1. Introduction
Tuberculosis (TB) is caused by
Mycobacterium tuberculosis and most often affects the lungs but can occur throughout the body. According to the 2020 World Health Organization (WHO) report [
1], 10 million people were estimated to be infected with TB worldwide. While CT imaging is increasingly preferred, the simple chest X-ray (CXR) remains a widely used imaging modality in TB screening protocols, particularly in low and middle resource regions. Early diagnosis plays a crucial role in improving patient care and increasing the survival rate. However, there is a significant shortage of medical experts in the poor resource regions. Automated techniques have been proposed to offset some of these challenges. However, it is unclear if these methods are generalizable across different datasets or concur with radiologist findings. These concerns can be addressed using automated segmentation methods that determine a prediction model to obtain highly accurate results over the training dataset while maintaining good generalization for cross-institutional test sets. Next, segmentation results could be compared with expert radiologist assessments to determine performance. However, deep learning (DL) methods are known to be data-hungry in that reliable, high-performing algorithms are dependent on good quality, large, varied, and well-labeled data. We are challenged by issues concerning varying image acquisition, the variability with which the TB-consistent findings may manifest in the images, and insufficiently or weakly labeled publicly available data sets. While we have little control over image quality, we can model the variation in disease presentation with richly labeled data. Here, we further discuss (i) the need for automated segmentation of TB-consistent findings, (ii) the need to train medical modality-specific segmentation models, and (iii) the methods proposed in this study to improve automated segmentation of TB-consistent findings in CXRs.
1.1. Need for Automated Segmentation of TB-Consistent Findings
Manual expert TB segmentation and localization is a very challenging and time-consuming task in disease screening due to the sparse availability of experts, particularly in resource-limited countries across the world. Overcoming the lack of richly annotated and publicly available data are the impetus of our effort to create a generalizable DL method that can semantically segment TB-consistent findings on CXRs. We envision that such a method could help radiologists reduce errors following initial interpretation and before finalizing the report with “flags” (segmentations), indicating potential TB findings. This could improve radiologist accuracy and improve patient care through an additional “set of eyes”, thereby augmenting the radiologist workflow to become more efficient. Automated segmentation could also serve as an initial point for radiology residents to better learn the characteristics of the disease manifestations by comparing their annotations of suspected abnormal findings and comparing with radiologist readings. Approved segmented findings could later be subjected to a multifactorial analysis, including measuring the lobar location, shape, and other quantitative features confined to the ROI and interactive with workflows. This segmentation approach could lead to a significant advancement in ROI segmentation, localization, and diagnosis in resourced-constrained areas. To develop such a method, we need to localize, segment, and recognize TB-consistent findings on CXRs.
1.2. Need to Train Medical Modality-Specific Segmentation Models
The challenge with TB is that the disease presents in a variety of shapes and sizes with different image intensities and may be obscured by or confused with superimposed or surrounding pulmonary structures. There are unique TB patterns (e.g., cavities, nodule clusters), including anatomic distributions that support a TB etiology (e.g., apical predominance, para hilar, costophrenic angles). Medical image segmentation is often the first step in isolating anatomical organs, sites for dimension measurement, counting, disease classification, intervention planning, etc. It is a difficult task considering a high degree of variability in medical image quality to include penetration and positioning [
2]. To overcome such variety, typical approaches in medical image segmentation develop solutions that are specific to the medical imaging modality, body part, or disease being studied [
3]. This results in the limited direct use of segmentation models commonly trained on natural images for medical image segmentation [
4]. There is an indispensable need to train generalizable medical modality-specific segmentation models to obtain high segmentation performance. The current literature leaves much room for progress in this regard. In this effort, we present our approach to this problem by building CXR modality-specific convolutional neural network (CNN) models for segmenting TB-consistent ROIs in CXRs. We provide background on these steps, i.e., classification and segmentation, in the following paragraphs.
We selected CNN models since they have demonstrated superior performance in natural and medical visual recognition tasks compared to conventional hand-crafted feature descriptors/classifiers [
5]. CNNs are typically used in supervised learning-based classification tasks where the input image is assigned to one of the class labels. Recent advances reported in the literature use conventional hand-crafted feature descriptors/classifiers and DL models for classifying CXRs as showing normal lungs or pulmonary TB manifestations [
6,
7]. These studies reveal that the DL models outperform conventional methods toward medical image classification tasks, particularly CXR analysis [
8]. The authors [
7] used the publicly available TB datasets, including the Shenzhen TB CXR, the Montgomery TB CXR [
6], the Belarus TB CXR [
9], and another private TB dataset from the Thomas Jefferson University Hospital, Philadelphia. The authors used ImageNet-pretrained AlexNet [
10] and GoogLeNet [
11] models to classify CXRs as showing normal lungs or pulmonary TB manifestations. To this end, the authors observed that an averaging ensemble of ImageNet-pretrained AlexNet and GoogLeNet models demonstrated statistically superior performance with an AUC of 0.99 (
p < 0.001) compared to their untrained counterparts. Another study [
12] used an atlas-based method to segment lungs and the scale-invariant feature transform (SIFT) algorithm to extract lung shape descriptor features from the CXRs in the Shenzhen TB CXR dataset to classify them as showing healthy or TB-infected lungs where they obtained an accuracy of 0.956 and an AUC of 0.99. In another study [
13], the authors used histogram of oriented gradient (HOG)-based feature descriptors with an SVM classifier to detect TB in CXRs in the India TB CXR collection [
13], resulting in an accuracy of 0.942 and AUC of 0.957. In another study, a computer-aided diagnostic system was developed [
14] using CNN models toward TB screening. The authors trained ImageNet-pretrained DL models on a private CXR data collection to classify the CXRs in the Shenzhen TB CXR collection as showing healthy or TB-infected lungs. The authors observed that the pretrained CNN models delivered a superior performance with an accuracy of 0.83 and AUC of 0.926 as compared to the baseline, untrained models. The authors [
15] proposed a simple CNN model to classify the CXRs in the Shenzhen TB CXR, Montgomery TB CXR, and Belarus TB CXR collections as showing healthy or infected lungs. They observed that the custom CNN model achieved superior performance with an accuracy of 0.862 and an AUC of 0.925. Another study used ImageNet-pretrained CNN models to classify a private collection of 10,848 CXRs toward TB detection [
16]. The authors obtained an accuracy of 0.903 and an AUC of 0.964.
Other studies demonstrate improved model robustness and generalization when the knowledge transfer is initiated from medical image modality-specific pretrained CNN models to a relevant medical visual recognition task [
17]. Unlike conventional transfer learning, such a knowledge transfer, has demonstrated superior model adaptation to a relevant target task, particularly when the target task suffers from limited data availability. The authors propose the benefits offered through modality-specific pretraining on a large collection of CXR images and then transferring and fine-tuning the learned knowledge toward detecting TB manifestations [
18]. To this end, the authors observed state-of-the-art (SOTA) performance using a stacked model ensemble with the Shenzhen TB CXR collection with an accuracy of 0.941 and an AUC of 0.995. In another study [
19], the authors proposed the benefits offered through modality-specific pretraining on a large collection of CXR images and then transferring and fine-tuning the learned knowledge toward detecting TB manifestations. The authors observed superior performance with an accuracy of 0.9489 while constructing modality-specific model ensembles toward classifying CXRs as showing normal lungs or TB manifestations. However, there is no available literature that discusses modality-specific knowledge transfer applied to other visual recognition tasks like segmentation, particularly concerning CXR analysis.
For our segmentation task, the goal is to obtain region-based segmentation, i.e., each pixel in the input image must be assigned to one of the class labels. However, the performance of these models is limited by the availability of annotated data. Medical imagery, in particular, is constrained by the highly limited availability of expert annotated samples. To overcome this limitation, a CNN-based model with a U-shaped architecture called the U-Net was proposed to analyze biomedical images [
20]. The authors demonstrated that the U-Net model delivered superior pixel-level class predictions even under conditions of sparse data availability. The U-Net model has thus become the principal segmentation model architecture to be used for natural and medical image segmentation tasks. Several U-Net model variants have been proposed, including V-Net [
21], improved attention U-Net [
22], nnU-Net [
23], and U-Nets using ImageNet-pretrained encoders [
24].
For CXR image analysis, U-Nets are prominently used to automate lung segmentation [
25,
26]. We find the literature is limited in other segmentation tasks, particularly for segmenting TB-consistent ROIs. There are no studies available at present that perform CXR-based TB-consistent ROI segmentation so that each pixel in the input image is assigned to one of the healthy or TB-consistent class labels. Thus, there is an essential need to (i) automate TB-consistent ROI segmentation through training SOTA segmentation models and (ii) help clinicians localize these ROIs and supplement clinical decision-making.
1.3. Proposed Methodology
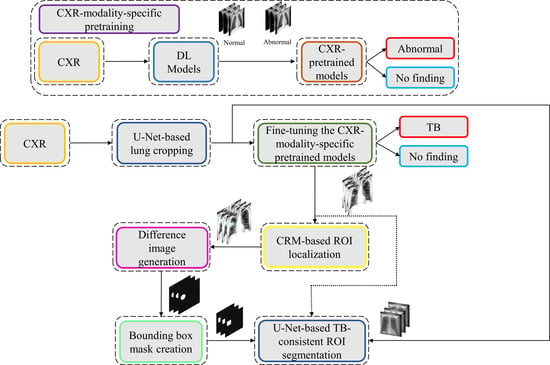
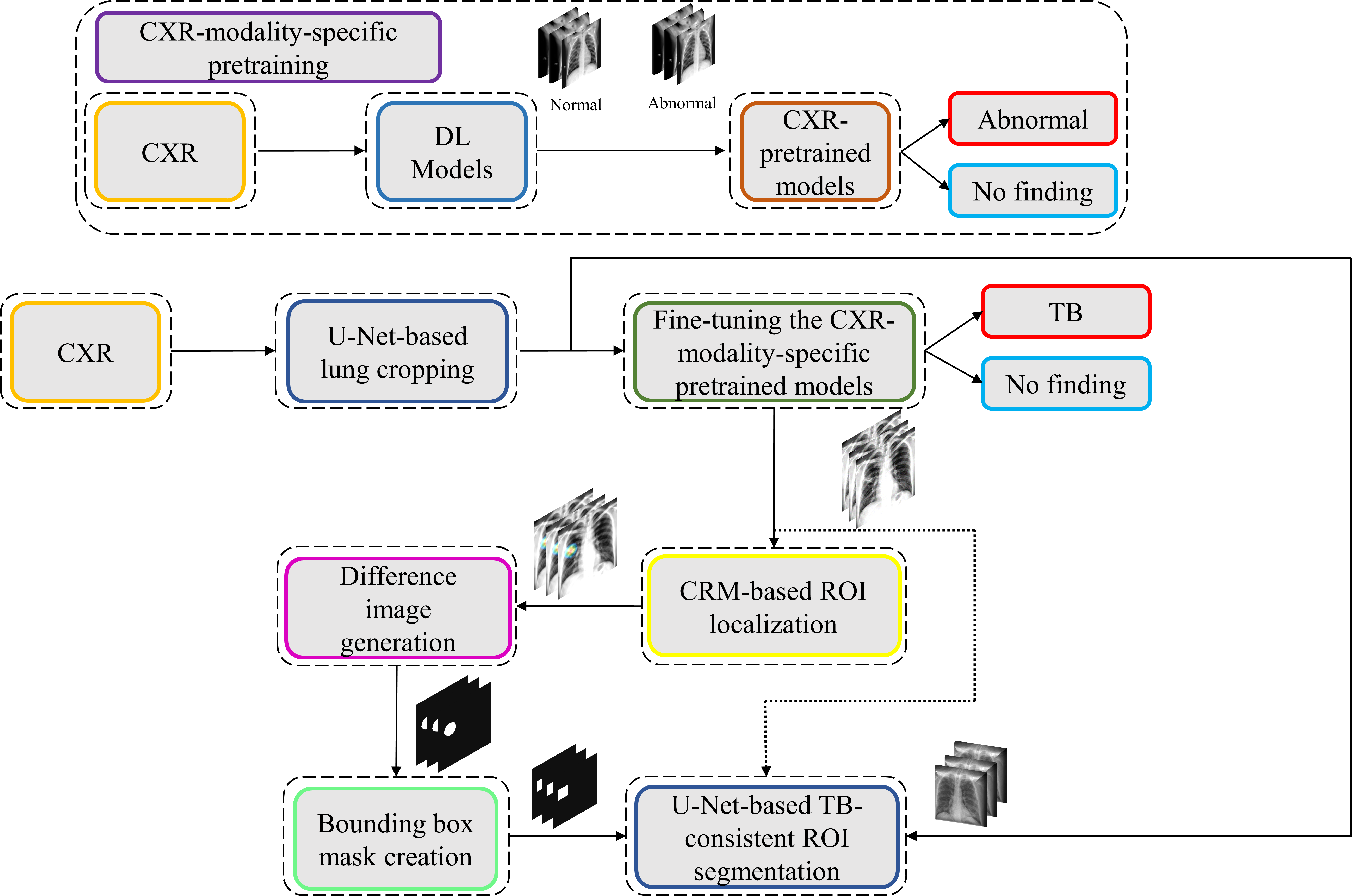
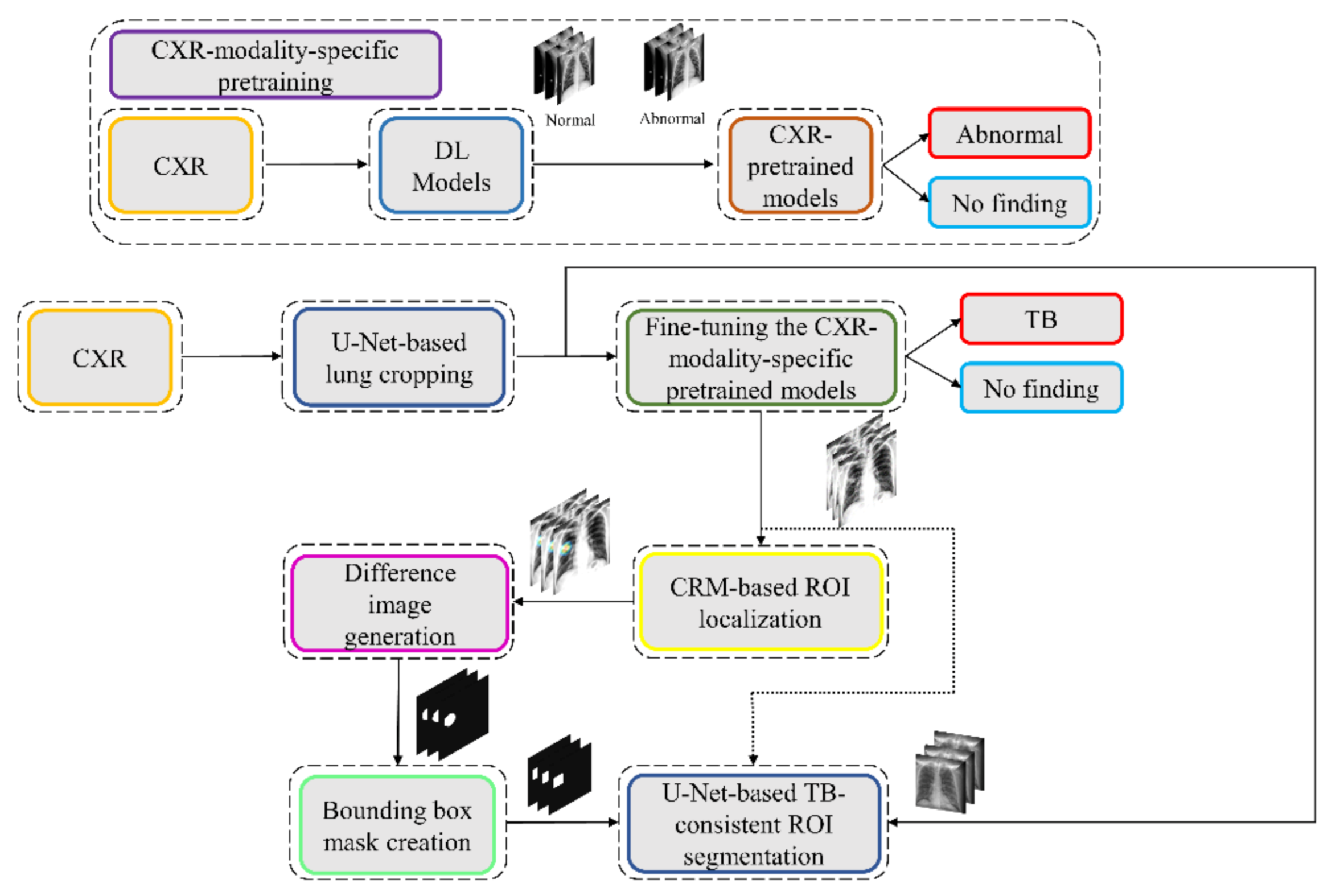
We propose a stage-wise methodology in this retrospective study.
We believe that this is the first study to i) use CXR modality-specific U-Net models to segment TB-consistent manifestations and ii) evaluate non-augmented training and AT segmentation performance using test data derived from the same training data distribution and other cross-institutional collections to determine model robustness and generalization to real-time applications. The combined use of CXR modality-specific U-Net models and AT is expected to improve segmentation performance and could be applied to an extensive range of medical segmentation tasks, including datasets from multiple institutions.
The remainder of this study is organized as follows:
Section 2 discusses the materials and methods,
Section 3 elaborates on the results,
Section 4 discusses the merits and limitations, and
Section 5 concludes the study.
2. Materials and Methods
The materials and methods are further divided into the following subsections: (i) dataset characteristics; (ii) statistical analysis; (iii) CXR modality-specific pretraining; (iv) lung segmentation and preprocessing; (v) model fine-tuning and weak TB-consistent localization; (vi) verifying ROI localization; (vii) TB-consistent ROI segmentation using U-Net models; (viii) selecting appropriate loss function and other evaluation metrics; (ix) reducing interobserver variability using simultaneous truth and performance level estimation (STAPLE)-based consensus ROI generation, and (x) task-appropriate data augmentation.
2.1. Dataset Characteristics
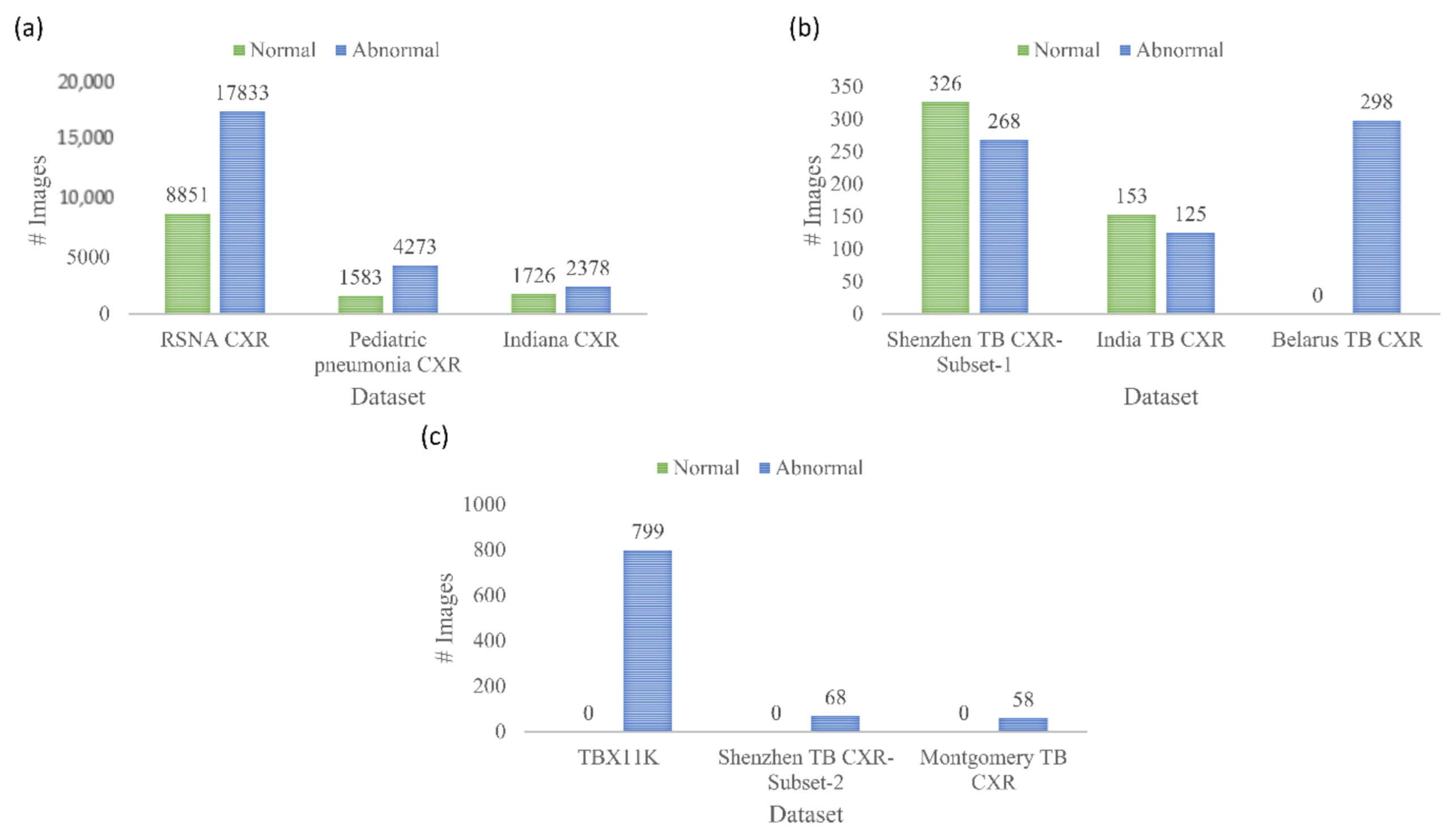
The following publicly available CXR collections are used in this retrospective research study:
(i) Shenzhen TB CXR: This de-identified dataset contains 326 CXRs showing normal lungs and 336 abnormal CXRs showing various TB manifestations [
6]. The CXRs are collected from Shenzhen No. 3 hospital in Shenzhen, China. Each image is tested with diagnostic microbiology gold standard and acquired as a part of routine clinical care. It is exempted from institutional review board (IRB) review (OHSRP #5357) by the National Institutes of Health (NIH) Office of Human Research Protection Programs (OHSRP) and made publicly available by the National Library of Medicine (NLM). In this study, we split this dataset into two: (i) Shenzhen TB CXR-Subset-1 consists of 326 CXRs showing normal lungs and 268 CXRs showing pulmonary TB manifestations. This dataset is used to fine-tune the CXR modality-specific pretrained DL models to classify CXRs as showing normal lungs or TB manifestations. (ii) Shenzhen TB CXR-Subset-2 consists of 68 abnormal CXRs showing pulmonary TB manifestations. This dataset is used to perform cross-institutional testing toward TB-consistent ROI segmentation.
(ii) Montgomery TB CXR: This de-identified dataset is collected by the TB control program of the Department of Health and Human Services (HHS), Maryland, USA. The data set is exempted from institutional review board (IRB) review (OHSRP#5357) by the National Institutes of Health (NIH) Office of Human Research Protection Programs (OHSRP) and made publicly available by the NLM [
6]. The collection includes 58 abnormal CXRs showing various TB manifestations and 80 CXRs showing normal lungs. Each image is tested with the diagnostic microbiology gold standard. Radiologist readings are made publicly available as text files. In this study, we used this dataset to perform cross-institutional testing toward TB-consistent ROI segmentation.
(iii) India TB CXR: The authors [
13] from the National Institute of TB and respiratory diseases, New Delhi, India, released two different CXR datasets that are collected using different X-ray machines. Dataset A includes 78 CXRs for each class, showing normal lungs and others with various TB manifestations. These images were obtained with the Diagnox-4050 X-ray machine. Dataset B includes 75 CXRs for each class, showing normal lungs and other TB manifestations, and is acquired using the PRORAD URS X-ray machine with Canon detectors. This dataset is used in this study to fine-tune the CXR modality-specific pretrained DL models to classify CXRs as showing normal lungs or TB manifestations.
(iv) Belarus TB CXR: The International TB portals program at the National Institute of Allergic and Infectious Diseases (NIAID) is a leading scientific resource of annotated CXRs and CT images of TB patients [
9]. The TB portal contains 298 CXRs showing various TB manifestations that are collected from patients in Belarus. This dataset is used to fine-tune the CXR modality-specific pretrained DL models to classify CXRs as showing normal lungs or TB manifestations.
(v) Tuberculosis X-ray (TBX11K) CXR: The authors [
35] have made available a collection of 11,200 CXR images that are categorized into normal (
n = 5000), sick, but not TB (
n = 5000), active TB (
n = 924), latent TB (
n = 212), active and latent TB (
n = 54) and uncertain TB (
n = 10) classes, where
n denotes the total number of CXRs in each class. Each image in the TBX11K collection is tested with diagnostic microbiology and annotated by the radiologists for TB manifestations. The images are de-identified and exempted for review by relevant institutions. The dataset also provides rectangular bounding box regions for TB-positive cases. Note that using bounding boxes instead of fine annotation implicitly introduces errors in the training since a fraction of non-TB pixels are treated as the positive class in pixelwise training. This dataset is used to train and evaluate the U-Net segmentation models toward TB-consistent ROI segmentation.
(vi) Pediatric pneumonia CXR: This collection [
36] includes 1583 anterior-posterior CXRs showing normal lungs and 4273 CXRs showing bacterial and viral pneumonia manifestations. The CXRs are collected from pediatrics of 1 to 5 years of age from the Guangzhou Women and Children’s Medical Center, China. The images are acquired as a part of routine clinical care with IRB approvals. This dataset is used to perform CXR modality-specific pretraining of the ImageNet-pretrained CNN models toward classifying CXRs as showing normal lungs or other abnormal pulmonary manifestations.
(vii) Radiological Society of North America (RSNA) CXR: A part of the NIH CXR collection [
37] is curated by the radiologists from RSNA and Society of Thoracic Radiology (STR) and made publicly available for a Kaggle challenge to detect pneumonia manifestations [
38]. The collection includes 8851 CXRs showing normal lungs, 11,821 CXRs showing other abnormal manifestations, but not pneumonia, and 6012 CXRs showing various pneumonia manifestations. The images are made available in DICOM format at 1024 × 1024-pixel resolutions. Ground truth (GT) disease annotations are made available for the CXRs belonging to the pneumonia class. This dataset is used in this study toward performing CXR modality-specific pretraining. (viii) Indiana CXR: This collection [
39] includes 2378 posterior-anterior CXRs showing abnormal pulmonary manifestations and 1726 CXRs showing normal lungs. These images are collected from various hospitals that are affiliated with the Indiana University School of Medicine. The dataset is de-identified, manually verified, archived at the NLM, and exempted from IRB review (OHSRP # 5357). This dataset is used during the CXR modality-specific pretraining stage. The datasets used in various stages of the proposed study and their distribution are summarized in
Figure 2.
2.2. Statistical Analysis
In this study, we used a 95% confidence interval (CI) to measure the error margin as the binomial (Clopper–Pearson’s) “exact” method and discriminate models’ performance. We used StatsModels v0.12.1 Python library to perform these analyses. Statistical approaches used only in subsets of this study are described in those specific sections of the manuscript.
2.3. CXR Modality-Specific Pretraining
In the first step of this stage-wise systematic study, we retrained a selection of ImageNet-pretrained DL models, including (i) VGG-16, (ii) VGG-19, (iii) Inception-V3, (iv) DenseNet-121, (v) ResNet-18, (vi) MobileNet-V2, (vii) EfficientNet-B0, and (viii) NasNet-Mobile on a combined collection of RSNA CXR, pediatric pneumonia CXR, and Indiana CXR datasets to introduce sufficient data diversity in terms of image acquisition and patient demographics into the training process. The models are selected based on their architectural diversity and SOTA performance in other visual recognition tasks. Recall that the ImageNet-pretrained DL models are trained using stock photography images from the Internet. Using out-of-the-box ImageNet-pretrained models for medical visual recognition tasks may lead to model overfitting and loss of generalization. This is because the transfer of weights from the majority dataset does not adequately generalize on smaller medical datasets. Literature studies have shown that compared to using ImageNet-pretrained CNN models, CXR modality-specific model retraining (i) delivers superior performance toward classifying CXRs as showing normal lungs or other pulmonary abnormal manifestations and (ii) improve ROI localization performance with added benefits of reduced overfitting, prediction variance, and computational complexity [
17]. CXR modality-specific pretraining converts the weight layers specific to the CXR modality and learns relevant features. The learned knowledge is transferred and fine-tuned to improve performance in a related target task. During this pretraining stage, the models are trained to classify CXRs as showing normal lungs or other abnormal manifestations.
The architectural depth and complexity of these models that are developed for natural visual recognition tasks may not be optimal for medical visual recognition because of issues concerning sparse data availability and varying feature representations. To this end, we performed empirical evaluations toward (i) identifying the best layer to truncate these models and (ii) appending task-specific heads to improve learning the underlying feature representation toward classifying the CXRs as showing normal lungs or other abnormal pulmonary manifestations. The truncated models are appended with the following task-specific layers: (i) a 3 × 3 convolutional layer with 512 filters, (ii) a global average pooling (GAP) layer, (iii) a dropout layer (empirically determined ratio = 0.5), and (iv) a final dense layer with Softmax activation to output prediction probabilities for the normal and abnormal classes.
During this training step, the combined CXR collection, including RSNA CXR, pediatric pneumonia CXR, and Indiana CXR datasets, is split at the patient-level into 80% for training and 20% for testing. With a fixed seed value, we allocated 10% of the training data toward model validation. The models are optimized using stochastic gradient descent (SGD) algorithm to minimize the categorical cross-entropy loss toward this classification task. Callbacks are used to check model performance, and the model checkpoints are stored after each epoch.
2.4. Lung Segmentation and Preprocessing
The performance of DL models is severely impacted by data quality. Irrelevant features may lead to biased learning and suboptimal model performance. The task of detecting TB or other pulmonary disease manifestations is confined to the lung regions. Thus, regions in CXRs other than the lungs are irrelevant to be learned by the models. Hence, it is crucial to segment the lung regions and train the lung ROI models to help them learn relevant features concerning normal lungs or other pulmonary manifestations.
The U-Nets are one of the most powerful CNN models that are used for precise and accurate segmentation of medical images [
20]. The principal advantage of U-Net is that it can handle data scarcity and learn from small training sets. The U-Net has a U-shaped architecture. It is composed of an encoder/contracting path and a decoder/expanding path and performs pixelwise class segmentations. The feature maps from the encoder’s various levels are passed over to the decoder to predict features at varying scales and complexities.
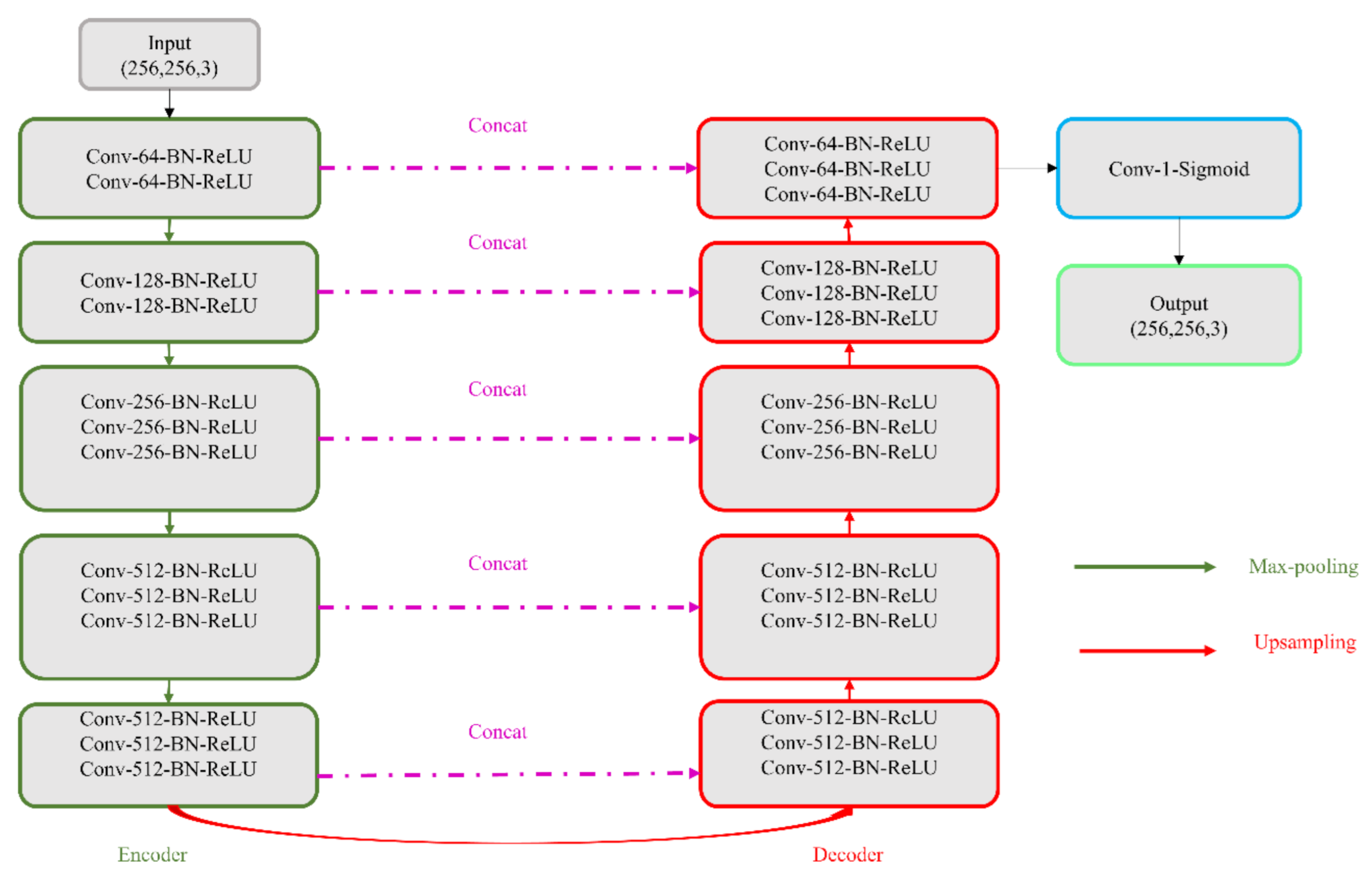
In this study, we propose CXR modality-specific VGG-16 and VGG-19 U-Nets, referred to as VGG-16-CXR-U-Net and VGG-19-CXR-U-Net models. These models use the CXR modality-specific pretrained VGG-16 and VGG-19 models from
Section 2.3 as the encoder backbone. The architecture of the VGG-16-CXR-U-Net and VGG-19-CXR-U-Net models are shown in
Figure 3. The encoder of the VGG-16-CXR-U-Net and VGG-19-CXR-U-Net models are each made up of five convolutional blocks, consisting of 13 and 16 convolutional layers, respectively, following the original VGG-16 and VGG-19 architecture. The green downward arrow at the bottom of each convolutional block in the encoder designates a max-pooling operation (2 × 2 filters, 2 strides) to reduce image dimensions. The decoder of the VGG-16-CXR-U-Net and VGG-19-CXR-U-Net models comprises five convolutional blocks and consists of 15 convolutional layers. The upward red arrow at the top of each convolutional block in the decoder signifies an upsampling operation that performs transposed convolutions to restore the image to its original dimensions. Each convolutional layer in the encoder and decoder is followed by batch normalization (BN) and ReLU activation. The pink arrow signifies skip-connections that combine the corresponding feature maps and restores the original image dimensions. Sigmoidal activation is used at the final convolutional layer to predict binary pixel values.
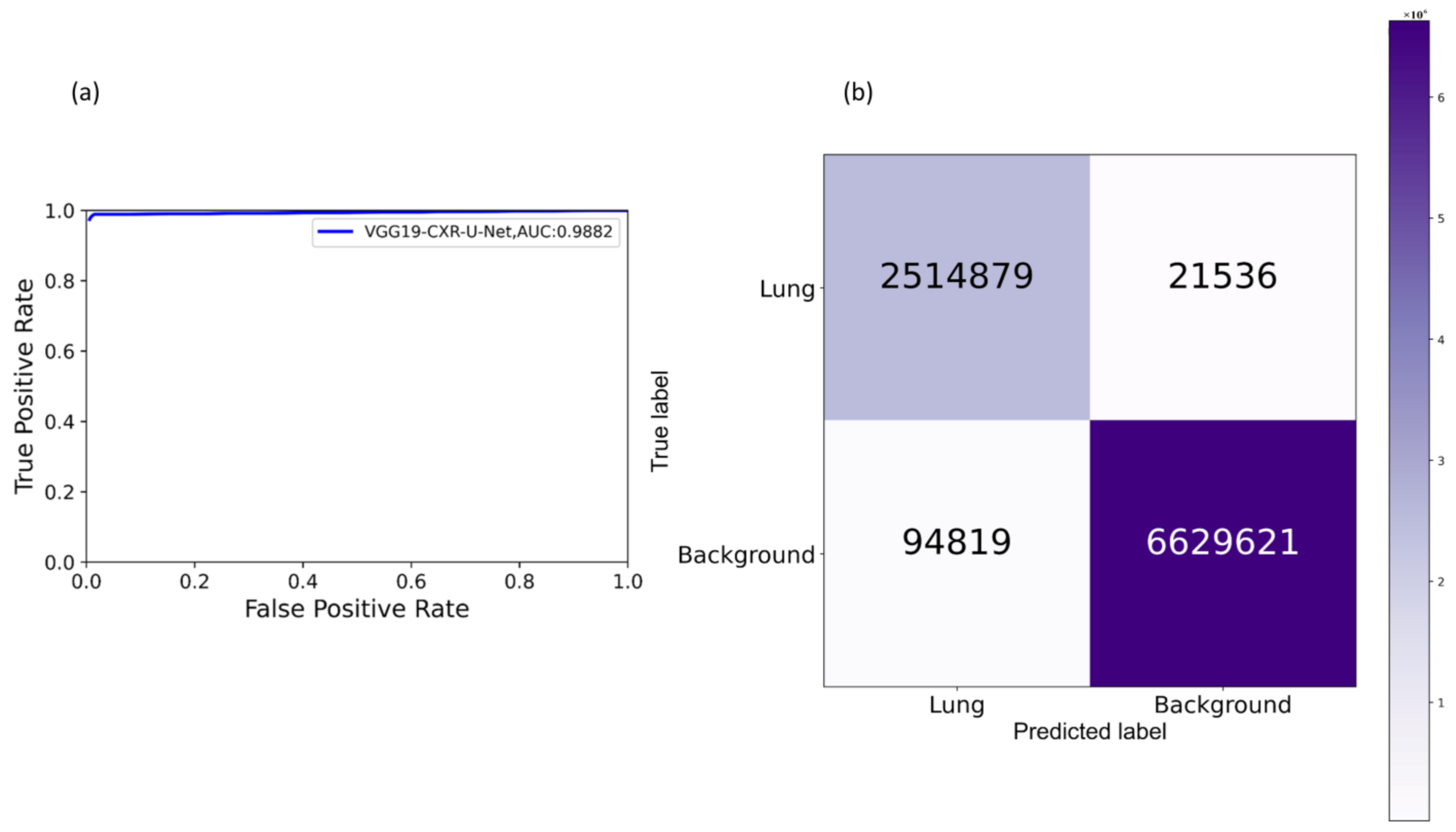
We evaluated the segmentation performance of the VGG-16-CXR-U-Net and VGG-19-CXR-U-Net models and other SOTA U-Net variants, including the standard U-Net, V-Net with ResNet blocks, improved attention U-Net, ImageNet-pretrained VGG-16 U-Net, and VGG-19-U-Net toward lung segmentation.
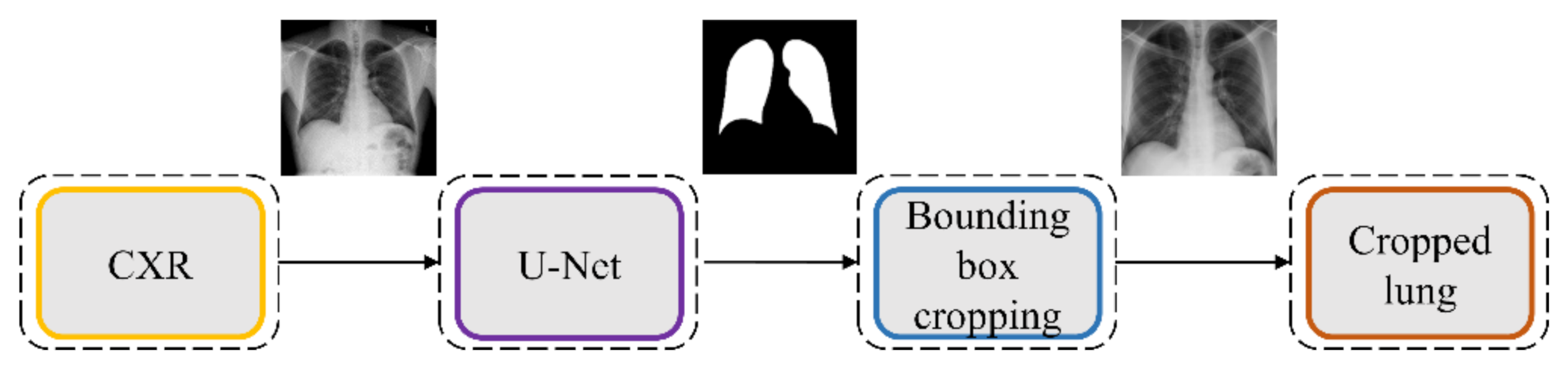
Figure 4 illustrates the lung segmentation workflow.
The models are trained on a publicly available collection of CXRs and their associated lung masks [
40]. We allocated 10% of the training data with a fixed seed value for validation. We introduced variability into the training process by augmenting the training input with random affine transformations, including horizontal flipping, height and width shifting, and rotations. The trained models are tested with the cross-institutional Montgomery TB CXR collection and their associated GT lung masks [
6]. We emphasize that such an evaluation with a cross-institutional test collection would provide a faithful performance measure since the test data have varying visual characteristics and are completely unseen during model training, thereby preventing data leakage and ensuring generalization.
The best performing model is used to generate lung masks at 256 × 256 spatial resolution. The generated lung masks are overlaid on the original CXR images to demarcate the lung boundaries and then cropped into a bounding box encompassing the lung pixels. We preprocessed these images by (i) resizing the cropped bounding boxes to 256 × 256 spatial resolution, (ii) improving contrast by saturating the bottom and top 1% of all image pixel values, (iii) normalizing the pixel values to the range (0–1), and (iv) performing mean subtraction and standardization such that the resulting distribution has a mean µ of 0 and a standard deviation σ of 1 as shown in Equation (1):
Here K is the original image, and Knorm is the normalized image.
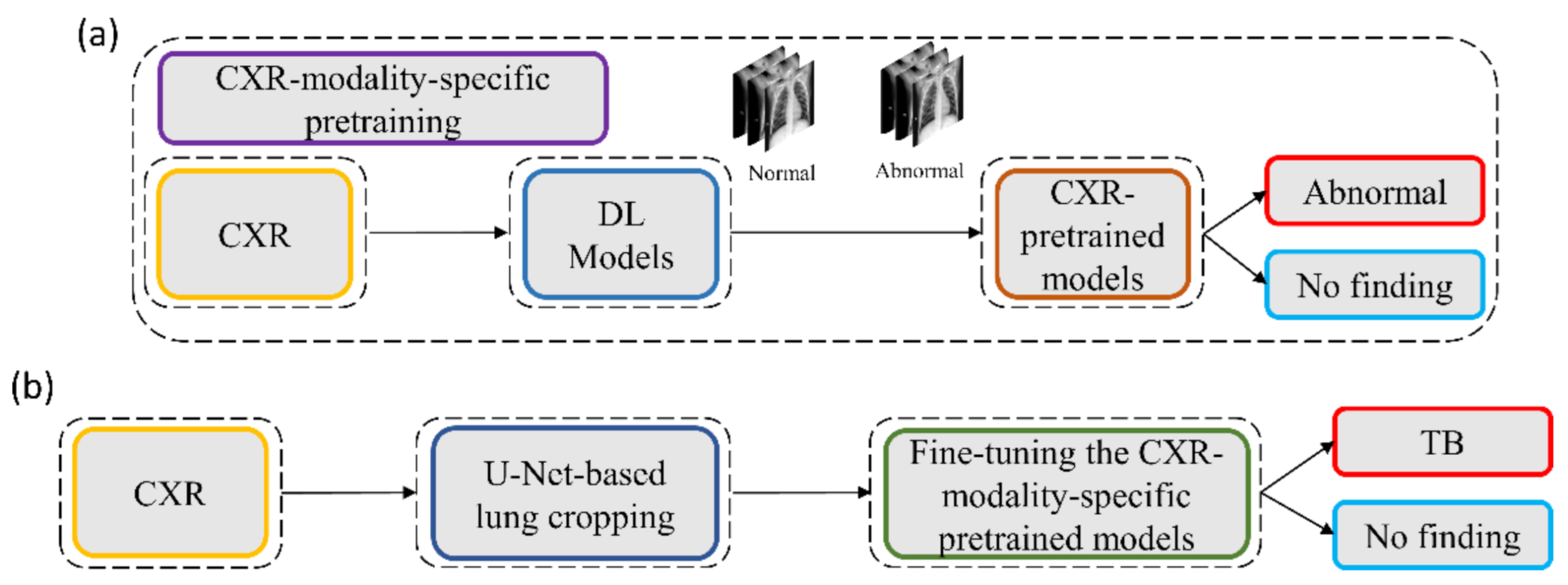
2.5. Model Fine-Tuning and Weak TB-Consistent Localization
The process workflow toward CXR modality-specific pretraining and fine-tuning is illustrated in
Figure 5.
The CXR modality-specific pretrained models are truncated at their deepest convolutional layer and appended with the following task-specific layers: (i) GAP, (ii) dropout (empirically determined ratio = 0.5), and (iii) dense layer with two neurons. The resulting models are fine-tuned using the lung-segmented, combined TB CXR collection, including India TB CXR, Belarus TB CXR, and Shenzhen TB CXR-Subset-1 datasets to classify them as showing normal lungs or pulmonary TB manifestations. The best-performing model from
Section 2.4 is used to segment the lungs in this collection.
During this training step, the combined TB CXR collection is split at the patient-level into 80% for training and 20% for testing. We allocated 10% of the training data toward validation with a fixed seed value. The performance of these fine-tuned models is compared to their baseline counterparts, i.e., the out-of-the-box ImageNet-pretrained CNNs that are fine-tuned on this collection. The models are optimized using the SGD algorithm to minimize the categorical cross-entropy loss toward this classification task. We used callbacks to check the internal states of the fine-tuned models.
The following metrics are used to evaluate models’ performance during CXR modality-specific pretraining and fine-tuning stages: (a) accuracy; (b) AUC; (c) sensitivity; (d) precision; (e) specificity; (f) F-measure; (g) Matthews correlation coefficient (MCC); and (h) diagnostic odds ratio (DOR).
2.6. Verifying ROI Localization
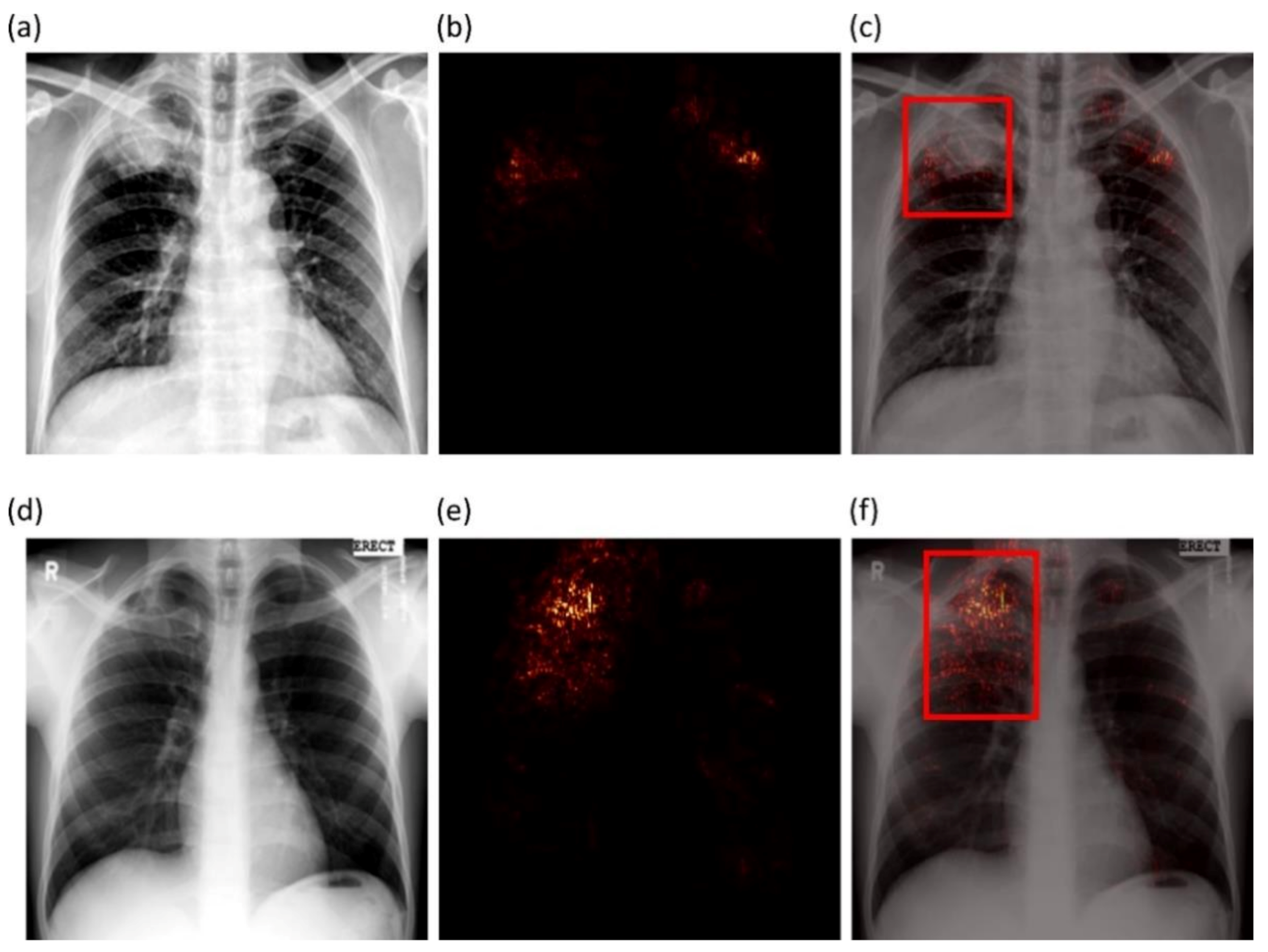
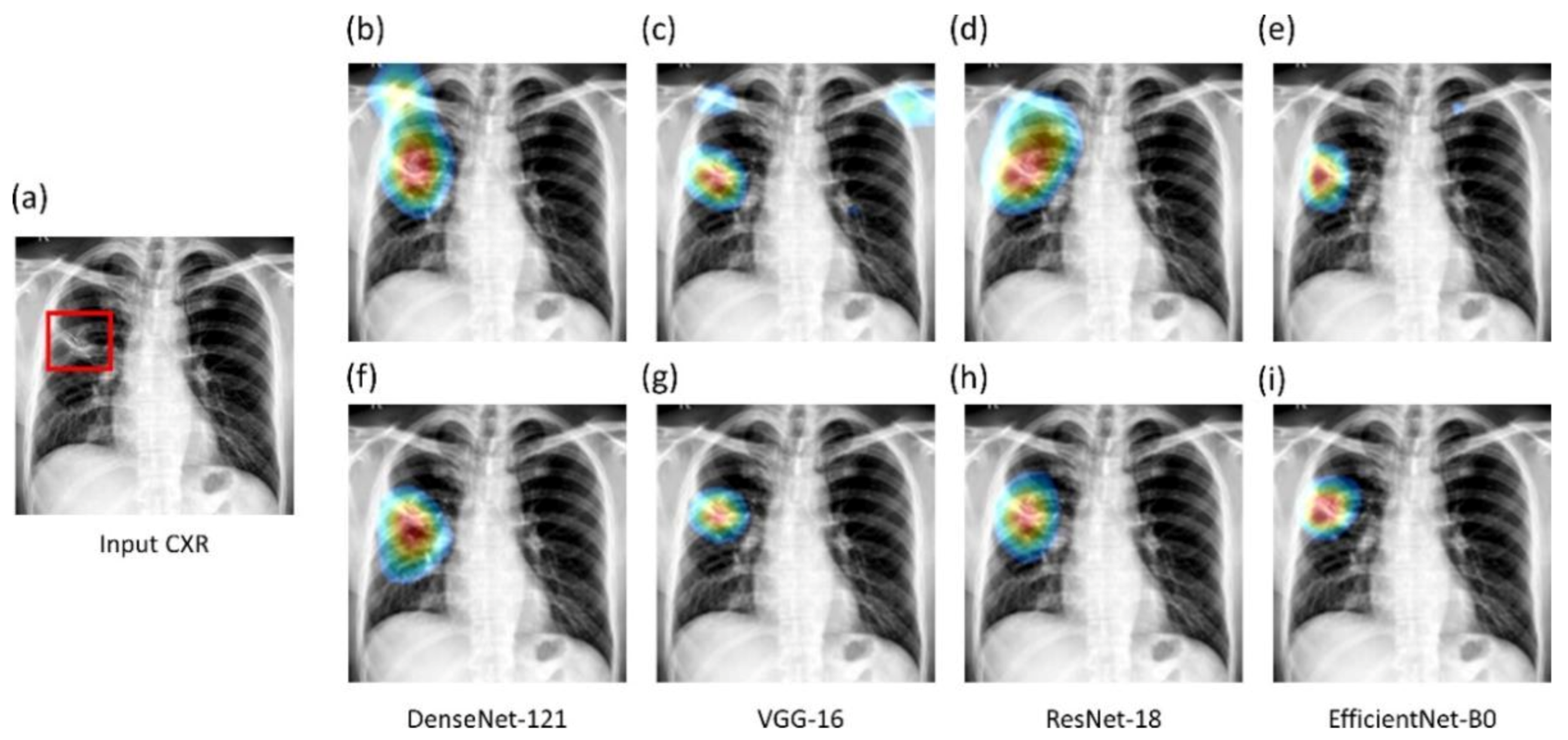
We used saliency maps and a CRM-based localization algorithm [
34] to interpret the learned behavior of the fine-tuned models toward detecting TB manifestations. These algorithms provide a visual interpretation of model predictions and supplement clinical decision-making. The algorithms differ by the methods in backpropagating the derivatives and the use of feature maps. Saliency maps measure the derivative of the output category score concerning the original input and generate a heat-map with the original input image resolution. A higher derivative value signifies the importance of that activation in contributing to the final category score. A smaller value for the derivative results in negligible impact, and the activation can thus be considered trivial toward final prediction.
CRM-based visualization algorithms are demonstrated to deliver superior localization performance as compared to the conventional class-activation map (CAM)-based localization, particularly toward medical image analysis [
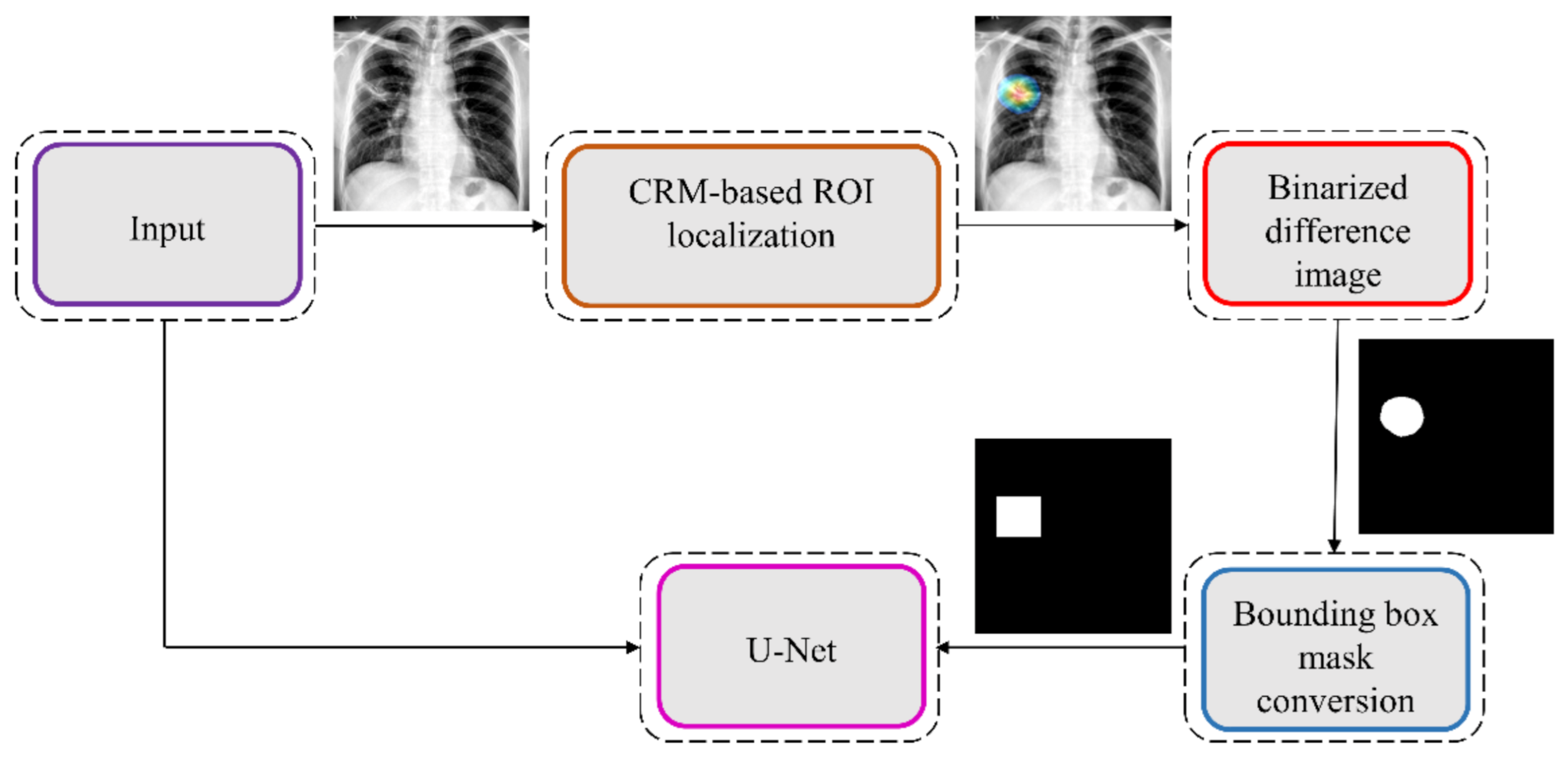
34]. Unlike CAM-based visualization, CRM-based localization underscores the fact that the feature maps contribute to decreasing the prediction scores for other class categories in addition to increasing the scores for the expected category. Such discrimination helps in maximizing the difference between these scores and results in superior discrimination of class-specific ROI by measuring the incremental mean-squared error from the output nodes. The features are extracted from the deepest convolutional layer of the best-performing fine-tuned model. The CRM algorithm is used to localize the ROI involved in classifying the CXRs as showing pulmonary TB manifestations. The feature map dimensions vary across the models. Hence, the CRMs are upscaled through normalization methods to match the spatial resolution of the input image. The computed CRMs are overlaid on the original image to localize the TB-consistent ROI that is used to categorize the CXRs as showing pulmonary TB manifestations. The CRMs are generated for the CXRs with TB-category labels toward visualizing the regions of TB manifestations. We further converted these CRM-based weak TB-consistent ROI localizations to binary ROI masks. The original CXRs and the associated ROI masks are used for further analysis.
2.7. TB-Consistent ROI Segmentation Using U-Net Models
The U-Net models used in this study are trained and evaluated on the publicly available train/test split of TBX11K CXR collection [
35] to segment pulmonary TB manifestations. The dataset includes rectangular bounding box annotations for 599 training and 200 test samples. We used the best-performing model from
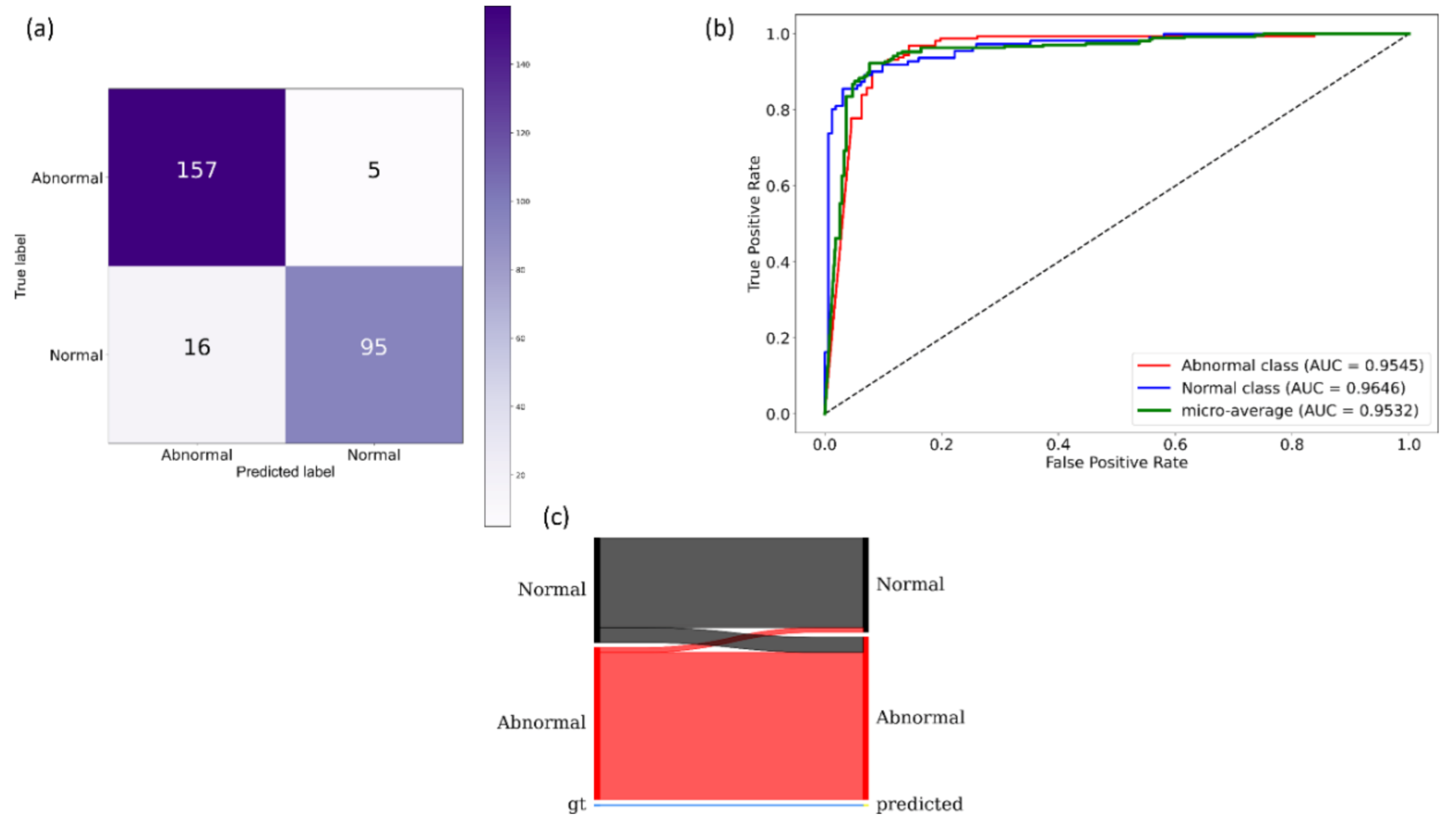
Section 2.4 to segment the lungs in this collection. Following lung segmentation, we rescaled the disease bounding box coordinates and converted them into binary masks. Recall that since we are using bounding boxes for training, a fraction of the pixels within these are false-positive (FP) training labels, which adversely impact our outcome. These masks and their associated CXRs are used to train and test the models. We used a fixed seed value to allocate 10% of the training data toward validation. Variability is introduced into the training process by augmenting the training data through affine transformations, including horizontal flipping, height and width shifting, and rotations. Callbacks are used to store model checkpoints, and the best performing model is used to segment TB-consistent ROI.
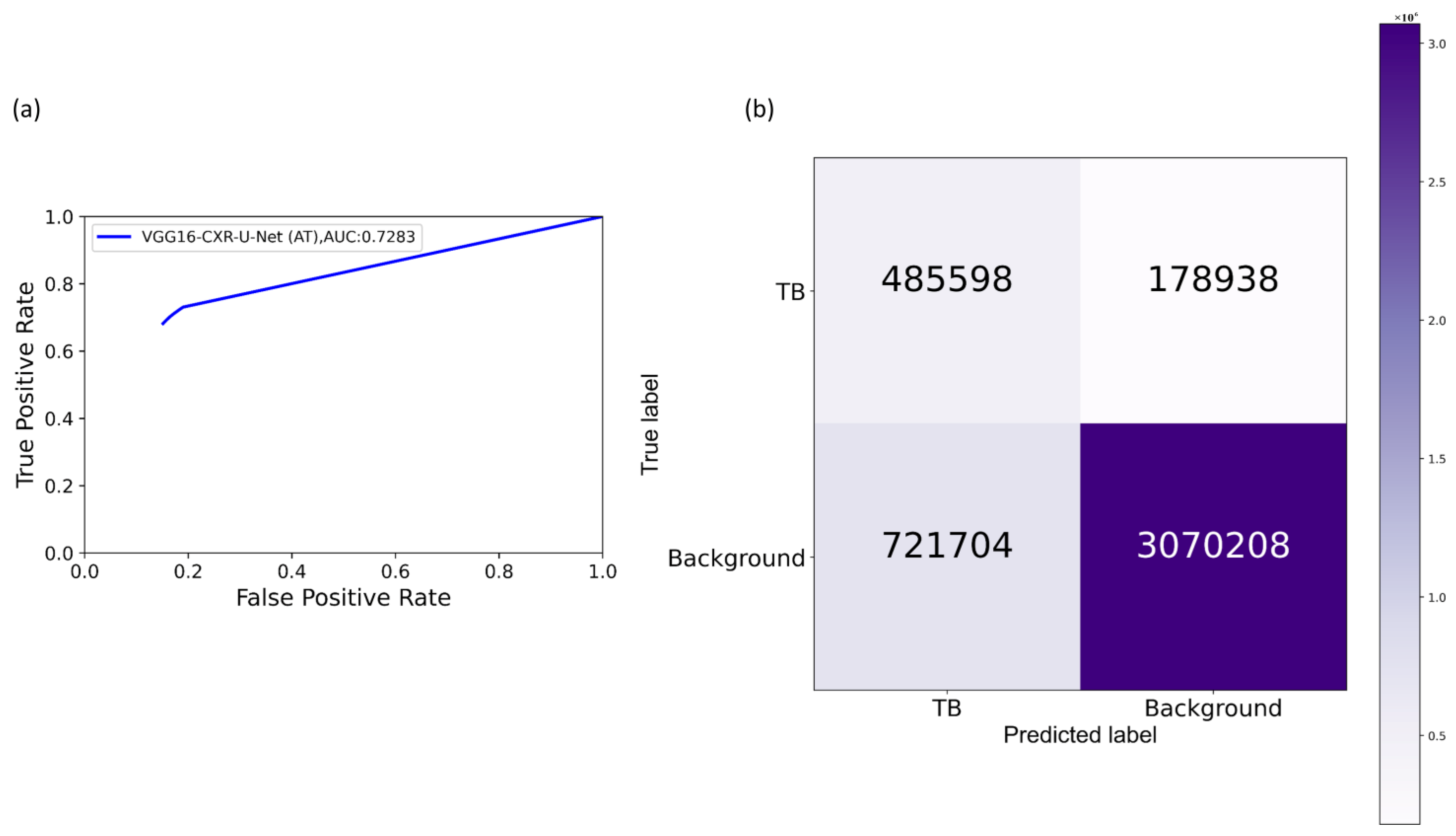
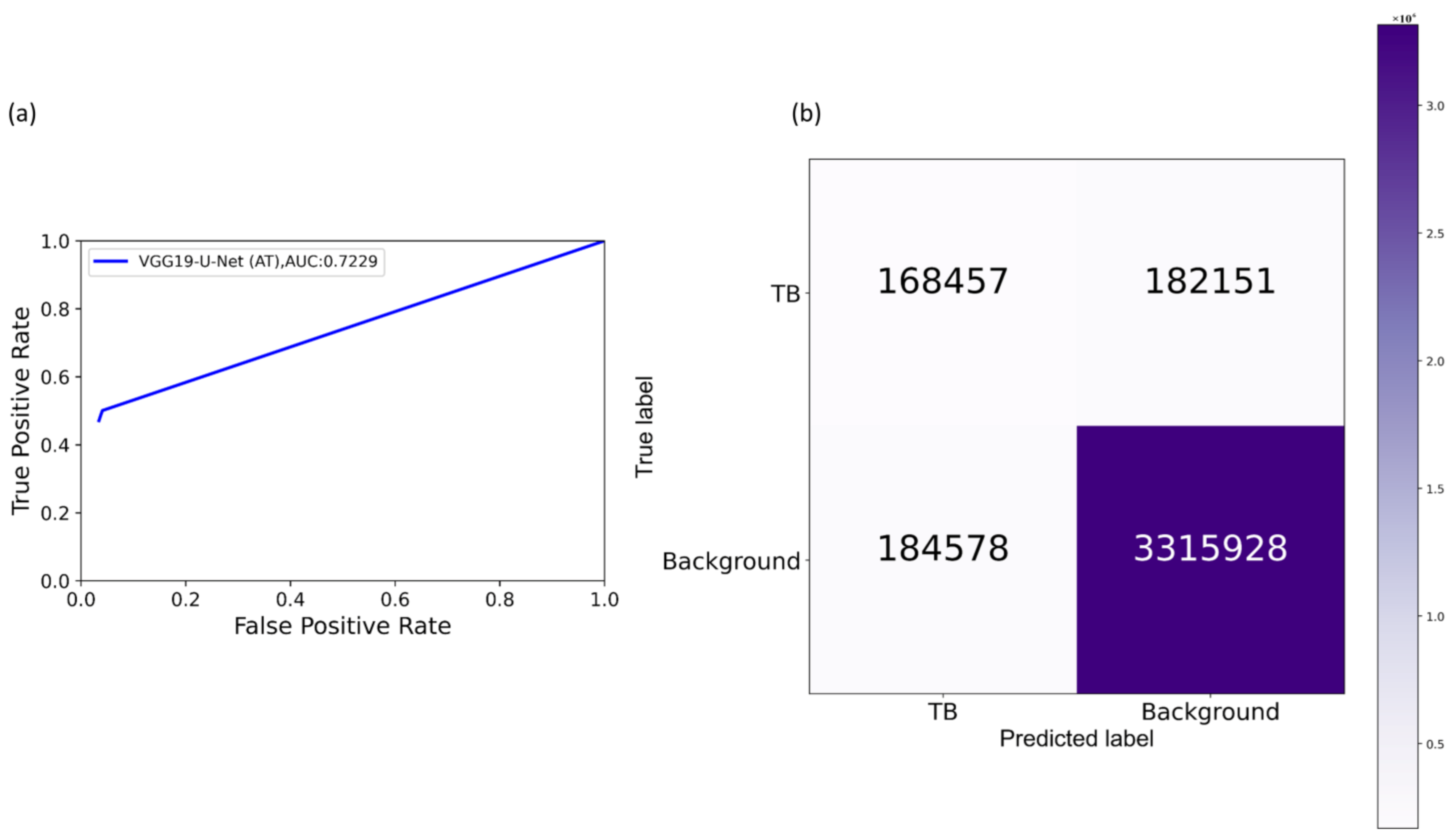
We further evaluated the performance of the U-Net models with cross-institutional test sets. The Shenzhen TB CXR-Subset-2 (n = 68) and the Montgomery TB CXR (n = 58) collections are individually used as test sets toward this evaluation. Such cross-institutional testing would demonstrate the generalization ability of the models and their suitability for real-time deployment because the test set is diverse and unseen during the training process.
2.8. Selecting Appropriate Loss Function and Other Evaluation Metrics
U-Net models, though having an excellent potential toward accurate medical image segmentation, often suffer from data imbalance. These issues are particularly prominent in applications that involve lung/TB-consistent ROI segmentation, where the number of lung/TB-consistent ROI pixels is markedly lower compared to the total image pixels. Such imbalanced training may lead to learning bias and may adversely impact segmentation performance. To alleviate issues due to these data imbalances, a generalized loss metric based on the Tversky index has been proposed [
22] that delivers superior performance compared to the conventional binary cross-entropy (BCE) loss. A superior tradeoff between sensitivity and precision is demonstrated using the Tversky loss function for imbalanced data segmentation tasks. In this study, we customized the hyperparameters α and
β of the Tversky loss function given by Equation (2).
Here a and b denote the set of predicted and GT binary labels, respectively, a0k is the probability of the pixel k to belong to the lung/TB-consistent ROI, a1k is the probability of the pixel k to belong to the background, b0k takes the value of 1 for a lung/TB-consistent ROI pixel and 0 for the background and vice versa for b1k. Through empirical evaluations, we observed that the values for the hyperparameters α = 0.3 and β = 0.7 demonstrated a good balance between precision and sensitivity and that higher values for β resulted in improved performance and generalization while using imbalanced data and helped to boost sensitivity. Accordingly, we used these hyperparameter values in the current study. We used callbacks to store model checkpoints after the completion of an epoch. The best of the stored checkpoints is used as the final model for the subsequent analysis.
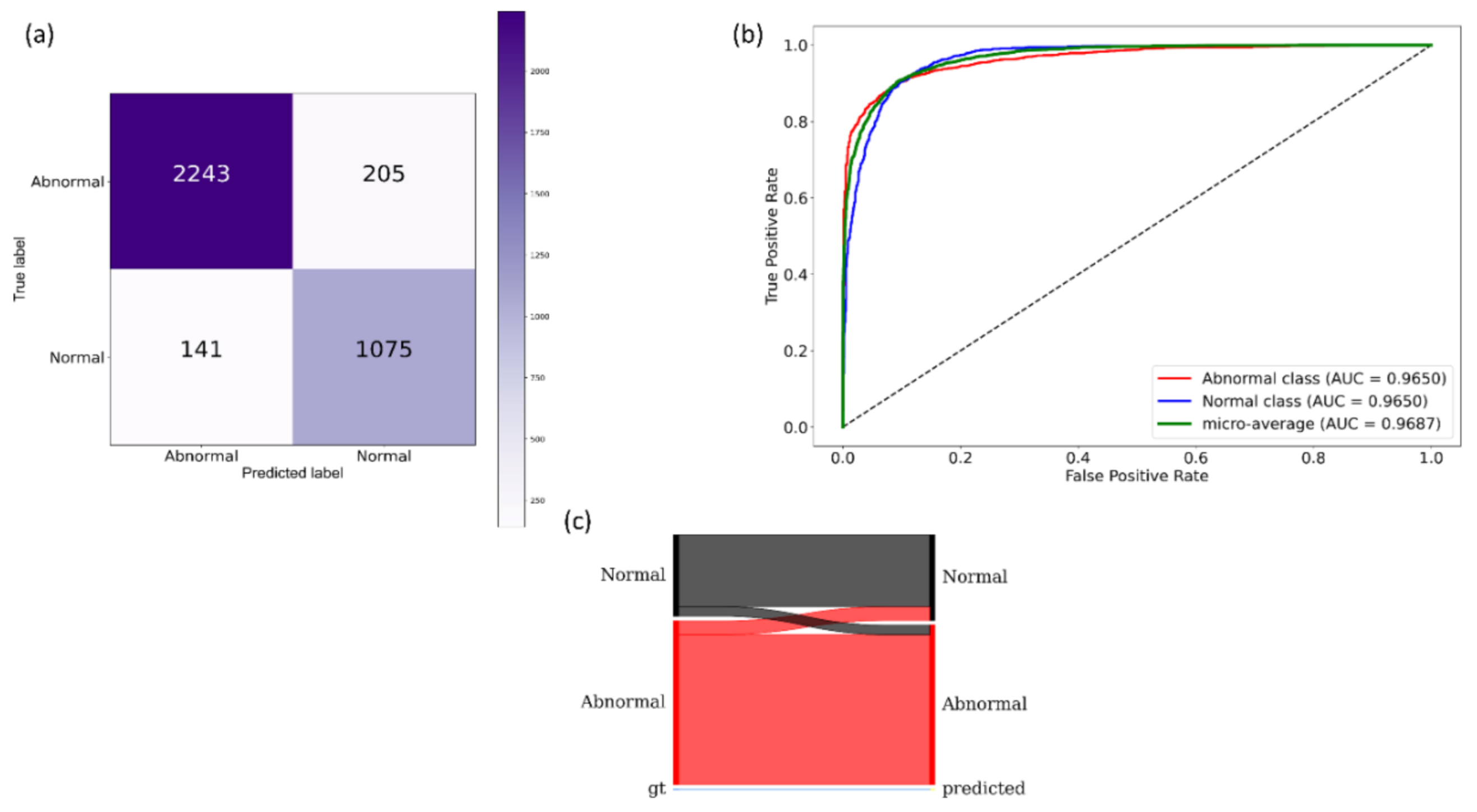
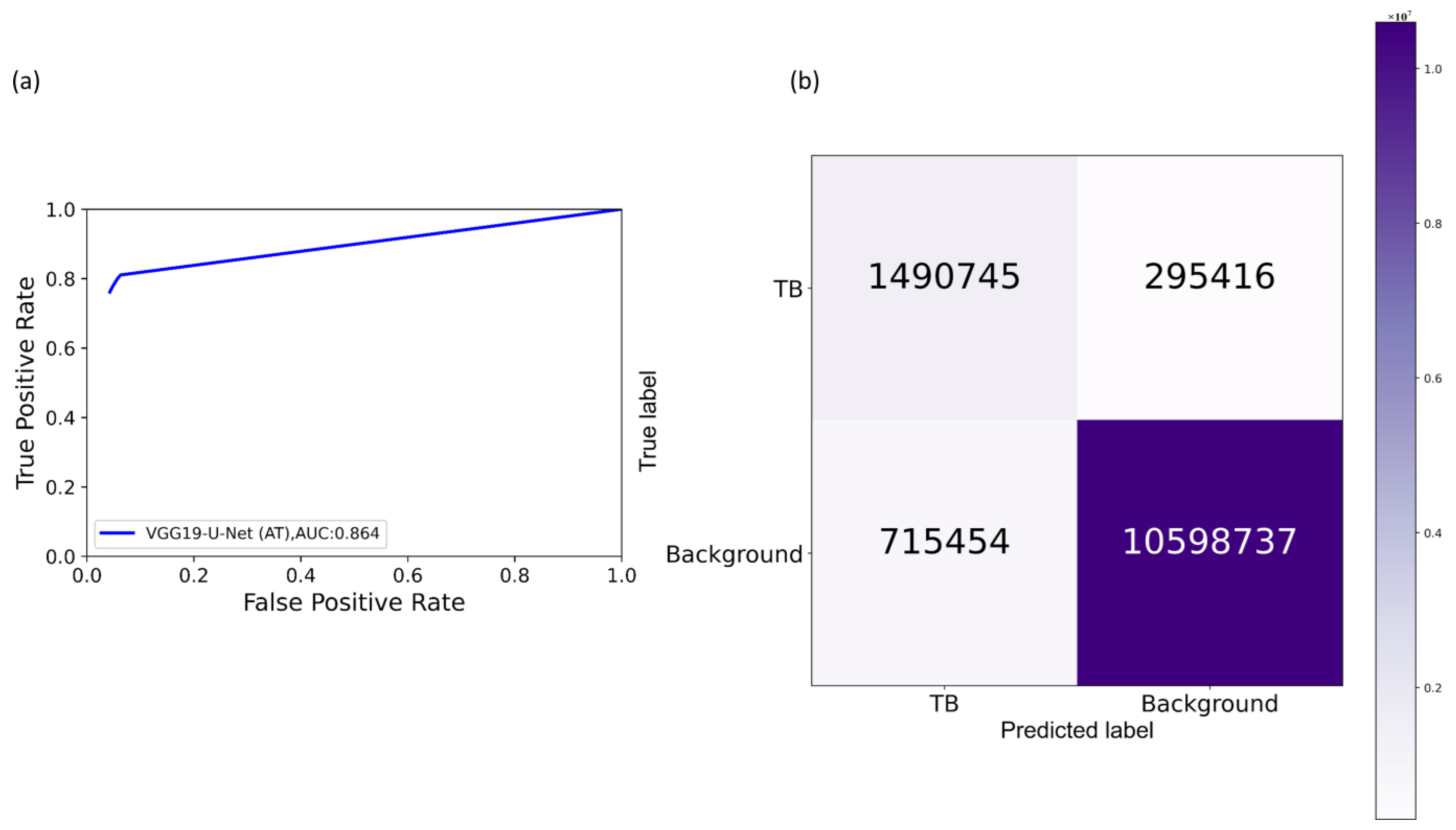
We measured segmentation performance in terms of the following metrics: (i) confusion matrix; (ii) Jaccard index, otherwise known as the intersection of union (
IOU); (iii) Dice index; and (iv) average precision (AP). The
IOU evaluation metric is widely used in image segmentation applications. It is given by a ratio as shown in Equation (3) below:
Here
TP,
FP, and
FN denote respectively true positives, false positives, and false negatives. Comparisons are made to GT from CXR interpretations by independent radiologists as described in
Section 2.9. While comparing the predicted masks with the GT masks, a TP indicates that the predicted mask overlaps with the GT mask, exceeding a predefined IOU threshold. The abbreviation FP indicates that the predicted mask has no associated GT mask. FN indicates that a GT mask has no associated predicted mask. The
Dice index is another evaluation metric widely used in segmentation and object detection tasks and is given by Equation (4).
The
Dice index is similar to and is positively correlated with
IOU. Like the
IOU, the
Dice index’s value ranges from 0 to 1, with the latter signifying a higher similarity between the GT and predicted masks. We computed the AP as the area under the precision-recall curve (AUPRC) as expressed in Equation (5).
Here
p denotes precision, and
r denotes sensitivity/recall. The values of precision and recall are given by Equation (6) and Equation (7).
The value of AP lies within 0 and 1. In this study, we computed AP as an average over multiple IOU thresholds ranging from 0.5 to 0.95 (in increments of 0.05), denoted by AP@[0.5:0.95].
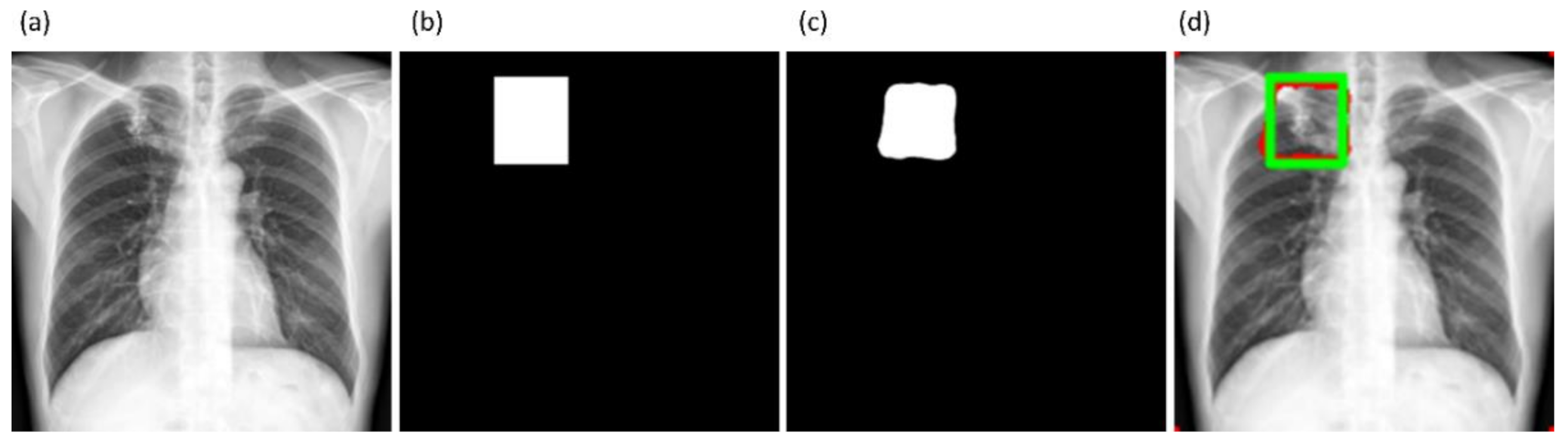
2.9. Reducing Inter-Observer Variability Using STAPLE-Based Consensus ROI Generation
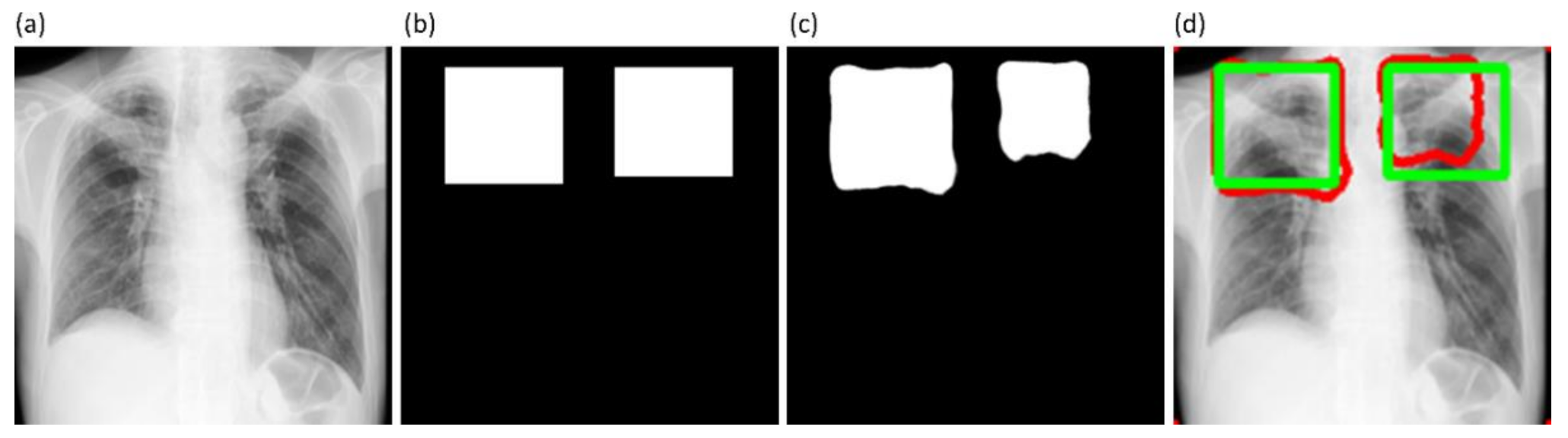
The GT disease annotations for Shenzhen TB CXR-Subset-2 are set by verification from two expert radiologists, hereafter referred to as R1 and R2. The GT annotations for the Montgomery TB CXR collection are set by the verification from two expert radiologists, hereafter referred to as R2 and R3. The expert R2 participated in both annotations. The collective experience of the experts counts to 65 years. The web-based VGG Image Annotator tool [
41] is used by radiologists to independently annotate these collections. The radiologists are asked to draw rectangular bounding boxes over the regions that they believed to show TB-consistent manifestations. We chose to use bounding boxes rather than fine segmentation to maintain similarity to the TBX11K data recognizing that there will be noisy pixels due to the bounding box and the variability from multiple expert annotators. The annotations are performed in independent sessions when the radiologists annotated the TB-consistent ROI in these CXR images. The annotations from individual radiologists are later exported to a JSON file for subsequent analyses. The experts’ annotations would be made publicly available upon acceptance.
We used the STAPLE algorithm [
42] to build a consensus ROI annotation from the experts’ annotations for the Shenzhen TB CXR-Subset-2 and Montgomery TB CXR data collections. STAPLE is widely used for validating the segmentation performance of the models by comparing them to that of expert annotations. An expectation–maximization methodology is used where the probabilistic estimate of a reference segmentation is computed from a collection of expert annotations and weighed by each expert’s estimated performance level. The segmented regions are spatially distributed based on this knowledge, satisfying constraints of homogeneity. The steps involved in measuring the consensus
ROI are as follows: Let
R = (
r1,
r2, ….,
rn)
N and
X = (
x1,
x2, ….,
xn)
N denote two column vectors, each containing
A elements. The elements in
R and X represent sensitivity and specificity parameters, respectively, characterizing one of
N segmentations. Let
B denote an
M × N matrix that describes segmentation decisions made for each image pixel. Let
C denote an indicator vector containing
M elements representing hidden, true binary segmentation values. The complete data can be written as (
B,
C), and the probability mass function as
f (
B,
C|
r,
x). The performance level of the experts, characterized by a tuple (
r,
x), is estimated by the expectation–maximization algorithm, which maximizes (
r′,
x′), the data log-likelihood function, given by Equation (8).
The STAPLE-generated consensus
ROI is then created as expressed in Equation (9).
Here
denote the annotations of the experts that annotated the given CXR dataset. We used the STAPLE-generated consensus
ROI as the standard reference, which reduces the aforementioned inter-reader variability across our multiple experts. Next, we converted these TB-consistent
ROI coordinates into binary masks that are used as the GT masks to evaluate the aforementioned TB segmentation models.
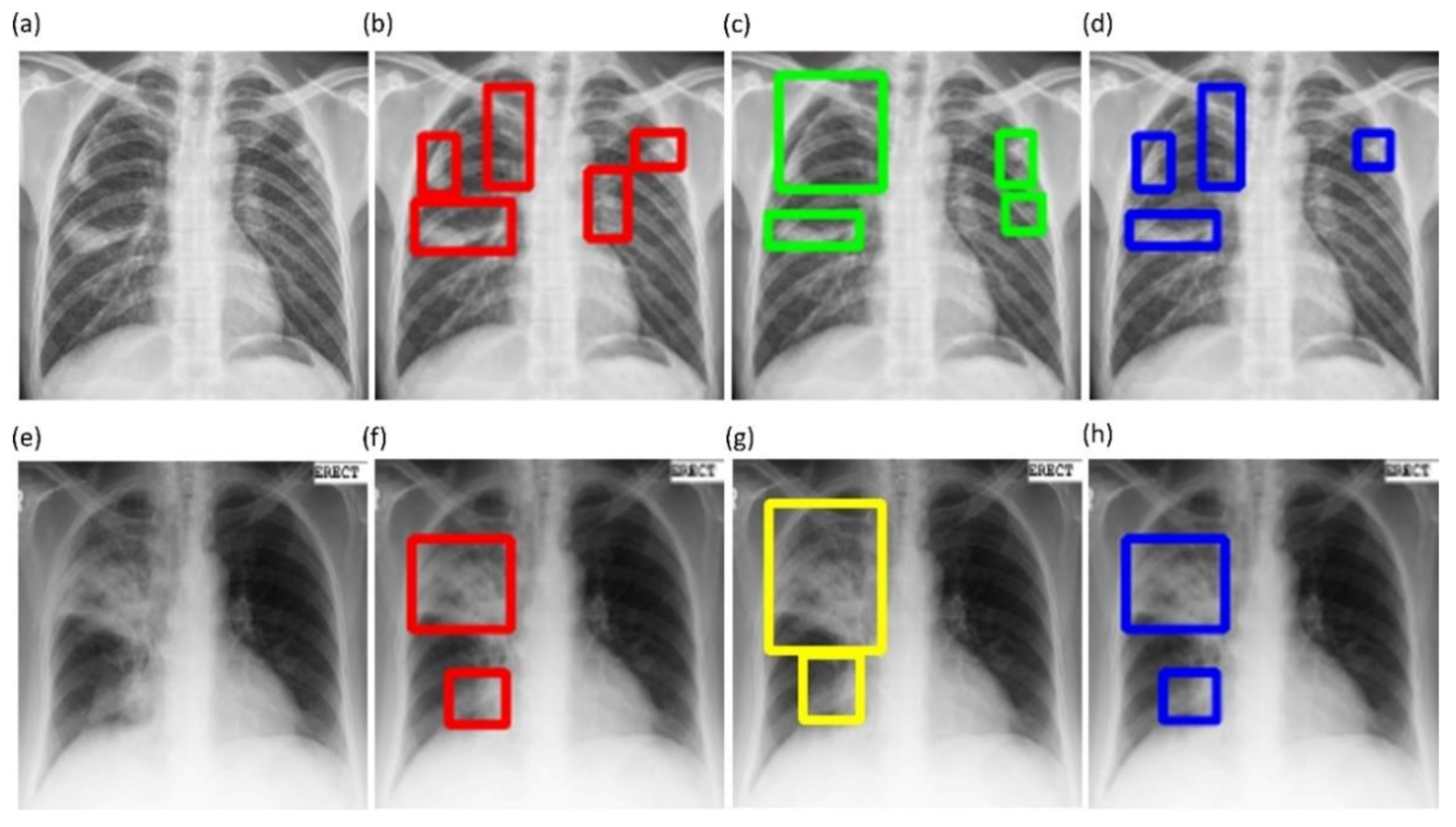
Figure 6 shows instances of TB-consistent
ROI annotations made by the radiologists and the STAPLE-generated consensus
ROI for a sample CXR instance from the Shenzhen TB CXR-Subset-2 and Montgomery TB CXR collections respectively.
2.10. Task-Appropriate Data Augmentation: Augmenting Training Data with Weak Localizations to Improve TB-Consistent ROI Segmentation
The binary masks obtained from weak TB-consistent ROI localizations using the best-performing fine-tuned model and their associated CXR images are used to perform AT of the models used in
Section 2.7 toward improving TB-consistent ROI segmentation. The performance with such AT is evaluated with the test set derived from TBX11K training distribution and individually with the cross-institutional Shenzhen TB CXR-Subset-2 and Montgomery TB CXR data collections. We used a fixed seed value toward allocating 10% of the training data toward validation. Variability is introduced into the training process by augmenting the training data through affine transformations, including horizontal flipping, height and width shifting, and rotations. Callbacks are used to store model checkpoints, and the best performing model is used to segment TB-consistent manifestations. The predicted masks are overlaid on the original CXR input to localize the TB-consistent ROI boundaries. The performance of the models with AT is evaluated and compared to those with non-augmented training using confusion matrix, IOU, Dice, and AP@[0.5:0.95] metrics. We used a Windows
® system with NVIDIA GeForce GTX 1080 Ti GPU, Intel Xeon CPU E3-1275 v6 3.80 GHz processor, Keras framework with Tensorflow backend, and CUDA support for accelerated GPU performance toward these evaluations.
4. Discussion
We made several key observations from the results of this stage-wise systematic study. Broadly, these are the need for (i) modality-specific knowledge transfer techniques, (ii) verifying ROI localization, (iii) reducing interobserver variability, (iv) selecting the appropriate loss function, (v) performing statistical analysis, (vi) evaluating with cross-institutional test collection, and (vii) selecting task-appropriate data augmentation methods. These observations are discussed in detail below.
Modality-specific knowledge transfer techniques: We note that CXR modality-specific pretraining helped improve performance in lung segmentation, fine-tuning, and TB segmentation and localization tasks over the non-modality-specific ImageNet-pretrained CNN models. Therefore, performing medical modality-specific training is a path toward improving model adaption and performance, reducing computational complexity and overfitting. The performance improvement may be attributed to the fact that the CXR modality-specific pretraining helped learn the lungs’ characteristics, including shape, texture, contour, and their combinations that are diverse from natural stock photographic images. The learned modality-specific knowledge, when transferred to a relevant modality-specific task, helped in superior weight initialization compared to ImageNet-pretrained weights and resulted in improved performance.
The VGG-16 and VGG-19 CXR modality-specific segmentation models were better not only to localize but to classify the findings, such as TB manifestations, using the CXR modality-specific pretrained/fine-tuned classification models. This training approach facilitated a generalized modality-specific knowledge transfer that helped the segmentation models to better discriminate the lungs from the background pixels and the classification models to differentiate abnormal lungs with TB manifestations from normal lungs. An added benefit of this approach is that it resulted in a marked reduction in the number of trainable parameters.
Verifying ROI localization: neural networks make use of inherent learning methods to identify salient features in the input data. However, data-driven DL models are considered back-boxes since they lack explainability. Therefore, it is crucial to determine if these models are predicting the expected classes for the right reasons. Saliency maps and other visual ablation studies help to investigate if the models learn salient feature representations conforming to the experts’ knowledge of the problem. In this study, we used saliency maps and CRM-based localization algorithms to illustrate and explain the localization behavior of the trained models. We observed that the TB-consistent ROI localization obtained with the CXR modality-specific fine-tuned models are superior to those obtained using the ImageNet-pretrained models. Such superior localization performance could be attributed to the following characteristics: (i) the fine-tuned models inherit CXR modality-specific knowledge compared to that transferred from the natural image domain; (ii) the transferred knowledge is relevant to the target modality; (iii) the fine-tuned models are empirically truncated at the optimal depth to learn relevant and salient feature representations. This helped to deliver superior classification and localization performance. These observations are reinforced by the suboptimal localization performance observed with the out-of-the-box ImageNet-pretrained models.
Reducing inter-observer variability: literature studies are limited concerning arriving at a consensus ROI when using GT annotations from multiple experts. This is particularly important for medical decision-making since different experts may have varying opinions on the extent or location of the disease-specific ROI. The inherent bias in the experts’ annotations may be due to a variety of explicit and implicit factors, including overall clinical experience, specific background in the disease manifestations, and tendency to be aggressive or conservative when treating/detecting disease, or simply missing the disease leading to FNs in the data. To overcome these challenges, we used the STAPLE algorithm to arrive at a consensus ROI by discovering and quantifying the experts’ bias and varying opinions about the TB-consistent ROI.
Selecting the appropriate loss function: segmentation models often suffer from class imbalance issues, particularly in medical image segmentation tasks. This is due to the highly localized ROI, spanning for a very small percentage of the total number of image pixels. The issues with using the conventional BCE loss for such class imbalanced segmentation tasks are as follows: (i) the BCE loss weighs all image pixels equally; (ii) the model demonstrates low BCE loss and hence higher segmentation accuracy even if it misses all ROI pixels that spans a small portion of the total image. In this study, we used a customized loss based on Tversky Index, an asymmetric similarity measure that generalizes IOU and Dice metrics. The use of a customized Tversky index-based loss function with empirically determined hyperparameter values for the problem under study helped to improve segmentation performance by providing a finer level of segmentation control compared to using a conventional BCE-based loss. Computing a single precision and recall score at a specific IOU threshold does not sufficiently describe the models’ behavior. In this study, we used AP@[0.5:0.95] to effectively integrate the AUPRC by averaging the precision score at multiple IOU thresholds ranging from 0.5 to 0.95 (in 0.05 increments). Such a measure would help to better demonstrate models’ generalization ability and stability toward the segmentation task.
Performing statistical analysis: literature studies have shown that research publications seldom perform statistical significance analyses while interpreting their results [
44]. We performed statistical analyses to investigate the existence of a statistically significant difference in the performance of the segmentation models based on the AP@[0.5:0.95] metric and classification models using the MCC metric. Such analysis helped to interpret model performance and other assumption violations.
Evaluating with cross-institutional test collection: It is indispensable to note that the data collected across institutions differ due to changes in imaging equipment, acquisition methods, processing protocols, and their combinations. These differences could notably affect their characteristics and render them qualitatively and quantitatively different across institutions. This may lead to suboptimal performance when the models trained with the imaging data from one institution are tested with the data from another institution. The evaluation with cross-institutional test sets helps to empirically determine the existence of cross-institutional data variability and its effect on model robustness and generalization.
Selecting task-appropriate data augmentation technique: The performance of DL models is shown to improve with an increase in data and computational resources. Training data augmentation significantly increases data diversity and thus the models’ robustness and generalization to real-time applications. However, literature studies extensively discuss the use of affine-transformation-based data augmentation methods like cropping, flipping, rotating, and image padding. There is a need for progress in investigating the use of task-specific data augmentation strategies that could better capture inherent data variability, particularly toward medical image analyses, and help to improve performance. In this study, we observed that augmenting the training data with TB-specific weak localization improved TB segmentation and localization with both the test data coming from the same training distribution and cross-institutions. This performance improvement may be attributed to the fact that CXR modality-specific pretraining and task-specific training data augmentation, i.e., augmenting training data with weak, TB-consistent ROI localizations, helped in added knowledge about CXRs and other diverse TB manifestations that resulted in superior weight initialization and improved segmentation performance with training distribution-similar and cross-institutional test sets.
Limitations: Regarding the limitations of the current study: (i) the numbers of publicly available CXRs showing pulmonary TB manifestations with expert ROI annotations are fairly small. In this study, we tried to alleviate this limitation by collecting expert annotations and generating STAPLE-based consensus ROI annotations for the publicly available Montgomery TB CXR and a subset of the Shenzhen TB CXR collections. However, future works could focus on training diversified models on large-scale CXR collections with sufficient data diversity and expert-annotated TB-specific ROIs and improve their confidence, robustness, and generalization toward real-time deployment. (ii) This study is evaluated to segment and localize TB-consistent findings. However, future research shall focus on testing against non-TB findings because TB-consistent findings, including nodules and cavities, are found in other abnormal pulmonary conditions. (iii) We augmented the training data with TB-specific weak ROI localizations to improve performance in a TB segmentation task. However, the effects of augmenting the training data with other pulmonary abnormality-specific localizations and the resulting performance are yet to be investigated. (iv) Considering limited data availability, this study proposes comparatively shallow VGG-16 and VGG-19 CXR modality-specific segmentation models be employed rather than other ImageNet-pretrained models toward the current task. With the availability of more annotated data, future research could propose diversified models with novel filters that may result in improved segmentation performance and reduction in computational complexity.


 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}