
Factors Affecting Landslide Susceptibility Mapping: Assessing the Influence of Different Machine Learning Approaches, Sampling Strategies and Data Splitting

 ,
,  and
and
Abstract
:
1. Introduction
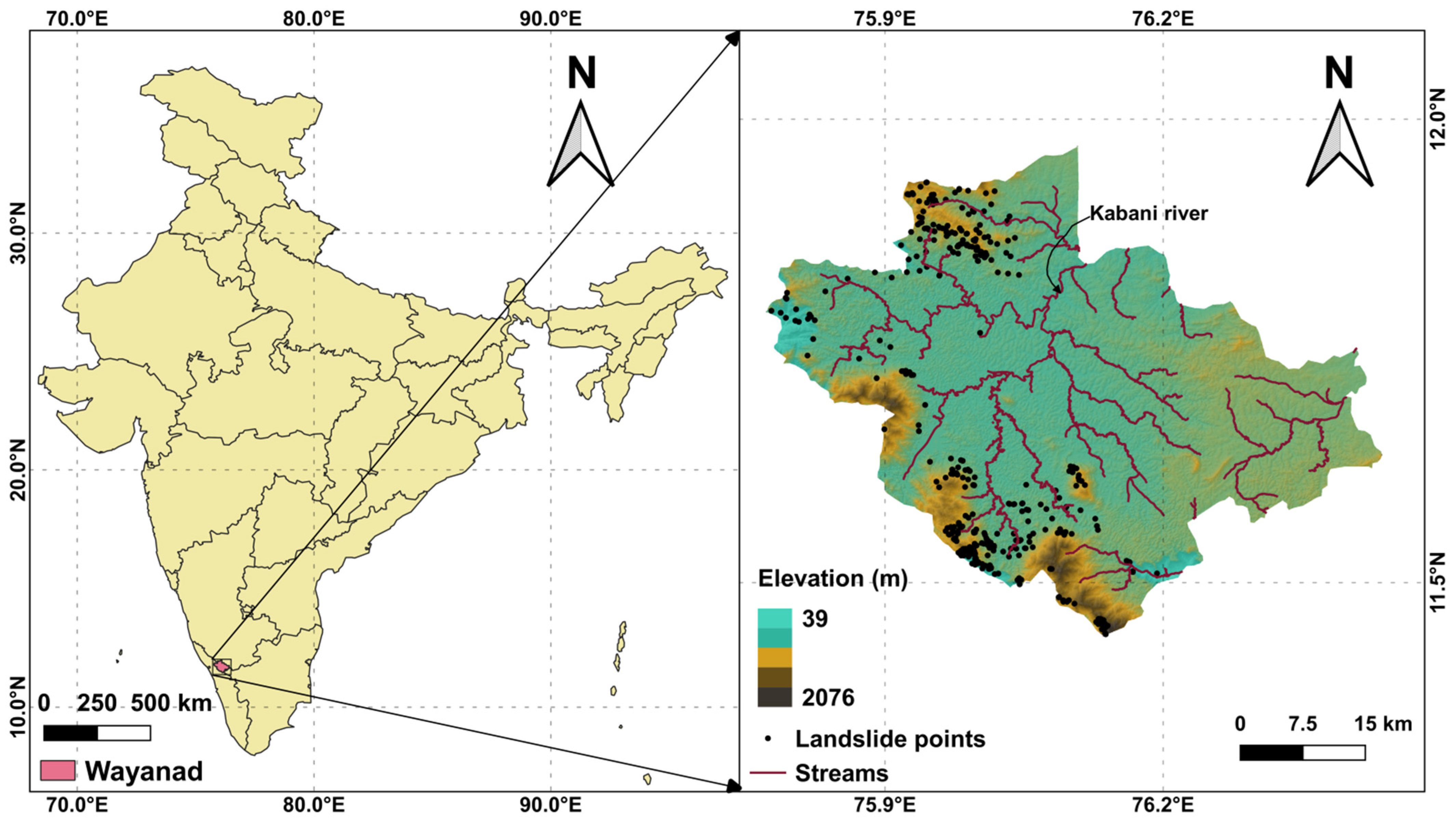
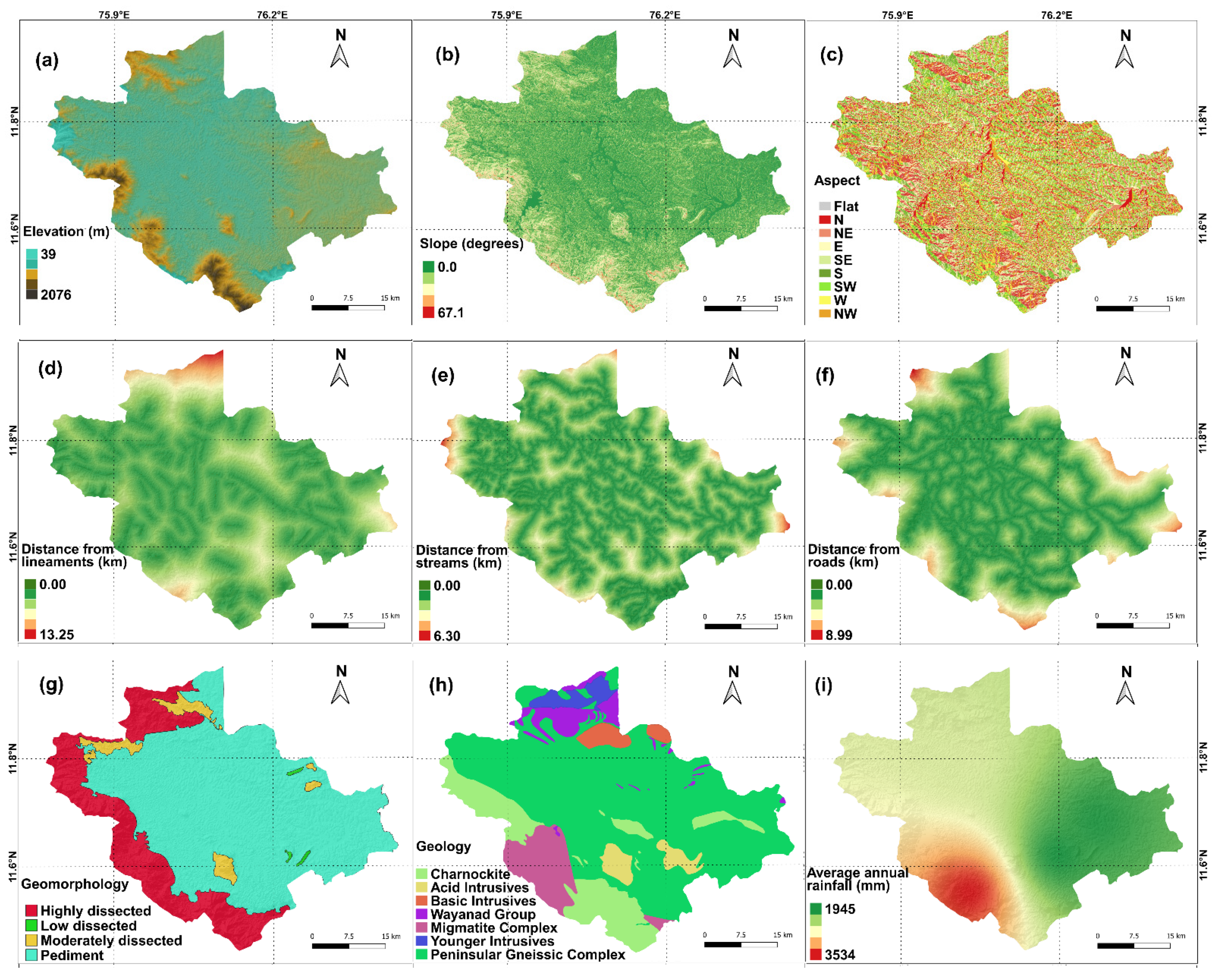
2. Study Area
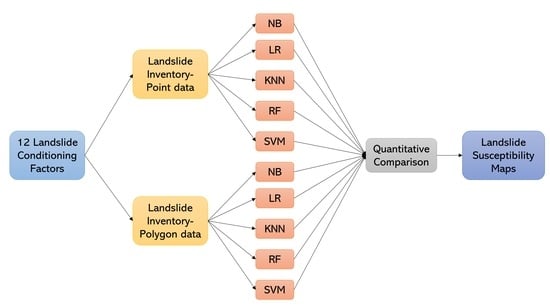
3. Methodology
3.1. Machine Learning Algorithms
3.1.1. Naïve Bayes
3.1.2. Logistic Regression
3.1.3. K-Nearest Neighbors
3.1.4. Random Forest
3.1.5. Support Vector Machines
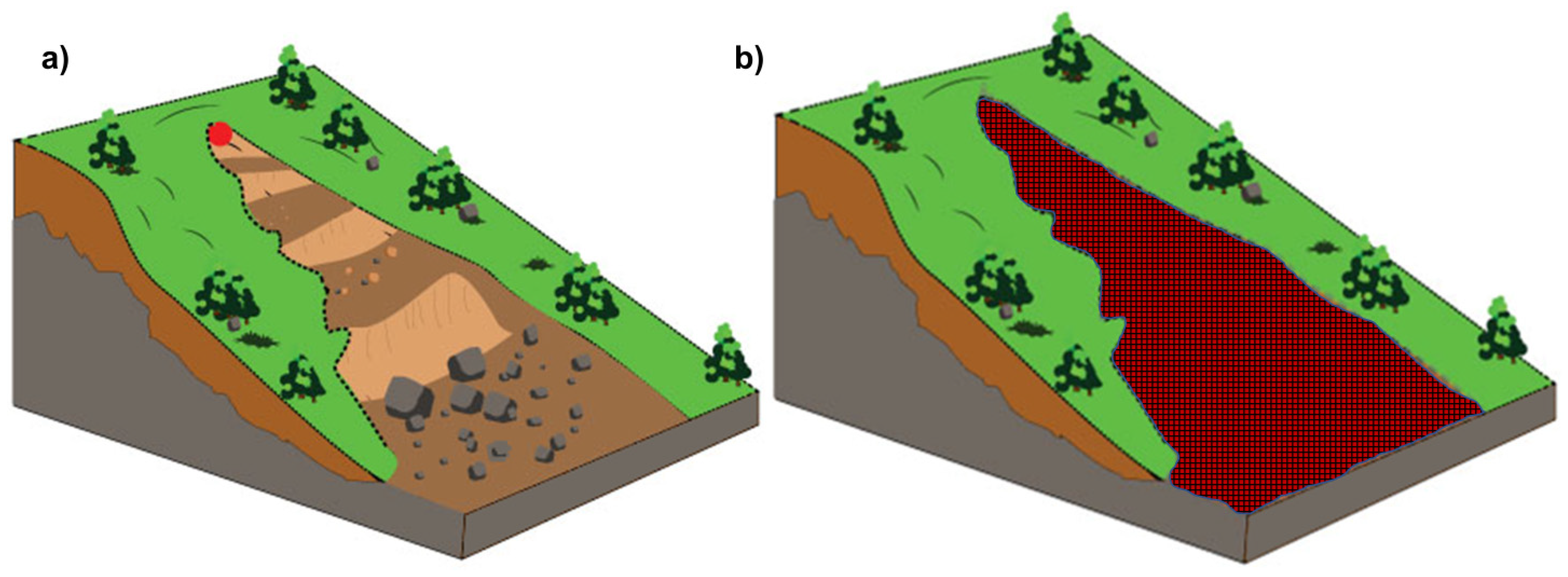
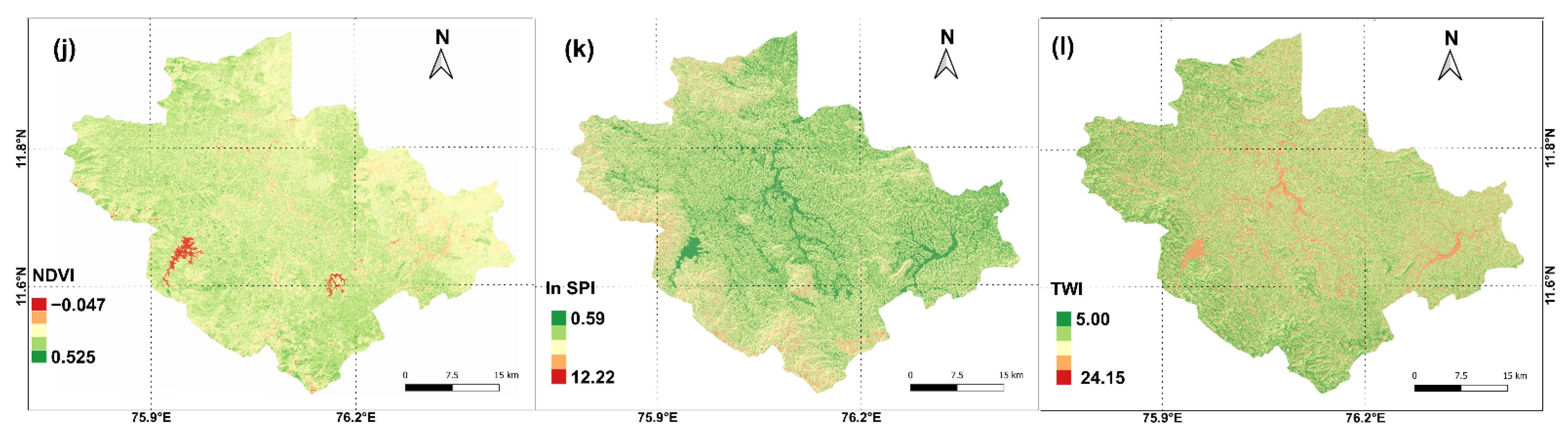
3.2. Data Collection and Sampling Strategies
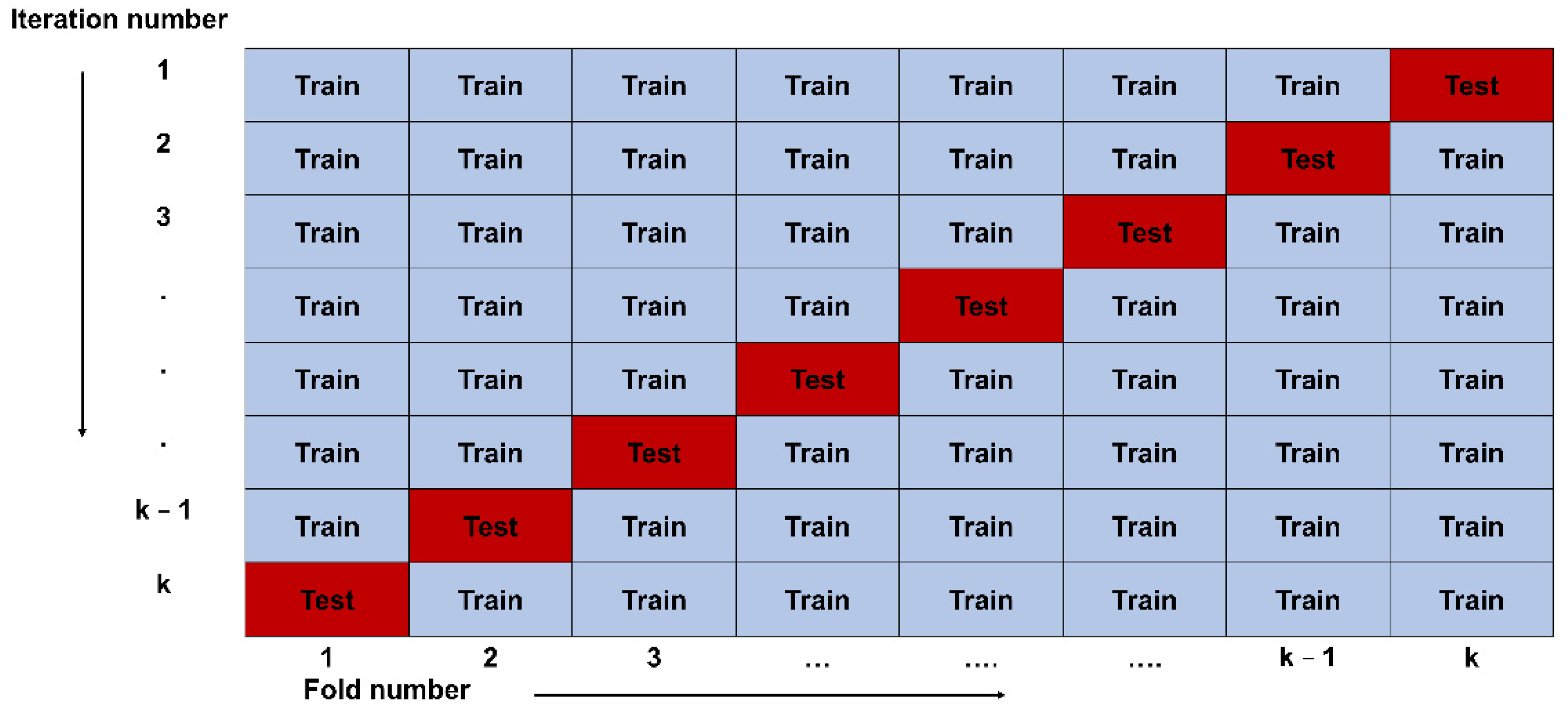
3.3. K-Fold Cross Validation and Data Splitting
3.4. Quantitative Comparison
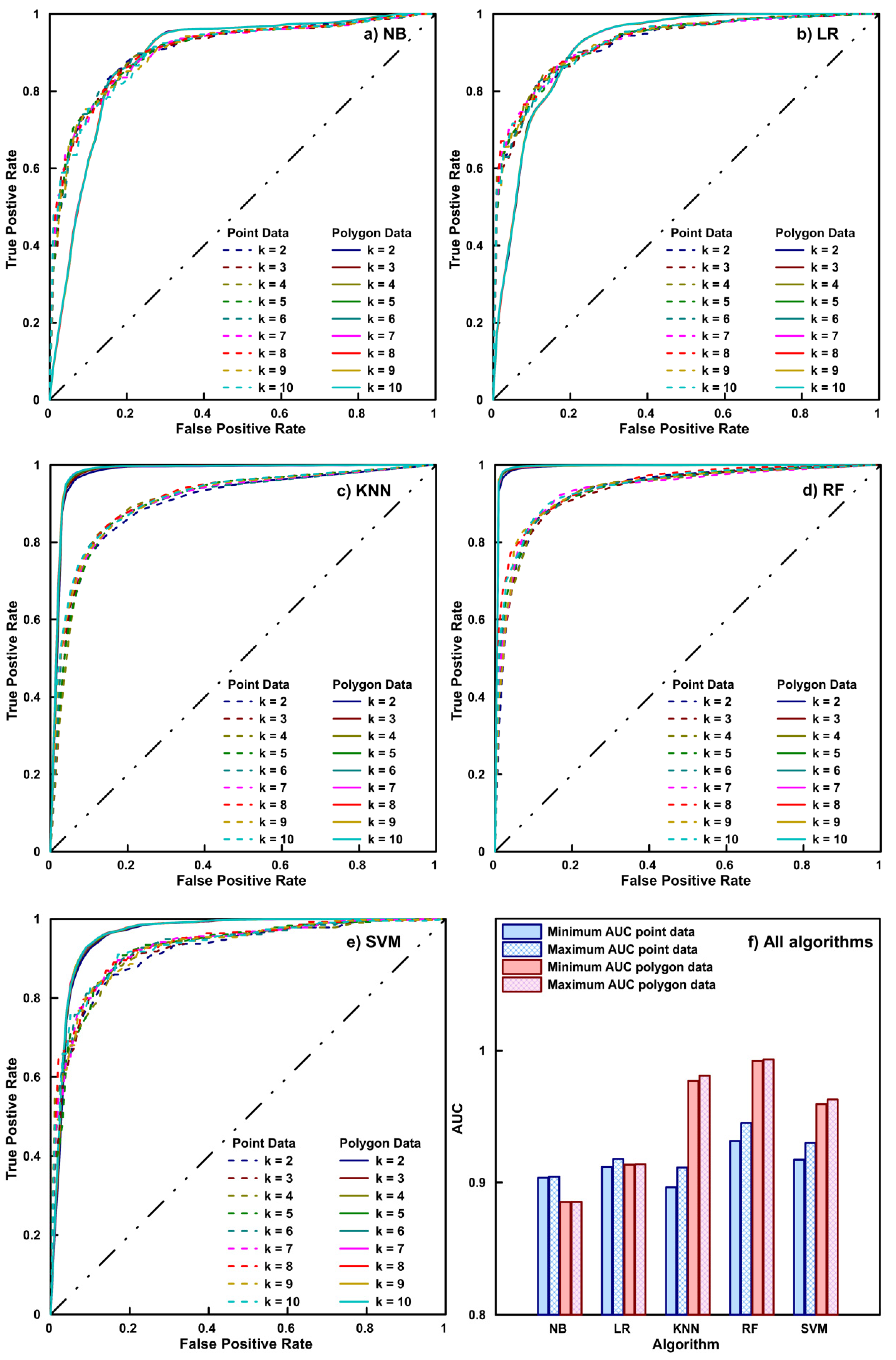
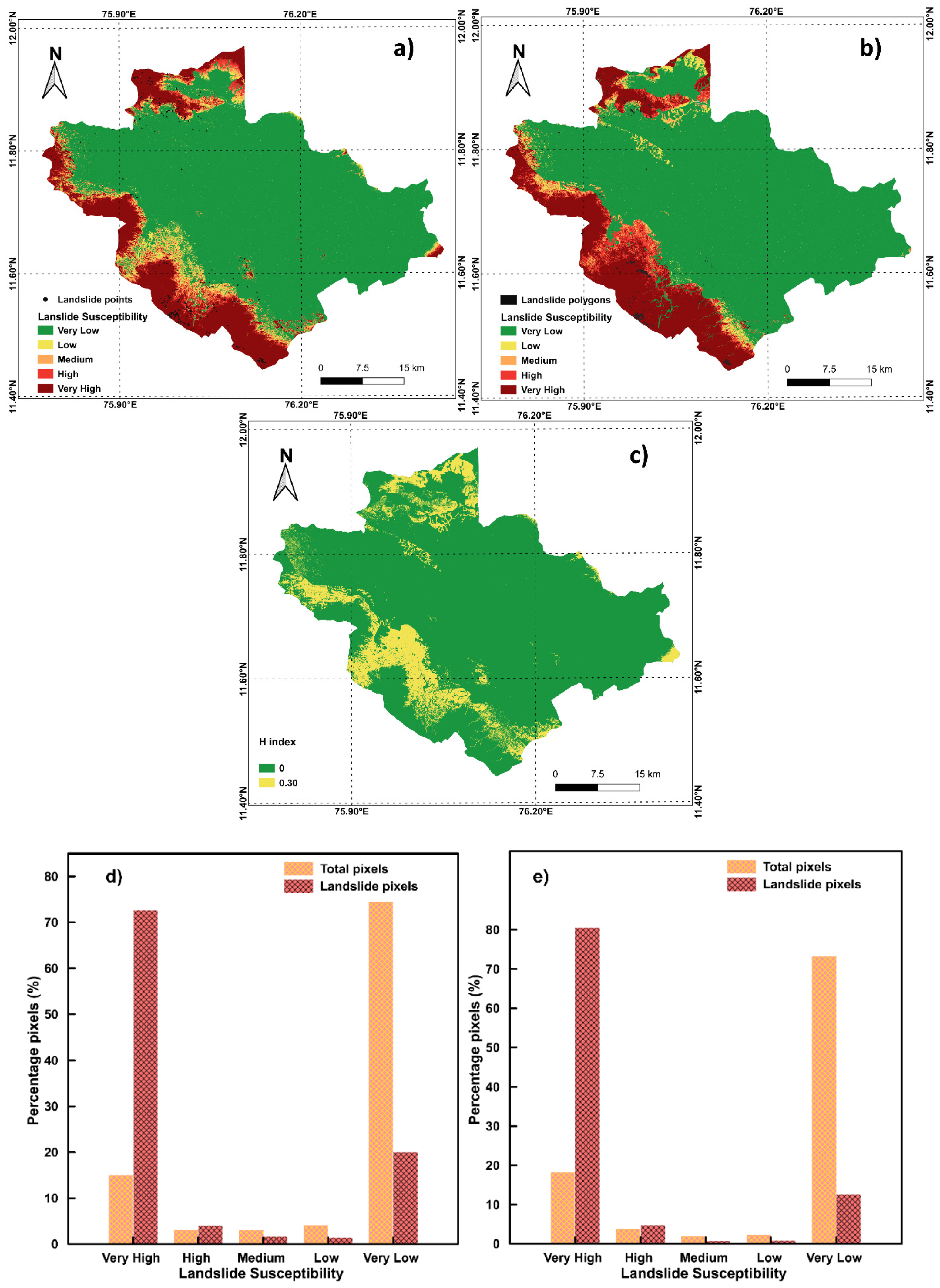
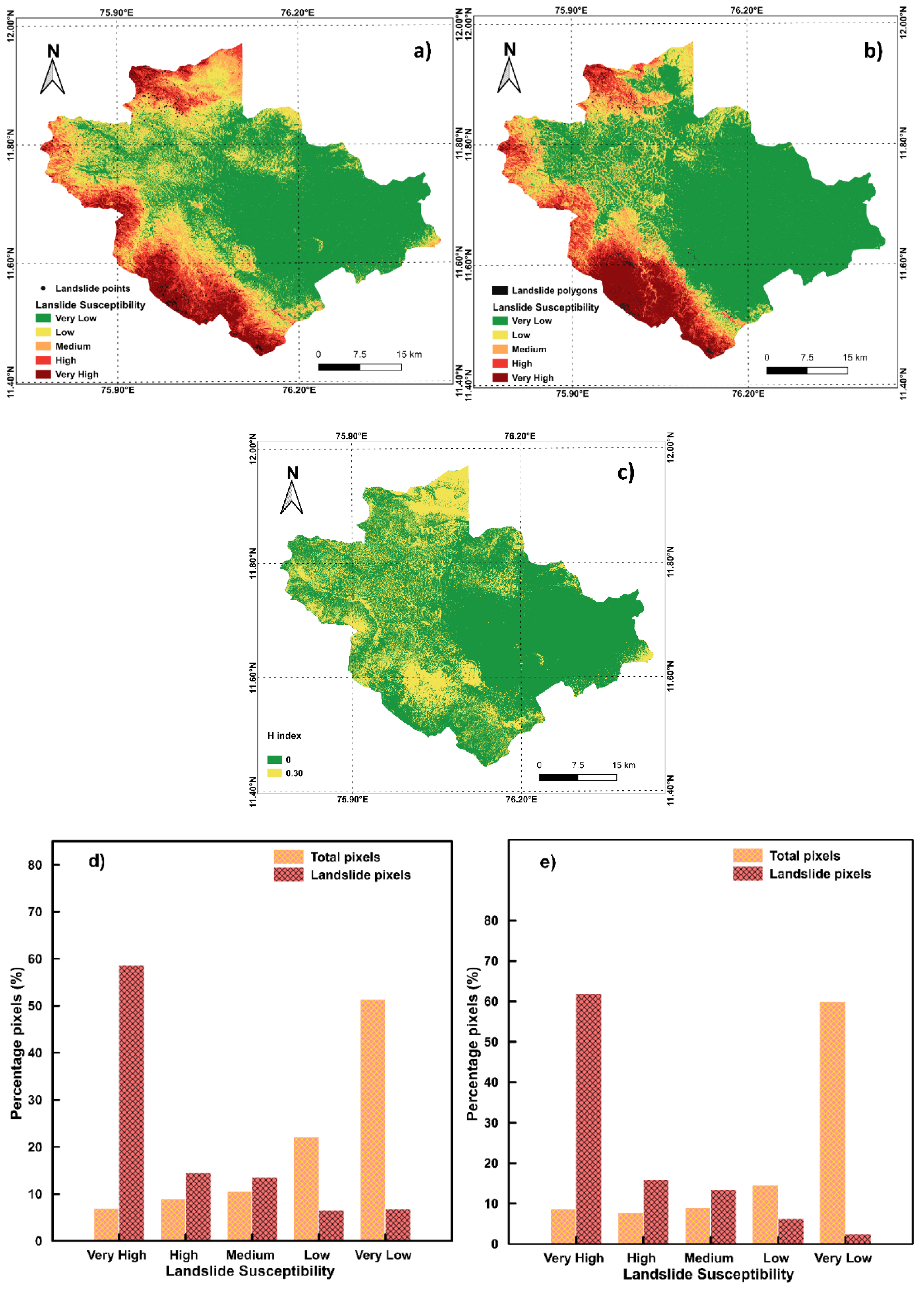
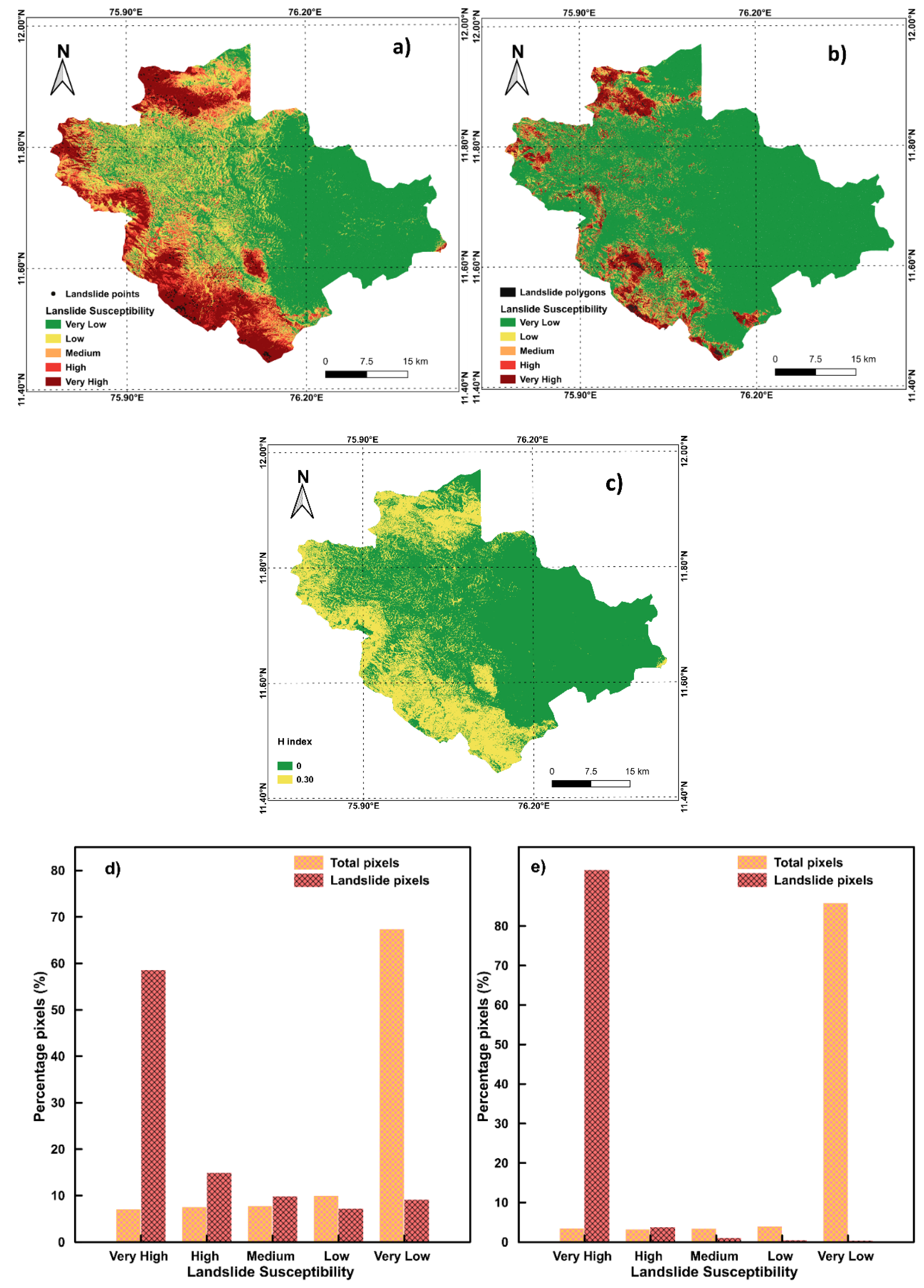
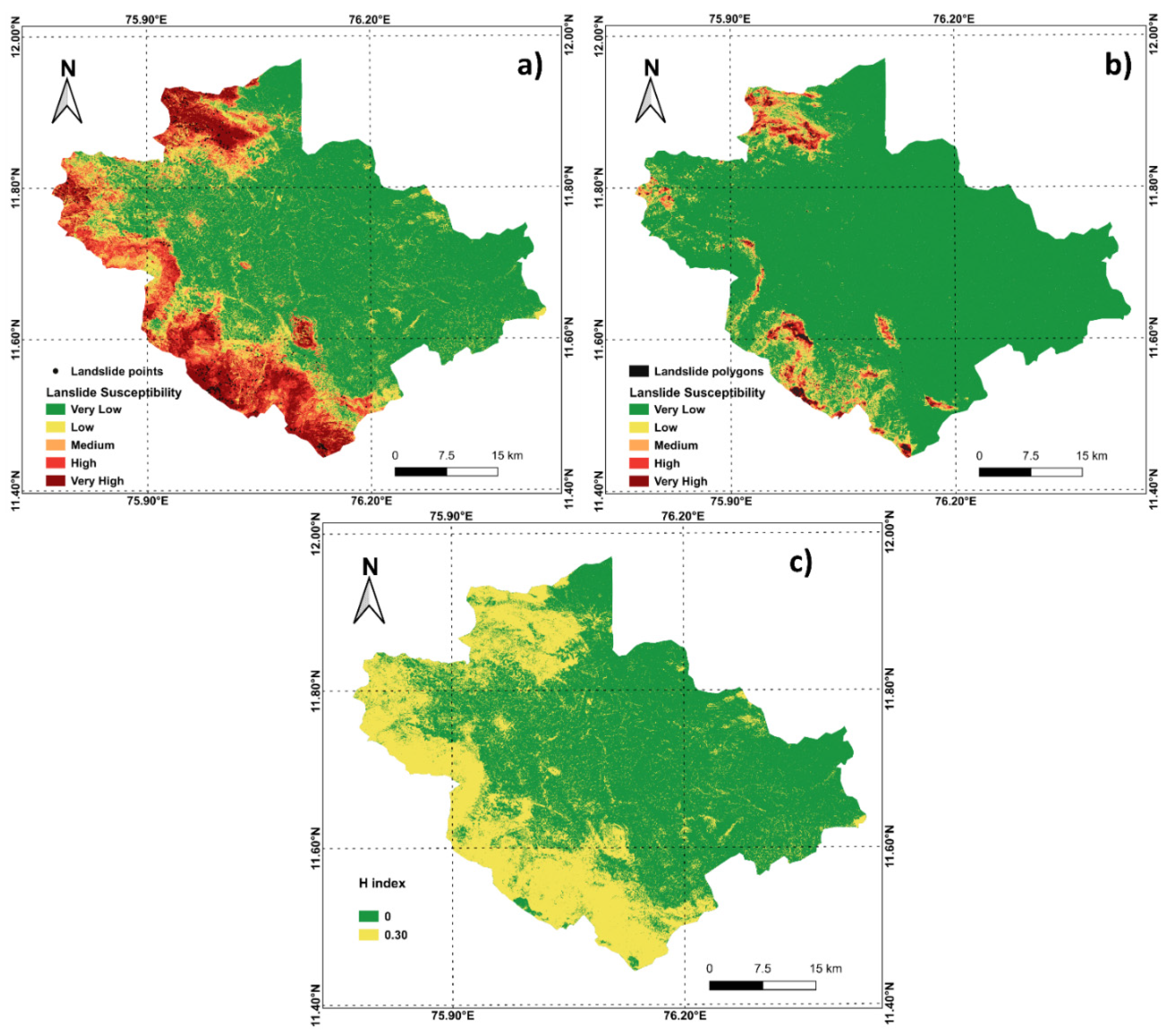
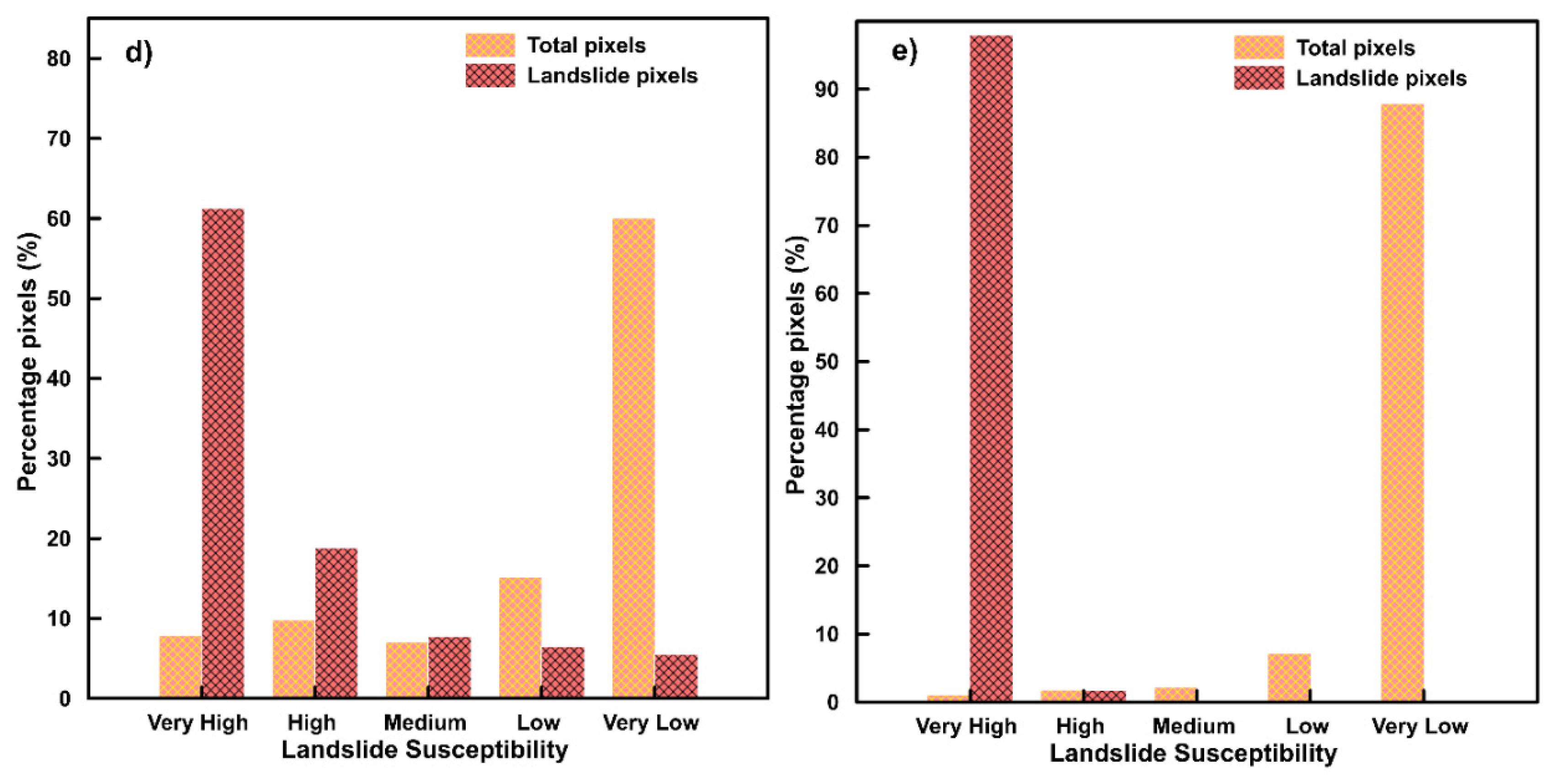
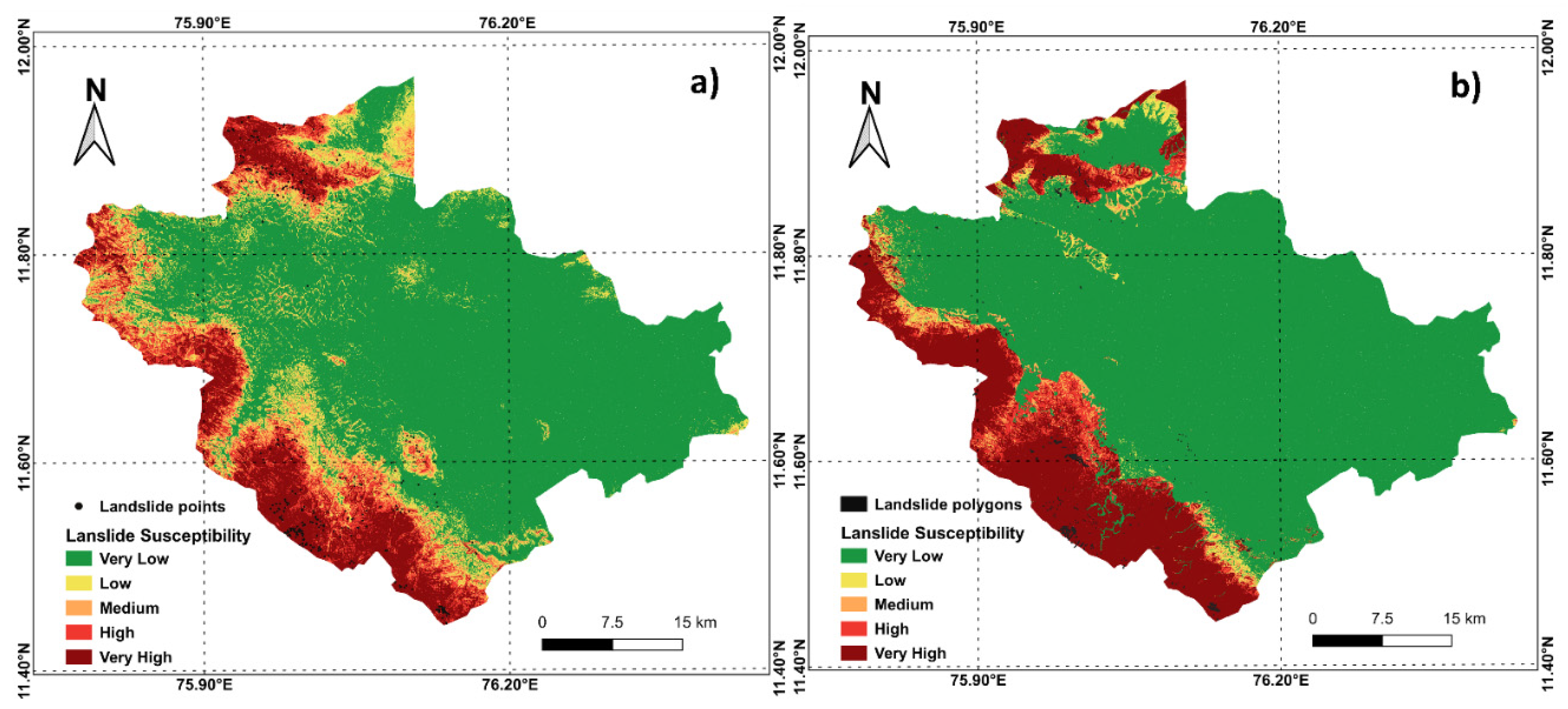
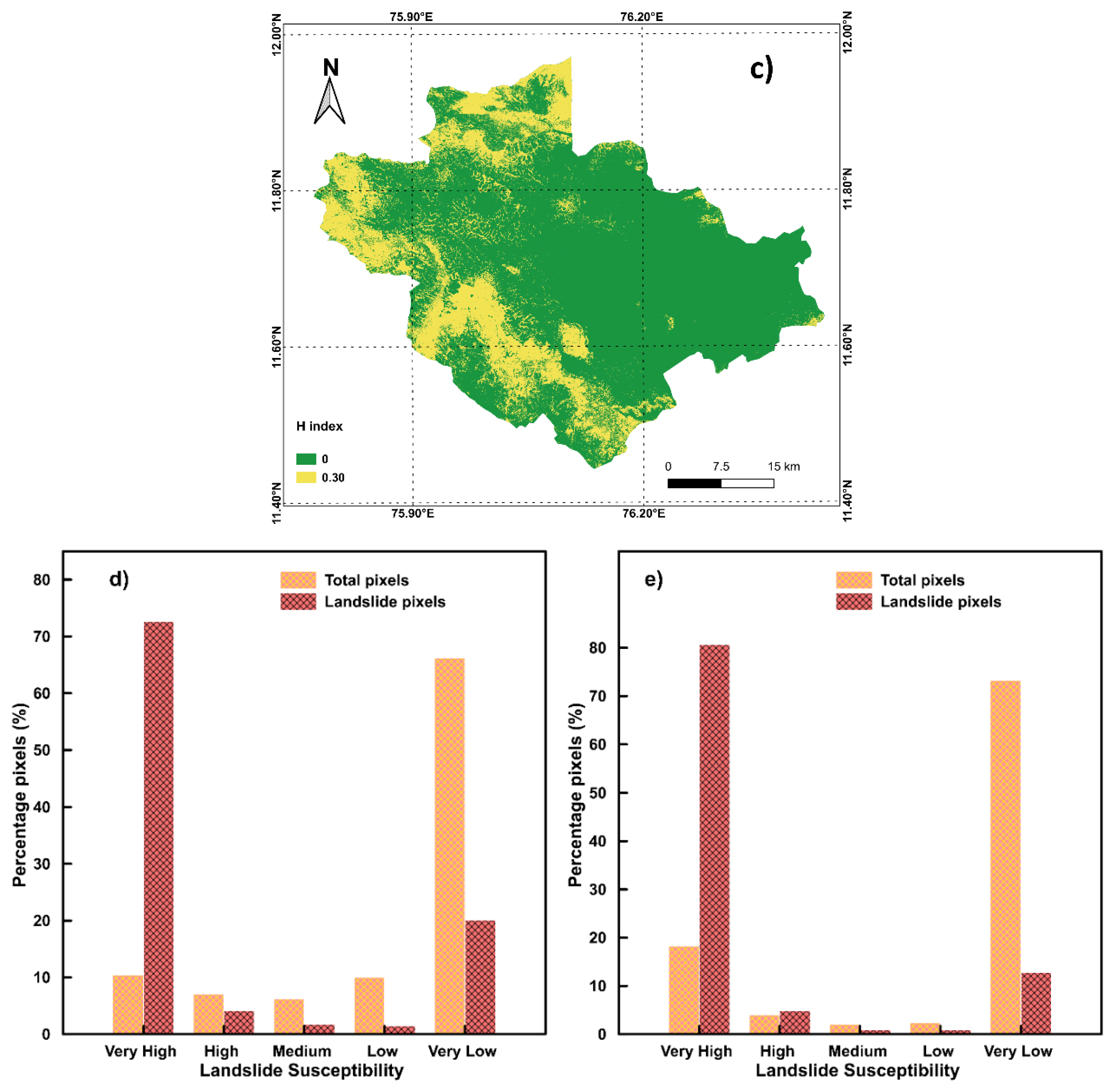
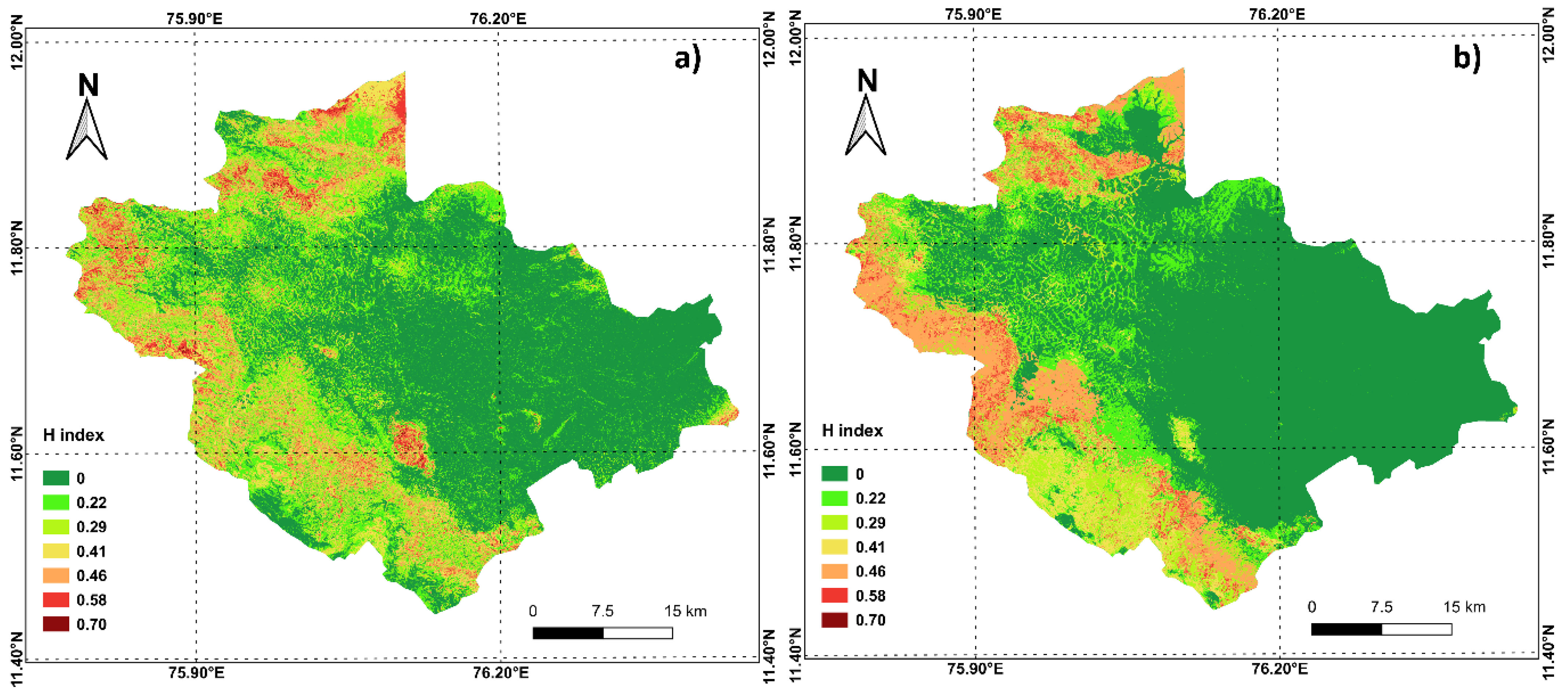
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Froude, M.J.; Petley, D.N. Global fatal landslide occurrence from 2004 to 2016. Nat. Hazards Earth Syst. Sci. 2018, 18, 2161–2181. [Google Scholar] [CrossRef] [Green Version]
- Dou, J.; Yunus, A.P.; Merghadi, A.; Shirzadi, A.; Nguyen, H.; Hussain, Y.; Avtar, R.; Chen, Y.; Pham, B.T.; Yamagishi, H. Different sampling strategies for predicting landslide susceptibilities are deemed less consequential with deep learning. Sci. Total Environ. 2020, 720, 137320. [Google Scholar] [CrossRef]
- Abraham, M.T.; Satyam, N.; Rosi, A.; Pradhan, B.; Segoni, S. Usage of antecedent soil moisture for improving the performance of rainfall thresholds for landslide early warning. Catena 2021, 200, 105147. [Google Scholar] [CrossRef]
- Pradhan, B.; Sameen, M.I. Effects of the Spatial Resolution of Digital Elevation Models and Their Products on Landslide Susceptibility Mapping, 1st ed.; Pradhan, B., Ed.; Springer: Cham, Switzerland, 2017; ISBN 978-3-319-55341-2. [Google Scholar]
- Merghadi, A.; Yunus, A.P.; Dou, J.; Whiteley, J.; Pham, B.T.; Bui, D.T.; Avtar, R.; Abderrahmane, B. Machine learning methods for landslide susceptibility studies: A comparative overview of algorithm performance. Earth Sci. Rev. 2020, 207, 103225. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Korup, O.; Stolle, A. Landslide prediction from machine learning. Geol. Today 2014, 30, 26–33. [Google Scholar] [CrossRef]
- Li, Y.; Liu, X.; Han, Z.; Dou, J. Spatial proximity-based geographically weighted regression model for landslide susceptibility assessment: A case study of Qingchuan area, China. Appl. Sci. 2020, 10, 1107. [Google Scholar] [CrossRef] [Green Version]
- Simon, N.; Crozier, M.; de Roiste, M.; Rafek, A.G. Point based assessment: Selecting the best way to represent landslide polygon as point frequency in landslide investigation. Electron J. Geotech. Eng. 2013, 18, 775–784. [Google Scholar]
- Süzen, M.L.; Doyuran, V. Data driven bivariate landslide susceptibility assessment using geographical information systems: A method and application to Asarsuyu catchment, Turkey. Eng. Geol. 2004, 71, 303–321. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shirzadi, A.; Shahabi, H.; Geertsema, M.; Omidvar, E.; Clague, J.; Thai Pham, B.; Dou, J.; Talebpour Asl, D.; Bin Ahmad, B.; et al. New ensemble models for shallow landslide susceptibility modeling in a semi-arid watershed. Forests 2019, 10, 743. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez, J.D.; Pérez, A.; Lozano, J.A. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 569–575. [Google Scholar] [CrossRef]
- Abraham, M.T.; Satyam, N.; Rosi, A.; Pradhan, B.; Segoni, S. The selection of rain gauges and rainfall parameters in estimating intensity-duration thresholds for landslide occurrence: Case study from Wayanad (India). Water 2020, 12, 1000. [Google Scholar] [CrossRef] [Green Version]
- Abraham, M.T.; Satyam, N.; Rosi, A. Empirical rainfall thresholds for occurrence of landslides in Wayanad, India. EGU Gen. Assem. 2020, 5194. [Google Scholar] [CrossRef]
- Department of Mining and Geology Kerala. District Survey Report of Minor. Minerals; Department of Mining and Geology Kerala: Thiruvananthapuram, India, 2016. [Google Scholar]
- Abraham, M.T.; Satyam, N.; Reddy, S.K.P.; Pradhan, B. Runout modeling and calibration of friction parameters of Kurichermala debris flow, India. Landslides 2021, 18, 737–754. [Google Scholar] [CrossRef]
- United Nations Development Programme. Kerala Post Disaster Needs Assessment Floods and Landslides-August 2018; United Nations Development Programme: Thiruvananthapuram, India, 2018. [Google Scholar]
- Hao, L.; van Westen, C.; Martha, T.R.; Jaiswal, P.; McAdoo, B.G. Constructing a complete landslide inventory dataset for the 2018 monsoon disaster in Kerala, India, for land use change analysis. Earth Syst. Sci. Data 2020, 12, 2899–2918. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.W.; Khosravi, K.; Yang, Y.; Pham, B.T. Assessment of advanced random forest and decision tree algorithms for modeling rainfall-induced landslide susceptibility in the Izu-Oshima Volcanic Island, Japan. Sci. Total Environ. 2019, 662, 332–346. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Miner, A.; Vamplew, P.; Windle, D.J.; Flentje, P.; Warner, P. A Comparative study of various data mining techniques as applied to the modeling of landslide susceptibility on the Bellarine Peninsula, Victoria, Australia. In Proceedings of the 11th IAEG Congress of the International Association of Engineering Geology and the Environment, Auckland, New Zealand, 5–10 September 2010; pp. 1327–1336. [Google Scholar]
- Cabrera, A.F. Logistic regression analysis in higher education: An applied perspective. High. Educ. Handb. Theory Res. 1994, 10, 225–256. [Google Scholar]
- Huang, X.; Wu, W.; Shen, T.; Xie, L.; Qin, Y.; Peng, S.; Zhou, X.; Fu, X.; Li, J.; Zhang, Z.; et al. Estimating forest canopy cover by multiscale remote sensing in northeast Jiangxi, China. Land 2021, 10, 433. [Google Scholar] [CrossRef]
- Omohundro, S.M. Five Balltree Construction Algorithms; Tech. Rep. TR-89-063; International Computer Science Institute (ICSI): Berkeley, CA, USA, 1947. [Google Scholar]
- Marjanovic, M.; Bajat, B.; Kovacevic, M. Landslide susceptibility assessment with machine learning algorithms. In Proceedings of the 2009 International Conference on Intelligent Networking and Collaborative Systems, IEEE, Barcelona, Spain, 4–6 November 2009; pp. 273–278. [Google Scholar]
- Bröcker, J.; Smith, L.A. Increasing the reliability of reliability diagrams. Weather Forecast. 2007, 22, 651–661. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the International Conference on Document Analysis and Recognition, ICDAR, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Chen, W.; Sun, Z.; Zhao, X.; Lei, X.; Shirzadi, A.; Shahabi, H. Performance evaluation and comparison of bivariate statistical-based artificial intelligence algorithms for spatial prediction of landslides. ISPRS Int. J. Geo Inf. 2020, 9, 696. [Google Scholar] [CrossRef]
- Zhou, X.; Wu, W.; Lin, Z.; Zhang, G.; Chen, R.; Song, Y.; Wang, Z.; Lang, T.; Qin, Y.; Ou, P.; et al. Zonation of landslide susceptibility in Ruijin, Jiangxi, China. Int. J. Environ. Res. Public Health 2021, 18, 5906. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Wu, W.; Qin, Y.; Lin, Z.; Zhang, G.; Chen, R.; Song, Y.; Lang, T.; Zhou, X.; Huangfu, W.; et al. Mapping landslide hazard risk using random forest algorithm in Guixi, Jiangxi, China. ISPRS Int. J. Geo-Inf. 2020, 9, 695. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Suppport vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Vapnik, V.; Lerner, A.Y. Recognition of patterns with help of generalized portraits. Avtomat. Telemekh 1963, 24, 774–780. [Google Scholar]
- Yao, X.; Dai, F.C. Support vector machine modeling of landslide susceptibility using a GIS: A case study. IAEG2006 2006, 793, 1–12. [Google Scholar]
- Gao, R.; Wang, C.; Liang, Z.; Han, S.; Li, B. A research on susceptibility mapping of multiple geological hazards in Yanzi river basin, China. ISPRS Int. J. Geo Inf. 2021, 10, 218. [Google Scholar] [CrossRef]
- Alaska Satellite Facility Distributed Active Archive Center (ASF DAAC) Dataset: ASF DAAC 2015, ALOS PALSAR Radiometric Terrain Corrected high res; Includes Material© JAXA/METI 2007. Available online: https://asf.alaska.edu/data-sets/derived-data-sets/alos-palsar-rtc/alos-palsar-radiometric-terrain-correction/ (accessed on 13 December 2020).
- Capitani, M.; Ribolini, A.; Bini, M. The slope aspect: A predisposing factor for landsliding? Comptes Rendus Geosci. 2013, 345, 427–438. [Google Scholar] [CrossRef]
- Zhang, T.; Han, L.; Zhang, H.; Zhao, Y.; Li, X.; Zhao, L. GIS-based landslide susceptibility mapping using hybrid integration approaches of fractal dimension with index of entropy and support vector machine. J. Mt. Sci. 2019, 16, 1275–1288. [Google Scholar] [CrossRef]
- Achour, Y.; Pourghasemi, H.R. How do machine learning techniques help in increasing accuracy of landslide susceptibility maps? Geosci. Front. 2020, 11, 871–883. [Google Scholar] [CrossRef]
- Ray, R.L.; Jacobs, J.M.; Cosh, M.H. Landslide susceptibility mapping using downscaled AMSR-E soil moisture: A case study from Cleveland Corral, California, US. Remote Sens. Environ. 2010, 114, 2624–2636. [Google Scholar] [CrossRef]
- Department of Economics and Statistics Government of Kerala Official website of Department of Economics & Statistics, Government of Kerala. Available online: http://www.ecostat.kerala.gov.in/index.php/agri-state-wyd (accessed on 5 September 2021).
- Fiorucci, F.; Ardizzone, F.; Mondini, A.C.; Viero, A.; Guzzetti, F. Visual interpretation of stereoscopic NDVI satellite images to map rainfall-induced landslides. Landslides 2019, 16, 165–174. [Google Scholar] [CrossRef]
- India Meteorological Department (IMD) Data Supply Portal. Available online: http://dsp.imdpune.gov.in/ (accessed on 3 May 2019).
- Sun, D.; Xu, J.; Wen, H.; Wang, Y. An optimized random forest model and its generalization ability in landslide susceptibility mapping: Application in two areas of Three Gorges Reservoir, China. J. Earth Sci. 2020, 31, 1068–1086. [Google Scholar] [CrossRef]
- Ou, P.; Wu, W.; Qin, Y.; Zhou, X.; Huangfu, W.; Zhang, Y.; Xie, L.; Huang, X.; Fu, X.; Li, J.; et al. Assessment of landslide hazard in Jiangxi using geo-information technology. Front. Earth Sci. 2021, 9, 178. [Google Scholar] [CrossRef]
- Chalkias, C.; Ferentinou, M.; Polykretis, C. GIS-based landslide susceptibility mapping on the Peloponnese Peninsula, Greece. Geosciences 2014, 4, 176–190. [Google Scholar] [CrossRef] [Green Version]
- El-Fengour, M.; El Motaki, H.; El Bouzidi, A. Landslides susceptibility modelling using multivariate logistic regression model in the Sahla Watershed in northern Morocco. Soc. Nat. 2021, 33. [Google Scholar] [CrossRef]
- Sharma, S.; Mahajan, A.K. Information value based landslide susceptibility zonation of Dharamshala region, northwestern Himalaya, India. Spat. Inf. Res. 2019, 27, 553–564. [Google Scholar] [CrossRef]
- Frattini, P.; Crosta, G.; Carrara, A. Techniques for evaluating the performance of landslide susceptibility models. Eng. Geol. 2010, 111, 62–72. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Landslide Susceptibility Maps Predicting Each Class | H-Index | ||||
|---|---|---|---|---|---|
| Class 1 | Class 2 | Class 3 | Class 4 | Class 5 | |
| 5 | 0 | 0 | 0 | 0 | 0.00 |
| 4 | 1 | 0 | 0 | 0 | 0.22 |
| 3 | 2 | 0 | 0 | 0 | 0.29 |
| 3 | 1 | 1 | 0 | 0 | 0.41 |
| 2 | 2 | 1 | 0 | 0 | 0.46 |
| 2 | 1 | 1 | 1 | 0 | 0.58 |
| 1 | 1 | 1 | 1 | 1 | 0.70 |
| Algorithm | NB | LR | KNN | RF | SVM |
|---|---|---|---|---|---|
| Point Data | |||||
| Min Accuracy (%) (k) | 82.70 (3) | 86.67 (3) | 83.00 (2) | 86.20 (3) | 84.80 (2) |
| Max Accuracy (%) (k) | 83.30 (8) | 87.41 (8) | 84.71 (8) | 88.12 (8) | 86.63 (8) |
| Min AUC (k) | 0.903 (3) | 0.912 (3) | 0.896 (2) | 0.932 (3) | 0.917 (2) |
| Max AUC (k) | 0.904 (8) | 0.920 (8) | 0.911 (8) | 0.954 (8) | 0.930 (8) |
| Polygon Data | |||||
| Min Accuracy (%) (k) | 83.32 (2) | 83.44 (2) | 93.23 (2) | 96.13 (2) | 91.00 (2) |
| Max Accuracy (%) (k) | 83.34 (6) | 83.45 (5) | 95.22 (8) | 98.14 (9) | 91.61 (9) |
| Min AUC (k) | 0.885 (2) | 0.914 (2) | 0.977 (2) | 0.992 (2) | 0.959 (2) |
| Max AUC (k) | 0.885 (6) | 0.914 (5) | 0.981 (8) | 0.993 (9) | 0.963 (9) |
| H Index | Point Data | Polygon Data |
|---|---|---|
| Percentage Pixels (%) | ||
| 0.00 | 47.56 | 58.06 |
| 0.22 | 19.31 | 13.25 |
| 0.29 | 13.04 | 7.47 |
| 0.41 | 8.93 | 6.96 |
| 0.46 | 7.52 | 11.48 |
| 0.58 | 3.47 | 2.77 |
| 0.70 | 0.17 | 0.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abraham, M.T.; Satyam, N.; Lokesh, R.; Pradhan, B.; Alamri, A. Factors Affecting Landslide Susceptibility Mapping: Assessing the Influence of Different Machine Learning Approaches, Sampling Strategies and Data Splitting. Land 2021, 10, 989. https://0-doi-org.brum.beds.ac.uk/10.3390/land10090989
Abraham MT, Satyam N, Lokesh R, Pradhan B, Alamri A. Factors Affecting Landslide Susceptibility Mapping: Assessing the Influence of Different Machine Learning Approaches, Sampling Strategies and Data Splitting. Land. 2021; 10(9):989. https://0-doi-org.brum.beds.ac.uk/10.3390/land10090989
Chicago/Turabian StyleAbraham, Minu Treesa, Neelima Satyam, Revuri Lokesh, Biswajeet Pradhan, and Abdullah Alamri. 2021. "Factors Affecting Landslide Susceptibility Mapping: Assessing the Influence of Different Machine Learning Approaches, Sampling Strategies and Data Splitting" Land 10, no. 9: 989. https://0-doi-org.brum.beds.ac.uk/10.3390/land10090989