1. Introduction
Extremadura is a region in Spain with the highest agricultural potential and one of the largest exporters of raw materials in the field of agriculture. Our region is characterized by its exports, among others, of fruits such as plums. In the European Union as a whole, Spain is considered to be one of the largest producers of plums. In recent years, the volume of tonnes produced has been growing, most of which is destined for export, thus creating an strong foreign market. According to the the United Nations Food and Agriculture Organization (FAO), production in Spain in 2019 reached 179,840 tonnes of plums, making it one of the top 13 producing countries in the world. Extremadura, with 4885 ha of area in production, in 2018 is the leading national producer, with more than 74,000 tonnes. In Extremadura, growing conditions are particularly favourable, allowing long production periods from June to September, with a range of varieties of different characteristics.
The consumption of fruit and vegetables, both on the domestic and foreign markets, increasingly demands strict quality parameters, as well as the objective of preserving fresh produce on the market for a longer period of time. This makes it necessary to provide technicians and growers with the necessary knowledge to ensure that their products are of the highest possible quality and to predict certain characteristics of the fruit at an early stage, as well as the most likely harvesting date. These predictions will allow growers to adopt corrective agronomic measures, if necessary, and to know the characteristics of their harvest and, therefore, adapt to market demand. The optimum state of commercial ripeness at harvest will be key to achieving an appetising product after transport and storage until it reaches its destination. This information would be fundamental for the organisation of the campaign, which is very complex.
Currently, a great part of fruit evaluation in the field is conducted by visual inspection techniques in combination with destructive measuring equipment, which not only takes time away from production, but also consumes valuable technician time that is sometimes not available, which has great limitations. This traditional method depends on the experience and criteria of the person carrying out the evaluation. There are many varieties of plums, each with a different ripening cycle and different external characteristics. Having a model that allows us to know the state of ripening and/or growth of the fruit would allow us to adjust agronomic practices, such as irrigation, adapted to the varieties, thus optimising water consumption. It seems reasonable that with the technology currently available, systems should be implemented which, supported by image analysis and computer processing, facilitate decision making by using the available information captured quickly, automatically and reliably. Therefore, these processes should now be supported by computer tools that allow farmers to make a decision to improve production, based on artificial intelligence.
The study presented in this paper is foccused on three plum varieties, Red Beaut, Black Diamond and Angeleno, present at the Agrarian Research Center La Orden-Valdesequera (CICYTEX, Center for Scientific and Technological Research of Extremadura) (
http://cicytex.juntaex.es/es/centros/la-orden-valdesequera, accessed on 17 November 2021). The main objective of this study is to identify the variety of the plums by means of an image captured by a conventional photo camera in order to subsequently detect the state of ripeness of the plum. We can focus this problem as a typical image classification problem with some peculiarities. The problem can be divided into two different sub-problems, both based on image recognition and classification: recognising the variety of plum in an image and, subsequently, recognising the ripening state of the plum. Each variety has its own ripening cycle, which implies that the study of ripening must be conducted independently for each of the varieties used in this study. We can observe two independent problems or we can build a chain of two recognition systems where we have to previously recognise the variety in order to estimate ripening. In order to understand the high difficulty level of this combined task, it is very important to highlight the nature of the images; they have been acquired in the field and in its natural environment. Unlike the images collected in a laboratory, these images have no position or illumination control, and they have different backgrounds: Sometimes there are shadows or high brights, and at many times there are partial occlusions, different zoom sizes and multiple fruits in the same picture. All of these image features turn the recognition and classification process into a more complex and more difficult achievement. In
Figure 1, we can observe examples of plum images and the natural conditions of their acquisition process. The images are organized into a matrix, where each row illustrates one variety and its ripening cycle. The image classification challenges are deeply related with the image diversity along the same variety and the image similarities between different varieties. The three varieties are very similar in early stages, and they become more diverse in advanced ripeness stages, particularly in color; the shape remains similar for untrained eyes.
In the last few years, a new area of study known as deep learning (DL) has emerged in the field of machine learning. This new area encompasses different techniques that are fundamentally characterized by a hierarchical learning process in which high-level structures are automatically built starting from low-level ones across multiple layers, starting from the raw data (i.e., the pixel values of an image). DL appears as an alternative to traditional machine learning methods, which require a careful selection of hand-designed features from which the classifier can detect patterns by means of one, two at most, nonlinear transformation of those features. These classical methods have proven to be quite effective for solving simple or well-delimited problems but encounter difficulties in dealing with real-world complex problems such as object and speech recognition. By contrast, DL techniques have hugely improved the state of the art in such complex tasks. In this study, we focus on a DL technique for supervised learning known as deep convolutional neural networks (CNN) [
1,
2], which has shown outstanding performances for visual objects recognition. CNN benefits from the spatial structure of input data, that is, the images.
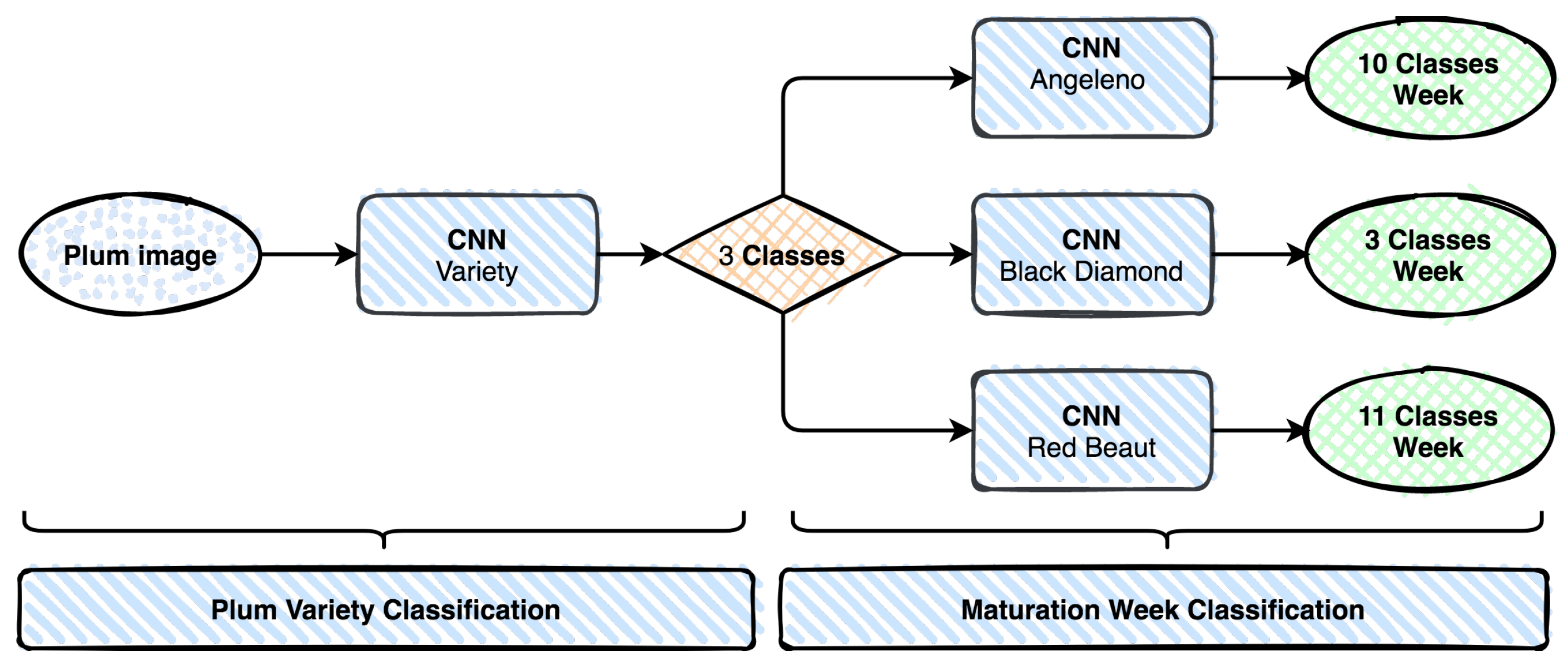
We propose a two-stage system based on DL with Convolutional Neural Networks (CNN). Among all the architectures available for CNNs applied to image classification, we used AlexNet, which has already proved is efficiency in this kind of problem [
3]. Our system will address distinct problems using the same input images: plum variety recognition and plum ripening estimation in weeks. We tackle each problem independently by using the same methodologies and taking advantage of acquired knowledge. Each stage of the problem uses a CNN based system; however, in order to estimate plum ripening, we need to know its variety because ripening cycles are distinct. Thus, we can use the output of the first classification system, which is variety, to chose the correct network to perform ripening classification. As a machine learning system, it needs to be trained and tested in order to figure out its accuracy quality.
This paper is organized as follows: In
Section 2, we present the state of the art for this kind of problem. In
Section 3, we make a system overview. In
Section 4, we detail our methodology for the described problem. In
Section 5, we describe and present our experiments and results. Finally, in
Section 6, we present our conclusions.
2. State of the Art
We consider artificial intelligence as a set of modern computing techniques permitting us to perform tasks based on data capture, analysis and decision making in a fully automated manner, but in many areas of application we are far from that reality. Artificial intelligence was postulated in 300 BC by Aristotle, who was the first to describe “in a structured way a set of rules, syllogisms, which describe a part of the workings of the human mind and which, when followed step by step, produce rational conclusions from given premises.” The next great contribution to artificial intelligence can be found in Alan Turing’s article “On computable numbers, with an application to the Entscheidungsproblem” [
4] where he establishes the theoretical basis for computer science, which will later give rise to the artificial intelligence we know today.
The great boom of artificial intelligence applied to the field of computer vision has allowed a significant advance in a multitude of problems. We can find synergies between agriculture and artificial intelligence [
5] as well as the incipient use of the so-called Internet of Things in agriculture [
6,
7,
8] and prediction models [
9].
As we can observe, artificial intelligence is beginning to take hold in agriculture and more recently in crops such as plums. Papers [
10,
11,
12] present results demonstrating the effectiveness of artificial intelligence applied to agriculture, most notably in Japanese plum. Works such as those presented in [
1,
2,
3,
13,
14,
15,
16,
17,
18] present results in the field of computer vision and DL; however, works that are precise and that research ripeness analysis of fruit using images collected in real environment and without capture constrains are insufficient.
By studying the use of computer vision techniques focused on food analysis, we can find a multitude of works such as those presented in [
19,
20,
21,
22,
23]. The great advances in this field allow us to study substantial information about the nature and attributes of the objects present in a scene, in this case food. However, we cannot only study objects on the basis of an RGB image that provides colour, shape, texture and so on. An important new feature is to be able to study regions of the electromagnetic spectrum where the human eye is unable to operate, such as in the ultraviolet (UV), near infrared (NIR) or infrared (IR). These analysis techniques are included in the so-called non-destructive techniques, which make it possible to analyse a food without having to destroy it unlike other techniques used in laboratories where it is necessary to destroy the food in order to extract certain quality indicators.
The general pattern of plum fruit growth has been described as a double sigmoid with three stages (Khan, 2016; Zuzunaga et al., 2001). In early maturing varieties, the time of fruit development is very short, and there is no clear definition of the beginning and end of each stage. However, although the fruit remains on the tree for several months in some late maturing varieties, some studies show a continuous growth of the fruit without clearly differentiating each stage as it occurs in other stone fruit trees [
24,
25,
26,
27].
The rentability of a fruit orchad is based on having detailed information on the phenology and physiology of the crop, as well as on the agro-ecological conditions imposed by specific growing conditions. The production of Japanese plums is mainly destined for fresh consumption, and its sale is based on its size, colour and flavour, which reflect the quality of the product. It is essential to know the agronomic behavior and the sensitivity to water stress in each stage of the fruit during the preharvest period in order to ensure optimal fruit quality [
28,
29].
4. Methodology
Therefore, identifying plum variety in an image as well as the ripening cycle is an ambitious objective that we accomplished with notable results by using DL with convolutional neural networks. Consequently, CNNs use an architecture based on three key principles [
15]: local receptive fields, shared weights and bias and pooling layer.
AlexNet, which was first proposed by Alex Krizhevsky et al. in the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC-2012) [
33] is a fundamental, simple and effective CNN architecture, which is mainly composed of cascaded stages, namely, convolution layers, pooling layers, rectified linear unit (ReLU) layers and fully connected layers. Specifically, AlexNet is composed of five convolutional layers: The first layer, the second layer, the third layer and the fourth layer are followed by the pooling layer, and the fifth layer is followed by three fully connected layers. For the AlexNet architecture, the convolutional kernels are extracted during the back-propagation optimization procedure by optimizing the entire cost function with the stochastic gradient descent (SGD) algorithm. Generally, the convolutional layers act upon the input feature maps with the sliding convolutional kernels in order to generate convolved feature maps, and the pooling layers operate on the convoluted feature maps to aggregate the information within the given neighborhood window with a max pooling operation or average pooling operation. The reason for why AlexNet is successful can be attributed to some of the practical strategies, for instance, the ReLU non-linearity layer and the dropout regularization technique.
The proposed method for the two-problem classification process is based on deep learning (DL) using the convolutional neuronal network AlexNet architecture. Two different approaches were considered: one based on DL process from scratch and another one based on transfer learning using the same CNN architecture AlexNet.
The standard AlexNet architecture is prepared for a 1000 classes problem: eighth-layer fully connected layer of output 1000 neurons (since there are 1000 classes). We transform the eighth layer into three classes, and we use the SoftMax function to compute the loss.
4.1. The Image Datasets
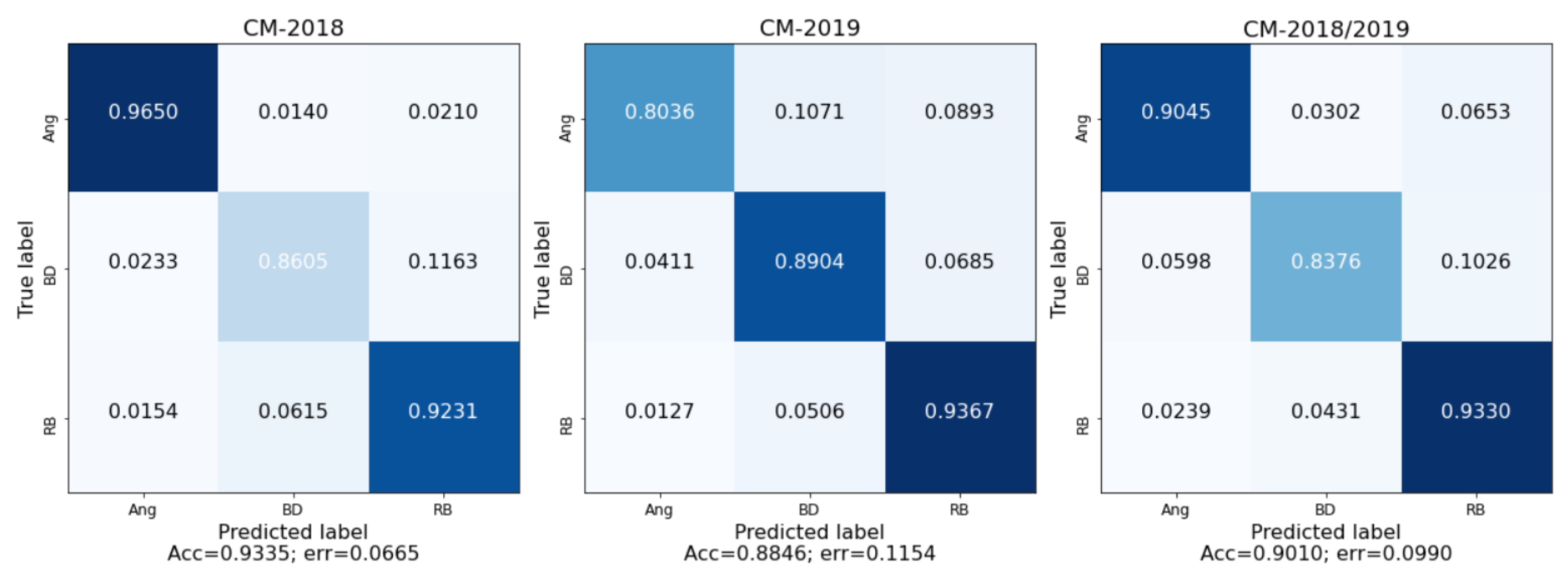
In this subsection, we present our image database and the construction processes of the datasets used for the two studied problems. In machine learning processes, the construction of the dataset is a very important task: It includes the definition of the training set validation set and test set, and it may include some image preprocessing, such as resizing cropping or filtering. Our image database was collected in the orchard during two ripening cycles and during 2 years, 2018 and 2019, with favorable climatic conditions (without rain) by using a regular camera, and it includes images of three varieties of plum: Angeleno, Black Diamond and Red Beaut. Each variety is also divided into balanced ripening classes as described in
Table 1.
The original images were collected in the plum orchard in real environments without image characteristics concerns. All images are have 1200 pixels in width and 800 pixels in height; however, in the majority of the cases, there is a lot of unnecessary information in the image because the fruit (plum) occupies a small part of the image that is typically centered despite as shown in
Figure 5. The Black Diamond variety images were only collected in three different weeks for the 2018 year. Due to logistic restrains, the natural ripening cycle is of 2 to 3 months.
As mentioned before, we will use neuronal networks for the classification process, particularly a CNN called AlexNet that was previously described. This network was designed for classification problems, and its architecture uses RGB images as inputs. The input images sizes are typified as squares of 256 pixels; thus, images with different sizes have to be transformed to the input square size. Usually, resizing or crop transformations or both are used to accomplish the desired size. During our study, we tested two different techniques for image size transformation, which resulted in two different datasets with different preprocessing techniques. We constructed two different datasets using different preprocessing techniques, each one with advantages and disadvantages. As depicted in
Figure 6, the first method consists of making a direct resize of the original images, from 1200 × 800 to 256 × 256. This kind of preprocessing does not maintain the image’s proportions and causes distortion; however, it retains all image information, including the borders. The obtained dataset will be called direct resized (DR). The second method used for preprocessing is illustrated in
Figure 7, and this technique begins with a proportional resize of the image where the image proportions are kept. An image resize is computed by transforming the smaller dimension from 800 pixels to 256 pixels; the larger dimension is also resized but in the same scale,
, obtaining a dimension of 384 pixels. Thus, the intermediate image is
. Then, the image is cropped in its horizontal dimension,
; this means a crop of 64 pixels at each image side. This method keeps the image proportions without any distortion; however, some parts of the image are lost, particularly the border sides. As observed in
Figure 5, the portion of the image that contains the fruit is usually relatively centered, and the crop almost does not affect the image information. This last method results in another dataset used in the experiments, and we will refer to it as resized and cropped (RC). Thus, for the purpose of plum variety classification, we developed two different datasets from the original database of images: DR and RC.
Therefore, the main goal of training a CNN is not to learn the data used during training but rather to be able to correctly classify unseen samples. A successful training session with the entire set would guarantee the required accuracy of the samples of the dataset, but this does not imply being able to obtain a similar or even acceptable level of accuracy on new data. Considering this, we can divide the dataset into two subsets: the training set and the validation set [
34]. However, the original dataset could also be partitioned in order to produce a third subset: the testing set.
The training set is used to fit the model. The network weights will be updated from it. The training set must be representative so that the model can learn the most important features to distinguish all classes. The accuracy on the training set tells us if the network configuration used is able to learn the data. Thus, if the model does not perform well on the training data, this means that the network architecture must be reviewed and improved.
A validation dataset is a dataset of examples used to tune the hyperparameters (i.e., the architecture) of a classifier. It is sometimes also called the development set or the “dev set.” An example of a hyperparameter for artificial neural networks includes the number of hidden units in each layer. The testing set (as mentioned above) should follow the same probability distribution as the training dataset.
In order to avoid overfitting, when any classification parameter needs to be adjusted, it is necessary to have a validation dataset in addition to training and test datasets. For example, if the most suitable classifier for the problem is sought, the training dataset is used to train candidate algorithms, and the validation dataset is used to compare their performances and decide which one to take; finally, the test dataset is used to obtain performance characteristics such as accuracy, sensitivity, specificity, F-measure and so on. The validation dataset functions as a hybrid: it comprises training data used for testing but neither as part of the low-level training nor as part of the final testing.
An application of this process is in early stopping, where the candidate models are successive iterations of the same network, and training stops when the error on the validation set grows and chooses the previous model (the one with minimum error). A test dataset is a dataset that is independent of the training dataset but that follows the same probability distribution as the training dataset. If a model fit to the training dataset also fits the test dataset well, minimal overfitting has taken place. A better fitting of the training dataset as opposed to the test dataset usually points to overfitting.
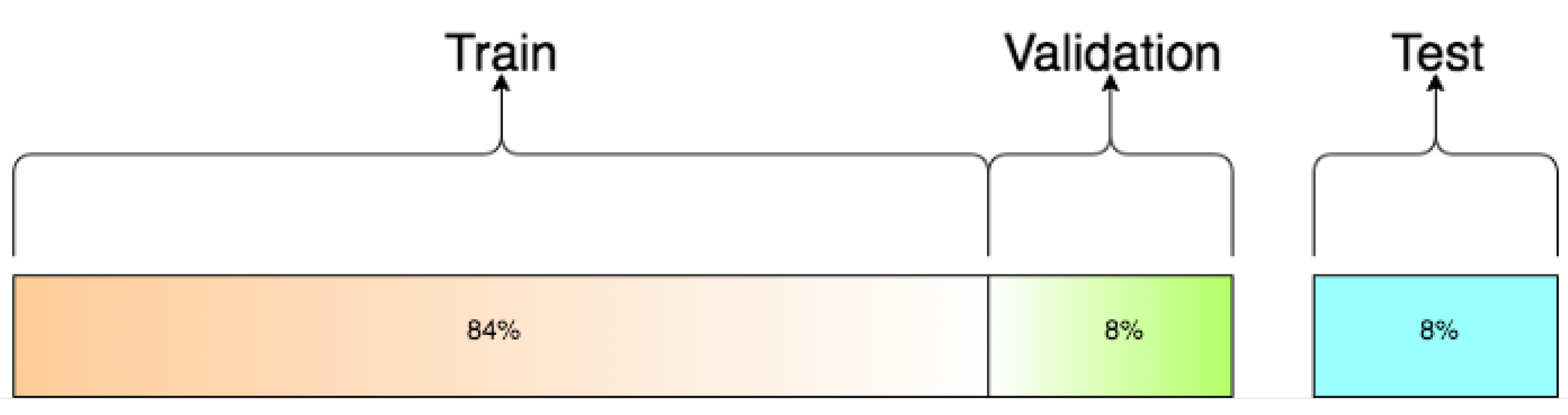
A test set is, therefore, a set of examples used only to assess the performance of a fully specified classifier such as many other aspects in DL; the train–test–validation split ratio is also quite specific to this use case, and it becomes easier to make judgement as we train and build more and more models. In our cases, we have three classes with unbalanced datasets, and all of them have the same importance in the classification problem and training; thus, it is important to keep the proportion or the probability distribution of the three classes in all subsets, training validation and test. In our case, we decided to use 84%, 8% and 8%, respectively (see
Figure 8).
4.2. Preprocessing
Some preprocessing operations are required to apply to the input images inputs, usually related with size or with the range of value representations. Typically, AlexNet receives images represented on an RGB colour space; this means that the images are three-dimensional arrays or a set of three matrices usually named channel one matrix for each Red, Green and Blue channel. The typical AlexNet implementation uses square images
pixels as patches of the original images. However, we may consider the image size 256 × 256, since almost every implementation cropped the original image for data augmentation purposes. We used square RGB images
with pixel values in the range
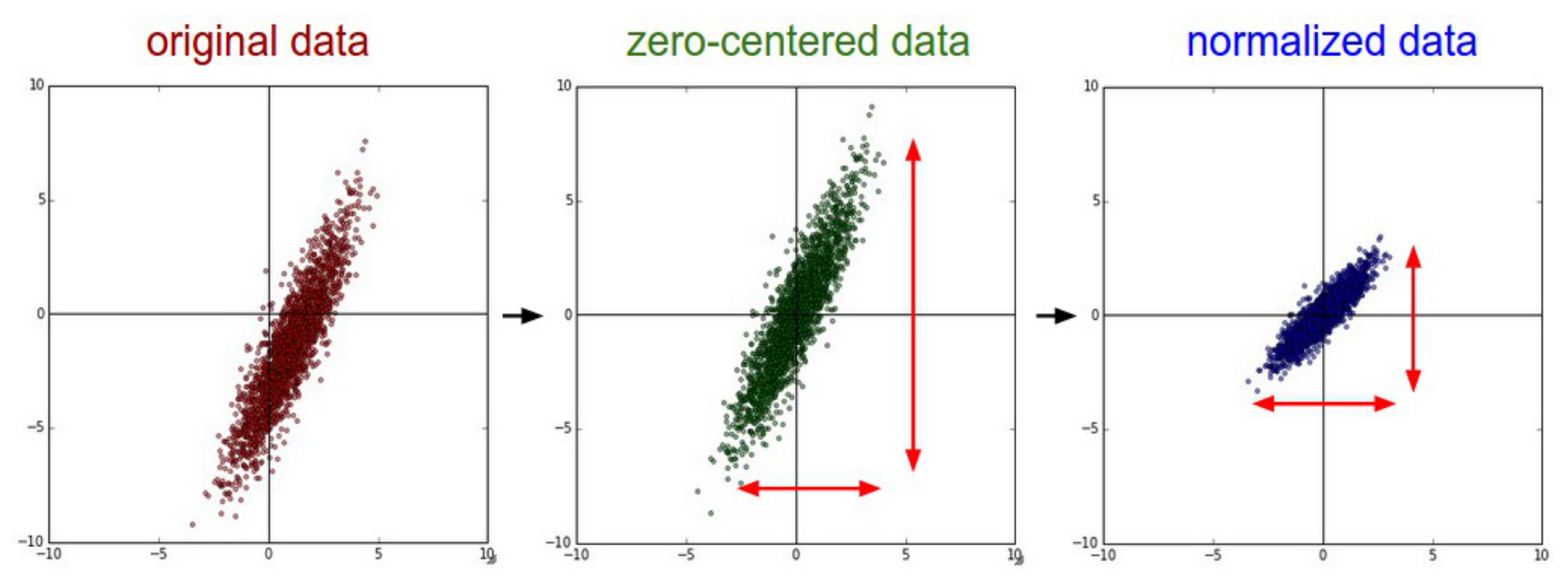
. To provide a more balanced set, it is common to zero center the pixel values. This can be performed simply by shifting all pixel values from the interval
to
. A more sophisticated approach computes the average image or the mean pixel of the training set and subtracts one of them from all input images. The mean image is represented by an image with a crop size, and the mean pixel is represented by a vector with three elements,
, where each element represents the mean value for the image channel. In this manner, we obtain a pixel value representation that is zero centered. These input intervals may cause the weights from the first layers, which are those that are more directly affected by the magnitude of the inputs, to receive large updates, causing an erratic learning procedure. It is common to use a normalization process to transform the values in the range
to a normalized range
, and we used a multiplier
for scaling. We can also use normalization by standard deviation, which will provide a dataset dependent interval, but on average the range remains similar.
Figure 9 illustrates the pipeline process with 2D data for better visualization from the original data to the re-centered data and the value range normalization.
For image pixel values preprocessing, we applied two subtraction techniques during our experiments stage, the mean image subtraction (MI) and the mean pixel subtraction (MP), and we created
Figure 10. We demonstrate the mean image representation obtained for a training dataset, and we also show mean pixel values computed for the same training dataset.
4.3. Data Augmentation
Showing different variations of the same image to a neural network helps prevent over-fitting as it is forced to not memorize the images. Often, it is possible to generate additional data from existing data in an easy manner [
35]. Among the many possibilities, we used two combined techniques: image translations and image reflections. The image translations consist of extracting random square patches from the
image, usually
. Each patch is also horizontally reflected (mirroring),
Figure 11. During our experiments, different square crop dimensions were used and tested. These two operations, translation and reflection, increase the size of our training set, and we used the resulting patches as inputs of the network (input images are
-dimensional because we assumed the square crop of 227 pixels).
During the test stage, the prediction was performed by using several cropped smaller images extracted from the original and their horizontal reflection: five extracted images sized
, four for each image corner and a centered one. These five images and the reflections are classified, and the final result is made by using the average of the result of the final softmax layer of the network. In
Figure 12, we are able to observe six original images and the resulting augmented dataset by using image random crops and horizontal mirroring.
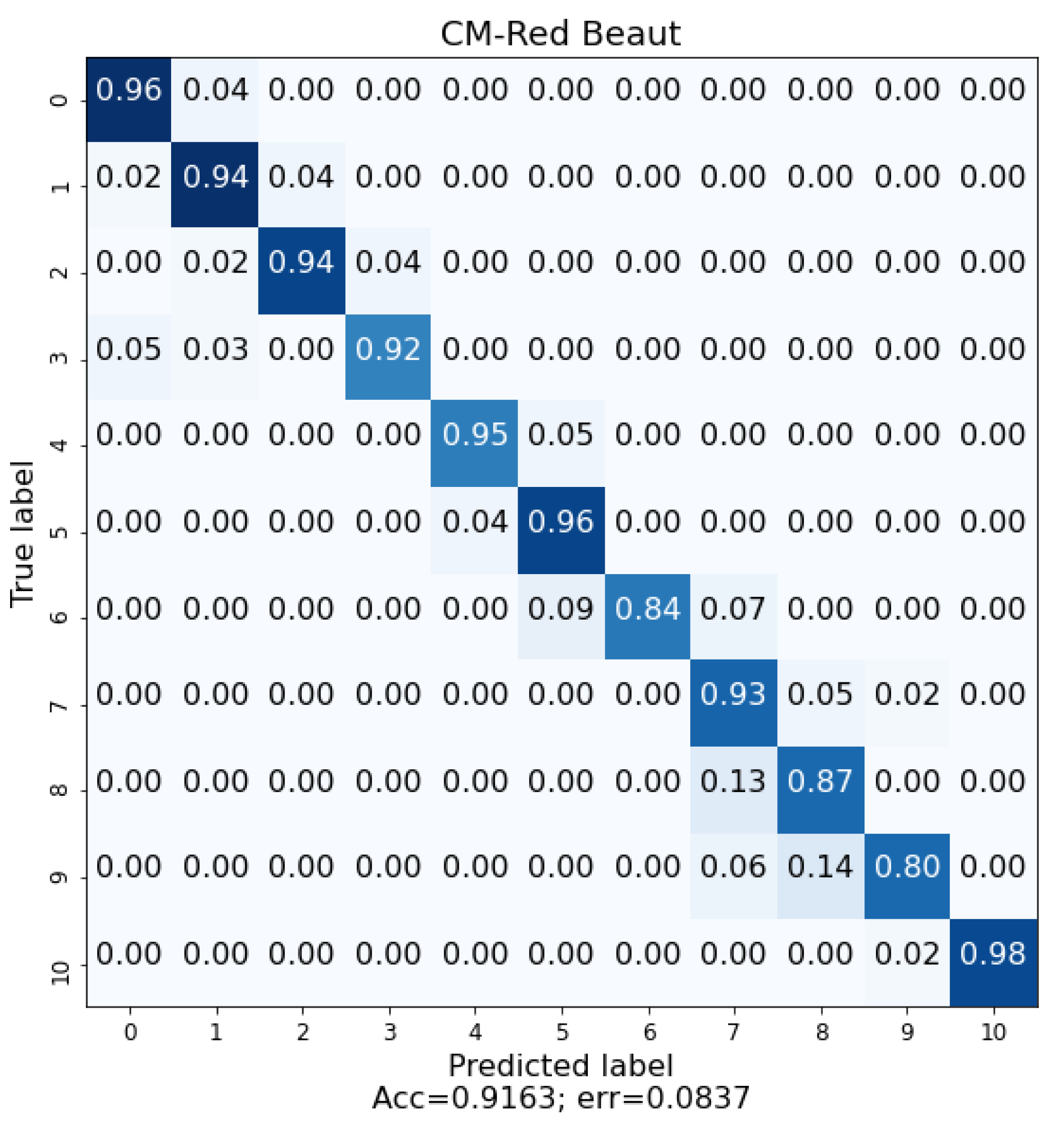
During the plum variety problem study, we had more then a 1500 images per class in the worst scenario, and some classes had more than 4000 images. However, for the ripening study, the number of classes is larger for each variety, and the total number of images is smaller once we had to split the plum dataset into three independent datasets. For the Angeleno ripening classification, we have a total of 4773 images for 10 ripening classes that correspond to a mean of 477 images per class. Aware of this potential problem, we applied an additional data augmentation process based on image rotations that have a larger base for a better training process. Each original image suffers a positive and negative rotation with 30
before the resize and crop processes; therefore, we multiply by three the number of images for each class, achieving a larger image dataset that is important for the network training stage in DL. The process is illustrated in
Figure 13.
4.4. Networks Architecture
Our two classification problems use a CNN architecture based on AlexNet [
3] with slight changes. Moreover, in the AlexNet layers, we are able to observe the kernels as well as the ReLUs and max pooling processes. The CNN is built by using eight layers and their corresponding weights: the first five layers are denominated convolutional layers (conv), and the following three layers are fully connected layers (FC). The last layer output is computed using a n-way softmax function. This softmax layer computes a probability distributions over the n classes (labels) used. For the variety classification problem, the number of classes is three. Although for the ripening problem, the number of classes proceeds from 3 to 11. To describe the network architecture and related processes, take as example the variety problem with three classes. For the remaining networks of the ripening problem, it is sufficient to change the number of classes according to each case. The first layer is a convolutional layer, and it computes several convolution between the 227 × 227 × 3 input image and 96 filters or kernels sized 11 × 11 × 3; the convolutional process uses a stride of four pixels. An example of those training kernels obtained for the plum variety classification problem is shown in
Figure 14.
The second layer, also a convolutinal layer, receives the output of the previous layer after a process of maximum overlap pooling and uses 256 kernels with sizes of 5 × 5 × 48 with respect to the convolutional process. The third layer uses the output of the second layer after the maximum overlap pooling process and convolves it with 384 kernels of size 3 × 3 × 256. The fourth convolutional layer uses 384 kernels with 3 × 3 × 192, and the last convolutional layer has 256 kernels of size 3 × 3 × 192. When the max pooling process is used, there is also a normalize process. Each of the following fully connected layers contains 4096 neurons, and the last layer performs a three-way softmax according the example in Equation (
1).
The Softmax transforms the
y values into
p probabilistic distribution values over three class labels. Our network uses the average across training cases of the log-probability of the correct label under the prediction distribution to compute loss [
3]; it is equivalent to the cross-entropy (Equation (
2)).
The goal is to minimize the loss function (
L), where
c represents the image class, and
i is the image number in the training set with
M images. The
values are the model’s prediction (i.e., the output of the softmax for a class), and
y values correspond to the class labels: one-hot encoded, zeros or ones. During the training process, we used back propagation to compute the gradient, and stochastic gradient descendent (SGD) [
36] is used as optimization method, namely first order optimizer; this means that it is based on analysis of the gradient of the objective. Consequently, in terms of neural networks, SGD and backpop are often applied together to make efficient updates. The updating rule for weights
during the training process is based on SGD, modeled by Equations (
3) and (
4).
i represents the iteration number,
v is the momentum variable,
is the learning rate and
is the average of the
th batch
of the derivative of the objective with respect to
w, evaluated at
[
3].
4.5. Transfer Learning
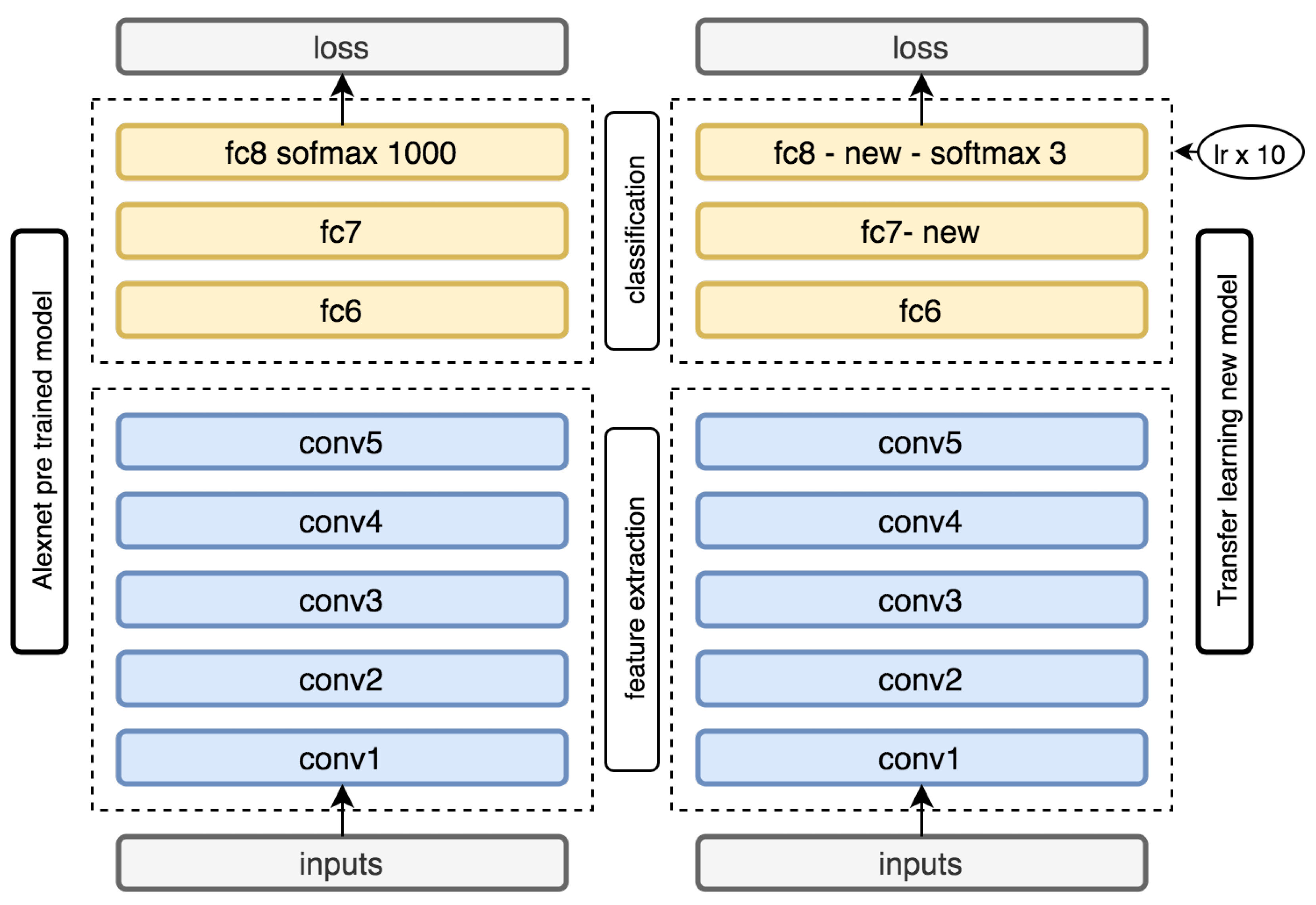
Transfer learning generally refers to a process where a model previously trained on one problem is used in some way on a second related problem.
In DL, transfer learning is a technique whereby a neural network model is first trained on a problem similar to the problem that is being solved. One or more layers from the trained model are then used in a new model trained on the problem of interest. Transfer learning has the benefit of decreasing the training time for a neural network model and can result in lower generalization error. The weights in re-used layers may be used as the starting point for the training process and adapted in response to the new problem. This usage treats transfer learning as a type of weight initialization scheme. DL systems and models are layered architectures that learn different features at different layers (hierarchical representations of layered features). These layers are then finally connected to a last layer or a group of layers, usually fully connected to obtain the final output. This layered architecture allows us to utilize a pre-trained network without its final layer or layers as a fixed feature extractor for other tasks (
Figure 15).
Our type of problem constitutes a typical image classification problem; thus, we used, as a basis for the transfer learning process, the AlexNet architecture and a pre-trained model. Considering the layer architecture of AlexNet, we used a natural subdivision into two groups of layers; the first five convolutional layers compose feature extraction, and the last two fully connected layers are responsible for using those features to produce a valid classification of the image. Thus, we built our transfer learning model by using part of the AlexNet pre-trained model, and we used the five initial layers with weights and biases previously trained for the ILSVRC2012 image classification competition. We substitute the last two fully connected layers by two new similar layers (fc7 and fc8), as shown in
Figure 15. The last layer uses softmax to compute classification and loss during training. To train the new model, we used the pre-trained model values for the bottom layers (feature extractor), and we randomly initialized the newly added layers. During the training stage, we used different learning rate multipliers for different layers. We used a larger learning rate multiplier (
) in the new fully connected layers. In this manner, we ensure that the classification layers suffer larger and faster changes during the training process, and the convolutional layers from the feature extractor have smaller and finer changes. This process is denominated fine tuning.
6. Conclusions
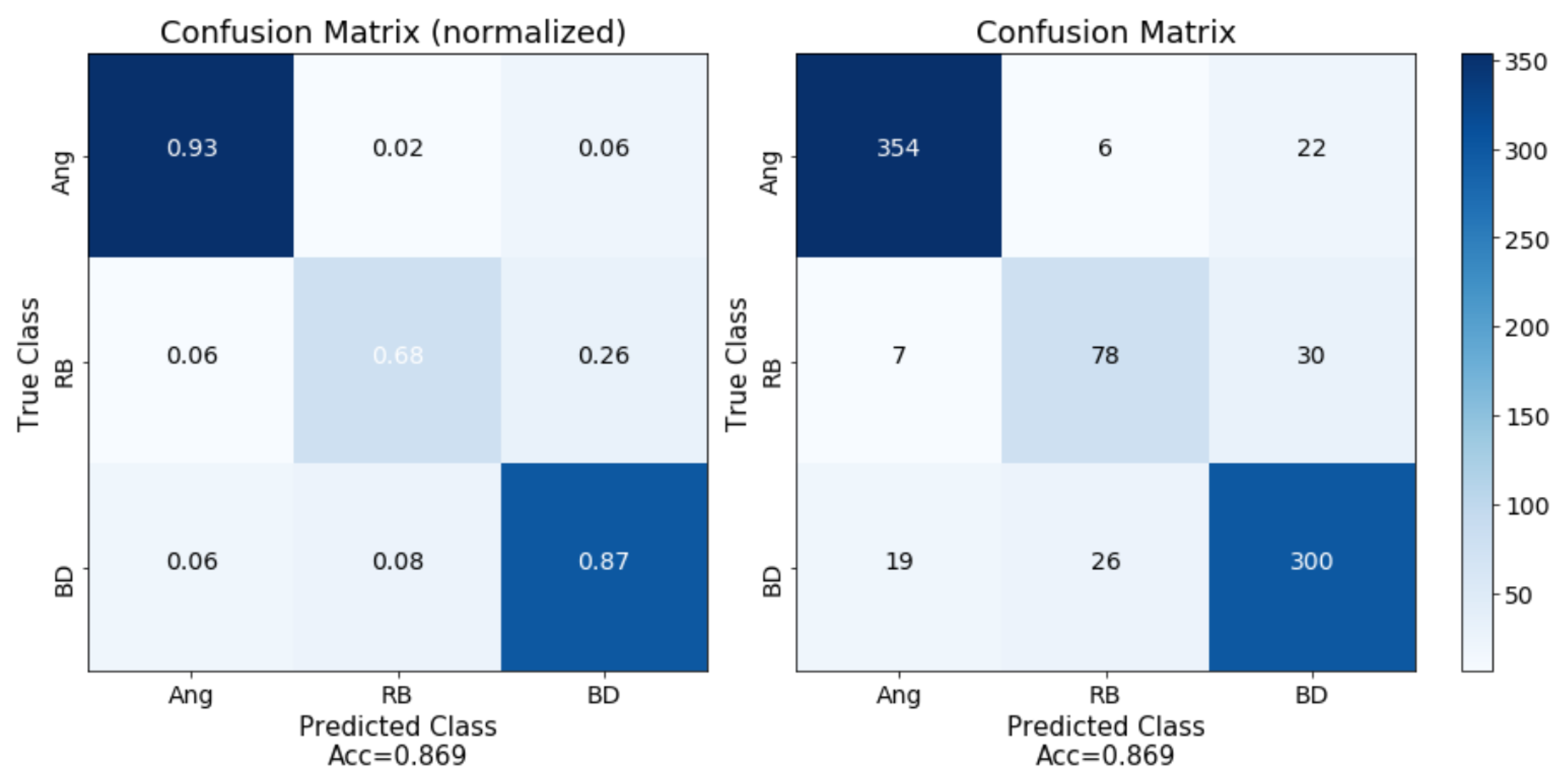
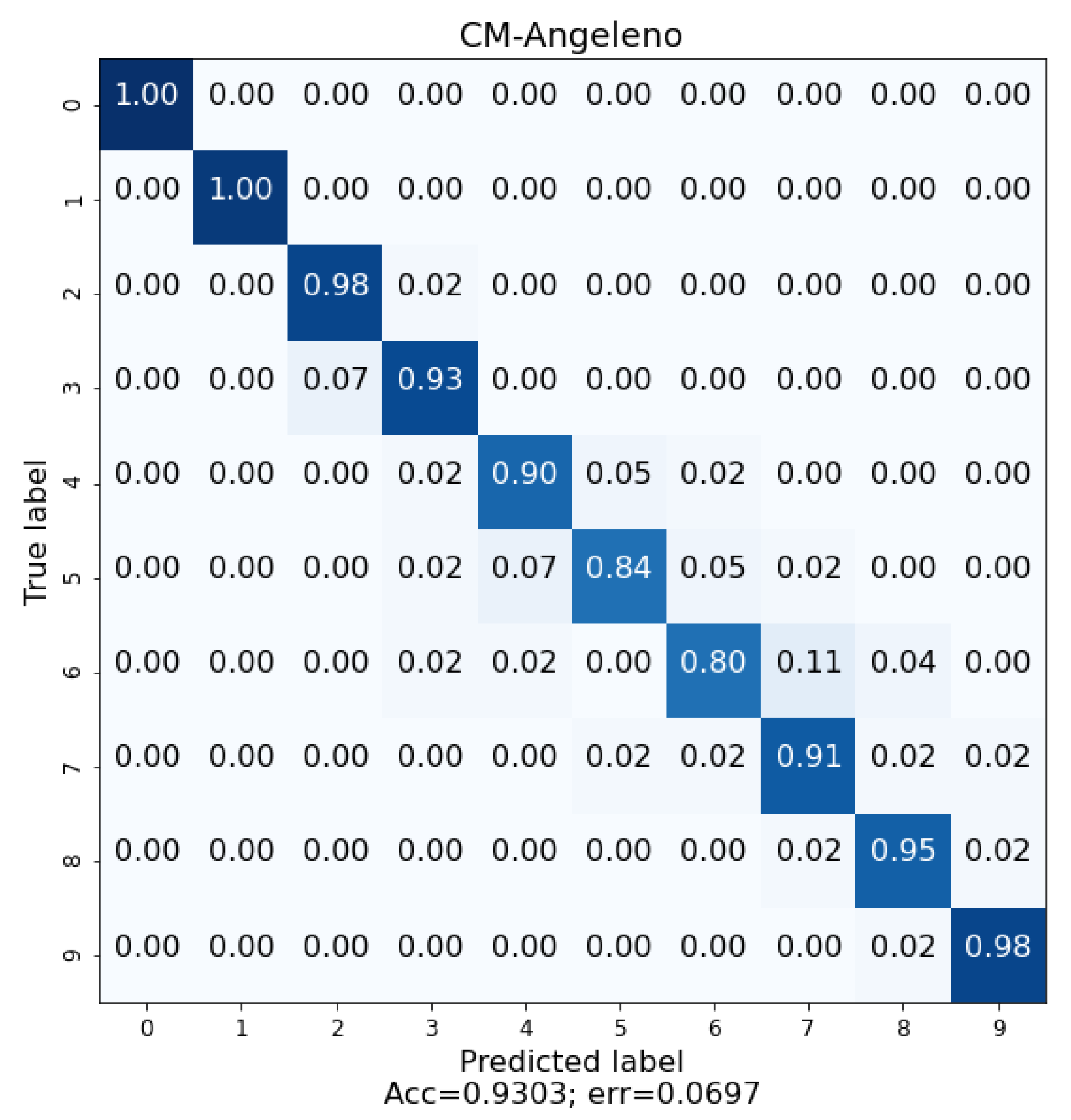
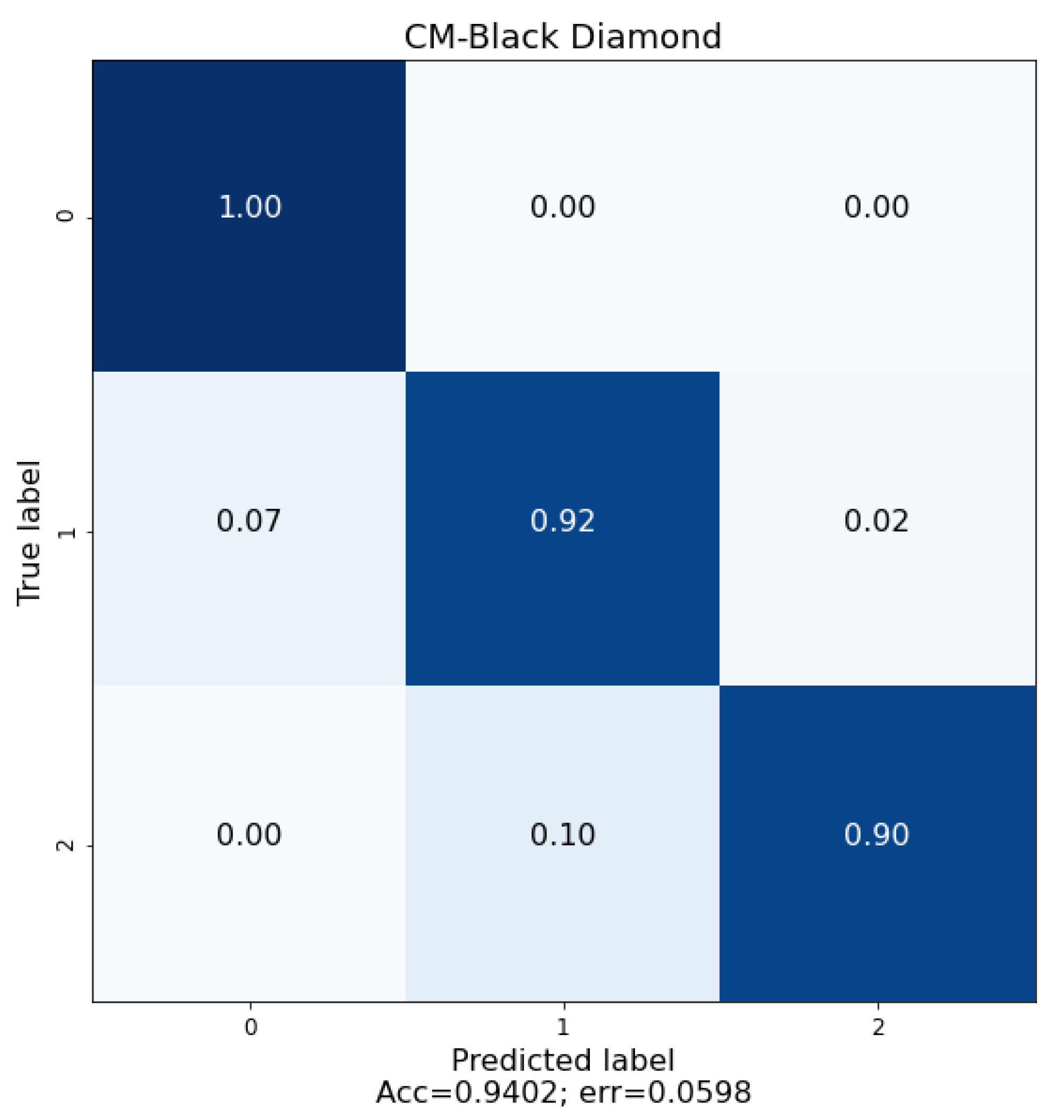
The cultivation of plums in Extremadura is very important, as the main activity of the region is centred on the primary sector. The digitalization in modern agriculture arrived to stay, and it is a fundamental tool nowadays. The crops are tracked by set of modern sensors that provide important information to farmers, allowing them to observe, in real time, the state of their crops. This modernization process results in important cost savings and in higher quality harvests. In this research study, we present and detail a research investigation with a tool based on DL that is able to differentiate three different plum varieties as well as their ripeness state by using images analysis. This system novelty consist of unsupervised and unconstrained conditions with respect to image acquisition. The algorithm was designed to work with uncontrolled photographic acquisition conditions. Therefore, the users can take a photograph with any device, camera, smartphone, etc., in the plum’s real environment, the orchard, regardless of the climatic conditions, light, focus and without centering or zoom restrictions. The system presents an accuracy of 92.83% for three varieties of plum by using images acquired directly in the field, Angeleno, Red Beaut and Black Diamond, with different ripening cycles. The system demonstrates a mean accuracy of 95.5% in the analysis of the ripeness of the plum, with knowledge its variety. This has allowed us to obtain a robust classification system that will allow users to differentiate between these varieties and their ripeness week. In future studies, we should try the same study but by using other more recent network architectures in addition to AlexNet.
The incorporation of artificial intelligence, particularly computer vision-based algorithms, in agriculture will allow farmers and technicians to have decision support systems available to them thanks to the amount of data that can be analyzed in a short period of time. The system presented in this article, once implemented in easy-to-use devices for farmers such as smartphones, will provide them with a tool that will allow them to observe the state of their orchards. The data presented in this paper are very promising for the advancement of Extremadura’s countryside.


 ,
, 























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}