3.1. Accuracy Evaluation
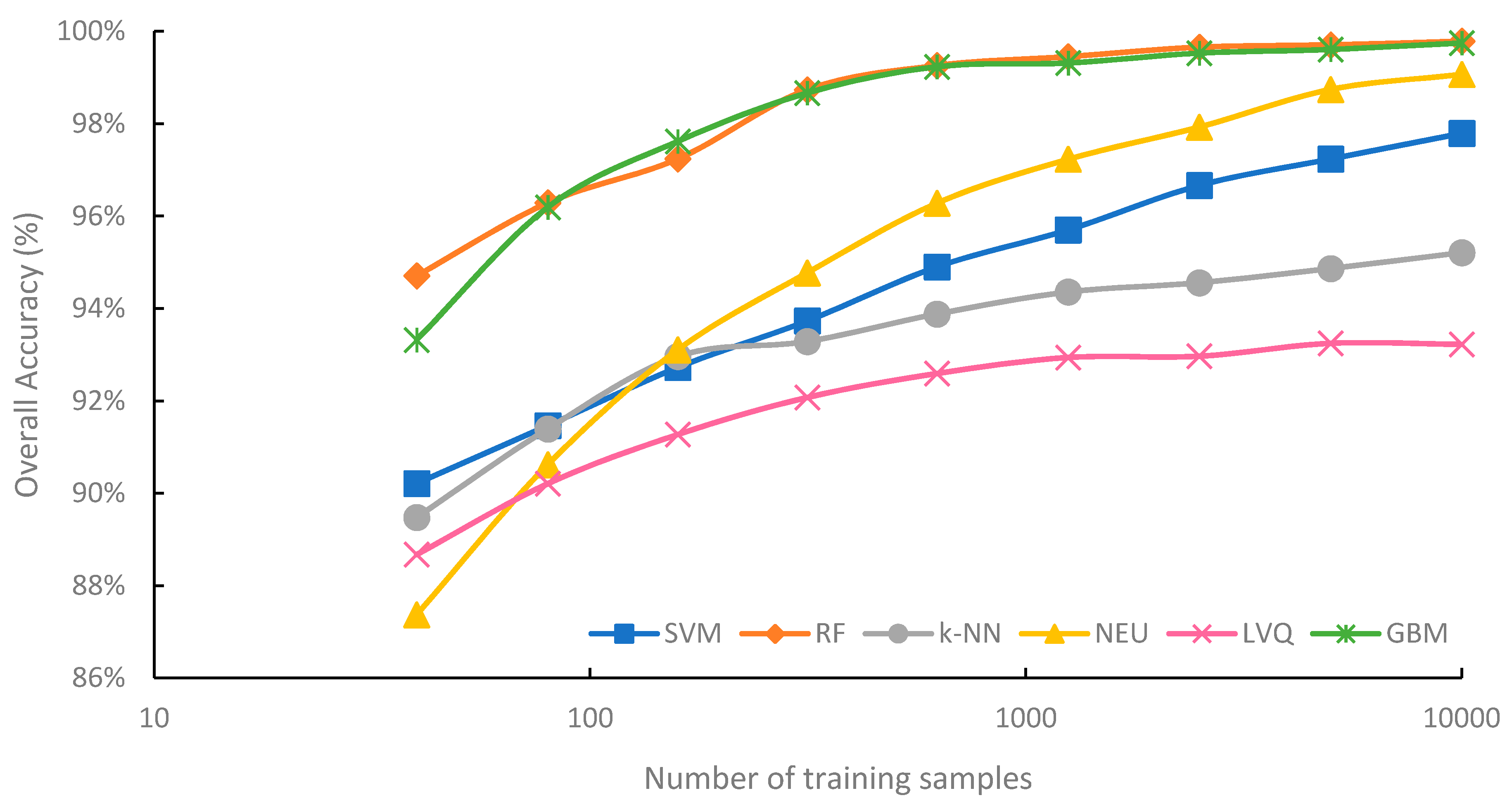
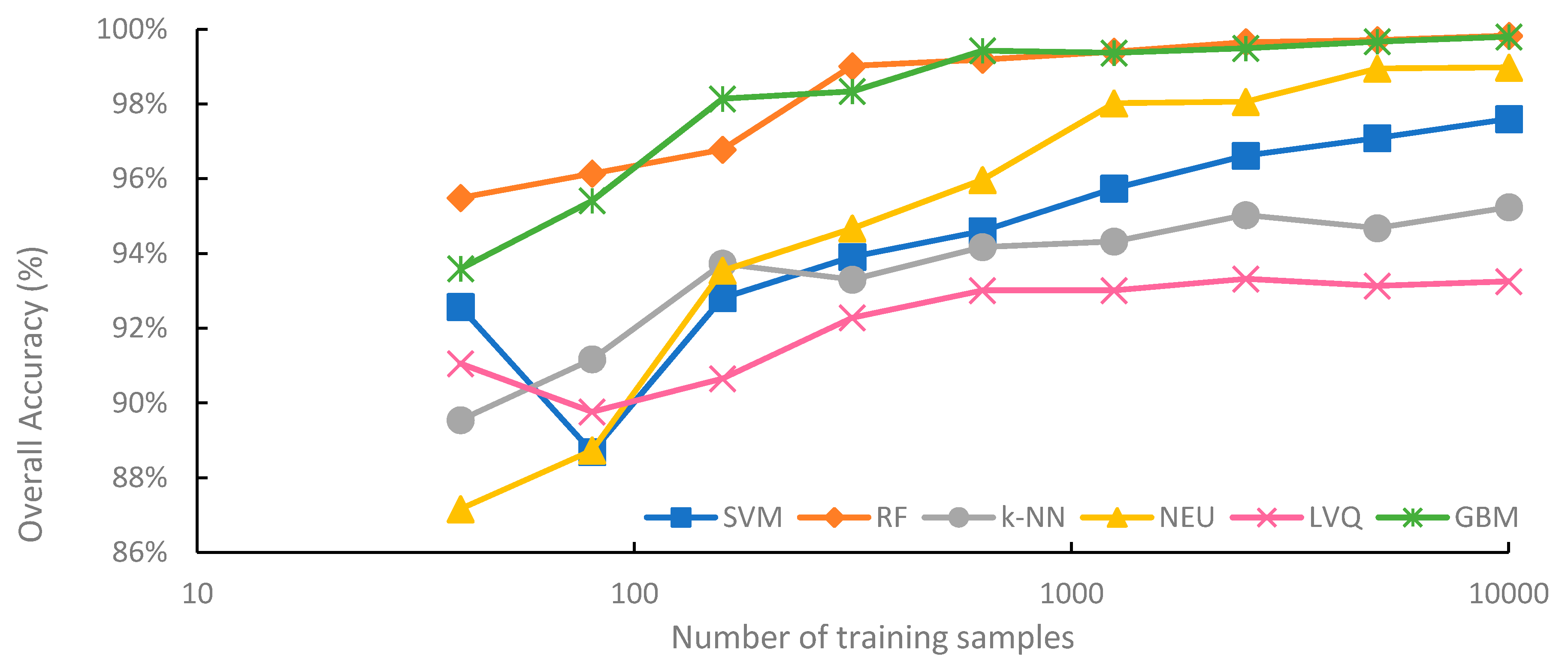
Figure 3 summarizes the mean overall accuracy of the six classification methods evaluated, based on sample size. Generally, overall accuracy increased with sample size. For all classification methods, highest average overall accuracy was produced from the 10,000-sample set, while the lowest average overall accuracy was produced from the 40-sample set. However, each classifier responded to increasing sample size differently. The highest average overall accuracy was 99.8%, for the RF classifications trained from the 10,000-sample set, while the lowest average overall accuracy was 87.4% for the NEU classifications trained from 40 samples.
The mean values shown in
Figure 3 hide considerable variation. This variation is therefore explored in
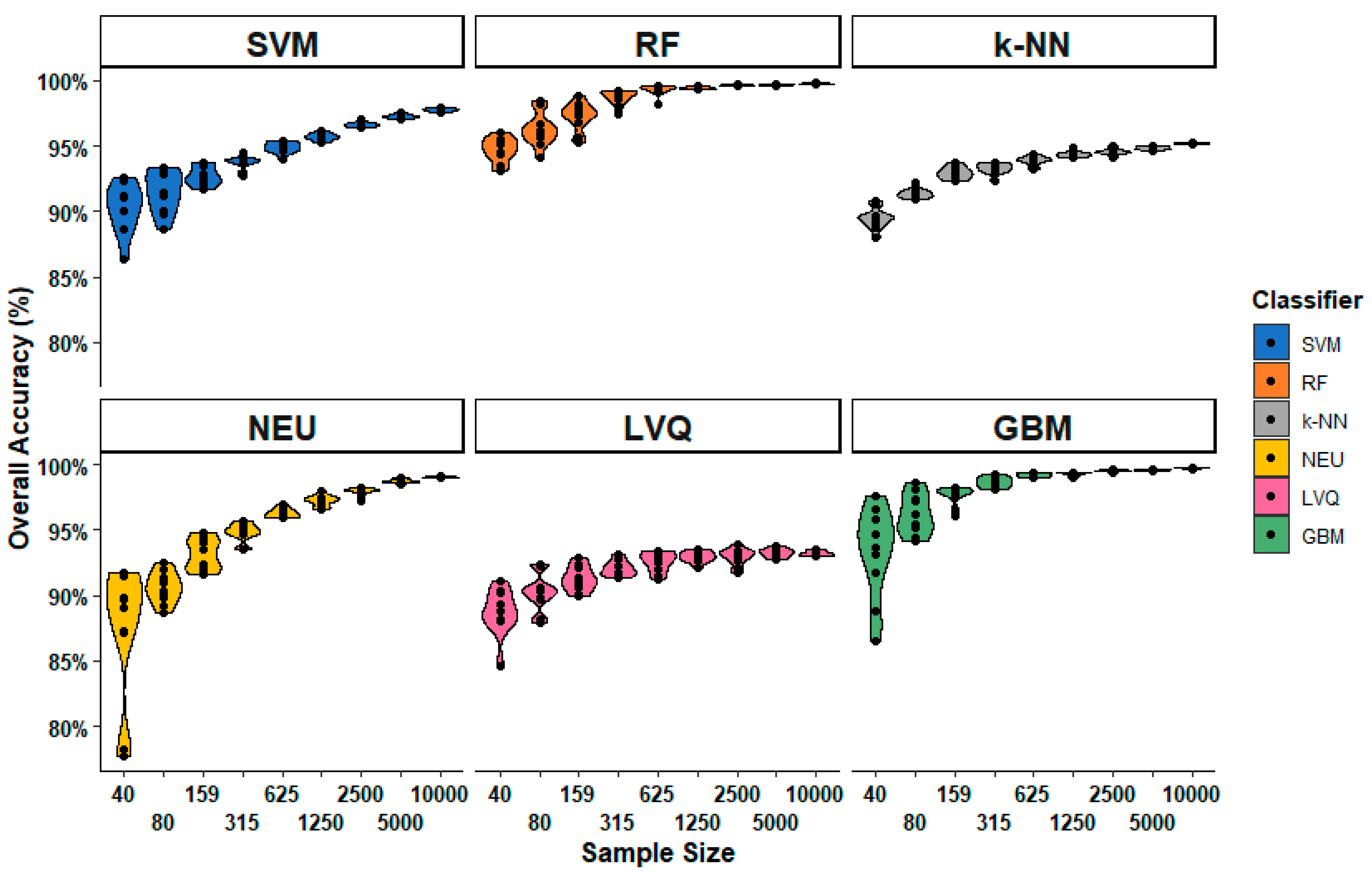
Figure 4, which shows the distribution of individual classification accuracies for each classification method and sample size. It is notable for each classification method, variation in the overall accuracy decreases as the sample size increases. This is expected; a small sample is more likely to produce a wider range of potential outcomes. However, the figure also shows that there are considerable differences between classifiers. For example, both RF and
k-NN appear to be good generalizers, in the sense that different training sets of the same size produce similar accuracies. In contrast, NEU and GBM produce a very wide range of accuracies with different training sets of the same size, especially for the smallest sample sets. When the number of training samples is very small, the specific samples chosen can be more important than the number of samples, even when the samples are drawn randomly, as in our experiments.
RF and GBM are notable for consistently achieving higher overall accuracy than the other four machine-learning algorithms, for all sample sizes. RF saw its highest average overall accuracy when trained from the 10,000-sample set (99.8%), and its lowest average accuracy when the training sample size was only 40 (94.7%). The lowest observed overall accuracy from an RF classification trained from 40 samples was 93.1%, while the highest was 99.8%, trained from 10,000 samples (
Appendix A). The difference between the highest and lowest overall accuracies of the 90 RF classifications was 6.7%, the smallest range of any classifier.
Although the overall accuracy of the RF classifier increased as training sample size increased, RF overall accuracy began to plateau when the sample size reached 1250. The difference in accuracy between the worst performing RF classification using 1250 samples and highest performing RF classification trained from 10,000 samples was just 0.5%. This plateauing of the overall accuracy is perhaps not very surprising; when classifications reach very high overall accuracy, there is little potential for further increases in overall accuracy. However, it is worth noting that the user’s and producer’s accuracies of all classes, on average, continued to increase with sample size (data not shown). Using a single classification iteration as an example, the user’s accuracy of the water class increased from 66.0% when trained from 1250 samples to 80.2% when trained from 10,000 samples.
GBM provided comparable average overall accuracy to RF and was generally the second-most accurate classifier. When trained from sample sizes larger than 40, the difference in mean overall accuracy between GBM and RF was consistently less than 0.5% for all sample sizes, with RF slightly outperforming GBM, except when trained from 159 samples, where mean overall accuracy of GBM was 0.4% higher than RF. It is notable that individual iterations of GBM classifications occasionally provided higher levels of overall accuracy than RF. For example, when trained from 40 samples, the highest reported overall accuracy for GBM was 97.6%, while the highest overall accuracy for RF was 96.0% (
Appendix A). When trained from samples sizes 80, 159, 315, and 625, some classification iterations of RF reported lower overall accuracies than the minimum reported accuracy by GBM for that sample size. Although GBM did have the second highest range of overall accuracy (
Figure 4) when trained from a single sample set, at 11.1%, variability in overall accuracy rapidly decreased when sample size was greater than 159.
NEU is notable for being the classification method most dependent on training sample size. For a training sample size of 315 or larger, the NEU classifier was the third-most accurate classifier (
Figure 3), with an average accuracy of 99.2% when trained with 10,000 samples. However, when trained with 40 samples, the average accuracy was 87.4%, the lowest average accuracy of the six methods. Of the six machine-learning algorithms investigated in this study, NEU had both the largest difference in average overall accuracy between the classifications trained from 10,000 and 40 samples, 11.7% (
Figure 3), and the largest range of accuracy of classifications trained from the same sample size, at 14.0%, from a low of 77.7% to a high of 91.7% when trained from 40 samples (
Figure 4). In addition, the 77.7% minimum accuracy for NEU was the lowest accuracy of all the 540 classifications.
The SVM classifier was generally intermediate in classification accuracy, generally ranking third or fourth in terms of average overall accuracy (
Figure 3). Of all the classifiers, SVM showed the greatest increase in average overall accuracy, 0.6%, for the increase in sample size from 5000 to 10,000. This is notable, as it suggests that SVM benefits from very large sample sets (n = 10,000) and does not plateau in accuracy as much as RF and GBM classifiers do when the sample size becomes very large (e.g., 1000 and greater). This is likely due to larger samples containing more examples in the feature space that can be used as support vectors to optimize the hyperplane, and thus identify a more optimal class decision boundary for the SVM classification. SVM, when compared to the other five classifiers, showed generally intermediate to large ranges of individual overall accuracies for specific sample sizes (
Figure 4). For example, SVM had the greatest range for 80 samples, and the second largest range when trained from 5000 and 10,000 samples.
k-NN produced the second-lowest average overall accuracy of the machine-learning classifiers for larger sample sizes, ranging from 315 to 10,000 (
Figure 3).
k-NN showed a tendency to plateau in accuracy when trained with large samples sets, with a difference in average overall accuracy of just 2.1% between training with 315 and 10,000 samples. Notably,
k-NN also had the smallest range of overall accuracy when sample sizes ranged from 40 to 159 (
Figure 4). This is surprising as
k-NN and other lazy learning classifiers acquire their information entirely from the training set.
LVQ had the lowest average overall accuracy among all six classifiers, except when trained the smallest sample size of 40. The performance gap between LVQ and the other five classifiers generally increased with sample size. Average overall accuracy of LVQ plateaued when the sample size reached 315, with a less than 1.2% difference between the average accuracy of LVQ trained from 315 samples at 92.1%, and 10,000 samples at 93.2%. LVQ is notable for generally large variations in overall accuracy at specific sample sizes, at least in comparison to other classifiers, when trained from large sample sets, ranging from 2500 to 10,000 samples. This suggests that LVQ may be more sensitive to the composition of the dataset than similar methods such as k-NN, as random training samples are selected as codebook vectors to optimize the model.
Variability in overall classification accuracy, (i.e.,
Figure 4), such as that of SVM, has important implications that are illustrated in
Figure 5. To create this figure, a single training set at each sample size (40, 80, etc.) was used to generate each of the six classifications. Although
Figure 5 is broadly similar to
Figure 3, the pattern is much noisy, with several cases where a larger number of training samples is actually less accurate than a smaller number. For example, for SVM, when the number of training samples increased from 40 to 80, the overall accuracy decreased by 3.9%, from 92.6% to 88.7%.
As indicated in
Table 7 and
Table 8, the lower performance of SVM trained with 80 samples compared to SVM trained with 40 samples was partly due the former classification’s lower user’s and producer’s accuracies for grassland and lower producer’s accuracy for forest, the majority class. It is surprising that these two classes, the largest classes by area, should vary so in accuracy. However, since the training samples are selected randomly, and SVM focuses exclusively on support vectors (i.e., potentially confused samples) for separating classes, it suggests SVM may be inherently more inconsistent in its likely accuracy for a particular size. For the SVM trained with just 40 samples, the water class, which has only 4 training samples, resulted in the second-lowest producer’s accuracy for all 54 classifications in this series, at 47.8%. This is evident in
Figure 6 in the visual analysis section.
The training samples at each size were selected independently, which means that the training sample with 80 samples is unlikely to include many, if any, of the samples from the 40-sample set. In a real-world application, an analyst considering expanding a training data set would naturally want to include any previously collected data in the expanded data set. Thus, an analyst deciding to add to training data set would not necessarily experience the kind of decline in accuracies shown in
Figure 5. However, the graph does illustrate that the benefits of increasing the sample size are not always predictable, and why it can be so difficult to generalize from individual experiments, particularly for classification methods such as SVM that appear to be quite sensitive to the specific training samples chosen.
3.2. Visual Analysis
Figure 6 illustrates example classifications for a subset region (see
Figure 1 for the subset location). For consistency, for each sample size (e.g., 40 samples), the same training data set was used for each classifier, and the overall accuracy of the resulting classifications is graphed in
Figure 5. Only the classifications with the highest and lowest overall accuracy for each classifier are shown in
Figure 6. In this iteration of the classifications, the SVM and LVQ classifications trained from 80 samples produced a lower overall accuracy than classifications trained from 40 samples.
Visual inspection of the example classifications (
Figure 6) indicates clear improvements in classifications trained from larger sample sets. Most of the errors were misclassifications of the soil and water classes. Notably, in the SVM classification trained from 80 samples, and the GBM classification trained from 40 samples many water objects were misclassified as soil and vice versa. These errors were reduced in the SVM classification trained from 10,000 samples. Although the user’s accuracy of water only increased by 2.5% between the SVM classification trained from 80 samples and the SVM classification trained from 10,000 samples, the producer’s accuracy of the water class improved by 39.1% and the user’s accuracy of the soil class improved by 35.1% (
Table 9).
Visual inspection of the best overall classification from the sample classifications, RF trained from 10,000 samples, displayed in
Figure 6, shows that while there were still some clear misclassifications of the water class, especially in the large lake located near 39°40′, −79°50′, and noted by the red circle in
Figure 7, overall classification quality was high.
In this iteration all classifiers generally mapped the forest class well, with the lowest user’s accuracy reported as 90.5% with k-NN, and the lowest producer’s accuracy reported as 89.0% with NEU, in both instances trained from 40 samples. As forest was the majority class in this case, comprising nearly 81% of the validation set, the good performance of the forest class by all classifiers contributed to relatively high overall accuracies for all classifications.
3.3. Computational Complexity
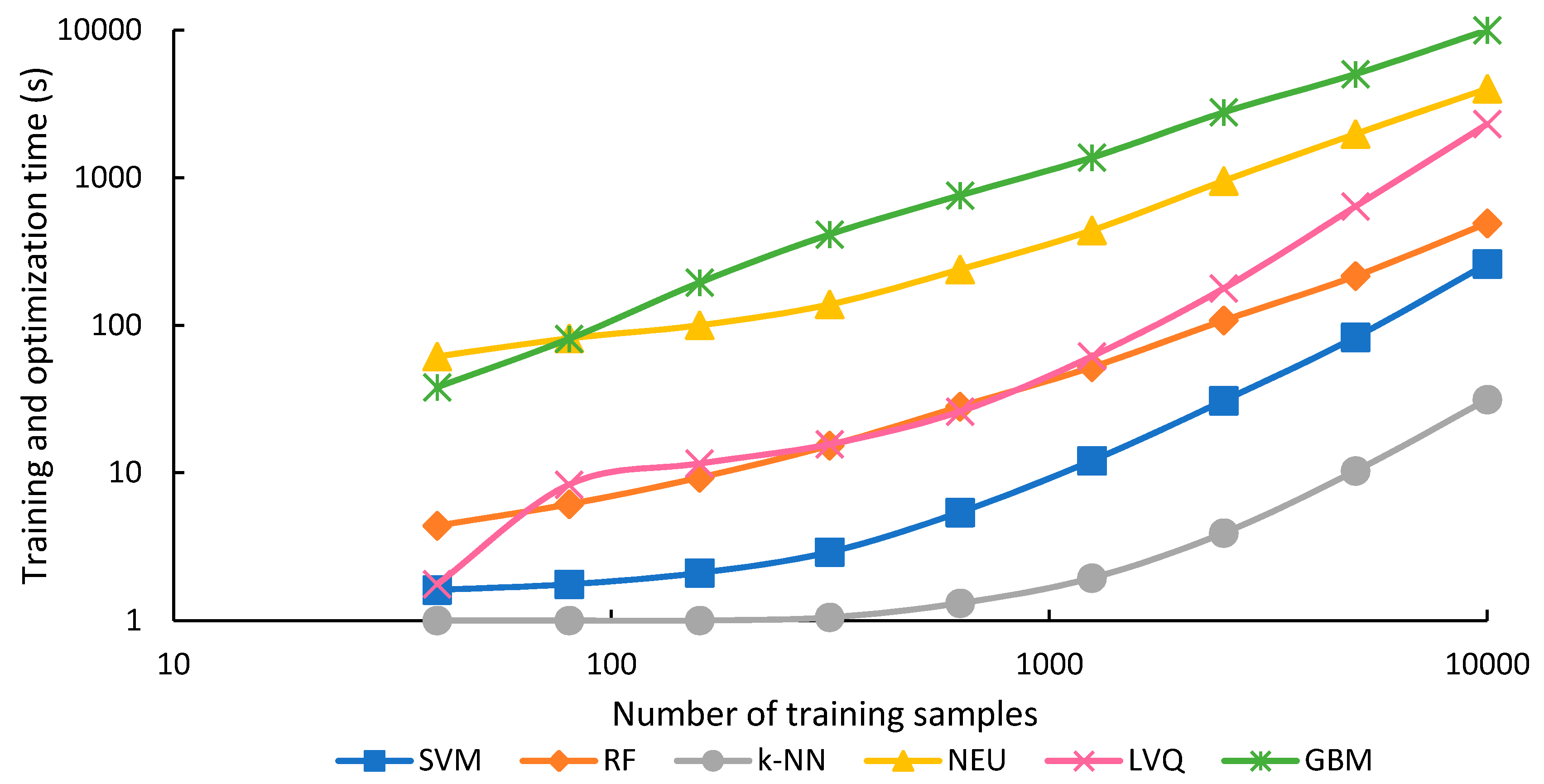
The training and optimization time for each classifier for each sample size is shown in
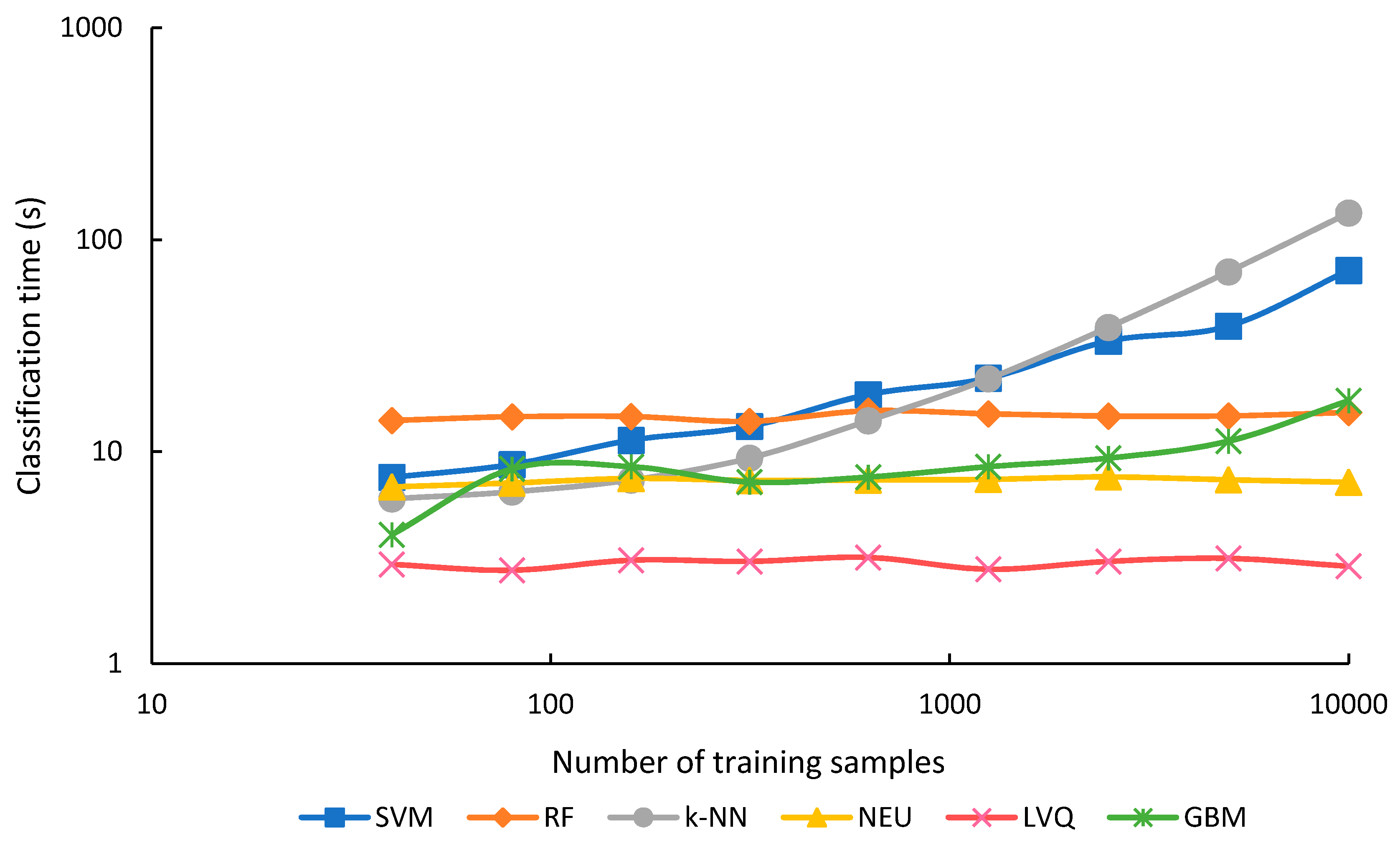
Figure 8, and the classification time in
Figure 9. Training and optimization time generally took much longer than classification for all classifiers, except for
k-NN and SVM when training set sizes were smaller than 2500, and RF when training set size was 159 or smaller. Training and optimization time generally increased for all classifiers as the training set size increased (
Figure 8). This is expected for most classifiers. However, for
k-NN, a lazy classifier, the increased time is presumably associated with the optimization, since this method has no training. In contrast to training and optimization time, classification time was generally unaffected by training sample size, except for SVM and
k-NN, and to a smaller degree, GBM (
Figure 9). Summing both training and classification time indicates that GBM was generally the most expensive algorithm in terms of processing time. NEU was second, LVQ third, RF fourth, SVM fifth, and
k-NN was the fastest of all algorithms.
GBM was generally the slowest algorithm in terms of training and optimization time (
Figure 8), and for all but the sample sets with 40 and 80 samples, was 2 to 3 times slower than the second-slowest algorithm, NEU. GBM was also very expensive in terms of computational resources; training the GBM classifier with 10,000 samples consumed over 27 GB of memory. GBM was generally intermediate in terms of classification time (
Figure 9). GBM was sensitive to numbers of training samples for the very smallest and largest training sets, but classification time was relatively constant for training sets between 80 and 2500 samples.
NEU was also slow in training and optimization time, almost two orders of magnitude slower than RF,
k-NN, and SVM. However, NEU was generally intermediate to fast in terms classification time. Overall, long processing times of NEU classifiers compared to other supervised machine-learning algorithms was also noted in [
2].
LVQ training and optimization time was the most sensitive to sample size, increasing 1310-fold, as the sample size increased from 40 to 10,000 samples. However, even with 10,000 samples, LVQ was less slow than GBM and NEU. On the other hand, LVQ was notably faster in classification time than all the other classifiers, irrespective of sample size.
RF generally took 4 times as long as SVM to train and optimize, though this difference declined for larger numbers of training samples, for example, to only 1.8 times as long with 10,000 samples. This suggests that the training and optimizing time for SVM does not scale as efficiently as RF with increasing sample size. Furthermore, RF training time could potentially be reduced by reducing the value of the parameter that determines the number of trees. Because RF classification was not affected by sample size, but SVM was, the rank of the two classifiers in terms of classification speed switched at a sample size of 315. Below this number of samples, SVM was faster, above it, RF was faster.
The
k-NN classifier was by far the most efficient classifier in terms of training and optimizing time, with the time for 40, 80, and 159 sample sizes taking less than 1 s, and the time for 2500 samples taking nearly 4 s. However, as a lazy learning classifier, requiring each unknown to be compared to the original training data,
k-NN classification was the method most sensitive to the training sample size. For training samples of 2500 and greater, it required the longest time for classification. In addition, the computation memory demands of
k-NN are potentially substantial for large numbers of training samples. For example, one approach to optimize the
k-NN search is to store in memory the distance between every pair of training instances, which tends to scale as a function of
n2, where
n is the number of training samples [
81].




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








