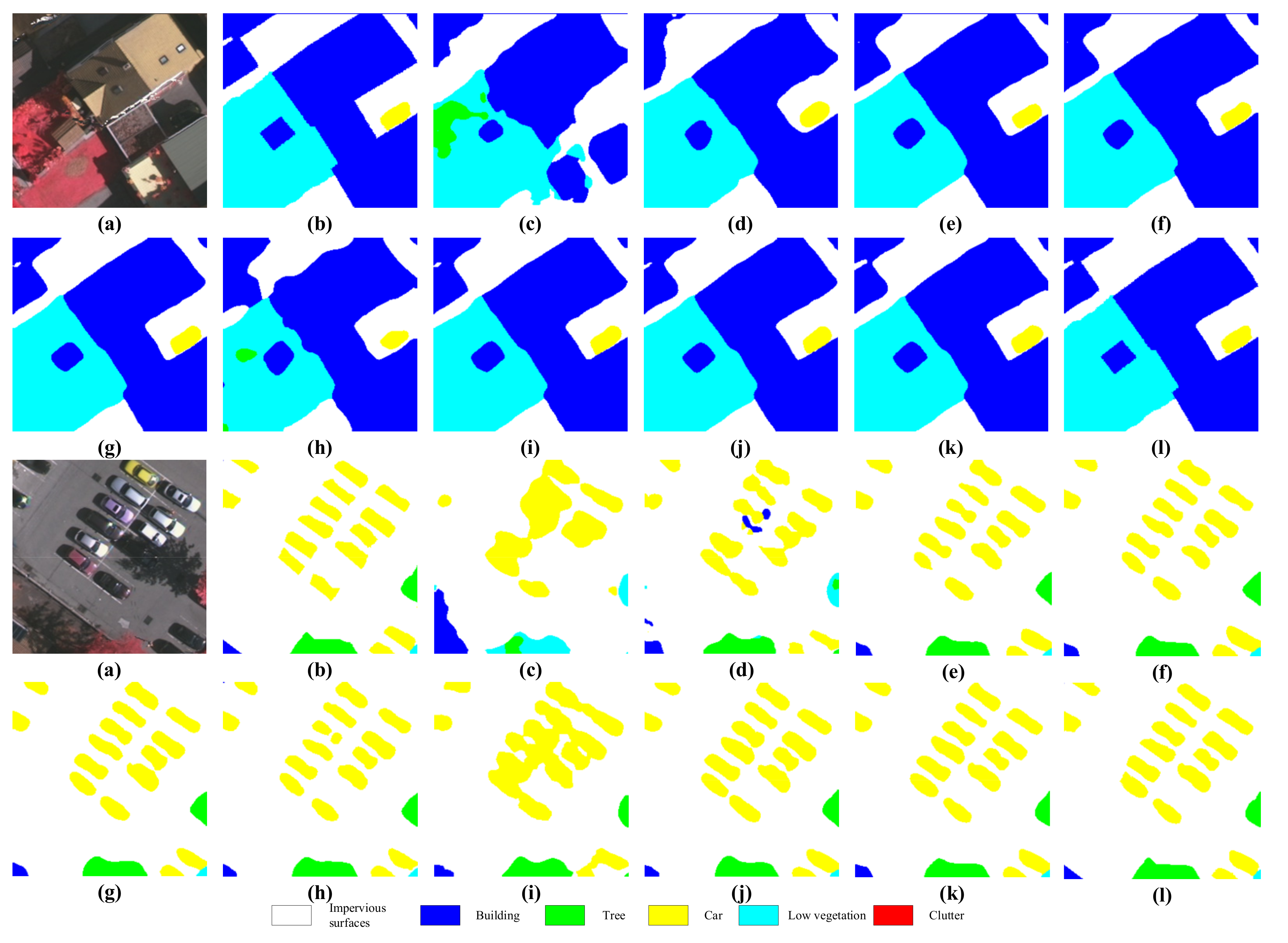
4.4.1. Results on Vaihingen Test Set
4.4.2. Results on Potsdam Test Set
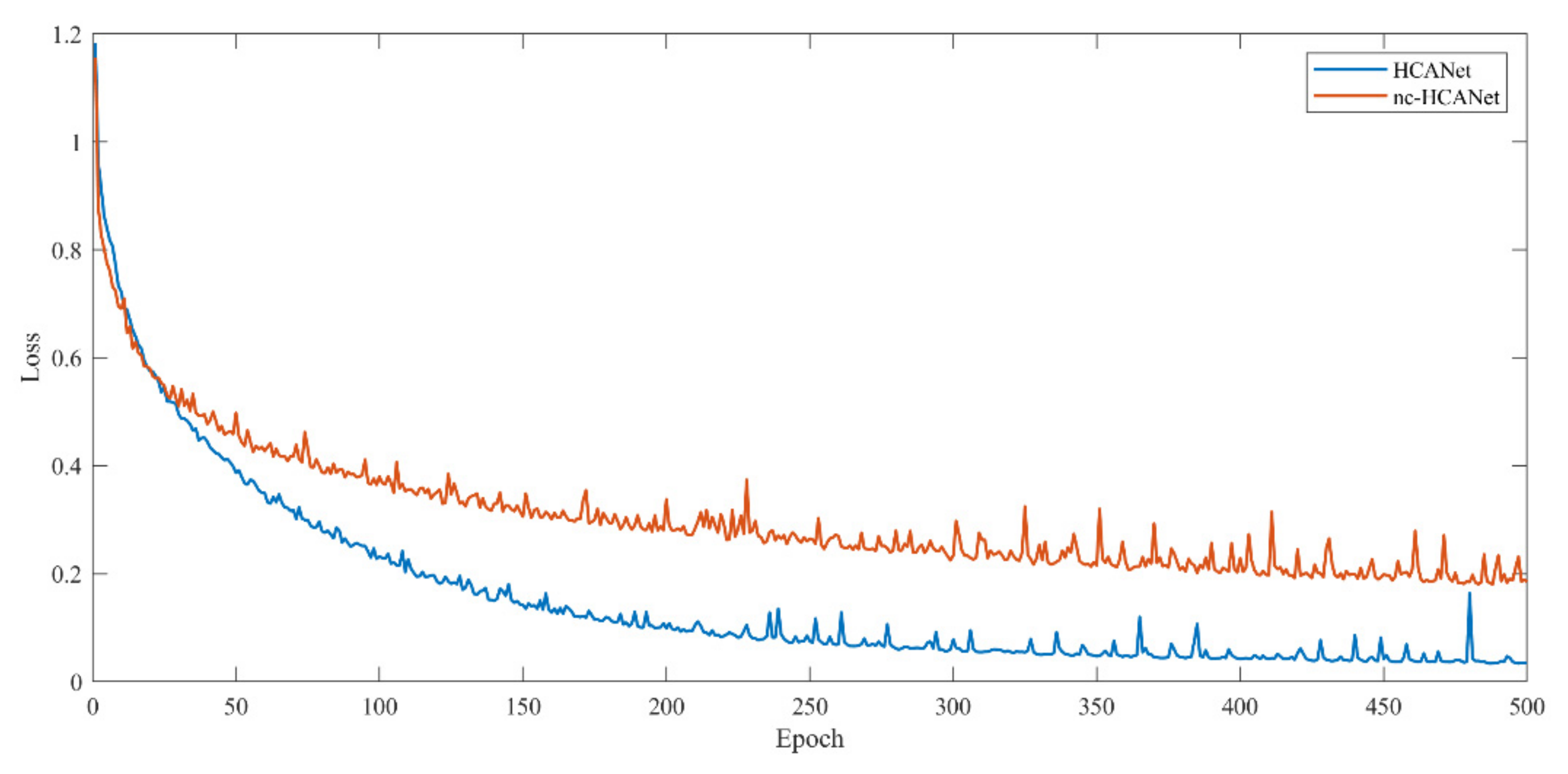
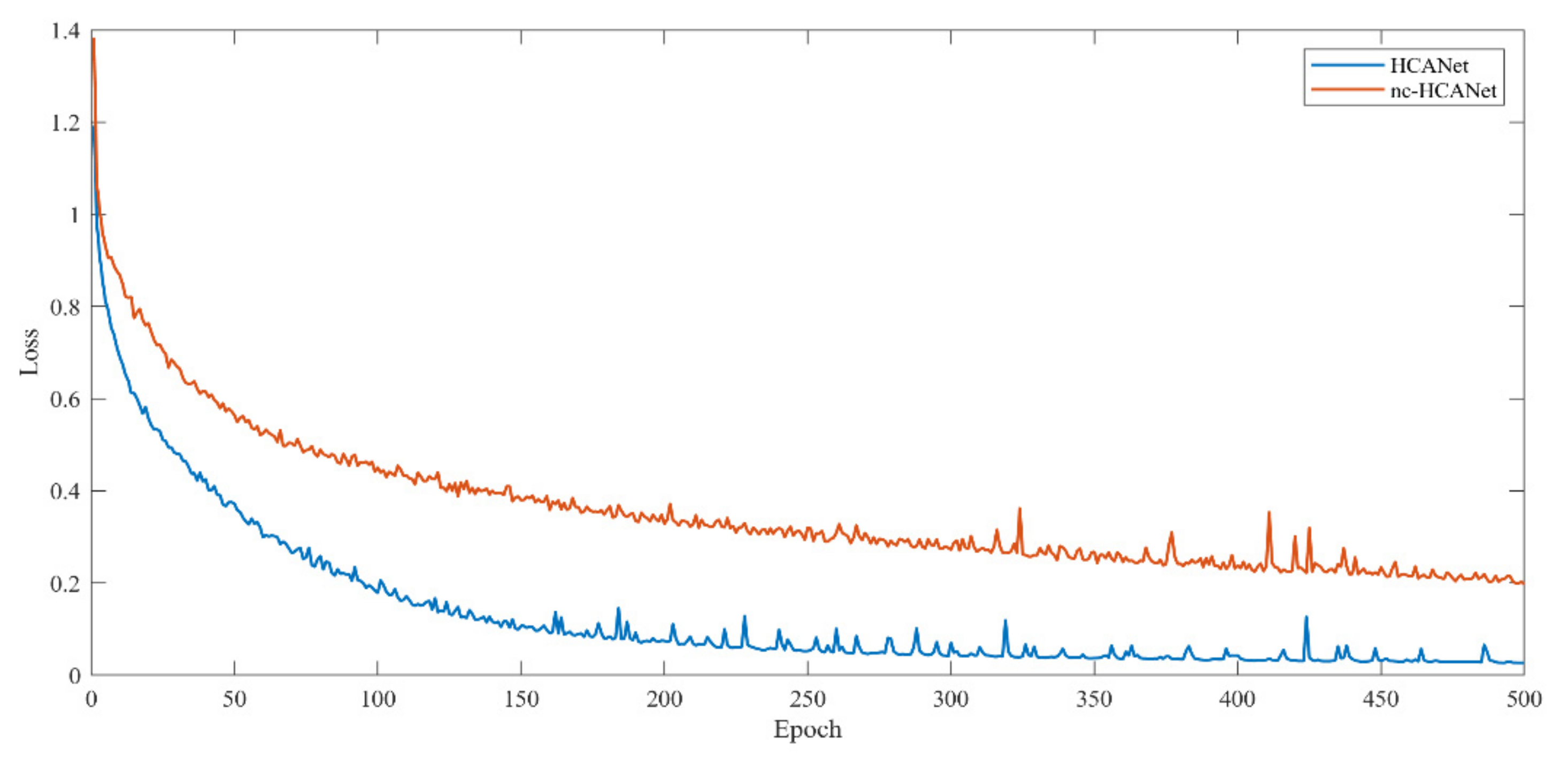
4.5. Ablation Study on CCRM
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Kouziokas, G.; Perakis, K. Decision support system based on artificial intelligence, GIS and remote sensing for sustainable public and judicial management. Eur. J. Sustain. Dev. 2017, 6, 397–404. [Google Scholar] [CrossRef]
- Azimi, S.; Fisher, P.; Korner, M.; Reinartz, P. Aerial LaneNet: Lane-marking semantic segmentation in aerial imagery using wavelet-enhanced cost-sensitive symmetric fully convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2920–2938. [Google Scholar] [CrossRef] [Green Version]
- Duan, W.; Maskey, S.; Chaffe, P.; Luo, P.; He, B.; Wu, Y.; Hou, J. Recent advancement in remote sensing technology for hydrology analysis and water resources management. Remote Sens. 2021, 13, 1097. [Google Scholar] [CrossRef]
- Zhang, X.; Jin, J.; Lan, Z.; Li, C.; Fan, M.; Wang, Y.; Yu, X.; Zhang, Y. ICENET: A semantic segmentation deep network for river ice by fusing positional and channel-wise attentive features. Remote Sens. 2020, 12, 221. [Google Scholar] [CrossRef] [Green Version]
- Anand, T.; Sinha, S.; Mandal, M.; Chamola, V.; Yu, R.F. AgriSegNet: Deep aerial semantic segmentation framework for iot-assisted precision agriculture. IEEE Sens. J. 2021. [Google Scholar] [CrossRef]
- Du, Z.; Yang, J.; Ou, C.; Zhang, T. Smallholder crop area mapped with a semantic segmentation deep learning method. Remote Sens. 2019, 11, 888. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Wang, C.; Li, J.; Xie, N.; Han, Y.; Du, J. Reconstruction bias U-Net for road extraction from optical remote sensing images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 2284–2294. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, K.; Ji, S. Simultaneous road surface and centerline extraction from large-scale remote sensing images using CNN-Based segmentation and tracing. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8919–8931. [Google Scholar] [CrossRef]
- Yoo, C.; Han, D.; Im, J.; Bechtel, B. Comparison between convolutional neural networks and random forest for local climate zone classification in mega urban areas using Landsat images. ISPRS J. Photogramm. Remote Sens. 2019, 157, 155–170. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, W.; Fang, Z. Multiple kernel-based SVM classification of hyperspectral images by combining spectral, spatial, and semantic information. Remote Sens. 2020, 12, 120. [Google Scholar] [CrossRef] [Green Version]
- Zheng, C.; Zhang, Y.; Wang, L. Multigranularity multiclass-layer markov random field model for semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020. [Google Scholar] [CrossRef]
- Kong, Y.; Zhang, B.; Yan, B.; Liu, Y.; Leung, H.; Peng, X. Affiliated fusion conditional random field for urban UAV image semantic segmentation. Sensors 2020, 20, 993. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Liu, Y.; Xie, Y.; Yang, W.; Zuo, X.; Zhou, B. Target classification and recognition for high-resolution remote sensing images: Using the parallel cross-model neural cognitive computing algorithm. IEEE Geosci. Remote Sens. Mag. 2020, 8, 50–62. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MCCAI), Munich, Germany, 5–9 October 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Chen, L.; Papandreou, G.; Schroff, F.; Hartwig, A. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Chen, Z. Superpixel-enhanced deep neural forest for remote sensing image semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2020, 159, 140–152. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3141–3149. [Google Scholar]
- Zhang, H.; Zhang, H.; Wang, C.; Xie, J. Co-Occurrent Features in Semantic Segmentation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 548–557. [Google Scholar]
- Yuan, Y.; Wang, J. Ocnet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Li, H.; Qiu, K.; Li, C.; Mei, X.; Hong, L.; Tao, C. SCAttNet: Semantic segmentation network with spatial and channel attention mechanism for high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local attention embedding to improve the semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 426–435. [Google Scholar] [CrossRef]
- Tian, Z.; He, T.; Shen, C.; Yan, Y. Decoders matter for semantic segmentation: Data-dependent decoding enables flexible feature aggregation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3121–3130. [Google Scholar]
- ISPRS. Vaihingen 2D Semantic Labeling Dataset. 2017. Available online: http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-vaihingen.html (accessed on 10 December 2017).
- ISPRS. Potsdam 2D Semantic Labeling Dataset. 2017. Available online: http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-potsdam.html (accessed on 10 December 2017).
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef] [Green Version]
- Muhammad, A.; Wang, J.; Cong, G. Convolutional neural network for the semantic segmentation of remote sensing images. Mob. Netw. Appl. 2021, 26, 200–215. [Google Scholar]
- Mou, L.; Hua, Y.; Zhu, X. A Relation-Augmented Fully Convolutional Network for Semantic Segmentation in Aerial Scenes. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 12416–12425. [Google Scholar]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef] [Green Version]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]
- He, C.; Li, S.; Xiong, D.; Fang, P.; Liao, M. Remote sensing image semantic segmentation based on edge information guidance. Remote Sens. 2020, 12, 1501. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Hu, J.; Li, S.; Samuel, A.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.; Kweon, I. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 31st Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, CA, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasethiern, P.; Vateekul, P. Semantic segmentation on remotely sensed images using an enhanced global convolutional network with channel attention and domain specific transfer learning. Remote Sens. 2019, 11, 83. [Google Scholar] [CrossRef] [Green Version]
- Cui, W.; Wang, F.; He, X.; Zhang, D.; Xu, X.; Yao, M.; Wang, Z.; Huang, J. Multi-scale semantic segmentation and spatial relationship recognition of remote sensing images based on an attention model. Remote Sens. 2019, 11, 1044. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid Attention Network for Semantic Segmentation. In Proceedings of the 29th British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Su, Y.; Wu, Y.; Wang, M.; Chen, J.; Lu, G. Semantic Segmentation of High Resolution Remote Sensing Image Based on Batch-Attention mechanism. In Proceedings of the 39th IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Yokohama, Japan, 28 July–2 August 2019; pp. 3856–3859. [Google Scholar]
- Deng, G.; Wu, Z.; Wang, C.; Xu, M.; Zhong, Y. CCANet: Class-constraint coarse-to-fine attentional deep network for subdecimeter aerial image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Chen, J.; Wang, H.; Guo, Y.; Zhang, Y.; Deng, M. Strengthen the feature distinguishability of geo-object details in the semantic segmentation of high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 2327–2340. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Sun, X.; Shi, A.; Huang, H.; Mayer, H. BAS4Net: Boundary-aware semi-supervised semantic segmentation network for very high resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2020, 13, 5398–5413. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Lyu, X.; Gao, H.; Tong, Y.; Cai, S.; Li, S.; Liu, D. Dual attention deep fusion semantic segmentation networks of large-scale satellite remote-sensing images. Int. J. Remote Sens. 2021, 42, 3583–3610. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Vaihingen | Potsdam |
|---|---|---|
| Bands used | NIR, R, G | NIR, R, G |
| GSD | 9 cm | 5 cm |
| Sub-patch size | 256 × 256 | |
| Data augmentation | Rotate 90, 180 and 270 degrees, Horizontally and vertically flip | |
| Hyper-Parameters | Settings |
|---|---|
| Backbone | ResNet 101 |
| Batch size | 16 |
| Learning strategy | Poly decay |
| Initial learning rate | 0.002 |
| Loss Function | Cross-entropy |
| Optimizer | Adam |
| Max epoch | 500 |
| Methods | Impervious Surfaces | Building | Low Vegetation | Tree | Car | Clutter | OA | mIoU |
|---|---|---|---|---|---|---|---|---|
| SegNet [15] | 92.37/78.87 | 90.96/75.71 | 80.61/62.11 | 77.22/57.98 | 60.61/51.11 | 73.39/57.98 | 79.19 | 63.43 |
| U-Net [17] | 92.71/78.72 | 90.84/76.61 | 79.95/62.25 | 77.67/58.33 | 69.87/55.27 | 74.41/58.33 | 80.91 | 65.11 |
| DeepLab V3+ [19] | 93.55/80.51 | 89.96/77.52 | 81.15/66.61 | 78.11/63.02 | 70.49/58.83 | 77.52/63.02 | 81.80 | 69.46 |
| CBAM [37] | 93.44/82.77 | 90.01/78.21 | 82.27/65.53 | 77.97/62.09 | 71.11/66.57 | 75.59/62.09 | 81.73 | 69.75 |
| DANet [21] | 93.62/83.54 | 90.13/77.95 | 83.31/69.03 | 78.54/63.05 | 70.94/65.18 | 76.62/63.05 | 82.19 | 70.03 |
| OCNet [23] | 93.31/83.78 | 91.22/79.01 | 84.49/68.15 | 79.61/62.98 | 72.25/67.79 | 79.53/62.98 | 83.40 | 71.20 |
| NLNet [38] | 93.28/83.66 | 89.95/78.08 | 83.34/68.85 | 78.18/63.33 | 70.99/65.59 | 76.12/63.33 | 81.98 | 70.55 |
| ResUNet-a [45] | 93.50/85.81 | 97.12/80.02 | 85.21/69.58 | 85.83/65.51 | 79.92/70.06 | 81.91/65.51 | 87.25 | 74.42 |
| SCAttNet [24] | 89.13/83.18 | 92.58/79.33 | 84.97/69.19 | 82.31/62.57 | 75.50/67.38 | 82.23/62.57 | 84.45 | 71.63 |
| HCANet | 93.69/86.68 | 95.11/79.95 | 86.67/70.04 | 87.71/69.38 | 82.21/72.55 | 81.56/69.38 | 87.83 | 75.46 |
| Methods | Impervious Surfaces | Building | Low Vegetation | Tree | Car | Clutter | OA | mIoU |
|---|---|---|---|---|---|---|---|---|
| SegNet [15] | 94.08/79.66 | 92.64/76.46 | 82.10/62.73 | 78.65/58.56 | 61.73/51.62 | 74.75/55.35 | 80.66 | 64.06 |
| U-Net [17] | 94.43/79.50 | 92.52/77.37 | 81.43/62.87 | 79.11/58.91 | 71.16/55.82 | 75.79/60.07 | 82.41 | 65.76 |
| DeepLab V3+ [19] | 95.28/81.31 | 91.62/78.29 | 82.65/67.27 | 79.56/63.65 | 71.79/59.42 | 78.95/70.97 | 83.31 | 70.15 |
| CBAM [37] | 95.17/83.59 | 91.68/78.99 | 83.79/66.18 | 79.41/62.71 | 72.43/67.23 | 76.99/63.96 | 83.24 | 70.44 |
| DANet [21] | 95.35/84.37 | 91.80/78.73 | 84.85/69.72 | 79.99/63.68 | 72.25/65.83 | 78.04/62.04 | 83.71 | 70.73 |
| OCNet [23] | 95.04/84.61 | 92.91/79.80 | 86.05/68.83 | 81.08/63.61 | 73.59/68.46 | 81.01/66.14 | 84.94 | 71.91 |
| NLNet [38] | 95.01/84.49 | 91.61/78.86 | 84.88/69.54 | 79.63/63.96 | 72.30/66.24 | 77.53/64.43 | 83.49 | 71.25 |
| ResUNet-a [45] | 95.22/86.66 | 98.92/80.82 | 86.79/70.27 | 87.42/66.16 | 81.40/70.76 | 83.43/76.29 | 88.86 | 75.16 |
| SCAttNet [24] | 90.78/84.01 | 94.29/80.12 | 86.54/69.88 | 83.83/63.19 | 76.90/68.05 | 83.75/68.81 | 86.02 | 72.34 |
| HCANet | 95.23/86.41 | 96.88/81.55 | 88.29/71.44 | 89.35/70.77 | 83.74/74.00 | 83.08/75.64 | 89.44 | 76.64 |
| Models | Vaihingen | Potsdam |
|---|---|---|
| nc-HCANet | 82.56/71.03 | 84.51/71.55 |
| HCANet | 87.83/75.46 | 89.44/76.64 |
| Models | Training Time Per Epoch (Seconds) | Inference Time (Milliseconds) |
|---|---|---|
| nc-HCANet | 376 ± 23 | 28.1 |
| HCANet | 391 ± 17 | 28.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Xu, F.; Xia, R.; Lyu, X.; Gao, H.; Tong, Y. Hybridizing Cross-Level Contextual and Attentive Representations for Remote Sensing Imagery Semantic Segmentation. Remote Sens. 2021, 13, 2986. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13152986
Li X, Xu F, Xia R, Lyu X, Gao H, Tong Y. Hybridizing Cross-Level Contextual and Attentive Representations for Remote Sensing Imagery Semantic Segmentation. Remote Sensing. 2021; 13(15):2986. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13152986
Chicago/Turabian StyleLi, Xin, Feng Xu, Runliang Xia, Xin Lyu, Hongmin Gao, and Yao Tong. 2021. "Hybridizing Cross-Level Contextual and Attentive Representations for Remote Sensing Imagery Semantic Segmentation" Remote Sensing 13, no. 15: 2986. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13152986