4.1. Solution of Global Optimization Problems
In applications, 13 numerical test problems are used to analyze the performance of ABCES algorithm. The related problems are given in
Table 1. For ABC and ABCES algorithms, population size is taken as 50. The results are obtained for different values of D ∈ {50,100,150,1000}. The number of evaluations has been used 100,000, 500,000, 1,000,000 values. Each application is run 30 times. Each initial population is determined randomly.
The results found with ABC and ABCES algorithms in 100,000 evaluations are given in
Table 2. 13 test functions are used, and the results are obtained for D = {50, 100, 150} in each function. In addition to the objective function and standard deviation values are given here. When D is 50, 100 and 150, ABCES algorithm has better results than ABC algorithm in SumSquares, Levy, Sphere, Rosenbrock, The Sum of Different Powers, Zakharov, Ackley, Step, Griewank, Rotated Hyper-Ellipsoid, Dixon–Price and Perm. ABC algorithm is only successful in Rastrigin. Apart from average objective function value, ABCES algorithm is more successful in the standard deviation values. This shows that the results obtained by using ABCES in 100,000 evaluations are more robust. The Wilcoxon signed rank test is used to determine the significance of the results and it is given in
Table 3. The evaluation is made according to
p = 0.05 level. 13 test functions are evaluated in 3 different dimensions (D = 50, 100, 150). Specifically, the significance of 39 results is examined. A significant difference is found in favor of the ABCES algorithm in 34 of these. This result indicates that ABCES algorithm is better in 34 objective function value. There is no significant difference in 4 results. In only one result, there is significant difference indicating that ABC algorithm is more good.
When the results are obtained in 100,000 evaluations are examined, it is seen that fast convergence continues in the problems. Therefore, it is determined that better results can be achieved in high iteration. Thus, the results found in 500,000 evaluations are given in
Table 4. In 500,000 evaluations, the quality of the solutions has improved at a high rate according to 100,000 evaluations in Levy, Sphere, The Sum of Different Powers, Zakharov, Ackley, Step, Rastrigin, Griewank and Rotated Hyper-Ellipsoid functions. The objective function values are
and below in all dimensions (D = 50, 100, 150) in SumSquares, Sphere, The Sum of Different Powers, Griewank and Rotated Hyper-Ellipsoid functions. The results obtained for D = 50 are
and below in Levy, Rastrigin and Step functions. They are between
and
for D = 100 and D = 150. Similarly, the objective function value obtained in Ackley function is between
and
. In Perm function, the dimensions affected to the results a lot. Although the objective function value is about
in D = 2, it is about
in D = 4. Along with that, it is about 5 in D = 6. In Rosenbrock function, objective function values between 0.1 and 1 are obtained. In Zakharov function, they are between 51 and 312. This function has the highest objective function value. At the same time,
Table 4 compares ABC and ABCDE algorithms. ABC algorithm is only better in Levy, Step and Dixon–Price functions. In other problems, the ABCES algorithm is more successful than the ABC algorithm. Although ABCES has better results in Levy and Step functions in 100,000 evaluations, this situation has changed in favor of the ABC algorithm in 500,000 evaluations. In Rastrigin function, while ABC algorithm is more successful in 100,000 evaluations, ABCES algorithm is better in 500,000 evaluations. The Wilcoxon signed rank test is performed between ABC and ABCES to determine the significance of the results obtained in 500,000 evaluations and it is given
Table 5. The analyses are performed according to
p = 0.05 level. The significance of 39 objective function values is examined. In 25 of them, a significant difference is obtained with ABCES algorithm. This result shows that ABCES algorithm is more successful than with ABC algorithm in these functions. ABC algorithm is only better in 8 of them. These results belong to Levy, Step and Dixon–Price functions which ABC algorithm is effective. In the remaining 6 results, no significant difference is found between ABC and ABCES. Despite ABCES is especially better in Rosenbrock function, it is not significant. Also, as in 100,000 evaluations, the best standard deviation values are generally obtained by ABCES algorithm in 500,000 evaluations.
It is very important the success that optimization algorithms show in high-dimensional problems. Therefore, the results obtained with ABC and ABCES algorithms are given for D = 1000 on SumSquares, Levy, Sphere, Rosenbrock, The Sum of Different Powers, Zakharov, Ackley, Step, Rastrigin, Griewank, Rotated Hyper-Ellipsoid and Dixon–Price functions in
Table 6. ABC algorithm is only better in Rastrigin function. ABCES is more successful in all other problems. In particular, in Rotated Hyper-Ellipsoid function, the objective function value is obtained as 6.40
by ABC algorithm and no effective solution is found. In contrast, it is achieved as 6.25
by using ABCES. Other than that, while the success rate of ABC algorithm on SumSquares, Sphere and The Sum of Different Powers functions is low, more effective results are obtained with ABCES algorithm. The Wilcoxon signed rank test is used to determine whether the results are significant, and it is given in
Table 7. The analyses are performed according to
p = 0.05 level. The significance status for 12 functions is examined. In 8 of them, a significant difference is found in favor of ABCES. In only one function, a significant difference is obtained with ABC algorithm. No significant difference is found in other functions. In addition, in all functions, the best standard deviation values are achieved by using ABCES. When the results given in
Table 6 and
Table 7 are evaluated, they show that ABCES algorithm is better than ABC algorithm on high-dimensional problems.
Comparison of GA, PSO, DE, ABC and ABCES algorithms is given in
Table 8. In the comparison, SumSquares, Sphere, Rosenbrock, Zakharov, Ackley, Step, Rastrigin, Griewank, Dixon–Price and Perm functions are used. Results of GA, PSO, DE and ABC algorithm are taken from [
44]. The results are given for population/colony size is 50 and number of evaluations is 500,000. In addition, values below
in [
44] are assumed as 0 (zero). For fair comparison, values below
are accepted as 0 (zero) in ABCES algorithm too. When the related table is analyzed, 0 (zero) are obtained with PSO, DE, ABC and ABCES algorithms in SumSquares, Sphere, Step functions. Algorithms other than GA and ABC reach 0 (zero) value in Zakharov function. Also, ABC and ABCES algorithms find 0 (zero ) value in Ackley function. The best results for Rastrigin, Griewank and Dixon–Price functions are achieved with ABC and ABCES algorithms. In addition, the best results for Rosenbrock and Perm are obtained by using ABCES Algorithm. These results given in
Table 8 show that ABCES algorithm is generally more successful than GA, PSO, DE, and ABC algorithm.
4.2. Training Neural Networks with ABCES Algorithm for the Identification of Nonlinear Static Systems
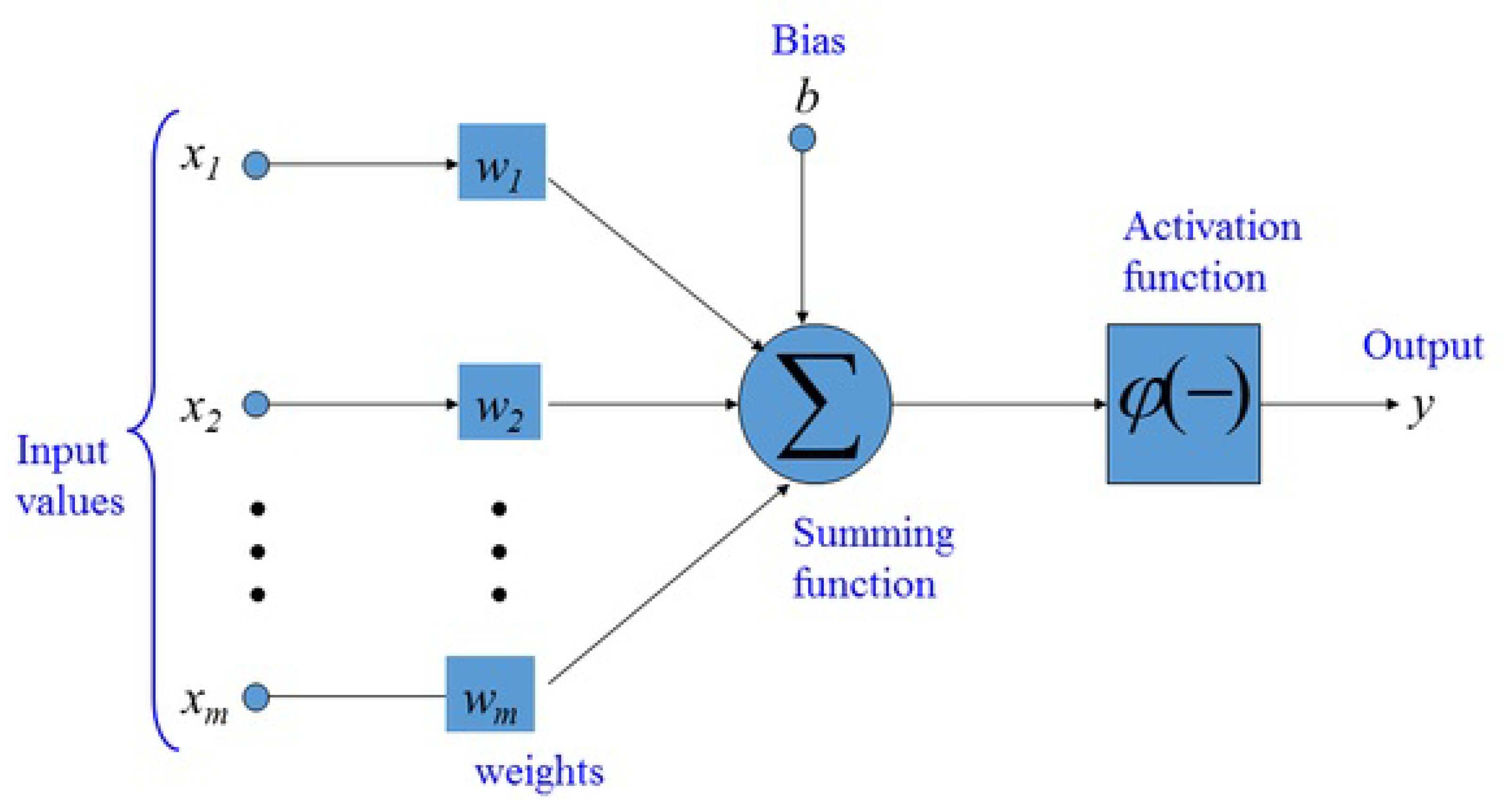
In this section, the performance of ABCES algorithm is assessed on neural network training for the identification of nonlinear static systems. In the applications, 6 nonlinear static systems (
) given in
Table 9 are used.
has one input.
and
consist of two inputs.
and
have three inputs.
has four inputs. Datasets are created using the equations given here. For
,
and
, y output value is obtained by using the input value(s) in the range of [0, 1]. The dataset contains 100 data for the first 3 systems. 80% of the dataset is used for training process and the rest is used for testing. The input values are in the range of [1, 6] for
. A dataset consisting of 216 data is created using 6 values for each input. 173 data points of the dataset belong to the training process. The rest are chosen for testing. A dataset with 125 data is created using related equation in
. Input values are in the range of [0, 1]. For
, input values are used in the range of [−0.25, 0.25] and a dataset consisting of 125 data is created. In
and
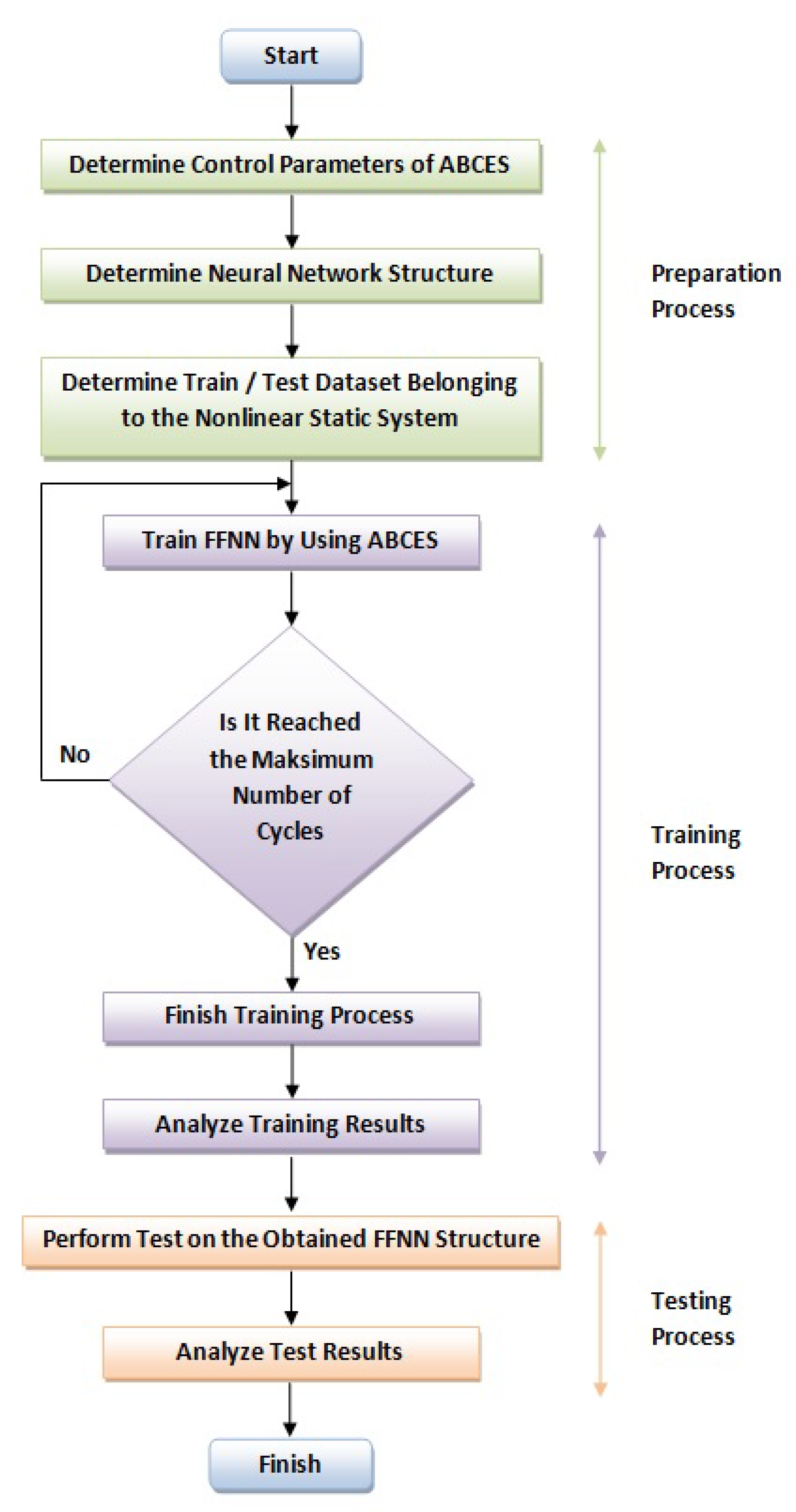
, 100 data points are used for the training process. The rest are chosen for testing. According to the dataset index value (i), mod (i, 5) = k operation is applied in all systems. If k = 0, the data is chosen for testing. Otherwise, it is included to dataset of the training process. There are two reasons for applying the mod operation according to 5 value: The first is to choose 80% of the dataset for the training process. In this case, the rest belong to the test dataset. It is ensured that the training dataset covers the whole dataset. This way, a more effective training process is realized. At the same time, the test dataset reflects the whole system. Feed forward neural network (FFNN) is used in this study. Sigmoid function is used for the neurons in the hidden layer and the output layer. Three different network structures are used for each system. 4, 8 and 12 neurons are used in the hidden layer. Training FFNN is realized via ABCES algorithm. Flow chart of FFNN training based on ABCES algorithm for the identification of nonlinear static systems is presented in
Figure 2. Before the training, the input and output pairs of the nonlinear static system are normalized in the range of [0, 1]. For ABCES algorithm, population size and maximum number of iterations are taken as 20 and 5000, respectively. The number of training and test data used for each system is given in
Table 9. MSE (mean squared error) calculated as in (
9) is used as error value for training and testing process. Here,
n is the number of samples.
is real output and
is predicted output. Each application is run 30 times to analyze it statistically. Mean error value (mean) and standard deviation (std) are obtained.
The results obtained with the ABCES algorithm are presented in
Table 10. The increase in the number of neurons in the hidden layer in
has increased the solution quality. The best mean error values for training and test are achieved with the 1-12-1 network structure. The number of neurons affects the mean training and test error values in
differently. Although the best mean training error value is found with 2-12-1, the best mean test error value is obtained with 2-8-1. The low number of neurons in
is more effective. The best mean error values for both training and test are achieved with 2-4-1. Close performance is observed in 3-8-1 and 3-12-1 network structures in
. Similarly, the best mean training error values for
are found with 3-8-12 and 3-12-1. However, the best mean test error value is obtained by using 3-4-1. All the best results in
are 4-12-1. When all systems are evaluated in general, it is possible to make four basic comments. First, network structure affects performance. Increasing or decreasing the number of neurons exhibits different behaviors depending on the system. Second, there is a difference between training and test errors. This situation can be explained by the selection of the training and test dataset. Third, generally low standard deviation values are obtained. This situation shows the stability of the solutions. Finally, the low error values found indicate that the ABCES algorithm is successful. In
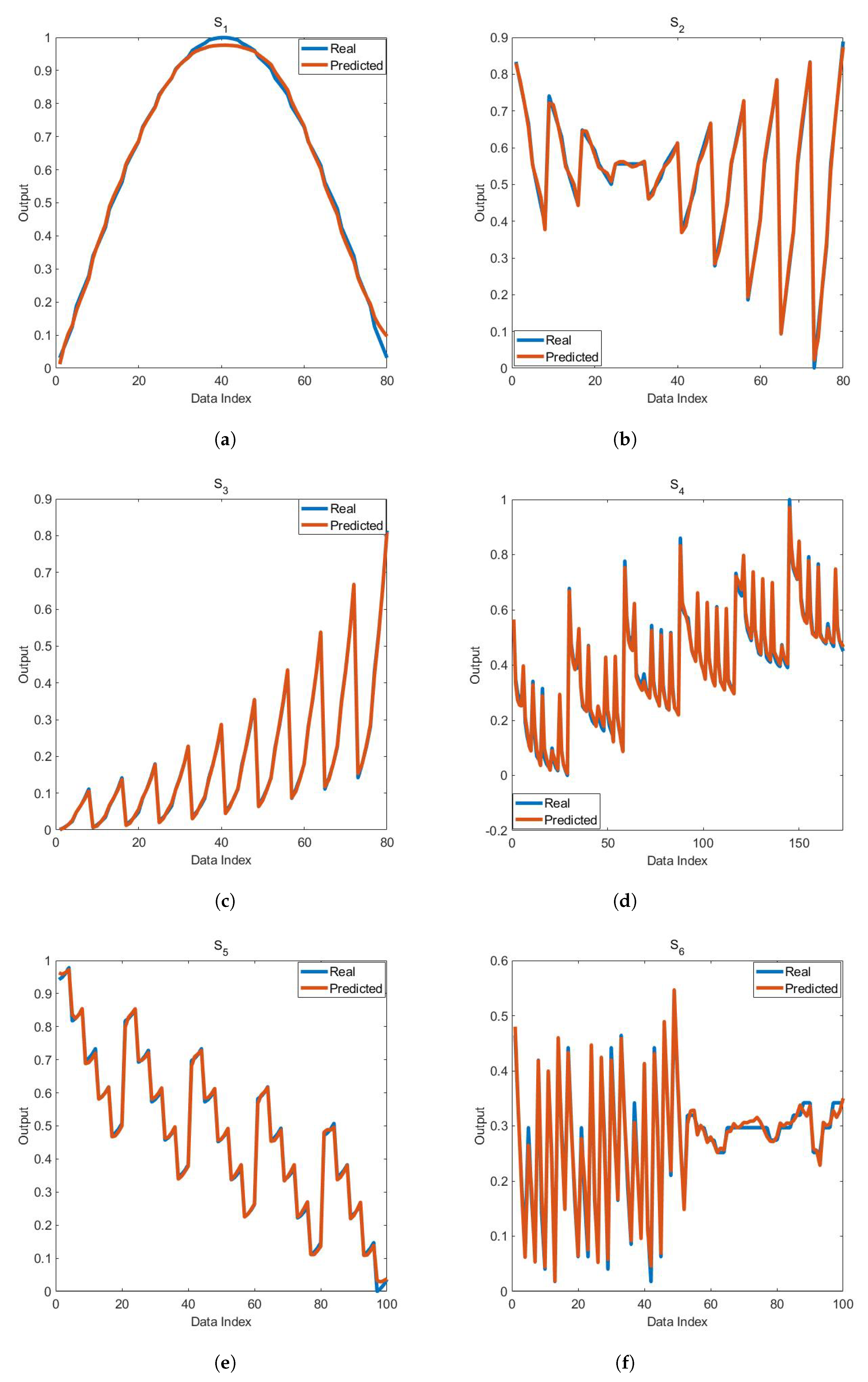
Figure 3, the graphs of the output found with ABCES algorithm and the real output are compared. It is seen that effective output graphics are obtained with ABCES algorithm in all systems. In fact, this is an indication that nonlinear static systems are identified with high accuracy.
It is compared with PSO, HS and ABC algorithm to better evaluate the performance of ABCES algorithm. The results are presented in
Table 11. In
, the best mean training and test error values are found by ABCES algorithm. ABC algorithm is more effective after ABCES algorithm. The same is true for
. The best mean training error value in
is found with ABCES. After ABCES, PSO is more effective. Although the best result in the mean test error value is obtained with ABCES, the worst results are found with HS. In
it is clear that ABCES is effective. In
, the best mean training error value is found with ABCES, while the best mean test error value is obtained via PSO. The best results in
are obviously found with ABCES. When the results are evaluated in general, ABCES algorithm is more successful in neural network training than others. After ABCES, the performances are listed as ABC algorithm, PSO and HS, respectively.
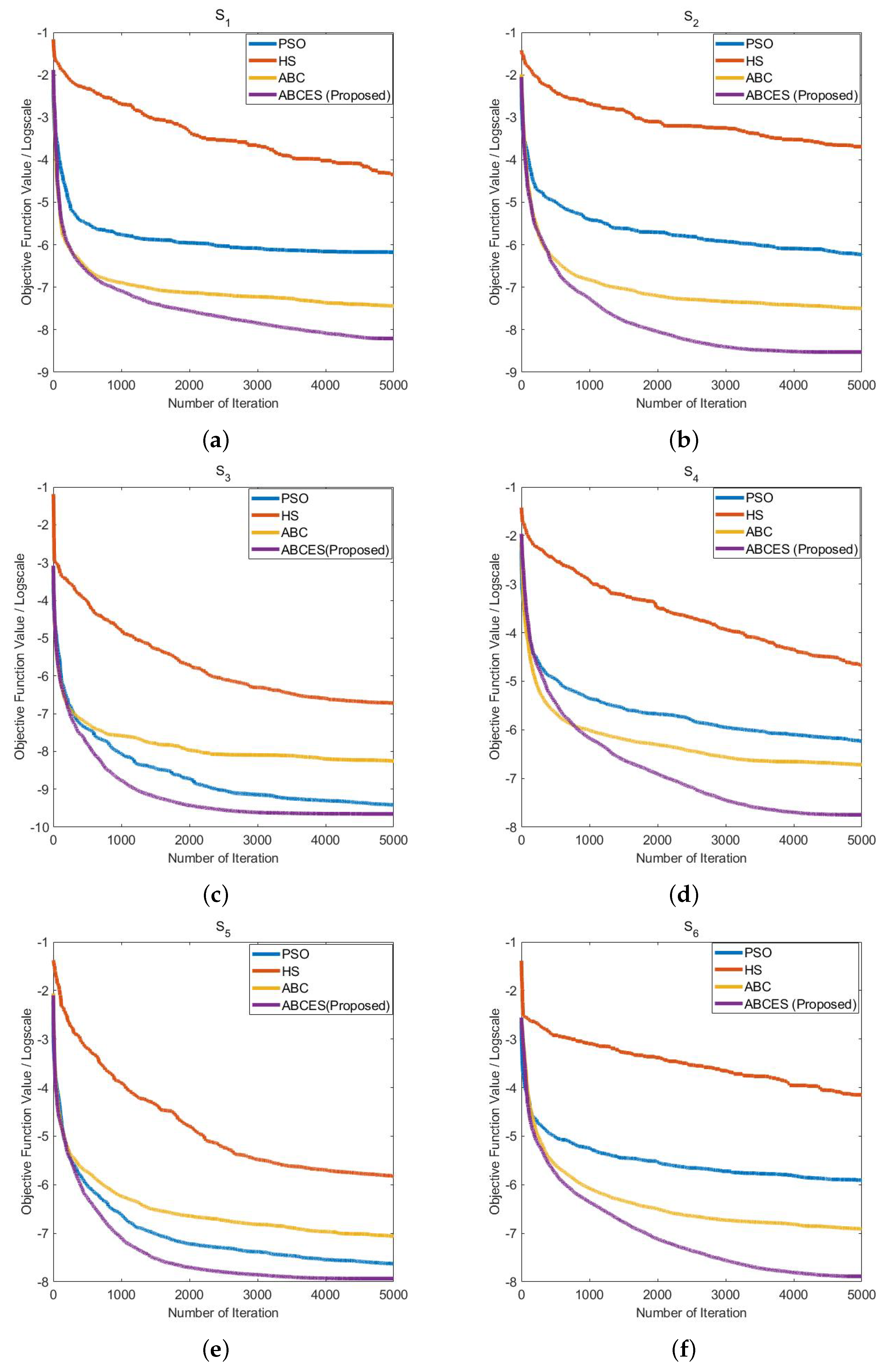
In
Table 11, it is seen that the solution quality of ABCES algorithm is better than other algorithms. Besides the quality of the solution, the convergence speed is also important. Therefore, the convergence graphs of PSO, HS, ABC and ABCES on all systems are compared in
Figure 4. It is observed that the convergence of ABCES algorithm is more effective on all systems. These graphics show that ABCES algorithm has better convergence speed than other algorithms. After the ABCES algorithm, the best convergence is achieved with the ABC algorithm, except
and
. PSO has a more effective convergence than the ABC algorithm on
and
.








{kind=link}
{kind=link}
{kind=link}
{kind=link}