Semi-Supervised Classification of the State of Operation in Self-Lubricating Journal Bearings Using a Random Forest Classifier

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Setup
2.2. Data Preprocessing
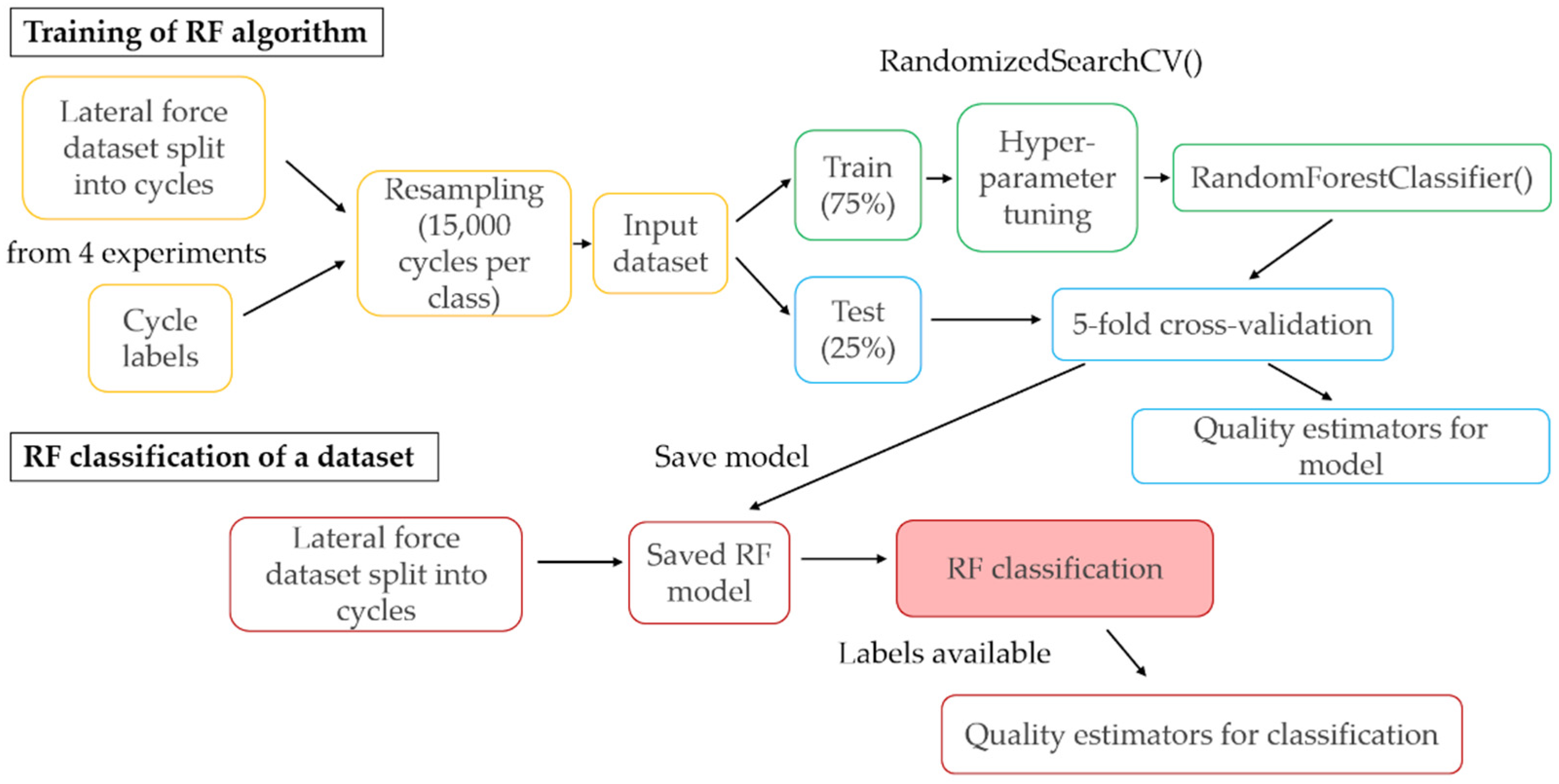
2.3. Random Forest Classifiers
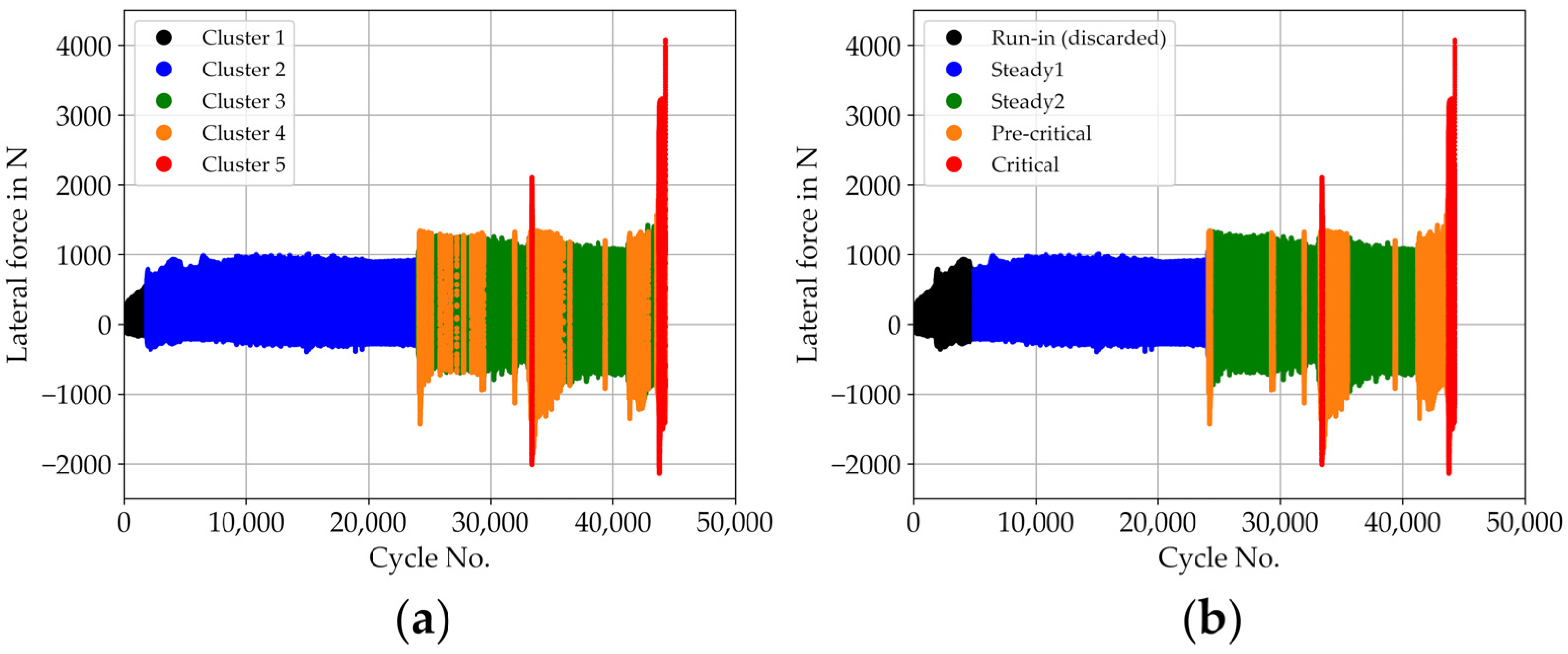
2.4. Labelling of Datasets and RF Model
3. Results
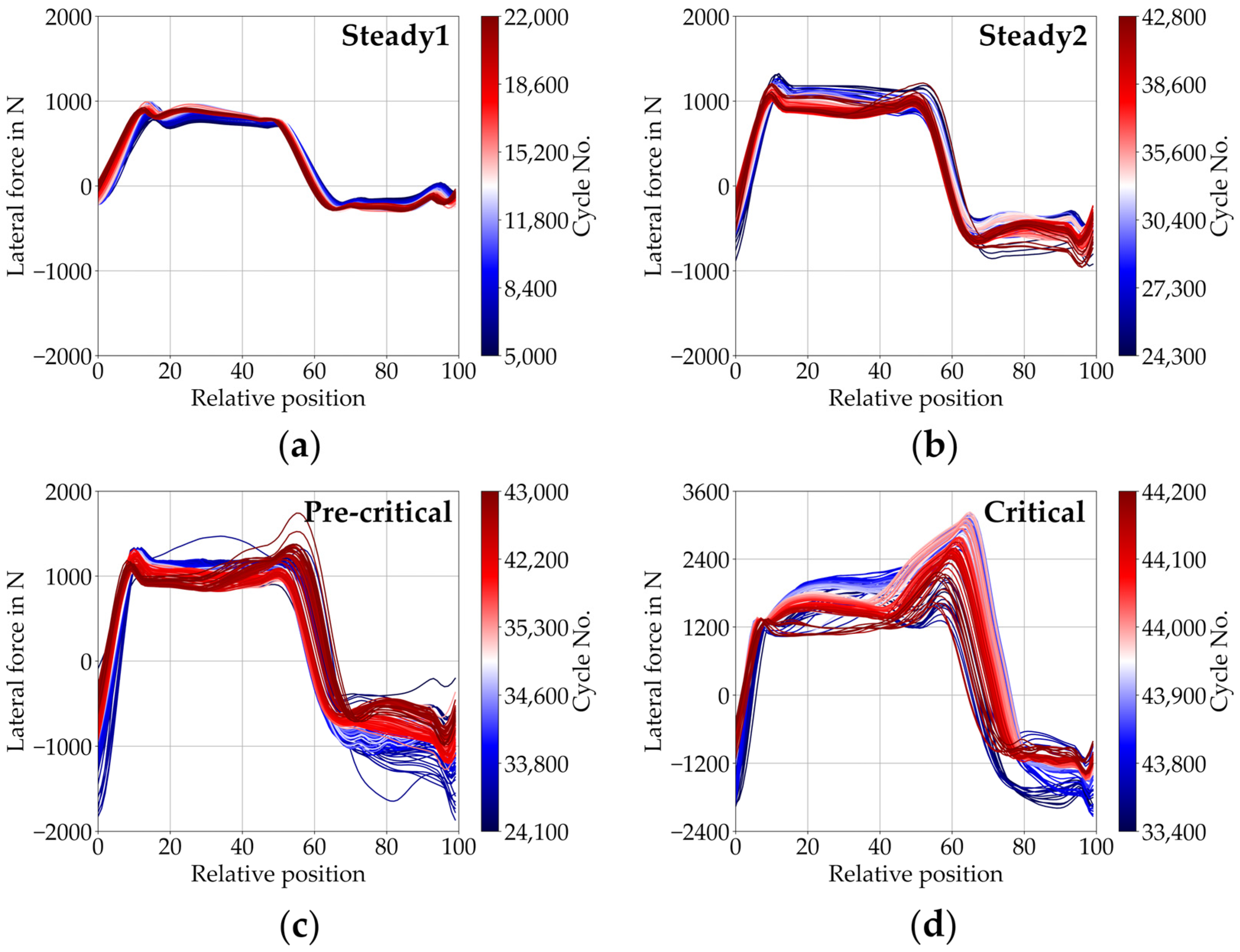
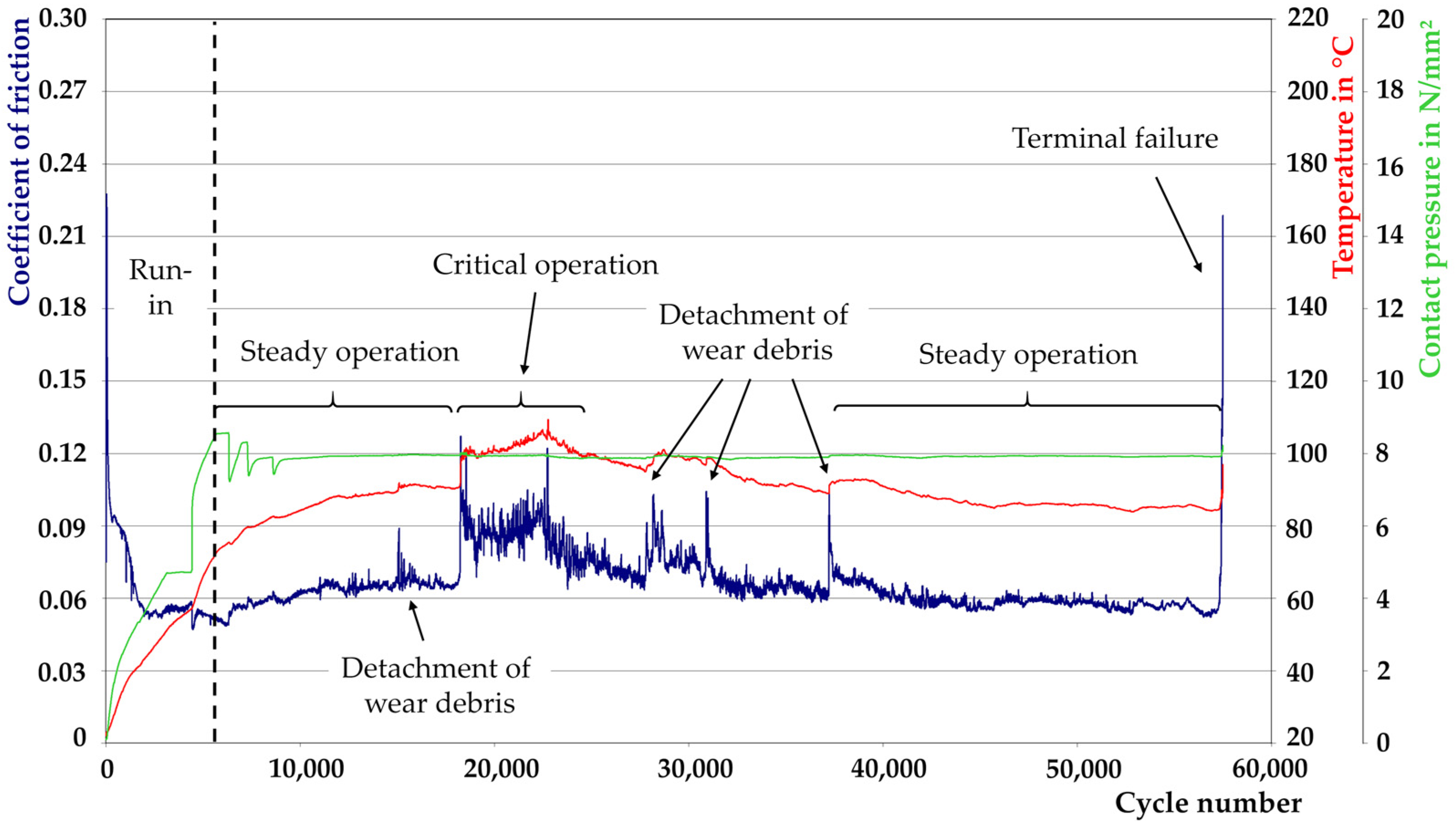
3.1. Frictional Behaviour
3.2. Classification of States of Operation
4. Discussion
5. Conclusions
- An RF algorithm, trained with high-resolution force signals of four experiments, showed a high degree of classification accuracy (0.939) after validation against a labelled dataset of another experiment.
- The labelling step is essential and preferably includes tribological expert knowledge. The proposed method offers the flexibility to choose within a range between fully automated and fully expert-related labelling.
- The application of a pre-trained algorithm to unlabelled data is very efficient and therefore can be used for immediate countermeasures to assist the self-recovering process of the system or to prevent major damage.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pech, M.; Vrchota, J.; Bednář, J. Predictive Maintenance and Intelligent Sensors in Smart Factory: Review. Sensors 2021, 21, 1470. [Google Scholar] [CrossRef] [PubMed]
- Gouarir, A.; Martínez-Arellano, G.; Terrazas, G.; Benardos, P.; Ratchev, S. In-process Tool Wear Prediction System Based on Machine Learning Techniques and Force Analysis. Procedia CIRP 2018, 77, 501–504. [Google Scholar] [CrossRef]
- Pandiyan, V.; Caesarendra, W.; Tjahjowidodo, T.; Tan, H.H. In-process tool condition monitoring in compliant abrasive belt grinding process using support vector machine and genetic algorithm. J. Manuf. Process. 2018, 31, 199–213. [Google Scholar] [CrossRef]
- Avendano, D.N.; Caljouw, D.; Deschrijver, D.; Van Hoecke, S. Anomaly detection and event mining in cold forming manufacturing processes. Int. J. Adv. Manuf. Technol. 2020, 1–16. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar]
- Saeidi, F.; Shevchik, S.; Wasmer, K. Automatic detection of scuffing using acoustic emission. Tribol. Int. 2016, 94, 112–117. [Google Scholar] [CrossRef]
- König, F.; Sous, C.; Chaib, A.O.; Jacobs, G. Machine learning based anomaly detection and classification of acoustic emission events for wear monitoring in sliding bearing systems. Tribol. Int. 2021, 155, 106811. [Google Scholar] [CrossRef]
- Pandiyan, V.; Prost, J.; Vorlaufer, G.; Varga, M.; Wasmer, K. Identification of Abnormal Tribological Regimes Using a Mi-crophone And Semi-Supervised Machine-Learning Algorithm. Friction 2021. accepted for publication on 3 April 2021. [Google Scholar]
- Shevchik, S.A.; Saeidi, F.; Meylan, B.; Wasmer, K. Prediction of Failure in Lubricated Surfaces Using Acoustic Time–Frequency Features and Random Forest Algorithm. IEEE Trans. Ind. Inform. 2016, 13, 1541–1553. [Google Scholar] [CrossRef]
- Moder, J.; Bergmann, P.; Grün, F. Lubrication Regime Classification of Hydrodynamic Journal Bearings by Machine Learning Using Torque Data. Lubricants 2018, 6, 108. [Google Scholar] [CrossRef] [Green Version]
- Thankachan, T.; Prakash, K.S.; Kamarthin, M. Optimizing the Tribological Behavior of Hybrid Copper Surface Composites Using Statistical and Machine Learning Techniques. J. Tribol. 2018, 140, 031610. [Google Scholar] [CrossRef]
- Bhaumik, S.; Mathew, B.R.; Datta, S. Computational intelligence-based design of lubricant with vegetable oil blend and various nano friction modifiers. Fuel 2019, 241, 733–743. [Google Scholar] [CrossRef]
- Deshpande, P.; Pandiyan, V.; Meylan, B.; Wasmer, K. Acoustic emission and machine learning based classification of wear generated using a pin-on-disc tribometer equipped with a digital holographic microscope. Wear 2021, 203622, 203622. [Google Scholar] [CrossRef]
- Mokhtari, N.; Pelham, J.G.; Nowoisky, S.; Bote-Garcia, J.-L.; Gühmann, C. Friction and Wear Monitoring Methods for Journal Bearings of Geared Turbofans Based on Acoustic Emission Signals and Machine Learning. Lubricants 2020, 8, 29. [Google Scholar] [CrossRef] [Green Version]
- Bustillo, A.; Pimenov, D.Y.; Mia, M.; Kapłonek, W. Machine-learning for automatic prediction of flatness deviation considering the wear of the face mill teeth. J. Intell. Manuf. 2021, 32, 895–912. [Google Scholar] [CrossRef]
- Boidi, G.; Da Silva, M.R.; Profito, F.J.; Machado, I.F. Using Machine Learning Radial Basis Function (RBF) Method for Predicting Lubricated Friction on Textured and Porous Surfaces. Surf. Topogr. Metrol. Prop. 2020, 8, 044002. [Google Scholar] [CrossRef]
- Sun, S.; Przystupa, K.; Wei, M.; Yu, H.; Ye, Z.; Kochan, O. Fast bearing fault diagnosis of rolling element using Lévy Moth-Flame optimization algorithm and Naive Bayes. Ekspolatacja Niezawodn. Maint. Reliab. 2020, 22, 730–740. [Google Scholar] [CrossRef]
- Argatov, I. Artificial Neural Networks (ANNs) as a Novel Modeling Technique in Tribology. Front. Mech. Eng. 2019, 5, 5. [Google Scholar] [CrossRef] [Green Version]
- Souza, R.M.; Nascimento, E.G.; Miranda, U.A.; Silva, W.J.; Lepikson, H.A. Deep learning for diagnosis and classification of faults in industrial rotating machinery. Comput. Ind. Eng. 2021, 153, 107060. [Google Scholar] [CrossRef]
- Rosenkranz, A.; Marian, M.; Profito, F.J.; Aragon, N.; Shah, R. The Use of Artificial Intelligence in Tribology—A Perspective. Lubricants 2020, 9, 2. [Google Scholar] [CrossRef]
- Kateris, D.; Moshou, D.; Pantazi, X.-E.; Gravalos, I.; Sawalhi, N.; Loutridis, S. A machine learning approach for the condition monitoring of rotating machinery. J. Mech. Sci. Technol. 2014, 28, 61–71. [Google Scholar] [CrossRef]
- Bergs, T.; Holst, C.; Gupta, P.; Augspurger, T. Digital image processing with deep learning for automated cutting tool wear detection. Procedia Manuf. 2020, 48, 947–958. [Google Scholar] [CrossRef]
- Glowacz, A. Fault diagnosis of electric impact drills using thermal imaging. Measurement 2021, 171, 108815. [Google Scholar] [CrossRef]
- Bustillo, A.; Pimenov, D.; Matuszewski, M.; Mikolajczyk, T. Using artificial intelligence models for the prediction of surface wear based on surface isotropy levels. Robot. Comput. Manuf. 2018, 53, 215–227. [Google Scholar] [CrossRef]
- Erdemir, A. Solid Lubricants and Self-Lubricating Films. In Modern Tribology Handbook, Volume One: Principles of Tribology; Bhushan, B., Ed.; CRC Press: Boca Raton, FL, USA, 2001; pp. 787–825. [Google Scholar]
- Neacşu, I.A.; Scheichl, B.; Vorlaufer, G.; Eder, S.J.; Franek, F.; Ramonat, L. Experimental Validation of the Simulated Steady-State Behavior of Porous Journal Bearings1. J. Tribol. 2016, 138, 031703. [Google Scholar] [CrossRef]
- Eder, S.; Ielchici, C.; Krenn, S.; Brandtner, D. An experimental framework for determining wear in porous journal bearings operated in the mixed lubrication regime. Tribol. Int. 2018, 123, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Boidi, G.; Krenn, S.; Eder, S.J. Identification of a Material–Lubricant Pairing and Operating Conditions That Lead to the Failure of Porous Journal Bearing Systems. Tribol. Lett. 2020, 68, 108. [Google Scholar] [CrossRef]
- Guo, J.; Du, H.; Zhang, G.; Cao, Y.; Shi, J.; Cao, W. Fabrication and tribological behavior of Fe-Cu-Ni-Sn-Graphite porous oil-bearing self-lubricating composite layer for maintenance-free sliding components. Mater. Res. Express 2020, 8, 015801. [Google Scholar] [CrossRef]
- Rodiouchkina, M.; Berglund, K.; Mouzon, J.; Forsberg, F.; Shah, F.U.; Rodushkin, I.; Larsson, R. Material Characterization and Influence of Sliding Speed and Pressure on Friction and Wear Behavior of Self-Lubricating Bearing Materials for Hydropower Applications. Lubricants 2018, 6, 39. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Pan, L.; Wang, S.; Wang, X.; Tomovic, M. An accelerated life test model for solid lubricated bearings used in space based on time-varying dependence analysis of different failure modes. Acta Astronaut. 2018, 152, 352–359. [Google Scholar] [CrossRef]
- Jisa, R.; Monetti, C.; Kelman, P. Selbstschmierende Gleitsysteme aus schadensanalytischer Sicht. Tribol. Schmier. 2005, 52, 26–29. [Google Scholar]
- Cihak-Bayr, U.; Steiner, H.; Glatzl, T.; Grundtner, R.; Pirker, F. Machine Learning Algorithms for Health Monitoring of Sliding Bearings. In Proceedings of the 60th German Tribology Conference, Göttingen, Germany, 23–25 September 2019; pp. 1–4. [Google Scholar]
- Jisa, R. Tribologische Wechselwirkungen von Selbstschmierenden Gleitelementen Basierend auf Kupferlegierungen und Graphit-Öl-Schmierstoffen. Ph.D. Dissertation, Technische Universität Wien, Vienna, Austria, 2007. [Google Scholar]
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.; Grout, J.; Corlay, S.; et al. Jupyter Notebooks—A Publishing Format for Reproducible Computational Workflows. In Proceedings of the 20th International Conference on Electronic Publishing, Göttingen, Germany, 7–9 June 2016; pp. 87–90. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; Van Der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nat. Cell Biol. 2020, 585, 357–362. [Google Scholar] [CrossRef]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 56–61. Available online: https://conference.scipy.org/scipy2010/slides/wes_mckinney_data_structure_statistical_computing.pdf (accessed on 26 April 2021).
- The HDF Group. The HDF5® Library & File Format. Available online: https://www.hdfgroup.org/solutions/hdf5/ (accessed on 18 September 2020).
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Louppe, G.; Wehenkel, L.; Sutera, A.; Geurts, P. Understanding Variable Importances in Forests of Randomized Trees. In Advances in Neural Information Processing Systems 26, Proceedings of the 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–10 December 2013. pp. 431–439. Available online: http://hdl.handle.net/2268/155642 (accessed on 3 May 2021).
- Nembrini, S.; König, I.R.; Wright, M.N. The revival of the Gini importance? Bioinformatics 2018, 34, 3711–3718. [Google Scholar] [CrossRef] [Green Version]
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How Many Trees in a Random Forest? In Proceedings of the Transactions on Petri Nets and Other Models of Concurrency XV; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2012; pp. 154–168. [Google Scholar]
- Probst, P.; Boulesteix, A.-L. To tune or not to tune the number of trees in random forest. J. Mach. Learn. Res. 2018, 18, 1–18. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Powers, D.M.W. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. Available online: https://arxiv.org/abs/2010.16061 (accessed on 1 May 2021).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Du-bourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Wiley, M.; Wiley, J.F. Advanced R Statistical Programming and Data Models: Analysis, Machine Learning, and Visualization; Apress: New York, NY, USA, 2019. [Google Scholar]
- Agrawal, T. Hyperparameter Optimization in Machine Learning: Make Your Machine Learning and Deep Learning Models More Efficient; Apress: New York, NY, USA, 2021. [Google Scholar]
- Elforjani, M.; Shanbr, S. Prognosis of Bearing Acoustic Emission Signals Using Supervised Machine Learning. IEEE Trans. Ind. Electron. 2018, 65, 5864–5871. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
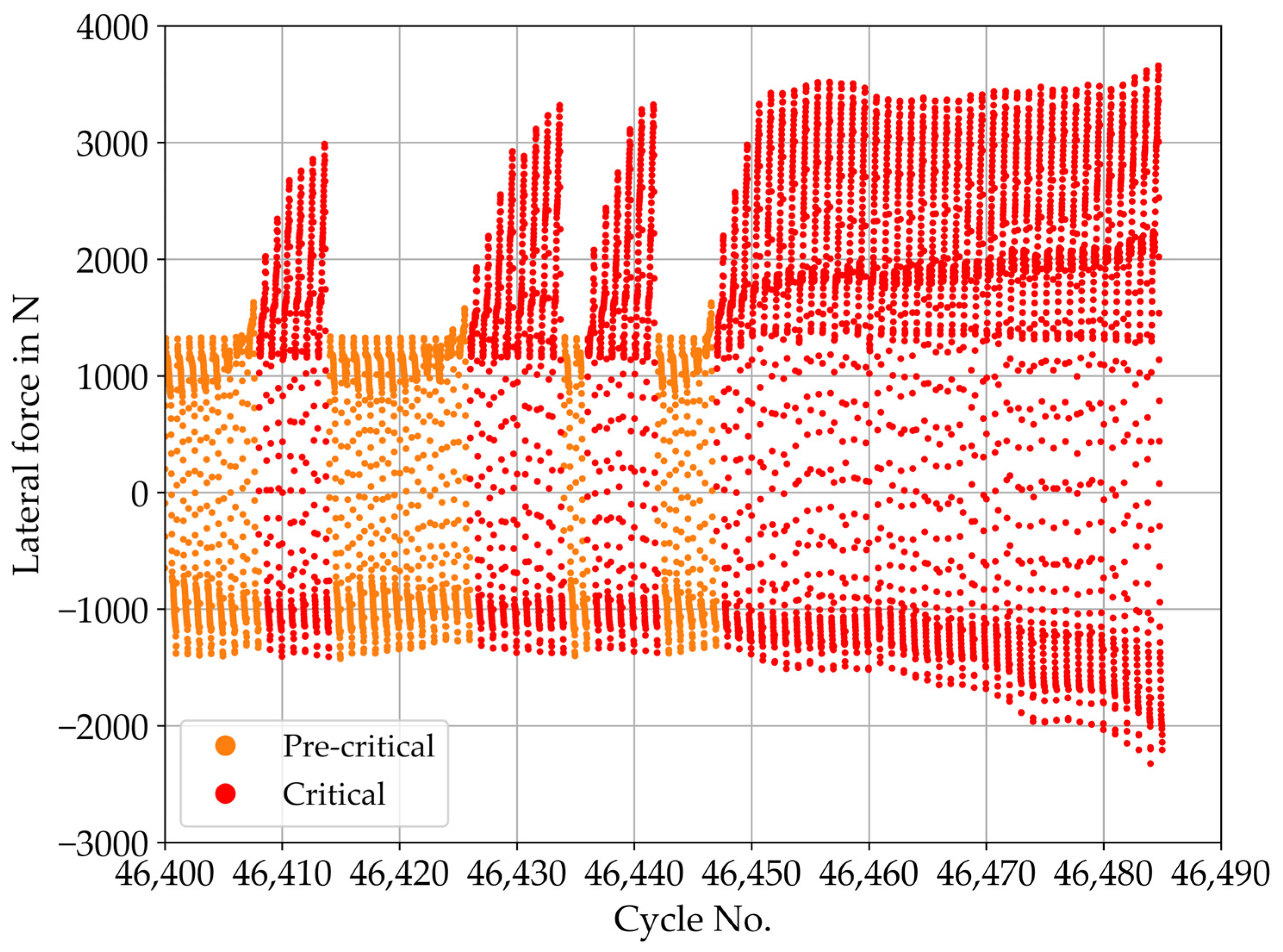{kind=link}
| Experiment No. | Cumulative Variance | Total Number of Cycles | Number of Cycles in Each Cluster (in Ascending Order) | ||||
|---|---|---|---|---|---|---|---|
| Experiment 1 | 0.79 | 46,485 | 66 | 1447 | 10,029 | 16,271 | 18,672 |
| Experiment 2 | 0.83 | 44,265 | 458 | 1992 | 4075 | 15,684 | 22,074 |
| Experiment 3 | 0.89 | 38,605 | 364 | 2690 | 5553 | 12,467 | 17,531 |
| Experiment 4 | 0.86 | 57,516 | 4532 | 8075 | 13,281 | 14,484 | 17,144 |
| Experiment 5 | 0.87 | 44,944 | 2043 | 3279 | 9904 | 10,905 | 18,813 |
| Experiment 6 | 0.80 | 35,388 | 38 | 2569 | 5214 | 13,443 | 14,124 |
| Experiment 7 | 0.80 | 39,822 | 245 | 1918 | 6411 | 12,718 | 18,530 |
| Experiment 8 | 0.84 | 54,782 | 1368 | 3359 | 9603 | 19,197 | 21,255 |
| Experiment 9 | 0.85 | 35,734 | 1193 | 5678 | 8896 | 9920 | 10,047 |
| State | No. of Cycles after k-Means | No. of Cycles after Manual Adaptation |
|---|---|---|
| Steady1 | 22,074 | 19,120 |
| Steady2 | 15,684 | 15,331 |
| Pre-critical | 4075 | 4263 |
| Critical | 458 | 551 |
| Class | No. of Cycles | Resampling Factor |
|---|---|---|
| Steady1 | 51,217 | 0.29 |
| Steady2 | 83,678 | 0.18 |
| Pre-critical | 21,177 | 0.71 |
| Critical | 1265 | 11.86 |
| Hyperparameter | Value |
|---|---|
| n_estimators | 101 |
| min_samples_split | 2 |
| min_samples_leaf | 1 |
| max_features | ‘sqrt’ |
| max_depth | 30 |
| bootstrap | True |
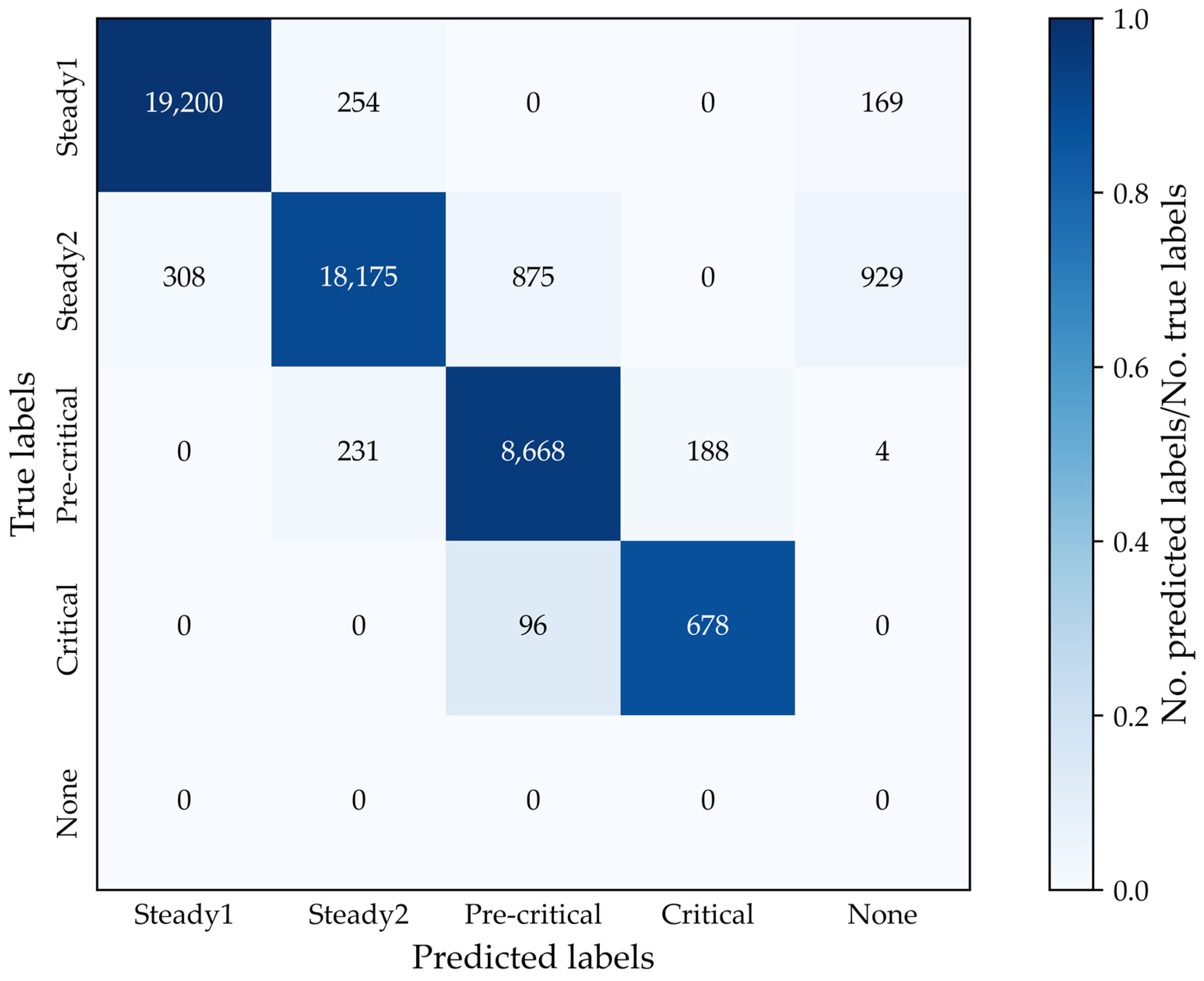
| Class | Precision | Recall |
|---|---|---|
| Steady1 | 0.98 | 0.98 |
| Steady2 | 0.97 | 0.90 |
| Pre-critical | 0.90 | 0.95 |
| Critical | 0.78 | 0.88 |
| Experiment No. | Total Running Time (Hours) | Start Pre-Critical Phase (Minutes before End) | Fraction of Total Running Time (%) |
|---|---|---|---|
| Experiment 1 | 15.4 | 7.5 | 0.8 |
| Experiment 2 | 14.8 | 73 | 8.3 |
| Experiment 3 1 | 12.3 | 113 | 15.3 |
| Experiment 4 | 19.1 | 2.5 | 0.2 |
| Experiment 5 | 14.7 | 4 | 0.5 |
| Experiment 6 | 11.1 | 1.5 | 0.2 |
| Experiment 7 | 13.5 | 60 | 7.4 |
| Experiment 8 | 18.3 | 211 | 19.2 |
| Experiment 9 | 11.7 | 5 | 0.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prost, J.; Cihak-Bayr, U.; Neacșu, I.A.; Grundtner, R.; Pirker, F.; Vorlaufer, G. Semi-Supervised Classification of the State of Operation in Self-Lubricating Journal Bearings Using a Random Forest Classifier. Lubricants 2021, 9, 50. https://0-doi-org.brum.beds.ac.uk/10.3390/lubricants9050050
Prost J, Cihak-Bayr U, Neacșu IA, Grundtner R, Pirker F, Vorlaufer G. Semi-Supervised Classification of the State of Operation in Self-Lubricating Journal Bearings Using a Random Forest Classifier. Lubricants. 2021; 9(5):50. https://0-doi-org.brum.beds.ac.uk/10.3390/lubricants9050050
Chicago/Turabian StyleProst, Josef, Ulrike Cihak-Bayr, Ioana Adina Neacșu, Reinhard Grundtner, Franz Pirker, and Georg Vorlaufer. 2021. "Semi-Supervised Classification of the State of Operation in Self-Lubricating Journal Bearings Using a Random Forest Classifier" Lubricants 9, no. 5: 50. https://0-doi-org.brum.beds.ac.uk/10.3390/lubricants9050050