1. Introduction
Urban information construction requires the rapid acquisition of a large amount of basic geographic information data. Extracting ground objects using remote sensing images has several advantages, such as large detection range, wide spatial coverage, timeliness, and low cost, making it an important means to construct and update geospatial databases [
1]. Road extraction is of great significance for GIS database updates, image matching, target detection, and digital mapping automation, to list a few. It is widely used in traffic management, land use analysis, and other fields [
2,
3,
4,
5]. With the increasing maturity of remote sensing technology and its applications, more and more scholars started to extract road information directly from very high-resolution (VHR) remote sensing images [
5,
6].
However, urban roads are generally distributed in a plane shape, especially in VHR images. The rich details of ground features add further complexity to the image information. As for spectral characteristics, there are a large number of the same objects with different spectra and the same spectra of different objects in the image. For example, the spectral characteristics of roads and buildings are very similar, while the spectral signature inside the road greatly differs. The existence of a large number of geometric topological features around the road leads to more challenges in road extraction [
7,
8,
9]. In addition, roads tend to be covered by the shadow cast from the adjacent three-dimensional structures in modern cities. Due to the aforementioned influencing factors, extracting road-related information from VHR remote sensing images has been considered to be a rather difficult task [
4].
Extracting road-related information from remote sensing images includes two major tasks: (1) road surface extraction and (2) road centerline extraction. Road surface extraction aims to generate pixel-level results, while road centerline extraction aims to extract road skeleton [
6].
With the great progress of space technology, mankind entered the era of space remote sensing in the 1970s [
10]. Scholars have carried out in-depth studies on road surface extraction models via a variety of approaches that include template matching [
11,
12,
13], knowledge-driven methods [
14,
15], and object-oriented methods [
5,
16,
17,
18]. Inspired by the roads seen on satellites, Ruzena et al. [
1] designed a computer program for the recognition and description of roads and their intersections in 1976. Helmut et al. [
19] used snakes to make up for the gap caused by the shelter of buildings and trees. Trinder et al. [
20] proposed a knowledge-based method to extract roads in an automatic manner. Their approaches consist of low-level image processing for edge detection and linking, mid-level processing for the formation of road structure, and high-level processing for the recognition of roads. Based on the anti-parallelism rule and the proximity rules, Dal Poz et al. [
21] achieved great results by taking advantage of the characteristics of parallel edges of roads leveraging road seed extraction and road network combination. Rasha et al. [
18] extracted roads from VHR images through three steps: feature extraction, graph-based segmentation, and post-processing. Li et al. [
5] viewed road areas as binary segmentation trees and combined them with various features to provide an effective method to extract roads from VHR satellite images in densely populated urban areas. Cao et al. [
22] chose GPS data for rapid centerline extraction to face challenges such as complex scenes and variable resolution. Liu et al. [
23] conducted road surface extraction based on the generalized Hough transform, which has low computational complexity and high time efficiency. In recent years, the advancement of deep learning offers a new solution to road surface extraction tasks. In 2010, Minh et al. [
24] attempted to apply neural network technology to road surface extraction tasks with the city-level spatial coverage. Since then, more and more studies have been conducted to extract roads from remote sensing images via convolutional neural networks. Wei et al. [
25] built the road-structure-based loss function by embedding the geometric structure of roads and proposed a road structure refined convolutional neural network approach for road surface extraction from aerial images. To facilitate the extraction of tree-blocked roads, Zhang et al. [
6] proposed a semantic segmentation neural network that combines the advantages of residual learning and Unet [
26] to extract the road area. Cheng et al. [
27] proposed a new cascading end-to-end convolutional neural network named CasNet, which handles road surface extraction and centerline extraction tasks simultaneously. Liu et al. [
28] proposed RoadNet, a multitask convolutional neural network to predict the road surfaces, edges, and centerlines. Lu et al. [
29] adopted U-Net as the basic network of multitask learning and improved the robustness of feature extraction by applying multiscale feature integration. Batra et al. [
30] conducted joint learning on the location and division of roads and further improved the connectivity of roads. Focusing on the modeling of road context information, Qi et al. [
31] proposed a well-designed spatial information reasoning structure. More recently, Zhang et al. [
32] developed a novel road surface extraction method based on improved generative adversarial networks.
In the aspect of road centerline extraction from remote sensing images, the research method mainly focuses on obtaining the linear road skeletons by applying two general steps: (1) thinning and (2) tracking, where the thinning is often carried out after the extraction of road surfaces [
33]. Amini et al. [
34] used the parallel line theory to obtain the road skeleton in rural areas after the process of road refinement. Zheng et al. [
35] extracted road centerlines from VHR satellite images using support vector machine and tensor voting techniques. Miao et al. [
36] first identified potential road sections and then applied multivariate adaptive regression splines to extract the centerlines of the road in VHR images. Cheng et al. [
37] targeted the problems of the existence of burr and the inability in the extraction of intersections. They obtained the segmentation results through semisupervised segmentation, multiscale filtering, and multidirection nonmaximum suppression in another study [
38]. Gao et al. [
39] proposed a semiautomatic road centerline extraction method combining edge constraints and fast marching. Zhou et al. [
40] reconstructed roads via boundary distance field and tensor field after obtaining preliminary road and road centerline results. The advance of deep learning has largely facilitated the extraction of road centerlines, especially in the last five years. Wei et al. [
41] obtained the confidence map of road centerline based on an end-to-end convolutional neural network and then achieved accurate road centerline extraction by nonmaximal inhibition. Zhang et al. [
42] proposed a learning-based road network extraction framework via a multisupervised generative adversarial network, jointly trained by the spectral and topology features of the road networks. Cascading deep learning framework based on multitask networks has been the mainstream idea to solve road-related tasks [
27,
28,
29], which builds the foundation of our work.
However, most existing road datasets under ideal conditions cannot provide more possibilities for the task of road extraction, and the image information is not fully utilized when two related tasks are extracted separately. In this paper, we propose a two-task and end-to-end convolution neural network, termed Multitask Road-related Extraction Network (MRENet), for road surface extraction and road centerline extraction. Inspired by the main structure of Unet [
26], we use atrous convolution to expand the receptive field of feature extraction in the encoder and apply pyramid scene parsing pooling module (PSP pooling) to fuse global context information for pixel-level annotations in the decoder [
14,
43]. Through information transmission and parameter sharing between the two tasks, the characteristics and the results of road surface extraction are fed into the road centerline network by a concatenating operation to achieve a rapid extraction of single-pixel road centerlines. We select the complex road scenes in China from remote sensing images in GF-2 (details can be found in
Section 2.3) and manually annotate the acquired images as the dataset. In terms of the loss function, we use a weighted binary cross-entropy function to alleviate the background imbalance of the datasets. Although Chinese cities were selected as experimental area, the proposed model is expected to be applicable in other complex urban scenes.
The contributions of this paper mainly include the following three aspects:
- (1)
We introduce a new challenging dataset derived from GF-2 VHR images. The introduced dataset contains complicated urban scenes, which can be better considered as a reflection of the real world, providing more possibilities for road-related information extraction, especially under less ideal situations.
- (2)
We propose a new network named MRENet that consists of atrous convolutions and a PSP pooling module. The experiments suggest that our approach outperforms existing approaches in both road surface extraction and road centerline extraction tasks.
- (3)
We conduct a group of band contrast experiments to investigate the effect of incorporating NIR band on experimental results.
The remainder of this paper is organized as follows.
Section 2 describes road features and data sources.
Section 3 elaborates on the proposed network.
Section 4 presents the experiments and analysis, detailing our comparative experiments and analysis of experimental results. Further discussions are arranged in
Section 5. Finally,
Section 6 presents a summary of our work.
2. Materials
One of the main reasons for the great success of deep learning lies in the massive training data. The performance of deep learning algorithms is largely dependent on the scale and annotation of the training dataset [
44]. Open-source databases in the computer vision domain have greatly stimulated the development of deep learning. Unlike conventional natural images, VHR remote sensing images own unique characteristics, such as diverse scales [
45], special perspectives [
46], and complex backgrounds [
47]. Thus, training deep learning models on remote sensing images often requires specialized databases. DOTA [
44], AID [
48], and other similar datasets, to a certain extent, greatly enriched the database of remote sensing images.
However, it is worth noting that road datasets from VHR remote sensing images are still rare and do not meet the demand. Existing datasets for road extraction, such as the datasets proposed in CasNet [
27] and RoadNet [
28], contain images that were taken under ideal conditions. Similarly, the datasets used by Das et al. [
7] and Cheng et al. [
27] use images with simple and clear backgrounds without any occlusion. The dataset proposed by Liu et al. [
28] is more challenging as its images include the situation of tree occlusion. The images in the aforementioned road datasets were mainly collected from Google Earth with RGB bands. However, modern urban complex road scenes (e.g., overpass and ring road) and the impact of municipal facilities and road greening are often not included. Thus, their low complexity is inadequate to be considered as a reflection of the real world [
44].
Complex urban roads are characterized by composite lane structures, dense traffic, and complex color scheme. In addition, the shadow from the vegetation on both sides of the road, along with the shelter of high-rise buildings, further adds complexity, making road extraction a very challenging task. With the abundant remote sensing data, it is of great importance to establish a challenging dataset with complex scenes, benefiting road extraction tasks in complex environments.
In the following sessions, we summarize the characteristics of the road surface and road centerline under the complex urban scenes of VHR remote sensing images.
2.1. Characteristics of the Road Surface
The urban roads in the VHR remote sensing image mainly include the urban trunk roads and the internal roads of the parcels. The challenges in road extractions from VHR remote sensing images lie in the variance of road width and the existence of traffic management lines, isolation belt, cars, and shadows (cast by poles, buildings, roadside trees, and overpasses).
In terms of geometric characteristics, urban roads are generally described as a narrow and nearly parallel area with a certain length, stable width, and obvious edge. Both the edge and the centerline have obvious linear geometric features, often with a large length–width ratio;
In terms of radiation characteristics, roads have distinct spectral characteristics compared with vegetation, soil, and water, but they can be easily confused with artificial structures such as parking lots. The grayscale of the road tends to change uniformly, which generally shows the color of black, white, and gray. However, due to the existence of a large number of vehicles and pedestrians on the surface, such noise interference is inevitable;
In terms of topological characteristics, urban roads are generally connected with each other, forming a road network with high connectivity;
2.2. Characteristics of the Road Centerline
In remote sensing images, roads are symmetrically distributed in a geometric structure. Road centerlines are important feature lines in the geometric design of road alignment. The extraction of road centerlines is to obtain a linear road skeleton, which is a smooth and complete symmetrical line with single-pixel width.
Road centerlines are generally connected and have unique characteristics that include strong connectivity, complex topology, accurate refinement, and the central axis. Thinning and tracking are the two commonly used methods to extract the road centerlines, where thinning is further expanded on the results of road extraction.
2.3. Description of Datasets
Given the small scale and low diversity in existing datasets [
49], we developed a new challenging dataset by collecting VHR images from the GF-2 satellite in complex scenes. We manually marked the accurate reference map of road surface and road centerlines. Our dataset consists of two subdatasets: (1) road surface extraction dataset and (2) road centerline extraction dataset.
The spatial resolution of multispectral bands and the panchromatic band from the GF-2 satellite are 4 m and 1 m, respectively, as shown in
Table 1. The multispectral bands for training and testing include four bands: near-infrared (NIR), red (R), green (G), and blue (B). We further discuss the band selection and suitability analysis of remote sensing images in
Section 5.1. The road width ranges from 5 pixels to 50 pixels, and the width of the road centerline is 1 pixel.
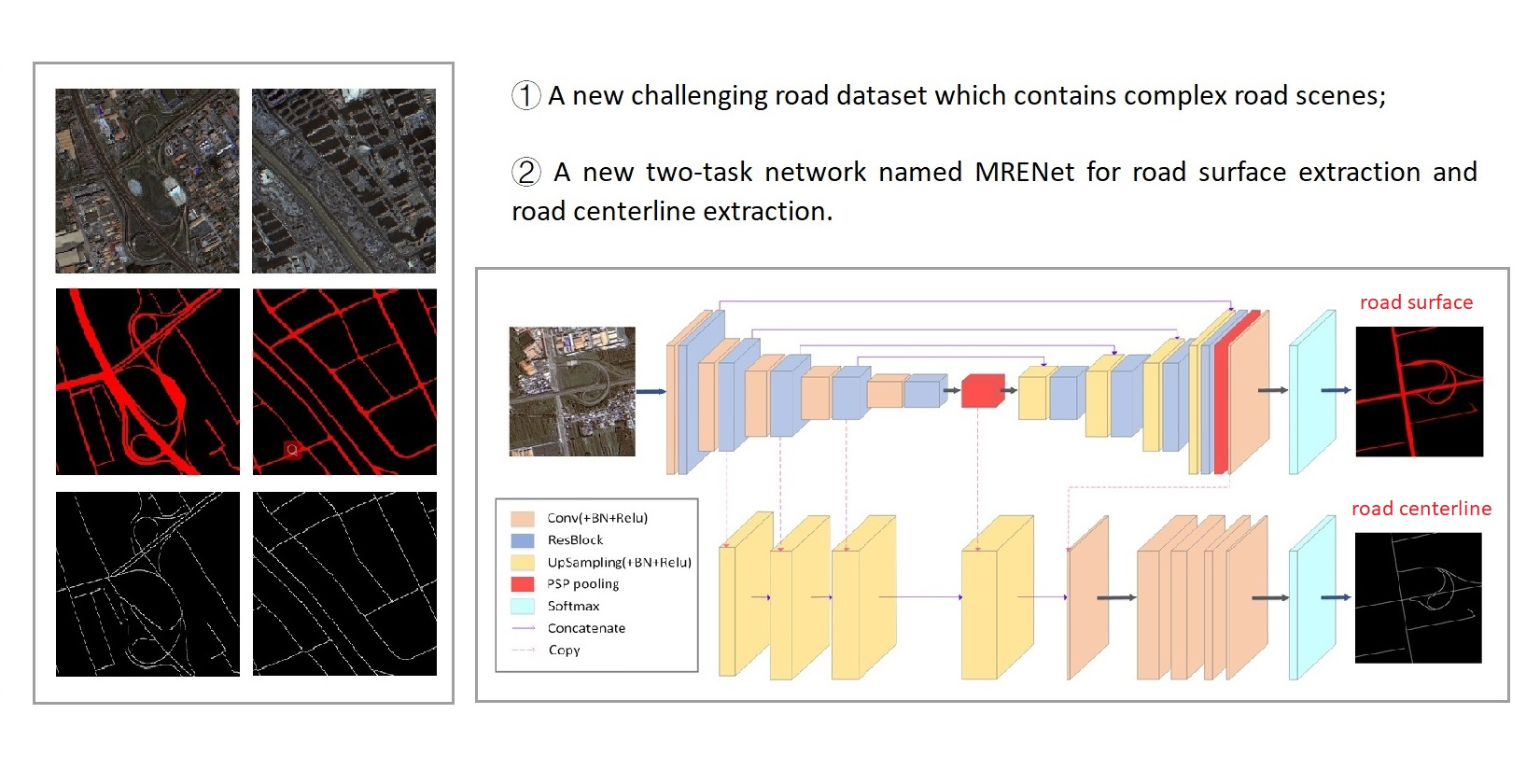
In the process of selecting areas and collecting samples, in order to avoid the problems of poor generalization ability and overfitting caused by excessive imbalance background, we deliberately select the concentrated area and typical area (e.g., overpasses, loops, intersections, etc.) and ignore regions with an excessive background in the image, as shown in
Figure 1. Compared with other datasets, the image background of the GF dataset is considered more complex, which can better represent the typical urban road situation in developing countries and in other complex urban fabrics.
All the testing images are not included in the training dataset, and they are uniformly cut into 256 × 256 pixels with overlapping of 64 pixels. A total of 13,590 images are divided into the training set, testing set, and validation set. 10,872 images are used to train the network, and the rest are evenly allocated for validation and testing.
3. Methodology
This section details the method proposed in this study. In particular,
Section 3.1 and
Section 3.2 introduce the theory of the Resblock and the pyramid scene parsing (PSP) pooling module.
Section 3.3 explains the advantages of multitask learning.
Section 3.4 presents the overall architecture of Multitask Road-related Extraction Network (MRENet).
3.1. ResBlock
In the process of semantic segmentation using FCN, the input image is first convoluted and further pooled, similar to the traditional CNN network. The convolution operation extracts image features, and the pooling operation enlarges the receptive field by reducing the image size. Two steps are repeated to obtain the most important features. In the decoding part, it is necessary to enlarge the size of the pooled image to its original size via upsampling. When the image size is reduced, the rich spatial information of pixels in the original images is lost, potentially leading to imbalanced local and global features.
VGGNet [
14] proves that using a small convolution kernel can effectively reduce the computational complexity of convolution operation rather than using a large convolution kernel. The deepening network structure and the regularization effect of a small convolution kernel also improve the performance of the model.
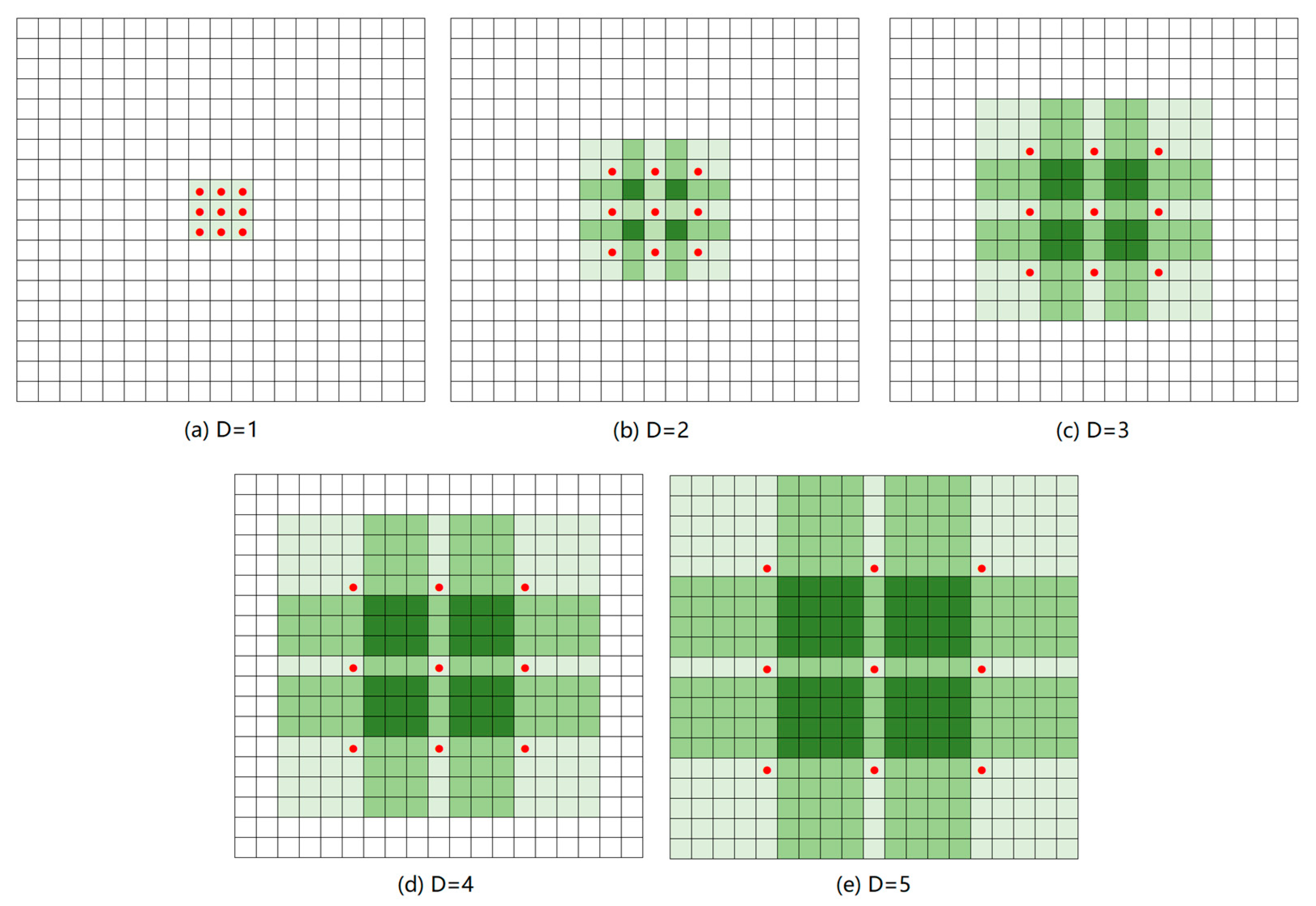
To obtain a larger receptive field and more spatial information without pooling operation, a common method is to introduce atrous convolution, a convolution that adds holes to the standard convolution layer to extract features. As shown in
Figure 2, compared with the ordinary convolution layer, the atrous convolution can effectively expand the receptive field of feature extraction, retaining the feature size and reducing the loss of spatial information of features without increasing parameters. It has been proved to be an effective feature extraction approach [
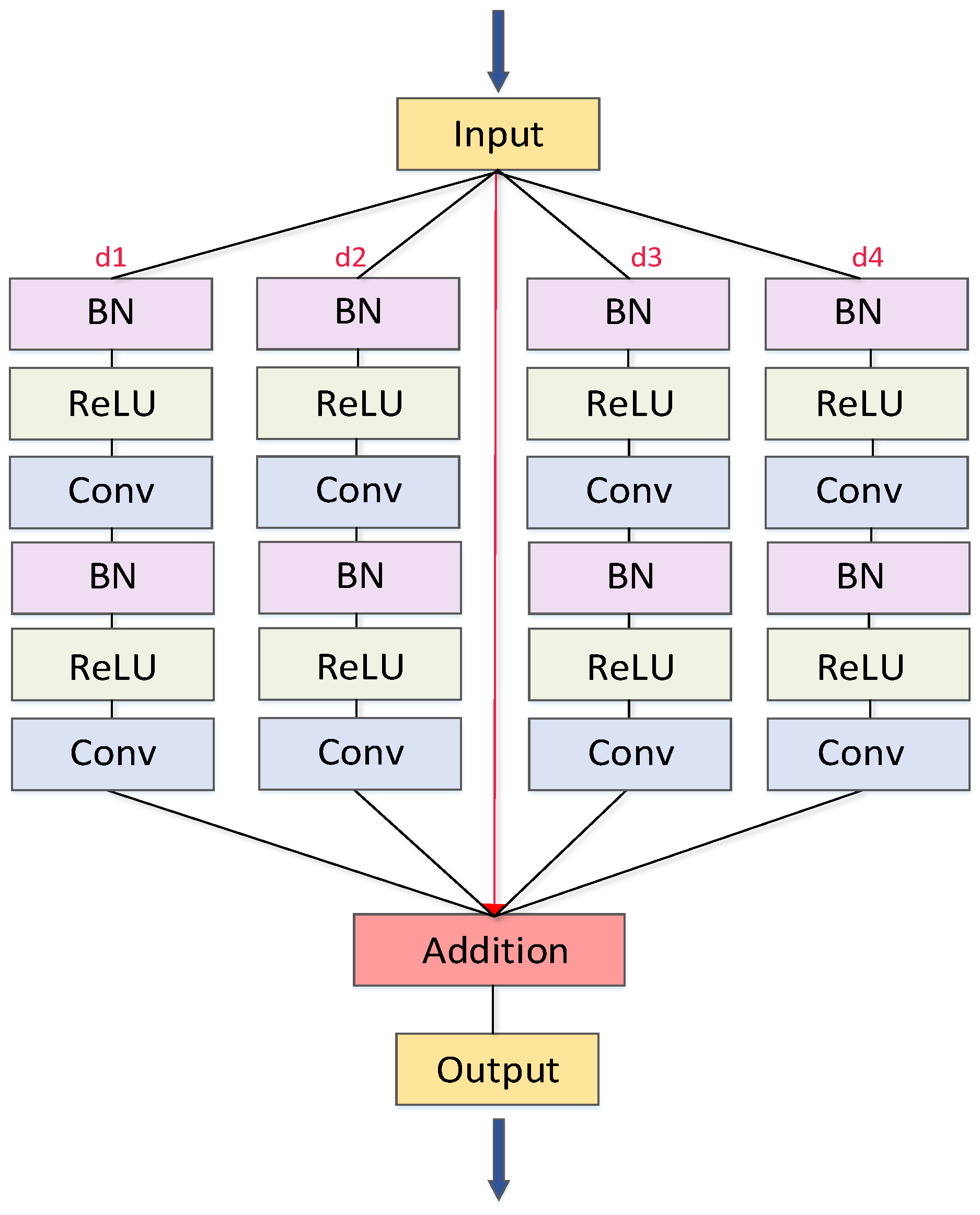
50]. We use multiple parallel atrous convolution branches in the Resblock module of the network to obtain the global characteristics of the road surface and road centerline in remote sensing images. As shown in
Figure 3, before each convolution operation, batch normalization and Relu activation function are used. The dilation rate is set to 1, 3, 15, and 31. For example, when the dilation rate is 31, the receptive field size is 123 × 123, which fully covers the road width (5–50 pixels). The parameters were derived from Diakogiannis et al. [
43].
The multiscale information can be obtained using different dilation rates on different scales. Each scale is an independent branch. These branches are combined by the addition operation and then connected by the next convolution layer. Such a design can effectively avoid redundant information, improve the performance by identifying the correlation among objects at positions in the image, effectively expand the receptive field of feature extraction, and avoid the loss of semantic meaning of a single-pixel in distinguishing small-scale feature extraction. In view of the problem of road extraction, more contextual information can be obtained by expanding the acceptance domain of feature extraction, which can well solve the problem of insufficient semantic features caused by the large coverage of ground objects and tree occlusion.
3.2. PSP Pooling
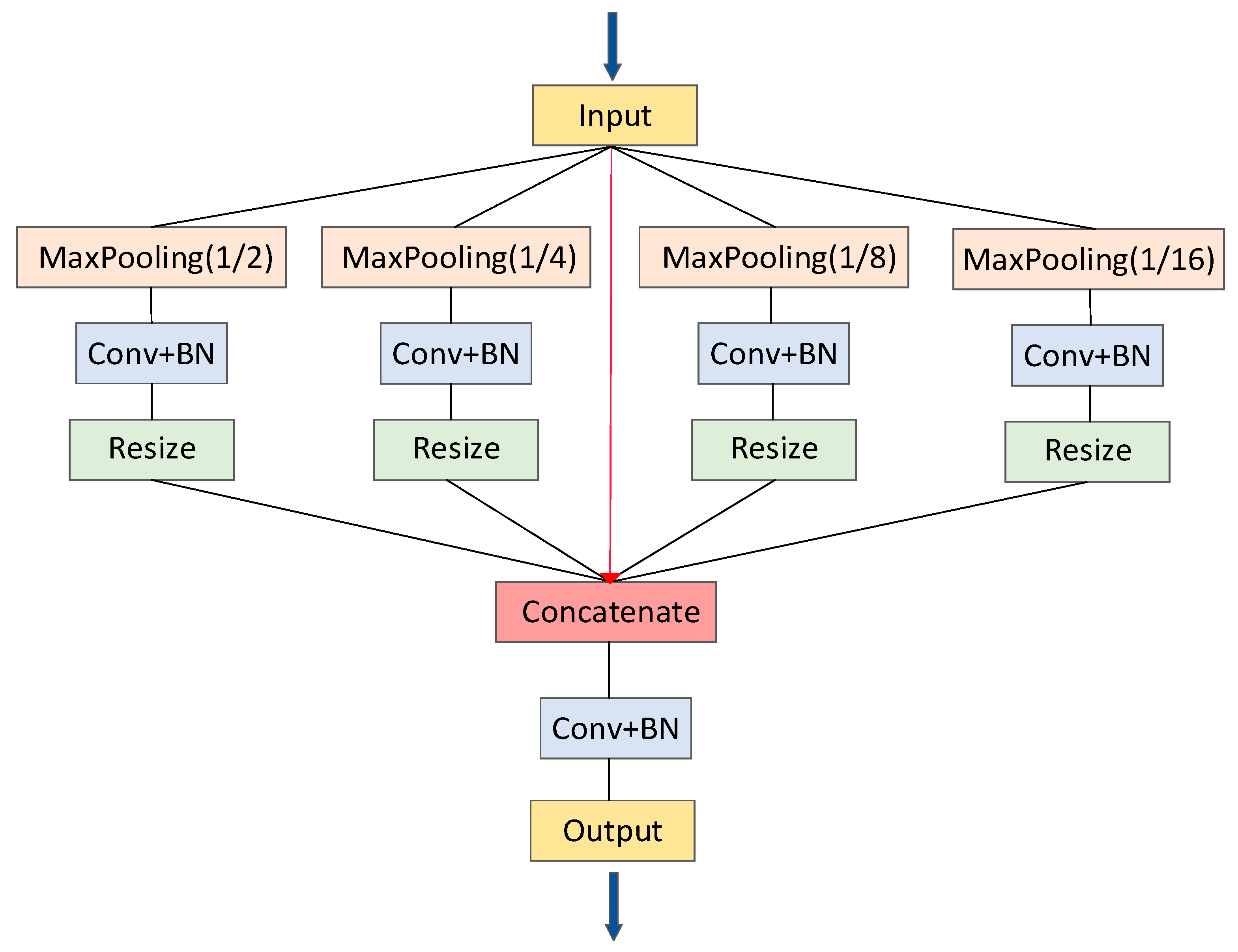
In the last stage of encoding and decoding, we apply PSP pooling to integrate multilevel features [
43,
51]. As shown in
Figure 4, the main idea of PSP pooling is to divide the initial input into four subregions at varying levels in the feature space and obtain the pooled features of these four subregions, respectively. A 1 × 1 convolution layer is used to reduce the dimension of the context features to maintain the weight of the global features. The size of the original image is further restored by a resize operation, and finally, the pyramid pooling features are obtained by splicing and fusion in the channel dimension.
The size of receptive fields in a neural network represents the range of context information obtained, but extraction errors can also occur after the acceptance domain has been expanded. The emphasis is on the need to fuse the key information received. The PSP pooling module integrates four different pyramidal scale features, leading to better characteristic expression ability. It can largely facilitate the integration of global context information of pixel-level annotation (low-level spatial information and high-level semantic information) and improve the performance of the model to distinguish roads from other ground objects [
52].
3.3. Multitask Learning
The basic idea of multitask learning is that when a task to be learned is similar or related, cross-sharing of information between tasks in the model may be advantageous [
53]. Multitask learning is achieved by learning tasks in parallel using shared representations. The shared representations lead to effective joint learning among multiple tasks [
54].
The tasks of road surface extraction and road centerline extraction are dependent to a certain extent. The road extraction results play a decisive role in the centerline extraction, while the centerline enhances the typical linear features of the road [
29]. Therefore, it is beneficial to introduce the concept of multitask learning towards a simultaneous extraction of the road surface and road centerline. Through information transmission and parameter sharing between the two tasks, massive training samples are not necessarily required, and the risk of overfitting is reduced.
Specifically, the problem of road surface extraction and road centerline extraction is to transfer the knowledge learned in the road surface extraction process to the road centerline extraction process. By cascading of two tasks, the features extracted from road surfaces are taken as the condition of centerline extraction, compensating for the potential problem of insufficient road centerline samples. Given the existence of noises and the unbalanced ratio between backgrounds and targets, deriving the optimal descent direction of the gradient is often computationally demanding. Multitask learning facilitates the feature sharing and transferring between road surface extraction and road centerline extraction, leading to the retrieval of complete semantic features and model robustness.
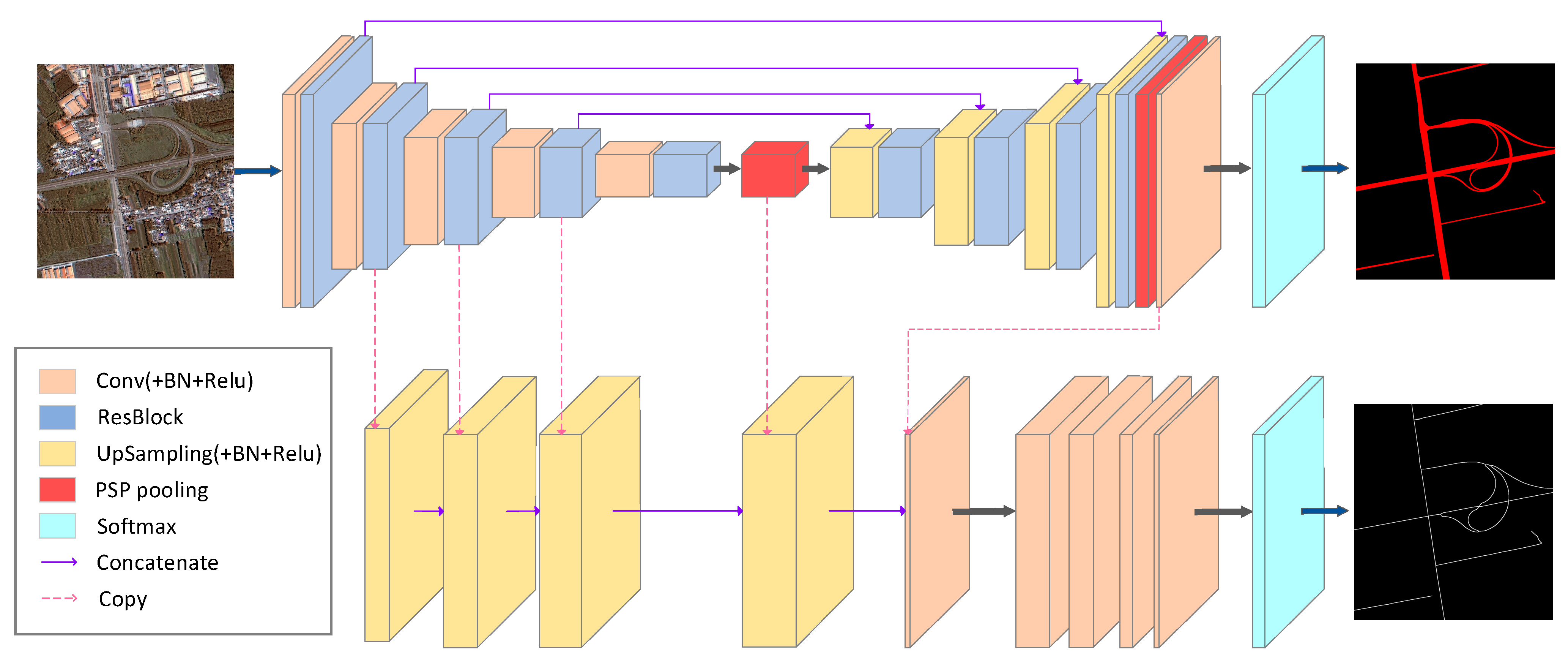
3.4. MRENet Architecture
In order to better solve the tasks of road surface extraction and road centerline extraction in complex scenes from VHR remote sensing images, we propose a new two-task, end-to-end deep learning network by adopting the Resblock module and PSP pooling module in the network based on the concept of multitask learning. The MRENet architecture is shown in
Figure 5. We regard the tasks of road surface extraction and road centerline extraction as two binary classification tasks. For road surface extraction, we use an encoder–decoder structure, i.e., a Resblock module, that uses multiple parallel atrous convolution branches to obtain the relationship between the road and environment backgrounds. The PSP pooling module further aggregates multiscale and multilevel features to obtain rich context information. Meanwhile, our network structure retains the skip connection structure in Unet [
26] and transmits the feature map directly from the encoder to the decoder through the combination operation. This information transmission achieves the integration of the deep and shallow features, providing more fine features for segmentation.
For road centerline extraction, we believe that the features extracted by the encoder in road surface extraction (e.g., road location, directionality, etc.) can be transferred and utilized in the task of road centerline extraction. We aim to achieve this convolution layer sharing to supplement the training difficulties caused by the lack of centerline samples. Different from CasNet [
27], we feed the road surface extraction results and the four convolution layers of the road network encoder into the road centerline network to achieve a rapid extraction of single-pixel road centerlines, as shown in
Figure 5.
Considering the unbalanced proportion of negative (background) and positive samples (road surface and road centerline) in the training dataset, we further improve the binary cross-entropy loss function by adding a corresponding weight for each category, which was determined by the proportion of the category in all samples.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}