
Generic Framework for Downscaling Statistical Quantities at Fine Time-Scales and Its Perspectives towards Cost-Effective Enrichment of Water Demand Records



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
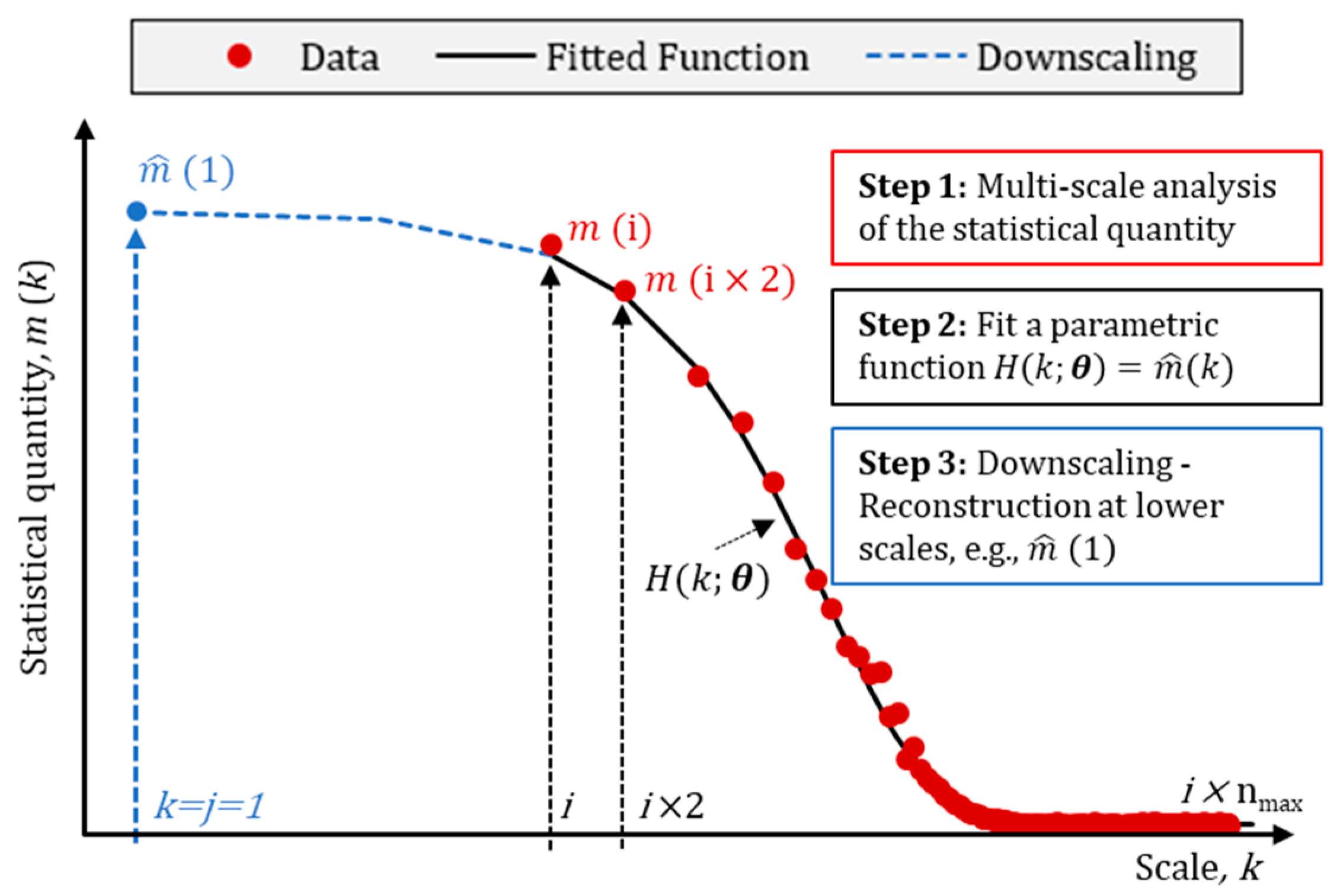
Is it possible to downscale/estimate/reconstruct statistical quantities of a process at fine time scales, given that only coarser-resolution measurements are available?
- (a)
- Multi-scale analysis of the statistical quantity of interest (i.e., obtain estimates at multiple levels of temporal aggregation);
- (b)
- Parsimonious, and theoretically consistent, parametric functions to model the multi-scale behaviour of the quantity of interest;
- (c)
- Exploitation of extrapolation capabilities of the functions to downscale the associated statistical quantities at finer scales.
2. A Methodological Framework for the Temporal Downscaling of Statistical Quantities
2.1. Key Concepts, Notation, and the Methodological Framework
Given that a set of statistical quantities,, is known at time scalesup to, whereis an integer index, downscale (reconstruct) the statistical quantityat a finer time scale, where and is an integer.
2.2. Multi-Scale Modelling of Variance and Auto-Dependence Structure
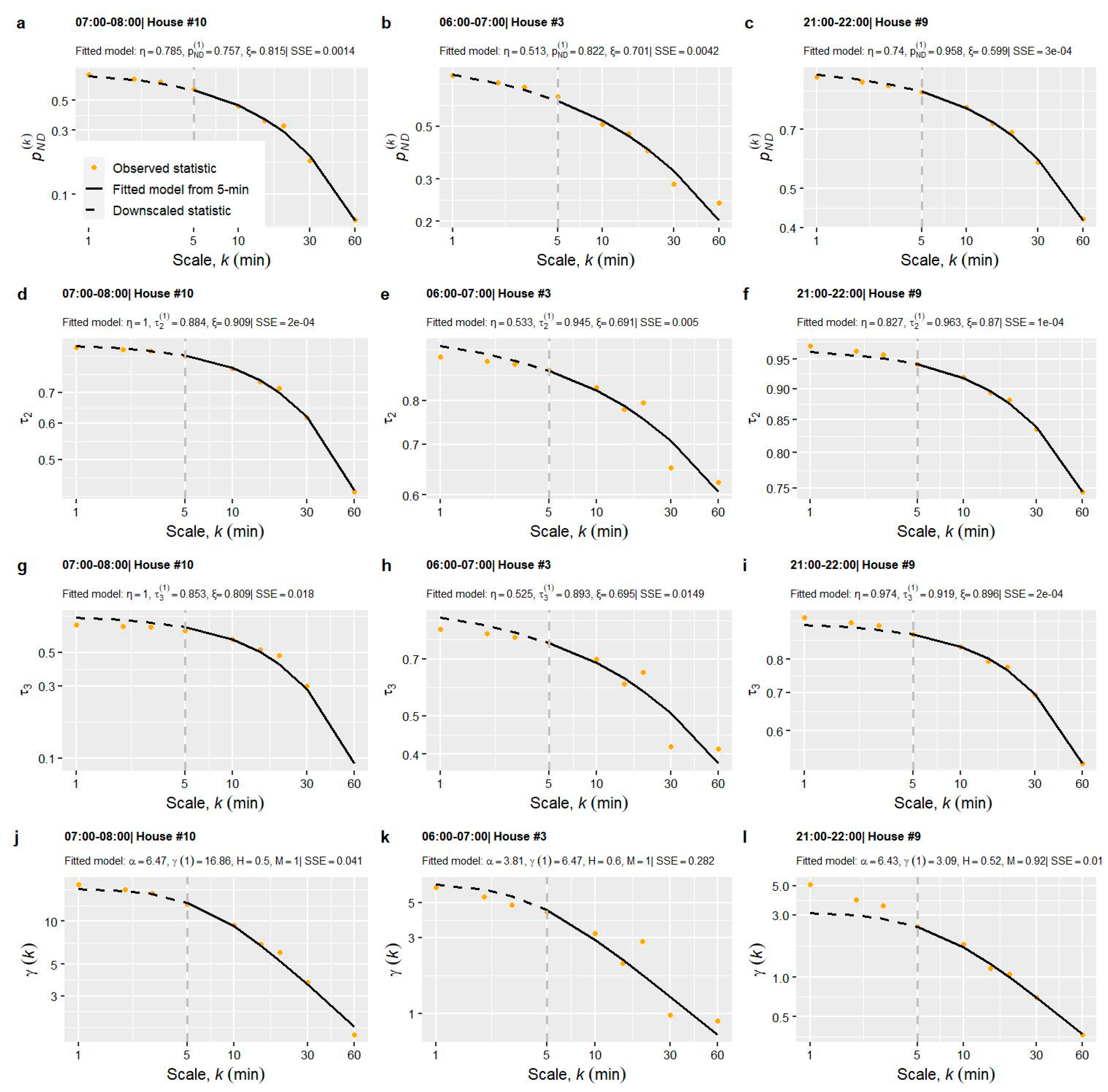
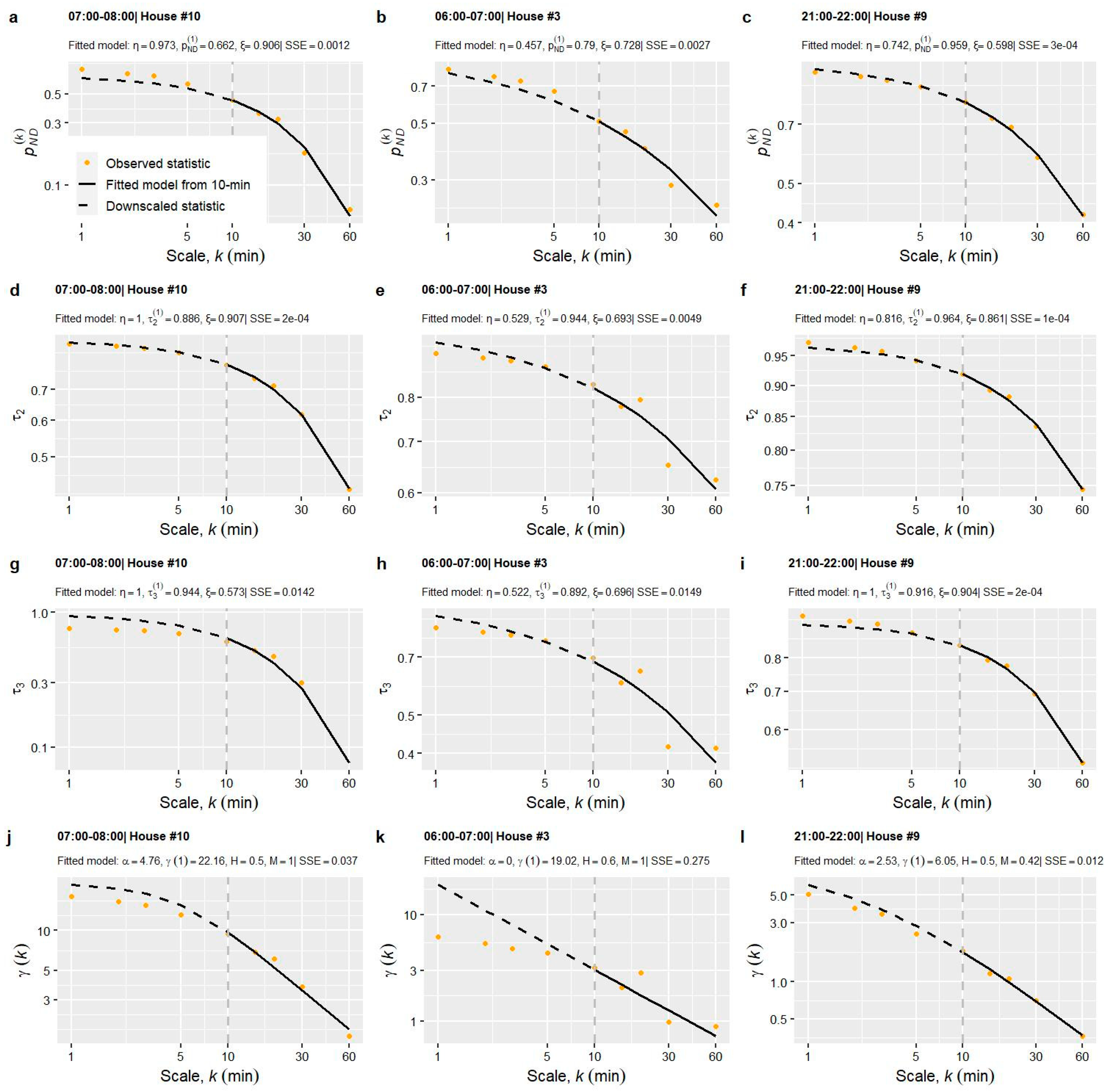
2.3. Multi-Scale Modelling of Bounded Statistics (Probability of Zero Value, L-Variance, L-Skewness)
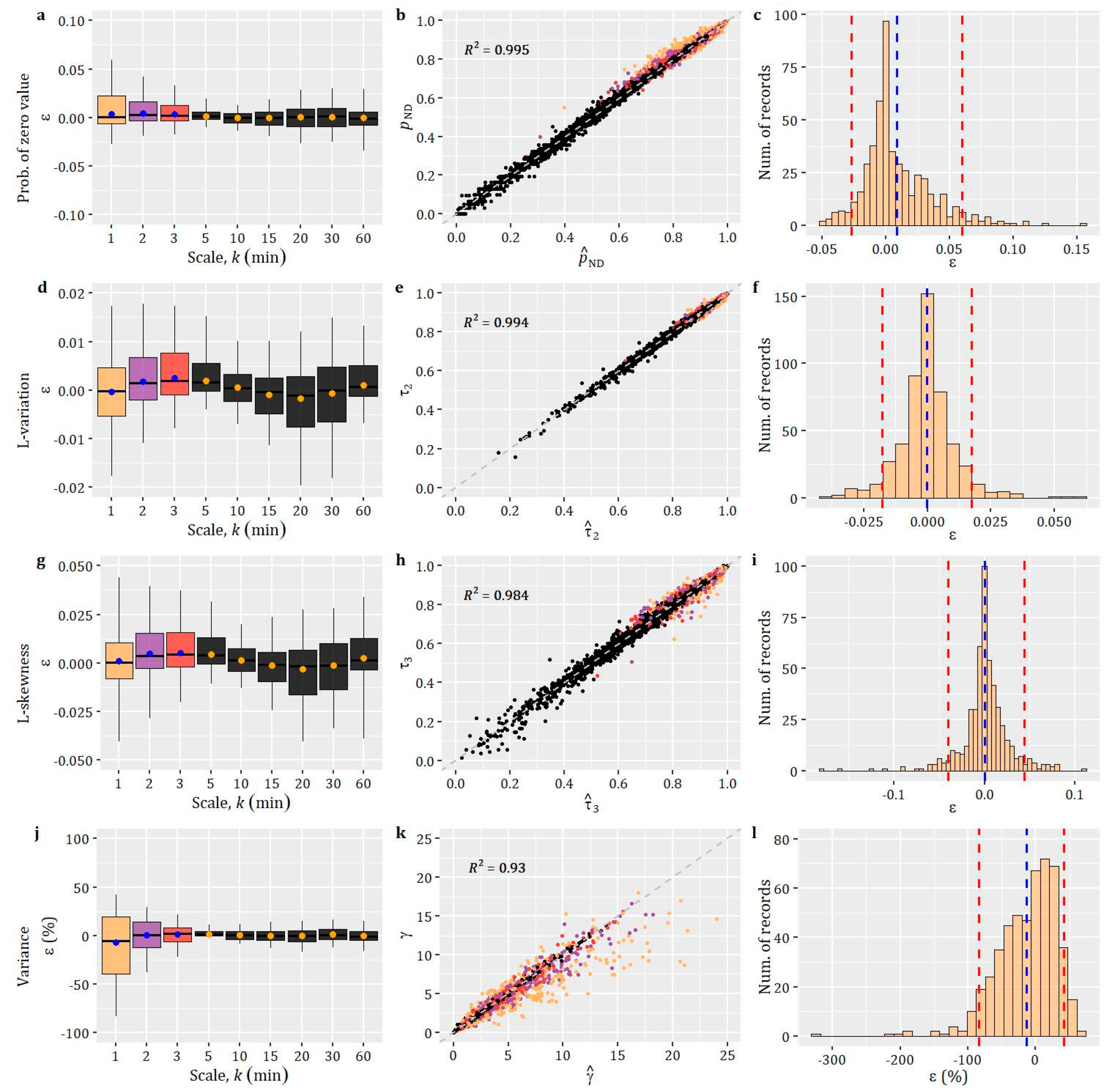
3. Demonstration of the Methodology
4. Discussion
4.1. Setting the Challenge
4.2. Towards Cost-Effective Enrichment of Water Demand Records
- [a]
- Multi-scale analysis of the available water demand datasets to obtain evidence on the marginal and stochastic characteristics of the process;
- [b]
- Methodologies to downscale essential elements (e.g., statistical quantities), involved in stochastic modelling of demand processes at finer scales;
- [c]
- Stochastic simulation methodologies to support the disaggregation of coarser-resolution measurements into finer increments, with an emphasis on the reproduction of the marginal and stochastic behaviour of the processes at multiple scales, simultaneously.
5. Conclusions and Recommendations for Future Research
- (a)
- Multi-temporal analysis of statistical quantities;
- (b)
- Use of parametric functions to model their multi-temporal behaviour;
- (c)
- Exploitation of extrapolation capabilities of these functions to downscale statistics at finer scales, based on estimates at coarser scales.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mayer, P.W.; DeOreo, W.B. Residential End Uses of Water. Am. Water Work. Assoc. 1999, 64, 36–42. [Google Scholar]
- Marvin, S.; Chappells, H.; Guy, S. Pathways of Smart Metering Development: Shaping Environmental Innovation. Comput. Environ. Urban. Syst. 1999, 23, 109–126. [Google Scholar] [CrossRef]
- Cominola, A.; Giuliani, M.; Piga, D.; Castelletti, A.; Rizzoli, A.E. Benefits and Challenges of Using Smart Meters for Advancing Residential Water Demand Modeling and Management: A Review. Environ. Model. Softw. 2015, 72, 198–214. [Google Scholar] [CrossRef] [Green Version]
- Cominola, A.; Giuliani, M.; Castelletti, A.; Rosenberg, D.E.; Abdallah, A.M. Implications of Data Sampling Resolution on Water Use Simulation, End-Use Disaggregation, and Demand Management. Environ. Model. Softw. 2018, 102, 199–212. [Google Scholar] [CrossRef] [Green Version]
- Monks, I.; Stewart, R.A.; Sahin, O.; Keller, R. Revealing Unreported Benefits of Digital Water Metering: Literature Review and Expert Opinions. Water 2019, 11, 838. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez-Iturbe, I.; Cox, D.R.; Isham, V. Some Models for Rainfall Based on Stochastic Point Processes. Proc. R. Soc. A Math. Phys. Eng. Sci. 1987, 410, 269–288. [Google Scholar] [CrossRef]
- Rodriguez-Iturbe, I.; Cox, D.R.; Isham, V. A Point Process Model for Rainfall: Further Developments. Proc. R. Soc. Lond. A Math. Phys. Eng. Sci. 1988, 417, 283–298. [Google Scholar]
- Kaczmarska, J.; Isham, V.; Onof, C. Point Process Models for Fine-Resolution Rainfall. Hydrol. Sci. J. 2014, 59, 1972–1991. [Google Scholar] [CrossRef] [Green Version]
- Onof, C.; Chandler, R.E.; Kakou, A.; Northrop, P.; Wheater, H.S.; Isham, V. Rainfall Modelling Using Poisson-Cluster Processes: A Review of Developments. Stoch. Environ. Res. Risk Assess. 2000, 14, 0384–0411. [Google Scholar] [CrossRef]
- Alvisi, S.; Franchini, M.; Marinelli, A. A Stochastic Model for Representing Drinking Water Demand at Residential Level. Water Resour. Manag. 2003, 17, 197–222. [Google Scholar] [CrossRef]
- Kossieris, P.; Makropoulos, C.; Creaco, E.; Vamvakeridou-Lyroudia, L.; Savic, D.A. Assessing the Applicability of the Bartlett-Lewis Model in Simulating Residential Water Demands. Procedia Eng. 2016, 154, 123–131. [Google Scholar] [CrossRef] [Green Version]
- Kossieris, P.; Tsoukalas, I.; Makropoulos, C.; Savic, D. Simulating Marginal and Dependence Behaviour of Water Demand Processes at Any Fine Time Scale. Water 2019, 11, 885. [Google Scholar] [CrossRef] [Green Version]
- Tsoukalas, I.; Efstratiadis, A.; Makropoulos, C. Stochastic Periodic Autoregressive to Anything (SPARTA): Modeling and Simulation of Cyclostationary Processes With Arbitrary Marginal Distributions. Water Resour. Res. 2018, 54, 161–185. [Google Scholar] [CrossRef]
- Tsoukalas, I.; Makropoulos, C.; Koutsoyiannis, D. Simulation of Stochastic Processes Exhibiting Any-Range Dependence and Arbitrary Marginal Distributions. Water Resour. Res. 2018, 54, 9484–9513. [Google Scholar] [CrossRef]
- Tsoukalas, I.; Kossieris, P.; Makropoulos, C. Simulation of Non-Gaussian Correlated Random Variables, Stochastic Processes and Random Fields: Introducing the AnySim R-Package for Environmental Applications and Beyond. Water 2020, 12, 1645. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. A Generalized Mathematical Framework for Stochastic Simulation and Forecast of Hydrologic Time Series. Water Resour. Res. 2000, 36, 1519–1533. [Google Scholar] [CrossRef] [Green Version]
- Efstratiadis, A.; Dialynas, Y.G.; Kozanis, S.; Koutsoyiannis, D. A Multivariate Stochastic Model for the Generation of Synthetic Time Series at Multiple Time Scales Reproducing Long-Term Persistence. Environ. Model. Softw. 2014, 62, 139–152. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. Generic and Parsimonious Stochastic Modelling for Hydrology and Beyond. Hydrol. Sci. J. 2016, 61, 225–244. [Google Scholar] [CrossRef]
- Papalexiou, S.M. Unified Theory for Stochastic Modelling of Hydroclimatic Processes: Preserving Marginal Distributions, Correlation Structures, and Intermittency. Adv. Water Resour. 2018, 115, 234–252. [Google Scholar] [CrossRef]
- Creaco, E.; de Paola, F.; Fiorillo, D.; Giugni, M. Bottom-Up Generation of Water Demands to Preserve Basic Statistics and Rank Cross-Correlations of Measured Time Series. J. Water Resour. Plan. Manag. 2020, 146, 06019011. [Google Scholar] [CrossRef]
- Gargano, R.; Tricarico, C.; del Giudice, G.; Granata, F. A Stochastic Model for Daily Residential Water Demand. Water Sci. Technol. Water Supply 2016, 16, 1753–1767. [Google Scholar] [CrossRef] [Green Version]
- Alvisi, S.; Ansaloni, N.; Franchini, M. Generation of Synthetic Water Demand Time Series at Different Temporal and Spatial Aggregation Levels. Urban. Water J. 2014, 11, 297–310. [Google Scholar] [CrossRef]
- Kossieris, P. Multi-Scale Stochastic Analysis and Modelling of Residential Water Demand Processes. Ph.D. Thesis, National Technical University of Athens, Athens, Greece, 2020; p. 304. [Google Scholar]
- Koutsoyiannis, D. Stochastics of Hydroclimatic Extremes—A Cool Look at Risk, 1st ed.; Kallipos: Athens, Greece, 2020. [Google Scholar]
- Dimitriadis, P.; Koutsoyiannis, D.; Iliopoulou, T.; Papanicolaou, P. A Global-Scale Investigation of Stochastic Similarities in Marginal Distribution and Dependence Structure of Key Hydrological-Cycle Processes. Hydrology 2021, 8, 59. [Google Scholar] [CrossRef]
- Beran, J. Statistics for Long-Memory Processes; CRC Press: Boca Raton, FL, USA, 1994; ISBN 0412049015. [Google Scholar]
- Rodriguez-Iturbe, I.; Gupta, V.K.; Waymire, E. Scale Considerations in the Modeling of Temporal Rainfall. Water Resour. Res. 1984, 20, 1611–1619. [Google Scholar] [CrossRef]
- Marani, M.; Zanetti, S. Downscaling Rainfall Temporal Variability. Water Resour. Res. 2007, 43, W09415. [Google Scholar] [CrossRef] [Green Version]
- Koutsoyiannis, D. An Entropic-Stochastic Representation of Rainfall Intermittency: The Origin of Clustering and Persistence. Water Resour. Res. 2006, 42, W01401. [Google Scholar] [CrossRef] [Green Version]
- Diez-Sierra, J.; del Jesus, M. Subdaily Rainfall Estimation through Daily Rainfall Downscaling Using Random Forests in Spain. Water 2019, 11, 125. [Google Scholar] [CrossRef] [Green Version]
- Cowpertwait, P.S.P.; O’Connell, P.E.; Metcalfe, A.V.; Mawdsley, J.A. Stochastic Point Process Modelling of Rainfall. II. Regionalisation and Disaggregation. J. Hydrol. 1996, 175, 47–65. [Google Scholar] [CrossRef]
- Beuchat, X.; Schaefli, B.; Soutter, M.; Mermoud, A. Toward a Robust Method for Subdaily Rainfall Downscaling from Daily Data. Water Resour. Res. 2011, 47, W09524. [Google Scholar] [CrossRef] [Green Version]
- Hosking, J.R.M. L-Moments: Analysis and Estimation of Distributions Using Linear Combinations of Order Statistics. J. R. Stat. Soc. Ser. B 1990, 52, 105–124. [Google Scholar] [CrossRef]
- Magini, R.; Pallavicini, I.; Guercio, R. Spatial and Temporal Scaling Properties of Water Demand. J. Water Resour. Plan. Manag. 2008, 134, 276–284. [Google Scholar] [CrossRef]
- Vertommen, I.; Magini, R.; da Conceição Cunha, M. Scaling Water Consumption Statistics. J. Water Resour. Plan. Manag. 2015, 141, 04014072. [Google Scholar] [CrossRef] [Green Version]
- Walski, T.; Chase, D.; Savic, D.; Grayman, W.; Beckwith, S.; Koelle, E. Advanced Water Distribution Modeling and Management, 1st ed.; Haestead Press: Ultimo, NSW, Australia, 2003; ISBN 0971414122. [Google Scholar]
- Koutsoyiannis, D. HESS Opinions “A Random Walk on Water”. Hydrol. Earth Syst. Sci. 2010, 14, 585–601. [Google Scholar] [CrossRef] [Green Version]
- Lombardo, F.; Volpi, E.; Koutsoyiannis, D.; Papalexiou, S.M. Just Two Moments! A Cautionary Note against Use of High-Order Moments in Multifractal Models in Hydrology. Hydrol. Earth Syst. Sci. 2014, 18, 243–255. [Google Scholar] [CrossRef] [Green Version]
- Dimitriadis, P.; Koutsoyiannis, D. Climacogram versus Autocovariance and Power Spectrum in Stochastic Modelling for Markovian and Hurst–Kolmogorov Processes. Stoch. Environ. Res. Risk Assess. 2015, 29, 1649–1669. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. The Hurst Phenomenon and Fractional Gaussian Noise Made Easy. Hydrol. Sci. J. 2002, 47, 573–595. [Google Scholar] [CrossRef]
- Kossieris, P.; Makropoulos, C. Exploring the Statistical and Distributional Properties of Residential Water Demand at Fine Time Scales. Water 2018, 10, 1481. [Google Scholar] [CrossRef] [Green Version]
- Papalexiou, S.M.; Koutsoyiannis, D. A Global Survey on the Seasonal Variation of the Marginal Distribution of Daily Precipitation. Adv. Water Resour. 2016, 94, 131–145. [Google Scholar] [CrossRef]
- Iliopoulou, T.; Koutsoyiannis, D. Revealing Hidden Persistence in Maximum Rainfall Records. Hydrol. Sci. J. 2019, 64, 1673–1689. [Google Scholar] [CrossRef]
- Buchberger, S.G.; Carter, J.T.; Lee, Y.H.; Schade, T.G. Random Demands, Travel Times, and Water Quality in Dead Ends; Report No. 294; American Water Research Foundation: Denver, CO, USA, 2003. [Google Scholar]
- Alvisi, S.; Ansaloni, N.; Franchini, M. Comparison of Parametric and Nonparametric Disaggregation Models for the Top-down Generation of Water Demand Time Series. Civil. Eng. Environ. Syst. 2016, 33, 3–21. [Google Scholar] [CrossRef] [Green Version]
- R Core Team R. A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Mullen, K.; Ardia, D.; Gil, D.; Windover, D.; Cline, J. DEoptim: An R Package for Global Optimization by Differential Evolution. J. Stat. Softw. 2011, 40, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Makropoulos, C.; Savić, D.A. Urban Hydroinformatics: Past, Present and Future. Water 2019, 11, 1959. [Google Scholar] [CrossRef] [Green Version]
- Stewart, R.A.; Nguyen, K.; Beal, C.; Zhang, H.; Sahin, O.; Bertone, E.; Vieira, A.S.; Castelletti, A.; Cominola, A.; Giuliani, M.; et al. Integrated Intelligent Water-Energy Metering Systems and Informatics: Visioning a Digital Multi-Utility Service Provider. Environ. Model. Softw. 2018, 105, 94–117. [Google Scholar] [CrossRef]
- Di Mauro, A.; Cominola, A.; Castelletti, A.; di Nardo, A. Urban Water Consumption at Multiple Spatial and Temporal Scales. A Review of Existing Datasets. Water 2020, 13, 36. [Google Scholar] [CrossRef]
- Babayan, A.V.; Kapelan, Z.S.; Savic, D.A.; Walters, G.A. Comparison of Two Methods for the Stochastic Least Cost Design of Water Distribution Systems. Eng. Optim. 2006, 38, 281–297. [Google Scholar] [CrossRef]
- Chung, G.; Lansey, K.; Bayraksan, G. Reliable Water Supply System Design under Uncertainty. Environ. Model. Softw. 2009, 24, 449–462. [Google Scholar] [CrossRef]
- Kapelan, Z.S.; Savic, D.A.; Walters, G.A. Multiobjective Design of Water Distribution Systems under Uncertainty. Water Resour. Res. 2005, 41, 1–15. [Google Scholar] [CrossRef]
- Hutton, C.J.; Kapelan, Z.; Vamvakeridou-Lyroudia, L.; Savić, D.A. Dealing with Uncertainty in Water Distribution System Models: A Framework for Real-Time Modeling and Data Assimilation. J. Water Resour. Plan. Manag. 2014, 140, 169–183. [Google Scholar] [CrossRef]
- Yang, X.; Boccelli, D.L. Simulation Study to Evaluate Temporal Aggregation and Variability of Stochastic Water Demands on Distribution System Hydraulics and Transport. J. Water Resour. Plan. Manag. 2014, 140, 04014017. [Google Scholar] [CrossRef]
- Savic, D.A. Coping with Risk and Uncertainty in Urban Water Infrastructure Rehabilitation Planning. Urban. Water 2005, 1–28. [Google Scholar] [CrossRef]
- Di Nardo, A.; Di Natale, M.; Gargano, R.; Giudicianni, C.; Greco, R.; Santonastaso, G.F. Performance of Partitioned Water Distribution Networks under Spatial-Temporal Variability of Water Demand. Environ. Model. Softw. 2018, 101, 128–136. [Google Scholar] [CrossRef]
- Bao, Y.; Mays, L.W. Model for Water Distribution System Reliability. J. Hydraul. Eng. 1990, 116, 1119–1137. [Google Scholar] [CrossRef]
- Nguyen, K.A.; Stewart, R.A.; Zhang, H.; Jones, C. Intelligent Autonomous System for Residential Water End Use Classification: Autoflow. Appl. Soft Comput. 2015, 31, 118–131. [Google Scholar] [CrossRef] [Green Version]
- DeOreo, W.B.; Heaney, J.P.; Mayer, P.W. Flow Trace Analysis to Access Water Use. J. Am. Water Work. Assoc. 1996, 88, 79–90. [Google Scholar] [CrossRef]
- Buchberger, S.G.; Wu, L. Model for Instantaneous Residential Water Demands. J. Hydraul. Eng. 1995, 121, 232–246. [Google Scholar] [CrossRef]
- Blokker, E.J.M.; Vreeburg, J.H.G.; van Dijk, J.C. Simulating Residential Water Demand with a Stochastic End-Use Model. J. Water Resour. Plan. Manag. 2010, 136, 19–26. [Google Scholar] [CrossRef]
- Garcia, V.J.; Garcia-Bartual, R.; Cabrera, E.; Arregui, F.; Garcia-Serra, J. Stochastic Model to Evaluate Residential Water Demands. J. Water Resour. Plan. Manag. 2004, 130, 386–394. [Google Scholar] [CrossRef]
- Creaco, E.; Kossieris, P.; Vamvakeridou-Lyroudia, L.; Makropoulos, C.; Kapelan, Z.; Savic, D. Parameterizing Residential Water Demand Pulse Models through Smart Meter Readings. Environ. Model. Softw. 2016, 80, 33–40. [Google Scholar] [CrossRef]
- Creaco, E.; Farmani, R.; Kapelan, Z.; Vamvakeridou-Lyroudia, L.; Savic, D. Considering the Mutual Dependence of Pulse Duration and Intensity in Models for Generating Residential Water Demand. J. Water Resour. Plan. Manag. 2015, 141, 04015031. [Google Scholar] [CrossRef]
- Nataf, A. Statistique Mathematique-Determination Des Distributions de Probabilites Dont Les Marges Sont Donnees. Comptes Rendus Acad. Des. Sci. 1962, 255, 42–43. [Google Scholar]
- Tsoukalas, I.; Efstratiadis, A.; Makropoulos, C. Stochastic Simulation of Periodic Processes with Arbitrary Marginal Distributions. In Proceedings of the 15th International Conference on Environmental Science and Technology (CEST2017), Rhodes, Greece, 31 August–2 September 2017. [Google Scholar]
- Tsoukalas, I.; Efstratiadis, A.; Makropoulos, C. Building a Puzzle to Solve a Riddle: A Multi-Scale Disaggregation Approach for Multivariate Stochastic Processes with Any Marginal Distribution and Correlation Structure. J. Hydrol. 2019, 575, 354–380. [Google Scholar] [CrossRef]
- Li, Z.; Buchberger, S.G. Effect of Time Scale on PRP Random Flows in Pipe Network. In Critical Transitions in Water and Environmental Resources Management; American Society of Civil Engineers: Reston, VA, USA, 2004; pp. 1–10. [Google Scholar]
- Blokker, E.J.M.; Vreeburg, J.H.G.; Buchberger, S.G.; van Dijk, J.C. Importance of Demand Modelling in Network Water Quality Models: A Review. Drink. Water Eng. Sci. Discuss. 2008, 1, 27–38. [Google Scholar] [CrossRef] [Green Version]
- Vertommen, I.; Magini, R.; da Conceicao Cunha, M.; Guercio, R. Water Demand Uncertainty: The Scaling Laws Approach. In Water Supply System Analysis—Selected Topics; InTech: London, UK, 2012; ISBN 978-953-51-0889-4. [Google Scholar]
- Magini, R.; Boniforti, M.; Guercio, R. Generating Scenarios of Cross-Correlated Demands for Modelling Water Distribution Networks. Water 2019, 11, 493. [Google Scholar] [CrossRef] [Green Version]
- Koutsoyiannis, D. Rainfall Disaggregation Methods: Theory and Applications. In Proceedings, Workshop on Statistical and Mathematical Methods for Hydrological Analysis; Università di Roma “La Sapienza”: Rome, Italy, 2003; pp. 1–23. [Google Scholar]
- Kossieris, P.; Makropoulos, C.; Onof, C.; Koutsoyiannis, D. A Rainfall Disaggregation Scheme for Sub-Hourly Time Scales: Coupling a Bartlett-Lewis Based Model with Adjusting Procedures. J. Hydrol. 2016, 556, 980–992. [Google Scholar] [CrossRef] [Green Version]
- Fiorillo, D.; Creaco, E.; de Paola, F.; Giugni, M. Comparison of Bottom-Up and Top-Down Procedures for Water Demand Reconstruction. Water 2020, 12, 922. [Google Scholar] [CrossRef] [Green Version]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kossieris, P.; Tsoukalas, I.; Efstratiadis, A.; Makropoulos, C. Generic Framework for Downscaling Statistical Quantities at Fine Time-Scales and Its Perspectives towards Cost-Effective Enrichment of Water Demand Records. Water 2021, 13, 3429. https://0-doi-org.brum.beds.ac.uk/10.3390/w13233429
Kossieris P, Tsoukalas I, Efstratiadis A, Makropoulos C. Generic Framework for Downscaling Statistical Quantities at Fine Time-Scales and Its Perspectives towards Cost-Effective Enrichment of Water Demand Records. Water. 2021; 13(23):3429. https://0-doi-org.brum.beds.ac.uk/10.3390/w13233429
Chicago/Turabian StyleKossieris, Panagiotis, Ioannis Tsoukalas, Andreas Efstratiadis, and Christos Makropoulos. 2021. "Generic Framework for Downscaling Statistical Quantities at Fine Time-Scales and Its Perspectives towards Cost-Effective Enrichment of Water Demand Records" Water 13, no. 23: 3429. https://0-doi-org.brum.beds.ac.uk/10.3390/w13233429