1. Introduction
Given the significant increase in the number of vehicles in recent years, there has been an increase in attention paid towards the safety evaluation of vehicles in both the industrial sector as well as in academia. The transmission is a core component of vehicles, providing power transfer and direction change. It is also a major source of vehicle failure and noise. In transmission, gears are the main parts and are significant factors in transmission safety. As a result, gear reliability assessment is a significant and direct indicator in terms of vehicle safety.
Regarding vehicle transmission gears, the data acquisition process is complicated and expensive, resulting in insufficient gear data collection, which increases the difficulty in evaluating gear reliability [
1]. Traditionally, the solutions of gear reliability assessment can be categorized into two parts: model-driven and data-driven techniques. For the former, gear reliability cannot be calculated directly; however, it can be estimated by two gear safety factors—bending and contact safety factors [
2]. To address both of these factors, the mechanical structure and operation process of transmission gears are both modeled to calculate gear safety factors [
3,
4,
5,
6,
7,
8]. Obviously, the accuracy of gear reliability assessment is determined by the precision of modeling. A lot of assumed conditions are required in the modeling process to guarantee solvability and availability. However, these conditions, with regard to theoretical physical equations, do not reflect transmission gears under realistic operating conditions, leading to objective deviations [
9]. For instance, the autoregressive model (AR) [
10] evaluates data using the autocorrelation function, but is vulnerable to data noise. The moving average (MA) [
11] model assesses data according to the weighted summation of present and past inputs, which is necessary to ensure the difference stationarity of data. However, gear data are unable to converge everywhere. The autoregressive moving average (ARMA) [
12] model uses the least square method to appraise current data. ARMA requires linear data, yet gear data are usually nonlinear; therefore, model-driven methods are not effective in gear reliability assessment.
For the latter, instead of assumed conditions, intrinsic relations between gear reliability and monitored parameters are learned from collected data. Data-driven techniques are motivated by implicit and explicit characteristics of collected data without constraint conditions and specific models, which are widely used to evaluate gear reliability. For example, a hybrid data-driven method combined by support vector data description and extreme learning machine is proposed to monitor the unhealthy status of wind turbines gears [
13]. Meanwhile, a deep structure of a denoising autoencoder is designed to assess wind turbines gears through analyzing the monitored vibration data [
14,
15], and an adaptive signal resampling model is established for the fault diagnosis of wind turbine gears with current signals [
16,
17]. A time series-histogram method is presented to predict the remaining useful life of aero-engine gears by extracting features of event data [
18]. In these methods, sample generation is the key; however, on the one hand, oversampling methods that are widely used to produce sufficient samples by learning the location relationship of the original data [
19], like random oversampling [
20] and synthetic minority over-sampling technique [
21], generate samples inside the ranges of the original data without consideration of the correlations among dimensions of the original data and instead deemed as independent. On the other hand, because the initial values of gear parameters in a test rig are empirically based on an engineer’s experience, collected real-world gear data are highly dense. Furthermore, one gear parameter has a high coupling relationship with other parameters [
22,
23]. The distance between any two samples in the gear data of vehicle transmission has lost correlation with their corresponding reliability, which indicates that general distance measurement (e.g., Euclidean distance and cosine distance) in oversampling methods cannot work on gear data effectively [
24]. Thus, oversampling methods are unable to produce reliable gear data for vehicle transmission.
Rather than producing samples based on location calculations of the original data in oversampling methods, another type of generative technique learns the inherent distribution from the original data and creates new samples under the estimated distributions. GAN [
25] is an attractive deep generative architecture that estimates the probability density or mass functions in a minimax game. A generator and a discriminator in the game confront each other. The generator tries to forge samples as real as the original data to confuse the discriminator. At the same time, the discriminator aims to distinguish the produced samples from the original data. With the estimated distribution, new samples from the generator are produced over the whole data space and are not constrained in the ranges of the original data.
Nevertheless, there exist three issues for expanding gear data using GAN to improve the effectiveness of gear reliability assessment. First, the training process of a traditional GAN in estimating the distribution without considering any class information may cause an over-generation of one class and an under-generation of other classes. This could cause imbalance issues and decrease the precision of reliability assessment [
26]. Second, according to the high density and coupling of collected gear data, GAN collapses easily and produces samples with close properties [
27]. Finally, produced samples from GAN and its variations have no label and cannot be used in reliability evaluation operation.
To address these issues, a novel approach is presented to acquire sufficient data for transmission gears, which improves the classification accuracy of gear reliability. In the model, we establish a CGAN-based model by implementing label information to produce representations with high diversity. According to this model, we can transform the unsupervised training process into a supervised training process by adding the label information of the sample, which will greatly improve the generation ability of the network, and not only learn the mapping between collected gear data and the degree of gear reliability, but also reflect the real situation of the gearbox under actual working conditions through the generated samples. Additionally, we propose a Wasserstein labeling scheme to label generated representations according to the characters of gear data. This labeling method based on Wasserstein distance can avoid the situation that there is no duplication between different categories of generated samples. By measuring the probability density relationship between the generated sample set and the real sample set, the generated sample can be correctly classified, thereby producing better label information. The main contributions of this paper are summarized as follows.
- 1.
A novel approach is proposed as a pretreatment for the gear reliability assessment of vehicle transmissions. With an estimated global distribution, this approach produces credible transmission gear representations to expand existing space and raises the efficiency of the gear reliability assessment.
- 2.
In the CGAN-based model, label information gains access to the distribution estimation to generate representations guided by label distribution. Furthermore, we introduce a mini-batch strategy to randomly sample original and forged representations from the generator and send these representations into the discriminator for differentiation, strengthening the diversity of generated representations.
- 3.
The proposed WL scheme names the generated representations based on the measurement between these representations and Wasserstein barycenter of gear reliability degrees. This scheme offsets the unlabeled ability of GAN and provides available labels for classifiers.
The rest of this paper is organized as follows. In
Section 2, a brief view of GAN and gear reliability is introduced. In
Section 3, we describe the proposed approach in detail. Experimental results are presented and discussed in
Section 4. Finally, in
Section 5, we conclude the paper, detailing the advantages of the proposed approach.
3. Materials and Methods
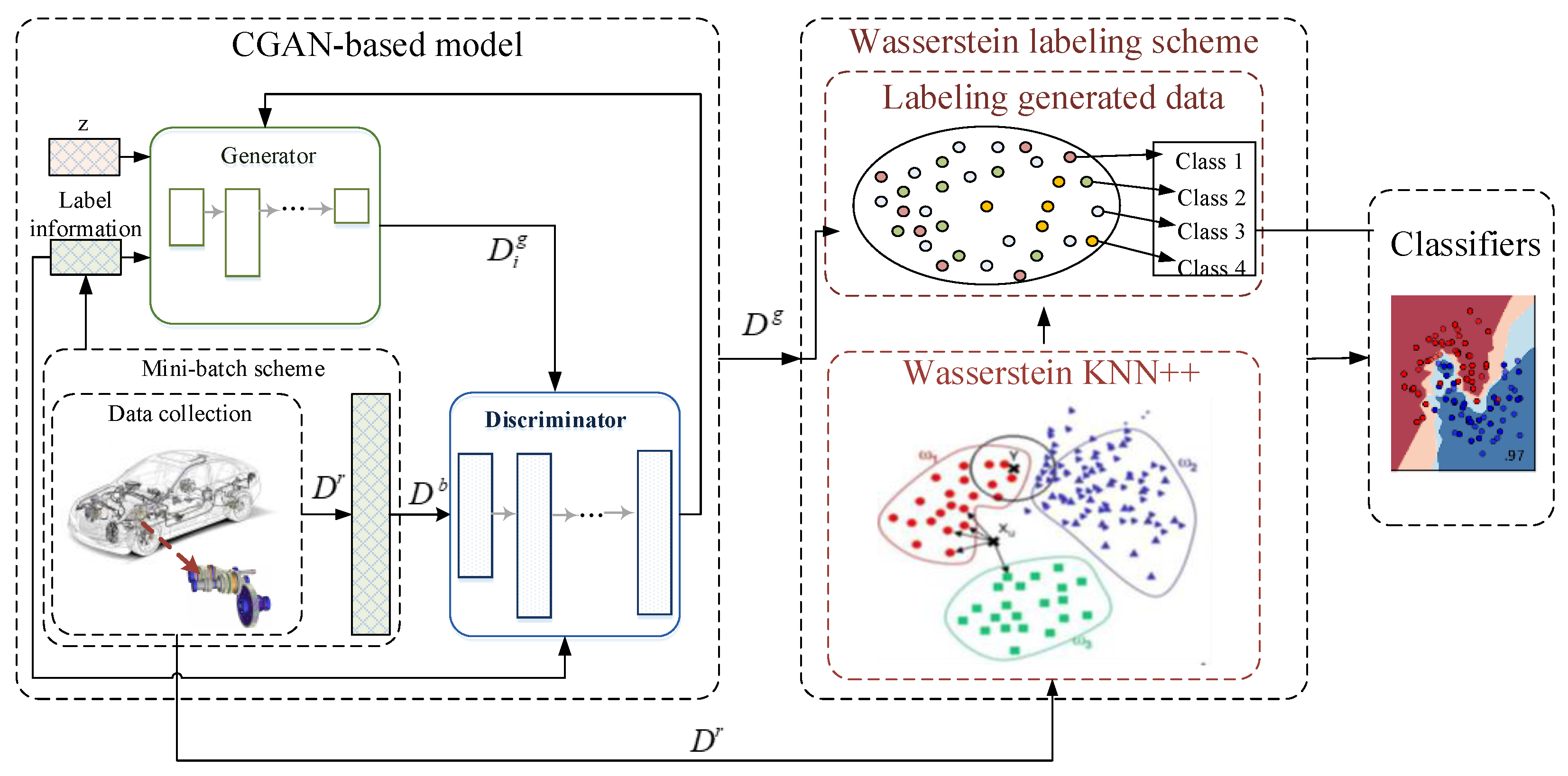
To address reliability assessment of vehicle transmission gears without mechanic modeling and particular conditions, the proposed approach contains two components to prepare for the evaluation of gear reliability with existing gear data (illustrated as in
Figure 2).
First, we need to process the gear data collected from the factory. When this kind of highly dimensional and small amount of data are directly put into the generator for generation, it will often cause non-convergence of the generation model. Therefore, this step is indispensable. In this step, our input is the original dataset with the same feature dimensions but different amounts of data under different categories. After data processing, the amount of data in different categories will remain balanced to reduce the imbalance between the data. It is convenient for the generation model.
Afterwords, we input low-dimensional noise with label information into the generator of our CGAN-based model. After the convolutional layer mapping, we get the generated data with the same dimension as the original dataset, then put them together into the discriminator. With the help of back propagation, the weight of the convolutional layers will be updated. In order to raise the diversity of generated representations in accordance with the characteristics of the gear data for the vehicle transmission, the mini-batch scheme is designed to sample certain amounts of original data and produced representations instead of training the discrimination with all representations. When the training is completed, our CGAN-based model will generate data with label information. We take out the generated data and remove the labels.
Finally, we input the generated data without label information into the k-nearest neighbor (KNN) model for classification based on Wasserstein distance. Through this model, we can make reasonable annotations for generated data, regardless of whether they coincide in different categories. The flow-process diagram of our proposed method is shown in
Figure 3. In addition, the definition of symbols in our article is scattered. We have listed those central and confusing symbols in
Table 1.
3.1. CGAN-Based Model
3.1.1. Data Processing
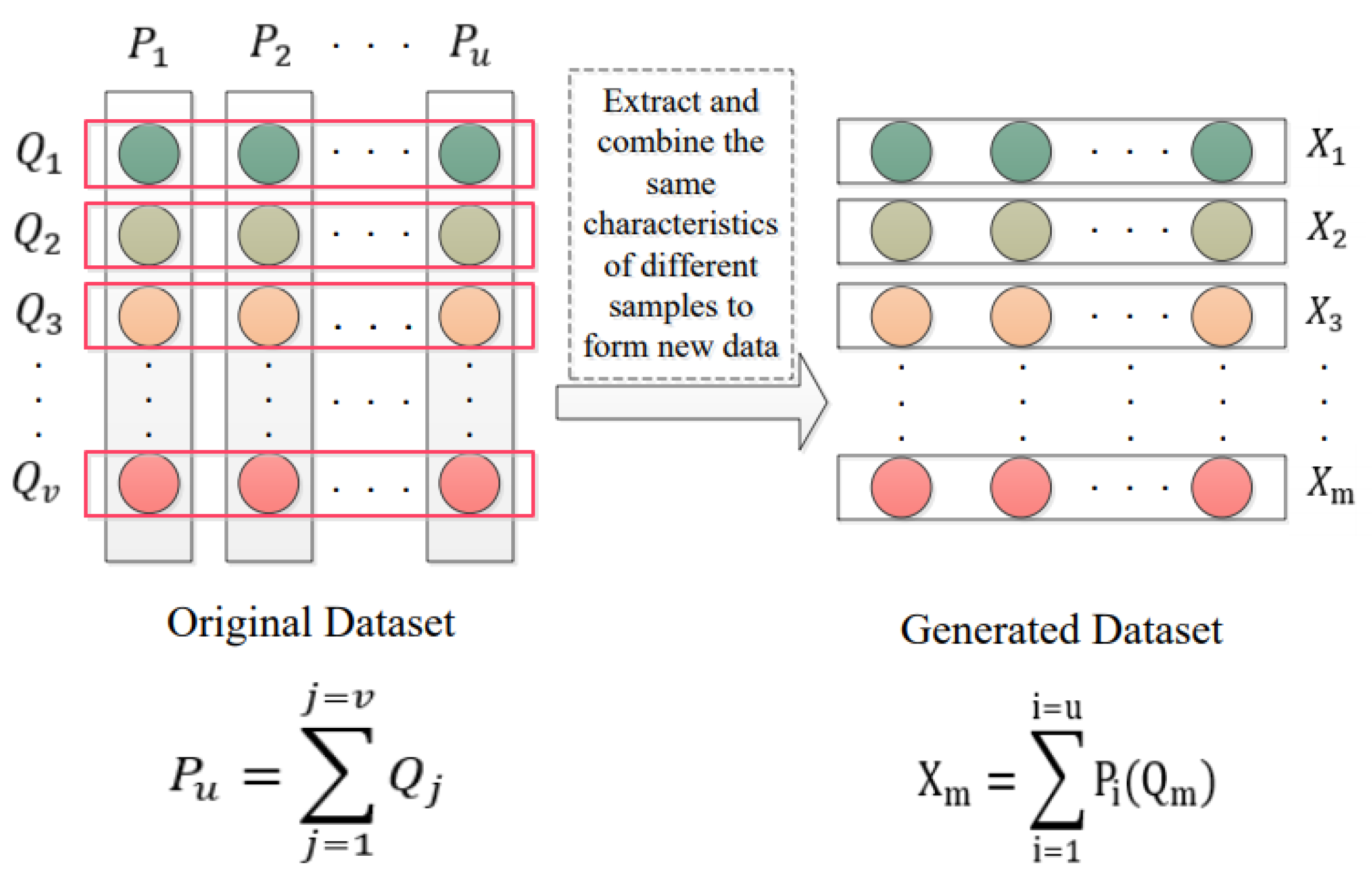
Compared with image data, structured data are close to orthogonal between the various features contained in the data; therefore, for the CGAN-based model, the discriminator cannot pass the gradient back to the generator according to the result of the generator for the iterative update in the processor. Before data generation, we extract and integrate the same features of all data to form a new dataset, as shown in
Figure 4, and after our model generates new features, we will merge these features to form new data again; as a result, we obtain an original dataset, with its objects
, its number of instances
u, with its attribute set
, its number of attributes
v, with its categories
and its number of categories
w. For the input of the network, a new dataset is constructed, and use
D to represent this dataset, with its objects
, its number of instances
m equal to
v, with its attribute set
, its number of attributes
d equal to
u, with its categories
and its number of categories
l equal to
v;
addresses real gear data and
represents produced data from our trained generator.
3.1.2. Model Structure
Due to the discrete nature of gear tooth data, when a single GAN is used to generate gear tooth data, the boundaries between different types of generated data are often blurred according to unconditional constraints, especially when similar to gear wheels. The gear data forms a dataset with a small gap between classes, so our generative model uses CGAN with conditional information.
and
in our CGAN-based model are both a neural network with multiple hidden layers. The minimax game is denoted as:
Mathematically, the solution of this game is to learn the joint probability function other than the probability function in GAN.
In terms of
, noise variables
z and label information
l are inputs and forged data
are outputs.
t is the iteration time. In the process of generating CGAN, the noise is used as an input for the purpose of making the network random, which can generate very complex distributions. The goal is to make it close to the distribution generated by real data. For the gear data we used, although we have combined these discrete data into a continuous distribution, the randomly added noise will not purposefully make our data distribution more in line with the real data distribution. When the dimension of the input noise is smaller than the amount of data contained in a single gear dataset, this noise will make our data more confusing. Therefore, in the process of CGAN generation, we placed a restriction on the noise according to the characteristics of the data, that is, the dimension of the noise must not be lower than the amount of data contained in a single gear dataset. For
, gear samples
x from
and
are inputs, and the computation result of objective function (Equation (
3)) is an output.
The details of our CGAN-based model are in Algorithm 1.
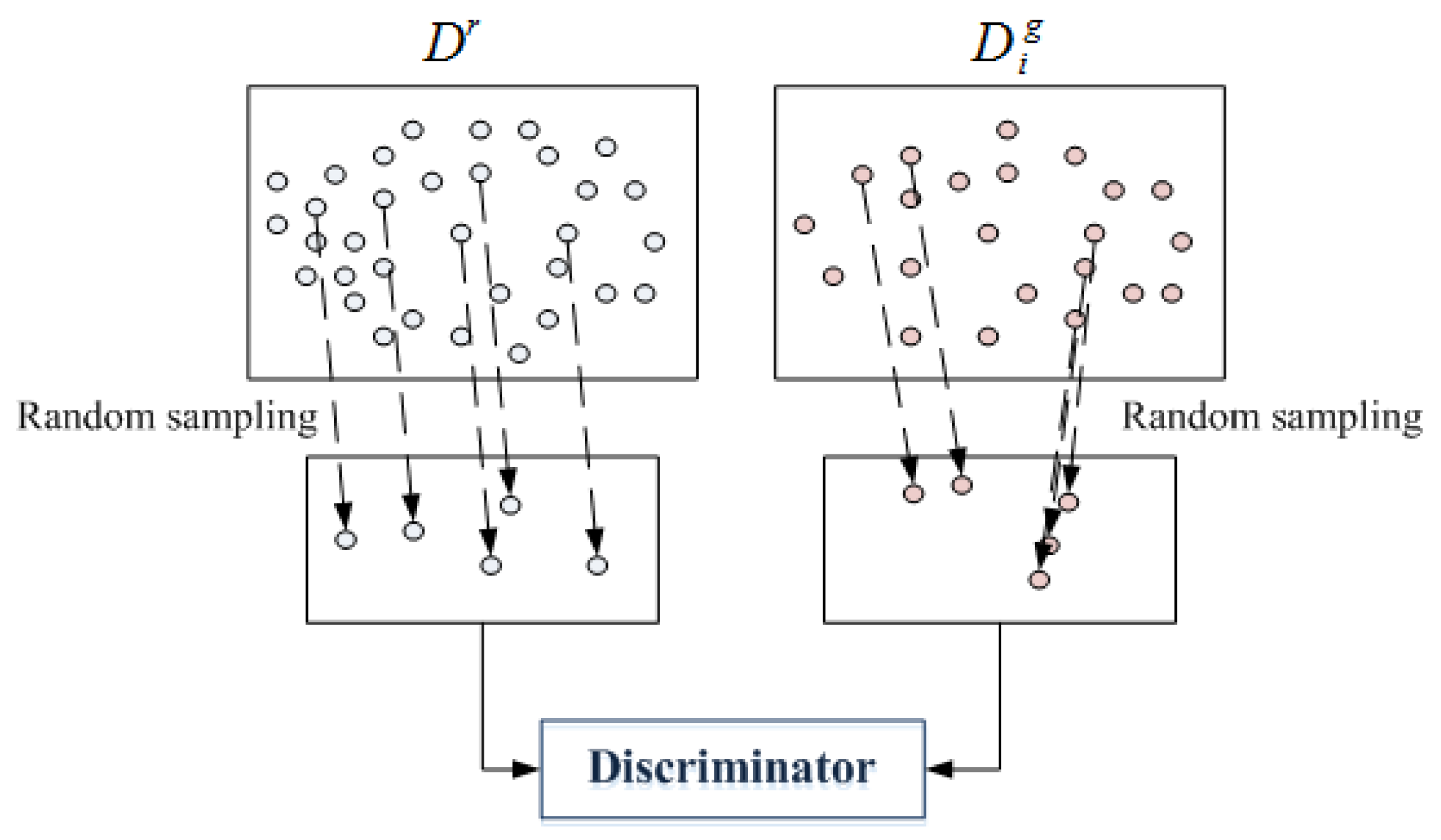
3.1.3. Mini-Batch Scheme
Typically,
would collapse due to the parameter settings, leading to the production of representations in one model. Thereby, to guarantee the diversity of generated representations, we adopt the mini-batch strategy on
as shown in
Figure 5.
Suppose that
b is the mini-batch size, we stochastically sample
b representations from
as
and
. Instead of accessing the entire
and
, we load
into
to compare with part of generated representations
.
where
and
are the number of representations in
and
.
The advantage of this strategy is that
is confronted with different real representations in every iteration. The generated representations at each iteration is compared with a portion of real representations, which enhances the diversity of generated representations.
| Algorithm 1: CGAN-based model for extracting the generated representations without label information |
![Actuators 10 00086 i001]() |
3.1.4. Network Optimization
Due to the high density and small amount of gear data, the generated representations are easily trapped into a group of a similar sample to the original. Although the mini-batch scheme is designed to deal with the overfitting issue, one category of gear data has an extremely small size, which aggravates the non-convergence problem. Therefore, instead of gradient descent method for
and
in GAN, we implement the Adamax optimizer to train both
and
, which computes exponential moving averages of gradients
and Hessian matrices
and provides a simpler range for the upper limit of the learning rate. Exponential decay rates are controlled by coefficients
, which are updated at each iteration.
and
represent the learning rates of the gradient with first order, and Hessian matrices are defined as:
where
and
are initial learning rates of
and
, respectively. The estimations of the first moment gradient and Hessian matrices at iteration
t are given as:
where
and
are gradients, computed with the following formulas:
and
are updated as follows.
The
and
are hyperparameters initialized with empirical evidence in the simulation. In the training process of the network, the reason why we use Adamax instead of the Adam that comes with CGAN is because Adam’s ability to adjust the learning rate changes based on a simpler range for the upper limit of the learning rate, as shown in (
9). The definition of this range allows our network to process discrete data without modifying the initialization deviation, and has a more flexible adjustment method and a smaller magnitude of change.
3.2. Wasserstein Labeling Scheme
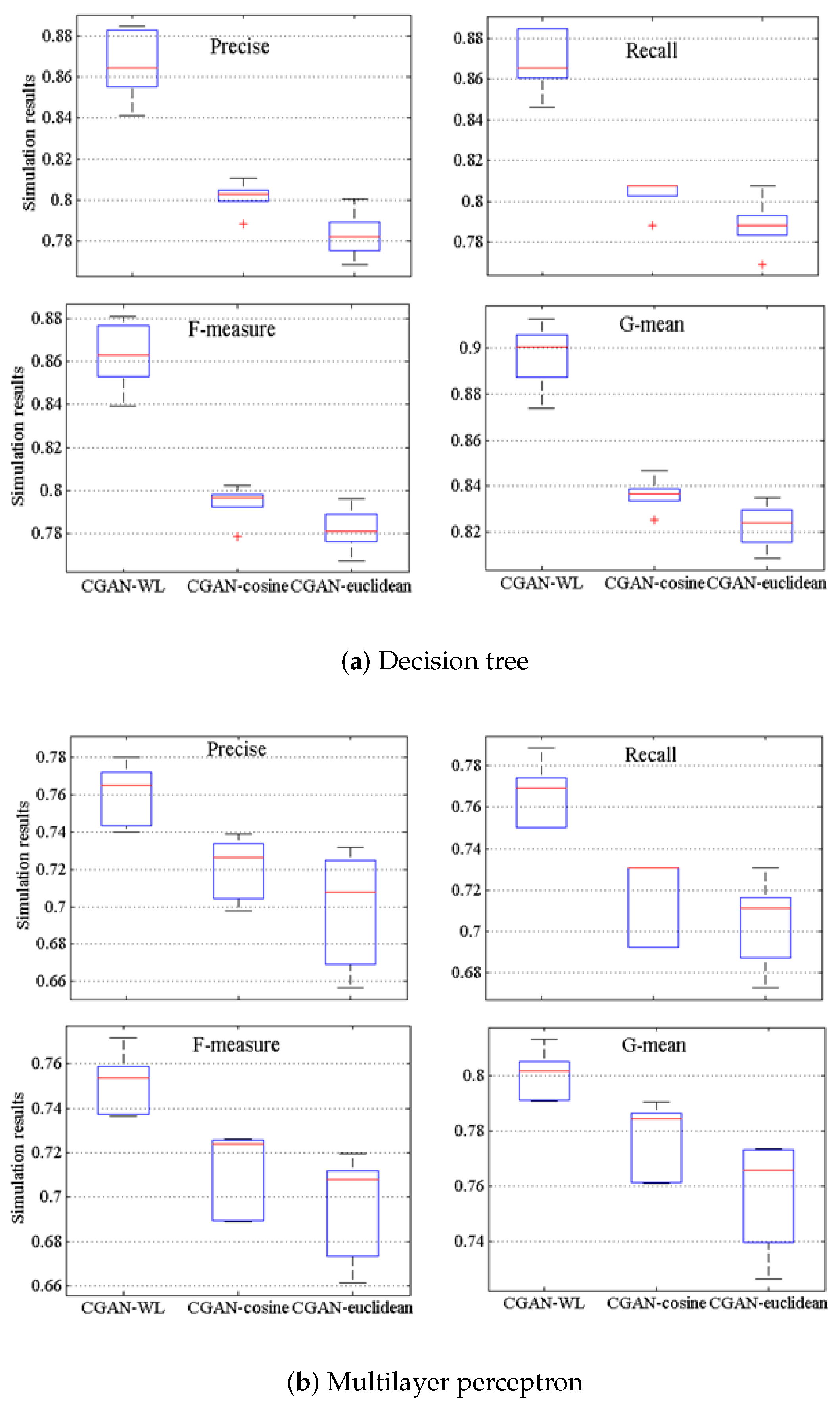
Considering that
from our CGAN-based model has no labels, it is necessary to tag the generated representations for classification. With regards to one specific property of gear data [
22], general distance measurement (e.g., Euclidean and cosine distance) cannot display well on transmission gear data. To label generated gear representations, the Wasserstein labeling scheme is proposed with a three-step process. First, a Wasserstein barycenter for gear data in each category of gear reliability is discovered by the k-nearest neighbor Wasserstein clustering algorithm. Then, the Wasserstein distance between each sample in the generated data and each Wasserstein barycenter is estimated by the Wasserstein critic. The details are shown in Algorithm 2.
3.2.1. Wasserstein Barycenter
We use
to represent all possible joint distribution combinations of
and
distribution combinations for each joint distribution
that can be sampled, and the distance between the samples can be calculated. Under the joint distribution
, the expected value
of the sample to the distance is obtained. At this time, we can define the earth-mover (EM) distance between the two samples as the lower bound of the expected value, as shown in the following formula.
| Algorithm 2: Wasserstein labeling scheme for assigning labels to the generated representations |
![Actuators 10 00086 i002]() |
The solution of finding the Wasserstein barycenter is transformed into optimizing the following formula:
where
p is the order of the Wasserstein distance, and is initialized as
. Thus,
is termed as
W in this paper. Let
be the transmission matrix in EM distance and
be the distance matrix,
Integrate Equation (
12) into Equation (
11), the optimal problem is changed into:
Suppose
as discrete description of a distribution,
x is the value of samples and
is the frequency of samples. Real gear data in each reliability are denoted as
, respectively. To resolve Equation (
13), the Sinkhorn iteration is designed to obtain
of
:
Then, the location of the Wasserstein barycenter in
is solved as:
Accordingly, a set of Wasserstein barycenters for gear reliability evaluation with existing gear data is obtained as .
3.2.2. Labeling Generated Data
Wasserstein distance between two datasets, take
and
for example, is given by
where
=
,
and
;
v is a
matrix with all values of 1.
Suppose
as
ith sample in
, the Wasserstein distance between
x and Wasserstein barycenter
of
kth reliability of transmission gear is denoted as:
After estimating the distance from each generated sample and each Wasserstein barycenter, the reliability with the minimum distance is used to tag the generated sample.
where
is the label of the generated sample
.
3.3. Discussion
3.3.1. The Necessity of Data Processing
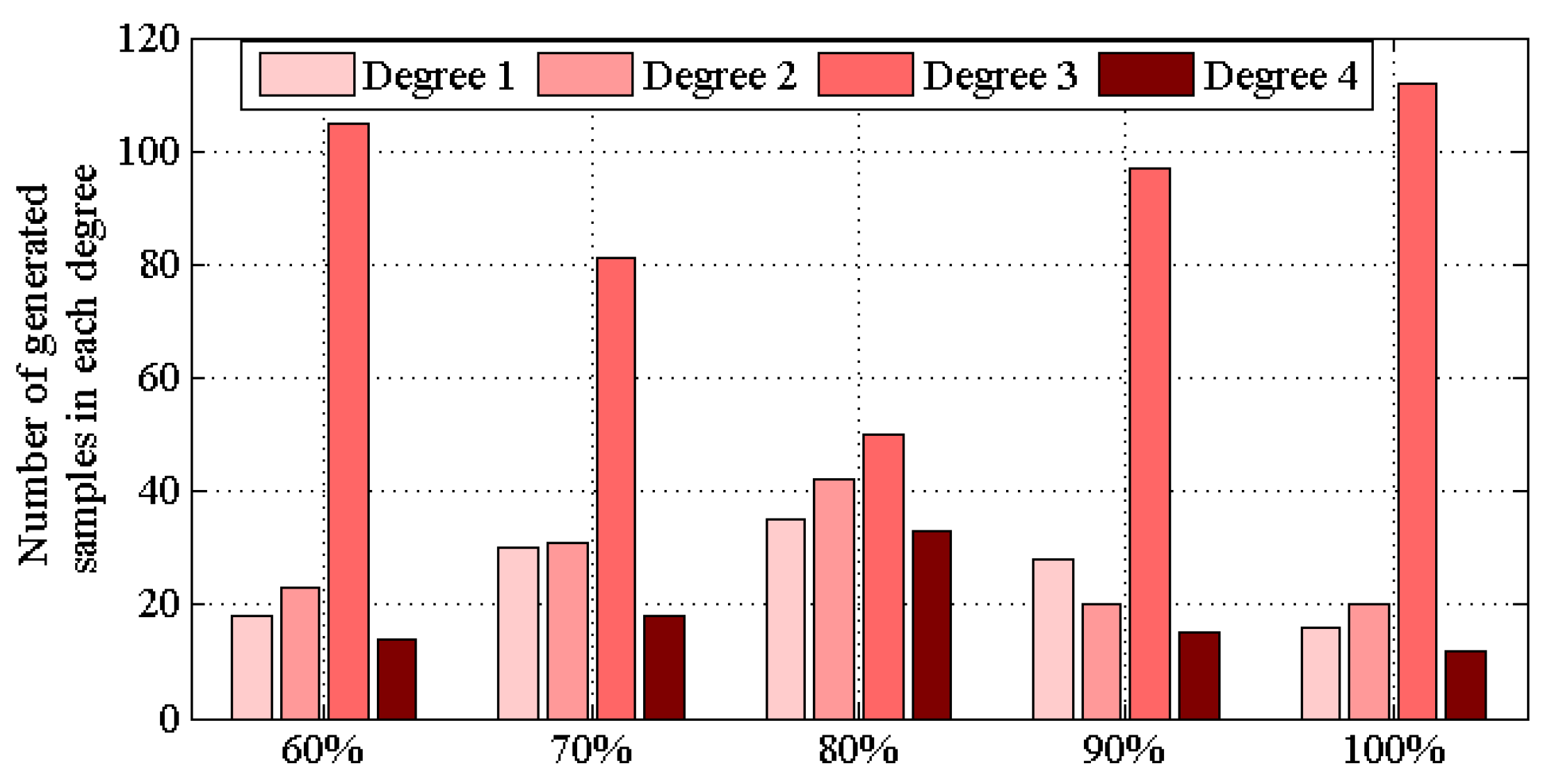
When analyzing unbalanced data, we use a set of gear data for specific analysis. In this dataset, occurrences of each reliability is 40/44/97/31 from class 1 to 4 and the dimension of each sample is 85. It can be seen that high reliability having the maximum samples is the most common operating condition. Although the number of samples between different categories is quite different, we can find that all samples have the same dimensional characteristics. The difference between gear data and other data is that the same dimensions represent the same characteristics. Therefore, we reorganize data in the same category according to feature dimensions. We also select them through the mini-batch scheme and form four categories with the same number of samples. For example, the samples in the first category are 85 and each has 40 dimensional features. Samples in the second class are also 85 and each has 40 dimensional features. We will discard the extra samples and repeat part of the data. In this method, CGAN improves performance in generating different classes of samples.
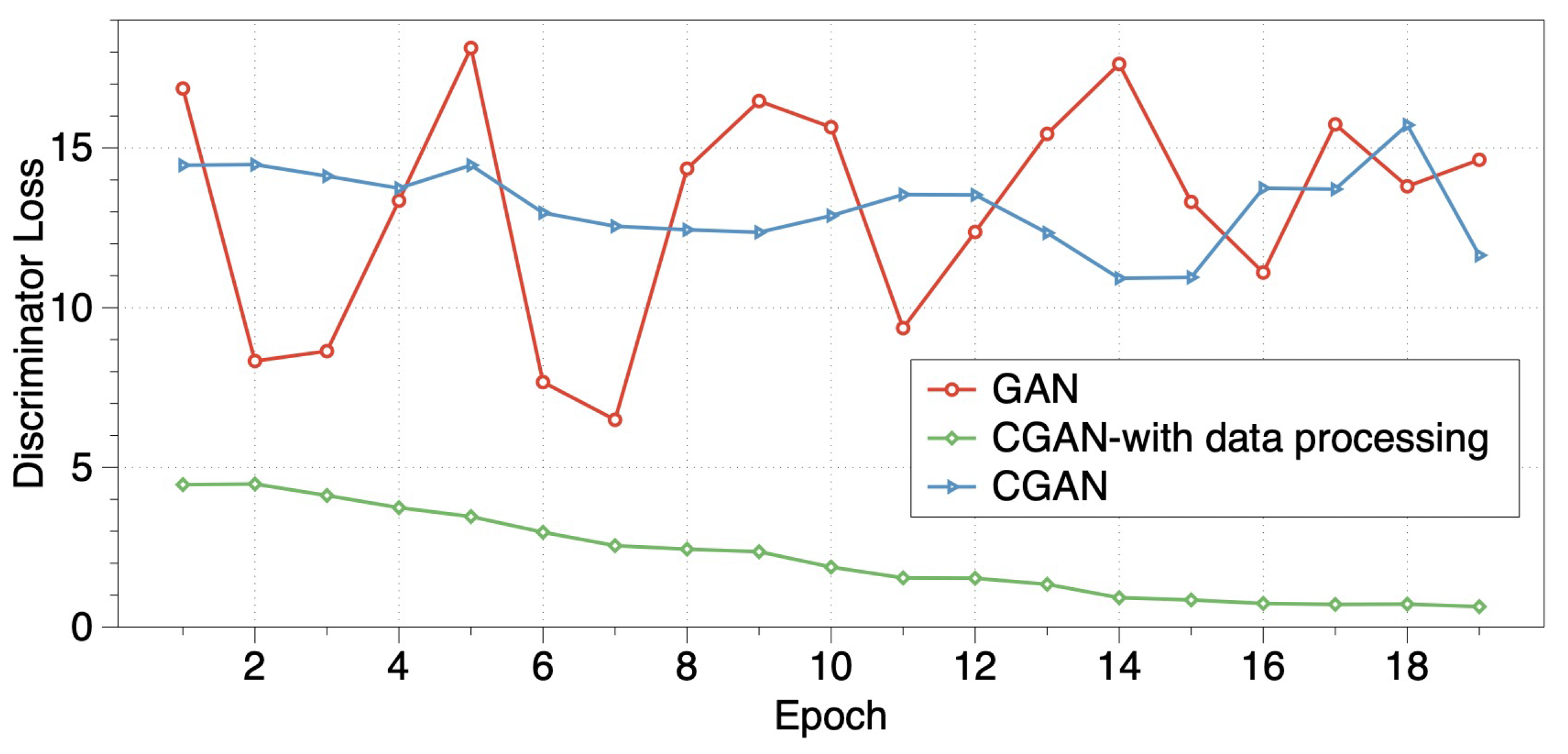
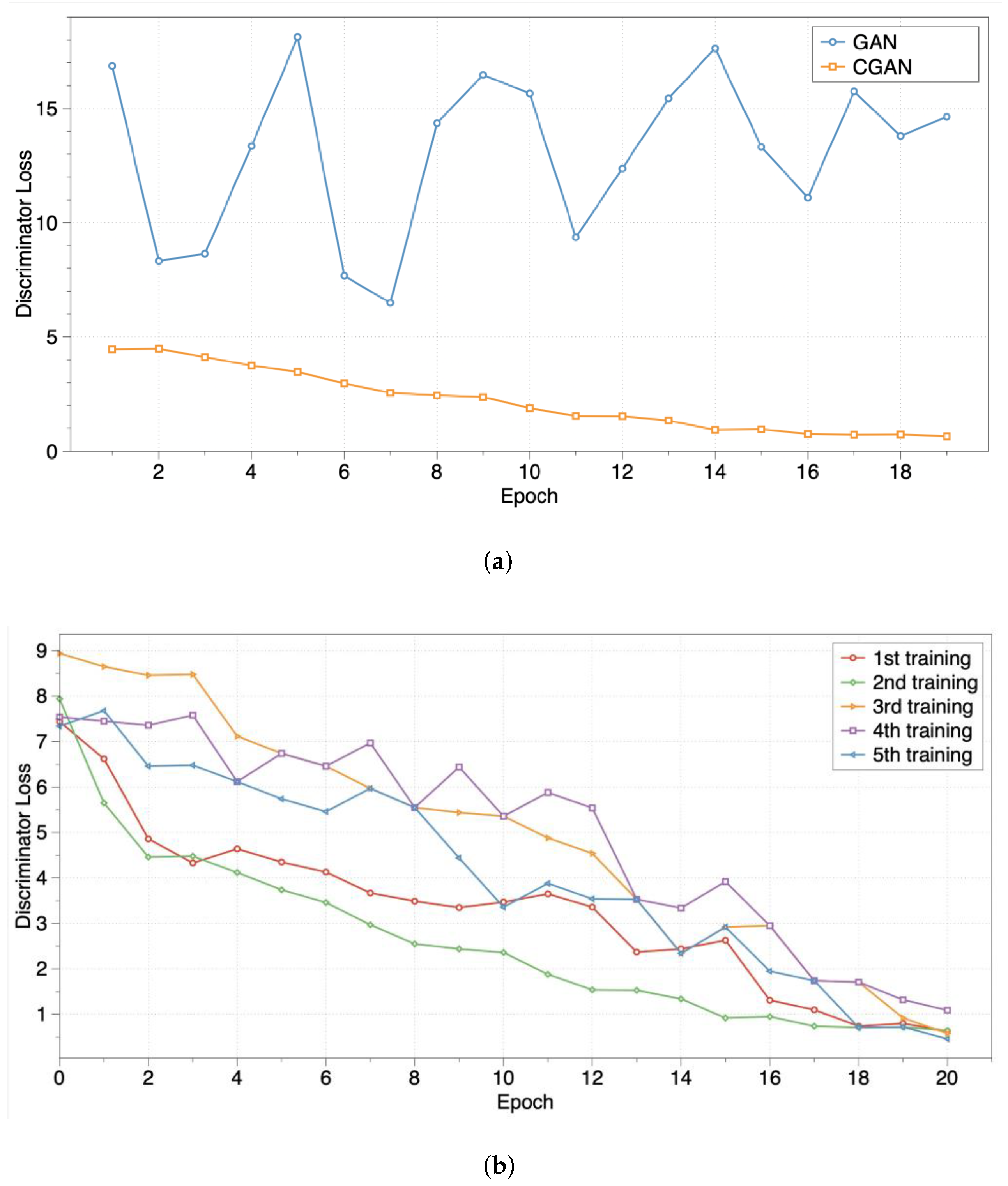
In order to analyze the performance of data processing, we observe the values of loss functions by using both our CGAN-based model and traditional GAN for transmission gear data. The results are shown in
Figure 6. When data processing is not used in the training process, loss values fluctuate with training epochs, which means that GAN and CGAN are unable to learn the right mapping relationship directly from the transmission gear data. After data processing is used in CGAN, the loss values are steadily declining with training epochs, which shows that the imbalance class issues are lightened.
3.3.2. Algorithm Performance
The method consists of Algorithms 1 and 2. In the CGAN-based model in Algorithm 1, we can generate new samples without label information in different class spaces. Then, generated data are filtered according to the Wasserstein distance in Algorithm. In order to explore the stability and convergence of these two algorithms, we observe the values of loss functions [
33] by using both our CGAN-based model and traditional GAN for transmission gear data. From
Figure 7a, discriminator loss values in Algorithm 1 are gradually decreasing with a consistent trend, whereas those values of the traditional GAN have uncertain fluctuations. This indicates that the convergence of our CGAN-based model is more stable on gear data than the traditional GAN. Furthermore, to avoid training randomness, we trained our CGAN-based model five times. Loss function curves of discriminator loss (as illustrated in
Figure 7b) have parallel trends. The loss values are decreasing with training epochs, which shows that our model has effective stability and required convergence for transmission gear data.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}