Segment-Based Land Cover Mapping of a Suburban Area—Comparison of High-Resolution Remotely Sensed Datasets Using Classification Trees and Test Field Points

Abstract
:
1. Introduction
1.1. Comparison of New Remotely Sensed Datasets for Land Cover Classification

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Data used | Classes | Method | Reference data for accuracy analysis | Overall accuracy |
|---|---|---|---|---|---|
| Aerial images: | |||||
| Thomas et al. 2003 [1] | Multispectral aerial imagery (ADAR 5500) | 5: water, pavement, rooftop, bare ground, vegetation | Segmentation (eCognition) and classification tree method (S Plus) | 356 sample locations labelled in the field or by photo interpretation | 70% |
| Sanchez Hernandez et al. 2007 [4] | Multispectral aerial imagery (Intergraph Z/I Imaging DMC) | 6: building, hard standing, grass, trees, bare soil, water | Segmentation and user-defined classification rules (eCognition) | 700 test pixels | 75.0% |
| Laser scanner data: | |||||
| Im et al. 2008 [7] | Height and intensity data from laser scanning (Optech ALTM 2050; “bare Earth” dataset and local height surface created before classification) | 5: building, tree, grass, road/parking lot, other artificial object | Segmentation (Definiens) and decision tree method (C5.0) | 200 reference points /study area from visual photo interpretation and on-site experts | 93.5%–95.0% (3 sites) |
| Chehata et al. 2009 [8] | Multi-echo and full-waveform laser scanner data (RIEGL LMS-Q560) | 4: buildings, vegetation, natural ground, artificial ground | Random forests | 398831 test samples | 94.35% |
| Optical satellite images: | |||||
| Chan et al. 2009 [13] | Multispectral and panchromatic Ikonos data | 9: water, grass, trees, buildings with dark roof, buildings with red roof, buildings with bright roof, roads, other man-made objects, shadow | Segmentation (eCognition), geometric activity features, classification using decision tree method (C5.0) or multi-layer perceptrons (MLP) (NeuralWorks Predict) | Visual interpretation of the study area (classified polygons) | 75% (decision tree) and 78.5% (MLP) |
| Xu and Li 2010 [15] | Pan-sharpened, multispectral QuickBird image | 7: tree, grass, soil, shadow, road, building, other impervious surface | Segmentation, computation of invariant moments, classification using support vector machines (SVM) | 328 sample polygons (47342 pixels) | 80.5% |
| SAR images: | |||||
| Niu and Ban 2010 [19] | RADARSAT-2, 6 multitemporal polarimetric images (ascending and descending data) | 9: high-density built-up, low-density built-up, water, crop1, crop2, crop3, road, street, golf, forest, park | Segmentation of Pauli image (eCognition), rule-based classification, multitemporal data fusion | Test areas and pixels based on QuickBird images and vector and map data | 82% |
| Qi et al. 2010 [20] | RADARSAT-2, polarimetric image | 4: water, vegetation, built-up area, barren land | Segmentation of Pauli image (eCognition), decision tree method (QUEST) | 287 field plots (15–54 pixels) | 89% |
| Reference | Data used | Classes | Method | Reference data for accuracy analysis | Overall accuracy |
|---|---|---|---|---|---|
| Aerial images and laser scanner data: | |||||
| Gamba and Houshmand 2002 [21] | Aerial image and height data from laser scanning (Optech) | 4: vegetation, buildings, roads, open areas | Fuzzy C means classification | 42790 samples based on manual classification of the aerial image | 68.9% (aerial image), 79.5% (aerial image and laser scanner data) |
| Huang et al. 2008 [22] | True colour and multispectral aerial imagery (Optech ALTM 4K02 and Vexcel UlraCam D), height and intensity data from laser scanning (Optech ALTM 3070; a normalized DSM created before classification) | 4: buildings, trees, roads, grass | A knowledge-based method with several stages | Test data sampled from aerial imagery | 93.90% and 93.87% (two areas) |
| Optical satellite images and laser scanner data: | |||||
| Chen et al. 2009 [23] | Pan-sharpened, multispectral QuickBird image and height data from laser scanning (First Class Infrared Laser sensor; a normalized DSM used) | 9: water, shadow, shrub, grassland, high building, crossroad, low building, road, vacant land | Segmentation and classification rules (eCognition) | 481 validation samples | 89.40% |
| Optical and SAR images: | |||||
| Ban et al. 2010 [24] | Multispectral QuickBird image and multitemporal RADARSAT SAR data (fine-beam C-HH, ascending and descending data) | 16: high-density built-up, low-density built-up, roads, forest, parks, golf courses, water, several types of agricultural land | Segmentation, nearest neighbour classification and rules (eCognition), decision level fusion to combine QuickBird and RADARSAT results | Test objects and pixels based on field data, ortho photos, Landsat ETM+ images, and vector and map data | 87.9% (QuickBird, 16 classes), 86.6% (RADARSAT, 11 classes), 89.5% (combined, 16 classes) |
1.2. Segment-Based Classification
1.3. Objectives of the Present Study
2. Study Area and Data
2.1. Study Area
2.2. Remotely Sensed Datasets

| Sensor | Acquisition date | Derived datasets in raster format | Pixel size | References |
|---|---|---|---|---|
| Intergraph DMC | 1 September 2005 |
| 0.3 m × 0.3 m | [47] |
| Optech ALTM 3100 laser scanner | 12 July 2005 |
| 0.3 m × 0.3 m (original point density about 2–4 points/m2) | [49] (TerraScan software used to create the DSMs and point classification); [47] (general description of the data) |
| QuickBird | 27 May 2003 |
(Off-nadir view angle of the sensor: 6.2°) | 2 m × 2 m (resampled from the original 2.4 m) | |
| E-SAR (DLR, German Aerospace Center) | 2 May 2001 |
(Multilooked data: theoretical resolution about 2 m in range and about 3 m (L) or about 2 m (X) in azimuth direction) (Depression angle of the sensor: 40°) | 1 m × 1 m (Test 4, see Section 3.2), resampled to 0.3 m (Test 5) | [48] |
2.3. Permanent Test Field Reference Points
3. Methods
3.1. Segmentation and Classification Methods
3.2. Classification Tests
- Aerial ortho image mosaic
- Laser scanner derived datasets and aerial ortho image mosaic
- QuickBird image
- E-SAR image data
- Laser scanner derived datasets and E-SAR image data
| Classification test | Data used (weight) | Scale (determines segment size) * | Composition of homogeneity criterion |
|---|---|---|---|
| Test 1 | Aerial ortho image mosaic: red (1), green (1), blue (1), NIR (1) | 100 | Colour 0.9, shape 0.1 (compactness 0.5, smoothness 0.5) |
| Test 2, high objects | Minimum DSM (1) | 10 | Colour 1, shape 0 |
| Test 2, ground objects | Aerial ortho image mosaic: red (1), green (1), blue (1), NIR (1) | 100 | Colour 0.9, shape 0.1 (compactness 0.5, smoothness 0.5) |
| Test 3 | QuickBird image: red (1), green (1), blue (1), NIR (1) | 40 | Colour 0.9, shape 0.1 (compactness 0.5, smoothness 0.5) |
| Test 4 | E-SAR data: LHH (1), LHV (1), LVV (1), XHH (1), XVV (1) | 80 | Colour 0.5, shape 0.5 (compactness 0.5, smoothness 0.5) |
| Test 5, high objects | Minimum DSM (1) | 10 | Colour 1, shape 0 |
| Test 5, ground objects | E-SAR data: LHH (1), LHV (1), LVV (1), XHH (1), XVV (1) | 100 | Colour 0.9, shape 0.1 (compactness 0.5, smoothness 0.5) |
3.3. Input Features for the Classification Tree Method
3.4. Accuracy Estimation
| Attributes for segments | Classification test | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |
| Customized attributes | |||||
| NDVI (calculated from mean values in the NIR and red channels) | × | × | × | ||
| LHH mean/LHV mean, LHH mean/LVV mean, LVV mean/LHV mean, XVV mean/LVV mean, XHH mean/LHH mean | × | × | |||
| Mean values | |||||
| Red, green, blue, NIR | × | × | × | ||
| Maximum DSM, minimum DSM | × | × | |||
| Slope | × | × | |||
| LHH, LHV, LVV, XHH, XVV | × | × | |||
| Standard deviations | |||||
| Red, green, blue, NIR | × | × | × | ||
| Maximum DSM, minimum DSM | × | × | |||
| Maximum DSM, minimum DSM | × | × | |||
| LHH, LHV, LVV, XHH, XVV | × | × | |||
| Brightness (Mean value of the mean values in the different channels) | |||||
| Brightness based on red, green, blue, and NIR channels | × | × | × | ||
| Brightness based on LHH, LHV, and LVV channels | × | × | |||
| Ratios (Mean value in one channel divided by the sum of the mean values in all channels) | |||||
| Red, green, blue, NIR | × | × | × | ||
| Attributes for segments | Classification test | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |
| Texture after Haralick: Grey Level Co-occurrence Matrix (GLCM) homogeneity, contrast, dissimilarity, entropy, angular 2nd moment, mean, standard deviation, and correlation; Grey Level Difference Vector (GLDV) angular 2nd moment and entropy | |||||
| Red, green, blue, NIR | × | × | × | ||
| Maximum DSM, minimum DSM | × | × | |||
| LHH, LHV, LVV, XHH, XVV | × | × | |||
| Geometry, extent: area, border length, length, length/width, width | × | × | × | × | × |
| Geometry, shape: asymmetry, border index, compactness, density, elliptic fit, radius of largest enclosed ellipse, radius of smallest enclosing ellipse, rectangular fit, roundness, shape index | × | × | × | × | × |
| Geometry, shape based on polygons: Area (excluding inner polygons), area (including inner polygons), average length of edges, compactness, length of longest edge, number of edges, number of inner objects, perimeter, standard deviation of length of edges | × | × | × | × | × |
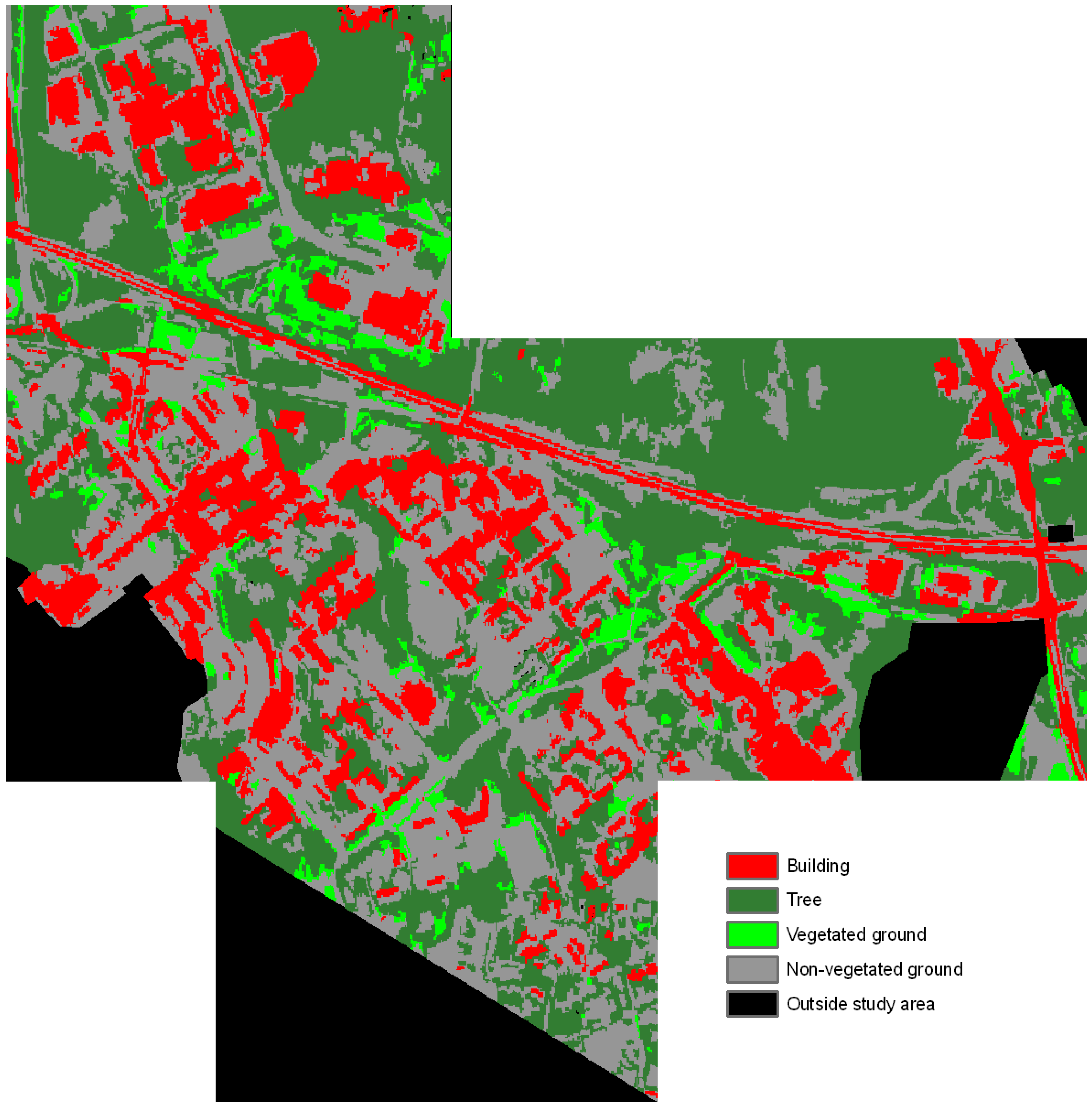
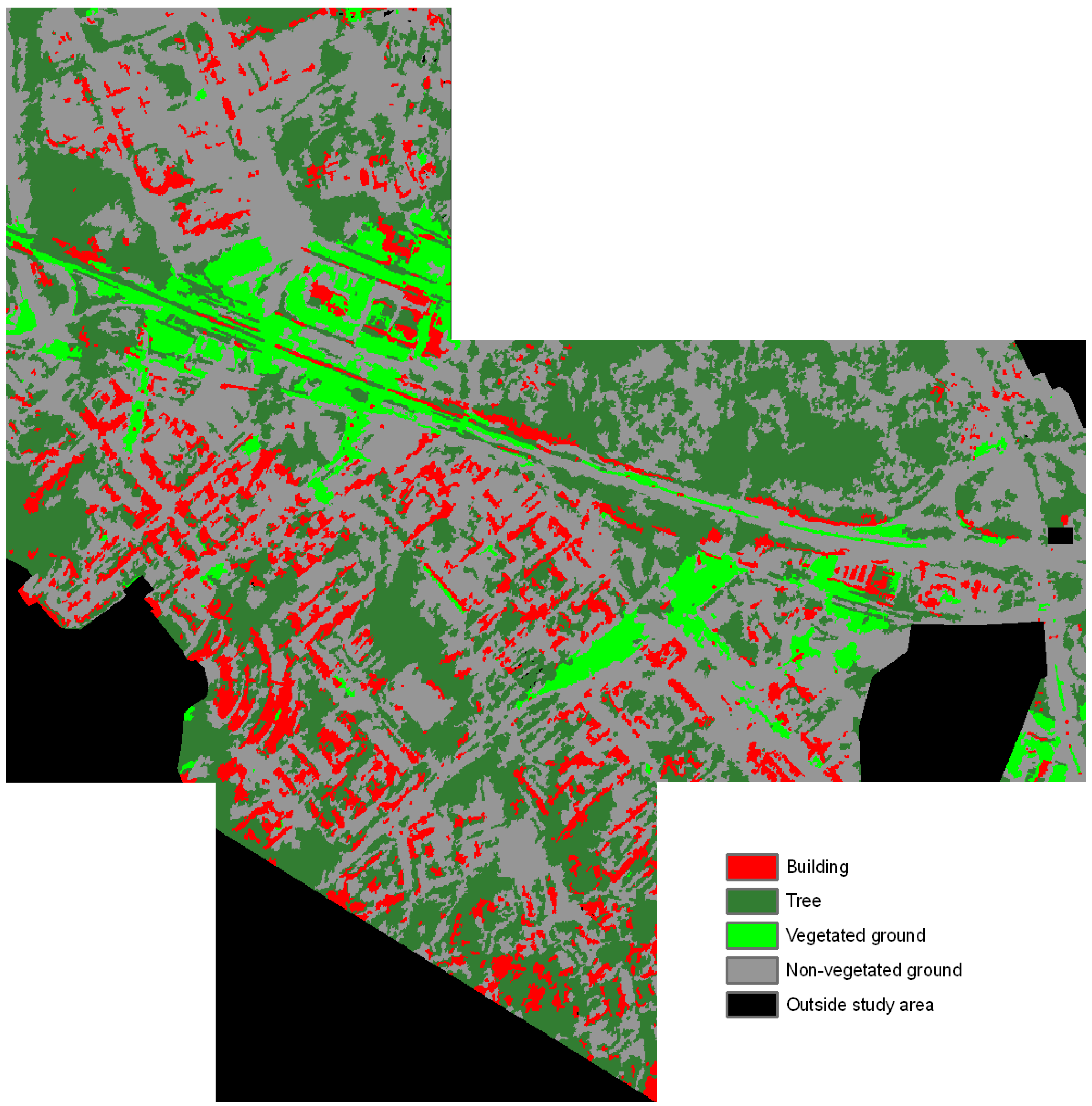
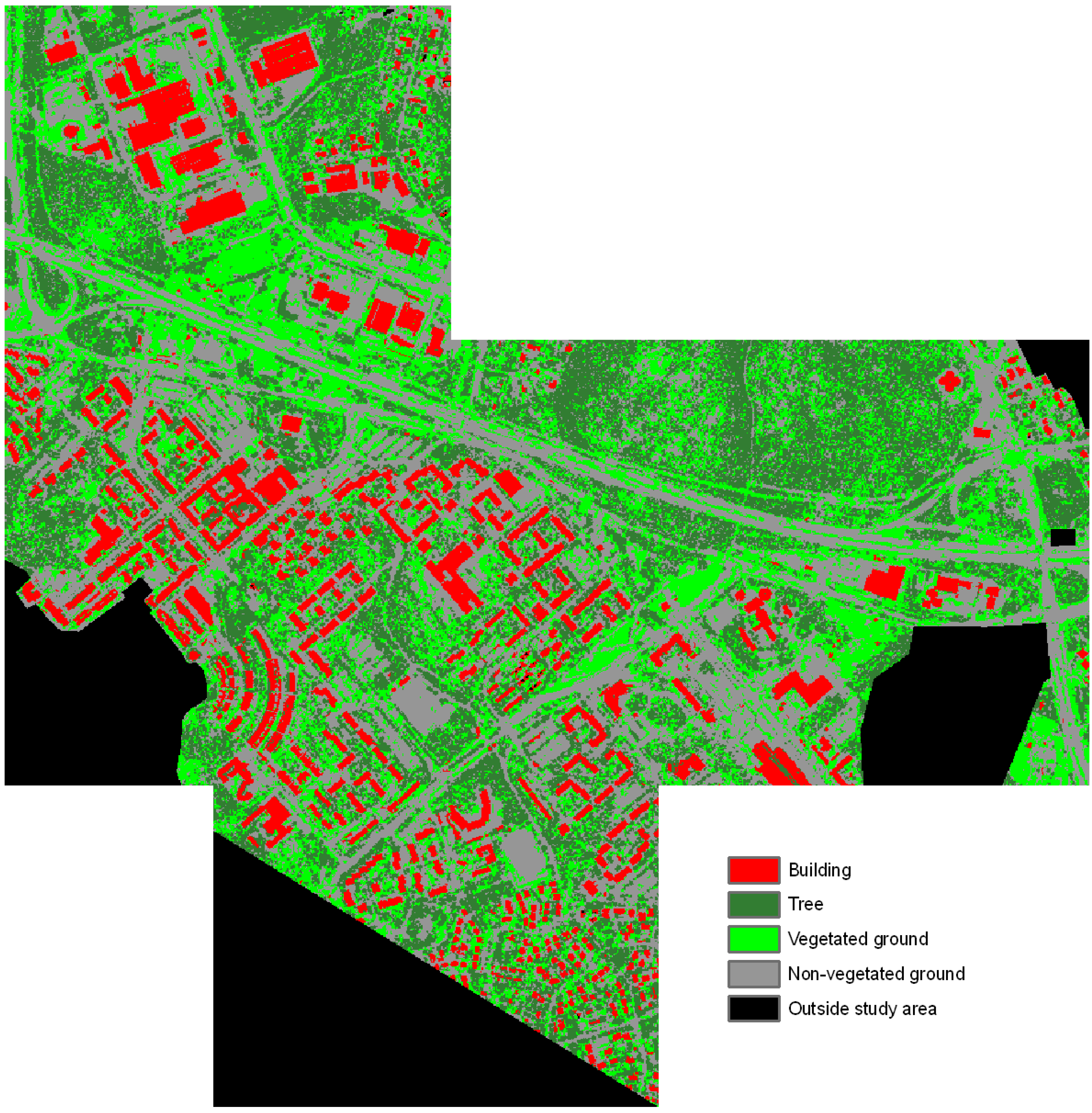
4. Results
| Classification test | Rules in the classification tree |
|---|---|
| Test 1 | IF Ratio NIR < 0.548739 IF Ratio NIR < 0.272026 → Building ELSE IF GLCM standard deviation blue < 40.6738 IF Density < 1.13185 → Non-vegetated ground ELSE → Building ELSE → Non-vegetated ground ELSE IF GLCM standard deviation blue < 43.841 IF GLCM contrast green < 2386.87 → Vegetated ground ELSE → Tree ELSE → Tree |
| Test 2, high objects | IF NDVI < 0.441429 → Building ELSE → Tree |
| Test 2, ground objects | IF NDVI < 0.526306 → Non-vegetated ground ELSE → Vegetated ground |
| Test 3 | IF NDVI < 0.358559 IF Ratio NIR < 0.256213 → Building ELSE → Non-vegetated ground ELSE IF Brightness < 263.028 → Tree ELSE → Vegetated ground |
| Test 4 | IF Mean LHH < 493.259 IF LVV mean/LHV mean < 2.37657 → Non-vegetated ground ELSE → Vegetated ground ELSE IF Standard deviation XHH < 227.942 → Tree ELSE → Building |
| Test 5, high objects | IF Slope < 23.659 → Building ELSE → Tree |
| Test 5, ground objects | IF Mean XHH < 294.742 → Non-vegetated ground ELSE IF Mean LHV < 131.277 → Vegetated ground ELSE IF GLCM Entropy min. DSM < 6.73737 → Non-vegetated ground ELSE → Vegetated ground |

| Classification | Reference (validation points) | Correctness | ||||
| Building | Tree | Vegetated ground | Non-vegetated ground | Sum | ||
| Building | 44 | 0 | 0 | 38 | 82 | 53.7% |
| Tree | 0 | 52 | 6 | 1 | 59 | 88.1% |
| Vegetated ground | 2 | 3 | 20 | 1 | 26 | 76.9% |
| Non-vegetated ground | 12 | 1 | 5 | 84 | 102 | 82.4% |
| Sum | 58 | 56 | 31 | 124 | 269 | |
| Completeness | 75.9% | 92.9% | 64.5% | 67.7% | ||
| Mean accuracy | 62.9% | 90.4% | 70.2% | 74.3% | ||
| Overall accuracy | 74.3% | |||||

| Classification | Reference (validation points) | Correctness | ||||
| Building | Tree | Vegetated ground | Non-vegetated ground | Sum | ||
| Building | 54 | 0 | 0 | 0 | 54 | 100% |
| Tree | 2 | 41 | 0 | 0 | 43 | 95.3% |
| Vegetated ground | 0 | 2 | 42 | 1 | 45 | 93.3% |
| Non-vegetated ground | 2 | 0 | 2 | 123 | 127 | 96.9% |
| Sum | 58 | 43 | 44 | 124 | 269 | |
| Completeness | 93.1% | 95.3% | 95.5% | 99.2% | ||
| Mean accuracy | 96.4% | 95.3% | 94.4% | 98.0% | ||
| Overall accuracy | 96.7% | |||||

| Classification | Reference (validation points) | Correctness | ||||
| Building | Tree | Vegetated ground | Non-vegetated ground | Sum | ||
| Building | 41 | 0 | 0 | 44 | 85 | 48.2% |
| Tree | 1 | 55 | 9 | 9 | 74 | 74.3% |
| Vegetated ground | 0 | 0 | 16 | 2 | 18 | 88.9% |
| Non-vegetated ground | 16 | 1 | 6 | 69 | 92 | 75.0% |
| Sum | 58 | 56 | 31 | 124 | 269 | |
| Completeness | 70.7% | 98.2% | 51.6% | 55.6% | ||
| Mean accuracy | 57.3% | 84.6% | 65.3% | 63.9% | ||
| Overall accuracy | 67.3% | |||||

| Classification | Reference (validation points) | Correctness | ||||
| Building | Tree | Vegetated ground | Non-vegetated ground | Sum | ||
| Building | 24 | 1 | 0 | 5 | 30 | 80.0% |
| Tree | 8 | 41 | 1 | 12 | 62 | 66.1% |
| Vegetated ground | 2 | 0 | 22 | 10 | 34 | 64.7% |
| Non-vegetated ground | 24 | 14 | 8 | 97 | 143 | 67.8% |
| Sum | 58 | 56 | 31 | 124 | 269 | |
| Completeness | 41.4% | 73.2% | 71.0% | 78.2% | ||
| Mean accuracy | 54.5% | 69.5% | 67.7% | 72.7% | ||
| Overall accuracy | 68.4% | |||||

| Classification | Reference (validation points) | Correctness | ||||
| Building | Tree | Vegetated ground | Non-vegetated ground | Sum | ||
| Building | 54 | 0 | 0 | 0 | 54 | 100.0% |
| Tree | 2 | 41 | 0 | 0 | 43 | 95.3% |
| Vegetated ground | 1 | 0 | 34 | 32 | 67 | 50.7% |
| Non-vegetated ground | 1 | 2 | 10 | 92 | 105 | 87.6% |
| Sum | 58 | 43 | 44 | 124 | 269 | |
| Completeness | 93.1% | 95.3% | 77.3% | 74.2% | ||
| Mean accuracy | 96.4% | 95.3% | 61.3% | 80.3% | ||
| Overall accuracy | 82.1% | |||||
5. Discussion
5.1. Results of the Classification Tests
5.2. Further Evaluation of the Results
5.3. Feasibility of the Classification Tree Method and Permanent Test Field Points for a Comparative Study
5.4. Practical Considerations
6. Conclusions
Acknowledgements
References
- Thomas, N.; Hendrix, C.; Congalton, R.G. A comparison of urban mapping methods using high-resolution digital imagery. Photogramm. Eng. Remote Sensing 2003, 69, 963–972. [Google Scholar]
- Walter, V. Object-based classification of remote sensing data for change detection. ISPRS J. Photogramm. 2004, 58, 225–238. [Google Scholar] [CrossRef]
- Kressler, F.P.; Franzen, M.; Steinnocher, K. Segmentation Based Classification of Aerial Images and Its Potential to Support the Update of Existing Land Use Data Bases. In Proceedings of the ISPRS Hannover Workshop 2005: High-Resolution Earth Imaging for Geospatial Information, Hannover, Germany, 17–20 May 2005; Available online: http://www.isprs.org/publications/related/hannover05/paper/papers.htm (accessed on 11 May 2011).
- Sanchez Hernandez, C.; Gladstone, C.; Holland, D. Classification of Urban Features from Intergraph’s Z/I Imaging DMC High Resolution Images for Integration into a Change Detection Flowline within Ordnance Survey. In Proceedings of the 2007 IEEE Urban Remote Sensing Joint Event, URBAN 2007-URS 2007, Paris, France, 11–13 April 2007.
- Xu, S.; Fang, T.; Li, D.; Wang, S. Object classification of aerial images with bag-of-visual words. IEEE Geosci. Remote Sens. Lett. 2010, 7, 366–370. [Google Scholar]
- Brennan, R.; Webster, T.L. Object-oriented land cover classification of lidar-derived surfaces. Can. J. Remote Sens. 2006, 32, 162–172. [Google Scholar] [CrossRef]
- Im, J.; Jensen, J.R.; Hodgson, M.E. Object-based land cover classification using high-posting-density LiDAR data. GISci. Remote Sens. 2008, 45, 209–228. [Google Scholar] [CrossRef]
- Chehata, N.; Guo, L.; Mallet, C. Airborne Lidar Feature Selection for Urban Classification Using Random Forests. In Proceedings of the ISPRS Workshop: Laserscanning’09, Paris, France, 1–2 September 2009; In International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences. Volume XXXVIII, Part 3/W8, pp. 207–212.
- Garcia-Gutierrez, J.; Gonçalves-Seco, L.; Riquelme-Santos, J.C. Decision Trees on Lidar to Classify Land Uses and Covers. In Proceedings of the ISPRS Workshop: Laserscanning’09, Paris, France, 1–2 September 2009; In International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences. Volume XXXVIII, Part 3/W8, pp. 323–328.
- Zhang, Q.; Wang, J. A rule-based urban land use inferring method for fine-resolution multispectral imagery. Can. J. Remote Sens. 2003, 29, 1–13. [Google Scholar] [CrossRef]
- Kux, H.J.H.; Araújo, E.H.G. Object-based image analysis using QuickBird satellite images and GIS data, case study Belo Horizonte (Brazil). In Object-Based Image Analysis: Spatial Concepts for Knowledge-Driven Remote Sensing Applications; Blaschke, T., Lang, S., Hay, G.J., Eds.; Springer: Berlin, Germany, 2008; pp. 571–588. [Google Scholar]
- Lackner, M.; Conway, T.M. Determining land-use information from land cover through an object-oriented classification of IKONOS imagery. Can. J. Remote Sens. 2008, 34, 77–92. [Google Scholar] [CrossRef]
- Chan, J.C.-W.; Bellens, R.; Canters, F.; Gautama, S. An assessment of geometric activity features for per-pixel classification of urban man-made objects using very high resolution satellite imagery. Photogramm. Eng. Remote Sensing 2009, 75, 397–411. [Google Scholar] [CrossRef]
- Bouziani, M.; Goita, K.; He, D.-C. Rule-based classification of a very high resolution image in an urban environment using multispectral segmentation guided by cartographic data. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3198–3211. [Google Scholar] [CrossRef]
- Xu, H.; Li, P. Urban land cover classification from very high resolution imagery using spectral and invariant moment shape information. Can. J. Remote Sens. 2010, 36, 248–260. [Google Scholar] [CrossRef]
- Corr, D.G.; Walker, A.; Benz, U.; Lingenfelder, I.; Rodrigues, A. Classification of Urban SAR Imagery Using Object Oriented Techniques. In Proceedings of IGARSS ’03, Toulouse, France, 21–25 July 2003; Volume 1, pp. 188–190.
- Chaabouni-Chouayakh, H.; Datcu, M. Coarse-to-fine approach for urban area interpretation using TerraSAR-X data. IEEE Geosci. Remote Sens. Lett. 2010, 7, 78–82. [Google Scholar] [CrossRef]
- Li, X.; Pottier, E.; Guo, H.; Ferro-Famil, L. Urban land cover classification with high-resolution polarimetric SAR interferometric data. Can. J. Remote Sens. 2010, 36, 236–247. [Google Scholar] [CrossRef]
- Niu, X.; Ban, Y. Multitemporal RADARSAT-2 Polarimetric SAR Data for Urban Land-Cover Mapping. In Proceedings of the ISPRS Technical Commission VII Symposium: 100 Years ISPRS Advancing Remote Sensing Science, Vienna, Austria, 5–7 July 2010; In International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences. Volume XXXVIII, Part 7A, pp. 175–180.
- Qi, Z.; Yeh, A.G.; Li, X.; Lin, Z. Land Use and Land Cover Classification Using RADARSAT-2 Polarimetric SAR Image. In Proceedings of the ISPRS Technical Commission VII Symposium: 100 Years ISPRS Advancing Remote Sensing Science, Vienna, Austria, 5–7 July 2010; In International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences. Volume XXXVIII, Part 7A, pp. 198–203.
- Gamba, P.; Houshmand, B. Joint analysis of SAR, LIDAR and aerial imagery for simultaneous extraction of land cover, DTM and 3D shape of buildings. Int. J. Remote Sens. 2002, 23, 4439–4450. [Google Scholar] [CrossRef]
- Huang, M.-J.; Shyue, S.-W.; Lee, L.-H.; Kao, C.-C. A knowledge-based approach to urban feature classification using aerial imagery with lidar data. Photogramm. Eng. Remote Sensing 2008, 74, 1473–1485. [Google Scholar] [CrossRef]
- Chen, Y.; Su, W.; Li, J.; Sun, Z. Hierarchical object oriented classification using very high resolution imagery and LIDAR data over urban areas. Adv. Space Res. 2009, 43, 1101–1110. [Google Scholar] [CrossRef]
- Ban, Y.; Hu, H.; Rangel, I.M. Fusion of Quickbird MS and RADARSAT SAR data for urban land-cover mapping: Object-based and knowledge-based approach. Int. J. Remote Sens. 2010, 31, 1391–1410. [Google Scholar] [CrossRef]
- Bellmann, A.; Hellwich, O. Sensor and data fusion contest: Information for mapping from airborne SAR and optical imagery (Phase I). In EuroSDR Official Publication No 50; EuroSDR: Frankfurt, Germany, 2006; pp. 183–215. [Google Scholar]
- Schistad Solberg, A.H.; Jain, A.K.; Taxt, T. Multisource classification of remotely sensed data: Fusion of Landsat TM and SAR images. IEEE Trans. Geosci. Remote Sens. 1994, 32, 768–778. [Google Scholar] [CrossRef]
- Kuplich, T.M.; Freitas, C.C.; Soares, J.V. The study of ERS-1 SAR and Landsat TM synergism for land use classification. Int. J. Remote Sens. 2000, 21, 2101–2111. [Google Scholar] [CrossRef]
- Amarsaikhan, D.; Ganzorig, M.; Ache, P.; Blotevogel, H. The integrated use of optical and InSAR data for urban land-cover mapping. Int. J. Remote Sens. 2007, 28, 1161–1171. [Google Scholar] [CrossRef]
- Pacifici, F.; Del Frate, F.; Emery, W.J.; Gamba, P.; Chanussot, J. Urban mapping using coarse SAR and optical data: Outcome of the 2007 GRSS data fusion contest. IEEE Geosci. Remote Sens. Lett. 2008, 5, 331–335. [Google Scholar] [CrossRef]
- Riedel, T.; Thiel, C.; Schmullius, C. Fusion of multispectral optical and SAR images towards operational land cover mapping in Central Europe. In Object-Based Image Analysis: Spatial Concepts for Knowledge-Driven Remote Sensing Applications; Blaschke, T., Lang, S., Hay, G.J., Eds.; Springer: Berlin, Germany, 2008; pp. 493–511. [Google Scholar]
- Hellwich, O.; Günzl, M.; Wiedemann, C. Fusion of SAR/INSAR data and optical imagery for landuse classification. Frequenz 2001, 55, 129–136. [Google Scholar] [CrossRef]
- Amarsaikhan, D.; Blotevogel, H.H.; van Genderen, J.L.; Ganzorig, M.; Gantuya, R.; Nergui, B. Fusing high-resolution SAR and optical imagery for improved urban land cover study and classification. Int. J. Image Data Fusion 2010, 1, 83–97. [Google Scholar] [CrossRef]
- Haala, N.; Brenner, C. Extraction of buildings and trees in urban environments. ISPRS J. Photogramm. 1999, 54, 130–137. [Google Scholar] [CrossRef]
- Hodgson, M.E.; Jensen, J.R.; Tullis, J.A.; Riordan, K.D.; Archer, C.M. Synergistic use of lidar and color aerial photography for mapping urban parcel imperviousness. Photogramm. Eng. Remote Sensing 2003, 69, 973–980. [Google Scholar] [CrossRef]
- Rottensteiner, F.; Trinder, J.; Clode, S.; Kubik, K. Using the Dempster-Shafer method for the fusion of LIDAR data and multi-spectral images for building detection. Inf. Fusion 2005, 6, 283–300. [Google Scholar] [CrossRef]
- Zhou, W.; Troy, A. An object-oriented approach for analysing and characterizing urban landscape at the parcel level. Int. J. Remote Sens. 2008, 29, 3119–3135. [Google Scholar] [CrossRef]
- Hofmann, P. Detecting buildings and roads from IKONOS data using additional elevation information. GeoBITGIS 2001, 6, 28–33. [Google Scholar]
- Kettig, R.L.; Landgrebe, D.A. Classification of multispectral image data by extraction and classification of homogeneous objects. IEEE Trans. Geosci. Electron. 1976, GE-14, 19–26. [Google Scholar] [CrossRef]
- Blaschke, T.; Lang, S.; Hay, G.J. Object-Based Image Analysis: Spatial Concepts for Knowledge-Driven Remote Sensing Applications; Springer: Berlin, Germany, 2008. [Google Scholar]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Addink, E.A.; Van Coillie, F.M.B. Geographic Object-Based Image Analysis. In Proceedings of GEOBIA 2010, Ghent, Belgium, 29 June–2 July 2010; Available online: http://geobia.ugent.be/proceedings/ (accessed on 11 May 2011).
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth, Inc.: Belmont, CA, USA, 1984. [Google Scholar]
- Friedl, M.A.; Brodley, C.E. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Lawrence, R.L.; Wright, A. Rule-based classification systems using classification and regression tree (CART) analysis. Photogramm. Eng. Remote Sensing 2001, 67, 1137–1142. [Google Scholar]
- Mancini, A.; Frontoni, E.; Zingaretti, P. Automatic Extraction of Urban Objects from Multi-Source Aerial Data. In Proceedings of CMRT09: Object Extraction for 3D City Models, Road Databases and Traffic Monitoring—Concepts, Algorithms and Evaluation, Paris, France, 3–4 September 2009; In International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences. Volume XXXVIII, Part 3/W4, pp. 13–18.
- Matikainen, L. Improving automation in rule-based interpretation of remotely sensed data by using classification trees. Photogramm. J. Fin. 2006, 20, 5–20. [Google Scholar]
- Matikainen, L.; Hyyppä, J.; Ahokas, E.; Markelin, L.; Kaartinen, H. Automatic detection of buildings and changes in buildings for updating of maps. Remote Sens. 2010, 2, 1217–1248. [Google Scholar] [CrossRef]
- Matikainen, L.; Karjalainen, M.; Kaartinen, H.; Hyyppä, J. Rule-based interpretation of high-resolution SAR images for map updating. Photogramm. J. Fin. 2004, 19, 47–62. [Google Scholar]
- Terrasolid. Homepage; Terrasolid Ltd.: Helsinki, Finland. Available online: http://www.terrasolid.fi/ (accessed on 11 May 2011).
- Baatz, M.; Schäpe, A. Multiresolution segmentation—An optimization approach for high quality multi-scale image segmentation. In Angewandte Geographische Informationsverarbeitung XII: Beiträge zum AGIT-Symposium Salzburg 2000; Strobl, J., Blaschke, T., Griesebner, G., Eds.; Wichmann: Heidelberg, Germany, 2000; pp. 12–23. [Google Scholar]
- Trimble GeoSpatial. Homepage; Trimble GeoSpatial: Munich, Germany. Available online: http://www.ecognition.com/ (accessed on 11 May 2011).
- The MathWorks. Homepage; The MathWorks, Inc.: Natick, MA, USA. Available online: http://www.mathworks.com/ (accessed on 11 May 2011).
- The MathWorks. Online Documentation for Statistics Toolbox; Version 6.1; The MathWorks, Inc.: Natick, MA, USA, 2007. [Google Scholar]
- Definiens. Definiens eCognition 8.0.1 Reference Book; Definiens AG: München, Germany, 2010. [Google Scholar]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; Lewis Publishers: Boca Raton, FL, USA, 1999. [Google Scholar]
- Helldén, U. A Test of Landsat-2 Imagery and Digital Data for Thematic Mapping, Illustrated by an Environmental Study in Northern Kenya; Rapporter och Notiser 47; University of Lund: Lund, Sweden, 1980. [Google Scholar]
- Schreier, G. Geometrical properties of SAR images. In SAR Geocoding: Data and Systems; Schreier, G., Ed.; Wichmann: Karlsruhe, Germany, 1993; pp. 103–134. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Lawrence, R.; Bunn, A.; Powell, S.; Zambon, M. Classification of remotely sensed imagery using stochastic gradient boosting as a refinement of classification tree analysis. Remote Sens. Environ. 2004, 90, 331–336. [Google Scholar] [CrossRef]
- Krieger, G.; Moreira, A.; Fiedler, H.; Hajnsek, I.; Werner, M.; Younis, M.; Zink, M. TanDEM-X: A satellite formation for high-resolution SAR interferometry. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3317–3341. [Google Scholar] [CrossRef]
- Matikainen, L.; Hyyppä, J.; Ahokas, E.; Markelin, L.; Kaartinen, H. An Improved Approach for Automatic Detection of Changes in Buildings. In Proceedings of the ISPRS Workshop: Laserscanning’09, Paris, France, 1–2 September 2009; In International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences. Volume XXXVIII, Part 3/W8, pp. 61–67.
© 2011 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Matikainen, L.; Karila, K. Segment-Based Land Cover Mapping of a Suburban Area—Comparison of High-Resolution Remotely Sensed Datasets Using Classification Trees and Test Field Points. Remote Sens. 2011, 3, 1777-1804. https://0-doi-org.brum.beds.ac.uk/10.3390/rs3081777
Matikainen L, Karila K. Segment-Based Land Cover Mapping of a Suburban Area—Comparison of High-Resolution Remotely Sensed Datasets Using Classification Trees and Test Field Points. Remote Sensing. 2011; 3(8):1777-1804. https://0-doi-org.brum.beds.ac.uk/10.3390/rs3081777
Chicago/Turabian StyleMatikainen, Leena, and Kirsi Karila. 2011. "Segment-Based Land Cover Mapping of a Suburban Area—Comparison of High-Resolution Remotely Sensed Datasets Using Classification Trees and Test Field Points" Remote Sensing 3, no. 8: 1777-1804. https://0-doi-org.brum.beds.ac.uk/10.3390/rs3081777