
Blood-Based Multi-Cancer Detection Using a Novel Variant Calling Assay (DEEPGENTM): Early Clinical Results

 , ,
, ,
Abstract
:Simple Summary
Abstract
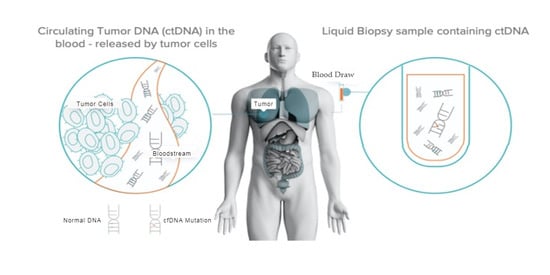
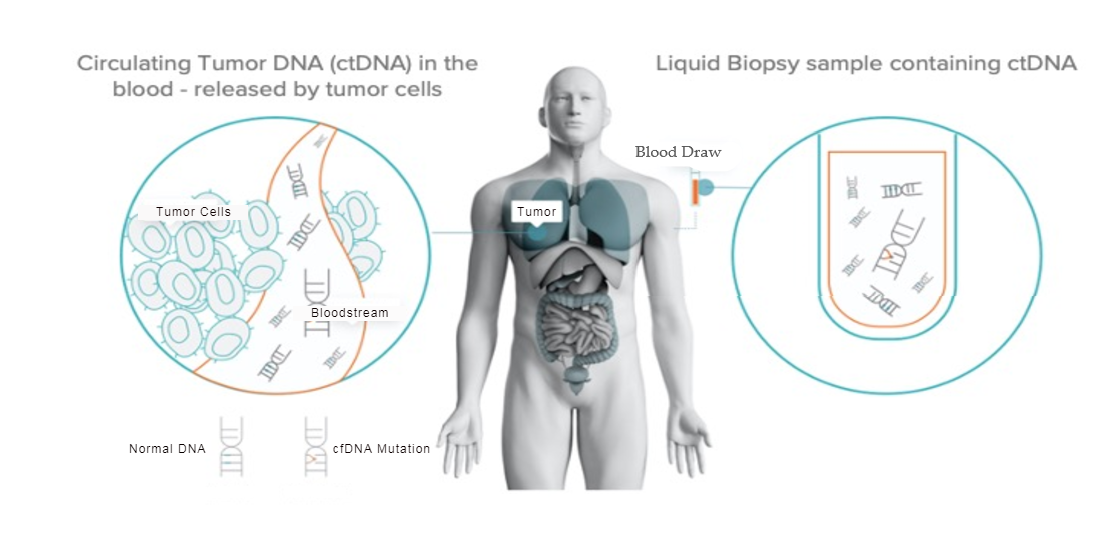
1. Introduction
2. Materials and Methods
2.1. Study Design and Participants
2.2. Sample Collection
2.3. DNA Preparation
2.4. Sequencing
2.5. Data Processing
2.6. Machine Learning
2.7. Classification of Cancer Versus Non-Cancer (Predictive Score)
2.8. Data Analysis
2.9. False Positive Controls
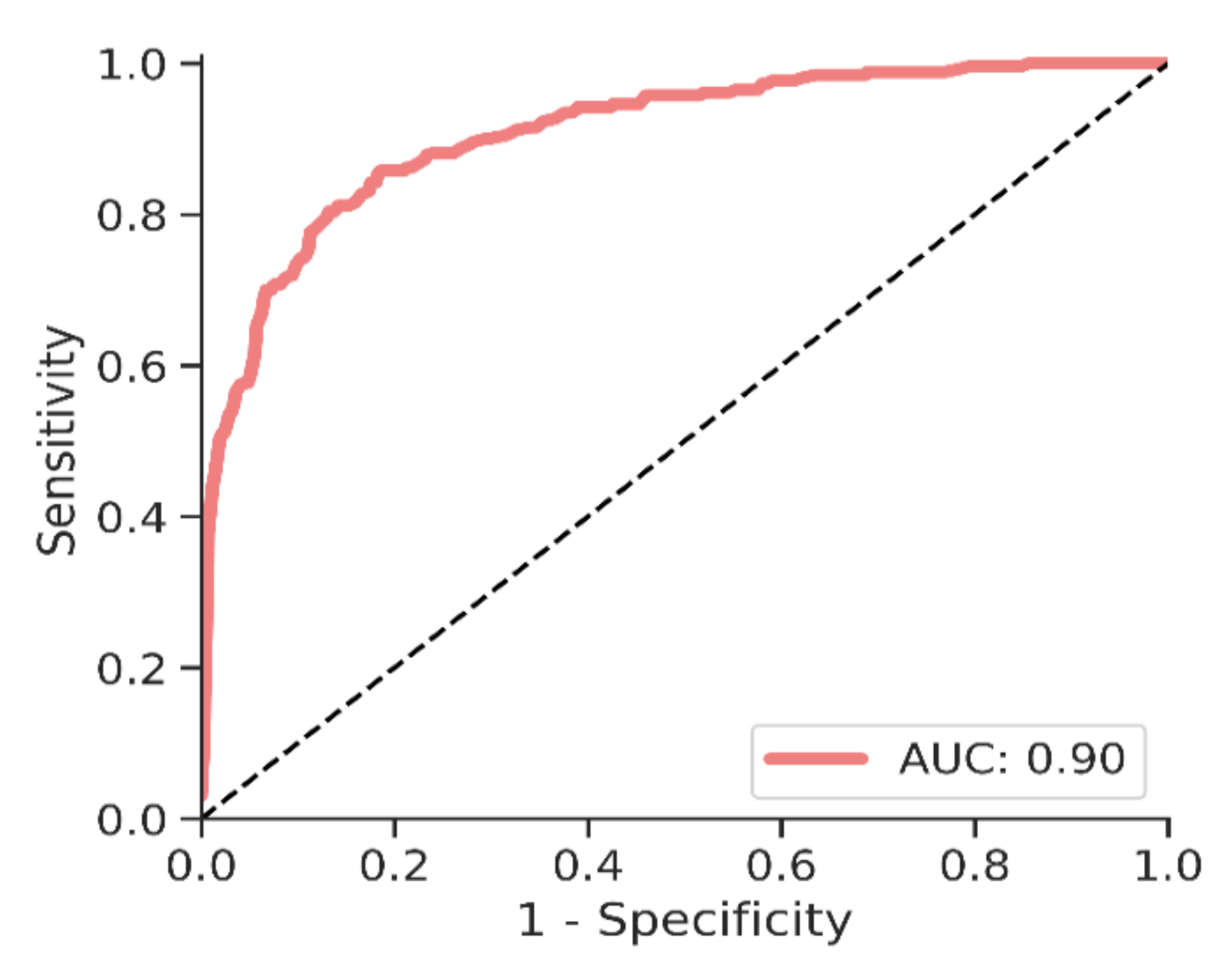
3. Results
3.1. Demographics
3.2. Cancer Identification
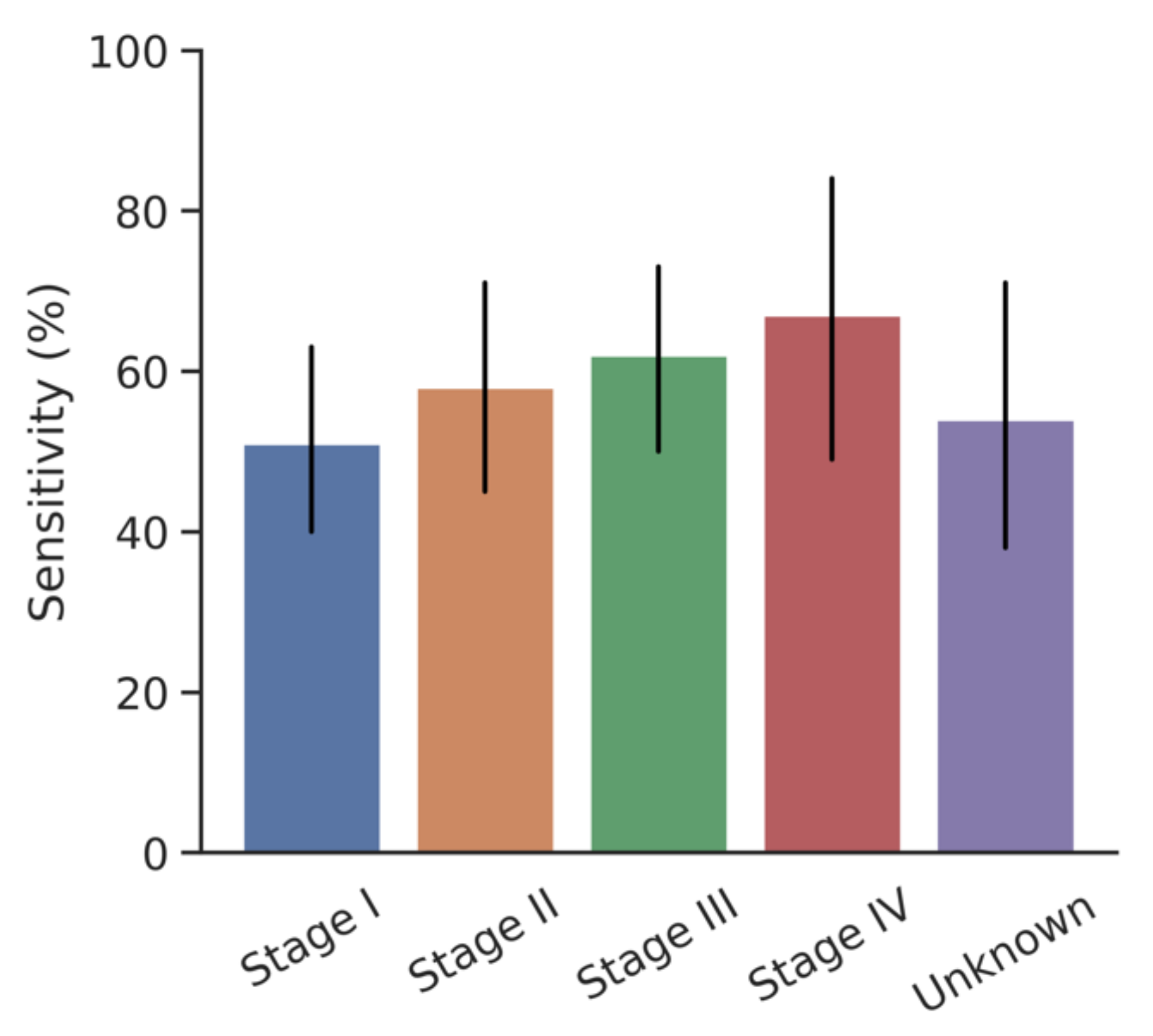
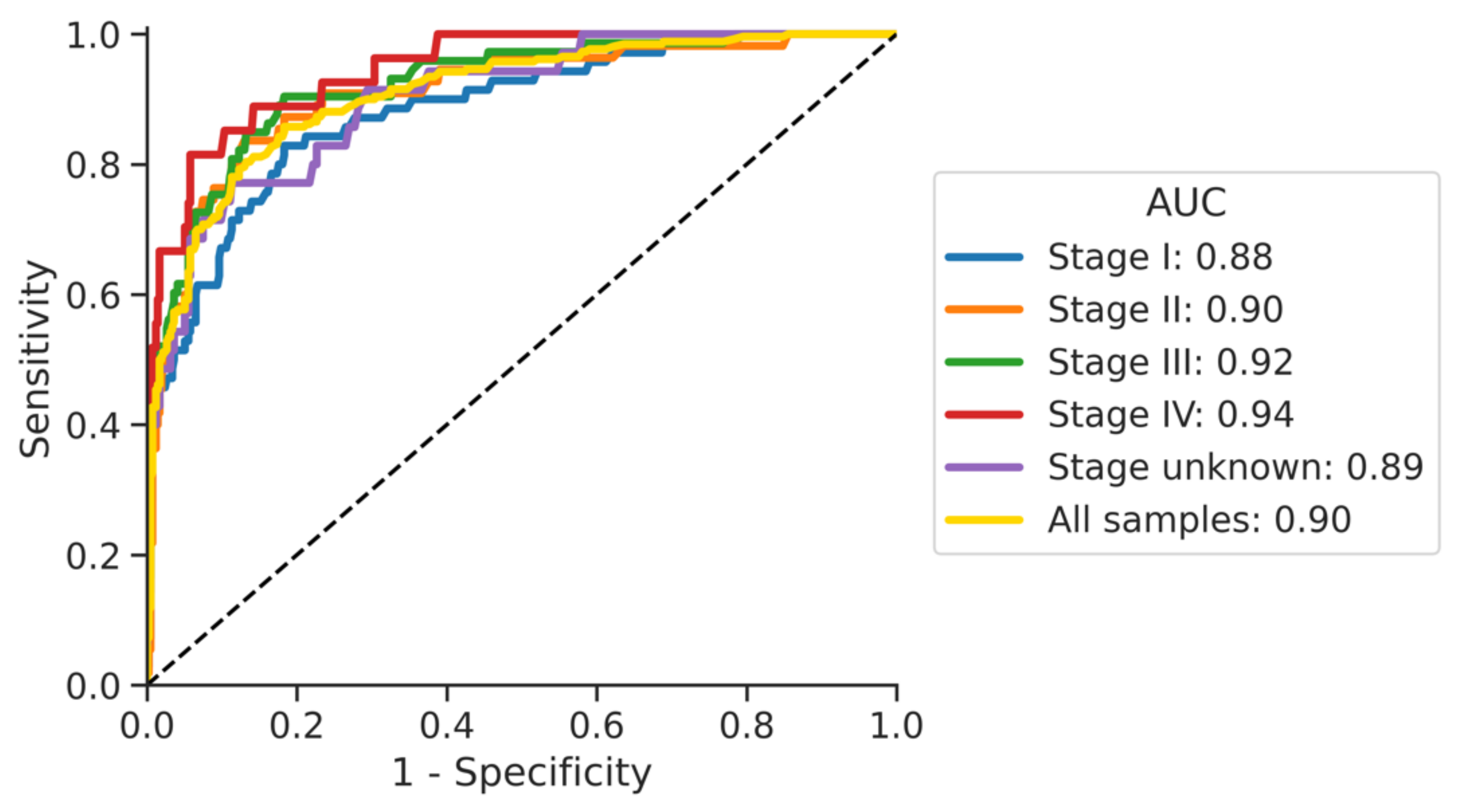
3.3. Impact of Cancer Stage
3.4. False Positive Controls
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Siegel, R.L.; Miller, K.D.; Fuchs, H.E.; Jemal, A. Cancer Statistics, 2021. CA Cancer J. Clin. 2021, 71, 7–33. [Google Scholar] [CrossRef]
- Smith, R.A.; Ba, K.S.A.; Brooks, D.; Fedewa, S.A.; Manassaram-Baptiste, D.; Saslow, D.; Wender, R.C. Cancer screening in the United States, 2019: A review of current American Cancer Society guidelines and current issues in cancer screening. CA Cancer J. Clin. 2019, 69, 184–210. [Google Scholar] [CrossRef]
- Singh, H.; Sethi, S.; Raber, M.; Petersen, L.A. Errors in cancer diagnosis: Current understanding and future directions. J. Clin. Oncol. 2007, 25, 5009–5018. [Google Scholar] [CrossRef]
- Dobson, C.M.; Russell, A.J.; Rubin, G.P. Patient delay in cancer diagnosis: What do we really mean and can we be more specific? BMC Health Serv. Res. 2014, 14, 387. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hanna, T.P.; King, W.D.; Thibodeau, S.; Jalink, M.; Paulin, G.A.; Harvey-Jones, E.; O’Sullivan, D.E.; Booth, C.M.; Sullivan, R.; Aggarwal, A. Mortality due to cancer treatment delay: Systematic review and meta-analysis. BMJ 2020, 371, m4087. [Google Scholar] [CrossRef] [PubMed]
- Loomans-Kropp, H.A.; Umar, A. Cancer prevention and screening: The next step in the era of precision medicine. NPJ Precis. Oncol. 2019, 3, 3. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, X.; Gole, J.; Gore, A.; He, Q.; Lu, M.; Min, J.; Yuan, Z.; Yang, X.; Jiang, Y.; Zhang, T.; et al. Non-invasive early detection of cancer four years before conventional diagnosis using a blood test. Nat. Commun. 2020, 11, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Shyr, D.; Liu, Q. Next generation sequencing in cancer research and clinical application. Biol. Proced. Online 2013, 15, 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Metzker, M.L. Sequencing technologies—the next generation. Nat. Rev. Genet. 2010, 11, 31–36. [Google Scholar] [CrossRef] [Green Version]
- Shen, S.Y.; Singhania, R.; Fehringer, G.; Chakravarthy, A.; Roehrl, M.H.A.; Chadwick, D.; Zuzarte, P.C.; Borgida, A.; Wang, T.T.; Li, T.; et al. Sensitive tumour detection and classification using plasma cell-free DNA methylomes. Nat. Cell Biol. 2018, 563, 579–583. [Google Scholar] [CrossRef] [PubMed]
- Cohen, J.D.; Li, L.; Wang, Y.; Thoburn, C.; Afsari, B.; Danilova, L.; Douville, C.; Javed, A.A.; Wong, F.; Mattox, A.; et al. Detection and localization of surgically resectable cancers with a multi-analyte blood test. Science 2018, 359, 926–930. [Google Scholar] [CrossRef] [Green Version]
- Aarthy, R.; Mani, S.; Velusami, S.; Sundarsingh, S.; Rajkumar, T. Role of Circulating Cell-Free DNA in Cancers. Mol. Diagn. Ther. 2015, 19, 339–350. [Google Scholar] [CrossRef]
- Rachiglio, A.M.; Abate, R.E.; Sacco, A.; Pasquale, R.; Fenizia, F.; Lambiase, M.; Morabito, A.; Montanino, A.; Rocco, G.; Romano, C.; et al. Limits and potential of targeted sequencing analysis of liquid biopsy in patients with lung and colon carcinoma. Oncotarget 2016, 7, 66595–66605. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heitzer, E.; Haque, I.S.; Roberts, C.E.S.; Speicher, M.R. Current and future perspectives of liquid biopsies in genomics-driven oncology. Nat. Rev. Genet. 2019, 20, 71–88. [Google Scholar] [CrossRef] [PubMed]
- Phallen, J.; Sausen, M.; Adleff, V.; Leal, A.; Hruban, C.; White, J.; Anagnostou, V.; Fiksel, J.; Cristiano, S.; Papp, E.; et al. Direct detection of early-stage cancers using circulating tumor DNA. Sci. Transl. Med. 2017, 9, eaan2415. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Diaz, L., Jr.; ABardelli, A. Liquid biopsies: Genotyping circulating tumor DNA. J. Clin. Oncol. 2014, 32, 579. [Google Scholar] [CrossRef] [PubMed]
- Trigg, R.; Martinson, L.; Parpart-Li, S.; Shaw, J. Factors that influence quality and yield of circulating-free DNA: A systematic review of the methodology literature. Heliyon 2018, 4, e00699. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goldfeder, R.L.; Priest, J.R.; Zook, J.M.; Grove, M.E.; Waggott, D.; Wheeler, M.T.; Salit, M.; Ashley, E.A. Medical implications of technical accuracy in genome sequencing. Genome Med. 2016, 8, 1–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gorgannezhad, L.; Umer, M.; Islam, M.N.; Nguyen, N.-T.; Shiddiky, M.J. Circulating tumor DNA and liquid biopsy: Opportunities, challenges, and recent advances in detection technologies. Lab Chip 2018, 18, 1174–1196. [Google Scholar] [CrossRef]
- Buscail, E.; Maulat, C.; Muscari, F.; Chiche, L.; Cordelier, P.; Dabernat, S.; Alix-Panabières, C.; Buscail, L. Liquid Biopsy Approach for Pancreatic Ductal Adenocarcinoma. Cancers 2019, 11, 852. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuderer, N.M.; Burton, K.A.; Blau, S.; Rose, A.L.; Parker, S.; Lyman, G.H.; Blau, C.A. Comparison of 2 Commercially Available Next-Generation Sequencing Platforms in Oncology. JAMA Oncol. 2017, 3, 996–998. [Google Scholar] [CrossRef] [PubMed]
- Stetson, D.; Ahmed, A.; Xu, X.; Nuttall, B.; Lubinski, T.J.; Johnson, J.H.; Barrett, J.C.; Dougherty, B.A. Orthogonal Comparison of Four Plasma NGS Tests with Tumor Suggests Technical Factors are a Major Source of Assay Discordance. JCO Precis. Oncol. 2019, 3, 1–9. [Google Scholar] [CrossRef]
- Hermann, B.T.; Pfeil, S.; Groenke, N.; Schaible, S.; Kunze, R.; Ris, F.; Bhakdi, J. DEEPGENTM—A Novel Variant Calling Assay for Low Frequency Variants. Genes 2021, 12, 507. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Duchesnay, E. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [Green Version]
- Thierry, A.R.; Mouliere, F.; El Messaoudi, S.; Mollevi, C.; Lopez-Crapez, E.; Rolet, F.; Gillet, B.; Gongora, C.; Dechelotte, P.; Robert, B.; et al. Clinical validation of the detection of KRAS and BRAF mutations from circulating tumor DNA. Nat. Med. 2014, 20, 430–435. [Google Scholar] [CrossRef]
- Guren, M.G. The global challenge of colorectal cancer. Lancet Gastroenterol. Hepatology 2019, 4, 894–895. [Google Scholar] [CrossRef] [Green Version]
- Pinsky, P.F.; Prorok, P.C.; Kramer, B.S. Prostate Cancer Screening-A Perspective on the Current State of the Evidence. N. Engl. J. Med. 2017, 376, 1285–1289. [Google Scholar] [CrossRef] [PubMed]
- Mandelker, D.; Zhang, L.; Kemel, Y.; Stadler, Z.K.; Joseph, V.; Zehir, A.; Pradhan, N.; Arnold, A.; Walsh, M.F.; Liying, Z.; et al. Mutation Detection in Patients with Advanced Cancer by Universal Sequencing of Cancer-Related Genes in Tumor and Normal DNA vs Guideline-Based Germline Testing. JAMA 2017, 318, 825–835. [Google Scholar] [CrossRef]
- Zubor, P.; Kubatka, P.; Kajo, K.; Dankova, Z.; Polacek, H.; Bielik, T.; Kudela, E.; Samec, M.; Liskova, A.; Vlcakova, D.; et al. Why the gold standard approach by mammography demands extension by multiomics? Application of liquid biopsy miRNA profiles to breast cancer disease management. Int. J. Mol. Sci. 2019, 20, 2878. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pantel, K.A.; lix-Panabières, C. Liquid biopsy and minimal residual disease—latest advances and implications for cure. Nat. Rev. Clin. Oncol. 2019, 16, 409–424. [Google Scholar] [CrossRef]
- Ravandi, F.; Jorgensen, J.L.; Thomas, D.A.; O’Brien, S.; Garris, R.; Faderl, S.; Huang, X.; Wen, S.; Burger, J.A.; Ferrajoli, A.; et al. Detection of MRD may predict the outcome of patients with Philadelphia chromosome–positive ALL treated with tyrosine kinase inhibitors plus chemotherapy. Blood 2013, 122, 1214–1221. [Google Scholar] [CrossRef] [PubMed]
- Oien, K.A. Pathologic Evaluation of Unknown Primary Cancer. Semin. Oncol. 2009, 36, 8–37. [Google Scholar] [CrossRef]
- Kim, H.; Kim, Y.-M. Pan-cancer analysis of somatic mutations and transcriptomes reveals common functional gene clusters shared by multiple cancer types. Sci. Rep. 2018, 8, 6041. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marquard, A.M.; Birkbak, N.J.; Thomas, C.E.; Favero, F.; Krzystanek, M.; Lefebvre, C.; Ferté, C.; Jamal-Hanjani, M.; Wilson, G.A.; Shafi, A.; et al. Tumor Tracer: A method to identify the tissue of origin from the somatic mutations of a tumor specimen. BMC Med. Genom. 2015, 8, 58. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abbosh, C.; Birkbak, N.J.; Swanton, C. Early stage NSCLC—challenges to implementing ctDNA-based screening and MRD detection. Nat. Rev. Clin. Oncol. 2018, 15, 577–586. [Google Scholar] [CrossRef] [PubMed]
- Chechlinska, M.; Kowalewska, M.; Nowak, R. Systemic inflammation as a confounding factor in cancer biomarker discovery and validation. Nat. Rev. Cancer 2010, 10, 2–3. [Google Scholar] [CrossRef]
- Colotta, F.; Allavena, P.; Sica, A.; Garlanda, C.; Mantovani, A. Cancer-related inflammation, the seventh hallmark of cancer: Links to genetic instability. Carcinogenesis 2009, 30, 1073–1081. [Google Scholar] [CrossRef] [Green Version]
- Barbie, D.A.; Tamayo, P.; Boehm, J.; Kim, S.Y.; Moody, S.E.; Dunn, I.F.; Schinzel, A.C.; Sandy, P.; Meylan, E.; Scholl, C.; et al. Systematic RNA interference reveals that oncogenic KRAS-driven cancers require TBK1. Nat. Cell Biol. 2009, 462, 108–112. [Google Scholar] [CrossRef]
- Multhoff, G.; Molls, M.; Radons, J. Chronic inflammation in cancer development. Front. Immunol. 2012, 2, 98. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Control n = 415 | All Cancer n = 260 | Bladder n = 25 | Prostate n = 29 | Lung n = 30 | Liver n = 27 | Pancreatic n = 40 | Colorectal n = 66 | Breast n = 43 |
|---|---|---|---|---|---|---|---|---|---|
| Age | |||||||||
| Mean (standard deviation) | 54.9 (15.5) | 65.4 (10.9) | 68.7 (11.1) | 64.9 (7.3) | 64.2 (9.6) | 67.5 (9.7) | 66.9 (9.4) | 65.2 (12.3) | 61.9 (12.3) |
| Sex, n (%) | |||||||||
| Male | 117 (28) | 136 (52) | 18 (72) | 29 (100) | 10 (33) | 20 (74) | 21 (52) | 38 (58) | 0 (0) |
| Female | 298 (72) | 124 (48) | 7 (28) | 0 (0) | 20 (67) | 7 (26) | 19 (48) | 28 (42) | 43 (100) |
| Comorbidities, n (%) | |||||||||
| Alzheimer’s | 1 (0.2) | 1 (0.4) | 0 (0.0) | 0 (0.0) | 0 (0.0) | 0 (0.0) | 0 (0.0) | 0 (0.0) | 1 (2) |
| Cardiovascular disease | 27 (7) | 28 (11) | 8 (32) | 1 (3) | 3 (10) | 4 (15) | 4 (10) | 6 (9) | 2 (5) |
| Diabetes | 31 (7) | 36 (14) | 4 (16) | 2 (7) | 2 (7) | 8 (30) | 8 (20) | 8 (12) | 4 (9) |
| Hypertension | 75 (18) | 108 (42) | 18 (72) | 8 (28) | 12 (40) | 15 (56) | 18 (45) | 23 (35) | 14 (33) |
| Kidney disease | 5 (1) | 14 (5) | 4 (16) | 2 (7) | 1 (3) | 0 (0.0) | 0 (0.0) | 5 (8) | 2 (5) |
| Obesity | 40 (10) | 30 (12) | 8 (32) | 2 (7) | 5 (17) | 3 (11) | 0 (0.0) | 5 (8) | 7 (16) |
| Respiratory disease | 18 (4) | 35 (13) | 7 (28) | 3 (10) | 9 (30) | 4 (15) | 4 (10) | 2 (3) | 6 (14) |
| Other | 141 (34) | 113 (43) | 18 (72) | 17 (59) | 16 (53) | 18 (67) | 12 (30) | 14 (21) | 18 (42) |
| None | 185 (45) | 30 (12) | 1 (4) | 3 (10) | 3 (10) | 1 (4) | 3 (8) | 10 (15) | 9 (21) |
| Unknown | 32 (8) | 46 (18) | 0 (0.0) | 2 (7) | 1 (3) | 5 (19) | 13 (32) | 25 (38) | 0 (0.0) |
| Risk Factors, n (%) | |||||||||
| Family History * | 182 (44) | 100 (38) | 4 (16) | 8 (28) | 14 (47) | 9 (33) | 14 (35) | 25 (38) | 26 (60) |
| Smoking History | 132 (32) | 110 (42) | 11 (44) | 11 (38) | 23 (77) | 13 (48) | 15 (38) | 25 (38) | 12 (28) |
| Medical Condition | 57 (14) | 65 (25) | 7 (28) | 11 (38) | 5 (17) | 8 (30) | 12 (30) | 18 (27) | 4 (9) |
| Other | 22 (5) | 47 (18) | 10 (40) | 8 (28) | 5 (17) | 14 (52) | 3 (8) | 5 (8) | 2 (5) |
| None | 104 (25) | 45 (17) | 8 (32) | 3 (10) | 2 (7) | 2 (7) | 3 (8) | 16 (24) | 11 (26) |
| Unknown | 51 (12) | 23 (9) | 4 (16) | 4 (14) | 0 (0) | 5 (19) | 6 (15) | 3 (5) | 1 (2) |
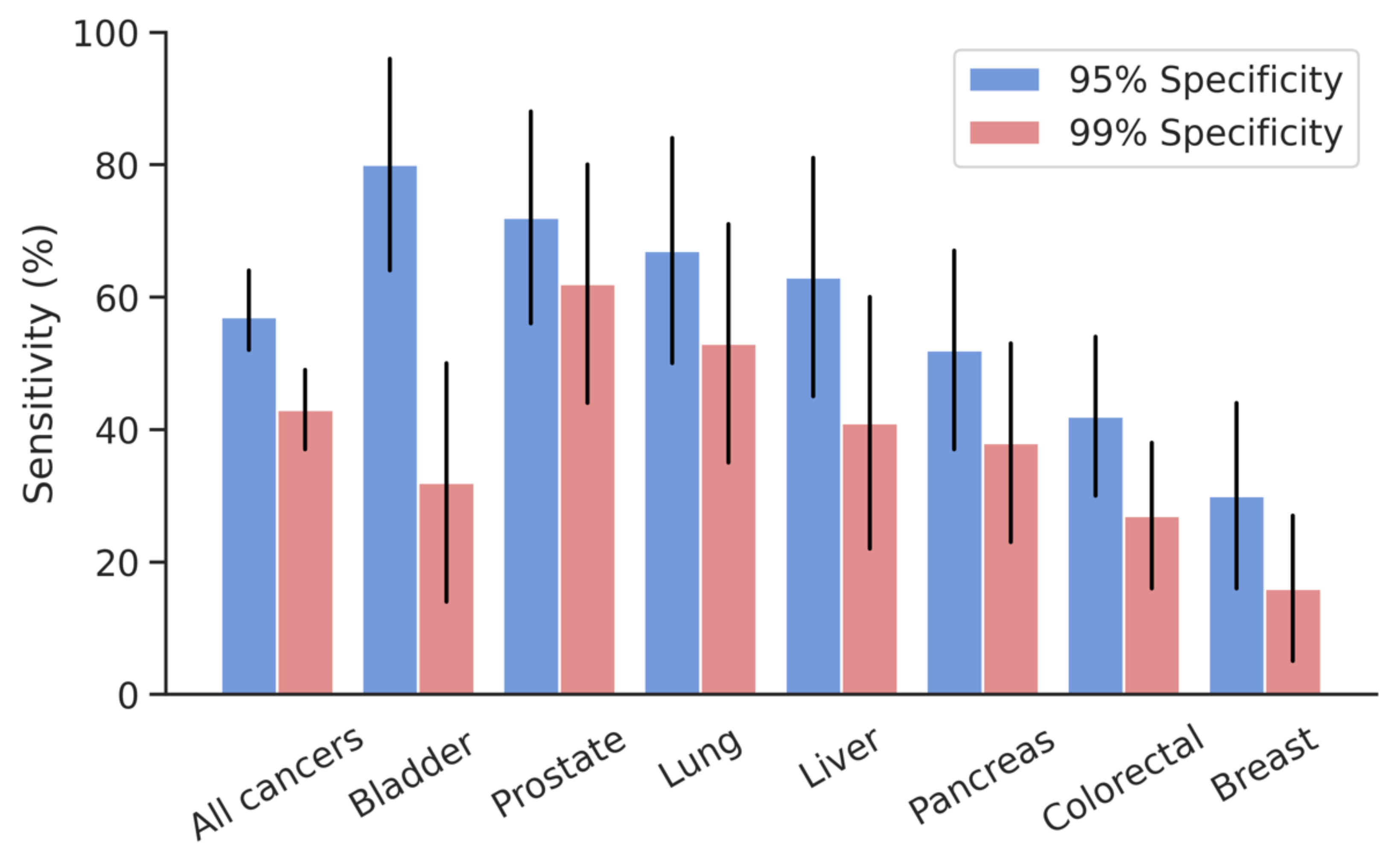
| Model | Number of Cancer Samples | Cancer Findings at 95% Specificity | Cancer Findings at 99% Specificity | ||||
|---|---|---|---|---|---|---|---|
| n | Correctly Identified Cancers, n | Sensitivity, % | 95% Confidence Interval, Lower Bound, Upper Bound | Correctly Identified Cancers, n | Sensitivity, % | 95% Confidence Interval, Lower Bound, Upper Bound | |
| All cancers | 260 | 150 | 57 | 52, 64 | 111 | 43 | 37, 49 |
| Bladder | 25 | 20 | 80 | 64, 96 | 8 | 32 | 14, 50 |
| Breast | 43 | 13 | 30 | 16, 44 | 7 | 16 | 5, 27 |
| Colorectal | 66 | 28 | 42 | 30, 54 | 18 | 27 | 16, 38 |
| Liver | 27 | 17 | 63 | 45, 81 | 11 | 41 | 22, 60 |
| Lung | 30 | 20 | 67 | 50, 84 | 16 | 53 | 35, 71 |
| Pancreas | 40 | 21 | 52 | 37, 67 | 15 | 38 | 23, 53 |
| Prostate | 29 | 21 | 72 | 56, 88 | 18 | 62 | 44, 80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ris, F.; Hellan, M.; Douissard, J.; Nieva, J.J.; Triponez, F.; Woo, Y.; Geller, D.; Buchs, N.C.; Buehler, L.; Moenig, S.; et al. Blood-Based Multi-Cancer Detection Using a Novel Variant Calling Assay (DEEPGENTM): Early Clinical Results. Cancers 2021, 13, 4104. https://0-doi-org.brum.beds.ac.uk/10.3390/cancers13164104
Ris F, Hellan M, Douissard J, Nieva JJ, Triponez F, Woo Y, Geller D, Buchs NC, Buehler L, Moenig S, et al. Blood-Based Multi-Cancer Detection Using a Novel Variant Calling Assay (DEEPGENTM): Early Clinical Results. Cancers. 2021; 13(16):4104. https://0-doi-org.brum.beds.ac.uk/10.3390/cancers13164104
Chicago/Turabian StyleRis, Frederic, Minia Hellan, Jonathan Douissard, Jorge J. Nieva, Frederic Triponez, Yanghee Woo, David Geller, Nicolas C. Buchs, Leo Buehler, Stefan Moenig, and et al. 2021. "Blood-Based Multi-Cancer Detection Using a Novel Variant Calling Assay (DEEPGENTM): Early Clinical Results" Cancers 13, no. 16: 4104. https://0-doi-org.brum.beds.ac.uk/10.3390/cancers13164104