
Modeling Interfacial Tension of N2/CO2 Mixture + n-Alkanes with Machine Learning Methods: Application to EOR in Conventional and Unconventional Reservoirs by Flue Gas Injection

 ,
,  , and
, and
Abstract
:1. Introduction
2. Data Collection
3. Methodology
3.1. Model Development
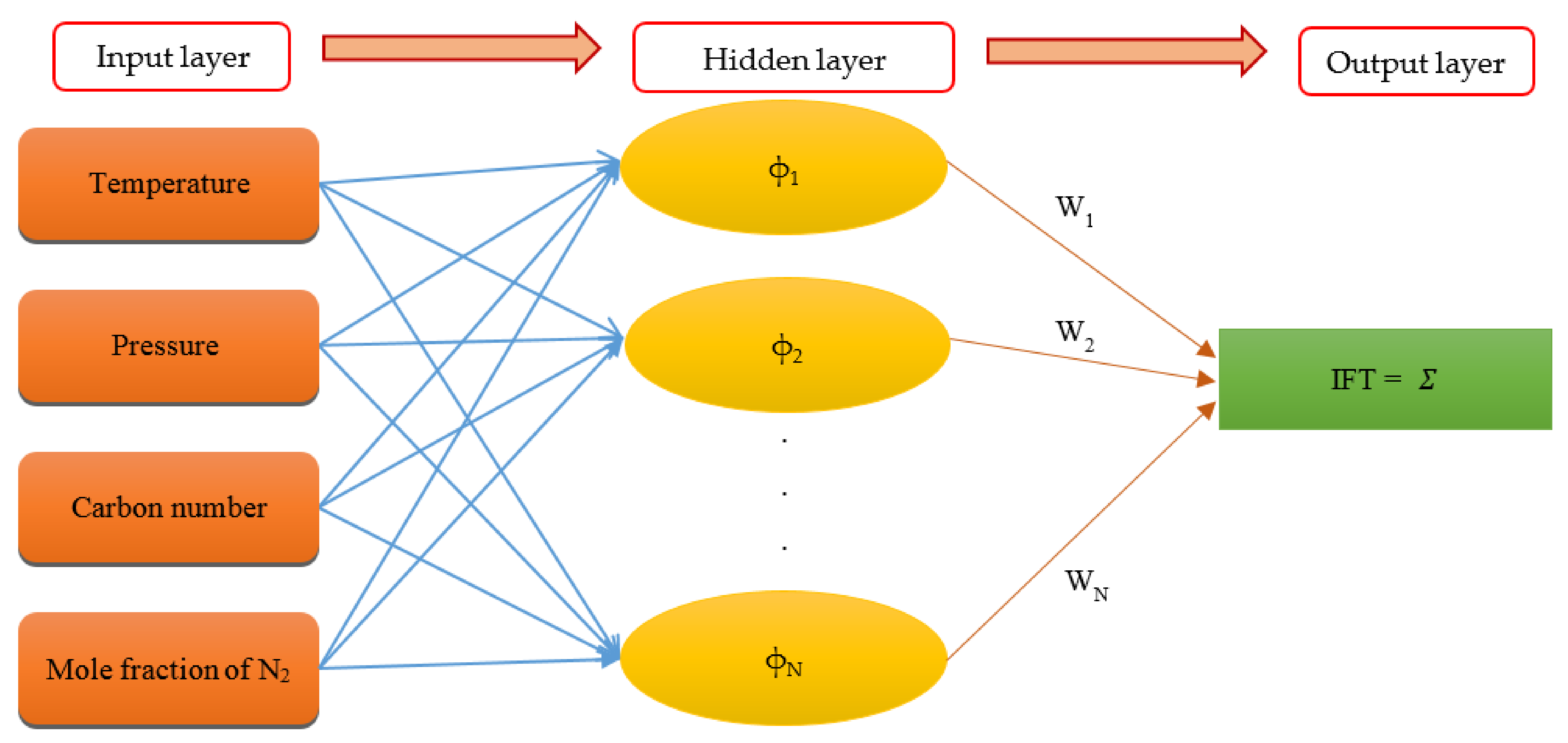
3.1.1. Multilayer Perceptron
3.1.2. Radial Basis Function Neural Network
3.1.3. Least Squares Support Vector Machine
3.1.4. Adaptive Neuro-Fuzzy Inference System
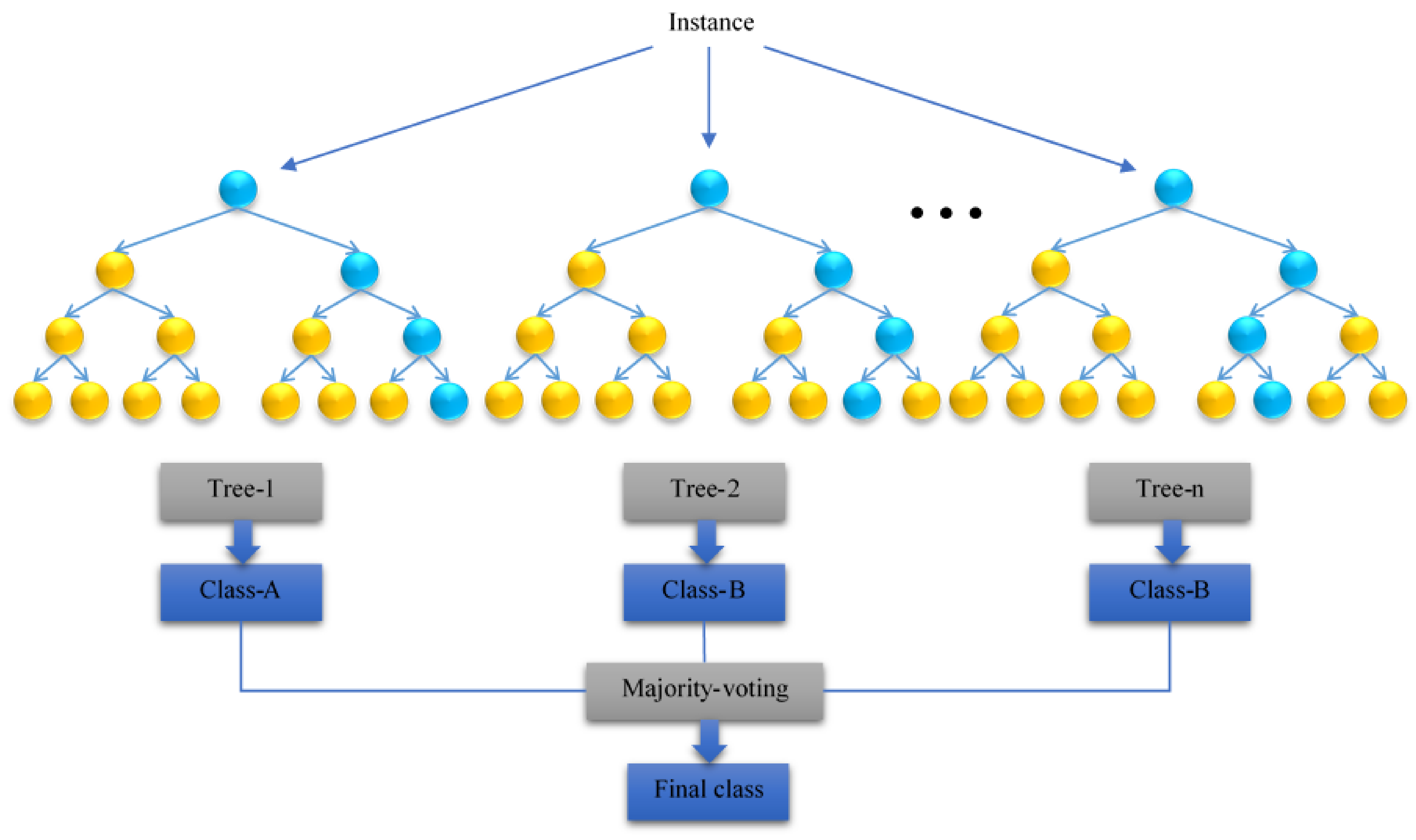
3.1.5. Extremely Randomized Tree (Extra-Tree)
3.1.6. Random Forest
3.2. Optimization Methods
3.2.1. Colliding Bodies Optimization (CBO)
3.2.2. Particle Swarm Optimization (PSO) Algorithm
3.2.3. Coupled Simulated Annealing (CSA)
3.2.4. Levenberg–Marquardt (LM) Algorithm
4. Results and Discussion
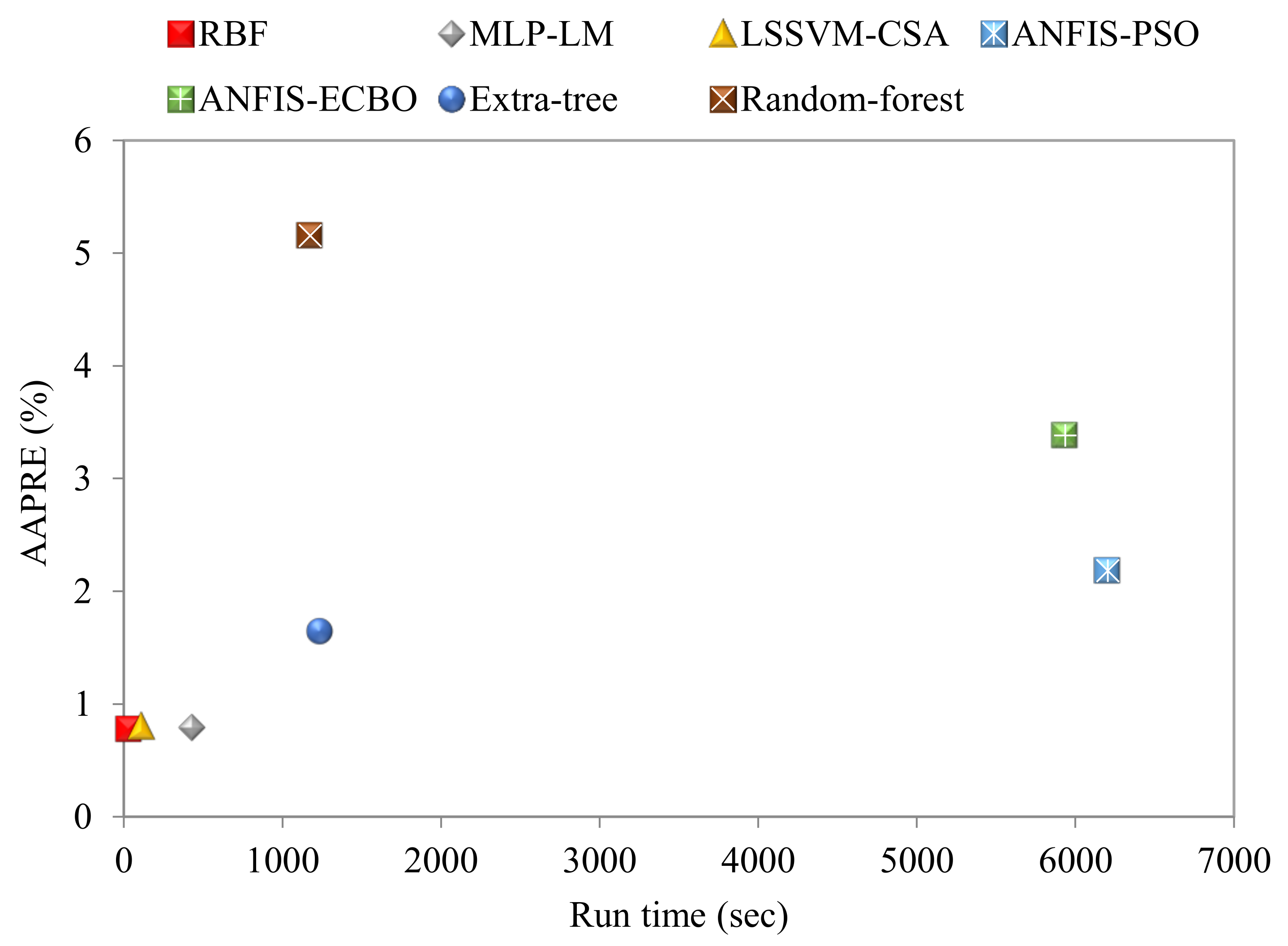
4.1. Comparison of ML Models
- Average percent relative error (APRE%):
- Average absolute percent relative error (AAPRE%):
- Root mean square error (RMSE):
- Standard errors (SD):
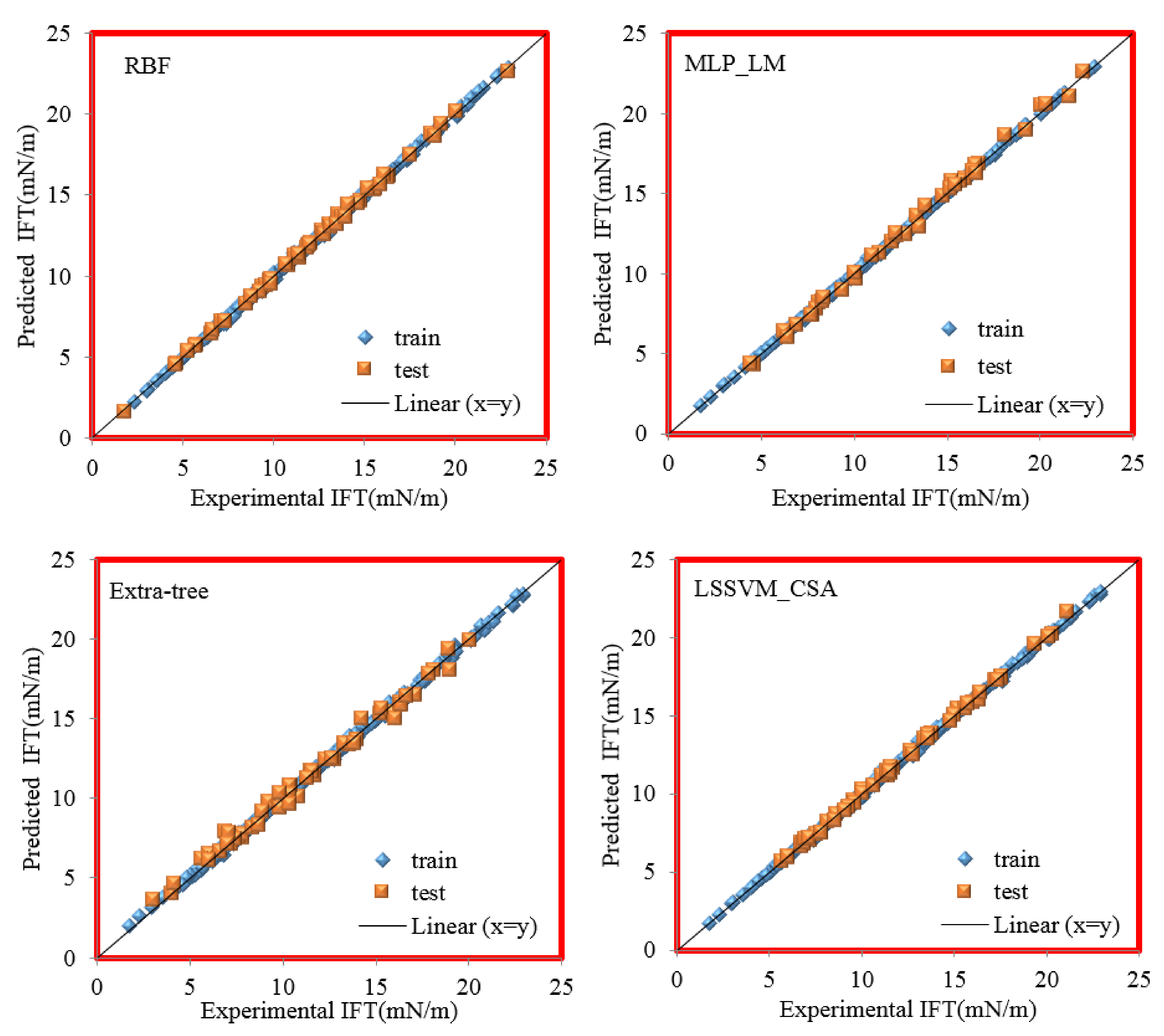
- Cross plot: In this graph, the estimated data by the models are plotted versus the laboratory data. Using this visual presentation, we can assess the deviation of the estimated data by the models from the actual data. The more data near the unit slope line, the greater the precision of the model in predicting the experimental data would be. Figure 6 displays the comparison between the output and target data by cross plots for all models. As can be seen, the data points are located near the unit slope line for the ML models, although the precision of the RBF, LSSVM–CSA, and MLP–LM models is higher for both testing and training sets.
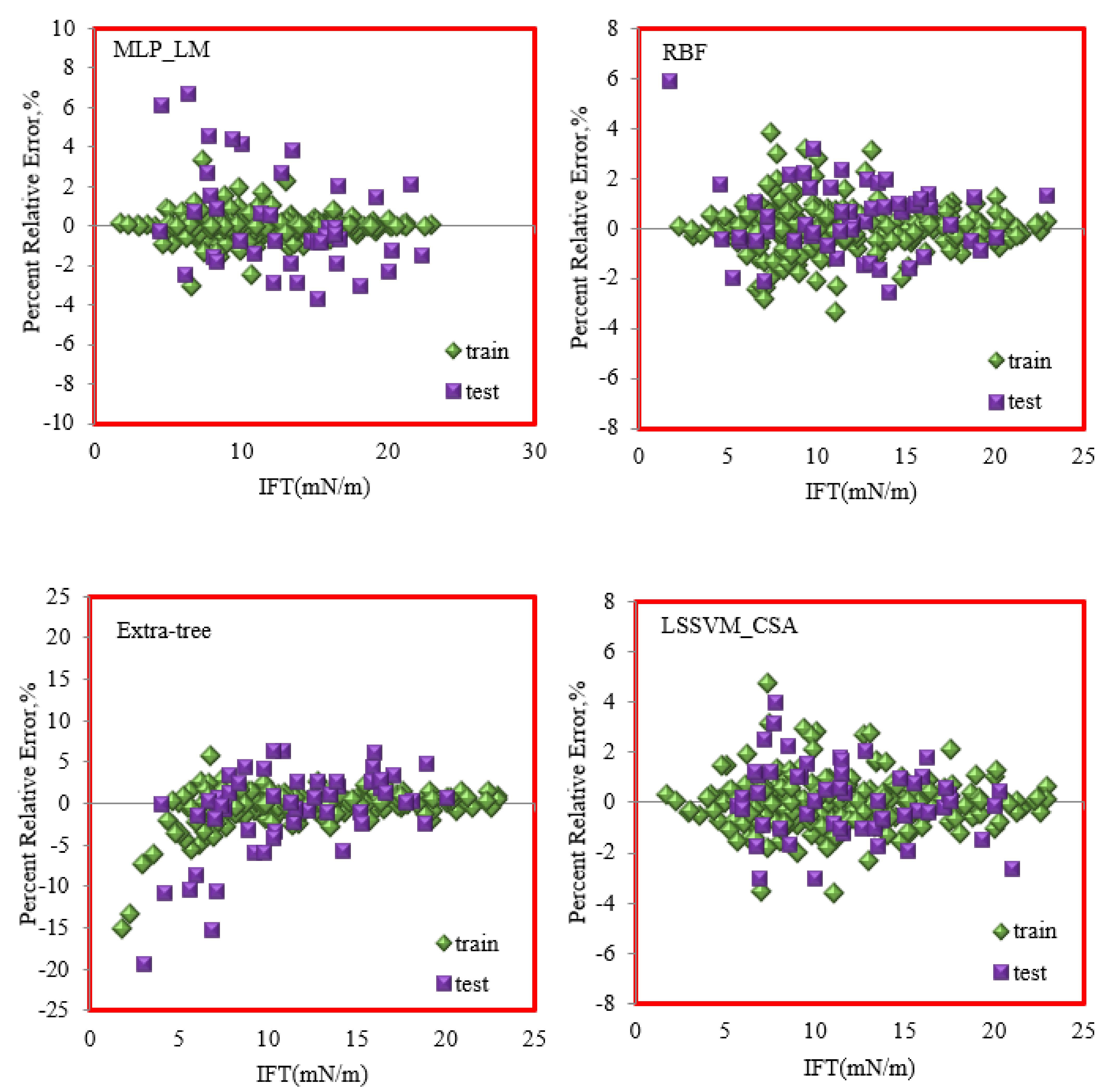
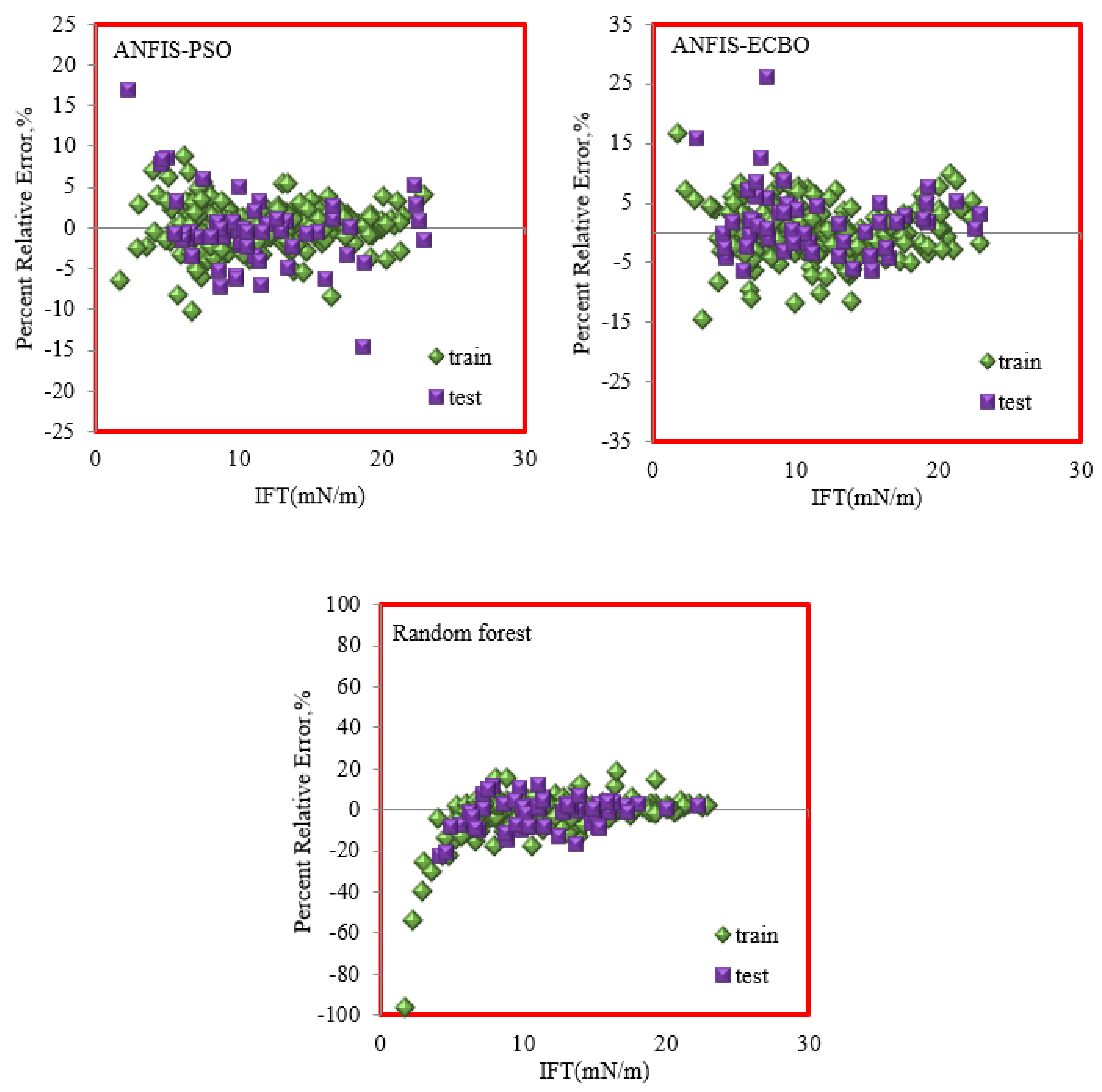
- Error distribution plot: This plot explains the percent relative error of each data point versus the real laboratory data or the independent parameters so to represent the error value or the possible error trend. If the error value is close to nil, it reveals that the estimated data and the laboratory data are close to each other, but the high scatter of the data around the zero-error line infers the poor performance of the model. Figure 7 depicts the error distribution plots for all proposed models in this work. Similarly, RBF and LSSVM–CSA are considered more precise models, having more data points with less error and a high concentration of data near the zero-error line.
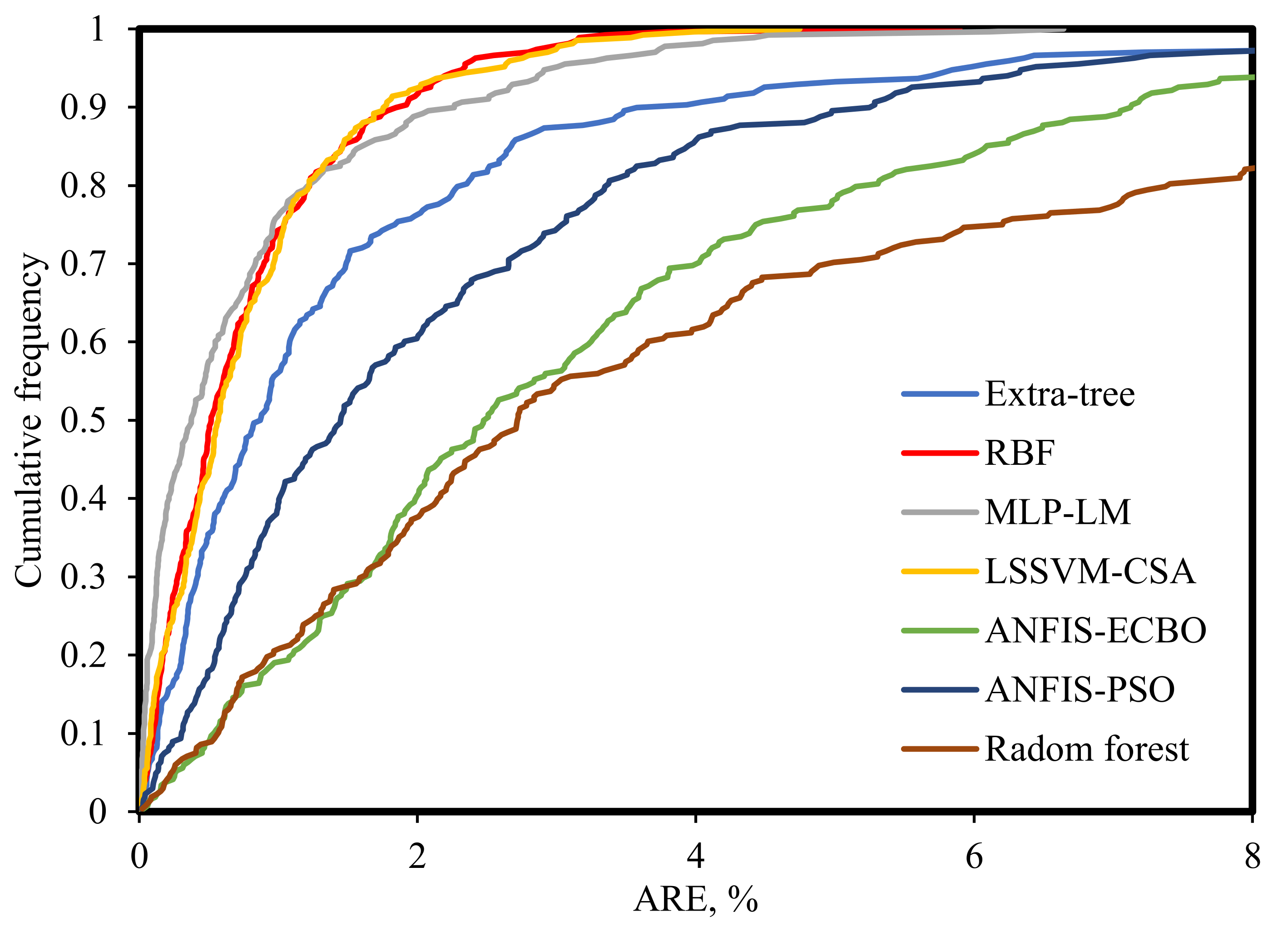
- Cumulative frequency plot: The error of each model in estimating any percentage of the data can be examined by plotting the cumulative frequency vs. the absolute relative error (ARE, %). Cumulative frequency graphs of all models are shown in Figure 8. The robustness of the RBF model is acceptable, since about 90% of the data have ARE lower than 1.8%. Moreover, the LSSVM–CSA and MLP–LM models have a high percentage of low-error data, which confirms the high reliability of these models along with the RBF model. The random forest and ANFIS–ECBO models display poorer performance compared to other ones.
4.2. Trend Analysis
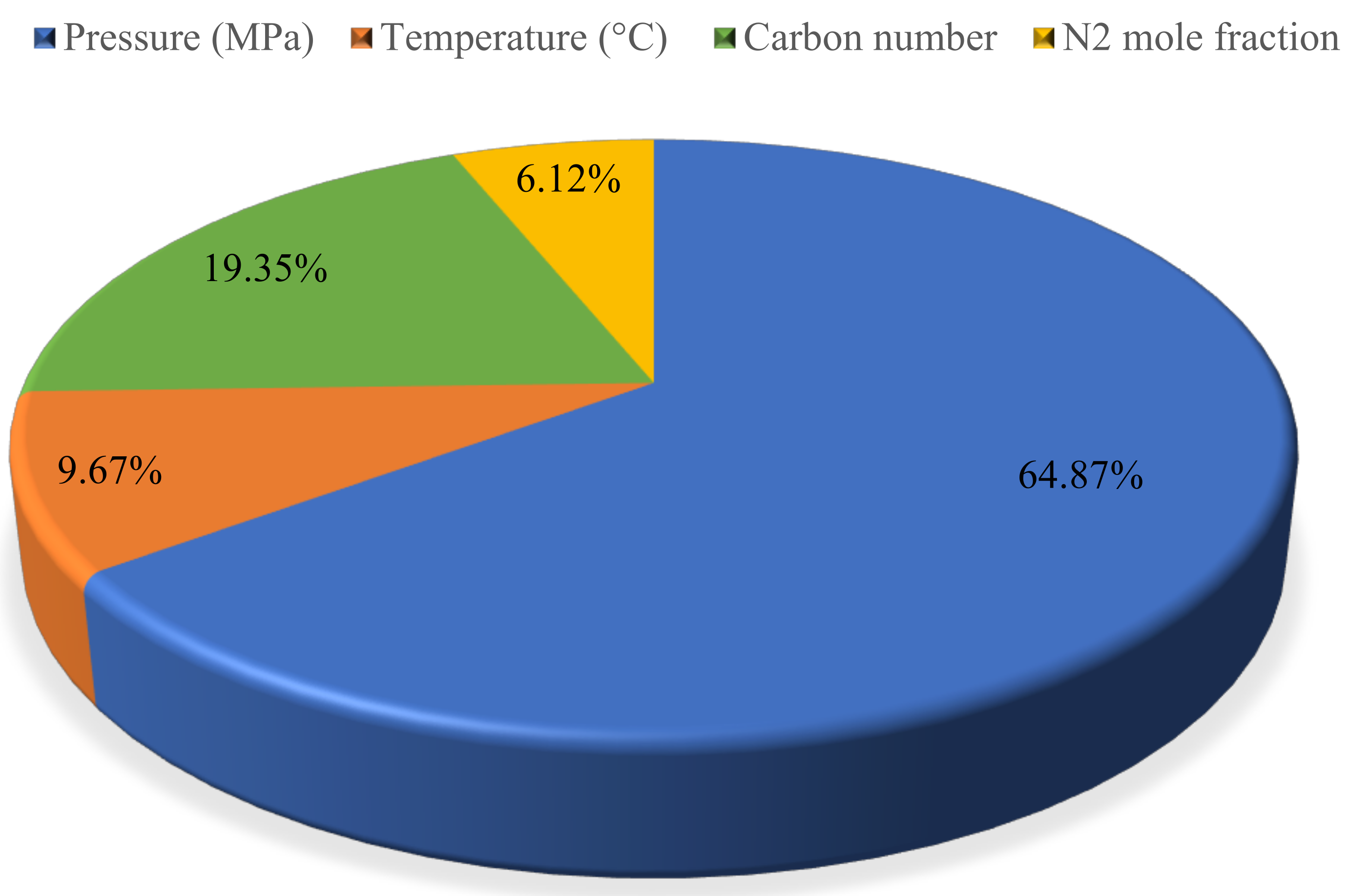
4.3. Sensitivity Analysis
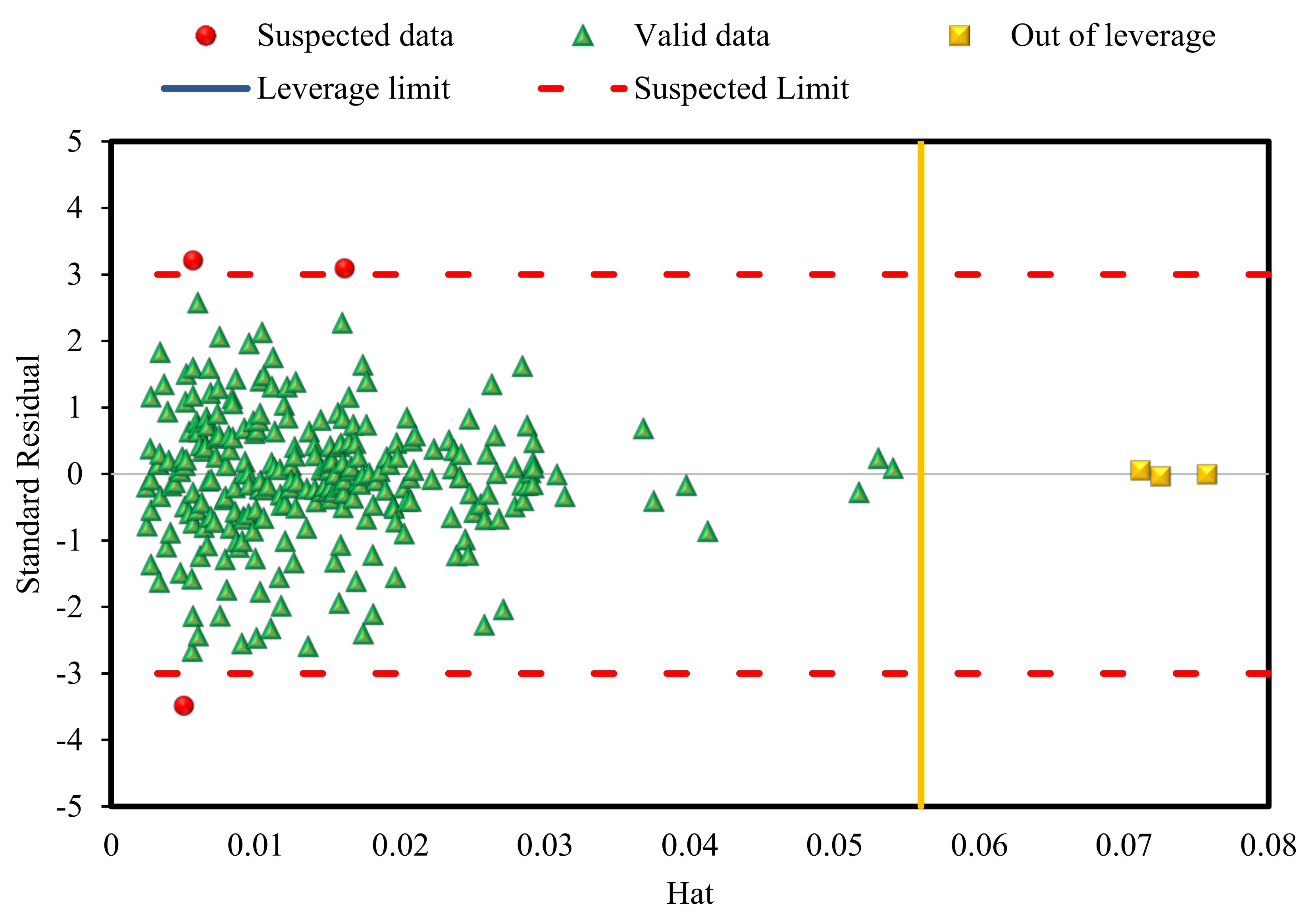
4.4. Model Reliability Assessment and Outlier Diagnostics
5. Conclusions
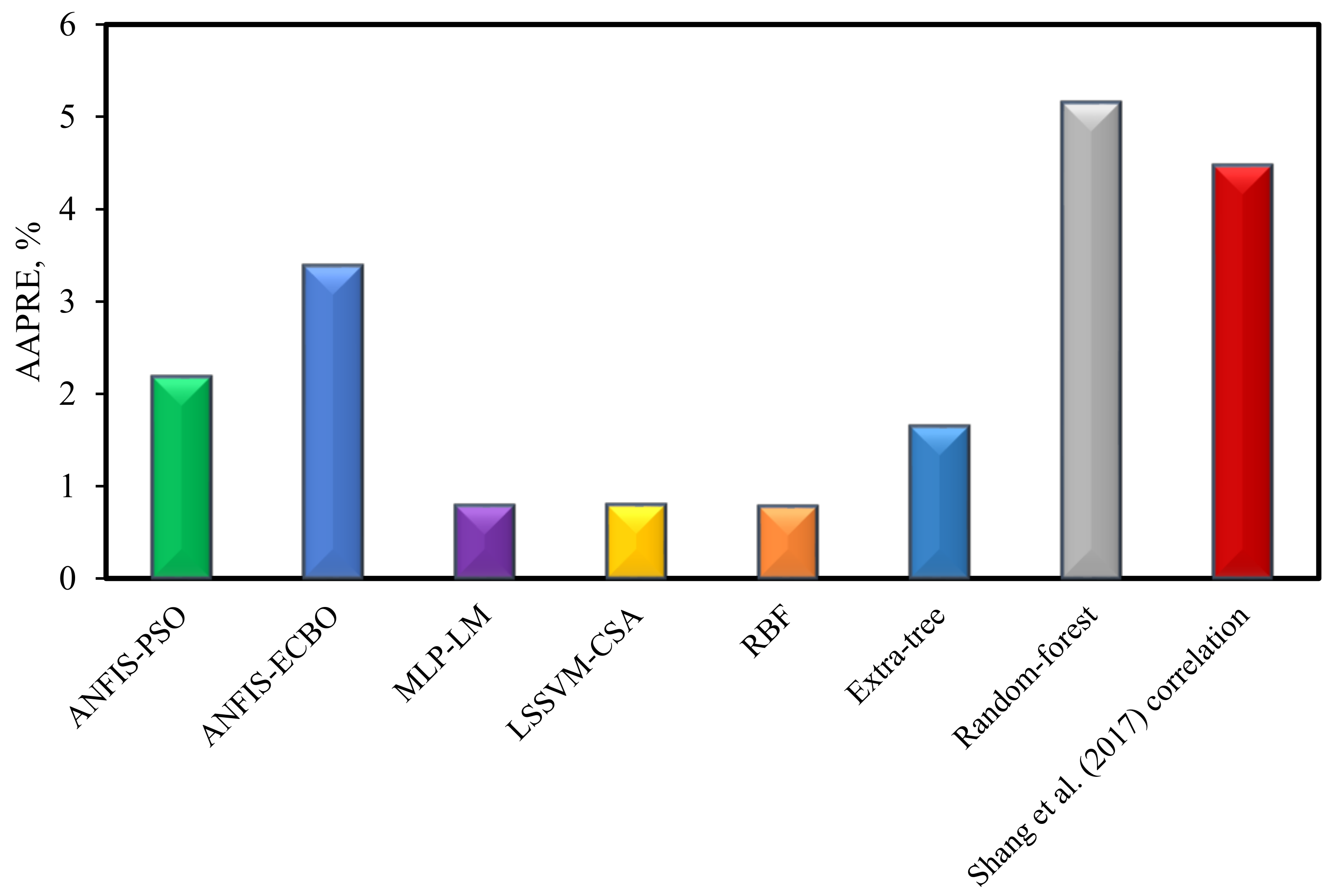
- The RBF model estimates all of the IFT data with superb accuracy, with an AAPRE of 0.77%, which outperformed all proposed models in this work and the literature. The RBF model successfully recognized the decreasing trend of IFT with increasing pressure and temperature.
- Moreover, LSSVM–CSA, MLP–LM, extra-tree, ANFIS–PSO, ANFIS–ECBO, and random-forest models followed the RBF model in terms of accuracy.
- According to the sensitivity analysis, pressure would have the greatest impact on the IFT of the N2/CO2 mixture + n-alkanes, followed by carbon number of n-alkanes, the temperature, and the mole fraction of N2y. Pressure and temperature have a decreasing impact on the IFT of the N2/CO2 mixture + n-alkanes.
- Finally, based on the leverage approach, only six data points were recognized to be outside of the scope of the model applicability, which proves the high reliability of the RBF model for estimating the IFT of the N2/CO2 mixture + n-alkanes.
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| APRE | Average percent relative error |
| ANFIS | Adaptive neuro-fuzzy inference system |
| AAPRE | Average absolute percent relative error |
| ARE | Absolute relative error |
| ANNs | Artificial neural networks |
| AI | Artificial intelligence |
| CBO | Colliding bodies optimization |
| CSA | Coupled simulated annealing |
| DL | Deep learning |
| Extra-tree | Extremely randomized trees |
| ECBO | Enhanced colliding bodies optimization |
| EOR | Enhanced oil recovery |
| FL | Fuzzy logic |
| IFT | Interfacial tension |
| LSSVM | Least square support vector machine |
| LM | Levenberg–Marquardt |
| ML | Machine learning |
| MLP | Multilayer perceptron |
| PSO | Particle swarm optimization |
| R2 | Coefficient of determination |
| RMSE | Root mean square error |
| RBF | Radial basis function |
| SD | Standard deviation |
| SVM | Support vector machine |
References
- Ameli, F.; Hemmati-Sarapardeh, A.; Schaffie, M.; Husein, M.M.; Shamshirband, S. Modeling interfacial tension in N2/n-alkane systems using corresponding state theory: Application to gas injection processes. Fuel 2018, 222, 779–791. [Google Scholar] [CrossRef]
- Bakyani, A.E.; Namdarpoor, A.; Sarvestani, A.N.; Daili, A.; Raji, B.; Esmaeilzadeh, F. A Simulation Approach for Screening of EOR Scenarios in Naturally Fractured Reservoirs. Int. J. Geosci. 2018, 9, 19–43. [Google Scholar] [CrossRef] [Green Version]
- Al Adasani, A.; Bai, B. Analysis of EOR projects and updated screening criteria. J. Pet. Sci. Eng. 2011, 79, 10–24. [Google Scholar] [CrossRef]
- Gajbhiye, R. Effect of CO2/N2 Mixture Composition on Interfacial Tension of Crude Oil. ACS Omega 2020, 5, 27944–27952. [Google Scholar] [CrossRef] [PubMed]
- Bender, S. Co-Optimization of CO2 Sequestration and Enhanced Oil Recovery and Co-Optimization of CO2 Sequestration and Methane Recovery in Geopressured Aquifers. Ph.D. Thesis, The University of Texas at Austin, Austin, TX, USA, 2011. [Google Scholar]
- Bender, S.; Akin, S. Flue gas injection for EOR and sequestration: Case study. J. Pet. Sci. Eng. 2017, 157, 1033–1045. [Google Scholar] [CrossRef]
- Roefs, P.; Moretti, M.; Welkenhuysen, K.; Piessens, K.; Compernolle, T. CO2-enhanced oil recovery and CO2 capture and storage: An environmental economic trade-off analysis. J. Environ. Manag. 2019, 239, 167–177. [Google Scholar] [CrossRef]
- Du, F.; Nojabaei, B. A Review of Gas Injection in Shale Reservoirs: Enhanced Oil/Gas Recovery Approaches and Greenhouse Gas Control. Energies 2019, 12, 2355. [Google Scholar] [CrossRef] [Green Version]
- Hoffman, B.T. Comparison of Various Gases for Enhanced Recovery from Shale Oil Reservoirs. In Proceedings of the SPE Improved Oil Recovery Symposium, Tulsa, OK, USA, 14–18 April 2012. [Google Scholar]
- Ratner, M.; Tiemann, M. An Overview of Unconventional Oil and Natural Gas: Resources and Federal Actions; Congressional Research Service: Washington, DC, USA, 2014.
- Jin, L.; Hawthorne, S.; Sorensen, J.; Pekot, L.; Kurz, B.; Smith, S.; Heebink, L.; Bosshart, N.; Torres, J.; Dalkhaa, C.; et al. Extraction of oil from the Bakken shales with supercritical CO2. In Proceedings of the SPE/AAPG/SEG Unconventional Resources Technology Conference, Austin, TX, USA, 17–21 July 2017. [Google Scholar]
- Fathi, E.; Akkutlu, I.Y. Multi-component gas transport and adsorption effects during CO2 injection and enhanced shale gas recovery. Int. J. Coal Geol. 2013, 123, 52–61. [Google Scholar] [CrossRef]
- Yu, W.; Lashgari, H.R.; Wu, K.; Sepehrnoori, K. CO2 injection for enhanced oil recovery in Bakken tight oil reservoirs. Fuel 2015, 159, 354–363. [Google Scholar] [CrossRef]
- Fathi, E.; Akkutlu, I.Y. Mass Transport of Adsorbed-Phase in Stochastic Porous Medium with Fluctuating Porosity Field and Nonlinear Gas Adsorption Kinetics. Transp. Porous Media 2011, 91, 5–33. [Google Scholar] [CrossRef]
- Yang, J.; Okwananke, A.; Tohidi, B.; Chuvilin, E.; Maerle, K.; Istomin, V.; Bukhanov, B.; Cheremisin, A. Flue gas injection into gas hydrate reservoirs for methane recovery and carbon dioxide sequestration. Energy Convers. Manag. 2017, 136, 431–438. [Google Scholar] [CrossRef]
- Sloan, E.D., Jr.; Koh, C.A. Clathrate Hydrates of Natural Gases; CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar]
- Rezaei, F.; Rezaei, A.; Jafari, S.; Hemmati-Sarapardeh, A.; Mohammadi, A.H.; Zendehboudi, S. On the Evaluation of Interfacial Tension (IFT) of CO2–Paraffin System for Enhanced Oil Recovery Process: Comparison of Empirical Correlations, Soft Computing Approaches, and Parachor Model. Energies 2021, 14, 3045. [Google Scholar] [CrossRef]
- Ghosh, A.; Chakraborty, D.; Law, A. Artificial intelligence in Internet of things. CAAI Trans. Intell. Technol. 2018, 3, 208–218. [Google Scholar] [CrossRef]
- Kalogirou, S. Applications of artificial neural-networks for energy systems. Appl. Energy 2000, 67, 17–35. [Google Scholar] [CrossRef]
- Ongsulee, P. Artificial intelligence, machine learning and deep learning. In Proceedings of the 15th International Conference on ICT and Knowledge Engineering (ICT&KE), Bangkok, Thailand, 22–24 November 2017; pp. 1–6. [Google Scholar]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- Barati-Harooni, A.; Soleymanzadeh, A.; Tatar, A.; Najafi-Marghmaleki, A.; Samadi, S.-J.; Yari, A.; Roushani, B.; Mohammadi, A.H. Experimental and modeling studies on the effects of temperature, pressure and brine salinity on interfacial tension in live oil-brine systems. J. Mol. Liq. 2016, 219, 985–993. [Google Scholar] [CrossRef]
- Amar, M.N.; Shateri, M.; Hemmati-Sarapardeh, A.; Alamatsaz, A. Modeling oil-brine interfacial tension at high pressure and high salinity conditions. J. Pet. Sci. Eng. 2019, 183, 106413. [Google Scholar] [CrossRef]
- Meybodi, M.K.; Shokrollahi, A.; Safari, H.; Lee, M.; Bahadori, A. A computational intelligence scheme for prediction of interfacial tension between pure hydrocarbons and water. Chem. Eng. Res. Des. 2015, 95, 79–92. [Google Scholar] [CrossRef]
- Najafi-Marghmaleki, A.; Tatar, A.; Barati-Harooni, A.; Mohebbi, A.; Kalantari-Meybodi, M.; Mohammadi, A.H. On the prediction of interfacial tension (IFT) for water-hydrocarbon gas system. J. Mol. Liq. 2016, 224, 976–990. [Google Scholar] [CrossRef]
- Emami Baghdadi, M.H.; Darvish, H.; Rezaei, H.; Savadinezhad, M. Applying LSSVM algorithm as a novel and accurate method for estimation of interfacial tension of brine and hydrocarbons. Pet. Sci. Technol. 2018, 36, 1170–1174. [Google Scholar] [CrossRef]
- Darvish, H.; Rahmani, S.; Sadeghi, A.M.; Baghdadi, M.H.E. The ANFIS-PSO strategy as a novel method to predict interfacial tension of hydrocarbons and brine. Pet. Sci. Technol. 2018, 36, 654–659. [Google Scholar] [CrossRef]
- Mehrjoo, H.; Riazi, M.; Amar, M.N.; Hemmati-Sarapardeh, A. Modeling interfacial tension of methane-brine systems at high pressure and high salinity conditions. J. Taiwan Inst. Chem. Eng. 2020, 114, 125–141. [Google Scholar] [CrossRef]
- Niroomand-Toomaj, E.; Etemadi, A.; Shokrollahi, A. Radial basis function modeling approach to prognosticate the interfacial tension CO2/Aquifer Brine. J. Mol. Liq. 2017, 238, 540–544. [Google Scholar] [CrossRef]
- Kamari, A.; Pournik, M.; Rostami, A.; Amirlatifi, A.; Mohammadi, A.H. Characterizing the CO2-brine interfacial tension (IFT) using robust modeling approaches: A comparative study. J. Mol. Liq. 2017, 246, 32–38. [Google Scholar] [CrossRef]
- Liu, X.; Mutailipu, M.; Zhao, J.; Liu, Y. Comparative Analysis of Four Neural Network Models on the Estimation of CO2–Brine Interfacial Tension. ACS Omega 2021, 6, 4282–4288. [Google Scholar] [CrossRef] [PubMed]
- Amar, M.N. Towards improved genetic programming based-correlations for predicting the interfacial tension of the systems pure/impure CO2-brine. J. Taiwan Inst. Chem. Eng. 2021, 127, 186–196. [Google Scholar] [CrossRef]
- Ahmadi, M.A.; Mahmoudi, B. Development of robust model to estimate gas–oil interfacial tension using least square support vector machine: Experimental and modeling study. J. Supercrit. Fluids 2016, 107, 122–128. [Google Scholar] [CrossRef]
- Ayatollahi, S.; Hemmati-Sarapardeh, A.; Roham, M.; Hajirezaie, S. A rigorous approach for determining interfacial tension and minimum miscibility pressure in paraffin-CO2 systems: Application to gas injection processes. J. Taiwan Inst. Chem. Eng. 2016, 63, 107–115. [Google Scholar] [CrossRef]
- Hemmati-Sarapardeh, A.; Mohagheghian, E. Modeling interfacial tension and minimum miscibility pressure in paraffin-nitrogen systems: Application to gas injection processes. Fuel 2017, 205, 80–89. [Google Scholar] [CrossRef]
- Shang, Q.; Xia, S.; Cui, G.; Tang, B.; Ma, P. Measurement and correlation of the interfacial tension for paraffin + CO2 and (CO2 +N2) mixture gas at elevated temperatures and pressures. Fluid Phase Equilib. 2017, 439, 18–23. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, Y.; Shang, L.; Feng, Q.; Gong, L.; Wu, K. A unified intelligent model for estimating the (gas + n-alkane) interfacial tension based on the eXtreme gradient boosting (XGBoost) trees. Fuel 2020, 282, 118783. [Google Scholar] [CrossRef]
- Mirzaie, M.; Tatar, A. Modeling of interfacial tension in binary mixtures of CH4, CO2, and N2-alkanes using gene expression programming and equation of state. J. Mol. Liq. 2020, 320, 114454. [Google Scholar] [CrossRef]
- Jianhua, T.; Satherley, J.; Schiffrin, D. Density and intefacial tension of nitrogen-hydrocarbon systems at elevated pressures. Chin. J. Chem. Eng. 1993, 1, 223–231. [Google Scholar]
- Wehle, H.-D. Machine Learning, Deep Learning and AI: What’s the Difference. Data Scientist Innovation Day. 2017, pp. 2–5. Available online: https://www.researchgate.net/publication/318900216_Machine_Learning_Deep_Learning_and_AI_What%27s_the_Difference (accessed on 30 August 2021).
- Mohammadi, M.-R.; Hadavimoghaddam, F.; Atashrouz, S.; Abedi, A.A.; Hemmati-Sarapardeh, A.; Mohaddespour, A. Modeling hydrogen solubility in alcohols using machine learning models and equations of state. J. Mol. Liq. 2021, 346, 117807. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Ameli, F.; Hemmati-Sarapardeh, A.; Tatar, A.; Zanganeh, A.; Ayatollahi, S. Modeling interfacial tension of normal alkane-supercritical CO2 systems: Application to gas injection processes. Fuel 2019, 253, 1436–1445. [Google Scholar] [CrossRef]
- Broomhead, D.; Lowe, D. Multivariable functional interpolation and adaptive networks. Complex Syst. 1988, 2, 321–355. [Google Scholar]
- Suykens, J.A.K.; Vandewalle, J. Least Squares Support Vector Machine Classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Wang, H.; Hu, D. Comparison of SVM and LS-SVM for regression. In Proceedings of the 2005 International Conference on Neural Networks and Brain, Beijing, China, 13–15 October 2005; pp. 279–283. [Google Scholar]
- Gharagheizi, F.; Eslamimanesh, A.; Farjood, F.; Mohammadi, A.H.; Richon, D. Solubility Parameters of Nonelectrolyte Organic Compounds: Determination Using Quantitative Structure–Property Relationship Strategy. Ind. Eng. Chem. Res. 2011, 50, 11382–11395. [Google Scholar] [CrossRef]
- Rafiee-Taghanaki, S.; Arabloo, M.; Chamkalani, A.; Amani, M.; Zargari, M.H.; Adelzadeh, M.R. Implementation of SVM framework to estimate PVT properties of reservoir oil. Fluid Phase Equilib. 2013, 346, 25–32. [Google Scholar] [CrossRef]
- Bahadori, A.; Vuthaluru, H.B. A novel correlation for estimation of hydrate forming condition of natural gases. J. Nat. Gas Chem. 2009, 18, 453–457. [Google Scholar] [CrossRef]
- Pelckmans, K.; Suykens, J.A.; Van Gestel, T.; De Brabanter, J.; Lukas, L.; Hamers, B.; De Moor, B.; Vandewalle, J. LS-SVMlab: A Matlab/c Toolbox for Least Squares Support Vector Machines; ESAT: Leuven, Belgium, 2002; Volume 142, pp. 1–2. [Google Scholar]
- Zadeh, L.A. Information and control. Fuzzy Sets 1965, 8, 338–353. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Amit, Y.; Geman, D. Shape Quantization and Recognition with Randomized Trees. Neural Comput. 1997, 9, 1545–1588. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Fouedjio, F. Exact Conditioning of Regression Random Forest for Spatial Prediction. Artif. Intell. Geosci. 2020, 1, 11–23. [Google Scholar] [CrossRef]
- Kaveh, A.; Mahdavi, V. Colliding bodies optimization: A novel meta-heuristic method. Comput. Struct. 2014, 139, 18–27. [Google Scholar] [CrossRef]
- Kaveh, A.; Ilchi Ghazaan, M. Computer codes for colliding bodies optimization and its enhanced version. Iran Univ. Sci. Technol. 2014, 4, 321–339. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Kuo, R.; Hong, S.; Huang, Y. Integration of particle swarm optimization-based fuzzy neural network and artificial neural network for supplier selection. Appl. Math. Model. 2010, 34, 3976–3990. [Google Scholar] [CrossRef]
- Kıran, M.S.; Özceylan, E.; Gündüz, M.; Paksoy, T. A novel hybrid approach based on Particle Swarm Optimization and Ant Colony Algorithm to forecast energy demand of Turkey. Energy Convers. Manag. 2012, 53, 75–83. [Google Scholar] [CrossRef]
- Karkevandi-Talkhooncheh, A.; Hajirezaie, S.; Hemmati-Sarapardeh, A.; Husein, M.M.; Karan, K.; Sharifi, M. Application of adaptive neuro fuzzy interface system optimized with evolutionary algorithms for modeling CO2-crude oil minimum miscibility pressure. Fuel 2017, 205, 34–45. [Google Scholar] [CrossRef]
- Suykens, J.; Vandewalle, J.; De Moor, B. Intelligence and cooperative search by coupled local minimizers. Int. J. Bifurc. Chaos 2001, 11, 2133–2144. [Google Scholar] [CrossRef]
- Hagan, M.T.; Menhaj, M.B. Training feedforward networks with the Marquardt algorithm. IEEE Trans. Neural Netw. 1994, 5, 989–993. [Google Scholar] [CrossRef] [PubMed]
- Hemmati-Sarapardeh, A.; Varamesh, A.; Husein, M.M.; Karan, K. On the evaluation of the viscosity of nanofluid systems: Modeling and data assessment. Renew. Sustain. Energy Rev. 2018, 81, 313–329. [Google Scholar] [CrossRef]
- Mohammadi, M.-R.; Hadavimoghaddam, F.; Pourmahdi, M.; Atashrouz, S.; Munir, M.T.; Hemmati-Sarapardeh, A.; Mosavi, A.H.; Mohaddespour, A. Modeling hydrogen solubility in hydrocarbons using extreme gradient boosting and equations of state. Sci. Rep. 2021, 11, 17911. [Google Scholar] [CrossRef] [PubMed]
- Mohammadi, M.-R.; Hadavimoghaddam, F.; Atashrouz, S.; Hemmati-Sarapardeh, A.; Abedi, A.; Mohaddespour, A. Application of robust machine learning methods to modeling hydrogen solubility in hydrocarbon fuels. Int. J. Hydrogen Energy 2021, 47, 320–338. [Google Scholar] [CrossRef]
- Leroy, A.M.; Rousseeuw, P.J. Robust Regression and Outlier Detection; Wiley: New York, NY, USA, 1987. [Google Scholar]
- Goodall, C.R. 13 Computation using the QR decomposition. Comput. Sci. 1993, 9, 467–508. [Google Scholar] [CrossRef]
- Gramatica, P. Principles of QSAR models validation: Internal and external. QSAR Comb. Sci. 2007, 26, 694–701. [Google Scholar] [CrossRef]
- Mohammadi, M.-R.; Hemmati-Sarapardeh, A.; Schaffie, M.; Husein, M.M.; Ranjbar, M. Application of cascade forward neural network and group method of data handling to modeling crude oil pyrolysis during thermal enhanced oil recovery. J. Pet. Sci. Eng. 2021, 205, 108836. [Google Scholar] [CrossRef]
- Mohammadi, M.-R.; Hemmati-Sarapardeh, A.; Schaffie, M.; Husein, M.M.; Karimian, M.; Ranjbar, M. On the evaluation of crude oil oxidation during thermogravimetry by generalised regression neural network and gene expression programming: Application to thermal enhanced oil recovery. Combust. Theory Model. 2021, 25, 1268–1295. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IFT (mN/m) | N2 (Mole Fraction) | Carbon Number | Temperature (°C) | Pressure (MPa) | |
|---|---|---|---|---|---|
| 1.75 | 0.25 | 5 | 30 | 0.1 | Minimum |
| 22.93 | 1 | 17 | 120 | 40.16 | Maximum |
| 10.33 | 0.25 | 13 | 40 | 0.1 | Mode |
| 11.11 | 0.25 | 11 | 60 | 7.8 | Median |
| 11.71 | 0.43 | 11.28 | 67.99 | 8.78 | Mean |
| 0.3833 | 1.1845 | 0.0067 | 0.4725 | 1.7978 | Skewness |
| −0.5802 | −0.6015 | −1.0395 | −1.0451 | 4.6985 | Kurtosis |
| R2 | SD | APRE % | AAPRE % | RMSE | Statistical Factor | |
|---|---|---|---|---|---|---|
| 0.996 | 0.0263 | −0.0100 | 1.9147 | 0.282 | Train | ANFIS–PSO |
| 0.989 | 0.0476 | −0.3639 | 3.241 | 0.5458 | Test | |
| 0.994 | 0.0982 | −0.0814 | 2.182 | 0.3515 | Total | |
| 0.988 | 0.0423 | 0.1674 | 3.206 | 0.4846 | Train | ANFIS–ECBO |
| 0.988 | 0.0597 | 2.0286 | 4.0881 | 0.5802 | Test | |
| 0.988 | 0.1441 | 0.5424 | 3.3838 | 0.5053 | Total | |
| 0.999 | 0.0065 | −0.0001 | 0.389 | 0.0645 | Train | MLP–LM |
| 0.996 | 0.0256 | 0.2437 | 1.991 | 0.2837 | Test | |
| 0.998 | 0.0429 | 0.0919 | 0.7868 | 0.154 | Total | |
| 0.999 | 0.0101 | −0.0110 | 0.7061 | 0.1102 | Train | LSSVM–CSA |
| 0.998 | 0.0146 | 0.1029 | 1.1449 | 0.1638 | Test | |
| 0.999 | 0.0359 | 0.0119 | 0.7945 | 0.1229 | Total | |
| 0.999 | 0.0098 | −0.0090 | 0.6844 | 0.1017 | Train | RBF |
| 0.998 | 0.0152 | 0.3838 | 1.1479 | 0.1569 | Test | |
| 0.999 | 0.0341 | 0.0701 | 0.7778 | 0.115 | Total | |
| 0.999 | 0.0207 | −0.2573 | 1.1612 | 0.1386 | Train | Extra-tree |
| 0.991 | 0.0527 | −0.8242 | 3.5599 | 0.4361 | Test | |
| 0.997 | 0.0759 | −0.3716 | 1.6445 | 0.2317 | Total | |
| 0.984 | 0.102 | −1.7619 | 4.9478 | 0.755 | Train | Random forest |
| 0.965 | 0.0795 | −1.7963 | 5.9719 | 0.619 | Test | |
| 0.981 | 0.2183 | −1.7689 | 5.1542 | 0.6487 | Total |
| Reference | R | H | IFT, | IFT, | Pressure (MPa) | Temperature | N2 (Mole Fraction) | Carbon Number | No. |
|---|---|---|---|---|---|---|---|---|---|
| Pred. (mN/m) | Exp. (mN/m) | (°C) | |||||||
| [36] | 3.204 | 0.00571 | 11.4096 | 11.04 | 8.01 | 60 | 0.25 | 13 | 1 |
| [36] | −3.4922 | 0.00509 | 12.6572 | 13.06 | 6.96 | 80 | 0.25 | 13 | 2 |
| [36] | 3.0862 | 0.01619 | 14.4079 | 14.05 | 5.97 | 40 | 0.25 | 15 | 3 |
| [39] | −0.0127 | 0.0758 | 2.2784 | 2.28 | 40.16 | 40 | 1 | 6 | 4 |
| [39] | −0.0398 | 0.0725 | 5.6152 | 5.62 | 40.1 | 40 | 1 | 8 | 5 |
| [39] | 0.04771 | 0.0711 | 8.0556 | 8.05 | 40.1 | 40 | 1 | 10 | 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salehi, E.; Mohammadi, M.-R.; Hemmati-Sarapardeh, A.; Mahdavi, V.R.; Gentzis, T.; Liu, B.; Ostadhassan, M. Modeling Interfacial Tension of N2/CO2 Mixture + n-Alkanes with Machine Learning Methods: Application to EOR in Conventional and Unconventional Reservoirs by Flue Gas Injection. Minerals 2022, 12, 252. https://0-doi-org.brum.beds.ac.uk/10.3390/min12020252
Salehi E, Mohammadi M-R, Hemmati-Sarapardeh A, Mahdavi VR, Gentzis T, Liu B, Ostadhassan M. Modeling Interfacial Tension of N2/CO2 Mixture + n-Alkanes with Machine Learning Methods: Application to EOR in Conventional and Unconventional Reservoirs by Flue Gas Injection. Minerals. 2022; 12(2):252. https://0-doi-org.brum.beds.ac.uk/10.3390/min12020252
Chicago/Turabian StyleSalehi, Erfan, Mohammad-Reza Mohammadi, Abdolhossein Hemmati-Sarapardeh, Vahid Reza Mahdavi, Thomas Gentzis, Bo Liu, and Mehdi Ostadhassan. 2022. "Modeling Interfacial Tension of N2/CO2 Mixture + n-Alkanes with Machine Learning Methods: Application to EOR in Conventional and Unconventional Reservoirs by Flue Gas Injection" Minerals 12, no. 2: 252. https://0-doi-org.brum.beds.ac.uk/10.3390/min12020252