1. Introduction
Designing an experiment is an essential stage in any research settings. Important planning decisions are taken in order to choose the most appropriate layout out of an array of design alternatives. Generating experimental designs relies on three basic principles: randomization, replication and blocking [
1,
2]. Replication enables estimation of experimental error variance and, adequate number of replicates provides with precise inferences. Randomization ensures that all experimental units are equally likely to receive any treatment, thus it minimizes systematic errors or bias induced by the experimenter. Finally, blocking controls for different sources of natural variation among experimental units, and when applied appropriately, controls for field variations and helps to reduce background noise. The generation of an optimal or near-optimal experimental design requires making best use of available information and resources with a goal of estimating statistical parameters of interest with the best accuracy and precision possible.
Plant breeders often conduct and analyze large field trials with the aim of selecting the best genotypes for future breeding [
3,
4], which is done by testing a large number of treatments (i.e., genotypes) in single or multiple locations. The basis for analysis of breeding trials relies on considering the genetic relationships between the genotypes. Often varied levels of relatedness, such as parent-offspring, half-sibs (where genotypes share a single parent) and full-sibs (where they share both parents) exist. Some of the common field experimental designs used in breeding include randomized complete block (RCB), incomplete block (IB) and row-column (RC) designs. RCB designs are, at present, the most common experimental layout used, due to its simplicity in terms of design and analysis. However, IB and RC designs are more adequate, particularly for large number of genotypes, as they control better for environmental spatial heterogeneity [
5]. Nevertheless, these experimental layouts have restrictions and are often more complex to analyze [
2].
Experimental treatments may not necessarily occur always with equal replications and, in addition, may not be equally represented in each block, as some treatments are available in larger quantities than others [
6]. Thus, scarce treatments will be missing in some blocks while others will be represented in all blocks with one or more replications per block, resulting in uneqaully replicated (UR) designs. This occurs, often by chance but sometimes by choice, due to differential availability of seeds or plants, rates in fecundity, greenhouse survival, loss of experimental units, etc.
Several UR designs have been proposed [
7,
8,
9,
10,
11]. An extreme case of these is the augmented block (AB) designs that are used mostly in early stages of breeding programs for evaluation of a large number of test treatments that are replicated only once, planted with control treatments that are replicated several times [
7,
8,
9,
10,
11]. Another case, is the partially replicated (p-rep) designs where a portion (
) of the test treatments are replicated at least twice, while the remaining treatments are replicated only once [
10]. All analyses of UR designs use the replicated treatments to estimate background variability and make spatial adjustments for field heterogeneity, thus often requiring fitting an spatial model.
Field experiments are often characterized by varied levels of environmental heterogeneity. The standard traditional designs and their analyses often assume that residuals are uncorrelated. However, when experimental units are located in close proximities, and thus sharing microsite variability, their responses are likely to be more similar than those farther apart [
12,
13] inducing spatial correlation. This requires the implementation of spatial analysis by specifying and fitting an appropriate error correlation structure. Several error structures are available [
14], a popular choice for breeding trials is the 2-dimensional separable autoregressive of first order [
4,
5,
10,
13,
15].
Another type of dependency between experimental units, that is critical for breeding programs, is the genetic relationships that arises due to relatives sharing some common alleles. This correlation is specified by defining a matrix of correlations between genotypes to be incorporated into the statistical model. Genetic relationships can be calculated using genetic theory [
16] based on pedigree information, or molecular data such as SNPs [
17] to form what is known as the numerator relationship matrix [
18].
Linear mixed models (LMM) allow for the incorporation of both spatial and genetic correlation structures, yielding to a more efficient use of the available information. LMM provide with estimates of variance components, which are used to calculate heritability, and to estimate best linear unbiased predictions of genetic effects (e.g., breeding values), which are used later to select outstanding genotypes. Hence, improvements in the design or analysis of breeding trials will translate into greater genetic gains as the best individuals are identified easier. For example, some studies, using spatial mixed models, have reported a positive impact on selection decisions and increased accuracy of genetic value predictions [
19].
The generation of improved experimental layouts may require optimization routines, a process that often is computationally intensive. Several computer procedures [
4,
10,
15] and software (such as CycDesigN, John and Williams [
20]) have been developed for the generation of experimental designs. However, most of these methods use approximations of optimality criteria [
10,
15], or they only incorporate spatial correlations [
20] or genetic correlations [
21] into the optimization routine. In addition, none of the available routines to generate complex designs are flexible enough to incorporate both spatial and genetic correlations.
1.1. Optimality Criteria
Statistically, a design is considered to be optimal if it maximizes the amount of information extracted from a fixed number of experimental units. Here, an optimal criterion is required in the process of generating an optimal or near optimal experimental design, the choice of which to use depends on the objective of the experiment [
22]. Most of these optimize a function of the variance-covariance matrix of treatment effects. The information matrix is used because standard errors of the mean (SEM) are calculated using the variance of treatment effects while standard error of differences (SED) are obtained from functions of variances and covariances. Information based
A- and
D-optimality criteria are perhaps the most frequently used [
10,
15,
22,
23,
24,
25,
26].
A-optimality was first introduced by Chernoff [
27] using the Fisher’s information variance-covariance matrix obtained under the framework of a fixed effects model. The objective function for
A-optimality is:
where
is the inverse of an information matrix (or variance-covariance matrix) of the treatment effects of a design
calculated from a given statistical model. More details are presented in
Section 2.
A-optimality criterion seeks to minimize the sum of the diagonal elements (i.e., trace) of the variance-covariance matrix of treatment effects. For a treatment factor that is assumed fixed, minimizing the trace implies minimizing the average variance of the best linear unbiased estimators (BLUE) of treatment effects. For random treatment factor, this implies minimizing the average variance of the best linear unbiased predictors (BLUP) of treatment effects.
A-optimality criterion is not scale invariant on the response variable; however, this does not affect blocked designs since treatments are on the same scale [
22].
D-optimality was first introduced by Wald [
28] with other researchers doing extensive work [
29,
30,
31,
32]. A design is
D-optimal if it minimizes the determinant of
, expressed as:
Minimizing the determinant of an inverse of an information matrix is equivalent to minimizing the generalized variance of the treatment effects [
22]. Hence, this criterion chooses an optimal design for which the volume of the multivariate joint confidence ellipsoid is minimized [
23]. A desirable property of this criterion is that it uses both the diagonal and off-diagonal values in the information matrix, it is scale invariant on the response variable and often computationally efficient [
22].
1.2. Study Objectives
Designing an experiment is an essential stage in any research settings, which determines the precision of the final results of the study. Although, there is a need to address generation of optimal experimental designs, focus has always been on the statistical analyses side with limited progress done on developing algorithms to generate optimal or near-optimal designs.
The main objective of this study is to develop statistical routines and evaluate computational and algorithmic procedures to generate optimal or near optimal field experimental designs. This is done by using a linear mixed model framework that considers simultaneously genetic and spatial dependencies between experimental units, as those found in typical plant breeding trials. A secondary objective is to evaluate and assess prediction accuracies of genetic effects and the estimation of heritabilities for improved and unimproved experimental designs. Statistical models were formulated for RCB, IB, AB and UR designs to evaluate a proposed pairwise swap algorithm on the generation of improved experimental designs for both A- and D-optimality criteria. These were evaluated under field conditions with varying levels of heritability, genetic relatedness, and spatial correlations. Genetic relationships were incorporated with a numerator relationship matrix calculated from pedigree information, and spatial correlations were modeled using a 2-dimensional separable autoregressive first order variance structure (AR1).
2. Materials and Methods
2.1. Statistical Model for RCB Designs
For RCB designs, the LMM considered in this study assumes blocks as fixed effects and treatments (genotypes) as random effects. The latter are assumed random as they are a sample from a much larger population. This model is expressed as
where
is a vector of observations;
is a vector of fixed effects (blocks),
is a vector of genetic random effects, and
is a vector of residual errors. Note here that the overall mean is abserved by the block effects.
and
are full column rank incidence matrices for the block and treatment effects, respectively. The assumptions for the random effects are:
with
, where
G and
R are variance-covariance matrices for the genetic effects and residual errors, respectively. If treatment effects are assumed to be genetically unrelated then
, where
is the additive genetic variance and
is an identity matrix. For related individuals,
, where
A corresponds to the additive genetic numerator relationship matrix among individuals, derived from pedigree information [
18]. If residual errors are assumed to be independent and identically distributed (
) then
, where
is the residual variance. For the case when residual errors are assumed to be correlated, a 2-dimensional separable autoregressive of first order spatial error structure to model spatial variability along the rows and columns of the experimental layouts was used [
33]. Here,
with
and
the matrices with autocorrelation parameters
and
for rows and columns, respectively, and ⊗ is the Kronecker product. These are formed with
and
, where
and
are the row and column absolute distances, respectively. Note that this model does not consider a nugget effect, but this can be easily incorporated. For the above model, narrow-sense heritability,
, is calculated as
. For simplicity, but without loss of generality, in later simulations
with
.
Variance components were estimated using Restricted Maximum Likelihood (REML) assuming that both
and
have multivariate normal distributions [
34]. Estimation of BLUE and BLUP are done using mixed model equations [
35] as:
The computation of the variance-covariance matrix of treatment effects,
, can be simplified by the following expression from [
24], which is later used to apply the
A- and
D-optimality criteria.
where
.
2.2. Statistical Model for Complex Designs
The complex field layouts considered in this study included IB, AB and UR designs, where both blocks and treatments are considered random effects, and an overall mean was included as the only fixed effect. This LMM is expressed as:
where
Here, is a vector of phenotypic observations; is the overall mean; is a vector of block random effects, such that ; is a vector of genetic random effects, such that ; and is a vector of residual errors, such that . Also, is a vector ones. and are incidence matrices for block and treatment effects, respectively. , and are variance-covariance matrices for blocks, treatments and residual errors, respectively. Block effects are assumed iid, hence , and genetic effects are assumed or , for genetically unrelated or related individuals, respectively. Similarly to the RCB model, the residuals errors have or , for independent or spatially correlated assumptions, respectively. All other variance components and matrices were defined previously.
Under the above model, the variance-covariance matrix of treatment effects,
, is obtained by using Equation (
7), and expanding
Z and
G based on Equation (
8) to obtain:
where
. This matrix
can be expressed as:
where
is the relevant portion that represents the variance-covariance matrix of treatment effects, to be used to perform the
A- and
D-optimality criteria in later stages.
2.3. Pairwise Swap Algorithm
The procedure to improve an experimental design layout was based on a pairwise swap (exchange) search algorithm. In brief, from an initial available layout, random pairs of treatments are swapped and evaluated using either an A- or D-optimality criterion, if a better layout is found then this is kept and a new swap is evaluated until a stopping criteria is reached.
The steps for this swap procedure in more detail follows: (i) randomly generate m experimental layouts , where ; (ii) for each layout, calculate and obtain a criterion value (that is, trace in case of A-optimality or determinant in case of D-optimality); (iii) select s experimental layouts with the smallest values; (iv) for each layout randomly interchange a pair of treatments within a block, between blocks and/or between a list of treatments to produce a new layout ; (v) recalculate the new criterion value ; (vi) if , then accept and use as the new layout, otherwise reject ; (vii) repeat steps (iv) to (vi) for a total of p iterations; (viii) select the best of the s imporved layouts.
For the improvement of the RCB designs the pair of treatments to be selected for swapping are selected from the same block in order to maintain the balanced nature of the experimental design. In contrast, for IB designs, given that in an incomplete block not all treatments are represented, then swapping pairs of treatments from within a block or between a block is allowed. In the case of AB designs, control treatments are allowed to be swaped only with a block but test treatments have no restrictions. Finally, general UR designs are generated from a list that identifies each treatment with its replication. These designs have no restrictions on the swapping of treatments due to its unbalanced nature. A complex case of UR can also be considered, where a list of treatments with constraints of allowed replications (i.e., minimum and maximum) is provided. Here, first a treatment is selected to determine if should be replaced by another random treatment according to its replication constraints, then, a second treatment was selected and checked for constraitns, and then this pair was allowed to swap freely.
2.4. Evaluation of the Swap Algorithm to Generate Designs
Performance evaluation of the above proposed swap algorithm was first conducted for RCB designs with specific number of treatments and blocks (see below), and a combination of heritability values ( = 0.1, 0.3, and 0.6), spatial correlation levels ( 0, 0.1, 0.3, 0.6 and 0.9), and genetic relationship structures (unrelated individuals, half-sib and full-sib families).
The scenarios and identify an RCB design with t = 30 genotypes generated using A- and D-optimality criteria, respectively. In these scenarios, there are b = 6 blocks, = 5 rows per block, = 6 columns per block. The independent (or unrelated) genetic structure considers the t genotypes to be unrelated. For half-sib families, pedigree consisted of a structure based on five parents with six offsprings each. Full-sib family pedigree consisted in a half-diallel with five parents for a total of 10 families (or crosses) with three offsprings each. Similarly, scenario identifies an RCB design with t = 196, b = 4, = 14 and = 14 generated based only on A-optimality criterion. Here, pedigree for half-sib families consisted of 32 parents, with approximately six offsprings each. For full-sib families pedigree consisted of a total of 30 parents in 68 families with approximately three offsprings each. Parents were arranged in groups of five to form half-diallel with 10 crosses each. Eight additional crosses between diallels were also included to connect diallels.
Each of the evaluated combinations of conditions was used to generate designs based on the model presented in
Section 2.1 that were replicated
times. Each replicate had
initial RCB designs iterated and the best design was selected (
) which was then optimized for
p = 5000 iterations to produce an improved experimental layout.
In a second stage, the complex experimental designs IB, AB and UR were evaluated. In contrast with RCB designs, these designs consider both blocks and treatments as random effects in their design and analysis (Equation (
8)) The IB designs were generated with
t = 30,
b = 6 blocks (
= 5 and
= 4); hence, each block had
experimental units, and each treatment was equally replicated
r = 4 times. For the AB designs,
= 492 unreplicated test treatments and
3 replicated control treatments that were replicated
= 12 times, arranged into
b = 3 blocks (
= 10 and
= 20); hence, each block had
experimental units where 164 belong to unreplicated test treatments. A complex UR design was generated with
t = 30 treatments arranged in
b = 6 blocks (
= 5 and
= 6), where each block had
experimental units, but treatments were unequally replicated, where the number of replications ranged between 4 and 8 based on a provided random list of treatment contraints.
As with the RCB design, evaluation of the swap algorithm for these complex designs was done for varying levels of genetic and environmental conditions, considering a combination of heritability values ( = 0.1, 0.3, and 0.6) and spatial correlation levels ( 0, 0.3, 0.6 and 0.9). The genetic relationship structures evaluated consisted of unrelated individuals, half-sib and full-sib families. For the IB and UR designs, pedigree for half-sib and full-sib was identical to the one presented earlier for the scenario. Also, in all designs, the variance of the blocks, , was set to be 20% of the total phenotypic variance. For the AB designs, pedigree for half-sib families from the unreplicated test treatments comprised of 41 parents each with 12 offsprings; full-sib families consisted in a half-diallel with 12 parents for a total of 35 families with approximately 14 offsprings each. In both cases, the control treatments were genetically unrelated between them and to the test treatments.
Each of the evaluated combinations of conditions was used to generate designs based on the model presented in
Section 2.1 that were replicated
times. Each replicate had
m = 100 initial random designs iterated and the best design was selected (
), which was then optimized for
iterations to produce an improved experimental layout.
For all the designs considered, in order to evaluate the improved experimental layouts, two measures of efficiency were defined. The initial design efficiency (IDE%) is the percent improvement, in terms of or , of the best (i.e., minimum trace or determinant) design without optimization (i.e., 0) from the m initial designs, in relation to the average value of these designs. In contrast, the overall design efficiency (ODE%) is the percent improvement after p iterations of the final selected design, in relation to the average value of the m initial designs.
All computations were implemented in
R [
36] using a high performance computer from the University of Florida, and code is available from the authors upon request.
2.5. Data Simulation for RCB Designs
Simulations were implemented to evaluate the accuracy and precision of the estimation of random genetic effects and estimate narrow-sense heritabilities from fitting a LMM for the RCB design. A response variable was simulated following the model
where
represents the observation on the
ith row and
jth column,
is an overall mean that was arbitrarily fixed to 10 units,
represents a
k-th random genotype effect and
is the structured residual error. A subset of the experimental conditions for RCB designs described in
Section 2.4 were considered here with spatial correlation levels of
and
and narrow-sense heritabilities of
,
and
with half-sib and full-sib families pedigree structures. Correlated genetic and residual effects were obtained based on the Cholesky decomposition of multivariate normal distributions with a zero expected value given by
and
, respectively. More details of the simulation process are described in [
5].
Three scenarios were generated, with a small experiment
and
both with 6 blocks exactly as described on
Section 2.4. A large experiment
was also generated as described in
Section 2.4, but with 16 blocks. A total of 12 conditions for each scenario were evaluated, each with
replicates,
and
iterations.
Analysis of data for the and scenarios was done by fitting two linear mixed models. Both of these models considered blocks as fixed effects, genotypes as random effects, but for the first case (Model 1) residual errors were modeled assuming independence, whereas for the second case (Model 2) residual errors were modeled by fitting an spatial correlation structure. For simplicity, under the scenario, only Model 2 was fitted. These analyses were performed for the initial designs (p = 0), and final improved designs.
Pearson’s product-moment correlation
between predicted and true simulated breeding values were computed, and estimation of heritabilities. The statistical package
R [
36] was used to simulate these conditions and the software ASReml-R v. 3.0 [
13] was used to fit all models and to estimate heritabilities.
3. Results
3.1. Design Efficiencies for RCB
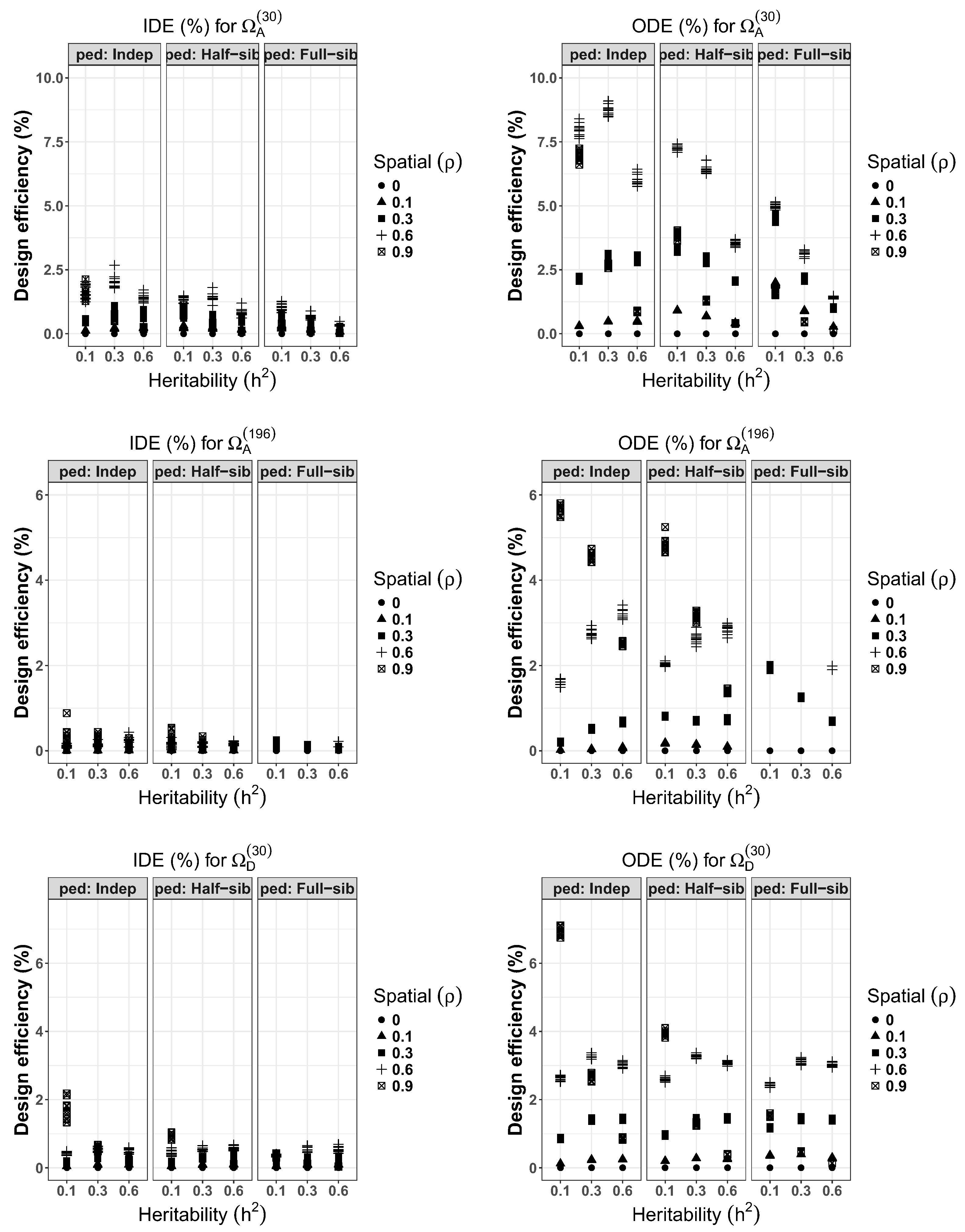
The evaluated conditions related to varying levels of heritability, genetic structure and spatial correlations for the RCB designs are shown in
Table 1 and
Figure 1. The results presented here show the percentage improvement in terms of reduction in average variance of the treatment effects when
A-optimality criterion is used and in terms of reduction in volume of the hypersphere when the
D-optimality criterion based on the IDE% and ODE% design efficiency measures.
As, expected, the average IDE% values for RCB designs were all smaller than their respective ODE% values. This would confirm the fact that randomly generating hundreds of experimental designs and simply choosing the best with respect to A- or D-optimality criteria results in designs with lower efficiencies compared to optimized designs. After applying the optimization procedure to improve the experimental layout, the average highest ODE% of 8.739 (S.E. = 0.065) from the optimal designs under was obtained from the set of genetically unrelated individuals when and . The only exceptions are the conditions with (i.e., no spatial correlation) that resulted in consistently null improvements. Relatively lower gains were observed within half-sib and full-sib families compared to structures with independent individuals. Specifically, the highest ODE% of 7.262 (0.031) among half-sib families occurred when and which was also the case among full-sib families that recorded the highest ODE% of 5.004 (0.034) when and . Also experiments with either half-sib or full-sib families appear to achieve higher reduction of average variance of treatment effects when the heritabilities are very low (i.e., ). In addition, for any given heritability level, often highest design improvement was achieved when the spatial correlation level was 0.6.
The results from the larger experimental show that, on average, the overall highest ODE% was obtained when the experiments consisted of genetically unrelated individuals with and (ODE% = 5.664, S.E. = 0.032). Also, among the genetically unrelated individuals, when , large improvements occurred when yielding a ODE% of 4.559 (0.032). However, for , large design improvements (ODE% = 3.213, S.E. = 0.036) occurred when . Considering the half-sib families, overall highest reduction in average variance of treatment effects of 4.834 (0.055) was observed when and . Similarly, among the full-sib families, highest ODE% of 3.040 (0.033) was obtained when and . These results indicate that an experiment with strong spatial correlations and with very low heritabilities may have considerable design improvements over experiments with high heritabilities and low spatial correlations.
The small experiments had the highest reduction in volume of the hypersphere (ODE% = 6.910, S.E. = 0.039) obtained when and among the genetically unrelated individuals. Similarly, the highest ODE% among half-sib family was 3.943 (0.024) obtained when and . Experiments with full-sib families recorded highest design efficiencies of 3.114 (0.023) when and . In general, for the same conditions ODE% values from D-optimality resulted in lower gains compared to A-optimality reflecting the nature of these optimization criteria. However, a Pearson’s product-moment correlation of between these criteria for and was obtained.
The number of successful swaps from the p = 5000 iterations for each condition and scenario were also monitored. The mean number of successful swaps for independent, half-sib and full-sib families in the scenario across all conditions were: 139 (range 96–208), 150 (93–244) and 178 (97–283). respectively. The average successful swaps under scenario were 185 (144–234), 190 (147–257) and 199 (131–260) for independent, half-sib and full-sib families, respectively. In contrast, under the successful swaps for the same genetic structures were larger, with values of 894 (830–959), 950 (828–1144) and 1024 (844–1281), respectively. In general, it was noted that higher number of successful swaps were obtained when the treatments had lower heritabilities and spatial correlation values.
3.2. Design Efficiencies for IB, AB and UR
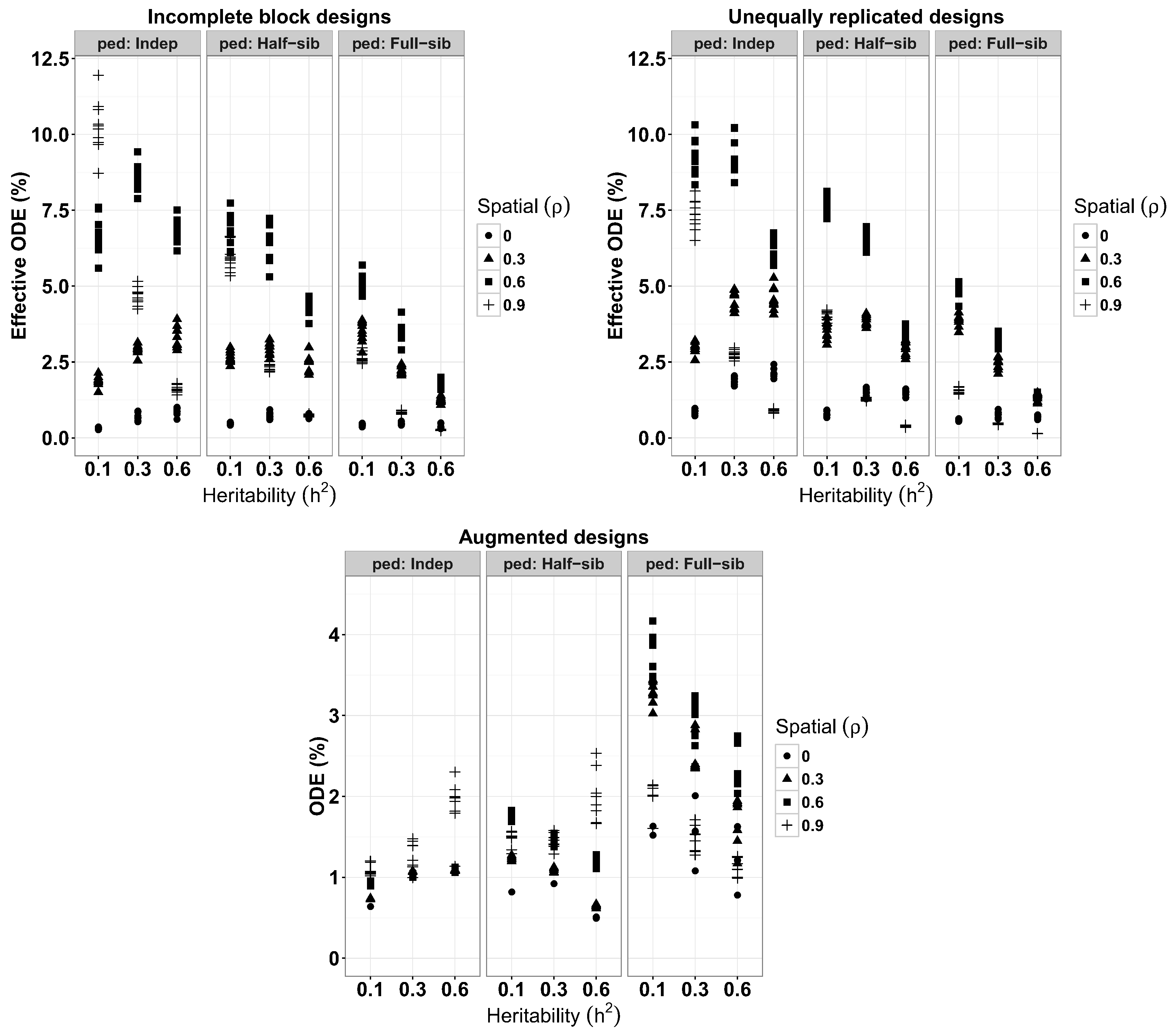
A summary of average ODE% for IB, AB and UR designs from each of the evaluated experimental conditions are given in
Table 2 and
Figure 2. IB designs achieved a highest average ODE% of 10.250 (S.E. = 0.274) when
and
. For designs with
of 0.3 and 0.6, mean highest reduction in average variance of treatment effects, with ODE% of 8.543 (0.139) and 6.854 (0.122), respectively, were obtained at
. For a given spatial correlation level, individual ODE% among full-sib families decrease with increasing heritability as shown in
Figure 2 with average highest ODE% obtained when the spatial correlation was 0.6 (
Table 2). Among half-sib families, a highest ODE% of 6.824 (0.163) was obtained when
at
. For heritabilities of 0.3 and 0.6, mean highest ODE% of 6.413 (0.180) and 4.337 (0.087) were obtained when
, respectively. Improvements for IB designs with full-sib families were ODE% of 5.082 (0.089), 3.511 (0.098) and 1.833 (0.047) for
,
and
, respectively, all of them obtained when
.
Results from the AB designs achieved the highest reduction of average variance of treatment effects among full-sib families when
and
, yielding an ODE% of 3.752 (0.093). Among the full-sib families, designs with heritabilities of 0.3 and 0.6 obtained their highest ODE% of 2.939 (0.092) and 2.387 (0.083) at spatial correlations of 0.6. As with the IB designs, the ODE% increased with increasing spatial correlation from
to
, and then decreased at a spatial correlation of 0.9 (see
Table 2). For generated AB designs with genetically unrelated individuals, a trend was observed of highest design improvements achieved when
at any levels of heritabilities with the highest value ODE% of 1.881 (0.120) obtained when
and
. Similarly, an ODE% of 2.002 (0.111) was the highest improvement achieved among half-sib families when
and
.
Figure 2 shows individual ODE% values with a tendency to increase with larger heritability and spatial correlation among genetically unrelated individuals, and it decreased with increasing heritability among half-sib and full-sib families, except when
and
among half-sib families.
Unequally replicated designs yielded, a highest average improvement level of 9.348 (0.190) achieved when
and
observed among genetically unrelated individuals. At
, the highest average design improvement of 9.283 (0.184) was observed at a spatial correlation of 0.6. In addition, when
, the highest average ODE% of 6.207 (0.110) was obtained at
among the genetically unrelated individuals. For a given heritability, among all genetic structures, ODE% increase with increasing spatial correlations up to
and then dropped as spatial correlation increases to
. In general, for a specified heritability and spatial correlation level, ODE% values appear to decrease as genetic relationships increases (see
Table 2). Also, for any given heritability, lower ODE% values were observed when spatial correlations were null (
) and in some conditions, when
with
.
3.3. Analysis of Simulated Data for RCB Designs
A summary of the results obtained from the analysis of simulated data are presented in
Table 3 and
Table 4 based on initial (i.e., un-improved) and final (i.e., improved) designs. These contain prediction accuracies for the estimation of genetic effects and heritabilities by fitting a LMM for the RCB design with and without a 2-dimensional separable spatial correlation structure denoted by Model 2 and 1, respectively.
Considering results from the improved designs and for
scenario under Model 2 (Equation (
3)), prediction accuracies of genetic effects among half-sib and full-sib families were found to be very high with
and 0.981, respectively, obtained when
. Similarly,
scenario under Model 2 resulted in strong prediction accuracies of genetic effects among half-sib and full-sib families with
and 0.982, respectively, also obtained when
. In all cases, Pearson’s correlation coefficients from the no-spatial model (Model 1) were lower than those from Model 2 but still very strong. For instance, prediction accuracies for
based on Models 1 and 2 among half-sib families were
and
, respectively, obtained when
. As expected, the lowest predictive ability under each scenario was found when layouts had the lowest spatial and heritability values.
Results from
scenario (
Table 4) had much stronger predictive ability of
for both half-sib and full-sib families when
. The lowest prediction accuracy occurred when
and
resulting in
values of 0.860 and 0.837 for half-sib and full-sib families, respectively. As expected, for the three scenarios (
,
and
), for a given level of spatial correlation,
increased with increasing
and similarly, for a given
value
increased with
.
Precision of the estimated heritabilities, measured using coefficient of variation (C.V. %), was found to be largest for smallest values, decreasing with increasing in both half-sib and full-sib families. In addition, C.V. % of heritability decreased considerably with increasing values. Conditions with smaller heritability values were relatively more variable, presenting higher C.V. % than for those with larger heritability. For a given heritability value, prediction accuracies increased with increase in spatial correlations only for the spatial correlation model (i.e., Model 2). The C.V. % of heritability for were notably smaller than for and scenarios, a result likely due to the larger number of experimental units used.
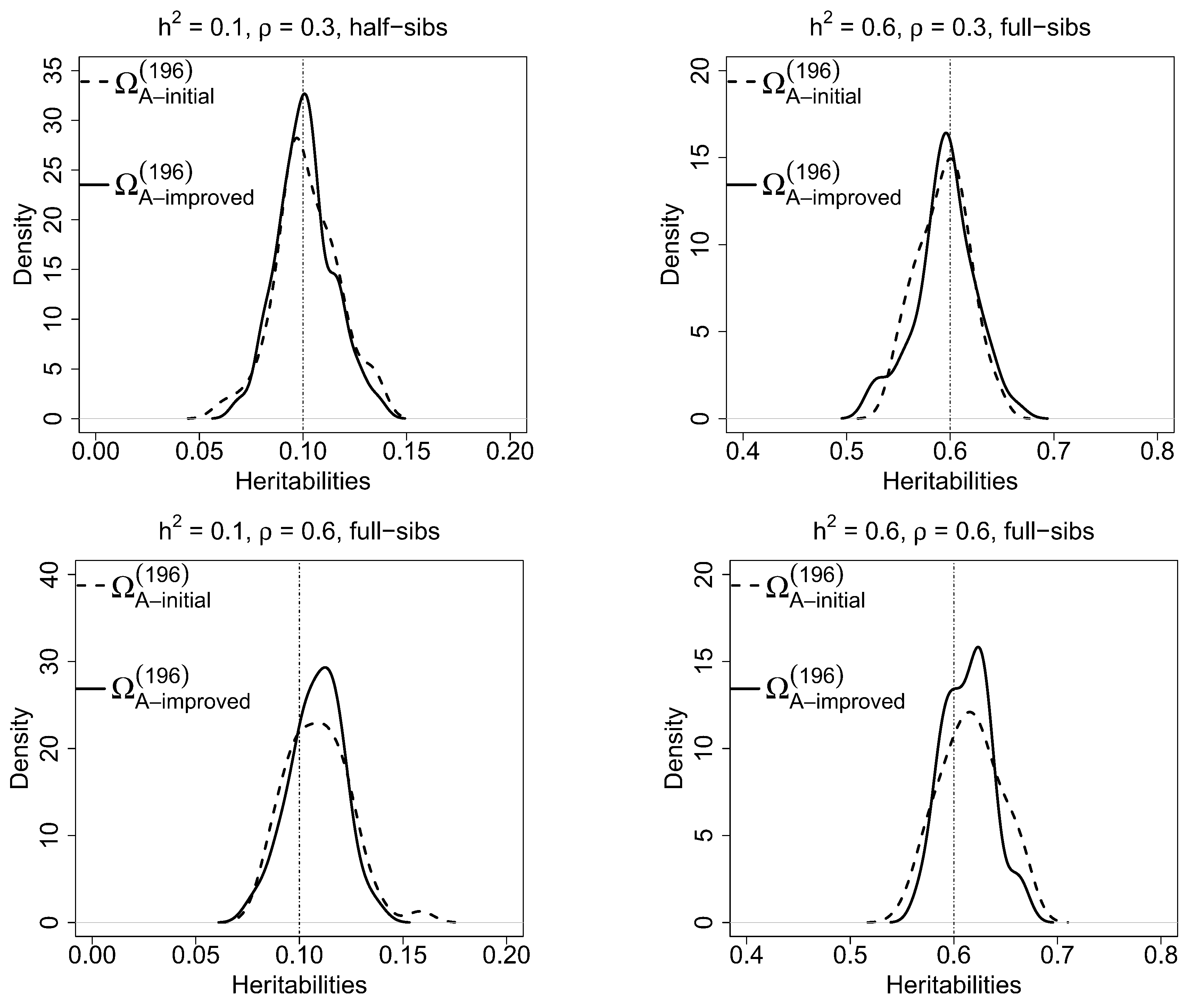
Kernel densities of estimated heritabilities for Model 2 based on
scenario are shown in
Figure 3 for selected conditions. Here, comparisons of estimated heritabilities between the initial and improved designs for full-sib and half-sib families are presented, which clearly indicates that final designs provide greater precisions (i.e., narrower distributions) than initial designs in estimating heritabilities.
4. Discussion
The primary aim for this study was to focus on algorithms and statistical procedures that can be useful on the generation of optimal field designs with correlated observations and to assess their efficiency considering a wide spectrum of typical field conditions. Although we demonstrate how to simulate data from a RCB design in
Section 2.5, this was only secondary to the generation of optimal designs and was necessary to show how we simulated the data for analysis and evaluate the accuracy and precision of genetic effects and heritabilties that were analyzed using ASReml-R v. 3.0 [
13]. Further details on simulating data for other complex designs have been discussed by other studies [
5].
Different experimental designs, and varying environmental and genetic conditions have a strong influence on the efficiency of field experiments. In this study, it was shown that, by the use of a linear mixed model framework to account for genetic relatedness and spatial correlation, it is possible to achieve important efficiency gains for the generation of experimental designs. Unlike other studies that have discussed optimality procedures by fitting mainly fixed effects models (e.g., [
20,
23]), the implemented procedure reported here provides with results that are practical for an array of field trial scenarios commonly used in plant studies.
For RCB designs, under the absence of spatial correlations (i.e., ), regardless of the level of heritability and genetic structures, there are no gains in optimizing designs using the implemented swap algorithm. In contrast, for IB, UR and AB designs, there were some moderate gains achieved for the evaluated conditions. This is expected due to the balanced and orthogonal nature of the RCB designs, whereas for the other designs rearrangement of the experimental units (for example, between different incomplete blocks), yields to better treatment pairwise comparisons. However, zero spatial correlation might not be a reasonable assumption, as in practice for any field trial there is always some level of spatial correlations. Nevertheless, under non-zero spatial correlations, all scenarios showed considerable improvements, particularly for the independent genetic structure. However, the positive effect of strong spatial correlations tends to diminish as the level of genetic relatedness between the treatments increases.
The input required for the generation of an improved experimental design under the proposed pairwise swap algorithm, includes a choice of number of iterations and optimality criterion.
Figure 4 presents an illustration for a RCB design based on
and
for genetically unrelated individuals, half-sib and full-sib families for
,
and
scenarios based on
50,000 iterations. For small RCB designs (
and
), the rate of improvement was high until 5000 to 10,000 iterations and flattens out thereafter. The large RCB design (
) showed that there was room for improvement even after 50,000 iterations, a result that is expected from experiments with large number of treatments [
20]. Interestingly, there was a small number of successful swaps. For example, with
scenario, for independent, half-sib and full-sib families, these reached only 178, 172 and 198 cases, with ODE% of 9.67, 7.00, and 3.52, respectively. In contrast for
, the successful swaps were 2589, 2685 and 2616, for the same genetic structures. Nevertheless, using 5000 iterations provides with a useful stopping criteria that limits the time required to run the optimizing procedure.
The decision between
A- and
D-optimality criteria depends on the aim, where the
A-optimality criterion minimizes the average treatment effect variance and
D-optimality criterion minimizes the generalized variance of the treatment effects, hence it considers covariances between pairs of treatment effects. Nevertheless, in this study, a strong Pearson’s product-moment correlation of
between
A- and
D-optimality criteria was detected. This is not completely unexpected as both criteria are a convex function of the eigenvalues of the information matrix [
22,
23].
Several measures of design efficiency can be evaluated. In this study, overall design efficiency (ODE%) was used. Other measures have been proposed, such as the average efficiency factor (a.e.f.) [
20] that compares the average pairwise variance of a given design layout against an RCB design with the same number of treatments and replicates. Nevertheless, a.e.f is only defined for designs where treatment is considered a fixed effect.
For all conditions evaluated the current study has shown that, for RCB designs based on
A-optimality criterion, gains of up to 8.7% can be achieved. Both small and large experiments with half-sib and full-sib families can achieve greater improvements under low heritability levels and moderate spatial correlation. Filho and Gilmour [
21] also reported larger improvements on those layouts with genetically unrelated individuals against those that accounted for genetic relatedness; however, their residuals were assumed independent.
For the data simulated for an RCB design, high prediction accuracies (≥0.90) of genetic additive effects were obtained from both initial and improved experimental layouts from models with and without spatial correlations. As expected, better prediction accuracies were found for the model that incorporated spatial correlations, particularly for the improved designs. This result is similar to the findings reported by [
5]. The current study has found that estimation of heritabilities was more accurate under improved designs for both models. Also, as expected, genotype effects estimated under layouts with small heritability values will exhibit larger C.V. % compared to layouts with large heritability values, and when the spatial correlations are low, the C.V. % for estimated heritability is larger, and vice-versa. The prediction accuracies of genetic values from larger experiments is higher compared to that from small experiments, but similar trends are observed as the accuracy increases with increasing levels of heritabilities.
In the case of more complex designs, such as IB, AB and UR, the highest average variance reduction of treatment effects of about 8.54%, 1.03% and 9.35%, respectively, were achieved when conducted with genetically unrelated individuals with heritabilities of and spatial correlations of . As indicated earlier, unlike RCB designs, it is still possible for these designs to improve their efficiencies even when spatial correlation is zero. It is expected that the improvement of the generation of these designs will require large number of iterations as a results of their unbalanced nature.
The proposed swap algorithm and procedures used here can be extended to include other experimental designs, genetic structures, and spatial variance-covariance structures (such as the ones described by [
12,
13,
14,
37,
38]). In addition, instead of using pedigree information to calculate a numerator relationship matrix, molecular markers can be used to calculate a genomic relationship matrix [
17]. The use of the relationship matrix within the mixed model framework is limited to only describing the additive genetic effects. However, the linear models can be extended with other matrices to consider all genetic effects, such as dominance and epistatis.
A similar algorithm to the one proposed here for the generation of experiments was developed by [
4], which also deals with correlated effects and residuals using a different optimization approach. However, it is expected that these two algorithms may result in nearly identical optimal solutions, given the similarity of these methods. Nevertheless, in the present study, findings about generation of experiments under an array of varying conditions apply to any algorithm that generates an optimal design, and this should assist on the use of these tools.
In order to generate field experiments, there is a need for known values of the different variance components (e.g., spatial correlation). This could be a limitation of the proposed algorithm; however, for most mature breeding programs there is always some level of information about what to expect on a field experiments. For example, some fields are dominated by patches (i.e., high spatial correlations) others are dominated by gradient. In addition, usually the same farms are used repeatedly to establish breeding trials, and pedigree information often is available to be used to calculate relationship matrices that can be incorporated in a design to be generated. The present study has evaluated an array of varying typical field conditions that can be used; hence, it is possible to asses and select the most appropriate condition to generate a desired design. Finally, even if a generated design is not fully optimum for its field conditions, it is likely to be always better than a design that ignores any type of spatial and/or genetic correlations. More complex designs than RCB might be required when conducting experiments with large number of treatment levels as is common on breeding experiments. Thus, it is advisable in these cases to use more complex layouts such as IB designs.
This study has demonstrated how to generate experiments with random initial arrangements and optimize them considering both spatial and/or genetic relatedness. When designing complex field experiments, it is important to start with an optimal design. Generating an optimal experiment assuming all parameters are fixed with no sort of correlations has been implemented by many other studies such as CycDesigN [
20]. A two step approach can be used where after the initial design is generated assuming no spatial or genetic correlations, then the second stage superimposes these realistic conditions. The strength of our method is that our algorithm can take any design and optimize it. The R-codes developed allow the user to input any initial design, or generate the design within our software. If the initial design is generated within this software, our current approach starts with a random design and models these correlations simultaneously in one step. The two-step approach was not implemented and can be viewed as a limitation of the study, but can be implemented in the future. For large experiments, long computation time were required to generate improved designs using a desktop computer. For example, the time taken for
scenario for 5000 iterations, was ∼2 min and for
scenario it took ∼30 min. Improved computation can be implemented with faster code and software to enable evaluation of experiments with large numbers of treatments. Additionally, other stochastic search algorithms, including simulated annealing, could yield potentially faster optimizations when compared to the pairwise swap algorithm proposed here.








{kind=link}
{kind=link}
{kind=link}
{kind=link}