
Data-Driven Geothermal Reservoir Modeling: Estimating Permeability Distributions by Machine Learning


Abstract
:1. Introduction
2. Method
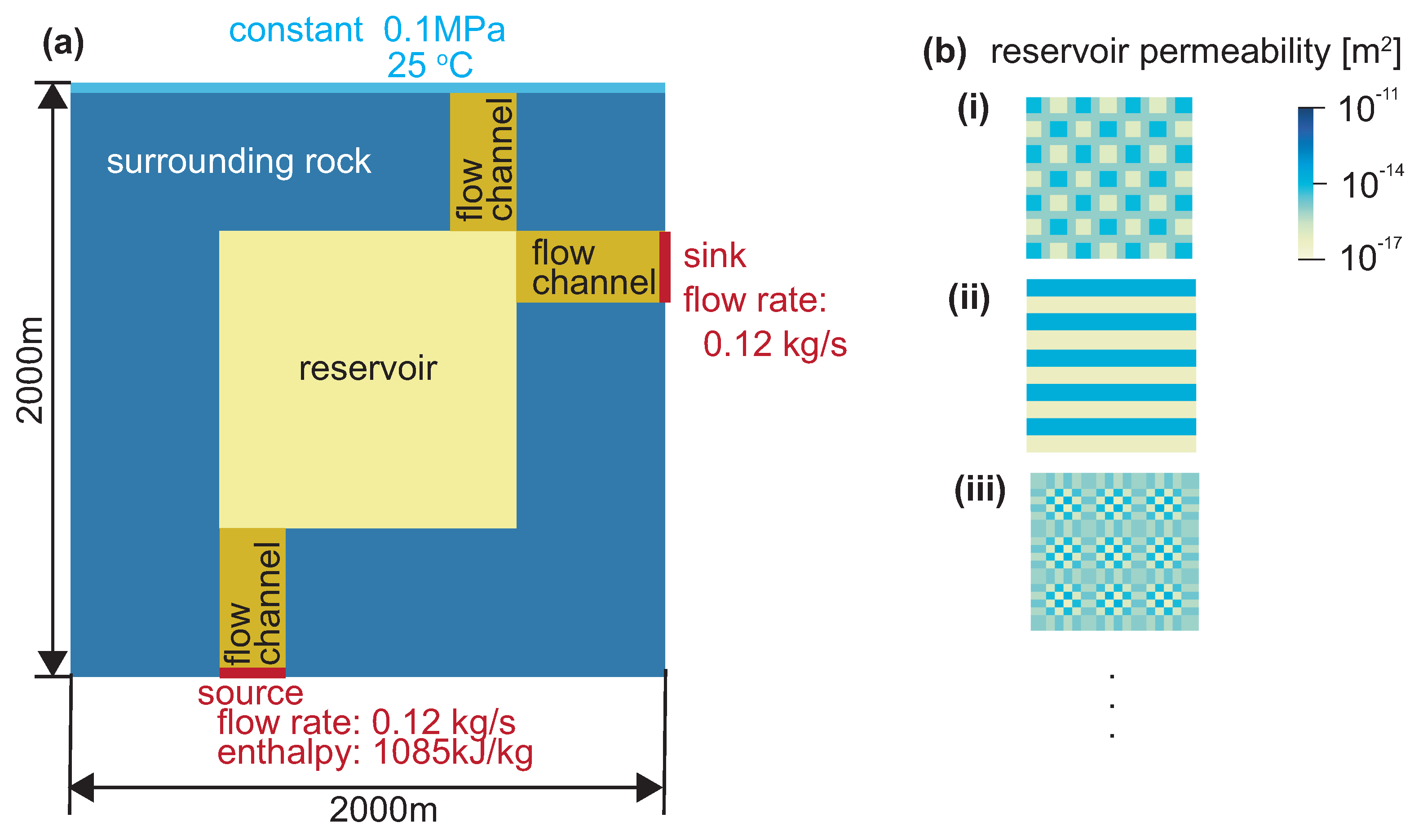
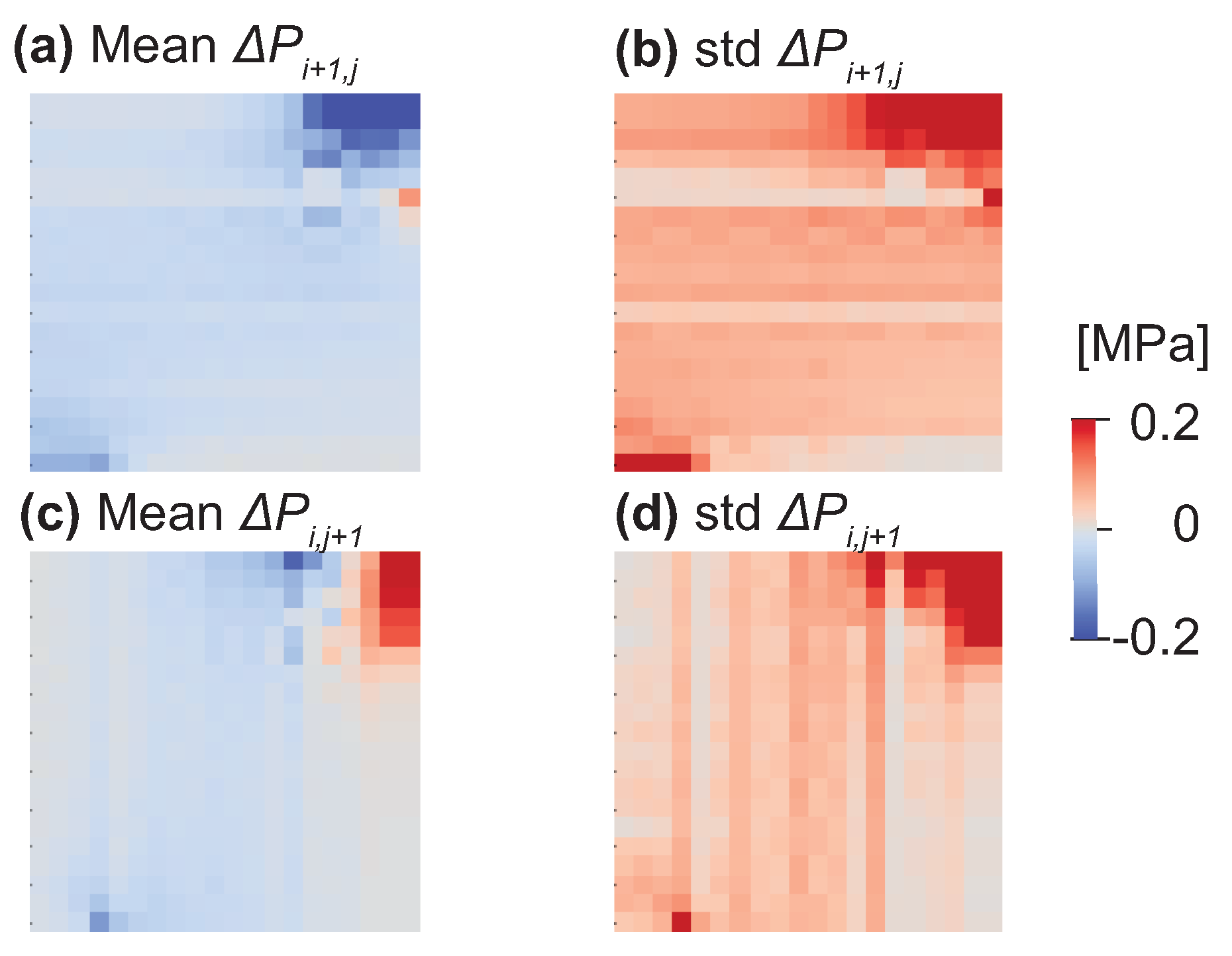
2.1. Preparation of Learning Data
2.2. Development of Machine Learning Model
3. Results
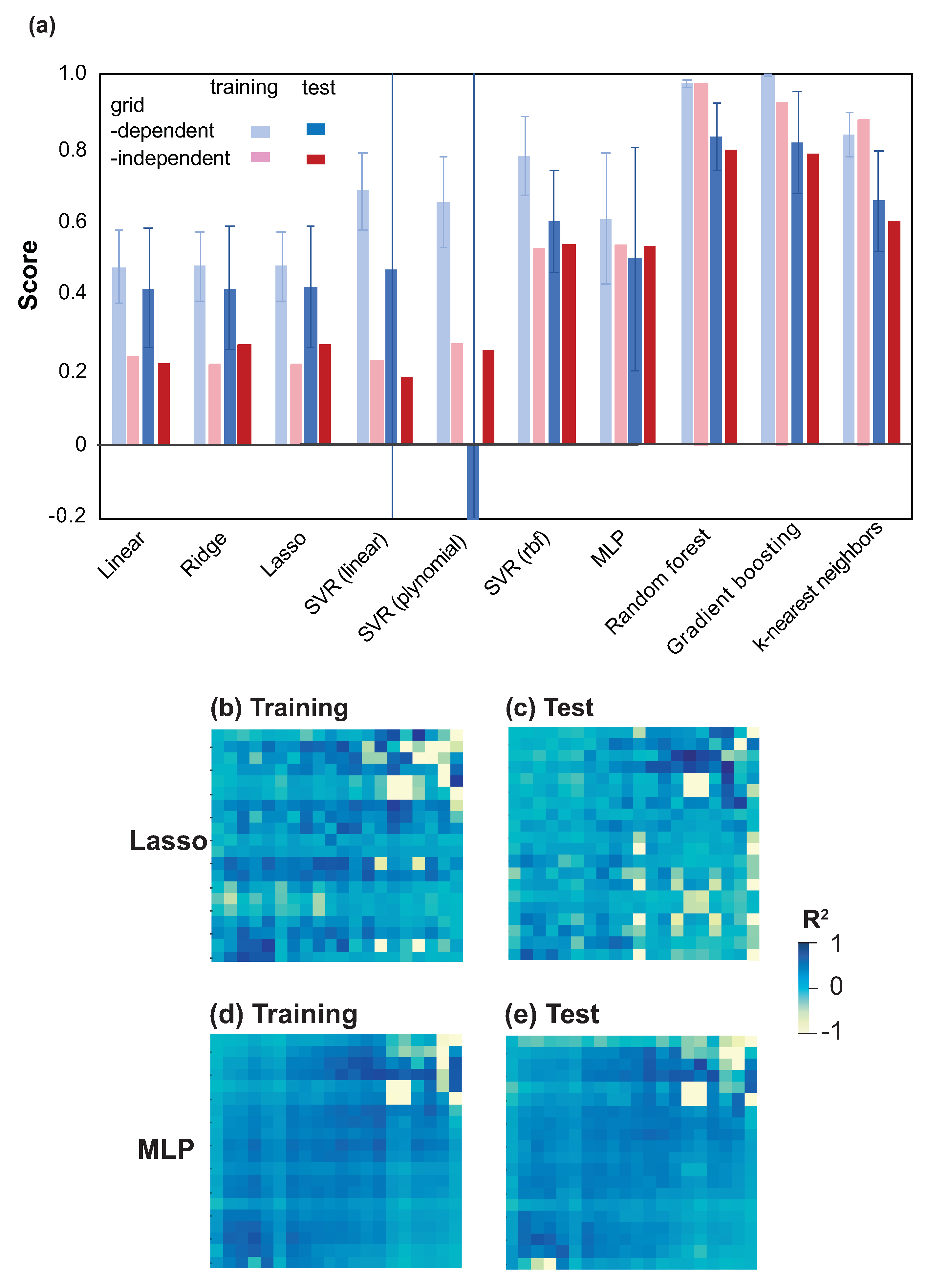
3.1. Model Selection
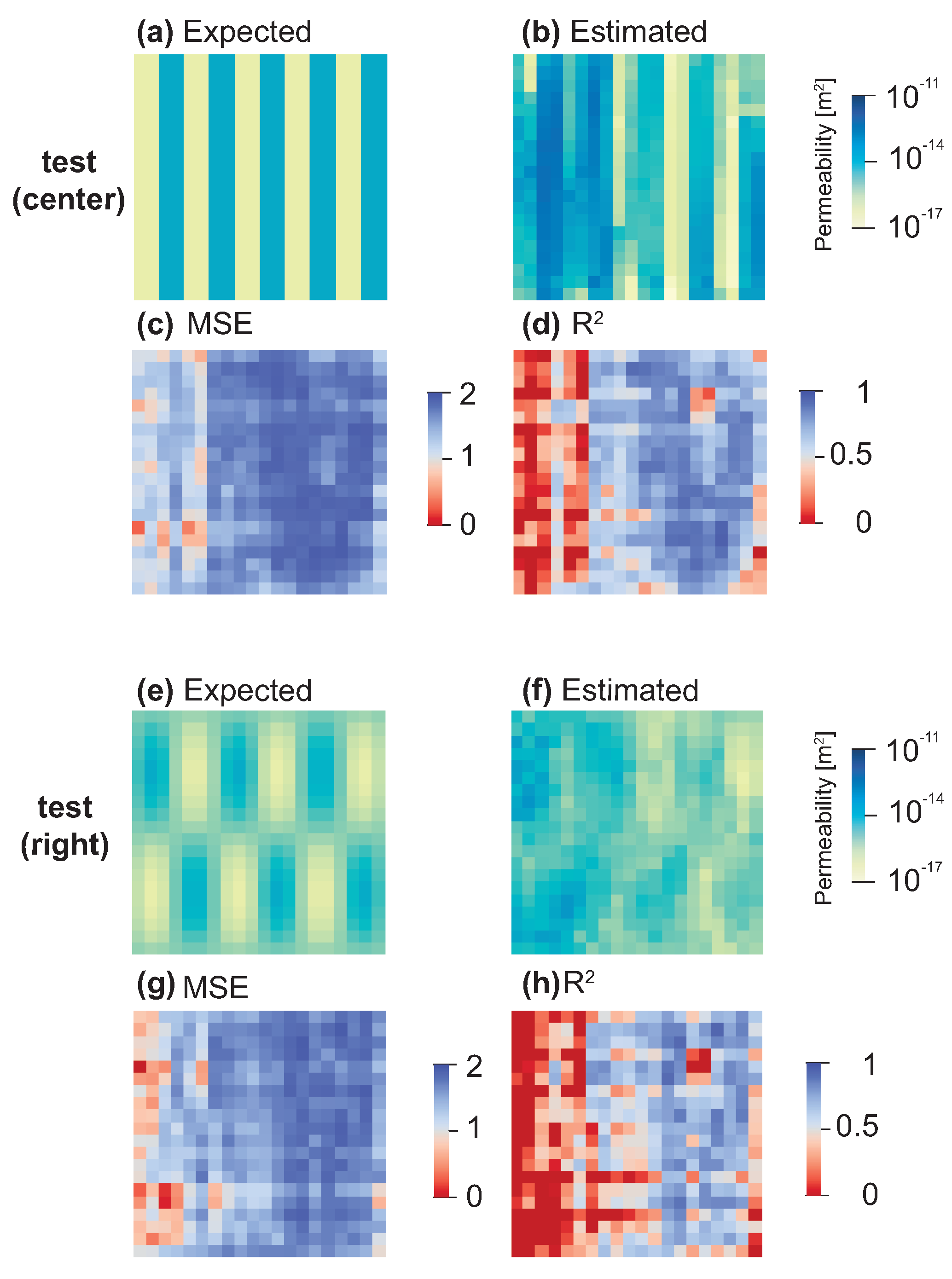
3.2. Estimation of Permeability Distributions
3.3. Estimation for Different Heat Source Conditions
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pruess, K.; Oldenburg, C.M.; Moridis, G.J. TOUGH2 User’s Guide, version 2; LBNL-43134; Lawrence Berkeley National Lab.: Berkeley, CA, USA, 1999. [Google Scholar]
- Vinsome, K.; Shook, M. Multi-purpose simulation. J. Pet. Sci. Eng. 1993, 9, 29–38. [Google Scholar] [CrossRef]
- Pritchett, J.W. STAR: A geothermal reservoir simulation system. In Proceedings of the World geothermal Congress, Florence, Italy, 18–31 May 1995; pp. 2959–2963. [Google Scholar]
- Keller, J.; Rath, V.; Bruckmann, J.; Mottaghy, D.; Clauser, C.; Wolf, A.; Seidler, R.; Bücker, H.M.; Klitzsch, N. SHEMAT-Suite: An open-source code for simulating flow, heat and species transport in porous media. SoftwareX 2020, 12, 100533. [Google Scholar] [CrossRef]
- Hughes, J.; Langevin, C.; Banta, E. Documentation for the MODFLOW 6 framework. In USGS: Techniques and Methods 6-A57; U.S. Geological Survey: Reston, VA, USA, 2017; p. 42. [Google Scholar]
- Mahmoodpour, S.; Singh, M.; Turan, A.; Bär, K.; Sass, I. Hydro-Thermal Modeling for Geothermal Energy Extraction from Soultz-sous-Forêts, France. Geosciences 2021, 11, 464. [Google Scholar] [CrossRef]
- Ganguly, S.; Kumar, M.S. Geothermal reservoirs—A brief review. J. Geol. Soc. India 2012, 79, 589–602. [Google Scholar] [CrossRef] [Green Version]
- Pratama, H.B.; Saptadji, N.M. Numerical simulation for natural state of two-phase liquid dominated geothermal reservoir with steam cap underlying brine reservoir. IOP Conf. Ser. Earth Environ. Sci. 2016, 42, 012006. [Google Scholar] [CrossRef]
- Manggala Putra, R.P.; Sutopo, S.; Pratama, H.B. Improved natural state simulation of Arjuno-Welirang Geothermal field, East Java, Indonesia. IOP Conf. Ser. Earth Environ. Sci. 2019, 254, 012022. [Google Scholar] [CrossRef]
- Jalilinasrabady, S.; Tanaka, T.; Itoi, R.; Goto, H. Numerical simulation and production prediction assessment of Takigami geothermal reservoir. Energy 2021, 236, 121503. [Google Scholar] [CrossRef]
- Grant, M.A.; Bixley, P.F. Geothermal Reservoir Engineering, 2nd ed.; Academic Press: Oxford, UK, 2011; p. 378. [Google Scholar]
- Finsterle, S.; Pruess, K. Development of Inverse Modeling Techniques for Geothermal Applications; LBNL-40039; Lawrence Berkeley Lab.: Berkeley, USA, 1997; p. 8. [Google Scholar]
- O’Sullivan, M.J.; Pruess, K.; Lippmann, M.J. State of the art of geothermal reservoir simulation. Geothermics 2001, 30, 395–429. [Google Scholar] [CrossRef]
- Finsterle, S. iTOUGH2 User’s Guide; LBNL-40040; Lawrence Berkeley Lab.: Berkeley, CA, USA, 2007; p. 137. [Google Scholar]
- Poeter, E.P.; Hill, M.C. UCODE, a computer code for universal inverse modeling. Comput. Geosci. 1999, 25, 457–462. [Google Scholar] [CrossRef]
- Doherty, J. Calibration and uncertainty analysis for complex environmental models. Groundwater 2015, 53, 673–674. [Google Scholar] [CrossRef]
- Bjarkason, E.K.; O’Sullivan, J.P.; Yeh, A.; O’Sullivan, M.J. Inverse modeling of the natural state of geothermal reservoirs using adjoint and direct methods. Geothermics 2019, 78, 85–100. [Google Scholar] [CrossRef]
- Assouline, D.; Mohajeri, N.; Gudmundsson, A.; Scartezzini, J.L. A machine learning approach for mapping the very shallow theoretical geothermal potential. Geotherm. Energy 2019, 7, 19. [Google Scholar] [CrossRef] [Green Version]
- Spichak, V.; Geiermann, J.; Zakharova, O.; Calcagno, P.; Genter, A.; Schill, E. Estimating deep temperatures in the Soultz-sous-Forêts geothermal area (France) from magnetotelluric data. Near Surf. Geophys. 2015, 13, 397–408. [Google Scholar] [CrossRef]
- Ishitsuka, K.; Kobayashi, Y.; Watanabe, N.; Yamaya, Y.; Bjarkason, E.; Suzuki, A.; Mogi, T.; Asanuma, H.; Kajiwara, T.; Sugimoto, T.; et al. Bayesian and neural network approaches to estimate deep temperature distribution for assessing a supercritical geothermal system: Evaluation using a numerical model. Nat. Resour. Res. 2021, 30, 3289–3314. [Google Scholar] [CrossRef]
- Rezvanbehbahani, S.; Stearns, L.A.; Kadivar, A.; Walker, J.D.; van der Veen, C.J. Predicting the geothermal heat flux in Greenland: A machine learning approach. Geophys. Res. Lett. 2017, 44, 12271–12279. [Google Scholar] [CrossRef] [Green Version]
- Siler, D.L.; Pepin, J.D.; Vesselinov, V.V.; Mudunuru, M.K.; Ahmmed, B. Machine learning to identify geologic factors associated with production in geothermal fields: A case-study using 3D geologic data, Brady geothermal field, Nevada. Geotherm. Energy 2021, 9, 17. [Google Scholar] [CrossRef]
- Gudmundsdottir, H.; Horne, R.N. Prediction modeling for geothermal reservoirs using deep learning. In Proceedings of the 45th Workshop on Geothermal Reservoir Engineering, Stanford University, Stanford, CA, USA, 10–12 February 2020; p. 12. [Google Scholar]
- Holtzman, B.K.; Paté, A.; Paisley, J.; Waldhauser, F.; Repetto, D. Machine learning reveals cyclic changes in seismic source spectra in Geysers geothermal field. Sci. Adv. 2018, 4, eaao2929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, K.; Huang, L.; Lin, R.; Hu, H.; Zheng, Y.; Cladohous, T. Delineating faults at the soda lake geothermal field using machine learning. In Proceedings of the 46th Workshop on Geothermal Reservoir Engineering, Stanford University, Stanford, CA, USA, 16–18 February 2021; p. 8. [Google Scholar]
- Zheng, Y.; Li, J.; Lin, R.; Hu, H.; Gao, K.; Huang, L.; Sciences, A.; Alamos, L. Physics-Guided Machine Learning Approach to Characterizing Small-Scale Fractures in Geothermal Fields. In Proceedings of the 46th Workshop on Geothermal Reservoir Engineering, Stanford University, Stanford, CA, USA, 16–18 February 2021; p. 9. [Google Scholar]
- Ali, S.S.; Nizamuddin, S.; Abdulraheem, A.; Hassan, M.R.; Hossain, M.E. Hydraulic unit prediction using support vector machine. J. Pet. Sci. Eng. 2013, 110, 243–252. [Google Scholar] [CrossRef]
- Al-Mudhafar, W.J. Integrating well log interpretations for lithofacies classification and permeability modeling through advanced machine learning algorithms. J. Pet. Explor. Prod. Technol. 2017, 7, 1023–1033. [Google Scholar] [CrossRef] [Green Version]
- Anifowose, F.; Abdulraheem, A.; Al-Shuhail, A. A parametric study of machine learning techniques in petroleum reservoir permeability prediction by integrating seismic attributes and wireline data. J. Pet. Sci. Eng. 2019, 176, 762–774. [Google Scholar] [CrossRef]
- Erofeev, A.; Orlov, D.; Ryzhov, A.; Koroteev, D. Prediction of porosity and permeability alteration based on machine learning algorithms. Transp. Porous Media 2019, 128, 677–700. [Google Scholar] [CrossRef] [Green Version]
- Kaydani, H.; Mohebbi, A.; Eftekhari, M. Permeability estimation in heterogeneous oil reservoirs by multi-gene genetic programming algorithm. J. Pet. Sci. Eng. 2014, 123, 201–206. [Google Scholar] [CrossRef]
- Sudakov, O.; Burnaev, E.; Koroteev, D. Driving digital rock towards machine learning: Predicting permeability with gradient boosting and deep neural networks. Comput. Geosci. 2019, 127, 91–98. [Google Scholar] [CrossRef] [Green Version]
- Al-Anazi, A.F.; Gates, I.D. Support vector regression for porosity prediction in a heterogeneous reservoir: A comparative study. Comput. Geosci. 2010, 36, 1494–1503. [Google Scholar] [CrossRef]
- Mo, S.; Zabaras, N.; Shi, X.; Wu, J. Deep autoregressive neural networks for high-dimensional inverse problems in groundwater contaminant source identification. Water Resour. Res. 2019, 55, 3856–3881. [Google Scholar] [CrossRef] [Green Version]
- Wen, G.; Tang, M.; Benson, S.M. Multiphase flow prediction with deep neural networks. arXiv 2019, arXiv:1910.09657. [Google Scholar] [CrossRef]
- Tang, M.; Liu, Y.; Durlofsky, L.J. A deep-learning-based surrogate model for data assimilation in dynamic subsurface flow problems. J. Comput. Phys. 2020, 413, 109456. [Google Scholar] [CrossRef] [Green Version]
- Jin, Z.L.; Liu, Y.; Durlofsky, L.J. Deep-learning-based surrogate model for reservoir simulation with time-varying well controls. J. Pet. Sci. Eng. 2020, 192, 107273. [Google Scholar] [CrossRef]
- Liu, Y.; Durlofsky, L.J. 3D CNN-PCA: A deep-learning-based parameterization for complex geomodels. Comput. Geosci. 2021, 148, 104676. [Google Scholar] [CrossRef]
- Ahmed, N.; Natarajan, T.; Rao, K.R. Discrete cosine transform. IEEE Trans. Comput. 1974, C-23, 90–93. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory, 2nd ed.; Springer Science & Business Media: Berlin/Heidelberg, Germany; Springer: New York, NY, USA, 2000. [Google Scholar] [CrossRef]
- Orr, G.B.; Müller, K.R. Neural Networks: Tricks of the Trade, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Mason, L.; Baxter, J.; Bartlett, P.; Frean, M. Boosting algorithms as gradient descent in function space. Proc. NIPS 1999, 12, 512–518. [Google Scholar] [CrossRef]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’19), Association for Computing Machinery, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Zhao, S.; Yue, X.; Zhang, S.; Li, B.; Zhao, H.; Wu, B.; Krishna, R.; Gonzalez, J.E.; Sangiovanni-Vincentelli, A.L.; Seshia, S.A.; et al. A review of single-source deep unsupervised visual domain adaptation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 473–493. [Google Scholar] [CrossRef]
- Teng, Y.; Koike, K. Three-dimensional imaging of a geothermal system using temperature and geological models derived from a well-log dataset. Geothermics 2007, 36, 518–538. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhang, S.; Turnadge, C.; Xu, T. Combining autoencoder neural network and Bayesian inversion to estimate heterogeneous permeability distributions in enhanced geothermal reservoir: Model development and verification. Geothermics 2021, 97, 102262. [Google Scholar] [CrossRef]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C.; Back, A.D. Face recognition: A convolutional neural-network approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Champion, K.; Lusch, B.; Nathan Kutz, J.; Brunton, S.L. Data-driven discovery of coordinates and governing equations. Proc. Natl. Acad. Sci. USA 2019, 116, 22445–22451. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Raissi, M.; Yazdani, A.; Karniadakis, G.E. Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations. Science 2020, 367, 1026–1030. [Google Scholar] [CrossRef] [PubMed]
- Harp, D.R.; O’Malley, D.; Yan, B.; Pawar, R. On the feasibility of using physics-informed machine learning for underground reservoir pressure management. Expert Syst. Appl. 2021, 178, 115006. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Parameters | SI Unit |
|---|---|---|
| Rock density | 2250 | kg/m |
| Porosity | 0.1 | - |
| Thermal conductivity | 2.5 | W/mC |
| Specific heat | 1000 | J/kgC |
| Methods | Parameters | Ranges |
|---|---|---|
| Linear | - | - |
| Ridge | 0.00001–100 | |
| Lasso | 0.00001–100 | |
| max iteration | 100,000 | |
| SVR (linear) | C | 0.01–10,000 |
| SVR (polynomial) | C | 0.01–10,000 |
| degree | 2–4 | |
| SVR (rbf) | C | 0.01–10,000 |
| 0.0001–100 | ||
| 0.0001–0.01 | ||
| MLP | solver | sgd, adam, lbfgs |
| activation | identity, logistic, | |
| relu, tanh | ||
| max layer size | 50–300 | |
| 0.001–1000 | ||
| Random forest | number of trees in the forest | 100–1000 |
| Gradient boosting | number of boosting stages to perform | 100–1000 |
| maximum depth | 3 | |
| k-nearest neighbors | number of neighbors | 3–7 |
| Conditions | |||
|---|---|---|---|
| Mass Flow Rate (kg/s) | Position | Score (R2) | |
| Training | 0.12 | left | 0.979 |
| Test | 0.12 * | left * | 0.789 |
| 0.04 | left * | 0.715 | |
| 0.4 | left * | 0.768 | |
| 0.12 * | center | 0.576 | |
| 0.12 * | right | 0.450 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suzuki, A.; Fukui, K.-i.; Onodera, S.; Ishizaki, J.; Hashida, T. Data-Driven Geothermal Reservoir Modeling: Estimating Permeability Distributions by Machine Learning. Geosciences 2022, 12, 130. https://0-doi-org.brum.beds.ac.uk/10.3390/geosciences12030130
Suzuki A, Fukui K-i, Onodera S, Ishizaki J, Hashida T. Data-Driven Geothermal Reservoir Modeling: Estimating Permeability Distributions by Machine Learning. Geosciences. 2022; 12(3):130. https://0-doi-org.brum.beds.ac.uk/10.3390/geosciences12030130
Chicago/Turabian StyleSuzuki, Anna, Ken-ichi Fukui, Shinya Onodera, Junichi Ishizaki, and Toshiyuki Hashida. 2022. "Data-Driven Geothermal Reservoir Modeling: Estimating Permeability Distributions by Machine Learning" Geosciences 12, no. 3: 130. https://0-doi-org.brum.beds.ac.uk/10.3390/geosciences12030130