
Identifying Urban Poverty Using High-Resolution Satellite Imagery and Machine Learning Approaches: Implications for Housing Inequality


Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Areas
2.2. Spatial Scale and Data Sources
2.3. Calculation of Features
2.4. Modeling Approaches
2.5. Model Performance Validation Method
3. Results
3.1. Model Performance
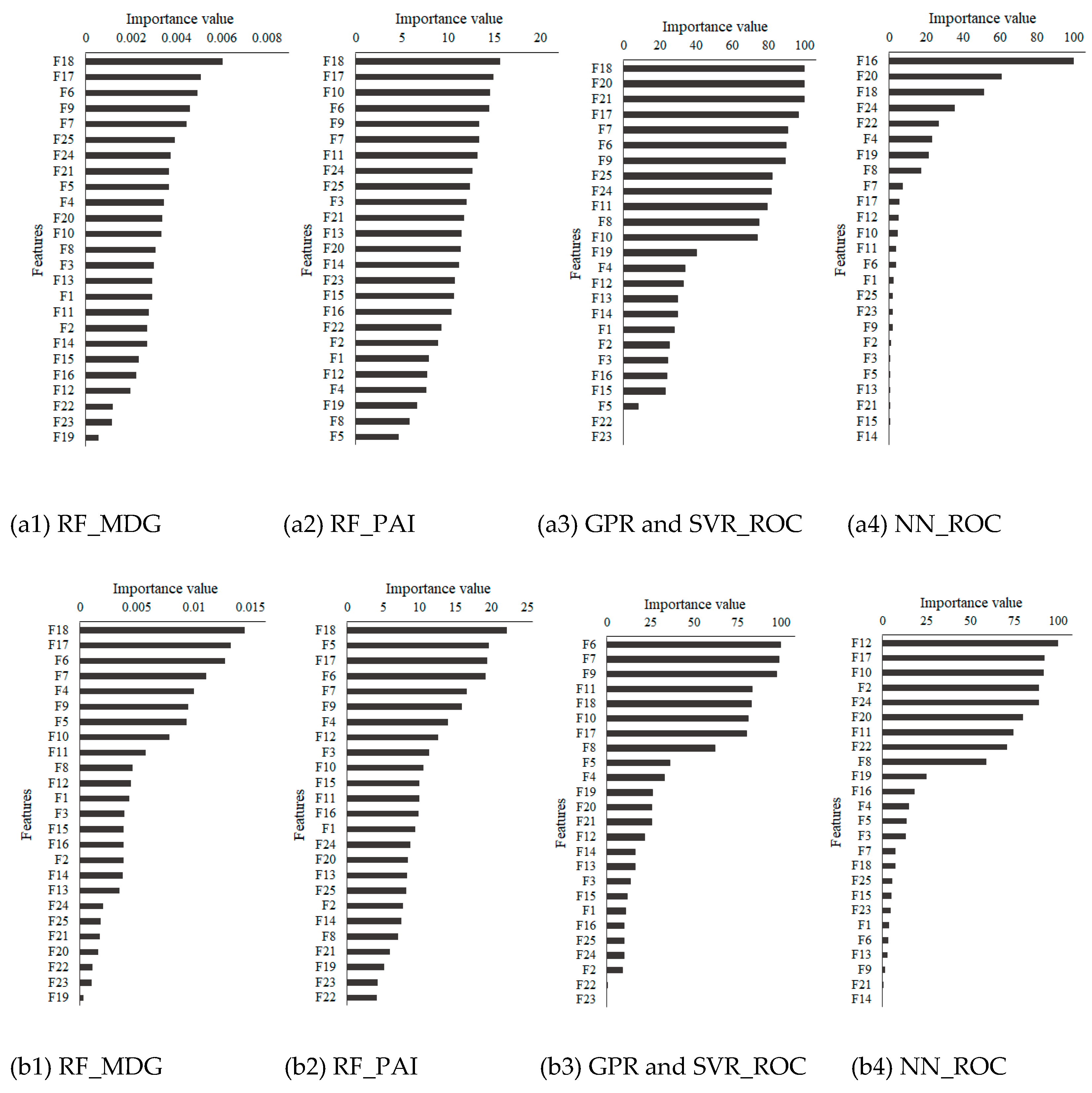
3.2. Important Variables for Identifying Urban Poverty
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, Y.; Liu, Y.S. The geography of poverty: Review and research prospects. J. Rural. Stud. 2019. [Google Scholar] [CrossRef]
- Christiaensen, L.; Todo, Y. Poverty Reduction during the Rural-Urban Transformation-the Role of the Missing Middle. World Dev. 2014, 63, 43–58. [Google Scholar] [CrossRef]
- Tang, S.S.; Pu, H.; Huang, X.J. Land Conversion and Urban Settlement Intentions of the Rural Population in China: A Case Study of Suburban Nanjing. Habitat. Int. 2016, 51, 149–158. [Google Scholar] [CrossRef]
- Sulemana, I.; Edward, N.A.; Emmanuel, A.C.; Jennifer, A.N.A. Urbanization and income inequality in Sub-Saharan Africa. Sustain. Cities Soc. 2019, 48, 1–8. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, X.L. The Residential Resettlement in Suburbs of Chinese Cities: A Case Study of Changsha. Cities 2017, 69, 46–55. [Google Scholar] [CrossRef]
- Chen, M.X.; Sui, Y.W.; Liu, W.D.; Liu, H.; Huang, Y.H. Urbanization Patterns and Poverty Reduction: A New Perspective to Explore the Countries along the Belt and Road. Habitat. Int. 2019, 84, 1–14. [Google Scholar] [CrossRef]
- Li, G.E.; Cai, Z.L.; Liu, X.J.; Liu, J.; Su, S.L. A Comparison of Machine Learning Approaches for Identifying High-Poverty Counties: Robust Features of DMSP/OLS Night-Time Light Imagery. Int. J. Remote. Sens. 2019, 40, 5716–5736. [Google Scholar] [CrossRef]
- Li, Y.H.; Jia, L.R.; Wu, W.H.; Yan, J.Y.; Liu, Y.S. Urbanization for Rural Sustainability--Rethinking China’s Urbanization Strategy. J. Clean. Prod. 2018, 178, 580–586. [Google Scholar] [CrossRef]
- Zeng, C.; Song, Y.; He, Q.S.; Liu, Y. Urban–rural income change: Influences of landscape pattern and administrative spatial spillover effect. Appl. Geogr. 2018, 97, 248–262. [Google Scholar] [CrossRef]
- Qin, H.; Liao, T.F. Labor Out-Migration and Agricultural Change in Rural China: A Systematic Review and Meta-Analysis. J. Rural. Stud. 2016, 47, 533–541. [Google Scholar] [CrossRef] [Green Version]
- Shi, Y.S.; Yu, Y.W. Whether Suburbanization Exacerbates or Alleviates Urban Diseases: Evidences from Shanghai, China. Econ. Geogr. 2016, 36, 47–54. [Google Scholar]
- Duque, J.C.; Royuela, V.; Noreña, M. A Stepwise Procedure to Determinate a Suitable Scale for the Spatial Delimitation of Urban Slums. In Defining the Spatial Scale in Modern Regional Analysis; Springer: Berlin/Heidelberg, Germany, 2012; pp. 237–254. [Google Scholar]
- He, S.J.; Liu, Y.T.; Wu, F.L.; Chris, W. Poverty Incidence and Concentration in Different Social Groups in Urban China, a Case Study of Nanjing. Cities 2008, 25, 121–132. [Google Scholar] [CrossRef]
- Chen, G.; Gu, C.L.; Wu, F.L. Urban Poverty in the Transitional Economy: A Case of Nanjing, China. Habitat. Int. 2006, 30, 1–26. [Google Scholar] [CrossRef]
- Appleton, S.; Song, L.; Xia, Q.J. Growing out of Poverty: Trends and Patterns of Urban Poverty in China 1988–2002. World Dev. 2010, 38, 665–678. [Google Scholar] [CrossRef] [Green Version]
- Panori, A.; Dimitris, B.; Psycharis, Y. SimAthens: A Spatial Microsimulation Approach to the Estimation and Analysis of Small Area Income Distributions and Poverty Rates in the City of Athens, Greece. Comput. Environ. Urban 2016, 63, 15–25. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y.; Xu, M.; Cao, X.Y.; Liu, S.J. Exploring Urban-Rural Disparity of the Multiple Deprivation Index in Guangzhou City from 2000 to 2010. Cities 2018, 79, 1–11. [Google Scholar] [CrossRef]
- Lucci, P.; Bhatkal, T.; Khan, K. Are We Underestimating Urban Poverty? World Dev. 2018, 103, 297–310. [Google Scholar] [CrossRef]
- Engstrom, R.; Newhouse, D.; Haldavanekar, V.; Copenhaver, A.; Hersh, J. Evaluating the Relationship between Spatial and Spectral Features Derived from High Spatial Resolution Satellite Data and Urban Poverty in Colombo, Sri Lanka. In Proceedings of the 2017 Joint Urban Remote Sensing Event (JURSE), Dubai, United Arab Emirates, 6–8 March 2017; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Graesser, J.; Cheriyadat, A.; Vatsavai, R.R.; Chandola, V.; Long, J.; Bright, E. Image Based Characterization of Formal and Informal Neighborhoods in an Urban Landscape. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1164–1176. [Google Scholar] [CrossRef]
- Duque, J.C.; Patino, J.E.; Ruiz, L.A.; Pardo-Pascual, J.E. Measuring Intra-Urban Poverty Using Land Cover and Texture Metrics Derived from Remote Sensing Data. Landsc. Urban Plan. 2015, 135, 11–21. [Google Scholar] [CrossRef]
- Owen, K.K.; Wong, D.W. An Approach to Differentiate Informal Settlements Using Spectral, Texture, Geomorphology and Road Accessibility Metrics. Appl. Geogr. 2013, 38, 107–118. [Google Scholar] [CrossRef]
- Zhao, X.; Yu, B.; Liu, Y.; Chen, Z.; Li, Q.; Wang, C.; Wu, J. Estimation of poverty using random forest regression with multi-source data: A case study in Bangladesh. Remote Sens. 2019, 11, 375. [Google Scholar] [CrossRef] [Green Version]
- Kraff, N.J.; Wurm, M.; Taubenbck, H. The dynamics of poor urban areas—analyzing morphologic transformations across the globe using Earth observation data. Cities 2020, 107, 1–17. [Google Scholar] [CrossRef]
- Wang, J.; Kuffer, M.; Roy, D.; Pfeffer, K. Deprivation pockets through the lens of convolutional neural networks. Remote Sens. Environ. 2019, 234, 111448. [Google Scholar] [CrossRef]
- Wang, J.; Kuffer, M.; Pfeffer, K. The role of spatial heterogeneity in detecting urban slums. Comput. Environ. Urban Syst. 2019, 73, 95–107. [Google Scholar] [CrossRef]
- Müller, I.; Taubenbck, H.; Kuffer, M.; Wurm, M. Misperceptions of predominant slum locations? spatial analysis of slum locations in terms of topography based on earth observation data. Remote Sens. 2020, 12, 2474. [Google Scholar] [CrossRef]
- Sandborn, A.; Engstrom, R.N. Determining the Relationship between Census Data and Spatial Features Derived from High-Resolution Imagery in Accra, Ghana. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1970–1977. [Google Scholar] [CrossRef]
- Patel, M.N.; Tandel, P. A Survey on Feature Extraction Techniques for Shape Based Object Recognition. Int. J. Comput. Appl. T. 2016, 137, 16–20. [Google Scholar]
- Gioi, R.G.V.; Jakubowicz, J.; Morel, J.M.; Randall, G. LSD: A Fast Line Segment Detector with a False Detection Control. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 722–732. [Google Scholar] [CrossRef] [PubMed]
- Ballard, D.H. Generalizing the Hough Transform to Detect Arbitrary Shapes. Pattern. Recogn. 1981, 13, 111–122. [Google Scholar] [CrossRef] [Green Version]
- Baraldi, A.; Parmiggiani, F. An Investigation of the Textural Characteristics Associated with Gray Level Cooccurrence Matrix Statistical Parameters. IEEE Trans. Geosci. Remote Sens. 1995, 33, 293–304. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 7, 971–987. [Google Scholar] [CrossRef]
- Ruiz, L.A.; Recio, J.A.; Fernández-Sarria, A.; Hermosilla, T. A Feature Extraction Software Tool for Agricultural Object-Based Image Analysis. Comput. Electron. Agric. 2011, 76, 284–296. [Google Scholar] [CrossRef] [Green Version]
- Sandri, M.; Zuccolotto, P. Variable Selection Using Random Forests. In Data Analysis, Classification and the Forward Search; Springer: Berlin/Heidelberg, Germany, 2006; pp. 263–270. [Google Scholar]
- Hu, L.R.; He, S.J.; Han, Z.X.; Xiao, H.; Su, S.L.; Weng, M.; Cai, Z.L. Monitoring Housing Rental Prices Based on Social Media: An Integrated Approach of Machine-Learning Algorithms and Hedonic Modeling to Inform Equitable Housing Policies. Land Use Policy 2019, 82, 657–673. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and Regression by RandomForest. R News 2002, 2, 18–22. [Google Scholar]
- Li, G.E.; Chang, L.Y.; Liu, X.J.; Su, S.L.; Cai, Z.L.; Huang, X.R.; Li, B.Z. Monitoring the Spatiotemporal Dynamics of Poor Counties in China: Implications for Global Sustainable Development Goals. J. Clean. Prod. 2019, 227, 392–404. [Google Scholar] [CrossRef]
- Cornejo, B.L.; Mateo, C.C.; Justo, J.S.; Sanz, S.S. Machine Learning Regressors for Solar Radiation Estimation from Satellite Data. Sol. Energy 2019, 183, 768–775. [Google Scholar] [CrossRef]
- Spradley, J.P.; Glazer, B.J.; Kay, R.F. Mammalian Faunas, Ecological Indices, and Machine-Learning Regression for the Purpose of Paleoenvironment Reconstruction in the Miocene of South America. Palaeogeogr. Palaeocl. 2019, 518, 155–171. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Gonzalez, R.; Fiacchini, M.; Iagnemma, K. Slippage Prediction for Off-Road Mobile Robots via Machine Learning Regression and Proprioceptive Sensing. Robot. Auton. Syst. 2018, 105, 85–93. [Google Scholar] [CrossRef] [Green Version]
- Hopfield, J.J. Neural Networks and Physical Systems with Emergent Collective Computational Abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef] [Green Version]
- Zeraatpisheh, M.; Ayoubi, S.; Jafari, A.; Tajik, S.; Finke, P. Digital Mapping of Soil Properties Using Multiple Machine Learning in a Semi-Arid Region, Central Iran. Geoderma 2019, 338, 445–452. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.L.; Zeileis, A.; Hothorn, T. Bias in Random Forest Variable Importance Measures: Illustrations, Sources and a Solution. BMC Bioinfor. 2007, 8, 25. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Anselin, L.; Syabri, I.; Kho, Y. GeoDa: An Introduction to Spatial Data Analysis. Geogr. Anal. 2006, 38, 5–22. [Google Scholar] [CrossRef]
- Niu, T.; Chen, Y.M.; Yuan, Y. Measuring urban poverty using multi-source data and a random forest algorithm: A case study in Guangzhou. Sustain. Cities Soc. 2020, 54, 102014. [Google Scholar] [CrossRef]
- Lejeune, Z.; Guillaume, X.; Marko, K. Housing quality as environmental inequality: The case of Wallonia, Belgium. J. Hous. Built. Environ. 2016, 31, 495–512. [Google Scholar] [CrossRef]
- Hu, L.R.; He, S.; Luo, Y.; Su, S.L.; Xin, J.; Weng, M. A social-media-based approach to assessing the effectiveness of equitable housing policy in mitigating education accessibility induced social inequalities in shanghai, China. Land Use Policy 2020, 94, 104513. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhang, X.L.; Chen, J.; Zhang, Y.Y. Do double-edged swords cut both ways? Housing inequality and haze pollution in Chinese cities. Sci. Total Environ. 2020, 719, 137404. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Feature | Measure | Variable | Description | Abbreviation |
|---|---|---|---|---|
| Geometric features | PERIMETER | PER | Perimeter of each object | F1 |
| Shape features | LSD | LSD_TotNum | Total number of lines | F2 |
| LSD_TotLen | Total line length | F3 | ||
| LSD_MeanLen | Mean line length | F4 | ||
| LSD_Var | Line variance | F5 | ||
| Texture features | GLCM | UNIFOR | GLCM uniformity | F6 |
| ENTROP | GLCM entropy | F7 | ||
| CONTRAS | GLCM contrast | F8 | ||
| IDM | GLCM inverse difference moment | F9 | ||
| COVAR | GLCM covariance | F10 | ||
| VARIAN | GLCM variance | F11 | ||
| HOG | HOG_Max | Histogram maximum | F12 | |
| HOG_Total | Histogram total | F13 | ||
| HOG_Mean | Histogram mean | F14 | ||
| HOG_Var | Histogram variance | F15 | ||
| HOG_SD | Histogram standard deviation | F16 | ||
| HOG_Kur | Histogram kurtosis | F17 | ||
| HOG_Skew | Histogram skewness | F18 | ||
| LBP | LBP_Max | Histogram maximum | F19 | |
| LBP_Total | Histogram total | F20 | ||
| LBP_Mean | Histogram mean | F21 | ||
| LBP_Var | Histogram variance | F22 | ||
| LBP_SD | Histogram standard deviation | F23 | ||
| LBP_Kur | Histogram kurtosis | F24 | ||
| LBP_Skew | Histogram skew | F25 |
| RF | GPR | SVR | NN | |
|---|---|---|---|---|
| Jiangxia | 0.3581 | 0.3653 | 0.5341 | 0.3492 |
| Huangpi | 0.5082 | 0.4231 | 0.5324 | 0.4937 |
| Variables | RF | GBR | SVR | NN | |
|---|---|---|---|---|---|
| Jiangxia | F18, F17, F7, F6 | 0.2974 | 0.3076 | 0.3674 | 0.3234 |
| Huangpi | 0.3980 | 0.4237 | 0.4843 | 0.4647 | |
| Jiangxia | F18, F17, F7, F6, F9 | 0.2903 | 0.3171 | 0.3655 | 0.2946 |
| Huangpi | 0.3911 | 0.4079 | 0.4808 | 0.4269 | |
| Jiangxia | F18, F17, F6, F7, F9, F10 | 0.2963 | 0.3246 | 0.4152 | 0.3110 |
| Huangpi | 0.3959 | 0.3878 | 0.4754 | 0.3783 | |
| Jiangxia | F18, F17, F6, F7, F9, F10, F11, F20, F24, F5 | 0.3258 | 0.3119 | 0.4793 | 0.3050 |
| Huangpi | 0.4488 | 0.4477 | 0.5111 | 0.4389 | |
| Jiangxia | F18, F17, F6, F7, F9, F10, F11, F24, F8, F4, F20, F5 | 0.3506 | 0.3194 | 0.4477 | 0.3019 |
| Huangpi | 0.4796 | 0.4649 | 0.5189 | 0.4235 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Cai, Z.; Qian, Y.; Chen, F. Identifying Urban Poverty Using High-Resolution Satellite Imagery and Machine Learning Approaches: Implications for Housing Inequality. Land 2021, 10, 648. https://0-doi-org.brum.beds.ac.uk/10.3390/land10060648
Li G, Cai Z, Qian Y, Chen F. Identifying Urban Poverty Using High-Resolution Satellite Imagery and Machine Learning Approaches: Implications for Housing Inequality. Land. 2021; 10(6):648. https://0-doi-org.brum.beds.ac.uk/10.3390/land10060648
Chicago/Turabian StyleLi, Guie, Zhongliang Cai, Yun Qian, and Fei Chen. 2021. "Identifying Urban Poverty Using High-Resolution Satellite Imagery and Machine Learning Approaches: Implications for Housing Inequality" Land 10, no. 6: 648. https://0-doi-org.brum.beds.ac.uk/10.3390/land10060648