1. Introduction
Accurate climate data are critical to the success of modelling processes in order to reduce uncertainty and achieve better prediction in hydrological impact studies. Unfortunately, reliable and long-term observed meteorological datasets are sparse and unavailable in some regions—especially sub-Saharan Africa and the Mediterranean—making hydrological studies a challenging task [
1,
2].
Alternatively, high-resolution gridded data have been developed to address these shortcomings; however, an understanding of their limitations in terms of observational uncertainties and reliability is important in order to address the twin issues of choice of dataset and suitability to represent basin features.
Some climate data products are more appropriate than others in their applications for climate change impact studies across different regions; therefore, careful and adequate assessment of their strengths and limitations is required in order to provide guidance for future climate and hydrological studies—especially in data-sparse basins. An accurate hydro-climatic impact study requires climate data at high temporal and spatial resolutions. The most accurate measurement devices are rain gauges, and although these are often situated on land and in populated areas for ease of measurement [
3], there are a limited number of ground-based rain gauge stations in most parts of the world for effective and efficient hydro-climatic studies with reduced uncertainty in spatial climate prediction. However, weather station records are typically site-specific, while most hydrological studies in environmental sciences research require aerial observations of climate data in order to achieve accurate modelling processes with minimal uncertainty in impact studies [
4].
Climate data have been seen to be an important component of hydrologic cycle analysis over time and space. The knowledge and understanding of their spatiotemporal dynamics are essential, and provide useful information for their practical applications in the field of agriculture, aquaculture, water resource and river basin management, and hazard and flood disaster warnings and management [
5,
6].
Climate and hydrological studies require complete and reliable rainfall and temperature records at good spatial and temporal resolutions [
7]. Unfortunately, climate records from various databases contain gaps or missing data points due to systematic errors, which are prevalent in the Mediterranean and sub-Saharan African countries, making hydrological studies difficult [
7,
8,
9]. Several gridded climate data developed by various modelling centres are used as alternatives, owing to their reliability, and are generated from the observed climate station data after quality control, with enhanced reliability analysis and long-term temporal and spatial coverage [
10].
In a hydro-climatic studies, the choice of gridded data for the process of bias correction of general circulation models in data-sparse regions indicates an essential procedure for climate change impact assessment studies [
11]. However, the choice of reference dataset that is available in either station data, or gridded products derived from observations [
12,
13], reanalysis data [
14,
15,
16], or remote sensing data [
17,
18], is critical in the overall uncertainty associated with projected climate change impact studies.
These datasets form the primary input in hydrological modelling studies and climate change impact studies for the accurate assessment of hydrological variables such as streamflow, runoff, soil moisture, evapotranspiration, etc., in order to manage hydropower operations, irrigation scheduling, and early warning systems for landslides and changes in future water availability for climate change and basin hydrological cycle assessment [
19].
A study conducted in Africa showed varying degrees of spatial mismatch between observed weather stations and reanalysis data [
20]. The techniques and efforts in the analysis vary based on temporal coverage, climate variables involved, and the region of interest [
21]. However, gridded and reanalysis data are being updated due to advances in the understanding of climate science over time, and detailed evaluation of their performance at the catchment scale in Africa is rarely found in literature, although this may be attributed to limited availability of reliable long-term climate records, expertise, and ease of access to data [
22,
23].
Studies have shown that high-resolution gridded data have been developed to provide valuable information on disaster management, initialisation and validation of numerical models, and resolving the diurnal global cycle of precipitation [
24,
25]. There are many gridded data products available at different timescales (hourly, daily, and monthly) with a finer resolution of 0.5° × 0.5°, which can provide insight that relates (but is not limited) to a model forecast of hydrological cycles, climate change trend analysis, climate downscaling, etc. [
13,
26,
27,
28,
29,
30,
31,
32,
33,
34].
The downside in the use of gridded and reanalysis climate data lies in the fact that gridded climate data are a combination of observed station data and quality-controlled statistical interpolation that could result in the attenuation of local climate signals, while reanalysis data are model-based forecasts that require parameterisation of the model, good assimilation technique, and high-quality observation [
21,
35,
36].
Gridded climate products are known to differ in their source, spatial and temporal resolutions, domain size (global coverage), and available timescales, and also exhibit different error bands due to interpolation procedures and considerable differences in general climatology, which are well known and acknowledged [
12,
37,
38,
39]. The choice and selection of reference datasets at the catchment scale should be based on observational uncertainty and purpose via critical analysis of the gridded data products. The development and application of gridded climate data is growing rapidly, especially due to the advances in knowledge of their spatiotemporal resolution, latency, and reliability. However, the uncertainty associated with their application across local and regional catchments is still a cause for concern, and has led to some studies related to the ability of the gridded data to replicate or mimic reliable but sparse ground-based data across the globe [
40,
41,
42,
43,
44,
45,
46,
47].
Furthermore, the performance of the gridded data is predicated on using individual or combined statistical metrics to replicate some particular characteristics of the observed data, and often exhibits contradictory results, making the decision making difficult [
6,
48,
49]. It has been posited that some gridded data have proven to be appropriate compared to others in specific applications and in certain regions around the world [
50], and a single statistical metric cannot justify the performance or suitability of a particular gridded dataset. Therefore, it is important to use various metrics to obtain an ideal solution, based on optimal performance across all metrics, especially in data-sparse regions—for prediction efficiency [
49,
51].
The objective of this study was to employ multi-criteria decision making to assess the performance of five widely used and recently updated gridded precipitation datasets and four temperature datasets in replicating the total and average monthly precipitation and temperature of available gauge-based records in the Lake Chad hydrological basin. This study was necessary to provide guidance on the choice of reference dataset(s) to be adopted for future research in the basin, depending on performance and purpose in hydro-climatic studies, in order to reduce uncertainty in predictions as well as computational time and resource costs.
Furthermore, the choice of the gridded dataset(s) in previous climate studies found in the literature on the Lake Chad basin, for example [
52,
53,
54,
55], has been based on their popularity and usage in other basins, without a proper justification of their suitability compared to other available products for improving the reliability of predictions and reducing model biases to provide an accurate representation of basin-scale hydrological features. Additionally, some of the products are only available in monthly time steps, which may not be suitable for downscaling of GCMs with daily time steps as input requirements in some hydrological models and climate change impact studies.
This study employs entropy-based symmetric uncertainty (SU) [
56]—a machine learning approach that has been found to be an efficient tool for the assessment of agreement in data that measure the shapes and patterns of data sequences via the concept of mutual information theory, by comparing the similarity between two long time-series climate datasets, and has found its application in various fields [
10,
57]. The benefit of this method is that it does not depend on the data distribution, unlike the statistical metrics used in other studies [
32,
40,
57]. Four statistical metrics were used in this study—namely, Taylor diagrams, modified index of agreement (md), Kling–Gupta efficiency (KGE), and normalised root-mean-square error (NRMSE)—and then finally trend analysis of the precipitation and temperature data at the annual and seasonal scales of the gridded and observed station records was compared for mean variability and temporal homogeneity across the basin.
5. Discussion
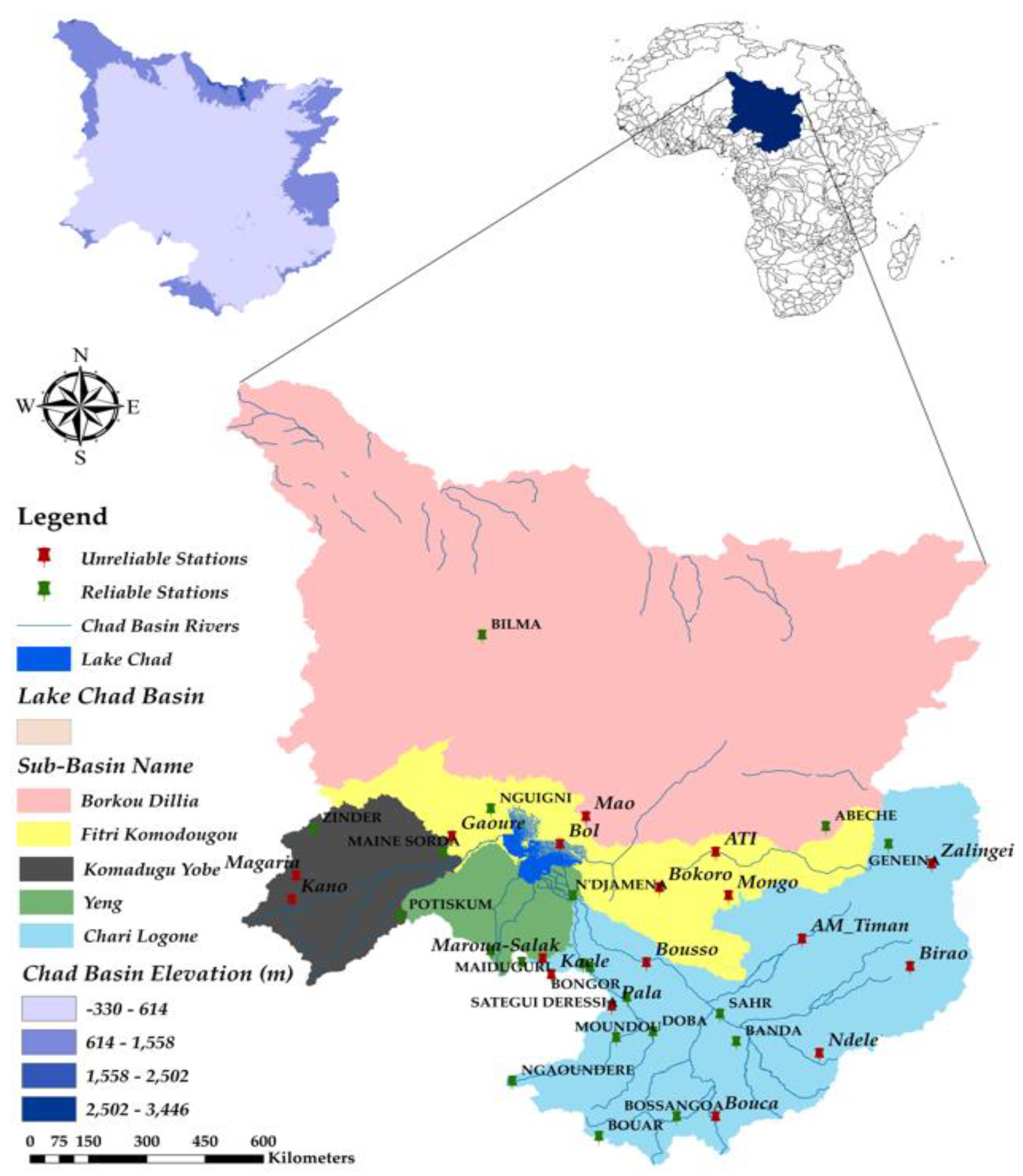
The performance of widely used, updated, and recently available high-resolution gridded precipitation and temperature datasets was assessed over the 15 available, quality-controlled, and reliable observed precipitation datasets and 12 temperature station records across the Lake Chad basin. The study’s temporal span was set to be 1979–2012 for consistency across all of the datasets, and met the requirements for a hydrological impact study. The study adopted a 0.5° resolution dataset, and finally extracted and interpolated the gridded dataset to station resolution using the inverse distance weighting method for consistency, making it adequate for regional studies.
In summary, the evaluated gridded climate datasets have proven to differ in their performance across the selected metrics, although the performance exhibited across all of the gridded climate datasets was promising—especially with regards to temperature, because climate models simulate temperature variables better than precipitation variables, as acknowledged in [
94] However, these notable differences observed in the performance of the gridded datasets may be misleading in the selection or choice of a dataset based on evaluation using a single metric. Therefore, a good gridded dataset should have the ability to accurately replicate the climate patterns and amplitude of spatial and temporal variability across different performance metrics, which is critical for thorough and accurate hydro-climatic applications. This, however, has been acknowledged by [
38], who stated that a single performance metric cannot adequately be relied upon for the selection of gridded datasets for global application. The merit of this methodology is predicated on the fact that the combination of multiple metrics for selection may reduce the chance of underperforming models exhibiting better performance for the wrong reasons [
1].
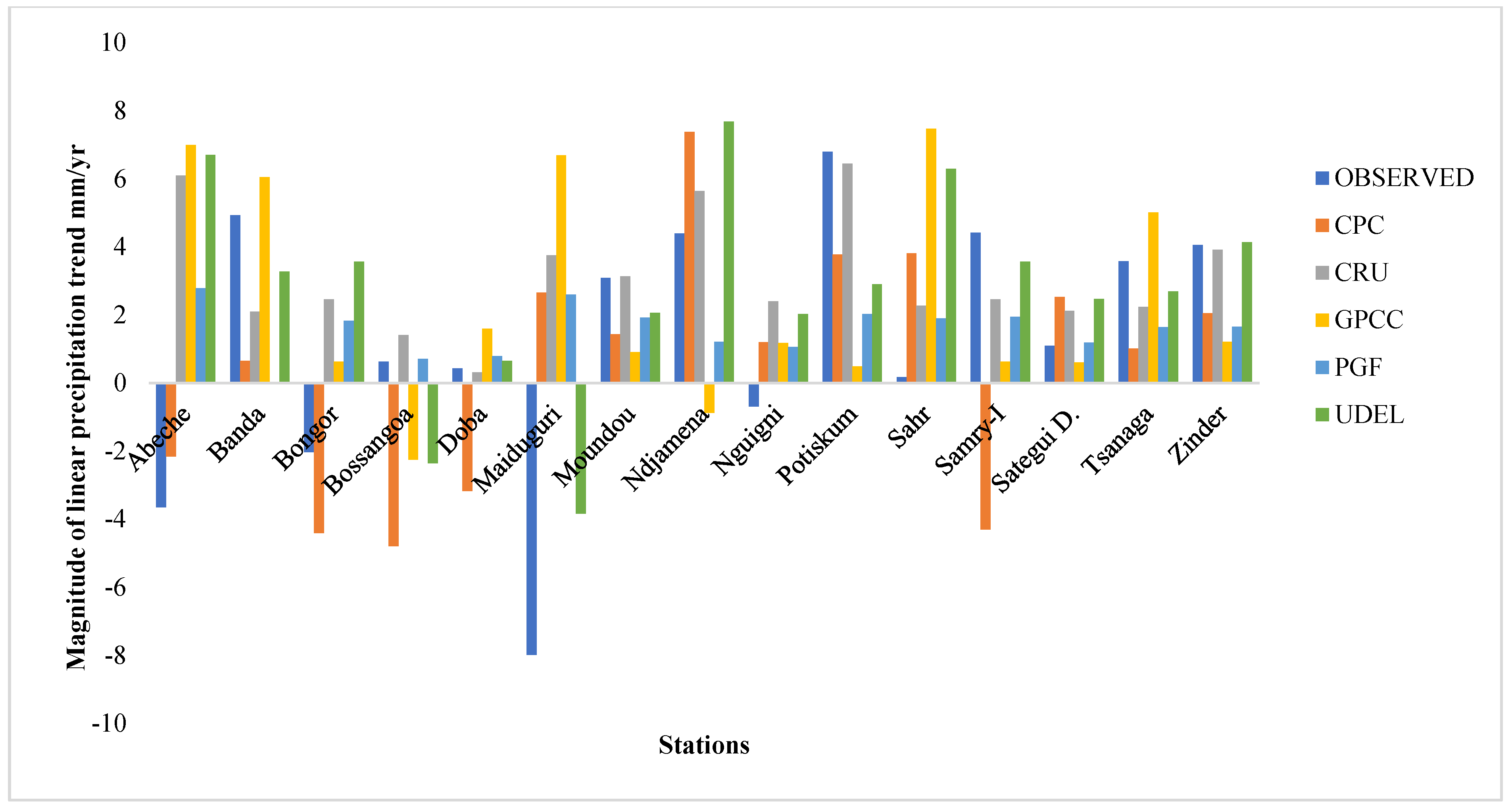
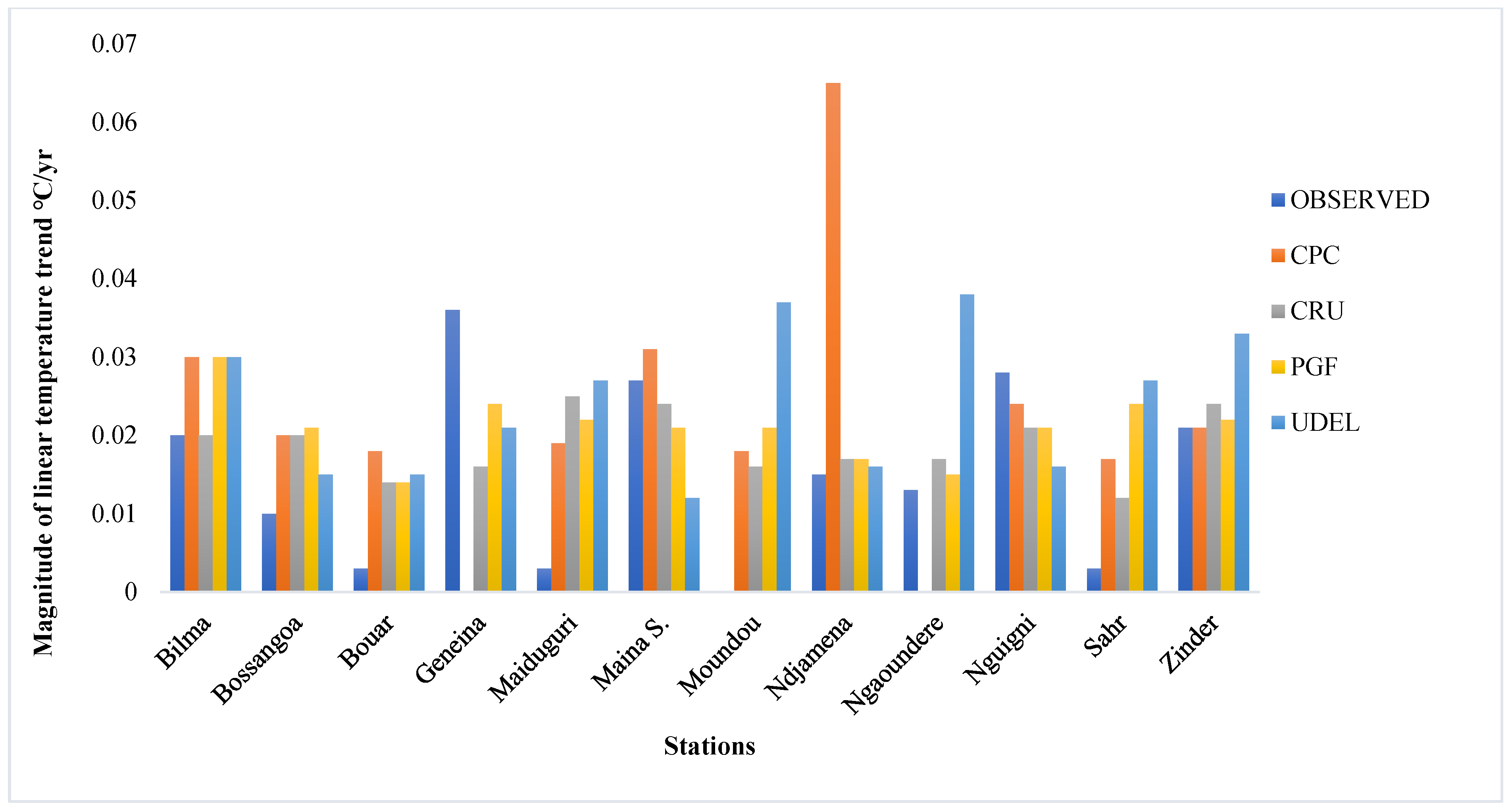
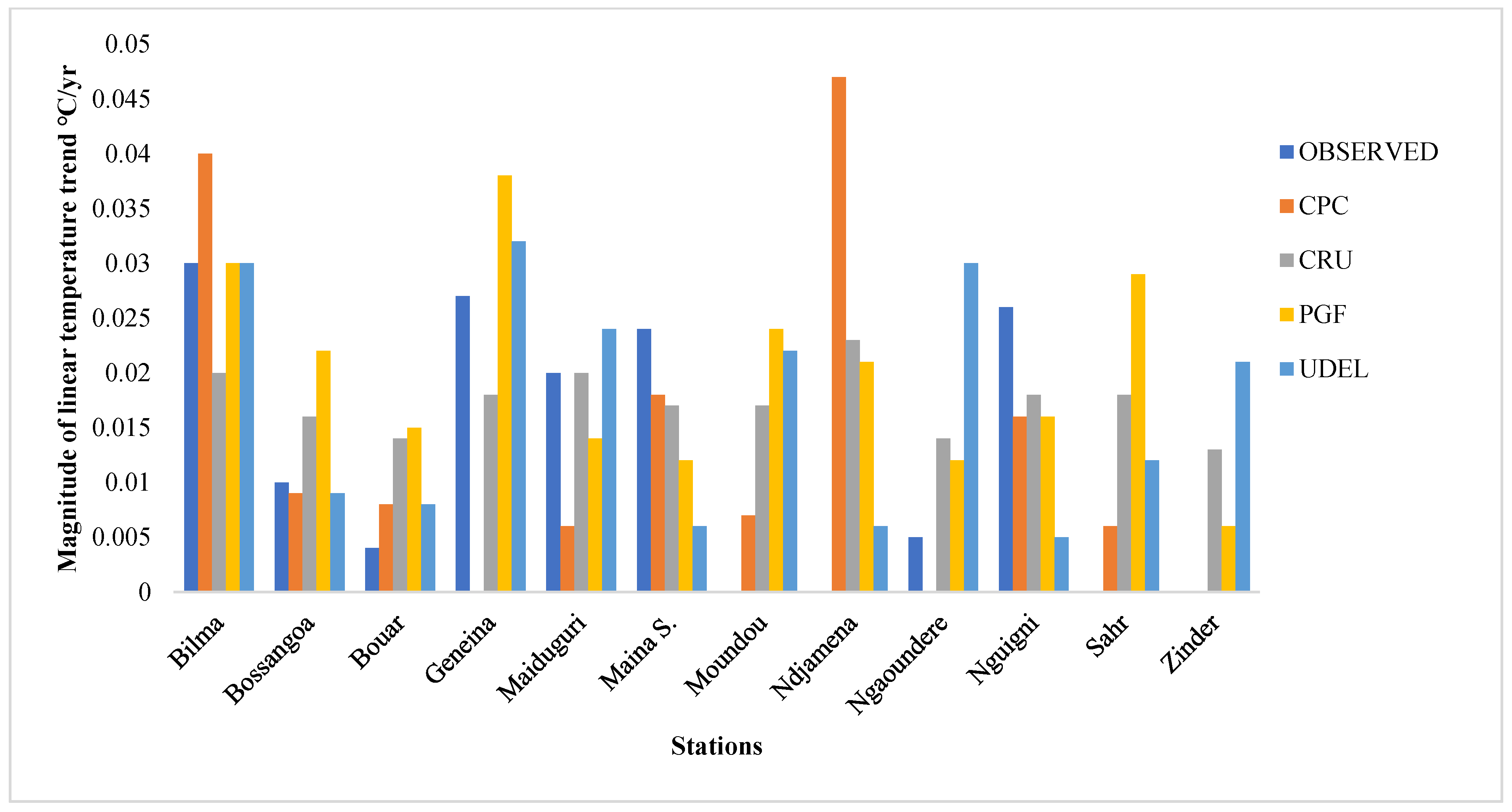
The gridded dataset exhibited some inherent weaknesses across the performance metrics, especially in simulating the trends and magnitude of precipitation and temperature across the annual and monsoon season timescales; for example, the CRU data was shown to have a better performance in replicating the observed station data relative to the other datasets, but overestimated the temperature trends across the annual and monsoon season timescales. However, the performance across the metrics considered in this study
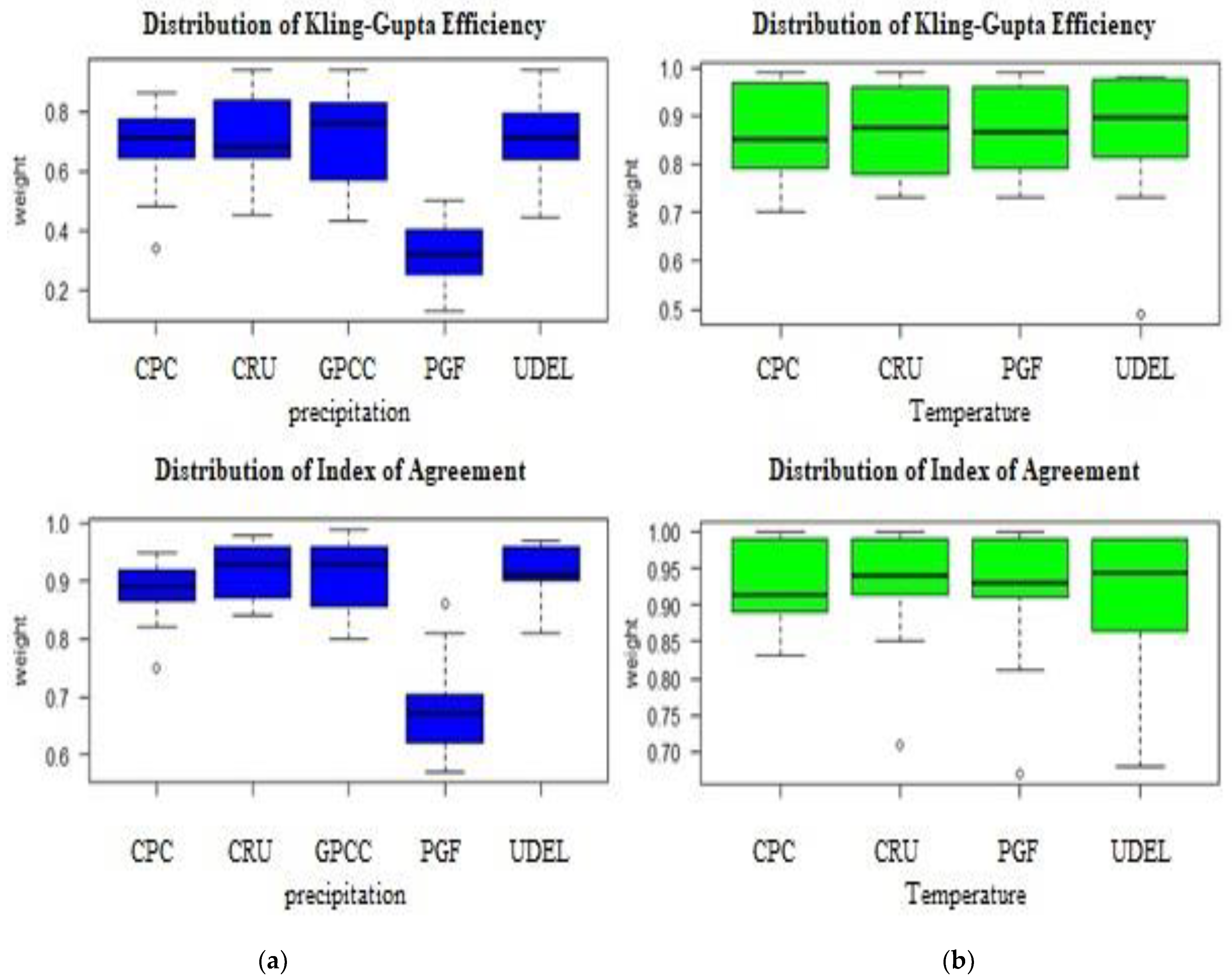
Table 11, revealed that the CRU data perform better in 5 out of 6 (83.3%) performance metrics considered for both precipitation and temperature, while CPC and GPCC have a relatively worse performance, with 3 out of 6 (50%) for precipitation, and PGF had 5 out of 6 (83%) for temperature in terms of the performance metrics. The superiority of the CRU data may be attributable to their employing a larger number of station data than other gridded datasets. However, the datasets were able to exhibit a satisfactory performance and represent the variability reasonably well, indicating that they possessed the ability to provide reliable hydro-climatic information with a lower level of uncertainty in their predictions.
The findings of this study, using multi-criteria decision making based on the assessment of the datasets by several performance metrics, revealed that the CRU, GPCC, and CPC precipitation datasets and the CRU and PGF temperature datasets showed better performance and, as such, should be recommended for application in hydro- climatic studies in the Lake Chad basin in order to enhance prediction and achieve a low level of uncertainty in terms of similarity to the observed station precipitation and temperature data, respectively. Furthermore, this was the first study to evaluate the performance and uncertainty associated with gridded precipitation and temperature datasets in the Lake Chad hydrological basin, and cannot be compared to previous studies. However, findings from other studies in regions with similar climatology have shown to be consistent with the present findings. For example, a study in the arid region of Pakistan indicated that GPCC was found to have an acceptable agreement with the observed dataset [
95]. The CRU dataset was also found to have a better performance in the Niger Delta region of Nigeria [
2], while GPCC, CRU, and CPC were consistent with the observed climate data in the mountainous region of South Africa [
47].
Furthermore, the findings from our analysis also acknowledge the limitations associated with the development of gridded datasets and their inherent sources of uncertainty—such as spatial aggregation, the temporal period of analysis, and input uncertainty [
96]—and offer ways to reduce the level of uncertainty associated with the observed station records—for example, sampling error, bias error, urbanisation effects, and rain gauge and thermometer exposure changes [
97]; therefore, caution has been taken in pursuit of a reliable assessment.
6. Conclusions
This paper evaluated the performance of a long-term time series of high-resolution gridded precipitation and temperature datasets and their suitability for hydro-climatic studies in the data-scarce Lake Chad basin. The emphasis in this assessment was to employ multiple performance metrics to evaluate the ability of the selected datasets to replicate the quality-controlled observed meteorological station records available, and to provide methodological guidance based on multi-criteria decision making as to the choice of reference dataset suitable for climate and hydrological impact studies in data-scarce regions.
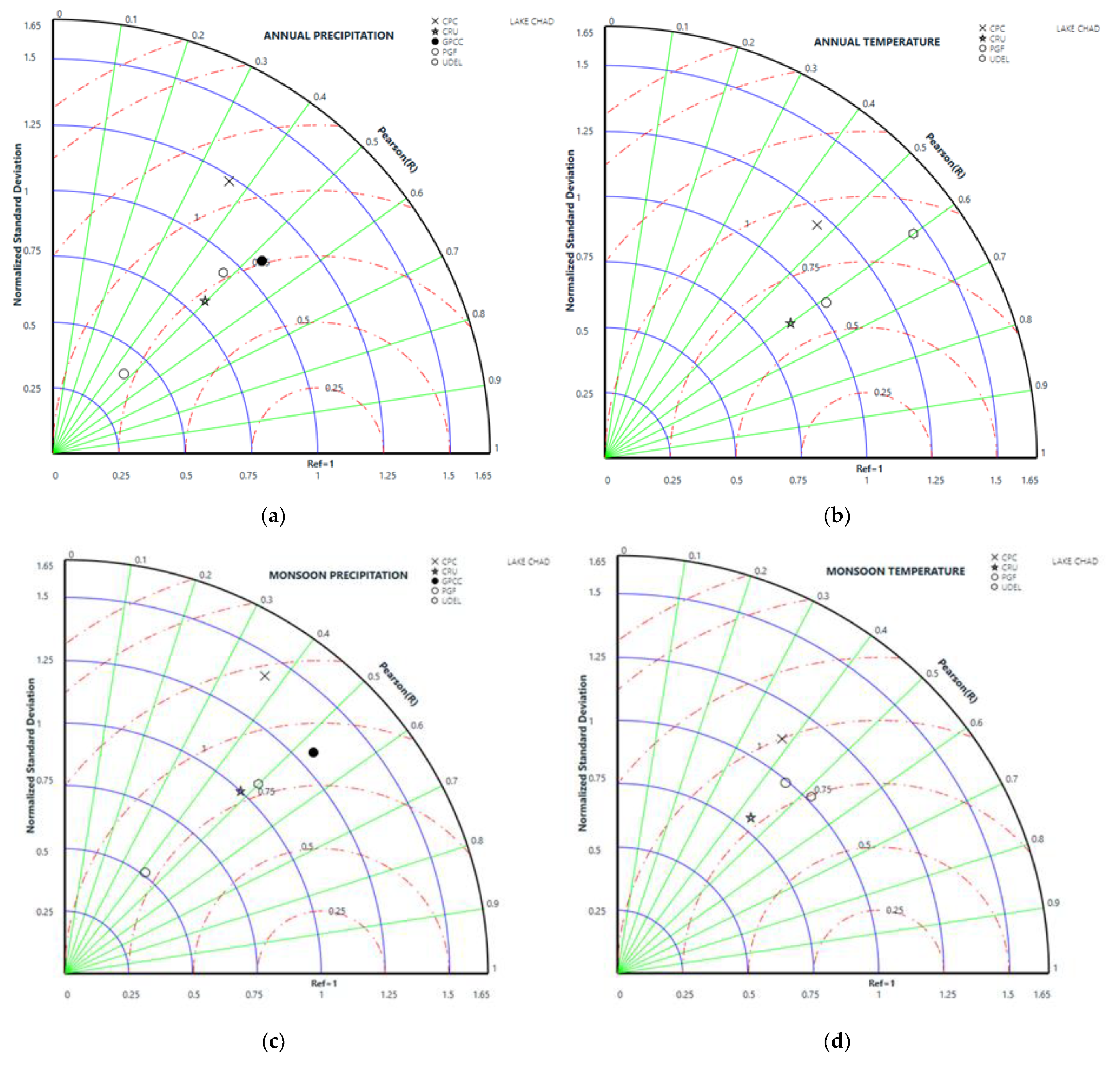
The results of the analysis revealed that all of the gridded precipitation datasets had the ability to replicate the observed climate record with varying levels of uncertainty—except for the PGF dataset, which exhibited unsatisfactory performance in terms of KGE, md, and NRMSE. However, all of the temperature datasets showed a strong agreement, and were consistent with the observed data. The results from the Taylor diagrams indicate a notable variability in normalised standard deviation across the annual, pre-monsoon, and monsoon season timescales, but have an acceptable Pearson’s correlation coefficient relative to the observed data records.
The trend analysis results show that the temperature datasets exhibit better ability in replicating the trends compared to precipitation datasets. Although there was a varying degree of mismatch in the magnitude of the trends across the stations, the CRU data exhibited a strong increasing temperature trend across all of the stations at the annual and monsoon season timescales, and tended to overestimate the temperature of the basin relative to the observed gauge data. However, the multi-criteria decision-making approach applied based on the performance exhibited across the metrics used in this study revealed that the CRU, GPCC, and CPC datasets are appropriate for precipitation, while the CRU and PGF datasets are appropriate for temperature, providing better replication of the basin’s climatology, with an acceptably low level of uncertainty in the prediction of climatic and hydrological variables for better policy planning and water resource management.
Furthermore, the results of this study highlight that the choice of gridded data is critical for fair representation of historical and projected future climate changes, as acknowledged in [
1]. Therefore, due to differences in the temporal resolution of gridded datasets, the daily CPC precipitation and PGF temperature datasets, along with the monthly CRU precipitation/temperature datasets, are recommended for the downscaling and bias correction of global climate models in hydrological modelling processes, depending on the input data requirements of hydrological models in the Lake Chad basin, as well as on the need for improvement in the development of climate models in order to better reproduce satisfactory temporal and spatial variability in climate indices, limit uncertainties, and improve prediction accuracy in the quantification of projected climate hazards and vulnerabilities for better water policy decision making.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}