1. Introduction
For the past two to three decades, large data generated from a variety of sources such as commercial organizations, educational institutes, social networking sites, research organizations, the gaming industry, and web-based applications are increasing with tremendous velocity. Large data cannot be stored in centralized server systems, and thus we require distributed storage and a computing environment for storing, accessing, and processing large data in a scalable manner. In such a case, the natural idea to emerge would be to use the powers of multiple autonomous computers capable of communicating with each other in a network to achieve a common goal. Accordingly, a similar infrastructure referred to as a distributed system (DS) [
1,
2] was developed. Modern cloud computing systems (CSSs) [
3], built on the principles of a distributed system, are capable of providing large storage and computing capacity in a scalable manner [
4,
5] with high availability and reliability [
6] for a wide range of data, computers, and concurrent-access-intensive services [
7,
8,
9,
10,
11,
12]. Such a capability in a cloud computing system is enabled by distributed file systems (DFS), which is considered to be one of the core components in such distributed systems.
In distributed systems, applications requiring large volumes of data are studied under “data-intensive computing”, in which most of the processing time is dedicated to reading/writing or manipulating the data. With the surge in the amount and pace with which the data are generated, the focus of distributed systems such as cloud computing has shifted from compute-intensive to data-intensive domain [
13]. The data to be processed in distributed systems can be broadly classified into three categories: structured, semistructured, and unstructured. When it comes to processing a huge amount of data generated at a tremendous rate, it is quite a challenging task to make decisions for those applications even in supercomputers [
14]. To address the challenges associated with handling large data sets in distributed systems, several programming models were developed by different internet service providers. Map-Reduce [
15,
16,
17,
18,
19], a parallel programming model, was developed by big internet service providers to perform computation on massive data sets [
15,
20] in data-intensive and distributed applications. The model was developed as an open-source project by Apache Hadoop (extension of the original Google File system developed by Google [
21]), in which the Hadoop distributed file system (HDFS) [
22] was used as a core component in the data storage system. HDFS offers high fault tolerance along with high scalability and is best suited for immutable files and web applications. However, when the files have to be concurrently accessed by multiple applications, HDFS faces difficulties to offer high throughput [
23]. Recently, the apache software foundation released a new version 3.2.2 for Hadoop. According to the work in [
24], Hadoop cannot guarantee isolated access to data for concurrent file access. BloobSeer [
23,
25] was developed to overcome this issue as it seamlessly supports concurrent file access, data-intensive applications, and versioning capabilities [
26].
In computing systems, the checkpointing technique periodically takes a snapshot of the states in a persistent storage device. Checkpointing has been used as one of the key mechanisms to provide a consistent state to the distributed storage system and ensure fault tolerance. When the system fails at any point during the execution of the applications, the system can recover and restart the application from one of the most recent checkpoints, without having to start the applications from the start. While checkpointing is a topic of interest for both practitioners and researchers, in this paper, we add a checkpointing restart method for BlobSeer DFS as such checkpoints can prevent data loss due to any system failures or restarts, especially in a distributed Cloud environment.
The rest of the paper is organized as follows.
Section 2 discusses the background of the Blobseer DFS along with related works on providing consistent state to a distributed storage system.
Section 3 explains in detail the proposed technique, while
Section 4 presents the experimental results along with discussions.
Section 5 concludes the work.
2. Related Works
In this section, we first discuss the background of BloobSeer, and then include the related works on various checkpointing mechanisms.
2.1. BlobSeer Distributed File System
BloobSeer [
23,
25] was developed to support concurrent file access, data-intensive applications, and versioning capabilities [
26]. BlobSeer DFS was developed to store big data, ensuring faster access to smaller parts of huge data objects and high throughput during concurrent data access. In BlobSeer, data are stored as a binary large object, termed as a blob. The blob can then be accessed through an interface. The same interface can be used to create blobs, read from blobs, and write to blobs. Another key feature of BlobSeer is the versioning—the ability to generate a separate identification number (version) for newly created or modified copies of existing blobs. The version number follows an incremental fashion for existing blobs while a random version number is generated for new blobs. BlobSeer ensures high throughput for concurrent access as the clients can access an existing or the most recent version of a blob by specifying the relevant version identification number [
27,
28]. The framework of BlobSeer DFS is depicted in
Figure 1. Data Providers (DPs), Provider Manager (PM), Metadata Providers (MPs), and Version Manager (VM) are the major components of BlobSeer DFS.
The clients can create, read, write, and append data from/to blobs along with concurrent access to the same data object. DPs store the chunks of data coming out of write or append operations. BlobSeer offers flexibility as new DPs can be added or the existing DPs can be removed from the system when required. PM maintains the information of the available storage space in the system and is responsible for scheduling the location of newly generated data chunks. The metadata information maintained by MP allows the identification of the chunks to make a snapshot version. The distributed metadata management scheme in BlobSeer allows efficient concurrent access to the metadata information. VM in BlobSeer is responsible for allocating version identification values to new write clients and the clients performing append operations on data objects.
The key file operations in BlobSeer DFS are read, write, and append. To read a file or data object, a client initially requests the VM by specifying the version number to be read. The VM then transfers the request to MPs. The MP then sends the requested range of metadata of the corresponding data object to the requested client. Once the client determines the location information of all the pages, the client can read the data from the corresponding providers simultaneously. For the write operation, the client first divides the data into several pages of specified sizes. The client then requests the PM for the list of DPs to write the data pages. After receiving the DP list from the PM, the client performs data write operations to multiple DPs simultaneously. If any of the write operations fail, the entire write operation is considered to be unsuccessful. This arrangement in BlobSeer ensures data consistency. Once the file write operation is successful, the client requests the VM for the assignment of a new version for the data object. The VM assigns the version number based on its version control policy. The file append operation is quite similar to the file write operation with the difference in the range of the offset for the append operation, which is fixed by the VM during the assignment of the version value. In BlobSeer, each data object is divided into fixed smaller parts, which can be specified at the time of data object creation. These fixed smaller parts are evenly distributed among storage space providers based on load balancing strategies, because of which multiple clients can concurrently access the data objects with high throughput. BlobSeer maintains decentralized metadata information to avoid a single point of failure during the concurrent data object access. For metadata information, a distributed segment tree is associated with each version of the data object. A distributed hash table is also used by metadata providers for efficient access to the metadata. Furthermore, BlobSeer implements linearizability semantics to provide concurrent access to data objects. When multiple write clients are accessing different parts of the same data object, the versioning-based control mechanism allows the clients to write all the different parts of the same data object simultaneously until the version-number assignment step. While assigning version numbers, the concurrent clients are serialized. The clients can function simultaneously only after they have been assigned the version number.
To employ BlobSeer for data-intensive applications in distributed systems, such as Cloud infrastructure, we must be able to stop and restart the framework from a consistent state [
29]. To offer a consistent state after a system restart, we propose a checkpoint functionality to stop and restart various components of the BlobSeer framework. This checkpoint functionality ensures consistent data operation after any stop and restart events. The proposed technique also facilitates the integration of the BlobSeer framework to virtual machines in Cloud infrastructure to make the framework a storage service in the Cloud by transferring the advantages of the framework. The proposed mechanism is expected to offer a new way, as an alternative to existing methods, for using the BlobSeer framework in a Cloud environment for more efficient data access, storage, and processing.
2.2. Checkpointing Mechanisms
Checkpointing has been used as one of the key mechanisms to provide consistent state to the distributed storage system and ensure a fault-tolerant DS [
30]. In this subsection, we describe various approaches adopted in the literature to implement checkpointing in DFS.
In computing systems, the checkpointing technique periodically takes a snapshot of the states in a persistent storage device. When the system fails at any point during the execution of the applications, the system can recover and restart the application from one of the most recent checkpoints, without having to start the applications from the start. In the literature [
31,
32], three main checkpointing approaches—uncoordinated, coordinated, and communication-induced—have been defined. Further discussion on these approaches is given as follows.
2.3. Uncoordinated Checkpoints
In this approach, while restarting after encountering a failure, the application processes check through an already finalized set of checkpoints and find one in a consistent state. The processes can then be resumed from the chosen consistent state. Usually, processes consider the checkpoints saved in a small space for better efficiency.
The uncoordinated approach has been discussed in the literature [
32]. Under this approach, processes identify local checkpoints individually. While restarting, the processes verify for an already finalized set of checkpoints, which are in a consistent state. From this consistent state, execution can be resumed. The advantage of this approach is that each process can consider a checkpoint as per their convenience. Processes can consider checkpoints which are saved in a small amount for efficiency purpose. One of the strong points of this approach is that each process can have the flexibility to take a checkpoint whenever the process requires one. For more efficient operations, the processes are even allowed to consider the checkpointing when the frozen state information size is small. However, there are some disadvantages to the approach. There is a possibility of the system rolling back to the starting state of the execution that can waste the resources and the work already done after the system has started. Additionally, the processes under this approach may consider checkpoints that are not a part of a globally consistent state. In an uncoordinated approach, initially, all the specified processes figure out the local checkpoints individually. Uncoordinated checkpointing forces each process to maintain multiple checkpoints which can incur a large storage overhead. At the time of a restart, the processes verify the existing list of finalized checkpoints to determine a consistent state from which the execution process can resume.
2.4. Coordinated Checkpoints
The need for multiple processes to coordinate to produce a globally consistent checkpoint state while finalizing the local checkpoints is highlighted in [
32]. Accordingly, a coordinated approach was incepted. Due to the coordination among all the processes, the recovery process is simplified and all the processes can start from the most recent available checkpoint state. This prevents the domino effect that was existent with an uncoordinated approach. More importantly, with the coordinated approach, the storage is minimized as only one persistent checkpoint has to be maintained. The limitation of the coordinated approach is the latency while finalizing the checkpoint as the approach requires the global checkpoint to be finalized prior to storing the checkpoints to be written into the permanent storage.
2.5. Communication-Induced Checkpoints
In a communication-induced approach, each process is forced to take checkpoints based on protocol-related information that is “piggybacked” on the application messages received from other processes. The checkpoints are taken in such a manner that the system-wide consistent always exists on the stable storage. This prevents the “domino effect” within the approach. Moreover, the processes are allowed to take some of their checkpoints independently (termed as local checkpoints) as well. However, while deciding on the globally consistent state, the processes are forced to take some additional checkpoints (forced checkpoints). The receiver of each application message uses the piggybacked information to determine if a receiver has a forced checkpoint. The forced checkpoint must be taken before the application can process the contents of the message, which can incur high latency and overhead. In contrast to coordinated checkpointing, no special coordination messages are exchanged in this approach.
In our work, we implement a checkpoint mechanism within a BlobSeer cluster based on uncoordinated checkpoint algorithms for their simplicity and associated benefits. In the future, we expect to explore the possibility of a new checkpoint approach based on speculation.
3. Proposed Approach
So as to ensure a consistent state to a distributed storage system in Cloud infrastructure from where any application processes can resume the operations, we propose an uncoordinated checkpoint-based restart method for the BlobSeer storage layer in a distributed environment. The uncoordinated checkpoint approach has been adopted in our proposed method due to the minimum overhead and efforts required for the approach and its convenient and speedy operation when compared to its counterparts. The uncoordinated checkpointing approach can be easily integrated into each component of BlobSeer without having to expense the overheads for the global state.
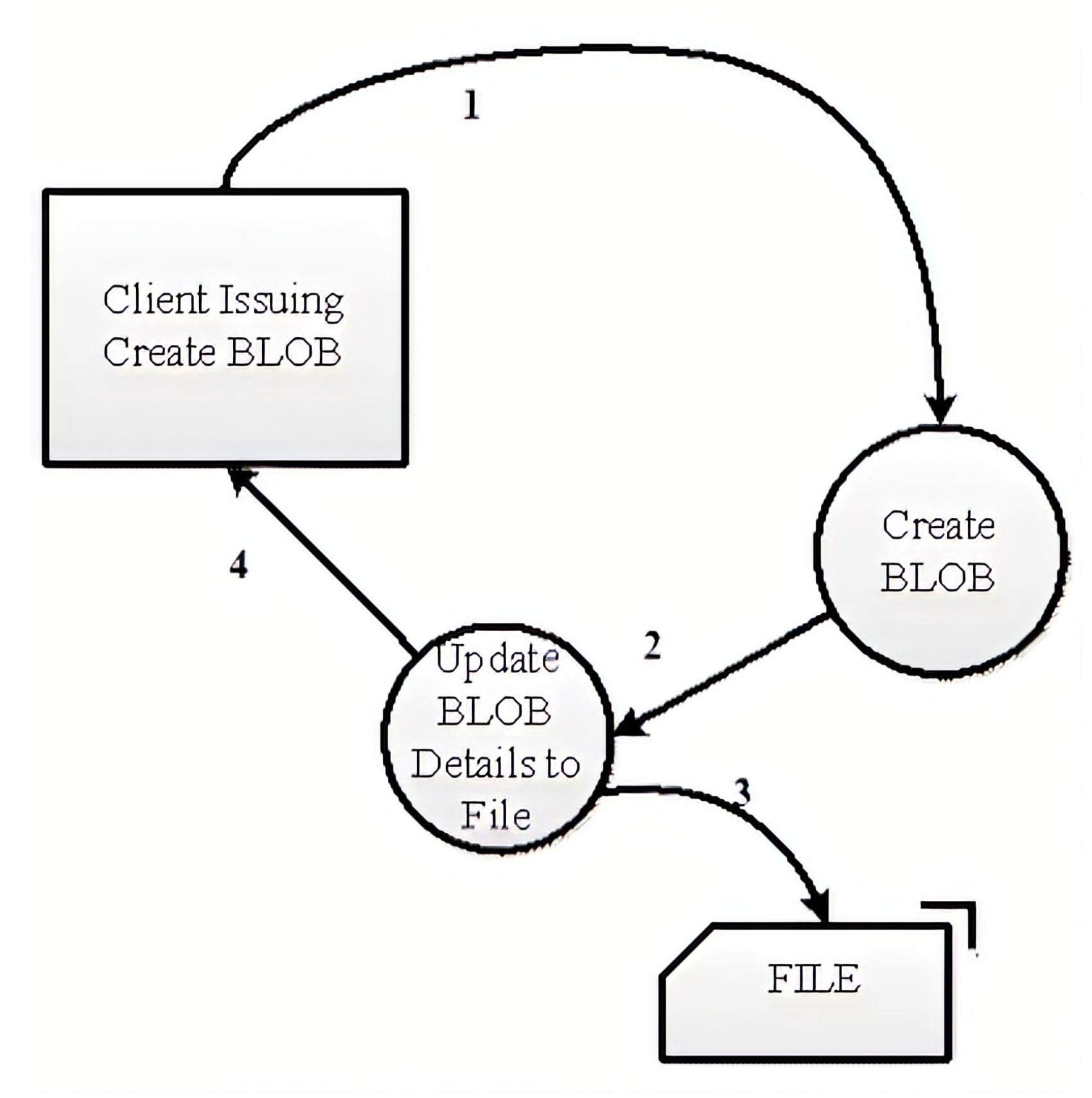
Figure 2 shows how an uncoordinated checkpointing can be implemented in the VM within the BlobSeer framework. As can be seen in the figure, checkpointing in the VM starts when a client issues a “CREATE_BLOB” request in the BlobSeer API. When the API is called, the checkpointing function creates the requested blob. The function then stores the blob-id and other relevant parameters. All these values are stored in a file. As there is only one Version Manager (VM) in the BlobSeer framework, there is no requirement for distributing the same information to other nodes. Single file storage is thus sufficient for version checkpointing. Apart from the blob-id, page size and replication count are stored in the file as “space” separated entries. The file is parsed during the restart phase after any failure is encountered in the storage system. In our proposed method, there is a counter that keeps track of the total number of blobs created. During the restart, the counter can start from the last value rather than starting from the zero (0) value. As such, storing the key information in a file as explained in our proposed method, which when parsed during any restart phase provides a consistent state for the VM in a distributed storage system in a distributed environment. The file in our proposed method is stored in “.txt” file format.
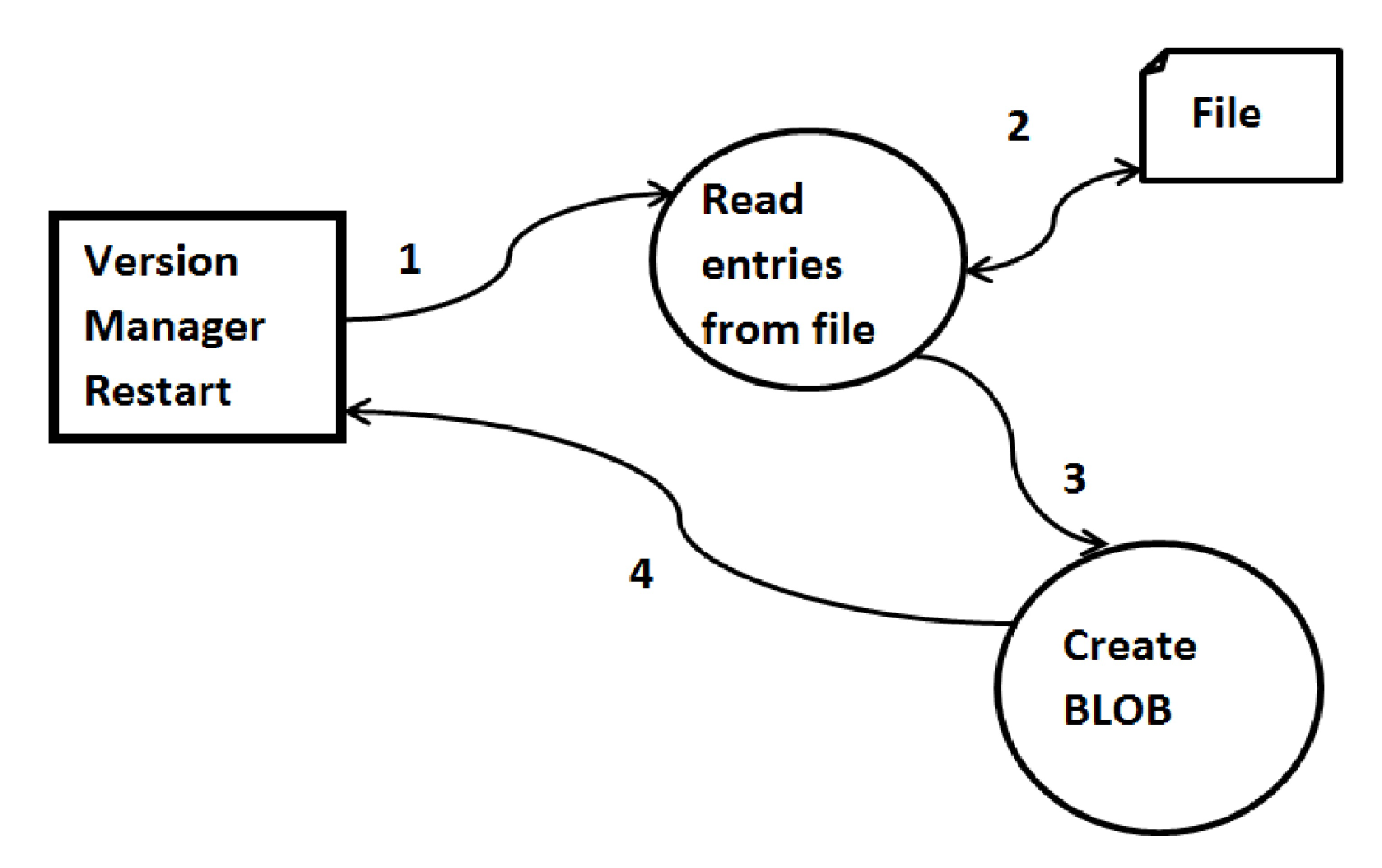
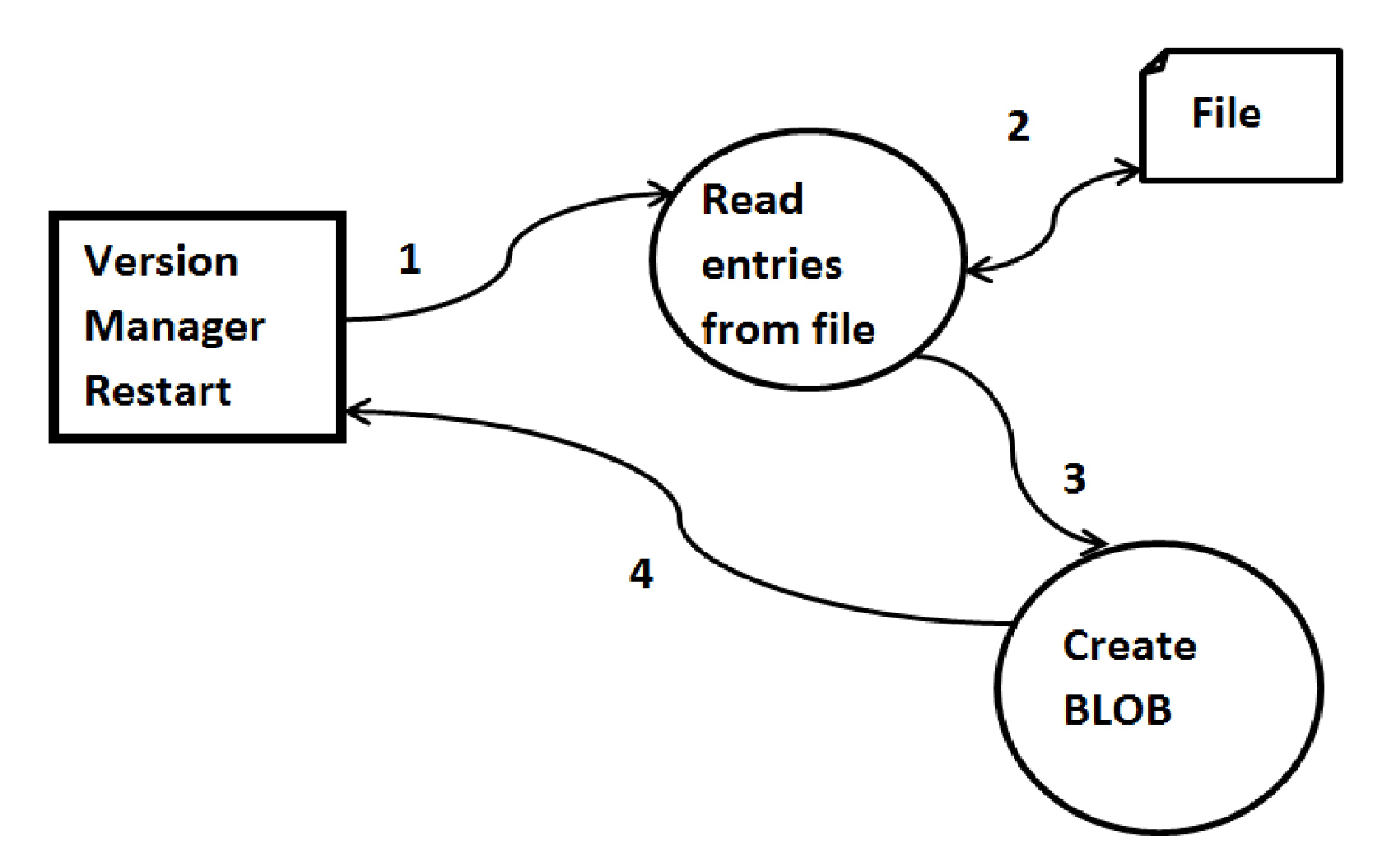
Figure 3 represents the processes that follow after the VM restarts after having encountered some failure. Once the VM restarts, the counter value for the total number of BLOBs created is initialized to 0. The VM then looks for any entries in the text file, where each entry in the file represents a new blob. Each entry in the file is read and parsed, based on which a new blob is created and its id is returned.
The checkpointing functionality in the metadata provider is shown in
Figure 4. The checkpointing starts once the client issues a write or append API. The data required for checkpointing for the data provider and the metadata provider is similar. Both components have <KEY, VALUE> pairs. When checkpoint data is built, the checkpoint data is stored with the key-value pairs and a new version is finally created.
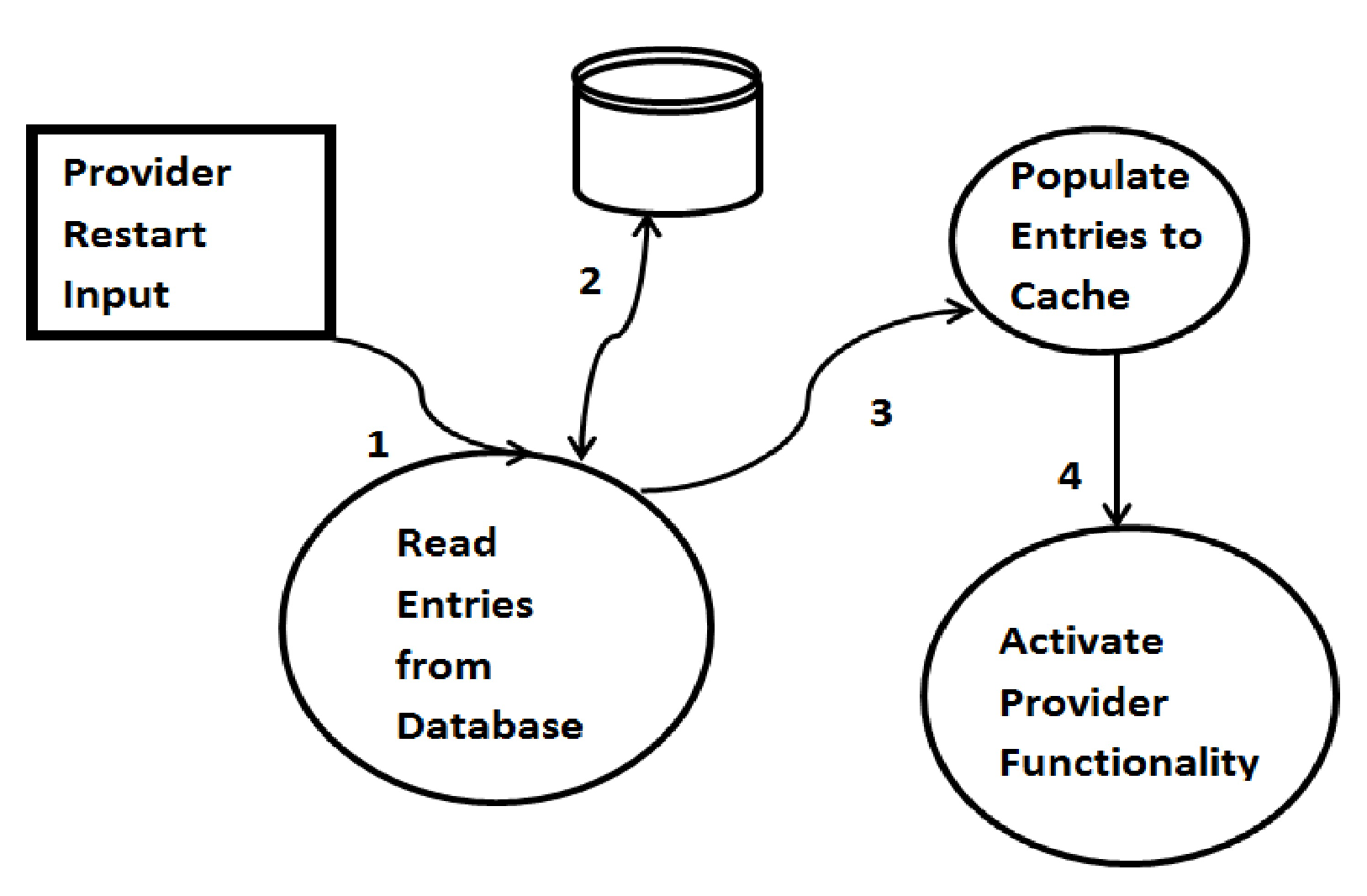
Figure 5 represents the processes that follow when the data provider or metadata provider restarts. Once the data provider or the metadata provider restarts, the entries in the database are looked for. If there are any entries in the database, those entries are populated to the cache as if they are currently in execution. A segment tree is consequently constructed. The same process is repeated for all the entries in the database. Once the process for all the entries is completed, the data provider or the metadata provider functions usually.
4. Experimental Results
In this section, we demonstrate the implementation of the checkpointing functionality in various components of the BlobSeer framework. We first present the details of the experimental setup and then explain the findings obtained by considering the restart approach for the VM and the data provider.
4.1. Experimental Setup
We consider a test environment built on a cluster consisting of five nodes. Each node has an Intel Core 2 Duo processor with 2.9 GHz frequency, 2 GB of RAM, and 500 GB of SATA HDD. The operating system on these nodes is Ubuntu and BlobSeer v1.1 is installed on top of the operating system. Out of the five nodes considered for the test, we install both the metadata provider and data provider in two nodes, the VM and provider manager in one node, and two different data providers in two different nodes. The multiple nodes within the cluster as considered in the experimental setup are taken to replicate the Cloud computing environment with an aim to demonstrate how the checkpointing functionality integrated with various components in the BlobSeer framework can provide a consistent state after restarting the system.
4.2. Check-Point Restart Approach of Version Manager
We demonstrate the checkpoint restart approach of the VM in BlobSeer with two different cases: the first being without the implementation of the restart approach and the second being after the implementation of the restart approach. The demonstration is discussed further as follows.
4.2.1. Without Restart Approach
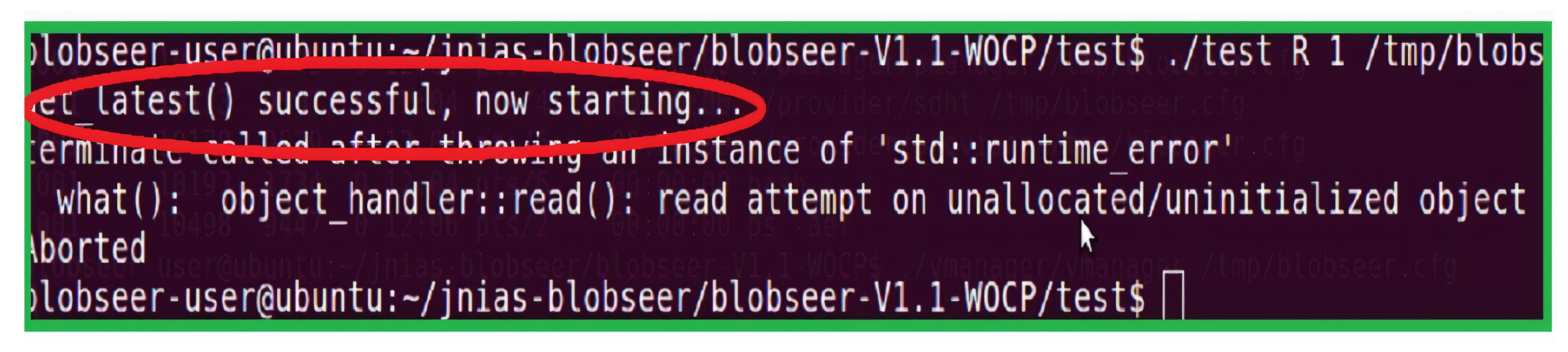
Figure 6 shows the execution of the read operation when the VM is unavailable during the system operation. In this experiment, we perform various normal operations of BlobSeer components: create a new blob, and write to and read from a blob. During the test, the VM was made unavailable by executing a kill operation. Given the role of the VM while executing the usual operations in BlobSeer, while attempting to execute a read operation, the system displayed
"Could not alloc latest version” message, as can be seen in
Figure 6 highlighted by red color.
In the next step of the demonstration, we restart the VM without implementing the restart (checkpointing) functionality and try to execute the read operation. As can be seen from
Figure 7, the VM has restarted, but the read operation was still unsuccessful. This is because the VM did not have any checkpointing functionality to store the version information about the data that was to be read. Consequently, the BlobSeer framework was unable to find a consistent state for the data after the restart and the read operation failed.
4.2.2. With Restart Approach
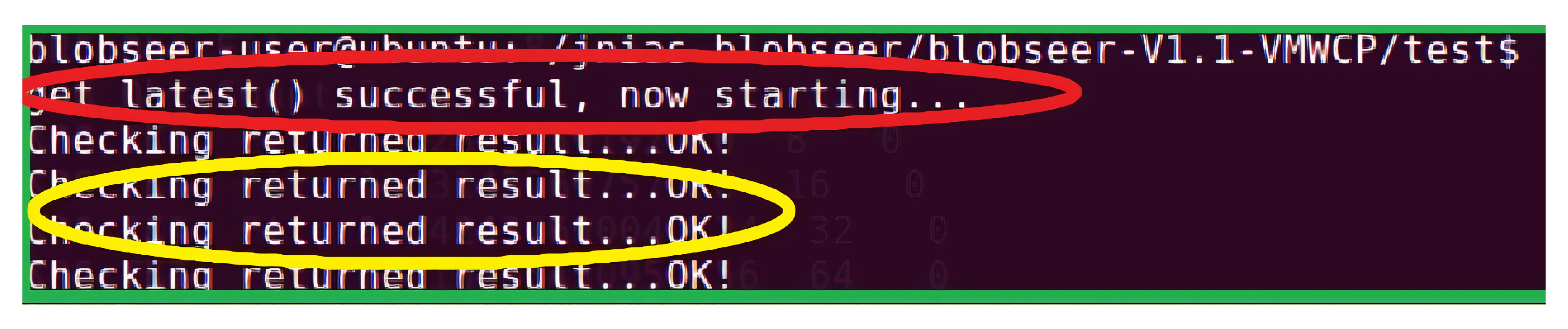
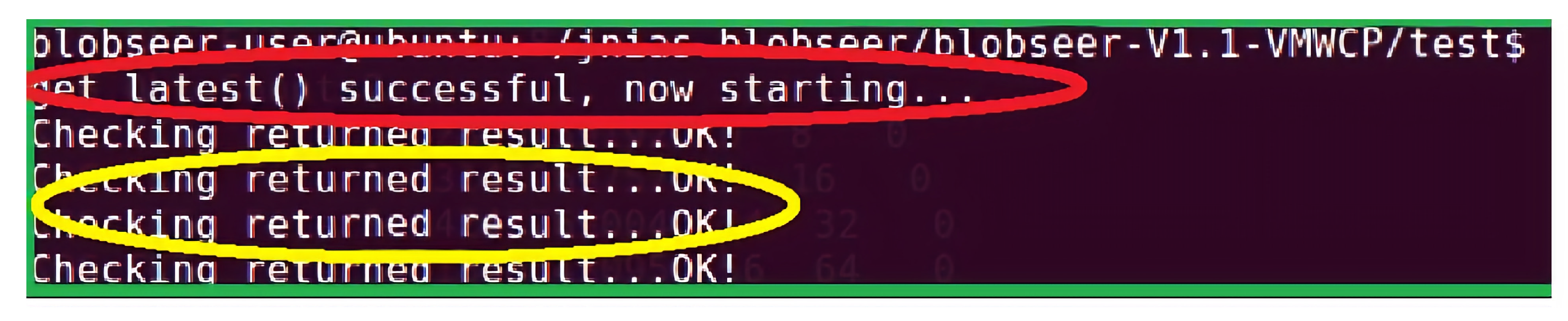
Figure 8 shows the same test with read operation when the VM is available within the BlobSeer framework. We executed the normal operations of creating a new blob, writing to and reading from a blob by making the VM available. As can be seen from the figure, the text highlighted in the red color confirms the availability of the VM that has the checkpointing functionality enabled. The texts in the yellow color confirm that the test read operation is successful and the blob information is restored. The test read operation was successful when the VM was made available with the checkpointing functionality as the system could retrieve the version information from the VM and get the relevant data object for the requested read operation. As such, checkpointing in the VM provided a consistent state for the data storage after the system restarted after having encountered some problems.
4.3. Checkpoint Restart Approach of Data Provider
We conduct similar experiments with the data provider within the BlobSeer framework to demonstrate the availability of a consistent state for data storage and operations with checkpointing functionality in data provider, yet another component in the BlobSeer framework. Further discussion on the findings with and without restart approach is made as follows.
4.3.1. Without Restart Approach of Data Provider
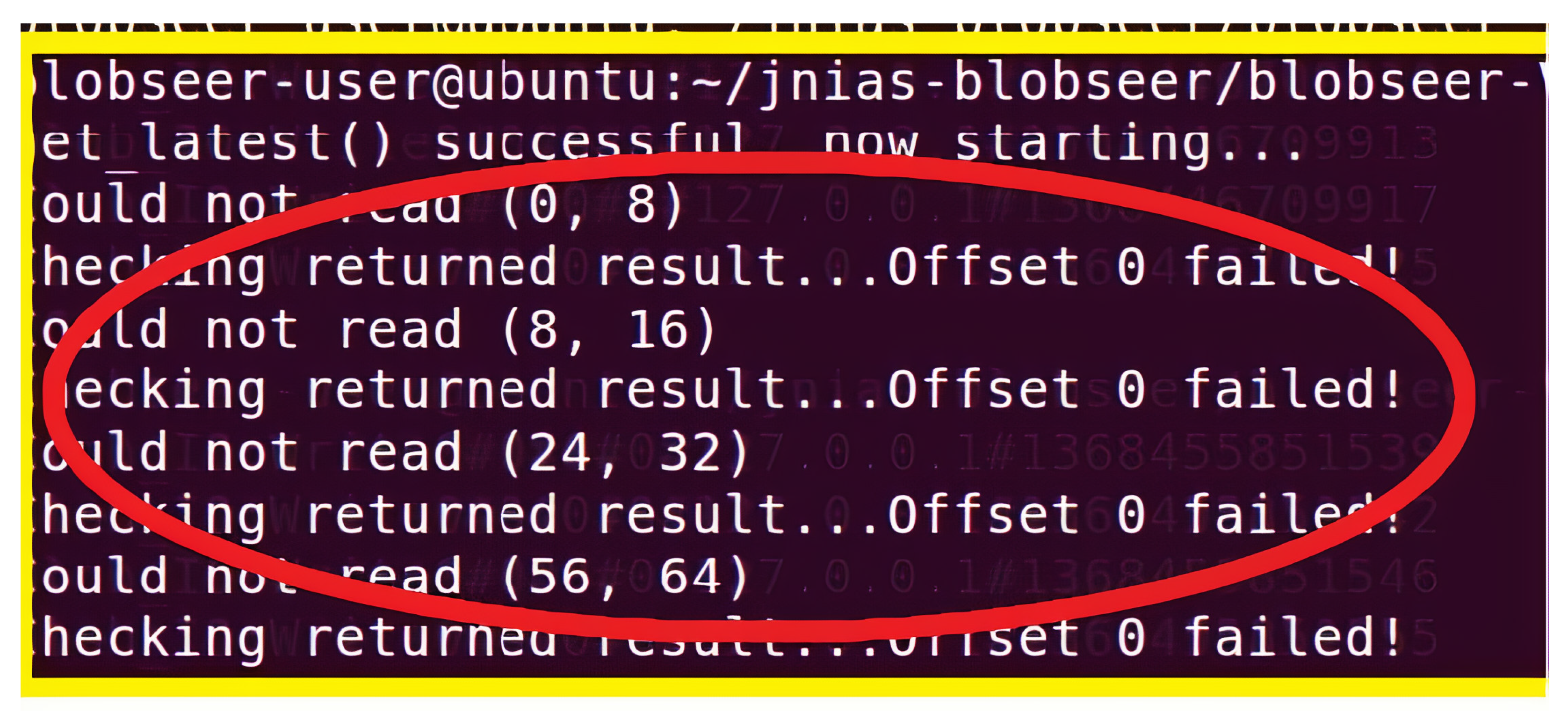
In a similar approach to our experimental tests, we tried to execute various normal operations (creating a new blob, reading from, and writing to a blob) in the system. For the test without the restart approach, we killed the data provider by executing a kill operation. We then ran a read from a blob operation to read the contents of the blob.
Figure 9 shows the outputs obtained while attempting to run the read operation when the data provider was unavailable. As can be seen from the figure, it is clear that the read operation failed. The text
"Could not read” confirms the failure of the read operation, which was all because of the unavailability of the data manager.
In the next step, the data manager was made available and the same read operation was executed.
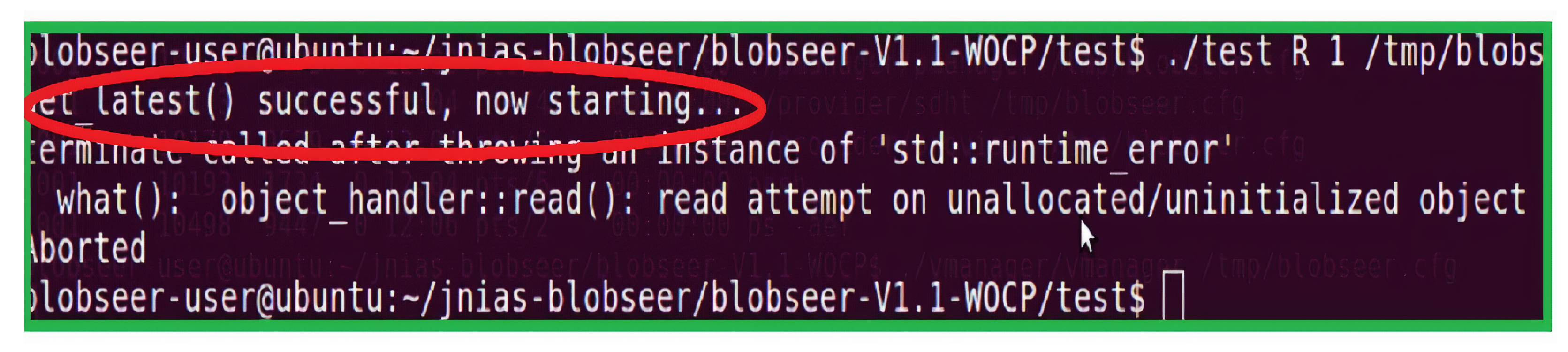
Figure 10 shows the set of outputs that were obtained during the test. As can be seen from the texts highlighted within the red color, the data manager was available to the system during the test. However, the read attempt still failed. This is because the data manager, without the checkpointing functionality, did not have the required information about the blob which the read operation was attempting to access. Thus, the BlobSeer framework in our test with the data manager could not provide a consistent state after the data manager restarted after having encountered some failure.
4.3.2. With Restart Approach of Data Provider
In an attempt to explore and investigate the availability of a consistent state with checkpointing functionality integrated to the data provider in the BlobSeer framework, we re-conducted the same experiment with normal operations by making the data manager available and enabling the checkpointing functionality in the data manager.
Figure 11 shows the list of output statements obtained during the test experiments while trying to execute the read operation on a blob. As can be seen from the texts within the red color in the figure, the data manager was available during the read operation. The texts in the yellow color confirm the successful completion of the read operation and the restoration of the blob information. As such, as demonstrated in our test, we can conclude that the checkpointing functionality, as enabled in the data provider within the BlobSeer framework, provided a consistent state for the data storage and operations in a distributed environment after the system restarted.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}