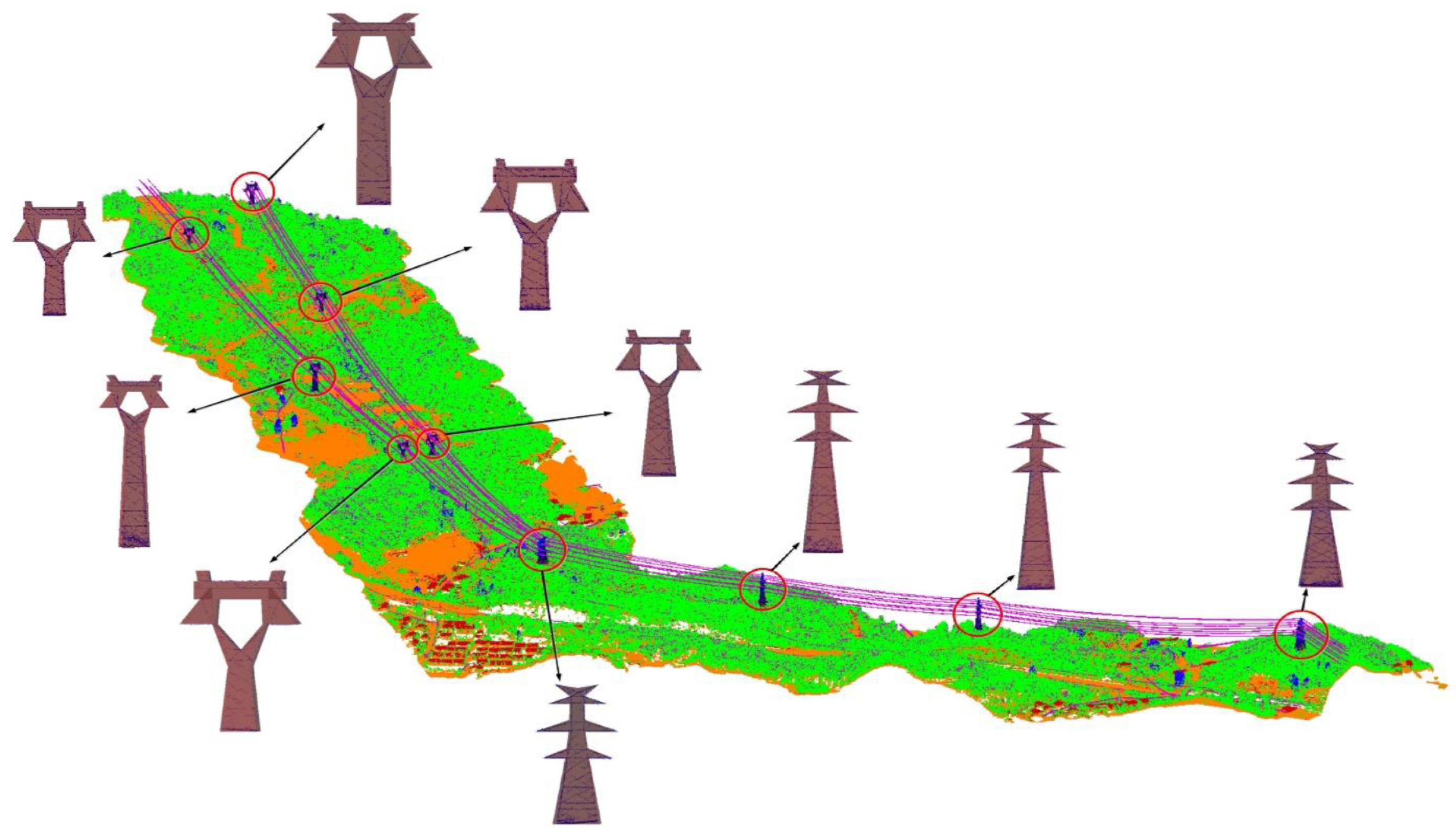
Once the pylon points have been extracted, the models are automatically reconstructed through an optimization method. The first step consists of specifying the 3D objects, which are represented by parameter sets. An energy formulation is then built to measure the coherence degree of the objects and extracted points. Finally, an MCMC method combining simulated annealing is used to optimize the energy formulation in order to find the optimal parameters of pylons. The pylons are constructed with regularity, thus we use a model-based method to reconstruct pylons. As seen in
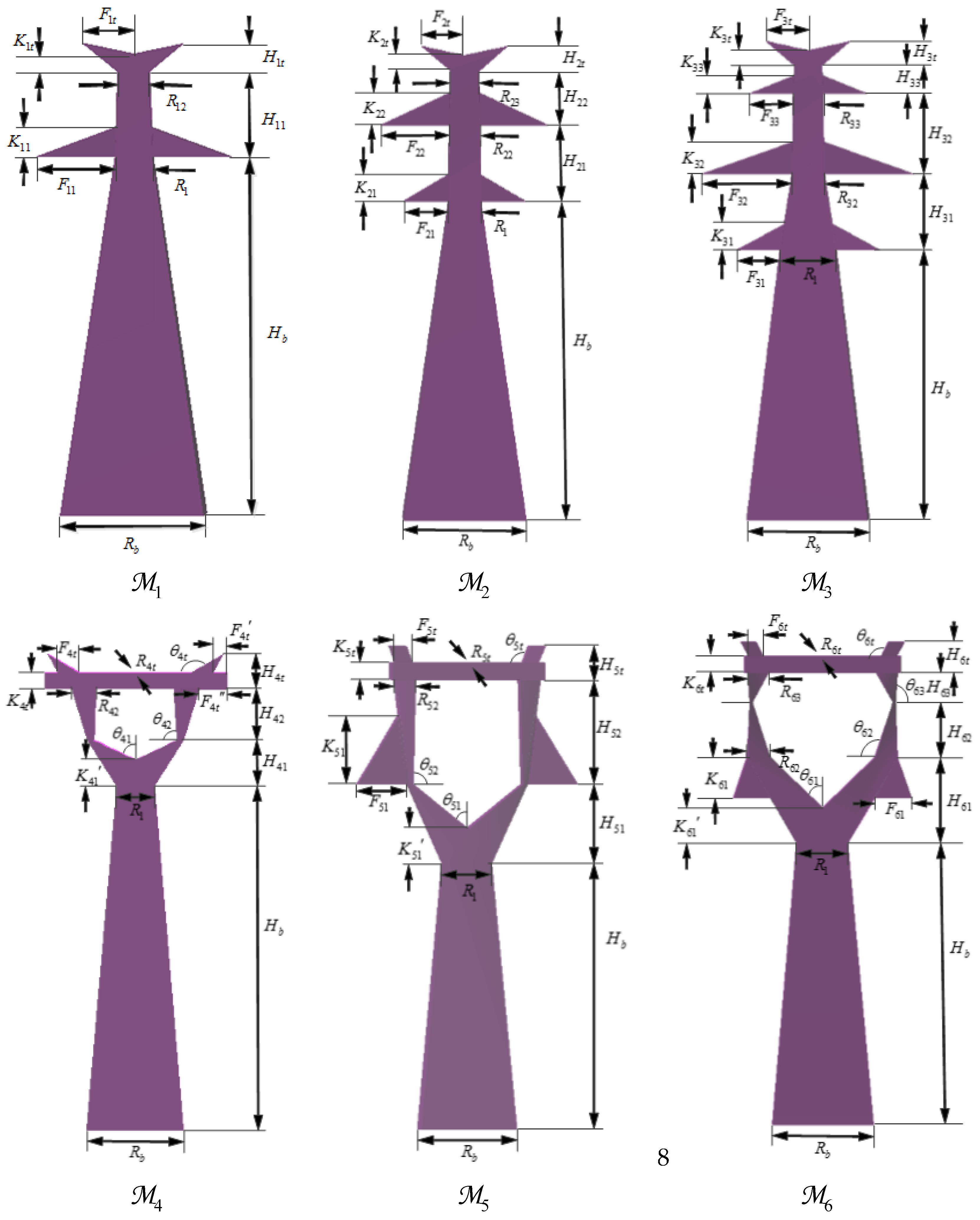
Figure 1, the number of arms of different pylons is different. However, with different positions of arms and various pylons with same number arms, only fitting the number of arms is not sufficient for precise reconstruction of pylons.
3.1. Library of 3D Objects
Pylons are constructed with regularity. The first step of the 3D reconstruction consists of specifying the 3D object models. We refer to the specification widely used in China for pylon construction.
The content of the library
is a very important thing: if it is too limited, the method loses generality. In this library, there are many of the common self-supporting pylons used in 220–500 kV power-line areas (
Figure 1). The kinds of pylons included in this library are widely used in China. At present, ultrahigh-voltage power-line systems are still under development in China. However, the content of the library could be widened if the power lines are upgraded to a higher voltage rank. The pylons carrying the same power-lines are usually with same type and similar parameters. However, in order to overcome the effects of topography, some different pylons are compatible to carry the same power-lines. We defined the compatibility: (1) the models
,
,
, and
can be used to carry one group of power lines; (2) meanwhile, two groups of power lines are simultaneously carried by models
and
.
For simplicity, the pylon models are represented using polyhedrons. The parameters of the pylon models are shown in
Figure 1. The pylon parameters are specified as the height, width of arms, the positions of turning points, and other specific parameters (
). Additionally, each pylon has general parameters (
): center point coordinates and main direction. Each pylon object reconstructed with this library is defined by an associated parameter set
.
The library includes a limited number of types. If a pylon cannot be reconstructed using a model in the library, a minimum external cube outside the data is used to represent the pylon object.
3.2. The Data-Driven Rough Type and Parameter Calculation
If we know the rough types and parameters of pylons, we can use a data-driven method [
29] to effectively reconstruct the pylons. We design an effective kernel (jumping kernel
(
Section 3.4.2)) to cleverly explore the optimal configuration and speedup the convergence by using the rough type and parameters.
Two general parameters of a pylon are first calculated. The center point XY coordinates are calculated using average values of the XY coordinates of all the points of the pylon. The center point Z coordinate is that of the lowest point of the pylon. The direction of the pylon can be calculated by analyzing the power lines connected to it. The rough direction of the pylon is set to be perpendicular to the power lines.
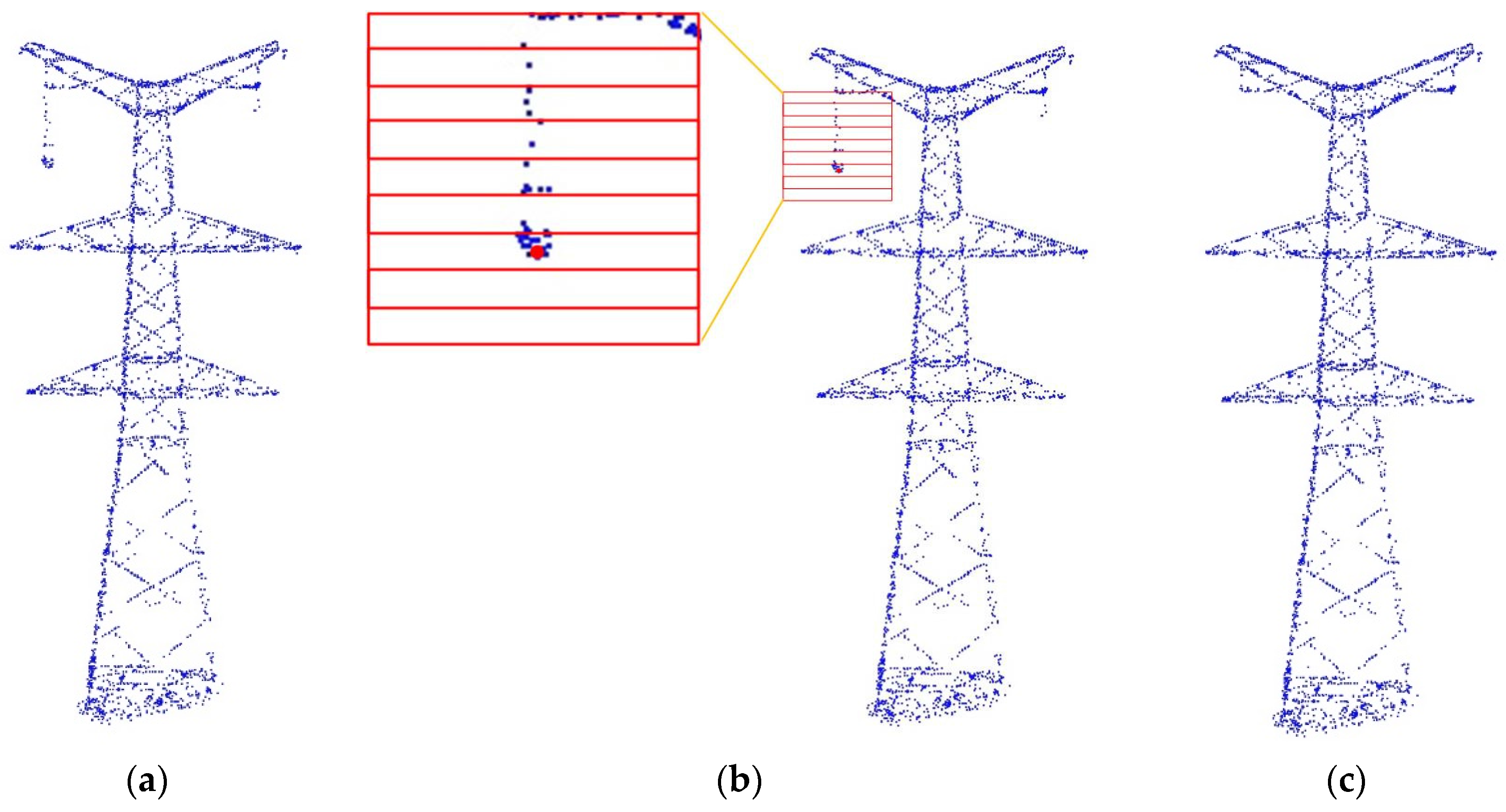
As seen in
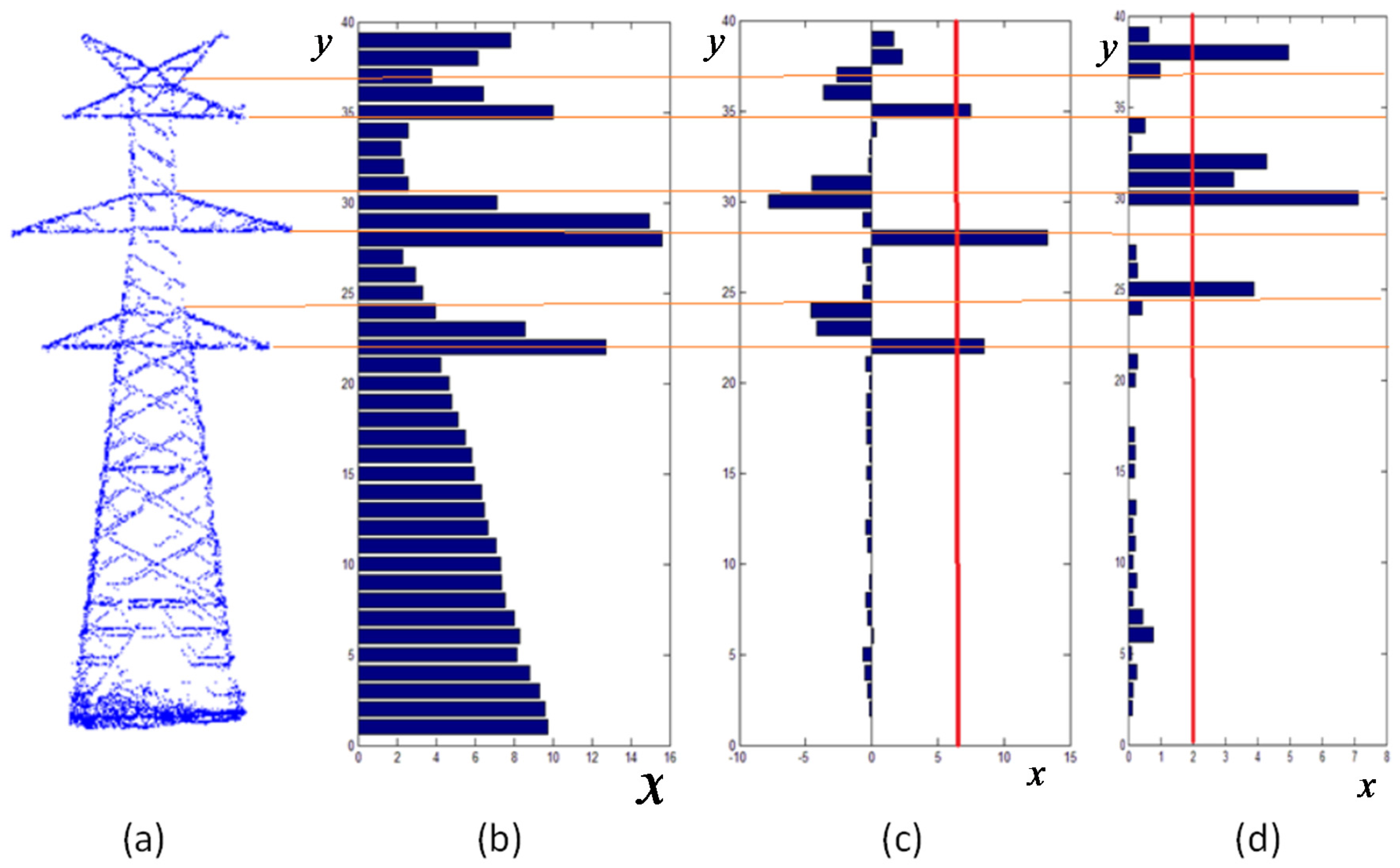
Section 3.1, the structures of pylons are regular, such as the cable arms being longer than their nearby parts. In order to determine the rough type and parameters of each pylon, we project all the points of a pylon onto its main plane (
Figure 2a). A vertical profile is sliced into several bins of a certain distance. The histogram for the length of the sliced profile is shown in
Figure 2b. The location of the arms can be determined by analyzing the changing length of the profiles. Usually, the projecting cable arms are longer than their nearby parts. The changing length of the arms can be represented using a derivative (
Figure 2c). The pylon’s turning points, which represent the connecting locations of different parts, can be detected using a second derivative (
Figure 2d). After determining the number and distribution of a pylon’s arms and turning points, we determine the rough type and parameters of this pylon by comparing it with models in the library.
3.3. Density and Gibbs Energy
In this section, we transform the reconstruction process (find the optimal types and parameters of pylons) to be a density optimization. The density is defined to measure the probability of the reconstructed objects corresponding to data of pylon points. The density can be defined in two ways: in a Bayesian framework, or through Gibbs energy. Using a Bayesian framework, the optimization is carried out over a posteriori density, which is obtained by multiplying the likelihood that provides the correspondence between the data and a configuration, by the a priori density. It needs complex computation of the normalizing constant. In this paper, a MCMC sampler coupled with a simulated annealing is used to the maximum density estimator
. This estimator also corresponds to the configuration minimizing the Gibbs energy
,
i.e.,
. This optimization technique is particularly interesting since the density does not need to be normalized (Equation (13)), and the complex computation of the normalizing constant is thus avoided [
30].
The notation for the density and Gibbs energy is firstly listed:
, the configuration space which represents the parameters of pylon objects.
, the data set of extracted pylon points, where is a set of points of the -th pylon.
is the number of pylons in the dataset.
, an element of the configuration space , which corresponds to a configuration of the 3D parametric model of the pylon. , where each object is specified by both a model of the library and an associated set of parameters .
, the number of parameters describing the model .
In this section, a mapping from the probability space to the configuration is built. Reconstructing the objects consists of finding the configuration of objects by maximizing the density .
The density under its Gibbs form:
where
is a normalizing constant. Moreover, the energy
can be expressed as a weighted sum of two terms: the data attachment term (
Section 3.3.1) measures the consistency of the object configuration with respect to the measured points, and the regularization term (
Section 3.3.2) favors or penalizes certain pylon configurations based on prior knowledge:
is a weighting parameter which tunes the importance of the prior energy
versus the data energy.
3.3.1. Data Coherence Term
We now focus on the data coherence term
, which aims at measuring the adequacy of reconstructed objects with respect to the extracted laser points of the pylons. The simplest way of defining it is to expand it as a sum over all objects in a configuration:
We now explain how the data term
, mapping from a reconstructed object
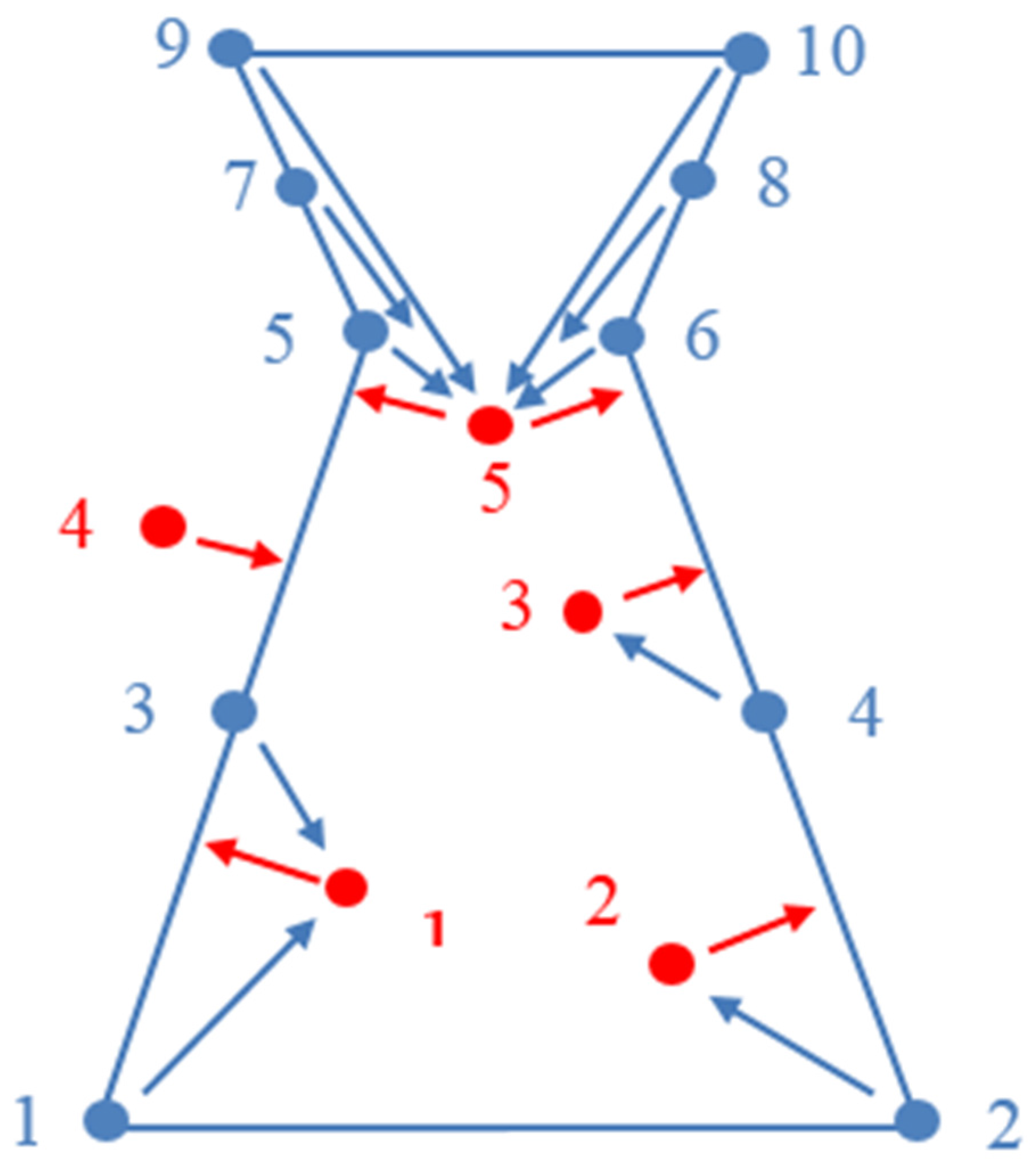
to be a real number, quantifies the relevance of an object with respect to its corresponding laser points. We naturally calculate the distance and measure the difference. The shorter the distance, the more likely the probability of finding a good object. The shapes of the pylon model represented using non-convex polyhedrons with multi-faces are complex. A shape may cause deviation if only the distances from the laser points to an object are used. As shown in
Figure 3, the part of the object that is higher than red point 5 is a vacancy without any laser points. However, the closest distance from red point 5 to the object cannot touch that part. Therefore, we design the distance with two mutual parts: (1) a normalized distance from the point set
to object
(denoted by red arrows in
Figure 3); and (2) a normalized Hausdorff distance from the key point set (corner points and central points of faces) of object
to the measured point set
(denoted by blue arrows in
Figure 3).
(1) Normalized Distance from Point Set to Object
We consider that a good object model should contain as many as laser points and the distance from laser point to the object model should be as near as possible. In order to penalize the points outside of the object, the distances of the points in and out of the object should have different weights. Because the models are represented using polyhedrons, whether a point in or out of a model (polyhedron) can be determined referring to the work of Schneider and Eberly [
31].
We first define a normalized distance from a laser point to its corresponding object , where the value of a point outside the object is bigger than that of a point inside the object:
(a) If point
is in the object
:
(b) If point
is out the object
:
where
is the nearest Euclidean distance from point
to object
, which can be calculated by referring to the work of Schneider and Eberly [
31].
is the largest value of
.
and
are two parameters that restrict the value of the normalized distance to a certain range. We set
and
.
After defining the normalized distance of a single point, the total normalized distance from the point set
to object
is set to be:
where
is every point in the point set,
N is the number of points.
has two parts: a mean and a maximum of the normalized distance. The mean value term is used to avoid the effects of different data densities. The maximum distance term is used to avoid the situation of partial mismatch.
(2) Normalized Hausdorff distance from the key point set of object to the measured point set
The Hausdorff distance from the key point set
of object
to the measured point set
is:
where
is the Euclidean distance of points
a and
b. In order to calculating the Hausdorff distance, we first calculate the nearest distance from the key point
a of object to its nearest laser point
b (denoted by blue arrows in
Figure 3). Then, the largest distance of the key point to be the Hausdorff distance from the key point set
of object
to the measured point set
.
The normalized Hausdorff distance is then set to be:
where
is the largest value of
.
Finally, the data term
defined using the distance is:
3.3.2. Regularization Term
The regularization energy is used to favor certain configurations of objects and to penalize certain others. It introduces interactions between neighboring objects. This reduces to the definition of a combination of simplified energy terms , where and are different objects. A neighborhood relationship must be set up to define the interactions: two distinct objects and are said to be neighbors if they are connected by power lines. The neighborhood relationship is denoted by ( represents the set of neighboring pairs).
The regularization term is expressed through summing all the two neighboring objects
and
:
where
is the characteristic function. The function
is defined as a mapping from
to
based on neighboring objects
and
.
In order to avoid electric shock, the power lines between neighboring pylons should be parallel and have sufficient gaps. In this way, the construction of neighboring pylons will satisfy certain demands. The function is defined in two situations:
(1) If the types of objects
and
are the same, the parameters are encouraged to be same in order to keep the power lines parallel:
where,
is the number of the parameters,
and
are the
k-th element of the parameter sets of objects
and
, respectively. We set
Dk to be the
k-th parameter distance and
is the maximum value of the
k-th parameter distance. In this term, the closer the parameters of the two objects, the lower the energy.
(2) If the types of objects are different, the neighboring objects should be compatible to carry the same power lines. The compatibility of pylons is defined in
Section 3.1. In this way, we simply define the function
to be a certain value:
Since different types of pylons connected by power lines are used much less than the situation of the same type, we set to be the maximum value of situation 1 (same pylon type), which can be learned by analyzing a training set. It is also easy to re-learn when changing the kind of data used.
Otherwise, the energy will be null.
3.4. Optimization
We now find the object configuration by maximizing the density . This is a non-convex optimization problem in a high and variable dimension space , since the models of pylons in the library are defined by different numbers of parameters. To sample from (i.e., to obtain some configurations of objects), a solution is to use an MCMC method. Such a procedure builds a Markov chain on the space of finite configurations of objects using a starting point and a Markovian transition kernel , which converges toward the target distribution (specified by the density ).
There are two basic requirements for Markov chain design [
29]. Firstly, the Markov chain should be ergodic. That is, from an arbitrary initial statement of configuration
, the Markov chain can visit any other states
in finite time, and converge to the required invariant distribution. In order to ensure the ergodicity, the jumping and non-jumping transformations (
Section 3.4.2) introduced converge to the desired distribution in this paper. Secondly, the Markov chain should have a stationary probability. This is replaced by a stronger condition of detailed balance equations which demand that every move should be reversible. The Metropolis-Hastings-Green MCMC framework [
32,
33,
34] used in this paper satisfies the detailed balance and reversibility requirements.
3.4.1. MCMC Procedure
The classical MCMC methods for constructing suitable transition kernels are well known. The two most popular methods are the Gibbs sampler [
35] and the Metropolis-Hastings method [
33,
34]. However, these methods cannot handle dimension jumps,
i.e., changes in dimension between samples. The reversible jump MCMC algorithm based on Metropolis-Hastings samplers in the general state spaces [
32] allows us to deal with a variable dimension state space. This technique has shown potential in various applications such as image segmentation [
29] and architectural object reconstruction [
19,
36].
The Metropolis-Hastings-Green sampler simulates a discrete Markov chain on the configuration space, which converges toward an invariant distribution (specified by the density, ). The transitions of this chain correspond to perturbations of the current configuration . We use the transitions of this chain corresponding to local perturbations, which means that only the parameters of one pylon object of the configuration is generally concerned with a perturbation of the current configuration. Each iteration of the sampler is composed of two steps. The first step consists of proposing a new state by perturbing the current state by using proposition kernels . The second step decides whether the perturbation is accepted to define the new state .
The acceptance ratio of a proposition from
is given by:
where
is the target distribution defined on configuration space
and specified by the density
, as defined in
Section 3.3; and
is the proposition kernel, which allows us to propose the different types of perturbations specified in
Section 3.4.2.
The acceptance probability of a perturbation from is then expressed by: .
In summary, the MCMC sampler is:
An MCMC algorithm has converged if its output can be safely thought of as coming from the true stationary distribution of the Markov chain. The convergence can be monitored through many methods, such as: Monte Carlo error checking [
37,
38] and the Celman-Rubin method [
39]. We mainly analyze the convergence through checking the trance plot. When the trance plot is stable, and without obvious trend and periodicity, the MCMC algorithm are thought to be converged.
3.4.2. Proposition Kernels
The kernels are designed in order to make the Markov chain converge to the desired distribution. The kernel specification plays a crucial role in the efficiency of the sampler. By proposing object configurations of interest, these appropriate kernels allow acceleration of the convergence by avoiding rejection of too many candidates.
We introduce two kinds of kernels in this paper: (1) jumping transformations; and (2) non-jumping transformations. The jumping kernels mainly explore the transformation direction of the configuration, and favor configurations that have a high density. The non-jumping kernels contribute to a detailed adjustment of the object parameters when the configuration is close to the optimal solution.
A kernel performs a perturbation from an object to an object , such that the current object configuration is perturbed into the configuration .
(1) Jumping transformations
Let us consider a perturbation from an object
of type
to an object
of type
. A bijection [
32] between the parameter space of the object types
and
is created:
is completed by auxiliary variables
simulated under a law
to provide
, and
by
into
, such that the mapping
between
and
is a bijection:
The ratio of the kernels in the acceptance ratio (Equation (13)) is then expressed by:
where
corresponds to the probability of choosing a jump from
to
. The following jumping transformation kernels,
i.e., distributions
, are used in this paper:
Kernel . This kernel proposes a new state according to a uniform distribution that ensures the Markov chain can visit any configuration of the state space:
where
is a distribution which distributes uniformly on domain
of parameter
.
This kernel is classic. The use of this single kernel is inefficient and thus we propose additional efficient kernels that explore the optimal configuration.
Kernel . In
Section 3.2, we described how the rough types and parameters of the pylons are determined. This information can be used to accelerate the convergence speed. This kernel cleverly explores the state space using a data-driven process and is efficient [
29]. The state
is proposed knowing the data. The probabilities
are focused on models of rough types. The state parameter
of pylon object
is proposed knowing the rough parameters
according to the Gaussian distribution
; in practice, we set
m.
Kernel . In power engineering, the adjacent pylons are commonly built with the same structures in order to be well-regularized and keep the power lines parallel. Thus, the types and parameters are the same. In this kernel, the parameter values of object are chosen depending on its neighboring objects. The probabilities are focused on some models of neighboring objects whose types are the same as object . The state parameter of object is proposed knowing the neighboring object according to a Gaussian distribution . Although this kernel is very useful for optimizing the configuration statement, it can block the current configuration in a local optimum. Thus, this kernel is used when the current configuration is close to the optimum.
(2) Non-jumping transformations
Non-jumping transformations do not involve changing the dimension of the configuration. Such a transformation randomly selects one object
in the current configuration and perturbs it to obtain a new version
. Instead of using uniformly generated parameters (kernel
), the perturbation is a zero-mean Gaussian random variable with variance
:
A Gaussian perturbation can be used to adjust details of the parameters rather than greatly changing their values.
A random walk is introduced to perform a local exploration of the configuration. The suitable acceptance ratio R (Equation (13)) is simply given by:
We set the process into two stages. At the beginning, when the accepted proposition rate is high, the process explores the density modes and favors configurations which have a high density. In this exploration stage, the jumping kernels are mainly used (). When the accepted proposition rate computed on 1000 iterations becomes lower than 0.05, the configuration is close to the optimal solution and does not evolve very much: it involves a detailed adjustment of the pylon parameters. In this second stage, the non-jumping kernel is mainly used (). In each stage, the jumping kernels are used equally ().
3.4.3. Convergence Associated Using Simulated Annealing
Simulated annealing is used to ensure convergence [
34]. The MCMC sampler is coupled with simulated annealing in order to find the optimum of the density. Instead of
, we use
in the optimization process, where
is a sequence of decreasing temperatures that tend to zero as
tends to infinity. Simulated annealing theoretically ensures convergence to the global optimum for any initial configuration
using a logarithmic temperature decrease; however, it is slow. In order to speed up the processing, we use a geometric decrease which gives an approximate solution close to the optimal one. Such a decrease was detailed in [
40]. The initial and final temperatures are estimated by sampling the configuration space and considering the variance of the global energy [
41].














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}