
Regional Geochemical Anomaly Identification Based on Multiple-Point Geostatistical Simulation and Local Singularity Analysis—A Case Study in Mila Mountain Region, Southern Tibet

Abstract
:1. Introduction
2. Methodology
2.1. Direct Sampling Algorithm (DS)
2.2. Local Singularity Analysis (LSA)
2.3. Anomaly Probability Fusion Based on Uncertainty Analysis
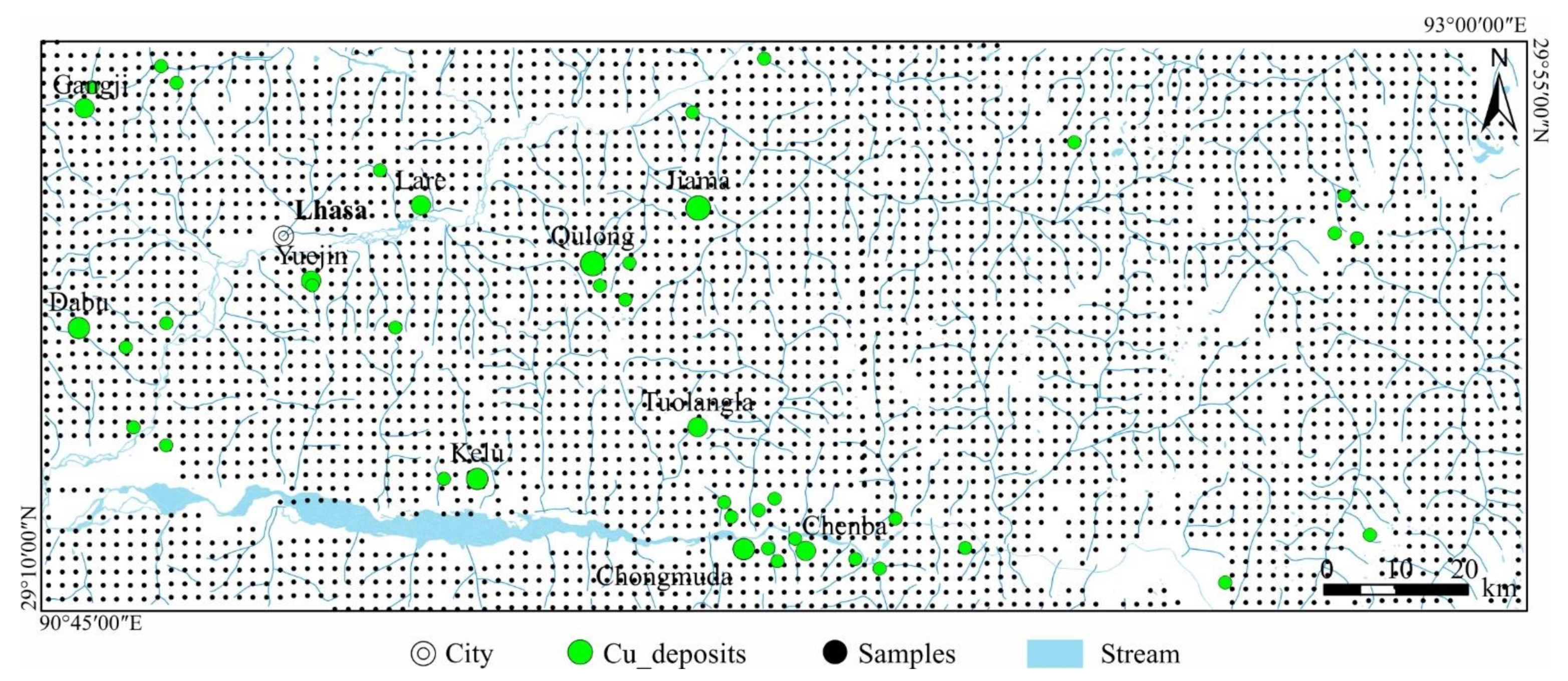
3. Study Area and Data
3.1. Geological Setting
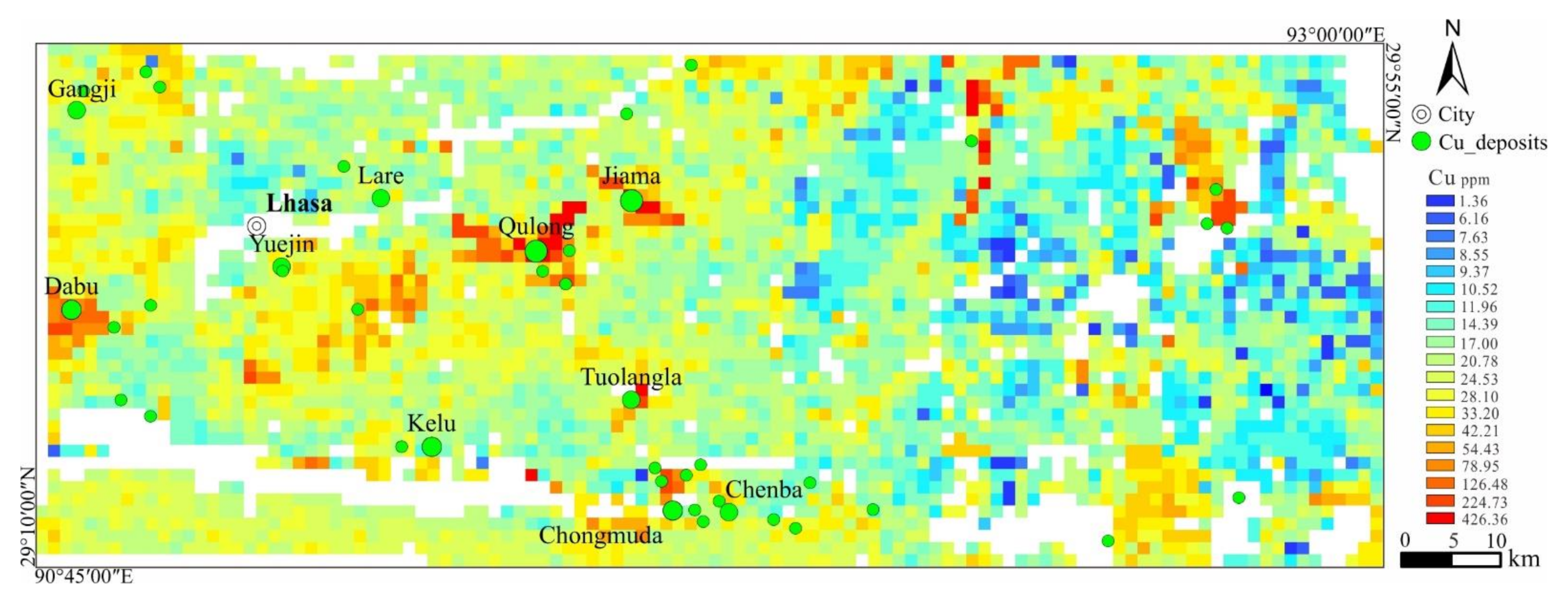
3.2. Geochemical Data
4. Results and Discussions
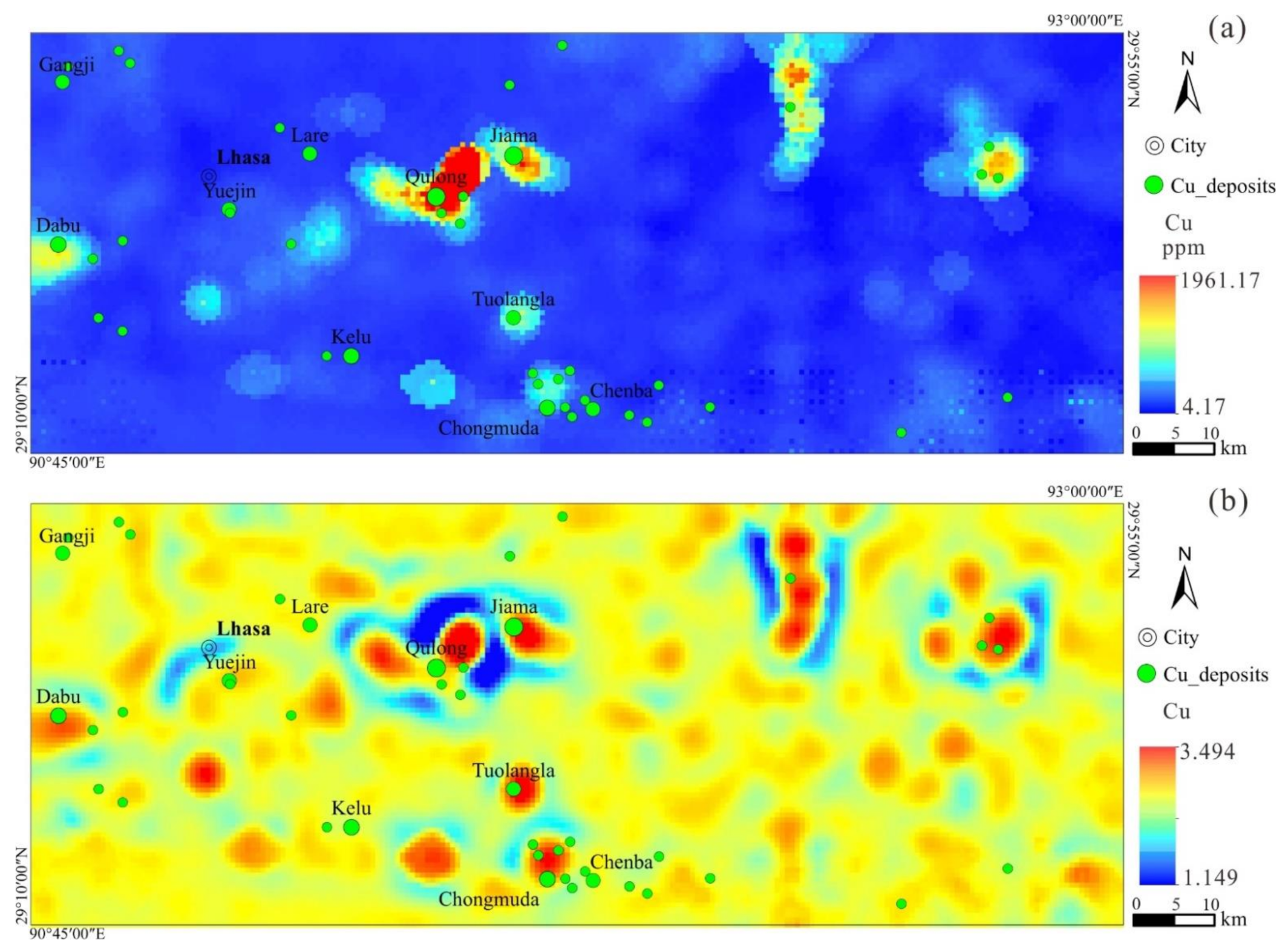
4.1. Direct Sampling Algorithm Simulation of Copper Element
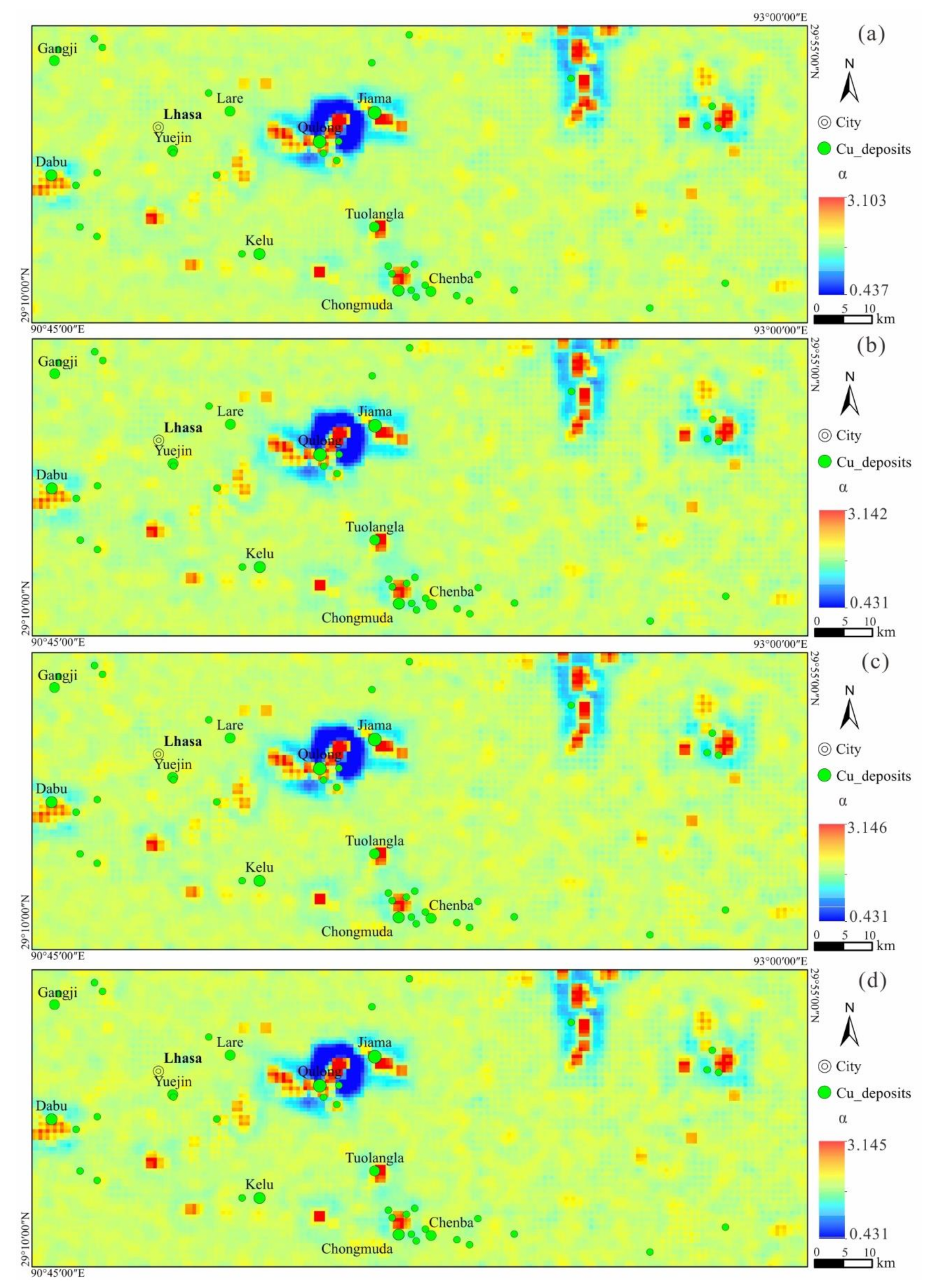
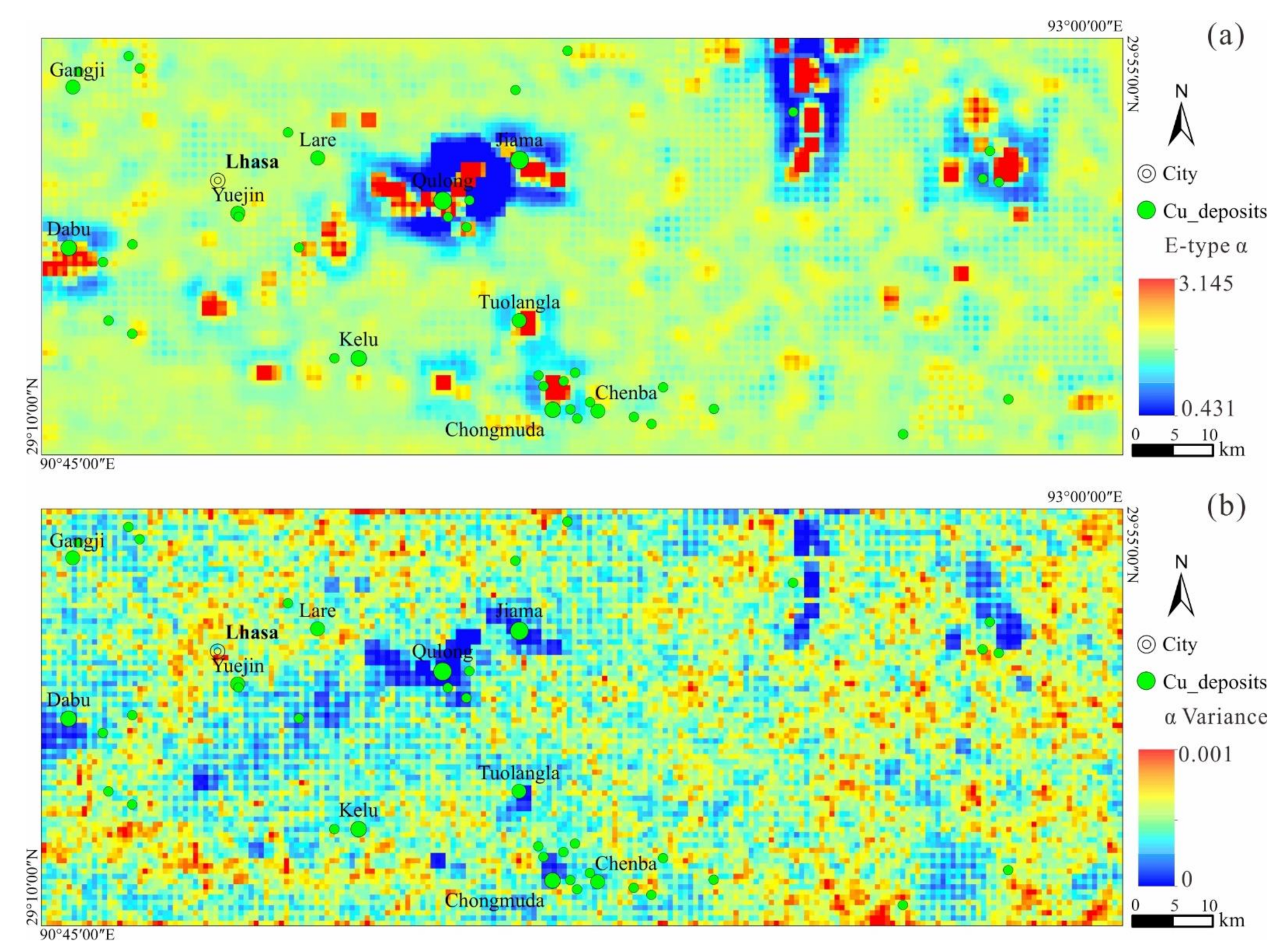
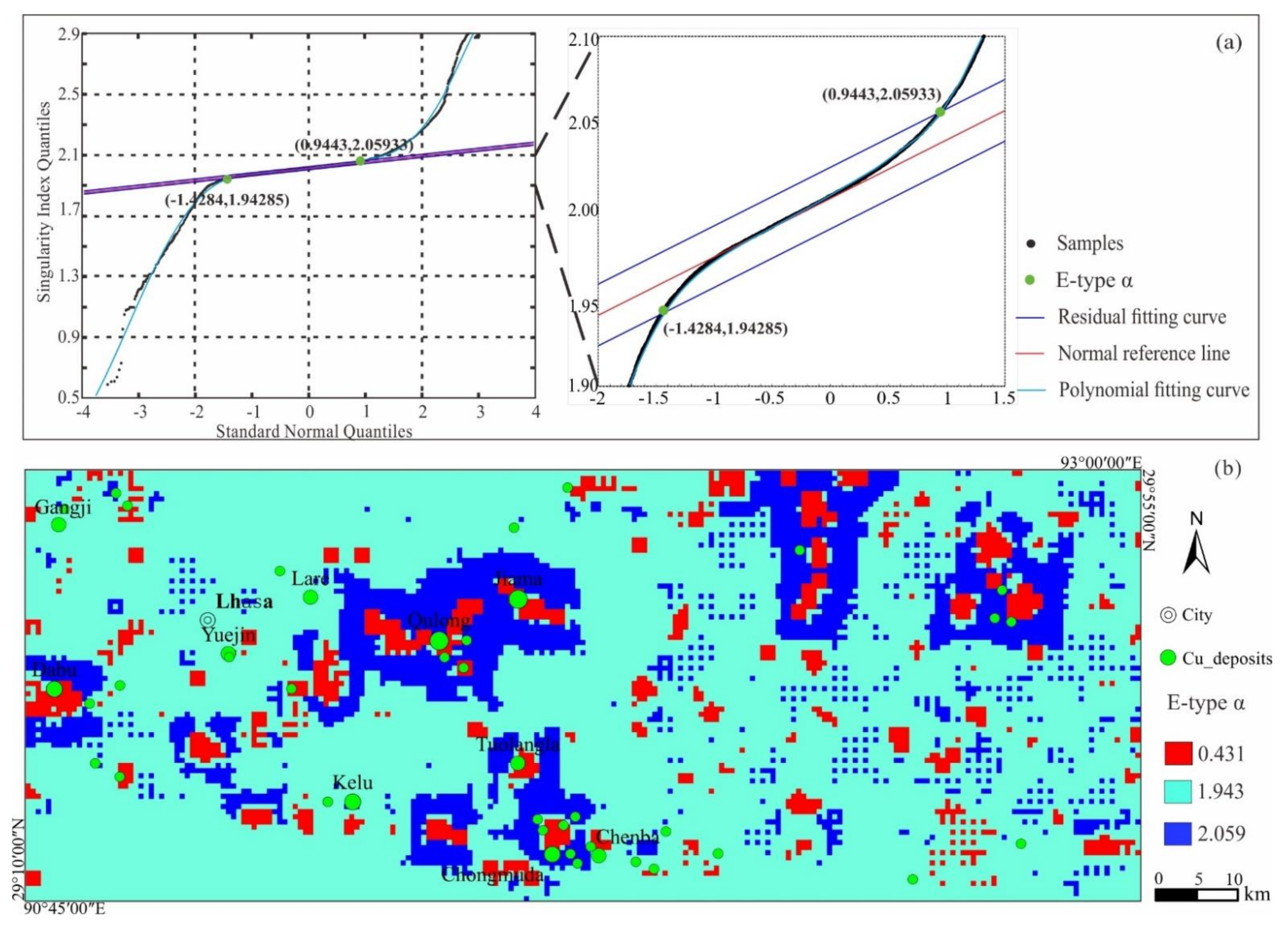
4.2. Stochastic Simulation-Based LSA
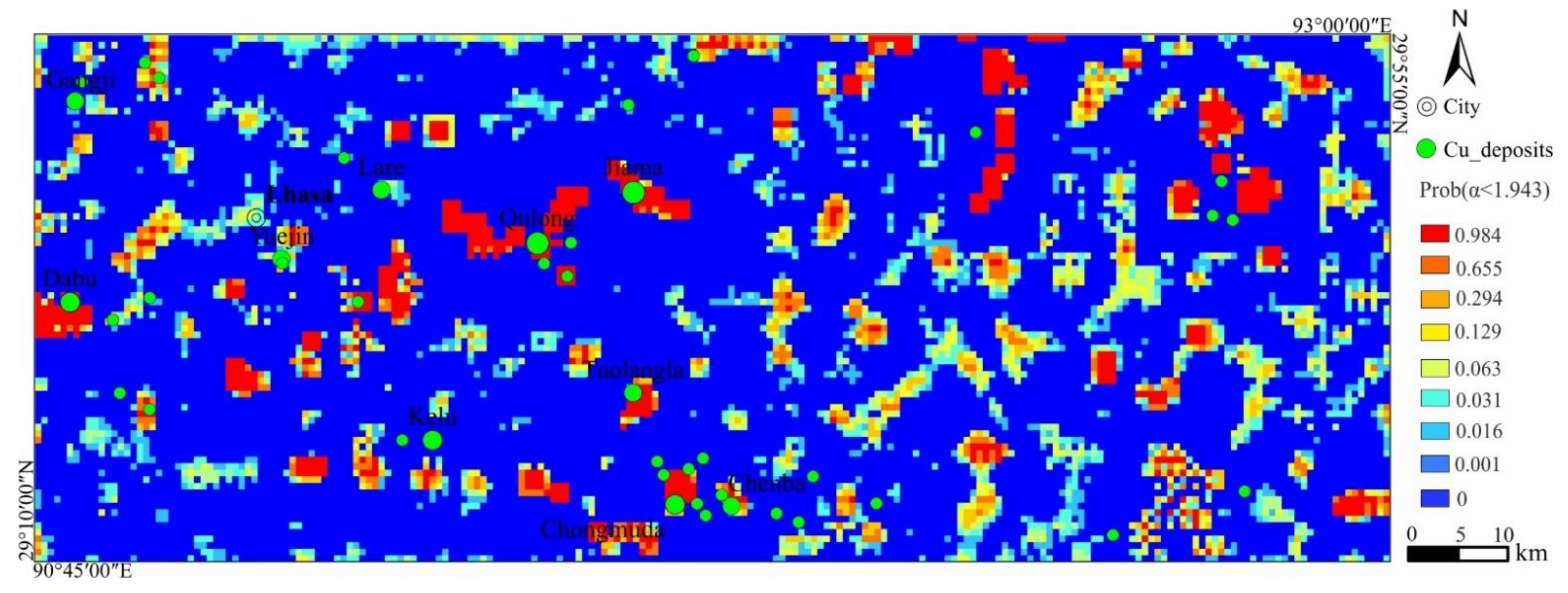
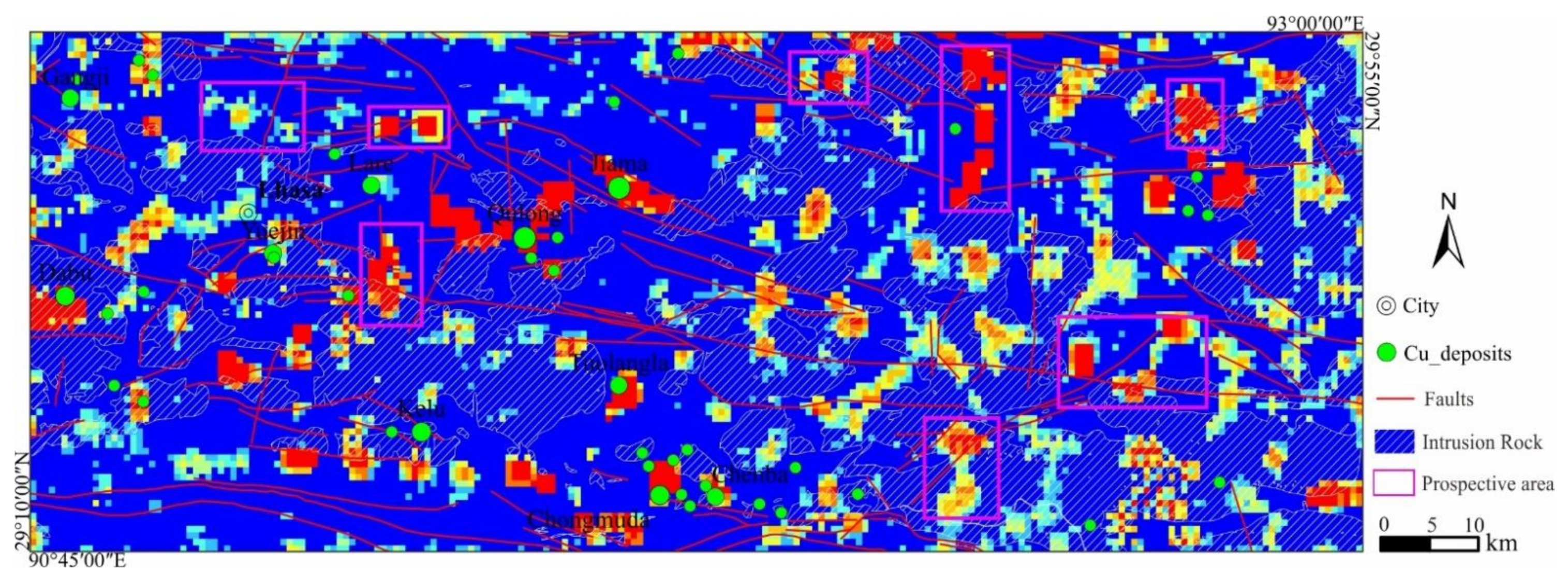
4.3. Uncertainty Assessment of Geochemical Anomaly
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cheng, Q. Singularity theory and methods for mapping geochemical anomalies caused by buried sources and for predicting undiscovered mineral deposits in covered areas. J. Geochem. Explor. 2012, 122, 55–70. [Google Scholar] [CrossRef]
- Xiong, Y.; Zuo, R.; Wang, K.; Wang, J. Identification of geochemical anomalies via local RX anomaly detector. J. Geochem. Explor. 2018, 189, 64–71. [Google Scholar] [CrossRef]
- Matheron, G. Traité de Géostatistique Appliquée; Éditions Technip: Paris, France, 1962. [Google Scholar]
- Huijbregts, C.J. Mining Geostatistics; Academic Press: Cambridge, MA, USA, 1978. [Google Scholar]
- Bilonick, R.A. An introduction to applied geostatistics. Technometrics 1989, 33, 483–485. [Google Scholar] [CrossRef]
- Shepard, D. A two-dimensional interpolation function for irregularly-spaced data. In Proceedings of the 1968 ACM National Conference, New York, NY, USA, 27–29 August 1968. [Google Scholar]
- Tilke, C. Statistics for Spatial Data; John Wiley & Sons Inc.: Hoboken, NJ, USA, 1993. [Google Scholar]
- Handcock, M.S.; Nychka, M.D. Kriging and splines: An empirical comparison of their predictive performance in some applications: Comment. J. Am. Stat. Assoc. 1994, 89, 401–403. [Google Scholar] [CrossRef]
- Collins, F.C. A Comparison of Spatial Interpolation Techniques in Temperature Estimation; Virginia Polytechnic Institute and State University: Blacksburg, VA, USA, 1995. [Google Scholar]
- Hartkamp, A.D.; De Beurs, K.; Stein, A.; White, J.W. Interpolation Techniques for Climate Variables Interpolation; International Maize and Wheat Improvement Center (CIMMYT): Mexico City, Mexico, 1999. [Google Scholar]
- Stahl, K.; Moore, R.D.; Floyer, J.A.; Asplin, M.G.; Mckendry, I.G. Comparison of approaches for spatial interpolation of daily air temperature in a large region with complex topography and highly variable station density. Agric. For. Meteorol. 2006, 139, 224–236. [Google Scholar] [CrossRef]
- Zuo, R. Exploring the effects of cell size in geochemical mapping. J. Geochem. Explor. 2012, 112, 357–367. [Google Scholar] [CrossRef]
- Goovaerts, P. Geostatistical modelling of uncertainty in soil science. Geoderma 2001, 103, 3–26. [Google Scholar] [CrossRef]
- Yue, L.; Qiuming, C.; Carranza, E.J.M.; Zhou, K. Assessment of geochemical anomaly uncertainty through geostatistical simulation and singularity analysis. Nat. Resour. Res. 2018, 28, 199–212. [Google Scholar]
- Mery, N.; Emery, X.; Cáceres, A.; Ribeiro, D.; Cunha, E. Geostatistical modeling of the geological uncertainty in an iron ore deposit. Ore Geol. Rev. 2017, 88, 336–351. [Google Scholar] [CrossRef]
- Qu, J.; Deutsch, C.V. Geostatistical simulation with a trend using gaussian mixture models. Nat. Resour. Res. 2017, 27, 347–363. [Google Scholar] [CrossRef]
- Paithankar, A.; Chatterjee, S. Grade and tonnage uncertainty analysis of an African copper deposit using multiple-point geostatistics and sequential gaussian simulation. Nat. Resour. Res. 2017, 27, 419–436. [Google Scholar] [CrossRef]
- Hosseini, S.A.; Asghari, O. Multivariate geostatistical simulation on block-support in the presence of complex multivariate relationships: Iron ore deposit case study. Nat. Resour. Res. 2018, 28, 125–144. [Google Scholar] [CrossRef]
- Rahimi, H.; Asghari, O.; Hajizadeh, F. Selection of optimal thresholds for estimation and simulation based on indicator values of highly skewed distributions of ore data. Nat. Resour. Res. 2018, 27, 437–453. [Google Scholar] [CrossRef]
- Guardiano, F.B.; Srivastava, R.M. Multivariate geostatistics: Beyond bivariate moments. In Geostatistics Troia ’92; Kluwer: Dordrecht, The Netherlands, 1993; Volume 1, pp. 133–144. [Google Scholar]
- Bezrukov, A.; Davletova, A.R. Methods of multiplepoint statistics in geological simulation practice: Prospects for application. In Proceedings of the SPE Russian Oil and Gas Conference and Exhibition, Moscow, Russia, 26–28 October 2010. (In Russian). [Google Scholar]
- Parra, Á.; Ortiz, J.M. Adapting a texture synthesis algorithm for conditional multiple point geostatistical simulation. Stoch. Environ. Res. Risk Assess. 2011, 25, 1101–1111. [Google Scholar] [CrossRef]
- Mahmud, K.; Mariethoz, G.; Caers, J.; Tahmasebi, P.; Baker, A. Simulation of Earth textures by conditional image quilting. Water Resour. Res. 2014, 50, 3088–3107. [Google Scholar] [CrossRef] [Green Version]
- Abdollahifard, M.J. Fast multiple-point simulation using a data-driven path and an efficient gradient-based search. Comput. Geosci. 2016, 86, 64–74. [Google Scholar] [CrossRef]
- Strebelle, S. Conditional simulation of complex geological structures using multiple-point statistics. Math. Geol. 2002, 34, 1–21. [Google Scholar] [CrossRef]
- Mariethoz, G.; Renard, P.; Straubhaar, J. The direct sampling method to perform multiple-point geostatistical simulations. Water Resour. Res. 2010, 46, W11536. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Mariethoz, G.; Liu, G.; Comunian, A.; Ma, X. Locality-based 3-D multiple-point statistics reconstruction using 2-D geological cross sections. Hydrol. Earth Syst. Sci. 2018, 22, 6547–6566. [Google Scholar] [CrossRef] [Green Version]
- Arpat, G.B.; Caers, J. Conditional simulation with patterns. Math. Geol. 2007, 39, 177–203. [Google Scholar] [CrossRef]
- Zhang, T.; Switzer, P.; Journel, A. Filter-Based classification of training image patterns for spatial simulation. Math. Geol. 2006, 38, 63–80. [Google Scholar] [CrossRef]
- Tahmasebi, P.; Hezarkhani, A.; Sahimi, M. Multiple-Point geostatistical modeling based on the cross-correlation functions. Comput. Geosci. 2012, 16, 779–797. [Google Scholar] [CrossRef]
- Bohling, G.C. Petroleum Geostatistics; Jef Caers Society of Petroleum Engineers: Richardson, TX, USA, 2005; p. 96. ISBN 978-1-55563-106-2. [Google Scholar]
- Mariethoz, G.; Caers, J. Multiple-Point Geostatistics: Stochastic Modeling with Training Images; Wiley-Blackwell: Hoboken, NJ, USA, 2014. [Google Scholar]
- Yang, L.; Hou, W.; Cui, C.; Cui, J. GOSIM: A multi-scale iterative multiple-point statistics algorithm with global optimization. Comput. Geosci. 2016, 89, 57–70. [Google Scholar] [CrossRef]
- Sadeghi, B.; Madani, N.; Carranza, E.J.M. Combination of geostatistical simulation and fractal modeling for mineral resource classification. J. Geochem. Explor. 2015, 149, 59–73. [Google Scholar] [CrossRef]
- Dagasan, Y.; Renard, P.; Straubhaar, J.; Erten, O.; Topal, E. Automatic parameter tuning of multiple-point statistical simulations for lateritic bauxite deposits. Minerals 2018, 8, 220. [Google Scholar] [CrossRef] [Green Version]
- Cheng, Q. Mapping singularities with stream sediment geochemical data for prediction of undiscovered mineral deposits in Gejiu, Yunnan Province, China. Ore Geol. Rev. 2007, 32, 314–324. [Google Scholar] [CrossRef]
- Cheng, Q.; Agterberg, F.P. Singularity analysis of ore-mineral and toxic trace elements in stream sediments. Comput. Geosci. 2009, 35, 234–244. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, K.; Cheng, Q. A new method for geochemical anomaly separation based on the distribution patterns of singularity indices. Comput. Geosci. 2017, 105, 139–147. [Google Scholar] [CrossRef]
- Lin, B.; Chen, Y.; Tang, J.; Wang, Q.; Song, Y.; Yang, C.; Wang, W.; He, W.; Zhang, L. 40Ar/39Ar and Rb-Sr ages of the tiegelongnan porphyry Cu-(Au) deposit in the Bangong Co-Nujiang metallogenic belt of Tibet, China: Implication for generation of super-large deposit. Acta Geol. Sin. (Engl. Ed.) 2017, 91, 602–616. [Google Scholar] [CrossRef]
- Lin, B.; Tang, J.X.; Chen, Y.C.; Song, Y.; Hall, G.; Wang, Q.; Yang, C.; Fang, X.; Duan, J.-L.; Yang, H.-H.; et al. Geochronology and genesis of the tiegelongnan porphyry Cu(Au) deposit in Tibet: Evidence from U–Pb, Re–Os dating and Hf, S, and H–O isotopes. Resour. Geol. 2017, 67, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.; Yang, C.; Wei, S.; Yang, H.; Fang, X.; Lu, H. Tectonic control, reconstruction and preservation of the Tiegelongnan porphyry and epithermal overprinting Cu (Au) deposit, central Tibet, China. Minerals 2018, 8, 398. [Google Scholar] [CrossRef] [Green Version]
- Lin, B.; Tang, J.; Chen, Y.; Baker, M.; Song, Y.; Yang, H.; Wang, Q.; He, W.; Liu, Z. Geology and geochronology of Naruo large porphyry-breccia Cu deposit in the Duolong district, Tibet. Gondwana Res. 2018, 66, 168–182. [Google Scholar] [CrossRef]
- Hou, Z.; Yang, Z.; Qu, X.; Meng, X.; Li, Z.; Beaudoin, G.; Rui, Z.; Gao, Y.; Zaw, K. The miocene gangdese porphyry copper belt generated during post-collisional extension in the Tibetan Orogen. Ore Geol. Rev. 2009, 36, 25–51. [Google Scholar] [CrossRef]
- Turner, S.; Hawkesworth, C.; Liu, J.; Rogers, N.; Kelley, S.; van Calsteren, P. Timing of Tibetan uplift constrained by analysis of volcanic rocks. Nature 1993, 364, 50. [Google Scholar] [CrossRef]
- Miller, C.H.; Schuster, R.; Klötzli, U.; Frank, W.; Purtscheller, F. Post-Collisional potassic and ultrapotassic magmatism in SW Tibet: Geochemical and Sr–Nd–Pb–O isotopic constraints for mantle source characteristics and petrogenesis. J. Petrol. 1999, 40, 1399–1424. [Google Scholar] [CrossRef]
- Chung, S.-L.; Liu, D.; Ji, J.; Chu, M.-F.; Lee, H.-Y.; Wen, D.-Y.; Lo, C.-H.; Lee, T.-Y.; Qian, Q.; Zhang, Q. Adakites from continental collision zones: Melting of thickened lower crust beneath southern Tibet. Geology 2003, 31, 1021–1024. [Google Scholar] [CrossRef] [Green Version]
- Pan, G.-T. Spatial temporal framework of the Gangdese Orogenic Belt and its evolution. Acta Petrol. Sin. 2006, 22, 521–533. [Google Scholar]
- Xiao, K.; Li, N.; Porwal, A.; Holden, E.-Y.; Bagas, L.; Lu, Y. GIS-Based 3D prospectivity mapping: A case study of Jiama copper-polymetallic deposit in Tibet, China. Ore Geol. Rev. 2015, 71, 611–632. [Google Scholar] [CrossRef]
- Zuo, R.; Cheng, Q.; Agterberg, F.P.; Xia, Q. Application of singularity mapping technique to identify local anomalies using stream sediment geochemical data, a case study from Gangdese, Tibet, western China. J. Geochem. Explor. 2009, 101, 225–235. [Google Scholar] [CrossRef]
- Xie, X. Analytical requirements in international geochemical mapping. In Analyst; London Society of Public Analysts, Royal Society of Chemistry: London, UK, 1995. [Google Scholar]
- Wang, X. Exploration geochemistry: Past achievements and future challenges. Earth Sci. Front. 2003, 10, 239–248. [Google Scholar]
- Wang, J.; Zuo, R. Identification of geochemical anomalies through combined sequential Gaussian simulation and grid-based local singularity analysis. Comput. Geosci. 2018, 118, 52–64. [Google Scholar] [CrossRef]
- Wang, J.; Zuo, R. Recognizing geochemical anomalies via stochastic simulation-based local singularity analysis. J. Geochem. Explor. 2019, 198, 29–40. [Google Scholar] [CrossRef]
- Goovaerts, P. Geostatistics for natural resources evaluation (Applied geostatistics). In Geostatistics for Natural Resources Evaluation; Oxford University Press: Oxford, UK, 1997. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inputs: | |
|---|---|
| m variables Z1, Z2,…, Zm to simulate | |
| Simulation grid, SG | |
| Training image, TI | |
| Set of conditioning data points | |
| Maximum number of neighbors n, distance threshold t, maximum fraction of TI scanned f | |
| Algorithm steps | |
| 1 | Migrate conditioning points to the corresponding grid nodes. |
| 2 | Define a simulation path. |
| 3 | Until all SG nodes have been visited, |
| 4 | Define the node x to be simulated. |
| 5 | Find Nx, made of the n closest neighbors of x. |
| 6 | Define the random path L of scanning TI. |
| 7 | For each node y on L, |
| 8 | Compute the distance d(Nx,Ny). |
| 9 | If d(Nx,Ny) < t |
| 10 | Z(x) = Z(y) |
| 11 | break |
| 12 | end if |
| 13 | if scanned > f |
| 14 | Z(x) = Z(y*), where y satisfies d(Nx,Ny*) is the smallest |
| 15 | break |
| 16 | end if |
| 17 | end for |
| 18 | end for |
| Output: Simulation grid, SG. | |
| Parameter | Notation | Value |
|---|---|---|
| Number of realizations | L | 200 |
| Number of points in the data event | n | 20 |
| Max fraction of input data to scan | f | 0.8 |
| Distance threshold | t | 0.02 |
| Search radii | r | 15 |
| Path type | Fully random path |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Liu, B.; Guo, K.; Li, B.; Kong, Y. Regional Geochemical Anomaly Identification Based on Multiple-Point Geostatistical Simulation and Local Singularity Analysis—A Case Study in Mila Mountain Region, Southern Tibet. Minerals 2021, 11, 1037. https://0-doi-org.brum.beds.ac.uk/10.3390/min11101037
Li C, Liu B, Guo K, Li B, Kong Y. Regional Geochemical Anomaly Identification Based on Multiple-Point Geostatistical Simulation and Local Singularity Analysis—A Case Study in Mila Mountain Region, Southern Tibet. Minerals. 2021; 11(10):1037. https://0-doi-org.brum.beds.ac.uk/10.3390/min11101037
Chicago/Turabian StyleLi, Cheng, Bingli Liu, Ke Guo, Binbin Li, and Yunhui Kong. 2021. "Regional Geochemical Anomaly Identification Based on Multiple-Point Geostatistical Simulation and Local Singularity Analysis—A Case Study in Mila Mountain Region, Southern Tibet" Minerals 11, no. 10: 1037. https://0-doi-org.brum.beds.ac.uk/10.3390/min11101037