
Optical Remote Sensing Image Denoising and Super-Resolution Reconstructing Using Optimized Generative Network in Wavelet Transform Domain


Abstract
:1. Introduction
- A method named RRDGAN is proposed. RRDGAN combines denoising and super-resolution reconstruction into a unified framework to obtain better quality optical remote sensing images.
- The generator of RRDGAN combines residual learning and dense connection to obtain better PSNR results, and the discriminator uses relativistic loss to make the entire network converge better. Generator also uses TV loss to reconstruct better details.
- RRDGAN is implemented in WT domain, which could handle different parts of LR image well, respectively.
2. Related Works
2.1. Optical Image Super-Resolution Reconstruction Method
2.2. Single Image Denoising Method
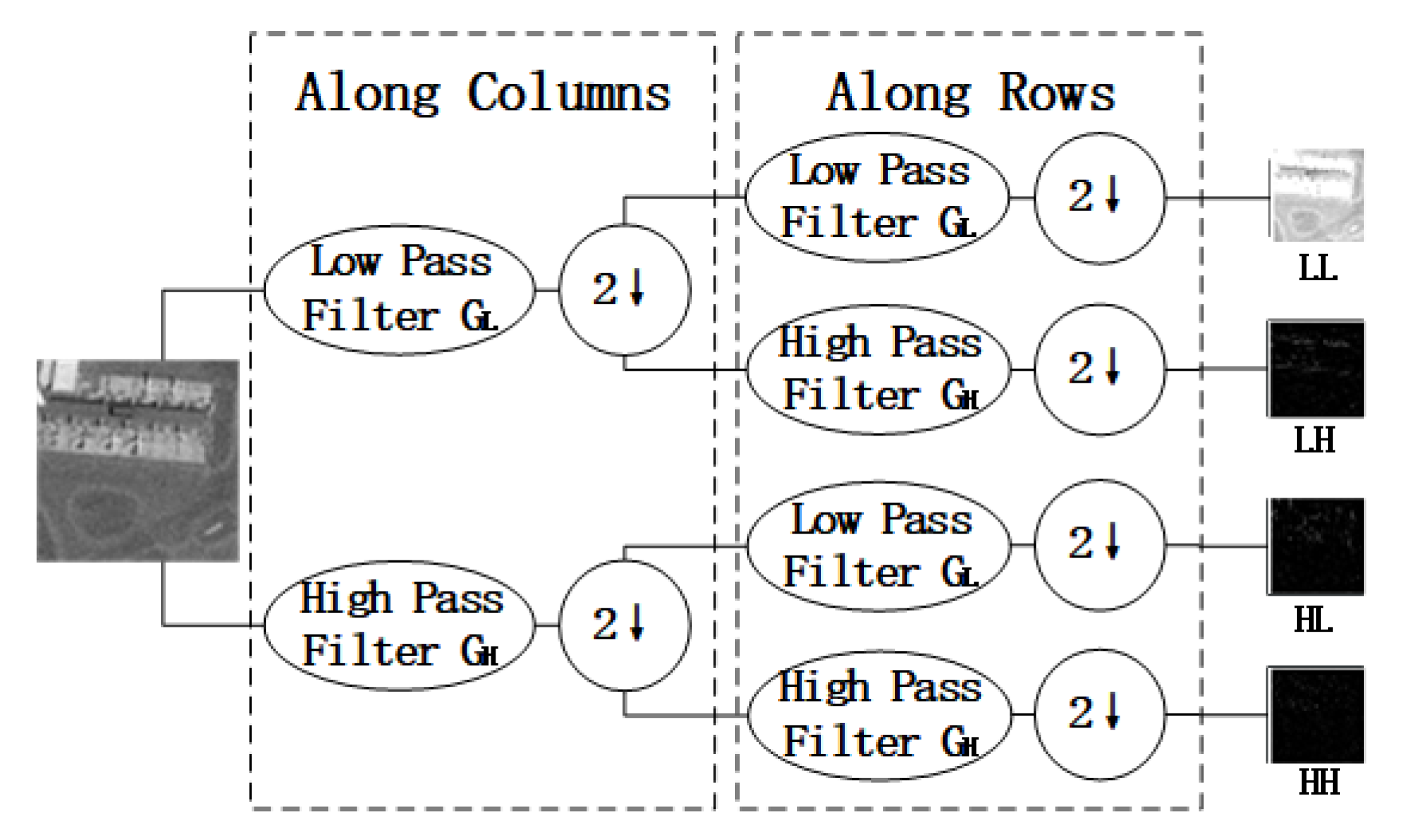
2.3. Single Image Restoration in Wavelet Transform Domain
3. Proposed Method
3.1. Problem Definition
3.2. Proposed Method
3.2.1. Network Architecture
3.2.2. The Loss Function
4. Experimental Results
4.1. DataSets
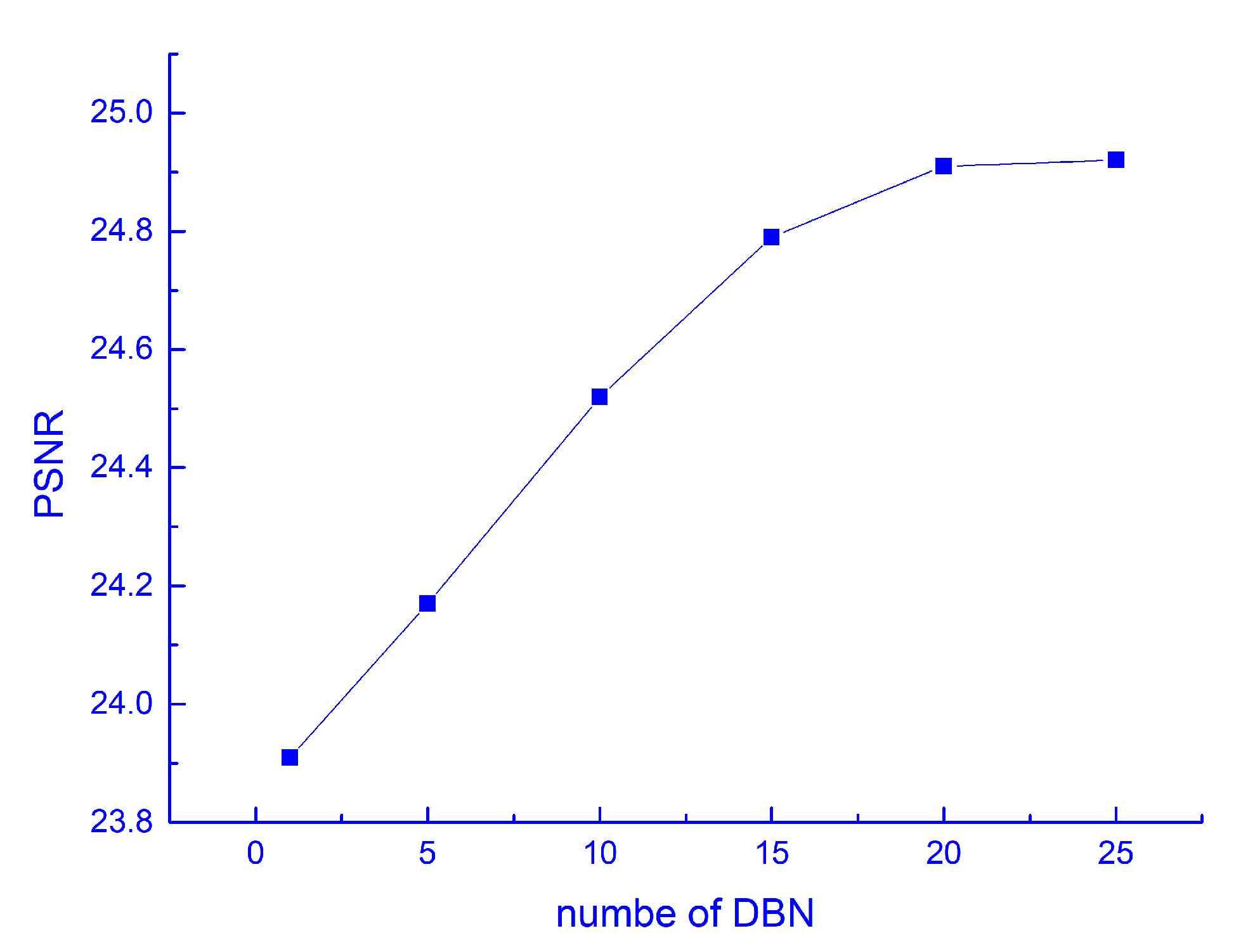
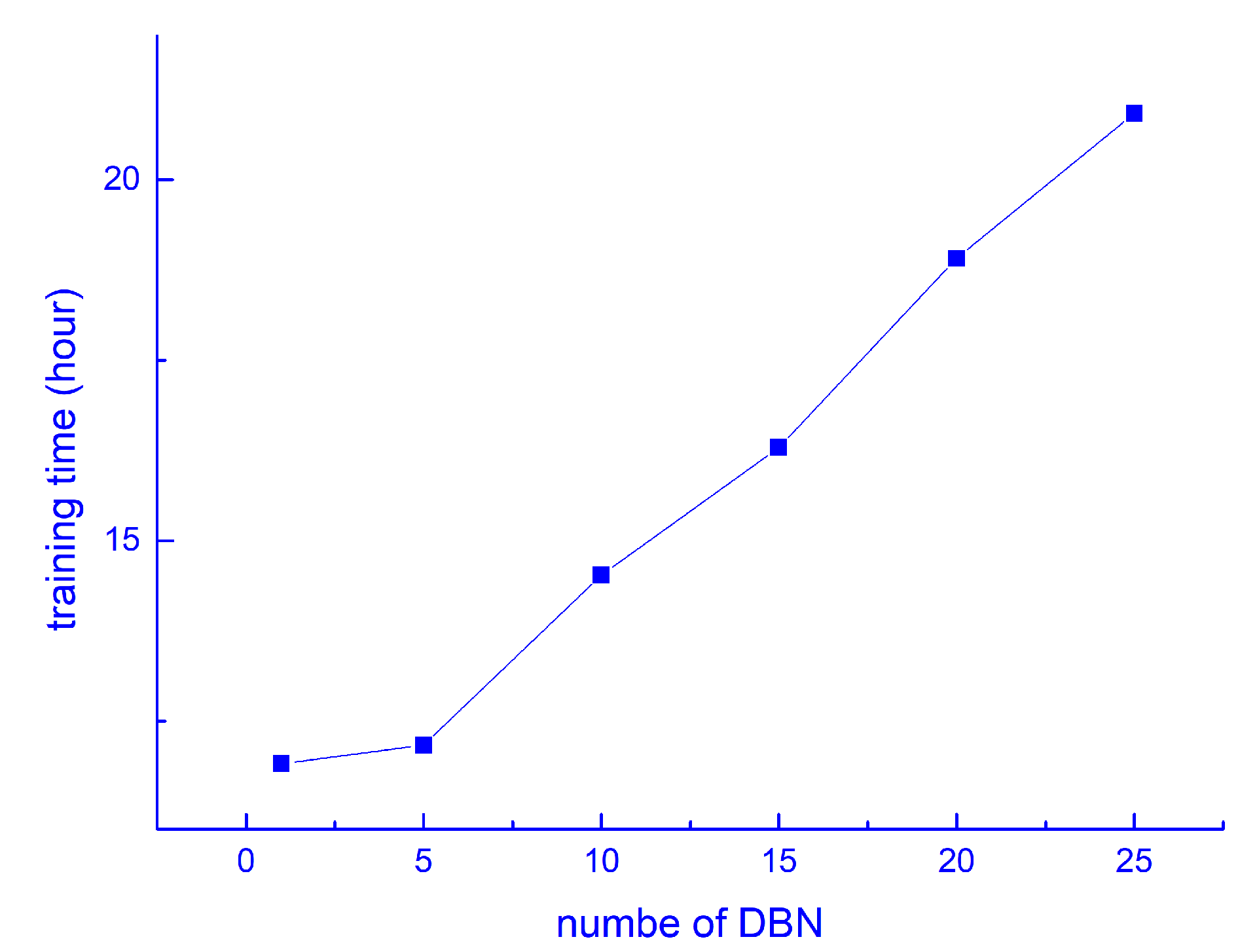
4.2. Implementation Details
4.3. Results and Analysis
5. Discussions
5.1. Different from ESRGAN
5.2. Deal with White Gaussian Noise
5.3. Others
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| HQ | High spatial Quality |
| LQ | Low spatial Quality |
| HR | High spatial Resolution |
| LR | Low spatial Resolution |
| CNN | Convolutional Neural Network |
| GAN | Generative Adversarial Network |
| TV | Total Variation |
| WT | Wavelet Transform |
References
- Xu, W.; Xu, G.; Wang, Y.; Sun, X.; Lin, D.; Wu, Y. Deep Memory Connected Neural Network for Optical Remote Sensing Image Restoration. Remote Sens. 2018, 10, 1893. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Hou, H.; Andrews, H. Cubic spline for image interpolation and digital filtering. IEEE Trans. Image Process. 1978, 26, 508–517. [Google Scholar]
- Dodgson, N. Quadratic interpolation for image resampling. IEEE Trans. Image Process. 1997, 6, 1322–1326. [Google Scholar] [CrossRef]
- Huang, T.; Tsai, R. Multi-frame image restoration and registration. Adv. Comput. Vis. Image Process. 1984, 1, 317–339. [Google Scholar]
- Kim, S.; Bose, N.; Valenauela, H. Recursive reconstruction of high resolution image from noisy undersampled multiframes. IEEE Trans. Acoust. Speech Signal Process. 1990, 38, 1013–1027. [Google Scholar] [CrossRef]
- Shao, Z.; Wang, L.; Wang, Z.; Deng, J. Remote Sensing Image Super-Resolution Using Sparse Representation and Coupled Sparse Autoencoder. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2663–2674. [Google Scholar] [CrossRef]
- Daoui, A.; Yamni, M.; Karmouni, H.; Sayyouri, M.; Qjidaa, H. Stable computation of higher order Charlier moments for signal and image reconstruction. Inf. Sci. 2020, 521, 251–276. [Google Scholar] [CrossRef]
- Hmimid, A.; Sayyouri, M.; Qjidaa, H. Image classification using separable invariant moments of Charlier-Meixner and support vector machine. Multimed. Tools Appl. 2018, 77, 1–25. [Google Scholar] [CrossRef]
- Yamni, M.; Daoui, A.; Karmouni, H.; Sayyouri, M.; Qjidaa, H.; Flusser, J. Fractional Charlier moments for image reconstruction and image watermarking. Signal Process. 2020, 171, 107509. [Google Scholar] [CrossRef]
- Mesbah, A.; Berrahou, A.; Hammouchi, H.; Berbia, H.; Qjidaa, H.; Daoudi, M. Lip Reading with Hahn Convolutional Neural Networks. Image Vis. Comput. 2019, 88, 76–83. [Google Scholar] [CrossRef]
- Li, F.; Xin, L.; Guo, Y.; Gao, D.; Kong, X.; Jia, X. Super-Resolution for GaoFen-4 Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2015, 15, 28–32. [Google Scholar] [CrossRef]
- Huang, G.; Zhuang, L.; Maaten, L. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Feng, X.; Su, X.; She, J.; Jin, H. Single Space Object Image Denoising and Super-Resolution Reconstructing Using Deep Convolutional Networks. Remote Sens. 2019, 11, 1910. [Google Scholar] [CrossRef] [Green Version]
- Glasner, D.; Bagon, S.; Irani, M. Super-resolution from a single image. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef]
- Pérez-Pellitero, E.; Salvador, J.; Ruiz-Hidalgo, J.; Rosenhahn, B. PSyCo: Manifold span reduction for super resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1837–1845. [Google Scholar]
- Timofte, R.; De Smet, V.; Van Gool, L. PSyCo: A+: Adjusted anchored neighborhood regression for fast super-resolution. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 111–126. [Google Scholar]
- Salvador, J.; Pérez-Pellitero, E. Naive Bayes super-resolution forest. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 325–333. [Google Scholar]
- Song, H.; Liu, Q.; Wang, G.; Hang, R.; Huang, B. Spatiotemporal Satellite Image Fusion Using Deep Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 821–829. [Google Scholar] [CrossRef]
- Kanakaraj, S.; Nair, M.S.; Kalady, S. SAR Image Super Resolution using Importance Sampling Unscented Kalman Filter. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 562–571. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Lee, J.; Lee, K. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 142–149. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Mahendran, A.; Vedaldi, A. Understanding Deep Image Representations by Inverting Them. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Alexia, J.-M. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5835–5843. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Guo, Q. Image Super-Resolution Using Dense Skip Connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Jain, V.; Seung, H. Natural image denoising with convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–10 December 2008; pp. 769–776. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [Green Version]
- Mao, X.; Shen, C.; Yang, Y. Image Restoration Using Convolutional Auto-encoders with Symmetric Skip Connections. arXiv 2016, arXiv:1606.08921. [Google Scholar]
- Nhat, N.; Peyman, M. A Wavelet-Based InterpolationRestoration Method For Superresolution (Wavelet Superresolution). Circuits Syst. Signal Process. 2000, 19, 321–338. [Google Scholar]
- Yang, J.; Zhao, Y.; Chan, J.; Xiao, L. A Multi-Scale Wavelet 3D-CNN for Hyperspectral Image Super-Resolution. Remote Sens. 2019, 11, 1557. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Li, J.; Xiao, H.; Jin, X.; Yan, S.; Feng, J. Dual Path Network. arXiv 2017, arXiv:1707.01629. [Google Scholar]
- Shi, W.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference On Advances in Geographic Information Systems, San Jose, CA, UAS, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Ma, C.; Yang, C.Y.; Yang, X.; Yang, M.H. Learning a no-reference quality metric for single-image super-resolution. CVIU 2017, 158, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a completely blind image quality analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Huang, H.; He, R.; Sun, Z.; Tan, T. Wavelet-SRNet: A Wavelet-Based CNN for Multi-scale Face Super Resolution. ICCV 2017, 2, 175–213. [Google Scholar]
- Lebrun, M. An analysis and implementation of the BM3D image denoising method. Image Process. Line 2012, 2, 175–213. [Google Scholar] [CrossRef] [Green Version]
- Buades, A.; Coll, B.; Morel, J.M. Non-Local Means Denoising. Image Process. Line 2011, 1, 208–212. [Google Scholar] [CrossRef] [Green Version]
- Matthews, I.; Cootes, T.F.; Bangham, J.A.; Cox, S.; Harvey, R. Extraction of visual features for lipreading. IEEE Trans. Pattern Anal. Mach. Vis. 2002, 24, 198–213. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scale | Bicubic | VDSR | SRResnet | SRGAN | ESRGAN | RRDGAN-MSE (Ours) | RRDGAN-VGG (Ours) |
|---|---|---|---|---|---|---|---|
| 4 | 23.83/1.36/6.72 | 28.12/2.72/5.1 | 28.57/3/4.23 | 24.35/3.09/2.58 | 24.89/3.18/2.08 | 24.89/3.18/2.23 | 24.91/3.42/2.01 |
| 4 | 24.12/1.53/6.5 | 28.45/3.07/5.21 | 28.71/3.30/3.6 | 24.97/3.34/2.45 | 25.52/3.42/2.06 | 25.52/3.42/2.18 | 25.63/3.81/1.98 |
| Class | Scale | Bicubic | VDSR | SRGAN | ESRGAN | RRDGAN-MSE (Ours) | RRDGAN-VGG (Ours) |
|---|---|---|---|---|---|---|---|
| airplane | 4 | 23.46/1.53/6.44 | 28.04/2.73/4.36 | 24.23/3/2.53 | 24.92/3/2.11 | 24.89/3.11/2.20 | 25.00/3.42/2.02 |
| baseballdiamond | 4 | 24.12/1.63/6.35 | 28.45/2.73/4.35 | 24.31/3/2.35 | 25.04/3/2.08 | 25.01/3.19/2.21 | 25.11/3.57/1.90 |
| beach | 4 | 24.21/1.53/6.85 | 28.53/2.73/4.52 | 24.62/2.80/2.86 | 25.04/2.80/2.31 | 25.03/3.03/2.32 | 25.13/3.42/2.23 |
| bridge | 4 | 24.35/1.63/6.96 | 28.61/2.73/4.31 | 24.71/3.03/2.94 | 24.85/3.03/2.45 | 24.83/3.23/2.42 | 24.91/3.81/2.36 |
| forest | 4 | 23.75/1.63/6.53 | 28.72/2.84/4.25 | 24.72/3.09/2.51 | 25.09/3.09/2.34 | 25.08/3.26/2.38 | 25.14/3.42/2.20 |
| groundtrack | 4 | 21.34/1.82/7.69 | 25.34/2.73/5.12 | 21.98/3.07/3.34 | 22.07/3.07/2.95 | 22.11/3.18/3.00 | 22.35/3.57/2.98 |
| intersection | 4 | 23.45/1.53/6.45 | 28.04/2.63/4.86 | 24.24/3/2.68 | 24.56/3/2.35 | 24.52/3.36/2.45 | 24.63/3.42/2.26 |
| mediumresidial | 4 | 24.13/1.42/6.14 | 28.37/2.80/4.26 | 24.61/3.09/2.75 | 25.0/3.09/2.13 | 24.91/3.23/2.15 | 25.10/3.42/2.08 |
| river | 4 | 24.51/1.53/6.43 | 28.69/2.73/4.59 | 24.70/3.15/2.62 | 25.18/3.15/2.32 | 25.12/3.23/2.40 | 25.25/3.81/2.26 |
| stadium | 4 | 24.46/1.38/6.86 | 28.66/2.63/4.39 | 24.71/3/2.43 | 25.16/3/1.86 | 25.12/3.18/2.11 | 25.21/3.69/2.01 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, X.; Zhang, W.; Su, X.; Xu, Z. Optical Remote Sensing Image Denoising and Super-Resolution Reconstructing Using Optimized Generative Network in Wavelet Transform Domain. Remote Sens. 2021, 13, 1858. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13091858
Feng X, Zhang W, Su X, Xu Z. Optical Remote Sensing Image Denoising and Super-Resolution Reconstructing Using Optimized Generative Network in Wavelet Transform Domain. Remote Sensing. 2021; 13(9):1858. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13091858
Chicago/Turabian StyleFeng, Xubin, Wuxia Zhang, Xiuqin Su, and Zhengpu Xu. 2021. "Optical Remote Sensing Image Denoising and Super-Resolution Reconstructing Using Optimized Generative Network in Wavelet Transform Domain" Remote Sensing 13, no. 9: 1858. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13091858