1. Introduction
Although evolution and rationality apparently favor selfishness, animals, including humans, often form cooperative relationships, each participant paying a cost to help one another. It is therefore a universal concern in biological and social sciences to understand what mechanism promotes cooperation. If individuals are in a kinship, kin selection fosters their cooperation via inclusive fitness benefits [
1,
2]. If individuals are non-kin, establishing cooperation between them is a more difficult problem. Studies of the Prisoner’s Dilemma (PD) game and its variants have revealed that repeated interactions between a fixed pair of individuals facilitates cooperation via direct reciprocity [
3,
4,
5]. A well-known example of this reciprocal strategy is Tit For Tat (TFT), whereby a player cooperates with the player’s opponent only if the opponent has cooperated in a previous stage. If one’s opponent obeys TFT, it is better to cooperate because in the next stage, the opponent will cooperate, and the cooperative interaction continues; otherwise, the opponent will not cooperate, and one’s total future payoff will decrease. Numerous experimental studies have shown that humans cooperate in repeated PD games if the likelihood of future stages is sufficiently large [
6].
In evolutionary dynamics, TFT is a catalyst for increasing the frequency of cooperative players, though it is not evolutionarily stable [
7]. Some variants of TFT, however, are evolutionarily stable; Win Stay Lose Shift (WSLS) is one such example in which a player cooperates with the player’s opponent only if the outcome of the previous stage of the game has been mutual cooperation or mutual defection [
8]. TFT and WSLS are instances of so-called reaction norms in which a player selects an action as a reaction to the outcome of the previous stage, i.e., the previous pair of actions selected by the player and the opponent [
9]. In two-player games, a reaction norm is specified by conditional probability
by which a player selects next action
a depending on the previous actions of the player and the opponent, i.e.,
and
, respectively.
Studies of cooperation in repeated games typically assume reaction norms as the subject of evolution. A problem with this assumption is that it describes behavior as a black box in which an action is merely a mechanical response to the previous outcome; however, humans and, controversially, non-human primates have a theory of mind in which they infer the state of mind (i.e., emotions or intentions) of others and use these inferences as pivotal pieces of information in their own decision-making processes [
10,
11]. As an example, people tend to cooperate more when they are cognizant of another’s good intentions [
6,
12]. Moreover, neurological bases of intention or emotion recognition have been found [
13,
14,
15,
16,
17]. Despite the behavioral and neurological evidence, there is still a need for a theoretical understanding of the role of such state-of-mind recognition in cooperation; to the best of our knowledge, only a few studies have focused on examining the interplay between state-of-mind recognition and cooperation [
18,
19].
From the viewpoint of state-of-mind recognition, the above reaction norm can be decomposed as:
where
s represents the opponent’s state of mind. Equation (1) contains two modules. The first module,
, handles the state-of-mind recognition; given observed previous actions
and
, a player infers that the player’s opponent is in state
s with probability
, i.e., a belief, and thinks that the opponent will select some action depending on this state
s. The second module,
, controls the player’s decision-making; the player selects action
a with probability
, which is a reaction to the inferred state of mind of opponent
s. In our present study, we are motivated to clarify what decision rule, i.e., the second module, is plausible and how it behaves in cooperation when a player infers an opponent’s state of mind via the first module. To do so, we use Markov Decision Processes (MDPs) that provide a powerful framework for predicting optimal behavior in repeated games when players are forward-looking [
20,
21]. MDPs even predict (pure) evolutionarily stable states in evolutionary game theory [
22].
The core of MDPs is the Bellman Optimality Equation (BOE); by solving the BOE, a player obtains the optimal decision rule, which is called the optimal policy, that maximizes the player’s total future payoff. Solving a BOE with beliefs, however, requires complex calculations and is therefore computationally expensive. Rather than solving the BOE naively, we instead introduce approximations of the belief calculation that we believe to be more biologically realistic. We introduce two models to do so and examine the possibility of achieving cooperation as compared to a null model (introduced in
Section 2.2.1) in which a player directly observes an opponent’s state of mind. In the first model, we assume that a player believes that an opponent’s behavior is deterministic such that the opponent’s actions are directly (i.e., one-to-one) related to the opponent’s states. A rationale for this approximation is that in many complex problems, people use simple heuristics to make a fast decision, for example a rough estimation of an uncertain quantity [
23,
24]. In the second model, we assume that a player correctly senses an opponent’s previous state of mind, although the player does not know the present state of mind. This assumption could be based on some external clue provided by emotional signaling, such as facial expressions [
25]. We provide the details of both models in
Section 2.2.2.
3. Results
Before presenting our results, we introduce a short hand notation to represent policies for each model. In Model 0, a policy is represented by character sequence , where is the optimal action if the opponent is in state . Model 0 has at most four possible policies, namely CC, CD, DC and DD. Policies CC and DD are unconditional cooperation and unconditional defection, respectively. With policy CD, an agent behaves in a reciprocal manner in response to an opponent’s present state; more specifically, the agent cooperates with an opponent in state H, hence the opponent cooperating at the present stage, and defects against an opponent in state U, hence the opponent defecting at the present stage. Policy DC is an asocial variant of policy CD: an agent obeying policy DC defects against an opponent in state H and cooperates with an opponent in state U. We call policy CD anticipation and policy DC asocial-anticipation. In Model 1, a policy is represented by four-letter sequence , where is the optimal action, with the agent’s and opponent’s selected actions and at the previous stage. In Model 2, a policy is represented by four-letter sequence , where is the optimal action, with the agent’s selected action and the opponent’s state at the previous stage. Models 1 and 2 each have at most sixteen possible policies, ranging from unconditional cooperation (CCCC) to unconditional defection (DDDD).
For each model, we identify four classes of optimal policy, i.e., unconditional cooperation, anticipation, asocial-anticipation and unconditional defection.
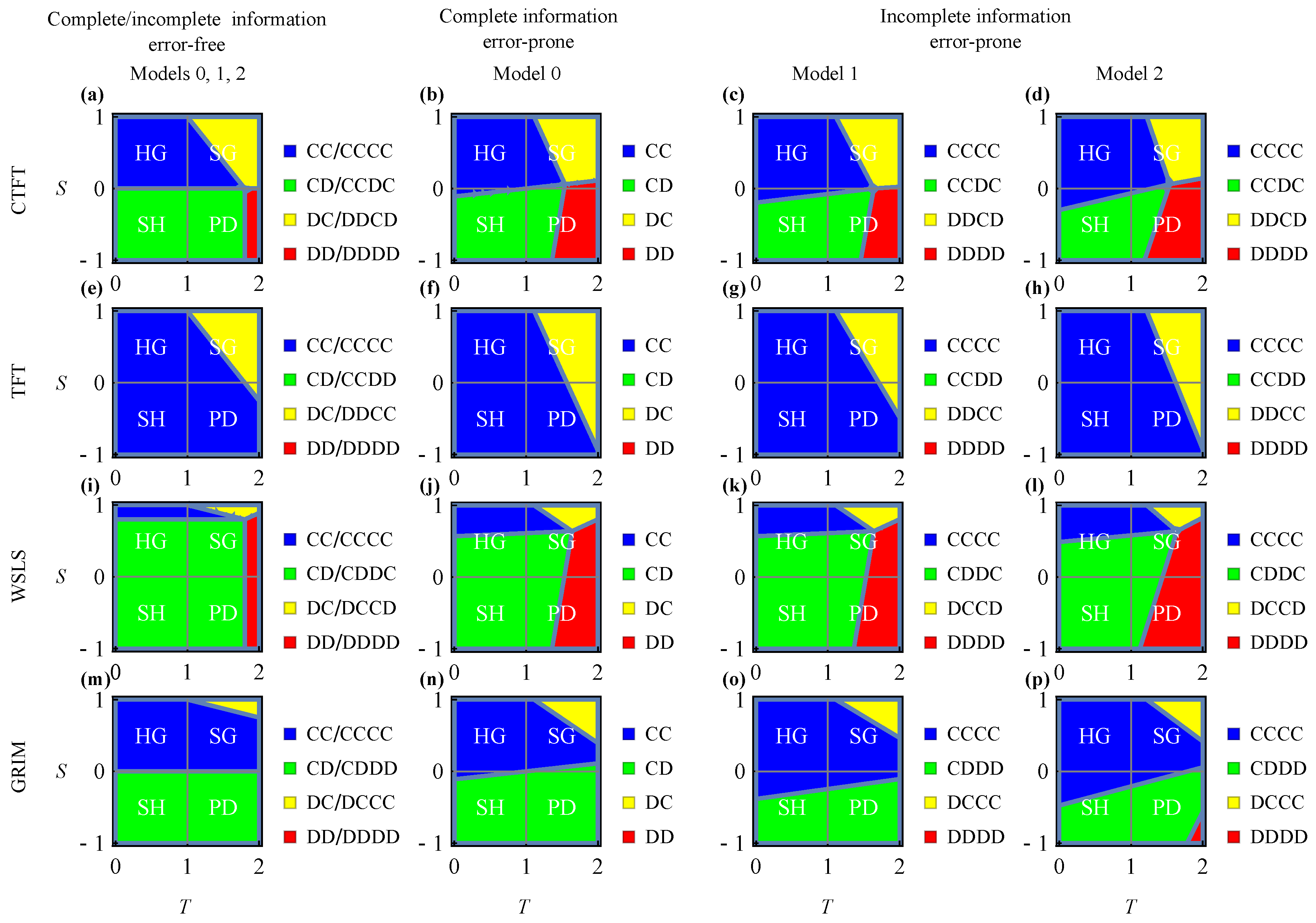
Figure 3 shows under which payoff conditions each of these policies are optimal, with a comprehensive description for each panel given in
Appendix D. An agent obeying unconditional cooperation (i.e., CC in Model 0 or CCCC in Models 1 and 2, colored blue in the figure) or unconditional defection (i.e., DD in Model 0 or DDDD in Models 1 and 2, colored red in the figure) always cooperates or defects, respectively, regardless of an opponent’s state of mind. An agent obeying anticipation (i.e., CD in Model 0, CCDC against CTFT, CCDD against TFT, CDDC against WSLS or CDDD against GRIM in Models 1 and 2, colored green in the figure) conditionally cooperates with an opponent only if the agent knows or guesses that the opponent has a will to cooperate, i.e., the opponent is in state H. As an example, in Model 0, an agent obeying policy CD knows an opponent’s current state, cooperating when the opponent is in state H and defecting when in state U. In Models 1 and 2, an agent obeying policy CDDC guesses that an opponent is in state H only if the previous outcome is (C, C) or (D, D), because the opponent obeys WSLS. Since the agent cooperates only if the agent guesses that the opponent is in state H, it is clear that anticipation against WSLS is CDDC. Finally, an agent obeying asocial-anticipation (i.e., DC in Model 0, DDCD against CTFT, DDCC against TFT, DCCD against WSLS or DCCC against GRIM in Models 1 and 2, colored yellow in the figure) behaves in the opposite way to anticipation; more specifically, the agent conditionally cooperates with an opponent only if the agent guesses that the opponent is in state U. This behavior increases the number of outcomes of (C, D) or (D, C), which induces the agent’s payoff in SG.
The boundaries that separate the four optimal policy classes are qualitatively the same for Models 0, 1 and 2, which is evident by comparing them column by column in
Figure 3, although they are slightly affected by the opponent’s errors, i.e.,
ϵ and
μ, in different ways. These boundaries become identical for the three models in the error-free limit (see
Table D1 and
Appendix E). This similarity between models indicates that an agent using a heuristic or an external clue to guess an opponent’s state (i.e., Models 1 and 2) succeeds in selecting appropriate policies, as well as an agent that knows an opponent’s exact state of mind (i.e., Model 0). To better understand the effects of the errors here, we show the analytical expressions of the boundaries in a one-parameter PD in
Appendix F.
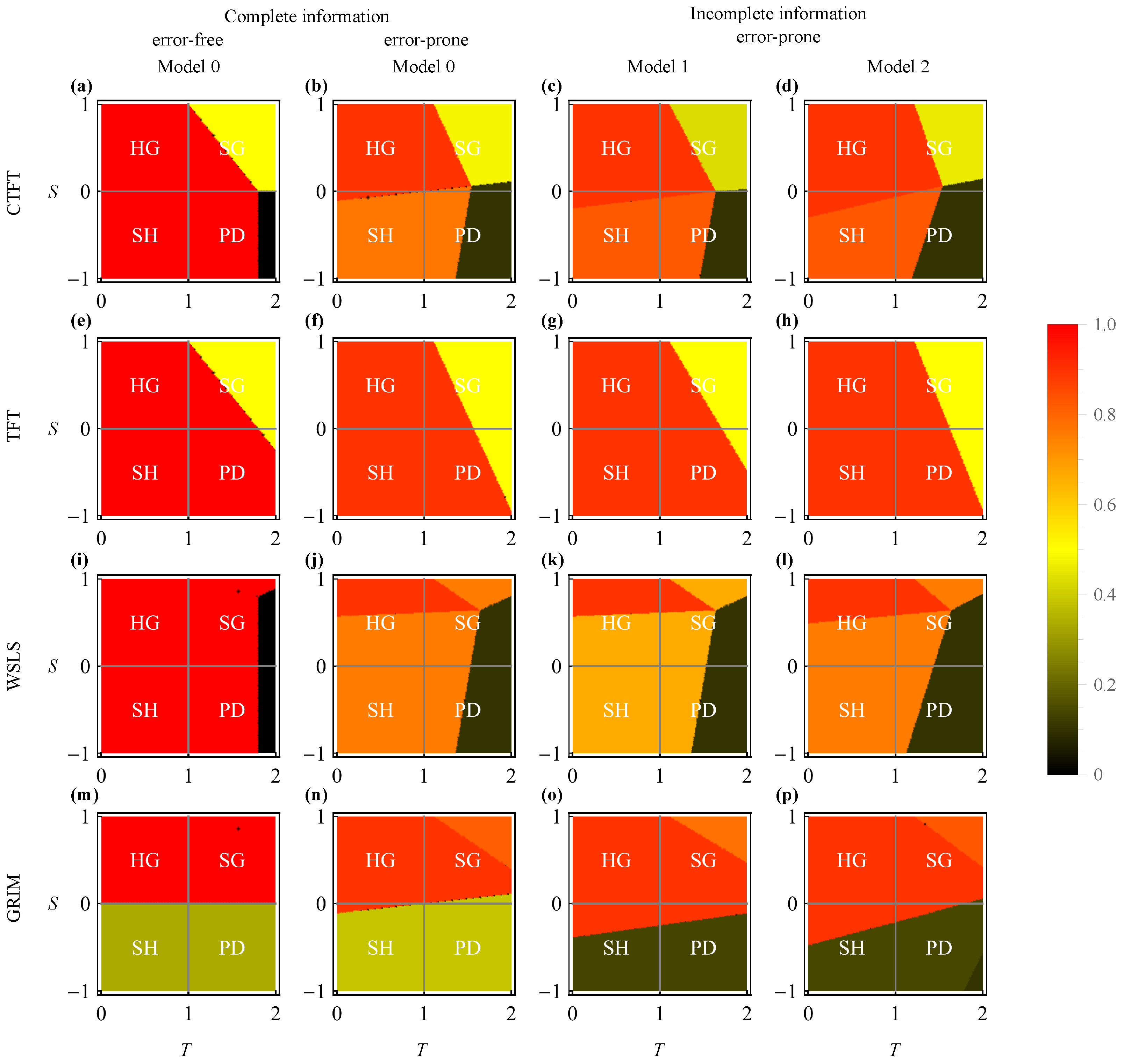
Although the payoff conditions for the optimal policies are rather similar across the three models, the frequency of cooperation varies.
Figure 4 shows the frequencies of cooperation in infinitely repeated games, with analytical results summarized in
Table 3 and a comprehensive description of each panel presented in
Appendix G. Hereafter, we focus on the cases of anticipation since it is the most interesting policy class we wish to understand. In Model 0, an agent obeying anticipation cooperates with probability
when playing against a CTFT or WSLS opponent, with probability
when playing against a TFT opponent and with probability
when playing against a GRIM opponent, where
μ and
ν are probabilities of error in the opponent’s state transition and the agent’s action selection, respectively. To better understand the effects of errors, these cooperation frequencies are expanded by the errors except for in the GRIM case. In all Model 0 cases, the error in the opponent’s action selection,
ϵ, is irrelevant, because in Model 0, the agent does not need to infer the opponent’s present state through the opponent’s action.
Interestingly, in Models 1 and 2, an agent obeying anticipation cooperates with a CTFT opponent with probability , regardless of the opponent’s error μ. This phenomenon occurs because of the agent’s interesting policy CCDC, which prescribes selecting action C if the agent self-selected action C in the previous stage; once the agent selects action C, the agent continues to try to select C until the agent fails to do so with a small probability ν. This can be interpreted as a commitment strategy to bind oneself to cooperation. In this case, the commitment strategy leads to better cooperation than that of the agent knowing the opponent’s true state of mind; the former yields frequency of cooperation and the latter . A similar commitment strategy (i.e., CCDD) appears when the opponent obeys TFT; here, an agent obeying CCDD continues to try to select C or D once action C or D, respectively, is self-selected. In this case, however, partial cooperation is achieved in all models; here, the frequency of cooperation by the agent is . When the opponent obeys WSLS, the frequency of cooperation by the anticipating agent in Model 2 is the same as in Model 0, i.e., . In contrast, in Model 1, the frequency of cooperation is reduced by to . In Model 1, because the opponent can mistakenly select an action opposite to what the opponent’s state dictates, the agent’s guess regarding the opponent’s previous state could fail. This misunderstanding reduces the agent’s cooperation if the opponent obeys WSLS; if the opponent obeys CTFT, the opponent’s conditional cooperation after the opponent’s own defection recovers mutual cooperation. When the opponent obeys GRIM, the agent’s cooperation fails dramatically. This phenomenon again occurs due to a commitment-like aspect of the agent’s policy, i.e., CDDD; once the agent selects action D, the agent continues to try to defect for a long time.
4. Discussion and Conclusions
In this paper, we analyzed two models of repeated games in which an agent uses a heuristic or additional information to infer an opponent’s state of mind, i.e., the opponent’s emotions or intentions, then adopts a decision rule that maximizes the agent’s expected long-term payoff. In Model 1, the agent believes that the opponent’s action-selection is deterministic in terms of the opponent’s present state of mind, whereas in Model 2, the agent knows or correctly recognizes the opponent’s state of mind at the previous stage. For all models, we found four classes of optimal policies. Compared to the null model (i.e., Model 0) in which the agent knows the opponent’s present state of mind, the two models establish cooperation almost equivalently except when playing against a GRIM opponent (see
Table 3). In contrast to the reciprocator in the classical framework of the reaction norm, which reciprocates an opponent’s previous action, we found the anticipator that infers an opponent’s present state and selects an action appropriately. Some of these anticipators show commitment-like behaviors; more specifically, once an anticipator selects an action, the anticipator repeatedly selects that action regardless of an opponent’s behavior. Compared to Model 0, these commitment-like behaviors enhance cooperation with a CTFT opponent in Model 2 and diminish cooperation with a GRIM opponent in Models 1 and 2.
Why can the commitment-like behaviors be optimal? For example, after selecting action C against a CTFT opponent, regardless of whether the opponent was in state H or U at the previous stage, the opponent will very likely move to state H and select action C. Therefore, it is worthwhile to believe that after selecting action C, the opponent is in state H, and thus, it is good to select action C again. Next, it is again worthwhile to believe that the opponent is in state H and good to select action C, and so forth. In this way, if selecting an action always yields a belief in which selecting the same action is optimal, it is commitment-like behavior. In our present study, particular opponent types (i.e., CTFT, TFT and GRIM) allow such self-sustaining action-belief chains, and this is why commitment-like behaviors emerge as optimal decision rules.
In general, our models depict repeated games in which the state changes stochastically. Repeated games with an observable state have been studied for decades in economics (see, e.g., [
35,
36]); however, if the state is unobservable, the problem becomes a belief MDP. In this case, Yamamoto showed that with some constraints, some combination of decision rules and beliefs can form a sequential equilibrium in the limit of a fully long-sighted future discount, i.e., a folk theorem [
21]. In our present work, we have not investigated equilibria, instead studying what decision rules are optimal against some representative finite-state machines and to what extent they cooperate. Even so, we can speculate on what decision rules form equilibria as follows.
In the error-free limit, the opponent’s states and actions have a one-to-one relationship, i.e., H to C and U to D. Thus, the state transitions of a PFSM can be denoted as , where is the opponent’s next state when the agent’s previous action was and the opponent’s previous state was . Using this notation, the state transitions of GRIM and WSLS can be denoted by HUUU and HUUH, respectively. Given this, in , we can rewrite the opponent’s present state s with present action r and previous state with previous action by using the one-to-one correspondence between states and actions in the error-free limit. Moreover, from the opponent’s viewpoint, in can be rewritten as , which is the agent’s pseudo state; here, because of the one-to-one relationship, the agent appears as if the agent had a state in the eyes of the opponent. In short, we can rewrite as in Model 1 and as in Model 2, where we flip the order of the subscripts. This rewriting leads HUUU and HUUH to CDDD and CDDC, respectively, which are part of the optimal decision rules when playing against GRIM and WSLS; GRIM and WSLS can be optimal when playing against themselves depending on the payoff structure. The above interpretation suggests that some finite-state machines, including GRIM and WSLS, would form equilibria in which a machine and a corresponding decision rule, which infers the machine’s state of mind and maximizes the payoff when playing against the machine, behave in the same manner.
Our models assume an approximate heuristic or ability to use external information to analytically solve the belief MDP problem, which can also be numerically solved using the Partially-Observable Markov Decision Process (POMDP) [
32]. Kandori and Obara introduced a general framework to apply the POMDP to repeated games of private monitoring [
20]. They assumed that the actions of players are not observable, but rather players observe a stochastic signal that informs them about their actions. In contrast, we assumed that the actions of players are perfectly observable, but the states of players are not observable. Kandori and Obara showed that in an example of PD with a fixed payoff structure, grim trigger and unconditional defection are equilibrium decision rules depending on initial beliefs. We showed that in PD, CDDD and DDDD decision rules in Models 1 and 2 are optimal against a GRIM opponent in a broad region of the payoff space, suggesting that their POMDP approach and our approach yield similar results if the opponent is sufficiently close to some representative finite-state machines.
Nowak, Sigmund and El-Sedy performed an exhaustive analysis of evolutionary dynamics in which two-state automata play
-strategy repeated games [
37]. The two-state automata used in their study are the same as the PFSMs used in our present study if we set
in the PFSMs, i.e., if we consider that actions selected by a PFSM completely correspond with its states. Thus, their automata do not consider unobservable states. They comprehensively studied average payoffs for all combinations of plays between the two-state automata in the noise-free limit. Conversely, we studied optimal policies when playing against several major two-state PFSMs that have unobservable states by using simplified belief calculations.
In the context of the evolution of cooperation, there have been a few studies that examined the role of state-of-mind recognition. Anh, Pereira and Santos studied a finite population model of evolutionary game dynamics in which they added a strategy of Intention Recognition (IR) to the classical repeated PD framework [
18]. In their model, the IR player exclusively cooperates with an opponent that has an intention to cooperate, inferred by calculating its posterior probability using information from previous interactions. They showed that the IR strategy, as well as TFT and WSLS, can prevail in the finite population and promote cooperation. There are two major differences between their model and ours. First, their IR strategists assume that an individual has a fixed intention either to cooperate or to defect, meaning that their IR strategy only handles one-state machines that always intend to do the same thing (e.g., unconditional cooperators and unconditional defectors). In contrast, our model can potentially handle any multiple-state machines that intend to do different things depending on the context (e.g., TFT and WSLS). Second, they examined the evolutionary dynamics of their IR strategy, whereas we examined the state-of-mind recognizer’s static performance of cooperation when using the optimal decision rule against an opponent.
Our present work is just a first step to understanding the role of state-of-mind recognition in game theoretic situations, thus further studies are needed. For example, as stated above, an equilibrium established between a machine that has a state and a decision rule that cares about the machine’s state could be called ‘theory of mind’ equilibrium. A thorough search for equilibria here is necessary. Moreover, although we assume it in our present work, it is unlikely that a player knows an opponent’s parameters, i.e., φ and w. An analysis of models in which a player must infer an opponent’s parameters and state would be more realistic and practical. Further, our present study is restricted to a static analysis. The co-evolution of the decision rule and state-of-mind recognition in evolutionary game dynamics has yet to be investigated.
multiple



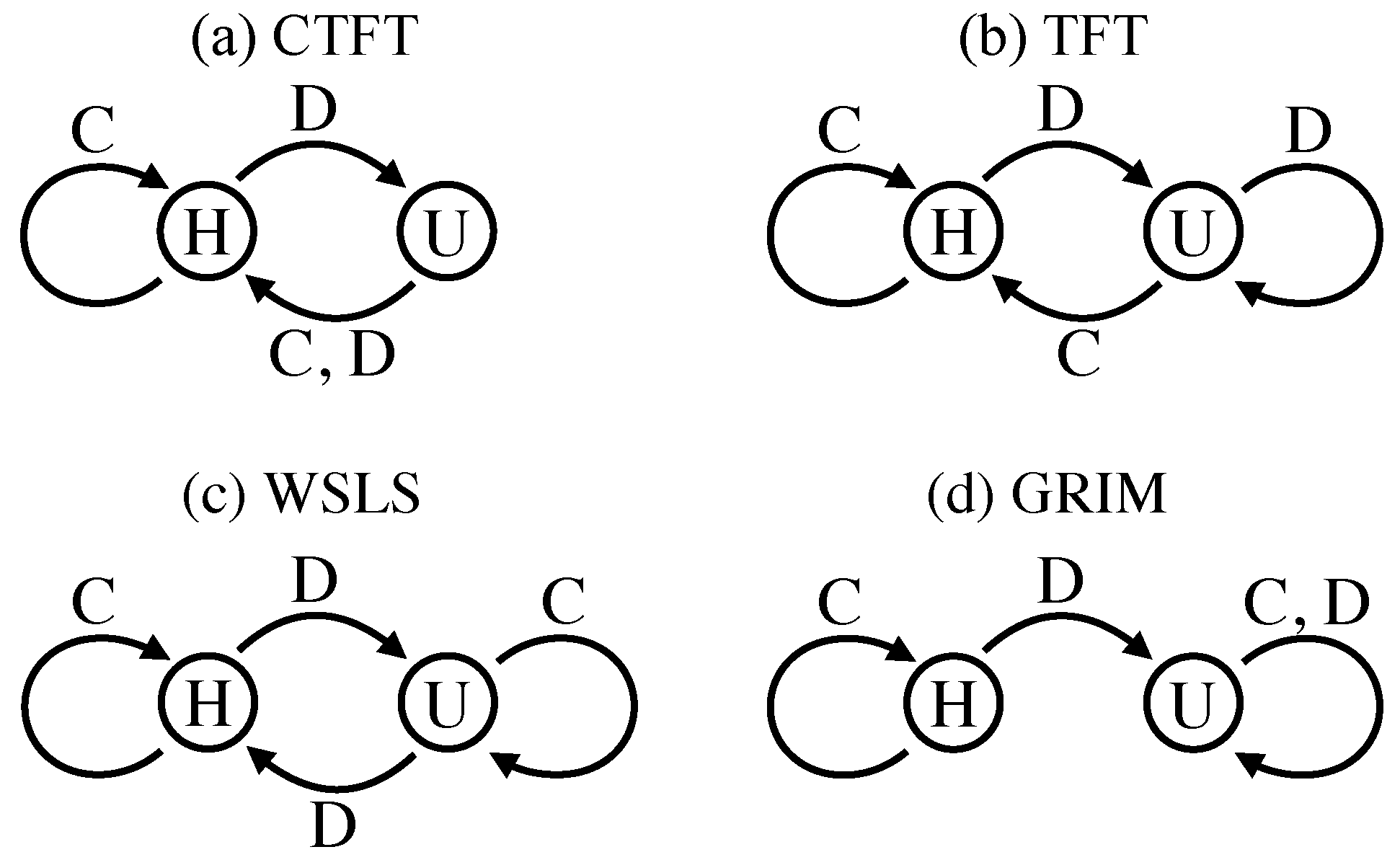{kind=link}
{kind=link}
{kind=link}
{kind=link}



