
A Dynamically Adjusted Subspace Gradient Method and Its Application in Image Restoration

1
Guangxi (ASEAN) Financial Research Center, Guangxi University of Finance and Economics, Nanning 530003, China
2
College of Mathematics and Information Science, Guangxi University, Nanning 530005, China
3
School of Business Administration, Guangxi University of Finance and Economics, Nanning 530003, China
4
Guangxi Key Laboratory Cultivation Base of Cross-Border E-Commerce Intelligent Information Processing, Guangxi University of Finance and Economics, Nanning 530003, China
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Symmetry 2021, 13(12), 2450; https://0-doi-org.brum.beds.ac.uk/10.3390/sym13122450
Submission received: 8 December 2021
/
Revised: 14 December 2021
/
Accepted: 15 December 2021
/
Published: 20 December 2021
(This article belongs to the Special Issue PDE, Optimization Modeling and Symmetry in Multi-Dimensional Data and Low-Level Vision Tasks)
Abstract
:In this paper, a new subspace gradient method is proposed in which the search direction is determined by solving an approximate quadratic model in which a simple symmetric matrix is used to estimate the Hessian matrix in a three-dimensional subspace. The obtained algorithm has the ability to automatically adjust the search direction according to the feedback from experiments. Under some mild assumptions, we use the generalized line search with non-monotonicity to obtain remarkable results, which not only establishes the global convergence of the algorithm for general functions, but also R-linear convergence for uniformly convex functions is further proved. The numerical performance for both the traditional test functions and image restoration problems show that the proposed algorithm is efficient.
1. Introduction
The Conjugate Gradient (CG) method is dedicated to solving the unconstrained optimization problem:
where is smooth and the gradient of at is marked . The advantages of its simple form and low storage requirements make the CG method a powerful tool for dealing with problem (1). It starts at a starting point and generates an iterative sequence in the following form:
that is, moves forward by one step along the search direction and reaches the -th iteration point .
The direction is usually defined as
where is CG parameter. The different corresponds to different CG methods, such as Polak and Ribiere (PRP) [1], Hestenes and Stiefel (HS) [2], Liu and Storey (LS) [3], Fletcher and Reeves (FR) [4], Dai and Yuan (DY) [5], and the conjugate descent (CD) method [6]. In addition, more relevant research and the progress of CG method can be found in the literature [7,8,9,10].
The step size can be obtained by different rules. In this paper, we focus on the following generalized line search, which has been shown to be very efficient for CG methods in [11].
where the definition of is as follows:
From Equation (5), we can find that is a convex combination of the function values to . The generalized line search is non-monotonic, which facilitates the establishment of the global convergence of the algorithm under milder conditions.
Subspace technology plays an extraordinary role in solving large-scale unconstrained optimization problems. As the scale of optimization problems to be dealt with continues to expand, subspace technology has attracted increased attention from researchers. Using subspace minimization technology with CG method, Yuan and Stoer [12] creatively proposed theSMCG method, in which the approximate function of is minimized on the subspace , and the expression of the search direction is derived:
where and are parameters, and . Obviously, the SMCG method is a further promotion based on the CG method, and at the same time, it has a profound influence on the subsequent vigorous development of subspace technology. Based on Yuan’s ideas above, Andrei [13] developed a new SMCG method, in which it further expands the search direction, develops into three subspaces, and used the acceleration strategy. Inspired by Andrei, Yang et al. [14] applied the technique of subspace minimization to another special three-term subspace and came up with a new SMCG method. On the same subspace, Li et al. [10] conducted a more in-depth study of Yang’s results, analyzed more complex three-parameter situations, and set different conditions to dynamically select the search direction under different dimensions of subspace. Subspace technology has more extensive applications. Dai [15] proposed a new method called BBCG by fusing it with the Barzilai–Borwein [16] method and compared the performance of several BBCG methods proposed in the article through numerical experiments. It was found that the BBCG3 method has better performance. Many scholars have also tried to integrate the idea of minimizing subspace into the trust region method. For related research, readers can refer to [17]. More research on the use of subspace technology to construct different methods is still in progress [18,19,20,21,22].
The outline of this article is as follows: in Section 2, we give preliminary information. In Section 3, the search direction is be discussed first, and then the obtained algorithm is proposed. Based on the above-mentioned work, under some mild assumptions, the global convergence of the algorithm for general functions is proved; more importantly, the result of R-linear convergence for uniformly convex functions is also established. Some numerical results for solving unconstrained opitmization problems and image restoration problems are shown in Section 4. The conclusion and discussion are presented in Section 5.
2. Preliminary
The main work of this section is: in the subspace , according to the different dimensions of , the discussion is divided into three cases; then, combined with the technique of subspace minimization, four forms of are determined, and the conditions for dynamic selection of each direction are given.
In this paper, the direction at is expected to minimize the quadratic approximation of the objective function,
on the subspace , where is regarded as an approximation of the Hessian matrix and is positive definite. Assuming satisfies the modified secant equation [23]
where . Combined with (4), obviously, .
3. Proposed Method
3.1. Direction Selection
According to the above discussion, as is known, the subspace may have three different dimensions; based on that, we analyze the selection of the search direction in the next section.
Case I: dim() = 3.
In this case, the direction can be expressed as
where are parameters to be determined. Substituting (9) into (7), we get
where , , . Inspired by the BBCG method [11], we set
where is an adaptive parameter, and its value remains the same throughout the whole paper. Setting , we not only find that , but we also show that its numerical performance is better than a constant. The matrix in (10) is represented by .
The positive definiteness of is presented in Lemma 1. Now that we assume that is positive definite, the unique solution of (10) can be calculated as follows:
where
- ,
- ,
- ,
- ,
- ,
- ,
- .
If is positive definite, then , so
Setting and substituting the variable value in Equation (12), we get
Considering the formula in Equation (13), we compute as
where , .
In order to make the algorithm perform better, in a manner similar to [7,24], we set the following conditions:
where are positive constants, .
Now, we prove that is positive definite.
Lemma 1.
If is calculated by Equation (15), then the matrix is positive definite.
Proof.
Using mathematical induction and , we can get ; because , so ; since , therefore . □
Case II: dim() = 2.
We define as
where are parameters. Similarly, substituting Equation (19) into the approximation function (7), we find
If , then Equation (20) has a unique solution:
Similar to the way that Equation in (11) is evaluated, we set ; apparently, . Furthermore, for the better performance of the algorithm, we require relevant variables to satisfy the condition in Equation (17).
As we all know, DY and HS methods have some good properties. For example, the finite termination of HS is helpful to improve the convergence rate. In view of the above considerations, we put forward an idea; when the conditions
are met, we take
where .
Above all, in the case of two-dimensional subspace, when the condition (17) is established, takes Equations (19) and (21); when the inequalities in Equations (22) and (23) are true, is calculated by Equation (24).
Case III: dim() = 1.
When dim() = 1, we adopt the method of the steepest descent, namely .
3.2. Description of DSCG Algorithm
In this section, we first introduce an acceleration strategy (Algorithm 1) [25] which has been shown to be quite efficient for the CG method. Then, we present our dynamically adjusted subspace conjugate gradient algorithm (DSCG, Algorithm 2) and prove that the direction satisfies sufficient descent.
| Algorithm 1: Acceleration Strategy. |
Step 1: Compute: and ; Step 2: Compute: and ; Step 3: If , then, compute and update the variables as , otherwise update the variables as . |
| Algorithm 2: DSCG. |
Step 1: Given , , , ,,. Let and . Step 2: When , stop, otherwise go to step 3. Step 3: Compute a stepsize that satisfies conditions (4) and (5), then adopt Algorithm 1 (acceleration strategy). Step 4: Compute the direction .
Step 5: Set , and go to step 2. |
3.3. Convergence Analysis
In this subsection, we focus on the convergence properties of the proposed algorithm (DSCG). The sufficient descent condition is crucial for a gradient descent algorithm. In order to establish the sufficient descent condition for the DSCG method, we firstly introduce the following lemma.
Proof.
If is generated by Equations (19) and (20), we get
where represents the minimum value of function with as the variable.
From Lemma 1, we find that , ; that is, there is a minimum value for , which is calculated to be .
Therefore, we can also get . □
Lemma 3.
Suppose is generated by the DSCG algorithm. Then, there is a constant , such that
Proof.
Based on the form of direction, we analyze this in three cases:
Case I: if , let , and thus it is proved.
Case II: When the direction is binomial, the following information must be considered.
We first discuss the case where is given by Equations (19) and (21); here, for , combined with the conditions (11), (17) and Lemma 2, the following results can be obtained:
When is determined by Equation (24), for , we have
for ; similarly, using (23), the same result can be obtained.
Case III: When the direction is computed by Equations (9) and (12), considering Lemma 2, we first prove that has an upper bound.
The above formula follows from Equations (11), (14), (15), and . By using the conditions in Equations (16) and (17), we have
Finally, using the conclusion of Lemma 2, it is concluded that
Summarizing all the above cases, we take
and thus complete the proof. □
In the remainder of this subsection, the global convergence of the algorithm for general functions is proved; more importantly, the result of R-linear convergence for uniformly convex functions is also established in this section. We first introduce two necessary assumptions.
Assumption 1.
Function is continuously differentiable and has a lower bound on .
Assumption 2.
The gradient function is Lipschitz continuous with a constant ; i.e.,
which means that . Remarkably, Assumption 1 is milder than the usual assumption: the level set is bounded.
Lemma 4.
Supposing is generated by a generalized line search (4) and satisfies Assumption 2, then
Lemma 5.
Lemma 6.
Let be generated by the DSCG algorithm. Then, there is a constant such that
Proof.
Similarly, we analyze it in three cases.
Case I: If , let , and thus it is proved.
When , using the same method, we can get (41).
Applying the above results, combined with Cauchy inequality and triangle inequality, we have
Case III: When is computed by Equations (9) and (12), Similarly, let us first discuss a lower bound of . Based on Equations (11), (13), and (15), we have
Based on the above results, it can be deduced further that
In conclusion, let
and thus (40) holds. □
Theorem 1.
Assuming that Assumptions 1 and 2 hold, the sequence is generated by the DSCG algorithm, and we have
Proof.
Combined with Lemmas 3, 4, and 6, it follows that
Since
therefore,
According to Assumption 1 and Lemma 5, it can be seen that has a lower bound, and so
Thus, we proved that Equation (49) holds. □
Theorem 2.
Supposing that Assumptions 1 and 2 hold, f is a uniformly convex function, and the unique minimizer is , the sequence is generated by the DSCG algorithm. For all k, there exists such that , . Then, there is a constant , which makes
Proof.
In the proof of Lemma 5, we know that , which implies that
Denote ; obviously, .
Let us first analyze the case when . Now, there is a subsequence such that
From Equation (2.15) of [26], we know that . Thus, there exists a convergent subsequence . We assume that
and so .
Through the expression of (1.6), we have
Combining the above three formulas, it is obvious that
Based on Equation (3.4) of [26], we know that the uniformly convex function f has the following property:
It is known that , g is Lipschitz continuous; thus, it follows that
Therefore, , and
From Equation (59), we can see that
Combined with condition (62),
Obviously, this conflicts with Equation (59), so ; i.e.,
Thus, there is an integer such that
It is deduced that . Define , from condition (55); obviously,
It follows from condition (69) that
Lemma 5 and imply that (54) holds. □
4. Numerical Results
In this section, we report the numerical performance of the DSCG algorithm from two aspects. Firstly, the algorithm is compared with TTS [13] and CG_DESCENT [27] algorithms on the normal unconstrained problem; secondly, the algorithm is applied to the image restoration problem, and the numerical results are observed.The running environment of all codes is a PC with 2.20 GHz CPU, 4.00 GB RAM memory, and the Windows 10 operating system.
4.1. Unconstrained Problem
The experiment selected 73 test functions, as shown in Table 1.
The dimensions of the function were set as £ºn = 3000, n = 6000, and n = 9000.
The iteration stop criterion is as follows: if or the number of iterations exceeds 1000 and , then the algorithm will terminate, where , when ; otherwise, .
The parameters used by the algorithm are .
The initial stepsize selection strategy [27] is
where represents the infinite norm.
TTS and CG_DESCENT use the parameters in their code. We apply the profiles of Dolan and Moré [28] to evaluate the effectiveness of the three algorithms and discuss the performance profiles of the algorithm in CPU, NFG, and NI in detail.
The meanings of some symbols in the text are as follows:
N0: The serial number of the test problem;
CPU: The running time of algorithm (seconds);
NFG: Total evaluation numbers of function and gradient;
NI: The number of iterations.
When the problem dimension is 9000, the CG_DESCENT method only solves 64 problems, while the other two methods successfully complete all the problems. Compared with other methods, the method represented by the top curve in a performance profile drawing can solve the most problems in the best time range.
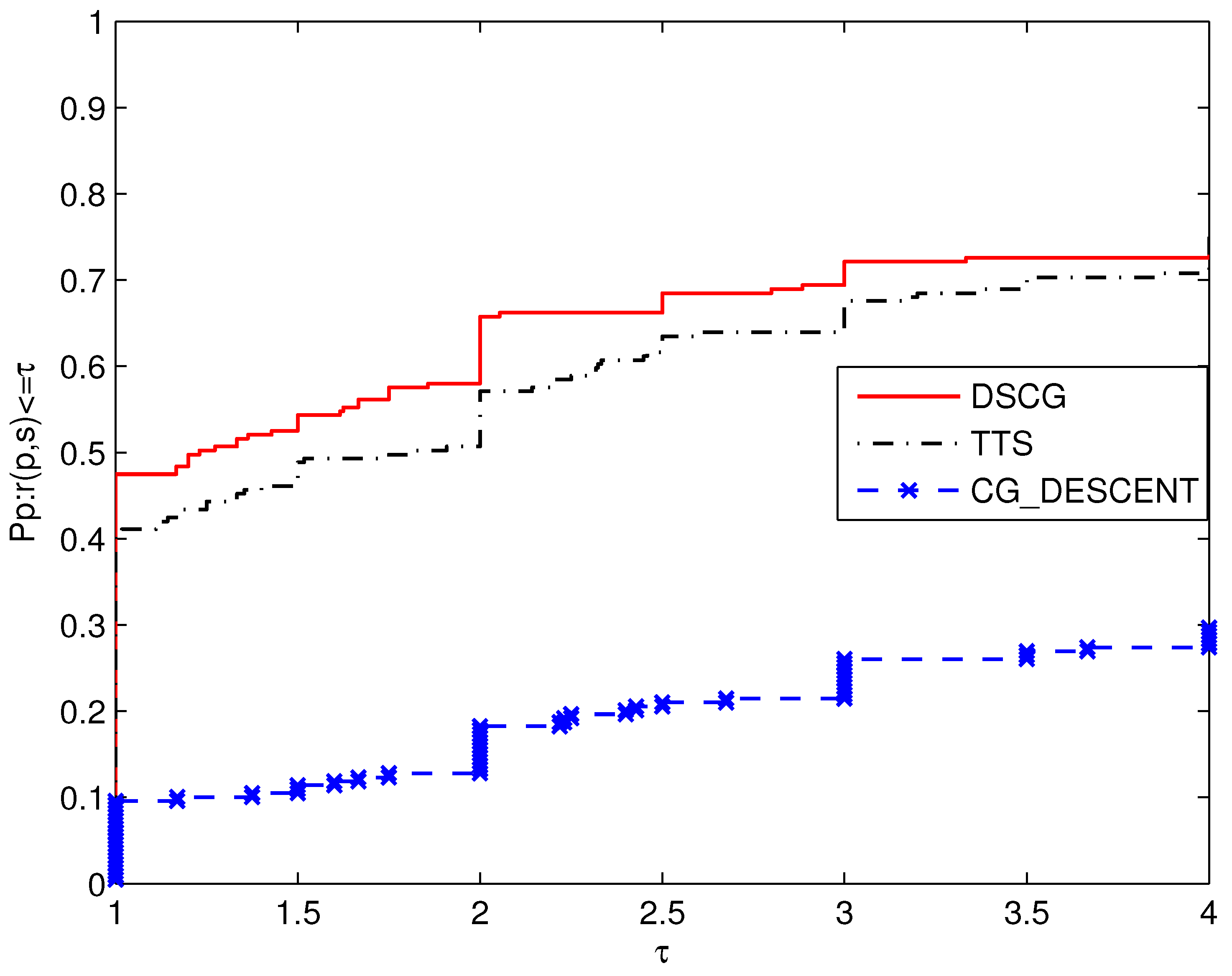
As shown in Figure 1, it is clear that the DSCG method is superior to other algorithms in terms of CPU time. Thiss corresponds to the top curve and can solve 47.49% of the test problems in the shortest time. In contrast, TTS is the fastest at solving 40.64% of the test problems, and CG_DESCENT is the fastest for only 9.59% of problems.
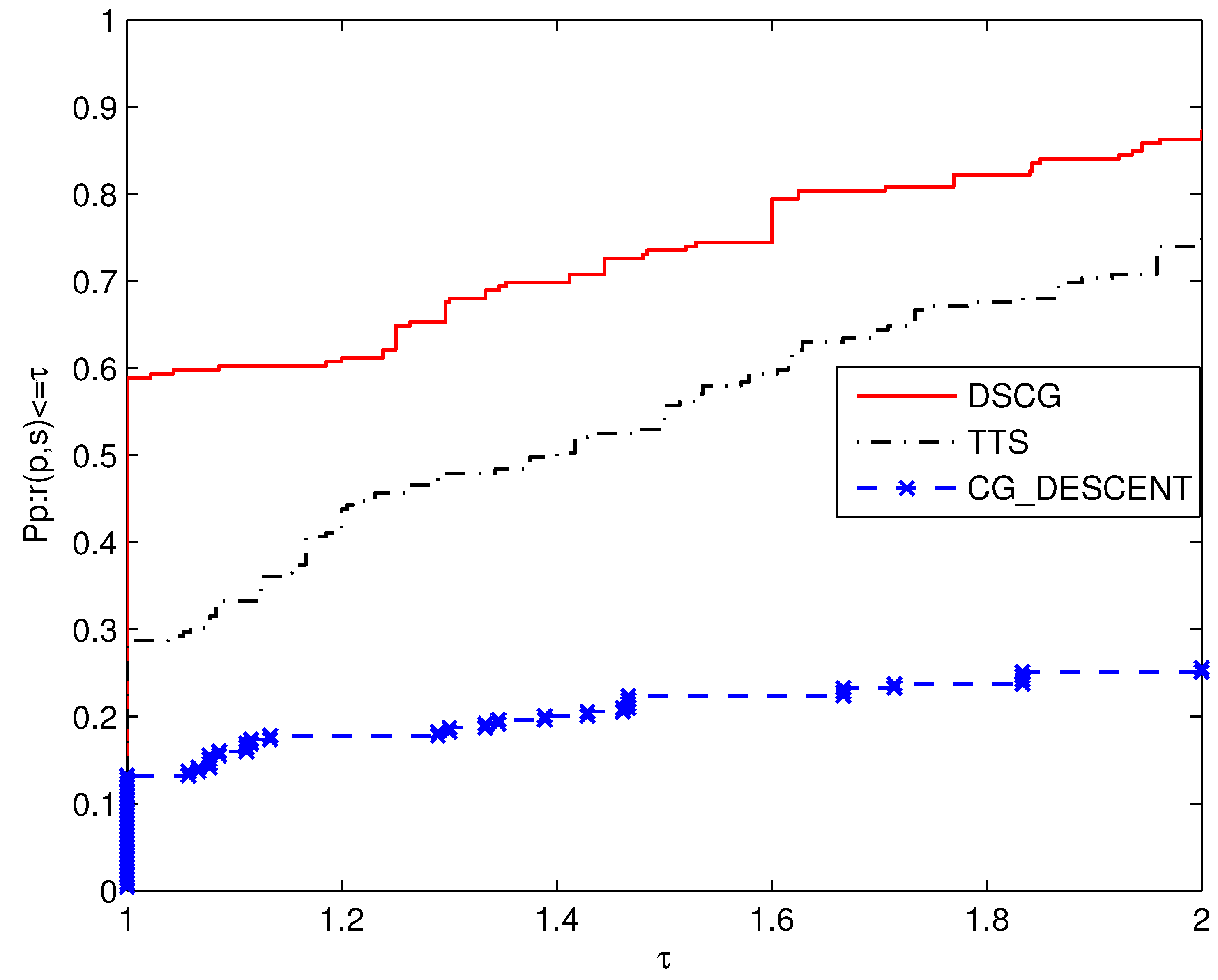
Now, let us focus on Figure 2. By comparison, it is found that DSCG requires fewer functions and gradient evaluations than other algorithms, which helps to simplify calculation and improve algorithm efficiency. It can solve 58.9% of the test problems with minimal function and gradient evaluations. TTS can solve 28.77% of the test problems with the least amount of function and gradient evaluations. The proportion of CG_DESCENT corresponds to 13.24%.
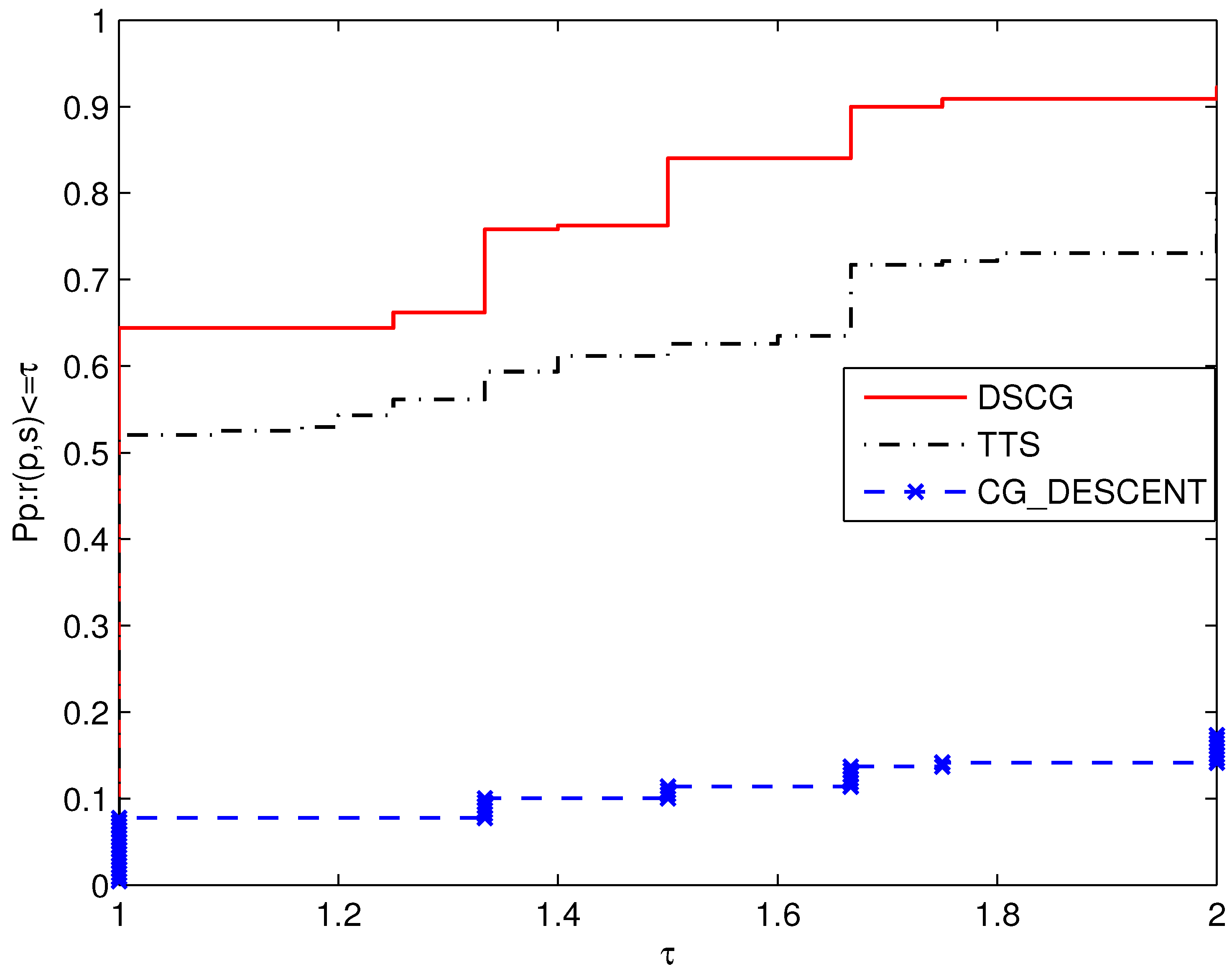
In addition, Figure 3 shows the performance comparison results of each algorithm in terms of the number of iterations. It can be seen from the figure that the performance of the DSCG algorithm is outstanding, as it can solve 64.38% of the problems with the minimum number of iterations. At the same time, TTS and CG_DESCENT have the least iterations in 52.05% and 7.76% of the problems, respectively.
The above three pictures of CPU, NFG, and NI contain some similar information. It is concluded that in the given test set, DSCG performs very well, with numerical results superior to those of TTS and CG_DESCENT.
4.2. Image Restoration Problem
The proposed DSCG is also applied to the problem of image restoration in this subsection. For more professional work in the field of image processing, please see [29,30]. In two scenes with different noise values, the blurred original image is repaired to make the picture clear and recognizable. This work has a wide range of applications in many fields of production and life, with important practical significance, and is also a difficult subject in the field of optimization. Its basic model is , where is the original image, is the blur matrix, represents noise, and is the image observed after noise reduction. The unknown noise value is usually obtained through
but because the image system is susceptible to noise and lack of information, it is difficult to obtain a satisfactory solution. In order to overcome the above shortcoming, the least square model is usually introduced,
where Y is the linear operator, represents the norm, and is the regularization parameter used to weigh the data item and the regularization term.
Stop condition: or ;
Tested picture: Barbara (), Baboon ().
The specific image repair results of the two algorithms under different noise values are shown in Figure 4 and Figure 5. Obviously, for a given set of pictures, both algorithms successfully completed the repair. Let us focus on the comparison on Table 2, which presents the CPU time spent in the repair process of algorithms.
Many works have focused on the image restoration problem, and more detailed references can be found in [31,32,33,34]. In this paper, we display the original image to be repaired, and the repaired results of DSCG, TTS, and CG_DESCENT from left to right.
Summarizing the information contained in the pictures and tables in this section, we have obtained two conclusions: (i) both algorithms are capable of repairing pictures within a reasonable time frame; (ii) with noise interference of 20% and 50%, DSCG is shown to be a promising algorithm.
5. Conclusions and Discussion
In this paper, an algorithm for dynamically adjusting direction was proposed, which corresponds to the directions of four calculation forms by satisfying different conditions. We discuss the selection of directions in a special three-term subspace using modified secant equations, subspace minimization techniques, and acceleration strategies. The algorithm has a good property: each search direction satisfies the sufficient descent condition. We use the nonmonotonic generalized line search to obtain remarkable results: under some mild assumptions, we not only prove the global convergence of the general function algorithm but also further prove the R-linear convergence of the uniformly convex function. Interestingly, we apply this algorithm to image restoration, and the algorithm has good numerical performance in both the unconstrained and image restoration problems, which fully demonstrates the efficiency of this algorithm.
Author Contributions
Conceptualization, J.H. and S.Y.; methodology, S.Y.; software and validation, Y.W.; visualization and formal analysis, Y.W.; writing—original draft preparation, Y.W.; supervision, G.X. and S.Y.; funding acquisition, G.X. and S.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Natural Science Foundation of China No. 71862003, Natural Science Foundation of Guangxi Province (CN) No. 2020GXNSFAA159014, Program for Innovative Team of Guangxi University of Finance and Economics, and the Special Funds for Local Science and Technology Development Guided by the Central Government grant number ZY20198003.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Polyak, B.T. The conjugate gradient method in extreme problems. USSR Comput. Math. Math. Phys. 1969, 9, 94–112. [Google Scholar] [CrossRef]
- Hestenes, M.R.; Stiefel, E.L. Methods of conjugate gradient for solving linear systems. Res. Natl. Bur. Stand. 1952, 6, 409–436. [Google Scholar] [CrossRef]
- Liu, Y.L.; Storey, C.S. Efficient generalized conjugate gradient, Part I: Theory. J. Optim. Theory Appl. 1964, 7, 149–154. [Google Scholar]
- Flether, R.; Reeves, C.M. Function minimization by conjugate gradient. Comput. J. 1964, 7, 149–154. [Google Scholar] [CrossRef] [Green Version]
- Dai, Y.H.; Yuan, Y.X. A nonlinear conjugate gradient method with a strong global convergence property. SIAM J. Optim. 2000, 10, 177–182. [Google Scholar] [CrossRef] [Green Version]
- Flecther, R. Practical Methods of Optimization, Unconstrained Optimization; Wiley: New York, NY, USA, 1988; Volume I. [Google Scholar]
- Li, Y.F.; Liu, Z.X.; Liu, H.W. A subspace minimization conjugate gradient method based on conic model for unconstrained optimization. Comput. Appl. Math. 2019, 38, 16. [Google Scholar] [CrossRef]
- Dai, Y.H.; Kou, C.X. A nonlinear conjugate gradient algorithm with an optimal property and an improved Wolfe line search. SIAM J. Optim. 2013, 23, 296–320. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Liu, Z.X.; Liu, H.W.; Wang, T.; Liu, Z.; Liu, H. A new subspace minimization conjugate gradient method based on tensor model for unconstrained optimization. Int. J. Comput. Math. 2019, 96, 1924–1942. [Google Scholar] [CrossRef]
- Li, M.; Liu, H.W.; Liu, Z.X. A new subspace minimization conjugate gradient method with nonmonotone line search for unconstrained optimization. Numer. Algorithms 2018, 79, 195–219. [Google Scholar] [CrossRef]
- Liu, H.; Liu, Z. An Efficient Barzilai-Borwein Conjugate Gradient Method for Unconstrained Optimization. J. Optim. Theory Appl. 2019, 180, 879–906. [Google Scholar] [CrossRef]
- Yuan, Y.; Stoer, J. A subspace study on conjugate gradient algorithms. Zamm J. Appl. Math. Mech. Z. Angew. Math. Mech. 1995, 75, 69–77. [Google Scholar] [CrossRef]
- Andrei, N. An accelerated subspace minimization three-term conjugate gradient algorithm for unconstrained optimization. Numer. Algorithms 2014, 65, 859–874. [Google Scholar] [CrossRef]
- Yang, Y.T.; Chen, Y.T.; Lu, Y.L. A subspace conjugate gradient algorithm for large-scale unconstrained optimization. Numer. Algorithms 2017, 76, 813–828. [Google Scholar] [CrossRef]
- Dai, Y.H.; Kou, C.X. A Barzilai-Borwein conjugate gradient method. Sci. China Math. 2016, 59, 1511–1524. [Google Scholar] [CrossRef]
- Barzilai, J.; Borwein, J.M. Two-point step size gradient methods. IMA J. Numer. Anal. 1988, 8, 141–148. [Google Scholar] [CrossRef]
- Wang, Z.H.; Yuan, Y. A subspace implementation of quasi-Newton trust region methods for unconstrained optimization. Numer. Math. 2006, 104, 241–269. [Google Scholar] [CrossRef]
- Yuan, Y.X. A review on subspace methods for nonlinear optimization. In Proceedings of the International Congress of Mathematics, Seoul, Korea, 13–21 August 2014; pp. 807–827. [Google Scholar]
- Fialko, S.; Karpilovskyi, V. Block subspace projection preconditioned conjugate gradient method in modal structural analysis. Comput. Math. Appl. 2020, 79, 3410–3428. [Google Scholar] [CrossRef]
- Hanzely, F.; Doikov, N.; Nesterov, Y.; Richtarik, P. Stochastic subspace cubic Newton method. In Proceedings of the International Conference on Machine Learning, PMLR, Montreal, QC, Canada, 6–8 July 2020; pp. 4027–4038. [Google Scholar]
- Moufawad, S.M. s-Step Enlarged Krylov Subspace Conjugate Gradient Methods. SIAM J. Sci. Comput. 2020, 42, A187–A219. [Google Scholar] [CrossRef]
- Soodhalter, K.M.; de Sturler, E.; Kilmer, M.E. A survey of subspace recycling iterative methods. GAMM-Mitteilungen 2020, 43, e202000016. [Google Scholar] [CrossRef]
- Babaie-Kafaki, S. Two modified scaled nonlinear conjugate gradient method. J. Comput. Appl. Math. 2014, 261, 172–182. [Google Scholar] [CrossRef]
- Yao, S.; Wu, Y.; Yang, J.; Xu, J. A three-term gradient descent method with subspace techniques. Math. Probl. Eng. 2021, 2021, 8867309. [Google Scholar] [CrossRef]
- Andrei, N. An acceleration of gradient descent algorithm with backtracking for unconstrained optimization. Numer. Algorithms 2006, 42, 63–73. [Google Scholar] [CrossRef]
- Zhang, H.C.; Hager, W.W. A nonmonotone line search technique and its application to unconstrained optimization. SIAM J. Optim. 2004, 14, 1043–1105. [Google Scholar] [CrossRef] [Green Version]
- Hager, W.W.; Zhang, H. A new conjugate gradient method with guaranteed descent and an efficient line search. SIAM J. Optim. 2005, 16, 170–192. [Google Scholar] [CrossRef] [Green Version]
- Dolan, E.D.; Moré, J.J. Benchmarking optimization software with performance profiles. Math. Program. 2002, 91, 201–203. [Google Scholar] [CrossRef]
- Versaci, M.; Calcagno, S.; Morabito, F.C. Fuzzy geometrical approach based on unit hyper-cubes for image contrast enhancement. In Proceedings of the 2015 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 19–21 October 2015; pp. 488–493. [Google Scholar]
- Rahim, S.S.; Palade, V.; Shuttleworth, J.; Jayne, C. Automatic screening and classification of diabetic retinopathy and maculopathy using fuzzy image processing. Brain Inform. 2016, 3, 249–267. [Google Scholar] [CrossRef] [PubMed]
- Hanjing, A.; Suantai, S. A fast image restoration algorithm based on a fixed point and optimization method. Mathematics 2020, 8, 378. [Google Scholar] [CrossRef] [Green Version]
- Padcharoen, A.; Kitkuan, D. Iterative methods for optimization problems and image restoration. Carpathian J. Math. 2021, 37, 497–512. [Google Scholar] [CrossRef]
- Ibrahim, A.H.; Kumam, P.; Kumam, W. A family of derivative-free conjugate gradient methods for constrained nonlinear equations and image restoration. IEEE Access 2020, 8, 162714–162729. [Google Scholar] [CrossRef]
- Fessler, J.A. Optimization methods for magnetic resonance image reconstruction: Key models and optimization algorithms. IEEE Signal Process. Mag. 2020, 37, 33–40. [Google Scholar] [CrossRef]
Figure 1.
Performance profiles for the CPU.

Figure 2.
Performance profiles for the NFG.

Figure 3.
Performance profiles for the NI.

Figure 4.
20% noise. (a) original image; (b) DSCG; (c) TTS; (d) CG_DESCENT.

Figure 5.
50% noise. (a) original image; (b) DSCG; (c) TTS; (d) CG_DESCENT.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The test problems.
| Test Problems | No. | Test Problems | No. |
|---|---|---|---|
| Extended Freudenstein and Roth Function | 1 | ARWHEAD Function (CUTE) | 38 |
| Extended Trigonometric Function | 2 | ARWHEAD Function (CUTE) | 39 |
| Extended Rosenbrock Function | 3 | NONDQUAR Function (CUTE) | 40 |
| Extended White and Holst Function | 4 | DQDRTIC Function (CUTE) | 41 |
| Extended Beale Function | 5 | EG2 Function (CUTE) | 42 |
| Extended Penalty Function | 6 | DIXMAANA Function (CUTE) | 43 |
| Perturbed Quadratic Function | 7 | DIXMAANB Function (CUTE) | 44 |
| Raydan 1 Function | 8 | DIXMAANC Function (CUTE) | 45 |
| Raydan 2 Function | 9 | DIXMAANE Function (CUTE) | 46 |
| Diagonal 1 Function | 10 | Partial Perturbed Quadratic Function | 47 |
| Diagonal 2 Function | 11 | Broyden Tridiagonal Function | 48 |
| Diagonal 3 Function | 12 | Almost Perturbed Quadratic Function | 49 |
| Hager Function | 13 | Tridiagonal Perturbed Quadratic Function | 50 |
| Generalized Tridiagonal 1 Function | 14 | EDENSCH Function (CUTE) | 51 |
| Extended Tridiagonal 1 Function | 15 | VARDIM Function (CUTE) | 52 |
| Extended Three Exponential Terms Function | 16 | STAIRCASE S1 Function | 53 |
| Generalized Tridiagonal 2 Function | 17 | LIARWHD Function (CUTE) | 54 |
| Diagonal 4 Function | 18 | DIAGONAL 6 Function | 55 |
| Diagonal 5 Function | 19 | DIXON3DQ Function (CUTE) | 56 |
| Extended Himmelblau Function | 20 | DIXMAANF Function (CUTE) | 57 |
| Generalized PSC1 Function | 21 | DIXMAANG Function (CUTE) | 58 |
| Extended PSC1 Function | 22 | DIXMAANH Function (CUTE) | 59 |
| Extended Powell Function | 23 | DIXMAANI Function (CUTE) | 60 |
| Extended Block Diagonal BD1 Function | 24 | DIXMAANJ Function (CUTE) | 61 |
| Extended Maratos Function | 25 | DIXMAANK Function (CUTE) | 62 |
| Extended Cliff Function | 26 | IXMAANL Function (CUTE) | D63 |
| Quadratic Diagonal Perturbed Function | 27 | DIXMAAND Function (CUTE) | 64 |
| Extended Wood Function | 28 | ENGVAL1 Function (CUTE) | 65 |
| Extended Hiebert Function | 29 | FLETCHCR Function (CUTE) | 66 |
| Quadratic Function QF1 Function | 30 | COSINE Function (CUTE) | 67 |
| Extended Quadratic Penalty QP1 Function | 31 | Extended DENSCHNB Function (CUTE) | 68 |
| Extended Quadratic Penalty QP2 Function | 32 | DENSCHNF Function (CUTE) | 69 |
| A Quadratic Function QF2 Function | 33 | SINQUAD Function (CUTE) | 70 |
| Extended EP1 Function | 34 | BIGGSB1 Function (CUTE) | 71 |
| Extended Tridiagonal-2 Function | 35 | Partial Perturbed Quadratic PPQ2 Function | 72 |
| BDQRTIC Function (CUTE) | 36 | Scaled Quadratic SQ1 Function | 73 |
| TRIDIA Function (CUTE) | 37 |
Table 2.
CPU time spent by algorithms (seconds).
| 20% Noise | Barbara | Baboon | Total |
| DSCG | 1.2656 | 1.2813 | 2.5469 |
| TTS | 1.2813 | 1.2656 | 2.5469 |
| CG_DESCENT | 1.4219 | 1.2969 | 2.7188 |
| 50% Noise | Barbara | Baboon | Total |
| DSCG | 2.0625 | 1.9688 | 4.0313 |
| TTS | 2.125 | 2.1719 | 4.2969 |
| CG_DESCENT | 2.0313 | 2.1875 | 4.2188 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Huo, J.; Wu, Y.; Xia, G.; Yao, S. A Dynamically Adjusted Subspace Gradient Method and Its Application in Image Restoration. Symmetry 2021, 13, 2450. https://0-doi-org.brum.beds.ac.uk/10.3390/sym13122450
AMA Style
Huo J, Wu Y, Xia G, Yao S. A Dynamically Adjusted Subspace Gradient Method and Its Application in Image Restoration. Symmetry. 2021; 13(12):2450. https://0-doi-org.brum.beds.ac.uk/10.3390/sym13122450
Chicago/Turabian StyleHuo, Jun, Yuping Wu, Guoen Xia, and Shengwei Yao. 2021. "A Dynamically Adjusted Subspace Gradient Method and Its Application in Image Restoration" Symmetry 13, no. 12: 2450. https://0-doi-org.brum.beds.ac.uk/10.3390/sym13122450
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.