Current and Emerging Methods for the Synthesis of Single-Stranded DNA


1
School of Chemical Engineering and Technology, Tianjin University, Tianjin 300072, China
2
Key Laboratory of Systems Bioengineering of Ministry of Education, Tianjin University, Tianjin 300072, China
3
SynBio Research Platform, Collaborative Innovation Center of Chemical Science and Engineering, Tianjin University, Tianjin 300072, China
*
Author to whom correspondence should be addressed.
Genes 2020, 11(2), 116; https://0-doi-org.brum.beds.ac.uk/10.3390/genes11020116
Submission received: 7 January 2020
/
Revised: 16 January 2020
/
Accepted: 18 January 2020
/
Published: 21 January 2020
(This article belongs to the Section Molecular Genetics and Genomics)
Abstract
:Methods for synthesizing arbitrary single-strand DNA (ssDNA) fragments are rapidly becoming fundamental tools for gene editing, DNA origami, DNA storage, and other applications. To meet the rising application requirements, numerous methods have been developed to produce ssDNA. Some approaches allow the synthesis of freely chosen user-defined ssDNA sequences to overcome the restrictions and limitations of different length, purity, and yield. In this perspective, we provide an overview of the representative ssDNA production strategies and their most significant challenges to enable the readers to make informed choices of synthesis methods and enhance the availability of increasingly inexpensive synthetic ssDNA. We also aim to stimulate a broader interest in the continued development of efficient ssDNA synthesis techniques and improve their applications in future research.
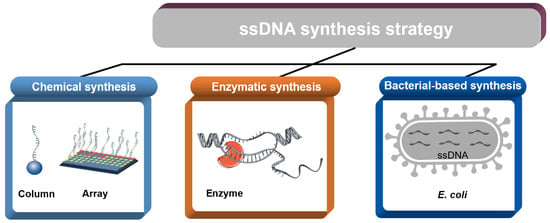
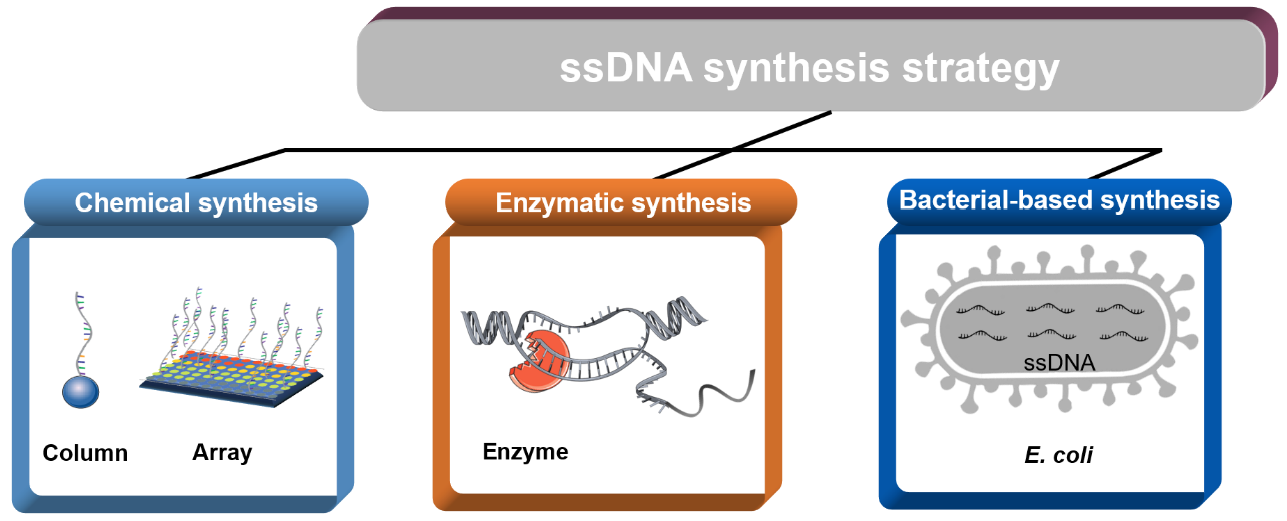
1. Introduction
DNA is the carrier of genetic information and as such it is an indispensable part of basic biological research, biomaterial science, and synthetic biology. The vast majority of modern biological research and bioengineering relies on synthetic custom DNA sequences, including oligonucleotides and longer constructs, such as synthetic genes and even entire chromosomes [1,2]. Breakthroughs that enable the large-scale, low-cost, and high-efficiency construction of desired DNA sequences could catalyze rapid progress in biological research and application [3]. Today, the complete reconstruction of viral and bacterial genomes is the proof of our synthetic ability [4,5,6]. There is no doubt that user-defined DNA synthesis has improved our ability to understand the interactions between DNA and protein [7,8,9,10], uncover the structural effects of regulatory elements that drive expression [11,12], as well as engineer the structural and functional characteristic of mammalian, yeast, and bacterial systems [13,14,15,16].
Although there are scalable methods for the production of double-stranded DNA (dsDNA) both in vitro and in vivo, equally efficient methodologies for the synthesis of single-stranded DNA (ssDNA) would be desirable for a number of special applications. In fact, the synthesis of ssDNA has become an enabling technology for modern DNA-based biomaterials. In this context, ssDNA is considered an elemental material with an intriguing application potential in many biological reactions and the broad applicability of related DNA nanotechnology [17]. For instance, ssDNA can be used as the scaffold for DNA nanotechnology [18,19,20], the donor DNA for clustered regularly interspaced short palindromic repeats (CRISPR) and CRISPR-associated protein 9 (Cas9) systems CRISPR-Cas9 systems [21,22], carrier for drug delivery [23], in molecular diagnostic [24], DNA-based data storage [25,26,27], and various nanoscale applications [28]. To meet these different application requirements, a variety of methods have been developed based on different principles. Thus, it is of great practical significance to choose the appropriate synthesis method for different application directions.
Here, we summarized the synthesis methods of ssDNA and divided the available approaches into the categories of chemical synthesis, enzyme synthesis, and bacteria-based synthesis. Chemical synthesis provides a powerful tool for the generation of custom ssDNA sequences. In fact, chemical synthesis is a method that can generate ssDNA without templates. Enzymatic synthesis encompasses the production of ssDNA by ligation or polymerization. Bacteria-based synthesis is a scalable approach that is based on fast-growing Escherichia coli (E. coli) cells as the host and offers mg-scale yields of ssDNA. This review focuses on representative methods of ssDNA synthesis in terms of both their principles and current challenges, providing a reference for researchers to better choose synthesis methods and thus increase the potential availability of ssDNA.
2. Chemical Synthesis
Single-stranded DNA fragments of less than 200 nt are mainly produced by direct chemical synthesis. The synthesis of short oligonucleotides is usually performed by different kinds of phosphoramidite chemistry methods, using either traditional column-based synthesizers or microarray-based synthesizers [29,30].
2.1. Column-Based Oligo Synthesis
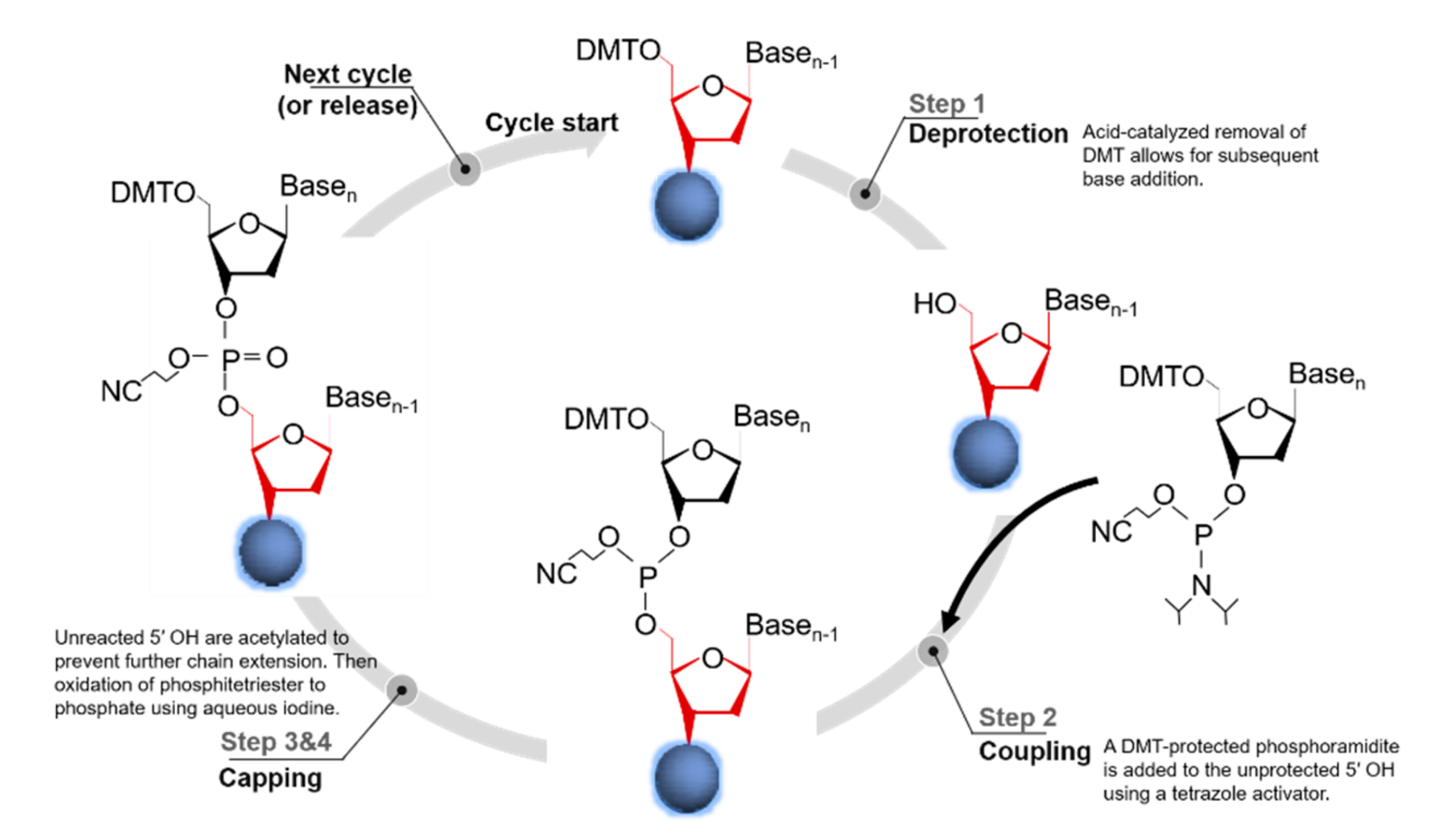
The methodology of using phosphodiesters for the de-novo synthesis of oligos can be dated back to the 1950s, with pioneering studies that used phosphodiester, H-phosphonate, and phosphotriester approaches [31,32,33]. However, a true breakthrough in oligos synthesis did not occur until the early 1980s [34,35,36], with the development of solid-phase phosphoramidite approaches and automated instruments. This scalable oligonucleotide synthesis method offered sufficient robustness and fidelity and is used in the current commercial synthesis of oligonucleotides. Standard column-based oligo synthesis is a cyclical process that elongates a chain of nucleotides from the 3′-end to the 5′-end.
The synthesis proceeds on the base of standard phosphoramidite chemistry, which consists of a four-step chain elongation cycle (Figure 1) [3], encompassing (1) deprotection, (2) coupling, (3) capping (optional), and (4) oxidation [37]. The next synthesis cycle is then continued via the removal of the dimethoxytrityl (DMT) protecting group from the 5′-terminal. After the nucleoside sequence has been fully synthesized, the completed sequence is chemically cleaved from the solid support and the protecting groups are removed. Column-based synthesis is highly suitable for automated oligonucleotide synthesizers, which can produce 96 to 384 oligos simultaneously at scales from 10 to 100 nmol at costs ranging between $0.05 and $0.15 (in 2014 US dollars) per base [3]. Beyond this length, the efficiency of oligonucleotide production is generally reduced due to a drop in the yield and accumulation of small errors that are introduced in each step of the synthesis cycle [38]. Notably, the most recent work on improvements in the synthesis strategy and the utilized chemistries focused on increasing the length and quality of the synthesized oligonucleotides [29]. It is a universal approach that a number of different strategies can be used to introduce modifications in the oligos for different applications [39]. Through improvement of the chemistry synthetic steps, oligomers containing about 600 nucleotides should be synthesized in the future [40].
2.2. Array-Based Oligo Synthesis
With the introduction of microarray oligonucleotide synthesis by Affymetrix in 1990 [41,42], who developed photoactivation-based chemical methods for spatially located oligonucleotide synthesis, the foundation was laid for DNA microarrays. Array-based platforms offer a massively parallel alternative to traditional columnar oligonucleotide synthesis [43]. It is also a much cheaper strategy for oligo synthesis, with costs varying from $0.00001 to $0.001 per base (in 2014 US dollars) [3]. Furthermore, novel chip synthesis technology was developed to replace the chemical reactions on the surface of the light-guided array. For example, Agilent and Twist Bioscience developed an approach based on inkjet printing technology [38], which can synthesize 244,000 sequences 20 to 230 nts in length or 2000 to 696,000 sequences 120 to 300 nts in length in each pool [44]. Furthermore, the technology of CustomArray [45] can synthesize 12,472 (12k chip) or 92,918 (90k chip) sequences of 10 to 170 nts on a single chip [44]. For the application of DNA chips, it is necessary to design reasonably according to the purpose of the research [46]. In DNA information storage, using the random access approach, over 200 MB of data (35 distinct files) was encoded and stored in nine synthesis pools, which included 13,448,372 unique DNA sequences of lengths ranging from 150 to 154 bases [47]. In diagnostics, combining array-based oligo synthesis with photolithography computer chip technology, more than 400,000 oligonucleotides could be produced, which could detect up to 9000 genes on the glass surface of 1.6 square centimeters [48]. Although this platform offers superior synthesis capabilities and lower cost, there are still some challenges with using it for DNA synthesis applications [49]. The product yields of array-based oligo synthesis are typically at the femtomolar scale, i.e., two to four orders of magnitude lower than traditional column-based synthesis [29]. There have been many attempts to increase the scale, quality, and quantity of multi-channel synthesized oligonucleotides [50,51]. Continued improvements in array design, along with the optimization of synthesis reagents and processes, will hopefully deliver platforms for the synthesis of high-quality oligo sequences from arrays, potentially establishing them as the go-to source for multi-channel oligo sequence for gene synthesis applications.
3. Enzymatic Synthesis
Enzymatic synthesis is a low-cost, fast, and stable way to synthesize ssDNA. This process can directly synthesize the longer oligos due to its exquisite specificity and mild conditions. Efficient synthesis of ssDNA fragments ranging in size from several hundred base pairs to 10+ kb is needed for numerous biotechnology applications. However, methods for the construction of long ssDNA fragments of individual genes need to address a set of different challenges. Here, we focus on several methods that use enzymes to synthesize ssDNA (Figure 2 and Table 1).
3.1. Terminal Deoxynucleotidyl Transferase
Terminal deoxynucleotide transferase (TdT) is a polymerase that indiscriminately adds deoxynucleotide triphosphates (dNTPs) to the 3′ end of an ssDNA, which makes it a natural candidate for enzymatic ssDNA synthesis (Figure 2a) [62,63]. TdT is characterized by low substrate specificity for nucleotides and template-independent polymerization [64], which makes TdT-based ssDNA synthesis methods compatible with various modified nucleotides and convenient subsequent purification [65]. Recent studies have shown that the coupling time of C, G, and T is 1.5 min while that of A is 3 min [53]. The average step-yield is 97.7%, which is comparable with the performance of early phosphorylated amidine DNA synthesis [35,53]. A major challenge in TdT synthesis is the control of the addition of single bases, since TdT enzymes tend to catalyze the addition of multiple bases per cycle [65]. Although the synthesis of ssDNA by TdT is still an emerging strategy, several challenges remain. For example, it is still difficult to find a suitable solid support, there are problems with low extension yields, and the overall length is limited. Consequently, there is still no implementation of a practical enzymatic oligonucleotide synthesizer based on TdT, but recent application requirements indicate that this is a promising method. Potentially, TdT can be used to synthesize relatively long chains cheaply and quickly, and has been successfully applied in signal amplification [66], single-nucleotide modified in DNA oligos [65], polymerization of building blocks [67], and chain synthesis for DNA information storage [68].
3.2. Transcription and Reverse Transcription
In vitro transcription and reverse transcription (ivTRT) is a method that involves three steps: Preparation of dsDNA templates, transcription of RNA from the dsDNA, and preparation of ssDNA from the RNA (Figure 2b) [54]. Specifically, the dsDNA template is converted to an RNA via transcription, and then the RNA is reverted back to ssDNA using a reverse transcriptase. For in vitro transcription, PCR products or plasmids (containing a restriction site) can be used as the dsDNA templates, and transcription is performed using a T7 promoter and the very strong T7 RNA polymerase [69]. The RNA template is finally cleaved using RNase H, which leaves a heteroduplex structure at the 3′ end of the DNA [55]. The ivTRT can be used to synthesize ssDNAs of various lengths (about 0.5~2 kb), which can be used for gene editing [54,70,71]. Furthermore, when fluorescent-labeled deoxyuridine triphosphates (dUTPs) (Cy3-dUTP or Cy5-dUTP) existed in the pending-test RNA samples, the fluorescent probes (ssDNA) could be produced from single-round reverse transcription [48]. However, this method is both labor intensive and expensive. Moreover, the use of nucleases can limit the product yield and requires DNA of impeccable quality [71].
3.3. Asymmetric Polymerase Chain Reaction
Asymmetric polymerase chain reaction (aPCR) is the simplest method for effective production of ssDNA with on-demand labeling [72]. In theory, it is a straightforward ssDNA production protocol, and appeared after the publication of the PCR technique (Figure 2c) [73]. This method provides a way to direct the synthesis of ssDNA from a dsDNA template, and it has been used to generate ssDNAs ranging from hundreds to thousands of nucleotides [17]. In an aPCR reaction system, there are two amplification primers in unequal concentrations, and two phases of amplification are used to produce the desired ssDNA. The first one involves dsDNA templates’ exponential amplification, and the second one of linear amplification is used for producing ssDNA [74]. While this may seem simple, aPCR is prone to producing nonspecific amplification and therefore generally requires extensive experimentation to optimize the yield of the desired ssDNA [72]. Numerous research groups have attempted to improve aPCR by identifying the appropriate ratio of primers, polymerases, number of amplification cycles, and purification methods [56,75]. This approach has previously been applied in the synthesis of short ssDNAs [72,73,76], and more recently for DNA origami scaffolds of up to the kb scale [56,77]. High purity ssDNA can be produced by combining aPCR with gel purification or enzymatic degradation of residual chains. In fact, ssDNAs greater than 15 kilobases (kb) in length have been synthesized using aPCR, and a fluorescently modified ssDNA of 2000 nt was used to fold DNA nanoparticles [56]. In the systematic evaluation of ligand by exponential enrichments (SELEX) procedure aPCR, especially used for the amplification of short ssDNA libraries, but it is prone to the creation of by-products and nonseparated bands [78]. Several reports of different protocols indicate that the initial optimization of the aPCR is not easy, and the amplification of different ssDNA does not follow a unique pattern and hence cannot be done using a single protocol.
3.4. Isothermal Amplification of ssDNA
Isothermal amplification techniques for ssDNA production rely on enzyme activity or designed primers to bypass the thermal denaturation of the dsDNA template. The initiation step was shown to be the key factor that limits the speed and efficiency in the isothermal reaction. Consequently, initiation is also the main source of variance among the related methods [79]. Based on the excellent sensitivity, most isothermal amplification techniques were well established to detect DNA [80].
3.4.1. Primer Exchange Reaction
A primer exchange reaction (PER) is a method that can isothermally produce ssDNA with custom DNA sequences in a programmable, autonomous, in situ, stepwise fashion with the aid of a strand-displacing polymerase (Figure 2d) [81]. The PER starts with the recognition and binding of a designed primer with an independent, customized sequence to its complementary sequence at the 3′-end of a catalytic hairpin structure. This hairpin contains a stop sequence that halts the polymerase-mediated extension reaction. The stop signal consists either of a G-C pair (if dGTP or dCTP are not used in the dNTP mix) or a modified base pair (i.e., iso-dG/iso-dC or methylated RNA) [57]. The newly extended primer then triggers the next round of extension in the programmable PER cascade that can autonomously synthesize DNA strand along the pre-prescribed pathway [57]. In the PER process, an arbitrary user-defined ssDNA strand is generated in situ only if the predesigned hairpin sets and the corresponding primer are both present. The PER cascade grows nascent strands of ssDNA with custom sequences for applications in nanodevices, signal amplifiers, logical computation, and molecular programming [58]. Although PER provides programmable synthesis of a user-specified ssDNA sequence in situ, the length is limited to 60 nt [82].
3.4.2. Rolling Circle Amplification
Rolling circle amplification (RCA) relies on an isothermal polymerase (typically the large fragment of Bsu, Bst, and E. coli DNA Polymerase I, or Φ29 DNA polymerase) to synthesize a long stretch of repeating ssDNA sequences in a single unit (Figure 2e) [83]. An RCA reaction requires four factors: A DNA polymerase, a corresponding DNA primer, a template, and deoxynucleotide triphosphates (dNTPs) [84]. In RCA reaction, nucleotides are added continuously to the annealed primer by the polymerase, which generates a long ssDNA with a repeating sequence [85]. RCA is a powerful induction system because it can produce large amounts of ssDNA at the scale of a micron and a detectable amplification of a single molecule [84]. Examples for microgram-scale ssDNA production include using cutter hairpins [86] or annealing of a complementary digestion splint to form double-stranded restriction sites [87,88]. Due to its simplicity, robustness, and high sensitivity, RCA is considered a powerful tool for sensitive detection [89,90,91]. Nevertheless, there are some drawbacks to this approach. For example, the amplification efficiency is relatively low and the reaction time is as long as 6 h [92]. Variations of RCA for the production of ssDNA include linear RCA (LRCA), branched RCA (BRCA), hyperbranched RCA (HRCA), RCA with multiple primers (multi-primer RCA), and rolling-ring lock-type probe amplification [93].
3.4.3. Other Isothermal Amplification Methods
The ssDNA produced by strand displacement amplification (SDA) or loop-mediated isothermal amplification (LAMP) has a high background, which makes separation a challenge [94]. However, the high sensitivity of these approaches has led to their wide use in other research areas [95,96,97,98]. Therefore, we offer a brief introduction to these methods. SDA is a nicking endonuclease-assisted isothermal polymerization reaction activated by four different specific primers, and its product is an ssDNA [98]. In a single SDA reaction, 109 copies of the target DNA can be produced in less than an hour [99]. LAMP can amplify a few copies of DNA into a billion within an hour using the specially designed primer sets and a DNA polymerase [100,101]. The most vital step in the LAMP protocol is primer design. Usually, four to six primers are employed to specifically identify six to eight different regions of the target gene, and thereby amplify the gene with highly efficient precision [102]. The strand displacement activity is unique to the LAMP polymerase enzyme, which does not have an exonuclease activity at the 5′-3′, and therefore leads to the production of ssDNA [103].
3.5. Separation of ssDNA from dsDNA
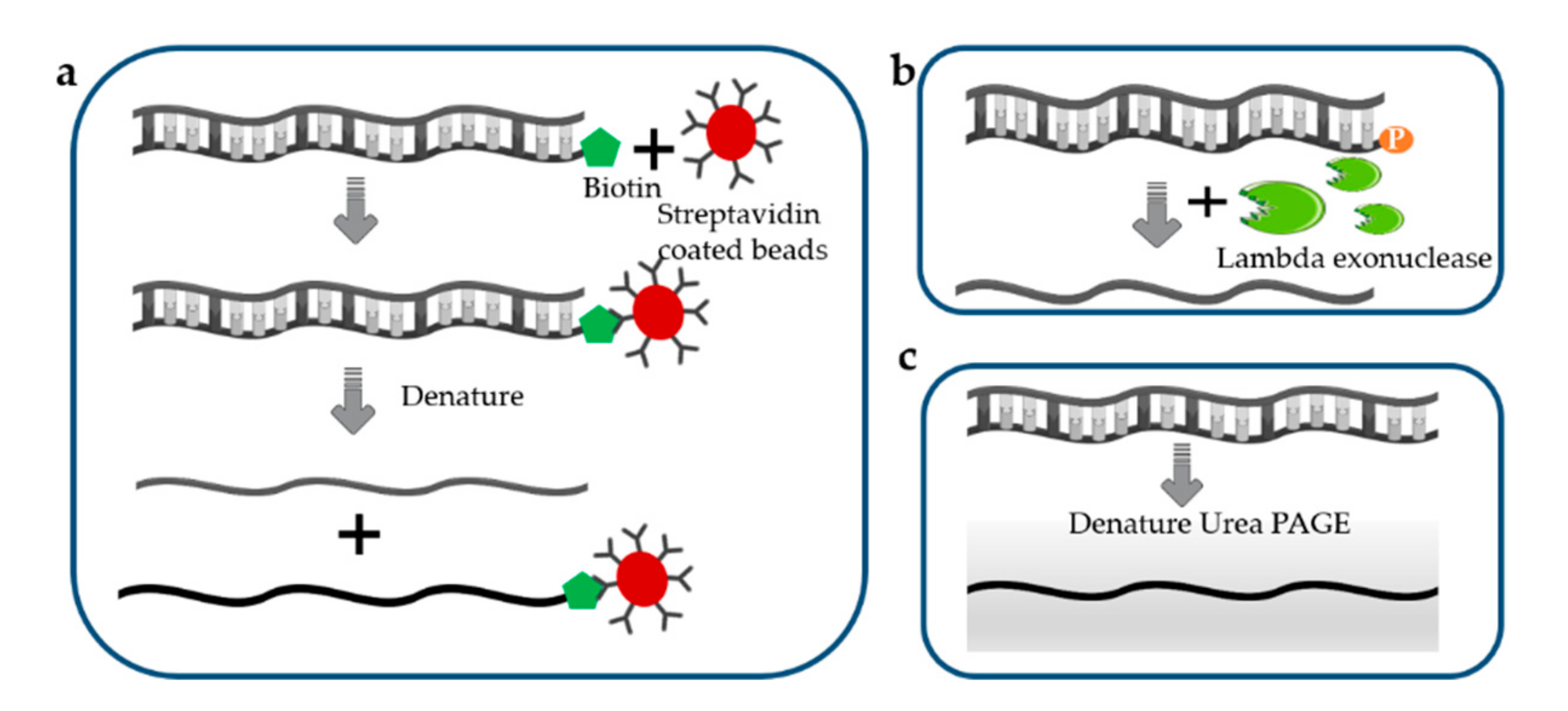
Enzymatic or chemical approaches for the denaturation of dsDNA to form ssDNA offer an alternative strategy for ssDNA production but are often limited by the required purification steps [104]. There are many methods that can effectively generate ssDNA from dsDNA, usually relying on biotin–streptavidin separation [105], selective lambda-exonuclease digestion [106,107], denaturing urea polyacrylamide gel electrophoresis, and capillary zone electrophoresis [108].
For biotin–streptavidin-based separation of ssDNA (Figure 3a), one of the primers is biotinylated at the 5′ end, and the resulting biotinylated PCR product can be effectively fixed on to magnetic beads coated with streptomycin. Due to the high affinity between biotin and streptavidin, the desired non-biotinylated strand are separated from the biotinylated strands using denaturing treatment [109,110]. The resulting products are subsequently concentrated by ethanol precipitation or using a commercial purification kit. The separation efficiency of this method can reach 70% [111]. Although ssDNA separation via the biotin–streptavidin interaction is strongly favored, the biotinylated strand may reanneal with the desired strands, leading to an increased ratio of non-specific recovery [112].
Lambda exonuclease is an exodeoxyribonuclease that digests the phosphorylated strand from the 5′ to the 3′ end (Figure 3b), so that only non-phosphorylated ssDNA remains in the system after digestion [113]. Although this method is a fast and efficient method for generating ssDNA with high efficiency and quality [114], it has fallen out of favor due to the fact that incomplete digestion of the PCR product results in the accumulation of dsDNA in the final products [74].
Denaturing urea polyacrylamide gel electrophoresis (Figure 3c) can be used to visualize the isolated ssDNA. The differential migration of strands with different sizes on the urea-denaturing polyacrylamide (PAGE) gels can highly facilitate the selective recovery of desired strand. In the amplification step, one primer is modified with a modified group, such as ribose residues that are cleavable by ribonuclease, or a hexaethylene glycol tag, pH-labile base, or fluorophore, to separate two strands of different size, enabling ssDNA purification. This is a very efficient separation method because the resulting target ssDNA is clearly distinguishable. However, this method is not efficient in terms of labor and overall workflow since the electrophoresis on a denaturing gel followed by purification process of ssDNA takes a long time.
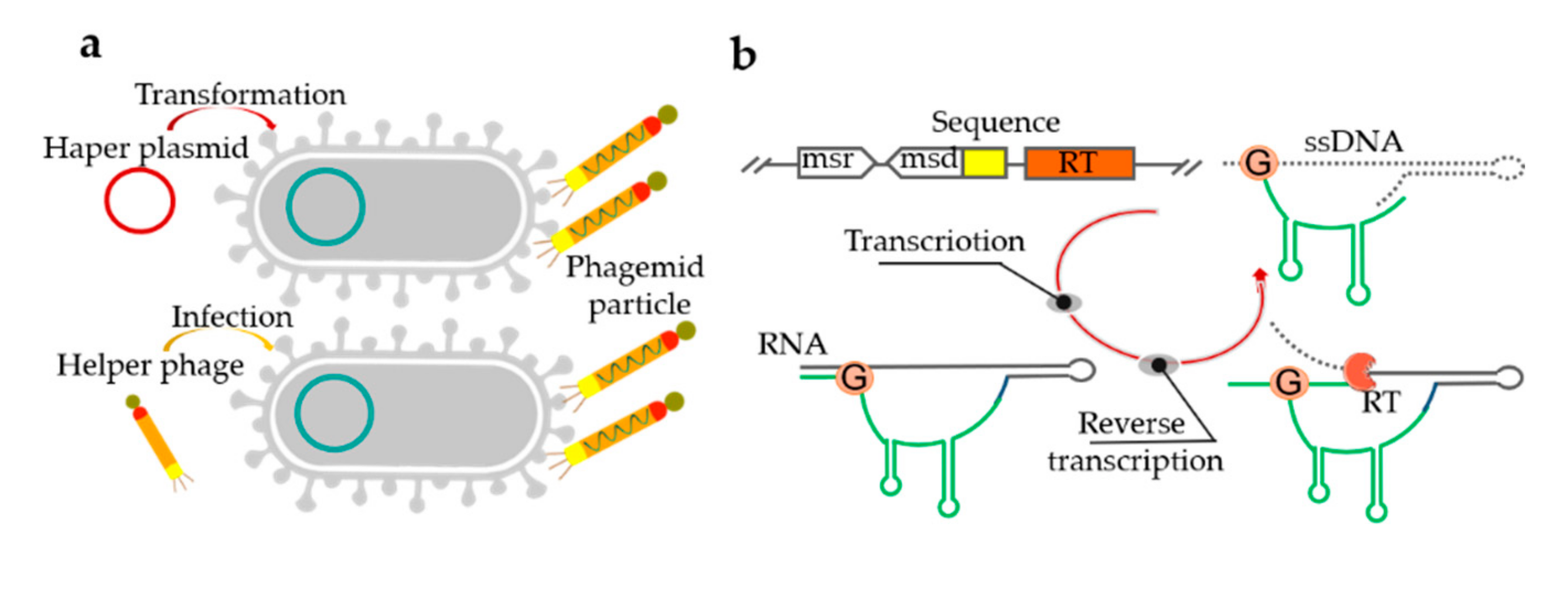
4. Bacteria-Based Production of ssDNA
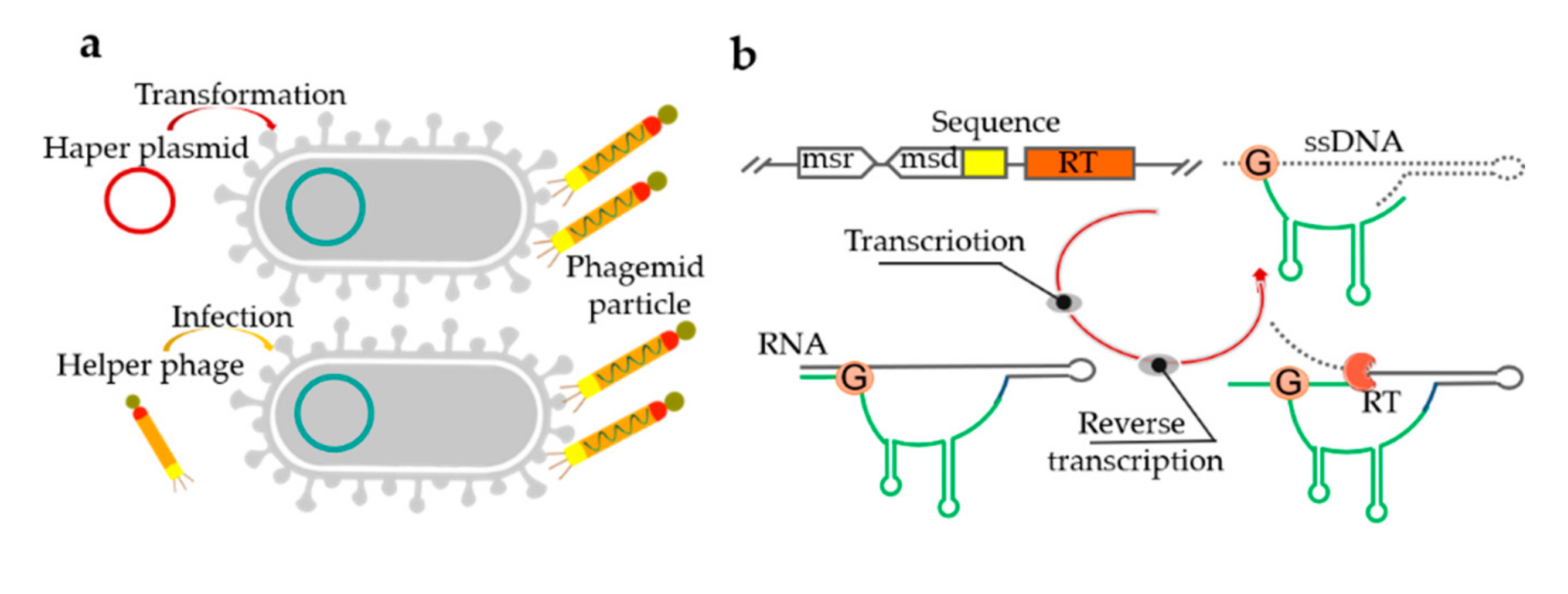
Bacteria-based platforms for ssDNA synthesis offer milligram-scale yields in shake flasks, which can even be boosted further using bioreactors [115]. Bacteria-based ssDNA production employs bacteriophages with fast-growing E. coli cells as the host [115]. In the process of the secretion of progeny phage particles, the ssDNA genome is assembled into the virion with the coat proteins without lysing the host, so that these host cells can continue to divide after infection [116]. However, the fixed sequence of the M13 genome has limited application in ssDNA production [117]. Consequently, phagemids with the capacity of accommodating the size of several kb custom inserts were introduced to produce ssDNA. However, it typically includes a fixed region (2–3 kb) comprising a host origin of replication sequence, a phage origin from M13 or f1, and an antibiotic resistance gene, which limits their usefulness in nanotechnology [118,119]. At the DNA level (preparation of ssDNA, cloning, transfection efficiency), phagemid libraries are easier to work with than phages [120]. When phagemid-carrying cells are infected with the “helper phage” or transformed with a “helper plasmid”, an ssDNA with a near arbitrary sequence can be generated (Figure 4a) [119]. Although phagemid libraries can produce more and purer ssDNA than phage libraries, their application is complicated by the necessity of introducing an ssDNA replication origin and the selection of gene sequences, as well as their limitation to canonical deoxyribonucleotides [56]. The protocol has been used to produce various ssDNA scaffolds for the efficient assembly of DNA origami structures [121]. Notably, a λ/M13 hybrid virus was used to produce a circular ssDNA of 51,466 nts in E. coli [117]. Although phage-based single-stranded DNA production techniques are very mature, they still have several drawbacks. It is not easy to control the nature of the helper phage and the time of phage infection [118]. Furthermore, the use of a helper phage can be laborious, costly, and inefficient. It has also been shown that ssDNA can be produced in vivo using a reverse transcriptase protein [1]. However, the ssDNA must be incorporated into a long DNA with a complex secondary structure from which it would need to be cleaved in an additional step.
Retrons are distinct genomic DNA sequences found in many bacteria that code for a reverse transcriptase and a unique ssDNA/RNA hybrid, and have also been used for ssDNA production in vivo. Retrons consist of a single ~2000-bp operon containing a reverse transcriptase and two RNA moieties (msr and msd) (Figure 4b) [1,55]. The msr-msd cassette in the retron is folded into a secondary structure, then RT recognizes it and reverse transcribes the RNA sequence to produce a hybrid RNA-ssDNA molecule called multi-copy single-stranded DNA (msDNA) [122,123]. When co-expressed with the recombinase (RT protein, msr-msd RNA moieties, and β protein), the intracellularly expressed ssDNAs can introduce precise mutations into genomic DNA, thus transforming transient cellular signals into genome-encoded memories [1]. A reversion assay was used to measure the efficiency of DNA writing within living cells and the architecture of circuit where input, write, and read operations are independently controlled. In the related reports, ssDNAs of 32 to 205 nt were expressed using reverse transcriptases and either assembled into DNA nanostructures in vivo or purified for in vitro assembly, manufacturing, intracellular scaffolding, and imaging [124].
Interestingly, it was shown that the RC-replicating plasmid pC194 from Gram-positive bacteria can replicate and produce a circular-ssDNA in E. coli [125,126]. Thus, based on the replication mechanism of pC194, we constructed an engineering platform and demonstrated that ssDNA with various lengths and sequences can be produced in E. coli cells (own manuscript in revision).
5. Discussion and Conclusions
To enable precision engineering, as well as to broaden the application and design principles of synthetic biology techniques, recent innovations have sought to synthesize ssDNA efficiently. The methods of ssDNA synthesis, combined with accurate design and improvements in the quality of ssDNA, have made remarkable developments towards this goal. In this review, we summarized the representative methods used for ssDNA synthesis, including chemical, enzymatic, and bacteria-based approaches. We aimed at stimulating a broader interest in the continued development of efficient ssDNA synthesis techniques and improving their applications in synthetic biology, nanotechnology, and basic biological research. To date, different synthesis schemes were selected to obtain ssDNA for various applications. Hence, we hope to provide a bridge for researchers to better choose appropriate synthesis methods and enhance the availability of increasingly inexpensive synthetic ssDNA. As research into DNA synthesis techniques continues to progress, we anticipate technological innovations that are tailored for subsequent applications, promising to gradually reduce the synthesis time and cost.
Author Contributions
Conceptualization, writing—original draft preparation, writing—review and editing, M.H.; supervision, H.Q. and J.Q.; project administration, funding acquisition, H.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Science Foundation of China, grant number 21476167, grant number 21778039, and grant number 21621004.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Farzadfard, F.; Lu, T.K. Genomically encoded analog memory with precise in vivo DNA writing in living cell populations. Science 2014, 346, 1256272. [Google Scholar] [CrossRef] [Green Version]
- Blackburn, G.M.; Gait, M.J.; Loakes, D.; Williams, D.M.; Egli, M.; Flavell, A.; Allen, S.; Fisher, J.; Haq, S.I.; Engels, J.W. Nucleic Acids in Chemistry and Biology; Royal Society of Chemistry: London, UK, 2006. [Google Scholar]
- Kosuri, S.; Church, G.M. Large-scale de novo DNA synthesis: Technologies and applications. Nat. Methods 2014, 11, 499–507. [Google Scholar] [CrossRef]
- Seguin, J.; Rajeswaran, R.; Malpica-Lopez, N.; Martin, R.R.; Kasschau, K.; Dolja, V.V.; Otten, P.; Farinelli, L.; Pooggin, M.M. De novo reconstruction of consensus master genomes of plant RNA and DNA viruses from siRNAs. PLoS ONE 2014, 9, e88513. [Google Scholar] [CrossRef] [PubMed]
- Giallonardo, F.D.; Töpfer, A.; Rey, M.; Prabhakaran, S.; Duport, Y.; Leemann, C.; Schmutz, S.; Campbell, N.K.; Joos, B.; Lecca, M.R. Full-length haplotype reconstruction to infer the structure of heterogeneous virus populations. Nucleic Acids Res. 2014, 42, e115. [Google Scholar] [CrossRef] [PubMed]
- Tyson, G.W.; Chapman, J.; Hugenholtz, P.; Allen, E.E.; Ram, R.J.; Richardson, P.M.; Solovyev, V.V.; Rubin, E.M.; Rokhsar, D.S.; Banfield, J.F. Community structure and metabolism through reconstruction of microbial genomes from the environment. Nature 2004, 428, 37. [Google Scholar] [CrossRef] [PubMed]
- Caruthers, M.H. Deciphering the protein-DNA recognition code. Acc. Chem. Res. 1980, 13, 155–160. [Google Scholar] [CrossRef]
- Kim, I.; Miller, C.R.; Young, D.L.; Fields, S. High-throughput analysis of in vivo protein stability. Mol. Cell. Proteom. 2013, 12, 3370–3378. [Google Scholar] [CrossRef] [Green Version]
- McLaughlin, R.N., Jr.; Poelwijk, F.J.; Raman, A.; Gosal, W.S.; Ranganathan, R. The spatial architecture of protein function and adaptation. Nature 2012, 491, 138. [Google Scholar] [CrossRef] [Green Version]
- Reynolds, K.A.; McLaughlin, R.N.; Ranganathan, R. Hot spots for allosteric regulation on protein surfaces. Cell 2011, 147, 1564–1575. [Google Scholar] [CrossRef] [Green Version]
- Patwardhan, R.P.; Lee, C.; Litvin, O.; Young, D.L.; Pe’er, D.; Shendure, J. High-resolution analysis of DNA regulatory elements by synthetic saturation mutagenesis. Nat. Biotechnol. 2009, 27, 1173. [Google Scholar] [CrossRef] [Green Version]
- Schlabach, M.R.; Hu, J.K.; Li, M.; Elledge, S.J. Synthetic design of strong promoters. Proc. Natl. Acad. Sci. USA 2010, 107, 2538–2543. [Google Scholar] [CrossRef] [Green Version]
- Goodman, D.B.; Church, G.M.; Kosuri, S. Causes and effects of N-terminal codon bias in bacterial genes. Science 2013. [Google Scholar] [CrossRef] [Green Version]
- Lai, W.K.; Pugh, B.F. Understanding nucleosome dynamics and their links to gene expression and DNA replication. Nat. Rev. Mol. Cell Biol. 2017, 18, 548. [Google Scholar] [CrossRef]
- Melnikov, A.; Murugan, A.; Zhang, X.; Tesileanu, T.; Wang, L.; Rogov, P.; Feizi, S.; Gnirke, A.; Callan, C.G., Jr.; Kinney, J.B. Systematic dissection and optimization of inducible enhancers in human cells using a massively parallel reporter assay. Nat. Biotechnol. 2012, 30, 271. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kwasnieski, J.C.; Mogno, I.; Myers, C.A.; Corbo, J.C.; Cohen, B.A. Complex effects of nucleotide variants in a mammalian cis-regulatory element. Proc. Natl. Acad. Sci. USA 2012. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heiat, M.; Ranjbar, R.; Latifi, A.M.; Rasaee, M.J.; Farnoosh, G. Essential strategies to optimize asymmetric PCR conditions as a reliable method to generate large amount of ssDNA aptamers. Biotechnol. Appl. Biochem. 2017, 64, 541–548. [Google Scholar] [CrossRef] [PubMed]
- Han, D.; Pal, S.; Nangreave, J.; Deng, Z.; Liu, Y.; Yan, H. DNA origami with complex curvatures in three-dimensional space. Science 2011, 332, 342–346. [Google Scholar] [CrossRef] [Green Version]
- Amodio, A.; Del Grosso, E.; Troina, A.; Placidi, E.; Ricci, F. Remote Electronic Control of DNA-Based Reactions and Nanostructure Assembly. Nano Lett. 2018, 18, 2918–2923. [Google Scholar] [CrossRef] [PubMed]
- Rothemund, P.W. Folding DNA to create nanoscale shapes and patterns. Nature 2006, 440, 297. [Google Scholar] [CrossRef] [Green Version]
- Huai, C.; Li, G.; Yao, R.; Zhang, Y.; Cao, M.; Kong, L.; Jia, C.; Yuan, H.; Chen, H.; Lu, D. Structural insights into DNA cleavage activation of CRISPR-Cas9 system. Nat. Commun. 2017, 8, 1375. [Google Scholar] [CrossRef] [Green Version]
- Cong, L.; Ran, F.A.; Cox, D.; Lin, S.; Barretto, R.; Habib, N.; Hsu, P.D.; Wu, X.; Jiang, W.; Marraffini, L. Multiplex genome engineering using CRISPR/Cas systems. Science 2013. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Douglas, S.M.; Bachelet, I.; Church, G.M. A logic-gated nanorobot for targeted transport of molecular payloads. Science 2012, 335, 831–834. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.H.; Yigit, M.V.; Mazumdar, D.; Lu, Y. Molecular diagnostic and drug delivery agents based on aptamer-nanomaterial conjugates. Adv. Drug Deliv. Rev. 2010, 62, 592–605. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.S.; Zhang, D.Y. Simulation-guided DNA probe design for consistently ultraspecific hybridization. Nat. Chem. 2015, 7, 545. [Google Scholar] [CrossRef] [Green Version]
- Gopinath, A.; Miyazono, E.; Faraon, A.; Rothemund, P.W. Engineering and mapping nanocavity emission via precision placement of DNA origami. Nature 2016, 535, 401. [Google Scholar] [CrossRef]
- Bhatia, D.; Arumugam, S.; Nasilowski, M.; Joshi, H.; Wunder, C.; Chambon, V.; Prakash, V.; Grazon, C.; Nadal, B.; Maiti, P.K. Quantum dot-loaded monofunctionalized DNA icosahedra for single-particle tracking of endocytic pathways. Nat. Nanotechnol. 2016, 11, 1112. [Google Scholar] [CrossRef] [Green Version]
- Kuzuya, A.; Sakai, Y.; Yamazaki, T.; Xu, Y.; Komiyama, M. Nanomechanical DNA origami ‘single-molecule beacons’ directly imaged by atomic force microscopy. Nat. Commun. 2011, 2, 449. [Google Scholar] [CrossRef]
- Hughes, R.A.; Ellington, A.D. Synthetic DNA Synthesis and Assembly: Putting the Synthetic in Synthetic Biology. CSH Perspect. Biol. 2017, 9. [Google Scholar] [CrossRef] [Green Version]
- Zaher, H.; Unrau, P. Methods in Molecular Biology. Oligonucleotide Synthesis: Methods and Applications; Herdewijn, P., Ed.; Humana Press Inc.: New York, NY, USA, 2004; Volume 288, p. 241. [Google Scholar]
- Michelson, A.M.; Todd, A.R. Nuckotides Part XXXII. Xynthesis of a Dithymidine Dinuleotide Containing a 3′: 5′-Internucleotidic Linkuge. J. Chem. Soc. 1955. [Google Scholar] [CrossRef]
- Hall, R.H.; Sir, A.T.; Webb, R.F. Nucleotides Part XLI. Mixed Anhydrides as Intermediates in the Synthesis of Dinucleoside Phosphates. J. Chem. Soc. 1957. [Google Scholar] [CrossRef]
- Gilham, P.T.; Khorana, H.G. Studies on Polynucleotides. I. A New and General Method for the Chemical Synthesis of the C5″-C3″ Internucleotidic Linkage. Syntheses of Deoxyribo-dinucleotides. J. Am. Chem. Soc. 1958, 80, 6212–6222. [Google Scholar] [CrossRef]
- Roy, S.; Caruthers, M. Synthesis of DNA/RNA and their analogs via phosphoramidite and H-phosphonate chemistries. Molecules 2013, 18, 14268–14284. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beaucage, S.; Caruthers, M.H. Deoxynucleoside phosphoramidites—A new class of key intermediates for deoxypolynucleotide synthesis. Tetrahedron Lett. 1981, 22, 1859–1862. [Google Scholar] [CrossRef]
- Caruthers, M.H. A Brief Review of DNA and RNA Chemical Synthesis; Portland Press Limited: London, UK, 2011. [Google Scholar]
- Ma, S.; Tang, N.; Tian, J. DNA synthesis, assembly and applications in synthetic biology. Curr. Opin. Chem. Biol. 2012, 16, 260–267. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeProust, E.M.; Peck, B.J.; Spirin, K.; McCuen, H.B.; Moore, B.; Namsaraev, E.; Caruthers, M.H. Synthesis of high-quality libraries of long (150mer) oligonucleotides by a novel depurination controlled process. Nucleic Acids Res. 2010, 38, 2522–2540. [Google Scholar] [CrossRef] [PubMed]
- Ni, S.; Yao, H.; Wang, L.; Lu, J.; Jiang, F.; Lu, A.; Zhang, G. Chemical modifications of nucleic acid aptamers for therapeutic purposes. Int. J. Mol. Sci. 2017, 18, 1683. [Google Scholar] [CrossRef]
- Caruthers, M.H. The chemical synthesis of DNA/RNA: Our gift to science. J. Biol. Chem. 2013, 288, 1420–1427. [Google Scholar] [CrossRef] [Green Version]
- Fodor, S.P.; Read, J.L.; Pirrung, M.C.; Stryer, L.; Lu, A.T.; Solas, D. Light-directed, spatially addressable parallel chemical synthesis. Science 1991, 251, 767–773. [Google Scholar] [CrossRef] [Green Version]
- Pease, A.C.; Solas, D.; Sullivan, E.J.; Cronin, M.T.; Holmes, C.P.; Fodor, S. Light-generated oligonucleotide arrays for rapid DNA sequence analysis. Proc. Natl. Acad. Sci. USA 1994, 91, 5022–5026. [Google Scholar] [CrossRef] [Green Version]
- Cheng, J.Y.; Chen, H.H.; Kao, Y.S.; Kao, W.C.; Peck, K. High throughput parallel synthesis of oligonucleotides with 1536 channel synthesizer. Nucleic Acids Res. 2002, 30, e93. [Google Scholar] [CrossRef] [Green Version]
- Meiser, L.C.; Antkowiak, P.L.; Koch, J.; Chen, W.D.; Kohll, A.X.; Stark, W.J.; Heckel, R.; Grass, R.N. Reading and writing digital data in DNA. Nat. Protoc. 2019. [Google Scholar] [CrossRef] [PubMed]
- Maurer, K.; Cooper, J.; Caraballo, M.; Crye, J.; Suciu, D.; Ghindilis, A.; Leonetti, J.A.; Wang, W.; Rossi, F.M.; Stöver, A.G. Electrochemically generated acid and its containment to 100 micron reaction areas for the production of DNA microarrays. PLoS ONE 2006, 1, e34. [Google Scholar] [CrossRef] [PubMed]
- Gao, X.; Gulari, E.; Zhou, X. In situ synthesis of oligonucleotide microarrays. Biopolymers 2004, 73, 579–596. [Google Scholar] [CrossRef] [PubMed]
- Organick, L.; Ang, S.D.; Chen, Y.-J.; Lopez, R.; Yekhanin, S.; Makarychev, K.; Racz, M.Z.; Kamath, G.; Gopalan, P.; Nguyen, B. Random access in large-scale DNA data storage. Nat. Biotechnol. 2018, 36, 242. [Google Scholar] [CrossRef] [PubMed]
- Beaucage, S.L. Strategies in the preparation of DNA oligonucleotide arrays for diagnostic applications. Curr. Med. Chem. 2001, 8, 1213–1244. [Google Scholar] [CrossRef]
- Abramova, T. Frontiers and approaches to chemical synthesis of oligodeoxyribonucleotides. Molecules 2013, 18, 1063–1075. [Google Scholar] [CrossRef]
- Wan, W.; Wang, D.; Gao, X.; Hong, J. Immobilized MutS-Mediated Error Removal of Microchip-Synthesized DNA. In Synthetic DNA; Springer: New York, NY, USA, 2017; pp. 217–235. [Google Scholar]
- Wan, W.; Li, L.; Xu, Q.; Wang, Z.; Yao, Y.; Wang, R.; Zhang, J.; Liu, H.; Gao, X.; Hong, J. Error removal in microchip-synthesized DNA using immobilized MutS. Nucleic Acids Res. 2014, 42, e102. [Google Scholar] [CrossRef] [Green Version]
- Loc’h, J.; Delarue, M. Terminal deoxynucleotidyltransferase: The story of an untemplated DNA polymerase capable of DNA bridging and templated synthesis across strands. Curr. Opin. Struct. Biol. 2018, 53, 22–31. [Google Scholar] [CrossRef]
- Palluk, S.; Arlow, D.H.; de Rond, T.; Barthel, S.; Kang, J.S.; Bector, R.; Baghdassarian, H.M.; Truong, A.N.; Kim, P.W.; Singh, A.K.; et al. De novo DNA synthesis using polymerase-nucleotide conjugates. Nat. Biotechnol. 2018, 36, 645–650. [Google Scholar] [CrossRef]
- Miura, H.; Quadros, R.M.; Gurumurthy, C.B.; Ohtsuka, M. Easi-CRISPR for creating knock-in and conditional knockout mouse models using long ssDNA donors. Nat. Protoc. 2018, 13, 195. [Google Scholar] [CrossRef]
- Xie, X.; Yang, R. Multi-copy single-stranded DNA in Escherichia coli. Microbiology 2017, 163, 1735–1739. [Google Scholar] [CrossRef] [PubMed]
- Veneziano, R.; Shepherd, T.R.; Ratanalert, S.; Bellou, L.; Tao, C.; Bathe, M. In vitro synthesis of gene-length single-stranded DNA. Sci. Rep. 2018, 8, 6548. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hollenstein, M. DNA Synthesis by Primer Exchange Reaction Cascades. ChemBioChem 2018, 19, 422–424. [Google Scholar] [CrossRef] [PubMed]
- Kishi, J.Y.; Schaus, T.E.; Gopalkrishnan, N.; Xuan, F.; Yin, P. Programmable autonomous synthesis of single-stranded DNA. Nat. Chem. 2018, 10, 155–164. [Google Scholar] [CrossRef] [Green Version]
- Johne, R.; Müller, H.; Rector, A.; Van Ranst, M.; Stevens, H. Rolling-circle amplification of viral DNA genomes using phi29 polymerase. Trends Microbiol. 2009, 17, 205–211. [Google Scholar] [CrossRef] [PubMed]
- Ali, M.M.; Li, F.; Zhang, Z.; Zhang, K.; Kang, D.-K.; Ankrum, J.A.; Le, X.C.; Zhao, W. Rolling circle amplification: A versatile tool for chemical biology, materials science and medicine. Chem. Soc. Rev. 2014, 43, 3324–3341. [Google Scholar] [CrossRef]
- Joneja, A.; Huang, X. Linear nicking endonuclease-mediated strand-displacement DNA amplification. Anal. Biochem. 2011, 414, 58–69. [Google Scholar] [CrossRef] [Green Version]
- Motea, E.A.; Berdis, A.J. Terminal deoxynucleotidyl transferase: The story of a misguided DNA polymerase. BBA-Proteins Proteom. 2010, 1804, 1151–1166. [Google Scholar] [CrossRef] [Green Version]
- Fowler, J.D.; Suo, Z. Biochemical, structural, and physiological characterization of terminal deoxynucleotidyl transferase. Chem. Rev. 2006, 106, 2092–2110. [Google Scholar] [CrossRef]
- Jensen, M.A.; Davis, R.W. Template-independent enzymatic oligonucleotide synthesis (TiEOS): Its history, prospects, and challenges. Biochemistry 2018, 57, 1821–1832. [Google Scholar] [CrossRef]
- Jang, E.K.; Son, R.G.; Pack, S.P. Novel enzymatic single-nucleotide modification of DNA oligomer: Prevention of incessant incorporation of nucleotidyl transferase by ribonucleotide-borate complex. Nucleic Acids Res. 2019, 47, e102. [Google Scholar] [CrossRef] [PubMed]
- Peng, F.; Liu, Z.; Li, W.; Huang, Y.; Nie, Z.; Yao, S. Enzymatically generated long polyT-templated copper nanoparticles for versatile biosensing assay of DNA-related enzyme activity. Anal. Methods 2015, 7, 4355–4361. [Google Scholar] [CrossRef]
- Tang, L.; Navarro, L.A., Jr.; Chilkoti, A.; Zauscher, S. High-Molecular-Weight Polynucleotides by Transferase-Catalyzed Living Chain-Growth Polycondensation. Angewandte Chemie 2017, 56, 6778–6782. [Google Scholar] [CrossRef]
- Lee, H.H.; Kalhor, R.; Goela, N.; Bolot, J.; Church, G.M. Terminator-free template-independent enzymatic DNA synthesis for digital information storage. Nat. Commun. 2019, 10, 2383. [Google Scholar] [CrossRef] [Green Version]
- Jie, G.; Ge, J.; Gao, X.; Li, C. Amplified electrochemiluminescence detection of CEA based on magnetic Fe3O4@ Au nanoparticles-assembled Ru@ SiO2 nanocomposites combined with multiple cycling amplification strategy. Biosens. Bioelectron. 2018, 118, 115–121. [Google Scholar] [CrossRef]
- Miura, H.; Gurumurthy, C.B.; Sato, T.; Sato, M.; Ohtsuka, M. CRISPR/Cas9-based generation of knockdown mice by intronic insertion of artificial microRNA using longer single-stranded DNA. Sci. Rep. 2015, 5, 12799. [Google Scholar] [CrossRef] [Green Version]
- Codner, G.F.; Mianné, J.; Caulder, A.; Loeffler, J.; Fell, R.; King, R.; Allan, A.J.; Mackenzie, M.; Pike, F.J.; McCabe, C.V. Application of long single-stranded DNA donors in genome editing: Generation and validation of mouse mutants. BMC Biol. 2018, 16, 70. [Google Scholar] [CrossRef]
- Tolnai, Z.; Harkai, Á.; Szeitner, Z.; Scholz, É.N.; Percze, K.; Gyurkovics, A.; Mészáros, T. A simple modification increases specificity and efficiency of asymmetric PCR. Anal. Chim. Acta 2019, 1047, 225–230. [Google Scholar] [CrossRef]
- Gyllensten, U.B.; Erlich, H.A. Generation of single-stranded DNA by the polymerase chain reaction and its application to direct sequencing of the HLA-DQA locus. Proc. Natl. Acad. Sci. USA 1988, 85, 7652–7656. [Google Scholar] [CrossRef] [Green Version]
- Marimuthu, C.; Tang, T.H.; Tominaga, J.; Tan, S.C.; Gopinath, S.C. Single-stranded DNA (ssDNA) production in DNA aptamer generation. Analyst 2012, 137, 1307–1315. [Google Scholar] [CrossRef]
- Ding, J.; Gan, S.; Ho, B. Single-stranded DNA oligoaptamers: Molecular recognition and LPS antagonism are length-and secondary structure-dependent. J. Innate Immun. 2009, 1, 46–58. [Google Scholar] [CrossRef]
- Wooddell, C.I.; Burgess, R.R. Use of asymmetric PCR to generate long primers and single-stranded DNA for incorporating cross-linking analogs into specific sites in a DNA probe. Genome Res. 1996, 6, 886–892. [Google Scholar] [CrossRef] [Green Version]
- Veneziano, R.; Ratanalert, S.; Zhang, K.; Zhang, F.; Yan, H.; Chiu, W.; Bathe, M. Designer nanoscale DNA assemblies programmed from the top down. Science 2016, 352, 1534. [Google Scholar] [CrossRef] [Green Version]
- Tolle, F.; Wilke, J.; Wengel, J.; Mayer, G. By-product formation in repetitive PCR amplification of DNA libraries during SELEX. PLoS ONE 2014, 9, e114693. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Tanner, N.A. Isothermal amplification of long, discrete DNA fragments facilitated by single-stranded binding protein. Sci. Rep. 2017, 7, 8497. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Chen, F.; Li, Q.; Wang, L.; Fan, C. Isothermal amplification of nucleic acids. Chem. Rev. 2015, 115, 12491–12545. [Google Scholar] [CrossRef]
- Baccouche, A.; Montagne, K.; Padirac, A.; Fujii, T.; Rondelez, Y. Dynamic DNA-toolbox reaction circuits: A walkthrough. Methods 2014, 67, 234–249. [Google Scholar] [CrossRef]
- Minev, D.; Guerra, R.; Kishi, J.; Smith, C.; Krieg, E.; Said, K.; Hornick, A.; Sasaki, H.; Filsinger, G.; Beliveau, B. Rapid and scalable in vitro production of single-stranded DNA. BioRxiv 2019. [Google Scholar] [CrossRef]
- Dean, F.B.; Nelson, J.R.; Giesler, T.L.; Lasken, R.S. Rapid amplification of plasmid and phage DNA using phi29 DNA polymerase and multiply-primed rolling circle amplification. Genome Res. 2001, 11, 1095–1099. [Google Scholar] [CrossRef] [Green Version]
- Gu, L.; Yan, W.; Liu, L.; Wang, S.; Zhang, X.; Lyu, M. Research progress on rolling circle amplification (RCA)-based biomedical sensing. Pharmaceuticals 2018, 11, 35. [Google Scholar] [CrossRef] [Green Version]
- Hollenstein, M. Generation of long, fully modified, and serum-resistant oligonucleotides by rolling circle amplification. Org. Biomol. Chem. 2015, 13, 9820–9824. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ducani, C.; Kaul, C.; Moche, M.; Shih, W.M.; Högberg, B. Enzymatic production of’monoclonal stoichiometric’single-stranded DNA oligonucleotides. Nat. Methods 2013, 10, 647. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nelissen, F.H.; Goossens, E.P.; Tessari, M.; Heus, H.A. Enzymatic preparation of multimilligram amounts of pure single-stranded DNA samples for material and analytical sciences. Anal. Biochem. 2015, 475, 68–73. [Google Scholar] [CrossRef] [PubMed]
- Van Emmerik, C.L.; Gachulincova, I.; Lobbia, V.R.; Daniëls, M.A.; Heus, H.A.; Soufi, A.; Nelissen, F.H.; van Ingen, H. Ramified rolling circle amplification for synthesis of nucleosomal DNA sequences. Anal. Biochem. 2020, 588, 113469. [Google Scholar] [CrossRef]
- Shi, D.; Huang, J.; Chuai, Z.; Chen, D.; Zhu, X.; Wang, H.; Peng, J.; Wu, H.; Huang, Q.; Fu, W. Isothermal and rapid detection of pathogenic microorganisms using a nano-rolling circle amplification-surface plasmon resonance biosensor. Biosens. Bioelectron. 2014, 62, 280–287. [Google Scholar] [CrossRef]
- Huang, R.; Li, S.; Liu, H.; Jin, L.; Zhao, Y.; Li, Z.; He, N. A simple fluorescence aptasensor for gastric cancer exosome detection based on branched rolling circle amplification. Nanoscale 2019. [Google Scholar] [CrossRef]
- Kim, T.-Y.; Lim, M.-C.; Woo, M.-A.; Jun, B.-H. Radial flow assay using gold nanoparticles and rolling circle amplification to detect mercuric ions. Nanomaterials 2018, 8, 81. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Li, L.; Duan, L.; Wang, X.; Xie, Y.; Tong, L.; Wang, Q.; Tang, B. High specific and ultrasensitive isothermal detection of microRNA by padlock probe-based exponential rolling circle amplification. Anal. Chem. 2013, 85, 7941–7947. [Google Scholar] [CrossRef]
- Demidov, V.V. Rolling-circle amplification in DNA diagnostics: The power of simplicity. Expert Rev. Mol. Diagn. 2002, 2, 542–548. [Google Scholar] [CrossRef]
- Zyrina, N.V.; Zheleznaya, L.A.; Dvoretsky, E.V.; Vasiliev, V.D.; Chernov, A.; Matvienko, N.I. BspD6I DNA nickase strongly stimulates template-independent synthesis of non-palindromic repetitive DNA by Bst DNA polymerase. Biol. Chem. 2007, 388, 367–372. [Google Scholar] [CrossRef]
- Cui, W.; Wang, L.; Xu, X.; Wang, Y.; Jiang, W. A loop-mediated cascade amplification strategy for highly sensitive detection of DNA methyltransferase activity. Sens. Actuators B Chem. 2017, 244, 599–605. [Google Scholar] [CrossRef]
- Meijer, L.H.; Joesaar, A.; Steur, E.; Engelen, W.; Van Santen, R.A.; Merkx, M.; De Greef, T.F. Hierarchical control of enzymatic actuators using DNA-based switchable memories. Nat. Commun. 2017, 8, 1117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Giuffrida, M.C.; Spoto, G. Integration of isothermal amplification methods in microfluidic devices: Recent advances. Biosens. Bioelectron. 2017, 90, 174–186. [Google Scholar] [CrossRef] [PubMed]
- Chen, A.; Gui, G.-F.; Zhuo, Y.; Chai, Y.-Q.; Xiang, Y.; Yuan, R. Signal-off electrochemiluminescence biosensor based on Phi29 DNA polymerase mediated strand displacement amplification for microRNA detection. Anal. Chem. 2015, 87, 6328–6334. [Google Scholar] [CrossRef]
- Fakruddin, M.; Mannan, K.S.B.; Chowdhury, A.; Mazumdar, R.M.; Hossain, M.N.; Islam, S.; Chowdhury, M.A. Nucleic acid amplification: Alternative methods of polymerase chain reaction. J. Pharm. Bioallied Sci. 2013, 5, 245. [Google Scholar] [CrossRef]
- Nagamine, K.; Hase, T.; Notomi, T. Accelerated reaction by loop-mediated isothermal amplification using loop primers. Mol. Cell. Probes 2002, 16, 223–229. [Google Scholar] [CrossRef]
- Notomi, T.; Okayama, H.; Masubuchi, H.; Yonekawa, T.; Watanabe, K.; Amino, N.; Hase, T. Loop-mediated isothermal amplification of DNA. Nucleic Acids Res. 2000, 28, e63. [Google Scholar] [CrossRef] [Green Version]
- Abdullahi, U.F.; Naim, R.; Taib, W.R.W.; Saleh, A.; Muazu, A.; Aliyu, S.; Baig, A.A. Loop-mediated isothermal amplification (LAMP), an innovation in gene amplification: Bridging the gap in molecular diagnostics; a review. Indian J. Sci. Technol. 2015, 8, 1. [Google Scholar] [CrossRef]
- Nagamine, K.; Kuzuhara, Y.; Notomi, T. Isolation of single-stranded DNA from loop-mediated isothermal amplification products. Biochem. Biophys. Res. Commun. 2002, 290, 1195–1198. [Google Scholar] [CrossRef]
- Damase, T.R.; Ellington, A.D.; Allen, P.B. Purification of single-stranded DNA by co-polymerization with acrylamide and electrophoresis. BioTechniques 2017, 62, 275–282. [Google Scholar] [CrossRef] [Green Version]
- Pagratis, N.C. Rapid preparation of single stranded DNA from PCR products by streptavidin induced electrophoretic mobility shift. Nucleic Acids Res. 1996, 24, 3645–3646. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Chao, J.; Pan, D.; Liu, H.; Huang, Q.; Fan, C. Folding super-sized DNA origami with scaffold strands from long-range PCR. Chem. Commun. 2012. [Google Scholar] [CrossRef] [PubMed]
- Erkelenz, M.; Bauer, D.M.; Meyer, R.; Gatsogiannis, C.; Raunser, S.; Sacca, B.; Niemeyer, C.M. A facile method for preparation of tailored scaffolds for DNA-origami. Small 2014, 10, 73–77. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; McGown, L.B. Sequence-based separation of single-stranded DNA at high salt concentrations in capillary zone electrophoresis. Electrophoresis 2016, 37, 2017–2024. [Google Scholar] [CrossRef] [PubMed]
- Wilson, R. Preparation of single-stranded DNA from PCR products with streptavidin magnetic beads. Nucleic Acid Ther. 2011, 21, 437–440. [Google Scholar] [CrossRef]
- Kilili, G.K.; Tilton, L.; Karbiwnyk, C.M. [Letter to the Editor] NaOH concentration and streptavidin bead type are key factors for optimal DNA aptamer strand separation and isolation. BioTechniques 2016, 61, 114–116. [Google Scholar] [CrossRef] [Green Version]
- Kao, W.S.; Li, H.W. An Efficient Bead-captured Denaturation Method for Preparing Long Single-stranded DNA. J. Chin. Chem. Soc. 2017, 64, 1065–1070. [Google Scholar] [CrossRef]
- Holmberg, A.; Blomstergren, A.; Nord, O.; Lukacs, M.; Lundeberg, J.; Uhlén, M. The biotin-streptavidin interaction can be reversibly broken using water at elevated temperatures. Electrophoresis 2005, 26, 501–510. [Google Scholar] [CrossRef]
- Kujau, M.J.; Wölfl, S. Efficient preparation of single-stranded DNA for in vitro selection. Mol. Biotechnol. 1997, 7, 333–335. [Google Scholar] [CrossRef]
- Engelhardt, F.A.; Praetorius, F.; Wachauf, C.H.; Brüggenthies, G.; Kohler, F.; Kick, B.; Kadletz, K.L.; Pham, P.N.; Behler, K.L.; Gerling, T. Custom-Size, Functional, and Durable DNA Origami with Design-Specific Scaffolds. ACS Nano 2019. [Google Scholar] [CrossRef]
- Kick, B.; Praetorius, F.; Dietz, H.; Weuster-Botz, D. Efficient production of single-stranded phage DNA as scaffolds for DNA origami. Nano Lett. 2015, 15, 4672–4676. [Google Scholar] [CrossRef] [PubMed]
- Kick, B.; Hensler, S.; Praetorius, F.; Dietz, H.; Weuster-Botz, D. Specific growth rate and multiplicity of infection affect high-cell-density fermentation with bacteriophage M13 for ssDNA production. Biotechnol. Bioeng. 2017, 114, 777–784. [Google Scholar] [CrossRef] [PubMed]
- Marchi, A.N.; Saaem, I.; Vogen, B.N.; Brown, S.; LaBean, T.H. Toward larger DNA origami. Nano Lett. 2014, 14, 5740–5747. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.; Dong, Q.; Ma, R.; Chen, Y.; Yang, J.; Sun, L.-Z.; Huang, C. Rapid isolation of highly pure single-stranded DNA from phagemids. Anal. Biochem. 2009, 389, 177–179. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nafisi, P.M.; Aksel, T.; Douglas, S.M. Construction of a novel phagemid to produce custom DNA origami scaffolds. Synth. Biol. 2018, 3. [Google Scholar] [CrossRef] [Green Version]
- Chasteen, L.; Ayriss, J.; Pavlik, P.; Bradbury, A. Eliminating helper phage from phage display. Nucleic Acids Res. 2006, 34, e145. [Google Scholar] [CrossRef] [Green Version]
- Praetorius, F.; Kick, B.; Behler, K.L.; Honemann, M.N.; Weuster-Botz, D.; Dietz, H. Biotechnological mass production of DNA origami. Nature 2017, 552, 84–87. [Google Scholar] [CrossRef]
- Lim, D.; Maas, W.K. Reverse transcriptase-dependent synthesis of a covalently linked, branched DNA-RNA compound in E. coli B. Cell 1989, 56, 891–904. [Google Scholar] [CrossRef]
- Shimada, M.; Inouye, S.; Inouye, M. Requirements of the secondary structures in the primary transcript for multicopy single-stranded DNA synthesis by reverse transcriptase from bacterial retron-Ec107. J. Biol. Chem. 1994, 269, 14553–14558. [Google Scholar] [CrossRef]
- Elbaz, J.; Yin, P.; Voigt, C.A. Genetic encoding of DNA nanostructures and their self-assembly in living bacteria. Nat. Commun. 2016, 7, 11179. [Google Scholar] [CrossRef]
- Riele, H.T.; Michel, B.; Ehrlich, S.D. Are single-stranded circles intermediates in plasmid DNA replication? EMBO J. 1986, 5, 631. [Google Scholar] [CrossRef]
- Bruand, C.; Ehrlich, S.D. UvrD-dependent replication of rolling-circle plasmids in Escherichia coli. Mol. Microbiol. 2000, 35. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Phosphoramidite-based oligonucleotide synthesis [3].
Figure 1.
Phosphoramidite-based oligonucleotide synthesis [3].

Figure 2.
Schematic representation of enzymatic ssDNA synthesis. (a) The mechanism of terminal deoxynucleotide transferase (TdT)-based ssDNA synthesis; (b) The mechanism of transcription and reverse transcription; (c) The mechanism of asymmetric polymerase chain reaction (aPCR); (d) The primer exchange reaction (PER) cycle and mechanism for ssDNA synthesis; (e) The mechanism of rolling circle amplification (RCA).
Figure 2.
Schematic representation of enzymatic ssDNA synthesis. (a) The mechanism of terminal deoxynucleotide transferase (TdT)-based ssDNA synthesis; (b) The mechanism of transcription and reverse transcription; (c) The mechanism of asymmetric polymerase chain reaction (aPCR); (d) The primer exchange reaction (PER) cycle and mechanism for ssDNA synthesis; (e) The mechanism of rolling circle amplification (RCA).

Figure 3.
Direct separation of ssDNA. (a) Biotin–streptavidin separation of ssDNA; (b) Lambda exonuclease digestion; (c) Denaturing urea polyacrylamide gel electrophoresis.
Figure 3.
Direct separation of ssDNA. (a) Biotin–streptavidin separation of ssDNA; (b) Lambda exonuclease digestion; (c) Denaturing urea polyacrylamide gel electrophoresis.

Figure 4.
Bacteria-based ssDNA synthesis. (a) Schematic of the two approaches to phagemid-based ssDNA production. The phagemid-carrying E. coli cells are infected with the “helper phage” or transformed with a “helper plasmid”, the ssDNA can be generated. (b) The processes of ssDNA production by bacterial reverse transcriptases (RTs). In transcription step, the msr-msd RNA folds into a secondary structure; In reverse transcription step, the RT recognizes this secondary structure and uses a conserved guanosine residue as a priming site; Finally, a hybrid RNA-ssDNA molecule is produced.
Figure 4.
Bacteria-based ssDNA synthesis. (a) Schematic of the two approaches to phagemid-based ssDNA production. The phagemid-carrying E. coli cells are infected with the “helper phage” or transformed with a “helper plasmid”, the ssDNA can be generated. (b) The processes of ssDNA production by bacterial reverse transcriptases (RTs). In transcription step, the msr-msd RNA folds into a secondary structure; In reverse transcription step, the RT recognizes this secondary structure and uses a conserved guanosine residue as a priming site; Finally, a hybrid RNA-ssDNA molecule is produced.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Comparison of enzymatic methods for the synthesis of ssDNA.
| Strategy | Template | Enzymes | Product Separation | Primer Design | Single Step Technique | Refs. |
|---|---|---|---|---|---|---|
| TdT | No | Terminal deoxynucleotide transferase | No | No | No | [52,53] |
| ivTRT | Yes | RNA polymerase, reverse transcriptase and RNaseH | Yes | Simple | No | [54,55] |
| aPCR | Yes | DNA polymerase | Yes | Simple | Yes | [56] |
| PER | Yes | DNA polymerase | Yes | Complex | Yes | [57,58] |
| RCA | Yes | DNA polymerase | Yes | Complex | Yes | [59,60] |
| SDA | Yes | DNA polymerase and strand-limited restriction endonuclease/nicking enzym | Yes | Complex | Yes | [61] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hao, M.; Qiao, J.; Qi, H. Current and Emerging Methods for the Synthesis of Single-Stranded DNA. Genes 2020, 11, 116. https://0-doi-org.brum.beds.ac.uk/10.3390/genes11020116
AMA Style
Hao M, Qiao J, Qi H. Current and Emerging Methods for the Synthesis of Single-Stranded DNA. Genes. 2020; 11(2):116. https://0-doi-org.brum.beds.ac.uk/10.3390/genes11020116
Chicago/Turabian StyleHao, Min, Jianjun Qiao, and Hao Qi. 2020. "Current and Emerging Methods for the Synthesis of Single-Stranded DNA" Genes 11, no. 2: 116. https://0-doi-org.brum.beds.ac.uk/10.3390/genes11020116
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.